
Abstract
In this study, U-Net based deep convolutional networks are used to achieve the segmentation of particle regions in a microscopic image of colorants. The material appearance of products is greatly affected by the distribution of the particle size. From that fact, it is important to obtain the distribution of the particle size to design the material appearance of products. To obtain the particle size distribution, it is necessary to segment particle regions in the microscopic image of colorants. Conventionally, this segmentation is performed manually using simple image processing. However, this manual processing leads to low reproducibility. Therefore, in this paper, to extract the particle region with high reproducibility, segmentation is performed using U-Net based deep convolutional networks. We improved deep convolutional U-Net type networks based on the feature maps trained for a microscopic image of colorants. As a result, we obtained more accurate segmentation results using the improved network than conventional U-Net.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Colorants are used to design the material appearance of products. The material appearance is affected by the distribution of the particle size, which is one of the characteristics of colorants [1]. Therefore, it is important to measure the distribution of the particle size to obtain products that have the designer’s intended material appearance.
It is necessary to segment the particle region in a microscopic image of colorants to obtain the distribution of the particle size. Conventionally, the segmentation of microscopic images of colorants is processed manually or using simple image processing, such as binarization with threshold values. However, if segmentation is performed manually, it takes a long time to segment the image, and the reproducibility of the segmentation results is low because the results differ depending on the operator. If segmentation is performed using simple image processing [2], correct segmentation results cannot be obtained in many cases because the color difference between the particles and the background in the microscopic image is not constant in most images.
Therefore, in this paper, we aim to achieve a segmentation method with high accuracy and high reproducibility. We focus on improving the accuracy of segmentation for large particles because such particles have a large effect on the material appearance of products. We use U-Net based deep convolutional networks to achieve our goal. Moreover, to perform segmentation with higher accuracy than conventional U-Net, we improve U-Net-type networks based on the feature maps trained on a microscopic image of colorants.
2 Dataset
The input data are shown in Fig. 1(a). Art papers printed using ink mixed with carbon black pigment and resin by a proofer were captured using a scanning electron microscope.

Example of a dataset
The output data in Fig. 1(b) were created by manually segmenting the image in Fig. 1(a) using image editing software called CLIP STUDIO. In this study, the number of images for learning is 60.
3 Deep Convolutional Networks of U-Net Architecture
In this study, we use U-Net based deep convolutional networks for segmentation. We considered that U-Net is suitable for the segmentation of a microscopic image because it is generally used for the segmentation of various types of images [3,4,5].
The network architecture based on U-Net consists of an encoder path and decoder path, as shown in Fig. 2. U-Net has a skip connection that connects the learning result in each layer in the encoder path to the same depth layer in the decoder path. Using this feature, data can be up-sampled to retain detailed information. Each pass has a convolutional layer block, and each block has two convolutional layers with a filter size of 3 × 3. In the encoder, max pooling with a stride size of 2 × 2 is applied to the end of each block except the last block, so the size of the feature maps decreases from 512 × 512 to 32 × 32. In the decoder, up-sampling with a stride size of 2 × 2 is applied to the end of each block except the last block, so the size of the feature maps increases from 32 × 32 to 512 × 512. Zero padding is used to maintain the output dimension for all the convolutional layers of both the encoder and decoder paths. The number of channels increases from 1 to 1024 in the encoder and decreases from 1024 to 2 in the decoder. Adam is used for optimization; it is one of the most frequently used optimization algorithms in neural network learning. In the process of training, binary cross-entropy is used as the loss function of the network. It is achieved to perform segmentation of microscopic images of colorant by U-Net architecture shown in Fig. 2 [6].

Conventional U-Net
4 Improved U-Net Architectures
In this section, we improve the conventional U-Net architecture. We examined the problem of the conventional U-Net architecture from the feature maps, and improved the U-Net architectures. We can visualize the learning process by outputting the feature maps to show the output of the artificial neurons in the hidden layer [7].
4.1 Changing the Number of Channels
First, we changed the number of channels, as shown in Fig. 3. We segmented the particle region in the microscopic images for colorants using U-Net before and after changing the number of channels. We summarize the results of segmentation using each U-Net in Fig. 8 in Sect. 5.

Improved U-Net #1: U-Net after the number of channels was changed
Next, we output the feature maps for each U-Net. Figures 4(a) and (c) show the feature maps in the shallow and deep layers before the number of channels was changed. From these figures, we confirm that a large number of filters were not used for learning, particularly in deep layers. Figures 4(b) and (d) show the feature maps in the shallow and deep layers after the number of channels was changed. The ratio of filters that were not used for learning decreased significantly compared with the ratio before the number of channels was changed. From these results, we considered that the number of channels before the change was excessive. Therefore, after this section, we use the number of channels after the change shown in Fig. 3.

Feature maps before and after the number of channels was changed
4.2 Improvement of the Deep Layer Architecture
When we segmented particles that were dark inside and did not have a sharp contour, we did not obtain appropriate results. Therefore, we had to improve the U-Net architectures to obtain highly accurate segmentation results for such particles.
Figure 5 shows the results of the feature map output when the particle image was learned. This feature maps shows that the contour of the particle was partially broken immediately after input and immediately before output, and was detected in the deepest layer. We consider that incorrect results were obtained because incorrect information as shown in Fig. 5(a) is passed to the decoder. Therefore, we propose two U-Net architectures that reduce the influence of information on the encoder side.

Part of the feature maps of the hidden layer in improved U-Net #1
We propose two U-Net architectures:
-
(1)
Improved U-Net #2: Delete skip connections in deep layers (Fig. 6).
Fig. 6. 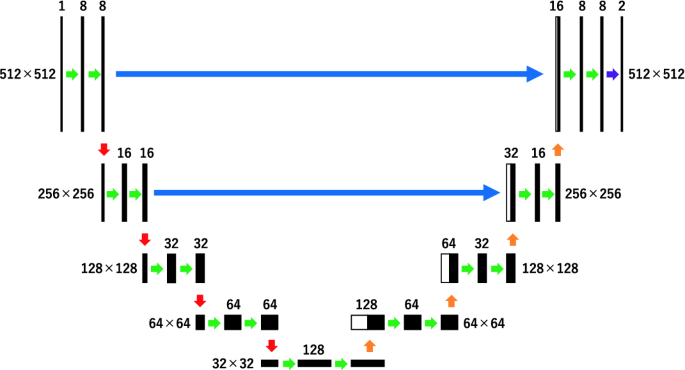
Improved U-Net #2: Delete some skip connections
-
(2)
Improved U-Net #3: Halve the weights of the two skip connections that connect the deep layers (Fig. 7).
Fig. 7. 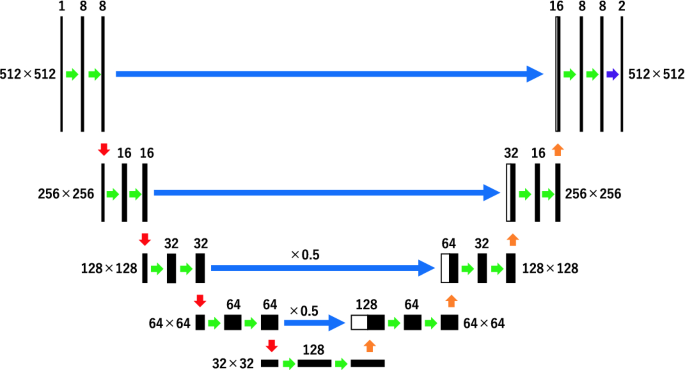
Improved U-Net #3: halve the weights of the two skip connections that connect the deep layers


In improved U-Net #2, we deleted two skip connections that connected the deep layers. In improved U-Net #3, we halved the weights of the two skip connections that connected the deep layers. These proposed methods are written in python using Keras.
5 Results
Figure 8 shows the image processing results that removed particles smaller than 400 pixels from the segmentation results using each U-Net architectures. The purpose of this study is to improve the segmentation accuracy for large particles preferentially. Therefore, we did not consider small particles that have little effect on material appearance. We used root mean squares error (RMSE) as an evaluation index between the segmentation results and ground truth data. Table 1 shows the RMSE and standard deviation. Improved U-Net #1 had the highest accuracy. The accuracy of improved U-Net #3 increased compared with the conventional U-Net. By contrast, improved U-Net #2 had the lowest accuracy. However, the segmentation results in Fig. 8(b) were more accurate for improved U-Net #2 and conventional U-Net than improved U-Net #1 and #3. The segmentation results in Fig. 8(c) were more accurate for improved U-Net #2 than conventional U-Net. We consider that the accuracy of the improved U-Net #2 was low because many noise parts were classified as particles. From the standard deviation in Table 1, we consider that the improved U-Net #2 had the largest variation in results. From these results, we consider that the improved U-Net #2 can segment large particles with high accuracy, but also segment the noise parts as particles.

Results of image processing after segmentation
6 Conclusion and Future Work
In this study, we segmented microscopic images of colorants using improved deep convolutional networks of U-Net architectures. As a result of comparing the RMSE values of each method, improved U-Net #1, for which the number of channels was changed, had the highest accuracy, and improved U-Net #2, which had skip connections deleted in deep layers, had the lowest accuracy. However, the segmentation results for large particles were obtained with high accuracy for improved U-Net #2. We consider that improved U-Net #2 obtained the best segmentation results compared with other U-Nets because we focused on the segmentation of large particles in this study. In future work, we propose a more appropriate evaluation method. In addition, in this study, we used the data of 512 × 512 image size. In the future, we will examine the effect of the image size using data of different image size. Moreover, we need to achieve the separation and segmentation of contacting particles. As a result, we expect that the particle size distribution can be obtained more accurately so that it can be used for practical application.
References
Gueli, A.M.: Effect of particle size on pigments colour. Color Res. Appl. 42(2), 236–243 (2017)
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 9(1), 62–66 (1979)
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Dong, H., Yang, G., Liu, F., Mo, Y., Guo, Y.: Automatic brain tumor detection and segmentation using U-net based fully convolutional networks. In: Valdés Hernández, M., González-Castro, V. (eds.) MIUA 2017. CCIS, vol. 723, pp. 506–517. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-60964-5_44
Zhang, Z.: Road extraction by deep residual U-Net. IEEE Geosci. Remote Sens. Lett. 15(5), 749–753 (2018)
Implementation of deep learning framework - Unet, using Keras. https://github.com/zhixuhao/unet Accessed 17 Jan 2020
Horwath, J.P.: Understanding important features of deep learning models for transmission electron microscopy image segmentation (2019). arXiv:1912.06077
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Tsunomura, M., Shishikura, M., Ishii, T., Takahashi, R., Tsumura, N. (2020). Segmentation of Microscopic Image of Colorants Using U-Net Based Deep Convolutional Networks for Material Appearance Design. In: El Moataz, A., Mammass, D., Mansouri, A., Nouboud, F. (eds) Image and Signal Processing. ICISP 2020. Lecture Notes in Computer Science(), vol 12119. Springer, Cham. https://doi.org/10.1007/978-3-030-51935-3_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-51935-3_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-51934-6
Online ISBN: 978-3-030-51935-3
eBook Packages: Computer ScienceComputer Science (R0)