
Abstract
Reliable quantitative analysis of digital rock images requires precise segmentation and identification of the macroporosity, sub-resolution porosity, and solid\mineral phases. This is highly emphasized in heterogeneous rocks with complex pore size distributions such as carbonates. Multi-label segmentation of carbonates using classic segmentation methods such as multi-thresholding is highly sensitive to user bias and often fails in identifying low-contrast sub-resolution porosity. In recent years, deep learning has introduced efficient and automated algorithms that are capable of handling hard tasks with precision comparable to human performance, with application to digital rocks super-resolution and segmentation emerging. Here, we present a framework for using convolutional neural networks (CNNs) to produce super-resolved segmentations of carbonates rock images for the objective of identifying sub-resolution porosity. The volumes used for training and testing are based on two different carbonates rocks imaged in-house at low and high resolutions. We experiment with various implementations of CNNs architectures where super-resolved segmentation is obtained in an end-to-end scheme and using two networks (super-resolution and segmentation) separately. We show the capability of the trained model of producing accurate segmentation by comparing multiple voxel-wise segmentation accuracy metrics, topological features, and measuring effective properties. The results underline the value of integrating deep learning frameworks in digital rock analysis.
Similar content being viewed by others


1 Introduction
Digital Rock Physics (DRP) has emerged as one of the superior technologies for studying porous media at the pore-scale (Andrä et al. 2013; Blunt et al. 2013; Bultreys et al. 2016a; Mostaghimi et al. 2017; Wildenschild and Sheppard 2013). DRP integrates high-resolution X-ray microtomographic imaging (micro-CT) with advanced computational methods for predicting geomaterial effective properties (Arns et al. 2004; Mostaghimi et al. 2013; Ramstad et al. 2010). DRP complements classic and slower laboratory investigations, namely Conventional Core Analysis (CCA) and Special Core Analysis (SCAL), through fast and reproducible modeling frameworks (Berg et al. 2017; Raeini et al. 2014). A standard ‘image and model’ framework usually consists of multiple steps including image segmentation. Image segmentation is paramount for accurate pore-scale modeling (Iassonov et al. 2009; Sheppard et al. 2004). Segmentation techniques commonly reported in the literature for DRP are global and adaptive thresholding (Andrä et al. 2013; Tuller et al. 2013), watershed algorithms (Garfi et al. 2020; Niu et al. 2020a), and converging active contours (Sheppard et al. 2004). Thorough reviews of segmentation methods have been presented and compared for DRP in the literature (Iassonov et al. 2009; Schlüter et al. 2014; Tuller et al. 2013). However, the downside of all these methods is that they require a certain level of user judgment and tuning. As a result, the segmentation outcome is highly susceptible to user bias and experience (Niu et al. 2020a).
Carbonate rocks host more than half of the world's oil and gas reserves (Harbaugh 1967). Carbonates often exhibit complex multimodal pore systems with sizes ranging from the nanoscale to the meter scale (cave systems scale) (Biswal et al. 2007). As a result, the characterization of such geomaterials is often challenging using micro-CT imaging, as the typical imaging resolution is often in the order of few micrometers (Andrä et al. 2013; Blunt et al. 2013).
The term microporosity is often used in the literature for different purposes. For example, the International Union of Pure and Applied Chemistry (IUPAC) defines a micropore as a pore with a width not exceeding 2 nm. Choquette and Pray (1970) defined a micropore in carbonate rocks as a pore smaller than 62.5 µm in diameter. This is while Pittman (1971) described micropores as pores less than one micrometer in diameter. In recent micro-CT studies, the fraction of the pore space with structures smaller than the voxel size is termed microporosity or sub-resolution (Lin et al. 2016; Liu and Mostaghimi 2018; Soulaine et al. 2016). In this study, the latter definition is used to define pores less than voxel size or pores smaller than 2.68 µm in size. Microporosity identification is important for flow and reactive transport modeling in porous media. The identification of sub-resolution porosity using dry images is subjective to the image quality in terms of the degree of noise and spatial resolution besides the segmentation algorithm used (Soulaine et al. 2016). Alternative non-invasive methods include combining micro-CT imaging with two-dimensional Scanning Electron Microscopy (SEM) (Othman et al. 2018; Peters 2009), and Differential Imaging (Boone et al. 2014; Knackstedt et al. 2006; Lin et al. 2016; Long et al. 2013). While SEM images provide unprecedented details of the pore geometry, the framework is time-consuming and the nature of two-dimensional analysis introduces high uncertainty, especially when it comes to the three-dimensional connectivity/continuity of the phases. Differential imaging frameworks involve taking X-ray scans of dry and contrast agent-saturated samples to identify microporosity. The process is perhaps one of the best options to resolve sub-resolution experimentally, boosting the contrast between the phases and making the segmentation task less prone to error. However, the method does not entirely remove inherited user bias in the segmentation method of choice and requires time-consuming sample flooding with a contrast agent, image registration and processing.
Deep learning frameworks using Convolutional Neural Networks (CNNs) introduced fast and robust methods for automated image processing (Ronneberger et al. 2015; Wan et al. 2014). If trained properly, these networks eliminate the user bias and achieve expert-level annotations/processing (Niu et al. 2020a). The interest in integrating deep learning in DRP frameworks is evident in recent years (Wang et al. 2021a) with application to lithology classification (Alzubaidi et al. 2021), image denoising (Chen et al. 2020; Niu et al. 2020b), binary and multi-phase segmentation (Ar Rushood et al. 2020; Karimpouli and Tahmasebi 2019; Wang et al. 2021b), super-resolution (Kamrava et al. 2019; Wang et al. 2019a, b), and predictive modeling of rock properties (Alqahtani et al. 2020, 2021; Chung et al. 2020a; Rabbani and Babaei 2021; Rabbani et al. 2020b). Thorough reviews have been published showing the diverse applications of DL in geoscience and DRP (Tahmasebi et al. 2020; Wang et al. 2021a). For segmentation problems in DRP, deep learning frameworks can be used to produce binary and multi-mineral segmentation according to the modeling problem. Binary segmentation is suitable for easier problems such as single-phase non-reactive flow (Ar Rushood et al. 2020; Varfolomeev et al. 2019), while multi-minerals segmentation is used for more detailed simulations such as reactive transport (Liu et al. 2018). In general, deep learning showed promising results compared to classic methods such as thresholding. Niu et al. (2020a) investigated the use of LeNet-5, a CNN architecture, for segmenting 2D images of North Sea Sandstone. The results showed that CNN segmentation outperformed the classic Otsu thresholding and watershed method by comparing their physical properties. Karimpouli and Tahmasebi (2019) experimented the use of SegNet architecture to produce a multi-mineral segmentation of a limited number of Berea Sandstone images augmented through stochastic reconstruction. The average reported pixel-wise categorical accuracy for the best model is %96. For super-resolution, (Wang et al. 2019b) experimented the use of different super-resolution network variants for obtaining high-resolution 2D images. The study shows the superiority of the performance of networks to classic methods, such as bicubic interpolation, with a 50–70% reduction in relative error. Other efforts by (Wang et al. 2019a; Wang et al. 2020a) applied a similar scheme using 3D images for training to obtain super-resolved volumes. The results show a better refinement of edge sharpness and reduction of noise compared to other classic interpolation methods. Kamrava et al. (2019) used a hybrid method of stochastic and deep learning algorithms to generate super-resolved images of shale formations. The stochastic reconstruction algorithm is used as an augmentation method for generating many image realizations that can be used for training. The results show the superiority of the trained network when the porosity and other metrics are used for comparison with other methods. Janssens et al. (2020) used real multi-resolution carbonate paired images to obtain more accurate segmentation that can be used as ground truth (GT) training data. However, the high-resolution data is not used as-is but downsampled using voxel averaging to obtain a grid size of similar dimensions to low-resolution data. The results of the study reveal improvements when computing several physical properties of the medium. All the previous efforts directed toward super-resolution have used interpolation methods (such as bicubic interpolation) to generate synthetic images pairs as a training dataset. This might not be ideal for practical applications because synthetically downsampled images do not possess the same features of real low-resolution images in terms of noise and partial volume effects. Several efforts have been directed toward reducing this limitation such as the use of unpaired data for training (Niu et al. 2020b; Zhu et al. 2017). In this work, multi-resolution scans have been used as-is, where the data has only been cropped and segmented to reveal the true interpolation/translation improvement offered by deep learning.
Herein, we propose a framework for using CNNs to generate a super-resolved segmentation of carbonates for better identifying sub-resolution porosity. We use a set of multi-resolution micro-CT scans to create a unique high (HR) and low-resolution (LR) dataset. While acquiring multi-resolution images is common in super-resolution methods, the presented approach alleviates the known trade-off between the field of view and spatial resolution. LR images capture a large field of view while HR images show more details and smaller features (i.e., identifying microporosity). By referring to the term ‘super-resolved’, we describe the process of translating ‘real’ LR micro-CT domains to grayscale or segmented HR domains using CNNs. The settings of imaging spatial resolution are designed carefully to resolve sub-resolution in the samples considered as much as possible based on the laboratory experiment. We utilize high-resolution region of interest scanning to fully facilitate easy identification of sub-resolution porosity in the HR imaging characterized by a distinguishable range of intensity values. The LR spatial resolution resolves microporosity poorly, showing partial volume effects. The HR images are segmented and utilized as GT for the CNN training. The gray LR and the segmented HR images are utilized for different deep learning experiments where the main target is to identify sub-resolution porosity accurately using the LR as an input. We compare the segmentation accuracy using three metrics: voxel-wise accuracy, geometry-based metrics, and the physical flow characteristics. This framework can be utilized to optimize current frameworks where the only requirement is to obtain a high-resolution region of interest and train the CNNs to interpolate the segmentation to a bigger field of view using the LR images.
2 Materials and Methods
2.1 Materials Description
Two carbonate Images shown in Fig. 1 were considered for training the CNNs. The first one is Indiana Limestone (ILS) which originates from the Salem formation near Bedford, Indiana, USA. ILS is mainly monomineralic rock with 98.8% calcite with the rare occurrences of quartz (< 1%) and clay minerals (< 1%). The main solid phases seen in ILS are Allochems, detrital skeletal of marine organisms (i.e., organic detritus), and authigenic calcite cement. Different types of porosities can be distinguished clearly in the HR micro-CT images including macroporosity (resolved and connected porosity between particles/grains), microporosity on the outer shells of the ooliths/carbonate grains (Intercrystal porosity), vugs (isolated or poorly connected pores that are larger than 1/16 mm in diameter), and intra-ooliths porosity (porosity within individual ooliths). The second carbonate is a more heterogeneous Middle Eastern carbonate (MEC) characterized by a variety of microporous ooliths, skeletal and non-skeletal microporous grains. Calcite accounts for more than (99% >) with the existence of minerals like aragonite and micrite. Similar porosity systems that can also be distinguished using the HR images are macroporosity, moldic intra-ooliths porosity (these are formed through selective processes i.e., local dissolution), vugs, and microporous equant cement. Features identifying porosity systems in carbonates have been further discussed in the literature (Arns et al. 2018; Cantrell and Hagerty 1999; Irajian et al. 2016; Ji et al. 2012).

(Upper): 1-inch core plug photographs of the Indiana Limestone and the Middle Eastern Carbonate. (Lower): a showcase of a 2D slice of the Indiana Limestone (Left) showing a macroporosity, b microporosity on the outer shells of the ooliths c vugs, d intra-oolith microporosity, e solid grain. Middle Eastern Carbonate (right) showing f macroporosity, g solid ooliths, h microporous equant cement, I intra-grain vugs, and k microporous ooliths
For the preliminary characterization of the samples, Brine permeability, Helium porosity, and permeability measurement were obtained for a 1-inch in diameter by 2-inch core plug of each rock (see Fig. 1). Then, smaller 6-mm core plugs were drilled from the bigger cores for micro-CT imaging. Finally, Mercury Intrusion Capillary Pressure (MICP) tests were performed on the 6 mm plugs. These tests were performed to assess in (1) choosing the imaging spatial resolutions and (2) choosing safe thresholds for GT segmentation.
2.2 Methods
2.2.1 Image Acquisition and Processing
Image acquisition was carefully designed in a way that clearly distinguishes a high percentage of the microporosity at least with a different shade of gray in the HR images. The MICP analysis provided in the "Appendix" (Fig. 12) shows a range of micropores below the imaging resolution in Table 1 with a peak of around 1 µm. We categorize voxels into pore, solids and micropores. Similar approaches have been presented for identifying microporosity and characterizing carbonate rocks in the literature (Bultreys et al. 2016b; Ghous et al. 2007; Soulaine et al. 2016). This leads to the prediction of permeability that is comparable with experimental measurements on larger cores as will be discussed in the results sections. The LR images were obtained with a voxel size four times larger than the HR. Both carbonate rocks were imaged at the Tyree X-ray facilities at the University of New South Wales using HeliScan™ micro-CT (Mark I). The system has a Hamamatsu X-ray tube with a diamond window and a high-quality flatbed detector (3072 × 3072 pixels, 3.75 fps readout rate). The machine has a tube current of 85 μA and a voltage of 80 kV. The samples were scanned in a double helix trajectory with 2880 projections per revolution and a filter length of 3 mm in the scanning conditions described in Table 1. The reconstruction was performed using QMango software (Kingston et al. 2011; Varslot et al. 2011) developed by the Australian National University. The imaging setup used to obtain the images with different resolutions is shown in Fig. 2. A rectangular central domain was cropped from each image and segmented into three phases (pore, solid, and micropores) using two methods: Otsu’s multi-thresholding algorithm (Otsu 1979) and Avizo Software ™ Segmentation Editor (version 2020.3; FEI Visualization Sciences Group) that uses a combination of watershed and hysteresis algorithms. Otsu’s multi-thresholding and watershed-hysteresis based methods have been utilized in literature for segmenting carbonate into three phases (Arns et al. 2005; Bultreys et al. 2015; Ji et al. 2012). Due to the size of the data, the manual creation of segmentation masks is not feasible. So, the ground truth segmentation of HR data was obtained through Avizo. In the Avizo segmentation editor, a conservative approach for segmentation was followed by choosing a ‘Safe’ range of intensities for each phase for the watershed/hysteresis processes. The safe ranges involve first choosing two cutoff thresholds that are certainly pore space and certainly solid matter. All voxels with intensities below the lower threshold are pore, and all voxels higher than the upper threshold are solid. Then, a third range for microporosity with upper and lower thresholds laying between the pore and solid threshold was defined where only obvious microporous textures were labeled. This was achieved based on a visual inspection of all slices of the volume. These regions were then initiated as seeds for watershed/hysteresis. The watershed transforms floods unlabeled regions using the image gradient using the Canny method (Canny 1986). The safe thresholding of GT resolved pore space was chosen to have a ‘macro’ pore space volume fraction equal to the one found in the MICP analysis for each sample (see "Appendix").

The Tyree X-ray micro-CT setup (upper), A schematic showing the imaging procedure used to obtain a multi-resolution image (middle), and slices of the middle eastern carbonate where the magnification showing the resolved microporosity (lower)
This method for identifying microporosity and other similar methods (Arns et al. 2005; Bultreys et al. 2015; Ji et al. 2012) can perhaps be plausible for mono-mineralic rocks. In mono-mineralic rocks, the lower grayscale levels in the solid matrix can be only associated with the existence of sub-resolution porosity (less dense materials). Also, it is important to emphasize this approach has limitations whereby the defined solid phase may still pose a small percentage of porosity at a lower scale (assuming microscale features can be distinguished). However, the effect of these fine-scale porosities is minor when computing macroscale effective properties, i.e., permeability. The identification of microporosity in multi-mineral rocks would require differential imaging frameworks (Boone et al. 2014; Knackstedt et al. 2006; Lin et al. 2016; Long et al. 2013).
2.2.2 Dataset, Network Architectures, Training, and Inference
The dataset used for training is titled ‘Multi-Resolution Complex Carbonates Micro-CT Dataset (MRCCM)’ and has been published in the Digital rock Portal (https://www.digitalrocksportal.org/projects/362) and freely available to be used for future studies. The data repository comprises multi-resolution raw tomograms and processed volumes of both carbonate rocks. The MICP analysis of both samples is included in the repository.
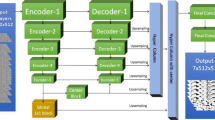
Two different frameworks shown in Fig. 3 were used to obtain the super-resolved segmentation. In one framework we segmented and super-resolved images in one Encoder-Decoder network (End-to-End super-resolved segmentation). In the second framework, we applied a 3D Enhanced Deep Residual Network (EDSR) (Lim et al. 2017) to obtain a super-resolved grayscale image and then segment the super-resolved using a separate encoder-decoder network. All the network architectures considered are three-dimensional because 3D CNNs tend to learn geometrical features in 3D space which helps in preserving topological features, i.e., connectivity, and generally delivers better results compared to 2D networks (Wang et al. 2021b).

A schematic showing the network architectures used for obtaining super-resolved segmentation. The top schematic is showing two highlighted architectures where a standard U-net block consists of double convolutional layers as in (Ronneberger et al. 2015) and b the Residual U-net block (U-ResNet) consists of triple convolutional layers with skip connections (Lee et al. 2017). The double convolution blocks (highlighted in yellow) at the end of the network increase the input domain size four times. The numbers under each block represent the number of feature maps at each level. In the bottom schematic super-resolved grayscale images are obtained using an EDSR network (c), then segmented using a U-ResNet network. The segmentations obtained from this network is referred to as EDSR-U-ResNet
The encoder-decoder networks used in both frameworks are mainly based on the U-net architecture (Ronneberger et al. 2015). This architecture was originally designed for 2D image segmentation purposes and has shown excellent performance for biomedical image segmentation and was later modified to handle volumetric data. U-net incorporates symmetric skip connections to link shallow features in the encoder to the equivalent level of the decoder through concatenation/summation. The skip connections improve CNNs performance by alleviating common drawbacks in backpropagation (Rumelhart et al. 1986) such as vanishing gradients in deep CNNs (Drozdzal et al. 2016). Furthermore, the skip connections also help to preserve and combine local and well-detailed features, such as edges, with global features without deep supervision (Panichev and Voloshyna 2019). In this work, we implemented multiple U-net variants where we compared the use of standard U-Net implementation against Residual U-Net. Residual U-Net borrows concepts from ResNet where residual blocks are utilized to achieve better performance.
All networks were trained using Adam optimizer with β1 = 0.9 and β2 = 0.999, and L2 regularization of 1e-5 and starting learning rate of 2e-4. The learning rate is halved dynamically during training each time the segmentation evaluation metric reaches a plateau (no improvement) on a separate validation set. The Sørensen–Dice coefficient (Dice 1945; Sørensen 1948) is used to compute loss between the network output and GT. The Sørensen–Dice coefficient is given the following formula:
where X, Y are two images, and the operator \(\left| {\text{X}} \right|\) refers to the number of voxels in image X. The symbol \(\cap\) refers to the intersection between the voxels of the two images. The training was run at least for 100 K iterations and stopped when the network learning rate falls below a predefined threshold (1-e6). PyTorch, a deep learning software package, was used to train the models on an NVIDIA TITAN RTX GPU installed on a PC with Intel I7-8700 CPU @3.20 GHz and a RAM of 64 GB. The U-net/U-Resnet models were trained with a batch size of 2 and domain size of 643 grayscale volumes where the network outputs a domain size of 2563 super-resolved segmented volume. For the EDSR-U-ResNet framework, the images were first upsampled using EDSR and then segmented using domain sizes of 1283. In total, 2300 training MEC subvolumes and 1800 ILS training subvolumes were used for training the presented models.
A brief description of the evaluation metrics considered is reported. These metrics include voxel-wise accuracy segmentation, topological characterization of each phase, and measurements of the effective flow properties. Because of the nature of the problem and the imaging framework and processing, several implications might affect how the results are assessed. These implications are caused by:
-
Registration of the HR and LR images is not exact, a misalignment in the range of 1–2 voxels may affect the voxel-wise metrics results.
-
Image quality/noise levels will significantly control the cutoff volume of resolved features/textures in the HR images, which may be impossible to identify in the LR images.
-
Watershed Transform, the GT segmentation method for HR images, requires the user to define ‘safe’ thresholds that act as a seed for determining the extent for each phase. While the method minimizes the effect of user bias in general, it still may affect the GT segmentation creation. Regardless of this happening as a source of error, the improvement in segmentation is granted because LR grayscale images are translated based on the HR images of the same region. This leaves less chance of erratic segmentation or user misjudgment.
All the numbers reported are computed from the testing set volumes. These volumes are not used while training or validation.
-
A.
Voxel-wise Accuracy:
We assessed the voxel-wise segmentation accuracy using two segmentation metrics, namely: the Jaccard similarity index (Jaccard 1912) and the accuracy of voxel classification using confusion matrices. Jaccard similarity index of phase (P) in two volumes (A) and (B) can be expressed as:
where \(A_{\left( P \right)}\) and \(B_{\left( P \right)}\) indicate the voxels in volumes A and B that are labeled as phase P, respectively. The operator \(\left| {\text{A}} \right|{ }\) indicates the number of voxels in volume A. The symbols \(\cap\) and \(\cup\) refer to the intersection and the union between the voxels of the two images, respectively. The confusion charts show the true and predicted voxels percentages of each phase. The diagonal values of the chart represent truly classified voxels percentage, and the off-diagonal values represent misclassified voxels percentage. The rate of false positivity and negativity are also reported outside the confusion matrices.
-
B.
Morphological Measurements
We measured two geometrical properties of each phase which are the porosity and the specific surface area (SSA). Furthermore, the topological connectivity wassured by computing Euler-Poincare characteristic (EC) for resolved macropores only. The porosity of each phase was computed through voxel counting. The specific surface area was computed through the discretization of the Crofton formula (Legland et al. 2011). EC was estimated using graph portioning where the numbers of vertices (Ѵ), edges (\(\in\)), faces (\({\mathcal{F}}),\). and solids (\({\mathcal{L}})\). of the volume were computed. EC can be written as (Legland et al. 2011):
Volume fractions, SSA EC are computed using MatImage, an open-source Matlab library for image processing (Legland 2021).
-
C.
Flow characteristics and pore networks
For assessing the flow characteristics of the output segmentation, single- and multi-phase flow simulations were performed. The comparison includes the segmentations oned from the HR and LR images using Otsu and watershed methods and the trained model Also, macropore and micropore pore network models were extracted for each image separately using PoreSpy (Gostick et al. 2019). Coordination numbers and average pores and throats sizes were compared from the extracted pore network models. The macropore network model was extracted from the resolved pore phase, and the micropore network model was extracted from the microporosity phase. The micropore network extraction aimed to give a general indication about the connectivity of the textures looking microporous and should not be misinterpreted to indicate the actual connections of unresolved pore space.
For single-phase flow, we signified the importance of assigning conductivity to the microporosity phase by comparing flow simulations with/without a conductivity assigned to the microporosity phase. The permeability was computed using the Pore Finite Volume Solver (PFVS) (Chung et al. 2019, 2020b; Wang et al. 2019c). PFVS assigns a conductivity to each voxel according to the proximity of the voxel to the solid wall and the radius of the inscribed flow channel that the voxel belongs to. For simplicity, the microporosity phase was assigned a voxel conductivity based on the Hagen–Poiseuille (Mortensen et al. 2005; Rabbani et al. 2020a; Schmid and Henningson 1994) law where the permeability (K) of a pore throat is assumed to approximately equal
for fluid flow with a low Reynolds number where R is the hydraulic throat radius. The contribution of microporosity is known to have lower permeability compared to macropores by several orders of magnitude (Soulaine et al. 2016). Therefore, the assignment of microporosity conductivity was based on the average pore throat radius estimated through the MICP analysis ran on the same cores (See "Appendix"). The conductivity in the microporous phase is estimated to be 2.45 × 10−13 m2 in the MEC and 1.25 × 10−13 m2 in the ILS.
For the multi-phase flow simulation, relative permeability was computed using MorphLBM (Wang et al. 2020b). This method applies an accelerated morphologically coupled multi-phase Lattice Boltzmann Method directly on the macropore space. The microporosity phase is assumed to be fully saturated with the wetting phase, and the absolute permeability of macropores is only considered. In the beginning, the fluid configuration is initialized morphologically and updated after LBM steady-state conditions are reached, with small increments of erosion and dilation to target saturation. The LBM simulation continues its execution at the same time as the small morphological increments are updated. Once the target saturation is achieved, the LBM is performed until the capillary number is stable. Then, the steady-state relative permeability point is recorded, and another cycle is launched. For the simulation compared in the results section, imbibition simulations were performed on each segmentation with relaxation applied every 1000 LBM timestep between morphs. The saturation increments were set to 5% with a capillarity tolerance of less than 10−3 per 1000 timesteps. The system capillary number was held below 10−5 to mimic capillary-dominated two-phase flow dynamics. The wettability was set to be uniform at 45 degrees for all solid voxels for simplicity.
3 Results and Discussion
All the comparisons reported were based on unseen/testing subvolumes of size 10243 voxels for the HR images and 2563 voxels for the LR images that correspond to a volume of size 20.6 mm3. This volume was considered here only for comparison purposes and might be subject to further heterogeneity effects at a bigger scale. The methods presented do not involve upscaling of the physical properties of the medium of interest but rather compares the segmentation accuracy of the models. As such, representative elementary volume analysis is not required for this purpose. Overall, 14 segmented volumes were compared for each of the two carbonate rock types, of which 4 segmented volumes were obtained from the HR and LR through Otsu and Avizo watershed segmentation methods, and 3 segmented HR volumes obtained through the frameworks described in Sect. (2.2.2).
3.1 Voxel-wise Accuracy
Voxel-wise accuracy was computed based on a separate testing volume of size 2563 in LR that were super-resolved to a volume of size 10243 and compared with the GT segmentation (watershed segmentation) for both carbonate rocks. Both testing volumes are around 20% of the entire tomogram imaged of each rock. The network frameworks generate batches of size 1283 that are stitched together to construct the testing volume. Three super-resolved segmentation for each rock was segmented and reconstructed, using U-net, U-Resnet, and EDSR-U-ResNet. The voxel-wise percentage of each phase is shown as a confusion matrix for ILS and MEC in Fig. 4 for all the networks. Overall, the U-ResNet scheme provides the best voxel-wise accuracy. The U-net results in second place and is very close to the performance margins of U-ResNet. EDSR-U-Resnet shows the highest discrepancy especially in segmenting the MEC rock sample. The same trends are observed in Fig. 5 as indicated by Jaccard similarity Index where in general U-Resnet tends to perform better than the other models. The confusion matrices in Fig. 4 and Jaccard indices in Fig. 5 show the microporosity phase with the highest margins of error (compared to solid and pore phases) both in falsely positive and negative classified voxels. Additionally, the error margins are higher in MEC compared to ILS in general, and this is likely due to the complex microporous textures in the MEC sample.

The confusion matrices showing the percentage of a phase in each cell. The rows of a confusion matrix represent the true class/GT, and the columns represent the predicted class by the network model. Diagonal and off-diagonal cells represent correctly and incorrectly identified phases classes, respectively. The row and column summaries shown outside the confusion matrices correspond to the percentages of false positive and false negative rates for true and predicted classes, respectively. Warmer color codes show higher error margins

Jaccard similarity index of each phase computed for networks’ segmentations as compared to the GT segmentation
A comparison between a region of interest for the different models’ segmentations is shown in Figs. 6 and 7. The difference maps in Figs. 6 and 7 reveal the misclassified voxels happen mostly at the boundaries, especially the solid/microporosity boundary. This fact is also clearly shown by the confusion matrices in Fig. 4. This is expected as the grayscale intensities of these boundaries can be impossible to detect, at least visually (see LR images in Figs. 6 and 7). Overall, the incorrect microporosity segmentation perhaps arises from two causes, (1) partial volume effects in LR images which might be interpreted as microporosity by the models and (2) the tendency of the models to smooth out edges of highly unresolved features/textures. The partial volume effects on the segmentation output are mostly evident near the grain boundaries characterized by strong blurring effects. The network performance is likely to improve by regularization (Jia et al. 2021) and using more task-specific loss functions (Caliva et al. 2019).

1st row: 2D slices of the ILS testing volume (LR and HR). 2nd and 3rd rows: LR (input to networks) and HR resolution grayscale region of interest as shown in the first row (red square), and the corresponding segmentation (GT watershed and networks segmentations). 4th row: difference maps where networks are compared to GT. The blue color corresponds to correctly classified voxels and the pink color to misclassified phase classes

1st row: 2D slices of the LR and HR MEC testing volume. 2nd and 3rd rows: LR (input to networks) and HR resolution grayscale region of interest as shown in the first row (red square), and the corresponding segmentation (GT watershed and networks segmentations). 4th row: difference maps where networks are compared to GT. The blue color corresponds to correctly classified voxels and the pink color to misclassified phase classes
From the network architecture perspective, the models’ performance ranking was consistent on both rocks where U-Resnet performed best. While the EDSR-U-Resnet framework uses two networks to obtain a super-resolved segmentation as shown in Fig. 3, this framework poses the highest discrepancy in voxel-wise accuracy. The comparison with other studied models that utilize end-to-end frameworks (LR to HR segmented image) might suggest that EDSR super-resolved grayscale images might not preserve the important features for accurate segmentation.
3.2 Morphological Comparison
As an addition to the reported voxel-wise metrics of networks segmentation accuracy, the morphological characteristics of the watershed, Otsu, and the networks segmented volumes are reported. In this section, the watershed and Otsu segmentation of LR and HR volumes are included for a broader comparison. This will give an indication of how CNNs can improve segmentation if compared with other classic methods. The comparison includes the volume fraction and SSA of each phase, and the Euler number of the effective medium pore space. These values are reported for the testing volumes of ILS and MEC in Tables 2 and 3, respectively. The measured volume fractions of the trained network segmented volumes clearly provide better results and lower relative difference if compared with the classic methods of segmenting LR volumes. The network segmentations are mainly erratic in estimating the microporosity phase as suggested by previous results, however, more conforming than Otsu HR segmentation where microporosity is overestimated if compared to the GT. The end-to-end models (U-net and U-Resnet) estimate the volume fractions with a relative difference of less than 10%, while the error is found to be up to 22% using the EDSR-U-Resnet framework. The error margins in estimating the SSA of the different segmentations are higher than the volume fractions estimation error margins. However, the SSA of the network segmentations are again found to be consistent, with a relative difference of less than 50%, while all the other segmentation showed significant relative errors (more than 100%) in the estimation of SSA in some phases. The extreme errors in estimating the SSA perhaps arise from the tendency of the classic methods to create a microporosity phase at solid grains and pore space boundary. This ‘coating’ effect is a by-product of strong partial volume effects and the nature of sharp global thresholding in classic methods. Consequently, this observation is expected in the segmentation of the LR volumes where partial volume effects are evident.
The topological connectivity of each segmentation macropore space is assessed based on the measured Euler Characteristic (EC). The results show significant variations in the computed connectivity of pore space with relative differences of around 80% to GT using the trained networks. The variation in EC mostly likely arises from strong imaging artifacts including the translation of partial volume effects to false microporosity. This may create undesired connections between solid grains and hence altering the computed EC. An example of this segmentation error can be seen in the EDSR-U-ResNet segmentation in Fig. 7. Also, there is always a limitation on the signal/representation that can be resolved as pore space in some parts of the LR images causing connectivity loss in the output network segmentation. Irrespectively, the network segmentations improve the connectivity measured when compared to the LR watershed and Otsu segmentation as shown in Tables 2 and 3. It is also anticipated that global thresholding (Otsu method) creates many isolated holes and solids, and redundant loops, hence the high error margins.
3.3 Macro- and Micropore Networks, Single- and Multi-phase Flow Analyses
The flow features of the segmented volumes are probably the most crucial measures for assessing the accuracy of the super-resolved segmentation. Hence, pore and micropore networks, single- and multi-phase flow simulations are analyzed. Macro- and micropore networks are extracted ‘separately’ for the different segmentations considered. The statistics of these networks and the single-phase permeability values are reported in Tables 4 and 5 for the ILS and MEC samples, respectively.
The coordination number (i.e., the average number of pore throats connected to a pore body) is computed to estimate the connectivity from the macropore and micropore networks. The results show more consistent trends when computing the coordination number of the macropore compared to the micropore networks. For the macropore networks, the LR segmentations show lower coordination numbers compared to the GT, this is perhaps due to the loss of tight pore throats during segmentation. However, the CNNs segmentation seems to preserve similar connections showing minor differences in the computed coordination number. For the micropore networks, the CNNs segmentation seems to overestimate the connections in general. This is mainly because the adherence to boundaries of the super-resolved segmentation is prone to relatively high errors. The average pore sizes, pore throat lengths and diameters show in general a similar trend, where the CNNs improve the computed statistics. Moreover, it is also generally observed that the ILS results are again more conforming compared to MEC because of the lower microporosity in ILS.
For single-phase flow, the permeability in Tables 4 and 5 is computed with and without assigning conductivity to the micropore phase. The addition of microporosity conductivity increases the computed permeability, as both rocks pose relatively high percentages of unresolved porosity. However, the contribution to the computed permeability might not be as significant to the macropore phase. In any case, the CNNs segmentation show more accurate permeability values compared to the simulation ran on LR segmented images. More interestingly, U-net and U-ResNet specifically present more accurate permeability values than the HR Otsu segmentation with and without microporous conductivity. Looking over all the results and metrics, it might be concluded that U-ResNet and U-net provide the best and second-best results, respectively. The permeability of the ground truth and networks show in general a good agreement with the experimental Helium permeability (Klingenberg-corrected) on bigger cores of the ILS (221 mD) and MEC (1092 mD) samples.
For further comparison, multi-phase flow experiments are run on the U-ResNet, LR, and HR watershed segmentations of both rocks using MorphLBM. The secondary imbibition experiments are simulated on the testing volumes macropore space using the Australian National Computational Infrastructure (NCI) supercomputer Gadi. The microporosity is assumed to be fully saturated with the wetting phase. The simulation of the LR watershed segmentation did not converge to a solution. The reason is likely to be the low connectivity of the pore space and the narrow flow paths. The results from the GT and U-ResNet show a good match on both MEC and ILS samples. The computed relative permeability curves in Fig. 8 show similar saturation endpoints for water (wetting phase) and oil (non-wetting phase). The topology of the non-wetting phase during pore desaturation is observed to be analogous in both GT and U-ResNet segmentation (see Fig. 9). The difference maps visualized in Fig. 9e show minor differences in the non-wetting phase distribution. These differences happen mainly: (1) at the boundary of grains/fluids interface (segmentation differences) and (2) the filling/desaturation of smaller pores, which perhaps arise from differences in the overall pore topology.

Secondary Imbibition Relative Permeability Curves of (left) the Indiana limestone and (right) Middle Eastern Carbonate. The ground truth and U-ResNet segmentation are compared. Matching curves and relative permeability endpoints with minimal differences are observed

Visualizations of the imbibition simulation on the Middle Eastern Carbonate cubic sample at wetting phase saturation of (Swp = 0.43). Upper: 3D visuals of the non-wetting phase distribution (red) in the a GT and the b U-ResNet segmentation. Lower: 2D slices showing the non-wetting phase distribution (yellow) of c the GT and d U-ResNet segmentations. The difference map in e shows most of the discrepancies happen in the filling of smaller pores and the boundaries of solid and fluids (segmentation differences)
4 Conclusions
The segmentation/identification of pore space, sub-resolution porosity, and the solid matrix are vital for reliable digital rock analysis frameworks. Deep learning workflows involving the utilization of CNNs to enhance the segmentation of grayscale images improve the overall outcome. CNNs can work in an end-to-end scheme to super-resolve and segment raw X-ray images, without any interference from the user. This reduces the user prejudice associated with classic segmentation methods which often require user input. Two CNNs training configurations were considered to super-resolve and segment grayscale images into pore, solids, and micropores. Firstly, U-Net and U-ResNet were trained in an end-to-end manner to super-resolve and segment images in one network. Secondly, EDSR-U-Resnet was trained to super-resolve grayscale images at once then segment the image (two different networks). The output segmentation of all the CNNs frameworks shows relatively consistent voxel-wise accuracy compared to the GT segmentation. The U-ResNet displayed the best performance with Jaccard indices of 0.92, 0.83, and 0.57 for solid, pore, and micropore phases, respectively. U-Net shows very close voxel-wise accuracy margins to U-ResNet (with less than 1% difference in Jaccard score). In general, the highest error margins are observed in the identification of the microporosity phase. This is perhaps due to the effects of the noise (partial volume effects) and extreme sub-resolution in the input LR images, making it impossible to identify microporosity by the CNNs (or even judging visually). The results also show the phases volume fractions of network segmentation are more conforming than using only LR segmentation or HR Otsu segmentation as compared to GT. The same trends in terms of network consistency are observed in measuring specific surface area, however, with higher relative errors (up to 46% using U-ResNet). The connectivity of the pore space as measured using EC number shows also high relative differences, when network and GT segmentations are compared (up to 92%). Regardless, the network segmentations show lower relative error compared to HR Otsu, LR watershed and Otsu segmentations (see Tables 2 and 3).
Additionally, macro- and micropore networks comparisons with GT show better results in terms of connectivity, pores, and pore throats sizes for CNNs segmentation. The same outcome trends are observed in single-phase permeability and relative permeability curves. Overall, the end-to-end training frameworks are found to be superior to using two networks for super-resolution and segmentation confirming the suitability of end-to-end learning to perform more complex tasks. The reason is likely to be the loss of important features that distinguish the different rock phases to obtain precise segmentation when upsampling LR images using super-resolution network. This leads to a general conclusion that end-to-end CNNs training for X-ray imaging super-resolution and processing promise a lot of improvements to current DRP frameworks. Similar applications to this study can be applied based on single or multiple rock types, where image acquisition includes LR imaging capturing high field of view and HR region of interest imaging capturing more explicit details of pore geometry. Also, the CNNs methods presented here do not necessarily highlight all potential improvements that can be gained. The CNNs frameworks presented only show a general workflow for improving the accuracy in segmentation and modeling. The interpolation of the presented methods on other rocks type can be established by adding subvolumes from the medium of interest to the current dataset and commencing training in a transfer learning scheme. This eliminates the need for training the models from the ground up. The results obtained with more sophisticated CNNs architectures, training data and ad hoc strategies are anticipated to boost the outcome accuracy. CNNs architectures such as HRNet-OCR (Tao et al. 2020), and EfficientNet (Tan and Le 2019) are few examples of the active research of improving network design and performance. The automation of DRP using CNNs would also benefit from including important physical properties, i.e., permeability, as a component in the loss function for optimizing the CNNs performance.
Data Availability
Original microcomputed tomograms, mercury intrusion capillary pressure data and CNNs training volumes will be made available on (https://www.digitalrocksportal.org/projects/362).
Code Availability
The code was developed using open-source libraries (Pytroch and Numpy) and can be requested by contacting the authors.
References
Alqahtani, N.J., Alzubaidi, F., Armstrong, R.T., Swietojanski, P., Mostaghimi, P.: Machine learning for predicting properties of porous media from 2d X-ray images. J. Pet. Sci. Eng. 184, 106514 (2020)
Alqahtani, N.J., Chung, T., Wang, Y.D., Armstrong, Ryan T., Swietojanski, P., Mostaghimi, P.: Flow-Based Characterization of Digital Rock Images Using Deep Learning. SPE J. 26, 1800–1811 (2021). https://doi.org/10.2118/205376-PA
Alzubaidi, F., Mostaghimi, P., Swietojanski, P., Clark, S.R., Armstrong, R.T.: Automated lithology classification from drill core images using convolutional neural networks. J. Pet. Sci. Eng. 197, 107933 (2021)
Andrä, H., et al.: Digital rock physics benchmarks—Part I: imaging and segmentation. Comput. Geosci. 50, 25–32 (2013)
Ar Rushood, I., et al.: Segmentation of X-ray images of rocks using deep learning. In: SPE Annual Technical Conference and Exhibition (2020)
Arns, C.H., Knackstedt, M.A., Pinczewski, W.V., Martys, N. (2004b). Virtual permeametry on microtomographic images. J. Pet. Sci. Eng. 45, 41–46. https://doi.org/10.1016/j.petrol.2004.05.001
Arns, C.H., et al.: Pore scale characterization of carbonates using X-ray microtomography. SPE-191379-PA, 10(04): 475–484 (2005)
Arns, C.H., et al.: Pore-type partitioning for complex carbonates: effective versus total porosity and applications to electrical conductivity. In: SPWLA 59th Annual Logging Symposium (2018)
Berg, C.F., Lopez, O., Berland, H.: Industrial applications of digital rock technology. J. Pet. Sci. Eng. 157, 131–147 (2017)
Biswal, B., Øren, P.E., Held, R.J., Bakke, S., Hilfer, R.: Stochastic multiscale model for carbonate rocks. Phys. Rev. E 75(6), 061303 (2007)
Blunt, M.J., et al.: Pore-scale imaging and modelling. Adv. Water Resour. 51, 197–216 (2013)
Boone, M.A., et al.: 3D mapping of water in oolithic limestone at atmospheric and vacuum saturation using X-ray micro-CT differential imaging. Mater. Charact. 97, 150–160 (2014)
Buiting, J.J.M., Clerke, E.A.: Permeability from porosimetry measurements: derivation for a tortuous and fractal tubular bundle. J. Petrol. Sci. Eng. 108, 267–278 (2013)
Bultreys, T., Van Hoorebeke, L., Cnudde, V.: Multi-scale, micro-computed tomography-based pore network models to simulate drainage in heterogeneous rocks. Adv. Water Resour. 78, 36–49 (2015)
Bultreys, T., De Boever, W., Cnudde, V.: Imaging and image-based fluid transport modeling at the pore scale in geological materials: a practical introduction to the current state-of-the-art. Earth Sci. Rev. 155, 93–128 (2016a)
Bultreys, T., et al.: Investigating the relative permeability behavior of microporosity-rich carbonates and tight sandstones with multiscale pore network models. J. Geophys. Res. Solid Earth 121(11), 7929–7945 (2016b)
Caliva, F., Iriondo, C., Morales Martinez, A., Majumdar, S., Pedoia, V.: Distance map loss penalty term for semantic segmentation. (2019) arXiv:1908.03679
Canny, J.: A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. PAMI 8(6), 679–698 (1986)
Cantrell, D.L., Hagerty, R.M.: Microporosity in arab formation carbonates, Saudi Arabia. Geoarabia 4(2), 129–154 (1999)
Chen, H., et al.: Super-resolution of real-world rock microcomputed tomography images using cycle-consistent generative adversarial networks. Phys. Rev. E 101(2), 023305 (2020)
Choquette, P.W., Pray, L.C.: Geologic nomenclature and classification of porosity in sedimentary carbonates. AAPG Bull. 54(2), 207–250 (1970)
Chung, T., Da Wang, Y., Armstrong, R.T., Mostaghimi, P.: CNN-PFVS: integrating neural network and finite volume models to accelerate flow simulation on pore space images. Transp. Porous Media 135(1), 25–37 (2020a)
Chung, T., Wang, Y.D., Armstrong, R.T., Mostaghimi, P.: Voxel agglomeration for accelerated estimation of permeability from micro-CT images. J. Pet. Sci. Eng. 184, 106577 (2020b)
Chung, T., Wang, Y.D., Armstrong, R.T., Mostaghimi, P.: Approximating permeability of microcomputed-tomography images using elliptic flow equations. SPE-191379-PA 24(03), 1154–1163 (2019)
Clerke, E.A., et al.: Application of Thomeer Hyperbolas to decode the pore systems, facies and reservoir properties of the Upper Jurassic Arab D Limestone, Ghawar field, Saudi Arabia: a “Rosetta Stone” approach. GeoArabia 13(4), 113–160 (2008)
Dice, L.R.: Measures of the amount of ecologic association between species. Ecology 26(3), 297–302 (1945)
Drozdzal, M., Vorontsov, E., Chartrand, G., Kadoury, S., Pal, C.: The importance of skip connections in biomedical image segmentation. In: Carneiro, G., et al. (eds.) Deep learning and data labeling for medical applications, pp. 179–187. Springer International Publishing, Cham (2016)
Garfi, G., John, C.M., Berg, S., Krevor, S.: The sensitivity of estimates of multiphase fluid and solid properties of porous rocks to image processing. Transp. Porous Media 131(3), 985–1005 (2020)
Ghous, A., et al.: 3D Characterisation of Microporosity in Carbonate Cores. In: SPWLA Middle East Regional Symposium (2007)
Gostick, J., Khan, Z., Tranter, T., Kok, M., Agnaou, M., Sadeghi, M., Jervis, R. PoreSpy: A python toolkit for quantitative analysis of porous Media Images. JOSS 4, 1296 (2019). https://doi.org/10.21105/joss.01296.
Harbaugh, J.W.: Chapter 7 carbonate oil reservoir rocks. In: Chilingar, G.V., Bissell, H.J., Fairbridge, R.W. (eds.) Developments in sedimentology, pp. 349–398. Elsevier, Amsterdam (1967)
Iassonov, P., Gebrenegus, T., Tuller, M.: Segmentation of X-ray computed tomography images of porous materials: A crucial step for characterization and quantitative analysis of pore structures, Water Resour. Res. 45, W09415 (2019). https://doi.org/10.1029/2009WR008087.
Irajian, A.-A., Bazargani-Guilani, K., Mahari, R., Solgi, A.: Porosity and rock-typing in hydrocarbon reservoirs case study in upper member of dalan formation in kish gas field, South of Zagros, Iran. Open J. Geol. 6(06), 399 (2016)
Jaccard, P.: The distribution of the flora in the alpine zone.1. New Phytol. 11(2), 37–50 (1912)
Janssens, N., Huysmans, M., Swennen, R.: Computed tomography 3D super-resolution with generative adversarial neural networks: implications on unsaturated and two-phase fluid flow. Materials 13(6), 1397 (2020)
Ji, Y., Baud, P., Vajdova, V., Wong, T.-F.: Characterization of pore geometry of indiana limestone in relation to mechanical compaction. Oil Gas Sci. Technol. Rev. IFP Energ. Nouv. 67(5), 753–775 (2012)
Jia, F., Liu, J., Tai, X.-C.: A regularized convolutional neural network for semantic image segmentation. Anal. Appl. 19(01), 147–165 (2021)
Kamrava, S., Tahmasebi, P., Sahimi, M.: Enhancing images of shale formations by a hybrid stochastic and deep learning algorithm. Neural Netw. 118, 310–320 (2019)
Karimpouli, S., Tahmasebi, P.: Segmentation of digital rock images using deep convolutional autoencoder networks. Comput. Geosci. 126, 142–150 (2019)
Kingston, A., Sakellariou, A., Varslot, T., Myers, G., Sheppard, A.: Reliable automatic alignment of tomographic projection data by passive auto-focus. Med. Phys. 38(9), 4934–4945 (2011)
Knackstedt, M.A., Arns, C.H., Ghous, A., Sakellariou, A., Senden, T.J., Sheppard, A.P., Sok, R.M., Averdunk, H., Pinczewski, W.V., Padhy, G.S., Ioannidis, M.A.: 3D imaging and flow characterisation of the pore space of carbonate core samples. Paper presented at the international symposium of the society of core analysts, Trondheim (2006)
Lee, K., Zung, J., Li, P., Jain, V., Seung, H.S.: Superhuman accuracy on the SNEMI3D connectomics challenge. (2017) arXiv:1706.00120
Legland, D., Kiêu, K., Devaux, M.-F.: computation of minkowski measures on 2D and 3D binary images. Image Anal. Stereol. (2011). https://doi.org/10.5566/ias.v26.p83-92
Legland, D.: imMinkowski (2021)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1132–1140 (2017)
Lin, Q., Al-Khulaifi, Y., Blunt, M.J., Bijeljic, B.: Quantification of sub-resolution porosity in carbonate rocks by applying high-salinity contrast brine using X-ray microtomography differential imaging. Adv. Water Resour. 96, 306–322 (2016)
Liu, M., Mostaghimi, P.: Reactive transport modelling in dual porosity media. Chem. Eng. Sci. 190, 436–442 (2018)
Liu, M., Shabaninejad, M., Mostaghimi, P.: Predictions of permeability, surface area and average dissolution rate during reactive transport in multi-mineral rocks. J. Pet. Sci. Eng. 170, 130–138 (2018)
Long, H., et al.: Multi-scale imaging and modeling workflow to capture and characterize microporosity in sandstone. In: International Symposium of the Society of Core Analysts, Napa Valley, California, USA (2013)
Mortensen, N.A., Okkels, F., Bruus, H.: Reexamination of Hagen-Poiseuille flow: shape dependence of the hydraulic resistance in microchannels. Phys. Rev. E 71(5), 057301 (2005)
Mostaghimi, P., Blunt, M.J., Bijeljic, B.: Computations of absolute permeability on Micro-CT images. Math. Geosci. 45(1), 103–125 (2013)
Mostaghimi, P., et al.: Cleat-scale characterisation of coal: an overview. J. Nat. Gas Sci. Eng. 39, 143–160 (2017)
Niu, Y., Mostaghimi, P., Shabaninejad, M., Swietojanski, P., Armstrong, R.T.: Digital rock segmentation for petrophysical analysis with reduced user bias using convolutional neural networks. Water Resour. Res. 56(2), e2019WR026597 (2020a)
Niu, Y., Wang, Y.D., Mostaghimi, P., Swietojanski, P., Armstrong, R.T.: An innovative application of generative adversarial networks for physically accurate rock images with an unprecedented field of view. Geophys. Res Lett. 47(23), e2020GL089029 (2020b)
Othman, F., Yu, M., Kamali, F., Hussain, F.: Fines migration during supercritical CO2 injection in sandstone. J. Nat. Gas Sci. Eng. 56, 344–357 (2018)
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 9(1), 62–66 (1979)
Panichev, O., Voloshyna, A.: U-net based convolutional neural network for skeleton extraction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 0–0 (2019)
Peters, C.A.: Accessibilities of reactive minerals in consolidated sedimentary rock: an imaging study of three sandstones. Chem. Geol. 265(1), 198–208 (2009)
Pittman, E.D.: Microporosity in carbonate rocks. AAPG Bull. 55(10), 1873–1878 (1971)
Rabbani, A., Babaei, M.: Image-based modeling of carbon storage in fractured organic-rich shale with deep learning acceleration. Fuel 299, 120795 (2021)
Rabbani, A., Babaei, M., Javadpour, F.: A triple pore network model (T-PNM) for gas flow simulation in fractured, micro-porous and meso-porous media. Transp. Porous Media 132(3), 707–740 (2020a)
Rabbani, A., Babaei, M., Shams, R., Wang, Y.D., Chung, T.: DeePore: a deep learning workflow for rapid and comprehensive characterization of porous materials. Adv. Water Resour. 146, 103787 (2020b)
Raeini, A.Q., Blunt, M.J., Bijeljic, B.: Direct simulations of two-phase flow on micro-CT images of porous media and upscaling of pore-scale forces. Adv. Water Resour. 74, 116–126 (2014)
Ramstad, T., Øren, P.-E., Bakke, S.: Simulation of two-phase flow in reservoir rocks using a lattice boltzmann method. SPE-191379-PA 15(04), 917–927 (2010)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pp. 234–241. Springer International Publishing, Cham (2015)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back-propagating errors. Nature 323(6088), 533–536 (1986)
Schlüter, S., Sheppard, A., Brown, K., Wildenschild, D.: Image processing of multiphase images obtained via X-ray microtomography: a review. Water Resour. Res. 50(4), 3615–3639 (2014)
Schmid, P.J., Henningson, D.S.: Optimal energy density growth in Hagen-Poiseuille flow. J. Fluid Mech. 277, 197–225 (1994)
Sheppard, A.P., Sok, R.M., Averdunk, H.: Techniques for image enhancement and segmentation of tomographic images of porous materials. Phys. A 339(1), 145–151 (2004)
Sørensen, T.J.: A method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. I kommission hos E. Munksgaard, København (1948)
Soulaine, C., Gjetvaj, F., Garing, C., Roman, S., Russian, A., Gouze, P., Tchelepi, H.: The impact of sub-resolution porosity of X-ray microtomography images on the permeability. Transp. Porous Media 113, 227–243 (2016)
Tahmasebi, P., Kamrava, S., Bai, T., Sahimi, M.: Machine learning in geo- and environmental sciences: from small to large scale. Adv. Water Resour. 142, 103619 (2020)
Tan, M., Le, Q.: Efficientnet: rethinking model scaling for convolutional neural networks In: International Conference on Machine Learning. PMLR, pp. 6105–6114 (2019)
Tao, A., Sapra, K., Catanzaro, B.: Hierarchical multi-scale attention for semantic segmentation. (2020) arXiv preprint arXiv:2005.10821.
Thomeer, J.H.M.: Introduction of a pore geometrical factor defined by the capillary pressure curve. SPE-58046-JPT 12(03), 73–77 (1960)
Thomeer, J.H.: Air permeability as a function of three pore-network parameters. SPE-58046-JPT 35(04), 809–814 (1983)
Tuller, M., Kulkarni, R. and Fink, W. (2013). Segmentation of X-Ray CT Data of Porous Materials: A Review of Global and Locally Adaptive Algorithms. In Soil–Water–Root Processes: Advances in Tomography and Imaging (eds S.H. Anderson and J.W. Hopmans). https://doi.org/10.2136/sssaspecpub61.c8
Varfolomeev, I., Yakimchuk, I., Safonov, I.: An application of deep neural networks for segmentation of microtomographic images of rock samples. Computers 8(4), 72 (2019)
Varslot, T., Kingston, A., Myers, G., Sheppard, A.: High-resolution helical cone-beam micro-CT with theoretically-exact reconstruction from experimental data. Med. Phys. 38(10), 5459–5476 (2011)
Wan, J., et al.: Deep learning for content-based image retrieval: a comprehensive study. In: Proceedings of the 22nd ACM international conference on Multimedia. Association for Computing Machinery, Orlando, Florida, USA, pp. 157–166 (2014)
Wang, Y., Teng, Q., He, X., Feng, J., Zhang, T.: CT-image of rock samples super resolution using 3D convolutional neural network. Comput. Geosci. 133, 104314 (2019a)
Wang, Y.D., Armstrong, R.T., Mostaghimi, P.: Enhancing resolution of digital rock images with super resolution convolutional neural networks. J. Pet. Sci. Eng. 182, 106261 (2019b)
Wang, Y.D., Chung, T., Armstrong, R.T., McClure, J.E., Mostaghimi, P.: Computations of permeability of large rock images by dual grid domain decomposition. Adv. Water Resour. 126, 1–14 (2019c)
Wang, Y.D., Armstrong, R.T., Mostaghimi, P.: Boosting resolution and recovering texture of 2D and 3D Micro-CT images with deep learning. Water Resour. Res. 56(1), e2019WR026052 (2020)
Wang, Y.D., et al.: Accelerated computation of relative permeability by coupled morphological and direct multiphase flow simulation. J. Comput. Phys. 401, 108966 (2020)
Wang, Y.D., Blunt, M.J., Armstrong, R.T., Mostaghimi, P.: Deep learning in pore scale imaging and modeling. Earth-Sci. Rev. 215, 103555 (2021a)
Wang, Y.D., Shabaninejad, M., Armstrong, R.T., Mostaghimi, P.: Deep neural networks for improving physical accuracy of 2D and 3D multi-mineral segmentation of rock micro-CT images. Appl. Soft Comput. 104, 107185 (2021b)
Wildenschild, D., Sheppard, A.P.: X-ray imaging and analysis techniques for quantifying pore-scale structure and processes in subsurface porous medium systems. Adv. Water Resour. 51, 217–246 (2013)
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. (2017) arXiv:1703.10593.
Acknowledgements
The authors acknowledge the Tyree X-ray CT Facility, a UNSW network laboratory funded by the UNSW Research Infrastructure Scheme, for the acquisition of the 3D micro-CT images.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest or competing interests involved in the subject matter or materials discussed in this manuscript.
Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Ethical Approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The MICP tests are performed using POREMASTER® by Quantachrome instruments on the 6 mm core plugs after X-ray imaging. For the MICP experiment analysis, a methodology presented by (Buiting and Clerke 2013; Clerke et al. 2008) is followed. This method fits multiple Thomeer hyperbolas (Thomeer 1983, 1960) to quantify the different pore systems in carbonates using superposition. This enables the identification of the porosity of macro- and micropores systems and their pore throat distribution. The pore volume fraction of each pore is determined based on the volume of mercury injected (%BVocc). The pore volume fraction obtained from the MICP for the macropore system is used to choose a safe threshold to complete the ground truth (watershed) segmentation. The pore throats distribution is estimated based on the minimum entry pressure (Pd) from Thomeer Hyperbola. The conductivity of the micropore system is then estimated based on the average pore throats for the single-phase permeability simulation. In the below figures, we show the Thomeer Hyperbolas (Figs. 10 and 11) and the pore throat distribution (Fig. 12) for the ILS and MEC samples.

The estimation of porosity contribution of each pore system in the ILS samples using Thomeer Hyperbola

The estimation of porosity contribution of each pore system in the MEC samples using Thomeer Hyperbola

Pore throat distribution of the ILS and MEC samples based on the MICP test
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alqahtani, N.J., Niu, Y., Wang, Y.D. et al. Super-Resolved Segmentation of X-ray Images of Carbonate Rocks Using Deep Learning. Transp Porous Med 143, 497–525 (2022). https://doi.org/10.1007/s11242-022-01781-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11242-022-01781-9