
Abstract
In the last decade, machine translation has become a popular means to deal with multilingual digital content. By providing higher quality translations, obfuscating the source language of a text becomes more attractive. In this paper, we analyze the ability to detect the source language from the translated output of two widely used commercial machine translation systems by utilizing machine-learning algorithms with basic textual features like n-grams. Evaluations show that the source language can be reconstructed with high accuracy for documents that contain a sufficient amount of translated text. In addition, we analyze how the document size influences the performance of the prediction, as well as how limiting the set of possible source languages improves the classification accuracy.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
The sampling on a random basis was required since the lcc dataset only contains random sentences, rather than cohesive documents.
- 6.
- 7.
- 8.
- 9.
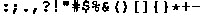
 \(\hat{\,}\)_\(\texttt {`|~}\).
\(\hat{\,}\)_\(\texttt {`|~}\). - 10.
We rely on the list of stop words provided by scikit-learn.
- 11.
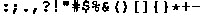

References
Aharoni, R., Koppel, M., Goldberg, Y.: Automatic detection of machine translated text and translation quality estimation. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, vol. 2, Baltimore, USA, June 2014, pp. 289–295. Association for Computational Linguistics (2014)
Bykh, S., Meurers, D.: Native language identification using recurring N-grams - investigating abstraction and domain dependence. In: Proceedings of the 24th International Conference on Computational Linguistics (COLING 2012),Mumbai, India, pp. 425–440, December 2012
Bykh, S., Meurers, D.: Exploring syntactic features for native language identification: a variationist perspective on feature encoding and ensemble optimization. In: Proceedings of the 25th International Conference on Computational Linguistics (COLING 2014), Dublin, Ireland, August 2014, pp. 1962–1973 (2017)
Bykh, S., Meurers, D.: Advancing linguistic features and insights by label-informed feature grouping: an exploration in the context of native language identification. In: Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016), pp. 739–749, December 2016
Caliskan, A., Greenstadt, R.: Translate once, translate twice, translate thrice and attribute: identifying authors and machine translation tools in translated text. In: Proceedings of the 6th International Conference on Semantic Computing (ICSC 2012), pp. 121–125. IEEE, September 2012
Goldhahn, D., Eckart, T., Quasthoff, U.: Building large monolingual dictionaries at the Leipzig corpora collection: from 100 to 200 languages. In: Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012) (2012)
Ionescu, R.T., Popescu, M.: Can string kernels pass the test of time in Native Language Identification? In: Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, pp. 224–234. Association for Computational Linguistics, September 2017
Ionescu, R.T., Popescu, M., Cahill, A.: Can characters reveal your native language? A language-independent approach to native language identification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), pp. 1363–1373. Association for Computational Linguistics, October 2014
Joachims, T.: Text categorization with support vector machines: learning with many relevant features. In: Nédellec, C., Rouveirol, C. (eds.) ECML 1998. LNCS, vol. 1398, pp. 137–142. Springer, Heidelberg (1998). https://doi.org/10.1007/BFb0026683
Koppel, M., Schler, J., Zigdon, K.: Automatically determining an anonymous author’s native language. In: Kantor, P., et al. (eds.) ISI 2005. LNCS, vol. 3495, pp. 209–217. Springer, Heidelberg (2005). https://doi.org/10.1007/11427995_17
Malmasi, S., Dras, M.: Language transfer hypotheses with linear SVM weights. In: Proceedings of the 2014 Conference on Empirical Methods in Natuarl Language Processing (EMNLP 2014), pp. 1385–1390. Association for Computational Linguistics, October 2014
Malmasi,S., et al.: A report on the 2017 native language identification shared task. In: Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, pp. 62–75. Association for Computational Linguistics, September 2017
Nirkhi, S., Dharaskar, R.V.: Comparative study of authorship identification techniques for cyber forensics analysis. Int. J. Adv. Comput. Sci. Appl. 4(5) (2013)
Pimienta, D., Prado, D., Blanco, A.: Twelve years of measuring linguistic diversity in the internet: balance and perspectives (2009)
Potthast, M., Hagen, M., Stein, B.: Author obfuscation: attacking the state of the art in authorship verification. In: Working Notes Papers of the CLEF 2016 Evaluation Labs, CEUR Workshop Proceedings. CLEF and CEUR-WS.org, September 2016
Rao, J.R., Rohatgi, P.: Can pseudonymity really guarantee privacy? In: Proceedings of the 9th Conference on USENIX Security Symposium, volume 9 of SSYM 2000, pp. 7–7. USENIX Association, August 2000
Stamatatos, E.: A survey of modern authorship attribution methods. J. Am. Soc. Inform. Sci. Technol. 60(3), 538–556 (2009)
Swanson, B., Charniak, E.: Extracting the native language signal for second language acquisition. In: Proceedings of NAACL-HLT, pp. 85–94. Association for Computational Linguistics, June 2013
Swanson, B., Charniak, E.: Data driven language transfer hypotheses. In: Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, volume 2: short papers, Gothenburg, Sweden, April 2014, pp. 169–173. Association for Computational Linguistics (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 Springer Nature Switzerland AG
About this paper

Cite this paper
Murauer, B., Tschuggnall, M., Specht, G. (2023). On the Influence of Machine Translation on Language Origin Obfuscation. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2018. Lecture Notes in Computer Science, vol 13396. Springer, Cham. https://doi.org/10.1007/978-3-031-23793-5_26
Download citation
DOI: https://doi.org/10.1007/978-3-031-23793-5_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-23792-8
Online ISBN: 978-3-031-23793-5
eBook Packages: Computer ScienceComputer Science (R0)