
Abstract
Learned value is known to bias visual search toward valued stimuli. However, some uncertainty exists regarding the stage of visual processing that is modulated by learned value. Here, we directly tested the effect of learned value on preattentive processing using temporal order judgments. Across four experiments, we imbued some stimuli with high value and some with low value, using a nonmonetary reward task. In Experiment 1, we replicated the value-driven distraction effect, validating our nonmonetary reward task. Experiment 2 showed that high-value stimuli, but not low-value stimuli, exhibit a prior-entry effect. Experiment 3, which reversed the temporal order judgment task (i.e., reporting which stimulus came second), showed no prior-entry effect, indicating that although a response bias may be present for high-value stimuli, they are still reported as appearing earlier. However, Experiment 4, using a simultaneity judgment task, showed no shift in temporal perception. Overall, our results support the conclusion that learned value biases perceptual decisions about valued stimuli without speeding preattentive stimulus processing.
Similar content being viewed by others

At any given moment, we can only attend to a small subset of the total information in the visual environment. During each moment, a number of cognitive processes collectively determine what information will be attended and what information will fall out of further processing. For the most part, different states of attention have been considered to be due to either bottom-up processes—driven by causes external to the individual—or top-down processes—driven by the goals of the observer. However, recent research has highlighted the contribution of sources of selection that are internal to the observer yet not determined by his or her current goals (Awh, Belopolsky, & Theeuwes, 2012). The learned value of stimuli is one such source of attentional bias (e.g., Anderson, Laurent, & Yantis, 2011a). These value-driven attention biases can occur even when the value-laden features of stimuli are task-irrelevant (e,g., Anderson et al., 2011a; Raymond & O’Brien, 2009). Although such results have reliably been observed in laboratory experiments, the particular stage, or stages, of perceptual processing affected by learned value is not yet understood. In this article, we assess the ability of learned value to affect visual priority in a task that does not require selective processing. First, however, we review what is known about the ways that learned value biases perceptual processing.
To study the effect of learned value on visual selection, studies have employed a two-phase structure, wherein different stimuli are repeatedly paired with different amounts of reward in a learning phase, and then attentional biases to these stimuli are compared in a test phase in which the reward contingency is removed (Anderson, 2014; Anderson, Laurent, & Yantis, 2011a, 2011b; MacLean & Giesbrecht, 2015; Miranda & Palmer, 2014; Raymond & O’Brien, 2009; Sali, Anderson, & Yantis, 2014). For example, Anderson, Laurent, and Yantis (2011b) trained participants to search for oriented bars within green or red circles among other colored distractor circles. For each participant, one target color had a high probability of producing a high reward, and the other target color had a high probability of producing a low reward. After participants had practiced this task, the reward contingencies were removed, and instead the participants searched for an oriented bar within a unique, diamond shape among distractor circles (similar to the added-singleton paradigm pioneered by Theeuwes, 1992). Critically, one of these circles on each trial would be colored in either red or green, and both of these singleton distractors led to slowed search times. Importantly, singletons in the color that had received high reward in the learning phase produced greater interference, indicating that the learned value of stimuli produces an attentional bias over and above that of perceptual salience.
As was recently noted by Müller, Rothermund, and Wentura (2016), the majority of studies on reward and attention have relied on search tasks to assess the prioritization of rewarded stimuli, and it is therefore unclear which stages of visual processing are affected by reward. These authors argued that reward effects in search may be due to delayed disengagement, as opposed to a preattentive boost for visual features with learned value. To support this argument, they reported data from a modified dot-probe task. After imbuing visual objects with value in a speeded-discrimination task, previously rewarded objects’ ability to orient attention when acting as exogenous cues was compared to that of neutral objects, as well as to that of objects associated with losses. Whereas rewarded objects led to a larger cue validity effect, comparison with neutral cues showed that the rewarded objects led to slower disengagement (i.e., a larger difference between neutral and invalidly cued response times [RTs]), but not to speeded orienting (i.e., no difference between neutral and validly cues RTs). Müller et al. argued that delayed disengagement from rewarded stimuli could explain the attentional biases measured in search tasks, which are assessed by a slowed RT when an object with learned value appears as a distractor.
Using a different paradigm, Hickey, Chelazzi, and Theeuwes (2011) argued instead that reward is able to affect the early stages of target detection and localization, and that this target enhancement mechanism is distinct from a distractor suppression mechanism that operates on a later stage of selection. Although this finding is based on the results of tasks in which the effect of rewards on intertrial priming, and not learned value, has been measured, their conclusion is consistent with a recent electrophysiological and behavioral study showing that reward history influences the early stages of visual attention selection, by altering the P1 amplitude (MacLean & Giesbrecht, 2015; see Hickey, Chelazzi, & Theeuwes, 2010, for a similar result using immediate reward), and also affects attentional capture, as indicated by the N2PC component (Qi, Zeng, Ding, & Li, 2013). Given that these studies involved associating learned values with stimuli, these results are inconsistent with Müller et al.’s (2016) conclusion that rewards solely produce delayed disengagement. Similarly, the suggestion that learned value solely delays disengagement is inconsistent with measures of oculomotor capture (Anderson & Yantis, 2012; Hickey & van Zoest, 2012; Theeuwes & Belopolsky, 2012). Instead, such results point to an effect of learned value that is preattentive, in the sense that it does not require first focusing attention on a particular object to be measured. Behavioral evidence of a preattentive locus of reward has also come from Kiss, Driver, and Eimer (2009), who showed that pop-out was enhanced for targets that often deliver higher rewards (see also Lee & Shomstein, 2014); however, Kristjánsson, Sigurjónsdóttir, and Driver (2010) subsequently showed that this pop-out advantage rapidly reverses following a change in the stimulus–reward contingencies, leaving uncertainty regarding whether learned value, as opposed to expected reward, operates at an early stage. What has been missing is a direct, behavioral demonstration that stimuli with imbued learned value are prioritized for perception.
Our goal in this study was to directly test the claim that learned value can enhance the preattentive processing of visual information. To do so, we employed judgments of stimulus onset (temporal order judgments [TOJs] and simultaneity judgments [SJs]), which are used to measure visual prior entry. Prior entry refers to the accelerated conscious perception of some stimuli at the expense of others, leading to earlier conscious perception of these stimuli (Scharlau, 2007; Spence & Parise, 2010). Prior entry is found to occur when attention is exogenously oriented to the location of an upcoming stimulus (Born, Kerzel, & Pratt, 2015; Hikosaka, Miyauchi, & Shimojo, 1993; Schneider & Bavelier, 2003; Shore, Spence, & Klein, 2001; Stelmach & Herdman, 1991). Although event-related potentials (ERPs) measured alongside TOJs do not always demonstrate accelerated processing (i.e., reduced peak latencies of the early components of the visual evoked potential), increases in the amplitudes of early components (e.g., the P1, N1, and P2) are reliably observed, indicating that behavioral prior-entry effects correspond to changes in early visual processing (McDonald, Teder-Sälejärvi, Di Russo, & Hillyard, 2005; Vibell, Klinge, Zampini, Spence, & Nobre, 2007). Importantly, these tasks can be used as “cueless” tasks that measure the attentional biases that are intrinsic to stimuli, such as the speeded processing found for low-spatial-frequency patches (West, Anderson, Bedwell, & Pratt, 2010), emotional faces (West et al., 2010; West, Anderson, & Pratt, 2009), and near surfaces (West, Pratt, & Peterson, 2013). Furthermore, the tasks do not require selective processing—in fact, both stimuli must be registered to make a response—and so provide an index of visual priority when all of the information is equally relevant. Thus, TOJs and SJs provide a window into the perceptual biases that may exist for stimuli with learned values before focal attention is engaged, since it is difficult to envision a mechanism by which delayed disengagement alone could affect the relative perceived onsets of stimuli.
In the present study, we used a learned-value paradigm modeled after Anderson, Laurent, and Yantis’s (2011b) study, with one major exception: Instead of monetary value, we assigned value using a point system. For Experiment 1, our goal was to replicate Anderson et al.’s (2011b) results, especially given that our point rewards did not map onto any monetary value. To do this, we followed their modified value-learning task with an additional singleton visual search task to establish that the value training was successful. We showed that when the additional singleton feature was associated with learned value, it slowed down visual search proportional to the size of its associated value. In Experiment 2, participants completed the same value-learning task as in Experiment 1, but were then tested using a novel TOJ paradigm to assess whether the learned value would modify visual priority. Experiments 3 and 4 measured the perception of temporal onset for rewarded stimuli using a reversed TOJ and an SJ task, to distinguish between three accounts of changes in perceptual judgments: true prior entry, response biases, and decision biases. To preview our results, we observed that although learned value biases temporal onset responses, such that highly valued stimuli are reported to be perceived earlier, they do not bias perception when simultaneity, and not order, is measured. This supports the proposal that learned value has effects on visual processing beyond delayed disengagement—specifically, in biasing perceptual decisions.
Experiment 1
As we noted above, the main purpose of this experiment was to verify that rewarding participants with points rather than money would result in typical value-learning effects.
Method
Participants
Twenty-two undergraduate psychology students naïve to the experiment were recruited from the University of Toronto. Each participant reported normal or corrected-to-normal visual acuity and color vision. Participants gave written informed consent for the experiment and were provided with course credit for participating. All experimental procedures were approved by the University of Toronto’s Office of Research Ethics and were in accordance with the Declaration of Helsinki.
Apparatus
The experiment was conducted using a Windows-run PC with a 19-in. CRT screen (1,024 × 768 resolution with 85-Hz refresh rate) in a quiet and dimly lit room. Participants sat and viewed the monitor from a distance of 50 cm, with their chin rested on a chinrest throughout the experiment. The experiment was run in MATLAB (The MathWorks, Natick, MA) using the Psychophysics Toolbox. Participants entered responses by using a standard keyboard.
Stimuli and procedure
Participants were tested in a dimly lit room for a single 1-h session. Prior to the experiment, participants were presented with the instructions in a PowerPoint presentation that included images of the visual stimuli used in the experiment alongside the written instructions. Participants were told to place their chin on the chinrest and to make fast and accurate responses on each trial of the experiment.
Each phase of the experiment began with a screen with instructions that reiterated the instructions that had been orally provided to the participants. The stimuli for both phases were presented against a uniform gray background with a white fixation cross, 0.4° in size, centered on the screen.
Training phase
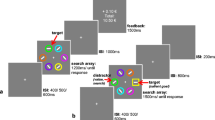
The training phase of Experiment 1 was used to imbue the stimuli with learned value by repeatedly pairing them with different rewards. See Fig. 1 for examples of the stimuli and the trial sequence. The trials in the training phase were made up of displays composed of four Landolt Cs, 1.5° in radius, drawn in four different colors, appearing at random positions, all centered 6.4° from fixation. Of these Landolt Cs, three with their gaps (0.36° in size) at top or bottom were the distractor stimuli, and one with its gap on the right or left was the target stimulus. The possible colors of each distractor stimulus were orange (RGB: 192, 192, 0), blue (RGB: 0, 192, 192), and yellow (RGB: 255, 128, 0); depending on the trial, the target stimulus could be either red (RGB: 255, 0, 0) or green (RGB: 0, 255, 0). The search display was presented until participants had made their response. Participants had to identify whether the gap on the colored circle was on the left or the right by pressing the left or the right arrow key, respectively. A feedback display followed the response to inform the participant of how many points he or she had earned for the completed trial; this feedback was presented in the center of the screen in white Arial font that varied in size depending on the reward magnitude. High rewards (200 points) were shown in large text (48 point, approximately 1.8° in height), whereas low rewards (20 points) were shown in smaller text (16 point, approximately 0.6° in height). The total number of points was presented for 1 s and was added to a running tally that was continuously visible at the top of the screen.

(Upper panels) Schematic of the training phase used in Experiments 1 and 2. Point-based rewards were delivered upon correct response input. Participants’ task was to report the gap location of the red or the green Landolt. (Lower panels) Schematic of the test phases of Experiments 1 and 2. The lower left panels depict a high-value singleton trial and a no-singleton trial in Experiment 1. The lower right panels depict a high-value temporal order judgment (TOJ) trial (top) and a low-value TOJ trial (bottom). The stimuli are not drawn to scale
Correct responses were followed by visual feedback indicating the total number of points earned during the training phase. High-reward targets were followed by 200 points (high-reward) feedback on 80% of the trials, and low-reward feedback on 20% of the trials. Low-reward targets were followed by 20 points (low-reward) feedback on 80% of the trials, and high-reward feedback on 20% of the trials. The high-reward and low-reward target colors were randomly assigned as red or green for each participant.
The training phase consisted of a variable number of trials grouped into 12 blocks. Prior to the end of the training phase, practice trials were provided. These trials were identical to actual trials, except that all visual stimuli were presented in white and the points earned on each trial were equal to 0 or to 10 points, for incorrect or correct trials, respectively. The practice phase ceased when participants had collected 100 points—in other words, once they had correctly completed ten trials. Between each block and after completion of the training phase, participants were given a short break. Each block was terminated after the participant had accumulated 2,500 points.
Test phase
For our test phase, we used an additional singleton task (Theeuwes, 1992). During this task, eight stimuli appeared on a search display, where each search stimulus was placed, evenly spaced, around the circumference of an imaginary circle, radius 6.4°, centered on fixation. Seven of these stimuli were Landolt Cs, 1.5° in radius, and the eighth stimulus was a Landolt square outline, 3.0° in width and height. Each Landolt had a 0.36° gap on either the left or the right side (forward facing or reverse). The target was defined as the square outline. Depending on the trial type, either all stimuli were colored white or all stimuli were colored white except one (the additional singleton), which was drawn in either the high-reward-associated or the low-reward-associated color. No feedback or points were provided following each test trial.
The search display was presented until participant had made their response. Each participant had to identify on which side, left or right, the gap was located on the square target, by pressing the “z” or the “m” key, respectively. The RT was measured from the onset of the visual stimuli to the response made by each participant.
The test phase of the experiment included 320 trials that were divided into eight blocks. Once again, practice trials were provided before this phase was completed. In total, RTs were compared in four conditions related to the addition singleton: no color, distractor color, high-value color, and low-value color. The high-value and low-value colors refer to the same colors used for the high-reward and low-reward targets in the training phase of the experiment. The target and additional singletons were equally likely to appear in each of the eight positions of the search array throughout the experiment. The additional singleton always appeared as a distractor. The search display stayed on the screen until the participant had made a response, and then the next search display was presented.
Results and discussion
Correct RTs in the acquisition were analyzed by dividing the training phase into first and last halves, each of which with high- and low-reward-associated targets. Trials were trimmed within subjects by removing trials with RTs outside two standard deviations of a participant’s mean RT. A Block × Reward analysis of variance (ANOVA) revealed a main effect of block, F(1, 21) = 27.10, p < .001, η p 2 = .56, but no main effect of reward, F(1, 21), = 0.84, p = .37, η p 2 = .04, and no interaction, F(1, 21) = 1.03, p = .32, η p 2 = .05, although RTs were numerically faster for high-reward, M = 519, SE = 5 ms, than for low-reward, M = 531 ms, SE = 4 ms, targets in the last half of the training phase. Thus, we did not find reliable evidence of a difference in RTs between high- and low-reward targets in our training phase.
In the test phase, the correct RTs and accuracy were M = 535 ms, SE = 15 ms, and M = 97.2%, SE = 0.6%, respectively. To determine whether the learned value from the training phase affected the allocation of attention in the test phase, the average correct RTs for the additional-singleton effects in the test phase were analyzed using a one-way, repeated measures ANOVA with Singleton Condition (low value, high value, and no singleton) as a factor. The averaged correct RT in each condition is shown in Fig. 2. A main effect of singleton type was present, F(2, 42) = 8.80, p = .001, η p 2 = .30. Follow-up contrasts revealed that low-value singletons slowed search times relative to no-singleton trials, F(1, 21) = 4.82, p = .04, η p 2 = .19, and, critically, that high-value singletons slowed search times even further, relative to low-value singletons, F(1, 21) = 6.15, p = .02, η p 2 = .23. No differences in accuracy were observed by singleton condition, F(2, 42) = 0.99, p = .38, η p 2 = .05. This demonstrates that, in a task that used points in lieu of monetary reward, learned value led to stable changes in attentional priority, such that stimuli associated with more reward produced increased distraction in a subsequent task.

Correct response times in the test phase of Experiment 1. Error bars represent one within-subjects standard error
Experiment 2
Given that we were able to show a learned-value effect on the allocation of attention in our version of the task used by Anderson et al. (2011b), we substituted a TOJ task in the test phase to measure whether learned value affected the speed with which the stimuli were processed. If learned value does increase preattentive visual priority, we expected that the stimuli associated with higher value should be perceived earlier than the stimuli with lower value.
Method
Participants
Thirty-one undergraduate psychology students naïve to the experiment were recruited from the University of Toronto. All reported normal or corrected-to-normal visual acuity and color vision. Participants were provided with a course credit in return for their participation in the experiment. None who had participated in Experiment 1 were participants in Experiment 2. All experimental procedures were approved by University of Toronto’s Office of Research Ethics and in accordance with the Declaration of Helsinki.
Apparatus
The apparatus used were identical to those in Experiment 1.
Stimuli and procedure
As in Experiment 1, the instructions were presented orally using a PowerPoint presentation, which included written instructions along with all the visual stimuli included in the experiment. All procedures used were identical to those of Experiment 1, with the exception of the test phase, which began with a screen reiterating the instructions presented prior to the experiment. Participants were asked to identify which of the two filled circles they thought had appeared first, by pressing the “z” key if the left circle had appeared first, or the “m” key if the right circle had appeared first. As in the training phase, they were asked to make fast and accurate responses and were given the opportunity to take a break between blocks.
As in the test phase of Experiment 1, participants were provided with ten practice trials in which the task was identical to that in the actual experiment, with the exception that the stimulus circles were white. In total, 384 trials were divided into eight blocks. Two circles resembling the Landolt Cs from the training phase, but with no gap (and a radius of 1.5°), were presented 6.4° away from the fixation cross on the horizontal meridian. The two circles were drawn in combinations of the colors used in the training phase. Two types of trials were used: the high-value or the low-value color appearing with a distractor color. The first circle appeared on the left or the right side of the fixation cross and was followed by the second circle, which appeared following a stimulus onset asynchrony (SOA) of 64, 32, or 16 ms. The two circles remained on the screen for 100 ms, after which they offset, and a response was collected.
Results and discussion
Three of the 31 participants were excluded from the TOJ analysis because their response accuracy was not significantly above chance across all reward colors and SOAs (in other words, they did not temporally discriminate the two stimuli). All analyses were performed on the remaining 28 participants. The average correct RTs during the training phase were again analyzed using a Block × Reward ANOVA. Unlike in Experiment 1, the learning phase of Experiment 2 revealed a marginal main effect of value, F(1, 27) = 4.31, p = .05, η p 2 = .14, such that high-value targets were reported faster, M = 549 ms, SE = 14 ms, than low-value targets, M = 560 ms, SE = 15 ms, as well as a main effect of block, F(1, 27) = 37.54, p < .001, η p 2 = .58.
For the TOJ task, trials were organized by two factors: the SOA between the valued and nonvalued color stimuli (six levels: –64, –32, –16, 16, 32, and 64 ms) and which valued color was used (low-value, high-value). The responses on these trials were used to fit two psychometric functions (cumulative Gaussian distributions) for each participant, parameterizing the probability of choosing the color with each learned value as having appeared first at each SOA, separately for the two valued colors. Fitting was accomplished using a maximum likelihood approach, with MATLAB’s fminsearch function being used to minimize the negative log-likelihood of the parameters of the psychometric function. As a result, prior entry could be assessed for each valued color by comparing the points of subjective simultaneity (PSSs) defined by the psychometric function (the point at which each stimulus is equally likely to be chosen, corresponding to the μ, or mean, parameter of the function).
The PSS for the low-value color, M = –3.78 ms, SE = 3, was not significantly different from 0, t(27) = 1.30, p = .21, indicating no prior entry for the low-value color as compared to a neutral color. Importantly, the PSS for the high-value color, M = –11 ms, SE = 4, was significantly different from 0, t(24) = 2.88, p = .007, indicating that high-value colors did receive prior entry (see Fig. 3). A direct comparison of the PSS values (Fig. 3) yielded the same conclusion, t(27) = 2.08, p = .047, but no differences in the slopes of the TOJs were evident, t(27) = 1.07, p = .29. These prior-entry results suggest that learned value is able to affect preattentive visual priority.

Results from Experiment 2’s test phase. The left panel depicts the across-participants average probabilities of reporting the valued stimulus as onsetting first for each stimulus onset asynchrony. The right panel depicts the averaged point of subjective simultaneity (PSS) values derived from individual participant fits. Error bars reflect one standard deviation of the mean
Experiment 3
Although Experiment 2 provided evidence that learned value leads to prior entry, the results were equally consistent with the possibility that learned value increases the choice salience of an object. A number of investigators have remarked that an increase in the probability of an object being chosen first in a TOJ can be observed because of either a true change in perceived temporal order or simply a bias to choose a particular object for report (Schneider & Bavelier, 2003; Shore, Spence, & Klein, 2001). As such, we ran a new group of participants through a task identical to the one we had used in Experiment 2, save for the fact that the participants were instructed to report the object that onset last. If the results of Experiment 2 were due to a bias to choose the rewarded stimulus, then we should observe a reversed effect on the PSSs of stimuli with learned value. However, if the results of Experiment 2 were due to perceptual prior entry, then no such reversal should occur.
Method
Participants
Thirty-one adult volunteers were recruited for Experiment 3. Each participant was compensated with either course credit or $10 for participation. All provided informed consent, and no participants had taken part in either Experiment 1 or 2. All experimental procedures were approved by the University of Toronto’s Office of Research Ethics and in accordance with the Declaration of Helsinki.
Apparatus, stimuli, and procedure
All of the apparatus, stimuli, and procedure were identical to those used in Experiment 2. Participants were simply instructed that, during the TOJ task, they should report which of the two stimuli onset last.
Results and discussion
Four participants were excluded, as in Experiment 2, on the basis of poor TOJ performance. The correct mean RTs for the training phase were analyzed in a Block × Value ANOVA. No main effect of value was observed, F(1, 26) = 1.54, p = .23, η p 2 = .06, but RTs were affected by block, F(1, 26) = 14.82, p = .001, η p 2 = .36, such that RTs were lower in the second half. A marginal Value × Block interaction was present, F(1, 26) = 3.57, p = .07, η p 2 = .12, so we analyzed the effects of value for the first and last halves of the training phase separately. In the first half, the RTs did not differ for high- and low-reward targets, t(26) = 0.23, p = .82, but RTs did differ in the second half, t(26) = 2.49, p = .02, suggesting that an RT benefit for high-value targets emerged later in the training phase.
PSS values for high- and low-value stimuli were estimated again by fitting a cumulative Gaussian distribution, except that now the fitted distribution was inverted (i.e., 1 – φ). Unlike in Experiment 1, neither low-value stimuli, t(26) = 1.35, p = .19, nor high-value stimuli, t(26) = 0.03, p = .97, showed a PSS shift from 0 (see Fig. 4). Following the analysis of TOJ effects by Shore et al. (2001), this indicates that the responses in Experiment 2 were likely due to a mixture of prior entry and decision biases. In the present experiment, the which-came-second? task pitted these two effect against each other, and they cancelled each other out. Thus, these results support the conclusion that learned value affects both perceptual and response biases in TOJs.

Results Experiment from 3’s test phase. The left panel depicts the across-participant average probabilities of reporting the valued stimulus as onsetting last for each stimulus onset asynchrony. The right panel depicts the averaged point of subjective simultaneity (PSS) values derived from individual participant fits. Error bars reflect one standard deviation of the mean
Experiment 4
Experiments 2 and 3 demonstrated that learned value can affect the perception of temporal order. However, whether this reflects true prior entry or not was still unclear. As had first been argued by Schneider and Bavelier (2003), TOJ tasks may be contaminated by a third type of bias—a decision bias. The TOJ task requires the detection two signals and comparing their onsets. Given the presence of sensory noise, some evidence threshold is necessary for detection of the onsets. A bias to report a valued stimulus may therefore reflect either an increase in the signal strength (i.e., a true change in the stimulus onset signal) or a change in its decision threshold. In Experiment 4, we measured perception of the onset of stimuli with learned value using an SJ task, in which participants reported whether two stimuli appeared at the same time or at different times. If stimuli with learned values indeed receive accelerated visual processing, we should observe a shifted point of subjective simultaneity (PSS) using this SJ task.
Method
Participants
Thirty-one participants were again recruited to participate in Experiment 4. All were compensated for their participation with $10. All experimental procedures were approved by University of Toronto’s Office of Research Ethics and in accordance with the Declaration of Helsinki.
Apparatus, stimuli, and procedure
Identical apparatus, stimuli, and procedure to those in the previous experiments were used in Experiment 4, with two exceptions. First, because simultaneity was to be reported in this task, we introduced trials in the test phase wherein the stimuli did onset simultaneously, randomly intermixed. To accommodate these extra trials, we increased the number of trials in the test phase from 384 to 448. In total, there were 28 trials at each of the six asynchronous onsets used in Experiments 2 and 3, as well as 56 trials with simultaneous onsets, per stimulus type (low value vs. neutral, high value vs. neutral). Second, instead of being instructed to report the stimulus that onset first, participants were instructed to report whether the stimuli appeared at the same or at different times. The “z” key was used to indicate a perceived simultaneous onset, and the “/” key was used to indicate a perceived asynchronous onset.
Results and discussion
Three participants were excluded from analysis due to poor performance in the SJ task. The data from the remaining 28 participants were analyzed for both the training and test phases. In the training phase, RTs were faster in the second half than in the first, F(1, 27) = 7.99, p = .009, η p 2 = .23. A main effect of value was present, F(1, 27) = 25.18, p < .001, η p 2 = .48, but value and block also interacted, F(1, 27) = 4.47, p = .044, η p 2 = .14. Paired-samples t tests indicated that, as in Experiment 3, no difference in RTs was present between high- and low-value trials in the first half of the training phase, t(27) = 1.01, p = .32, but RTs were faster for high- than for low-value trials in the second half, t(27) = 3.54, p = .001.
SJs were analyzed by fitting responses to the difference between a cumulative Gaussian distribution and an inverse Gaussian distribution, as in Schneider and Bavelier (2003). Paired-samples t tests showed no differences between the parameters fitted for high- and low-value SJs, ts(27) < 0.44, ps > .66, and, critically, no difference in PSSs between high- and low-value stimuli (see Fig. 5), t(27) = 0.25, p = .80. These results challenge the conclusion that learned value leads to accelerated visual processing per se, and instead favor an account wherein perceptual decision thresholds are lowered for valued stimuli, leaving the speed of sensory processing unchanged. One potential explanation for why we found a PSS shift in our TOJ tasks, but not the SJ task, comes from van Eijk, Kohlrausch, Juola, and van de Par (2010), who showed that PSS estimates in TOJ tasks can reflect a shift toward the stimulus with greater temporal sensitivity. Fitting our data with asymmetric slopes (i.e., different means and standard deviations for the valued-stimulus-leading and valued-stimulus-trailing components of the response distribution), however, did not yield slope differences, t(27)s < 1.57, ps > .13. As such, our data cannot speak to this possibility.

Responses to high- and low-value stimuli in the simultaneity judgment task. The left panel depicts the aggregate mean simultaneity reports for each stimulus onset asynchrony (SOA). The right panel depicts the average estimated point of subjective simultaneity (PSS) values. Error bars depict one within-subjects standard error
General discussion
In the present study, we sought to establish whether learned value can affect preattentive processing of previously rewarded visual information, using a behavioral measurement. In Experiment 1, we replicated the findings of Anderson et al. (2011b), confirming that our training procedure was able to produce a value-driven attentional bias. In Experiment 2, we used an identical training phase to imbue stimuli with differential learned values. Using a temporal order judgment task, we observed that stimuli with a greater learned value were perceived to onset earlier than stimuli with a lower learned value, but equivalent exposures and task relevance histories. Experiment 3 showed that these effects were not entirely due to simple response biases. Critically, however, Experiment 4 showed no such difference in perceived simultaneity between high- and low-value stimuli. Schneider and Bavelier (2003) argued that such a pattern of results—a shifted PSS for attended stimuli in TOJ tasks, but not in SJ tasks—indicates that no sensory acceleration occurs due to attention, but rather that the decision criteria used to estimate the onset times are affected. Indeed, research has shown that the PSS estimates in TOJ and SJ tasks do not necessarily correlate (van Eijk, Kohlrausch, Juola, & van de Par, 2008). One explanation for why this occurs is that biased PSS values in TOJ tasks occur due to a bias to report the stimulus that has better temporal resolution (van Eijk et al., 2010). However, we did not observe differences in sensitivity when value-laden stimuli onset first, as compared to last, in our SJ task. It is important to note that SJ and TOJ tasks may reflect decisions based on different sensory information; specifically, SJ judgments may often be based on the total duration of both stimuli, if the stimulus durations are fixed (see Love, Petrini, Cheng, & Pollick, 2013). Therefore, the inference that no prior entry occurs for stimuli with learned value from our data requires the supposition that the lack of a PSS shift in SJ tasks, accompanied by shifted PSS values in TOJ tasks, should be interpreted as a postperceptual decision bias, consistent with the dominant view in the prior-entry literature (see García-Pérez & Alcalá-Quintana, 2015; Schneider & Bavelier, 2003). As such, we concluded that the learned values acquired in our task did not produce prior entry.
Several studies measuring the effects of recently delivered rewards on selective attention have shown what may be considered early effects of reward on selection (Hickey et al., 2010, 2011). In particular, priming of pop-out is enhanced after reward delivery (Kiss et al., 2009), and visual priming similarly leads to shifts in the PSSs measured by both TOJ and SJ tasks (Theeuwes & Van der Burg, 2013). Given the lack of a clear PSS shift across tasks, despite consistent stimulus value learning, we suggest that the consequences of recent reward and learned value for visual processing may in fact differ. As such, future research should compare the effects of recently delivered reward and learned value with caution; although the distracting effects of stimuli associated with reward over the short and the long term in search may be similar, the broader visual effects of reward and value may not be identical. Although detailed descriptions of how moment-to-moment rewards may result in lasting attentional biases have been advanced (Failing & Theeuwes, 2016; Rombouts, Bohte, Martinez-Trujillo, & Roelfsema, 2015), our results suggest that this process is worth investigating in detail. As we noted earlier, Kristjánsson et al. (2010) found that the effect of reward on priming of pop-out rapidly changes when reward contingencies change, leaving open the possibility that removing the reward contingencies (as is necessarily done in studies of learned value) may affect the early sensory consequences of reward more than the later consequences (i.e., response and decisions biases). However, this is inconsistent with the ERP findings of MacLean and Giesbrecht (2015).
The issue of how stimulus–reward pairings do or do not accumulate into lasting value-driven biases may benefit from an integration with the rich literature on the mechanisms of intertrial priming of attention (Becker, 2008; Kristjánsson & Campana, 2010; Kruijne & Meeter, 2016; Olivers & Meeter, 2006). Indeed, Sha and Jiang (2016) have recently argued that value-driven attention may rely on target-history-related priming. Although our results showed value-dependent differences in capture—that is, high-value stimuli were perceived and reported as onsetting faster than low-value stimuli—both stimuli had a history of task relevance, raising the possibility that stimulus value is learned for attended stimuli only (but see Le Pelley, Pearson, Griffiths, & Beesley, 2015). If the developing literature on learned value and attention seeks to account for real-world attentional biases (e.g., Field & Cox, 2008), then characterizing the mechanisms underlying the learning of stimulus value will be of critical importance.
One potentially significant difference between our experiments and those experiments that have shown early effects of learned value is that we used a moneyless reward-learning task. The majority of value-driven attention studies have relied on monetary incentive to create stimuli with value associations. Three exceptions are Shomstein and Johnson (2013), who showed a reversal of object-based attention when more points were awarded for the correct detection of targets in noncued objects, regardless of whether the points led to monetary reward or were simply accumulated; Miranda and Palmer (2014), who showed that combining points and sound effects (as well as a “high-score” counter) could produce similar learned-value effects for stimuli paired with higher reward; and Roper and Vecera (2016), who paired correct responses to different target stimuli with the presentation of different denominations of currency, finding that those stimuli paired with the appearance of larger denominations led to greater attentional capture. Though it appears that monetary reward is not necessary to entrain learned value as measured using search times, it is possible that not all rewards affect perception equally, or that the longevity of different rewards’ effects on attention differ. Indeed, Miranda and Palmer did not find that points alone could create value-driven attention effects, whereas points were sufficient to affect attention in both Shomstein and Johnson’s and our experiments. Although differences exist in each case between the specific tasks and point values used, we note that, in our task, higher points reduced the number of trials that participants needed to complete, because each block of trials simply required a criterion value of accumulated points in order to be completed. In our paradigm, then, learned value may have been predicated on the reduction in time or effort that accompanied higher point values. As the old adage goes, time is money, and the subjective impact of high reward in our task translated to a reduction in the potential number of trials to be completed. Although participants were clearly sensitive to this reward, it may not have biased attention in quite the same way as the receipt of money. One reason for this could be that the delivery of money (even symbolic) would be considered positive reinforcement, whereas earning points that reduce the number of trials to be completed could arguably be considered negative reinforcement (the removal of impending effort). As such, these types of rewards may produce different effects on selection.
Another salient difference between Miranda and Palmer’s (2014) experiments, which showed no effect of points alone on attention, and the experiments in which nonmonetary rewards led to value-driven attention (Shomstein & Johnson, 2013; Roper & Vecera, 2016; the present experiments) was a difference in feedback complexity. The experiments in which nonmonetary reward has led to value-driven attention have used consistent mappings between a particular feedback stimulus and high or low rewards. In our experiment, the high rewards were always “200 points” and the low rewards “20 points”; in Shomstein and Johnson’s experiments, the high rewards were always “6 points” and the low rewards “1 point”; and in Roper and Vecera’s experiments, the high rewards were always depictions of $20 and the low rewards depictions of $5. Indeed, Miranda and Palmer’s successful demonstrations of nonmonetary, value-driven attention (Exps. 1 and 3) seem to have occurred when a particular sound (an “electric whip”) accompanied the positive feedback; points, when awarded, varied with participants’ RTs, meaning that the high reward values, although five times larger on average than the low reward values, could change across trials, perhaps making the reward–stimulus associations more difficult to learn. This is not to say that consistent mapping is sufficient for reward learning, since Roper and Vecera found no value-driven attentional biases when monetary amounts did not appear as monetary images, but instead as simple numeric amounts (even when they were preceded by dollar signs). However, a consistent mapping between high value and a particular stimulus that conveys high value may be important for the rapid formation of value-driven attentional biases. If this is the case, it suggests that the associations between value and attention may be underlain by the associations between stimuli (i.e., between target stimuli and the stimuli that signal reward, but not between target stimuli and abstract reward). Although the use of different types of reward may be responsible for these conflicting results, insofar as our lack of prior entry conflicts with ERP data, ultimately we see this as an advantage for the literature on reward, value, and attention. One goal of research into the effects of reward and value on attention must be generalizable across theories, so testing different types of rewards (e.g., positive emotional expressions; Anderson, 2016) will be essential to understanding the nuances of motivated attention.
References
Anderson, B. A. (2014). Value-driven attentional priority is context specific. Psychonomic Bulletin & Review, 22, 750–756.
Anderson, B. A. (2016). Social reward shapes attentional biases. Cognitive Neuroscience, 7, 30–36. doi:10.1080/17588928.2015.1047823
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011a). Learned value magnifies salience-based attentional capture. PLoS ONE, 6(e27926), 1–6. doi:10.1371/journal.pone.0027926
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011b). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108, 10367–10371.
Anderson, B. A., & Yantis, S. (2012). Value-driven attentional and oculomotor capture during goal-directed, unconstrained viewing. Attention, Perception, & Psychophysics, 74, 1644–1653.
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437–443. doi:10.1016/j.tics.2012.06.010
Becker, S. I. (2008). The mechanism of priming: Episodic retrieval or priming of pop-out? Acta Psychologica, 127, 324–339. doi:10.1016/j.actpsy.2007.07.005
Born, S., Kerzel, D., & Pratt, J. (2015). Contingent capture effects in temporal order judgments. Journal of Experimental Psychology: Human Perception and Performance, 41, 995–1006.
Failing, M., & Theeuwes, J. (2016). Reward alters the perception of time. Cognition, 148, 19–26. doi:10.1016/j.cognition.2015.12.005
Field, M., & Cox, W. M. (2008). Attentional bias in addictive behaviors: A review of its development, causes, and consequences. Drug and Alcohol Dependence, 97, 1–20. doi:10.1016/j.drugalcdep.2008.03.030
García-Pérez, M. A., & Alcalá-Quintana, R. (2015). Converging evidence that common timing processes underlie temporal-order and simultaneity judgments: A model-based analysis. Attention, Perception, & Psychophysics, 77, 1750–1766. doi:10.3758/s13414-015-0869-6
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010). Reward changes salience in human vision via the anterior cingulate. Journal of Neuroscience, 30, 11096–11103. doi:10.1523/JNEUROSCI.1026--10.2010
Hickey, C., Chelazzi, L., & Theeuwes, J. (2011). Reward has a residual impact on target selection in visual search, but not on the suppression of distractors. Visual Cognition, 19, 117–128. doi:10.1080/13506285.2010.503946
Hickey, C., & van Zoest, W. (2012). Reward creates oculomotor salience. Current Biology, 22, R219–R220. doi:10.1016/j.cub.2012.02.007
Hikosaka, O., Miyauchi, S., & Shimojo, S. (1993). Focal visual attention produces illusory temporal order and motion sensation. Vision Research, 33, 1219–1240. doi:10.1016/0042-6989(93)90210-N
Kiss, M., Driver, J., & Eimer, M. (2009). Reward priority of visual target singletons modulates event-related potential signatures of attentional selection. Psychological Science, 20, 245–251. doi:10.1111/j.1467-9280.2009.02281.x
Kristjánsson, À., & Campana, G. (2010). Where perception meets memory: A review of repetition priming in visual search tasks. Attention, Perception, & Psychophysics, 72, 5–18. doi:10.3758/APP.72.1.5
Kristjánsson, À., Sigurjónsdóttir, Ó., & Driver, J. (2010). Fortune and reversals of fortune in visual search: Reward contingencies for pop-out targets affect search efficiency and target repetition effects. Attention, Perception, & Psychophysics, 72, 1229–1236. doi:10.3858/APP.72.5.1229
Kruijne, W., & Meeter, M. (2016). Implicit short- and long-term memory direct our gaze in visual search. Attention, Perception, & Psychophysics, 78, 761–773.
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158–171.
Lee, J., & Shomstein, S. (2014). Reward-based transfer from bottom-up to top-down search tasks. Psychological Science, 25, 466–475.
Love, S. A., Petrini, K., Cheng, A., & Pollick, F. E. (2013). A psychophysical investigation of differences between synchrony and temporal order judgments. PLoS ONE, 8, e54798. doi:10.1371/journal.pone.0054798
MacLean, M. H., & Giesbrecht, B. (2015). Neural evidence reveals the rapid effects of reward history on selective attention. Brain Research, 1606, 86–94.
McDonald, J. J., Teder-Sälejärvi, W. A., Di Russo, F., & Hillyard, S. A. (2005). Neural basis of auditory-induced shifts in visual time-order perception. Nature Neuroscience, 8, 1197–1202. doi:10.1038/nn1512
Miranda, A. T., & Palmer, E. M. (2014). Intrinsic motivation and attentional capture from gamelike features in a visual search task. Behavior Research Methods, 46, 159–172. doi:10.3758/s13428-013-0357-7
Müller, S., Rothermund, K., & Wentura, D. (2016). Relevance drives attention: Attentional bias for gain- and loss-related stimuli is driven by delayed disengagement. Quarterly Journal of Experimental Psychology, 69, 752–763. doi:10.1080/17470218.2015.1049624
Olivers, C. N. L., & Meeter, M. (2006). On the dissociation between compound and present/absent tasks in visual search: Intertrial priming is ambiguity driven. Visual Cognition, 13, 1–28. doi:10.1080/13506280500308101
Qi, S., Zeng, Q., Ding, C., & Li, H. (2013). Neural correlates of reward-driven attentional capture in visual search. Brain Research, 1532, 32–43.
Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation the consequences of value learning in an attentional blink task. Psychological Science, 20, 981–988. doi:10.1111/j.1467-9280.2009.02391.x
Rombouts, J. O., Bohte, S. M., Martinez-Trujillo, & Roelfsema, P. R. (2015). A learning rule that explains how rewards teach attention. Visual Cognition, 23, 179–205.
Roper, Z. J. J., & Vecera, S. P. (2016). Funny money: The attentional role of monetary feedback detached from expected value. Attention, Perception, & Psychophysics, 78, 2199–2212. doi:10.3758/s13414-016-1147-y
Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance, 40, 1654–1664. doi:10.1037/a0037267
Sha, L. Z. & Jiang, Y. V. (2016). Components of reward-driven attentional capture. Attention, Perception, & Psychophysics, 78(2), 403-414.
Scharlau, I. (2007). Perceptual latency priming: A measure of attentional facilitation. Psychological Research, 71, 678–686.
Schneider, K. A., & Bavelier, D. (2003). Components of visual prior entry. Cognitive Psychology, 47, 333–366. doi:10.1016/S0010-0285(03)00035-5
Shomstein, S., & Johnson, J. (2013). Shaping attention with reward: Effects of reward on space- and object-based selection. Psychological Science, 24, 2369–2378.
Shore, D. I., Spence, C., & Klein, R. M. (2001). Visual prior entry. Psychological Science, 12, 205–212. doi:10.1111/1467-9280.00337
Spence, C., & Parise, C. (2010). Prior-entry: A review. Consciousness and Cognition, 19, 364–379. doi:10.1016/j.concog.2009.12.001
Stelmach, L. B., & Herdman, C. M. (1991). Directed attention and perception of temporal order. Journal of Experimental Psychology: Human Perception and Performance, 17, 539–550. doi:10.1037/0096-1523.17.2.539
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606. doi:10.3758/BF03211656
Theeuwes, J., & Belopolsky, A. V. (2012). Reward grabs the eye: Oculomotor capture by rewarding stimuli. Vision Research, 74, 80–85.
Theeuwes, J., & Van der Burg, E. (2013). Priming makes a stimulus more salient. Journal of Vision, 13(3), 21. doi:10.1167/13.3.21
van Eijk, R. L. J., Kohlrausch, A., Juola, J. F., & van de Par, S. (2008). Audiovisual synchrony and temporal order judgments: Effects of experimental method and stimulus type. Perception & Psychophysics, 70, 955–968. doi:10.3758/PP.70.6.955
van Eijk, R. L. J., Kohlrausch, A., Juola, J. F., & van de Par, S. (2010). Temporal order judgment criteria are affected by synchrony judgment sensitivity. Attention, Perception, & Psychophysics, 72, 2227–2235. doi:10.3758/APP.72.8.2227
Vibell, J., Klinge, C., Zampini, M., Spence, C., & Nobre, A. C. (2007). Temporal order is coded temporally in the brain: Early event-related potential latency shifts underlying prior entry in a cross-model temporal order judgment task. Journal of Cognitive Neuroscience, 19, 109–120.
West, G. L., Anderson, A. K., Bedwell, J. S., & Pratt, J. (2010). Red diffuse light suppresses the accelerated perception of fear. Psychological Science, 21, 992–999. doi:10.1177/0956797610371966
West, G. L., Anderson, A. K., & Pratt, J. (2009). Motivationally significant stimuli show visual prior entry: Evidence for attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 35, 1032–1042. doi:10.1037/a0014493
West, G. L., Pratt, J., & Peterson, M. A. (2013). Attention is biased to near surfaces. Psychonomic Bulletin & Review, 20, 1213–1220. doi:10.3758/s13423-013-0455-7
Author note
This work was supported by the Natural Science and Engineering Resource Council of Canada under Grant No. 194537.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Rajsic, J., Perera, H. & Pratt, J. Learned value and object perception: Accelerated perception or biased decisions?. Atten Percept Psychophys 79, 603–613 (2017). https://doi.org/10.3758/s13414-016-1242-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1242-0