
Abstract
While a delicious dessert being presented to us may elicit strong feelings of happiness and excitement, the same treat falling slowly away can lead to sadness and disappointment. Our emotional response to the item depends on its visual motion direction. Despite this importance, it remains unclear whether (and how) cortical areas devoted to decoding motion direction represents or integrates emotion with perceived motion direction. Motion-selective visual area V5/MT+ sits, both functionally and anatomically, at the nexus of dorsal and ventral visual streams. These pathways, however, differ in how they are modulated by emotional cues. The current study was designed to disentangle how emotion and motion perception interact, as well as use emotion-dependent modulation of visual cortices to understand the relation of V5/MT+ to canonical processing streams. During functional magnetic resonance imaging (fMRI), approaching, receding, or static motion after-effects (MAEs) were induced on stationary positive, negative, and neutral stimuli. An independent localizer scan was conducted to identify the visual-motion area V5/MT+. Through univariate and multivariate analyses, we demonstrated that emotion representations in V5/MT+ share a more similar response profile to that observed in ventral visual than dorsal, visual structures. Specifically, V5/MT+ and ventral structures were sensitive to the emotional content of visual stimuli, whereas dorsal visual structures were not. Overall, this work highlights the critical role of V5/MT+ in the representation and processing of visually acquired emotional content. It further suggests a role for this region in utilizing affectively salient visual information to augment motion perception of biologically relevant stimuli.
Similar content being viewed by others


Imagine reaching out to hand a piece of cake to an eagerly awaiting child. Now imagine pulling that cake away before the child is able to taste it. The emotional response to the cake shifts; excitement becomes disappointment. The response to the dessert depends on the motion. While the cake itself does not change, its motion towards or away from the child both can create two immediate and potent, yet diametrically opposed, reactions. Motion information is meaningful in how we appraise the world and what behaviours may need to be selected to respond appropriately. Determining whether, and how, areas of the brain involved in motion processing can integrate emotional valence is needed for a comprehensive understanding of how an organism updates their perceptional experience to reflect the behavioural significance of objects around them.
When visual information reaches occipital areas, it diverges along canonical dorsal and ventral pathways (Milner and Goodale, 1993); dorsal visual regions mediate the execution of visually guided actions towards objects in our environment, while ventral visual regions mediate our perception of the visual world (an "action" stream vs. "perception" stream for visual processing; Milner and Goodale, 2008). Distinct functional differences exist between these two pathways (the precise nature of which is still under investigation; see Brogaard, 2012; Foley et al., 2015; Freud et al., 2016; Mann et al., 2021), yet they maintain extensive bilateral communication (Buchel and Friston, 1997; Milner and Goodale, 2008; Kravitz et al., 2013).
Emotionally relevant objects typically enhance processing in visual cortices (Vuilleumier, 2005; Pessoa and Adolphs, 2010). Yet evidence of this effect is observed mainly with processes mediated by the ventral-stream, including object identification and perceptual quality (Mitchell and Greening, 2012). While enhancing these perceptual features of biologically significant stimuli is likely adaptive, other characteristics may be equally important. For example, accurately representing the position and movement of threatening objects or determining whether the approaching object is harmful or desired are both critical tasks in response selection. (Panksepp, 1990; Panksepp, 1998; Mobbs et al., 2009; Aupperle et al., 2015; Qi et al., 2018; Meyer et al., 2019; Mobbs et al., 2020; Yeung and Chan, 2020). Consistent with the importance of affect in behavioural guidance, emotional valence has been shown to modulate activity in motion-processing areas in the human brain, including area V5/MT+ (Attar et al., 2010; Kolesar et al., 2017).
The visual processing structure V5/MT+ often is defined by its general motion-sensitivity (Zeki et al., 1991; Tootell et al., 1995b; Huk et al., 2002), making it a prime target for investigation of motion-emotion interactions. V5/MT+, however, is not a homogenous region; it contains at least four subregions, each characterized by specific organizational patterns and reactivity (e.g., retinotopic wedges or ipsi vs. contralateral motion; Kolster et al., 2010; Gao et al., 2020). Although human neuroimaging studies often are unable to examine the V5/MT+ complex with enough spatial resolution to detect all of these subregions independently, distinct zones sensitive to global flow versus general motion often are observed (Smith et al., 2006; Ohlendorf et al., 2008; Gaglianese et al., 2023).
Definitive placement of V5/MT+ complex in dual pathway frameworks of visual processing is a challenge (Born and Bradley, 2005; Gilaie-Dotan et al., 2013; Kravitz et al., 2013). While traditionally associated with the dorsal visual stream (Born and Bradley, 2005; Arall et al., 2012; Cloutman, 2013; but see Gilaie-Dotan, 2016), V5/MT+ also displays patterns of connectivity consistent with ventral stream structures (Nassi and Callaway, 2007; Abe et al., 2018). For example, both V5/MT+ and ventral visual regions—but not dorsal visual regions—display robust anatomical and functional connectivity with the amygdala (Baizer et al., 1993; Young et al., 1994; Amaral et al., 2003; Furl et al., 2013)—a region often noted for its role in emotional processing (LeDoux, 1992; Vuilleumier, 2005). Further commonalities between processing in V5/MT+ and ventral visual structures include their susceptibility to optical illusions (Tootell et al., 1995a; He et al., 1998; Antal et al., 2004) and their sensitivity to emotion in postures (de Gelder and Hadjikhani, 2006) and dynamic facial expressions (Furl et al., 2013). This contrasts with patterns observed for dorsal stream processes, which appear less sensitive to optical illusions (Aglioti et al., 1995; Haffenden and Goodale, 1998) and where the impact of emotion is less clear. For example, observation of emotion-based increases in neural activity in dorsal visual areas (de Gelder et al., 2004; Goldberg et al., 2012, 2014; El Zein et al., 2015; Engelen et al., 2015; Solanas et al., 2020) are contrasted by null effects of emotionally salient environments on dorsally mediated behaviours (e.g., visually guided targetting; Kryklywy and Mitchell, 2014; Enns et al., 2017).
Extending canonical classification of visual pathways, a third visual processing stream—one dedicated to social perception—has been recently proposed (Pitcher and Ungerleider, 2021). Notably, many of the motion-sensitive “dorsal” structures identified in previous work as processing emotional information, such as those sensitive to social response planning (Kong et al., 2021) and body posture (de Gelder et al., 2015; Engelen et al., 2015; Zhan et al., 2018), also are implicated in this newly outlined processing stream. These include the V5/MT+ complex and the posterior superior temporal sulcus (de Gelder et al., 2004; Goldberg et al., 2014; El Zein et al., 2015; Engelen et al., 2015). Furthermore, given the extensive cross stream connectivity throughout visual processing areas, it remains unclear whether emotional information is independently decoded in V5/MT+ and other motion sensitive regions, or whether emotion representation in these structures is solely the result of feedforward signalling from other visual processing areas.
We used functional magnetic resonance imaging to investigate the interaction between emotion and visual motion perception by leveraging the motion aftereffect (MAE; Tootell et al., 1995a). Specifically, we deployed a two-pronged approach to determine the impact of perceived motion direction and emotional content on neural processing in motion sensitive regions. We first used univariate statistical analyses to target emotional reactivity in functionally localized regions of interest (ROIs) sensitive to stimulus motion (with a particular emphasis on V5/MT+). This was followed by a multivariate statistical approach to determine how representation of emotional information varies across visual processing regions. Specifically, these analyses interrogate whether representations of emotional information is shared, i.e., similar in content and strength information, or unique between regions; the former indicated information likely propagated between structures, and the later indicative of emotional processing in the region. Participants viewed concentric rings that approached (expanded), receded (contracted), or alternated motion direction, followed by a static target image with positive, negative, or neutral emotional content. Based on the MAE (Wohlgemuth, 1911; Mather et al., 1998), static images presented after coherent motion appear to move in the opposite direction (to recede following approaching motion or to approach following receding motion) while images that appear after alternating motion patterns should appear static. To determine what type of information influences patterns of neural activation in response to the emotional events, pattern component modelling (PCM; Kriegeskorte and Kievit, 2013; Diedrichsen et al., 2018; Kryklywy et al., 2023) was conducted to estimate response-pattern similarities in different brain regions and to determine the extent to which these were driven by specific representational patterns of interest (POIs, e.g., presented visual motion, perceived visual emotion, emotional experience, etc.). These multivariate analyses were conducted in concert with more traditional univariate approaches. Specific ROIs were primary visual cortex (V1), ventral visual structures (vVS), dorsal visual structures (dVS), and visual area V5/MT+. These structures were targeted to investigate the extent of emotional representations in areas assigned to particular visual processing streams, and particularly for V5/MT+, wherein the designation within these streams is unclear.
From previous research describing anatomical connectivity between neural regions processing visual motion and emotion (Amaral and Price, 1984; Young et al., 1994; Amaral et al., 2003) and the behavioural effects observed in actions recruiting ventral visual regions (Lang et al., 1998; Kryklywy and Mitchell, 2014), we predicted that both the strength of the perceived MAE and its neural correlates should be influenced by emotional valence and motion direction. Behaviourally, we expected images that appeared to be approaching would elicit higher emotional arousal ratings similar to that observed during actually looming stimuli (Mobbs et al., 2010; Coker-Appiah et al., 2013; Low et al., 2015) as well as to illusions of motion and spatial distance (Muhlberger et al., 2008). Neurally, we predicted that both individually and group defined V5/MT+ ROIs would display increased activation for emotional compared to neutral images, similar to those previously observed in ventral visual areas (Morris et al., 1998; Vuilleumier and Driver, 2007). Secondary to these predictions, emotion was not expected to modulate activity in regions canonically associated with the dorsal visual stream but was expected to impact activity throughout the ventral visual pathway. For the multivariate analysis, we predicted that in visual structures, we would identify representational pattern components consistent with their canonical roles: V1 representations would include representational patterns for multiple low-level features. We predict that while ventral visual structures would maintain these representations, dorsal visual structures would not represent emotion- or identity-based features (Kryklywy et al., 2013; 2018; Kryklywy and Mitchell, 2014). Consistent with behavioural evidence suggesting that area V5/MT+ shares overlapping anatomical and functional architecture with ventral visual structures (Baizer et al., 1993; Young et al., 1994; Tootell et al., 1995a; He et al., 1998; Amaral et al., 2003; Antal et al., 2004; Furl et al., 2013), it was expected to represent both motion and emotion components.
Methods
Subjects
Nineteen healthy human subjects (13 females; 6 males; x̄age = 22.6, standard deviation [SD] = 3.70) participated in the experiment. All participants reported no history of neurological or psychiatric illness, were right-handed, had normal hearing, normal or corrected-to-normal vision, and were fluent English speakers. This sample size provides the ability to detect medium-to-large effect sizes in our primary analyses (3 x 3 repeated-measures ANOVAs; see below) greater than 0.35 (Sullivan and Feinn, 2012), with a critical F of 2.66 at a power of 0.80. This effect size consistent with those calculated from previous neuroimaging work investigating motion aftereffects in the V5/MT+ complex (Taylor et al., 2000; Huk et al., 2001), adjusted for potential inflation related to post-hoc calculations (Reddan et al., 2017; Funder and Ozer, 2019). The study was approved by the Health Science Research Ethics Board at the University of Western Ontario.
Stimuli and apparatus
Four unique motion video clips were created for this study in VPixx (VPixx Technologies). Two unique video clips were utilized as adaptation stimuli to induce the motion after-effect in the main experimental task. These consisted of concentric circles (1.64 cycles/degree; alternating black/white), which contracted or expanded relative to a central fixation point at a constant rate of 2 Hz (1.2 degrees/s). After-effects created by these stimuli are a perceptual drift of images in the opposite direction of the initial movement (Bowditch and Hall, 1882). A third video, consisting of concentric circles that alternated between expansion and contraction (motion at 2 Hz/1.2 degrees/s) every 2 seconds, was used as a no-after-effect control condition. A fourth video was created for the V5/MT+ localizer consisting of 200 short line segments (0.5º visual angle) randomly oriented either vertically or horizontally and moving at a constant velocity in one of eight directions for 20 s (3.28 º/s).
Twenty-seven images were chosen from the International Affective Pictures System stimulus set (IAPS: Lang et al., 2008; Supplemental Table ST1). To aid in the selection of these images, a pilot study (n = 10) was conducted to ensure that the spatial layout of visually salient features did not vary between emotional categories. For this pilot study, participants were presented with 78 IAPS images (35 negative, 25 neutral, and 35 positive). Image valence was defined based on the standardized rating manual provided with the IAPS stimulus set, which included 9-point Likert scale ratings for valence and arousal (higher scores indicated greater pleasantness and arousal respectively; image rating was conducted on a 9-point Likert scale; Lang et al., 2008). Participants were presented each stimulus for 2 s and were instructed to freely view each image during this time. Eye-behaviour was monitored using a fast video-based eye-tracker at 1,000 Hz (EyeLink 1000, SR Research). Subsequent analysis examined the percentage of time spent fixated within the centre of the image (<20° from the midpoint) in contrast to the periphery (>60° from the midpoint) for each image (reported as %C - %P). Nine pictures were chosen from each emotional category that allowed for the best matched spatial salience (i.e., regions of the visual field that held gaze during free viewing) between categories (positive vs. neutral: t(16) = 0.12 p > 0.10; negative v. neutral: t(16) = 0.15; p > 0.10; positive v. negative: t(16) = 0.29; p > 0.10). Following this, additional analyses were conducted using these standardized ratings of the stimuli to ensure that the resulting positive and negative stimuli were balanced for arousal (positive = 5.40, negative = 5.52; t(16) = 0.47; p > 0.10) and absolute valence deviations from neutral (positive = 7.56, negative = 2.86, scale-defined neutral = 5; t(16) = 1.52; p > 0.10). In addition, physical properties were compared between categories to ensure a match on low-level visual features by subjecting each image to a wavelet analysis similar to that used previously (Delplanque et al., 2007). For this, each red, green, blue, and grayscale layer of the image was decomposed into eight frequency bands (512, 256, 128, 64, 32, 16, 8, 4, and <2 cycles per image). An examination of the energy within each band indicated no significant differences between the positive, negative, or neutral stimulus categories (all corrected ps > 0.10). Furthermore, absolute luminance levels did not significantly differ between categories (positive vs. neutral: t(16) = 0.069; p > 0.10; negative vs. neutral: t(16) = 0.89; p > 0.10; positive vs. negative: t(16) = 0.93; p > 0.10). Due to the constraints imposed by equating the objective visual properties of the images across categories, other content-related visual features were unable to be matched. For example, of the nine stimulus exemplars in each of the positive, negative, and neutral image sets, five, two, and zero images contain human features respectively (see ST1 for full stimulus index). In addition, eight different neutral IAPS images were selected for use in a prescan practice task.
All stimuli were presented in the scanner by using a Silent Vision™ Extended Range XR Fiber Optic Visual System (SV-7021), allowing for presentation of stimuli within a 30° (horizontal) by 23° (vertical) field of view, which was filled by both the adaptation and test stimuli. A prescan practice task consisting of a shortened version of the motion-adaptation paradigm with MAEs induces on nonemotional target stimuli (see Supplemental materials for additional details) was conducted on a Lenovo ThinkPad W540 (1,920 X 1,080 pixels, refresh rate 60 Hz) at a viewing distance of ~40 cm.
Procedure
V5/MT+ localization
Before the anatomical scan and experimental task, participants completed a single functional localizer run to identify area V5/MT+ by using conventional methods (Tootell et al., 1995b; Huk et al., 2002; Emmerling et al., 2016). The run began with an initial 3-s fixation period. Following this, participants were presented with moving line segments (18 s), a fixation cross on an otherwise blank screen (1-3 s), stationary line segments (18 s), and an additional fixation cross (1-3 s; 40 s per cycle total). This sequence was repeated 8 times within a run followed by a 12-s fixation period, for a total run duration of ~5 min, 35 s. Of note, the localizer paradigm utilized visual motion in multiple directions for each motion trial as opposed to the standard contract/expanding motion patterns to ensure that there would be no inadvertent MAEs created.
Experimental task
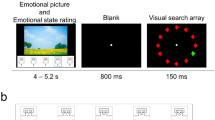
In the scanner, participants performed the “emotional MAE task” (Fig. 1A). To acclimatize to task timing, participants completed a short practice version of the scanning task before entering the scanner. Individual runs began with an initial fixation period of 2.5 s and ended with a fixation period of 14 s. Each trial within a run began with a 0.5-s static fixation cross, followed by a motion video (10 s; contracting, expanding or alternating). Immediately after the cessation of this video, one of 27 target images was presented for 3 s. During the presentation of both the motion video and the target image, participants were instructed to maintain fixation on a centrally located red fixation cross. Pending the motion video that had preceded them, perception of the target images was subject to visual motion-aftereffect, wherein they appeared to be moving in the opposite direction of the preceding stimulus. The utilization of MAEs allows for explicit control of the visual properties of the imagery across motion directions such that the perceived motion direction can be manipulated while keeping the actual physical parameters of the affective picture unchanged. Spatial frequencies and spectral components of the images remained stable within emotion conditions, yet the motion properties varied. After presentation of the target image, a black fixation cross appeared for 1.5, 2.0, or 2.5 s (randomized between trials) followed by two questions in random order: “To what extent did the image move [towards you/away from you/ around]?” (illusion quality rating) and “How emotionally arousing was the image?” (emotional arousal rating). All responses were given on a five-point Likert scale ranging from “Very Little” to “Very Much” and collected with an MRI-compatible five-response button box. Each question was presented for 2.5 s. A single run consisted of an image from each emotional category (positive, negative, neutral) presented following each of the motion patterns (contracting, expanding, alternating) three times, resulting in 27 trials per run (with individual run duration ~9 m 30 s). Trial orders were randomized within each run for each participant. Participants completed six experimental runs (162 total trials = 18 trials per combination of 3 motion adaptation directions x 3 test-stimulus emotional valences, with each of the 27 images paired with each direction twice).

MAE paradigm and RSA-PCM schematics. (A) In the emotional MAE task, following a brief fixation period, participants were presented with a pattern of consistent motion that was expanding from a central fixation point (producing a receding MAE), contracting to fixation (producing an approaching MAE), or alternating direction between expansion and contraction around fixation (producing no MAE). Direction of motion in the adaptation videos and MAEs are indicated by red and blue arrows respectively and appear in the figure only for illustrative purposes. Emotion icons indicate potentially emotionality of complex scenes and are not representative of the target stimuli used. Following each trial, two questions were presented in random order to assess the impact of direction and emotion on the perception of illusory motion and emotional arousal. (B) Representational similarity analyses were conducted comparing voxel-wise similarity of conditions across all individual experimental runs and task component (adaptation, aftereffect, and motion conditions). These were subsequently averaged across run resulting in a similarity matrix indicating representational similarity across, and within conditions. (C) Pattern component analyses were performed to determine component patterns of the observed representational states for each ROI. Predefined components were fit to the representational patterns of the random sample (RS) using Bayesian information criterion (BIC) analyses. The best fitting component was held in the model (green box/arrow) and fit with the observed data in combination with all remaining components independently. This process was repeated until the optimum component combination was identified. A linear regression model (LM) was used to fit the identified components to the RS similarity data. A new reconstructed component was then created by combining the weighted RS component models and fit to the held-out participants (HO)
Behavioural analysis
For the analysis of the behavioral illusion quality rating and emotional arousal ratings during the fMRI task, separate 3 (MAE Direction: approach, recede, static) X 3 (Emotion: negative, neutral, positive) repeated-measures analyses of variance (ANOVAs) were conducted. Assumptions of sphericity were tested with a Mauchly’s test, with application of a Greenhouse-Geisser correction when necessary. Furthermore, to assist in interpretation of nonsignificant results, a subsequent Bayes Factor ANOVA with identical structure was conducted. Bonferroni corrections were performed on each set of follow-up comparisons to account for multiple comparisons. All behavioural analyses were conducted with the statistical software R (R Core Team, 2013) with the package BayesFactor.
Imaging acquisition and analysis
MRI acquisition and preprocessing
Subjects were scanned during the task using a 3-Tesla Siemens Magnetom Prisma MRI scanner with a 32-channel head coil. fMRI images were taken with a T2*-weighted gradient-echo echo-planar imaging sequence (repetition time [TR] = 1,250 ms, echo time [TE] = 30 ms; field of view [FOV] = 192 mm, 96 x 96 matrix; multi-band acceleration factor = 3). All scanner images were acquired during a single scanning session. For all functional runs during the experimental task, complete brain coverage was obtained with 57 interleaved slices of 2-mm isovoxel resolution. A series of 268 functional images were collected during the V5/MT+ localizer run, and 456 for each experimental run. A whole-brain, high resolution T1-weighted anatomical scan was obtained between the functional localizer scan and the emotional MAE runs (TR = 2,300 ms, TE = 4.25 ms; FOV = 25.6 cm, 192 axial slices; voxel size = 1-mm isovoxel resolution; 256 x 240 matrix).
V5/MT+ localizer preprocessing
Analysis of the localizer scan was conducted with traditional univariate approaches. Regressors of interest were generated for both the dynamic and static visual conditions. These task-based regressors were modelled as block events with a duration of 18 s using AFNI’s default hemodynamic response function (i.e., 3dDeconvolve, [BLOCK 18,1]). In addition, the six parameters derived from motion correction (3 translations and three rotations) were included as regressors of no interest. The general linear model resulted in a β coefficient and t value for each voxel during both dynamic and static image presentation.
Experimental task preprocessing
Analysis of the fMRI data was conducted by using Analysis of Functional NeuroImages (AFNI v2016) software (Cox, 1996) at both the individual and group levels. To correct for motion, all volumes were registered to the functional volume acquired closest in time to the anatomical scan. The dataset for each participant was spatially smoothed (using an isotropic 4-mm, full-width, half-maximum Gaussian kernel). Time series data were normalized by dividing the signal intensity of a voxel at each time point by the mean signal intensity of that voxel for each run and multiplying the result by 100. Thus, resultant regression coefficients represent the percent signal change from the mean activity. For univariate analyses in the primary experimental task, nine regressors of interest were generated for the emotional MAE test phase, modeling the presentation time course for each of the nine conditions of interest (target image: 3 MAE directions X 3 emotional categories). To factor out the hemodynamic responses from the motion adaptation stimuli, three regressors of no interest were generated from the three kinds of adaptation periods (i.e., contracting, expanding and alternating motion concentric circles). One additional regressor was created to factor out the hemodynamic response related to the subjective rating questions (illusion quality and arousal). These task-based regressors were modelled by convolving box-car functions with AFNI’s default hemodynamic response function and the ANFI function 3dDeconvolve. In addition, to account for low-frequency temporal drift in the signal, additional regressors of no interest modeled a linear drift and a quadratic trend for each time series and to account for head motion, the six parameters derived from motion correction (3 translations and three rotations) also were included as regressors of no interest. Note, a separate control set of control analyses were performed on the motion data to examine participant motion across conditions. These included a 3 (direction) X 3 (emotion) rm-ANOVA conducted on each the six motion parameter parameters. No significant effects were identified (all p > 0.09). The general linear model resulted in a β coefficient and t value for each voxel and task regressor.
To facilitate multivariate analyses for similarity within conditions, two additional convolutions were performed, again with the AFNI function 3dDeconvolve. The first fit the hemodynamic response function to each motion-aftereffect regressor for all six experimental runs independently, while a single regressor modeled motion videos across run and direction thus resulting in 55 unique β coefficients (6 runs X 9 MAE conditions of interest + 1 motion video regressor). A second convolution was required to minimize the mathematically necessary anticorrelation of β coefficients resultant from fitting temporally adjacent and locked conditions. This fit the hemodynamic response function to each adaptation regressor for all six experimental runs independently, while a single regressor modeled MAE periods across run and direction thus resulting in 19 unique β coefficient (6 runs X 3 adaptation conditions of interest + 1 MAE regressor). All subsequent multivariate analyses were conducted on the run specific β coefficients. All six motion parameters described above regressors were included in both. To facilitate group analyses each individual’s data were transformed into the standard MNI space. For exploratory, whole brain analyses of the main experimental task, please see Supplemental Material S2 and Supplemental Table ST2.
Functional ROIs
Individually defined ROIs: V5MT+
To assess the impact of emotion on human visual motion processing, we targeted areas canonically implicated in these processes. Specifically, initial ROI analyses focused on functionally defined V5/MT+ regions identified by an independent localizer scan at the individual subject level. Given the relatively small volume of this region, and the expected inter-subject variability in brain morphology (Huang et al., 2019), defining this ROI independently for each participant allowed for maximal sensitivity in its interrogation. Swallow et al. (2003), a multistage process was used to identify the V5/MT+ complex at the single-subject level. First, general linear models were used to contrast single subject activity during the presentation of moving versus stationary stimuli in the functional localizer task. At a threshold of p < 0.001, a significant cluster containing V5/MT+ was contiguous with significant activation in additional early visual areas, including V1, V2, and V3 in 18 of 19 participants. To remove visual areas that are not specifically motion-sensitive regions (Tootell et al., 1995b), thresholds were adjusted until the resulting ROIs appeared the appropriate size (<1,000 mm3) and location of V5/MT+ as canonical descriptions of the area (Tootell et al., 1995b; Dumoulin et al., 2000). For full description of single subject V5/MT+ ROIs, see Supplemental Table ST3. Subsequently, these areas were used as functionally derived ROIs and applied to the MAE task to facilitate both univariate and multivariate analyses. For the univariate analysis, a 3 (MAE Direction; approaching, receding, static) X 3 (Emotion: negative, neutral, positive) repeated measures ANOVA was conducted on the percent signal change data derived from the left and right V5/MT+. Assumptions of sphericity were tested with a Mauchly’s test, with application of a Greenhouse-Geisser correction when necessary. Multivariate analyses are described below.
Group-derived ROIs: V5/MT+ localizer scan
To assess the impact of emotion on human visual motion processing in areas beyond V5/MT+ ROIs, a series of group-based, whole-brain analyses were conducted on the functional localizer data to identify general neural regions that were modulated by contrasting motion versus stationary stimuli. These allowed an exploratory investigation of motion-sensitive regions identified independent of our primary experimental task as the localizer was not optimized for this purpose (see Vanduffel et al., 2001 for alternatives). Data were thresholded to allow for the identification of group-derived bilateral V5/MT+ clusters noncontiguous with early visual areas (p < 0.0005; surviving correction to p < 0.01 through a spatial clustering operation performed by 3dClustSim –acf, v2016; Cox et al., 2017). All other surviving clusters were subsequently isolated as independent ROIs (Table 1). To investigate task-dependent activity within these ROIs, the percent signal change from each ROI was extracted for each condition of interest during the primary experimental task (i.e., during emotional MAE). To determine the extent to which activity within these ROIs were driven by both the presence of MAEs and emotional content of a stimulus, a 3 (MAE Direction: approaching, receding, static) X 3 (Emotion: negative, neutral, positive) repeated-measures ANOVA was conducted. Assumptions of sphericity were tested with a Mauchly’s test, with application of a Greenhouse-Geisser correction when necessary. Follow-up paired t-tests were conducted to investigate any significant effects.
Structural ROIs
To assess the representation of motion and emotion in regions processing in visual motion-areas and to be able to compare this to patterns of representation in the canonical dorsal and ventral visual pathways, we generated four additional regions of interest to be used in multivariate analyses of our main experimental task. Three bilateral regions of interest (ROIs) were generated from the standard anatomical atlas (MNI_caez_ml_18) implemented in the Analysis of Functional NeuroImages (AFNI) software package (Cox, 1996) covering primary visual cortex (V1), ventral visual cortices (vVS), and dorsal visual cortices (dVS). While the extent of coverage of these ROIs is not ideal for investigation of specific subregions in these streams, it is meant to facilitate allowing investigation of multivariate representation of information processed within the broad divisions of visual processing pathways (see Supplemental Figure SF1 and Supplemental Table ST4 for a full anatomical descriptions of these ROIs). An additional ROI was derived from the individual subject V5/MT+ localizer scan. This ROI was defined by overlaying all individually defined V5/MT+ ROIs (see Supplemental Table ST2) to create a compound ROI of the area using the AFNI function 3dcalc. These regions (vVS, dVS, and V5/MT+) were chosen due to their role in visual classification (Kanwisher et al., 1997; Kravitz et al., 2013), visual guidance of behaviour (Milner and Goodale, 1993; Brogaard, 2012; Cloutman, 2013), and motion perception (Tootell et al., 1995b; Born and Bradley, 2005; Smith et al., 2006) respectively.
RSA and pattern component specification
To identify and compare the representational pattern elicited by the experimental conditions, representational similarity analysis (RSA; Fig. 1B) was performed by using the PyMVPA Python package (Hanke et al., 2009). Pattern component analyses followed procedures outlined in Kryklywy et al. (2023). For each participant, a vector was created containing the spatial patterns derived from β coefficients from each voxel related to each condition in each ROI. Pairwise Pearson coefficients were calculated between all vectors of a single ROI, resulting in a similarity matrix containing correlations across all 12 conditions (3 valence categories X 3 afterimage categories + 3 motion videos) for each participant. Fisher transformations were performed to ensure similarity metrics were normally distributed before comparisons between participants.
Representational patterns of interest (POIs) were generated to represent the similarity matrices that would be observed in the experimental data if it were to be a perfect representation of one of thirteen distinct potential sources of information related to the visual or emotional experience of the trial (see POI Glossary in Table 2 for details). Specifically, POIs were constructed for six visual constructs and seven valence-related constructs. For visual constructs, the POIs modelled included: 1) perceived approach, 2) perceived recession, 3) general perceived motion with a unique static representation), 4) general perceived motion without a unique static representation, 5) linear motion direction effects (approach-related activity as anticorrelated with receding), and 6) image identity (i.e., the specific group of images used). Valence POIs related to the emotional quality of the images viewed. These were defined independently to reflect both the valence of the image, as well as the valence of the trial outcome (e.g., a receding negative image is a positive outcome). The valence-based POIs modeled: 7) all valenced images (i.e., represents positive or negative stimuli collectively as distinct from neutral stimuli), 8) positive images (versus negative or neutral collectively), 9) negative images (versus positive or neutral images collectively), 10) a linear image valence spectrum (i.e., positive images anticorrelated with negative images), 11) positive outcome, 12) negative outcomes, and 13) a linear outcome valence spectrum (adaptive outcomes [positive stimulus approach or negative stimulus receding] anticorrelated with maladaptive outcomes [positive stimulus receding or negative stimulus approaching]).
Pattern component modelling, a novel neuroimaging technique (Diedrichsen et al., 2018; Kryklywy et al., 2021a; 2023), was conducted to identify and fit the POIs that best described observed similarity in each of the four ROIs. To avoid overfitting of the data by the PCM procedures, we performed a Monte-Carlo cross validation (Picard and Cook, 1984) (MCCV) with 1,000 iterations. For each iteration, initial analyses were conducted on a randomly selected (RS) subset of ten participants (RS = 10), with results validated against the remaining nine participants (the “hold-out”; HO = 9). These parameters were chosen to maximize cross-validation performance by minimizing CV-variance while maximizing model selection accuracy given our initial sample size (Arlot and Celisse, 2010; Valente et al., 2021).
In the current experiment, many of the modeled representational patterns of interest (POIs) contained overlapping similarity; thus, a traditional regression including all potential components as predictors would be insufficient to identify those that are most informative. To accommodate this, PCM conducted in data from each RS implemented iterative Bayesian Information Criterion (BIC) with an uninformed greedy best-first search (GBFS) algorithm (Doran and Michie, 1966) to determine the POI combinations that best explained the observed correlation. First-level model fitting identified the single POI most predictive of the observed similarity patterns. This was then tested in combination with all remaining POIs to which combination led to the greatest improvement in model fit, and this process was repeated until the addition of no other POIs led to improved fit. Improved fit due defined as a ΔBIC > 2 (Fabozzi, 2014). If multiple POI combinations at a given search level resulted in a statistically equivalent “best fit” (i.e., ΔBIC from the absolute best fit < 2), all equivalent paths were extended to completion (Fabozzi, 2014). POIs present in the completed path with the lowest end BIC score were identified as contributing to representations in that region. Correlation matrix transformations were performed by using Matlab r2019a (The MathWorks, Natick, MA), and BIC analyses were conducted with the lme4 statistical package in R 4.0.2 (R Core Team, 2013). Custom code for the PCM analyses is available in the R package PCMforR (Kryklywy et al., 2021b). This approach allowed for the identification of multiple sources of information as they simultaneously contribute to observed representational patterns, rather than any single information construct. By iteratively performing these analyses (1,000 samples of n = 10), we were able to identify the proportion of subsamples identifying a specific POI as contributing to the observed similarity patterns in the experimental data (POI identification rate). POI identification rates were compared to chance identification (average # of POIs identified per iteration / total # of POIs for each ROI.
Results
Behavioural results
A 3 (MAE Direction) X 3 (Emotion) repeated-measures ANOVA, paired with a Bayes factor ANOVA of similar structure were conducted on the illusion quality ratings (Fig. 2A). These yielded a significant main effect of MAE direction (F(1.48,26.71) = 52.06 p < 0.001) with decisive evidence for the alternate hypothesis (H1; BF10 > 100). Critically, the approaching and receding after-effects were rated to be significantly more robust (i.e., created a stronger motion illusion) than the static aftereffects (t(18) = 8.50; p < 0.001 and t(18) = 4.78; p < 0.001 respectively; Fig. 2A). In addition, approaching images were seen as having significantly more apparent motion than receding images (t(18) = 6.26; p < 0.001). No significant main effect of emotion (F(1.12, 20.20) = 0.60, p > 0.10) emerged, consistent with strong evidence for the null hypothesis (BF10 = 0.070 ± 2.35%). In addition, the ANOVA identified no MAE direction X emotion interaction (F(4, 72) = 2.22, p = 0.075), supported by strong evidence for the null hypothesis (BF10 = 0.07 ± 3.01%).

Behavioural effects of MAE direction and emotion. (A) The direction of illusory motion was found to significantly impact illusion quality ratings. Both approaching and receding MAEs elicited significantly higher quality of illusion than static afterimages. (B) Ratings of perceived arousal were modulated by emotion and showed a significant motion X direction interaction. Main effect of emotion is indicated on the figure legend. For all plots, bottom/top of boxes indicate 25th and 75th percentile respectively; whiskers extend smallest/largest value (no further than 1.5 X interquartile range). *p < 0.05; **p < 0.01; ***p < 0.001
A 3 X 3 repeated-measures ANOVA and Bayes factor ANOVA of similar design were applied to the emotional arousal data (Fig. 2B). These yielded a significant main effect of emotion (F(2,36) = 54.29, p < 0.001), with decisive evidence for the H1 (BF10 >100). This effect was characterized by significantly greater emotional arousal ratings for both negative and positive images compared with neutral images (t(18) = 7.50; p < 0.001 and t(18) = 4.53; p < 0.001 respectively) as well as significantly higher emotional arousal ratings for negative images compared with positive images (t(18) = 3.27; p = 0.007). No main effect of MAE direction was identified in the arousal data (F(2,36) = 1.724, p = 0.19), with strong evidence to support H0 (BF10 = 0.064 ± 1.11%). A significant MAE direction X emotion interaction emerged (F(4,72) = 4.78, p = 0.002), albeit unsupported by Bayesian analyses (BF10 = 0.092 ± 3.06%). A subsequent series of paired t-tests (all reported p values subject to Bonferroni correction) determined the interaction effect was driven by increased arousal during negative and positive image trials compared to neutral image trials in all motion directions (all ps <0.001), and significantly greater arousal for negative image trials compared to positive image trials during approaching (p = 0.016), but not receding or static trials (p = 0.12 and p = 0.25 respectively; Fig. 2B).
Univariate imaging results
Individually Defined ROIs: V5/MT+
Initial analyses addressed whether emotional images augmented activity in V5/MT+, similar to their effects on areas traditionally associated with the ventral visual stream. Individually defined ROIs generated from the V5/MT+ localizer scan (Fig. 3A; for group overlap in V5/MT+ identification) were applied to the data from the emotional MAE task (an independent data set), and a 3 (MAE Direction) X 3 (Emotion) repeated measures ANOVA was conducted on the percent signal change data derived from the left and right V5/MT+.

V5/MT+ responses to emotion and perceived MAE direction within individually defined ROIs. (A) Spatial overlap of subject ROIs for bilateral V5/MT+ (Participant #3). (B) Activity in bilateral V5/MT+ across participants was modulated as a function of illusory motion, with both approach and recede MAE trials eliciting significantly more activity than static control trials. (C) Activity in this region was also modulated as a function of emotion. Both positive and negative trials elicited significantly more activity than neutral trials. No direction by emotion interaction was observed. Error bars represent standard error of the mean. For all plots, bottom/top of boxes indicate 25th and 75th percentile respectively; whiskers extend smallest/largest value (no further than 1.5 X interquartile range). *p < 0.05; **p < 0.01; ***p < 0.001
A main effect of MAE direction (right: F(1.48,26.59) = 13.28, p < 0.001; left: F(2,36) = 3.85, p = 0.031; Fig. 3B) emerged, with decisive evidence against the null hypotheses observed in the right hemisphere (BF10 > 100) and inconclusive evidence for or against the null hypothesis observed in the left hemisphere (BF10 = 0.48 ± 0.89%). As expected, there was enhanced V5/MT+ activation to approaching (right: p = 0.0033; left p = 0.0073) and receding trials (right: p = 0.0028; left p = 0.0056) compared with static trials, and no difference in activation between approaching and receding stimuli (right: p = 1; left p = 1). More importantly, a significant main effect of emotion emerged in both hemispheres (right: F(1.44,25.99) = 6.42, p = 0.009; left: F(2,36) = 3.81, p = 0.032; Fig. 3C), again supported by substantial evidence against the null hypotheses (right BF10 = 4.32 ± 1.18%; left BF10 = 5.47 ± 0.73%). This was characterized by increased activity for trials containing a positive target image compared with trials containing a neutral target image (right: p = 0.0095 0.001; left p = 0.012) and increased activity in left V5/MT+ to trials with a negative compared with a neutral image (p = 0.023) but not in right V5/MT+ (p = 0.12). No significant differences were noted between the emotional categories (negative vs. positive) in either hemisphere (both ps = 1). No significant MAE direction X emotion interaction was found (right: F(4,72) = 0.58, p = 0.832; left: F(4,72) = 0.58, p = 0.68) with strong support for the null hypothesis (right BF10 = 0.055 ± 4.67%; left BF10 = 0.080 ± 5.11%). Note p values for all paired comparisons have been subject to Bonferroni correction. By overlaying individually defined V5/MT+ ROIs, a compound V5/MT+ ROI was obtained that extended over motion-sensitive MT regions for all participants (see Section "Structural ROIs"). This mask was created for use in subsequent multivariate statistics.
Group-derived ROIs: V5/MT+ localizer scan
A paired t-test was performed on whole-brain localizer scan data to identify widespread regions across participants with differential activation for moving versus static pictures, including potential regions associated with the dorsal visual stream (Table 1; Fig. 4). This isolated bilateral clusters of activation located along V5/MT+ (Fig. 4A), as well as widespread early visual processing areas. In additional, two separate regions of dorsal occipital lobe were identified, including portions of the superior parieto-occipital cortex (SPOC; Fig. 4B), which likely corresponds to the motion-selective visual area V6 (Pitzalis et al., 2015), and the cuneus (BA19 /prostrita; Mikellidou et al., 2017, Fig. 4D), as well as one region along the parahippocampal gyrus (Fig. 4C), and one on the precentral gyrus (possibly a motor-confound; Fig. 4C). These ROIs were applied to the experimental task data, and a 3 (MAE Direction) X 3 (Emotion) repeated-measures ANOVA was conducted on the percent signal change data extracted from each. Therefore, this analysis examined the impact of illusory motion and emotion on signal in neural regions identified as being responsive to actual motion in the original localizer.

Group-defined motion-selective ROIs. Group-defined ROIs were identified by contrasting neural activity in motion versus static viewing conditions during the functional localizer, identifying regions of the occipital and middle temporal lobes (ventral visual stream) which respond preferentially to moving, but not static imagery (green). Independent bilateral V5/MT+ regions were identified separate from a large ventral visual cluster (blue circles). In addition, areas of the dorsal occipital lobe (SPOC and dorsal BA18/19; orange circles), parahippocampal gyrus, and post-central gyrus displayed preferential activation to the static control than the motion condition (yellow)
Consistent with the individually defined V5/MT+ ROIs, both left and right group-defined V5/MT+ ROIs were modulated significantly by the emotional quality of the image (right: F(2,36) = 10.75, p < 0.001, BF10 = 53.0 ± 0.96%; left: F(2,36) = 26.07, p < 0.001, BF10 > 100). This effect was characterized by significantly greater activity for positive and negative stimuli compared with neutral stimuli (right V5/MT+: p < 0.001 and p = 0.009 respectively; left V5/MT+: both p < 0.001) and no difference between positive and negative stimuli (p = 0.14). A significant main effect of MAE direction was identified within right V5/MT+ (F(2,36) = 13.43, p < 0.001, BF10 > 100), characterized by greater activity for approaching and receding stimuli compared with perceptually stationary stimuli (p < 0.001 for both contrasts) and no difference between approaching and receding stimuli (p = 0.22). No significant main effect of MAE direction was identified in left V5/MT+ (F(2,36) = 1.49, p = 0.24), consistent with substantial evidence in favour of the null hypothesis (BF10 = 0.20 ± 1.23%)). No significant MAE direction by emotion interaction observed in either hemisphere (right: F(4,72) = 0.674, p = 0.61; left: F(2.68,48.3) = 0.78, p = 0.83), supported by strong evidence for the null hypothesis (BF10 = 0.068 ± 1.53%).
Investigation of a large occipital cluster identified as motion sensitive in the V5/MT+ Localizer scan (including bilateral regions of both early and ventral visual cortices with the cluster extending into V1, V2, LOC; Table 1; Fig. 4) found it to display similar responses to emotional content as observed in V5/MT+ (ME Emotion: F(1.401,25.215) = 6.40, p = 0.0042, BF10 = 55.59 ± 0.64%). By contrast, main effects of emotion were not observed in other visual regions identified in the functional localizer as motion-sensitive, including dorsal visual regions and visual regions less defined within the dorsal-ventral framework (SPOC and BA 18/19 respectively; Fig. 4; all ps > 0.20, BF10 < 0.23). Furthermore, no significant main effect of MAE direction or MAE direction by emotion interaction was identified in either of these visual regions (all ps > 0.25, BF10 < 0.28). No significant main effects or interaction involving emotion were identified within the precuneus (all ps > 0.09, BF10 < 0.40) or parahippocampal gyrus (all ps > 0.27, BF10 < 0.3).
Multivariate analyses
To identify the emotional properties of information represented across visual areas, we conducted Pattern Component Modelling, with a cross validation procedure (CV; for full details, see Table 3; Fig. 5). Results presented include 1) the strength of representation for Patterns of Interest (POIs) identified as contributing to similarity representations in the random sample, 2) the subsequent fit of these POIs when applied as predictors to similarity patterns observed in the help out participants. This technique allows for the identification of predicted POIs in neural regions subserving multiple, or integrative functions, as well as from representational states prone to signal noise. Specifically, it allows the interrogation of representational patterns that may not be the dominant representations in the area (i.e., they explain low overall variance) yet do make significant contribution to the overall representational patterns.

Monte-Carlo CV of PCM analyses. Pattern component modelling was performed through 1,000 iterations Monte-Carlo cross-validation procedure with a random sample (RS) of 10 participants and nine held-out (HO) participants. (A) Potential representational pattern of interest (POIs), reflecting operationalized states of experience (Table 2), are presented along the top of the figure, with results from each ROI present below. The proportion of MCCV iterations identifying each pattern as a contributing to observed representational patterns in each brain region is indicated by the teal bars. The average β value for components for only those POIs contributing to the representational pattern at a rate significantly greater than chance is presented overlaid on the relevant component (peach bar; scale to the right). (B) Average POI fit in the RS and HO. Red bars (right) indicate the proportion of variability in the RS attributed to the identified POI identified in the PCM analyses. Light yellow bars (left) indicate the proportion of variability in the HO attributed to the identified POI. POI components, and their relevant weight were identified in the RS only. No significant differences emerged in R2 between the RS and HO for any of the tested brain regions. Error bars represent standard deviation for each MCCV distribution. Abbreviations for POIs identified at a rate significantly greater than chance: Real motion, nonspecific (RMNS); Image set identity (Set); Image valence, all salience (IVAll); Image valence, linear (IVLin). Abbreviations for all noncontributing POIs can be found in Table 2
RSA with pattern component modeling
V1: Representations in V1 were explained by a combination of POIs modelling the general presence of actual visual motion of the stimuli (βRMNS = 0.196), the specific set of images observed (βSet = 0.181), the emotional salience of the images (βIVAll = 0.096) and the valence of the images represented along a linear spectrum (βIVLin = −0.090). Together, these weighted components predicted an average of 23.9% of the variance in the remaining held-out participants. (R2 = 0.239, F(1, 700) = 223.95, p < 0.001, β = 1.00). These results suggest that V1 represents multiple features of visual experience, including motion, valence, identity, and emotional salience.
Ventral visual structures
In a pattern similar to V1, the representations in the ventral visual stream (vVS) were significantly explained by POIs modelling varied visual features. Specifically, identified components included the general presence of actual visual motion in the stimuli (βRMNS = 0.236), the specific set of images observed (βSet = 0.064), the emotional salience of the images (βIVAll = 0.097) and the valence of the images along a linear spectrum (βIVLin = −0.030). A reconstructed component generated from these weighted components predicted an average of 22.6% of the variance in the remaining held-out participants (R2 = 0.226, F(1, 700) = 209.43, p < 0.001, β = 1.00). The similarity of the POIs that best explain the representations in V1 and vVS, with their similarity of representational strength (i.e., beta weights) suggest a continuity of processing for a number of visual features between these regions.
Dorsal visual stream
In the dorsal visual stream (dVS), POIs modelling the general presence of actual visual motion in the stimuli (βRMNS = 0.392) and the emotional salience of the images—as defined by standardized ratings (Lang et al., 2008)—were found to be represented (βIVAll = 0.073). A recombination of these weighted components explained and average of 29.4% of variance in the held-out participants (R2 = 0.294, F(1, 700) = 302.28, p < 0.001, β = 0.99). These results suggest that dVS is important in representing information about motion in any direction as well as image salience, but, importantly, does not represent specific features for static visual identification (i.e., no representation for image identity), or any specific valence-based information (positive vs. negative) of the trials.
V5/MT+
With a component combination similar to V1 and vVS, and divergent from dVS, representations in V5/MT+ were significantly explained by a combination of POIs modelling varied visual features. Specifically, identified components included the general presence of actual visual motion in the stimuli (βRMNS = 0.370), the specific set of images observed (βSet = 0.099), the emotional salience of the images (βIVAll = 0.150) and the valence of the images along a linear spectrum (βIVLin = −0.038). Together, these weighted POIs predicted an average of 30% of variance in the held-out participants (R2 = 0.30, F(1, 700) = 302.13, p < 0.001, β = 0.98). Of note, while the component patterns identified in this region were highly consistent to those in V1 and vVS, the representational weight of actual visual motion (βRMNS) was more consistent to that observed in dVS. This demonstrates that V5/MT+ is unique in that it represents both real visual motion and the valence of the images (dissociating between positive from negative valenced images). Additionally, the identification of valence-based processing by multivariate but not univariate approached suggest that these representations are coded by activity pattern changes across multiple voxels (Kriegeskorte et al., 2008), likely indicating population coding of this information (Chikazoe et al., 2014).
Discussion
The present study investigated the impact of emotion on the motion processing region V5/MT+. Consistent with predictions, increased activity in this region was observed during motion aftereffects compared to static control conditions and for emotional compared to neutral images; however, in contrast to what was expected, no emotion-direction interactions were observed. Furthermore, both univariate and multivariate analyses demonstrated that the emotional valence of a visual stimulus changed the neural activity and observable representational patterns throughout the ventral visual stream, but not in dorsal stream areas responsive to visual motion (i.e., SPOC or dorsal BA18/19). Similarly, representational similarity analyses (RSA) conducted with theory-driven Pattern Component Modelling (PCM) determined that the representational profile of the V5/MT+ complex more closely aligned with those observed in primary and ventral rather than dorsal visual regions. Consistent with the univariate results, area V5/MT+ represented both motion and emotion, with these factors represented as independent, rather than integrated, components. Specifically, V5/MT+ houses valence-based representations of emotional content and image identity, consistent with those observed in early and ventral visual regions. Representation patterns in dorsal visual structures did not include valence or identity features but was instead limited to motion and general saliency. The strength of representation for real visual motion (i.e., the adaptation videos; βRMNS) in V5/MT+, however, was consistent with that observed in traditionally dorsal regions (and notably greater than in ventral structures), suggesting a similar degree of processing for visual motion across these regions. These results suggest that V5/MT+ is unique in its emotional visual processing. Its shares similar sensitivity to visual motion as the canonical dorsal stream yet responds to emotional information in a manner more consistent with ventral-visual processing. These results are interpreted with reference to the impact of emotion in the preparation for, and representation of, motion in visual processing areas.
Motion modulation of emotional arousal
In the current study, emotional arousal ratings were modulated by both stimulus valence and direction of perceived motion relative to the viewer’s position. Approaching negative images were found to elicit the highest emotional arousal rating. This effect is in line with conceptualizations of arousal as a state designed to elicit biological preparedness, particularly the idea that proximal approaching threats place greater demands on behaviour than retreating ones (Panksepp, 1990; 1998; Mobbs et al., 2009; 2020; Abe et al., 2018) and that arousal increases with threat proximity (e.g., a tarantula; Mobbs et al., 2010). Behavioural analyses suggest that motion-specific effects of on arousal we limited to negative stimuli—consistent with previous work (Sato and Yoshikawa, 2007), increased arousal of neutral stimuli did not depend on the direction of motion. It is important to note that the principal manipulation in the current study relied on illusory motion, thus keeping other visual properties (e.g., size) constant, yet it was capable of impacting not only motion perception, but also emotional arousal ratings and activation in emotion-sensitive brain areas. This highlights the potential value of motion after-effects for examining how motion and changes in apparent stimulus proximity may interact with other stimulus features, such as emotional significance, to influence brain and behaviour.
Neural responses to emotion
Large areas of the ventral visual stream dedicated to object perception (including inferior occipital and middle temporal lobe; Milner and Goodale, 2006) and primary visual cortices displayed valence-specific fluctuations in neural activity, and multivariate patterns associated with emotional content, which are both consistent with previous work (Lang et al., 1998; Morris et al., 1998; Vuilleumier and Driver, 2007). Of note, however, while efforts were made to statistically match many visual characteristics across valence categories (see Section "Stimuli and Apparatus"), the preference towards naturalistic images in the current work meant that exact matching was not possible. Thus, one should take appropriate caution when interpreting cross-valence results with additional work using scrambled images with control spectral components would be useful to further tease apart these effects. The observed effects, however, are consistent with initial predictions. Specifically, similar robust valence-based effects were observed across, bilateral V5/MT+, ventral visual areas an primary visual cortex, while substantially less emotional responsivity was observed in dorsal visual regions, despite the fact that this V5/MT+ is traditionally associated with dorsal stream processing (Buchel and Friston, 1997; Born and Bradley, 2005). Representational patterns in area V5/MT+ were found to be most strongly predicted by the general emotional salience of the images (POI: IVAll), with highly correlated activational states for emotional images regardless of valence polarity. This suggests that this region may be particularly tuned towards integrating the emotional salience (Vuilleumier, 2005; Vuilleumier and Driver, 2007; Pessoa and Adolphs, 2010; Mitchell and Greening, 2012) of stimuli to its observer-centered movements.
Interestingly, the observation of enhanced processing V5/MT+ is not limited to objects of emotional salience but rather occurs with increased attentional salience of many forms (Huk et al., 2001). Thus, some of the observed effects may not reflect an emotion-specific changes to V5/MT+ processed but rather demonstrate how emotional information can leverage mechanisms of general attentional prioritization. Additional work may be needed to determine the emotion specificity of effect observed in this area. Either interpretation, however, is consistent with recent evidence that motion cues can facilitate object perception (e.g., aggressive movements facilitating the detection of threat in crowded visual scenes; van Boxtel and Lu, 2012; Parasuraman and Galster, 2013). Although we predicted little influence of emotion on dorsal visual processing (Kryklywy et al., 2013; Kryklywy and Mitchell, 2014; further supported from the current univariate analyses; Kryklywy et al., 2018), representational patterns reflecting the non-valenced emotional salience (POI: IVAll) were observed in these regions. This incongruence between the current univariate and multivariate results may reflect either fundamentally different types of neural encoding detectable by these analyses (i.e., population coding vs. activation coding; see Kriegeskorte and Kievit, 2013; Kryklywy et al., 2018) and highlight the benefit of multipronged analytic approaches.
Limited emotional influence on univariate activation of dorsal visual regions was observed in the current work. While this is superficially incongruent with previous studies that have observed robust emotion-related effects to dynamic body and facial expressions in canonically dorsal areas (Lang et al., 1998; de Gelder et al., 2004; de Gelder and Hadjikhani, 2006; Grecucci et al., 2013; Goldberg et al., 2012; 2014; Engelen et al., 2015), it is important to note that previous work often provided clear conspecific social contexts in their emotional stimuli. By contrast, the current paradigm incorporated emotional visual scenes that consisted of objects and contexts. Some of these scenes involved humans interacting (e.g., laughing children), and others did not (e.g., snarling dog). While seemingly minor, it become important when considering the potential role of the dorsal stream in social response selection (Kong et al., 2021), and evidence from the current work demonstrating that emotional salience of images processed in earlier visual regions may still maintain representation in dorsal structures. Alternatively, a recent proposal of a third visual stream—one located along the middle and superior temporal gyrus and implicated in processing visual cues for social perception (Pitcher and Ungerleider, 2021)—may help to illuminate how our visual system may process social cues. Within this novel framework, the emotionality of social information may more efficiently communicate to dorsal processing regions, whereas the emotionality of nonsocial cues (as presented in the current work) stays relatively confined to ventral areas during visual processing. Additional work delineating the interconnectivity of this newly proposed pathway with canonical processing streams is required, however, before further interpretation of these results.
Neural responses to motion
As predicted from previous work (Tootell et al., 1995a; Culham et al., 1999; Antal et al., 2004; Fawcett et al., 2007; Hogendoorn and Verstraten, 2013), the V5/MT+ complex displayed preferential response to apparent motion in an image. In addition, the traditional role of V5/MT+ in motion-based processing (Buchel and Friston, 1997; Born and Bradley, 2005) was supported by representational similarity analyses. Representation patterns observed in V5/MT+ were found to be driven in part by the real visual motion (i.e., distinct representational patterns for the adaptation videos) presented during the individual trials. Pattern component modeling analyses in this region, however, did not identify pattern components representing the perceived motion (i.e., no shared representational patterns between the adaptation videos and motion after-effects).
One possible explanation is that illusory motion is processed by a separate neural mechanism than real motion. Motion direction is encoded in the brain by cumulative activity across a population of neurons rather than by individual neural firings, (i.e., a population code; Georgopoulos et al., 1986; 1988; Maynard et al., 1999). Different patterns of visual motion may be represented by partially, or even nonoverlapping groups of neurons, rather than different levels of activity within a single population. Thus, the experience of a motion after-effect following sustained motion in one direction may be the result of down-regulation, or fatigue, of cell populations representing the initial direction of presented motion rather than an up-regulation of the cell populations representing the direction of the subsequent illusionary motion (Anstis et al., 1998). In this manner, the activation patterns representing real visual motion may not overlap with those representing congruent motion aftereffects and thereby would go undetected by similarity-based analyses. This mechanism of fatigue, however, has been challenged by evidence that motion-aftereffect storage persists beyond the expected time course for neural fatigue (Watamaniuk and Heinen, 2007) and that it can be generated from still photos with suggested motion (Winawer et al., 2008). Furthermore, this mechanism is challenged by the univariate analyses conducted in the current work. In these, activation in V5/MT+ was found to have increased activity during MAE conditions versus static image conditions. This suggests that a down-regulation of neural activity is unlikely and also indicates that whereas overall activation may change for individual voxels across motion aftereffects, the relative pattern of activity between voxels remains stable. At this point, it should be noted that delineating population-based encoding from activity V5/MT+ (or any other brain region) remains a notably challenging endeavour (Bartels et al., 2008). Activity in this region has been found to both increase and decrease is response to coherent motion (Becker et al., 2008), among other forms of heterogenic responding (Laycock et al., 2007; Kayser et al., 2010; Emmerling et al., 2016; Liu and Pack, 2017; Gaglianese et al., 2023). Thus, appropriate caution should be taken for all interpretation of the V5/MT+ results.
An alternative explanation to the neural fatigue theory to explain a limited representation of illusory motion in V5/MT+ can be evoked when considering the time course of modelled events in the current work. If real and illusory visual motion are coded by overlapping populations of neurons, it may be that the time course modeled in the representational similarity analyses extend beyond the extinction of the visual illusion, thus including stationary imagery as well. This may have resulted in diluted representational patterns of motion during aftereffect conditions and led to the reduced similarity observed between the illusory and real motion conditions. Canonical evidence of motion aftereffect phenomena suggests that this speed of decay is unlikely given the paradigm used (Hershenson, 1989). It may be instead that illusory motion, including the motion after-effect, is not confined to a single region as early explanations proposed (He et al., 1998). Rather, motion aftereffects likely depend multiple levels of processing across numerous regions (Mather et al., 2008) and timescales (Shioiri et al., 2021). Thus, targeting component modeling to single regions may miss some of the larger network-wide encoding that may underlie perceptual and cognitive experience.
Related to the targeted, motion-sensitive regions, the motion localizer employed in the current task, while known to produce robust activation in V5/MT+ (Tootell et al., 1995b; Vanduffel et al., 2001; Huk et al., 2002), is a relatively simple form of motion localizer. Other localizers now exist that use more complex motion stimuli (Russ et al., 2021). These methods involve the use of optic flow patterns and structure (Vanduffel et al., 2002; Nelissen et al., 2006) or methods that allow for deciphering the type of motion to which regions respond (Jastorff et al., 2012). The inclusion of such localizers in future work may lead to additional refinement in the characterization of motion-sensitive areas by reducing the potential to overestimate the area of the V5/MT+ complex and thus enhancing the specificity of future results.
Emotional motion: V5/MT+ activation
Interactions between emotion direction and emotion in the V5/MT+ complex were not observed in the current work. Representational patterns for motion and emotion were found to be orthogonal to each other—they did not manifest as shared representational patterns—suggesting that these features are not interactive in this region. This contrasts previous work showing that changing facial expressions elicits greater activity in V5/MT+ than dynamic neutral faces (Furl et al., 2013). This change, however, may have been driven by the emotionality of the stimuli independent of its motion. As the V5/MT+ ROIs interrogated in the current work (clustered due to their general responsivity to visual motion) are an amalgamation of multiple distinct subregions (Smith et al., 2006; Kolster et al., 2010; Gao et al., 2020), they likely receive signals of motion and emotion from independent sources, modulated by the previous experience with the items. These signals likely includes reciprocal connections with early visual cortices guiding motion perception (Laycock et al., 2007; Vetter et al., 2015), as well as feedback projections from affect-sensitive central structures (e.g., amygdalae) guiding valence representations (Vuilleumier, 2005; Amting et al., 2010; Pessoa and Adolphs, 2010; Mitchell and Greening, 2012; Kryklywy et al., 2020). This suggests that there are multiple channels of processing that occur in the V5/MT+ complex, with potentially distinct circuitry for motion direction and emotion. This is consistent with earlier evidence of anatomical and functional heterogeneity in this region (Smith et al., 2006; Kolster et al., 2010; Gao et al., 2020).
In addition to receiving both emotional and nonemotional visual input, heterogeneity of function for the V5/MT+ complex extends to its visual processing role, independent of emotional signaling. V5/MT+ displays multifaceted encoding of visual signals, including both motion direction (Salzman et al., 1992) and velocity (McKeefry et al., 2008; Grasso et al., 2018), as well as additional roles in motion detection (Newsome and Pare, 1988; Liu and Pack, 2017) and visual prediction (Vetter et al., 2015). The localization of these functional contributions to V5/MT+ versus other visual regions (e.g., area V3; McKeefry et al., 2008) may depend on the familiarity of a visual experience to an observer, rather than the objective visual feature (Liu and Pack, 2017). Subjective changes in visual experience due to changes in V5/MT+ activity may not reflect the objective ability to interact with a moving object (Grasso et al., 2018). In the current paradigm, the use of MAEs to generate perceptual motion may constrain some of the normal visual features used to assess motion direction. For example, by using a consistent velocity and width for visual stimuli in the adaptation period, depth-related cues, such as speed and size (faster/larger at closer distances), may not have been perceptually manipulated in a natural way. Previous work has highlighted these depth features as a driver of activity in V5/MT+ (Nadler et al., 2013; Sanada and DeAngelis, 2014; Kim et al., 2015, 2016), as well as being particularly important for attention allocation (Lin et al., 2008; Rokers et al., 2008). Given the relationship between object depth and approach and avoidance in effective emotional responding (Panksepp, 1990; 1998; Mobbs et al., 2009; Qi et al., 2018; Meyer et al., 2019), additional work is required to fully delineate the impact of depth cues as they relate to emotion representation in regions processing visual motion. Another potentially confounding factor regarding the interpretation of depth and approach cues on object salience is the possibility of physical contact with the object. Approaching cues may be interpreted as on a collision course with the observer, thus gaining additional relevance and influencing V5/MT+ activity in a manner that may supersede the valence-based salience (Lin et al., 2008). This again highlights the need for additional work to fully disentangle the impact of emotion and depth related cues as they pertain to visual processing in V5/MT+.
Current and previous work regarding V5/MT+ emotion-motion integration differed in the way motion direction was presented relative to the observer. Specifically, the present study examined the effects of emotion and direction with stimuli that appeared to change position relative to the observer (i.e., approaching vs receding motion) while previous work often has utilized emotional imagery presented as though viewed by an uninvolved third party (i.e., perpendicular motion). It is possible that emotion has a general priming effect on V5/MT+, wherein increased emotional relevance leads to enhanced motion prediction or preparation of movement regardless of direction. This is consistent with theories that conceptualize threat response as an increase in physiological readiness in times of heightened emotion or stress (Saper, 2002; Tsigos and Chrousos, 2002). Distinct valence-defined representation patterns (POI: IVLin) were identified in V1, ventral visual structures, and V5/MT+ dorsal visual regions. By contrast, univariate analysis conducted in V5/MT+ did not identify valence-based changes in activity (i.e., they showed equivalent activation changes to positive and negative stimuli). Multivariate analyses demonstrated that a sensitivity to nonspecific arousal (POI: IVAll) was observed with varying strength of expression across all tested visual regions: (i.e., V1, VVS, V5/MT+, and DVS). Together, these results suggests that while signals of emotional salience are likely tagged early in visual processing and propagates throughout much of visual cortex, appraisal of the emotional valence direction of these signals is limited to nondorsal regions.
Conclusions
The current study investigated the impact of emotion and perceived motion on perceptual and neural responses related to visual scenes. Activity in area V5/MT+ was modified by, and showed distinct representational spaces for, both the emotional valence and the perceived motion of an image. Specifically, both approaching and receding images were found to elicit significantly more activity compared with static images, whereas both negative and positive images elicited significantly more activity than neutral images. Furthermore, although similar emotion-related enhancements were observed across widespread areas of the ventral visual stream, no such effects were observed in areas of the dorsal visual stream. Subsequent pattern component modelling performed in visual regions (early, ventral, and dorsal visual regions, as well as V5/MT+) demonstrated again that motion representation in V5/MT+ was similar to that in dorsal visual structures, while emotion in V5/MT+ region was more similar to that in ventral visual structures. Overall, these data provide evidence that visual emotional salience can influence processing in area V5/MT+ and highlights the potential value of motion after-effects for investigating how movement relative to the observer interacts with other stimulus features to affect brain and behaviour.
Data availability
Raw and partially proccessed data is available for dowload at OpenNeuro.org
Code availability
Not applicable.
References
Abe, H., Tani, T., Mashiko, H., Kitamura, N., Hayami, T., Watanabe, S., Sakai, K., Suzuki, W., Mizukami, H., Watakabe, A., Yamamori, T., & Ichinohe, N. (2018). Axonal projections from the middle temporal area in the common marmoset. Frontier Neuroanat, 12, 89.
Aglioti, S., DeSouza, J. F., & Goodale, M. A. (1995). Size-contrast illusions deceive the eye but not the hand. Current Biology, 5(6), 679–685.
Amaral, D. G., & Price, J. L. (1984). Amygdalo-cortical projections in the monkey (Macaca fascicularis). J Comp Neurology, 230(4), 465–496.
Amaral, D. G., Behniea, H., & Kelly, J. L. (2003). Topographic organization of projections from the amygdala to the visual cortex in the macaque monkey. Neuroscience, 118(4), 1099–1120.
Amting, J. M., Greening, S. G., & Mitchell, D. G. (2010). Multiple mechanisms of consciousness: The neural correlates of emotional awareness. J Neurosci, 30(30), 10039–10047.
Anstis, S., Verstraten, F. A., & Mather, G. (1998). The motion aftereffect. Trends in Cognitive Sciences, 2(3), 111–117.
Antal, A., Varga, E. T., Nitsche, M. A., Chadaide, Z., Paulus, W., Kovacs, G., & Vidnyanszky, Z. (2004). Direct current stimulation over MT+/V5 modulates motion aftereffect in humans. Neuroreport, 15(16), 2491–2494.
Arall, M., Romeo, A., Super, H. (2012) Role of feedforward and feedback projections in figure-ground responses. In Visual Cortex-Current Status and Perspectives. IntechOpen.
Arlot, A., & Celisse, A. (2010). A survey of cross-validation procedures. Statistical Surveys, 4, 40–79.
Attar, C. H., Muller, M. M., Andersen, S. K., Buchel, C., & Rose, M. (2010). Emotional Processing in a Salient Motion Context: Integration of Motion and Emotion in Both V5/hMT+ and the Amygdala. Journal of Neuroscience, 30(15), 5204–5210.
Aupperle, R. L., Melrose, A. J., Francisco, A., Paulus, M. P., & Stein, M. B. (2015). Neural substrates of approach-avoidance conflict decision-making. Hum Brain Mapp, 36(2), 449–462.
Baizer, J. S., Desimone, R., & Ungerleider, L. G. (1993). Comparison of subcortical connections of inferior temporal and posterior parietal cortex in monkeys. Visual Neuroscience, 10(1), 59–72.
Bartels, A., Logothetis, N. K., & Moutoussis, K. (2008). fMRI and its interpretations: An illustration on directional selectivity in area V5/MT. Trends Neuroscience, 31(9), 444–453.
Becker, H. G., Erb, M., & Haarmeier, T. (2008). Differential dependency on motion coherence in subregions of the human MT+ complex. European Journal of Neuroscience, 28(8), 1674–1685.
Born, R. T., & Bradley, D. C. (2005). Structure and function of visual area MT. Annual Review Neuroscience, 28, 157–189.
Bowditch, H. P., & Hall, G. S. (1882). Optical Illusions of Motion. J Physiol, 3(5–6), 297–312. 292.
Brogaard, B. (2012). Vision for Action and the Contents of Perception. Journal of Philosophy, 109(10), 569–587.
Buchel, C., & Friston, K. J. (1997). Modulation of connectivity in visual pathways by attention: Cortical interactions evaluated with structural equation modelling and fMRI. Cereb Cortex, 7(8), 768–778.
Chikazoe, J., Lee, D. H., Kriegeskorte, N., & Anderson, A. K. (2014). Population coding of affect across stimuli, modalities and individuals. Nature Neuroscience, 17(8), 1114–1122.
Cloutman, L. L. (2013). Interaction between dorsal and ventral processing streams: where, when and how? Brain and Language, 127(2), 251–263.
Coker-Appiah, D. S., White, S. F., Clanton, R., Yang, J., Martin, A., & Blair, R. J. (2013). Looming animate and inanimate threats: The response of the amygdala and periaqueductal gray. Social Neuroscience, 8(6), 621–630.
Cox, R. W. (1996). AFNI: software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research, 29(3), 162–173.
Cox, R. W., Chen, G., Glen, D. R., Reynolds, R. C., & Taylor, P. A. (2017). fMRI clustering and false-positive rates. Proceedings of the National Academy of Sciences United States of America, 114(17), E3370–E3371.
Culham, J. C., Dukelow, S. P., Vilis, T., Hassard, F. A., Gati, J. S., Menon, R. S., & Goodale, M. A. (1999). Recovery of fMRI activation in motion area MT following storage of the motion aftereffect. Journal of Neurophysiology, 81(1), 388–393.
de Gelder, B., & Hadjikhani, N. (2006). Non-conscious recognition of emotional body language. Neuroreport, 17(6), 583–586.
de Gelder, B., Snyder, J., Greve, D., Gerard, G., & Hadjikhani, N. (2004). Fear fosters flight: A mechanism for fear contagion when perceiving emotion expressed by a whole body. Proceedings of the National Academy of Sciences of the United States of America, 101(47), 16701–16706.
de Gelder, B., de Borst, A. W., & Watson, R. (2015). The perception of emotion in body expressions. Wiley Interdisciplinary Reviews: Cognitive Science, 6(2), 149–158.
Delplanque, S., Diaye, K. N., Scherer, K., & Grandjean, D. (2007). Spatial frequencies or emotional effects? A systematic measure of spatial frequencies for IAPS pictures by a discrete wavelet analysis. Journal of Neuroscience Methods, 165(1), 144–150.
Diedrichsen, J., Yokoi, A., & Arbuckle, S. A. (2018). Pattern component modeling: A flexible approach for understanding the representational structure of brain activity patterns. Neuroimage, 180(Pt A), 119–133.
Doran, J. E., & Michie, D. (1966). Experiments with the Graph Traverser Program. Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, 294(1437), 235–259.
Dumoulin, S. O., Bittar, R. G., Kabani, N. J., Baker, C. L., Jr., Le Goualher, G., Bruce Pike, G., & Evans, A. C. (2000). A new anatomical landmark for reliable identification of human area V5/MT: A quantitative analysis of sulcal patterning. Cereb Cortex, 10(5), 454–463.
El Zein, M., Wyart, V. & Grezes, J. (2015) Anxiety dissociates the adaptive functions of sensory and motor response enhancements to social threats. Elife, 4, e10274. https://doi.org/10.7554/eLife.10274
Emmerling, T. C., Zimmermann, J., Sorger, B., Frost, M. A., & Goebel, R. (2016). Decoding the direction of imagined visual motion using 7T ultra-high field fMRI. Neuroimage, 125, 61–73.
Engelen, T., de Graaf, T. A., Sack, A. T., & de Gelder, B. (2015). A causal role for inferior parietal lobule in emotion body perception. Cortex, 73, 195–202.
Enns, J. T., Brennan, A. A., & Whitwell, R. L. (2017). Attention in action and perception: Unitary or separate mechanisms of selectivity? Temporal Sampling and Representation Updating, 236, 25–52.
Fabozzi, F. J. (2014). The basics of financial econometrics : Tools, concepts, and asset management applications. John Wiley & Sons Inc.
Fawcett, I. P., Hillebrand, A., & Singh, K. D. (2007). The temporal sequence of evoked and induced cortical responses to implied-motion processing in human motion area V5/MT+. European Journal of Neuroscience, 26(3), 775–783.
Foley, R. T., Whitwell, R. L., & Goodale, M. A. (2015). The two-visual-systems hypothesis and the perspectival features of visual experience. Consciousness and Cognition, 35, 225–233.
Freud, E., Plaut, D. C., & Behrmann, M. (2016). What Is Happening in the Dorsal Visual Pathway. Trends in Cognitive Sciences, 20(10), 773–784.
Funder, D. C., & Ozer, E. (2019). Evaluating Effect Size in Psychological Research: Sense and Nonsense. Advances in Methods and Practices in Psychological Science, 2(2), 156–168.
Furl, N., Henson, R. N., Friston, K. J., & Calder, A. J. (2013). Top-down control of visual responses to fear by the amygdala. Journal of Neuroscience, 33(44), 17435–17443.
Gaglianese, A., Fracasso, A., Fernandes, F. G., Harvey, B., Dumoulin, S. O. & Petridou, N. (2023) Mechanisms of speed encoding in the human middle temporal cortex measured by 7T fMRI. Human Brain Mapping, 44(5), 2050–2061. https://doi.org/10.1002/hbm.26193
Gao, J., Zeng, M., Dai, X., Yang, X., Yu, H., Chen, K., Hu, Q., Xu, J., Cheng, B., & Wang, J. (2020). Functional Segregation of the Middle Temporal Visual Motion Area Revealed With Coactivation-Based Parcellation. Frontiers in Neuroscience, 14, 427.
Georgopoulos, A. P., Schwartz, A. B., & Kettner, R. E. (1986). Neuronal population coding of movement direction. Science, 233(4771), 1416–1419.
Georgopoulos, A. P., Kettner, R. E., & Schwartz, A. B. (1988). Primate motor cortex and free arm movements to visual targets in three-dimensional space. II. Coding of the direction of movement by a neuronal population. Journal of Neuroscience, 8(8), 2928–2937.
Gilaie-Dotan, S. (2016). Visual motion serves but is not under the purview of the dorsal pathway. Neuropsychologia, 89, 378–392.
Gilaie-Dotan, S., Saygin, A. P., Lorenzi, L. J., Egan, R., Rees, G., & Behrmann, M. (2013). The role of human ventral visual cortex in motion perception. Brain, 136(Pt 9), 2784–2798.
Goldberg, H., Preminger, S., & Malach, R. (2012). Naturalistic emotional stimuli preferentially activate the human dorsal stream visual system. Journal of Molecular Neuroscience, 48, S43–S43.
Goldberg, H., Preminger, S., & Malach, R. (2014). The emotion-action link? Naturalistic emotional stimuli preferentially activate the human dorsal visual stream. Neuroimage, 84, 254–264.
Grasso, P. A., Ladavas, E., Bertini, C., Caltabiano, S., Thut, G., & Morand, S. (2018). Decoupling of Early V5 Motion Processing from Visual Awareness: A Matter of Velocity as Revealed by Transcranial Magnetic Stimulation. Journal of Cognitive Neuroscience, 30(10), 1517–1531.
Grecucci, A., Giorgetta, C., Bonini, N., & Sanfey, A. G. (2013). Reappraising social emotions: the role of inferior frontal gyrus, temporo-parietal junction and insula in interpersonal emotion regulation. Frontiers in Human Neuroscience, 7, 523.
Haffenden, A. M., & Goodale, M. A. (1998). The effect of pictorial illusion on prehension and perception. Journal of Cognitive Neuroscience, 10(1), 122–136.
Hanke, M., Halchenko, Y. O., Sederberg, P. B., Hanson, S. J., Haxby, J. V., & Pollmann, S. (2009). PyMVPA: A python toolbox for multivariate pattern analysis of fMRI data. Neuroinformatics, 7(1), 37–53.
He, S., Cohen, E. R., & Hu, X. (1998). Close correlation between activity in brain area MT/V5 and the perception of a visual motion aftereffect. Current Biology, 8(22), 1215–1218.
Hershenson, M. (1989). Duration, Time Constant, and Decay of the Linear Motion Aftereffect as a Function of Inspection Duration. Perception & Psychophysics, 45(3), 251–257.
Hogendoorn, H., & Verstraten, F. A. (2013). Decoding the motion aftereffect in human visual cortex. Neuroimage, 82, 426–432.
Huang, T., Chen, X., Jiang, J., Zhen, Z., & Liu, J. (2019). A probabilistic atlas of the human motion complex built from large-scale functional localizer data. Human Brain Mapping, 40(12), 3475–3487.
Huk, A. C., Ress, D., & Heeger, D. J. (2001). Neuronal basis of the motion aftereffect reconsidered. Neuron, 32(1), 161–172.
Huk, A. C., Dougherty, R. F., & Heeger, D. J. (2002). Retinotopy and functional subdivision of human areas MT and MST. Journal of Neuroscience, 22(16), 7195–7205.
Jastorff, J., Popivanov, I. D., Vogels, R., Vanduffel, W., & Orban, G. A. (2012). Integration of shape and motion cues in biological motion processing in the monkey STS. Neuroimage, 60(2), 911–921.
Kanwisher, N., McDermott, J., & Chun, M. M. (1997). The fusiform face area: a module in human extrastriate cortex specialized for face perception. Journal of Neuroscience, 17(11), 4302–4311.
Kayser, A. S., Buchsbaum, B. R., Erickson, D. T., & DEsposito, M. (2010). The functional anatomy of a perceptual decision in the human brain. J Neurophysiol, 103(3), 1179–1194.
Kim, H. R., Angelaki, D. E., & DeAngelis, G. C. (2015). A functional link between MT neurons and depth perception based on motion parallax. Journal of Neuroscience, 35(6), 2766–2777.
Kim, H. R., Angelaki, D. E. & DeAngelis, G. C. (2016) The neural basis of depth perception from motion parallax. Philosophical Transactions of the Royal Society B: Biological Sciences, 371(1697),
Kolesar, T. A., Kornelsen, J., & Smith, S. D. (2017). Separating Neural Activity Associated With Emotion and Implied Motion: An fMRI Study. Emotion, 17(1), 131–140.
Kolster, H., Peeters, R., & Orban, G. A. (2010). The retinotopic organization of the human middle temporal area MT/V5 and its cortical neighbors. Journal of Neuroscience, 30(29), 9801–9820.
Kong, X., Kong, R., Orban, C., Wang, P., Zhang, S., Anderson, K., Holmes, A., Murray, J. D., Deco, G., van den Heuvel, M., & Yeo, B. T. T. (2021). Sensory-motor cortices shape functional connectivity dynamics in the human brain. Nature Communications, 12(1), 6373.
Kravitz, D. J., Saleem, K. S., Baker, C. I., Ungerleider, L. G., & Mishkin, M. (2013). The ventral visual pathway: an expanded neural framework for the processing of object quality. Trends in Cognitive Sciences, 17(1), 26–49.
Kriegeskorte, N., & Kievit, R. A. (2013). Representational geometry: integrating cognition, computation, and the brain. Trends in Cognitive Sciences, 17(8), 401–412.
Kriegeskorte, N., Mur, M., & Bandettini, P. (2008). Representational similarity analysis - connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2, 4.
Kryklywy, J. H., & Mitchell, D. G. (2014). Emotion modulates allocentric but not egocentric stimulus localization: Implications for dual visual systems perspectives. Experimental Brain Research, 232(12), 3719–3726.
Kryklywy, J. H., Macpherson, E. A., Greening, S. G., & Mitchell, D. G. (2013). Emotion modulates activity in the what but not where auditory processing pathway. Neuroimage, 82, 295–305.
Kryklywy, J. H., Macpherson, E. A., & Mitchell, D. G. V. (2018). Decoding auditory spatial and emotional information encoding using multivariate versus univariate techniques. Experimental Brain Research, 236(4), 945–953.
Kryklywy, J. H., Ehlers, M. R., Anderson, A. K., & Todd, R. M. (2020). From Architecture to Evolution: Multisensory Evidence of Decentralized Emotion. Trends in Cognitive Sciences, 24(11), 916–929.
Kryklywy, J. H., Dudarev, V., & Todd, R. M. (2021). Sense and timing: Localizing objects during emotional distraction. Journal of Experimental Psychology: Human Perception and Performance, 47(8), 1113–1131.
Kryklywy, J. H., Forys, B. J. & Todd, R. M. (2021b) Pattern component modeling for R. Hosted at Guthub. https://github.com/bf777/PCMforR
Kryklywy, J. H., Ehlers, M. R., Beukers, A. O., Moore, S. R., Todd, R. M. & Anderson, A. K. (2023) Decomposing Neural Representational Patterns of Discriminatory and Hedonic Information during Somatosensory Stimulation. eNeuro, 10(1). https://doi.org/10.1523/ENEURO.0274-22.2022
Lang, P. J., Bradley, M. M., Fitzsimmons, J. R., Cuthbert, B. N., Scott, J. D., Moulder, B., & Nangia, V. (1998). Emotional arousal and activation of the visual cortex: An fMRI analysis. Psychophysiology, 35(2), 199–210.
Lang, P. J., Bradley, M. M., & N., C. B. (2008). International affective picture system (IAPS): Affective ratings of pictures and instruction manual. University of Florida.
Laycock, R., Crewther, D. P., Fitzgerald, P. B., & Crewther, S. G. (2007). Evidence for fast signals and later processing in human V1/V2 and V5/MT+: A TMS study of motion perception. Journal of Neurophysiology, 98(3), 1253–1262.
LeDoux, J. E. (1992). Brain mechanisms of emotion and emotional learning. Current opinion in Neurobiology, 2(2), 191–197.
Lin, J. Y., Franconeri, S., & Enns, J. T. (2008). Objects on a collision path with the observer demand attention. Psychological Science, 19(7), 686–692.
Liu, L. D., & Pack, C. C. (2017). The Contribution of Area MT to Visual Motion Perception Depends on Training. Neuron, 95(2), 436-446 e433.
Low, A., Weymar, M., & Hamm, A. O. (2015). When threat is near, get out of here: Dynamics of defensive behavior during freezing and active avoidance. Psychological Science, 26(11), 1706–1716.
Mann, D. L., Fortin-Guichard, D., & Nakamoto, H. (2021). Review: Sport performance and the two-visual-system hypothesis of vision: two pathways but still many questions. Optometry and Vision Science, 98(7), 696–703.
Mather, G., Verstraten, F., & Anstis, S. M. (1998). The motion aftereffect : A modern perspective. The MIT Press.
Mather, G., Pavan, A., Campana, G., & Casco, C. (2008). The motion aftereffect reloaded. Trends in Cognitive Sciences, 12(12), 481–487.
Maynard, E. M., Hatsopoulos, N. G., Ojakangas, C. L., Acuna, B. D., Sanes, J. N., Normann, R. A., & Donoghue, J. P. (1999). Neuronal interactions improve cortical population coding of movement direction. Journal of Neuroscience, 19(18), 8083–8093.
McKeefry, D. J., Burton, M. P., Vakrou, C., Barrett, B. T., & Morland, A. B. (2008). Induced deficits in speed perception by transcranial magnetic stimulation of human cortical areas V5/MT+ and V3A. Journal of Neuroscience, 28(27), 6848–6857.
Meyer, C., Padmala, S., & Pessoa, L. (2019). Dynamic threat processing. Journal of Cognitive Neuroscience, 31(4), 522–542.
Mikellidou, K., Kurzawski, J. W., Frijia, F., Montanaro, D., Greco, V., Burr, D. C., & Morrone, M. C. (2017). Area Prostriata in the Human Brain. Current Biology, 27(19), 3056-3060 e3053.
Milner, A. D., & Goodale, M. A. (1993). Visual pathways to perception and action. Progress in Brain Research, 95, 317–337.
Milner, A. D., & Goodale, M. A. (2006). The visual brain in action (2nd ed.). Oxford University Press.
Milner, A. D., & Goodale, M. A. (2008). Two visual systems re-viewed. Neuropsychologia, 46(3), 774–785.
Mitchell, D. G., & Greening, S. G. (2012). Conscious perception of emotional stimuli: Brain mechanisms. Neuroscientist, 18(4), 386–398.
Mobbs, D., Marchant, J. L., Hassabis, D., Seymour, B., Tan, G., Gray, M., Petrovic, P., Dolan, R. J., & Frith, C. D. (2009). From threat to fear: the neural organization of defensive fear systems in humans. Journal of Neuroscience, 29(39), 12236–12243.
Mobbs, D., Yu, R., Rowe, J. B., Eich, H., FeldmanHall, O., & Dalgleish, T. (2010). Neural activity associated with monitoring the oscillating threat value of a tarantula. Proceedings of the National Academy of Sciences United States of America, 107(47), 20582–20586.
Mobbs, D., Headley, D. B., Ding, W., & Dayan, P. (2020). Space, Time, and Fear: Survival Computations along Defensive Circuits. Trends in Cognitive Sciences, 24(3), 228–241.
Morris, J. S., Friston, K. J., Buchel, C., Frith, C. D., Young, A. W., Calder, A. J., & Dolan, R. J. (1998). A neuromodulatory role for the human amygdala in processing emotional facial expressions. Brain, 121(Pt 1), 47–57.
Muhlberger, A., Neumann, R., Wieser, M. J., & Pauli, P. (2008). The impact of changes in spatial distance on emotional responses. Emotion, 8(2), 192–198.
Nadler, J. W., Barbash, D., Kim, H. R., Shimpi, S., Angelaki, D. E., & DeAngelis, G. C. (2013). Joint representation of depth from motion parallax and binocular disparity cues in macaque area MT. Journal of Neuroscience, 33(35), 14061–14074. 14074a.
Nassi, J. J., & Callaway, E. M. (2007). Specialized circuits from primary visual cortex to V2 and area MT. Neuron, 55(5), 799–808.
Nelissen, K., Vanduffel, W., & Orban, G. A. (2006). Charting the lower superior temporal region, a new motion-sensitive region in monkey superior temporal sulcus. Journal of Neuroscience, 26(22), 5929–5947.
Newsome, W. T., & Pare, E. B. (1988). A selective impairment of motion perception following lesions of the middle temporal visual area (MT). Journal of Neuroscience, 8(6), 2201–2211.
Ohlendorf, S., Sprenger, A., Speck, O., Haller, S., & Kimmig, H. (2008). Optic flow stimuli in and near the visual field centre: A group FMRI study of motion sensitive regions. PLoS One, 3(12), e4043.
Panksepp, J. (1990). The psychoneurology of fear: Evolutionary perspectives and the role of animal models in understanding human anxiety. In G. D. Burrows, M. Roth, & R. Noyes Jr. (Eds.), Handbook of Anxiety: The neurobiology of anxiety. Amsterdam: Elsevier Science BV.
Panksepp, J. (1998). Affective neuroscience : The foundations of human and animal emotions. Oxford University Press.
Parasuraman, R., & Galster, S. (2013). Sensing, assessing, and augmenting threat detection: behavioral, neuroimaging, and brain stimulation evidence for the critical role of attention. Frontiers in human Neuroscience, 7, 273.
Pessoa, L., & Adolphs, R. (2010). Emotion processing and the amygdala: From a low road to many roads of evaluating biological significance. Nature Reviews Neuroscience, 11(11), 773–783.
Picard, R. R. & Cook, R. D. (1984) Cross-validation of regression models. Journal of the American Statistical Association, 79(387), 575–583. https://doi.org/10.2307/2288403
Pitcher, D., & Ungerleider, L. G. (2021). Evidence for a Third Visual Pathway Specialized for Social Perception. Trends in Cognitive Sciences, 25(2), 100–110.
Pitzalis, S., Fattori, P., & Galletti, C. (2015). The human cortical areas V6 and V6A. Vis Neurosci, 32, E007.
Qi, S., Hassabis, D., Sun, J., Guo, F., Daw, N., & Mobbs, D. (2018). How cognitive and reactive fear circuits optimize escape decisions in humans. Proceedings of the National Academy of Sciences United States of America, 115(12), 3186–3191.
R Core Team (2013) R: A language and environment for statistical computing.
Reddan, M. C., Lindquist, M. A., & Wager, T. D. (2017). Effect Size Estimation in Neuroimaging. JAMA Psychiatry, 74(3), 207–208.
Rokers, B., Cormack, L. K., & Huk, A. C. (2008). Strong percepts of motion through depth without strong percepts of position in depth. Journal of Vision, 8(4), 6 1-10.
Russ, B. E., Petkov, C. I., Kwok, S. C., Zhu, Q., Belin, P., Vanduffel, W., & Hamed, S. B. (2021). Common functional localizers to enhance NHP & cross-species neuroscience imaging research. Neuroimage, 237, 118203.
Salzman, C. D., Murasugi, C. M., Britten, K. H., & Newsome, W. T. (1992). Microstimulation in visual area MT: Effects on direction discrimination performance. Journal of Neuroscience, 12(6), 2331–2355.
Sanada, T. M., & DeAngelis, G. C. (2014). Neural representation of motion-in-depth in area MT. Journal of Neuroscience, 34(47), 15508–15521.
Saper, C. B. (2002). The central autonomic nervous system: Conscious visceral perception and autonomic pattern generation. Annual Review Neuroscience, 25, 433–469.
Sato, W. & Yoshikawa, S. (2007) Enhanced experience of emotional arousal in response to dynamic facial expressions. Journal of Nonverbal Behavior, 31(2), 119–135. https://doi.org/10.1007/s10919-007-0025-7
Shioiri, S., Matsumiya, K., & Tseng, C. H. (2021). Contribution of the slow motion mechanism to global motion revealed by an MAE technique. Scientific Reports, 11(1), 3995.
Smith, A. T., Wall, M. B., Williams, A. L., & Singh, K. D. (2006). Sensitivity to optic flow in human cortical areas MT and MST. European Journal of Neuroscience, 23(2), 561–569.
Solanas, M. P., Vaessen, M. J. & de Gelder, B. (2020) The role of computational and subjective features in emotional body expressions. Scientific Reports, 10(1),
Sullivan, G. M., & Feinn, R. (2012). Using effect size-or why the p value is not enough. Journal of Graduate Medical Education, 4(3), 279–282.
Swallow, K. M., Braver, T. S., Snyder, A. Z., Speer, N. K., & Zacks, J. M. (2003). Reliability of functional localization using fMRI. Neuroimage, 20(3), 1561–1577.
Taylor, J. G., Schmitz, N., Ziemons, K., Grosse-Ruyken, M. L., Gruber, O., Mueller-Gaertner, H. W., & Shah, N. J. (2000). The network of brain areas involved in the motion aftereffect. Neuroimage, 11(4), 257–270.
Tootell, R. B., Reppas, J. B., Dale, A. M., Look, R. B., Sereno, M. I., Malach, R., Brady, T. J., & Rosen, B. R. (1995). Visual motion aftereffect in human cortical area MT revealed by functional magnetic resonance imaging. Nature, 375(6527), 139–141.
Tootell, R. B., Reppas, J. B., Kwong, K. K., Malach, R., Born, R. T., Brady, T. J., Rosen, B. R., & Belliveau, J. W. (1995). Functional analysis of human MT and related visual cortical areas using magnetic resonance imaging. Journal of Neuroscience, 15(4), 3215–3230.
Tsigos, C., & Chrousos, G. P. (2002). Hypothalamic-pituitary-adrenal axis, neuroendocrine factors and stress. Journal of Psychosomatic Research, 53(4), 865–871.
Valente, G., Castellanos, A. L., Hausfeld, L., De Martino, F. & Formisano, E. (2021) Cross-validation and permutations in MVPA: Validity of permutation strategies and power of cross-validation schemes. Neuroimage, 118145. https://doi.org/10.1016/j.neuroimage.2021.118145
van Boxtel, J. J., & Lu, H. (2012). Signature movements lead to efficient search for threatening actions. PLoS One, 7(5), e37085.
Vanduffel, W., Fize, D., Mandeville, J. B., Nelissen, K., Van Hecke, P., Rosen, B. R., Tootell, R. B., & Orban, G. A. (2001). Visual motion processing investigated using contrast agent-enhanced fMRI in awake behaving monkeys. Neuron, 32(4), 565–577.
Vanduffel, W., Fize, D., Peuskens, H., Denys, K., Sunaert, S., Todd, J. T., & Orban, G. A. (2002). Extracting 3D from motion: Differences in human and monkey intraparietal cortex. Science, 298(5592), 413–415.
Vetter, P., Grosbras, M. H., & Muckli, L. (2015). TMS over V5 disrupts motion prediction. Cereb Cortex, 25(4), 1052–1059.
Vuilleumier, P. (2005). How brains beware: Neural mechanisms of emotional attention. Trends in Cognitive Sciences, 9(12), 585–594.
Vuilleumier, P., & Driver, J. (2007). Modulation of visual processing by attention and emotion: Windows on causal interactions between human brain regions. Philosophical Transactions of the Royal Society B: Biological Sciences, 362(1481), 837–855.
Watamaniuk, S. N., & Heinen, S. J. (2007). Storage of an oculomotor motion aftereffect. Vision Research, 47(4), 466–473.
Winawer, J., Huk, A. C., & Boroditsky, L. (2008). A motion aftereffect from still photographs depicting motion. Psychological Science, 19(3), 276–283.
Wohlgemuth, A. (1911) On the after-effect of seen movement, Cambridge
Yeung, M. K., & Chan, A. S. (2020). Executive function, motivation, and emotion recognition in high-functioning autism spectrum disorder. Research in Developmental Disabilities, 105, 103730.
Young, M. P., Scannell, J. W., Burns, G. A., & Blakemore, C. (1994). Analysis of connectivity: Neural systems in the cerebral cortex. Reviews in the Neurosciences, 5(3), 227–250.
Zeki, S., Watson, J. D., Lueck, C. J., Friston, K. J., Kennard, C., & Frackowiak, R. S. (1991). A direct demonstration of functional specialization in human visual cortex. Journal of Neuroscience, 11(3), 641–649.
Zhan, M., Goebel, R. & de Gelder, B. (2018) Ventral and Dorsal Pathways Relate Differently to Visual Awareness of Body Postures under Continuous Flash Suppression. eNeuro, 5(1). https://doi.org/10.1523/ENEURO.0285-17.2017
Acknowledgments
The authors thank Dr. Jody Culham (Brain and Mind Institute, University of Western Ontario) for helpful discussion on experimental design and anatomical nomenclature/interpretation. This work was funded by an NSERC Discovery Grant (RGPIN-2018-05515) to D. G. V. Mitchell.
Funding
This work was funded by an NSERC Discovery Grant (RGPIN-2018-05515) to D. G. V. Mitchell.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests
The authors have no competing interest to declare.
Ethics approval
The study was approved by the Health Science Research Ethics Board at the University of Western Ontario.
Consent to participate
All participant granted informed consent for their participation.
Consent for publication
Not applicable.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
• V5/MT+ represented orthogonal signals of emotion and motion.
• Emotion representations were consistent with patterns in V1/ventral visual areas; motion representations were consistent with patterns in dorsal visual areas.
• The findings are interpreted within recent characterization of V5/MT+ as part of a third visual pathway for dynamic aspects of social-perception.

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
Cite this article
Kryklywy, J.H., Forys, B.J., Vieira, J.B. et al. Dissociating representations of affect and motion in visual cortices. Cogn Affect Behav Neurosci 23, 1322–1345 (2023). https://doi.org/10.3758/s13415-023-01115-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-023-01115-2