
Abstract
Self-relevant stimuli (i.e. meaningful/important to the observer and related to the self) are typically remembered better than other-relevant stimuli. However, whether a self-relevance memory benefit could be conferred to a novel neutral face, remains to be seen. Recent studies have shown that emotional responses to neutral faces can be altered by using a preceding sentence as context that varies in terms of self-relevance (self/other-relevant) and valence (positive/negative; e.g. "S/he thinks your comment is dumb/smart"). We adapted this paradigm to investigate whether the context conferred by the preceding sentence also impacts memorability of the subsequently presented face. Participants saw faces primed with contextual sentences and rated how aroused, and how positive or negative, the faces made them feel. Later incidental recognition accuracy for the faces was greater when these had been preceded by self-relevant compared to other-relevant sentences. Faces preceded by self-relevant contexts were also rated as more arousing. There was no impact of sentence valence on arousal ratings or on recognition memory for faces. Sentence self-relevance and valence interacted to affect participants’ ratings of how positive or negative the faces made them feel during encoding, but did not interact to impact later recognition. Our results indicate that initial social encounters can have a lasting effect on one’s memory of another person, producing an enhanced memory trace of that individual. We propose that the effect is driven by an arousal-based mechanism, elicited by faces perceived to be self-relevant.
Similar content being viewed by others


Introduction
Recognition of faces is one of our most important social abilities (Hou & Liu, 2019) and recognition impairments can have a large impact on forming and maintaining social relationships (e.g. Yardley et al., 2008; Dalrymple et al., 2014; Fine, 2012). There are many physical factors during an initial interaction that can later impact recognition memory for faces, including lighting, viewpoint, and physical features (see Johnston & Edmonds, 2009; Bruce and Young, 1986 for reviews). However, we also know that accompanying a target with another that is semantically meaningful enhances memorability of the target (Skinner & Fernandes, 2010), and preliminary evidence suggests that pairing a face with conceptual detail (e.g. a name), can provide a memorial benefit to the face (Schwartz & Yovel, 2016). We are still learning about what types of semantic information can confer memory benefits to faces, and how these are conferred.
Recent studies have demonstrated that the social context in which a neutral face is presented can impact participants’ emotional responses to those faces (Koji & Fernandes, 2010; McCrackin & Itier, 2018; Schwarz et al., 2013; Wieser et al., 2014; Klein et al., 2015; Wieser & Moscovitch, 2015), but it is unclear whether this social context could also impact recognition memory for those faces. In many of these studies (McCrackin & Itier, 2018; Wieser et al., 2014; Klein et al., 2015; Schwarz et al., 2013), neutral faces were primed with sentences that provided a meaningful social context. These sentences varied in self-relevance (referring to the participant or to someone else) and valence (a positive or negative comment; e.g. “She thinks you/he have/has no/great personality”). Participants found faces preceded by self-relevant statements to be more arousing, and self-relevance and valence interacted to impact how positive or negative the faces made participants feel (McCrackin & Itier, 2018; Schwarz et al., 2013; Wieser et al., 2014; Klein et al., 2015; Wieser & Moscovitch, 2015). That is, faces preceded by positive self-relevant contexts made participants feel more positive than faces preceded by positive other-relevant contexts. Similarly, faces preceded by negative self-relevant contexts made participants feel more negative than those preceded by negative other-relevant faces. The present study extends this line of work to determine whether a face's contextual self-relevance and valence during an initial encounter can also impact later recognition memory for that face.
There is good reason to believe that contextual self-relevance may impact recognition memory for neutral faces. It has long been noted that information processed with reference to the “self” yields enhanced memory performance in comparison to other-relevant information (e.g. Ferguson et al., 1983; Bower & Gilligan, 1979; Rogers, Kuiper, & Kirker, 1977; Symons & Johnson, 1997; Macrae et al., 2004; Conway, 2005). Although this effect has yet to be extended to novel interactions with faces, self-relevance effects have been reported using various paradigms (see Symons & Johnson, 1997; Klein, 2012, for reviews). Perhaps the most common paradigm used is the Self-Referential Encoding Task, in which participants endorse whether or not a trait is descriptive of themselves or another person. Adjectives describing the self are typically better recalled and recognized than adjectives describing another character (Hudson et al., 2020; Kuiper & Derry, 1982; Symons & Johnson, 1997). Symons and Johnson (1997) argued that targets receive a memory benefit because the self-manipulation invoked elaborative processing or enhanced depth of processing, known to boost memory (Craik & Lockhart, 1972). Within this theoretical framework, faces viewed within self-relevant verbal contexts may receive an enhanced depth of processing at encoding leading to better subsequent recognition. However, one could also argue that the faces of novel people are not directly self- or other-relevant by themselves – they are only made so by pairing them with semantic information. If the memory benefit is conveyed only by the inherent self-relevance of the stimulus, then we would not see a memory benefit appear.
Aside from depth of processing, due to the social value of faces, the emotional impact (McCrackin & Itier, 2018; Schwarz et al., 2013; Wieser et al., 2014; Klein et al., 2015; Wieser & Moscovitch, 2015) of seeing a face within a self-relevant context, or in a positive or negative one, may play a key role in influencing face memorability. There is extensive research showing that emotional stimuli are remembered better than neutral stimuli (Bradley, Greenwald, Petry, & Lang, 1992; Cahill & McGaugh, 1996; Kensinger & Corkin, 2003a, 2003b, see Kensinger, 2004 for review) and that memory for neutral targets, including words (Lee & Fernandes, 2018), objects (Senn & Radomsky, 2012), and faces (Mealey, Daood, & Krage, 1996; Kinzler & Shutts, 2008; Bate et al., 2009; but see Barclay & Lalumière, 2006) can be enhanced by associating or pairing targets with emotional stimuli. Importantly then, it does appear possible that an emotional tag can confer the emotion memory enhancement to an otherwise neutral stimulus such as a neutral face. Part of this emotional impact on memory appears to be arousal based. Generally, memory is better for stimuli that are more arousing (see Storbeck & Clore, 2008; Deffenbacher, 1994 for reviews), though too much arousal, within the context/scene, can occasionally impair memory for faces (MacLin, MacLin & Malpass, 2001, see Christianson, 1992; Deffenbacher et al., 2004, for reviews).
The emotional impact on memory may also be partly valence based. Within the literature on emotional memory enhancement of neutral faces, there appears to be different reports regarding valence specific memory effects. That is, studies that have compared positive and negative valence conditions have found differences in memory benefit, depending on valence. Typically, studies have reported enhanced remembering of neutral faces paired with negatively valenced character details. Young adult participants found neutral faces described as a “cheater”, to be more memorable than those paired with “trustworthy” or “altruist” (Mealey, Daood, & Krage, 1996) and children remembered neutral faces described as “mean” better than “nice” ones (Kinzler & Shutts, 2008). Better recognition memory for mean/cheating faces was proposed to be an adaptive mechanism to remember those who it may be costly to interact with (Mealey, Daood, & Krage, 1996). However, it should be noted that two similar studies failed to replicate the effect of the “cheater” label (Barclay & Lalumière, 2006; Mehl & Buchner, 2008) and one study found an opposite pattern, with better recognition of faces paired with nice than negative statements (Bate et al., 2009). Given the mixed evidence regarding positive and negative valence, it is important to consider, and compare, the influence of both valences, on memory for neutral faces.
The goal of the current study was to further clarify whether valence and self-reference can impact memory for novel, neutral faces. In the present study, faces were associated with positive or negative opinions about the participant, or about someone else. One could argue that, similar to remembering a face described as" mean" or "cheating", it would be adaptive to remember someone who has said something mean about you. Finally, this paradigm allowed us to determine, for the first time, whether a self-relevant memory benefit can be conferred to a novel (neutral) face with sentences referring directly to the participants. We predicted, based on the literature reviewed earlier, that faces viewed in self-relevant contexts would be more accurately recognized during the surprise recall test than faces viewed in other-relevant contexts. A similar prediction was made for faces viewed in negative compared to positive contexts.
Methods
Participants
A meta-analysis conducted by Symons and Johnson (1997) stated that the mean effect size for the self-referential encoding effect is d = .50. With this effect size, using G*Power 3 (Faul, Erdfelder, Lang, & Buchner, 2007), we calculated that a sample size of 44 would be sufficient to detect a significant difference at an alpha of .05, with power of .95. In our current study, seventy-five University of Waterloo (UW) undergraduate students participated. All were between the ages of 18 and 29 with normal or corrected-to-normal vision, and no history of psychiatric or neurological disorders. To ensure that participants had sufficient prior exposure to Caucasian faces and no face-related impairments, all reported living in Canada or the United States for the past five years and rated their ability to recognize people as at least a 7 out of 10 on a Likert-type scale.
Participants were excluded if they read less that 46 of the 48 contextual sentences during the encoding block (see section 2.5.1; n=7), for responding with a valence and arousal rating of 1 for nearly every encoding trial (n=1), for not making any valence or arousal ratings (n=1), and for having recall accuracy rates (see section 2.5.3) equal to or below 0 in one or more conditions (n=3). This left a final sample of 63 participants for analysis (mean age: 20.13, SD = 1.55; 33 female, 30 male).
Face stimuli
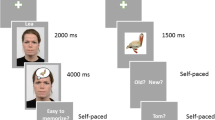
The images of 48 male and 48 female Caucasian faces were selected from the Chicago Face Database (version 2.0). All individuals displayed a neutral expression with direct gaze and wore a gray t-shirt (Fig. 1). Images were edited with the GNU Image Manipulation Program (GIMP 2.8) to remove overly distinguishing facial features (e.g. moles, acne and freckles) and objects (e.g. hair clips, different coloured undershirts) that could be used to recognize the individuals. The images were sorted into two female and two male groupsFootnote 1 based on visual similarity (as judged by the authors) to try and keep each group balanced in terms of hair colour, hair style, distinguishing features, etc. Each group then served either as the encoding faces or the distractor faces, depending on the version randomly assigned to each participant (see section 2.4). Images were centrally presented on a white screen, subtending approximately 10° horizontally and 15° vertically.

Sample trial in the a) encoding stage and the b) recall stage
Contextual sentences
The contextual sentences were selected from McCrackin and Itier (2018), and varied in self-relevance (self-relevant or other-relevant) and valence (positive or negative). For information about the original sentence construction and validation, please see McCrackin and Itier (2018). We selected twelve sentence descriptors, and each descriptor had four sentence versions (e.g. “He thinks you/she have/has no personality/great personality”) corresponding to each of our four conditions (self-relevant positive, self-relevant negative, other-relevant positive and other-relevant negative), for a total of 48 sentences. These descriptors targeted three areas thought to represent core fears associated with social anxiety (Moscovitch, 2009; Moscovitch et al., 2013), with four descriptors referencing social competence (great/ no personality, intelligence/unintelligence, social adeptness/ social awkwardness, and being enjoyable/unenjoyable to meet with), four referencing physical attractiveness (healthy/greasy hair, lovely/ugly face, neat/ sloppy appearance, and being attractive/unattractive), and four referencing overt signs of anxiety (panicking/unafraid, tense/calm, mumbling/clear, and looking refreshed/sweaty). The four descriptors selected for each category were the four with the highest valence and self-relevance interaction score in each category in the original sentence validation study (see McCrackin & Itier, 2018).
Experimental design
After providing informed consent, participants filled out a demographics questionnaire. They then completed the encoding portion of the computer task on a CRT monitor (resolution of 1600x1200), with their head resting on a chinrest 65cm from the monitor. Their dominant eye (determined with the Miles test, Miles, 1930) was tracked using an Eyelink 1000 eye-tracker at a 1000Hz sampling rate to later ensure that participants read the contextual sentence in each trial.
A sample trial in the encoding stage is depicted in Fig. 1a. Participants were informed that they would be rating their emotional responses to individuals expressing opinions about them (the participant) or about someone else. They were asked to read the sentence describing the opinion, fixate on the following fixation cross, and then observe the face of the individual holding that opinion. They were then asked to rate how positive or negative the face made them feel (using the number keys from 1/very negative to 9/very positive) and how affectively aroused the face made them feel (using the number keys from 1/very unaroused to 9/very aroused), with four seconds provided to make each rating. Participants were given a minimum of four practice trials (using faces different than those from the experimental trials) to ensure that they could complete their ratings on each trial within the required time. If they were unable to during the first round of practice trials, more were completed until they became accustomed to the trial progression. They were not informed that their memory for the faces would later be tested.
The encoding stage was programmed to ensure that all participants completed the task in the same amount of time. On each trial, the sentence was presented for 4000ms, the fixation cross for 1000ms, the face for 3000ms, and then the valence and arousal rating screens for 4000ms, regardless of when participants made their responses. Following the encoding task, participants were asked to count backwards from 300 by threes for one minute. This ensured that no faces were rehearsed in working memory. Again, the time it took to give the instructions and complete this task were fixed so each participant took the same amount of time.
Participants were then given a surprise recognition task (Fig. 1b) with 96 faces, 48 of which were old (i.e. used in the encoding task) and 48 were new. Participants indicated whether the faces displayed to them were old or new by pressing the up or down arrow keys with their dominant hand. This response mapping was counterbalanced across participants. They were asked to make their responses as quickly as possible, but not at the cost of accuracy.
Individuals were assigned sequentially to one of eight study versions, which varied which faces were paired with which context sentence. In versions 1 to 4, the first set of male and female faces were presented during encoding (see Section 2.2), and the second set were presented during recall as distractors. In versions 5-8, this was reversed. Each individual face was paired once with each type of sentence condition (self-relevant positive, self-relevant negative, other positive, other negative), corresponding to the 4 versions in which it was used during encoding. In each version, there were 48 trials randomly displayed in the encoding block, for a total of 12 trials per condition across the study.
Data analysis
Ensuring that participants read the contextual sentences during encoding
Eye-tracking data were used to confirm that participants had read the sentences during the encoding block. A rectangular region of interest (subtending 32.71o horizontally and 3.72o vertically) was created to span the sentences. Any trials in which participants had not made at least two fixations in this area were concluded to have not been read, and if participants did not read at least 46 of the 48 trials they were excluded from analysis.
If participants missed two or less trials, the participant’s data were kept. However, the data corresponding to those particular trials were rejected from analysis. This included the valence and arousal ratings during the encoding block for that trial (see section 2.4.2) and the hit rate and accuracy for the face featured in those trials during the recall block (see section 2.4.3). Overall, included participants read most of the sentences, with an average of only 0.11 (SD = 0.36) total trials removed per participant.
Encoding data analysis
Average ratings of each participant’s valence and arousal in the encoding stage were calculated for the four conditions. A within-subjects Analyses of Variance (ANOVA) with factors of self-relevance (2; self, other) and valence (2; positive, negative) was run on valence ratings, and another on arousal ratings. Trials in which participants failed to indicate their rating before the trials progressed were not included in these averages. However, participants responded during most trials, only missing an average of 0.19 (SD = 0.29) valence and 0.32 (SD = 0.39) arousal ratings per condition.
Recognition data analysis
The hit rate for each participant and condition was calculated by taking the number of faces recalled correctly for each condition (minus any faces removed for not reading the sentence), and dividing by the maximum score a participant could receive for each condition (12 for most participants, but 11 if the participant had a trial from that condition removed for not reading the sentence). The false alarm rate for each participant was calculated by taking the total number of lures (new faces), and dividing by 48, which is the maximum number of false alarms. Finally, average accuracy rates (hit rate – false alarm rate) for each condition during the recall stage were calculated for each participant. These accuracy rates were entered into a within-subjects ANOVA with factors of self-relevance (2; self, other) and valence (2; positive, negative). Mean false alarm rate was .14 (SD = .10); this cannot be broken down by condition as novel faces were never seen within a sentence context.
Results
Valence and arousal ratings during encoding
We analyzed ratings of valence and arousal made during the encoding phase in response to how each face made the participant feel. These were analyzed to determine whether each type of statement evoked different emotional responses, as measured by both valence and arousal.
Firstly, there was a main effect of sentence valence on valence ratings, F(1,62) = 88.20, MSE=.83, p < .001, ηp2=.59, which was qualified by a valence by self-relevance interaction, F(1,62) = 32.03, MSE=.24, p <.001, ηp2=.34 (Fig. 2a). Paired comparisons indicated that ratings were more positive for faces preceded by sentences that were positive and self-relevant than positive and other-relevant (t(62) = 4.27, SE = .08, p<.001, Cohen's d=.54); ratings were more negative for faces preceded by sentences that were negative and self-relevant than negative and other-relevant (t(62) = -4.18, SE = .09, p<.001, Cohen's d=-.53). There was no main effect of self-relevance on valence ratings, F(1,62) = .17, MSE=.19, p =.68, ηp2=.003.

Participant ratings during the encoding phase of a) valence (how positive or negative the face made them feel, ranging from 1/very negative to 9/very positive) and b) arousal (how affectively aroused the face made them feel, ranging from 1/very unaroused to 9/very aroused). The boxes encompass data between the 25th and 75th percentiles, and for each condition the mean (black dot) and median (solid line) are shown. Note that there was an interaction between valence and self-relevance on valence ratings, and a main effect of self-relevance on arousal ratings
There was also a main effect of sentence self-relevance on arousal ratings, F(1,62) = 19.90, MSE=.22, p <.001, ηp2=.24, driven by higher arousal ratings in response to faces preceded by sentences that were self-, as opposed to, other-relevant (Fig. 2b). There was no main effect of sentence valence (F(1,62) = 1.31, MSE=.50, p =.26, ηp2=.021), nor an interaction between sentence valence and self-relevance (F(1,62) = .24, MSE=.26, p =.63, ηp2=.004) on arousal ratings.
Recognition memory for faces
Accuracy rate
There was a main effect of sentence self-relevance, F(1,62) = 4.93, MSE=.014, p = .030, ηp2=.074 (Fig. 3), driven by better recognition accuracy for faces preceded by self-relevant contexts (sentences) during the encoding phase than those viewed in other-relevant contextsFootnote 2. There was no main effect of sentence valence, F(1,62) = .57, MSE=.015, p = .45, ηp2=.009, nor an interaction between self-relevance and valence, F(1,62) = .17, MSE=.016, p = .68, ηp2=.003. The same pattern was observed for hit rate.Footnote 3

Participant accuracy (hit rate – false alarm rate). Boxes encompass the points between the 25th and 75th percentiles, with the mean (black dot) and median (solid line) indicated for each condition. Note that there was a main effect of self-relevance on accuracy
Discussion
The present study investigated whether the valence and self-relevance of the context in which a face is first encountered can impact later recognition memory for those faces. We primed novel neutral faces with sentences varying in self-relevance and valence, and had participants rate their emotional responses to each face. Faces were each preceded with either a positive or negative statement about the participant or about someone else. In this way, the various sentences provided a meaningful semantic context for the faces during encoding. During a surprise recognition test for the faces, we assessed whether this context would confer a memory benefit to the otherwise neutral faces.
During the recognition test, participants had better recognition accuracy for faces that had been viewed in self-relevant contexts. This effect resembles past self-relevance memory effects reported for words, despite the paradigms being quite different. Memory benefits are typically reported for words that participants have intentionally contemplated in reference to the self versus someone else (Bower & Gilligan, 1979; Rogers, Kuiper, & Kirker, 1977; Symons & Johnson, 1997; Macrae et al., 2004; Hudson et al., 2020; Cunningham et al., 2014; Turk, Cunningham & Macrae, 2008; see Symons & Johnson, 1997; Klein, 2012, for reviews). Here, self-relevance was conferred by the sentence preceding the face and still produced an enhancement in recognition accuracy for the face. This is a key finding as it shows that not only do items processed directly as self-relevant receive a memory enhancement, but so do neutral faces primed by a self-relevant sentence.
Up to this point, it was thought that an elaborative thought process (Symons & Johnson, 1997) or a deep level-of-processing (Craik & Lockhart, 1972) was required to produce the self-reference effect on memory. Our findings support results reported by Turk, Cunningham and Macrae (2008), in which the self-reference effect was observed with a more implicit form of processing. In their study, participants showed better recognition of trait adjectives paired alongside pictures of themselves (self-relevant) compared to pictures of neutral others (other-relevant), regardless of how much elaborative processing of the adjective was required. That is, our study supports their claim that statements or traits that are only implicitly processed in association to the self, can be sufficient to produce a self-reference effect, or confer a self-reference effect onto associated stimuli.
In addition to these behavioural studies, electroencephalography (see Knyazev, 2013, for a review) studies using similar paradigms have begun to shed light on the neural impact of putting faces into self-relevant contexts. Based on this work, we propose below a possible mechanism leading to enhanced memory performance. Event related potential (ERP) studies suggest that self-relevance leads to enhanced visual processing of faces from 150ms up to 750ms post-face presentation (McCrackin & Itier, 2018; Wieser et al., 2014; Klein et al., 2015). This protracted modulation spans the Early Posterior Negativity (EPN) thought to reflect attention-driven enhanced processing of emotional stimuli (see Schupp et al., 2006; Olofsson et al., 2008 for reviews), and the Late Positive Potential (LPP), thought to reflect elaborative cognitive appraisal of emotional content (see Schupp et al., 2006; Hajcak et al., 2010; Olofsson et al., 2008 for reviews). Both the EPN (e.g. Junghöfer et al., 2001; Schupp et al., 2004) and LPP (e.g. Rellecke et al., 2012; Itier & Neath-Tavares, 2017; Schupp et al., 2006; Schacht & Sommer, 2009; Bradley et al., 2007) have been presumed to be modulated by arousal in various paradigms and with various types of stimuli. These results support the view that self-relevance may modulate the arousal of faces, and that this arousal in turn confers a memory benefit as has been observed in previous memory research (see Storbeck & Clore, 2008; Deffenbacher, 1994 for reviews). This arousal-based mechanism idea is further supported by the finding that faces seen within self-relevant contexts, in the present study, were more arousing during encoding and also better remembered. This impact of self-relevance on rated arousal of neutral faces replicates findings from previous studies (McCrackin & Itier, 2018; Schwarz et al., 2013; Wieser et al., 2014; Klein et al., 2015; Wieser & Moscovitch, 2015), suggesting it is a reliable effect.
There have been two related studies which manipulated how relevant neutral faces were to an observer, using context sentences in a less direct manner (Bell, Giang & Buchner, 2012; Kroneisen, 2018). The sentences implied that the pictured individual may be harmful to those around them or harmful to themselves (e.g. "throws a beer bottle at people" versus "slits his wrists"), with the assumption that the former is more relevant to participants. However, this is a less powerful manipulation of self-relevance than the present one, in which the participant is directly referred to using pronouns like "you" or "your". The emotional and memorial impact seems to be quite different between these two types of manipulations. Bell, Giang and Buchner (2012) and Kroneisen (2018) found a source memory benefit for the condition assumed to be more relevant to the participant, but there was no recognition benefit. We believe that we found a recognition memory benefit in our study because our self-relevance manipulation impacted participants' arousal, while Bell, Giang, and Buchner’s (2012) manipulation had no impact on arousal. Indeed, it appears that using a more direct self-relevance manipulation as in our study (i.e. referring directly to the participant), that impacts arousal, is what is needed to provide a benefit to recognition memory.
We also replicated the finding that ratings of valence were impacted by self-relevance, and that this depended on sentence valence (McCrackin & Itier, 2018; Schwarz et al., 2013; Wieser et al., 2014; Klein et al., 2015; Wieser & Moscovitch, 2015). Specifically, faces preceded by self-relevant positive sentences made participants feel more positive than those preceded by other-relevant positive sentences. Similarly, faces preceded by self-relevant negative sentences made participants feel more negative than those preceded by other-relevant negative sentences. That is, self-relevance exacerbated the effect of context valence on participants’ feelings. However, we do not believe the mechanism for memory enhancement is valence based since neither contextual valence, nor its interaction with contextual self-relevance, impacted face memory or participant arousal ratings.
The lack of valence effect on memory was unexpected, as previous research has demonstrated that there can be a memory benefit for negative versus positive stimuli (e.g. Inaba, Nomura, & Ohira, 2005), and this includes children's memory for neutral faces given negative semantic tags like "mean" (Kinzler & Shutts, 2008) or adults' memory for "cheaters" (Mealey, Daood, & Krage, 1996). Arguably, it is adaptive to remember individuals who put us at risk (Mealey, Daood, & Krage, 1996), and we hypothesized that a similar mechanism might be seen here to remember faces bearing negative opinions or mean personalities. However, there have been conflicting results using similar paradigms (Barclay & Lalumière, 2006; Mehl & Buchner, 2008; Bate et al. 2009) and we should note that recent studies have found no impact of valence on the Self-Referential Encoding Task for words (D’Argembeau, Comblain, & Van der Linden, 2005; Gliskey & Marquine, 2009; Yang, Truong, Fuss, & Bislimovic, 2012, but see Hudson et al., 2020, for positivity and self reference bias).
One possible explanation for why valence of context sentences had no effect on recognition memory for faces is discussed by Bell and Buchner (2010). They found that recognition of faces with negative semantic tags was not better than that of faces with positive tags, but that it was actually source memory that was impacted. That is, participants were more accurate in their source memory decisions for faces associated with a “disgusting” description, than a neutral or pleasant description. Therefore, it was not that they had enhanced recognition for negatively-tagged faces, but that they were more accurate in knowing that the face was associated with a negative description. They argued that increased familiarity for negative faces, without better source memory, could actually increase an individual's risk of harm, because we tend to approach familiar faces. However, remembering the specific negative connotations linked to the person is what would truly be adaptive. As such, an interesting future direction would be to compare source memory (i.e. memory for the sentences or their key words) with face recognition memory in a similar paradigm. The use of a Remember-Know-New paradigm (e.g. Hirshman & Master, 1997) could be particularly informative as the categories it measures are meant to reflect full recollections of the target and associated context (Remember responses), versus gist-based memory (Know responses).
In summary, the present study demonstrated that the self-relevance of the context in which a face is first encountered impacts later recognition memory for that face. Specifically, we showed that priming faces with sentences that were self- compared to other-relevant enhanced later memory for those faces. When sentences were self-relevant, ratings of arousal increased, and so did memory for the subsequently presented novel neutral face. Such a finding is in line with related ERP literature, suggesting self-relevance effects in memory for faces is driven by an arousal-based mechanism.
Notes
Female group 1 identities: 001, 006, 009, 013, 023, 027, 029, 037, 038, 039, 201, 203, 208, 209, 211, 212, 218, 225, 228, 230, 232, 234, 237, 244. Female group 2: 003, 005, 007, 008, 014, 015, 020, 022, 024, 025, 030, 031, 033, 034, 035, 036, 200, 217, 220, 221, 223, 247, 252. Male group 1: 001, 003, 004, 010, 011, 015, 020, 022, 025, 028, 200, 205, 207, 211, 216, 217, 229, 232, 235, 242, 252, 254, 256, 257. Male group2: 006, 009, 013, 016, 017, 019, 024, 029, 035, 203, 204, 208, 209, 212, 213, 222, 227, 230, 231, 234, 239, 240, 245, 253
Upon request from a reviewer, we also performed an additional identical analysis adding in two of the eliminated participants. One was a participant for which eye-tracking demonstrated had missed reading 10 out of the 48 sentences, which potentially left enough data to obtain meaningful averages for each condition. The other was a participant who did not make any responses during the encoding task; they may have been paying attention to the task but either did not realize they had to respond, or responded too slowly on each trial. The results remained the same with these additions: main effect of self-relevance (F(1,64) = 5.39, MSE =.014, p=.023, ηp2=.078), no effect of valence (F(1,64) = .42, MSE =.015, p=.52, ηp2=.006), nor an interaction (F(1,64) = .002, MSE =.019, p=.97, ηp2<.001).
The statistics are identical for hit rate, given that each participant's accuracy is calculated by subtracting a constant (the false alarm rate) from the hit rate for each condition.
References
Barclay, P., & Lalumière, M. L. (2006). Do people differentially remember cheaters?. Human Nature, 17(1), 98-113.
Bate, S., Haslam, C., Jansari, A., & Hodgson, T. L. (2009). Covert face recognition relies on affective valence in congenital prosopagnosia. Cognitive Neuropsychology, 26(4), 391-411.
Bell, R., & Buchner, A. (2010). Valence modulates source memory for faces. Memory & Cognition, 38(1), 29-41.
Bell, R., Giang, T., & Buchner, A. (2012). Partial and specific source memory for faces associated to other- and self-relevant negative contexts. Cognition & Emotion, 26, 1036-1055.
Bower, H. & Gilligan, S. G. (1979). Remembering information related to one’s self. Journal of Research in Personality, 13, 420-432.
Bradley, M., Greenwald, M., Petry, M., & Lang, P. (1992). Remembering pictures: Pleasure and arousal in memory. Journal of Experimental Psychology: Learning, Memory and Cognition, 18(2), 379-390.
Bradley, M. M., Hamby, S., Löw, A., & Lang, P. J. (2007). Brain potentials in perception: picture complexity and emotional arousal. Psychophysiology, 44(3), 364-373.
Bruce, V., & Young, A. (1986). Understanding face recognition. British journal of psychology, 77(3), 305-327.
Cahill, L. & McGaugh, J.L. (1996). Modulation of memory storage. Current Opinion in Neurobiology, 6(2), 237-242.
Christianson, S. (1992). Emotional stress and eyewitness memory: A critical review. Psyhcological Bulletin, 11(2), 284-309.
Conway, M. A. (2005). Memory and the self. Journal of memory and language, 53(4), 594-628.
Craik, F. I., & Lockhart, R. S. (1972). Levels of processing: A framework for memory research. Journal of verbal learning and verbal behavior, 11(6), 671-684.
Cunningham, S. J., Brebner, J. L., Quinn, F., & Turk, D. J. (2014). The self-reference effect on memory in early childhood. Child Development, 85(2), 808-823.
D'Argembeau, A., Comblain, C., & Van der Linden, M. (2005). Affective valence and the self-reference effect: Influence of retrieval conditions. British Journal of Psychology, 96(4), 457-466.
Dalrymple, K. A., Fletcher, K., Corrow, S., das Nair, R., Barton, J. J., Yonas, A., & Duchaine, B. (2014). “A room full of strangers every day”: The psychosocial impact of developmental prosopagnosia on children and their families. Journal of Psychosomatic Research, 77(2), 144-150.
Deffenbacher, K. A. (1994). Effects of arousal on everyday memory. Human Performance, 7(2), 141-161.
Deffenbacher, K. A., Bornstein, B. H., Penrod, S. D., & McGorty, E. K. (2004). A meta-analytic review of the effects of high stress on eyewitness memory. Law and Human Behavior, 28(6), 687-706.
Faul, F., Erdfelder, E., Lang, A-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175-191. https://doi.org/10.3758/BF03193146
Ferguson, T. J., Rule, G. R. and Carlson, D. (1983). Memory for personally relevant information. Journal of Personality and Social Psychology, 44(2), 251–261.
Fine, D. R. (2012). A life with prosopagnosia. Cognitive neuropsychology, 29(5-6), 354-359.
Gliskey, E. L. & Marquine, M. J. (2009). Semantic and self-referential processing of positive and negative trait adjectives in older adults. Memory, 17(2), 144-157.
Hajcak, G., MacNamara, A., & Olvet, D. M. (2010). Event-related potentials, emotion, and emotion regulation: an integrative review. Developmental neuropsychology, 35(2), 129-155.
Hirshman, E., & Master, S. (1997). Modeling the conscious correlates of recognition memory: Reflections on the remember-know paradigm. Memory & Cognition, 25(3), 345-351.
Hou, C., & Liu, Z. (2019). The survival processing advantage of face: The memorization of the (un) trustworthy face contributes more to survival adaptation. Evolutionary Psychology, 17(2), 1474704919839726.
Hudson, A., Wilson, M.J.G., Green, E.S., Itier, R.J., Henderson, H.A. (2020). Are you as important as me? Self-other discrimination within trait-adjective processing. Brain and Cognition, 142:105569.
Inaba, M., Nomura, M., & Ohira, H. (2005). Neural evidence of effects of emotional valence on word recognition. International Journal of Psychophysiology, 57(3), 165-173.
Itier, R. J., & Neath-Tavares, K. N. (2017). Effects of task demands on the early neural processing of fearful and happy facial expressions. Brain research, 1663, 38-50.
Johnston, R. A., & Edmonds, A. J. (2009). Familiar and unfamiliar face recognition: A review. Memory, 17(5), 577-596.
Junghöfer, M., Bradley, M. M., Elbert, T. R., & Lang, P. J. (2001). Fleeting images: a new look at early emotion discrimination. Psychophysiology, 38(2), 175-178.
Kensinger, E. A., & Corkin, S. (2003a). Effect of negative emotional content on working memory and long-term memory. Emotion, 3(4), 378.
Kensinger, E. A., & Corkin, S. (2003b). Memory enhancement for emotional words: Are emotional words more vividly remembered than neutral words? Memory & Cognition, 31(8), 1169-1180.
Kensinger, E. A. (2004) Remembering emotional experiences: the contribution of valence and arousal. Reviews in Neurosciences, 15(4), 241-251.
Kroneisen, M. (2018). Is he important to me? Source memory advantage for personally relevant cheaters. Psychonomic Bulletin Review, 25, 1129-1137.
Kinzler, K. D., & Shutts, K. (2008). Memory for “mean” over “nice”: The influence of threat on children’s face memory. Cognition, 107(2), 775-783.
Klein, S. B. (2012). A role for self-referential processing in tasks requiring participants to imagine survival on the savannah. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(5), 1234.
Klein, F., Iffland, B., Schindler, S., Wabnitz, P., & Neuner, F. (2015). This person is saying bad things about you: The influence of physically and socially threatening context information on the processing of inherently neutral faces. Cognitive, Affective, & Behavioral Neuroscience, 15(4), 736–748.
Knyazev, G. G. (2013). EEG correlates of self-referential processing. Frontiers in human neuroscience, 7, 264. https://doi.org/10.3389/fnhum.2013.00264
Koji, S., & Fernandes, M.A. (2010) Does it matter where we meet? The Role of Emotional Context in Evaluative First Impressions. Canadian Journal of Experimental Psychology, 64(2), 107-116
Kuiper, N., & Derry, P. (1982). Depressed and nondepressed content self-reference in mild depressives. Journal of Personality, 50(1), 67-80.
Lee, C., & Fernandes, M. A. (2018). Emotional Encoding Context Leads to Memory Bias in Individuals with High Anxiety. Brain Sciences, 8(1), 6.
MacLin, O. H., MacLin, M. K., & Malpass, R. S. (2001). Race, arousal, attention, exposure and delay: An examination of factors moderating face recognition. Psychology, Public Policy, and Law, 7(1), 134-152.
Macrae, C. N., Moran, J. M., Heatherton, T. F., Banfield, J. F., & Kelley, W. M. (2004). Medial prefrontal activity predicts memory for self. Cerebral cortex, 14(6), 647-654.
Mealey, L., Daood, C., & Krage, M. (1996). Enhanced memory for faces of cheaters. Ethology and sociobiology, 17(2), 119-128.
Mehl, B., & Buchner, A. (2008). No enhanced memory for faces of cheaters. Evolution and Human Behavior, 29(1), 35-41.
Miles, W. R. (1930). Ocular dominance in human adults. The Journal of General Psychology, 3(3), 412–430.
McCrackin, S. D., & Itier, R. J. (2018). Is it about me? Time-course of self-relevance and valence effects on the perception of neutral faces with direct and averted gaze. Biological psychology, 135, 47-64.
Moscovitch, D. A. (2009). What is the core fear in social phobia? A new model to facilitate individualized case conceptualization and treatment. Cognitive and Behavioral Practice, 16(2), 123-134.
Moscovitch, D. A., Rowa, K., Paulitzki, J. R., Ierullo, M. D., Chiang, B., Antony, M. M., & McCabe, R. E. (2013). Self-portrayal concerns and their relation to safety behaviors and negative affect in social anxiety disorder. Behaviour research and therapy, 51(8), 476-486.
Olofsson, J. K., Nordin, S., Sequeira, H., & Polich, J. (2008). Affective picture processing: an integrative review of ERP findings. Biological psychology, 77(3), 247-265.
Rellecke, J., Sommer, W., & Schacht, A. (2012). Does processing of emotional facial expressions depend on intention? Time-resolved evidence from event-related brain potentials. Biological Psychology, 90(1), 23–32.
Rogers, T. B., Kuiper, N. A., & Kirker, W. S. (1977). Self-reference and the encoding of personal information. Journal of personality and social psychology, 35(9), 677.
Schacht, A., & Sommer, W. (2009). Emotions in word and face processing: Early and late cortical responses. Brain and Cognition, 69(3), 538–550.
Schupp, H. T., Öhman, A., Junghöfer, M., Weike, A. I., Stockburger, J., & Hamm, A. O. (2004). The facilitated processing of threatening faces: an ERP analysis. Emotion, 4(2), 189.
Schupp, H. T., Flaisch, T., Stockburger, J., & Junghöfer, M. (2006). Emotion and attention: event-related brain potential studies. Progress in brain research, 156, 31-51.
Schwartz, L., & Yovel, G. (2016). The roles of perceptual and conceptual information in face recognition. Journal of Experimental Psychology: General, 145(11), 1493.
Schwarz, K.A. et al., (2013). Why are you looking like that? How the context influences evaluation and processing of human faces. Social cognitive and affective neuroscience, 8(4), 438–45.
Senn, J. M., & Radomsky, A. S. (2012). Well that changes everything! The genesis of memory bias for threat with implications for delayed onset in anxiety disorders. Journal of behavior therapy and experimental psychiatry, 43(4), 1019-1025.
Skinner, E. & Fernandes, M.A. (2010) Effect of Study Context on Item Recollection. The Quarterly Journal of Experimental Psychology, 63(7), 1318-1334
Storbeck, J., & Clore, G. L. (2008). Affective arousal as information: How affective arousal influences judgments, learning, and memory. Social and personality psychology compass, 2(5), 1824-1843.
Symons, C. S., & Johnson, B. T. (1997). The self-reference effect in memory: a meta-analysis. Psychological bulletin, 121(3), 371.
Turk, D. J., Cunningham, S. J., & Macrae, C. N. (2008). Self-memory biases in explicit and incidental encoding of trait adjectives. Consciousness and cognition, 17(3), 1040-1045.
Wieser, M.J. et al., 2014. Not so harmless anymore: How context impacts the perception and electrocortical processing of neutral faces. NeuroImage, 92, 74–82.
Wieser, M. J., & Moscovitch, D. A. (2015). The effect of affective context on visuocortical processing of neutral faces in social anxiety. Frontiers in psychology, 6.
Yang, L., Truong, L., Fuss, S., & Bislimovic, S. (2012). The effects of ageing and divided attention on the self-reference effect in emotional memory: Spontaneous or effortful mnemonic benefits? Memory, 20(6), 596-607.
Yardley, L., McDermott, L., Pisarski, S., Duchaine, B., & Nakayama, K. (2008). Psychosocial consequences of developmental prosopagnosia: A problem of recognition. Journal of psychosomatic research, 65(5), 445-451.
Acknowledgements
We would like to warmly thank Brenna Myers-Bishop, Zora (Zelin) Chen, Amie Durston and Mariem Hamdy for their help with data collection.
Open practices statement
Our datasets, generated and analysed in the current study, are available in the Open Science Framework repository and can be accessed at the following link: https://osf.io/9azet/?view_only=050f788310f6401e9defebc1ff6f0e90 This experiment was not pre-registered.
Funding
This work was supported by grants from the Natural Sciences and Engineering Research Council of Canada (NSERC Discovery Grant #418431 to author RJI and #05605 to author MAF), as well as the Canada Foundation for Innovation (CFI, #213322) and the Canada Research Chair (CRC, #213322 and #230407) program to RJI. SDM was supported by a Queen Elizabeth II Graduate Scholarship for Science and Technology (QEII-GSST).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Disclosure statement
We report no potential conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
McCrackin, S.D., Lee, C.M., Itier, R.J. et al. Meaningful faces: Self-relevance of semantic context in an initial social encounter improves later face recognition. Psychon Bull Rev 28, 283–291 (2021). https://doi.org/10.3758/s13423-020-01808-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-020-01808-6