
Abstract
The reverse-reward contingency (RRC) task involves presenting subjects with a choice between one plate containing a large amount of food and a second plate containing a small amount of food. Subjects are then required to select the smaller of the two options in order to receive the larger-magnitude reward. The RRC task is a commonly used paradigm for assessing complex cognition, such as inhibitory control, in subjects. To date, the RRC task has not been tested with pet dogs as subjects, and it may provide insights to their ability to perceive quantities of differing magnitudes. Nine dogs were tested in an RRC task involving three conditions. In Condition 1, plates of food were presented, and the dogs were allowed to consume their choice. In Condition 2, plates with different-sized symbols resembling the quantities of food in Condition 1 were presented, and dogs received food quantities of the same size as their choice (e.g., a larger-magnitude reward for selecting the plate with the larger shape). In Condition 3, the same plates were presented, but dogs received a reverse-sized quantity of food, relative to their choice (e.g., a smaller-magnitude reward for selecting the plate with the larger shape). A novel addition here to the traditional RRC task was the inclusion of a third, empty (control) plate that was present throughout all conditions, and no programmed consequences were provided when that plate was selected. Our results were consistent with the previous RRC literature: All dogs developed and maintained a preference for the larger stimulus option across conditions. The use of symbolic representations did not ameliorate performance on the RRC task. Applied implications are discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Dogs will choose optimally when given a choice between a large and a small amount of food (Ward & Smuts, 2007; West & Young, 2002). These findings are similar to those from other organisms, such as dolphins (Kilian, Yaman, von Fersen, & Güntürkün, 2003), salamanders (Krusche, Uller, & Dicke, 2010), orangutans (Call, 2000), rats (Meck & Church, 1983), and human children (Huntley-Fenner & Cannon, 2000). Many of these experiments have used both food and nonfood items. However, to our knowledge, research with dogs has only used food for comparisons between quantities.
Within the animal literature, a long-debated issue is whether nonhuman animals can comprehend symbols in ways similar to humans (Addessi & Rossi, 2011). Understanding symbolic comprehension could be fundamental to how an animal perceives the world around it. One common function of symbolic stimuli is that they allow the subject to inhibit strong behavioral predispositions; the reverse-reward contingency (RRC) task is one common inhibition task (Addessi & Rossi, 2011).
Prior to the RRC task, subjects are typically presented with an initial discrimination task in which the subject receives a large-magnitude reward for selecting the larger stimulus (e.g., with food and a visual stimulus) and a small-magnitude reward for selecting the smaller stimulus. Subjects make repeated choices in this condition until optimal responding is observed. Optimal responding is considered to occur when the subject primarily selects the larger stimulus to receive the large-magnitude reward. Then the subject completes the RRC task, which involves presenting them with a choice between the same stimuli used in the previous condition, but the consequences obtained for their selection are reversed. That is, under the RRC, subjects must select the smaller stimulus to receive a large-magnitude reward, and select the larger stimulus to receive a small-magnitude reward.
The RRC task allows researchers to examine whether animals will reverse their learning, and it might be used as a measure of inhibitory control (Albaich-Serrano & Call, 2014). That is, after giving the subject a recent history of responding in a specific way, the RRC task allows researchers to examine whether the subject will perform incongruently with that history once a change in environmental contingencies is enacted. Typically, the final phase is at least as long as the first phase and continues for a predetermined number of sessions (e.g., Addessi & Rossi, 2011; Carlson, Davis, & Leach, 2005; Silberberg & Fujita, 1996) or until responding is stable (e.g., Kralik, 2012). Boysen and Berntson (1995) conducted the RRC task with chimps and found that subjects continued to respond to the large stimulus when the contingencies for responding were reversed. Many other nonhuman primate species, including mangabeys (Albaich-Serrano, Guillén-Salazar, & Call, 2007), Japanese macaques (Silberberg & Fujita, 1996), orangutans (Schumaker, Palkovitch, Beck, Guagnano, & Morowitz, 2001), and lemurs (Genty, Palmier, & Roeder, 2004) have been tested with similar arrangements. All have demonstrated difficulty reversing responding when food is used to optimize the magnitude of the reward received. Despite the equal, and often longer, amount of time available to reverse this learning history, many species still fail to learn the change in contingencies.
One potential modification to the RRC task is to provide a choice between analogous symbolic stimuli instead of using food directly. Analogous stimuli share features similar to those of the food received (e.g., quantity, surface area). For example, Boysen, Berntson, Hannan, and Cacioppo (1996) replaced different candy quantities with rocks in a one-to-one ratio (i.e., each rock represented one piece of candy if that option was chosen). They found that chimps were still unable to reverse their preference from the larger quantity to the smaller quantity during the RRC task, despite the use of analogous symbols. The effect of analogous symbols in the RRC task was also tested with capuchin monkeys in a study conducted by Addessi and Rossi (2011). Here, food items were replaced in a one-to-one ratio with objects familiar to the capuchin monkeys (i.e., tokens). The results indicated that capuchins continued to choose suboptimally, by persisting in selecting the larger quantity of tokens in the reversal phase (RRC task).
In addition to nonhuman primate species, research using the RRC task with analogous stimuli has been conducted with 3- and 4-year-old human children (Carlson et al., 2005). Similar to Boysen et al. (1996), Carlson, Davis, and Leach replaced candy in a one-to-one ratio with rocks. Their results were consistent with Boysen et al.’s findings, in that children were unable to reverse their preference from the larger to the smaller quantity of rocks, despite the reversal in the reward magnitudes.
Canis lupus familiaris has demonstrated reversal learning in previous experiments (e.g., Lazarowski et al., 2014; Milgram, Head, Weiner, & Thomas, 1994; Tapp et al., 2003). However, in the canine literature, reversal learning has been studied exclusively using extinction reversals. In an extinction reversal arrangement, subjects first complete a discrimination task (i.e., choosing one stimulus leads to food, and choosing the other stimulus leads to nothing). In the subsequent extinction reversal, choosing the other stimulus now results in delivery of food, and choosing the first stimulus now results in nothing (i.e., extinction; e.g., Lazarowski et al., 2014; Milgram et al., 1994; Tapp et al., 2003). Extinction reversal tasks differ from the RRC task (described previously) used with other organisms, in which the two options always produce rewards, albeit rewards of two different magnitudes. This major disparity between reversal-learning methods makes previous canine performance under extinction reversals difficult to compare with the responding of other species under the RRC task.
The purpose of the present study was twofold. First, we investigated whether dogs would choose optimally when presented with analogous stimuli instead of with food items (i.e., choosing the large stimulus resulted in the larger amount of food, and choosing the small stimulus resulted in the smaller amount of food). We predicted that dogs would be able to discriminate between stimuli associated with two different magnitudes of reward. Second, we investigated whether dogs would choose optimally when the contingencies were reversed (i.e., the RRC task). Given the previous literature on the RRC task with other species, we predicted that dogs would fail to reverse responding in the RRC task. Using the RRC methods common in previous research would allow for valid comparisons of reversal learning and inhibitory control between dogs and other species.
Method
Subjects and setting
Nine of the 18 dogs initially recruited served as subjects in the present study (see Table 1 for further information). Seven of the dogs did not meet the prerequisites for inclusion (see below), one dog was excluded due to unrelated health issues, and one withdrew due to relocation. The dogs were recruited via flyers posted around the University of Florida campus as well as at Camp Marlin, a local pet boarding and sitting facility. Sessions were conducted in settings familiar to the dog (i.e., the dog owner’s home or a private area at Camp Marlin). Dogs were excluded from the study if they showed a lack of food motivation or required a command before they would approach food. Lack of food motivation was determined if the dog did not approach food within 30 s on three consecutive exposure trials (described below). Finally, dogs were also excluded if the owner reported any history of aggression, if the dog demonstrated precursors to aggression (e.g., growling), or if the dog was averse to being handled by unfamiliar people during the preference assessment.
Preference assessment
We first conducted a paired-stimulus preference assessment (Fisher et al., 1992) with each dog, to identify a highly preferred food to be used during the experiment. All preference assessments involved the same three foods: turkey, bologna, and American cheese. All three foods were presented in pairs until all possible pairs had been presented in a counterbalanced fashion. Therefore, each preference assessment consisted of a total of six trials. The highest-preferred food (i.e., the one chosen most often) was used throughout all experimental sessions.
General experimental procedure
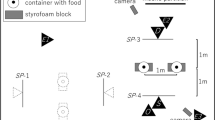
Prior to each trial, the experimenter arranged three square, laminated paper plates (20 cm × 20 cm) in front of the dog. Each plate contained a piece of food (Condition 1) or a visual stimulus (Conditions 2 and 3). Three plates were presented across all conditions. One contained a small stimulus (either a 1 cm × 1 cm piece of food, in Condition 1, or an identical-sized white square, in Conditions 2 and 3); one contained a large stimulus (5 cm × 5 cm); and one contained no stimuli and remained empty (control). The plates were slightly tilted (approximately 30 deg), so that the dogs could see the stimuli, and were placed 1 m apart in a straight line such that they would be approximately equidistant from the dog.
Once the plates were arranged, the dog and the handler entered the room and stood at a designated spot 2 m away from the plates. The experimenter stood out of the dog’s sight in order to avoid cueing choices. Dogs were released by the handler and were given approximately 10 s to walk to a plate and make a choice. We counted a choice for a particular plate when dogs consumed the food (Condition 1) or touched the plate with their nose (Conditions 2 and 3). After a choice was made, the remaining options were immediately removed, and the corresponding consequence occurred (see below for the consequences in each condition). If a choice was not made (e.g., if the dog walked away), the handler reset the dog at the starting location and the trial was reconducted; if a choice was not made on the second trial, the session was terminated for the day (i.e., session-termination criteria). Each session consisted of nine trials, to counterbalance the positions of the plates across all locations: left, middle, and right. The criterion to end Conditions 1 and 2 was selection of the larger reward option on 78% or more of trials for three consecutive sessions (i.e., stability criterion). This criterion was chosen in order to decrease the probability of completing a condition by chance. Several sessions were conducted per day, and they were extended across an additional day (or days) when a dog met the session-termination criteria (described above); this continued until dogs had completed all phases of the RRC task. All changes from one condition of the study to the next occurred within the same testing day; thus, changes in contingencies did not occur across days or with large breaks between the sessions.
Exposure trials
Prior to the first session of each condition, each dog completed nine exposure trials. The exposure trials ensured that the dogs experienced the consequences of each plate across all conditions before choices between plates were measured. The experimental arrangement of these trials was identical to the one described above, with the exception that a single option was presented on each trial until all three plates (i.e., small, large, and control) had been presented in all three positions (i.e., left, middle, and right). The handler put the dog in the start position and allowed the dog to visually examine the plate from 2 m away. The dog was then released and allowed to consume (Condition 1) or touch (Conditions 2 and 3) the option. In Conditions 2 and 3, the corresponding consequence was immediately provided by the experimenter (see below for each condition). Once the dog had consumed the food or completed a 3-s waiting period (i.e., control plate), the experimenter picked up the plate and the dog was reset at the starting position for the next trial.
Condition 1: Food
In the first condition, dogs were given a choice between three plates: two contained different quantities of food, and one was empty (control). Specifically, dogs chose between a plate with a small piece of food (one piece, cut 1 cm × 1 cm), a plate with a large piece of food (one piece, cut 5 cm × 5 cm), and a plate with no food. Once a choice had been made and either the food was consumed or the 3-s waiting period had expired (control condition), the dog was reset for the next trial.
There were three purposes for this condition. First, it identified whether discrimination between food and no-food plates readily occurred. This discrimination would be observed through little to no responding to the control plate. Second, it identified whether discrimination between the small- and large-food options occurred. This discrimination would be observed through greater responding to the plate with a larger magnitude of food than to the plate with a smaller magnitude of food. Third, it established a relationship between the visual size of the piece of food and the magnitude of the food reward as a consequence. Establishing a relationship between stimulus size and food amount was important, because the stimuli used in the succeeding conditions shared the same exact dimensions as the food in Condition 1.
Condition 2: Analogous stimuli
In this condition, dogs were given a choice between three black plates: Two contained white squares identical in size to the small and large foods presented in Condition 1, and one plate remained completely black (control). When the dog had touched a plate, a piece of food that was the same size as the selected square was delivered to the dog. Choosing the control plate resulted in no programmed consequences (i.e., extinction). The purpose of this condition was to establish the relationship between the size of the analogous visual stimulus and the magnitude of the food reward as a consequence.
Condition 3: RRC condition
The procedures in this condition were identical to those in the previous condition, with two exceptions. First, choosing the plate with the smaller square resulted in delivery of the large piece of food (5 cm × 5 cm). Second, choosing the plate with the larger square resulted in delivery of the small piece of food (1 cm × 1 cm). The consequences of selecting the control plate were identical to those in the previous conditions (i.e., no programmed consequence). Dogs remained in Condition 3 until they had completed at least the same number of sessions they had completed in Condition 2 and until responding was stable. Stable responding for this condition was defined as no trend in responding for a minimum of three consecutive sessions, evaluated visually by comparing the session-by-session data on the percentages of selections of each plate by each dog. This condition served as the RRC test, to determine whether dogs would switch their preference to the smaller visual stimulus that yielded the larger-magnitude edible consequence (i.e., whether they would switch in order to continue responding optimally).
Data analysis
Across conditions, a stimulus was considered the optimal choice if it yielded the large-magnitude food reward. Statistical significance was calculated using the last three sessions (i.e., responding at stability) for each condition. This was done because preference has been shown to differ depending on whether the organism is adapting to changes in schedules of reinforcement or is responding with stability (e.g., Bailey & Mazur, 1990; Myerson & Hale, 1988). Percentages of optimal choices were calculated for each session by adding the number of optimal choices and dividing by the total number of trials (i.e., nine). To determine whether optimal responding changed across the three conditions at the group level, we conducted a repeated measures analysis of variance using the average percentages of optimal responding between all three conditions. We also sought to determine whether optimal responding changed across contingencies for each individual dog. To do this, we conducted individual Student’s paired t tests on the average percentages of optimal responding across Conditions 2 and 3. Bonferroni corrections were used to control for the family-wise error rate across individual comparisons and to maintain α = .05.
Results
The mean numbers of sessions (± SD) to reach criterion across dogs were 6.89 (± 3.76), 5.78 (± 3.87), and 7.00 (± 3.57), for Conditions 1, 2, and 3, respectively. Figure 1 shows the average percentage of choices allocated to each plate for the last three sessions, averaged across dogs. A statistically significant average difference in optimal choices was made by dogs across the three conditions [F(2, 16) = 276.50, p < .001, ηp2 = .972]. Post-hoc tests using a Bonferroni correction revealed a significant difference in optimal responding between the first and third conditions (p < .001) and between the second and third conditions (p = .001). However, no difference in optimal responding was observed between the first and second conditions (p = 1.00). The dogs chose similar proportions of optimal choices in Condition 2 and Condition 1. In addition, dogs chose less optimally in Condition 3 (the RRC task).

Average percentages of choices allocated to each plate option, averaged across dogs in the last three sessions of Conditions 1, 2, and 3. Error bars represent standard deviations.
The average percentages of optimal choices for the last three sessions across each condition are displayed for each dog in Fig. 2. The results of all individual statistical analyses corresponded to the statistical analyses at the group level. We observed a significant difference in optimal choices between Condition 2 and Condition 3 for all dogs (p < .005). That is, all dogs continued to choose the large visual stimulus in Condition 3, despite receiving the smaller-magnitude food as a reward.

Average percentages of optimal choices at stability in the last three sessions, plotted across dogs. White bars depict responding during Condition 1, dark gray bars during Condition 2, and black bars during Condition 3. Range bars are added only for Condition 3, since Conditions 1 and 2 had stability criteria in place prior to advancing to the next condition.
Discussion
We initially evaluated whether dogs would demonstrate preference for a larger food reward when choosing between food items directly (Condition 1). We then evaluated whether dogs would maintain optimal responding and choose a large-analogous stimulus that resulted in a larger-magnitude food reward (Condition 2). Finally, we evaluated whether dogs would maintain optimal responding under the RRC test (Condition 3). We found that the use of analogous symbolic representations did not change the dogs’ choice of the large stimulus in Condition 2. However, the use of analogous symbolic representation did not facilitate performance on the RRC task. That is, all dogs continued to choose the stimulus previously associated with the large-magnitude food reward, despite receiving the small-magnitude food reward instead in Condition 3. Thus, all dogs developed and maintained a preference for the larger stimulus option across conditions. Our results are consistent with the previous literature evaluating the performance of other species under RRCs.
The reason that most species fail to optimize responding in the RRC task is still largely debated. Some proposed explanations include a predisposition toward larger quantities, behavioral momentum, and the reinforcing effects of the small-magnitude reward. Boysen and Berntson (1995) argued for a predisposition explanation in nonhuman primates. Specifically, suboptimal responding in RRC tasks could have been due to a competing response bias. That is, the animal might have perceived larger stimuli as being more rewarding, even though the contingency did not support that bias. Boysen et al. (1996) found that the overall size of the stimuli correlated to the disparity between the two choices. Thus, the larger the stimulus, the more interference (or bias) they found. These results could occur because dogs are highly adaptive scavengers (Butler & du Toit, 2002; Schmidt & Mech, 1997). Thus, dogs may have a bias for larger stimuli as an affective heuristic (i.e., large stimulus equals large reward; Pattison & Zentall, 2014).
A second explanation could be provided by behavioral momentum theory (BMT; e.g., Nevin, Mandell, & Atak, 1983). BMT attempts to explain why a learned behavior persists after the amount or frequency of a reward that follows the behavior is reduced or eliminated. The robust literature on BMT has shown that increasing the number of reinforcing events in the presence of a stimulus increases the degree to which the behavior persists when the reinforcer amount or frequency changes (Nevin & Shahan, 2011). In the present experiment, many reinforcing events occurred in the presence of the larger stimulus. It is possible that responding to the larger stimulus persisted in Condition 3 when the schedules of reinforcement changed because of the number of times the reward had been paired with that stimulus in Conditions 1 and 2 (i.e., because of the processes underlying BMT). Importantly, BMT offers precise quantitative predictions for resistance to change and how one can measure behavioral momentum (Nevin, 2002). Thus, BMT offers one testable hypothesis for future research on responding in RRC tasks.
Alternatively, persistence in selecting the larger stimulus might be influenced by continued contact with reinforcement for selection of the larger stimulus, albeit this being associated with a smaller-magnitude reinforcer during the RRC task. That is, suboptimal choice might occur because the organism continues to receive some amount of food following the suboptimal response (i.e., a smaller-magnitude reward for selecting the larger stimulus). Thus, the smaller-magnitude reward may still function as reinforcement for continuing to choose the larger stimulus previously associated with the larger quantity. Although the contingencies in the initial discrimination task produced discriminated responding, responding during the RRC task was not sensitive to the change in magnitude of the reinforcement during Condition 3 of the present study. In addition, the empty plate as a stimulus in the control condition was never associated with reinforcement and resulted in low levels of responding across all conditions. Thus, the reinforcement hypothesis accounts both for observations of suboptimal responding in RRC tasks, in which both choices lead to food, and for observations of optimal responding in extinction reversals, in which one choice leads to food and the other choice results in extinction (e.g., Silberberg & Fujita, 1996). Stated succinctly, any reward will do, but no reward is no good.
The fact that dogs persist in responding despite a drastic change in contingencies has at least one major implication. As we stated previously, many studies, including those conducted with dogs, have shown that animals reliably discriminate between differing quantities of food (Petrazzini & Wynne, 2016). Our results from Condition 1 replicated these findings and showed that dogs readily choose a larger reward over smaller ones. However, we also demonstrated that through a specific learning history (i.e., Conditions 2 and 3), dogs persisted in their pattern of responding despite receiving a smaller-magnitude reinforcer (Condition 3). This effect could result in contingencies that are extremely effective in maintaining performance over time with the use of smaller magnitudes of reinforcement. These outcomes might have implications for applied animal training within a variety of contexts (e.g., pet homes, shelters) and could give validity to certain methodologies, such as the use of jackpots (i.e., a procedure capitalizing on differential reinforcement, in which a larger magnitude of food is given when a dog skips a planned shaping step or completes a more difficult task than what was previously taught).
In summary, the present study extends use of a behavioral inhibition task (RRC) to a novel species (Canis lupus familiaris). Our results show that canines are able to choose optimally when both food and analogous stimuli are used. However, dogs were unable to reverse their responding in order to receive optimal rewards when the contingencies were switched. This supports previous reports of similar task arrangements with other species. The mechanisms that lead to the difficulty of reversal found across species is yet to be understood. At least three hypotheses have been offered, but none has been sufficiently researched to provide a convincing account for all of the data observed to date. Future research will need to use more rigorous methods and control procedures. At a minimum, the history of reinforcement for choosing a larger over a smaller stimulus needs to be controlled (e.g., Nevin et al., 1983). This will elucidate the precise effect that reinforcement history has on RRC task performance. In addition, once history is controlled, experimental arrangements can test the influence of other potential underlying mechanisms on this, and other, complex cognitive tasks.
References
Addessi, E., & Rossi, S. (2011). Tokens improve Capuchin performance in the reverse-reward contingency task. Proceedings of the Royal Society B, 278, 849–854.
Albaich-Serrano, A., & Call, J. (2014). A reversed-reward contingency task reveals causal knowledge in chimpanzees (Pan troglodytes). Animal Cognition, 17, 1167–1176. https://doi.org/10.1007/s10071-014-0749-9
Albaich-Serrano, A., Guillén-Salazar, F., & Call, J. (2007). Mangabeys (Cercocebus torquatus lunulatus) solve the reverse contingency task without a modified procedure. Animal Cognition, 10, 387–396. https://doi.org/10.1007/s10071-007-0076-5
Bailey, J. T., & Mazur, J. E. (1990). Choice behavior in transition: Development of preference for the higher probability of reinforcement. Journal of the Experimental Analysis of Behavior, 53, 409–422.
Boysen, S. T., & Berntson, G. G. (1995). Responses to quantity: Perceptual versus cognitive mechanisms in chimpanzees (Pan troglodytes). Journal of Experimental Psychology: Animal Behavior Processes, 21, 82–86. https://doi.org/10.1037/0097-7403.21.1.82
Boysen, S. T., Berntson, G. G., Hannan, M. B., & Cacioppo, J. T. (1996). Quantity-based inference and symbolic representation in chimpanzees (Pan troglodytes). Journal of Experimental Psychology: Animal Behavior Processes, 22, 76–86. https://doi.org/10.1037/0097-7403.22.1.76
Butler, J. R. A., & du Toit, J. T. (2002). Diet of free-ranging domestic dogs (Canis familaris) in rural Zimbabwe: Implications for wild scavengers on the periphery of wildlife reserves. Animal Conservation, 5, 29–37.
Call, J. (2000). Estimating and operating on discrete quantities in orangutans (Pongo pygmaeus). Journal of Comparative Psychology, 114, 136–147.
Carlson, S. M., Davis, A. C., & Leach, J. G. (2005). Less is more: Executive function and symbolic representation in preschool children. Psychological Science, 16, 609–616. https://doi.org/10.1111/j.1467-9280.2005.01583.x
Fisher, W., Piazza, C. C., Bowman, L. G., Hagopian, L. P., Owens, J. C., & Slevin, I. (1992). A comparison of two approaches for identifying reinforcers for persons with severe and profound disabilities. Journal of Applied Behavior Analysis, 25, 491–498.
Genty, E., Palmier, C., & Roeder, J. J. (2004). Learning to suppress responses to the larger of two rewards in two species of lemurs, Eulemur fulvus and E. macaco. Animal Behavior, 67, 925–932.
Huntley-Fenner, G., & Cannon, E. (2000). Preschoolers’ magnitude comparisons are mediated by a preverbal analog mechanism. Psychological Science, 11, 147–152.
Kilian, A., Yaman, S., von Fersen, L., & Güntürkün, O. (2003). A bottlenose dolphin discriminates visual stimuli differing in numerosity. Learning & Behavior, 31, 133–142. https://doi.org/10.3758/BF03195976
Kralik, J. D., (2012). Rhesus macaques spontaneously generalize to novel quantities in a reverse-reward contingency task. Journal of Comparative Psychology, 126, 255–262.
Krusche, P., Uller, C., & Dicke, U. (2010). Quantity discrimination in salamanders. Journal of Experimental Biology, 213, 1822–1828.
Lazarowski, L., Foster, M. L., Gruen, M. E., Sherman, B. L., Case, B. C., Fish, R. E., . . . Dorman, D. C. (2014). Acquisition of a visual discrimination and reversal learning task by Labrador retrievers. Animal Cognition, 17, 787–792.
Meck, W. H., & Church R. M. (1983). A mode control model of counting and timing processes. Journal of Experimental Psychology: Animal Behavior Processes, 9, 320–334. https://doi.org/10.1037/0097-7403.9.3.320
Milgram, N. W., Head, E., Weiner, E., & Thomas, E. (1994). Cognitive functions and aging in the dog: Acquisition of nonspatial visual tasks. Behavioral Neuroscience, 108, 57–68.
Myerson, J., & Hale, S. (1988). Choice in transition: A comparison of melioration and the kinetic model. Journal of the Experimental Analysis of Behavior, 49, 291–302.
Nevin, J. A. (2002). Measuring behavioral momentum. Behavioural Processes, 57, 187–198.
Nevin, J. A., Mandell, C., & Atak, J. R. (1983). The analysis of behavioral momentum. Journal of the Experimental Analysis of Behavior, 39, 49–59.
Nevin, J. A., & Shahan, T. A. (2011). Behavioral momentum theory: Equations and applications. Journal of the Experimental Analysis of Behavior, 44, 877–895. https://doi.org/10.1901/jaba.2011.44-877
Pattison, K. F., & Zentall, T. R. (2014). Suboptimal choice by dogs: when less is better than more. Animal Cognition, 17, 1019–1022.
Petrazzini, M. E. M., & Wynne, C. D. L. (2016). What counts for dogs (Canis lupis familiaris) in a quantity discrimination task? Behavioural Processes, 122, 90–97.
Schmidt, P. A., & Mech, L .D. (1997). Wolf pack size and food acquisition. American Naturalist, 150, 513–517.
Schumaker, R. W., Palkovitch, A. M., Beck, B. B., Guagnano, G. A., & Morowitz H. (2001). Spontaneous use of magnitude discrimination and ordination by the orangutan (Pogo pygmaeus). Journal of Comparative Psychology, 115, 385–391.
Silberberg, A., & Fujita, K. (1996). Pointing at smaller food amounts in an analogue of Boysen and Bernston’s (1995) procedure. Journal of the Experimental Analysis of Behavior, 66, 143–147.
Tapp, P. D., Siwak, C. T., Estrada, J., Head, E., Mugenburg, B. A., Cotman, C. W., & Milgram, N. W. (2003). Size and reversal learning in the Beagle dog as a measure of executive function and inhibitory control in aging. Learning and Memory, 10, 64–73.
Ward, C., & Smuts, B. B. (2007). Quantity-based judgements in the domestic dog (Canis lupus familiaris). Animal Cognition, 10, 71–80.
West, R. E., & Young, R. J. (2002). Do domestic dogs show any evidence of being able to count? Animal Cognition, 5, 183–186. https://doi.org/10.1007/s10071-002-0140-0
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Fernand, J.K., Amanieh, H., Cox, D.J. et al. Any reward will do: Effects of a reverse-reward contingency on size preference with pet dogs (Canis lupus familiaris). Learn Behav 46, 472–478 (2018). https://doi.org/10.3758/s13420-018-0343-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13420-018-0343-0