
Abstract
This chapter serves as a primer in utilizing ordinary least squares (OLS) in higher education research, by providing an overview of this commonly used quantitative approach, which often includes simple linear regression models and multiple linear regression models. The first section of the chapter reviews current literature to explain ways that OLS allows researchers to identify the goals of OLS and differentiate them from basic descriptive analyses and bivariate analyses. It then discusses the types of research questions that may be answered by OLS. The second section walks readers through an example application of OLS using a real-world dataset, reviewing the definitions, key components, and analytic steps in using OLS. The following section addresses important considerations in testing statistical assumptions and the influence of assumption violation before applying OLS. The fourth section further discusses the significance of considering heterogeneous effects in contemporary higher education. The chapter closes with topics related to interpreting findings, as well as the broader application of OLS in higher education research contexts.
Nicholas Hillman was the Associate Editor for this chapter.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

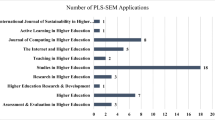

Notes
- 1.
The statistical property of unbiasedness refers to whether “an estimator whose expected value of its sampling distribution equals the true value of the population parameter” (Ezell & Land, 2005, p. 943). When the sample estimate is neither an underestimate nor an overestimate of the unknown population parameter, it is unbiased.
- 2.
The public-use data is available at https://nces.ed.gov/datalab/. One major difference between the public-use data and restricted-use data is around how analytic weights are provided in this complex survey design. For example, variance estimation is provided through both Balanced Repeated Replication (BRR) and a Taylor series linearization, but only the BRR variance estimation method is supported for users of public-use data (Duprey et al., 2020).
- 3.
The dependent variable indicates the total tuition and fees charged at the primary institution during the first academic year in postsecondary education after high school completion or exit. This value accounted for students’ attendance status to reflect students’ number of months enrolled full- or part-time in a given academic year. The primary institution was identified based on transcript records with the earliest start date excluding summer enrollments immediately following high school completion/exit.
- 4.
Note that the hierarchical procedure, sometimes called block-wise entry procedure, is used to add or remove variables from regression model in multiple steps. This is different from hierarchical linear modeling when data have a nested structure (e.g., class sections, departments, colleges).
- 5.
Note that percent refers to the rate of change, which is different from actual percentage points change. For example, if the baseline undergraduate enrollment being Pell-eligible is 30%, and it increased by 10 percent in a given year. The new undergraduate enrollment being Pell-eligible is 30% + (30% ×10%) = 33%. If it increased by 10 percentage points in a given year, the new undergraduate enrollment being Pell-eligible is 30% + 10% = 40%.
- 6.
IPEDS defines race/ethnicity based on categories developed in 1997 by the Office of Management and Budget (OMB). These categories “describe groups to which individuals belong, identify with, or belong in the eyes of the community” (NCES, n.d.). In particular, individuals indicating their ethnicity as Hispanic/Latino are defined as “a person of Cuban, Mexican, Puerto Rican, South or Central American, or other Spanish culture or origin, regardless of race” (NCES, n.d.).
References
Abdallah, W., Goergen, M., & O’Sullivan, N. (2015). Endogeneity: How failure to correct for it can cause wrong inferences and some remedies. British Journal of Management, 26(4), 791–804. https://doi.org/10.1111/1467-8551.12113
Aiken, L. S., West, S. G., & Reno, R. R. (1991). Multiple regression: Testing and interpreting interactions. Sage.
Allison, P. D. (2001). Missing data. Sage.
Allison, P. D. (2009). Fixed effects regression models. Sage.
An, B. P. (2013a). The influence of dual enrollment on academic performance and college readiness: Differences by socioeconomic status. Research in Higher Education, 54(4), 407–432. https://doi.org/10.1007/s11162-012-9278-z
An, B. P. (2013b). The impact of dual enrollment on college degree attainment: Do low-SES students benefit? Educational Evaluation and Policy Analysis, 35(1), 57–75. https://doi.org/10.3102/0162373712461933
An, B. P. (2015). The role of academic motivation and engagement on the relationship between dual enrollment and academic performance. The Journal of Higher Education, 86(1), 98–126. https://doi.org/10.1353/jhe.2015.0005
An, B. P., & Taylor, J. L. (2019). A review of empirical studies on dual enrollment: Assessing educational outcomes. In M. B. Paulsen & L. W. Perna (Eds.), Higher education: Handbook of theory and research (Vol. 34, pp. 99–151). Springer. https://doi.org/10.1007/978-3-030-03457-3_3
Archibald, R. B., & Feldman, D. (2006). State higher education spending and the tax revolt. The Journal of Higher Education, 77(4), 618–644. https://doi.org/10.1353/jhe.2006.0029
Attewell, P., Lavin, D., Domina, T., & Levey, T. (2006). New evidence on college remediation. The Journal of Higher Education, 77(5), 886–924.
Attewell, P., Monaghan, D., & Kwong, D. (2015). Data mining for the social sciences: An introduction. University of California Press.
Avery, C., Howell, J. S., & Page, L. (2014). A review of the role of college applications on students’ post-secondary outcomes. College Board. https://jeric.ed.gov/?id=ED556466
Babyak, M. A. (2004). What you see may not be what you get: A brief, nontechnical introduction to overfitting in regression-type models. Psychosomatic Medicine, 66(3), 411–421.
Bahr, P. R. (2019). The labor market returns to a community college education for noncompleting students. The Journal of Higher Education, 90(2), 210–243. https://doi.org/10.1080/00221546.2018.1486656
Bailey, M., & Dynarski, S. (2011). Inequality in post-secondary education. In G. J. Duncan & R. J. Murnane (Eds.), Whither opportunity? Rising inequality, schools and children’s life chances (pp. 117–132). Sage.
Bailey, T., Calcagno, J. C., Jenkins, D., Leinbach, T., & Kienzl, G. (2006). Is student-right-to-know all you should know? An analysis of community college graduation rates. Research in Higher Education, 47, 491–519. https://doi.org/10.1007/s11162-005-9005-0
Baker, D. J., & Doyle, W. R. (2017). Impact of community college student debt levels on credit accumulation. The Annals of the American Academy of Political and Social Science, 671(1), 132–153. https://doi.org/10.1177/0002716217703043
Baker, T. L., & Vélez, W. (1996). Access to and opportunity in postsecondary education in the United States: A review. Sociology of Education, 69, 82–101.
Balfanz, R., DePaoli, J. L., Ingram, E. S., Bridgeland, J. M., & Fox, J. H. (2016). Closing the college gap: A roadmap to post-secondary readiness and attainment. Civic Enterprises. https://eric.ed.gov/?id=ED572785
Barnett, E. (2018). Differentiated dual enrollment and other collegiate experiences: Lessons from the STEM early college expansion partnership. Community College Research Center, Teachers College, Columbia University. http://www.jff.org/publications/differentiated-dual-enrollment-and-other-collegiate-experiences
Berger, A., Turk-Bicakci, L., Garet, M., Song, M., Knudson, J., Haxton, C., Zeiser, K., Hoshen, G., Ford, J., Stephan, J., Keating, K., & Cassidy, L. (2013). Early college, early success: Early college high school initiative impact study. American Institutes for Research. https://files.eric.ed.gov/fulltext/ED577243.pdf
Bielby, R. M., House, E., Flaster, A., & DesJardins, S. L. (2013). Instrumental variables: Conceptual issues and an application considering high school course taking. In M. B. Paulsen (Ed.), Higher education: Handbook of theory and research (Vol. 28, pp. 263–321). Springer. https://doi.org/10.1007/978-94-007-5836-0_6
Biswas, A., Das, S., & Das, S. (2019). OLS: Is that so useless for regression with categorical data? In A. K. Laha (Ed.), Advances in analytics and applications (pp. 227–242). Springer. https://doi.org/10.1007/978-981-13-1208-3_18
Boatman, A., Evans, B. J., & Soliz, A. (2017). Understanding loan aversion in education: Evidence from high school seniors, community college students, and adults. AERA Open, 3(1), 1–16. https://doi.org/10.1177/2332858416683649
Bohrnstedt, G. W., & Carter, T. M. (1971). Robustness in regression analysis. Sociological Methodology, 3, 118–146.
Burnham, K. P., Anderson, D. R., & Huyvaert, K. P. (2011). AIC model selection and multimodel inference in behavioral ecology: Some background, observations, and comparisons. Behavioral Ecology and Sociobiology, 65, 23–35. https://doi.org/10.1007/s00265-010-1029-6
Cabrera, A. F., & La Nasa, S. M. (2000). Understanding the college-choice process. New Directions for Institutional Research, 2000(107), 5–22.
Card, D., & Payne, A. A. (2021). High school choices and the gender gap in STEM. Economic Inquiry, 59(1), 9–28. https://doi.org/10.1111/ecin.12934
Castleman, B. L., & Page, L. C. (2017). Parental influences on postsecondary decision making: Evidence from a text messaging experiment. Educational Evaluation and Policy Analysis, 39(2), 361–377. https://doi.org/10.3102/0162373716687393
Cellini, S. R. (2009). Crowded colleges and college crowd-out: The impact of public subsidies on the two-year college market. American Economic Journal: Economic Policy, 1(2), 1–30. https://doi.org/10.1257/pol.1.2.1
Cellini, S. R., & Chaudhary, L. (2014). The labor market returns to a for-profit college education. Economics of Education Review, 43, 125–140. https://doi.org/10.1016/j.econedurev.2014.10.001
Cellini, S. R., & Goldin, C. (2014). Does federal student aid raise tuition? New evidence on for-profit colleges. American Economic Journal: Economic Policy, 6(4), 174–206. https://doi.org/10.1257/pol.6.4.174
Cheslock, J. J., & Gianneschi, M. (2008). Replacing state appropriations with alternative revenue sources: The case of voluntary support. The Journal of Higher Education, 79(2), 208–229. https://doi.org/10.1353/jhe.2008.0012
Cheslock, J. J., & Rios-Aguilar, C. (2011). Multilevel analysis in higher education research: A multidisciplinary approach. In J. C. Smart & M. B. Paulsen (Eds.), Higher education: Handbook of theory and research (Vol. 26, pp. 85–123). Springer. https://doi.org/10.1007/978-94-007-0702-3_3
Cohen, J. (1994). The earth is round (p < .05). American Psychologist, 49(12), 997–1003. https://doi.org/10.1037/0003-066X.49.12.997
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences (3rd ed.). Erlbaum.
Conway, K. M. (2009). Exploring persistence of immigrant and native students in an urban community college. The Review of Higher Education, 32(3), 321–352. https://doi.org/10.1353/rhe.0.0059
Coughlin, C., & Castilla, C. (2014). The effect of private high school education on the college trajectory. Economics Letters, 125(2), 200–203. https://doi.org/10.1016/j.econlet.2014.09.002
Cowan, J., & Goldhaber, D. (2015). How much of a “running start” do dual enrollment programs provide students? The Review of Higher Education, 38(3), 425–460. https://doi.org/10.1353/rhe.2015.0018
Cumming, G. (2014). The new statistics: Why and how. Psychological Science, 25(1), 7–29.
D’Amico, M. M., Dika, S. L., Elling, T. W., Algozzine, B., & Ginn, D. J. (2014). Early integration and other outcomes for community college transfer students. Research in Higher Education, 55, 370–399. https://doi.org/10.1007/s11162-013-9316-5
Dannenberg, M., & Hyslop, A. (2019). Building a fast track to college: An executive summary. Alliance for Excellent Education. http://edreformnow.org/wp-content/uploads/2019/02/ERN-AEE-Fast-Track-FINAL.pdf
DeAngelo, L., & Franke, R. (2016). Social mobility and reproduction for whom? College readiness and first-year retention. American Educational Research Journal, 53(6), 1588–1625. https://doi.org/10.3102/0002831216674805
DesJardins, S. L., & Toutkoushian, R. K. (2005). Are students really rational? The development of rational thought and its application to student choice. In J. C. Smart (Ed.), Higher education: Handbook of theory and research (pp. 191–240). Springer.
Dowd, A. C., Cheslock, J. J., & Melguizo, T. (2008). Transfer access from community colleges and the distribution of elite higher education. The Journal of Higher Education, 79(4), 442–472. https://doi.org/10.1353/jhe.0.0010
Doyle, W. R. (2012). The politics of public college tuition and state financial aid. The Journal of Higher Education, 83(5), 617–647.
Doyle, W. R., Dziesinski, A. B., & Delaney, J. A. (2021). Modeling volatility in public funding for higher education. Journal of Education Finance, 46(4), 563–591.
Duprey, M. A., Pratt, D. J., Wilson, D. H., Jewell, D. M., Brown, D. S., Caves, L. R., Kinney, S. K., Mattox, T. L., Ritchie, N. S., Rogers, J. E., Spagnardi, C. M., Wescott, J. D., & Christopher, E. M. (2020). High school longitudinal study of 2009 (HSLS:09) postsecondary education transcript study and student financial aid records collection: Data file documentation. U.S. Department of Education. https://nces.ed.gov/pubs2020/2020004.pdf
Evans, B. J. (2019). How college students use advanced placement credit. American Educational Research Journal, 56(3), 925–954. https://doi.org/10.3102/0002831218807428
Evans, B. J. (2021). Understanding the complexities of experimental analysis in the context of higher education. In L. W. Perna (Ed.), Higher education: Handbook of theory and research (Vol. 36, pp. 611–661). Springer. https://doi.org/10.1007/978-3-030-44007-7_12
Evans, B. J., Boatman, A., & Soliz, A. (2019). Framing and labeling effects in preferences for borrowing for college: An experimental analysis. Research in Higher Education, 60(4), 438–457. https://doi.org/10.1007/s11162-018-9518-y
Ezell, M. E., & Land, K. C. (2005). Ordinary least squares (OLS). In K. Kempf-Leonard (Ed.), Encyclopedia of social measurement (pp. 943–950). Elsevier. https://doi.org/10.1016/B0-12-369398-5/00171-7
Faircloth, S. C., Alcantar, C. M., & Stage, F. K. (2015). Use of large-scale data sets to study educational pathways of American Indian and Alaska native students. New Directions for Institutional Research, 2014(163), 5–24. https://doi.org/10.1002/ir.20083
Fanelli, D. (2012). Negative results are disappearing from most disciplines and countries. Scientometrics, 90(3), 891–904. https://doi.org/10.1007/s11192-011-0494-7
Ferguson, C. J., & Heene, M. (2012). A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Perspectives on Psychological Science, 7(6), 555–561. https://doi.org/10.1177/1745691612459059
Fernandez, F., Fu, Y.-C., Hu, X., & Moradel, J. J. (2023). Examining the influence of Texas’ strategic plan for increasing university research: Loose coupling and research production at regional public universities. The Journal of Higher Education, advance online publication. https://doi.org/10.1080/00221546.2023.2192161
Fowles, J. (2014). Funding and focus: Resource dependence in public higher education. Research in Higher Education, 55, 272–287. https://doi.org/10.1007/s11162-013-9311-x
Frederick, A. B., Schmidt, S. J., & Davis, L. S. (2012). Federal policies, state responses, and community college outcomes: Testing an augmented Bennett hypothesis. Economics of Education Review, 31(6), 908–917. https://doi.org/10.1016/j.econedurev.2012.05.009
Fryer, R. G., & Greenstone, M. (2010). The changing consequences of attending historically black colleges and universities. American Economic Journal: Applied Economics, 2(1), 116–148.
Furquim, F., Corral, D., & Hillman, N. (2020). A primer for interpreting and designing difference-in-differences studies in higher education research. In L. W. Perna (Ed.), Higher education: Handbook of theory and research (Vol. 35, pp. 1–58). Springer. https://doi.org/10.1007/978-3-030-31365-4_5
Gansemer-Topf, A. M., & Schuh, J. H. (2006). Institutional selectivity and institutional expenditures: Examining organizational factors that contribute to retention and graduation. Research in Higher Education, 47(6), 613–642. https://doi.org/10.1007/s11162-006-9009-4
Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
Giani, M. (2019). The correlates of credit loss: How demographics, pre-transfer academics, and institutions relate to the loss of credits for vertical transfer students. Research in Higher Education, 60(8), 1113–1141. https://doi.org/10.1007/s11162-019-09548-w
Giani, M., Alexander, C., & Reyes, P. (2014). Exploring variation in the impact of dual-credit coursework on postsecondary outcomes: A quasi-experimental analysis of Texas students. The High School Journal, 97(4), 200–218.
Goldrick-Rab, S., Kelchen, R., Harris, D. N., & Benson, J. (2016). Reducing income inequality in educational attainment: Experimental evidence on the impact of financial aid on college completion. American Journal of Sociology, 121(6), 1762–1817. https://doi.org/10.1086/685442
Gottfried, M. A., & Plasman, J. S. (2018). Linking the timing of career and technical education coursetaking with high school dropout and college-going behavior. American Educational Research Journal, 55(2), 325–361. https://doi.org/10.3102/0002831217734805
Grubb, J. M., Scott, P. H., & Good, D. W. (2017). The answer is yes: Dual enrollment benefits students at the community college. Community College Review, 45(2), 79–98. https://doi.org/10.1177/0091552116682590
Guo, S., & Fraser, M. (2015). Propensity score analysis (2nd ed.). Sage.
Gurantz, O. (2015). Who loses out? Registration order, course availability, and student behaviors in community college. The Journal of Higher Education, 86(4), 524–563. https://doi.org/10.1353/jhe.2015.0021
Harper, S. R., Carini, R. M., Bridges, B. K., & Hayek, J. C. (2004). Gender differences in student engagement among African American undergraduates at historically black colleges and universities. Journal of College Student Development, 45(3), 271–284. https://doi.org/10.1353/csd.2004.0035
Harrell, F. E. (2001). Regression modeling strategies: With applications to linear models, logistic regression, and survival analysis. Springer.
Hearn, J. C. (1984). The relative roles of academic, ascribed, and socioeconomic characteristics in college destinations. Sociology of Education, 57(1), 22–30.
Hearn, J. C. (1988). Attendance at higher-cost colleges: Ascribed, socioeconomic, and academic influences on student enrollment patterns. Economics of Education Review, 7(1), 65–76.
Hearn, J. C. (1991). Academic and nonacademic influences on the college destinations of 1980 high school graduates. Sociology of Education, 64(3), 158–171.
Hemelt, S. W., & Marcotte, D. E. (2011). The impact of tuition increases on enrollment at public colleges and universities. Educational Evaluation and Policy Analysis, 33(4), 435–457. https://doi.org/10.3102/0162373711415261
Hemelt, S. W., & Swiderski, T. (2022). College comes to high school: Participation and performance in Tennessee’s innovative wave of dual-credit courses. Educational Evaluation and Policy Analysis, 44(2), 313–341. https://doi.org/10.3102/01623737211052310
Hillman, N. W. (2012). Tuition discounting for revenue management. Research in Higher Education, 53(3), 263–281. https://doi.org/10.1007/s11162-011-9233-4
Hillman, N., & Weichman, T. (2016). Education deserts: The continued significance of “place” in the twenty-first century. American Council on Education Center for Policy Research and Strategy.
Hoffmann, J. P. (2004). Generalized linear models: An applied approach. Pearson.
Howell, J. S., & Pender, M. (2016). The costs and benefits of enrolling in an academically matched college. Economics of Education Review, 51, 152–168. https://doi.org/10.1016/j.econedurev.2015.06.008
Hu, S., & Hossler, D. (2000). Willingness to pay and preference for private institutions. Research in Higher Education, 41(6), 685–701.
Hu, X., & Ortagus, J. C. (2023). National evidence of the relationship between dual enrollment and student loan debt. Educational Policy, 37(5), 1241–1276. https://doi.org/10.1177/08959048221087204
Hu, X., Fernandez, F., & Gándara, D. (2021). Are donations bigger in Texas? Analyzing the impact of a policy to match donations to Texas’ emerging research universities. American Educational Research Journal, 58(4), 850–882. https://doi.org/10.3102/0002831220968947
Huitema, B. E., Mckean, J. W., & Mcknight, S. (1999). Autocorrelation effects on least-squares intervention analysis of short time series. Educational and Psychological Measurement, 59(5), 767–786.
Hunt, J. M., Tandberg, D. A., & Park, T. J. (2019). Presidential compensation and institutional revenues: Testing the return on investment for public university presidents. The Review of Higher Education, 42(2), 619–640. https://doi.org/10.1353/rhe.2019.0009
Ishitani, T. T., & McKitrick, S. A. (2016). Are student loan default rates linked to institutional capacity? Journal of Student Financial Aid, 46(1), 17–37.
Jaccard, J., & Turrisi, R. (2003). Interaction effects in multiple regression. Sage.
Jacoby, D. (2006). Effects of part-time faculty employment on community college graduation rates. The Journal of Higher Education, 77(6), 1081–1103. https://doi.org/10.1353/jhe.2006.0050
Jaquette, O., Curs, B. R., & Posselt, J. R. (2016). Tuition rich, mission poor: Nonresident enrollment growth and the socioeconomic and racial composition of public research universities. The Journal of Higher Education, 87(5), 635–673. https://doi.org/10.1353/jhe.2016.0025
Kane, T. J., & Rouse, C. E. (1995). Labor-market returns to two- and four-year college. The American Economic Review, 85(3), 600–614.
Kanny, M. A. (2015). Dual enrollment participation from the student perspective. New Directions for Community Colleges, 2015, 59–70. https://doi.org/10.1002/cc.20133
Kilgo, C. A., Ezell sheets, J. K., & Pascarella, E. T. (2015). The link between high-impact practices and student learning: Some longitudinal evidence. Higher Education, 69, 509–525. https://doi.org/10.1007/s10734-014-9788-z
Killgore, L. (2009). Merit and competition in selective college admissions. The Review of Higher Education, 32(4), 469–488.
Kim, J., & Shim, W. (2019). What do rankings measure? The U.S. news rankings and student experience at liberal arts colleges. The Review of Higher Education, 42(3), 933–964. https://doi.org/10.1353/rhe.2019.0025
Kim, J., DesJardins, S. L., & McCall, B. P. (2009). Exploring the effects of student expectations about financial aid on postsecondary choice: A focus on income and racial/ethnic differences. Research in Higher Education, 50, 741–774. https://doi.org/10.1007/s11162-009-9143-x
Kim, J., Kim, J., DesJardins, S. L., & McCall, B. P. (2015). Completing algebra II in high school: Does it increase college access and success? The Journal of Higher Education, 86(4), 628–662. https://doi.org/10.1353/jhe.2015.0018
Klasik, D., & Zahran, W. (2022). The art of sophisticated quantitative description in higher education research. In L. W. Perna (Ed.), Higher education: Handbook of theory and research (Vol. 37). Springer. https://doi.org/10.1007/978-3-030-76660-3_12
Labaree, D. F. (1997). Public goods, private goods: The American struggle over educational goals. American Educational Research Journal, 34(1), 39–81. https://doi.org/10.3102/00028312034001039
Leigh, D. E., & Gill, A. M. (1997). Labor market returns to community colleges: Evidence for returning adults. Journal of Human Resources, 32(2), 334–353.
Lever, J., Krzywinski, M., & Altman, N. (2016). Model selection and overfitting. Nature Methods, 13, 703–704. https://doi.org/10.1038/nmeth.3968
Li, A. Y., & Gándara, D. (2020). The promise of “free” tuition and program design features: Impacts on first-time college enrollment. In L. W. Perna & E. J. Smith (Eds.), Improving research-based knowledge of college promise programs (pp. 219–240). American Educational Research Association.
Li, A. Y., & Kelchen, R. (2021). Institutional and state-level factors related to paying back student loan debt among public, private, and for-profit colleges. Journal of Student Financial Aid, 50(2), 1–19. https://doi.org/10.55504/0884-9153.1686
Lin, C.-H., Borden, V. M. H., & Chen, J.-H. (2020). A study on effects of financial aid on student persistence in dual enrollment and advanced placement participation. Journal of College Student Retention: Research, Theory & Practice, 22(3), 378–401. https://doi.org/10.1177/1521025117753732
Linsenmeier, D. M., Rosen, H. S., & Rouse, C. E. (2006). Financial aid packages and college enrollment decisions: An econometric case study. Review of Economics and Statistics, 88(1), 126–145.
Liu, X., & Borden, V. (2019). Addressing self-selection and endogeneity in higher education research. In J. Huisman & M. Tight (Eds.), Theory and method in higher education research (Vol. 5, pp. 129–151). Emerald. https://doi.org/10.1108/S2056-375220190000005009
Long, J. S., & Freese, J. (2014). Regression models for categorical dependent variables using Stata. Stata Press.
López, N., Erwin, C., Binder, M., & Chavez, M. J. (2018). Making the invisible visible: Advancing quantitative methods in higher education using critical race theory and intersectionality. Race Ethnicity and Education, 21(2), 180–207. https://doi.org/10.1080/13613324.2017.1375185
MacKinnon, J. G. (2013). Thirty years of heteroskedasticity-robust inference. In X. Chen & N. Swanson (Eds.), Recent advances and future directions in causality, prediction, and specification analysis (pp. 437–461). Springer. https://doi.org/10.1007/978-1-4614-1653-1_17
Malcom-Piqueux, L. (2015). Application of person-centered approaches to critical quantitative research: Exploring inequities in college financing strategies. New Directions for Institutional Research, 2014(163), 59–73. https://doi.org/10.1002/ir.20086
Marken, S., Gray, L., & Lewis, L. (2013). Dual enrollment programs and courses for high school students at postsecondary institutions: 2010–11 (NCES 2013–002). U.S. Department of Education. National Center for Education Statistics. https://nces.ed.gov/pubs2013/2013002.pdf
McCall, B. P., & Bielby, R. M. (2012). Regression discontinuity design: Recent developments and a guide to practice for researchers in higher education. In J. Smart & M. Paulsen (Eds.), Higher education: Handbook of theory and research (Vol. 27, pp. 249–290). Springer. https://doi.org/10.1007/978-94-007-2950-6_5
McCambly, H., Aguilar-Smith, S., Felix, E., Hu, X., & Baber, L. (2023). Community colleges as racialized organizations: Outlining opportunities for equity. Community College Review, advance online publication. https://doi.org/10.1177/00915521231182121
McClure, K. R., & Titus, M. (2018). Spending up the ranks? The relationship between striving for prestige and administrative expenditure at U.S. public research universities. The Journal of Higher Education, 89(6), 961–987. https://doi.org/10.1080/00221546.2018.1449079
McLendon, M. K., Hearn, J. C., & Mokher, C. G. (2009). Partisans, professionals, and power: The role of political factors in state higher education funding. The Journal of Higher Education, 80(6), 686–713.
McNeish, D. M. (2014). Analyzing clustered data with OLS regression: The effect of a hierarchical data structure. Multiple Linear Regression Viewpoints, 40(1), 11–16.
Mehl, G., Wyner, J., Barnett, E., Fink, J., & Jenkins, D. (2020). The dual enrollment playbook: A guide to equitable acceleration for students. Aspen Institute. https://ccrc.tc.columbia.edu/publications/dual-enrollment-playbook-equitable-acceleration.html
Miles, J. (2005). Tolerance and variance inflation factor. In B. S. Everitt & D. C. Howell (Eds.), Encyclopedia of statistics in behavioral science. https://doi.org/10.1002/0470013192.bsa683
Minaya, V. (2021). Can dual enrollment algebra reduce racial/ethnic gaps in early STEM outcomes? Evidence from Florida. Community College Research Center. https://ccrc.tc.columbia.edu/publications/dual-enrollment-algebra-stem-outcomes.html
Minicozzi, A. (2005). The short term effect of educational debt on job decisions. Economics of Education Review, 24(4), 417–430. https://doi.org/10.1016/j.econedurev.2004.05.008
Monks, J. (2014). The role of institutional and state aid policies in average student debt. The Annals of the American Academy of Political and Social Science, 655(1), 123–142. https://doi.org/10.1177/0002716214539093
Moretti, E. (2004). Estimating the social return to higher education: Evidence from longitudinal and repeated cross-sectional data. Journal of Econometrics, 121(1–2), 175–212. https://doi.org/10.1016/j.jeconom.2003.10.015
Museus, S. D. (2023). An evolving QuantCrit: The quantitative research complex and a theory of racialized quantitative systems. In L. W. Perna (Ed.), Higher education: Handbook of theory and research (Vol. 38, pp. 631–664). Springer. https://doi.org/10.1007/978-3-031-06696-2_5
Museus, S. D., Lutovsky, B. R., & Colbeck, C. L. (2007). Access and equity in dual enrollment programs: Implications for policy formation. Higher Education in Review, 4, 1–19.
National Center for Education Statistics. (n.d.). IPEDS 2022–23 data collection system. View Glossary. https://surveys.nces.ed.gov/ipeds/public/glossary
Olitsky, N. H. (2014). How do academic achievement and gender affect the earnings of STEM majors? A propensity score matching approach. Research in Higher Education, 55(3), 245–271. https://doi.org/10.1007/s11162-013-9310-y
Page, L. C., & Scott-Clayton, J. (2016). Improving college access in the United States: Barriers and policy responses. Economics of Education Review, 51, 4–22. https://doi.org/10.1016/j.econedurev.2016.02.009
Park, J. J., & Kim, S. (2020). Harvard’s personal rating: The impact of private high school attendance. Asian American Policy Review, 30, 79–80.
Park, T. J., Flores, S. M., & Ryan, C. J. (2018). Labor market returns for graduates of Hispanic-serving institutions. Research in Higher Education, 59(1), 29–53. https://doi.org/10.1007/s11162-017-9457-z
Perna, L. W. (2003). The private benefits of higher education: An examination of the earnings premium. Research in Higher Education, 44(4), 461–472.
Pigott, T. D., & Polanin, J. R. (2020). Methodological guidance paper: High-quality meta-analysis in a systematic review. Review of Educational Research, 90(1), 24–46. https://doi.org/10.3102/0034654319877153
Pike, G. R. (1991). Using structural equation models with latent variables to study student growth and development. Research in Higher Education, 32(5), 499–524. https://doi.org/10.1007/BF00992625
Pompelia, S. (2020). Dual enrollment access. Education Commission of the State. https://files.eric.ed.gov/fulltext/ED602439.pdf
Porter, S. R. (2015). Quantile regression: Analyzing changes in distributions instead of means. In M. B. Paulsen (Ed.), Higher education: Handbook of theory and research (Vol. 30, pp. 335–382). Springer. https://doi.org/10.1007/978-3-319-12835-1_8
Pretlow, J., & Wathington, H. D. (2014). Expanding dual enrollment: Increasing postsecondary access for all? Community College Review, 42(1), 41–54. https://doi.org/10.1177/0091552113509664
Rask, K. (2010). Attrition in STEM fields at a liberal arts college: The importance of grades and pre-collegiate preferences. Economics of Education Review, 29(6), 892–900. https://doi.org/10.1016/j.econedurev.2010.06.013
Reynolds, C. L., & DesJardins, S. L. (2009). The use of matching methods in higher education research: Answering whether attendance at a 2-year institution results in differences in educational attainment. In J. C. Smart (Ed.), Higher education: Handbook of theory and research (Vol. 24, pp. 47–97). Springer. https://doi.org/10.1007/978-1-4020-9628-0_2
Ridgeway, G., Kovalchik, S. A., Griffin, B. A., & Kabeto, M. U. (2015). Propensity score analysis with survey weighted data. Journal of Causal Inference, 3(2), 237–249. https://doi.org/10.1515/jci-2014-0039
Ro, H. K., Fernandez, F., & Kim, S. (2023). Understanding political efficacy among Asian American undergraduates at research universities. Journal of Student Affairs Research and Practice, 60(2), 150–163. https://doi.org/10.1080/19496591.2021.1994409
Rodriguez, A., Furquim, F., & DesJardins, S. L. (2018). Categorical and limited dependent variable modeling in higher education. In M. B. Paulsen (Ed.), Higher education: Handbook of theory and research (Vol. 33, pp. 295–370). Springer. https://doi.org/10.1007/978-3-319-72490-4_7
Roksa, J., & Velez, M. (2012). A late start: Delayed entry, life course transitions and bachelor’s degree completion. Social Forces, 90(3), 769–794. https://doi.org/10.1093/sf/sor018
Rosenthal, R. (1979). The file drawer problem and tolerance for null results. Psychological Bulletin, 86(3), 638–641. https://doi.org/10.1037/0033-2909.86.3.638
Royall, R. M. (1986). The effect of sample size on the meaning of significance tests. The American Statistician, 40(4), 313–315.
Salkind, N. J., & Frey, B. B. (2021). Statistics for people who (think they) hate statistics. Sage.
Santiago, D. A. (2007). Choosing Hispanic-serving institutions (HSIs): A closer look at Latino students’ college choices. Excelencia in Education. https://eric.ed.gov/?id=ED506053
Schudde, L. (2018). Heterogeneous effects in education: The promise and challenge of incorporating intersectionality into quantitative methodological approaches. Review of Research in Education, 42(1), 72–92. https://doi.org/10.3102/0091732X18759040
Scott-Clayton, J., & Minaya, V. (2016). Should student employment be subsidized? Conditional counterfactuals and the outcomes of work-study participation. Economics of Education Review, 52, 1–18. https://doi.org/10.1016/j.econedurev.2015.06.006
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22(11), 1359–1366. https://doi.org/10.1177/0956797611417632
Sjoquist, D. L., & Winters, J. V. (2015). State merit-based financial aid programs and college attainment. Journal of Regional Science, 55(3), 364–390. https://doi.org/10.1111/jors.12161
Slavin, R., & Smith, D. (2009). The relationship between sample sizes and effect sizes in systematic reviews in education. Educational Evaluation and Policy Analysis, 31(4), 500–506. https://doi.org/10.3102/0162373709352369
Smith, K., Jagesic, S., Wyatt, J., & Ewing, M. (2018). AP STEM participation and postsecondary STEM outcomes: Focus on underrepresented minority, first-generation, and female students. College Board. https://eric.ed.gov/?id=ED581514
Sterling, T. D. (1959). Publication decisions and their possible effects on inferences drawn from tests of significance – Or vice versa. Journal of the American Statistical Association, 54(285), 30–34.
Stewart, D.-L. (2020). Twisted at the roots: The intransigence of inequality in U.S. higher education. Change, 52(2), 13–16.
Stratton, L. S. (2014). College enrollment: An economic analysis. In M. B. Paulsen (Ed.), Higher education: Handbook of theory and research (Vol. 29, pp. 327–384). Springer.
Strauss, L. C., & Volkwein, J. F. (2002). Comparing student performance and growth in 2- and 4-year institutions. Research in Higher Education, 43(2), 133–161.
Tabron, L. A., & Thomas, A. K. (2023). Deeper than wordplay: A systematic review of critical quantitative approaches in education research (2007–2021). Review of Educational Research, advance online publication. https://doi.org/10.3102/00346543221130017
Taylor, J. L. (2015). Accelerating pathways to college: The (in)equitable effects of community college dual credit. Community College Review, 43, 355–379. https://doi.org/10.1177/0091552115594880
Taylor, J. L., Allen, T. O., An, B. P., Denecker, C., Edmunds, J. A., Fink, J., Giani, M. S., Hodara, M., Hu, X., Tobolowsky, B. F., & Chen, W. (2022). Research priorities for advancing equitable dual enrollment policy and practice. University of Utah. https://cherp.utah.edu/_resources/documents/publications/research_priorities_for_advancing_equitable_dual_enrollment_policy_and_practice.pdf
Thomas, N., Marken, S., Gray, L., & Lewis, L. (2013). Dual credit and exam-based courses in US public high schools: 2010-11 (NCES 2013-001). U.S. Department of Education/National Center for education statistics. https://nces.ed.gov/pubs2013/2013001.pdf
Titus, M. A. (2009). The production of bachelor’s degrees and financial aspects of state higher education policy: A dynamic analysis. The Journal of Higher Education, 80(4), 439–468. https://doi.org/10.1353/jhe.0.0055
Turner, N. (2012). Who benefits from student aid? The economic incidence of tax-based federal student aid. Economics of Education Review, 31(4), 463–481. https://doi.org/10.1016/j.econedurev.2011.12.008
Tyler, J. H., Murnane, R. J., & Willett, J. B. (2003). Who benefits from a GED? Evidence for females from High School and Beyond. Economics of Education Review, 22(3), 237–247. https://doi.org/10.1016/S0272-7757(02)00054-7
Waddell, G. R., & Singell, L. D. (2011). Do no-loan policies change the matriculation patterns of low-income students? Economics of Education Review, 30(2), 203–214. https://doi.org/10.1016/j.econedurev.2010.10.004
Webber, D. A. (2016). Are college costs worth it? How ability, major, and debt affect the returns to schooling. Economics of Education Review, 53, 296–310. https://doi.org/10.1016/j.econedurev.2016.04.007
Webber, D. A., & Ehrenberg, R. G. (2010). Do expenditures other than instructional expenditures affect graduation and persistence rates in American higher education? Economics of Education Review, 29(6), 947–958. https://doi.org/10.1016/j.econedurev.2010.04.006
Weisberg, S. (2014). Applied linear regression (4th ed.). Wiley.
Wells, R. S., & Stage, F. K. (2015). Past, present, and future of critical quantitative research in higher education. New Directions for Institutional Research, 2014(163), 103–112. https://doi.org/10.1002/ir.20089
What Works Clearinghouse. (2022). What Works Clearinghouse procedures and standards handbook, version 5.0. U.S. Department of Education, Institute of Education Sciences, National Center for Education Evaluation and Regional Assistance (NCEE). https://ies.ed.gov/ncee/wwc/Handbooks
Whatley, M. (2022). Introduction to quantitative analysis for international educators. Springer.
Wilkinson, L., & APA Task Force on Statistical Inference. (1999). Statistical methods in psychology journals: Guidelines and explanations. American Psychologist, 54(8), 594–604. https://doi.org/10.1037/0003-066X.54.8.594
Wolniak, G. C., & Engberg, M. E. (2019). Do “high-impact” college experiences affect early career outcomes? The Review of Higher Education, 42(3), 825–858. https://doi.org/10.1353/rhe.2019.0021
Wolniak, G. C., & Pascarella, E. T. (2007). Initial evidence on the long-term impacts of work colleges. Research in Higher Education, 48(1), 39–71. https://doi.org/10.1007/s11162-006-9023-6
Yeung, R., Gigliotti, P., & Nguyen-Hoang, P. (2019). The impact of U.S. news college rankings on the compensation of college and university presidents. Research in Higher Education, 60(1), 1–17. https://doi.org/10.1007/s11162-018-9501-7
Zhang, L. (2010). The use of panel data models in higher education policy studies. In J. C. Smart (Ed.), Higher education: Handbook of theory and research (Vol. 25, pp. 307–350). Springer. https://doi.org/10.1007/978-90-481-8598-6_8
Zinth, J. (2018). STEM dual enrollment: Model policy components. Education Commission of the States. https://www.ecs.org/wp-content/uploads/STEM-Dual-Enrollment-Model-Policy-Components.pdf
Zinth, J., & Barnett, E. (2018). Rethinking dual enrollment to reach more students. Promising practices. Education Commission of the States. https://eric.ed.gov/?id=ED582909
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Section Editor information
Appendices
Appendix A: Data Preparation for Illustration Replication
The public-use HSLS:09 data can be found at https://nces.ed.gov/datalab/. Once the student-level dataset is downloaded and opened in Stata, the following commands were run to generate the OLS example data.dta file.
***sample selection*** *Generate sample with known primary first-year institution identified by 2017 . keep if X5PFYEAR > 0 (14,815 observations deleted) *Exclude students who did not have any dual credit indicated in their postsecondary transcript . drop if X5HSCRDERN <= 0 (6,954 observations deleted) *Exclude students with no valid values of the tuition level of a primary first-year institution . drop if X5PFYTUITION < 0 (1 observation deleted) ***variable selection*** **sociodemographic characteristics in 11th grade** *sex* . recode X2SEX (1=0) (2=1) (-9=.) . label define X2SEXF 0 "Male" 1 "Female", replace . label values X2SEX X2SEXF *race/ethnicity* . recode X2RACE (-9=.) *family income* . recode X2FAMINCOME (-8=.) *parental education* . recode X2PAREDU (-8=.) *dependent indicator* . gen dependent = 0 . replace dependent = 1 if P2DEPENDNUM>0 **students’ expectations of college and costs in 11th grade *educational expectations* . replace X2STUEDEXPCT=. if X2STUEDEXPCT<0 *financial aid expectation* . gen finaidexp = 0 . replace finaidexp=1 if S2QUALNEED==1| S2QUALACHIEVE==1 *the importance of cost of attendance when choosing a college* . recode S2COSTATTEND (-9=.)(-8=.)(-7=.) **academic performance** *high school overall GPA (honor-weighted)* . replace X3TGPAWGT=. if X3TGPAWGT < 0 *the number of AP/IB credits earned . recode X3TCREDAPIB (-9=.)(-8=.)(-7=.)(-6=.)(-1=.) **high school characteristics** *high school location* . recode X3LOCALE (-9=.)(-8=.)(-7=.)(-1=.) *high school control* . recode X3CONTROL (-9=.)(-8=.)(-7=.)(-1=.) (3=2) **enrollment intensity** . recode X5PFYENRLSTAT (-9=.) **Create a hypothetical unit var for independence testing because the public-use data suppressed school ID** . egen SimuID = group(X3REGION X3CONTROL X3LOCALE X2SCHOOLCLI) **Fill missing values with the variable's median value . fillmissing X2FAMINCOME X2PAREDU X3TGPAWGT X2STUEDEXPCT X3TCREDAPIB X3LOCALE X3CONTROL S2COSTATTEND X5PFYENRLSTAT SimuID, with(median) **Keep only relevant variables for demonstration purposes . keep X5PFYTUITION X5HSCRDERN X2SEX X2RACE X2FAMINCOME X2PAREDU dependent S2COSTATTEND finaidexp X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB X3LOCALE X3CONTROL X5PFYENRLSTAT firstgen lowinc SimuID STU_ID *Save file . save "OLS example data.dta", replace
Appendix B: HSLS Variables Used for the Illustrated Example
Dependent Variable | Tuition and fees charged at primarily first-year institution (logged) | continuous | X5PFYTUITION | |
Independent Variables | The number of known dual credits earned | discrete | X5HSCRDERN | |
Control Variables | sociodemographic characteristics in their 11th grade | Sex | 0 = Male; 1 = Female | X2SEX |
Race/Ethnicity | 1 = White; 2 = Black/African American, non-Hispanic; 3 = Hispanic; 4 = Asian or Native Hawaiian/Pacific Islander, non-Hispanic; 5 = American Indian or Alaska Native, non-Hispanic; 6 = More than one race, non-Hispanic | X2RACE | ||
Total family income from all sources | 1 = less than or equal to $15,000; 2 = family income > $15,000 and <= $35,000; 3 = family income > $35,000 and <= $55,000; 4 = family income > $55,000 and <= $75,000; 5 = family income > $75,000 and <= $95,000; 6 = family income > $95,000 and <= $115,000; 7 = family income > $115,000 and <= $135,000; 8 = family income > $135,000 and <= $155,000; 9 = family income > $155,000 and <=$175,000; 10 = family income > $175,000 and <= $195,000; 11 = family income > $195,000 and <= $215,000; 12 = family income > $215,000 and <= $235,000; 13 = family income above $235,000 | X2FAMINCOME | ||
Parents’/guardians’ highest level of education | 1 = No postsecondary degree, 2 = Associate’s degree; 3 = Bachelor’s degree; 4 = Master’s degree; 5 = Ph.D./M.D/Law/other high level professional degree | X2PAREDU | ||
Number of dependents on respondent’s parents | discrete | P2DEPENDNUM | ||
Students’ expectations of college and associated costs in their 11th grade | How far in school sample member thinks the respondent will get | 1 = No postsecondary degree or don’t know; 2 = Associate’s degree attempt or attainment; 3 = Bachelor’s degree attempt or attainment; 4 = Master attempt or attainment; 5 = Ph.D./M.D./law degree/high level professional degree attempt or attainment | X2STUEDEXPCT | |
whether students expect being qualified for financial aid based on financial need or academic achievement | 0 = No; 1 = Yes | S2QUALNEED, S2QUALACHIEVE | ||
Importance of cost of attendance when choosing college/school | 1 = Very important; 2 = Somewhat important; 3 = Not at all important | S2COSTATTEND | ||
academic performance in 12th grade | Overall GPA, honors-weighted | discrete | X3TGPAWGT | |
Credits earned in AP/IB combined | discrete | X3TCREDAPIB | ||
high school characteristics | Location | 1 = Urban; 2 = Suburban; 3 = Town; 4 = Rural | X3LOCALE | |
Control | 1 = Public; 2 = Catholic or other private | X3CONTROL | ||
Enrollment status first-year in college | students’ enrollment intensity status | 1 = Exclusively part time; 2 = Exclusively part time; 3 = Mixed full time and part time | X5PFYENRLSTAT | |
Appendix C: Diagnosis and Data Recoding to Address Assumption Violations
. use "OLS example data.dta", clear **Stata code used in Section 2 *Generate descriptive summary of the dependent and focal independent variables only (Table 1) . sum X5PFYTUITION X5HSCRDERN, detail *Run simple regression (Table 2 & Table 3) . regress X5PFYTUITION X5HSCRDERN *Generate scatterplot with CI (Figure 1a) . twoway (scatter X5PFYTUITION X5HSCRDERN) (lfitci X5PFYTUITION X5HSCRDERN, lcolor(black) color(%50)) ,legend(order(2 "95% CI" 3 "Fitted values")) scheme(s1mono) xtitle("The number of dual credits earned in high school") ytitle("Tuition and Fees Charged", size(small)) *Use hierarchical procedures to select control variables (Table 4) . nestreg: regress X5PFYTUITION X5HSCRDERN (i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent) (i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT) (X3TGPAWGT X3TCREDAPIB) (i.X3LOCALE i.X3CONTROL) (i.X5PFYENRLSTAT) *Test omitted variable . regress X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT . linktest . estat ovtest *Test overfitting . overfit: regress X5PFYTUITION . overfit: regress X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT *Generate descriptive summary of all variables . sum X5PFYTUITION X5HSCRDERN X2SEX X2RACE X2FAMINCOME X2PAREDU dependent S2COSTATTEND finaidexp X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB X3LOCALE X3CONTROL X5PFYENRLSTAT, detail *Generate scatter plot matrix (results omitted) . graph matrix X5PFYTUITION X5HSCRDERN X2SEX X2RACE X2FAMINCOME X2PAREDU dependent S2COSTATTEND finaidexp X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB X3LOCALE X3CONTROL X5PFYENRLSTAT *Calculate the correlation matrix [Option 1] . correlate X5PFYTUITION X5HSCRDERN X2SEX X2RACE X2FAMINCOME X2PAREDU dependent S2COSTATTEND finaidexp X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB X3LOCALE X3CONTROL X5PFYENRLSTAT *Calculate the correlation matrix [Option 2] (Table 5) . pwcorr X5PFYTUITION X5HSCRDERN X2SEX X2RACE X2FAMINCOME X2PAREDU dependent S2COSTATTEND finaidexp X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB X3LOCALE X3CONTROL X5PFYENRLSTAT, star(.05) bonferroni **Stata code used in Section 3 *1. multicollinearity *Perform multiple linear regression model . regress X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Calculate VIF for each independent variable . vif *Recode race* . recode X2RACE(8=1)(3=2)(4=3)(5=3)(2=4)(7=4)(1=5)(6=6) . label define X2RACEF 1 "White, non-Hispanic" 2 "Black, non-Hispanic" 3 "Hispanic" 4 "AAPI, non-Hispanic" 5 " Amer. Indian/Alaska Native, non-Hispanic" 6 "More than one race, non-Hispanic", replace . label values X2RACE X2RACEF *Recode parent education level* . recode X2PAREDU (2=1)(3=1)(4=2)(5=3)(6=4)(7=5) . label define X2PAREDUF 1 "No postsecondary degree" 2 "AA" 3 "BA" 4 "Master" 5 "Doctoral or Prof", replace . label values X2PAREDU X2PAREDUF *Recode education aspiration* . recode X2STUEDEXPCT (2=1)(3=1)(4=1)(5=2)(6=2)(7=3)(8=3) (9=4)(10=4)(11=5)(12=5)(13=1) . label define X2EDEXPF 1 "No postsecondary degree or don't know" 2 "AA attempt or attainment" 3 "BA attempt or attainment" 4 "Master attempt or attainment" 5 "Doctoral or Prof attempt or attainment", replace . label values X2STUEDEXPCT X2EDEXPF *Rerun regression model and calculate VIF (code omitted) **2. linearity** *Perform revised multiple linear regression model . regress X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Generate standardized residuals . predict r, resid *Plot standardized residuals against the predictor variables . scatter r X5HSCRDERN, scheme(s1mono) **Plot augmented partial residuals with lowess smoothed line (Figure 3a) . acprplot X5HSCRDERN, scheme(s1mono) lowess *Plot the pattern to the residual against the fitted (predicted) values with a reference line at y=0 . rvfplot, yline(0) scheme(s1mono) *Conduct numerical tests: Breusch-Pagan / Cook-Weisberg test for heteroskedasticity (the Breusch-Pagan test) . estat hettest *Drop standardized residuals for subsequent analyses . drop r *Transform dependent variable with natural log . gen log_X5PFYTUITION = ln(X5PFYTUITION) *Perform revised multiple linear regression model . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Generate standardized residuals . predict r, resid *Plot standardized residuals against the predictor variables . scatter r X5HSCRDERN, scheme(s1mono) **Plot augmented partial residuals with lowess smoothed line (Figure 3b) . acprplot X5HSCRDERN, scheme(s1mono) lowess **Plot augmented partial residuals with lowess smoothed line for other continuous/discrete variables . scatter r X3TGPAWGT, scheme(s1mono) . acprplot X3TGPAWGT, scheme(s1mono) lowess . scatter r X3TCREDAPIB, scheme(s1mono) . acprplot X3TCREDAPIB, scheme(s1mono) lowess **3. Normality *Plot a kernel density plot to be overlaid on a normal density plot (Figure 4) . kdensity r, normal scheme(s1mono) *Plot a standardized normal probability (p-p) plot (Figure 5) . pnorm r, scheme(s1mono) *Plot the quantiles of a var against the quantiles of a normal distribution (Figure 6a) . qnorm r, scheme(s1mono) *Conduct numerical tests: perform the shapiro-wilk w test for normality with 4<=n<=2000 observations . swilk r * Conduct numerical tests for inter-quartile range and symmetric distribution . iqr r *Drop standardized residuals for subsequent analyses . drop r **Address influential observations** *Perform revised multiple linear regression model . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Predict the studentized residual . predict r, rstudent *Display stem-and-leaf plots . stem r *Drop influential observations . drop if abs(r) > 3 *Re-plot the quantiles of a var against the quantiles of a normal distribution after excluding influential observations (Figure 6b) . qnorm r, scheme(s1mono) *Drop studentized residuals for subsequent analyses . drop r **4. equal variance (homoscedasticity)** *Perform revised multiple linear regression model . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Plot the pattern to the residual against the fitted (predicted) values with a reference line at y=0 (figure 7b) . rvfplot, yline(0) scheme(s1mono) * Conduct numerical tests: Breusch-Pagan / Cook-Weisberg test for heteroskedasticity (the Breusch-Pagan test) . estat hettest **5. independence** *Generate standardized residuals . predict r, resid *Plot the standardized residuals against the unit variable (Figure 8) . scatter r SimuID, scheme(s1mono) xtitle(SimuID) **Save file . save "OLS example data final.dta", replace
Appendix D: Full Model Specification for Results Interpretation
. use "OLS example data final.dta", clear **Test interaction effect between the focal independent variable and institutional control*** . regress log_X5PFYTUITION c.X5HSCRDERN##i.X3CONTROL i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Plot interaction effect of c.X5HSCRDERN*i.X3CONTROL (Figure 9a) . margins X3CONTROL, at (X5HSCRDERN = (1(1)21)) . marginsplot, scheme(s1mono) yscale(range(8.4 9.2)) **Test interaction effect between the focal independent variable and Hispanic race*** . gen Hispanic=0 . replace Hispanic=1 if X2RACE==3 . regress log_X5PFYTUITION c.X5HSCRDERN i.X2RACE c.X5HSCRDERN#i.Hispanic i.X2SEX i.X2FAMINCOME i.X2PAREDU i.dependent X3TGPAWGT i.X2STUEDEXPCT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.S2COSTATTEND i.finaidexp i.X5PFYENRLSTAT *Plot interaction effect of c.X5HSCRDERN*i.Hispanic (Figure 9b) . margins Hispanic, at (X5HSCRDERN = (1(1)21)) . marginsplot, scheme(s1mono) yscale(range(8.4 9.2)) *Generate coefficients for Hispanic and non-Hispanic group . margins, dydx(X5HSCRDERN) at(Hispanic=(0 1)) ***Subgroup analysis *Generate a scatterplot with 95% CI for non-Hispanic Students Subgroup (Figure 10a) . twoway (lfitci log_X5PFYTUITION X5HSCRDERN if Hispanic==0) (scatter log_X5PFYTUITION X5HSCRDERN if Hispanic==0, msymbol(o)), legend(order(1 "95% CI" 2 "Fitted values" 3 "non-Hispanic Students")) xtitle("The number of dual credits earned in high school") ytitle("Tuition and Fees Charged", size(small)) graphregion(color(white)) scheme(s1mono) *Generate a scatterplot with 95% CI for Hispanic Students Subgroup (Figure 10b) . twoway (lfitci log_X5PFYTUITION X5HSCRDERN if Hispanic==1) (scatter log_X5PFYTUITION X5HSCRDERN if Hispanic==1, msymbol(o)), legend(order(1 "95% CI" 2 "Fitted values" 3 "Hispanic Students")) xtitle("The number of dual credits earned in high school") ytitle("Tuition and Fees Charged", size(small)) graphregion(color(white)) scheme(s1mono) *Run multiple linear regression for the non-Hispanic student subgroup . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT if Hispanic==0 . est store nonHispanicStudents *Run multiple linear regression for the Hispanic student subgroup . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT if Hispanic==1 . est store HispanicStudents *Compare regression coefficients across groups . suest nonHispanicStudents HispanicStudents . test [nonHispanicStudents_mean]X5HSCRDERN = [HispanicStudents_mean]X5HSCRDERN *Generate output tables with user-written command outreg2 (Table 6) . outreg2 [nonHispanicStudents HispanicStudents] using regsub_output, stats(coef se) alpha(0.001, 0.01, 0.05) asterisk(coef) dec(3) adjr2 replace . seeout **Final Model Specifications** *Include the dependent variable and the focal independent variable . regress log_X5PFYTUITION X5HSCRDERN . est store Model1 *Add the block of sociodemographic variables . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent . est store Model2 *Add the block of cost expectation variables . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT . est store Model3 *Add the block of academic performance variables . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB . est store Model4 *Add the block of high school characteristics variables . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL . est store Model5 *Add the block of enrollment intensity variables . regress log_X5PFYTUITION X5HSCRDERN i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT . est store Model6 *Add the interaction term (Table 7) . regress log_X5PFYTUITION X5HSCRDERN c.X5HSCRDERN#i.Hispanic i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT . est store Model7 *Calculate robust standard errors . regress log_X5PFYTUITION X5HSCRDERN c.X5HSCRDERN#i.Hispanic i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT, vce(robust) . est store Model8 *Generate output tables with user-written command outreg2 (Table 8) . outreg2 [Model1 Model2 Model3 Model4 Model5 Model6 Model7 Model8] using reg_output, stats(coef se) alpha(0.001, 0.01, 0.05) asterisk(coef) dec(3) adjr2 replace . seeout *Generate standardized beta . regress log_X5PFYTUITION X5HSCRDERN c.X5HSCRDERN#i.Hispanic i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT, beta *Generate predicted values holding covariates at their means . regress log_X5PFYTUITION X5HSCRDERN c.X5HSCRDERN#i.Hispanic i.X2SEX i.X2RACE i.X2FAMINCOME i.X2PAREDU i.dependent i.S2COSTATTEND i.finaidexp i.X2STUEDEXPCT X3TGPAWGT X3TCREDAPIB i.X3LOCALE i.X3CONTROL i.X5PFYENRLSTAT . margins, at(X5HSCRDERN =(3 6 9 12 15 18 30)) atmeans
Rights and permissions
Copyright information
© 2024 Springer Nature Switzerland AG
About this entry

Cite this entry
Hu, X. (2024). Using Ordinary Least Squares in Higher Education Research: A Primer. In: Perna, L.W. (eds) Higher Education: Handbook of Theory and Research. Higher Education: Handbook of Theory and Research, vol 39. Springer, Cham. https://doi.org/10.1007/978-3-031-38077-8_13
Download citation
DOI: https://doi.org/10.1007/978-3-031-38077-8_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-38076-1
Online ISBN: 978-3-031-38077-8
eBook Packages: EducationReference Module Humanities and Social SciencesReference Module Education