
Abstract
Previous research has demonstrated effects of both orthographic neighborhood size and neighbor frequency in word recognition in Chinese. A large neighborhood—where neighborhood size is defined by the number of words that differ from a target word by a single character—appears to facilitate word recognition, while the presence of a higher-frequency neighbor has an inhibitory effect. The present study investigated modulation of these effects by a word’s predictability in context. In two eye-movement experiments, the predictability of a target word in each sentence was manipulated. Target words differed in their neighborhood size (Experiment 1) and in whether they had a higher-frequency neighbor (Experiment 2). The study replicated the previously observed effects of neighborhood size and neighbor frequency when the target word was unpredictable, but in both experiments neighborhood effects were absent when the target was predictable. These results suggest that when a word is preactivated by context, the activation of its neighbors may be diminished to such an extent that these neighbors do not effectively compete for selection.
Similar content being viewed by others

In sentence reading, the processing of a word is affected by lexical properties such as frequency (Inhoff & Rayner, 1986; Rayner & Duffy, 1986) and the presence of orthographic neighbors (Andrews, 1989, 1997; Carreiras et al., 1997; Pollatsek et al., 1999). In addition, contextual variables such as a word’s predictability (Balota et al., 1985; Ehrlich & Rayner, 1981; Rayner & Well, 1996) and plausibility (Rayner et al., 2004; Warren & McConnell, 2007) also influence processing. In the present study, we manipulated the orthographic neighborhood and the predictability of target words in Chinese sentences, in two eye-movement experiments, to assess whether orthographic neighborhood effects are modulated by predictability. The reduction or elimination of neighborhood effects when a target word is predictable would suggest that a predictable target word is preactivated to such an extent that the word’s neighbors do not effectively compete for selection. Although effects of both orthographic neighborhood and predictability have been demonstrated numerous times, we know of no studies that have examined these variables simultaneously, in either alphabetic orthographies or in character-based orthographies (with the exception of a very recent study focusing on readers with central visual field deficits; Sauvan et al., 2020). Such studies may provide important insight into how predictability influences lexical processing.
The important role of prediction in lexical processing has been repeatedly demonstrated (Balota et al., 1985; Ehrlich & Rayner, 1981; Rayner & Well, 1996) and is captured in models of eye movements in reading such as E-Z Reader (Reichle et al., 2009). Current accounts of predictability effects in sentence reading (e.g., Luke & Christianson, 2016; Staub, 2015) propose that a predictable word is preactivated by the sentence context, approximately in proportion to its cloze probability, and that such pre-activation facilitates early stages of lexical processing. One important source of evidence in favor of an early locus for predictability effects is that this variable consistently influences the very earliest eye-movement measures (i.e., word skipping and first fixation duration; see Staub, 2015, for a review).
However, several empirical results present potential challenges for this view. For example, the predictability effect on early eye movement measures in reading is usually found to be additive with, rather than interactive with, the effect of word frequency (Ashby et al., 2005; Hand et al., 2010; Kretzschmar et al., 2015; Rayner et al., 2004; cf. Sereno et al., 2018). In addition, Staub (2020) has recently shown that predictability demonstrates only very weak, if any, interaction with visual contrast and font difficulty in the earliest eye-movement measures. These findings are arguably surprising on the view that predictability influences early processing stages by means of preactivation, given that these stages are, presumably, also influenced by factors such as frequency and contrast.
The current study further explored the nature of predictability effects on lexical processing by examining how the effect of predictability interacts with orthographic neighborhood effects in Chinese reading. Chinese has a nonalphabetic writing system in which each word is composed of one or more characters; each character is a morpheme that makes a contribution to word meaning. A significant feature of the Chinese writing system is that there is no explicit indication of word boundaries, which causes Chinese readers to rely on semantic contextual information to segment words (Huang et al., 2021) and process words (Braze & Gong, 2017).
Due to the difference in scripts, orthographic neighbors are also defined differently between alphabetic languages and Chinese. In alphabetic languages, a word’s orthographic neighbors are the words that can be created by changing one letter of the stimulus word while preserving the letters at other positions (Coltheart et al., 1977). In Chinese, however, orthographic neighbors can be defined in various ways, none of which are precise analogues of the notion of “neighbor” in alphabetic scripts. On the character level, characters sharing the same radical (Q. L. Li et al., 2011; Wang et al., 2014; Wu & Chen, 2003; F. L. Yang & Wu, 2014) or sharing around two thirds of strokes (Dong et al., 2015) may be defined as orthographic neighbors. Furthermore, characters’ orthographic neighbors can also be defined visually, based on the degree of pixel overlap, specifically Levenshtein distance (Sun et al., 2018). On the word level, orthographic neighbors may be defined as words that only have one constituent character difference while sharing the other characters in each position (Huang et al., 2006; Tsai et al., 2006). Because words are clearly critical processing units in Chinese sentence reading (X. Li & Pollatsek, 2020; J. M. Yang et al., 2009; Zhou & Li, 2021), and because predictability is usually regarded as a property of words, in the current research we focused on neighborhood effects at the word level. Nevertheless, it is important to recognize the important differences between neighbors in Chinese and in alphabetic languages; in particular, in the former case there is likely to be meaning as well as orthographic overlap, due to the fact that neighbors share a morpheme.
Previous studies have found that in Chinese reading, the recognition of a word is affected by its orthographic neighbors. The recognition of a word is facilitated when it has many neighbors compared with few (the facilitatory Neighborhood Size effect, henceforth the NS effect; Li et al., 2015; Tsai et al., 2006). Also, words with higher frequency neighbors are harder to process than words without higher frequency neighbors (the inhibitory Neighbor Frequency effect, henceforth the NF effect; Huang et al., 2006; Li et al., 2017). Though as we have noted, the notion of orthographic neighbor in Chinese is not closely analogous to the notion of neighbor in alphabetic scripts, it is also important to note that both facilitatory NS effects (Andrews, 1997; Sears et al., 1995; Yates et al., 2008; cf. Pollatsek et al., 1999) and inhibitory NF effects (Acha & Perea, 2008; Grainger, 1990; Grainger & Jacobs, 1996; Grainger & Segui, 1990; Perea & Pollatsek, 1998) have been observed in alphabetic languages.
Both the NS effect and the NF effect in Chinese can potentially be explained by the Chinese Reading Model (henceforth CRM; Li & Pollatsek, 2020). Based on the Interactive Activation Model (McClelland & Rumelhart, 1981; Rumelhart & McClelland, 1982), the CRM proposes that Chinese words are connected to position-specific characters through excitatory or inhibitory connections, while connected to each other through inhibitory connections. Visual input activates the matching position-specific characters, which then activate the corresponding words. To be specific, all the characters in the perceptual span are activated, and all the possible words formed by these characters (i.e., orthographic neighbors) are activated and compete with each other for recognition. The representation of each candidate word is continuously excited by the visual input and inhibited by orthographic neighbors. Once one of these candidates wins the competition, the word is identified/recognized. In this process, both NS (how many neighbors a word has) and NF (whether or not a word has higher frequency neighbors) affect lexical identification. The facilitatory NS effect occurs when the activation from a large number of words feeds back to facilitate character recognition, while the inhibitory NF effect occurs when the activation of a high frequency neighbor inhibits activation of the target word. From this perspective, word-level orthographic neighbors have an important role in lexical processing in Chinese reading. Therefore, the current research could offer important insights about the mechanisms of lexical processing in Chinese sentence reading by investigating how orthographic neighbor effects are modulated by predictability.
In the current study, we explored whether predictability reduces or even eliminates the effect of a word’s neighborhood in Chinese reading. To be specific, will the preactivation of target words that are highly predictable based on their prior context be strong enough to eliminate the activation of neighbors? Or will neighbors still be activated and having a detectable effect on the word recognition process even with preactivated target words? If the preactivation of a highly predictable word is strong enough to prevent the activation of neighbors (due to lateral inhibitory connections at the word level), neighbors would exert little or no influence during the word recognition process. Thus, there would no longer be a facilitatory NS effect, nor an inhibitory NF effect. Such a pattern would provide clear evidence that bottom-up activation of neighbors can be squashed by context in Chinese reading. On the other hand, it is also possible that predictability does not influence neighbor effects. Even though a word is preactivated, its neighbors may still be activated and compete with the target for recognition. In this case, neighbor effects are expected in both high- and low-predictability conditions. Such a pattern would suggest that contextual information has limited effects on bottom-up activation of neighbors.
We conducted two eye-tracking experiments to test these two possibilities. In Experiment 1, the target word did not have a higher frequency neighbor, and we explored the interaction between NS and predictability. In Experiment 2, NS did not differ between sets of target words, and we explored the interaction between NF and predictability.
Experiment 1
In this experiment, we explored whether the NS effect in Chinese is modulated by predictability in sentence reading. Importantly, and in contrast to Experiment 2, all target words were the highest frequency member in their neighbor groups.
Participants
Forty-two students (30 females, age range 18-40 years) from universities around the Institute of Psychology, Chinese Academy of Sciences participated in the experiment. The number of participants was determined based on the method proposed by Westfall et al. (2014). A pilot study with the same material and procedure reported below was conducted on 20 participants. Their total reading times on the target words in the low-predictability condition were analyzed using linear mixed-effect models focusing on the effect of NS, since previous studies found reliable facilitatory NS effects in isolated word recognition and in neutral sentence context in Chinese (Tsai et al., 2006). The powerSim function (Judd et al., 2012) was used to explore how power varies as a function of participant number. Results showed that when the participant number was 40, the power reached .85. All participants were native speakers of Mandarin Chinese and had normal or corrected-to-normal vision.
Materials
We focus on two-character words’ orthographic neighborhood effects, due to the fact that 72% of Chinese words are two-character words (according to the Lexicon of Common Words in Contemporary Chinese Research Team, 2008). For example, “花园” (/hua1yuan2/, garden) and “花店” (/hua1dian4/, flower store) both have the constituent “花” (/hua1/, flower) in the first position. These two words can be called first character orthographic neighbors. On the other hand, “花园” (/hua1yuan2/, garden) and “公园” (/gong1yuan2/, park), which share the second constituent “园” (an area of land for a certain purpose), are second character orthographic neighbors. Because the leading character has a dominant influence on word recognition in Chinese (Huang et al., 2006), we focus on first character orthographic neighbors.
There were two groups of target words: words with large NS (the number of neighbors ranged from 10 to 91, M = 28.25), and words with small NS (the number of neighbors ranged from 1 to 6, M = 3.64). Each group contained 28 words. All of these target words do not have any higher frequency neighbor (they are the highest frequency words in their neighbor groups). The descriptive features of these words are summarized in Table 1. Pairs of sentences were composed so that in one sentence of the pair, a large NS target word was predictable and a small NS target word was unpredictable, and in the other sentence, this was reversed; see Table 2 for an example. Target words’ predictability in each condition was estimated in a cloze task (Taylor, 1953). Twenty university students participated in this task, in which each sentence was presented to participants up to the word before the target word. Participants were asked to write down the first word that came to their mind on reading the preceding fragment. The proportions of target words given by participants were calculated as their cloze probability. In the high-predictability condition all target words had cloze probability greater than .80, while in the low-predictability condition target words’ cloze probability was lower than .10. The cloze probability of target words did not differ significantly between the large NS and small NS groups, as shown in Table 1.
In sum, there were four conditions: words with large NS and high predictability, words with large NS and low predictability, words with small NS and high predictability, and words with small NS and low predictability. Each condition contained 28 sentences. All of these sentences (112 in total) were normed by 10 native Mandarin speakers on a 7-point scale to ensure that they were grammatical and acceptable. The norming scores of sentences with target words associated with large or small NS were matched within high- and low-predictability conditions, as shown in Table 1. The lengths of the sentences varied from 15 to 28 characters. These 112 experimental sentences were pseudorandomly divided into two lists to ensure that each list contained all the target words, but only one version (either high or low predictability) of the sentences for each target word. In addition, there were 30 fillers and five practice trials in each list.
Apparatus
Participants’ eye movements were recorded using an EyeLink 1000 eye tracker with a sampling rate of 1000 Hz. Each sentence was presented in one line in the middle of a 21-inch cathode ray tube (CRT) monitor. Participants were seated 57 cm away from the monitor. Following a 3-point horizontal calibration and validation, the maximum gaze-position error was less than 0.5°. Eye movements were recorded from the right eye, but viewing was binocular.
Procedure
Participants were tested individually. The experiment started with a brief instruction and a standard horizontal three-point grid calibration and validation. Then, five practice trials were run to ensure that the participants understood the task and were familiar with the apparatus. Critical experimental trials were run after the practice trials. Participants were required to read sentences on the screen silently. At the beginning of each trial, a drift check was conducted. Each sentence appeared after participants fixated on a character-sized box at the location of the first character of each sentence. After finishing reading one sentence, participants were asked to press a button so that the original sentence disappeared and was replaced by a meaning-related question, to which the participant then responded by button press. The entire experiment lasted 30 mins.
Results
Four eye movement measures on the target words were analyzed. First fixation duration (FFD) is the duration of the first fixation in a region. Gaze duration (GD) is the sum of the fixation durations before the eyes first move out of a region. Total reading time (TT) is the sum of the durations of all fixations in a region. Skipping rate (SKR) is the probability of a region being skipped.
The mean response accuracy was 93%. We chose only the correctly answered trials for the final analysis. Fixations shorter than 80 ms or longer than 1,000 ms were removed. Linear mixed-effects (LME) models (Baayen et al., 2008) were constructed for log-transformed FFD, GD, and TT (because the distributions of these measures were not normal, especially for TT, which was strongly right-skewed), and a generalized LME model was used on the SKR. Target words’ NS (large vs. small) and predictability (high vs. low) as well as their interaction were treated as fixed effects, specifying participants and items as crossed random effects.Footnote 1 The target word was defined as the experimental item; thus, while predictability is a within-item manipulation, NS is between-item. Fixed effects in these models were centered, with the factor levels coded as −.5 and .5. The random effects structure of the models was trimmed down from the maximal structure (i.e., random intercepts and slopes for all fixed effects, for both subjects and items) when the models failed to converge based on Bates et al. (2015). The statistical procedure was conducted using the lmer program (Bates et al., 2011) and lmerTest program (Kuznetsova et al., 2017) in R (version 3.5.1; R Core Team 2018).
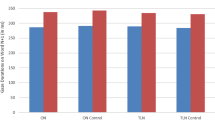
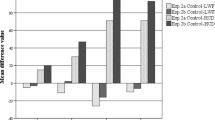
As shown in Table 3, the main effect of predictability was significant in FFD and TT, and marginally significant in GD and SKR (p = .05 and .07, respectively; see Table 4 for details). Words with low predictability had longer fixations (FFD, GD, and TT) and lower SKR than words with high predictability. The main effect of NS was significant in TT and marginally significant in GD and SKR (p = .08 and .05 respectively). Words with large NS had shorter fixations and higher SKR than words with small NS. The interaction between NS and predictability was significant in TT.
Paired comparisons (conducted using emmeans package; Lenth, 2018) of TT indicated that a significant facilitatory NS effect was observed in the low-predictability condition (t = −4.01, p <.005) but not in the high-predictability condition (t = 0.44, p = .66). A Bayes factor analysis was further conducted on log-transformed TT to determine the strength of evidence for the null/significant NS effect in the high-/low-predictability conditions. The Bayes factors were computed using the lmBF function from the BayesFactor package for R (Morey et al., 2015). Following Abbott and Staub (2015) and Staub and Goddard (2019), in all analyses, we assumed the default Cauchy prior for effect size. In each condition, Bayes Factors were calculated to compare a model that included subject and item intercepts and the NS effect to a null model that included only subject and item intercepts. This analysis favored the null model in the high-predictability condition by a factor of 0.131, which delivered evidence against the NS effect. In the low-predictability condition, the Bayes factor was 31.118, offering supportive evidence for the observed NS effect.
Experiment 2
In this experiment, we aimed to explore whether the NF effect is modulated by predictability in sentence reading. In this experiment, all target words had a large NS.
Participants
Sixty-two students (43 females, age range 18–40 years) from universities around the Institute of Psychology, Chinese Academy of Sciences participated in the experiment. To find out how many participants were needed in Experiment 2, a pilot study with the same material and procedure reported below was conducted on 20 participants. Their TT on the target words in the low-predictability condition was analyzed using linear mixed-effect models focusing on the effect of NF, since previous studies found reliable inhibitory NF effects in isolated word recognition in Chinese (Huang et al., 2006; M. F. Li et al., 2017). Results showed that when the participant number was 60, the power reached .80. All participants were native speakers of Mandarin Chinese and had normal or corrected-to-normal vision. None of them participated in Experiment 1. Two participants were excluded from the data analysis due to their low accuracy on comprehension questions ( <75%).
Materials
There were two groups of target words: words with higher frequency neighbors (HFN) and words without HFN. Each group contained 27 words. All of these words have a large NS. The descriptive features of these words are summarized in Table 5. For each target word, two sentences were composed so that the target word was highly predictable in the high-predictability condition and was not predictable at all in the low-predictability condition. Target words’ predictability in each condition was estimated in a cloze task which was conducted on 20 participants in a similar way to Experiment 1. In the high-predictability condition, all target words had cloze probability greater than .70, while in the low-predictability condition target words’ cloze probability was lower than .15. The cloze probability of target words in two groups was matched, as shown in Table 5.
It should be noted that, instead of using the same sentence frames for high- and low-predictability words as in Experiment 1 (as illustrated in Table 2), we used different sentence frames for high- and low-predictability words in Experiment 2 (as illustrated in Table 6). As pointed out by Rayner et al. (2004), when a design as in Experiment 1 is used, the sentence frames in the high-predictability condition are always highly constraining toward one specific word, which means that in the low-predictability condition, it is not only the case that the target word is unpredictable, but that some other word is highly predictable. This arrangement could conceivably result in longer than normal fixation times on the unpredictable target words, since readers might have been expecting one word but encountered another. This is suggested by the norming scores of the sentences in Experiment 1: For words in both large and small NS groups, the sentences in the high-predictability condition were more natural and acceptable than in the low-predictability condition, ps <.001. Although previous studies found that this counterpredictability may have little effect on lexical processing as long as the unpredictable words were plausible (Frisson et al., 2017), we wanted to further explore the potential interaction between predictability and neighbor effects by matching the acceptability of sentences in high- and low-predictability conditions. Thus, in Experiment 2, different sentence frames were used for high- and low-predictability words. Similar to Experiment 1, all the sentences were normed by 10 native Mandarin speakers on a 7-point scale to measure their acceptability. The norming scores of sentences with target words that with or without HFN were matched within and cross high- and low-predictability conditions, as shown in Table 5.
In sum, there were 108 experimental sentences (54 words × 2 versions of sentences) which were pseudorandomly divided into two lists to ensure that each list contained all the target words, but only one version (either high or low predictability) of the sentences for each target word. In addition, there were 58 fillers and five practice trials in each list.
Apparatus
Same as in Experiment 1.
Procedure
Same as in Experiment 1.
Results
Similar to Experiment 1, four eye-movement indexes (FFD, GD, TT, and SKR) on the target words were analyzed. The mean response accuracy for the 60 participants was 96%. The methods of data cleaning and modelling are the same as in Experiment 2, except substituting NS with NF.
As shown in Table 7, the main effect of predictability was significant for all eye-movement measures. Words with low predictability had longer fixations (FFD, GD, and TT) and lower SKR than words with high predictability (Table 8). The main effect of NF was significant in TT, with words with HFN having longer TT than words without HFN. The interaction between NF and predictability was significant in TT and marginally significant in GD (p = .09).
A paired comparison on TT indicated that a significant inhibitory NF effect was observed in the low-predictability condition (t = 4.75, p <.001) but not in the high-predictability condition (t = −0.25, p = .80). A Bayes factor analysis was further conducted to determine the strength of evidence for the null/significant NF effect in the high-/low-predictability condition. This analysis favored the null model in the high-predictability condition by a factor of 0.118, which delivered evidence against the NF effect. In the low-predictability condition, the Bayes factor was 256.68, offering supportive evidence for the observed NF effect.
General discussion
We conducted two eye-tracking experiments to investigate whether predictability modulates neighbor effects in Chinese reading. Target words’ predictability and NS or NF were manipulated. In both experiments, we observed a significant main effect of predictability: compared with words with low predictability, words with high predictability were associated with shorter processing times (FFD, GD, and TT) and higher SKR. This predictability benefit effect is consistent with previous studies in English (Rayner & Well, 1996) and Chinese (Rayner et al., 2005). In addition, we observed a facilitatory NS effect in TT in Experiment 1 when controlling the number of HFN, which is consistent with previous studies in alphabetic languages (Carreiras et al., 1997; Pollatsek et al., 1999; Sears et al., 1995) and Chinese (Huang et al., 2006). In Experiment 2, we observed an inhibitory NF effect in TT, which is consistent with previous studies in alphabetic languages (Perea & Pollatsek, 1998) and Chinese (Huang et al., 2006; Li et al., 2017).
More importantly, we observed a clear modulation of neighborhood effects by predictability. In the TT measure, in the low-predictability condition we observed a significant facilitatory NS effect in Experiment 1, and a significant inhibitory NF effect in Experiment 2, but neither of these effects were in evidence in the high-predictability condition. Furthermore, the null and significant effects of the neighborhood manipulations in the high- and low-predictability conditions respectively, in both experiments, were confirmed by Bayes Factor analysis.
The reliable interaction between predictability and neighbor effects indicates that in Chinese sentence reading, neighbor effects (both NS and NF effects) can be modulated by the word’s predictability based on prior context. Specially, when context strongly constrains towards the target word, the effects from neighbors can be squashed. We assume that in the high-predictability conditions, target words are preactivated to a level that results in inhibition of the activation of neighbors, leading to little or no effect from the neighbors. On the other hand, in the low-predictability condition, target words are not preactivated. Thus, neighbors that are activated by the visual input strengthens the activation of sublexical (character) units, ultimately facilitating recognition of the target (the facilitatory NS effect), or laterally inhibiting the activation of the target if the neighbors are more frequent (the inhibitory NF effect).
In the current research, we found neighbor effects on TT in both experiments, which were qualified by an interaction with predictability. The main effect of NS or NF did not reach significance in the earlier measures. However, it is important to note that in both experiments, all measures showed trends in the expected direction in the low-predictability conditions. Indeed, paired comparisons for these conditions reveal that the facilitatory NS effect was marginally significant on FFD (t = −1.74, p = .09) and significant on GD (t = −2.28, p = .03); the inhibitory NF effect was significant on GD (t = 2.24, p = .03). On the other hand, paired comparisons for the high-predictability conditions did not reveal any significant neighbor effect on either FFD or GD (ps <.6). Thus, we think that drawing a clear distinction between the presence of neighbor effects on TT and their absence in earlier measures would not actually be warranted. We do not see a reason to suppose that neighbor effects are exclusively “late” effects. It should be noted that as described in the result sections, the interactions between NF and predictability were not significant for FFD and GD (except a trend of interaction of GD in Experiment 2). Thus, the claims here are accompanied by a caveat, and the trends here need to be confirmed in future empirical research.
Despite the fact that we found similar patterns of neighborhood effects in Chinese and alphabetic languages, it should be noted that it remains unclear whether the predictability-by-neighborhood interactions observed in the current study would be obtained in alphabetic languages. There are two reasons for this uncertainty. First, compared to readers in alphabetic languages, Chinese readers have a stronger reliance on contextual semantic information in lexical processing and word segmentation due to the lack of word boundaries. Thus, prediction generated from prior context may affect lexical processing to a different extent in Chinese and alphabetic languages. Second, orthographic neighbors are defined differently in Chinese and alphabetic languages. The processing effects of neighbors sharing a character in a certain position may not be the same as the effects of neighbors differing on a position-specific letter. Chinese orthographic neighbors on the word level (the definition used in the current research), may be seen as analogous to English words like sunflower, sunbird, sunblock, and sunbathe.Footnote 2 In addition, as mentioned above, there are many different ways to define orthographic neighbors in Chinese. It remains unclear whether the observed predictability-by-neighborhood interactions would hold when using other operational definitions of neighbors. Further research is needed to tackle these questions.
In conclusion, in the current research, we conducted two eye-tracking experiments to investigate whether neighbor effects can be modulated by predictability in Chinese reading. A clear interaction between predictability and neighbor effects was observed in two experiments, with both the facilitatory NS effect and the inhibitory NF effect being eliminated when the target was highly predictable. These findings indicate that in Chinese sentence reading, predictability and orthographic neighbors jointly affect lexical processing, and neighbor effects can be eliminated by high predictability.
Notes
Models using raw data of FFD, GD, and TT did not differ in patterns of significance from the ones using the log-transformed data, for both experiments.
We thank an anonymous reviewer for this comparison.
References
Abbott, M. J., & Staub, A. (2015). The effect of plausibility on eye movements in reading: Testing E-Z Reader’s null predictions. Journal of Memory and Language, 85, 76–87. https://doi.org/10.1016/j.jml.2015.07.002
Acha, J., & Perea, M. (2008). The effect of neighborhood frequency in reading: Evidence with transposed-letter neighbors. Cognition, 108, 290–300. https://doi.org/10.1016/j.cognition.2008.02.006
Andrews, S. (1989). Frequency and neighbourhood effects on lexical access: Activation or search? Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 802–814. https://doi.org/10.1037/0278-7393.15.5.802
Andrews, S. (1997). The effect of orthographic similarity on lexical retrieval: Resolving neighbourhood conflicts. Psychonomic Bulletin & Review, 4, 439–461. https://doi.org/10.3758/BF03214334
Ashby, J., Rayner, K., & Clifton, C. (2005). Eye movements of highly skilled and average readers: Differential effects of frequency and predictability. The Quarterly Journal of Experimental Psychology Section A, 58, 1065–1086. https://doi.org/10.1080/02724980443000476
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59, 390–412. https://doi.org/10.1016/j.jml.2007.12.005
Balota, D. A., Pollatsek, A., & Rayner, K. (1985). The interaction of contextual constraints and parafoveal visual information in reading. Cognitive Psychology, 17, 364–390. https://doi.org/10.1016/0010-0285(85)90013-1
Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015). Parsimonious mixed models. ArXiv Preprint: 1506.04967.
Bates, D., Mächler, M., & Bolker, B. M. (2011). LME4: linear mixed-effects models using S4 classes (R Package Version 0.999375-39) [Computer software]. http://CRAN.R-project.org/package=lme4
Braze, D., & Gong, T. (2017). Orthography, word recognition and reading. In E. M. Fernandez & H. Cairns (Eds.), Handbook of psycholinguistics (Chapter 12). Wiley-Blackwell. https://doi.org/10.1002/9781118829516.ch12
Carreiras, M., Perea, M., & Grainger, J. (1997). Effects of orthographic neighborhood in visual word recognition: Cross-task comparisons. Journal of Experimental Psychology: Learning, Memory, & Cognition, 23, 857–871. https://doi.org/10.1037//0278-7393.23.4.857
Coltheart, M., Davelaar, E., Jonasson, J. T., & Besner, D. (1977). Access to the internal lexicon. In S. Dornic (Ed.), Attention and performance, VI (pp. 535–555). Erlbaum.
Dong, J., Yang, S., & Wang, Q. (2015). N400-like effect of stroke-based neighborhood size in Chinese characters. Journal of Neurolinguistics, 35, 120–134.
Ehrlich, S. F., & Rayner, K. (1981). Contextual effects on word perception and eye movements during reading. Journal of Verbal Learning and Verbal Behavior, 20, 641–655. https://doi.org/10.1016/S0022-5371(81)90220-6
Frisson, S., Harvey, D., & Staub, A. (2017). No prediction error cost in reading: Evidence from eye movements. Journal of Memory and Language, 95, 200–214. https://doi.org/10.1016/j.jml.2017.04.007
Grainger, J. (1990). Word frequency and neighborhood frequency effects in lexical decision and naming. Journal of Memory and Language, 29, 228–244. https://doi.org/10.1016/0749-596X(90)90074-A
Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103, 518–565. https://doi.org/10.1037/0033-295x.103.3.518
Grainger, J., & Segui, J. (1990). Neighborhood frequency effects in visual word recognition: A comparison of lexical decision and masked identification latencies. Perception & Psychophysics, 47(2), 191–198.
Hand, C. J., Miellet, S., O’Donnell, P. J., & Sereno, S. C. (2010). The frequency-predictability interaction in reading: It depends where you ' re coming from. Journal of Experimental Psychology: Human Perception and Performance, 36, 1294–1313. https://doi.org/10.1037/a0020363
Huang, H. W., Lee, C. Y., Tsai, J. L., Lee, C. L., Hung, D. L., & Tzeng, O. J. L. (2006). Orthographic neighborhood effects in reading Chinese two-character words. NeuroReport, 17, 1061–1065. https://doi.org/10.1097/01.wnr.0000224761.77206.1d
Huang, L., Staub, A., & Li, X. (2021). Prior context influences lexical competition when segmenting Chinese overlapping ambiguous strings. Journal of Memory and Language, 118, Article 104218.
Inhoff, A. W., & Rayner, K. (1986). Parafoveal word processing during eye fixations in reading: Effects of word frequency. Perception & Psychophysics, 40, 431–439. https://doi.org/10.3758/BF03208203
Judd, C. M., Westfall, J., & Kenny, D. A. (2012). Treating stimuli as a random factor in social psychology: A new and comprehensive solution to a pervasive but largely ignored problem. Journal of Personality and Social Psychology, 103, 54–69. https://doi.org/10.1037/a0028347
Kretzschmar, F., Schlesewsky, M., & Staub, A. (2015). Dissociating word frequency and predictability effects in reading: Evidence from coregistration of eye movements and EEG. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41, 1648–1662. https://doi.org/10.1037/xlm0000128
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82. https://doi.org/10.18637/jss.v082.i13
Lenth, R. (2018). Emmeans: Estimated marginal means, aka least-squares means (R package version 1.1) [Computer software]. https://CRAN.R-project.org/package=emmeans
Lexicon of Common Words in Contemporary Chinese Research Team. (2008). Lexicon of common words in contemporary Chinese. Commercial Press
Li, M. F., Gao, X. Y., Chou, T. L., & Wu, J. T. (2017). Neighborhood frequency effect in Chinese word recognition: Evidence from naming and lexical decision. The Journal of Psycholinguistic Research, 46, 227–245. https://doi.org/10.1007/s10936-016-9431-5
Li, M. F., Lin, W. C., Chou, T. L., Yang, F. L., & Wu, J. T. (2015). The role of orthographic neighborhood size effects in Chinese word recognition. Journal of Psycholinguistic Research, 44, 219–236.
Li, Q. L., Bi, H. Y., Wei, T. Q., & Chen, B. G. (2011). Orthographic neighborhood size effect in Chinese character naming: Orthographic and phonological activations. Acta Psychologica, 136, 35–31.
Li, X., & Pollatsek, A. (2020). An integrated model of word processing and eye-movement control during Chinese reading. Psychological Review. Advanced online publication. https://doi.org/10.1037/rev0000248
Luke, S. G., & Christianson, K. (2016). Limits on lexical prediction during reading. Cognitive Psychology, 88, 22–60. https://doi.org/10.1016/j.cogpsych.2016.06.002
McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88, 375–407. https://doi.org/10.1037/0033-295X.88.5.375
Morey, R. D., Rouder, J. N., & Jamil, X. (2015). BayesFactor: Computation of Bayes factors for common designs (Version 0.9.11) [Computer software]. http://bayesfactorpcl.r-forge.r-project.org
Perea, M., & Pollatsek, A. (1998). The effects of neighborhood frequency in reading and lexical decision. Journal of Experimental Psychology: Human Perception & Performance, 24, 767–779. https://doi.org/10.1037//0096-1523.24.3.767
Pollatsek, A., Perea, M., & Binder, K. (1999). The effects of “neighborhood size” in reading and lexical decision. Journal of Experimental Psychology: Human Perception & Performance, 25, 1142–1158. https://doi.org/10.1037//0096-1523.25.4.1142
Rayner, K., Ashby, J., Pollatsek, A., & Reichle, E. D. (2004). The effects of frequency and predictability on eye fixations in reading: Implications for the E-Z Reader model. Journal of Experimental Psychology: Human Perception and Perfosrmance, 30, 720–732. https://doi.org/10.1037/0096-1523.30.4.720
Rayner, K., & Duffy, S. A. (1986). Lexical complexity and fixation times in reading: Effects of word frequency, verb complexity, and lexical ambiguity. Memory & Cognition, 14, 191–201. https://doi.org/10.3758/BF03197692
Rayner, K., Li, X., Juhasz, B. J., & Yan, G. (2005). The effect of word predictability on the eye movements of Chinese readers. Psychonomic Bulletin & Review, 12, 1089–1096. https://doi.org/10.3758/BF03206448
Rayner, K., & Well, A. D. (1996). Effects of contextual constraint on eye movements in reading: A further examination. Psychonomic Bulletin & Review, 3, 504–509. https://doi.org/10.3758/BF03214555
Reichle, E. D., Warren, T., & McConnell, K. (2009). Using E-Z Reader to model the effects of higher level language processing on eye movements during reading. Psychonomic Bulletin & Review, 16, 1–21. https://doi.org/10.3758/PBR.16.1.1
Rumelhart, D. E., & McClelland, J. L. (1982). An interactive activation model of context effects in letter perception: Part 2. The contextual enhancement effect and some tests and extensions of the model. Psychological Review, 89, 60–94.
Sauvan, L., Stolowy, N., Aguilar, C., François, T., Gala, N., Matonti, F., Castet, E., & Calabrese, A. (2020). The inhibitory effect of word neighborhood size when reading with central field loss is modulated by word predictability and reading proficiency. Scientific Reports, 10, 1–13. https://doi.org/10.1038/s41598-020-78420-0
Sears, C. R., Hino, Y., & Lupker, S. J. (1995). Neighborhood size and neighborhood frequency effects in word recognition. Journal of Experimental Psychology: Human Perception and Performance, 21, 876–900.
Sereno, S. C., Hand, C. J., Shahid, A., Yao, B., O’Donnell, P. J. (2018). Testing the limits of contextual constraint: Interactions with word frequency and parafoveal preview during fluent reading. Quarterly Journal of Experimental Psychology, 1, 302–313. https://doi.org/10.1080/17470218.2017.1327981
Staub, A. (2015). The effect of lexical predictability on eye movements in reading: Critical review and theoretical interpretation. Language and Linguistics Compass, 9, 311–327. https://doi.org/10.1111/lnc3.12151
Staub, A. (2020). Do effects of visual contrast and font difficulty on readers’ eye movements interact with effects of word frequency or predictability? Journal of Experimental Psychology: Human Perception and Performance, 46, 1235–1251. https://doi.org/10.1037/xhp0000853
Staub, A., & Goddard, K. (2019). The role of preview validity in predictability and frequency effects on eye movements in reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45, 110–127. https://doi.org/10.1037/xlm0000561
Sun, C. C., Hendrix, P., Ma, J., & Baayen, H. (2018). Chinese lexical database (CLD): A large-scale lexical database for simplified Mandarin Chinese. Behavior Research Methods, 50. https://doi.org/10.3758/s13428-018-1038-3
Taylor, W. L. (1953). “Cloze procedure”: A new tool for measuring readability. Journalism Quarterly, 30, 415–433. https://doi.org/10.1177/107769905303000401
Tsai, J. L., Lee, C. Y., Lin, Y. C., Tzeng, O. J., & Hung, D. L. (2006). Neighborhood size effects of Chinese words in lexical decision and reading. Language and Linguistics, 7, 659–675.
Wang, J., Tian, J., Han, W., Liversedge, S. P., & Paterson, K. B. (2014). Inhibitory stroke neighbour priming in character recognition and reading in Chinese. The Quarterly Journal of Experimental Psychology, 67(11), 2149–2171.
Warren, T., & McConnell, K. (2007). Investigating effects of selectional restriction violations and plausibility violation severity on eye-movements in reading. Psychonomic Bulletin & Review, 14, 770–775.
Westfall, J., Kenny, D. A., & Judd, C. M. (2014). Statistical power and optimal design in experiments in which samples of participants respond to samples of stimuli. Journal of Experimental Psychology: General, 143, 2020–2045. https://doi.org/10.1037/xge0000014
Wu, J. T., & Chen, H. C. (2003). Chinese orthographic priming in lexical decision and naming. Chinese Journal of Psychology, 45, 75–95.
Yang, F. L., & Wu, J. T. (2014). Orthographic inhibition between characters with identical semantic radicals in primed character decision tasks. Chinese Journal of Psychology, 56, 49–63.
Yang, J. M., Wang, S. P., Chen, H. C., & Rayner, K. (2009). The time course of semantic and syntactic processing in Chinese sentence comprehension: Evidence from eye movements. Memory & Cognition, 37, 1164–1176.
Yates, M., Friend, J., & Ploetz, D. M. (2008). The effect of phonological neighborhood density on eye movements during reading. Cognition, 107, 685–692. https://doi.org/10.1016/j.cognition.2007.07.020
Zhou, J., & Li, X. (2021). On the segmentation of Chinese incremental words. Journal of Experimental Psychology: Learning, Memory, and Cognition. Advance online publication. https://doi.org/10.1037/xlm0000984
Author note
This research was supported by the Sino-German Collaborative Research Project “Crossmodal Learning” NSFC 62061136001/DFG TRR169, and a grant from the National Natural Science Foundation of China (31970992). All the R code and original data are available (https://osf.io/nz4xs/).
Funding
This research was supported by the Sino-German Collaborative Research Project “Crossmodal Learning” NSFC 62061136001/DFG TRR169, and a grant from the National Natural Science Foundation of China (31970992) to Xingshan Li.
Author information
Authors and Affiliations
Contributions
Panpan Yao: Conceptualization, Methodology, Software, Investigation, Formal analysis, Visualization, Writing—Original draft preparation
Adrian Staub: Formal analysis, Visualization, Writing—Review and Editing
Xingshan Li: Conceptualization, Methodology, Formal analysis, Visualization, Supervision, Writing—Reviewing and Editing, Funding acquisition
Corresponding author
Additional information
Declarations
Conflicts of interest/competing interests
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Ethics approval
This project was approved by the Institutional Review Board of the Institute of Psychology of Chinese Academy of Science (No. H20005).
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
The participant has consented to the submission of their data to the journal.
Data availability
The original data and materials are available (https://osf.io/nz4xs/).
Code availability
The R code in both experiments are available (https://osf.io/nz4xs/).
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yao, P., Staub, A. & Li, X. Predictability eliminates neighborhood effects during Chinese sentence reading. Psychon Bull Rev 29, 243–252 (2022). https://doi.org/10.3758/s13423-021-01966-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-021-01966-1