



Abstract
Stars of a common origin are thought to have similar, if not nearly identical, chemistry. Chemical tagging seeks to exploit this fact to identify Milky Way subpopulations through their unique chemical fingerprints. In this work, we compare the chemical abundances of dwarf stars in wide binaries to test the abundance consistency of stars of a common origin. Our sample of 31 wide binaries is identified from a catalog produced by cross-matching Apache Point Observatory Galactic Evolution Experiment spectroscopic survey (APOGEE) stars with UCAC5 astrometry, and we confirm the fidelity of this sample with precision parallaxes from Gaia DR2. For as many as 14 separate elements, we compare the abundances between components of our wide binaries, finding they have very similar chemistry (typically within 0.1 dex). This level of consistency is more similar than can be expected from stars with different origins (which show typical abundance differences of 0.3–0.4 dex within our sample). For the best-measured elements, Fe, Si, K, Ca, Mn, and Ni, these differences are reduced to 0.05–0.08 dex when selecting pairs of dwarf stars with similar temperatures. Our results suggest that APOGEE dwarf stars may currently be used for chemical tagging at the level of ∼0.1 dex or at the level of ∼0.05 dex when restricting for the best-measured elements in stars of similar temperatures. Larger wide binary catalogs may provide calibration sets, in complement to open cluster samples, for ongoing spectroscopic surveys.
Export citation and abstract BibTeX RIS
1. Introduction
Wide binaries are bound pairs of stars separated by as much as ∼1 pc. Several formation scenarios exist for these systems, including the dynamical unfolding of triple systems (Reipurth & Mikkola 2012), association of stellar pairs during the dissolution of stellar clusters (Kouwenhoven et al. 2010; Moeckel & Clarke 2011), turbulent fragmentation (Lee et al. 2017), and the gravitational attraction of nearby pre-stellar cores (Tokovinin 2017). All of these scenarios imply that wide binaries should be born at roughly the same time, from very similar pre-stellar material. The co-eval and co-chemical nature of these pairs allows them to be used for a variety of unique astrophysical applications, such as the calibration of otherwise difficult-to-assess M-dwarf metallicities (Lépine et al. 2007; Rojas-Ayala et al. 2010; Montes et al. 2018), of the age-magnetic activity relation of stars (Garcés et al. 2011; Chanamé & Ramírez 2012), of the age–metallicity relation (Rebassa-Mansergas et al. 2016), of the initial–final mass relation for white dwarfs (Zhao et al. 2012; Andrews et al. 2015), and for tests of the presence and nature of dark matter in the Milky Way (Bahcall et al. 1985; Yoo et al. 2004) and in ultra-faint dwarf galaxies (Peñarrubia et al. 2016).
The co-eval and co-chemical nature of wide binaries has been largely justified on theoretical grounds; only a handful of studies have been performed demonstrating this premise observationally. Makarov et al. (2008) provided evidence that wide binaries are co-eval, and Kraus & Hillenbrand (2009) showed that wide binaries in the Tauris-Auriga association have ages more consistent than the association as a whole. More work has focused on the chemical composition of wide binaries. Initial studies by Gizis & Reid (1997) and Gratton et al. (2001) demonstrated the overall consistency in the metallicity of a handful of wide binaries. Desidera et al. (2004, 2006) focused on iron and found that the components of a sample 50 wide binaries typically show [Fe/H] measurements consistent to within 0.02 dex. Rarely did these studies extend beyond Fe abundances; exceptions include Desidera et al. (2006) who additionally study vanadium and Martín et al. (2002) who focus on lithium.
Separately, the elemental abundances of a number of wide binaries that host planets have been studied in detail using high-resolution spectra. These include X0-2N/X0-2S (Teske et al. 2013, 2015), 16 Cyg A/B (Laws & Gonzalez 2001; Ramírez et al. 2011; Schuler et al. 2011; Tucci Maia et al. 2014), HAT-P-1 (Liu et al. 2014), HD 20872/20871 (Mack et al. 2014), and HD 80606/80607 (Mack et al. 2016; Liu et al. 2018). Additionally, as part of a large spectroscopic study, Brewer et al. (2016) discussed the detailed abundance differences of nine wide binaries. These studies often find small but significant differences in the detailed abundance patterns of wide binary components hosting planets, which has been attributed to the accretion of planetesimals (Mack et al. 2014). However, accretion is only one source of the elemental abundance differences between stars with initially identical chemistry; dredge-up, mixing, and radiative levitation can all act to alter the surface elemental abundances of a star (Schuler et al. 2011; Dotter et al. 2017; Souto et al. 2018). Furthermore, uncertainties in fundamental stellar parameters such as Teff and log g can alter the apparent abundances of stars (e.g., Teske et al. 2015). Detailed study of putatively co-chemical stars, such as wide binaries, that span a significant age range can help determine the extent to which these various effects alter the chemistry of stars throughout their lifetimes.
In Andrews et al. (2018a), hereafter Paper I, we cross-matched our sample of wide binaries from Andrews et al. (2017) that were identified in the Tycho-Gaia Astrometric Solution (TGAS; Lindegren et al. 2016) with data from the Large Sky Area Multi-Object Fibre Spectroscopic Telescope (LAMOST; Luo et al. 2015), and the Radial Velocity Experiment (RAVE; Kunder et al. 2017) spectroscopic surveys. Using the combined sample of 177 wide binaries, in Paper I we argued that wide binaries have Fe abundances consistent within measurement uncertainties, which supports the premise that wide binary components have a common origin.
In Paper I we further suggested that wide binaries can be used to test chemical tagging, the process of identifying co-eval stellar subpopulations in the Galaxy using chemistry. This is based on the idea that stars of a common origin share unique chemical fingerprints (Freeman & Bland-Hawthorn 2002). Initial tests of chemical tagging have shown promising results (e.g., De Silva et al. 2007; Mitschang et al. 2014; Hogg et al. 2016; Kos et al. 2018). Yet the usefulness of future chemical tagging efforts depends on each stellar population having a unique chemical abundance pattern, and it is unclear exactly how similar the chemistry of stars of a common origin actually are. Various studies have shown that the abundances of stars in open clusters are typically consistent to within ∼0.03 dex (e.g., Bovy 2016; Ness et al. 2018). However, these studies and others typically focus on nearby, young, metal-rich populations. As we demonstrated in Paper I, wide binaries offer an opportunity to test chemical tagging across a wider range of ages and metallicities.
In a recent study, Simpson et al. (2018) compared the abundances measured by GALactic Archaeology with HERMES (GALAH) (De Silva et al. 2015) for co-moving stellar pairs identified in TGAS by Oh et al. (2017), finding significant abundance differences in five of eight stellar pairs. This is in stark contrast to the results from Paper I. However, in Paper I the abundance measurements were principally limited to overall metallicity (we additionally tested Mg, Al, Si, and Ti abundances, but these are rather imprecise, which prevented us from making any strong conclusions), whereas Simpson et al. (2018) compared the abundances of over 15 separate elements for each of their eight pairs. Note that these stellar pairs cannot be formally bound since they all have separations larger than the Jacobi (tidal) radius of 1.7 pc for solar mass stars in the solar neighborhood. While it is possible that they may be members of moving groups or ionized (but formerly bound) binaries (Jiang & Tremaine 2010), follow-up analysis using data from Gaia DR2 (of the wide binary sample in Andrews et al. 2017) indicates that most stellar pairs at such wide separations have discrepant parallaxes and radial velocities (RVs), indicating they are the chance coincidence of unassociated stars (Andrews et al. 2018b).
If the components of wide binaries were to be found to show large abundance differences, it would pose a problem for chemical tagging studies, as it suggests that at least some stars of a common origin have significantly variable abundance patterns. Therefore, we aim to compare the elemental abundances of wide binary components in a consistent manner for multiple elements using a larger sample than explored previously. To do so, we require high-resolution spectra for both stars in a large number of wide binaries. In this work, we perform an independent search for the correlated motions of closely separated stars (angular separations less than 2'), which is indicative of binarity, using proper motions from the UCAC5 astrometric catalog (Zacharias et al. 2017) and RVs from the Apache Point Observatory Galactic Evolution Experiment spectroscopic survey (APOGEE). Based on data taken with a fiber-fed spectrograph (Majewski et al. 2017), the latest APOGEE data release (DR14; Abolfathi et al. 2018; Holtzman et al. 2018; Jönsson et al. 2018) contains the abundances of more than 14 elements and RVs for ≈263,000 stars.
In Section 2, we outline the process we use to identify our sample of wide binaries in the APOGEE-UCAC5 cross-matched catalog. We analyze the abundance consistency of wide binary components for 14 elements in Section 3. The level of chemical consistency we observe has implications for chemical tagging, which we discuss in Section 4. Finally, in Section 5 we provide some conclusions and ideas for future directions.
2. Wide Binaries in APOGEE-UCAC5 Catalog
To undertake our test of chemical tagging, we require a sample of sufficiently separated binaries for which spectra can be obtained independently for each component. These spectra must have a high enough spectral resolution and signal-to-noise ratio (S/N) that accurate abundances for multiple elements can be obtained. With a spectral resolution of R ≈ 22,500, and a typical S/N in excess of 100, the APOGEE survey delivers spectra of high enough quality for this test. The APOGEE Stellar Parameters and Chemical Abundances Pipeline (ASPCAP), the spectroscopic pipeline for APOGEE, derives parameters for nearly all the stars observed by APOGEE (García Pérez et al. 2016). These parameters include the effective temperature (Teff) and surface gravity (log g), as well as abundance measurements for more than a dozen separate elements (and as many as 19 for some well-measured stars).
APOGEE calibrates its measured log g to detailed astroseismic models of giant stars in the Kepler field, while cluster stars are used to calibrate other stellar parameters (Holtzman et al. 2015; García Pérez et al. 2016). The latest APOGEE data release, DR14, additionally includes stellar abundance calibrations for dwarf stars based on open clusters (Holtzman et al. 2018), but note that log g is not calibrated for dwarf stars. In Section 3.4, we briefly discuss how this may affect elemental abundance determinations.
In addition to elemental abundances, the APOGEE reduction features comparisons with spectral templates that provide RV measurements with precisions typically better than ∼0.1 km s−1. However, to identify wide binaries robustly, precise proper motions are also required. We cross-match APOGEE stars with the UCAC5 proper motion catalog, which is calibrated to Gaia DR1, to obtain the proper motion of each star. Combined, this provides precise measurements of five of the six dimensions of phase space for stars in the APOGEE catalog: positions from the Sloan Digital Sky Survey (SDSS; York et al. 2000), RVs from APOGEE, and proper motions from UCAC5. Note that SDSS also provides several value-added catalogs with model-dependent distance estimates (the sixth phase space dimension)9 ; however, our tests show that individual distances estimated in this way are often too inaccurate for our needs.
Throughout the remainder of this section, we provide a brief overview of the procedure we follow to identify a robust sample of wide binaries. We refer the reader to the Appendix for details. These include a description of how we cross-match the APOGEE spectroscopic and UCAC5 astrometric catalogs in Appendix A.1, and of how we identify a set of candidate wide binaries within this sample in Appendix A.2. Additionally, we discuss how we produce a sample of random alignments for comparison, and how we select a pure sample of wide binaries from our candidate pairs in Appendices A.3 and A.4, respectively.
Within the joint APOGEE-UCAC5 cross-matched catalog, we search for pairs of stars closely separated in phase space using an adaptation of the Bayesian method we previously used in Andrews et al. (2017) to identify wide binaries in TGAS. In Andrews et al. (2017), we were able to use parallactic distances from TGAS; however, these are unavailable for most APOGEE stars. On the other hand, because APOGEE provides RVs, we are still matching stars using five of six phase space dimensions.
In our model, each stellar pair can be assigned one of two classes, C: either the two stars in the pair are unassociated (C1) or they form a wide binary (C2). We therefore want to identify genuine binaries accurately within all 0.5N (N − 1) possible combinations of two stars within our APOGEE-UCAC5 cross-matched catalog. This amounts to calculating the following probability:

where we have used Bayes' theorem to convert the posterior probability,  , into calculable terms. Appendix A.2 provide details for how we calculate each of the terms in Equation (1).
, into calculable terms. Appendix A.2 provide details for how we calculate each of the terms in Equation (1).
For comparison, we also require a null sample: pairs of stars with similar kinematics that are not wide binaries. In Andrews et al. (2017) we were able to generate this sample by matching our parent catalog with a version of itself having shifted positions; so long as the shift is large enough, every pair found from this matching exercise will be a contaminating pair. Because APOGEE fields are relatively small (3° in diameter), shifting the positions of APOGEE stars will often move them out of the survey area. Here, we produce a sample of random alignments by selecting those pairs of stars identified by our algorithm, but with very low posterior probability:  . As we show below, these stars cannot be wide binaries. At the same time, our analysis in Appendix A.4 suggests that we obtain a robust sample of wide binaries by selecting those stars with
. As we show below, these stars cannot be wide binaries. At the same time, our analysis in Appendix A.4 suggests that we obtain a robust sample of wide binaries by selecting those stars with  . None of the stars in these binaries were flagged with the ASPCAP STAR_BAD flag, which would indicate that the measured stellar parameters may be unreliable.
. None of the stars in these binaries were flagged with the ASPCAP STAR_BAD flag, which would indicate that the measured stellar parameters may be unreliable.
The left two panels of Figure 1 compare the proper motion in right ascension and declination for the components of the wide binaries that we identify, those pairs with  . Measurement uncertainties are smaller than the data points. That the data points lie on top of the one-to-one line is expected since the UCAC5 proper motions are included in the matching algorithm.
. Measurement uncertainties are smaller than the data points. That the data points lie on top of the one-to-one line is expected since the UCAC5 proper motions are included in the matching algorithm.

Figure 1. We compare the UCAC5 proper motions in both R.A. (μα) and decl. (μδ) in the left two panels. As an independent test, of the fidelity of our APOGEE sample, we cross-match the subset of our sample with posterior probability above 90% and in Gaia DR2. The third panel shows that the binaries in our sample have consistent parallaxes for the 25 binaries that are measured by Gaia, while the rightmost panel shows that the binaries also have consistent RVs (except for possibly one system), for the 11 binaries with RVs measured by Gaia DR2.
Download figure:
Standard image High-resolution imageAs an independent test, we cross-match our resulting sample of 36 binaries with the recently released Gaia DR2 astrometric catalog (Gaia Collaboration et al. 2018) and find 25 candidate pairs in which both stars have parallaxes measured by Gaia. We compare the parallaxes of the stars in the 25 pairs in the third panel of Figure 1. The rightmost panel shows the subsample with RVs measured with Gaia. There is only one pair that clearly falls off the one-to-one line, which has an RV discrepancy of 4.8 ± 1.9 km s−1. Further epochs of RV observations are required to determine if these stars are unassociated or if one of these stars hosts a hidden companion. The clear consistency between the parallaxes and RVs of the stars in these pairs (we provide standard deviations on the differences in these quantities in Figure 1) suggests that our sample is free from contamination by chance coincidences, in agreement with our analysis in the Appendix.
In addition to abundances and RVs, the spectroscopic pipeline in APOGEE provides measurements of log g (which is uncalibrated for dwarfs) and Teff for the stars in our pairs, which we show in Figure 2. All but one of the wide binaries in our sample are comprised of main sequence stars. For the 25 pairs of stars that we have cross-matched using Gaia DR2, we show in Figure 3 the Gaia GBP–GRP color against the absolute Gaia G magnitude. Figure 3 confirms that all but two stars in our sample are on the main sequence.

Figure 2. The log g and Teff of the components in our binaries as measured by APOGEE are indicated with blue markers and linked by black lines. Gray background points show the log g and Teff of 10,000 random APOGEE stars. Only one of our pairs is comprised of giant stars; all others are comprised of dwarf stars.
Download figure:
Standard image High-resolution image
Figure 3. The Gaia-based color–magnitude diagram for the 25 pairs in our sample with counterparts in the Gaia DR2 catalog. Gray points in the background show random stars from the Gaia DR2 catalog.
Download figure:
Standard image High-resolution imageAPOGEE has measured stellar abundances for multiple chemical elements for 31 of the 36 binaries identified by our algorithm, including the one pair of giants. These 31 binaries form the sample used throughout this work.
3. Results
3.1. Comparison with LAMOST
In Paper I we compared measurements of [Fe/H] of the two stars in each wide binary in a sample identified in TGAS, but with Fe abundances measured by RAVE and LAMOST. Here, we focus on the subset of the sample from Paper I with [Fe/H] measured by LAMOST, as these stars had spectra with a very high S/N, typically above 200. In Figure 4 we show that the typical LAMOST measurement uncertainties for our wide binaries are better than 0.05 dex and often as small as 0.01 dex. However, according to Luo et al. (2015), the reported LAMOST uncertainties are underestimated; repeat measurements of the same stars indicate a typical [Fe/H] uncertainty of ∼0.06 dex (see also the detailed comparison between stars measured by both LAMOST and APOGEE; Anguiano et al. 2018). We would like to compare the typical LAMOST measurement uncertainties with those of APOGEE. If one uses the reported APOGEE uncertainties on [Fe/H] (FE_H_ERR column), one finds typical precisions of ∼0.02 dex. However, as described in Holtzman et al. (2018) the APOGEE DR14 Fe abundance uncertainties are known to be somewhat larger as they do not propagate uncertainties in [M/H]. Therefore, we use a more realistic formulation for [Fe/H] uncertainties: ![${\sigma }_{[\mathrm{Fe}/{\rm{H}}]}^{2}={\sigma }_{[\mathrm{Fe}/{\rm{M}}]}^{2}+{\sigma }_{[{\rm{M}}/{\rm{H}}]}^{2}$](https://content.cld.iop.org/journals/0004-637X/871/1/42/revision1/apjaaf502ieqn5.gif) . The blue histogram in Figure 4 shows APOGEE abundance precisions in [Fe/H] for our sample to be actually of order 0.07 dex.
. The blue histogram in Figure 4 shows APOGEE abundance precisions in [Fe/H] for our sample to be actually of order 0.07 dex.

Figure 4. APOGEE consistently measures [Fe/H] abundances with a precision ∼0.06 dex (blue). Although the typical LAMOST spectrum provides measurements of [Fe/H] with a precision less than 0.02 dex (orange), repeat measurements of the same LAMOST stars indicate that the real uncertainty closer to 0.06 dex (Luo et al. 2015).
Download figure:
Standard image High-resolution imageIn Figure 5, we show the comparison between [Fe/H] of both stars in each wide binary for both the LAMOST sample and our APOGEE binaries identified here. We provide Spearman ρ correlation coefficients in the bottom right corners of both panels (a value of unity corresponds to perfect correlation, while zero is equivalent to no correlation). The top panel shows a strong correlation (with the exception of two LAMOST data points, which we suspect are contaminants; see discussion in Paper I). The bottom panel shows the corresponding sample of random alignments. The smaller scatter of the [Fe/H] in our wide binary sample as compared to the sample of random alignments provides further evidence that our wide binary sample is likely free of contamination.

Figure 5. We compare the [Fe/H] of each star in our wide binary samples (top panel) as measured by APOGEE in this work and by LAMOST in Paper I. The sample presented in this work spans a narrower range of metallicities than both the LAMOST sample of wide binaries and either sample of random alignments in the bottom panel. Dramatic differences in the scatter between the top panel, which shows our wide binaries, and the bottom panel, which shows the set of random alignments, suggest that our binary samples have minimal contamination.
Download figure:
Standard image High-resolution imageThe top panel of Figure 5 further demonstrates that the sample of stars in APOGEE typically have higher metallicities than the LAMOST binaries sample. This is likely because the APOGEE pointings are disk dominated and include stars at low Galactic latitudes, whereas LAMOST typically focuses on stars at higher Galactic latitudes.
3.2. Metallicity
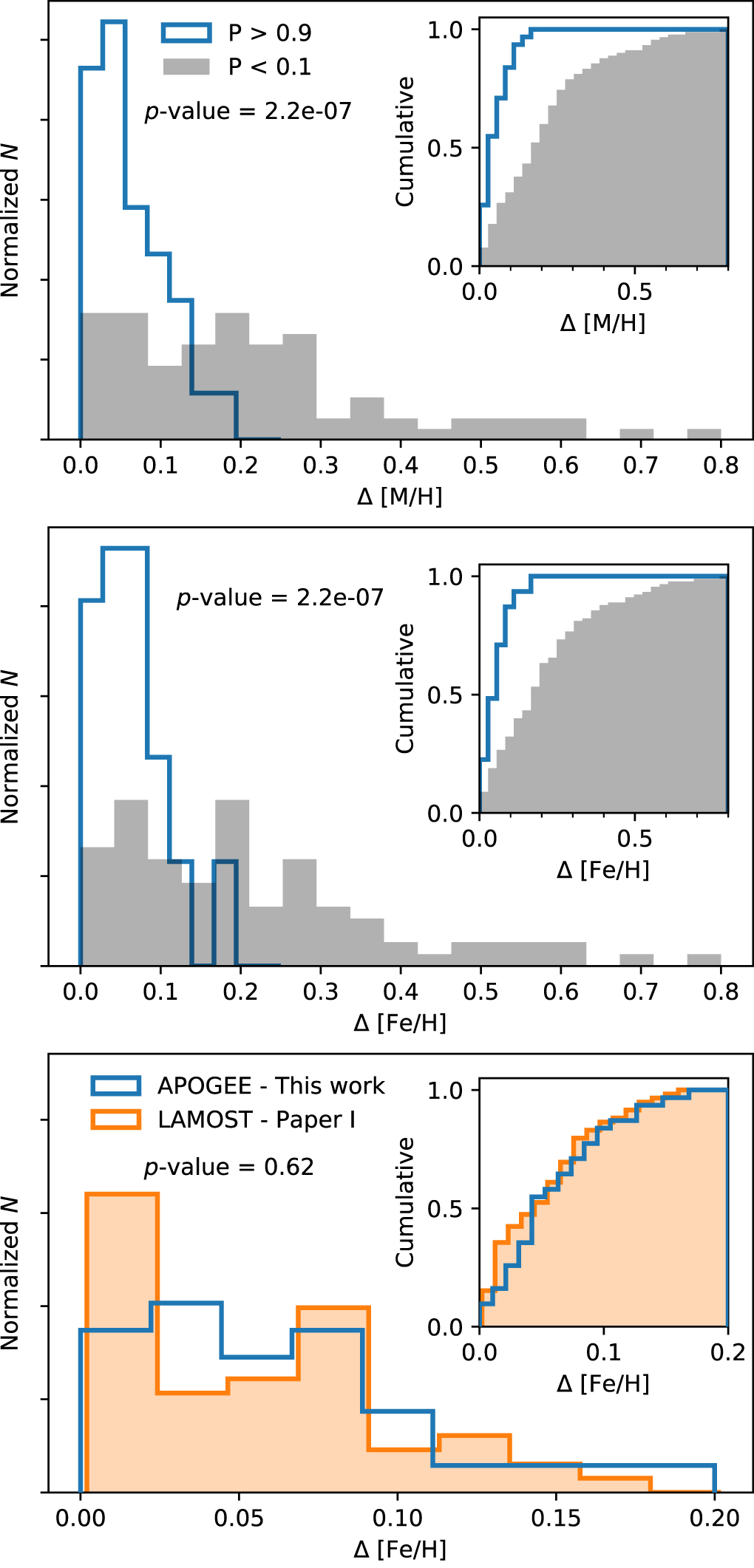
We first focus on the consistency of [M/H] between component stars of our wide binaries. The top panel of Figure 6 compares the metallicity differences between the two stars in our binaries (blue) with our random alignments sample (gray). Our sample of wide binaries has significantly more consistent metallicities compared with our sample of random alignments. This conclusion can be seen more clearly from the inset at the top right of the top panel, which shows the cumulative distribution. Quantitatively, we provide p-values calculated using a two-sample Kolmogorov–Smirnov test beneath the plot legend that show the two samples are unlikely to be drawn from the same distribution at the level of nearly 10−7. We find that [M/H] of the stars in our binaries are typically consistent to within ∼0.1 dex. We discuss the implications of this further in Section 4.

Figure 6. For the stars in our wide binary sample (blue), the primary metallicity indicator determined by ASPCAP (García Pérez et al. 2016), [M/H], is consistent to ∼0.1 dex (top panel). Fe, one of the most accurately measured elements, has a similar level of consistency within our wide binary sample (middle panel). The chance pairings of unassociated stars (gray; generated by taking the sample of stellar pairs with P < 0.1) show a much wider distribution in the top and middle panels, extending Δ[M/H] and Δ[Fe/H] to ∼0.6 dex. The distribution of APOGEE-measured Δ[Fe/H] is similar to the distribution of [Fe/H] differences of TGAS wide binaries with LAMOST spectra (orange), as discussed in Paper I (bottom panel). Fe abundances of wide binary components typically agree to within ∼0.1 dex.
Download figure:
Standard image High-resolution image3.3. Iron
We next focus on [Fe/H], as it is one of the most reliably measured elements in both LAMOST and APOGEE. The middle panel of Figure 6 shows that our wide binary sample (blue) shows much more consistent [Fe/H] than our random alignments sample (gray), paralleling the top panel showing [M/H]. Again, p-values show the distributions are unlikely to be drawn from the same distribution at the level of ∼10−7. As in the top panel, the inset in the middle panel compares the cumulative distributions. These distributions reiterate the close [Fe/H] consistency that was seen previously in Figure 5.
The bottom panel of Figure 6 compares the Fe abundance differences of our wide binaries (blue) to that of the LAMOST sample (orange) from Paper I. The distribution of Δ[Fe/H] is nearly identical between both samples (p-value of 0.65; qualitatively seen even more clearly in the cumulative distribution inset), despite the different sample selection methods, telescopes, spectral ranges, spectrographs, and analysis pipelines. As suggested by Luo et al. (2015), reported LAMOST uncertainties in [Fe/H] are underestimated and ought to be ∼0.06 dex. Likewise, Figure 4 shows that the uncertainties of the stars in our APOGEE samples (when accounting for uncertainties in [M/H]) are also ∼0.06 dex. It is somewhat remarkable that both LAMOST and APOGEE, experiments with two very different designs and 10× different spectral resolutions, and presumably different systematics, show a nearly identical distribution of Δ[Fe/H].
3.4. Elemental Abundances
We use the X_M, M_H, X_M_ERR, and M_H_ERR columns to calculate the abundances and their associated uncertainties with respect to H:


where X is substituted for the individual elements. Throughout the remainder of this work, as elemental abundances and their uncertainties, we use the values calculated using the formulation in Equations (2) and (3).
Figure 7 expands our comparison of elements to the APOGEE-measured abundances (using the formulation above) of C I, O, Mg, Al, Si, P, S, K, Ca, Ti, V, Mn, Fe (which we repeat for comparison), and Ni. Other elements not shown here that are measured by APOGEE, such as Na and Cr, either have too few pairs with measured values, or the measurement uncertainties are too large for useful comparisons. We provide abundances for C as derived from C I lines in stars where it is measured, because in this case the adopted ASPCAP methodology applies for dwarf stars. The bottom right panel of Figure 7 additionally compares the overall metallicity as measured by ASPCAP.

Figure 7. The abundance differences for 14 separate elements of the stars in our sample of wide binaries (not every element is measured for every star). The bottom right panel compares the overall metallicity. Red data points indicate pairs in which ASPCAP-derived ΔTeff < 100 K between stars in a binary pair. Spearman ρ correlation coefficients for pairs with ΔTeff < 100 K (red) as well as pairs with ΔTeff > 100 K (black) are shown in the bottom right corner of each panel. Most panels show that selecting stars with consistent Teff produces stronger correlations. Blue backgrounds in each panel compare the abundances of randomly selected APOGEE stars paired with each other.
Download figure:
Standard image High-resolution imageDespite spanning a dynamic range of ∼0.5 dex, the abundances of the elements in each pair show, to varying degrees, a qualitative consistency across all of the elements. Quantitatively, Spearman ρ correlation coefficients (in black) are provided in the bottom right of each panel. All elements compared have positive and relatively large correlations.
Blue backgrounds in Figure 7 show the abundance differences of random APOGEE dwarfs paired together. We previously noted in Figure 5 that the stars in our APOGEE wide binaries have [Fe/H] abundances that are larger than that of our random alignments on average. Figure 7 shows that this trend extends across all elements we test: there is a consistent tail of systems with elemental abundances higher than that of random pairings of APOGEE stars. Since higher metallicity stars tend to be younger (Edvardsson et al. 1993), this trend could indicate that wide binaries (at least those in the Solar Neighborhood) tend to be younger (a possibility discussed by Makarov et al. 2008). However, recent work has shown that there may not be a clearly defined age–metallicity trend among Milky Way stars (e.g., Casagrande et al. 2011). Further study is required to determine: (a) whether this trend remains with larger samples, (b) whether our method is more likely to identify wide binaries among high-metallicity stars, or (c) whether wide binaries are more common at higher metallicity (and possibly younger ages).
We summarize the elemental abundance differences in the second column of Table 1, where we provide the standard deviation of the abundance differences for each element for our sample of binaries. These standard deviations are calculated from the subset of our 31 wide binaries in which both stars have ASPCAP abundances for that element (typically at least 27 pairs).
Table 1. Standard Deviations of the Distribution of Observed Abundance Differences
| ASPCAP | Random Alignments | The Payne | ASPCAP |
 × Median × Median |
Open | ||||
|---|---|---|---|---|---|---|---|---|---|
| Element | All | ΔTeff < 100 K | All | ΔTeff < 100 K | All | ΔTeff < 100 K | Repeats | Uncertainty | Clusters |
| Δ[C I/H] | 0.12 | 0.08 | 0.33 | 0.32 | ⋯ | ⋯ | 0.09 | 0.13 | ⋯ |
| Δ[O/H] | 0.15 | 0.14 | 0.32 | 0.45 | 0.24 | 0.15 | 0.12 | 0.13 | 0.01 |
| Δ[Mg/H] | 0.15 | 0.13 | 0.27 | 0.20 | 0.16 | 0.02 | 0.06 | 0.10 | 0.01 |
| Δ[Al/H] | 0.16 | 0.22 | 0.41 | 0.59 | 0.13 | 0.05 | 0.15 | 0.13 | 0.02 |
| Δ[Si/H] | 0.11 | 0.08 | 0.26 | 0.18 | 0.10 | 0.04 | 0.06 | 0.10 | 0.01 |
| Δ[P/H] | 0.14 | 0.11 | 0.43 | 0.38 | ⋯ | ⋯ | 0.18 | 0.13 | ⋯ |
| Δ[S/H] | 0.31 | 0.20 | 0.26 | 0.19 | 0.34 | 0.15 | 0.20 | 0.17 | 0.02 |
| Δ[K/H] | 0.09 | 0.07 | 0.32 | 0.37 | 0.34 | 0.26 | 0.19 | 0.12 | 0.03 |
| Δ[Ca/H] | 0.09 | 0.06 | 0.32 | 0.41 | 0.10 | 0.13 | 0.08 | 0.10 | 0.02 |
| Δ[Ti/H] | 0.19 | 0.19 | 0.39 | 0.49 | 0.38 | 0.14 | 0.21 | 0.14 | 0.03 |
| Δ[V/H] | 0.32 | 0.10 | 0.46 | 0.37 | ⋯ | ⋯ | 0.34 | 0.15 | 0.02 |
| Δ[Mn/H] | 0.11 | 0.06 | 0.40 | 0.43 | 0.19 | 0.15 | 0.07 | 0.11 | 0.02 |
| Δ[Fe/H] | 0.08 | 0.04 | 0.33 | 0.37 | 0.12 | 0.01 | 0.04 | 0.09 | 0.01 |
| Δ[Ni/H] | 0.09 | 0.04 | 0.32 | 0.38 | 0.17 | 0.07 | 0.07 | 0.10 | 0.01 |
| Δ[M/H] | 0.08 | 0.04 | 0.33 | 0.38 | ⋯ | ⋯ | 0.03 | 0.09 | ⋯ |
| Number of Pairs | |||||||||
| 31 | 5 | 93 | 18 | 25 | 3 | ∼1400 | 31 | ⋯ | |
Note. We compare the results for our sample of 31 binaries along with the subsample of our binaries showing similar Teff. In the next two columns, we compare the abundances of the stars in our random alignments sample. We additionally provide the abundance differences for 25 of our 31 binaries as determined by The Payne (Ting et al. 2018). In the next two columns, we compare with the abundance differences derived from repeated observations of the same Dwarf Stars by APOGEE, as well as  median uncertainties of the 62 stars in our sample of 31 wide binaries. Finally, in the rightmost column we provide the abundance consistency of open cluster stars as determined by Bovy (2016).
median uncertainties of the 62 stars in our sample of 31 wide binaries. Finally, in the rightmost column we provide the abundance consistency of open cluster stars as determined by Bovy (2016).
Download table as: ASCIITypeset image
Red points in Figure 7 show those pairs having a Teff difference between the two components less than 100 K. Quantitatively, the red correlation coefficients in the bottom right of each panel show that the abundance consistency typically improves when selecting stars with similar Teff. The abundance differences of these pairs are quantified in the third column of Table 1.
In Figure 8, we compare the distribution of elemental abundance differences for our sample of wide binaries (blue), normalized to the measurement uncertainties, with that of our sample of random alignments (orange). The random alignment sample is scaled to show the distribution of abundance differences for our sample size. For all elements measured, the abundances of our wide pairs are more consistent than for our random alignments sample. Table 1 provides the abundance consistency of our random alignments sample, both for the entire sample (fourth column) and for the subset of our random alignments sample having Teff differences between components less than 100 K (fifth column). Both columns comparing abundances of our random alignments sample show typical abundance differences 0.3–0.4 dex. With typical differences ∼0.1 dex, our wide binary sample has significantly more consistent elemental abundances. We provide p-values (in orange; calculated from an Anderson–Darling two-sample test) from comparing our wide binary sample to our random alignments sample. Most elements show p-values less than 0.01, which indicates that our wide binary sample shows significantly more consistent elemental abundances than our sample of random alignments.

Figure 8. We compare the abundance differences, normalized to the measurement uncertainties, of our wide binary sample (blue) with the abundance differences of our sample of random alignments (orange). Black Gaussian curves display the expectation if the abundance differences were due to measurement uncertainties alone. In nearly every case, our distribution is less extended that our random alignments sample but consistent with black Gaussian curves. This result is justified quantitatively by the p-values calculated from the two-sample Anderson–Darling comparison tests for each element, comparing our wide binary sample to the expectation from uncertainties alone (black) and to our random alignments sample (orange). In addition to each of the individual elements, we show the distribution of overall metallicity differences, Δ[M/H], in the bottom right panel.
Download figure:
Standard image High-resolution imageFigure 8 additionally shows black, Gaussian curves indicating the expectation of abundance differences in our sample were they produced entirely from measurement uncertainties. We provide p-values (in black) comparing the black, Gaussian expectation from measurement uncertainties alone, with the observed abundance differences. Most—but not all—elements show abundance differences that are consistent with being due to measurement uncertainties alone. The exceptions are Mg, Ti, and V. Ti and V are poorly measured elements for APOGEE, and we will not discuss these further. On the other hand, Mg is one of the best-measured elements. The consistency of Mg abundances in Figure 7, indeed, seems to show that the distribution of systems is spread beyond measurement uncertainties. When restricting to those five systems with similar Teff, four show very close [Mg/H] consistency, but one outlier remains. It is therefore possible that wide binaries show genuine Mg abundance differences.
Alternatively, the fact that APOGEE dwarf stars have uncalibrated surface gravities could be causing some of the elemental abundance discrepancies we observe (Teske et al. 2015). For instance Brewer et al. (2015) find that different methods for measuring log g result in abundances that differ by ≈0.06 dex. Furthermore, these authors find that the differences are particularly acute for Mg abundances. Improved log g measurements may therefore improve the abundance accuracy of APOGEE dwarf star samples. Further study with larger APOGEE samples is required before more definitive conclusions can be drawn.
As an independent test of the spectroscopic abundances of our sample, we additionally compute standard deviations in the abundance differences for the 25 binaries in our sample that have abundances measured by The Payne (Ting et al. 2018). These abundances are computed using the same APOGEE spectra used by ASPCAP, but using a physically motivated machine learning method. In Table 1 we provide these values in the sixth column for all 25 pairs that cross-match and in the seventh column for the three pairs of those 25 that have ΔTeff < 100 K. For most abundances, The Payne shows similar, or slightly larger, abundance differences than those measured by ASPCAP. We note that when selecting for stars with similar Teff, the abundances as measured by The Payne become much more consistent, but one should take these results as only preliminary since these are computed for only three binaries.
In Figure 9, we show these mean abundance differences (top panel) and the mean abundance differences, normalized to the measurement uncertainties (bottom panel) as a function of the minimum S/N of the APOGEE spectra. Unsurprisingly, the top panel shows that the abundance consistency improves with increasing S/N. For the few binaries in which both stars have S/N > 200, mean elemental abundances are consistent to ∼0.07 dex. The bottom panel shows the mean elemental abundance differences, normalized to the measurement uncertainties. Ignoring the two largest outliers shows no strong trend exists with S/N.

Figure 9. The mean absolute differences (top panel) and mean differences normalized to the measurements uncertainties (bottom panel) between the components in our wide binary sample as a function of the worst S/N of the pair. The clear trend in the top panel shows that as the S/N improves, the abundance consistency improves. Once the measurement uncertainties are taken into account, which we show in the bottom panel, this trend largely disappears (especially once two outliers are removed). Red points highlight those pairs with ΔTeff < 100 K.
Download figure:
Standard image High-resolution image4. Implications for Chemical Tagging
Although APOGEE is principally calibrated for giant stars, our results suggest that APOGEE dwarf stars can currently be used for chemical tagging at the level of ∼0.1 dex for Teff ranging from 3500–6500 K, an abundance consistency much better than the ∼0.3–0.4 dex consistency we find for our sample of random alignments. For comparison, Ness et al. (2018) find a level of chemical consistency for APOGEE giant stars within open clusters to be approximately 0.03 dex. There is no obvious reason why giant stars would intrinsically have significantly more consistent abundances than dwarf stars in our sample. Furthermore, focused studies of the elemental consistency of dwarf stars in clusters, such as the work by Liu et al. (2016) who study solar-like stars in the Hyades, find elemental variations at the level of ∼0.02 dex. In the tenth column of Table 1, we show the typical abundance consistency identified by Bovy (2016) for stars in open clusters. The relatively larger abundance differences we find for our wide binaries would seem to suggest that with future improvements to ASPCAP that present a better treatment of dwarfs, better precision could be possible.
As a test of the cited ASPCAP abundance uncertainties, we search the APOGEE catalog for stars that have been measured multiple times, but where the measurements have been processed independently throughout ASPCAP10 , as described in Holtzman et al. (2018). There are ≈1400 such stars with log g > 4.0 and abundance measurements for both spectra in APOGEE DR14. Since the star's intrinsic abundances will be identical between measurements, the abundance scatter in these measurements provides an assessment of random uncertainties in the ASPCAP pipeline, holding all other properties constant. The eighth column of Table 1 summarizes the standard deviations of the abundance differences and shows that these differences range between 0.04 dex for Fe and 0.34 dex for V, but are typically ∼0.1 dex. These differences are of similar order to, but slightly more consistent than, the differences seen in our wide binary sample. Taking [Fe/H] as an example, using repeat measurements of APOGEE stars, we find typical differences of 0.04 dex, while our binaries show differences of 0.08 dex.
The wide binary pairs in our sample are rarely comprised of two stars with the same Teff and log g, whereas repeat observations of the same star by APOGEE will necessarily measure the same star with identical underlying characteristics. Abundance measurements of stars with different stellar parameters are known to suffer from systematics (Holtzman et al. 2018). APOGEE abundances are calibrated based on dwarf stars in open clusters, but our results suggest that further improvement may be possible; the elemental consistency we observe improves for stars in wide binaries with similar Teff. This improved elemental consistency for binaries becomes similar in magnitude to the typical abundance differences observed by APOGEE for the same stars (compare "ASPCAP" binaries with ΔTeff < 100 K with "ASPCAP Repeats" in Table 1).
In Figure 10, we graphically display the abundance consistencies of our wide binaries from Table 1. We show abundance consistencies of our wide binaries as measured by ASCAP (blue) and The Payne (orange). We additionally show the typical abundance difference observed for the same APOGEE star observed during different epochs on different plates (green) as well as the median ASPCAP uncertainty measured for our wide binaries (gray). We overplot the subset of our binaries with ΔTeff < 100 K as black error bars on top of the blue and orange, solid bars.

Figure 10. We summarize the quantities in Table 1, comparing the abundance consistencies as measured by the ASPCAP pipeline (blue), The Payne (orange), and for dwarf stars with repeated measurements by ASCPAP (green). The extent of the bars corresponds to ±1σ in Δ[X/H] for the stellar pairs. The distributions for all the binaries in our sample are shown as colored bars, while the subset of those binaries with ΔTeff < 100 K are shown as black vertical lines. Selecting stars of similar Teff typically improves the abundance consistency. For each element we show the median measurement uncertainties for the stars in our wide binaries as given by ASPCAP (gray). For nearly every element, the cited measurement uncertainties are very similar to the observed dispersion. At the far right, we compare the overall metallicity consistency as determined by the ASPCAP fit to atmospheric parameters.
Download figure:
Standard image High-resolution imageIn addition to the continuing improvements to the ASPCAP pipeline with each successive data release (see discussion in Holtzman et al. 2018), efforts are underway to reduce the systematic effects present in spectroscopic data using both data-driven methods (The Cannon; Ness et al. 2015) and physically motivated methods (The Payne; Ting et al. 2018). Currently, The Cannon is only calibrated for giant stars, while The Payne has no such limitation. Table 1 and Figure 10 show that for our sample The Payne offers no significant improvement over the abundances measured by ASPCAP, and in many cases the abundances are somewhat worse. There is limited evidence that the abundances as measured by The Payne are particularly consistent for stars with similar Teff, but one should take these results as only preliminary since these are computed for only three binaries.
Until further improvements are made, chemical tagging with APOGEE dwarf stars across a range of Teff seems to reach a precision of ∼0.1 dex. Experiments requiring more precise abundance consistencies may find that stars of different origins overlap in abundance space. This phenomenon was described by Ness et al. (2018) as chemical "doppelgängers": unassociated stars that have very similar chemistry. These authors find that 0.3% of field giant stars have abundances consistent with at least one unassociated field star at the level of 0.03 dex across 20 separate elements. For dwarf stars with 14 measured elements at a precision of 0.1 dex, the chemical fingerprints that are meant to distinguish stars formed in different subpopulations may not be very discerning. We suspect that the current level of abundance precision may be enough to supplement astrometry and kinematics in identifying Milky Way subpopulations, but are likely not yet enough for identifying subpopulations based on chemistry alone.
If further precision with dwarf stars is required, our results indicate that one ought to apply chemical tagging algorithms to stars with a similar Teff, as argued by Dotter et al. (2017). When doing so, we find an elemental abundance consistency approaching 0.05 dex for the best-measured elements: Fe, Si, K, Ca, Mn, Fe, and Ni. One should view these quantitative results with caution, as these are determined using only five pairs with ΔTeff < 100 K, but these first results are encouraging. Future tests using larger samples of APOGEE dwarf stars in open clusters and wide binaries will help to better characterize the abundance consistency of APOGEE dwarf stars of a common origin.
5. Conclusions
By cross-matching APOGEE stars with UCAC5 astrometry, we produce a joint catalog of Galactic stars with proper motions, RVs, and stellar abundances for at least 14 elements. We adapt the algorithm we previously used to identify wide binaries within TGAS (using positions, proper motions, and parallaxes; Andrews et al. 2017) to identify wide binaries in the cross-matched APOGEE-UCAC5 catalog (using positions, proper motions, and RVs). After using multiple methods to ensure the fidelity of our sample, including examining Gaia DR2 parallaxes, we obtain a sample of 31 wide binaries in the APOGEE-UCAC5 catalog.
After comparing as many as 14 separate elements, we find the abundances of our wide binaries are consistent to the level of ∼0.1 dex, much more consistent than the 0.3–0.4 dex consistency we see for our sample of random alignments. For all elements tested except Mg, Ti, and V, the abundance differences we observe are consistent with being due to measurement uncertainties, reaffirming our argument from Paper I (based on [Fe/H] and metallicity only) that wide binary components have a common chemical nature. Our results here contradict those of Simpson et al. (2018), who find significant chemical differences between the components of five of the eight co-moving stellar pairs that they studied; however, as previously mentioned, their sample contained unbound stellar pairs that are unlikely to have a common origin. Therefore, our results suggest that APOGEE dwarf stars may currently be used for chemical tagging at the level of ∼0.1 dex. An improved consistency of ∼0.05 dex is reached when using stars of similar Teff and selecting only the best-measured elements: Fe, Si, K, Ca, Mn, and Ni.
Although we find that wide binaries have similar abundances across multiple elements—too similar to have anything other than a common origin—the abundance measurements have not yet reached the level of consistency previously observed for dwarf stars in open clusters (e.g., Liu et al. 2016). Much effort has been spent improving the abundance measurements for giant stars in APOGEE; however, our results suggest that further improvements for the abundance determinations for dwarf stars may be possible.
Depending on the cause of the elemental abundance differences we observe, there may be serious implications for the ability of chemical tagging to identify dwarf stars of a common origin at a higher precision than the 0.05 dex level reached here. If there is an intrinsic variation in the chemistry of stars of a common origin, then different substructures in our Galaxy may not have a truly unique chemical fingerprint. Detailed studies of open clusters show that intrinsic differences are of order 0.02–0.05 dex (e.g., Liu et al. 2016; Gao et al. 2018). If, on the other hand, the abundance differences seen here are due to mixing processes (Dotter et al. 2017; Souto et al. 2018) or the accretion of rocky bodies (Gonzalez 1997; Schuler et al. 2011; Mack et al. 2014; Oh et al. 2018), chemical tagging with current databases may only be effective if stars with a similar temperature are used or if one relies on only elements with low condensation temperatures. If the abundance differences are principally due to uncertainties in the abundance measurements, larger samples of co-chemical stars such as wide binaries can help with these calibrations and thereby improve elemental abundance measurements.
The recently released Gaia DR2 catalog now contains astrometry for 109 stars, and wide binary samples identified within this much larger catalog (e.g., El-Badry & Rix 2018a) can be cross-matched with current and future data releases from large-scale spectroscopic surveys (e.g., El-Badry & Rix 2018b). These samples will allow for an extension of the work we present here, using larger samples, with more elements identified across a broader range of wavelengths.
J.J.A. acknowledges funding from the European Research Council under the European Union's Seventh Framework Programme (FP/2007–2013)/ERC Grant Agreement n. 617001.
B.A., H.L., C.H., and S.R.M. acknowledge support from NSF grant AST1616636.
J.C. acknowledges support from CONICYT project Basal AFB-170002 and by the Chilean Ministry for the Economy, Development, and Tourisms Programa Iniciativa Cientfica Milenio grant IC 120009, awarded to the Millennium Institute of Astrophysics.
Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS website is www.sdss.org.
SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, the Chilean Participation Group, the French Participation Group, Harvard-Smithsonian Center for Astrophysics, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University.
Appendix: Identifying our Sample
A.1. Cross-matching APOGEE with UCAC5
The UCAC5 astrometric catalog was produced by performing new reductions of the US Naval Observatory CCD Astrograph Catalog, using stars from TGAS as the reference catalog (Zacharias et al. 2017). By cross-matching with Gaia DR1, the UCAC5 catalog contains improved proper motions for 107 million stars with typical accuracies of 1–2 mas yr−1 (R = 11–15 mag) and degrading to ∼5 mas yr−1 at R = 16.
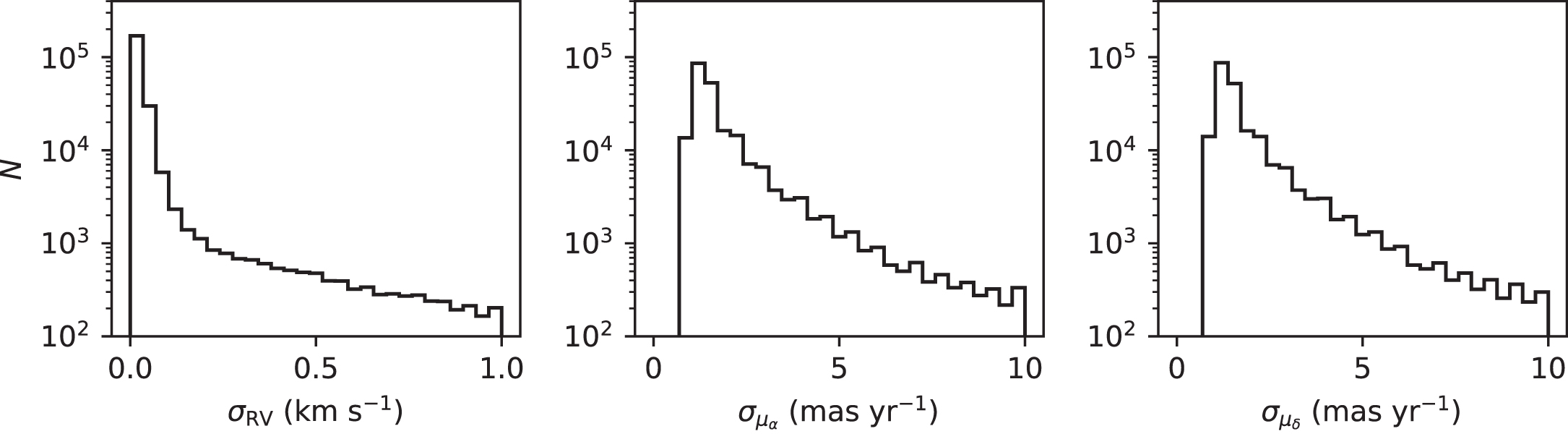
Using a comparison of positions in equatorial coordinates between the surveys, we selected stars where ( , and find a total of 223,754 stars in common between APOGEE DR14 and UCAC5. In Figure 11, we present the uncertainty distributions for the APOGEE-UCAC5 catalog in RV and proper motion. We find that the typical RV precisions are better than 0.1 km s−1, while typical proper motion precisions are 1–2 mas yr−1.
, and find a total of 223,754 stars in common between APOGEE DR14 and UCAC5. In Figure 11, we present the uncertainty distributions for the APOGEE-UCAC5 catalog in RV and proper motion. We find that the typical RV precisions are better than 0.1 km s−1, while typical proper motion precisions are 1–2 mas yr−1.

Figure 11. Precisions of the joint APOGEE-UCAC5 catalog in RV (left), proper motion in R.A. (center), and proper motion in decl. (right).
Download figure:
Standard image High-resolution imageWe also show the distribution of the RVs, proper motions, and spectro-photometric distances (provided by a value-added APOGEE catalog, calculated using the Bayesian algorithm described in Santiago et al. 2016) for the APOGEE-UCAC5 catalog in Figure 12. The black lines in the RV and proper motions panel show the fits used in the identification algorithm. See the following section for details.

Figure 12. Distribution of the joint APOGEE-UCAC5 catalog for RVs (left), proper motions (center), and APOGEE spectro-photometric distances (right). Black lines on the RV and proper motion panels show the fits to these distributions used in the wide binary identification algorithm.
Download figure:
Standard image High-resolution imageA.2. Identifying Wide Binaries
Our method for identifying wide binaries within our joint APOGEE-UCAC5 catalog is based on the Bayesian method from Andrews et al. (2017). The method, as we apply it here, uses the positions (α, δ), proper motions (μα, μδ), and RVs of stars within the catalog to calculate the likelihood that any pair of stars is either a genuine binary (C2) or a chance coincidence of unassociated stars (C1). We begin by defining the angular separation (θ) and proper motion difference (Δμ) between two stars using the small angle approximation:


where  . Numeric subscripts denote values associated with each of the two stellar components.
. Numeric subscripts denote values associated with each of the two stellar components.
Each stellar pair in APOGEE is defined by 10 observables (and their associated measurement uncertainties) corresponding to five phase space dimensions (positions, proper motions, and RVs) for each of two stars. We reduce the dimensionality of each stellar pair to seven, which we contain within two sets, xi and xk:


where primed quantities denote observed quantities with measurement uncertainties that must be accounted for.
We calculate the posterior distribution as defined by Equation (1) in Section 2. The denominator is separated in the same way as in Andrews et al. (2017, see Equation (8)). This requires determining quantities that effectively serve as Bayesian priors:  and
and  . To calculate these terms, we take the identical method as in Andrews et al. (2017, see Equations (9)–(14)). We refer the reader to that work for details. To wit, the prior for any stellar pair to be a random alignment scales with the square of the local density in phase space, whereas the prior on any pair to be a wide binary scales linearly with the local stellar density in phase space. Normalization constants for these scalings are determined from the fact that there are ≈0.5 N2 total random alignments, whereas there are fbN total binaries in the APOGEE catalog, where fb is the binary fraction, which we take to be 50%.
. To calculate these terms, we take the identical method as in Andrews et al. (2017, see Equations (9)–(14)). We refer the reader to that work for details. To wit, the prior for any stellar pair to be a random alignment scales with the square of the local density in phase space, whereas the prior on any pair to be a wide binary scales linearly with the local stellar density in phase space. Normalization constants for these scalings are determined from the fact that there are ≈0.5 N2 total random alignments, whereas there are fbN total binaries in the APOGEE catalog, where fb is the binary fraction, which we take to be 50%.
A.2.1. Binary Likelihood
We next wish to calculate the first term in the numerator,  . We first convolve over the actual proper motion and RV differences to account for measurement uncertainties:
. We first convolve over the actual proper motion and RV differences to account for measurement uncertainties:

where we have substituted xi and xk for their components and split terms based on their independence: measured quantities are only dependent upon their underlying values (and measurement uncertainties). We have also made the approximation that there is no dependence on ΔRV from Δμ. The last two terms in the integrand are straightforwardly evaluated as Gaussian distributions centered on each stellar pair's measurement of Δμ and ΔRV, with a variance equal to the square of the measurement uncertainties. Note that  . The analytic nature of these two terms allows this integral to be easily evaluated using Monte Carlo random sampling:
. The analytic nature of these two terms allows this integral to be easily evaluated using Monte Carlo random sampling:

where Δμj and ΔRVj are N random variates, drawn from Gaussian distributions defined by measurements of Δμ and ΔRV. We use 104 random draws to accurately evaluate the summation in Equation (9).
Studies identifying wide binaries traditionally assume that wide binary components must have the same proper motions and RVs, but as astrometry and RV measurements have improved in recent years, the orbital velocity of even the widest binaries can be detected (see Figure 8 in Andrews et al. 2017). Because this orbital motion must be accounted for, evaluating the terms,  and
and  , in Equation (9) is not straightforward. Newtonian gravity provides the orbital velocity of a binary as a function of stellar masses, separation, eccentricity, and mean anomaly. For a particular orientation on the sky, the projected separation, tangential velocity, and RV can be determined. We generate 104 random stellar binaries with primary masses drawn from a Salpeter IMF, a flat mass ratio distribution, a log flat distribution for the orbital separation, a thermal eccentricity distribution, and random orientations on the sky.
, in Equation (9) is not straightforward. Newtonian gravity provides the orbital velocity of a binary as a function of stellar masses, separation, eccentricity, and mean anomaly. For a particular orientation on the sky, the projected separation, tangential velocity, and RV can be determined. We generate 104 random stellar binaries with primary masses drawn from a Salpeter IMF, a flat mass ratio distribution, a log flat distribution for the orbital separation, a thermal eccentricity distribution, and random orientations on the sky.
To translate from physical units (projected separation and tangential velocity) to angular units (angular separation and proper motion) we convolve with the spectro-photometric distance (Santiago et al. 2016) distribution provided by the value-added APOGEE catalog, which is shown in the bottom panel of Figure 12. Most APOGEE stars in our sample are located within the nearest 500 pc, but a significant tail extends to distances of several kpc. Our tests indicate that individual stellar distances are not accurate enough to include in our matching algorithm; however we assume that the bulk distribution is representative of the catalog. In practice, our results are not sensitive to the exact distance distribution with which we convolve.
To evaluate  for any arbitrary μ and θ, we construct a kernel density estimate (KDE) representation of the distribution of random binaries. We likewise represent
for any arbitrary μ and θ, we construct a kernel density estimate (KDE) representation of the distribution of random binaries. We likewise represent  with a KDE. Returning to Equation (9), we calculate the summand using terms for which we now have representations for:
with a KDE. Returning to Equation (9), we calculate the summand using terms for which we now have representations for:

where  is calculated from the distribution of angular separations previously generated.
is calculated from the distribution of angular separations previously generated.
Our search is limited to stellar pairs with angular separations less than 2'. For each of these pairs, we calculate the sum in Equation (10) using 104 random samples of Δμj and Δ RVj. The resulting quantity provides the likelihood that any particular stellar pair can be a wide binary.
A.2.2. Random Alignments Likelihood
In our Bayesian algorithm, we also require a corresponding likelihood to be calculated that represents the possibility for each stellar pair to be formed from two unassociated stars. As was performed when determining our binary likelihood, we account for measurement uncertainties in Δμ and the two RVs by convolving over their underlying values:


where we have separated terms based on independence: observed (primed) quantities are dependent only on their underlying values and the corresponding measurement uncertainties, the RVs are assumed to be independent of each other, and since the two stars are unrelated, θ, Δμ, and the two RVs are all uncorrelated.
We can evaluate this triple integral with a Monte Carlo sum:

where Δμj, RV1,j, and RV2,j are all N random deviates drawn from Gaussian distributions centered on their observationally derived values and with standard deviations equal to the measurement uncertainties. We now discuss how each of the terms in Equation (13) can be calculated in turn.
 is the likelihood of randomly finding two stars with a proper motion difference of Δμ. This can be approximated as 2πP(μα, μδ) Δμ = P(μ)Δμ/μ, where P(μ) is the distribution of proper motions of stars in the APOGEE catalog. The middle panel of Figure 12 shows the actual distribution of proper motions, while the black line shows our approximation generated by piecing together a KDE representation of the distribution for stars with μ < 200 mas yr−1, and fitting a straight line in log-space to those stars with larger μ.
is the likelihood of randomly finding two stars with a proper motion difference of Δμ. This can be approximated as 2πP(μα, μδ) Δμ = P(μ)Δμ/μ, where P(μ) is the distribution of proper motions of stars in the APOGEE catalog. The middle panel of Figure 12 shows the actual distribution of proper motions, while the black line shows our approximation generated by piecing together a KDE representation of the distribution for stars with μ < 200 mas yr−1, and fitting a straight line in log-space to those stars with larger μ.
Likewise,  provides a corresponding probability of finding stellar pairs with the observed angular separation, which in an analogous way to the previous term can be approximated as 2πθP(α, δ). Here, P(α, δ) is determined using a KDE representation of the stellar density across the sky.
provides a corresponding probability of finding stellar pairs with the observed angular separation, which in an analogous way to the previous term can be approximated as 2πθP(α, δ). Here, P(α, δ) is determined using a KDE representation of the stellar density across the sky.
Finally, P(RV1,j) and P(RV2,j) are both priors on the RVs, which we formulate from the overall RV distribution of APOGEE stars, shown as the blue distribution in the left panel of Figure 12. We approximate this distribution using the black line, which is calculated using a KDE representation of the data for stars with RVs between −200 and 200 km s−1, and by fitting a line to the distribution in log-space outside this range.
We now have expression for all the terms to calculate the random alignment likelihood in Equation (13). We use 104 random samples to evaluate this integral.
With this binary likelihood, we can now evaluate the posterior probability in Equation (1). We apply our full expression for the posterior probability to all 33,786 pairs of stars in our APOGEE-UCAC5 catalog with angular separations less than 2', finding 1282 with posterior probabilities above 10−3. From this sample, we must determine the limiting probability, which separates wide binaries from unassociated pairs of stars that by chance have similar kinematics.
A.3. Forming a Random Alignments Sample
In Andrews et al. (2017), we performed a second search in which we match the TGAS catalog with a version of itself that is shifted by +2° in decl. and +3 mas yr−1 in both proper motion dimensions. Every resulting pair identified by our algorithm is a chance coincidence. By comparing our original candidate binary sample with the catalog of chance alignments, we calibrated the limiting posterior probability that defines our sample. For our sample of APOGEE binaries, the identical test is ineffective because APOGEE is not an all-sky survey; APOGEE fields are smaller than the 2° shift we previously used.
Instead, as a first test, we perform an analogous exercise, comparing our APOGEE-UCAC5 catalog with a version of itself shifted in declination by only +1', but also by +20 km s−1 in RV and +5 mas yr−1 in proper motion. We find the +1' shift is smaller than the APOGEE field of view, but large enough to keep most genuine binaries from artificially being identified within the shifted version of the catalog when combined with the proper motion and RV shifts. Despite this, we find nine pairs from our initial catalog search that were recovered in our shifted catalog. After removing these by hand, we produce a sample of 74 random alignments with angular separations between 2'' and 2'.
A.4. Assessing the Limiting Posterior Probability
We compare the angular separation against the posterior probability between the two samples in the bottom panel of Figure 13. The top panel shows the normalized distribution of posterior probabilities. Our method of identifying random alignments underestimates the rate of chance alignments because the shifts in RV and proper motion applied to created our shifted catalog are relatively large. However, the random alignments sample characterizes the area in phase space where contamination is higher. Both panels of Figure 13 show an excess of candidate pairs with posterior probabilities near unity and small angular separations, indicative of genuine wide binaries. This suggests that we would like to apply a limiting posterior probability larger than 80%.

Figure 13. The angular separation as a function of each stellar pair's posterior probability of being a wide binary for both our candidates (blue) and our random alignments sample (yellow). The top panel shows the normalized distribution of posterior probabilities for both samples. Our method to identify random alignments underestimates the contamination fraction because the large shifts in RV and proper motion applied to the shifted catalog reduce its overlap with the original catalog; the contamination rate is actually much higher than comparison of the relative rates of blue to yellow points would suggest. Despite this, our random alignments sample should occupy the same parameter space as contamination in our wide binary candidates. The candidates at low posterior probability are most likely contamination due to chance coincidence, whereas the cluster of stellar pairs with posterior probabilities near unity and small angular separations are likely to be genuine.
Download figure:
Standard image High-resolution imageAs a consistency check, we compare the Fe abundance measured by APOGEE, [Fe/H], of wide binary components, as a function of the posterior probability assigned by our method. In Paper I we determined that wide binaries have metallicities consistent to ≲0.2 dex. The top panel of Figure 14 shows that pairs at high posterior probabilities tend to have smaller Fe abundance differences, compared with those pairs at posterior probabilities closer to zero. The bottom panel shows the corresponding comparison between the posterior probability and the error-weighted metallicity difference; y-axis values correspond to the number of standard deviations away from zero. Gray backgrounds depict the running average in the metallicity difference, which shows a significant narrowing of the distribution as posterior probabilities increases, with a clear shift around a probabilities of 0.3.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 14. We compare the posterior probability of our candidates to the metallicity difference, both absolute (top panel) and normalized to the measurement uncertainty (bottom panel), between the stellar components in each sample. That the metallicity of the pairs becomes more consistent with increasing posterior probability indicates that our statistical method is successful at identifying wide binaries. This figure serves as a consistency check, since based on our previous work in Paper I, we expect that wide binaries typically have metallicities consistent to within at least 0.2 dex.
Download figure:
Standard image High-resolution image{kind=link}
Despite the decrease in running average at posterior probabilities of ≈0.3, the distribution of posterior probability and angular separation of our random alignments sample shows that random alignments may have posterior probabilities as high as 0.4 or higher. Since we would like to obtain a relatively low contamination sample, we therefore elect to select as our sample only those stellar pairs with posterior probabilities above 0.9. Figure 1 shows that when cross-matching with Gaia DR2, our sample with posterior probabilities above 90% have closely matching parallaxes. For the remainder of this work, we draw our conclusions from this sample.
Footnotes
- 9
- 10
APOGEE often takes repeat measurements of partially overlapping fields, with spectra occasionally taken for the same stars on both plates, by chance.