
Abstract
Human action perception is so powerful that people can identify movement efficiently in the absence of pictorial information, such as in point-light displays. Interest is growing in this type of stimulus for research in neuroscience. This interest stems from the advantage of separating the component of pure human action kinematics from other pictorial information, such as facial expression and muscle contraction. Although several groups have previously developed datasets of human point-light actions, due to the lack of datasets composed of daily actions with short durations, we developed 20 biological and 40 control (scrambled) point-light movements by using the technique of recording people wearing reflector patches. The videos are about 1 s long. Subsequently, we performed a judgment task in which 100 participants (50 male and 50 female) evaluated each video according to three categories: human action resemblance, performed action, and gender of actor. We present the mean scores of each evaluation for each video, and further propose a selection of the most suitable videos to be used as human point-light action displays and scrambled point-light displays for control. Finally, we discuss our findings on the gender attributions of the point-light displays.
Similar content being viewed by others
Humans can recognize conspecific movements with high accuracy. This skill is important to comprehend the intentions of others in order to develop proper responses and social behavior toward them (Buccino, Binkofski, & Riggio, 2004). Action perception is so powerful that human movement identification is efficient even in the absence of pictorial information, such as contour, texture, and facial expression.
The first work identifying such efficiency dates to 1973, when Johansson developed point-light video displays of people performing movements (Johansson, 1973). The study, which focused on the visual perception of motion patterns, introduced point-light action stimuli developed by filming actors performing movements while dressed in dark suits with small light-reflecting patches attached to the joints. Several years later, Cutting (1978) created an algorithm that allowed the creation of synthetic point-light walkers in lateral view. Other groups adapted this algorithm to explore different aspects, such as visual presentation angles (e.g., adapting it to nonlateral orientations; Brand & Hertzmann, 2000; Hodgins, Wooten, Brogan, & O’Brien, 1995; Li, Wang, & Shum, 2002; Liu & Popović, 2002; Verfaillie, De Troy, & Van Rensbergen, 1994).
The growing interest in these types of stimuli relies on the advantage of separating the component of pure human action kinematics from other pictorial information, such as facial expression and muscle contraction. Thus, partial or full-body point-light actions have been used extensively in behavioral studies concerning vision, kinematics, multisensory integration, motor perception, and motor learning (Calvo-Merino, Ehrenberg, Leung, & Haggard, 2010; Elsner, Falck-Ytter, & Gredebäck, 2012; Graf et al., 2007; Hodges, Hayes, Breslin, & Williams, 2005; Petrini, Holt, & Pollick, 2010; Springer, Brandstadter, & Prinz, 2013; Stadler, Springer, Parkinson, & Prinz, 2012; Thomas & Shiffrar, 2010). Furthermore, they have been applied to investigate the brain processing underlying the visual and motor properties of actions, by means of functional magnetic resonance imaging (Beauchamp, Lee, Haxby, & Martin, 2003; Grossman et al., 2000; Saygin, Wilson, Hagler, Bates, & Sereno, 2004), electroencephalography (Hirai, Watanabe, Honda, & Kakigi, 2009; Krakowski et al., 2011; Ulloa & Pineda, 2007), and transcranial magnetic stimulation (Grossman, Battelli, & Pascual-Leone, 2005; van Kemenade, Muggleton, Walsh, & Saygin, 2012).
Because these are valuable stimuli for studying visual and motor processes, and considering creation and validation of such videos are time consuming and complex, databases are useful. Therefore, three different groups of researchers developed databases of point-light stimuli: Thomas Shipley and Jonathan Brumberg (Vision Lab at Temple University and the Department of Cognitive and Neural Systems at Boston University) created 79 video stimuli comprising both animal and human movements by using a markerless technique (unpublished work; database available at http://astro.temple.edu/~tshipley/mocap/MarkerlessMoCap.pdf). Frank Pollick’s group (Biological Motion and Action Understanding Laboratory at the University of Glasgow) created 4,080 human point-light videos using the classical markers technique (Ma, Paterson, & Pollick, 2006). Vanrie and Verfaillie (2006; Laboratory for Experimental Psychology at Catholic University of Leuven) created a set of 22 synthetic human point-light actions using an algorithm that allowed for both 2-D and 3-D presentations, as well as velocity and visual angle manipulation. Hence, the first two databases were created on the basis of actual human motion using two different techniques, whereas the last was developed using a synthetic algorithmic approach.
Nevertheless, when we decided to perform research using point-light motion, we could not find a set of videos suitable for our purposes. Those we found were either too long or too few, or featured unnatural resemblances to human movement, and combining stimuli from different databases is an unconventional and undesirable option. Our main concern with the available stimulus sets was the lack of standardized short videos depicting one cycle of movement and a further small sample of different actions depicting natural models in natural velocity. Pollick’s movement database, although composed of numerous videos, actually consists of a small set of actions (walking, knocking, lifting, and throwing) recorded by 30 different actors and charged with different emotional states (neutral, angry, happy, and sad). In addition, they are too long (the video clips are 30 s long) for certain research purposes. Experiments with electroencephalogram and neuromodulatory techniques use short stimuli during the evaluation of brain processes with high temporal resolution and when testing the possibility of modulating stimuli perception.
Moreover, to collect an adequate amount of data, such tests require repetition of the same category of stimuli. Thus, a corpus with action variability is desirable. Although it is interesting for studying the sources of variability within a specific action (e.g., individual and emotional aspects of actions), Pollick’s set does not provide action variety. A variety of actions offers a different advantage: It is suitable for visual and motion perception experiments in which repetition of the exact same movement is not applicable. In addition, for further control, we believed our set should have a validated high rate of correct action identification when presented for the desired length. Finally, none of the databases has a set of control stimuli built with the same technique as the biological motion ones. Therefore, we decided to record our own set of point-light walkers and release the videos after proper evaluation.
We opted for the classical Johansson (1973) technique—that is, real human recordings with the use of markers. This decision stemmed from the disadvantages attached to other techniques. Shipley’s markerless technique is labor-intensive and results in poor precision of joint localization; thus, the actions are less natural and precise. With respect to synthetic actions created with algorithms, although computer graphics attempt to incorporate dynamic properties and physical models, they do not accurately simulate the complexity of natural human motion (Runeson, 1994). In contrast, video recordings with reflective patches preserve the richness and complexity of real-life animated kinematics (see Dekeyser, Verfaillie, & Vanrie, 2002, for a review of techniques).
Therefore, considering standardized stimulus sets are valuable research tools for accessing normative data, we aimed to contribute to the diversity of available point-light stimuli created with reflexive patches. Furthermore, we created a set of scrambled point-light movements, often used as control stimuli in action observation experiments (e.g., Krakowski et al., 2011; Ulloa & Pineda, 2007; van Kemenade, Muggleton, Walsh, & Saygin, 2012), using the patch marker technique.
It is noteworthy that the gender recognition of point-lighter figures is a matter of debate. Some studies show correct gender recognition, but in others gender attribution is random. Two proposed theories have attempted to uncover how observers judge gender in pictorial-free stimuli. One theory argues that the centers of moment (the ratio of the shoulder width to the sum of the hip and shoulder widths) of males and females differ, and so can indicate gender (Cutting, 1978). In contrast, the other theory favors motion hints promoted by differences in the lateral sway of the hips and shoulders (Mather & Murdoch, 1994). A meta-analysis performed by Pollick, Kay, Heim, and Stringer (2005) showed that the level of performance expected is around 66%. Furthermore, the conditions of stimulus presentation (such as the view angle) and the natural variability of human shape and movements influence gender cues and their use by observers. Importantly, both gender theories are based on synthetic displays of walking movements.
Moreover, previous research has shown stimulus-gender effects on stimulus perception, specifically (1) point-light gender interference with perceived in-depth orientation—that is, the so-called gender-facing bias, showing that male point-lighters are more associated with movements toward and female point-lighters with motion away from the observer (see Schouten, Troje, Brooks, van der Zwan, & Verfaillie, 2010; Schouten, Troje, & Verfaillie, 2011)—and (2) a correlation between stimulus gender and observer sex in the perceived orientation (Schouten et al., 2013). This introduces the possibility that other features could be perceived differently according to gender. Hence, although the role of hip markers in gender identification needs further research to be clarified, we attempted to minimize gender cues by positioning the hip patch on the center of the pelvis instead of on the pelvic bones. This change allowed us to minimize gender bias (i.e., variations in perceptions of movement due to gender-related features) and use real performers instead of algorithms that produce an androgynous display. Considering this is a new dataset being tested and all additional information can be helpful when researchers are searching for suitable stimuli for specific research, gender attribution is interesting additional information. Thus, we provided this during the validation of our set.
Finally, visual and motor expertise effects have been extensively demonstrated for complex actions such as ballet (Calvo-Merino et al., 2010; Calvo-Merino, Glaser, Grèzes, Passingham, & Haggard, 2005; Calvo-Merino, Grèzes, Glaser, Passingham, & Haggard, 2006), capoeira (Calvo-Merino et al., 2005), basketball (Proverbio, Crotti, Manfredi, Adorni, & Zani, 2012), and gymnastics (Babiloni et al., 2009). Specifically, expertise affects accuracy in movement judgments, which are processed differently even by the brains of experts and nonexperts. Therefore, we sought to build diverse and mainly simple actions identifiable by the majority of the population to eliminate or at least dilute this possible effect for following experiments.
Our main goal was to create a point-light video dataset optimized for high-resolution brain research. This often requires relatively short stimulus presentation time and a clear contrast between successful action perception and the lack of it. Therefore, an experimental set of action stimuli and a control set of scrambled moving points were created. Scrambled point-lights are the most common control stimuli for point-light walkers because of its similarity to motion and visual features, with only the biological element (i.e., the human shape) eliminated. The disruption of the coherent percept of a moving human body allow us to separate the physiological measures specifically related to human motion and those related to motion in general. For consistency, the two sets were created using the same recording and editing methods and tools. Furthermore, we aimed to ensure that the biological and scrambled stimuli would correctly fulfill their purposes—that is, that the first set would be highly identifiable as human actions with no identification of actor gender, and that the latter should not resemble human actions. We achieved our overall goals in two steps: we (1) created a dataset of ~1,000-ms-long experimental (biological) and control (scrambled) point-light displays using the reflective-markers technique, and (2) tested the validity of these sets on human participants.
Method
Stimulus development
To eliminate, or at least dilute, the effect of expertise mentioned above, we selected mostly everyday actions identifiable by the majority of the population, such as walking and pointing, or actions that although not performed daily are commonly executed and/or observed. Thus, we planned a set of 20 movements, recorded in frontal view using a male and a female actor, resulting in the 40 movements referred to in Table 3 below.
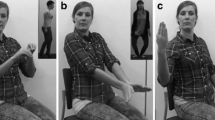
To produce the selected movements, Caucasian amateur athletes enrolled in the physical education course—one male and one female—were invited and accepted to participate voluntarily in performing the movements. The two volunteers were dressed in black suits, and 12 spheres (3 cm in diameter) coated in light-reflecting material were attached to each suit. For biological movement production, we attached the spheres at the main joints (ankles, knees, wrists, elbows, and shoulders) and on the forehead and center of the pelvis. For scrambled movement, we distributed the spheres along the volunteers’ bodies avoiding major joints and visually inspected the shapes formed during movement to avoid resemblance to human shape.
The recording of 40 biological and 40 scrambled point-light movements took place at the Tamboré Unit of Mackenzie Presbyterian University in a specially prepared dark room (black walls and floor, and light-shielded) in the Laboratory of Movement Science, always supervised by a physical educator (second author) and the first author of the present study. The volunteers were positioned one at a time at a mark on the floor and instructed individually about each of the movements to be performed. A metronome sound was set in the room to guide the velocity and rhythm of actions. For movements that required body displacement, such as walking, the recording was not stationary. In this first case, athletes were instructed to walk toward the camera. We aimed to record each movement three times for posterior selection; thus, each performer carried out each movement at least three times, and when the supervisors considered one of the performed movements inadequate, the supervisors asked the performers to repeat it until a satisfactory performance was captured. The movements were recorded using a JVC video camera (GR-D290u) mounted on a tripod.
Following this step, three judges (namely the first and second authors and a third physical education student who was unaware of the purpose of the experiment) separately watched all recordings and chose the recorded movements that best represented the proposed actions. All judges performed this process twice, with an interval of at least one week between sessions. From these visual analyses, we obtained six judgments. Then, by calculating the percentage of times each video was chosen, we selected those with the highest concordance between judges to compose our set. The mean percentage of votes for the clips chosen to represent each action was 73.33%.
We edited the selected stimuli using the video editor software VegasPro. The editing consisted of erasing any undesired reflections that appeared in the films (e.g., the floor marker and the wall marker that identified the movements by number). Furthermore, we cut the videos into one cycle of action to keep it within a length of 900 to 1,300 ms. We did this because some actions are cyclic and thus repeated several times during one execution (e.g., “jumping jack” and “jumping rope”). The time window range of 900 to 1,300 ms was the minimum time we found to represent one complete cycle of each action at natural speed. During the editing, two movements, lateral stretching to the left and to the right, were eliminated due to the impossibility of presenting them in less than 2 s, which made them unsuitable for our set. We similarly edited the scrambled videos, although we excluded none. It is impossible to set the endpoint of a nonaction; hence, the scrambled videos were cut into a time window range of 900 to 1,100 ms in order to add some length variability in this category, as it is the case for biological videos.
As we mentioned above, we excluded two biological movements because we could not depict a complete cycle in the stipulated time. Thus, we submitted to validation the remaining 18 biological movements. A male and a female performed the movements, resulting in a set of 36 biological movements. Concerning the scrambled movements, a male and a female actor each performed 20 movements, resulting in 40 different scrambled point-light movements.
Stimulus selection task
The task consisted of watching two blocks of videos. One block contained only the biological movements (BM), and the other block contained only the scrambled movements (SM). We adopted this strategy to avoid participant bias. A pilot study with ten participants revealed that random presentation of BM and SM in the same block results in a constant comparison of two distinct categories of stimuli resulting in a ceiling effect. All BM received a rating of 5, and all SM received a rating of 1 from nine of the ten participants. One participant distributed a few 4 ratings for the BMs. The clear difference made biological identification obvious, and we aimed to find the most representative biological and control actions within each category.
Half of the participants (25 male and 25 female) watched the BM block first and then the SM block, and the other half watched the blocks the other way around. Furthermore, the order of the BM and SM videos was random inside their respective blocks. Participants were required to be attentive while watching the videos. Following each video, the participants were asked to answer three questions presented on separate screens, in the following order: (1) ”How much did the observed movement resemble a human action?” (5-point Likert scale with 1 being nothing alike and 5 being very much alike), (2) ”What was the action performed?,” and (3) ”Was it possible to identify the gender of the actor? If yes, please state the gender.” We requested that participants provide verbal responses and all response times were unlimited (please see Fig. 1).

Experimental design. Before the beginning of each block, a task instruction was presented on the screen. Next, a screen informed participants to pay attention and that each video had a mean duration of 1 s. When participants felt they were ready and pressed a button, the trials were presented according to the following structure: fixation cross, (A) video stimuli of ~1,000 ms, and judging screens—namely, Likert scales for the questions (B) “How much did the observed movement resemble a human action?,” (C) “What was the action performed?,” and (D) “Was it possible to identify the gender of the actor? If yes, please state the gender.” The judgment screens had no time limits, and the researcher advanced to the next screen after obtaining the participant’s verbal response
Statistical analyses
Initially, we performed statistical analyses to evaluate possible judgment differences according to the sex (group) of the participants. Specifically, we compared male and female gender attributions for each movement according to group and actor gender (for SM and BM). For the SM video set, we performed repeated measures analysis of variance (ANOVA) for the percentage of null, female, and male attributions considering Group as between-subjects factor. For BM we performed another repeated measures ANOVA comparing percentage of correct, incorrect, and null attributions for male or female actors, considering Group as between-subjects factor.
Furthermore, we tested for possible group differences while attributing a score for human action resemblance. Therefore, we performed univariate ANOVA for the mean score of each SM considering Group as a factor. For BM movements, we performed two repeated measures ANOVAs, for mean scores and for correct action attributions of each BM, considering Actor and Group as a within- and a between-subjects factor, respectively. For all analyses, we adopted α = 5%. Since all biological and scrambled videos received high and low scores, respectively, for the judgments of human resemblance, the biological stimuli were flagged as being highly identifiable when the action was correctly identified at a rate of 60% in each group. In turn, the scrambled stimuli were flagged as being appropriate when they received action attributions from less than 50% of each group. Such cutoffs were applied in order to avoid attributions made by chance.
Finally, because we found differences for gender attributions and movement resemblances according to the groups and actors performing the actions, we opted to describe the ratings of movement resemblance and gender attribution to each video in each set separated by groups.
Results
Participants
Fifty male (five left-handed; mean age = 26.66 ± 4.60) and 50 female (nine left-handed; mean age = 23.2 ± 5.04) graduate or undergraduate students participated in the study. In an attempt to have generalizable results, we invited participants from diverse areas of knowledge—namely business, biology, law, economy, engineering, physiotherapy, photography, massotherapy, psychology, pedagogy, advertising, occupational therapy, video and audio editing, marketing, and public relations, as well as from flight commissioner, host, and security training.
Descriptive analyses and selection of the SM and BM videos
For the SM, we calculated the means and standard deviations of the rates given by each group, female (F) and male (M), to the first question—that is, “How much did the observed movement resemble a human action?” We then calculated the percentages of action attribution to each movement according to group (Table 1).
To select the SM suitable for composing a control dataset in subsequent procedures—that is, those that resembled human actions less closely—we adopted as our main criterion percentages of action attribution lower than 50% for both groups (M and F). All scrambled stimuli received low and similar rates for human resemblance. Thus, we opted to select those that could be less associated or compared with a describable movement. The chosen stimuli are indicated with asterisks in Table 1.
From our SM analyses, one may observe in Table 1 that all videos received low ratings on resemblance to human actions, ranging in mean values from 1.32 to 3.32. Furthermore, we could identify 14 videos with low ratings shown to be impossible to attribute to actions by more than 50% of both the F and M groups (please see Table 5 in the supplementary material). Concerning gender attributions, Table 2 indicates that gender was judged to be null in 77% of the trials performed by females, and in 69% of the trials performed by males.
For the BM, we also calculated the means and standard deviations of the rates given by each group (F and M) to the first question. We calculated the percentages of correct action attributions—that is, when the perceived action corresponded to the actual action performed in the recording. The actions were always classified in accordance with the equivalent translation in the list from Portuguese. However, some words also have close synonyms in Portuguese: For example, “walk” is equally represented by andar and caminhar. In such cases, we computed close synonyms as being correct. Except for the movement of throwing performed by the female (F-throw), more than 50% of the participants identified all BM stimuli correctly. Furthermore, for the BM set we were also interested in gender attributions. To address this matter, we calculated the percentages of correct, incorrect, and nonidentifiable gender attributions.
From our BM analyses (see Table 3), we found that the videos received correct action attributions from more than 60% of the participants in both groups, except for the movements “throw,” “point,” and “forehand.” Thus, we could identify 15 videos with high ratings of movement resemblance and correct action accuracy (please see Table 6 in the supplementary material). Among the gender attributions we found inconsistencies—that is, variations according to the gender of the executor, gender of the participant, and the performed action—depicted in Table 4.
Discussion and conclusions
We built and evaluated a set of short videos of point-light biological and nonbiological movements. As we demonstrated, people correctly, at a rate above chance, identified the human figures and the biological actions performed in the absence of pictorial information, even when only briefly exposed to the stimuli. Three action types from the BM category—”throw,” “forehand,” and “point”—were the only types recognized less than 70% of the time. The other 15 actions were identified with high accuracy when performed by a male and by a female athlete.
All stimuli presented here seem valid for conducting experiments with action perception. However, for subsequent experiments, the choice to include the stimuli with lower rates should align with the specific requirements of each experiment design. It is arguable that the lower accuracy in these movements could indicate that hip-swing kinematics provide valuable information for these specific movements. Nevertheless, it might be that participants had more difficulty naming the action or that the athletes performed the action less accurately. This seems more likely, considering that the action of “throw,” which was the least recognized, involved throwing a ball over the head in a frontal view, an action that requires considerably less hip movement than, for example, a “squat” or a “high kick” (both correctly identified more than 90% of the time).
According to Johansson (1973), placing the patches over the hipbones is preferable but not essential for obtaining accurate results. Accordingly, our data revealed that 15 of 18 actions were correctly identified by more than 60% of the volunteers from both groups. Thus, it is improbable that the absence of hip patches had significantly undermined action identification. However, it is not possible to compare our ratings with previous studies due to the lack of validation tasks (e.g., Ma, Paterson, & Pollick, 2006) and inconsistency between the stimuli created and the evaluation protocols (Shipley & Brumberg, n.d.; Vanrie & Verfaillie, 2004).
Furthermore, we created control stimuli (SM) using the same technique. Similarly, we were able to select the suitable ones with low human resemblance and no possible attribution of action. To our knowledge, this is the first framework to provide point-light control scrambled stimuli using the exact same marker procedure used to build the biological motion, and furthermore, with evaluations of both.
Considering gender attributions, we expected no possible attributions for the SM, and that they would not depict human shapes and thus not have defined genders. As our analyses demonstrated, our stimuli fulfilled that requirement. Concerning the BM set, gender attribution varied according to the movement and the performer. However, most participants still were unable to define the actor’s gender in the majority of our videos. It is possible that we minimized gender definition by centering the pelvic patch and minimizing the cues of hip size and swing that had been indicated in previous studies as allowing gender recognition (Cutting, 1978; Mather & Murdoch, 1994). Another possibility is that gender attribution might vary according to the performer and his or her physical biotype.
Moreover, when attributing gender, both the male and female groups showed a tendency to judge the actor as male. Such a gender bias has been previously reported in several studies (Schouten et al., 2010; Troje, Sadr, Geyer, & Nakayama, 2006; Troje & Szabo, 2006; van der Zwan et al., 2009). Thus, it seems that in the absence of hip cues, people still more often associate point-light walkers with the male gender. This may explain why, although gender attributions in the SM set were very low, we also observed more male gender than female gender attributions. Notwithstanding, correct gender attribution generally was low, irrespective of the performer. In addition, concerning the applicability of our set, having all movements performed by both genders confers the advantage of possibly counterbalancing the genders of the performers in experiments.
Finally, another key advantage of our set is stimulus length. Because it is composed of short videos of recognizable actions, it is suitable for experiments requiring brief stimulus presentations. This is often the case when using high-temporal-resolution technologies such as electroencephalography and transcranial magnetic stimulation, and for assessing behavioral measures during or after neuromodulation.
References
Babiloni, C., Del Percio, C., Rossini, P. M., Marzano, N., Iacoboni, M., Infarinato, F., . . . Eusebi, F. (2009). Judgment of actions in experts: A high-resolution EEG study in elite athletes. NeuroImage, 45, 512–521. doi:10.1016/j.neuroimage.2008.11.035
Beauchamp, M. S., Lee, K. E., Haxby, J. V., & Martin, A. (2003). fMRI responses to video and point-light displays of moving humans and manipulable objects. Journal of Cognitive Neuroscience, 15, 991–1001.
Brand, M., & Hertzmann, A. (2000). Style machines. Computer Graphics Proceedings, Annual Conference Series, 547, 183–192.
Buccino, G., Binkofski, F., & Riggio, L. (2004). The mirror neuron system and action recognition. Brain and Language, 89, 370–376. doi:10.1016/S0093-934X(03)00356-0
Calvo-Merino, B., Glaser, D. E., Grèzes, J., Passingham, R. E., & Haggard, P. (2005). Action observation and acquired motor skills: An fMRI study with expert dancers. Cerebral Cortex, 15, 1243–1249. doi:10.1093/cercor/bhi007
Calvo-Merino, B., Grèzes, J., Glaser, D. E., Passingham, R. E., & Haggard, P. (2006). Seeing or doing? Influence of visual and motor familiarity in action observation. Current Biology, 16, 1905–1910. doi:10.1016/j.cub.2006.07.065
Calvo-Merino, B., Ehrenberg, S., Leung, D., & Haggard, P. (2010). Experts see it all: Configural effects in action observation. Psychological Research, 74, 400–406.
Cutting, J. E. (1978). Generation of synthetic male and female walkers through manipulation of a biomechanical invariant. Perception, 7, 393–405.
Dekeyser, M., Verfaillie, K., & Vanrie, J. (2002). Creating stimuli for the study of biological-motion perception. Behavior Research Methods, Instruments, & Computers, 34, 375–382. doi:10.3758/BF03195465
Elsner, C., Falck-Ytter, T., & Gredebäck, G. (2012). Humans anticipate the goal of other people’s point-light actions. Frontiers in Neuroscience, 3(120), 1–7.
Graf, M., Reitzner, B., Corves, C., Casile, A., Giese, M., & Prinz, W. (2007). Predicting point-light actions in real-time. NeuroImage, 36(Supp. 2), T22–T32. doi:10.1016/j.neuroimage.2007.03.017
Grossman, E., Donnelly, M., Price, R., Pickens, D., Morgan, V., Neighbor, G., & Blake, R. (2000). Brain areas involved in perception of biological motion. Journal of Cognitive Neuroscience, 12, 711–720. doi:10.1162/089892900562417
Grossman, E. D., Battelli, L., & Pascual-Leone, A. (2005). Repetitive TMS over posterior STS disrupts perception of biological motion. Vision Research, 45, 2847–2853.
Hirai, M., Watanabe, S., Honda, Y., & Kakigi, R. (2009). Developmental changes in point-light walker processing during childhood and adolescence: An event-related potential study. Neuroscience, 161, 311–325. doi:10.1016/j.neuroscience.2009.03.026
Hodges, N. J., Hayes, S. J., Breslin, G., & Williams, A. M. (2005). An evaluation of the minimal constraining information during observation for movement reproduction. Acta Psychologica, 119, 264–282.
Hodgins, J. K., Wooten, W. L., Brogan, D. C., & O’Brien, J. F. (1995). Animating human athletics. In Proceedings of ACM SIGGRAPH 95 (pp. 71–78). New York, NY: ACM Press.
Johansson, G. (1973). Visual perception of biological motion and a model for its analysis. Perception & Psychophysics, 14, 195–204.
Krakowski, A. I., Ross, L. A., Snyder, A. C., Sehatpour, P., Kelly, S. P., & Foxe, J. J. (2011). The neurophysiology of human biological motion processing: A high-density electrical mapping study. NeuroImage, 56, 373–383. doi:10.1016/j.neuroimage.2011.01.058
Li, Y., Wang, T., & Shum, H. (2002). Motion texture: A two-level statistical model for character motion synthesis. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques (pp. 465–472). New York, NY: ACM Press.
Liu, C. K., & Popović, Z. (2002). Synthesis of complex dynamic character motion from simple animations. In Proceedings of ACM SIGGRAPH 2002 (pp. 408–416). New York, NY: ACM Press.
Ma, Y., Paterson, H. M., & Pollick, F. E. (2006). A motion capture library for the study of identity, gender, and emotion perception from biological motion. Behavior Research Methods, 38, 134–141. doi:10.3758/BF03192758
Mather, G., & Murdoch, L. (1994). Gender discrimination in biological motion displays based on dynamic cues. Proceedings of the Royal Society B, 258, 273–279.
Petrini, K., Holt, S. P., & Pollick, F. (2010). Expertise with multisensory events eliminates the effect of biological motion rotation on audiovisual synchrony perception. Journal of Vision, 10(5), 2:1–14. doi:10.1167/10.5.2
Pollick, F. E., Kay, J. W., Heim, K., & Stringer, R. (2005). Gender recognition from point-light walkers. Journal of Experimental Psychology: Human Perception and Performance, 31, 1247–1265. doi:10.1037/0096-1523.31.6.1247
Proverbio, A. M., Crotti, N., Manfredi, M., Adorni, R., & Zani, A. (2012). Who needs a referee? How incorrect basketball actions are automatically detected by basketball players’ brain. Scientific Reports, 2(883).
Runeson, S. (1994). Perception of biological motion: The KSD-principle and the implications of a distal versus proximal approach. In G. Jansson, S. S. Bergström, & W. Epstein (Eds.), Perceiving events and objects (pp. 383–405). Hillsdale, NJ: Erlbaum.
Saygin, A. P., Wilson, S. M., Hagler, D. J., Jr., Bates, E., & Sereno, M. I. (2004). Point-light biological motion perception activates human premotor cortex. Journal of Neuroscience, 24, 6181–6188.
Schouten, B., Troje, N. F., Brooks, A., van der Zwan, R., & Verfaillie, K. (2010). The facing bias in biological motion perception: Effects of stimulus gender and observer sex. Attention, Perception, & Psychophysics, 72, 1256–1260. doi:10.3758/APP.72.5.1256
Schouten, B., Troje, N. F., & Verfaillie, K. (2011). The facing bias in biological motion perception: Structure, kinematics, and body parts. Attention, Perception, & Psychophysics, 73, 130–143.
Schouten, B., Davila, A., & Verfaillie, K. (2013). Further explorations of the facing bias in biological motion perception: Perspective cues, observer sex, and response times. PlosOne, 8(2), e56978.
Shipley, T. F., & Brumberg, J. S. (n.d.). Markerless motion-capture for point-light displays (Technical report). Retrieved from http://astro.temple.edu/~tshipley/mocap/MarkerlessMoCap.pdf
Springer, A., Brandstadter, S., & Prinz, W. (2013). Dynamic simulation and static matching for action prediction: Evidence from body part priming. Cognitive Science, 37, 936–952.
Stadler, W., Springer, A., Parkinson, J., & Prinz, W. (2012). Movement kinematics affect action prediction: Comparing human to non-human point-light actions. Psychological Research, 76, 395–406. doi:10.1007/s00426-012-0431-2
Thomas, J. P., & Shiffrar, M. (2010). I can see you better if I can hear you coming: Action-consistent sounds facilitate the visual detection of human gait. Journal of Vision, 10(12), 14:1–11. doi:10.1167/10.12.14
Troje, N. F., & Szabo, S. (2006). Why is the average walker male? Journal of Vision, 6(6), 1034. doi:10.1167/6.6.1034
Troje, N. F., Sadr, J., Geyer, H., & Nakayama, K. (2006). Adaptation aftereffects in the perception of gender from biological motion. Journal of Vision, 6(8), 850–857. doi:10.1167/6.8.7
Ulloa, E. R., & Pineda, J. A. (2007). Recognition of point-light biological motion: Mu rhythms and mirror neuron activity. Behavioural Brain Research, 183, 188–194.
van der Zwan, R., Machatch, C., Kozlowski, D., Troje, N. F., Blanke, O., & Brooks, A. (2009). Gender bending: Auditory cues affect visual judgements of gender in biological motion displays. Experimental Brain Research, 198, 373–382. doi:10.1007/s00221-009-1800-y
Van Kemenade, B. M., Muggleton, N., Walsh, V., & Saygin, A. P. (2012). Effects of TMS over premotor and superior temporal cortices on biological motion perception. Journal of Cognitive Neuroscience, 24, 896–904.
Vanrie, J., & Verfaillie, K. (2004). Perception of biological motion: A stimulus set of human point-light actions. Behavior Research Methods, Instruments & Computers, 36(4), 625–629.
Vanrie, J., & Verfaillie, K. (2006). Perceiving depth in point-light actions. Perception & Psychophysics, 68, 601–612. doi:10.3758/BF03208762
Verfaillie, K., De Troy, A., & Van Rensbergen, J. (1994). Transsaccadic integration of biological motion. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20, 649–670. doi:10.1037/0278-7393.20.3.649
Author note
O.M.L. has a FAPESP PhD grant (2012/24696-1) and was supported by a CAPES PDSE grant (99999.002966/2014-00). P.S.B. is a CNPq research fellow (304164/2012-7).
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 83 kb)
Rights and permissions
About this article

Cite this article
Lapenta, O.M., Xavier, A.P., Côrrea, S.C. et al. Human biological and nonbiological point-light movements: Creation and validation of the dataset. Behav Res 49, 2083–2092 (2017). https://doi.org/10.3758/s13428-016-0843-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-016-0843-9