
Abstract
In this article, we validate an experimental paradigm, SPaM, that we first described elsewhere (Luke & Christianson, Memory & Cognition 40:628–641, 2012). SPaM is a synthesis of self-paced reading and masked priming. The primary purpose of SPaM is to permit the study of sentence context effects on early word recognition. In the experiment reported here, we show that SPaM successfully reproduces results from both the self-paced reading and masked-priming literatures. We also outline the advantages and potential uses of this paradigm. For users of E-Prime, the experimental program can be downloaded from our lab website, http://epl.beckman.illinois.edu/.
Similar content being viewed by others

The masked-priming paradigm has had a considerable impact on the study of visual word recognition (Forster & Davis, 1984; Kinoshita & Lupker, 2003). In the sort of masked-priming lexical-decision experiment typical of the visual word recognition literature, participants are presented with a target letter string in isolation on a computer screen and are asked to decide whether the target is a word. Targets are preceded by primes, which are letter strings presented for very brief durations, typically 30–60 ms. The primes are either sandwiched between two visual masks, usually a string of hash marks or other nonletter symbols (forward and backward masked priming), with the target following the second mask, or they simply follow a forward mask and precede the target (forward masked priming). Because of the mask(s), the primes are not consciously visible to participants. Masked priming is extremely useful in probing the very earliest stages of visual word recognition. Primes that resemble the target word in some ways but differ in others (e.g., both share the same letters, but in different orders) allow us to determine whether those similarities facilitate or inhibit word recognition, and also to determine the time course of the effect by varying prime duration.
The self-paced word-by-word reading paradigm (Aaronson & Ferres, 1984; Aaronson & Scarborough, 1976; Just, Carpenter, & Woolley, 1982) is another established paradigm, with a long history of service in psycholinguistics. In most self-paced reading experiments, participants read a sentence one word or phrase as a time, pressing a button to reveal the next portion of the sentence. In cumulative self-paced reading, the earlier words or phrases stay in view; in noncumulative self-paced reading, each buttonpress remasks the previous words or phrases, while at the same time revealing the next word or phrase. Reading times in self-paced reading are comparable to those observed in natural reading, making it useful for studying various aspects of language processing. Self-paced reading allows researchers to simulate fairly natural reading, but it removes access to any information associated with the upcoming word. In this way, the processing of each newly revealed word can be strictly timed from the buttonpress that reveals it to the one that removes it and reveals the next word. In normal reading, some low-level analysis is performed on words before they are fixated (i.e., in the parafovea; see Rayner, 1998). Although it is often possible to determine what sorts of information are available in the parafovea and what sorts are not available until a word is fixated in the fovea using even more naturalistic eyetracking methods (cf. Rayner, Pollatsek, Ashby, & Clifton, 2012), it can be argued that self-paced reading’s encapsulation of processing on each individual word makes the results more straightforward to interpret.
Both masked priming and self-paced reading have strengths and weaknesses. Masked priming is thought to tap nonconscious processing of individual words, but in this paradigm words are presented one at a time, divorced from the larger linguistic context in which words usually appear. In self-paced reading, words are embedded in context, but because the paradigm only provides a measure of the total time spent processing the word, it is difficult to dissociate early and late (or nonconscious and conscious) stages of processing. These complementary sets of strengths and weaknesses have prompted us to combine the two paradigms into a new one, which we introduced in Luke and Christianson (2012). We call this new paradigm SPaM, because it combines self-paced word-by-word reading and masked priming. In SPaM, a participant reads sentences one word at a time, pressing a button to view each new word in a noncumulative, self-paced fashion. After the buttonpress, a prime is presented in the location of the next word, after which the next word appears. This paradigm, described in more detail below, is similar to one first described by Trueswell and Kim (1998), but it improves and expands on their paradigm in several ways (see the Discussion section). The most notable improvement is that in SPaM, a prime appears before every word in the sentence instead of before a single target word. This makes the individual primes much less likely to be detected.
As a combination of masked priming and self-paced reading, SPaM is a useful tool for investigating context effects on the earliest stages of visual word recognition. In Luke and Christianson (2012), we used this paradigm to explore the effect of a semantically constraining context on the effectiveness of a particular class of masked primes known as transposed-letter primes. The transposed-letter (TL) effect is based on a growing body of research in visual word recognition that has demonstrated that under most circumstances, masked primes containing letter transpositions are significantly less disruptive to word recognition than are appropriately matched primes with letter substitutions (Forster, Davis, Schoknecht, & Carter, 1987; Perea & Lupker, 2003a, b; Schoonbaert & Grainger, 2004). This means that the TL prime jugde can facilitate the recognition of judge, while the letter substitution control prime jupte does not. Using SPaM, we observed significant TL priming when the target words appeared in nonconstraining contexts, but not when they appeared in constraining contexts in which they were highly predictable. We interpreted this finding as indicating that readers use semantic context to make predictions about both letter identity and position in upcoming words, and that these predictions have an early influence on visual word recognition.
In Luke and Christianson (2012), we showed that the SPaM procedure can replicate standard findings from the TL-priming literature. We did not investigate or report any self-paced reading effects in that study, and as SPaM is a synthesis of masked priming and self-paced reading, it is necessary to show that it can successfully and concurrently reproduce standard findings from both paradigms. This was the primary goal of the experiment reported below. With regard to the self-paced reading results, we should observe significant effects of word frequency and word length (Just et al., 1982) and of predictability (e.g., Rayner & Well, 1996), as well as end-of-clause and end-of-sentence wrap-up effects (Aaronson & Scarborough, 1976; Just et al., 1982).
Additionally, the present experiment included prime conditions that are used as control conditions in the masked-priming literature but that were not tested in Luke and Christianson (2012): namely, a no-prime condition and a nonword prime condition consisting of random letter strings, in addition to the identity and unrelated-word prime conditions. Since priming studies by their nature require a baseline condition against which to measure priming effects, we felt that it was important to establish that all of these potential control conditions behave as expected in SPaM. As in our previous study, we expected to see robust identity priming. Furthermore, according to the masked-priming literature, unrelated-word primes and random-letter primes should have similar effects (Perea, Fernández, & Rosa, 1998). The no-prime condition, however, should be faster than the other control conditions (Davis, 2003; Forster, Mohan, & Hector, 2003). By including these prime conditions, this experiment, in combination with Luke and Christianson (2012), should confirm that in SPaM the control primes most commonly used in masked-priming studies behave as expected.
A further purpose of the present experiment was to substantiate two claims made in Luke and Christianson (2012) about SPaM. In that study, only one word in the sentence actually served as a target word; the other words were always preceded by identity primes and were not analyzed. We suggested that because in SPaM every word in every sentence is preceded by some kind of prime, in principle it would be possible to include multiple critical prime–target pairs in each sentence. To verify that this was indeed the case, every word in every sentence in the present experiment was primed and included in the analysis. We also claimed that priming every word in the sentence was an effective way to prevent participants from noticing the presence of the masked primes, an issue that had arisen in previous integrations of masked priming with self-paced reading (Trueswell & Kim, 1998) or with eyetracking (Sereno & Rayner, 1992). The present experiment also provided an opportunity to verify that in SPaM the primes are difficult to detect, even when each word in the sentence is preceded by a nonidentity prime.
Method
Participants
A group of 62 people from the University of Illinois at Urbana-Champaign community participated. Postexperiment debriefings revealed that two of these participants were able to detect the presence of the primes, and they were excluded; no other participants reported noticing the presence of the primes. The large majority of the participants were recruited from the Educational Psychology subject pool. All were compensated for their time with either course credit or $5.
Materials
The experimental stimuli included 192 sentences. These represented a variety of sentence structures and lengths. The sentences had an average of 11.4 words (range: 7–17 words). Every word in each sentence was preceded by one of four primes: an identity prime, no prime (a string of the nonletter symbol “+”), a string of random letters, or a random-word prime (see Table 1). The random letters were chosen so that the overall word shape would be preserved. The random-word primes were chosen by a computer from a large set of words, with the only criterion being that the prime and the target must be of the same length. Prime type varied between sentences, but within sentences the prime type was the same for all words. For each sentence, a simple yes/no comprehension question was constructed. For example, for the sentence in Table 1, the question was “Was the cake warm?” These questions were presented after each sentence to ensure that participants read the sentences for meaning.
Included in the stimuli were 98 sentences taken from Schwanenflugel (1986). Each of these 98 sentences contained a target word that was highly predictable, with a cloze scoreFootnote 1 between .2 and 1. The predictable target word was the 8th in the sentence, on average, and these sentences were on average 12 words long. These sentences with predictable words were included to confirm that predictability effects on reading times are observable in SPaM, as they are in normal reading (e.g., Drieghe, Brysbaert, Desmet, & De Baecke, 2004; Ehrlich & Rayner, 1981; Rayner, Slattery, Drieghe, & Liversedge, 2011; Rayner & Well, 1996). In Luke and Christianson (2012), a marginally significant effect of cloze score was observed on reading times in Experiment 2, suggesting that SPaM should be able to detect predictability effects. However, because one of the primary purposes of SPaM is to investigate context effects on masked priming, and because the effect was only marginally significant in the earlier experiment, it seemed prudent to reproduce this effect using a more standard set of predictability norms, such as those in Schwanenflugel (1986). These predictable words were analyzed separately.
Procedure
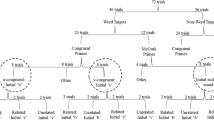
The experiment was run using E-Prime software (Schneider, Eschman, & Zuccolotto, 2002), version 2.0 professional. Participants were seated 75 cm away from a 20-in. CRT monitor, with the refresh rate set to 100 MHz. The participants made responses on a standard game controller. All items were presented in black 14-point text on a white background. The steps of the SPaM procedure described below are illustrated in Fig. 1. Participants first saw a fixation cross at the left side of the screen. When a participant pressed the NEXT button, the target sentence appeared on the screen, with hash marks (#) in place of the letters. Each time that the participant pressed the NEXT button, the following steps occurred. First, the letters of the just-read word (word N – 1) were replaced with underlines (_). Then there was a 10-ms pause before word N appeared. This pause was included to give the participant time to complete the short planned saccade to the target word (word N) before the prime appeared. The hash marks of word N were then replaced by the prime, which remained on screen for 50 ms (typical prime durations in single-word lexical-decision tasks are between 40 and 60 ms). The four types of primes are illustrated in Table 1. After 50 ms, the prime was replaced by the target word. A subsequent buttonpress replaced word N with underlines, and after a 10-ms pause, the sequence began again for word N + 1. Self-paced reading was thus noncumulative, and the masking of the prime was forward. Reading times were measured from the onset of the target word. After the last word in the sentence was presented and the NEXT button was pressed, participants saw a yes/no comprehension question in the center of the screen, which they answered by means of buttons labeled YES and NO on the game controller. After the question was answered, the fixation cross reappeared, and the process began again. The sentences were presented in a random order for each participant.

The SPaM procedure. After each buttonpress, three events occur. First, the currently visible word is removed, and no word is visible for 10 ms. This provides time for the participant’s eyes to complete a movement to the next word. Then, the prime appears for the designated duration, in this case 50 ms. Finally, the target word appears and remains visible until the participant presses a button. The random-letter prime condition is illustrated here
In masked priming, it is a common practice to present the prime in lowercase letters and the target in uppercase. This minimizes the overlap of visual features, which is important if the priming is to be attributed to shared lexical representations rather than to, say, visual sensory memory. This practice was impractical here, as it would have required presenting the entire sentence in uppercase, and our goal was to make the participants’ task as like normal reading as possible. Instead, the visual overlap of prime and target was minimized by presenting them in different fonts and by italicizing the prime. Some evidence has indicated that manipulations of case and of font have similar effects on the electrophysiological response to masked primes (Chauncey, Holcomb, & Grainger, 2008), and the results reported in Luke and Christianson (2012), as well as those reported below, show that this choice did not significantly affect the magnitude or pattern of masked-priming effects. The fonts used were Courier New for the primes and Lucida Console for the targets. Both fonts are monospace, meaning that all letters are the same width, which ensures that all primes and targets were the same width. With non-monospace fonts, the primes and targets would not have appeared in the same location on the screen, which would have put the prime in a location other than where the participant was looking. Other fonts could be used instead, as long as those fonts were also monospace.
In previous integrations of masked priming with self-paced reading (Trueswell & Kim, 1998) and with eyetracking (“fast priming”; Sereno & Rayner, 1992), in which only the target word was primed, participants were highly likely to detect the primes and had to be instructed to ignore them. In SPaM, every word was preceded by a prime, which we found from pilot testing helped to reduce the likelihood that the primes would be detected. This eliminated any need to draw attention to the prime by instructing participants to ignore it.
Results
Reading times were measured from the onset of each word, and not from the previous buttonpress or the onset of the prime. The reason for this was that the onsets of the prime, the 10-ms saccade pause, and the target word were synched with the monitor’s vertical blank, so there was a small amount of variability in the onsets of all three of these events. While the amount of variability was small for each event, and the prime duration was consistently 50 ms, pilot testing revealed that the sum total of this variability was sufficient to obscure some priming effects.
Every word in every sentence served as a target and as a data point in the overall data set. From this large set, reading time outliers shorter than 100 ms and longer than 2,000 ms were removed before analysis. These values were chosen on the basis of analysis of pilot data and on the observed distribution of reading times. All data points were discarded from sentences when the comprehension question was answered incorrectly. Data for extremely short words (less than three letters long) were also removed. Altogether, approximately 1.5 % of the data was discarded. The remaining data included observations from 875 unique words, for a total of 98,938 data points.
The data were then analyzed using a linear mixed effects model (Baayen, Davidson, & Bates, 2008). Possible predictors included prime condition (identity, no prime, random letters, random words), trial number, clause position (end of clause vs. within clause), and sentence position (end of sentence vs. within sentence), as well as word length (length of the target word, in letters: mean = 4.9, range = 3–12) and log word frequency (log frequency of the target word from the CELEX database, http://celex.mpi.nl/: mean = 8.86, range = 1.1–13.9; before analysis, frequency was residualized to remove collinearity with word length). All continuous predictors were centered.
The random-effects structure of the model was fitted using likelihood ratio tests. Random intercepts for participants and items were included, as well as random by-participants and by-items slopes for all predictors. The fixed-effects structure of the model was fitted using a stepwise selection procedure, and fixed effects and interactions were retained in the model only if they were significant or marginally so (i.e., p < .1). We obtained p values using Markov chain Monte Carlo sampling. Reading times were log transformed. The final, best-fitting model included prime condition, trial number, word length, log word frequency, clause position, and sentence position, as well as the interaction of log word frequency and prime condition.
Priming effects
Figure 2 shows the mean reading times in the four prime conditions. The model output revealed that reading times were faster in the identity prime condition than in the three control conditions. These differences were greatest, and equivalent, for the random-word and random-letter control conditions (random words, coeff. = 0.035, SE = 0.0067, t = 5.23, p < .001; random letters, coeff. = 0.034, SE = 0.007, t = 4.79, p < .001). The no-prime condition, while also significantly slower than the identity prime condition (coeff. = 0.018, SE = 0.0031, t = 2.83, p < .01), only differed from the identity condition by 5 ms, and it was 5 ms faster than the other control conditions.

Reading times in the four prime conditions. Error bars represent standard errors. A significant effect of identity priming is apparent. The no-prime condition is faster than the other control conditions, and the random-letter and random-word prime conditions do not differ, consistent with previous research
Self-paced reading effects
The other predictors revealed that SPaM also reproduces standard findings from the self-paced reading literature. There was a significant effect of trial (coeff. = −0.0022, SE = 0.00002, t = −109.73, p < .001), indicating that participants sped up as they progressed through the experiment (effect size = 121 ms). Residual log word frequency was also a significant predictor of reading times (coeff. = −0.0063, SE = 0.0029, t = −2.19, p < .05), with more-frequent words being read faster. This effect is illustrated in Fig. 3. Frequency interacted with prime condition in the random-letter prime condition only (coeff. = −0.0025, SE = 0.001, t = −2.52, p < .05), indicating that the frequency effect was larger in this condition (40 ms) than in the identity prime condition (25 ms). This also means that priming effects relative to a random-letter control were slightly stronger for words in the lower half of the frequency range (about 12 ms) than for words in the higher-frequency half (about 8.75 ms).

Effect of word frequency in each prime condition. The slopes of the lines reveal a significant negative relationship between residual log word frequency and reading times in each prime condition, an effect that is statistically stronger in the random-letter condition. The different intercepts also reveal the significant identity priming effect. Lines represent the regression lines fitted by the linear mixed model analysis in each prime condition
Clause wrap-up effects were also observed (coeff. = 0.89, SE = 0.038, t = 2.38, p < .05), with words at the ends of clauses being read an average of 27 ms longer. Significantly more time was spent on words at the ends of sentences, as well (coeff. = 0.12, SE = 0.025, t = 5.01, p < .001; effect size = 107 ms). We found a significant and positive effect of length (coeff = 0.022, SE = 0.0024, t = 9.1, p < .001; effect size = 60 ms), with more time being spent on words with more letters. This effect is illustrated in Fig. 4.

Effect of word length in each prime condition. A significant and positive relationship between word length and reading times is apparent in the line slopes in all prime conditions. The different intercepts also reveal the significant identity-priming effect. Lines represent the regression lines fitted by the linear mixed model analysis in each prime condition
To explore the effect of predictability as well as any possible interactions between predictability and prime condition, we performed a separate analysis on the predictable target words from the 98 sentences taken from Schwanenflugel (1986), using cloze score (M = .6, range = .2 to 1) as a continuous predictor, as well as prime condition as a categorical predictor. In this analysis, the difference between the identity prime and no-prime conditions was smaller than that observed in the overall analysis (3 ms) and was not significant (t = 0.7). The identity prime condition was still faster than the random-letter and random-word conditions, by 19 and 14 ms, respectively (for random letters, coeff. = 0.064, SE = 0.013, t = 4.8, p < .001; for random words, coeff. = 0.05, SE = 0.013, t = 3.73, p < .001).
As a word’s predictability increased, reading time decreased (coeff = −0.1, SE = 0.042, t = −2.47, p < .05; effect size = 21 ms). Figure 5 illustrates this effect, which was statistically constant across prime conditions (all interaction ts < 1.12). This indicates that the more predictable a word is, the faster it is read.

Effect of predictability in each prime condition. A significant and negative relationship between predictability and reading times is apparent in the line slopes in all four prime conditions. The different intercepts also reveal the significant identity-priming effect. Lines represent the regression lines fitted by the linear mixed model analysis in each prime condition
Discussion
The SPaM paradigm produced the expected patterns of results. Identity primes were facilitative relative to both a nonword prime made from random letters and an unrelated-word prime. Furthermore, performance levels with these two control primes did not differ from each other, as has been observed for other masked-priming tasks (Perea et al., 1998). The no-prime condition was faster than the other control conditions, again consistent with previous research (Davis, 2003; Forster et al., 2003).
With regard to the self-paced reading results, SPaM also performed as expected. Significant effects of the frequency, length, and predictability of target words were observed, as well as clause and sentence wrap-up effects. Interestingly, target word frequency interacted with prime condition, indicating a steeper slope for frequency in the random-letter condition than in the other conditions. This contrasts with previous research (Forster & Davis, 1984), in which no influence of frequency on priming was observed. The effect observed was rather small, however, and it is likely that we were able to detect it only because of our large number of data points. Prime type did not interact with the other variables.
These results show that the SPaM technique replicates standard findings from both the masked-priming and self-paced reading literatures. In combination with the results of Luke and Christianson (2012), the findings show that SPaM is an effective synthesis of both paradigms; SPaM produces the expected results for a variety of masked primes, including transposed-letter and substitution primes, random-letter strings, and unrelated words, and produces the frequency, length, predictability, and wrap-up effects seen in the self-paced reading literature.
As mentioned in the introduction, other researchers have attempted to combine masked priming with either self-paced reading (Trueswell & Kim, 1998) or eyetracking (Sereno & Rayner, 1992). In these studies, which did not prime every word, the primes were detected quite often—so often, in fact, that participants had to be instructed to ignore the primes. By contrast, while a handful of participants in Luke and Christianson (2012) were aware of a “flash” preceding each word, only one of the participants reported noticing the presence of the primes, and none of the participants were able to identify any of them. Likewise, out of the 62 participants involved in the present study, only two had to be excluded because they reported noticing the primes. Thus, SPaM is an improvement over previous implementations because the primes are difficult to detect, and thus are truly “masked.”
Another advantage of priming every word in the sentence is that it is possible to include more than one prime–target pair per sentence, or even, as we did here, to make every word in the sentence a target word. This permits a great deal of data collection in not too many trials, and it does not appear to increase the likelihood that the primes will be detected.
SPaM also uses a string of hash marks (#) as the forward mask, as is commonly done in masked-priming studies, which is a more effective forward mask that those used in previous implementations (Trueswell & Kim, 1998). As we noted in Luke and Christianson (2012), SPaM also has certain advantages over fast priming (Sereno & Rayner, 1992), the integration of masked priming with eyetracking. The most notable of these advantages, other than reduced prime detection, is that in fast priming a great deal of the data are unusable, and many participants have to be discarded altogether. By contrast, only about 1.5 % of the data in this experiment were discarded, and all participants provided usable data. Another advantage of SPaM over fast priming is that fast priming requires an eyetracker with a sampling rate of at least 1000 Hz (i.e., a relatively expensive eyetracker), whereas SPaM does not. This means that researchers who currently do masked priming can run SPaM on the same hardware that they are currently using. Thus, although SPaM is not as similar to natural reading as is eyetracking, it is preferable for researchers who want to use masked priming in a sentence context. For a further comparison of SPaM and eyetracking, see our previous study.
SPaM is primarily intended as a tool for investigating or controlling the effects of sentence context on lexical access, and it has proven effective in this role (Luke & Christianson, 2012). Even so, SPaM does have certain advantages over traditional masked priming that might make it preferable even when context is not an issue. During masked-priming experiments, participants typically perform a lexical-decision or naming task. One advantage of SPaM is that it is closer to natural reading, because participants are not required to perform any additional task other than to simply read the target words. A second advantage, related to the first, is that unlike in the lexical decision task participants see no consciously visible nonwords during the SPaM procedure. A final advantage is the possibility of exploring the effects of priming on the spillover words that follow the target words.
Conclusion
SPaM is an experimental paradigm for investigating word processing during reading. This paradigm is a synthesis of self-paced reading and masked priming. Its primary purpose is to permit the study of sentence context effects on early word recognition. In order to show that SPaM is an effective synthesis of the two paradigms, we replicated standard findings from both the self-paced reading and masked-priming literatures. We also outlined the advantages of this paradigm and its possible uses.
Notes
A cloze score is obtained by presenting participants with a portion of a sentence, usually everything up to but not including the target word, and asking them to provide the missing word. Cloze scores represent the proportions of responses given that matched the expected target word.
References
Aaronson, D., & Ferres, S. (1984). The word-by-word reading paradigm: An experimental and theoretical approach. In D. E. Kieras & M. A. Just (Eds.), New methods in reading comprehension research (pp. 31–68). Hillsdale: Erlbaum.
Aaronson, D., & Scarborough, H. S. (1976). Performance theories for sentence coding: Some quantitative evidence. Journal of Experimental Psychology: Human Perception and Performance, 2, 56–70. doi:10.1037/0096-1523.2.1.56
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59, 390–412. doi:10.1016/j.jml.2007.12.005
Chauncey, K., Holcomb, P. J., & Grainger, J. (2008). Effects of stimulus font and size on masked repetition priming: An event-related potentials (ERP) investigation. Language and Cognitive Processes, 23, 183–200. doi:10.1080/01690960701579839
Davis, C. J. (2003). Factors underlying masked priming effects in competitive network models of visual word recognition. In S. Kinoshita & S. J. Lupker (Eds.), Masked priming: The state of the art (pp. 67–95). New York, NY: Psychology Press.
Drieghe, D., Brysbaert, M., Desmet, T., & De Baecke, C. (2004). Word skipping in reading: On the interplay of linguistic and visual factors. European Journal of Cognitive Psychology, 16, 79–103. doi:10.1080/09541440340000141
Ehrlich, S. F., & Rayner, K. (1981). Contextual effects on word perception and eye movements during reading. Journal of Verbal Learning and Verbal Behavior, 20, 641–655. doi:10.1016/S0022-5371(81)90220-6
Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 680–698. doi:10.1037/0278-7393.10.4.680
Forster, K. I., Davis, C., Schoknecht, C., & Carter, R. (1987). Masked priming with graphemically related forms: Repetition or partial activation? Quarterly Journal of Experimental Psychology, 39A, 211–251. doi:10.1080/14640748708401785
Forster, K. I., Mohan, K., & Hector, J. (2003). The mechanics of masked priming. In S. Kinoshita & S. J. Lupker (Eds.), Masked priming: State of the art (pp. 3–37). New York, NY: Psychology Press.
Just, M. A., Carpenter, P. A., & Woolley, J. D. (1982). Paradigms and processes in reading comprehension. Journal of Experimental Psychology: General, 111, 228–238. doi:10.1037/0096-3445.111.2.228
Kinoshita, S., & Lupker, S. J. (2003). Masked priming: The state of the art. New York, NY: Psychology Press.
Luke, S. G., & Christianson, K. (2012). Semantic predictability eliminates the transposed-letter effect. Memory & Cognition, 40, 628–641. doi:10.3758/s13421-011-0170-4
Perea, M., Fernández, L., & Rosa, E. (1998). El papel del status léxico y la frecuencia del estímulo-señal en la condición no relacionada con la técnica de presentación enmascarada del estímulo-señal [The role of the lexical status and the frequency of the unrelated prime in the masked priming technique]. Psicológica, 19, 311–319.
Perea, M., & Lupker, S. J. (2003a). Does jugde activate COURT? Transposed-letter similarity effects in masked associative priming. Memory & Cognition, 31, 829–841. doi:10.3758/BF03196438
Perea, M., & Lupker, S. J. (2003b). Transposed-letter confusability effects in masked form priming. In S. Kinoshita & S. J. Lupker (Eds.), Masked priming: The state of the art (pp. 97–120). New York, NY: Psychology Press.
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422. doi:10.1037/0033-2909.124.3.372
Rayner, K., Pollatsek, A., Ashby, J., & Clifton, C., Jr. (2012). The psychology of reading (2nd ed.). New York, NY: Psychology Press.
Rayner, K., Slattery, T. J., Drieghe, D., & Liversedge, S. P. (2011). Eye movements and word skipping during reading: Effects of word length and predictability. Journal of Experimental Psychology: Human Perception and Performance, 37, 514–528. doi:10.1037/a0020990
Rayner, K., & Well, A. D. (1996). Effects of contextual constraint on eye movements in reading: A further examination. Psychonomic Bulletin & Review, 3, 504–509. doi:10.3758/BF03214555
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime user’s guide. Pittsburgh: Psychology Software Tools.
Schoonbaert, S., & Grainger, J. (2004). Letter position coding in printed word perception: Effects of repeated and transposed letters. Language and Cognitive Processes, 19, 333–367. doi:10.1080/01690960344000198
Schwanenflugel, P. J. (1986). Completion norms for final words of sentences using a multiple production measure. Behavior Research Methods, 18, 363–371. doi:10.3758/BF03204419
Sereno, S. C., & Rayner, K. (1992). Fast priming during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 18, 173–184. doi:10.1037/0096-1523.18.1.173
Trueswell, J. C., & Kim, A. E. (1998). How to prune a garden path by nipping it in the bud: Fast priming of verb argument structure. Journal of Memory and Language, 39, 102–123. doi:10.1006/jmla.1998.2565
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Luke, S.G., Christianson, K. SPaM: A combined self-paced reading and masked-priming paradigm. Behav Res 45, 143–150 (2013). https://doi.org/10.3758/s13428-012-0239-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-012-0239-4