
Abstract
Discourse comprehension requires one to process information that is actively maintained in working memory (WM). Therefore, we hypothesized that individual differences in comprehension would be predicted better by working memory tasks that capture the concurrent demands of processing and maintenance of the same memory elements (i.e., content-embedded tasks) than by WM tasks that require the maintenance of an extraneous memory load during processing (e.g., complex span tasks). Two hundred sixty-one undergraduates completed three content-embedded tasks, three complex span tasks, and three measures of comprehension. Results of structural equation modeling indicated that the content-embedded tasks accounted for a greater amount of variance in comprehension than did complex span tasks. Thus, tasks that require one to coordinate the processing and maintenance of task-specific memory elements are preferable for capturing the relationship between WM and comprehension.
Similar content being viewed by others


Text processing is a highly complex cognitive task in that its successful completion depends on the coordinated processing and maintenance of several different kinds of information, including words and the concepts they denote, the syntactic and semantic relationships between words within a sentence, the semantic relationships between ideas within and between sentences, and general world knowledge. Indeed, a widespread assumption among contemporary models of text comprehension is that successful comprehension depends heavily on the effective use of limited working memory (WM) resources (e.g., Goldman, Varma, & Coté, 1996; Graesser, Gernsbacher, & Goldman, 2003; Just & Carpenter, 1992; Kintsch, 1998; Perfetti, 1988; van den Broek, 2010).
Consistent with this assumption, research has repeatedly demonstrated that individual differences in WM predict variance in comprehension. The most common approach to measuring WM has involved complex span tasks (see Conway et al., 2005; Kane et al., 2004). For example, Daneman and Carpenter’s (1980) original reading span (RSPAN) task required participants to read a series of unrelated sentences aloud, after which they were asked to recall the last word of each sentence. Given concerns that sentence-final words were being generated from recall of the gist of the sentence, rather than from maintenance in working memory (Conway et al., 2005), more recent versions of the RSPAN task typically present an unrelated target (e.g., a word or letter) after each sentence to be maintained for subsequent recall after the end of the sentence set. The operation span (OSPAN) task is conceptually similar, requiring the processing of arithmetic equations along with maintenance of unrelated targets that follow each equation. More generally, complex span measures include both processing and maintenance task components. Of greatest interest for present purposes, a key feature of these measures is that the content to be processed and the content to be maintained are independent of one another. Even Daneman and Carpenter’s original version of the RSPAN task involved maintenance of information that was irrelevant to subsequent processing (preceding sentence-final words were irrelevant to processing the content of subsequent sentences).
A second category of WM measures includes tasks, referred to here as content-embedded tasks, that also require processing and maintenance of information to perform successfully (Cowan, 1999; Kyllonen & Christal, 1990; Woltz, 1988). Content-embedded measures differ critically from complex span tasks in one key respect: The content to be maintained is processing relevant rather than processingirrelevant. As was previously described, in complex span tasks, the information that must be maintained is extraneous to the processing task. In content-embedded tasks, the information that is being processed or updated in WM is also the information that must be maintained for subsequent output. For example, in the digit-recoding task, participants are presented with a string of numerals that they are required to maintain in WM and process (e.g., if the digit string was 7 3 8 4 2 5, questions might include, “What number came after 4?” and “What is the difference between the third and last numbers?”). Thus, in contrast to complex span tasks, the content that must be maintained for output in content-embedded tasks is processing relevant rather than extraneous.
Although both content-embedded tasks (e.g., Was & Woltz, 2007) and complex span tasks (e.g., Engle, Carullo, & Collins, 1991) correlate with measures of comprehension, complex span tasks have been the WM measure of choice. Indeed, the volume of studies that have examined associations between complex span tasks and comprehension is too vast to be summarized here (for recent reviews, see Carretti, Borella, Cornoldi, & De Beni, 2009; Daneman & Merikle, 1996; Unsworth & Engle, 2007b), whereas Was and Woltz reported the only prior study to examine the association between content-embedded tasks and comprehension. Most important, no prior research has directly compared the association between comprehension and WM as measured by complex span tasks versus content-embedded tasks.
This direct comparison is informative because comprehension theory predicts that content-embedded tasks will be more effective than complex span tasks for capturing the association between WM and comprehension. A core assumption of models of comprehension is that comprehension relies on concurrent maintenance and processing of task-relevant content. For example, according to the construction-integration (CI) model (Kintsch, 1988, 1998), the conundrum of comprehension is that all of the information in a text far exceeds the capacity of WM and, thus, cannot be processed concurrently, yet comprehension requires integration of information across sentences and sections. According to the CI model, this problem is solved by processing text in cycles in which comprehension processes operate on one segment of text at a time (roughly corresponding to a sentence). In brief, each cycle involves temporarily maintaining a small amount of information from the previous cycle, inputting new information from the current text segment, and then integrating the old and new information. To maintain coherence across segments, a subset of the most central information is maintained in WM to participate in the next processing cycle. Thus, comprehension is heavily dependent on maintaining task-relevant content in WM both within and across processing cycles. The key point here is that whereas complex span tasks do not require maintenance of process-relevant information in WM, content-embedded tasks of WM do require such maintenance and, thus, are predicted to show stronger associations with comprehension.
In the present investigation, we used three content-embedded tasks, three complex span tasks, and three measures of comprehension to derive latent factors capturing individual differences in each of these constructs. Because the content-embedded tasks required individuals to process and update information actively maintained in WM, as does comprehension, we expected content-embedded tasks to account for a greater amount of unique variance in comprehension than would complex span measures of WM that relied on the active maintenance of content that was extraneous to the processing task.
Method
Participants
Two hundred sixty-one undergraduates at a large Midwestern state university participated as part of a larger study and received either partial course credit or monetary compensation.
Materials and procedure
Complex span tasks
All three complex span tasks were modified versions of those described in Kane et al. (2004): OSPAN, RSPAN, and counting span (CSPAN). We selected these three measures on the basis of convention, in that these complex span measures are the most commonly used to create the latent WM construct in factor analyses and structural equation models (e.g., Colom, Rebollo, Abad, & Shih, 2006; Conway, Cowan, Bunting, Therriault, & Minkoff, 2002; Engle, Kane, &Tuholski, 1999a; Léphine & Barrouillet, 2005; Mogle, Lovett, Stawski, & Sliwinski, 2008; Unsworth & Engle, 2007a). Conway et al. (2005) provided a methodological guide and review of complex span measures, suggesting and providing evidence that CSPAN, OSPAN, and RSPAN are valid and reliable measures of WM. Performance on each task was computed using partial-credit unit scoring (for details, see Conway et al., 2005).
In the OPSAN task, participants read a mathematical operation aloud (e.g., “Is (4 × 2) + 3 = 12?”), reported whether it was correct, and then read a target word aloud (e.g., home). Immediately thereafter, the experimenter pressed a key to present the next operation–word pair onscreen [e.g., “Is (9 ÷ 3) + 4 = 7? APPLE”]. Following the final pair of the trial, participants recalled the target words in serial order (e.g., home, apple). The OSPAN task consisted of 15 experimenter-paced trials that ranged from two to six operation–word pairs. The words and the order of set sizes were initially randomized, and that order was used for all participants.
In the RSPAN task, participants read a sentence aloud (e.g., “Mr. Owens left the lawnmower in the lemon”), reported whether it made sense, and then read an unrelated word aloud (e.g., eagle). Once the word was read aloud, the experimenter pressed a key to present the next sentence–word pair, and so on. After the final pair of each trial, participants wrote the target words in serial order. The RSPAN task consisted of 15 experimenter-paced trials that ranged from two to six sentence–word pairs presented in a fixed random order.
In the CSPAN task, participants were presented with a random array of shapes, each of which contained from three to nine dark blue circles, as well as a varying number of light blue circles and dark blue squares. Participants were asked to count the number of dark blue circles, to click on each one using the mouse (a checkmark appeared on the dark blue circle once they clicked on it), and to memorize the total number for a later recall test. After clicking on the last dark blue circle within an array, a new array appeared onscreen. After participants completed the final array, a recall cue appeared, and they recalled the total number of dark blue circles from each array in that trial in serial order. For instance, if the first array had three dark blue circles, the second had eight, and the third had two, the participant would type “3, 8, 2.” Again, the task consisted of 15 trials that ranged from two to six arrays (i.e., two to six to-be-remembered numbers) presented in a fixed random order.
Content-embedded tasks
Variants of all three content-embedded tasks have been used in previous research (Ackerman, Beier, & Boyle, 2002; Kyllonen & Christal, 1990; Was & Woltz, 2007; Woltz, 1988).
On each of the 18 trials in the alphabet WM task, participants were presented with either one or two nonadjacent letters from the alphabet for 2.5 s, followed by a transformation direction and number (−3, −2, −1, + 1, + 2, + 3). Participants were instructed to increment or decrement each stimulus letter according to the transformation value (e.g., ME . . . −2 = KC). The transformation value remained on the screen until the participant was ready to respond. Participants were instructed to solve the problem before advancing to the response alternative screen. Once participants advanced to the response alternative screen, they were given 6 sto choose an option by pressing a number key from 1 to 8. The time limit was imposed to prevent participants from solving the problems while examining the alternatives in the response window.
The 18 trials occurred in two blocks of 9 trials. The trials of each block represented a 2 × 2 × 3 design with number of stimulus letters (one or two), forward or backward recoding direction, and recoding distance (one, two, or three) as the design facets. The order of trials within each block was randomized for each participant.
In each of the 24 trials in the ABCD WM task, participants interpreted three statements that, together, defined the order of the letters A,B,C, and D. One statement defined the order of A and B (e.g., “B comes after A,” interpreted as AB). Another statement defined the order of C and D (e.g., “D comes before C,” interpreted as DC). The third statement defined the order of AB relative to CD (e.g., “Set 1 comes after Set 2,” interpreted as DCAB). The order of the three statements and the ordering operations in each statement were varied across trials. Processing time for each statement was self-paced, with a limit of 20 s. After interpreting all three statements, participants selected a response from an alphabetized list of eight possible orders. The 24 trials were divided into two 12-trial blocks.
On each trial in the digit-recoding task, participants were presented with six digits at a rate of 2.25 s per digit. Participants then answered two questions presented one at a time about the order of the numbers (e.g., if the digit string was 9 3 4 6 2 5, questions might include, “What number precedes 2?” and “What is the difference between the first and last numbers?”). All answers were numeric, and participants entered them on the keyboard number pad. The 24 trials were divided into two 12-trial blocks.
Comprehension measures
Our three comprehension measures included (1) the reading comprehension task from the Air Force Officer Qualifying Test (see Kane et al., 2004), (2) the Shipley Vocabulary Test (Zachary, 1986), and (3) the ACT (previously, American College Testing Program, Inc.) assessment reading scores (participants granted consent for their ACT scores to be accessed from the registrar).
Results
Four of the 261 participants had accuracies of zero for one or more of the WM measures. These participants’ data were eliminated from analyses. Table 1 displays the means, standard deviations, reliability estimates, and intercorrelations among the nine observed variables. Two features of the data are noteworthy. First, reliability estimates for all tasks are acceptable (values displayed on the matrix diagonal). Second, the tasks representing each construct had reasonably high correlations with one another. One concern about the intercorrelations factor is that CSPAN was more strongly correlated with the CE tasks than with the other span tasks. This issue is addressed further below.
Structural equation modeling
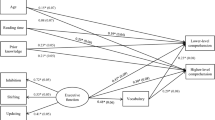
Figure 1 presents the hypothesized model with standardized path coefficients represented in the model (the standardized coefficients are shown in boldface, and estimated factor correlations are shown in parentheses). Analysis of the structural equation model indicated that the model was a good fit to the data. Fit indices for the model are as follows: χ2(24, N = 256) = 65.67, p < .001, CFI = .93, and RMSEA = .08. Although the χ2 statistic is significant, values for CFI and RMSEA indicated that the model provides an adequate fit of the data.Footnote 1 The correlation between the latent factors of span and content-embedded WM indicates that although the two factors share common variance, the majority of the variance in the two factors (approximately 56%) is not shared.

Structural equation model with standardized parameter estimates. Estimates contained in parentheses represent factor correlations. All paths, with the exception of the direct effect of complex span on comprehension, are significant at the .01 level. Error variance is not represented
Of greatest interest, the focus of the present investigation was to determine whether the content-embedded measures of WM account for a greater amount of unique variance in comprehension than do complex span measures of working memory. In the tested model, the estimated standardized total effects of span on comprehension were β = .15, and the total effects of content-embedded WM on comprehension were β = .56. These results indicated that the content-embedded factor accounted for 31% of unique variance in comprehension, whereas complex span accounted for only 2% of unique variance in comprehension.
Table 1 shows that CSPAN correlated more highly with the content-embedded tasks than with the other span tasks. In contrast to RSPAN and OSPAN, in which the memoranda are completely unrelated to the processing stimuli, in CSPAN the memoranda are related to the processing stimuli. Our decision to include CPSAN as a complex span task in the initial hypothesized model was based on convention, given the history of previous research in which these three tasks have been combined to create a latent WM factor (e.g., Engle et al., 1999a). However, CSPAN arguably aligns conceptually with content-embedded tasks as defined here. Accordingly, we also tested a model in which CSPAN was loaded on the content-embedded factor, and this modification improved model fit, χ2(24, N = 256) = 31.12, p = .01; CFI = .99, RMSEA = .03. Eliminating CSPAN from the model altogether also did not qualitatively alter the conclusions supported by the conventionally motivated model reported in Fig. 1.
Discussion
Reading comprehension (and many other complex cognitive tasks more generally) requires one to process task-relevant information that is actively maintained in WM. Therefore, a theoretically motivated prediction is that individual differences in comprehension will be predicted better by WM tasks that capture this concurrent demand than tasks that do not. The present results confirm this hypothesis by demonstrating that content-embedded tasks of WM are a superior measure for capturing the association between comprehension and WM.
The present data also provide evidence that complex span tasks and content-embedded WM tasks reflect related but separable WM processes. One interpretation is that complex span measures more heavily reflect individual differences in the ability to control attention to actively maintain memory elements in the face of interference or distraction (Conway & Engle, 1994; Engle et al., 1999a). For example, processing the sentences or equations in the RSPAN and OSPAN tasks may interfere with maintaining the extraneous word lists, which is the goal of the task.
In contrast, the content-embedded WM tasks provide a more direct measure of an individual’s ability to maintain information in WM that is relevant to the cognitive process being performed. To successfully complete the content-embedded tasks, one must process information currently active in working memory, which is akin to what occurs during comprehension. These tasks also may require controlled attention, but the key difference between content-embedded and complex span tasks is that, for content-embedded tasks, one must continually update processing-relevant information that is being maintained in WM, whereas for complex span tasks, one must simply keep information active in WM while completing the processing required for an unrelated task.
The stronger relationship between the content-embedded factor and comprehension may also indicate that this factor reflects general cognitive ability better than does the complex span factor. The complex span tasks are all structured in a similar manner, whereas successful completion of each of the content-embedded tasks requires different processing and memory load demands. The methodological differences among the observed variables, yet cohesion of the latent content-embedded factor represent a cognitive ability more general than the more specified ability to maintain a memory load during interference.An interesting direction for future research will be to explore the associations between content-embedded tasks, complex span tasks, and conventional measures of general cognitive ability.
One possible criticism of the present investigation concerns the use of CSPAN as a complex span task. As was described earlier, our inclusion of CSPAN as an indicator of complex span was motivated by a sizable number of prior studies that have used CSPAN, OSPAN, and RSPAN to capture complex span. One possible explanation for the larger correlations between CSPAN and the content-embedded measures is that CSPAN is not as reliable a measure of complex span as OSPAN and RSPAN. Indeed, in some investigations in which the same three complex span measures have been used, CSPAN has been found to produce higher zero-order correlations with tasks representing constructs other than do RSPAN and OSPAN (e.g., Engle, Tuholski, Laughlin, & Conway, 1999b; Mogle et al., 2008). Nonetheless, the most important point for present purposes is that all variants of the model (CSPAN loading on the complex span factor, CSPAN loading on the content-embedded factor, or CSPAN removed from the model) support the same qualitative conclusions.
A second possible reason that CSPAN correlates with the content-embedded tasks is that CSPAN requires participants to remember information related to the processing component of the task (to revisit, CSPAN involves counting the number of dark blue circles in a series of arrays and maintaining those numbers in memory for later recall). In general, complex span tasks can be content-embedded tasks under conditions in which the processing component is contentcongruent with the memory component. Although the most frequently used complex span tasks (RSPAN and OSPAN) do not meet these requirements, other span tasks, such as CSPAN, may do so.
In sum, the present investigation shows that individual differences in comprehension are predicted better by content-embedded measures than by complex span measures of WM. The present evidence supports the theoretical hypothesis that the coordination of interrelated content within a limited capacity system is particularly important to individual differences in comprehension. Complex span measures provide valuable insights regarding individual differences in the ability to actively maintain elements in WM in the face of distraction or during unrelated processing. However, it is our recommendation that when researchers are interested in exploring the relationship between WM and comprehension, content-embedded tasks will capture more of their relationship and, hence, should provide a more useful measure of WM. More generally, comprehension is just one among many complex cognitive processes that involve high contentcongruency between memory elements and processing, and thus we would also recommend further exploration and use of content-embedded tasks to capture the relationship between WM and other complex cognitive processes of this sort.
Notes
We also tested a model in which complex span and content-embedded tasks loaded on one factor that predicted variance in comprehension. This one-factor model did not provide an adequate fit to the data. Fit indices for the one-factor model were as follows: χ2(26, N = 256) = 97.13, p < .001; CFI = .89, RMSEA = .10. Furthermore, the one-factor model produced a larger AIC than did the two-factor model (AIC = 153.13 and 125.67, respectively). Using the χ2 difference to compare models, a nonsignificant difference would indicate that the more parsimonious model is a better fit of the data. The χ2difference comparison of the two-models indicates that the χ2statistic for the one-factor model is significantly larger than that for the two-factor model, χ 2Difference (2) = 31.46, p < .001. Thus, the two-factor model provides a better fit.
References
Ackerman, P. L., Beier, M. E., & Boyle, M. O. (2002). Individual differences in working memory within a nomological network of cognitive and perceptual speed abilities. Journal of Experimental Psychology. General, 131, 567–589.
Carretti, B., Borella, E., Cornoldi, C., & De Beni, R. (2009). Role of working memory in explaining the performance of individuals with specific reading comprehension difficulties: A meta-analysis. Learning and Individual Differences, 19, 246–251. doi:10.1016/j.lindif.2008.10.002
Colom, R., Rebollo, R., Abad, F. J., & Shih, P. C. (2006) Complex span tasks, simple span tasks, and cognitive abilities: A reanalysis of key studies. Memory & Cognition, 34, 158–171.
Conway, A. R. A., & Engle, R. W. (1994). Working memory and retrieval: A resource-dependent inhibition model. Journal of Experimental Psychology. General, 123, 354–373.
Conway, A. R. A., Cowan, N., Bunting, M. F., Therriault, D. J., & Minkoff, S. R. B. (2002). A latent variable analysis of working memory capacity, short-term memory capacity, processing speed, and general fluid intelligence. Intelligence, 30, 163–183.
Conway, A. R. A., Kane, M. J., Bunting, M. F., Hambrick, D. Z., Wilhelm, O., & Engle, R. W. (2005). Working memory span tasks: A methodological review and user's guide. Psychonomic Bulletin & Review, 12, 769–786.
Cowan, N. (1999). An embedded-processes model of working memory. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 62–101). Cambridge: Cambridge University Press.
Daneman, M., & Carpenter, P. A. (1980). Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior, 19, 450–466.
Daneman, M., & Merikle, P. M. (1996). Working memory and language comprehension: A meta-analysis. Psychonomic Bulletin & Review, 94, 143–151.
Engle, R. W., Carullo, J. J., & Collins, K. W. (1991). Individual differences in working memory for comprehension and following directions. Journal of Educational Research, 84, 253–262.
Engle, R. W., Kane, M. J., & Tuholski, S. W. (1999a). Individual differences in working memory capacity and what they tell us about controlled attention, general fluid intelligence, and functions of the prefrontal cortex. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 102–134). Cambridge: Cambridge University Press.
Engle, R. W., Tuholski, S. W., Laughlin, J. E., & Conway, A. R. A. (1999b). Working memory, short-term memory, and general fluid intelligence: A latent variable approach. Journal of Experimental Psychology. General, 128, 309–331.
Goldman, S. R., Varma, S., & Coté, N. (1996). Extending capacity-constrained construction integration: Toward “smarter” and flexible models of text comprehension. In B. K. Britton & A. C. Graesser (Eds.), Models of understanding text (pp. 73–113). Mahwah, NJ: Erlbaum.
Graesser, A. C., Gernsbacher, M. A., & Goldman, S. R. (2003). Handbook of discourse processes. Mahwah, NJ: Erlbaum.
Just, M. A., & Carpenter, P. A. (1992). A capacity theory of comprehension: Individual differences in working memory. Psychological Review, 99, 122–149.
Kane, M. J., Hambrick, D. Z., Tuholski, S. W., Wilhelm, O., Payne, T. W., & Engle, R. W. (2004). The generality of working memory capacity: A latent-variable approach to verbal and visuospatial memory span and reasoning. Journal of Experimental Psychology. General, 133, 189–217.
Kintsch, W. (1988). The use of knowledge in discourse processing: A construction-integration model. Psychological Review, 95, 163–182.
Kintsch, W. (1998). Comprehension: A paradigm for cognition. New York: Cambridge University Press.
Kyllonen, P. C., & Christal, R. E. (1990). Reasoning ability is (little more than) working memory capacity? Intelligence, 14, 389–433.
Léphine, R., & Barrouillet, P. (2005). What makes working memory spans so predictive of high-level cognition? Psychonomic Bulletin & Review, 12, 165–170.
Mogle, J. A., Lovett, B. J., Stawski, R. S., & Sliwinski, M. J. (2008). What’s so special about working memory?An examination of the relationships among working memory, secondary memory, and fluid intelligence. Psychological Science, 19, 1071–1077. doi:10.1111/j.1467-9280.2008.02202.x
Perfetti, C. A. (1988). Verbal efficiency in reading ability. In M. Daneman, G. E. MacKinnon, & T. G. Waller (Eds.), Reading research: Advances in theory and practice (Vol. 6, pp. 109–143). San Diego, CA: Academic Press.
Unsworth, N., & Engle, R. W. (2007a). The nature of individual differences in working memory capacity: Active maintenance in primary memory and controlled search from secondary memory. Psychological Review, 114, 104–132. doi:10.1037/0033-295X.114.1.104
Unsworth, N., & Engle, R. W. (2007b). On the division of short-term and working memory: An examination of simple and complex span and their relation to higher order abilities. Psychological Bulletin, 133, 1038–1066.
van den Broek, P. (2010). Using texts in science education: Cognitive processes and knowledge representations. Science, 328, 453–456.
Was, C. A., & Woltz, D. J. (2007). Reexamining the relationship between working memory and comprehension: The role of available long-term memory. Journal of Memory and Language, 56, 86–102.
Woltz, D. J. (1988). An investigation of the role of working memory in procedural skill acquisition. Journal of Experimental Psychology. General, 117, 319–331.
Zachary, R. (1986). Shipley institute of living scale revised manual. Los Angeles: Western Psychological Services.
Author information
Authors and Affiliations
Corresponding author
Additional information
An erratum to this article is available at http://dx.doi.org/10.3758/s13428-013-0346-x.
Rights and permissions
About this article
Cite this article
Was, C.A., Rawson, K.A., Bailey, H. et al. Content-embedded tasks beat complex span for predicting comprehension. Behav Res 43, 910–915 (2011). https://doi.org/10.3758/s13428-011-0112-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-011-0112-x