
Abstract
A problem frequently encountered in point process modeling is that event times are usually not known. The only available information is the number of events over a given interval. Calculus and regularization present a convenient framework to perform inference in these circumstances through explicit formulas for this class of mixed doubly point processes. As an application, we present a novel way of dealing with uncertainties in the computation of disability-adjusted life year, which is a measure of overall disease burden in populations.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

1 Introduction
Background and motivation of the study. In most applications concerning point processes, we are generally confronted with the problem that we do not have the times at which events have taken place. In such cases, the only information we have is the number of events over a given interval, but the event times are unknown. For example, since there can be many automobile accidents per day in the USA, it is common to record the number of accidents for that day, rather than the exact times at which these events happened.
The purpose of the present article is to spell out closed-form solutions for some functionals of the number of events over a given interval within a class of point processes that exhibit self and externally excitatory interactions. Intuitively, a process is self-exciting if the occurrence of past events makes the occurrence of future events more probable.
The origin of point processes incorporating both self- and external excitations date back to 2002, when the authors Brémaud and Massoulié (2002) introduced this model under very general conditions. In this paper, we perform inference on a model that combines both self-exciting behavior and externally exciting components as set forth in Dassios and Zhao (2011), where they incorporated the shot-noise Cox processes (Mohler 2013) as the external component while maintaining the Hawkes process (Hawkes 1971) for self-excitations. We shall henceforth call this process the Hawkes–Cox model.
Related work. Inference for point processes with the combined elements of endogenous and exogenous components have been studied in the machine learning community. Linderman and Adams (2014) introduced a multidimensional counting process combining a sparse log Gaussian Cox process (Møller et al. 1998) and a Hawkes component to uncover latent networks in the point process data. They showed how the superposition theorem of point processes enables the formulation of a fully Bayesian inference algorithm. Mohler (2013) considered a self-exciting process with background rate driven by a log Gaussian Cox process and performed inference based on an efficient Metropolis adjusted Langevin algorithm for filtering the intensity. Simma and Jordan (2010) proposed an expectation–maximization inference algorithm for Cox-type processes incorporating self-excitations via marked point processes and applied to a very large social network data.
We note that a variety of methods have been developed for the estimation of self or external excitations for point processes: variational flavors (Mangion et al. 2011), expectation propagation (Cseke and Heskes 2011), and the usage of thinning points and uniformization for non-stationary renewal processes, (Gunter et al. 2014; Teh and Rao 2011).
Perhaps the most intimately related work to ours is that of Da Fonseca and Zaatour (2014) where the authors looked at the functionals of event counts over an interval for a Hawkes process (Hawkes 1971). In this work, we proposed an inference procedure for the Hawkes–Cox model which captures both the self and external excitatory relationships over a given interval. As a by product, we extend some theoretical calculations needed to give explicit higher moments to calculate the covariance structure while generalizing the results of Da Fonseca and Zaatour (2014).
Contributions. Consider the scenario where we do not know the exact times at which events happen, but we have the number of events that have occurred in a given interval. We propose an inference procedure to learn the Hawkes–Cox model that can capture both self- and external excitatory relationships under these circumstances. Our major contributions are as follows: (i) We develop closed-form solutions of some functionals for the Hawkes–Cox process. (ii) Special attention is given to the covariance function of event counts over an interval. We show that the covariance structure over the number of jumps in an interval enjoys analytical tractability. This measure is extremely important as it supports the clustering property of the self-exciting property of the Hawkes process and the external excitation features of the Cox process. (iii) We developed an inference procedure through \(L_2\) regularization to learn parameters where estimation is almost instantaneous. (iv) We finally conclude by demonstrating the usefulness of applying Hawkes–Cox to model financial trade volumes.
2 The Hawkes–Cox Framework
Background on point processes. This section introduces some pieces of counting process theory needed in what follows. The homogeneous Poisson process \(\hat{N}=\{\hat{N}(t):t\ge 0\}\) with intensity m has the following properties: (a) The process starts at 0 with \(\hat{N}=0\); (b) the process has independent increments, i.e., for any \(t_i,i=0,...,n\) the increments \(\hat{N}_{t_1}-\hat{N}_{t_{i-1}}\) are mutually independent; (c) there exists a non-decreasing right continuous function \(m:[0,\infty )\rightarrow [0,\infty )\) with \(m(0)=0\) such that the increments \(\hat{N}_t-\hat{N}_s\) for \(0<s<t<\infty \) have a Poisson distribution with mean value function \(m(t)-m(s)\).
The Hawkes–Cox Model. We are interested in a counting process N(t) whose behavior is affected by past events, which contains both self- and externally excitation elements. Our point process N(t) has a non-negative \(\mathcal {F}_t-\) stochastic intensity function \(\lambda (t)\) of the form:
where \(\mathcal {B},\mathcal {H}\) and \(\mathcal {C}\) are functions whose definitions will be made precise in Definition 1 below. The sequence \((T_i)_{i\ge 1}\) denotes the event times of N, where the occurrence of an event induces the intensity to grow by an amount \(\mathcal {H}(Y_i,t\!-\!T_i)\): this element captures self-excitation. At the same time, external events can occur at times \(S_i\) and stimulate with a portion of \(\mathcal {C}(X_i,t\!-\!T_i)\): this is the externally excited part. The quantities X and Y are positive random elements describing the amplitudes by which \(\lambda \) increases during event times. The quantity \(\mathcal {B}_0:\mathbb {R}_+\mapsto \mathbb {R}_+\) denotes the deterministic base intensity. We write \(N_t:=N(t)\) and \(\lambda _t:=\lambda (t)\) to ease notation and \(\{\mathcal {F}_t\}\) being the history of the process and contains the list of times of events up to and including t, i.e. \(\{T_1,T_2,...,T_{N_t}\}\).

A sample of a Hawkes–Cox process. In the top plot, the blue line corresponds to the counting process of interested event times, while the black line shows the counting process of the external event times. The bottom graph plots the realized intensity function \(\lambda _t\)
We now give specific forms for \(\mathcal {B},\mathcal {H}\) and \(\mathcal {C}\) through the definition of the Hawkes–Cox model.
Definition 1
The Hawkes–Cox process is a point process N on \({\mathbb {R}}^{+}\) with the non-negative \(\mathcal {F}_t\) conditional random intensity
for \(t\ge 0\), where we have the following features:
-
Deterministic background. \(a\ge 0\) is the constant mean-reverting level, \(\lambda _0>a\) is the initial intensity at time \(t=0\), \(\delta >0\) is the constant rate of exponential decay. \(\mathcal {B}_0(t)=a+(\lambda _0-a)e^{-\delta t}\);
-
External excitations. \(X_i\) are levels of excitation from an external factor. They form a sequence of independent and identically distributed positive elements with distribution function \(H(c),c>0\). \(S_i\) are the times at which external events happen and it follows a Poisson process \(J_t\) of constant rate \(\rho >0\). Similar kernel types are used in Fisher and Banerjee (2010); Du et al. (2015), to name a few. Note that \(\mathcal {C}(X_i,t-S_i):=X_i e^{-\delta (t-S_i)}\).
-
Self-excitations. \(Y_i\) are levels of self-excitation, a sequence of independent and identically distributed positive elements with distribution function \(G(h),h>0\), occurring at random \(T_i\). Following the occurrence of events, the impact of these events will saturate and the rate at which this occurs is determined by the constant \(\delta \). Note that \(\mathcal {H}(Y_i,t-T_i):=Y_i e^{-\delta (t-T_i)}\).
For illustration, we present a sample simulation path obtained from the above parameterization in Fig. 1, showing generated event times. From this figure, we can see that the intensity process is excited by both the event times of interest (in crosses \(\times \)) and the external events (in circle \(\circ \)).
Note that from Definition 1, if we set \(X\equiv 0\) and Y to be a constant, we retrieve the model proposed by Hawkes (1971). If we set \(Y\equiv 0\) and X to be a positive random elements, we get the model proposed by Cox and Isham (1980). In addition, setting \(X=Y=0\) returns us the inhomogeneous Poisson process, Daley and Vere-Jones (2003). Furthermore, letting \(X=Y=0\) and \(\lambda _0=a\) simplify to the Poisson process.
2.1 The Choice of Kernel and the Rôle of \(\delta \)
The kernel for the externally excited component is known as the shot noise (Cox and Isham 1980; Møller 2003) where \(\mathcal {C}(X_i,t-S_i)=X_i e^{-\delta (t-S_i)}.\) This is a deliberate choice with \(\delta \) being shared between the background rate \(\mathcal {B}_0\) \(\mathcal {H}\) and \(\mathcal {C}\) to ensure that the process inherits the Markov property, see Brémaud and Massoulié (2002); Blundell et al. ( 2012). This property is essential to the derivation of the functionals in Sect. 3. The term \(\delta \) determines the rate at which the process decays exponentially from following arrivals of self-excited and externally excited events.
3 Dynkin’s Formula
The Markov property is the key property that allows one to invoke certain tools to obtain the moments for the number of events in an interval, rather than the number of events at a current time \(t>0\). Among these tools are the infinitesimal generator and martingale techniques. For a Markov process \(X_t\), consider a function \(f : D \rightarrow \mathbb {R}\). The infinitesimal generator of the process denoted \(\mathcal {A}\), is defined by
For every function f in the domain of the infinitesimal generator, the process
is a martingale (Øksendal and Sulem 2007). Thus, for \(t > s\), we have
by the martingale property of M. Rearranging, we finally obtain Dynkin’s formula (see, Øksendal and Sulem (2007))
In the following section, we will heavily rely on this formula to compute some distributional properties of the Hawkes–Cox process.
4 Theoretical Moments
Our aim is to compute the following quantities: mean, variance and covariance of the number of events in an interval \(\tau \), rather than at a fixed time t, as investigated by Dassios and Zhao (2011). To do so, we appeal to the techniques and manipulations presented in the previous section.
To ease notations, the first and second moments of levels of self- and external excitations X and Y, respectively, are denoted by
as well as the constant
First note that the joint process of \(\{(\lambda _t,N_t)\}_{t\ge 0}\) is a Markov process. This can be seen by proving that the expression \(\lambda _{T_k}\) only depends on \(\lambda _{T_{k-1}}\) and \(\{N_t:T_{k-1}\le t\le T_k\}\). By the Markov property and using the results in Øksendal and Sulem (2007); Davis (1984), the infinitesimal generator of the process \((t,\lambda _t,N_t)\) acting on a function \(f(t,\lambda ,n)\) is given by
4.1 The Moments of Counts in an Interval
In order to obtain the expected number of jumps for an interval (s, t], we apply Dynkin’s formula as in Eq. (3). By setting \(f(t,\lambda ,n)=n\), we have that \(\mathcal {A}n = \lambda \). Since \(N_t-N_s-\int _s^t \lambda _u du\) is a martingale, we have \(\mathbb {E}[N_t-N_s-\int _s^t\mathcal {A}N_u du|\mathcal {F}_s]=0\). Rearranging, we get
Due to Fubini’s Theorem, we interchange the order of expectation and the integral subsequently yields
Remark that this equation could have been obtained by recalling that \((N_t-\int ^t_0\lambda _sds)_{t\in [0,T]}\) is a martingale, by definition of the intensity of a point process, Daley and Vere-Jones (2003).
We can now give an explicit expression for the expectation of the number of events in an interval.
Proposition 1
The expectation of the number of jumps over an interval \(\tau \) is given by
Proof
An application of tower property of expectation yields
for \(s<t\). Setting \(t\!\leftarrow \! t\!+\!\tau \) and \(s\!\leftarrow \! t\) and letting \(t \!\rightarrow \! \infty \) and under the stationary condition \(\mu _{1G} < \delta \), we obtain the expression in Eq. (6). \(\blacksquare \)
We interpret this quantity as the long-run expectation of the number of events during a given time interval of length \(\tau \).
We now calculate the long-run variance of the number of jumps during an interval of length \(\tau \). We first note that
We proceed by calculating the first quantity on the RHS in Eq. (7). First, note that
Given the previous two results, we can now state the expression for the variance of the number of events in an interval of length \(\tau \):
Proposition 2
The variance of the number of jumps over an interval \(\tau \) is given by
4.2 The Covariance
We now turn to perhaps the most important quantity: the covariance function which carries information regarding the clustering nature of Hawkes–Cox. To calculate this cross-expectation of the number of events during different time intervals, we first need to determine the following expression:
where \(t_0<t<t_1<t_2<t_3\). For simplicity, we let \(\tau :=t_1-t\) and \(\tau =t_3-t_2\). We further define the lag of Hawkes–Cox as \(\tilde{\tau }:=t_2-t_1\). We state the following:
Proposition 3
The covariance of the number of jumps in a given interval \(\tau \) with lag \(\tilde{\tau }\) can be explicitly expressed as
5 Learning and Optimization
We present an optimization technique to learn the parameters of the Hawkes–Cox process. Consider the cost function \(\mathcal {J}\) of the following form:
where \(C^{\varphi }_i(t)\) denotes the theoretical function of moments for Hawkes–Cox. \(C^{\varphi }_1(t)=\mathbb {E}(N_{t+\tau }-N_{t})\), \(C^{\varphi }_2(t)=\textrm{Var}(N_{t+\tau }-N_{t})\) and
and \(C_i\) being the corresponding empirical function of moments in a given interval \(\tau \) and lag \(\tilde{\tau }\) where \(\lambda _{reg}\) is a parameter that controls the level of regularization in the optimization scheme with F being the regularization term. The first role of the penalization term F is to ensure uniqueness of the solution. Indeed, if F is convex in the \(\varphi \), then for \(\lambda _{reg}\) large enough, the entire functional \(\mathcal {J}\) will be convex and the solution will be unique. Note that the difference in the square terms are deviations of the theoretical functions of moments against the corresponding empirical values. Let the parameters of interest be \(\varphi \). The learned parameter \(\hat{\varphi }\) is obtained from
where \(\varphi \) is the parameter of interest. The details of optimization tools are presented in the experiment section.
6 Synthetic Experiments
We evaluate our proposed optimization method using both simulated and real-world data, and show that our approach significantly outperforms the baseline.
With estimation being almost instantaneous, we demonstrate the usefulness of Hawkes–Cox to model financial trade volumes. Empirical evidence have shown that trading activity is not a random process but rather produces time sequences that exhibit clustering behavior (Filimonov and Sornette 2012). If it was the case, a homogeneous Poisson process would have been a suitable candidate to model trade arrival times. Possible exogenous liquidity and news shocks are being capture through the external excitation component of Hawkes–Cox.
We show that our model achieves better accuracy in the prediction compared to MLE and also a homogeneous Point process (HPP).
6.1 Calibration
The experiments on assessing the stability and accuracy of the learned parameters from the Hawkes–Cox process are studied. First, we illustrate the generation of the synthetic data. Then we briefly review the MLE method before presenting the calibration results obtained with the proposed optimization method.
6.1.1 Synthetic Data Generation
For simplicity, we assume the levels of excitation \(X_\cdot \) and \(Y_\cdot \) be drawn from random elements of exponential distribution with mean parameter \(\psi \). One reason is that this makes the data generation process simple since an efficient simulation algorithm is available (Dassios and Zhao 2011). To avoid giving more weight to some parameters over others, we simply assume the following ground truth parameters for the simulation of the synthetic data. All parameters are set to a value of 1 except for the decay \(\delta \) and the initial intensity \(\lambda _0\). The decay parameter \(\delta \) is set to a value of 2 because it has to be greater than \(\psi \) to respect the stationarity condition (Brémaud and Massoulié 1996; Brémaud et al. 2002), while \(\lambda _0\) is set to 2 such that \((\lambda _0 - a)\) is non-zero. In addition, we arbitrarily set the maturity time T to 5,000 to allow for long-term stationary conditions to be achieved. We spell out the values of the parameters in Table 2 for ease of reading.
6.1.2 Maximum Likelihood Estimation
For practical applications, the MLE method has frequently been employed as the standard for parameter estimation on statistical models due to the lack of efficient and fast inference algorithms for large datasets. Presumably, the popularity of using MLE is due to Ozaki (1979) who first applied MLE procedures to estimate parameters of a Hawkes process. For example, despite the Markov chain Monte Carlo (MCMC) methods giving exact solutions in the limiting cases, they may be too slow for many practical applications (Kuss and Rasmussen 2005). Other inference techniques, albeit faster than MCMC, are still comparatively slower compared to MLE for practical purposes. Here, we use MLE to learn the set of parameters \(\varphi = \{a , \delta , \psi , \rho \}\).
To account for randomness from the simulations, the MLE result is obtained from 100 samples of Hawkes–Cox processes simulated with the ground truth parameters described in Sect. 6.1.1 or Table 2. The technical approach for computing the minimum is by using a bounded constrained optimizer built upon MATLAB function fminsearch, which in turn employs the Nelder–Mead simplex method (Nelder and Mead 1965). We bound our search space from 0 to 10.
We find that the learned MLE parameters, presented in the first row of Table 3, are close to the ground truth parameters, where their standard errors are displayed in the corresponding brackets. However, a careful inspection of their 95 % confidence intervals (i.e., ± two standard errors from the estimates) suggests that the estimates are not adequate, as the confidence intervals for a, \(\delta \) and \(\psi \) failed to contain the true values. Additionally, in Table 3, we compute the mean absolute difference (MAD) of the learned parameters against their ground truth values. This MAD value for MLE suggests that the learned parameters only deviate from (on average) the true values by 0.13.
We report that the MLE method takes quadratic time to run due to the evaluation of the loglikelihood function. In our case, we find that each MLE took around 846 s to complete.
6.1.3 \(L_2-\)Regularization
We replicate the above experiments but now with the proposed \(L_2-\)regularization method described Sect. 5. Since estimation is almost instantaneous, we perform the assessment by simulating 1,000 sample paths of Hawkes–Cox processes. We repeat the experiments for different configurations of the tuning parameters, that is, interval \(\tau \) in the range of 0.5–10.0, and regularization parameter \(\lambda _{reg}\) in the range of 0.0–1.0.
We present the MAD of the learned parameters against the true values corresponding to various configurations in Table 1, and the most accurately learned parameters from varying the \(\lambda _{reg}\) is tabulated in Table 3. Interestingly, we find that the higher the interval \(\tau \), we require a higher regularization parameter \(\lambda _{reg}\) to obtain the best results. Additionally, we also observe that the best parameter fitting gets worse (in terms of MAD) the higher the \(\tau \), this is most likely due to information loss as we aggregate over counts over a coarser granularity. Similarly, note that the standard errors increase as well.
We conclude that our method produces estimations that are very close to the true values as compared to the MLE method, as illustrated in Table 3. Further, in contrast to the MLE method, our regularization technique only took 1.2 s (175 times faster than MLE) for parameter estimations, on average (Table 4).
7 Disability Adjusted Life Years
DALY. The notion of the disability-adjusted life year (DALY) has been introduced in the 1990s. DALYs are important measurements that link the burden of disease in populations with the degree of morbidity, disability, and long-term survival. They were initially developed to gauge the global burden of disease and to determine a strategy for the evaluation of health benefits and its associated cost-effectiveness. One DALY is the equivalent of a year of healthy life lost if a person had not experienced a particular disease. Different theoretical and methodological challenges persist, which are likely to affect both the computation and interpretation of DALY estimates (Mathers et al. 2008).
The computation of DALY and its challenges. DALY calculations consist of two smaller estimates: (i) the number of years lived with disability (YLD); and (ii) the number of years of life lost (YLL) associated with the condition of interest. DALYs are estimated as the sum of the YLD and YLL pillars. YLD for different diseases is calculated using disease-specific disability weights that range between 0 (perfect health) and 1 (death) and the duration of disability. YLL is calculated using estimates of mortality associated with the condition of interest when untreated, life expectancy, and age at death.
At times, scarce, reliable population-based data on disease parameters, specifically incidence of deaths and diseases, make estimating DALY of a specific disease difficult, especially in lower middle-income economies (Kularatna et al. 2013; Wyber et al. 2015). Hence, standard techniques to deal with this uncertainty is to employ a sampling-based estimation procedure. In this approach, each parameter is modeled by a probability distribution centered upon the optimal estimate of the parameter with a range reflecting uncertainty (Puett et al. 2019; Noguera Zayas et al. 2021). Typically, disability weights were modeled using the continuous uniform distribution and the expected number of deaths were modeled using the Poisson distribution.
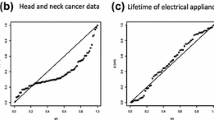
Proposed methodologies. Standard methods dictate the use of Poisson distribution to obtain estimates for the expected number of deaths and specific diseases. Recall that in a Poissonian framework, the probability of the number of deaths occurring in an age group happens with a fixed average rate, and is independent of the time since the last event. We propose the use of the intensity function in Eq. (2), for modeling purposes, which relaxes the Poisson assumption of stationary increments. It allows for the possibility that the rates need not be constant but can vary with time. This choice of intensity is general enough to encapsulate certain stylized facts of rates of deaths and diseases, such as nonlinear trend characteristics. Here, we illustrate the estimation procedure by applying the techniques presented earlier to obtain an estimate for the parameters for Hawkes–Cox process model, generalizing the Poissonian feature that is widely used in the literature. We first suppose that we observe the number of deaths (or number of diseases) across age groups, as tabulated in Table 5. For simplicity, we further suppose that there are three parameters to estimate, absorbed in \(\theta \in \mathbb {R}^3\). Define the function \(\mathcal {A}_{\theta }\) which takes the form
where \(m_1\), \(m_2\), and \(m_3\) denote the observed mean, variance, and covariance of the number of events within an interval with a predetermined specification of \(\tau \) and \(\delta \) given in (10), (11), and (12), respectively. The quantities \(h^{\tau }_1\), \(h^{\tau }_2\), and \(h^{\tau }_3\) given in (6), (8), and (9), respectively, are functions of the parameters. Let \(R_i\) denote the number of deaths (or number of diseases) falling in age group i. Furthermore, let N be the number of age groups remaining. In this case, we have
where \(\Delta = \lceil \delta /\tau \rceil \). One can then evaluate \(\hat{\theta }\) such that \(\mathcal {A}_{\hat{\theta }}=0\) using standard methods of moment matching (Hall 2004). With the estimated parameters, one can then obtain distributions related to the number of deaths and specific diseases. By a similar token, the same procedures may be applied to obtain suitable distributional properties for different age groups. This framework gives a natural way to deal with uncertainties in DALY computations, which subsumes the Poissonian assumptions.
8 Concluding Remarks
In this paper, we derive explicit moments and the covariance function of the number of events over an interval for the Hawkes–Cox process. The future evolution of this point process is influenced by the timing of past events whose intensities are affected by a self-exciting mechanism and an exogenous component. We develop an inference procedure through regularizations taking into account the theoretical functionals and showing that estimation is almost immediate. Empirical experiments on real data sets demonstrate its superior scalability and predictive performance.
References
Blundell, C., Beck, J., & Heller, K. A. (2012). Modelling reciprocating relationships with Hawkes processes. In Advances in Neural Information Processing Systems, (Vol. 25, pp. 2600–2608). Curran Associates.
Brémaud, P., & Massoulié, L. (1996). Stability of nonlinear Hawkes processes. The Annals of Probability, 24(3), 1563–1588.
Brémaud, P., & Massoulié, L. (2002). Power spectra of general shot noises and Hawkes point processes with a random excitation. Advances in Applied Probability, 34(1), 205–222.
Brémaud, P., Nappo, G., & Torrisi, G. L. (2002). Rate of convergence to equilibrium of marked Hawkes processes. Journal of Applied Probability, 39(1), 123–136.
Cox, D. R., & Isham, V. (1980). Point Processes. Chapman & Hall.
Cseke, B., & Heskes, T. (2011). Approximate marginals in latent Gaussian models. Journal of Machine Learning Resesarch, 12, 417–454.
Da Fonseca, J., & Zaatour, R. (2014). Hawkes process: fast calibration, application to trade clustering, and diffusive limit. Journal of Futures Markets, 34(6), 548–579.
Daley, D. J., & Vere-Jones, D. (2003). An Introduction to the Theory of Point Processes, Elementary Theory and Methods, (2nd ed., Vol. I). Springer.
Dassios, A., & Zhao, H. (2011). A dynamic contagion process. Advances in Applied Probability, 43(3), 814–846.
Davis, M. H. A. (1984). Piecewise-deterministic Markov processes: a general class of nondiffusion stochastic models. Journal of the Royal Statistical Society. Series B. Methodological, 46(3), 353–388.
Du, N., Wang, Y., He, N., and Song, L. (2015). Time-sensitive recommendation from recurrent user activities. In Advances in Neural Information Processing Systems 28, 3474–3482. Curran Associates.
Filimonov, V., & Sornette, D. (2012). Quantifying reflexivity in financial markets: Toward a prediction of flash crashes. Physical Review E, 85(5), 056108(1–9).
Fisher, N., & Banerjee, A. (2010). A novel kernel for learning a neuron model from spike train data. In Advances in Neural Information Processing Systems 23, 595–603. Curran Associates.
Gunter, T., Lloyd, C., Osborne, M. A., & Roberts, S. J. (2014). Efficient Bayesian nonparametric modelling of structured point processes. In Uncertainty in Artificial Intelligence (UAI).
Hall, A. (2004). Generalized Method of Moments. Oxford University Press.
Hawkes, A. G. (1971). Spectra of some self-exciting and mutually exciting point processes. Biometrika, 58(1), 83–90.
Kularatna, S., Whitty, J. A., Johnson, N. W., & Scuffham, P. A. (2013). Health state valuation in low- and middle-income countries: A systematic review of the literature. Value in Health, 16(6), 1091–1099.
Kuss, M., & Rasmussen, C. E. (2005). Assessing approximate inference for binary Gaussian process classification. Journal of Machine Learning Research, 6, 1679–1704.
Linderman, S. W., & Adams, R. P. (2014). Discovering latent network structure in point process data. In Thirty-First International Conference on Machine Learning (ICML).
Mangion, A. Z., Yuan, K., Kadirkamanathan, V., Niranjan, M., & Sanguinetti, G. (2011). Online variational inference for state-space models with point-process observations. Neural Computation, 23, 1967–1999.
Mathers, C., Fat, D. M., & Boerma, J. T. (2008). The global burden of disease: 2004 update.
Mohler, G. (2013). Modeling and estimation of multi-source clustering in crime and security data. The Annals of Applied Statistics, 7(3), 1525–1539.
Møller, J. (2003). Shot noise Cox processes. Advances in Applied Probability, 35(3), 614–640.
Møller, J., Syversveen, A. R., & Waagepetersen, R. P. (1998). Log Gaussian Cox processes. Scandinavian Journal of Statistics, 25(3), 451–482.
Nelder, J. A., & Mead, R. (1965). A simplex method for function minimization. The Computer Journal, 7(4), 308–313.
Noguera Zayas, L. P., Rüegg, S., & Torgerson, P. (2021). The burden of zoonoses in paraguay: A systematic review. PLOS Neglected Tropical Diseases, 15(11), 1–27.
Øksendal, B., & Sulem, A. (2007). Applied Stochastic Control of Jump Diffusions (2nd edn.). Springer.
Ozaki, T. (1979). Maximum likelihood estimation of Hawkes’ self-exciting point processes. Annals of the Institute of Statistical Mathematics, 31(1), 145–155.
Puett, C., Bulti, A., & Myatt, M. (2019). Disability-adjusted life years for severe acute malnutrition: Implications of alternative model specifications. Public Health Nutrition, 22, 2729–2737.
Simma, A., & Jordan, M. I. (2010). Modeling events with cascades of poisson processes. In UAI (pp. 546–555). AUAI Press.
Teh, Y. W., & Rao, V. (2011). Gaussian process modulated renewal processes. In Advances in Neural Information Processing Systems, (Vol. 24, pp. 2474–2482). Curran Associates.
Wyber, R., Vaillancourt, S., Perry, W., Mannava, P., Folaranmi, T., & Celi, L. A. (2015). Big data in global health: Improving health in low- and middle-income countries. Bulletin of the World Health Organization, 93(3).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Lee, Y., Vo, T.V., Ni, D., Mu, G. (2023). Life Events that Cascade: An Excursion into DALY Computations. In: Canci, J.K., Mekler, P., Mu, G. (eds) Quantitative Models in Life Science Business. SpringerBriefs in Economics. Springer, Cham. https://doi.org/10.1007/978-3-031-11814-2_7
Download citation
DOI: https://doi.org/10.1007/978-3-031-11814-2_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11813-5
Online ISBN: 978-3-031-11814-2
eBook Packages: Economics and FinanceEconomics and Finance (R0)