
Abstract
The EEG feature known as the Reward Positivity (RewP) is elicited by reward receipt and appears to reflect sensitively and specifically positive prediction errors during reinforcement learning. Yet, the RewP also is modulated by state and trait affect, suggesting that it has a more complex computational role than simple reinforcement surprise. We conducted a series of experiments aimed to investigate underlying affect processing reflected in the RewP during a reinforcement learning task. In the first experiment (N = 25), we manipulated the type of rewards a person could win (simple points or hedonically-appraised pictures). Although there were no differences in the amplitudes of the RewP for different types of rewards, there was a significant correlation between the individual rating of liking for the images and RewP amplitude. In a second experiment (N = 25), we manipulated reinforcement rates (easy vs. hard) and affective picture content (liked vs. ambivalent) to examine the potential interaction of prediction error and liking on RewP amplitude. We again found a significant relationship between liking and RewP amplitude, however, only in the hard condition. These findings suggest that the RewP reflects cortical computations of reward surprise as well as hedonic liking, identifying it as a possible nexus where multidimensional value is computed.
Similar content being viewed by others

Introduction
The Reward Positivity (RewP) is a positive going voltage deflection appearing ~200 ms over frontal central sites following reward receipt. Numerous studies have shown that the RewP is sensitive to the acquisition of simple forms of reward, such as points (Bellebaum et al., 2010; Wu & Zhou, 2009; Yeung & Sanfey, 2004), or abstract icons, such as fruit or colored arrows (Angus et al., 2015; Holroyd et al., 2008; Proudfit, 2015). It is known that the RewP is enhanced to larger magnitude gains (Proudfit, 2015) and to more surprising outcomes (Holroyd et al., 2008), demonstrating that it specifically and sensitively reflects the degree of positive reward prediction error (Cavanagh, 2015). Yet this overreliance on a one-dimensional feedback limits the understanding of the boundary conditions of the RewP and ignores motivational influences, which may modulate this signal independent of expectation violation. Previous literature has highlighted important multidimensional aspects of reward (Berridge, 1996; Berridge et al., 2009; Robinson & Berridge, 2008), including incentive motivation (“wanting”) and hedonic impact (“liking”). An enhanced understanding of the motivational aspects of emotion and how it relates to reward learning can offer more sophisticated insights into aberrant processes in clinical populations. Indeed, recent investigations of hedonic types of reward have further added to the growing understanding of clinical phenomena, such as autism spectrum disorder (Sabatino et al., 2011), depression (Kumar et al., 2008), and alcohol use disorder (Schacht et al., 2014). In the current report, we continue a line of work investigating whether this signal is sensitive to hedonic appraisal (e.g., “liking”). Indeed, this question of hedonic appraisal underlying the RewP has been rigorously tested in an ongoing research program (Table S1). These studies have identified various experimental confounds (e.g., sex effects in idiosyncratic selection, use of difference waves, etc.), which have been critical to consider when isolating the effect of liking on RewP amplitude.
Earlier work involving the RewP and pleasant imagery found that novel, pleasant images primarily evoked an enhanced N2 component, obscuring the RewP (Brown & Cavanagh, 2018). Paired picture and point rewards revealed main effects of liking and point magnitude on RewP amplitude, but no interaction was detected. While this evidence suggested an influence of affective value on the RewP, the continued presence of a novelty-induced N2 component may have obscured the ability to discern the boundary conditions and effect size induced by affective images. This complication was addressed in a subsequent report, where methodological and analytical techniques were used to isolate signals of reward from novelty evoked by emotional imagery (Brown & Cavanagh, 2020). This methodological technique leveraged the tendency for reward prediction errors to migrate to the first predictor of a reward: participants were initially presented with a simple colored shape indicating the valence and type of forthcoming feedback (picture or point). The results from this study revealed intact RewP components elicited by a variety of feedback type but lacked a specific modulation of the RewP by affective images. Thus, the effective quantification of affective influence on the RewP remains elusive. However, a recent report by Peterburs et al. (2019) showed that RewP amplitudes were larger when participants won a more preferred chocolate type than when they won a less preferred type (milk vs. white chocolate). The current series of studies were designed to extend these findings by investigating whether the RewP is specifically modulated by individual differences in hedonic appraisal in the absence of confounding influences.
Following extensive pilot testing (see Supplement), we used standardized affective stimuli and collected individual preference ratings to examine individual differences in hedonic appraisal (operationally defined as pleasantness ratings). In Experiment 1, we examined if the RewP evoked to simple predictive cues differed depending on what type of subsequent reward type it predicted (points or images). We hypothesized that RewP amplitudes would be larger for cues predicting pleasant images than for cues predicting images of points. Next, we hypothesized that an individual’s hedonic appraisal (pleasantness rating) of the reward would have a modulatory effect on the RewP. In Experiment 2, we examined whether the RewP differed when directly elicited by different hedonically appraised image classes. We hypothesized that RewP amplitudes would be larger for (1) more surprising rewards (70% reinforcing > 90% reinforcing) as well as (2) points paired with the more pleasantly rated image (puppies > cows). In both experiments, only individual ratings of liking accounted for significant variance in affect-related RewP amplitudes.
Method
Participants
Based on our prior report (Brown & Cavanagh, 2018), affective pictures boosted the RewP as a fixed effect with Cohen’s d = 0.47. A power analysis (α = 0.05, β = 0.80, Cohen’s f = 0.24, # of measures = 4) suggested a required sample size of 25. In Experiment 1, we recruited 25 participants (15 females) with a mean age of 21.68 (standard deviation [SD] = 5.23); 44% of our participants identified as Latinx/Hispanic, 12% identified as Native American/Alaskan, 4% identified as Asian, 4% identified as other, and 36% identified as non-Hispanic white. Exclusion criteria included a history of head injury that resulted in loss of consciousness for more than 5 minutes, a history of epilepsy, or current use of psychiatric or neurological drugs. Participants received class credits for completing the experiment. The Institutional Review Board of the University of New Mexico approved the study protocol.
Procedure
Image Rating Task
All experimental tasks were programmed in Matlab using Psychtoolbox (Brainard, 1997). To obtain ratings of pleasantness for the picture rewards used for the subsequent learning task, an image rating task was completed first. Participants were presented with an image from one of five hedonically appraised picture categories: puppies, babies, nature scenes, chairs, and negative images. These image classes were based on picture types that were rated as very positive, neutral, or very negative from the International Affective Picture System (IAPS)(Lang et al., 2008), but these specific pictures were curated from internet searches (i.e., “Hi-Definition Puppy Images”). Participants also viewed and rated the types of point feedback icons (i.e., green +1; yellow null bar, red −1) that they were to receive in the subsequent learning task. Each of the 8 types of images (5 pictures, 3 icons) were the same size and were presented six times (totaling 48 trials); all pictures were novel. Participants rated how pleasant the image was on a scale from 1 (very unpleasant) to 9 (very pleasant). Regardless of their highest-rated choice, the puppy category was used as the image rewards in the subsequent learning task. Extensive pilot testing revealed that this was the consistently highest-rated class and that the benefits of standardization outweighed any potential benefit of idiosyncratically preferred stimuli (see Figs. S1, S2, and S3).
Individual variability in pleasantness ratings across participants for these image classes were subsequently used as a measure of individual preference for picture types. Before continuing on to the learning task, participants were required to have higher ratings for the rewarding feedback classes (puppy image and green +1) than the neutral feedback classes (chairs and yellow null bars), and all four of these classes had to be rated higher than negatively valenced classes (negative images and red −1). All participants met this criterion. This rating task took an average of 7.73 minutes to complete.
Reinforcement learning task
During the reinforcement learning task, the participants were presented with an imperative stimulus (colored shapes) and were instructed to learn the correct response (left button or right button) based on subsequent feedback (reward or punishment). Each stimulus type had an optimal response that would lead to reward with a 70% probability. See Fig. 1 for a schematic of trial types and timing information. Each unique stimulus always led to the same motivational (win-neutral vs. avoid-lose) and image (points or pictures) outcome. For clarity, MOTIVATION refers to the win-neutral vs. avoid-lose condition dimension, VALENCE refers to a better (reward) vs. worse (punishment) outcome, and PICTURE TYPE refers to the presentation of points vs. pictures.

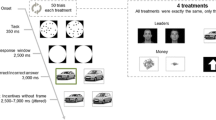
Experiment 1: Pleasantness ratings and reinforcement learning task. a Bar plots from the image rating task displaying mean pleasantness ratings for potential outcomes. Puppy images were rated as more pleasant than +1 (p = 0.007); however, chairs and yellow null bars were not rated as significantly different (p = 0.991). During the task, participants were presented with a stimulus (b) predicting a specific picture type (points or pictures) and motivation (win or avoid). Participants press a left or right button for each cue and would be presented feedback (c). d Display of typical experimental trials leading to point or picture feedback. RewPs were quantified during outcome cue presentation (indicated by an orange box for display purposes only). In order to avoid the influence of picture-reward novelty (i.e., enhanced N2), participants were presented with a simple shape (either a sun or a cloud) that reliably indicated the upcoming feedback (e.g., sun = point feedback, cloud = picture feedback). The color of the cue indicated the valence of the upcoming feedback (green = reward, red = punishment) Line plots (e) display accuracy scores. There were no significant accuracy differences between the conditions
In order to avoid the influence of a novelty evoked N2 component to novel pictures (Brown & Cavanagh, 2020), feedback consisted of two distinct parts. The first outcome feedback was a colored shape that indicated the valence and image class of feedback that was to come next. These outcome icons were a cloud or a sun that reliably indicated image class (counterbalanced across participants, e.g., cloud = point feedback, sun = picture feedback) where the color of the shape indicated the valence (better = green, worse = red). The RewP was assessed to this initial outcome feedback.
Following a 1,000-ms outcome icon presentation time, the image was presented. Positively valenced (better) feedback consisted of a green +1 (rewarding win point condition), a yellow bar (rewarding avoid point condition), a picture of a puppy (rewarding win picture condition), or a picture of a chair (rewarding avoid picture condition). Negatively valenced (worse) feedback consisted of a yellow bar (punishing win point condition), a red −1 (punishing avoid point condition), a chair (punishing win picture condition), or a negative image (punishing avoid picture condition). There were 40 trials per condition (160 trials total). For picture feedback conditions, participants were presented novel, never-before-seen images: 40 novel puppy images, 40 novel negative images, and 80 novel chair images (since chairs could represent either a reward or punishment). The task took ~29 minutes on average to complete.
Data acquisition and preprocessing
Electrophysiological data were collected with a 64 Ag–AgCl electrodes embedded in a stretch-lycra cap with a sampling rate of 500 Hz with low and high cutoffs at 0.01-100 Hz. CPz served as the reference electrode and Fpz as the ground electrode. Data were recorded with a Brain Vision system (Brain Products GmbH, Munich, Germany). Vertical electrooculogram (VEOG) activity generated by blinks was recorded by two auxiliary electrodes placed superior and inferior to the left pupil.
All EEG processing was conducted in Matlab, with some EEGlab functions (Delorme & Makeig, 2004). First, data were epoched around outcome cue screen onset (−1,000 to 3,000 ms). CPz was recreated via computation of the average reference (EEGlab function pop_reref.m). Very ventral electrodes (FT9, FT10, TP9, and TP10) were then removed, because they tended to be unreliable. The average reference was then recomputed for the remaining 60 electrodes. EEG data for ERPs was filtered between 0.01 to 20 Hz. Using statistical deviations from the mean for each EEG channel, FASTER (Nolan et al., 2010) identified artifacts in each epoch for later rejection. Eye blink activities were removed following ICA (runica; Makeig et al., 1996). Epochs were then baseline corrected (−200 to 0 ms before feedback onset) and averaged to derive the event related potential (ERP). The RewP was quantified as the mean amplitude from 200–350 ms at electrode site Cz. Greenhouse-Geisser adjusted ANOVAs and planned comparison decompositions were used for data analyses. Reports of effect sizes for ANOVA are partial-η2.
Results
Behavioral Results
Figure 1adepicts pleasantness ratings across feedback conditions. Motivated by the sex effects in accuracy observed in the pilot experiments (see Supplement), we conducted a 2 (MOTIVATION: win vs. avoid) × 2 (PICTURE TYPE: point vs. picture) × 2 (SEX: male vs. female) ANOVA for pleasantness ratings. This analysis revealed a significant win > avoid main effect (F(1,23) = 54.540, p < 0.001, η2 = 0.703), a picture > point main effect (F(1,23) = 10.283, p = 0.004, η2 = 0.309), as well as a MOTIVATION × PICTURE TYPE interaction (F(1,23) = 6.773, p = 0.016, η2 = 0.227). To unpack this interaction, we performed two Bonferroni-protected paired samples t-tests for each level of MOTIVATION separately. These analyses revealed a significant a significant picture > point effect (t(24) = 3.661, p = 0.001, d = 0.733), whereby pictures of puppies were rated as more pleasant than images of a green +1. The multiple comparison t-test comparing chairs and yellow bars failed to reveal a significant rating difference (t(24) = 0.496, p = 0.624, d = 0.099). Taken together, this suggests that our participants preferred viewing the positive images more than viewing a green +1; however, the preference for rewarding images in the avoid conditions (yellow bar or images of chairs) were virtually the same. Lastly, there were no main effects or interactions with SEX (all p values > 0.191).
Figure 1e depicts average accuracy across conditions. The 2 (PICTURE TYPE: point vs. picture) × 2 (MOTIVATION: win vs. avoid) × 2 (SEX: male vs. female) ANOVA for response accuracy revealed no significant main effects or interactions (all p values > 0.415). Because we failed to see any sex differences in pleasantness rating or accuracy rates, we opted to not include sex into our ERP analyses for the main report; however, the sex differences for Experiments 1 and 2 can be seen in the supplement (Fig. S4). To note, the ERP results also failed to reveal any significant sex effects.
ERP Figure 2a depicts ERPs for cue outcomes predicting trial feedback (picture and point ERPs can be seen in Fig. S5). Our hypothesis was that RewP amplitudes would be larger for cues predicting pleasant images than for cues predicting images of points. A 2 (PICTURE TYPE: point vs. picture) × 2 (MOTIVATION: win vs. avoid) ANOVA was conducted for each valence (reward and punishment) separately. This analysis failed to reveal any main effects or interactions for rewards (all p values > 0.415) or punishment (all p values > 0.218). This finding fails to support our first hypothesis that the RewP would differ between cues predicting point vs. picture rewards.

ERPs at electrode site Cz locked to the predictive colored cue. Even though the hedonic outcome was a subsequent point or picture, all these ERPs were time locked to the preceding predictive stimuli: either the cloud or the sun. a RewP (200–350 ms) did not differ between MOTIVATION or PICTURE TYPE conditions. Topographic maps (averaged over the 200-350 ms temporal window) for rewarding outcomes reveal maximal voltage around the vertex. b Line plots display means and error bars for the RewPs for each condition, revealing no ERP amplitude differences between the conditions
ERP-Pleasant Rating Correlations
Our second hypothesis was that an individual’s hedonic appraisal (pleasantness rating) of the reward would have a modulatory effect on the RewP. To confirm the specificity of this hypothesis, we compared change scores within each MOTIVATION condition by subtracting each participant’s pleasantness rating for the avoid outcomes (yellow bar or chair image) from their win outcomes (green +1 or puppy image). We then applied the same calculation for the RewP for the different conditions. Although this hypothesis was specific to affectively liked pictures, we display the correlations for both point and picture conditions for clarity and transparency. We found a significant relationship for the change-scores for picture gains (r = 0.434, p = 0.030), but not for point change-scores (r = 0.272, p = 0.189), in line with our hypothesis that the RewP is sensitive to a dimension of hedonic appraisal (Fig. 3). As expected, correlations with the reward-minus-punishment difference wave were weaker that these reward-specific contrasts (Fig. S6).
Experiment 1 Discussion
In Experiment 1, we compared RewP amplitudes to cues predicting point or picture rewards. Although we saw no differences in learning or RewP amplitudes between rewarding cues across conditions, we did see that RewPs evoked for cues predicting positive image rewards were enhanced by the degree of the individual hedonic appraisal of those images. This relationship was absent for the points condition. Taken together, these findings support the hypothesis that hedonic information is contained within the RewP. Experiment 2 was designed to replicate this finding with continued methodological improvement to isolate hedonic influence on the RewP.

Scatterplots for RewP amplitudes and pleasantness ratings change-scores. The more a person rated an image of a puppy above that of their rating for an image of a chair positively correlated with a larger RewP evoked for the cue predicting winning a puppy image than the RewP evoked for a cue predicting an image of a chair. This effect was only seen for emotional image types of feedback. *p < 0.05
Experiment 2
In Experiment 2, we manipulated reinforcement rate in order to orthogonalize the two documented moderators of the RewP: reward surprise and hedonic impact. First, we removed the motivation dimension from the design and instead opted to manipulate the reinforcement rates (90% or 70% reinforcement). Next, to hold image complexity constant, picture feedback was categorized into pleasant vs. more ambivalent images of similar visual complexity. Here, we decided to use images of puppies vs. cows. In an earlier pilot study (Fig. S3) we found that participants rated images of puppies more pleasant than images of cows (p < 0.001), yet cows were rated as more pleasant than both chairs (p < 0.001) and negative images (p < 0.001). By utilizing a similarly complex yet less-liked class of images, we hope to further isolate the hedonic sensitivity of the RewP observed in Experiment 1. Importantly, in Experiment 2, we removed the predictive cue used to evoke the RewP in Experiment 1 and opted instead to analyze neural activity at the time of feedback presentation. This decision was made to investigate directly the influence very pleasant (and less pleasant) images would have on reward processing. As seen in previous reports (Brown & Cavanagh, 2020), the inclusion of complex imagery with simple dichotomous outcomes was expected to evoke an enhanced N2 signal which may obscure but does not obliterate the affective influence on the RewP.
Methods
A power analysis based on the effect size of Experiment 1 (α = 0.05, β = 0.80, partial η2 = 0.06, # of measures = 4) suggested a required sample size of 23; in Experiment 2, we ran 25 participants (19 females, mean age = 19.61) for uniformity with Experiment 1. Our participants reported that 68% identified as Latinx/Hispanic, 4% identified as Asian, 4% identified as black, and 24% identified as non-Hispanic white. Experimental procedures were the same as in Experiment 1, except where noted below.
After making a button selection, participants were presented with 1 of 80 total novel images of either a puppy or a cow (regardless of correct or incorrect button selection). Rewarding and punishing feedback was presented to the participant as a colored screen (reward = green; punishment = red) with the image in front center screen. Figure 4b displays a typical trial where a participant won a point and another where a participant lost a point. Because all feedback types contained a vivid, complex image, any influence of novelty was expected to be the same between conditions. In Experiment 2, we also manipulated reinforcing rates between cue conditions (easy = 90% reinforcing; hard = 70% reinforcing) in order to assess if reward surprise would interact with the affective influence in the RewP. All other experimental protocols and data processing procedures were the same between Experiment 1 and Experiment 2. There were 40 trials per condition (160 trials total), and the task took ~27 minutes on average to complete.

Experiment 2 task description and behavioral results. During the task, participants were presented with a cue (a) predicting differing reinforcing rates (90% vs. 70% reinforcement) and animal image (puppy or cow). b Display of typical experimental trials leading to puppy or cow feedback. ERPs were time-locked to the presentation of trial feedback (indicated by an orange box for display purposes only). Animal images (puppy or cow) were paired with the presentation of reinforcement, regardless of whether the participant won or lost. Line plots (c) display accuracy scores. There was a significant easy > hard accuracy main effect (p < 0.001), but no main effect for the different animal images (p = 0.371). d Mean pleasantness ratings for reward outcomes. Puppy images were rated as more pleasant than cow images (p < 0.001), and both image types were rated as more pleasant than neutral or negative images (all p values < 0.001)
Results
Behavioral Results
Figure 4c depicts accuracy across conditions. The 2 (DIFFICULTY: easy vs. hard) × 2 (ANIMAL: puppy vs. cow) × 2 (SEX: male vs. female) ANOVA for response accuracy revealed a significant easy > hard main effect (F(1,24) = 32.955, p < 0.001, η2 = 0.579). There were no other significant main effects or interactions (all p values > 0.123).
The 2 (ANIMAL: puppy vs. cow) × 2 (SEX: male vs. female) ANOVA for pleasantness ratings revealed a significant puppy > cow main effect (F(1,24) = 38.885, p < 0.001, η2 = 0.628), but no main effect (p = 0.129) or interaction with sex (p = 0.403). Similar to Experiment 1, we did not see any significant sex differences in our behavioral data and thus did not include this variable in our ERP analyses, however we display these data in the Supplement for posterity (Fig. S4).
ERP Results
Figure 5 depicts ERPs for cue outcomes predicting trial feedback. This analysis compared RewP amplitudes in a 2 (ANIMAL: puppy vs. cow) × 2 (DIFFICULTY: easy vs. hard) ANOVA, which only revealed a significant main effect of DIFFICULTY (hard > easy; F(1,24) = 14.992, p = 0.001, η2 = 0.384). There were no other significant effects (all p values > 0.116). This finding partially supports our hypothesis that RewP amplitudes were affected by reward surprise but fails to support the hypothesis of a main or interactive effect of the hedonic impact of emotional imagery.

Condition-specific ERPs taken from electrode site Cz and scatterplots for RewP amplitude differences and pleasantness rating differences. This analysis revealed a main effect of difficulty supporting previous literature that RewPs are sensitive to more surprising outcomes. However, there was no difference in animal picture type, suggesting that the RewP is not affected by fixed effects of emotional imagery. Topographic maps for wins (average voltage across 200-350 ms) reveal strong activity in parietal and occipital areas, which is unsurprising given that performance feedback (green or red screen) was paired with a complex image (puppy or cow). The bottom panel displays change-score correlations between pleasantness rating and ERPs contrasting puppy and cow images. For the hard condition (70% reinforcement rate), the individual differences relationship between liking and RewP amplitude from Experiment 1 were replicated; however, this effect was not seen in the easy condition (90% reinforcement rate). *p < 0.05
ERP-Pleasant Rating Change-Score Correlations
In order to assess if RewP was again related to individual differences in pleasantness ratings of the two animal picture types, we replicated the change-score correlation analysis from Experiment 1. We compared change scores for RewP amplitudes evoked for puppy vs. cow feedback, separated by reinforcement rate (easy vs. hard). The bottom panel of Fig. 5 depicts scatterplots displaying these relationships. We replicated the change-score correlations seen in Experiment 1 in the hard condition (r = 0.461, p = 0.018); however, this effect was not present in the easy condition (r = −0.201, p = 0.336). As expected, correlations with the reward-minus-punishment difference wave were weaker that these reward-specific contrasts (Fig. S7).
General Discussion
In the current report, we demonstrated how individual hedonic appraisals predicted larger RewPs to pleasant stimuli. However, in both experiments, we failed to observe any condition-specific RewP enhancement for visually pleasant images. Taken together, it appears that the influence of hedonic impact on the RewP is highly idiosyncratic and independent of other moderators like magnitude (Brown & Cavanagh, 2018), although questions remain about how this effect interacts with reward surprise (Experiment 2).
Recent reports have illustrated the RewP as a reliable neural response with a high degree of internal consistency and test-retest reliability (Ethridge & Weinberg, 2018; Levinson et al., 2017) with the potential to inform our understanding of a host of psychological and neurological disorders, such as depression (Cavanagh et al., 2019; Nelson et al., 2016), anxiety disorders (Takács et al., 2015), substance use disorder (Baker et al., 2016; Euser et al., 2013), and Parkinson’s disease (Brown et al., 2020). Although some studies have revealed differences between clinical and healthy groups in the overall amplitude of the RewP, behavioral learning differences are rarer, suggesting that the RewP may be influenced by additional variance information in addition to the characteristic features of +RPE signals. Indeed, a recent article (Cavanagh et al., 2019) highlighted these discrepancies and proposed that an altered RewP in depression may primarily reflect motivation or affective influences, and not necessarily an impaired ability to learn.
Prior findings also have suggested that the RewP is a signal that blends subjective hedonic experience and reward information. A simple point-evoked RewP has been shown to be enhanced when presented alongside an accompanying positive image (Brown & Cavanagh, 2018) or when a person experiences approach-motivated emotions (Angus et al., 2015). Together, these reports expand on a growing body of literature which reveals RewPs are not only sensitive to outcome valence (reward vs. punishment) but other factors, such as individual preference (Peterburs et al., 2019) and current motivational states (Huvermann et al., 2021). Our findings reported here provide additional evidence for this idea from multiple formal experiments. Taken together, the RewP appears to represent a multidimensional marker of a transdiagnostic construct integrating reward responsiveness and reward learning, as outlined by the Research Domain Criteria framework (National Institution of Mental Health, 2015).
In a recent report, we used source localization techniques between high and low reward surprise RewPs (i.e., no confounding influence of N2) to argue that orbitofrontal and ventromedial areas may be a major contributor to the RewP (Cavanagh et al., 2019). If the RewP is indeed an amalgam of value-based reward outcome and hedonic appraisal, these ventral cortical areas seem like likely contributors. The orbital frontal cortex (OFC) has been strongly associated with value computations (Kennerley & Walton, 2011) and hedonic experience (Kringelbach, 2005). Additionally, the vmPFC also has been implicated in the processing of subjective value (Peters & Büchel, 2010; Levy & Glimcher, 2011; O’Doherty, 2011), emotional value (Winecoff et al., 2013), and the merging of affective meaning (Roy et al., 2012), commensurate with the predicted multidimensional sensitivity of the RewP. Anecdotally, midbrain dopaminergic projections have been shown to alter the functional circuitry of the OFC (Kahnt & Tobler, 2017), further illustrating a system which is sensitive to RPE, yet also influenced by hedonic or motivational states.
This unified interpretation of the multidimensional aspects of the RewP will engender a more comprehensive understanding of how value is computed (Levy & Glimcher, 2011). We suggest that the RewP is influenced by cortical computations of reward surprise as well as hedonic liking, identifying it as a possible nexus where multidimensional value is computed.
References
Angus, D. J., Kemkes, K., Schutter, D. J. L. G., & Harmon-Jones, E. (2015). Anger is associated with reward-related electrocortical activity: Evidence from the reward positivity. Psychophysiology, 52(10), 1271–1280. https://doi.org/10.1111/psyp.12460
Baker, T. E., Wood, J. M. A., & Holroyd, C. B. (2016). Atypical valuation of monetary and cigarette rewards in substance dependent smokers. Clinical Neurophysiology, 127(2), 1358–1365. https://doi.org/10.1016/j.clinph.2015.11.002
Bellebaum, C., Polezzi, D., & Daum, I. (2010). It is less than you expected: The feedback-related negativity reflects violations of reward magnitude expectations. Neuropsychologia, 48(11), 3343–3350. https://doi.org/10.1016/j.neuropsychologia.2010.07.023
Berridge, K. C. (1996). Food reward: brain substrates of wanting and liking. Neuroscience and Biobehavioral Reviews, 20(1), 1–25. https://doi.org/10.1016/0149-7634(95)00033-B
Berridge, K. C., Robinson, T. E., & Aldridge, J. W. (2009). Dissecting components of reward: “liking”; “wanting,” and learning. Current Opinion in Pharmacology, 9(1), 65-73. https://doi.org/10.1016/j.coph.2008.12.014.
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436. https://doi.org/10.1163/156856897X00357
Brown, D. R., & Cavanagh, J. F. (2018). Rewarding images do not invoke the reward positivity: They inflate it. International Journal of Psychophysiology, 132, 226–235. https://doi.org/10.1016/j.ijpsycho.2018.02.012
Brown, D. R., & Cavanagh, J. F. (2020). Novel rewards occlude the reward positivity, and what to do about it. Biological Psychology, 151, 107841. https://doi.org/10.1016/j.biopsycho.2020.107841
Brown, D. R., Richardson, S. P., & Cavanagh, J. F. (2020). An EEG marker of reward processing is diminished in Parkinson’s disease. Brain Research, 1727, 146541. https://doi.org/10.1016/j.brainres.2019.146541
Cavanagh, J. F. (2015). Cortical delta activity reflects reward prediction error and related behavioral adjustments but at different times. NeuroImage, 110, 205–216. https://doi.org/10.1016/j.neuroimage.2015.02.007.
Cavanagh, J. F., Bismark, A. W., Frank, M. J., & Allen, J. J. B. (2019). Multiple dissociations between comorbid depression and anxiety on reward and punishment processing: Evidence from computationally informed EEG. Computational Psychiatry, 3, 1–17. https://doi.org/10.1162/CPSY
Delorme, A., & Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics. Journal of Neuroscience Methods, 13, 9–21. https://doi.org/10.1016/j.jneumeth.2003.10.009
Ethridge, P., & Weinberg, A. (2018). Psychometric properties of neural responses to monetary and social rewards across development. International Journal of Psychophysiology, 132, 311–322. https://doi.org/10.1016/j.ijpsycho.2018.01.011.
Euser, A. S., Greaves-Lord, K., Crowley, M. J., Evans, B. E., Huizink, A. C., & Franken, I. H. A. (2013). Blunted feedback processing during risky decision making in adolescents with a parental history of substance use disorders. Development and Psychopathology, 25(4pt1), 1119–1136. https://doi.org/10.1017/S0954579413000412
Holroyd, C. B., Pakzad-Vaezi, K. L., & Krigolson, O. E. (2008). The feedback correct-related positivity: Sensitivity of the event-related brain potential to unexpected positive feedback. Psychophysiology, 45(5), 688–697. https://doi.org/10.1111/j.1469-8986.2008.00668.x
Huvermann, D. M., Bellebaum, C., & Peterburs, J. (2021). Selective Devaluation Affects the Processing of Preferred Rewards. Cognitive, Affective and Behavioral Neuroscience. https://doi.org/10.3758/s13415-021-00904-x
Kahnt, T., & Tobler, P. N. (2017). Dopamine modulates the functional organization of the orbitofrontal cortex. Journal of Neuroscience, 37(6), 1493–1504. https://doi.org/10.1523/JNEUROSCI.2827-16.2016
Kennerley, S. W., & Walton, M. E. (2011). Decision making and reward in frontal cortex: Complementary evidence from neurophysiological and neuropsychological studies. Behavioral Neuroscience, 125(3), 297–317. https://doi.org/10.1037/a0023575
Kringelbach, M. L. (2005). The human orbitofrontal cortex: Linking reward to hedonic experience. Nature Reviews Neuroscience, 6(9), 691–702. https://doi.org/10.1038/nrn1748
Kumar, P., Waiter, G., Ahearn, T., Milders, M., Reid, I., & Steele, J. D. (2008). Abnormal temporal difference reward-learning signals in major depression. Brain, 131(8), 2084–2093. https://doi.org/10.1093/brain/awn136
Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (2008). International affective picture system (IAPS): Affective ratings of pictures and instruction manual. Technical Report A-8. University of Florida, Gainesville, FL.
Levinson, A. R., Speed, B. C., Infantolino, Z. P., & Hajcak, G. (2017). Reliability of the electrocortical response to gains and losses in the doors task. Psychophysiology, 54(4), 601–607. https://doi.org/10.1111/psyp.12813
Levy, D. J., & Glimcher, P. W. (2011). Comparing apples and oranges: using reward-specific and reward-general subjective value representation in the brain. Journal of Neuroscience, 31(41), 14693-14707. https://doi.org/10.1523/JNEUROSCI.2218-11.2011
Makeig, S., Bell, A. J., Jung, T.-P., & Sejnowski, T. J. (1996). Independent Component Analysis of Electroencephalographic Data. Advances in Neural Information Processing Systems, 8, 145–151. https://doi.org/10.1109/ICOSP.2002.1180091
National Institution of Mental Health. (2015). Research Domain Criteria (RdoC) (Retrieved from) https://www.nimh.nih.gov/research/research-funded-by-nimh/rdoc/index.shtml.
Nelson, B. D., Perlman, G., Klein, D. N., Kotov, R., & Hajcak, G. (2016). Blunted neural response to rewards as a prospective predictor of the development of depression in adolescent girls. American Journal of Psychiatry, 173(12), 1223–1230. https://doi.org/10.1176/appi.ajp.2016.15121524
Nolan, H., Whelan, R., & Reilly, R. B. (2010). FASTER: Fully Automated Statistical Thresholding for EEG artifact Rejection. Journal of Neuroscience Methods, 192(1), 152–162.
O’Doherty, J. P. (2011). Contributions of the ventromedial prefrontal cortex to goal-directed action selection. Annals of the New York Academy of Sciences, 1239, 118-129.
Peterburs, J., Sannemann, L., & Bellebaum, C. (2019). Subjective preferences differentially modulate the processing of rewards gained by own vs. observed choices. Neuropsychologia, 132, 107139. https://doi.org/10.1016/j.neuropsychologia.2019.107139
Peters, J., & Büchel, C. (2010). Neural representations of subjective reward value. Behavioural Brain Research, 213(2), 135-141.
Proudfit, G. H. (2015). The reward positivity: From basic research on reward to a biomarker for depression. Psychophysiology, 52(4), 449–459. https://doi.org/10.1111/psyp.12370
Robinson, T. E., & Berridge, K. C. (2008). The incentive sensitization theory of addiction: Some current issues. Philosophical Transactions of the Royal Society B: Biological Sciences, 363(1507), 3137–3146. https://doi.org/10.1098/rstb.2008.0093
Roy, M., Shohamy, D., & Wager, T. D. (2012). Ventromedial prefrontal-subcortical systems and the generation of affective meaning. Trends in Cognitive Sciences, 16(3), 147–156. https://doi.org/10.1016/j.tics.2012.01.005
Sabatino, A., Richey, J. A., Bodfish, J. W., Dichter, G. S., & Rittenberg, A. M. (2011). Reward Circuitry Function in Autism During Face Anticipation and Outcomes. Journal of Autism and Developmental Disorders, 42(2), 147–160. https://doi.org/10.1007/s10803-011-1221-1
Schacht, J., Anton, R., & Myrick, H. (2014). Functional neuroimaging studies of alcohol cue reactivity: A quantitative meta-analysis and systematic review. Addiction Biology, 18(1), 121–133. https://doi.org/10.1111/j.1369-1600.2012.00464.x.Functional
Takács, Á., Kóbor, A., Janacsek, K., Honbolygó, F., Csépe, V., & Németh, D. (2015). High trait anxiety is associated with attenuated feedback-related negativity in risky decision making. Neuroscience Letters, 600, 188–192. https://doi.org/10.1016/j.neulet.2015.06.022
Winecoff, A., Clithero, J. A., Carter, R. M., Bergman, S. R., Wang, L., & Huettel, S. A. (2013). Ventromedial prefrontal cortex encodes emotional value. Journal of Neuroscience, 33(27), 11032-11039.
Wu, Y., & Zhou, X. (2009). The P300 and reward valence, magnitude, and expectancy in outcome evaluation. Brain Research, 1286, 114–122. https://doi.org/10.1016/j.brainres.2009.06.032
Yeung, N., & Sanfey, A. G. (2004). Independent Coding of Reward Magnitude and Valence in the Human Brain. Journal of Neuroscience, 24(28), 6258–6264. https://doi.org/10.1523/JNEUROSCI.4537-03.2004
Acknowledgments
This project was supported by 1R01MH119382-01.
Author information
Authors and Affiliations
Corresponding author
Additional information
The data and materials for all experiments will be available on OpenNeuro.org
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 653 kb)
Rights and permissions
About this article

Cite this article
Brown, D.R., Jackson, T.C.J. & Cavanagh, J.F. The reward positivity is sensitive to affective liking. Cogn Affect Behav Neurosci 22, 258–267 (2022). https://doi.org/10.3758/s13415-021-00950-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-021-00950-5