
Abstract
Reward history, physical salience, and task relevance all influence the degree to which a stimulus competes for attention, reflecting value-driven, stimulus-driven, and goal-contingent attentional capture, respectively. Theories of value-driven attention have likened reward cues to physically salient stimuli, positing that reward cues are preferentially processed in early visual areas as a result of value-modulated plasticity in the visual system. Such theories predict a strong coupling between value-driven and stimulus-driven attentional capture across individuals. In the present study, we directly test this hypothesis, and demonstrate a robust correlation between value-driven and stimulus-driven attentional capture. Our findings suggest substantive overlap in the mechanisms of competition underlying the attentional priority of reward cues and physically salient stimuli.
Similar content being viewed by others


A substantial body of research links associative reward learning to changes in how visual stimuli are processed. In a covert-attention task, selection of the target is slowed by the presence of a task-irrelevant stimulus previously associated with reward (Anderson, Laurent, & Yantis, 2011a, 2011b), with the reward-associated distractor triggering a spatially localized shift of attention (e.g., Anderson et al., 2011b; Failing & Theeuwes, 2014). In an overt-attention task, previously reward-associated but currently task-irrelevant stimuli evoke more frequent saccades compared with value-neutral stimuli (Anderson & Yantis, 2012; Le Pelley, Pearson, Griffiths, & Beesley, 2015; Theeuwes & Belopolsky, 2012). Importantly, these attention effects can be observed even when the previously reward-associated stimulus is both explicitly task irrelevant and physically nonsalient (one of multiple differently colored stimuli, where stimulus color is not relevant to the task of selecting the target), demonstrating that reward history uniquely contributes to the control of attention (see Anderson, 2013, 2016; Chelazzi, Perlato, Santandrea, & Della Libera, 2013; Failing & Theeuwes, 2018, for reviews).
More recent research has begun to probe the neural underpinnings of attentional capture by learned reward cues. Previously reward-associated but nonsalient and currently task-irrelevant stimuli evoke elevated activity in regions of the visual corticostriatal loop, including the extrastriate visual cortex (Anderson, Laurent, & Yantis, 2014; Donohue et al., 2016; Hopf et al., 2015; MacLean & Giesbrecht, 2015) and the caudate tail (which is involved in the control of eye movements; Yamamoto, Monosov, Yasuda, & Hikosaka, 2012; see also Anderson et al., 2016; Anderson et al., 2014; Yamamoto, Kim, & Hikosaka, 2013). Similarly, reward-associated objects evoke stronger object-specific patterns of brain activity in object-selective visual cortex (Barbaro, Peelen, & Hickey, 2017; Hickey & Peelen, 2015).
One appealing hypothesis that has arisen from these findings is that the process of associative learning between rewards and the visual experiences that predict them lead to plasticity in the visual perceptual system, such that reward cues come to evoke stronger perceptual representations. This idea is further supported by several sources of evidence. The receipt of reward is associated with the activation of stimulus-specific representations of the cue that predicted the reward, in the same visual areas subserving value-driven attentional capture (Anderson, 2017), suggesting that reward signals serve as teaching signals to the visual system. That is, reward signals potentiate the visual representations that preceded them, strengthening the response of the visual system to the same input in future encounters (see Anderson, in press, for a review). Further consistent with this, the magnitude of reward-evoked striatal dopamine is predictive of subsequent attentional capture by reward cues (Anderson et al., 2017). Reward-mediated priming, a phenomenon by which the receipt of reward magnifies the priming of the target-defining feature experienced on that trial (Hickey et al., 2010a, 2010b; Hickey, Keiser, & Peelen, 2015) could be explained as a transient consequence of such a teaching signal. This proposed mechanism also dovetails nicely with theories of perceptual learning (Herzog & Fahle, 1999; Roelfsema & van Ooyen, 2005; Roelfsema, van Ooyen, & Watanabe, 2010; Sasaki, Nanez, & Watanabe, 2010; Seitz, Lefebvre, Watanabe, & Jolicoeur, 2005; Seitz & Watanabe, 2005), and findings that perceptual learning can be modulated by associative reward learning (Seitz, Kim, & Watanabe, 2009; Serences & Saproo, 2010). Causal evidence for the role of early visual cortical representations in value-driven attention was provided by a study in which transcranial random noise stimulation of visual cortex during reward learning potentiated subsequent attentional capture by reward cues (van Koningsbruggen, Ficarella, Battelli, & Hickey, 2016).
In light of this evidence, it is tempting to conclude that associative reward learning causes reward-predictive cues to be processed more robustly at a perceptual level, as if the stimulus was made to be more perceptually salient. In this respect, a reward cue competes for attention in an analogous fashion to a physically salient stimulus, requiring a similar degree of goal-directed control to ignore. However, no direct comparisons between attention to stimuli that are physically salient and attention to previously reward-associated but otherwise nonsalient stimuli have been made. To the degree that reward cues and physically salient stimuli compete for attention similarly in the brain, individuals who are more susceptible to attentional capture by one type of stimulus should also be more susceptible to attentional capture by the other. That is, if an individual is less effective at suppressing attention to bottom-up salience signals, and physical salience and reward salience are represented similarly in the visual system, then this individual should exhibit a similar level of difficulty suppressing attention to reward cues. In the present study, we provide a direct test of this prediction.
That two different measures of attentional capture would correlate would itself be of little informational value, were it the case that distractibility reflects a broad trait-like characteristic of a person. However, surprisingly weak correlations among different experimental measures of attentional capture have been observed (Kawahara & Kihara, 2011; Roque, Wright, & Boot, 2016), casting some measure of doubt on the idea that different attentional capture tasks all probe the same underlying mechanism of control. Given such findings, it cannot be taken for granted that resisting attentional capture by physically salient stimuli and previously reward-associated stimuli requires the same mechanisms of control, especially if these two types of stimuli were to activate fundamentally different representations that independently compete for selection.
In the present study, participants first completed a training phase in which the task was to fixate a red or green color-defined target. One target color was associated with greater monetary reward when fixated compared with the other, with the color-to-reward mapping counterbalanced across participants. Then, participants completed a test phase in which the task was to fixate a shape-defined target from amongst differently colored nontargets. On a subset of trials, one of the nontargets was rendered in a previously reward-associated color from training. Oculomotor capture by these previously reward-associated distractors was assessed. We used an oculomotor measure of attentional capture in a saccade-to-target task given the robust test–retest reliability of this measure (Anderson & Kim, in press) and concern over the potentially weak internal reliability of RT-based measures (e.g., Ataya et al., 2012; Field, Marhe, & Franken, 2014; Roque et al., 2016). Finally, participants completed a similar shape-search task, except now the critical distractor was a color singleton, either a blue among white shapes or a white among blue shapes. Oculomotor capture by this color singleton was assessed, and the magnitude of oculomotor capture across the two tasks was compared.
Method
Participants
Fifty-six participants were recruited from the Texas A&M University community. Participants were compensated with money earned in the experimental task. All reported normal or corrected-to-normal visual acuity and normal color vision. Data collection was considered complete at the end of the week that the target of 50 participants was reached, which would provide the ability to detect correlations as small as ±0.28. All procedures were approved by the Texas A&M University Institutional Review Board and conformed with the principles outlined in the Declaration of Helsinki.
Apparatus
A Dell OptiPlex equipped with MATLAB software and Psychophysics Toolbox extensions (Brainard, 1997) was used to present the stimuli on a Dell P2717H monitor. The participants viewed the monitor from a distance of approximately 70 cm in a dimly lit room. Eye position was monitored using an EyeLink 1000 Plus desktop mount eye tracker (SR Research). Head position was maintained using an adjustable chin rest (SR Research).
Training phase
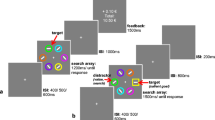
Each trial consisted of a fixation display, a search array, and a reward feedback display (see Fig. 1). The fixation display remained on-screen until eye position was registered within 1.1° of the center of the fixation cross for a continuous period of 500 ms. The search array was then presented for 1,000 ms or until a fixation on the target was registered. The search array consisted of six colored circles, one of which was red or green on each trial. The color of the other five circles was drawn randomly from the set (blue, cyan, purple, orange, yellow, white) on each trial without replacement. Each circle was approximately 3.6° visual angle in diameter, placed at equal intervals along an imaginary circle with a radius of 10.2°. The reward feedback display was presented for 1,500 ms, and consisted of the money earned on the current trial along with the updated total earnings (if the participant failed to fixate the target before the timeout limit, then the word “Miss” was presented in place of the money earned). A 1,000-ms blank screen was inserted between the search and feedback displays, and each trial concluded with a 500-ms blank interval.

Sequence and time course of trial events for each experimental task
Participants were instructed to fixate (“look directly at”) the red or green circle on each trial, and were informed that they would earn a small amount of money each time they did this within the time limit. Red and green target circles appeared equally often across trials within a block, with each color appearing equally often in each of the six stimulus positions. Correctly fixating one color target (red or green, counterbalanced across participants) was associated with an 80% probability of a high reward of 15¢, and a 20% probability of a low reward of 3¢ (high-value color), while for the other target color these percentages were reversed (low-value color). Each block consisted of 60 trials, the order of which was randomized.
Test phase
Each trial consisted of a fixation display (until fixation was acquired for a continuous period of 500 ms), a search array (1,000 ms or until a fixation on the target was registered), a 1,000 ms blank interval, and, in the event of an incorrect response, a feedback display (1,000 ms). Each trial concluded with a 500 ms blank interval (see Fig. 1). Targets were now defined as the unique shape, either a diamond among circles or a circle among diamonds (equally often), which participants were instructed to fixate. The colors of the shapes were irrelevant to the task, and participants were instructed to ignore color. The feedback display consisted of the word “Miss” presented at the center of the screen. To maximize sensitivity to attentional capture by the distractors, participants were not required to fixate the target first in order avoid receiving “Miss” feedback (i.e., they only needed to fixate the target within the 1,000-ms limit).
One of the nontarget shapes was rendered in the color of the formerly high-value target (high-value distractor) on one third of the trials, and likewise in the color of the formerly low-value target (low-value distractor) on another third of the trials. On the remaining one-third of trials, none of the shapes were rendered in the color of a formerly reward-predictive target (distractor-absent trials). Stimuli other than the critical distractor were drawn from the same color set used for nontargets in the test phase, and the same stimulus positions were used. Targets and distractors appeared equally often in each of the six possible stimulus positions across trials within a block. Each block consisted of 90 trials, the order of which was randomized.
Additional singleton task
The additional singleton task (see Theeuwes, 1992) was similar to the test phase, except that on distractor-absent trials, the all of the shapes were either blue or white (see Fig. 1). On distractor-present trials, one of the nontargets was rendered in the color not used for the other shapes on that trial (e.g., blue circle among four white circles and a white diamond). The distractor was present on half of all trials within a block, and was blue and white equally often. The target was blue and white equally often. Targets and distractors appeared equally often in each of the six possible stimulus positions across trials within a block. Each block consisted of 60 trials, the order of which was randomized.
Procedure
Participants completed four blocks of trials of the training phase, three blocks of trials of the test phase, and three blocks of trials of the additional singleton task, in that order. Eye position was calibrated prior to each block of trials using nine-point calibration, and was manually drift corrected by the experimenter as necessary (the need for which was evident when acquiring initial fixation at the outset of each trial). Each of the three experimental tasks was preceded by interactive instructions that included practice trials with and without the time-out limit. Participants were paid the amount of money earned in the training phase at the completion of the experiment.
Data analysis
We measured which of the six shape stimuli was initially fixated on each trial (i.e., the first stimulus fixated). Fixation of a stimulus was registered if eye position remained within a region extending 0.7° around the stimulus for a continuous period of at least 50 ms (100 ms on the target to trigger the termination of the stimulus array; see Nissens, Failing, & Theeuwes, 2017; Theeuwes & Belopolsky, 2012). Percentage of initial fixations on a distractor were taken over all trials within the respective condition. On distractor-absent trials, in order to quantify the probability of initially fixating a distractor for the sake of comparison, one of the nontargets was dummy-coded as the critical distractor on each trial using the same parameters that were used to define the position of the critical distractors on distractor-present trials (i.e., same counterbalance of position relative to the target position; note that averaging across all nontarget fixations produces the same pattern of results). A planned comparison focused on the difference in oculomotor capture between high-value and low-value distractor trials, given the importance of this comparison in establishing value dependence (Anderson & Halpern, 2017; Sha & Jiang, 2016); Bonferroni correction was applied to the two additional post hoc comparisons (α = 0.025). The probability of fixating a nontarget other than the critical distractor (while accounting for the number of such stimuli on each trial) did not differ across distractor conditions, p = .242, and so was not separately considered for each condition.
In relating value-driven attentional capture to stimulus-driven attentional capture, we tested two models: one in which stimulus-driven attentional capture was predicted from attentional capture by the low-value distractor, and another in which it was predicted from attentional capture by both low-value and high-value distractors (the results remain essentially unchanged if fixations on nontargets on distractor-absent trials is also included in the models: p = .005 and BF = 10.92). Model comparisons were performed using JASP software, using both parametric (change in R2) and Bayesian regression approaches; a Bayes factor favoring one model >3 was considered to reflect evidence in favor of that model (see Rouder, Speckman, Sun, Morey, & Iverson, 2009).
Results
Training phase
Neither accuracy, t(55) = 0.44, p = 0.662, nor time to register a correct fixation, t(55) = 1.76, p = .085, differed between low-value targets (Ms = 95.3% and 474 ms) and high-value targets (Ms = 95.5% and 459 ms).
Stimulus-driven attentional capture
Participants initially fixated the irrelevant color singleton on 47.2% of trials (SD = 15.7%), which serves as our individual differences measure of stimulus-driven attentional capture. A valid target fixation within the time-out limit was registered on 89.4% of trials. Consistent with a prior report demonstrating the high reliability of an oculomotor measure of value-driven attentional capture (Anderson & Kim, in press), the reliability of our measure of stimulus-driven attentional capture was highly robust as assessed via split-half reliability (odd vs. even trials), r = .782, attesting to its appropriateness for the purposes of the present study.
As a rough indicator of saccadic latency, we correlated the time to fixate the target when it was the first stimulus fixated to the magnitude of stimulus-driven attentional capture. This analysis revealed a significant negative correlation, r = −.457, p < .001, suggesting that participants who were slower to initiate saccades were generally less susceptible to attentional capture, consistent with prior results linking saccadic latency to stimulus-driven attentional capture (e.g., Donk & van Zoest, 2008; van Zoest, Donk, & Theeuwes, 2004).
Value-driven attentional capture
During the test phase, the frequency of errant distractor fixations differed across the three distractor conditions, F(2, 110) = 21.48, p < .001, ηp2 = 0.281 (see Fig. 2). Most critically, the difference in the frequency of initial fixations between the high-value distractor and the low-value distractor was significant, t(55) = 2.53, p = .014, d = 0.34. Post hoc contrasts further revealed that both the high-value distractor, t(55) = 5.94, p < .001, d = 0.79, and the low-value distractor, t(55) = 5.30, p < .001, d = 0.71, drew initial fixations more frequently than a nontarget on distractor-absent trials. A valid fixation was registered on the target within the time-out limit on 93% of all trials, which did not differ across the three distractor conditions, F(2, 110) = 0.87, p = .421 (high value: 92.8%, low value: 92.3%, distractor absent: 92.6%). The frequency of initial fixations on the high-value distractor serves as our individual differences measure of value-driven attentional capture. As with stimulus-driven attentional capture, time to fixate the target when it was the first stimulus fixated was negatively correlated with the frequency of fixations on a high-value distractor, r = −.283, p = .034, although the relationship was somewhat less robust. Across the two tasks, the time to fixate the target reflected a highly reliable individual differences measure, r = .835, p < .001.

Proportion of errant saccades by stimulus type in the test phase. Error bars reflect within-subjects confidence intervals. *p < .05. **p < .001. (Color figure online)
Relating value-driven and stimulus-driven attentional capture
Value-driven attentional capture was robustly correlated with stimulus-driven attentional capture, r = .484, p < .001 (see Fig. 3). To determine whether the value of the distractor specifically contributed to this relationship, we contrasted two models aimed at predicting stimulus-driven attentional capture: a null model including only the frequency of fixations on the low-value distractor and an alternative model including the frequency of fixations on both the low-value and high-value distractor. The null model includes attentional capture by a stimulus that both served as a former target and has some associated value, and the question is whether attentional capture by a higher value stimulus predicts stimulus-driven attentional capture over and above these influences. Consistent with this logic, there was a significant correlation between the frequency of fixations on a high-value and low-value distractor, r = .323, p = .015, in part reflecting a common influence of selection history (see Anderson & Halpern, 2017; Sha & Jiang, 2016), which the model accounts for (see Supplemental Table 1 for a complete list of all correlations across variables).

Correlation between the proportion of trials on which a high-value distractor was fixated in the test phase and the proportion of trials on which a physically salient distractor was fixated in the additional singleton task
Attentional capture by the high-value distractor predicted unique variance in the magnitude of stimulus-driven attentional capture. The alternative model accounted for significantly more variance in stimulus-driven attentional capture (adjusted R2 = .307) than the null model (adjusted R2 = .191), F(1, 53) = 10.06, p = .003. Bayesian regression analysis strongly favored the alternative model over the null model, with a BF = 16.39. These relationships remain robust, although somewhat reduced, if time to fixate a target in the value-driven attentional capture task is also included in the null model (p = .008 and BF = 6.62), suggesting that individual differences in saccadic latency cannot alone explain the relationship between stimulus-driven and value-driven attentional capture.
Discussion
Neuroimaging data suggests that reward cues come to evoke stronger perceptual representations following associative reward learning (Anderson et al., 2014; Barbaro et al., 2017; Donohue et al., 2016; Hickey & Peelen, 2015; Hopf et al., 2015; MacLean & Giesbrecht, 2015; van Koningsbruggen et al., 2016), leading to the hypothesis that reward salience is in some respects analogous to perceptual salience. In the present study, we confirm an important prediction arising from this hypothesis: Susceptibility to attentional capture by nonsalient stimuli previously associated with reward is well-predicted by susceptibility to attentional capture by physically salient stimuli. That is, individuals who are more susceptible to distraction by nonsalient reward cues are also more susceptible to distraction by physically salient stimuli that were never associated with reward and vice versa. This relationship remained robust when accounting for oculomotor capture by low-value stimuli, suggesting that it is particular to susceptibility to value-based distraction rather than a reflection of more general attentional abilities (i.e., error proneness in target selection) or selection history (attentional capture by any former target).
The order of attention tasks completed was consistent across participants, with the assessment of stimulus-driven attentional capture occurring after the assessment of value-driven attentional capture. This was done to minimize the variability in these measures across participants, maximizing our ability to detect significant covariance if present. However, a limitation of this approach is that it precludes meaningful comparison in the magnitude of attentional capture across tasks, as it is possible that attentional capture generally becomes more or less severe with practice and/or fatigue. Another limitation of the present study concerns our focus on oculomotor capture. We chose to measure attentional capture using oculomotor measures due to their increased reliability, which is important for analyses probing individual differences. However, the majority of studies on value-driven attentional capture use measures of response time, which are influenced by both covert and overt attentional processes (see, e.g., Anderson & Yantis, 2012). Recently, it has been proposed that value-driven attention reflects dissociable biasing signals in the salience map of parietal cortex and the oculomotor system of the basal ganglia (Anderson, in press), and it is possible that the conclusions of the present study only apply to the latter of these signaling mechanisms. Caution is therefore warranted in generalizing the findings of the present study to measures of covert attentional orienting.
The nature of the variance shared by these two mechanisms of attentional control is unclear, owing to limitations inherent to correlational data. One possibility is that reward history modulates stimulus representation in early visual areas, serving as an analog for physical salience. Another possibility is that the influence of reward history and physical salience on the representation of visual stimuli arise at fundamentally different stages of information processing, later converging on a common priority map (see Awh, Belopolsky, & Theeuwes, 2012) and similarly competing for selection. Efficiency in ignoring such sources of potential distraction may arise from processes related to the suppression of salient but irrelevant signals on the priority map (see Gaspelin & Luck, 2018) and/or processes related to boosting the signal associated with the target. Such goal-directed attention abilities may be mediated by individual differences in motivation and/or arousal. There was some evidence that slower saccadic latencies were associated with reduced capture across tasks, potentially reflecting some measure of trait-like variability in the carefulness of responding, although the relationship between value-driven and stimulus-driven attentional capture remained significant when accounting for this influence. Importantly, a robust correlation would not be observed if value-driven attention and stimulus-driven attention reflected fundamentally independent representations of priority and recruited fundamentally different mechanisms of control to overcome, which would be at odds with current theories of the neural mechanisms of value-driven attention.
More broadly, our findings are consistent with across-domain mechanisms of attentional control. Reward cues, distinguishable only by the relationship between particular features and previously experienced outcomes, were not in and of themselves physically salient in the present experiment. Yet individuals who were less effective at resisting attentional capture by reward cues were similarly less effective at suppressing physically salient visual signals. It seems not to be the case that such across-domain distractibility is reducible to a broad trait-like ability to control the focus of attention (Kawahara & Kihara, 2011; Roque et al., 2016). Our findings therefore suggest that, although the underlying mechanism is ultimately dissociable (Anderson, 2013; Awh et al., 2012), value-driven (once learned) and stimulus-driven priority have a similar influence on the control of attention, producing a generalizable susceptibility to distraction.
References
Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3), 7, 1–16.
Anderson, B. A. (2016). The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences, 1369, 24–39.
Anderson, B. A. (2017). Reward processing in the value-driven attention network: Reward signals tracking cue identity and location. Social, Cognitive, and Affective Neuroscience, 12, 461-467.
Anderson, B. A. (in press). Neurobiology of value-driven attention. Current Opinion in Psychology.
Anderson, B. A., & Halpern, M. (2017). On the value-dependence of value-driven attentional capture. Attention, Perception, and Psychophysics, 79, 1001-1011.
Anderson, B. A., & Kim, H. (in press). Test–retest reliability of value-driven attentional capture. Behavior Research Methods.
Anderson, B. A., Kuwabara, H., Wong, D. F., Gean, E. G., Rahmim, A., Brasic, J. R., . . . Yantis, S. (2016). The role of dopamine in value-based attentional orienting. Current Biology, 26, 550–555.
Anderson, B. A., Kuwabara, H., Wong, D. F., Roberts, J., Rahmim, A., Brasic, J. R., & Courtney, S. M. (2017). Linking dopaminergic reward signals to the development of attentional bias: A positron emission tomographic study. NeuroImage, 157, 27–33.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011a). Learned value magnifies salience-based attentional capture. PLOS ONE, 6(11), e27926.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011b). Value-driven attentional capture. Proceedings of the National Academy of Sciences, USA, 108, 10367–10371.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2014). Value-driven attentional priority signals in human basal ganglia and visual cortex. Brain Research, 1587, 88–96.
Anderson, B. A., & Yantis, S. (2012). Value-driven attentional and oculomotor capture during goal-directed, unconstrained viewing. Attention, Perception, and Psychophysics, 74, 1644–1653.
Ataya, A. F., Adams, S., Mullings, E., Cooper, R. M., Attwood, A. S., & Munafò, M. R. (2012). Internal reliability of measures of substance-related cognitive bias. Drug and Alcohol Dependence, 121, 148–151.
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437–443.
Barbaro, L., Peelen, M. V., & Hickey, C. (2017). Valence, not utility, underlies reward-driven prioritization in human vision. Journal of Neuroscience, 37, 10438–10450.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C. (2013). Rewards teach visual selective attention. Vision Research, 85, 58–72.
Donk, M., & van Zoest, W. (2008). Effects of salience are short-lived. Psychological Science, 19, 733–739.
Donohue, S. E., Hopf, J. M., Bartsch, M. V., Schoenfeld, M. A., Heinze, H. J., & Woldorff, M. G. (2016). The rapid capture of attention by rewarded objects. Journal of Cognitive Neuroscience, 28, 529–541.
Failing, M. F., & Theeuwes, J. (2014). Exogenous visual orienting by reward. Journal of Vision, 14(5/6), 1–9.
Failing, M., & Theeuwes, J. (2018). Selection history: How reward modulates selectivity of visual attention. Psychonomic Bulletin and Review, 25, 514–538.
Field, M., Marhe, R., & Franken, I. H. A. (2014). The clinical relevance of attentional bias in substance use disorders. CNS Spectrums, 19, 225–230.
Gaspelin, N., & Luck, S. J. (2018). The role of inhibition in avoiding distraction by salient stimuli. Trends in Cognitive Sciences, 22, 79–92.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010a). Reward changes salience in human vision via the anterior cingulate. Journal of Neuroscience, 30, 11096–11103.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010b). Reward guides vision when it's your thing: Trait reward-seeking in reward-mediated visual priming. PLOS ONE, 5, e14087.
Hickey, C., Keiser, D., & Peelen, M. V. (2015). Reward guides attention to object categories in real-world scenes. Journal of Experimental Psychology: General, 144, 264–273.
Hickey, C., & Peelen, M. V. (2015). Neural mechanisms of incentive salience in naturalistic human vision. Neuron, 85, 512–518.
Herzog, M. H., & Fahle, M. (1999). Effects of biased feedback on learning and deciding in a vernier discrimination task. Vision Research, 39, 4232–4243.
Hopf, J. M., Schoenfeld, M. A., Buschschulte, A., Rautzenberg, A., Krebs, R. M., & Boehler, C. N. (2015). The modulatory impact of reward and attention on global feature selection in human visual cortex. Visual Cognition, 23, 229–248.
Kawahara, J. I., & Kihara, K. (2011). No commonality between attentional capture and attentional blink. The Quarterly Journal of Experimental Psychology, 64, 991–1008.
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158–171.
MacLean, M. H., & Giesbrecht, B. (2015). Neural evidence reveals the rapid effects of reward history on selective attention. Brain Research, 1606, 86–94.
Nissens, T., Failing, M., & Theeuwes, J. (2017). People look at the object they fear: Oculomotor capture by stimuli that signal threat. Cognition & Emotion, 31(8), 1707–1714.
Roelfsema, P. R., & van Ooyen, A. (2005). Attention-gated reinforcement learning of internal representations for classification. Neural Computation, 17, 2176–2214.
Roelfsema, P. R., van Ooyen, A., & Watanabe, T. (2010). Perceptual learning rules based on reinforcers and attention. Trends in Cognitive Sciences, 14, 64–71.
Roque, N. A., Wright, T. J., & Boot, W. R. (2016). Do different attention capture paradigms measure different types of capture? Attention, Perception, & Psychophysics, 78, 2014–2030.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin and Review, 16, 225–237.
Sasaki, Y., Nanez, J. E., & Watanabe, T. (2010). Advances in visual perceptual learning and plasticity. Nature Reviews Neuroscience, 11, 53–60.
Seitz, A. R., Kim, D., & Watanabe, T. (2009). Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron, 61, 700–707.
Seitz, A., Lefebvre, C., Watanabe, T., & Jolicoeur, P. (2005). Requirement for high-level processing in subliminal learning. Current Biology, 15, R753–R755.
Seitz, A., & Watanabe, T. (2005). A unified model for perceptual learning. Trends in Cognitive Sciences, 9, 329–334.
Serences, J. T., & Saproo, S. (2010). Population response profiles in early visual cortex are biased in favor of more valuable stimuli. Journal of Neurophysiology, 104, 76–87.
Sha, L. Z., & Jiang, Y. V. (2016). Components of reward-driven attentional capture. Attention, Perception, & Psychophysics, 78, 403–414.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception and Psychophysics, 51, 599–606.
Theeuwes, J., & Belopolsky, A. V. (2012). Reward grabs the eye: Oculomotor capture by rewarding stimuli. Vision Research, 74, 80–85.
van Koningsbruggen, M. G., Ficarella, S. C., Battelli, L., & Hickey, C. (2016). Transcranial random noise stimulation of visual cortex potentiates value-driven attentional capture. Social, Cognitive, and Affective Neuroscience, 11, 1481–1488.
van Zoest, W., Donk, M., & Theeuwes, J. (2004). The role of stimulus-driven and top-down control in saccadic visual selection. Journal of Experimental Psychology: Human Perception and Performance, 30, 746–759.
Yamamoto, S., Kim, H. F., & Hikosaka, O. (2013). Reward value-contingent changes in visual responses in the primate caudate tail associated with a visuomotor skill. Journal of Neuroscience, 33, 11227–11238.
Yamamoto, S., Monosov, I. E., Yasuda, M., & Hikosaka, O. (2012). What and where information in the caudate tail guides saccades to visual objects. Journal of Neuroscience, 32, 11005–11016.
Acknowledgements
Special thanks to Mark Britton and Ming-Ray Liao for assistance with data collection.
Funding
The reported research was supported in part by a start-up package to BAA from Texas A&M University, and NARSAD Young Investigator Grant 26008 to BAA and NIH grant R01-DA046410 to BAA.
Author information
Authors and Affiliations
Contributions
B.A.A. developed the study concept. B.A.A. and H.K. designed and programmed the experimental task. H.K. coded the data, which B.A.A. subsequently analyzed. B.A.A. and H.K. contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest statement
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(DOCX 14 kb)
Rights and permissions
About this article

Cite this article
Anderson, B.A., Kim, H. On the relationship between value-driven and stimulus-driven attentional capture. Atten Percept Psychophys 81, 607–613 (2019). https://doi.org/10.3758/s13414-019-01670-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01670-2