
Abstract
Research shows that humans spontaneously follow another individual’s gaze. However, little remains known on how they respond when multiple gaze cues diverge across members of a social group. To address this question, we presented participants with displays depicting three (Experiment 1) or five (Experiment 2) agents showing diverging social cues. In a three-person group, one individual looking at the target (33% of the group) was sufficient to elicit gaze-facilitated target responses. With a five-person group, however, three individuals looking at the target (60% of the group) were necessary to produce the same effect. Gaze following in small groups therefore appears to be based on a quorum-like principle, whereby the critical level of social information needed for gaze following is determined by a proportion of consistent social cues scaled as a function of group size. As group size grows, greater agreement is needed to evoke joint attention.
Similar content being viewed by others


Both human and nonhuman primates follow conspecifics’ social cues, which are typically conveyed by their eye and head direction (Emery, 2000). Experimentally, this gaze following behavior is often investigated using the gaze-cuing task, in which observers view images of faces looking toward or away from a response target (Frischen, Bayliss, & Tipper, 2007). Despite the fact that the social gaze cue remains task irrelevant and participants are instructed to ignore it, people typically respond faster to gazed-at relative to not-gazed-at targets (Driver et al., 1999; Friesen & Kingstone, 1998; Hayward & Ristic, 2017). This well-established result is interpreted as indicating that others’ gaze direction elicits spontaneous orienting of attention and facilitates responses to gazed-at targets (Bayliss, Bartlett, Naughtin, & Kritikos, 2011). More generally, this finding showcases one of the most basic evolutionary advantageous behaviors, which allows humans to quickly utilize and respond to social information in the environment (van Vugt, 2014; Zuberbühler, 2008).
Remarkably, to date, gaze following has mostly been examined in dyadic contexts, in which one observer responds to social gaze cues displayed by another agent. In real life, however, humans typically encounter more than one agent at the time, with multiple people often looking in different directions. How do humans respond to such multiple and diverging social cues? Intuitively, one might hypothesize that observes would systematically follow the direction of the majority of location-directed cues. A recent study on human crowds supports this intuition, suggesting that observers preferentially follow gaze cues displayed by the group majority (Sun, Yu, Zhou, & Shen, 2017).
However, it remains unknown if the “majority” principle similarly applies to small social groups of six or fewer individuals (Dunbar, Duncan, & Nettle, 1995), which in contrast to crowds (e.g., a family meal vs. an audience at a football match) afford mutual interactions and joint attention states and require efficient handling of individual members’ social cues (David-Barrett & Dunbar, 2013; Lewin, 1951). Research on social influence shows that perceivers are biased toward an opinion when it reaches a relevant proportion of group consensus (MacCoun, 2012). While in large groups this “relevant proportion” is often represented by the group majority (Insko, Smith, Alicke, Wade, & Taylor, 1985), in small groups it may also reflect the group minority (Tanford & Penrod, 1984). Thus, the proportion of group consensus needed to bias perceivers’ responses may be mediated by group size, with larger groups requiring larger group-relevant consensus. In turn, responding to divergent gaze cues displayed by the members of a small social group may follow a “quorum-like” principle, in which the proportion of consistent social cues needed to bias an observer’s attention would increase as a function of group size. Reflecting the animal decision-making literature (Ward & Webster, 2016), here we use the term quorum to denote instances in which the probability of a behavior changes dynamically as a function of the number of individuals exhibiting that same behavior.
In the current study, we tested if the relevant proportion of social cues needed to elicit gaze following in small groups follows a majority or a quorum-like principle. To do so, we utilized an adapted gaze-cuing task in which we manipulated the proportion of consistent gaze cues displayed by three (Experiment 1) and five (Experiment 2) agent groups. If humans compute group social visual information using the majority rule, we expected to find gaze-facilitated target responses only when the group majority, independently of the group size, displayed consistent gaze cues. If, on the other hand, humans compute social visual information using a quorum-like approach, we expected to find that the relevant proportion of gaze cues needed for gaze-facilitated target responses would increase with group size. Our results supported the quorum-like principle.
Experiment 1
Method
Participants
Thirty-six undergraduates (31 females; mean age = 20.16 years; age range: 18–23 years), naïve to the purpose of the study, with normal or corrected-to-normal vision, participated in the study in return for course credits. All procedures were in accordance with the World Medical Association Declaration of Helsinki (2013) and were approved by the University’s research ethics board. The sample size was chosen based on past work examining the effects of inconsistent perspectives on the visual processing of social information (Capozzi, Cavallo, Furlanetto, & Becchio, 2014), and an a priori power analysis with dz = .5, α = .05, 1 −β = .90 (Faul, Erdfelder, Lang, & Buchner, 2007).
Apparatus and stimuli
Stimulus presentation and data collection were controlled by Experiment Builder (SR Research). Stimuli (created using Smith Micro’s Poser 9 software) included three male faces (varying in size from 4.4 to 5 cm in width and 7.1 to 7.5 cm in height), three placeholder objects—a cube, a cylinder, and a sphere (varying in size from 2.1 to 2.5 cm in width and 2.1 to 2.5 cm in height)—used to facilitate inference of line of sight, and capital letters N and H (1.5 × 2 cm) used as response targets. The stimulus sequence was presented on a 16-in. CRT monitor at an approximate viewing distance of 60 cm.
Design
A repeated-measures design with two factors was used. The first factor, the number of faces cuing the target, had four levels—zero, one, two, or three faces cuing the target. In the one_face_cuing condition, the target appeared at the location cued by one face, while the two remaining faces cued the opposite location. In the two_faces_cuing condition, the target appeared at the location cued by two faces, while the remaining face cued the opposite location. To compare the relative strength of gaze following as a function of the number of inconsistent gaze cues, we also included two conditions in which the target appeared at the location cued by no face (zero_faces_cuing) and by all faces (three_faces_cuing).
To investigate the time course of gaze following in multiagent contexts, the second factor manipulated the time between the onset of the cue display and the onset of the target between 300 and 900 ms.
The two factors were manipulated equiprobably, with a trial sequence presented in a pseudorandom order within participants. No face or groups of faces provided relevant information about the target. Each face identity appeared equally often at each position, and each target type occurred equally often in either the left or right position.
Procedure
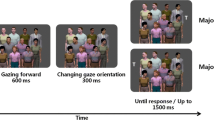
Each trial started with a 600-ms fixation display (see Fig. 1a). Then, a display with all three faces turned toward the central placeholder was shown (see Fig. 1b). After 1,500 ms, each face turned either toward the left or toward the right object (see Fig. 1c). The faces turned either in the same direction, creating the zero_faces_cuing or the three_faces_cuing conditions, or in different directions, creating the one_face_cuing and two_faces_cuing conditions. After 300 ms or 900 ms, a response target, demanding an identification response, was presented on either the left or right object (see Fig. 1d). The faces and the target remained visible until response or until 2,500 ms had elapsed. A feedback tone was presented upon missed or erroneous response. Intertrial interval was 600 ms.

Illustration of stimuli and an example stimulus presentation sequence for Experiment 1. After the presentation of a 600-ms fixation cross (a), three faces and three objects appeared directed at the central object for 1,500 ms (b). Then, the faces turned toward one of the lateral objects (c). After 300 or 900 ms, a response target appeared in one of the two peripheral locations. The target could be cued by zero, one (illustrated here), two, or three faces (d). The display showing the target remained visible until response or for 2,500 ms. Intertrial interval was 600 ms
Participants were instructed to identify the target quickly and accurately by pressing one of two adjacent keyboard keys marked in yellow and blue. Key response-target identity assignment was counterbalanced across participants. Participants were instructed to ignore the face cues, and to maintain central fixation. After 16 practice trials, in which only response targets appeared, the experiment proceeded over 576 trials split into four blocks.
Results
We examined response accuracy and RT using repeated-measures ANOVAs, run as a function of the number of faces cuing the target and cue–target interval. Bonferroni correction was applied where appropriate.
Participants performed the task well, with 95.5% average accuracy and no differential effects across experimental conditions (Fs < 1.736, .778 < ps < .946). RT analyses were based on correct trials, and additionally excluded any anticipatory and timed-out responses (i.e., responses faster than 200 ms and slower than 1,200 ms, 6.16% of trials). Figure 2 plots mean RTs as a function of the number of faces cuing the target.

RT analysis revealed a significant linear contrast, F(1, 35) = 17.632, p < .0001, ηp2 = .335, following from a main effect of the number of faces cuing, F(3, 105) = 10.093, p < .0001, ηp2 = .224. We explored this effect using paired-sample t tests, which compared performance at adjacent conditions (i.e., zero_faces_cuing vs. one_face_cuing, one_face_cuing vs. two_faces_cuing, two_faces_cuing vs. three_faces_cuing). In contrast to a “majority rule,” predicting that gaze-facilitated target responses would emerge when two out of three faces displayed consistent cues to the target, our data indicated that reliable gaze following emerged already with one agent looking at the target, as the comparison between zero_faces_cuing (M = 565; 95% CI =[537, 594]) and one_face_cuing (M = 558; 95% CI [532, 584]) yielded a significant difference, t(35) = 2.667, p = .036, dz = .479. No difference between the one_face_cuing and the two_faces_cuing (M = 557; 95% CI [530, 585]) conditions was found, t(35) = .204, p > .999, dz = .032. Following from past work (e.g., Capozzi et al., 2014), the most pronounced target facilitation was observed when all three faces (M = 550; 95% CI [523, 576]) cued the target, t(35) = 3.091, p = .012, dz = .522.
The ANOVA also indicated a reliable main effect of cue–target interval, F(1, 35) = 9.080, p = .005, ηp2 = .206, with faster overall responses at 900 ms (M = 554; 95% CI [527,581]) relative to the 300 ms (M = 561; 95% CI [534, 587]), demonstrating a typical foreperiod effect (Hayward & Ristic, 2015). The interaction between number of faces cuing and cue–target interval was not significant, F(3, 105) = .522, p = .668, ηp2 = .015.
Thus, Experiment 1 revealed that when participants were presented with divergent social visual cues from a group of three agents, one person looking at the target, a proportional representation of only 33%, was sufficient to elicit gaze-facilitated target responses. This finding supports the notion that the proportion of social cues needed to bias observers’ attention in small groups does not follow a majority principle. To test if this relevant proportion is modulated by group size, in Experiment 2, we increased the size of the group from three to five.
Experiment 2
Method
Participants
Thirty-two new naïve volunteer students participated (24 females; mean age = 20.59 years; age range: 18–26 years). None took part in the previous experiment, and all reported normal or corrected-to-normal vision. The sample size mirrored Experiment 1 preserving power tolerance of .80 > 1 − β < .90.
Apparatus, stimuli, design, and procedure
All parameters were identical to Experiment 1, except that (a) the number of faces was increased from three to five, by adding two additional male identities; (b) the number of faces cuing the target could be zero, one, two, three, four, or five; and (c) to account for the increase in the experimental conditions, 864 trials divided across six blocks were run. Each face identity appeared in each of five possible positions equally often. Group arrangement was manipulated randomly such that each face could turn to the left or right independently of other faces. Figure 3 shows example stimulus configurations.

Example of stimulus configurations for Experiment 2. Depending on the target location, images depict stimulus displays for the zero_ or five_faces_cuing condition (a), one_ or four_faces_cuing condition (b), and two_ or three_faces_cuing condition (c)
Results
Analyses mirrored Experiment 1. Participants performed the task well, with overall accuracy of 96.5% and no modulation of accuracy performance as a function of experimental variables (Fs < 2.271, .075 < ps < .310). Mean correct RTs, trimmed for anticipations and response timeouts (5.44% trials), were examined using a repeated-measures ANOVA as a function of the number of faces cuing the target and the cue–target interval. Figure 4 plots mean RTs as a function of the number of faces cuing the target.

Again, a significant linear contrast, F(1, 31) = 17.824, p < .0001, ηp2 = .365, followed the main effect of the number of faces cuing, F(5, 155) = 6.516, p < .0001, ηp2 = .174. However, post hoc t tests demonstrated that reliable gaze-facilitated responses now emerged only when three agents looked at the target, t(31) = 2.231, p = .033, dz = .478, with faster responses in the three_faces_cuing condition (M = 563; 95% CI [533, 593]) relative to the two_faces_cuing condition (M = 569; 95% CI [539, 600]). As before, the most pronounced performance facilitation was found when all five faces (M = 556; 95% CI [526, 586]) cued the target, t(31) = 2.100, p = .044, dz = .377. No other comparison was significant (ts < 1.00, .875 < ps < 947).
The ANOVA also indicated a main effect of cue–target time, F(1, 31) = 13.764, p = .001, ηp2 = .307, with overall faster RTs at the 900 ms (M = 560; 95% CI [530, 590]) relative to the 300 ms (M = 569; 95% CI [539, 600]), with no significant interaction with the number of faces cuing, F(5, 155) = .546, p = .741, ηp2 = .017.
In sum, the results from Experiment 2 showed that when participants were presented with divergent social visual cues from a group of five agents, the critical amount of consistent social information needed to facilitate their target responses was three people, or the group’s proportional representation of 60%. This is in contrast to Experiment 1, in which a proportional representation of 33% was sufficient for the same response. Together, these data provide the first demonstration of a quorum-like representation of social visual information in small groups and indicate that the relevant proportion of gaze cues needed for a gaze-facilitated response increases with group size.
General discussion
How do people respond to diverging social cues displayed by members of a group? Previous work suggests that they would follow a “majority rule,” in that their attention would become biased toward the gaze direction displayed by the group majority (Sun et al., 2017). In contrast, and offering support for a “quorum-like” principle, here we show that a minority representation was sufficient to bias observers’ attention in a three-person group (Experiment 1) and that the proportion of gaze cues needed to elicit gaze following was modulated by group size (Experiment 2). Specifically, in Experiment 1, when viewing three agents with inconsistent gaze cues, participants responded to the target faster when it was cued by one agent relative to when it was cued by no agents. That is, a 33% proportional representation was sufficient to facilitate target responses. A different pattern of results emerged in a group of five agents (Experiment 2), in which a 60% proportional representation (or consistent cues from three out of five agents) was needed for gaze-facilitated target responses. Collectively, these data support the “quorum-like” hypothesis, by showing that the amount of social information needed for a gaze-following response does not follow a simple majority rule, but is determined by a relative proportion of social information computed as a function of group size.
Our finding is broadly consistent with past work on gaze following in human crowds, which showed that reliable gaze following emerged when seven out of 10 (i.e., 70%), but not when six out of 10 agents (i.e., the strict majority of 60%) displayed consistent visual social cues (Sun et al., 2017). Along with our data, this observation also supports a quorum-like principle, as a relevant proportion, rather than a strict majority of social cues, appears to have guided observers’ responses in both cases (see also Dyer, Johansson, Helbing, Couzin, & Krause, 2009). Although our results are consistent with data supporting unique mechanisms of gaze perception (Bayliss et al., 2011) and higher order social processing (e.g., Capozzi, Bayliss, Elena, & Becchio, 2015), it remains possible that the processes that govern multiagent social information processing may also involve some contribution of domain-general attentional mechanisms. However, the human ability to track multiple nonsocial stimuli appears to be constrained mostly by the spatial resolution of attention (Franconeri, Jonathan, & Scimeca, 2010), whereas in the social domain, information processing is modulated by group size reflecting a power function, whereby increases in the group size are associated with increases in the size of the majority representation needed to sway responses in favor of the group’s opinion (Latané & Wolf, 1981). It remains to be determined if such a power rule also applies to the computation of the relevant proportion of social visual cues in multiagent contexts as well as the extent to which such an effect may rely solely on social information processing (see also Capozzi & Ristic, 2018).
Our data also indicated that observers’ responses were most strongly modulated by a consistent social perspective. Both experiments found that a nonconflicting social perspective (i.e., when all agents looked in the same direction), elicited the most powerful facilitation of target responses. This is in line with existing research that shows facilitated performance for consistent relative to inconsistent perspectives displayed by multiple agents (Capozzi et al., 2014). It also dovetails with work showing that a consistent group perspective may be understood as representing a single line of sight (e.g., Capozzi, Becchio, Willemse, & Bayliss, 2016; Gallup et al., 2012). An intriguing question related to this notion emerges from Experiment 1, which indicated an absence of a reliable difference between the responses to the targets occurring at locations cued by one face and those occurring at locations cued by two faces. Speculatively, this might be taken to suggest that participants compute the gaze cues from one and two agents similarly. Research on face perception indicates that humans are equipped with mechanisms that allow for an ensemble perception of group gaze (Sweeny & Whitney, 2014). Future research is needed to determine whether humans are also equipped with mechanisms that would allow ensemble computation of gaze cues from two (or more) subgroups.
A novel theoretical insight that follows from our data is that humans do not apply a majority rule when responding to inconsistent visual social cues displayed by agents in small social groups. Instead, they appear to use a quorum-like heuristic, in which the proportion of social cues perceived as relevant increases with group size. These results provide a compelling instance of a sophisticated social mechanism that allows for a quick computation of the relative relevance of social information, and fluctuates as a function of group size. Previous research shows that increased group size modulates the perceived reliability and generalizability of social information (Capozzi et al., 2015; Mason, Dyer, & Norton, 2009). We add to this literature by showing that humans also utilize group size information in order to determine the proportional relevance of available social cues. This is consistent with research on consensus decision-making in social animals (Sumpter, Krause, James, Couzin, & Ward, 2008), and carries implications for understanding the mechanisms that allow humans to benefit from socially acquired information in the exploration of the environment. Specifically, utilizing information about group size may serve an important function in handling conflicting social information (e.g., Merkle, Sigaud, & Fortin, 2015). While information acquired from social sources may not always yield optimal decisions, utilizing information about group size may serve a preventative function in progressively decreasing, as group size increases, the risk of following uninformative social cues (Giraldeau, Valone, & Templeton, 2002).
In sum, when humans encounter divergent visual social cues from members of a small social group, they follow the gaze direction displayed by a relevant proportion of agents. This relevant proportion is determined by and increases with group size. This result highlights the general notion that contextual and environmental factors play an important role in the dynamic interpretation of available social information.
References
Bayliss, A. P., Bartlett, J., Naughtin, C. K., & Kritikos, A. (2011). A direct link between gaze perception and social attention. Journal of Experimental Psychology: Human Perception and Performance, 37(3), 634–644. https://doi.org/10.1037/a0020559
Capozzi, F., & Ristic, J. (2018). How attention gates social interactions. Annals of the New York Academy of Sciences, advance online publication, 1-20. https://doi.org/10.1111/nyas.13854
Capozzi, F., Bayliss, A. P., Elena, M. R., & Becchio, C. (2015). One is not enough: Group size modulates social gaze-induced object desirability effects. Psychonomic Bulletin & Review, 22(3), 850–855. https://doi.org/10.3758/s13423-014-0717-z
Capozzi, F., Becchio, C., Willemse, C., & Bayliss, A. P. (2016). Followers are not followed: Observed group interactions modulate subsequent social attention. Journal of Experimental Psychology: General, 145(5), 531–535. https://doi.org/10.1037/xge0000167
Capozzi, F., Cavallo, A., Furlanetto, T., & Becchio, C. (2014). Altercentric intrusions from multiple perspectives: Beyond dyads. PLOS ONE, 9(12), e114210. https://doi.org/10.1371/journal.pone.0114210
David-Barrett, T., & Dunbar, R. I. M. (2013). Processing power limits social group size: Computational evidence for the cognitive costs of sociality. Proceedings of the Royal Society B: Biological Sciences, 280(1765), 20131151–20131151. https://doi.org/10.1098/rspb.2013.1151
Driver, J., Davis, G., Ricciardelli, P., Kidd, P., Maxwell, E., & Baron-Cohen, S. (1999). Gaze perception triggers reflexive visuospatial orienting. Visual Cognition, 6(5), 509–540. https://doi.org/10.1080/135062899394920
Dunbar, R. I. M., Duncan, N. D. C., & Nettle, D. (1995). Size and structure of freely forming conversational groups. Human Nature, 6(1), 67–78. https://doi.org/10.1007/BF02734136
Dyer, J. R. G., Johansson, A., Helbing, D., Couzin, I. D., & Krause, J. (2009). Leadership, consensus decision making and collective behaviour in humans. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 364(1518), 781–789. https://doi.org/10.1098/rstb.2008.0233
Emery, N. J. (2000). The eyes have it: The neuroethology, function and evolution of social gaze. Neuroscience and Biobehavioral Reviews, 24(6), 581–604. https://doi.org/10.1016/S0149-7634(00)00025-7
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Franconeri, S. L., Jonathan, S. V., & Scimeca, J. M. (2010). Tracking multiple objects is limited only by object space not by speed, time, or capacity. Psychological Science, 21(7), 920–925.
Friesen, C. K., & Kingstone, A. (1998). The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychonomic Bulletin & Review, 5(3), 490–495. https://doi.org/10.3758/BF03208827
Frischen, A., Bayliss, A. P., & Tipper, S. P. (2007). Gaze cueing of attention: Visual attention, social cognition, and individual differences. Psychological Bulletin, 133(4), 694–724. https://doi.org/10.1037/0033-2909.133.4.694
Gallup, A. C., Hale, J. J., Sumpter, D. J. T., Garnier, S., Kacelnik, A., Krebs, J. R., & Couzin, I. D. (2012). Visual attention and the acquisition of information in human crowds. Proceedings of the National Academy of Sciences, 109(19), 7245–7250. https://doi.org/10.1073/pnas.1116141109
Giraldeau, L.-A., Valone, T. J., & Templeton, J. J. (2002). Potential disadvantages of using socially acquired information. Philosophical Transactions of the Royal Society B, 357(1427), 1559–1566. https://doi.org/10.1098/rstb.2002.1065
Hayward, D. A., & Ristic, J. (2015). Exposing the cuing task: The case of gaze and arrow cues. Attention, Perception, & Psychophysics, 77(4), 1088–1104. https://doi.org/10.3758/s13414-015-0877-6
Hayward, D. A., & Ristic, J. (2017). Feature and motion-based gaze cuing is linked with reduced social competence. Scientific Reports, 7, 44221. https://doi.org/10.1038/srep44221
Insko, C. A., Smith, R. H., Alicke, M. D., Wade, J., & Taylor, S. (1985). Conformity and group size: The concern with being right and the concern with being liked. Personality and Social Psychology Bulletin, 11(1), 41–50. https://doi.org/10.1177/0146167285111004
Latané, B., & Wolf, S. (1981). The social impact of majorities and minorities. Psychological Review, 88(5), 438–453. https://doi.org/10.1037/0033-295X.88.5.438
Lewin, K. (1951). Field theory in social science. New York: Harper.
Loftus, G. R., & Masson, M. E. J. (1994). Using confidence intervals in within-subject designs. Psychonomic Bulletin and Review, 1(4), 476–490. https://doi.org/10.3758/BF03210951
MacCoun, R. J. (2012). The burden of social proof: Shared thresholds and social influence. Psychological Review, 119(2), 345–372. https://doi.org/10.1037/a0027121
Mason, M. F., Dyer, R. L., & Norton, M. I. (2009). Neural mechanisms of social influence. Organizational Behavior and Human Decision Processes, 110(2), 152–159. https://doi.org/10.1016/j.obhdp.2009.04.001
Merkle, J. A., Sigaud, M., & Fortin, D. (2015). To follow or not? How animals in fusion-fission societies handle conflicting information during group decision-making. Ecology Letters, 18(8), 799–806. https://doi.org/10.1111/ele.12457
Sumpter, D. J. T., Krause, J., James, R., Couzin, I. D., & Ward, A. J. W. (2008). Consensus decision making by fish. Current Biology, 18(22), 1773–1777. https://doi.org/10.1016/j.cub.2008.09.064
Sun, Z., Yu, W., Zhou, J., & Shen, M. (2017). Perceiving crowd attention: Gaze following in human crowds with conflicting cues. Attention, Perception, & Psychophysics, 79(4), 1039–1049. https://doi.org/10.3758/s13414-017-1303-z
Sweeny, T. D., & Whitney, D. (2014). Perceiving crowd attention: Ensemble perception of a crowd’s gaze. Psychological Science, 25(10), 1903–1913. https://doi.org/10.1177/0956797614544510
Tanford, S., & Penrod, S. (1984). Social influence model: A formal integration of research on majority and minority influence processes. Psychological Bulletin, 95(2), 189–225. https://doi.org/10.1037/0033-2909.95.2.189
van Vugt, M. (2014). On faces, gazes, votes, and followers: Evolutionary psychological and social neuroscience approaches to leadership. In J. Decety & Y. Christen (Eds.), New frontiers in social neuroscience (pp. 93–110). Heidelberg: Srpinger.
Ward, A. J. W., & Webster, M. (2016). Sociality : The behaviour of group-living animals.https://doi.org/10.1007/978-3-319-28585-6
Zuberbühler, K. (2008). Gaze following. Current Biology, 18(11), R453–R455. https://doi.org/10.1016/j.cub.2008.03.015
World Medical Association, Inc. (WMA) (2013). WMA Declaration of Helsinki – Ethical Principles for Medical Research Involving Human Subjects; 64th WMA General Assembly, Fortaleza, Brazil, October 2013. Retrieved from https://www.wma.net/policies-post/wma-declaration-of-helsinki-ethical-principles-for-medical-research-involving-human-subjects/
Acknowledgements
Supported by the Social Science and Humanities Research Council of Canada (SSHRC; F.C. and J.R.), Fonds de Recherche du Québec—Société et culture (FRQSC; FC), Natural Sciences and Engineering Council of Canada (NSERC; J.R.), William Dawson Chairs Fund (J.R.), Leverhulme Trust Project Grant RPG-2016-173 (A.P.B.). Many thanks to K. Stadel for support in data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Capozzi, F., Bayliss, A.P. & Ristic, J. Gaze following in multiagent contexts: Evidence for a quorum-like principle. Psychon Bull Rev 25, 2260–2266 (2018). https://doi.org/10.3758/s13423-018-1464-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-018-1464-3