
Abstract
For research evaluation, publication lists need to be matched to entries in large bibliographic databases, such as Thomson Reuters Web of Science. This matching process is often done manually, making it very time consuming. This paper presents the use of character n-grams as automated indicator to inform and ease the manual matching process. The similarity of two references was identified by calculating Salton’s cosine for their common character n-grams. As a complementary and confirmatory measure, Kondrak’s Levenshtein distance score, based on the character n-grams, is used to re-measure the similarity of the top matches resulting from Salton’s cosine. These automated matches were compared to results from completely manual matching. Incorrect matches were examined in depth and possible solutions suggested. This method was applied to two independent datasets, to validate the results and inferences drawn. For both datasets, the Salton’s score based on character n-grams proves to be a useful indicator to distinguish between correct and incorrect matches. The suggested method is compared with a baseline which is based on word unigrams. Accuracy of the character and word based systems are 96.0 and 94.7 %, respectively. Despite a small difference in accuracy, we observed that the character based system provides more correct matches when the data contains abbreviations, mathematical expressions or erroneous text.



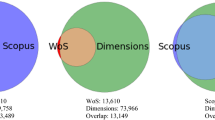
Data sourced from Thomson Reuters Web of Knowledge

Similar content being viewed by others

References
Abdulhayoglu, M. A., & Thijs, B. (2013). Matching bibliometric data from publication lists with large databases using n-grams. In Proceedings of 14th international society of scientometrics and informetrics conference (ISSI-2013), Vienna, Austria, Vol. 2, pp. 1151–1158.
Abou-Assaleh, T., Cercone, N., Keselj, V., & Sweidan, R. (2004). Detection of new malicious code using n-grams signatures. In PST, pp. 193–196.
Apache Lucene. (2014). http://lucene.apache.org. Accessed 2014.
Bilenko, M., Mooney, R., Cohen, W., Ravikumar, P., & Fienberg, S. (2003). Adaptive name matching in information integration. IEEE Intelligent Systems, 18(5), 16–23.
Cavnar, W. B. (1993). n-Gram-based text filtering for TREC-2. Ann Arbor, 1001, 48113-4001.
Cavnar, W. B., & Trenkle, J. M. (1994). n-Gram-based text categorization. In Proceedings of SDAIR-94, 3rd annual symposium on document analysis and information retrieval, Las Vegas, US, pp. 161–175.
Cohen, J. D. (1995). Highlights: Language- and domain-independent automatic indexing terms for abstracting. Journal of the American Society for Information Science, 46, 162–174.
Cohen, W., Ravikumar, P., & Fienberg, S. (2003). A comparison of string metrics for matching names and records. In KDD workshop on data cleaning and object consolidation (Vol. 3, pp. 73–78).
Elmagarmid, A. K., Ipeirotis, P. G., & Verykios, V. S. (2007). Duplicate record detection: A survey. IEEE Transactions on Knowledge and Data Engineering, 19(1), 1–16.
Fisher, J., Wang, Q., Wong, P., & Christen, P. (2013). Data cleaning and matching of institutions in bibliographic databases. Organization, 238, 99–103.
Gencosman, B. C., Ozmutlu, H. C., & Ozmutlu, S. (2014). Character n-gram application for automatic new topic identification. Information Processing and Management, 50(6), 821–856.
Giles, C. L., Bollacker, K. D., & Lawrence, S. (1998). CiteSeer: An automatic citation indexing system. In Digital 98 libraries. Third ACM conference on digital libraries, pp. 89–98.
Glänzel, W., & Czerwon, H. J. (1996). A new methodological approach to bibliographic coupling and its application to the national, regional and institutional level. Scientometrics, 37(2), 195–221.
Glänzel, W., & Schoepflin, U. (1994). Little scientometrics, big scientometrics… and beyond? Scientometrics, 30(2), 375–384.
Gong, C., Huang, Y., Cheng, X., & Bai, S. (2008). Detecting near-duplicates in large-scale short text databases. In Washio, T., Suzuki, E., Ting, K. M., Inokuchi, A. (Eds.), Advances in knowledge discovery and data mining (pp. 877–883). Berlin: Springer.
Järvelin, A., Talvensaari, T., & Järvelin, A. (2008). Data driven methods for improving mono-and cross-lingual IR performance in noisy environments. In Proceedings of the second workshop on analytics for noisy unstructured text data (pp. 75–82).
Kanaris, I., Kanaris, K., Houvardas, I., & Stamatatos, E. (2007). Words versus character n-grams for anti-spam filtering. International Journal on Artificial Intelligence Tools, 16(6), 1047–1067.
Kešelj, V., Peng, F., Cercone, N., & Thomas, C. (2003). n-Gram-based author profiles for authorship attribution. In Proceedings of the conference pacific association for computational linguistics, PACLING, 3 (pp. 255–264).
Kondrak, G. (2005). n-Gram similarity and distance. In Proceedings of the twelfth international conference on string processing and information retrieval (SPIRE 2005), Buenos Aires, Argentina, pp. 115–126.
Larsen, B. (2004). References and citations in automatic indexing and retrieval systems—Experiments with the boomerang effect. PhD thesis, Royal School of Library and Information Science.
Lawrence, S., Giles, C. L., & Bollacker, K. D. (1999). Autonomous citation matching. In Etzioni, O., Muller, J. P., & Bradshaw, J. M. (eds.), AGENTS’99. Proceedings of the third annual conference on autonomous agents, May 1–5, 1999, Seattle, WA, USA (pp. 392–393). New York: ACM Press.
Levenshtein, V. I. (1966). Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics-Doklady, 10, 707–710.
Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval. Cambridge: Cambridge University Press.
MATLAB Release. (2014). The MathWorks, Inc., Natick, Massachusetts, USA.
McCallum, A., Nigam, K., & Ungar, L. H. (2000). Efficient clustering of high-dimensional data sets with application to reference matching. In Proceedings of the sixth ACM SIGKDD international conference on knowledge discovery and data mining (pp. 169–178).
McNamee, P. (2008). Textual representations for corpus-based bilingual retrieval. PhD thesis, University of Maryland (Baltimore County).
Mcnamee, P., & Mayfield, J. (2004). Character n-gram tokenization for European language text retrieval. Information Retrieval, 7(1–2), 73–97.
Miao, Y., Kešelj, V., & Milios, E. (2005). Document clustering using character n-grams: a comparative evaluation with term-based and word-based clustering. In Proceedings of the 14th ACM international conference on information and knowledge management (pp. 357–358).
Mihalcea, R., & Nastase, V. (2002). Letter level learning for language independent diacritics restoration. In Proceedings of the 6th conference on natural language learning (CoNLL) (105–111).
Mustafa, S. H. (2005). Character contiguity in n-gram-based word matching: The case for Arabic text searching. Information Processing and Management, 41(4), 819–827.
Pasula, H., Marthi, B., Milch, B., Russell, S., & Shpitser, I. (2002). Identity uncertainty and citation matching. In Weiss, Y. (Ed.), Advances in neural information processing systems. Conference on neural information processing systems (pp. 1401–1408). British Columbia: MIT Press.
Piskorski, J., & Sydow, M. (2007). String distance metrics for reference matching and search query correction. In W. Abramowicz (Ed.), BIS 2007. LNCS (Vol. 4439, pp. 353–365). Eidelberg: Springer. doi:10.1007/978-3-540-72035-5-27.
Qu, S., Wang, S., & Zou, Y. (2008). Improvement of text feature selection method based on tfidf. In Future information technology and management engineering (pp. 79–81).
Sen, S. K., & Gan, S. K. (1983). A mathematical extension of the idea of bibliographic coupling and its applications. Annals of Library Science and Documentation, 30(2), 78–82.
Tomović, A., Janičić, P., & Kešelj, V. (2006). n-Gram-based classification and unsupervised hierarchical clustering of genome sequences. Computer Methods and Programs in Biomedicine, 81(2), 137–153.
Van Raan, A. F. J. (1997). Scientometrics: state-of-the-art. Scientometrics, 38(1), 205–218.
Vilares, J., Vilares, M., & Otero, J. (2011). Managing misspelled queries in IR applications. Information Processing and Management, 47(2), 263–286.
Zamora, E. M., Pollock, J. J., & Zamora, A. (1981). The use of trigram analysis for spelling error detection. Information Processing and Management, 17, 305–316.
Acknowledgments
The authors would like to thank Prof. Wolfgang Glänzel and Diane Gal for their valuable remarks.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Abdulhayoglu, M.A., Thijs, B. & Jeuris, W. Using character n-grams to match a list of publications to references in bibliographic databases. Scientometrics 109, 1525–1546 (2016). https://doi.org/10.1007/s11192-016-2066-3
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-016-2066-3