
Abstract
We evaluate pseudo-real-time out-of-sample nowcasts for Swedish GDP employing factor models and mixed-data sampling regressions with single predictor variables. These two model classes can handle the data irregularities of a ragged-edge sample and differing sampling frequencies. The results show that pooling of the nowcasts outperforms a simple benchmark, even though only very few of the underlying specifications achieve improved accuracy individually. Moreover, we assess the accuracy of the density forecasts, i.e., the uncertainty around the point forecasts. The post-crisis period after 2008 turns out to be a more difficult period to nowcast precisely. However, indicator variables prove more useful post-crisis as then the performance relative to univariate benchmarks improves.







Similar content being viewed by others
Notes
See also the manual of the MIDAS MATLAB toolbox.
GDP is typically published in the second month after the corresponding quarter, which amounts to 5 months after the latest observation \(T_q\).
There exist other alternative lag polynomials. The two most commonly used are the Almon lag and the beta polynomial (see Ghysels et al. (2007)).
The q dynamic factors are estimated as the principal components of the spectral density matrix, which is obtained by smoothing the periodogram with a Bartlett lead-lag window of \(H=60\) months. The periodogram is estimated based on auto-covariances up to \(M=24\) months of leads and lags. Moreover, the smooth relationship is obtained by filtering out fluctuations at frequencies larger than \(\pi /6\). See “Appendix B” in Marcellino and Schumacher (2010) for details.
Note that the F-VAR specification implies a multivariate likelihood and cannot be directly compared to the BIC of the MIDAS equations. The class of F-VAR models is therefore excluded in this weighting scheme.
In Swedish: Konjunkturinstitutets Konjunkturbarometer, see http://www.konj.se/publikationer/konjunkturbarometern.html.
Due to the first-differencing operator, the 1993q1 value disappears.
Which is unlikely when each test is based on the same sample.
For example, the F-MID-EC specifications with \(w=3\) months of information show very low MSEs (see “Appendix A”, Fig. 7). According to the DM test, the MSE is, however, not significantly lower than the benchmark at 5% significance level.
The factor MIDAS specifications F-MID-EM, F-MAR-EM, F-MID-EC, F-MAR-EC are grouped together and labeled F-MIDAS.
Note that flash estimates are only released regarding the second quarter; hence, quarterly National Accounts statistics are published five times a year. Moreover, the Riksbank publishes forecasts underlying monetary policy decisions six times a year. Hence, two forecast occasions are based on the same National Account statistics.
The GDP series is though the August snapshot with the 2014q2 number being the flash estimate.
References
Aastveit KA, Trovik T (2012) Nowcasting Norwegian GDP: the role of asset prices in a small open economy. Empir Econ 42(1):95–119
Altissimo F, Cristadoro R, Forni M, Lippi M, Veronese G (2010) New eurocoin: tracking economic growth in real time. Rev Econ Stat 92(4):1024–1034
Andersson MK, Aranki T, Reslow A (2017) Adjusting for information content when comparing forecast performance. J Forecast 36(7):784–794
Andreou E, Ghysels E, Kourtellos A (2010) Regression models with mixed sampling frequencies. J Econom 158(2):246–261
Andreou E, Ghysels E, Kourtellos A et al (2011) Forecasting with mixed-frequency data. Oxford handbook of economic forecasting, pp 225–245
Angelini E, Camba-Méndez G, Giannone D, Reichlin L, Rünstler G (2011) Short-term forecasts of euro area GDP. Econom J 14(1):C25–C44
Baffigi A, Golinelli R, Parigi G (2004) Bridge models to forecast the euro area GDP. Int J Forecast 20(3):447–460
Bai J, Ghysels E, Wright JH (2013) State space models and MIDAS regressions. Econom Rev 32(7):779–813
Bańbura M, Modugno M (2014) Maximum likelihood estimation of factor models on data sets with arbitrary pattern of missing data. J Appl Econom 29(1):133–160
Bańbura M, Rünstler G (2011) A look inte the factor model black box: publication lags and the role of hard and soft data in forecasting GDP. Int J Forecast 27(2):333–346
Barhoumi K, Darné O, Ferrara L (2010) Are disaggregate data useful for factor analysis in forecasting French GDP? J Forecast 29(1–2):132–144
Bates JM, Granger CWJ (1969) The combination of forecasts. Oper Res Soc 20(4):451–468
Bera CM, Jarque AK (1982) Model specifications tests: a simultaneous approach. J Econom 20(1):59–82
Bergström R (1995) The relationship between manufacturing production and different business survey series in Sweden 1968–1992. Int J Forecast 11(3):379–393
Berkowitz J (2001) Testing density forecasts, with applications to risk management. J Bus Econ Stat 19(4):465–474
Billstam M, Frändèn K, Samuelson J, Österholm P (2016) Quasi-real-time data of the economic tendency survey. National Institute of Economic Research working paper, no 143
Bodo G, Golinelli R, Parigi G (2000) Forecasting industrial production in the euro area. Empir Econ 25(4):541–561
Boivin J, Ng S (2005) Understanding and comparing factor-based forecasts. Int J Cent Bank 1(3):117–151
Clark TE, McCracken MW (2010) Averaging forecasts from VARs with uncertain instabilities. J Appl Econom 25(1):5–29
Clemen RT (1989) Combining forecasts: a review and annotated bibliography. Int J Forecast 5:559–583
Clements MP, Galvão AB (2008) Macroeconomic forecasting with mixed-frequency data: forecasting output growth in the United States. J Bus Econ Stat 26(4):546–554
Clements MP, Galvão AB (2009) Forecasting US output growth using leading indicators: an appraisal using MIDAS models. J Appl Econom 24(7):1187–1206
D’Agostino A, Giannone D (2012) Comparing alternative predictors based on large-panel factor models. Oxf Bull Econ Stat 74(2):306–326
Diebold FX, Mariano RS (1995) Comparing predictive accuracy. J Bus Econ Stat 13(3):253–263
Doornik JA, Hansen H (2008) An omnibus test for univariate and multivariate normality. Oxf Bull Econ Stat 70(1):927–939
Eickmeier S, Ziegler C (2008) How successful are dynamic factor models at forecasting output and inflation? A meta-analytic approach. J Forecast 27(3):237–265
Flodberg C, Österholm P (2015) A statistical analysis of revisions of Swedish national accounts data. National Institute of Economic Research working paper, no 136
Forni M, Hallin M, Lippi M, Reichlin L (2000) The generalized dynamic factor model: identification and estimation. Rev Econ Stat 82(4):540–554
Forni M, Hallin M, Lippi M, Reichlin L (2005) The generalized dynamic factor model: one-sided estimation and forecasting. J Am Stat Assoc 100(471):830–840
Galvão AB (2013) Changes in predictive ability with mixed frequency data. Int J Forecast 29(3):395–410
Geweke J, Amisano G (2011) Optimal prediction pools. J Econom 164(1):130–141
Geweke J, Amisano G (2012) Prediction with misspecified models. Am Econ Rev 102(3):482–486
Ghysels E, Wright JH (2012) Forecasting professional forecasters. J Bus Econ Stat 27(4):504–516
Ghysels E, Sinko A, Valkanov R (2007) MIDAS regression: further results and new directions. Econom Rev 26(1):53–90
Giannone D, Reichlin L, Small D (2008) Nowcasting: the real-time informational content of macroeconomic data. J Monet Econ 55(4):665–676
Gneiting T, Raftery AE (2007) Strictly proper scoring rules, prediction and estimation. J Am Stat Assoc 102(477):359–378
Good IJ (1952) Rational decisions. J R Stat Soc Ser B (Methodological) 14:107–114
Griliches Z (1967) Distributed lags: a survey. Econometrica 35(1):16–49
Hansson J, Jansson P, Löf M (2005) Business survey data: do they help in forecasting GDP growth? Int J Forecast 21(2):377–389
Hendry DF, Clements MP (2004) Pooling of forecasts. Econom J 7(12):1–31
Iversen J, Laséen S, Lundvall H, Söderström U (2016) Real-time forecasting for monetary policy analysis: the case of Sveriges Riksbank. CEPR discussion papers, no 11203
Jarque AK, Bera CM (1987) A test for normality of observations and regression residuals. Int Stat Rev 55:163–172
Koskinen L, Öller L-E (2004) A classifying procedure for signalling turning points. J Forecast 23(3):197–214
Kuzin V, Marcellino M, Schumacher C (2013) Pooling versus model selection for nowcasting GDP with many predictors: empirical evidence for six industrialized countries. J Appl Econom 28(3):392–411
Luciani M, Ricci L (2014) Nowcasting Norway. Int J Cent Bank 10(4):215–248
Marcellino M, Schumacher C (2010) Factor MIDAS for nowcasting and forecasting with ragged-edge data: a model comparison for German GDP. Oxf Bull Econ Stat 72(4):518–550
Naser H (2015) Estimating and forecasting Bahrein quarterly GDP growth using simple regression and factor-based methods. Empir Econ 49(2):449–479
Öller L-E, Hansson K-G (2004) Revision of national accounts: Swedish expenditure accounts and GDP. J Bus Cycle Meas Anal 19(19):363–385
Öller L-E, Tallbom C (1996) Smooth and timely business cycle indicators for noisy Swedish data. Int J Forecast 12(3):389–402
Österholm P (2014) Survey data and short-term forecasts of Swedish GDP growth. Appl Econ Lett 21(2):135–139
Palm F, Zellner A (1992) To combine or not to combine? Issues of combining forecasts. J Forecast 11(5):687–701
Rahiala M, Teräsvirta T (1993) Business survey data in forecasting the output of Swedish and Finnish metal and engineering industries: a Kalman filter approach. J Forecast 12(3–4):255–271
Rünstler G, Barhoumi K, Benk S, Cristadoro R, den Reijer A, Jakaitiene A, Jelonek P, Rua A, Ruth K, van Nieuwenhuyze C (2009) Short-term forecasting of GDP using large monthly data sets: a pseudo real-time forecast evaluation exercise. J Forecast 28(7):595–611
Smirnov N (1948) Table for estimating the goodness of fit of empirical distributions. Ann Math Stat 19(2):279–281
Stock JH (2006) Forecasting with many predictors. In: Elliot G, Granger C, Timmermann A (eds) Handbook of economic forecasting, vol 1. Elsevier, Amsterdam, pp 516–554
Stock JH, Watson MW (2002) Macroeconomic forecasting using diffusion indexes. J Bus Econ Stat 20(2):147–162
Timmerman A (2006) Forecast combinations. In: Elliot G, Granger C, Timmermann A (eds) Handbook of economic forecasting, vol 1. Elsevier, Amsterdam, pp 136–196
Wallis K (1986) Forecasting with an econometric model: the “ragged edge” problem. J Forecast 19(5):1–13
Author information
Authors and Affiliations
Corresponding author
Additional information
The analysis is to a large extent based on MATLAB code kindly provided by Christian Schumacher. The source code for the model specifications is (indirectly) provided by Marta Bańbura, Mario Forni, James LeSage, Gerhard Rünstler, Kevin Sheppard and Arthur Sinko. All remaining errors are ours.
Appendices
Appendix A: MSE ratio of all models
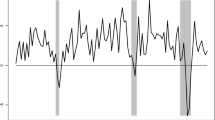
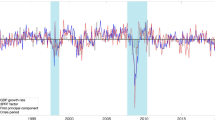
The figures show the relative nowcast accuracy of the MID, MAR and factor model specifications, respectively (Fig. 5). Overall, most model specifications perform poorly, no significant improvement in nowcast accuracy in comparison with the benchmark. There are some economic indicators that seem better though, e.g., kibar14 and kibar28 in Fig. 6. kibar14 is the confidence indicator for the manufacturing industry, and kibar28 is the current backlog of the manufacturing industry, both variables are part of the Economic Tendency Survey (Table 3).
Appendix B: Data
The data set consists of 92 predictor variables. Around half of the variables originate from the Economic Tendency Survey of the Swedish National Institute of Economic Research. Other survey series consist of different indices of the Purchasing Managers Index (PMI) regarding mainly Sweden and some regarding the US. The remaining data originate from Statistics Sweden or are financial data.
The times series are rendered stationary by following one of the codes: (1) = no transformation; (2) first differences; (3) first differences of logarithms. The stationarity inducing transformations are imposed without employing formal unit root testing procedures. Most of the time series are downloaded in an already seasonally adjusted format, denoted by SA in the description. The remaining time series with seasonal fluctuations are adjusted using Census-X12 prior to the forecast simulations. All the series are, moreover, screened for extreme outliers, which are defined as observations that differ from their sample median by more than six times their sample interquartile range.
The sample period consists of the first month of 1993, 1993m1 until 2014m6, and correspondingly 1993q1–2014q2 for quarterly GDP growth rates \(y_{t_q}\). The data set is downloaded in July 2014Footnote 12 and, hence, represents only the fully revised historical series, or the 2014m7 snapshot, or vintage, of the data.
Rights and permissions
About this article

Cite this article
den Reijer, A., Johansson, A. Nowcasting Swedish GDP with a large and unbalanced data set. Empir Econ 57, 1351–1373 (2019). https://doi.org/10.1007/s00181-018-1500-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-018-1500-1