
Abstract
Contemporary theory in cognitive neuroscience distinguishes, among the processes and utilities that serve categorization, explicit and implicit systems of category learning that learn, respectively, category rules by active hypothesis testing or adaptive behaviors by association and reinforcement. Little is known about the time course of categorization within these systems. Accordingly, the present experiments contrasted tasks that fostered explicit categorization (because they had a one-dimensional, rule-based solution) or implicit categorization (because they had a two-dimensional, information-integration solution). In Experiment 1, participants learned categories under unspeeded or speeded conditions. In Experiment 2, they applied previously trained category knowledge under unspeeded or speeded conditions. Speeded conditions selectively impaired implicit category learning and implicit mature categorization. These results illuminate the processing dynamics of explicit/implicit categorization.
Similar content being viewed by others

Categorization is an essential cognitive ability and an important topic of cognitive and neuroscience research (e.g., Ashby & Maddox, 2011; Brooks, 1978; Knowlton & Squire, 1993; Medin & Schaffer, 1978; Murphy, 2003; Nosofsky, 1987; Smith & Minda, 1998). The contemporary categorization literature contains an influential multiple-systems perspective (Ashby, Alfonso-Reese, Turken, & Waldron, 1998; Ashby & Ell, 2001; Cook & Smith, 2006; Erickson & Kruschke, 1998; Homa, Sterling, & Trepel, 1981; Rosseel, 2002) that proposes that multiple categorization utilities in cognition use different information-processing principles to serve different ecological needs.
In particular, among the processes and utilities that serve categorization, cognitive and neuroscience researchers have distinguished between explicit and implicit categorization. The explicit system learns using focused attentional processes that target individual stimulus features. It learns through hypothesis testing and something like logical reasoning. It depends on working memory and executive attention. It produces category knowledge that is declaratively conscious. The implicit system learns using multidimensional processes that can integrate across stimulus features. It depends on associative-learning processes to link stimulus to adaptive responses. It produces category knowledge that is opaque to declarative consciousness. These processing attributes are documented in many studies (e.g., Ashby et al., 1998; Ashby & Maddox, 2011; Ashby & Valentin, 2005; Maddox & Ashby, 2004; Maddox, Ashby, & Bohil, 2003; Maddox & Ing, 2005).
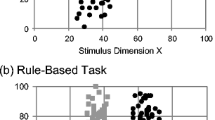
Explicit and implicit categorization have been differentiated using rule-based (RB) and information-integration (II) category tasks. In Fig. 1, each Category A and B instance (gray and black symbols, respectively) is a conjoint stimulus presenting values from perceptual dimensions X and Y. The RB task (Fig. 1A) fosters explicit category learning. Category A and B instances are contrasted only by their Y-axis position. A horizontal category boundary—that is, a dimensional rule with a central criterion along the Y-axis—partitions the categories. The mean and variation along the X dimension are identical for both categories, providing no useful information for category decisions. Participants are not presented with the whole stimulus space. They see individual instances with feedback following each response, and they must discover category rules within this trial-by-trial framework. Many researchers have granted explicit rules an important role in categorization (e.g., Ahn & Medin, 1992; Erickson & Kruschke, 1998; Feldman, 2000; Medin, Wattenmaker, & Hampson, 1987; Nosofsky, Palmeri, & McKinley, 1994; Regehr & Brooks, 1995; Shepard, Hovland, & Jenkins, 1961), and thus fully understanding rule-based categorization remains an important empirical goal.

Illustrative tasks. Two categorization tasks, showing the positions in XY space of Category A exemplars (gray symbols) and Category B exemplars (black symbols)
The II task (Fig. 1B) fosters implicit learning. This task is oriented in the stimulus space so that the minor diagonal partitions the categories. Dimensions X and Y present partially valid information for categorization. One-dimensional hypotheses are not adaptive. Participants must integrate information across dimensions into a category decision. Humans’ category-learning systems do accomplish this integration—but the resulting learning is procedural and inexpressible. II tasks have also been influential in the literature (e.g., Brooks, 1978; Kemler Nelson, 1984; Maddox & Ashby, 2004; Smith, Tracy, & Murray, 1993). To be clear, this article focuses on explicit and implicit category learning, and on RB and II category learning. However, we mean no implication that humans have only these two categorization processes or utilities, or that all tasks can be pigeon-holed into one of these two categorization processes or utilities. In fact, there is evidence that other memory systems sometimes contribute to human category learning (Casale & Ashby, 2008).
The RB and II tasks are an elegant minimal pair within cognitive science, because they differ only in the analytic–nonanalytic aspect that is crucial to their theoretical context and to the present research. In all other respects—category size, within-category exemplar similarity, between-category exemplar separation, the discriminability of the categories, the d′ of the category task, the proportion correct achievable by an ideal observer—the tasks are precisely matched. The tasks are simply rotations of the same exemplar distributions 45 degrees through stimulus space. Thus, RB and II tasks are matched for every aspect that could affect difficulty a priori. Confirming this equivalency, two studies have shown that these category tasks are matched for learning difficulty when they are learned by a species (pigeons, Columba livia) that may lack the ability to form dimensional category rules (Smith et al., 2011; see also Smith et al., 2012). Robert Cook (personal communication, Dec. 2013) has demonstrated for a third time pigeons’ equivalent learning of RB and II tasks.
The theoretical dissociation between explicit and implicit category-learning utilities is supported by studies of their brain organization and by studies of neuropsychological populations (Ashby & Ennis, 2006). Cognitive psychological research has also empirically dissociated these systems (Maddox & Ashby, 2004). For example, Waldron and Ashby (2001) showed that only RB category learning was impaired by a concurrent task that competed for the resources of working memory and executive attention—consistent with the hypothesis that the RB utility is dependent on those same resources. Maddox et al. (2003) and Maddox and Ing (2005) showed that II category learning is especially impaired if the feedback is delayed—consistent with the hypothesis that the implicit utility depends on the time-locked updating of neural connections prompted by the reinforcement signal. The multiple-systems perspective accounts intuitively for these and many other results.
Most recently, Smith et al. (2014) asked participants to learn RB and II tasks under deferred-rearranged feedback. Summary feedback was given only after each trial block and this feedback was rearranged with all positive outcomes and then all negative outcomes clustered separately. This prevented participants from using trial-by-trial feedback to form stimulus–response linkages. It prevented associative learning. Smith et al. (2014) hypothesized that deferred-rearranged feedback—by disabling associative learning—would eliminate all II category learning but leave RB learning unscathed (because participants could evaluate their explicit category rule equally well after a trial or after a trial block). This hypothesis was strongly confirmed. Smith et al. (2014) also hypothesized that participants trying to learn II categories under deferred-rearranged feedback would fall back onto RB strategies—the only viable strategy in a reinforcement environment that defeated associative learning. Participants did so. No single-system account explains these results, but the idea of explicit category rules held in working memory explains them intuitively because explicit rules are not dependent upon trial-by-trial immediate feedback. In fact, no single-system account can account for even a few of the many reported RB–II dissociations (Maddox & Ashby, 2004). Moreover, Ashby (2014) demonstrated that the approach of state-trace theory—used in recent articles to support the single-system position (e.g., Newell, Dunn, & Kalish, 2010)—cannot support any inferences about the number of category-systems at work in producing a data set.
Therefore, in this article we adopted the working hypothesis—consistent with the consensus in neuroscience—that these dissociable category-learning utilities exist, and we addressed an empirical problem that remains unexplored. Thus, we considered for the first time the time course of learning in these two category-learning utilities.
What should this time course be like? The dominant theoretical idea came from Kemler Nelson’s (1984) seminal research. She found that intentional learners adopt an analytic mode of cognition that comprises stimulus analysis, deliberate hypothesis generation/evaluation, and the formulation of explicit rules. This information-processing description would suggest that RB category learning should be more deliberate, more cognitively controlled, more staged and systematic—and slower. In contrast, Kemler Nelson (1984) hypothesized that incidental learners adopt a nonanalytic mode of cognition that depends on the direct, nonderived, immediate response to unanalyzed stimulus wholes. It could be predicted to be faster, and, in fact, Smith and Kemler Nelson (1984) showed that it could be faster.
Cognitive–developmental research supported the same theoretical intuitions. Garner’s (1974) speeded-classification tasks revealed that young children, children with mental retardation, and impulsive children dimensionalize their perceptual worlds less strongly than adults. They appreciate stimuli more holistically. They group items more often by unanalyzed, multidimensional similarity than by sharply attended single stimulus features. Formally, they treat perceptual dimensions as more integral (not attentionally separated) than separable (attentionally separated---Kemler, 1982a, b; Shepp, Burns, & McDonough, 1980; Smith & Kemler Nelson, 1984, 1988; Ward, 1983). The organizing theme in this literature was that those populations—lacking the mature complement of reflective, analytic–dimensional cognitive utilities—were reliant on an implicit, immature, and impulsive mode of nonanalytic cognition. This theme would point to a faster unfolding for the nonreflective, nonanalytic processes of II category learning. Broadbent (1977) also distinguished global perceptual processing (fast and effortless) from detailed perceptual processing (slow and effortful). Other two-stage models of stimulus comparison have contrasted a fast, preattentive comparator that operates on wholes and a slower, optional comparator that checks feature by feature (e.g., Bamber, 1969; Krueger, 1973). Therefore, a natural hypothesis in our study was that II category learning would be more robust facing severe reaction-time deadlines.
But there is another viable hypothesis. Young children sometimes perseverate on task-irrelevant stimulus features (Aschkenasy & Odom, 1982; Kemler, 1978; Shepp et al., 1980; Smith & Kemler Nelson, 1988). In such cases, children are impulsively analytic processors, not impulsively holistic ones. This might argue for the possibility of a narrow dimensional focus in a categorization task under strict response deadlines. Huang-Pollock, Maddox, and Karalunas (2011) recently showed that children have greater difficulty than adults transitioning from one-dimensional, RB strategies to the appropriate II approach. This recent finding complements the previous work of Ward and Scott (1987; see also Ward, 1988; Ward, Vela, & Hass, 1990), who studied category learning by young children and found that they were sometimes engaged not in holistic processing but in perseveratively analytic processing. Likewise, Smith and Shapiro (1989) studied adults’ speeded category learning. They found that speeded conditions sometimes produced narrow, rigid analysis, as participants chose any attribute in a temporal storm and stuck to it rigidly despite the errors it caused. Lamberts (1998) also found that under deadline conditions, categorization performance grew dependent on single stimulus dimensions. Thus, another viable hypothesis in our study was that RB category learning—that allows this narrow dimensional focus—would be more robust facing severe response deadlines.
Predictions
Research like that of Smith and Kemler Nelson (1984), Garner (1974), and Ell, Ing, and Maddox (2009) illuminates the deliberate, controlled, working-memory intensive characteristics of RB learning. Response deadlines could disrupt the systematic, hypothesis-testing behavior supporting explicit categorization. These studies have suggested that explicit categorization should be hurt by response deadlines.
Alternatively, studies involving delayed-feedback in simple category tasks with deferred-delayed feedback (e.g., Maddox et al., 2003; Maddox & Ing, 2005; Smith et al., 2014) show that II learners then fall back on non-optimal RB strategies. Furthermore, cognitive–developmental research suggests that rigid, analytical, single-dimensional analysis can overpower appropriate holistic processing in children. These studies as well as speeded-categorization studies (Lamberts, 1998; Smith & Shapiro, 1989) suggest that II category learning might be hurt under response deadlines.
Experiment 1
Experiment 1 explored response deadlines as a possible constraint on RB or II category learning. We used the RB–horizontal (RBh) and II–minor (IIm) diagonal tasks (Fig. 1A and B, respectively) because pilot data had shown that under standard conditions they produced good learning, typical learning curves, and consistently appropriate decision strategies as shown by formal-mathematical modeling. This pilot data is described in the supplementary materials. Participants learned RBh or IIm tasks under unspeeded conditions or facing strict deadlines for making categorization responses. This comparison gave us a first look at the time course of RB and II category learning.
Method
Participants
The participants were 124 undergraduates from the University at Buffalo (UB)—with the demographic characteristics of UB’s Department of Psychology Research Participant Group—who participated as partial fulfillment of a psychology course requirement. There were 31 participants in each of the four conditions: RB-unspeeded, RB-deadline, II-unspeeded, and II-deadline.
Stimuli
The stimuli were unframed rectangles containing green lit pixels, presented on a black background in the computer screen’s top center. The rectangles varied in size and the numbers of lit pixels. There were 101 sizes (Levels 0–100). A rectangle’s width in pixels was calculated as 100 + Level. Its height was given by round(width/2). Rectangles varied from 100 × 50 (Level 0) to 200 × 100 (Level 100). Dimension Size is the X-axis in Fig. 1’s stimulus spaces.
The rectangles’ proportional pixel density—that is, the proportion of the total pixel positions illuminated—also had 101 levels. A level’s proportional density was given by .05 × 1.018Level. For Level 0, the proportional density was .05. For Level 100, proportional density was .2977. Dimension Density is the Y-axis in Fig. 1’s stimulus spaces. Stimuli were viewed from about 24 in., presented on a 17-in. monitor (800 × 600 resolution). Figure 2 illustrates the stimulus space by showing its four corners—Stimulus 0 0 (lower left, small–sparse), Stimulus 100 0 (lower right, big–sparse), Stimulus 0 100 (upper left, small–dense), and Stimulus 100 100 (upper right, big–dense).

Illustrative stimuli. The stimuli were unframed rectangles containing green illuminated pixels. Box Size (dimension X) and Box Density (dimension Y) had 101 levels (Levels 0 to 100) that were concretized into stimuli using formulae specified in the text. Shown are: Stimulus 0 0 (small–sparse), Stimulus 100 0 (big–sparse), Stimulus 0 100 (small–dense), and Stimulus 100 100 (big–dense)
Category structures
Category exemplars were chosen using Ashby and Gott’s (1988) randomization technique. Categories were defined by bivariate normal distributions along two stimulus dimensions that ranged along an abstract 0-to-100 scale. Table 1 gives the specifics of the statistical distributions that defined the RBh and IIm category tasks. As each category exemplar was selected from a category distribution as a coordinate pair in abstract stimulus space, the abstract values were transformed into concrete stimuli with two visual features (size, density) according to the formulas already given. Following the procedures in Smith et al. (2014), each participant received his or her own sample of randomly selected category exemplars appropriate to their assigned category task. To control for statistical outliers, category exemplars were not presented if their Mahalanobis distance (e.g., Fukunaga, 1972) from the category mean was greater than 3.0. Instead, other potential exemplars were selected randomly until the distance criterion was met. The two category structures are shown in Fig. 1. For the RBh task, only density was relevant to correct categorization. For the IIm task, both dimensions were partially informative about correct categorization. Information had to be integrated across dimensions to support performance.
Categorization trials
Each trial consisted of a pixel box of a designated size and a designated density for that trial, presented at the center-top of a computer screen against a black background. Below each stimulus was a letter “A” and a letter “B” toward the left and right side of the screen, respectively, and a cursor in the middle. To assign the stimulus to Category A or B, participants pressed the S or L key (spatially correspondent on the keyboard to the “A” and “B” on the screen). Once either key was pressed, feedback was immediately given.
When the participant assigned the stimulus to the correct category, he or she received a high-pitched “whoop” sound. Immediately following this, CORRECT +1 was displayed in green text for about half a second. If the participants were incorrect, they were given an 8-s timeout, accompanied by a low-pitched “buzz” sound. During the timeout, INCORRECT –1 appeared on the screen in red text. For each trial, the participant’s cumulative score was also shown, below CORRECT +1 or INCORRECT –1.
We made Experiment 1 responsive to two current methodologies in this area. Some have instituted a masking stimulus that appears where the stimulus had been just after the participant responds “A” or “B” and before the delivery of feedback. This prevents participants from keeping the stimulus that they had just seen available in iconic memory as reinforcement arrives (Maddox et al., 2003; Maddox, Bohil, & Ing, 2004; Nomura et al., 2007). Others have not deemed this mask necessary (Ashby & Crossley, 2010; Casale, Roeder, & Ashby, 2012; Smith, Beran, Crossley, Boomer, & Ashby, 2010).
To incorporate both methodologies, participants with masking saw a solid green rectangle flashed briefly on the screen where the stimulus had been after the participant had assigned the stimulus to Category A or B. The mask used was the same size in all trials, and was larger than the largest possible rectangle. Following the brief mask, feedback was given immediately. Participants without masking saw the categorized stimulus disappear and then feedback was given with the backdrop of a black, blank screen. This methodological variation apparently made very little difference in either the behavior of the tasks or in the unspeeded–speeded contrasts we observed. Sixty-four participants completed the task with masking (16 per condition). Sixty participants completed the task without masking (15 per condition).
In the speeded or deadline condition, participants were also penalized when they did not answer within the 600-ms deadline. So, not responding in time was treated as an error. Participants received the 8-s error buzz while LATE –1 appeared on the screen in yellow text.
Instructions
Participants were told that they would categorize boxes of green pixels into Category A or B. They were told that they would have to guess at first, but would learn how to respond correctly. They were told about gaining or losing points for correct or incorrect responses, and about the feedback and accompanying sounds. The instructions also reflected the speeded and unspeeded contingencies. Participants were told that they would have very little time to answer (deadline condition) or as much time as needed to answer (unspeeded condition). Finally, they were told about the cash prizes that would be given to participants with the highest scores in the experiment, which we hoped would motivate them in the task. Participants acknowledged having read all the instructions, and the trials began.
Procedure
Participants were placed randomly—based on their sequential participant number—into the RB or II task and into the speeded (deadline) or unspeeded condition. Randomly selected categorization trials continued until the session duration of 50 minutes was reached.
Formal modeling
Formal models (Maddox & Ashby, 1993) let us characterize the decisional strategies of individual participants. We modeled the data from each participant’s last 100 trials when their performance strategy had matured. The models tested and the procedures for modeling are described briefly now.
The rule-based model assumes the participant uses a decision criterion on one stimulus dimension (rectangle size or pixel density). Modeling specified the vertical or horizontal line through the stimulus space that partitions best a participant’s Category A and Category B responses. This model has two free parameters: a perceptual noise variance and a criterion value on the relevant dimension.
The information-integration model assumes participants divide the stimulus space using a nonvertical, nonhorizontal linear decision bound—that is, using some diagonal through the stimulus space. The outcome of modeling is to specify the slope and intercept of the line drawn through the stimulus space that would best partition the participant’s Category A and Category B responses. This model had three free parameters: a perceptual noise variance and the slope and intercept of the linear decision bound.
The best-fitting values for the models’ free parameters were estimated using maximum-likelihood methods. Modeling evaluated which model would have most likely created the distribution in the stimulus space of the Category A and B responses that a participant actually made. The Bayesian Information Criterion (BIC, Schwarz, 1978) determined the best-fitting model BIC =r lnN – 2 lnL, where r is the number of free parameters, N is the sample size, and L is the model’s likelihood given the data.
Results and discussion
Preliminary analyses: Two category-learning processes
First, we confirmed that there were qualitatively different category-learning processes at work in the RB and II tasks. These analyses helped rule out the state-trace single-system arguments that Ashby (2014) discounted on independent grounds, and the difficulty-based single-system arguments that Smith et al. (2014) ruled out. Figure 3A shows a backward learning curve for the RB-unspeeded condition. We aligned the trial blocks at which participants reached criterion (Block 0)—sustaining .85 accuracy for 100 trials—to show the path by which they solved the RB task. RB performance transformed at Block 0 (.57-precriterion; .93-postcriterion). Performance stabilized. Learning ended. Accuracy topped out. Figure 3A understates this transformation. Block –1 performance is inflated because sometimes it contains the first trials of participants’ criterion run (compare Block –2 performance). Block 0 performance is deflated because sometimes the criterion run starts a few trials into the block (compare Block 1 performance).

(A, B) Backward learning curves for RB-unspeeded and II-unspeeded participants in Experiment 1, constructed as described in the text
Single-system exemplar models cannot fit this qualitative change. They fit learning curves through gradual changes to sensitivity and attentional parameters. The change in Fig. 3A is not gradual. These models cannot explain so sharp a change, or why there was no change in sensitivity or attention until Block 0, or why sensitivity and attention suddenly surged then. But all aspects of Fig. 3A flow from assuming the discovery of an explicit categorization rule that suddenly transforms performance.
We graphed the II-unspeeded condition in the same way (Fig. 3B). This graph contains a general lesson for understanding backward learning curves. The seeming performance change at Block 0 is only a statistical artifact. To see this, note that the performances averaged into Block –1 cannot be .85, .90, .95, or 1.0. (These criterion performance levels defined Block 0 and they would redefine Block –1 as Block 0.) Therefore, the distribution of Block –1 performances is truncated high. Likewise, the performances averaged into Block 0 can only be .85, .90, .95, or 1.0. Only these can define criterion and occur at Block 0. The distribution of Block 0 performances is truncated low. If one assumes the same underlying competence both pre- and post-criteria, but samples only blocks that fit the pre- and post-performance criteria, truncation alone produces an expected performance gap of .16 between pre- and post-criterion. Remarkably, this is what participants showed (.17) in their backward curve for the II task. Thus, Fig. 3B shows no learning transition at criterion, only sampling constraints caused by the definition of criterion. In contrast, extensive simulations show that Fig. 3A’s pre- and post-criterion performances are so extreme that they are true-score estimates of the underlying competence—they are unaffected by sampling constraints. All of Fig. 3A’s transition reflects a change in underlying competence.
II learning was gradual and incremental with no sudden transition. This is the category-learning process that single-system exemplar models fit well and that represents an associative form of category learning that it is important to understand well. Exemplar models have contributed by increasing our understanding of this system. However, the RB transition reveals a qualitative transition from chance to ceiling performance that cannot be explained by this single-system theory. RB–II dissociative phenomena like that demonstrated here clearly indicate that there are two category-learning utilities, not just one.
Nor can one resort to differential difficulty to explain RB–II dissociative phenomena like that shown here. These tasks are controlled for every structural aspect of difficulty (see the introduction), so appealing to intrinsic perceptual–discriminative difficulty is impossible. Such an appeal would also ignore that the nature of the learning trajectory is profoundly different between the tasks. For those interested in a fuller discussion of the difficulty hypothesis, we have included it in the supplementary materials.
Concluding provisionally that there were two different category-learning processes at work in our RB and II tasks, we proceeded to examine the effects of the deadline condition on these two processes.
Accuracy-based analyses
Figure 4 shows performance across tasks and deadline conditions for the first thirteen 20-trial blocks from the beginning of the task. To compare participants’ final levels of learning across tasks and deadline conditions, we found the proportion correct for all participants in their last 100 category-response trials. We excluded late trials from the analysis because those stimuli were neither categorized correctly nor incorrectly, and because the second type of error (lateness—that occurred only in the deadline conditions) would change the definition of performance level across the conditions of interest.

Average proportion correct over the first thirteen 20-trial blocks for the RB-unspeeded, RB-deadline, II-unspeeded, and II-deadline conditions in Experiment 1. The averages include the data from the 117 out of 124 participants who completed at least 260 trials
These proportion-correct data were analyzed using the GLM procedure in SAS 9.3. The analysis was a three-way analysis of variance (ANOVA) with task-type (RB, II), mask type (present, absent), and condition (unspeeded, deadline) as between-participants factors. The ANOVA produced just the following two significant effects. There was a significant main effect of condition, F(1, 116) = 29.50, p < .0001, η p 2 = .203, indicating that terminal levels of performance were higher in the unspeeded condition. Participants were .88 and .74 correct during the unspeeded and deadline conditions, respectively. The analysis also revealed a significant interaction between task and condition, F(1, 116) = 3.92, p = .050, η p 2 = .033, reflecting the fact that the deadline condition compromised performance in the II task selectively. Participants learning the II task were .88 and .69 correct in the unspeeded and deadline conditions, respectively. The cost to the response deadline was 19 %, a serious decline in performance. Participants learning the RB task were .88 and .79 correct in these conditions. The cost to the response deadline for RB learners was only 9 %, less than half as much.
Post hoc comparisons were done to examine whether in each of the tasks (RB, II) the last 100 deadline trials were significantly less accurate than the last 100 unspeeded trials. Tukey’s HSD test showed that in the II task, the deadline condition was significantly less accurate. In the RB task this was not the case. This confirms that introducing a deadline hurt II more than RB category learning.
We conducted a complementary set of analyses that measured improvements in learning by comparing initial and terminal levels of performance. These analyses are reported in the supplementary materials, and they reached identical conclusions.
Model-based analyses
We modeled the performance of all participants using procedures already specified. This let us confirm that participants overall did adopt appropriate decision strategies. It let us search for strategy disruptions when participants learn RB or II tasks under deadline conditions. It let us ask whether deadline conditions might cause a systematic change in the character of participants’ decision strategies that would further theoretical development in this area.
Figure 5 shows the best-fitting decision bounds for the four conditions. The decision bounds for the RB-unspeeded participants were tightly organized along the midline of the Y dimension. They chose consistently an appropriate strategy toward completing the RBh task by applying a one-dimensional rule involving density. The decision bounds for the RB-deadline participants were remarkably similar, confirming from the perspective of formal modeling that the deadline had little effect on RB category learning. Smaller aspects of the data confirm this as well. The number of guessers in the two conditions was about the same: four and six in RB-unspeeded and RB-deadline conditions. The number of participants with strictly one-dimensional decision bounds on the Y-axis actually increased from the unspeeded condition to the deadline condition, from 15 to 19. If anything, participants became more analytic under deadline. This is good to bear in mind as we consider next decisional strategies in the II category tasks. In short, all modeling results converged with the accuracy results to suggest that deadline conditions hardly affected participants’ RB category learning and decision strategies.

The decision bounds that provided the best fits to the last 100 category responses of the participants in RB-unspeeded, RB-deadline, II-unspeeded, and II-deadline conditions in Experiment 1
The decision bounds for the II-unspeeded participants were largely organized appropriately along the minor diagonal of the stimulus space. These participants chose collectively a decision strategy for the II task by which they learned to integrate the informational signals provided by the two stimulus dimensions.
In sharp contrast, the decision bounds for the II-deadline condition look like a game of Pick Up Sticks. Modeling confirmed that the deadline condition had a seriously negative impact on II category learning. Smaller aspects of the data confirm this as well. The deadline requirement increased the number of guessers from zero in the II-unspeeded condition to seven in the II-deadline condition. These participants cannot be shown in Fig. 5—and therefore the figure actually underestimates the learning disorganization caused by the deadline. Strikingly, the deadline also increased the number of participants who had one-dimensional decision bounds from five to 13. This suggests that speed actually pushed participants toward more analytic and dimensional decisional strategies in the II task, a suggestion that we pursue in the discussion. Of course, these strategies were inappropriate to the II task.
Experiment 2
Experiment 2 explored the effect of a response deadline on the application of already trained category knowledge. Now participants were trained (140 trials) in either the RBh task or the IIm task. These tasks were chosen for reasons already described and discussed in the supplementary materials. Then, in two successive 140-trial transfer phases, participants applied their category knowledge under unspeeded and speeded conditions. These transfer phases were presented to every participant but order was counter-balanced across participants (unspeeded–speeded, speeded–unspeeded).
Method
Participants
Participants were 89 University at Buffalo undergraduates who participated as partial fulfillment of a psychology-course requirement. The data from 17 participants were not analyzed because they barely learned (<70 % correct on the last training block). The data from three participants were not analyzed because they showed a significant drop in their speeded or unspeeded phases from the first 40 trials to the last 40 trials (an effect of fatigue or loss of task engagement). The data from nine participants were not analyzed because they did not complete all 420 trials (three 140-trial phases). There were 15 participants in each of four counterbalanced conditions: RB unspeeded–speeded (RBUS), RB speeded–unspeeded (RBSU), II unspeeded–speeded (IIUS), and II speeded–unspeeded (IISU).
Procedure
All aspects of the stimuli, feedback, the category structures, the category tasks, and the formal modeling were like those described in Experiment 1.
Results and discussion
Training trials
Figure 6A shows by 20-trial blocks the average proportion correct achieved during training by each group. Participants showed robust learning. Participants in the RB and II conditions, respectively, improved over seven blocks from .67 to .92 and from .64 to .85. They improved overall from .66 to .89 correct. The shorter training phase in Experiment 2 than in Experiment 1 produced a very small RB performance advantage at the end of training. The training phase gave us a sound basis for comparing the unspeeded and speeded application of trained category knowledge in the testing phases that followed next.

Training and testing performance in Experiment 2. (A) Average proportion correct over the 20-trial training blocks for participants in the RB and II tasks. (B) Average proportion correct over the 20-trial testing blocks for unspeeded and deadline phases in the RB and II tasks
Unspeeded vs speeded categorization
Figure 6B shows, by 20-trial blocks the average proportion correct achieved during the speeded and unspeeded testing phases by each group. To compare unspeeded and speeded categorization, we found the overall proportion correct of all participants in the 140-trial testing phases. In scoring performances, the trials on which participants responded too slowly to meet the response-time deadline were excluded from analysis because those stimuli were not categorized correctly or incorrectly. Therefore, the proportions correct are based on fewer than 140 trials for each participant in the deadline conditions of the experiment. This also explains why in Fig. 6 there are only six blocks for the deadline conditions.
These proportion-correct data were analyzed using the GLM procedure in SAS 9.3. The analysis was a three-way analysis of varianace (ANOVA) with task-type (RB, II) and condition order (unspeeded–speeded, speeded–unspeeded) as between-participants factors, and condition (speeded, unspeeded) as a within-participants factor. The ANOVA produced just three significant effects.
First, there was a significant main effect for task, F(1, 56) = 15.22, p < .001, η p 2 = .212, indicating that performance levels were higher in the RB condition (.89 correct overall) than in the II condition (.83 correct overall).
Second, there was a significant main effect for condition, F(1, 56) = 83.09, p < .001, η p 2 = .593, indicating that performance levels were higher in the unspeeded condition (.90 correct overall) than in the speeded condition (.82 correct overall).
Third, and most important, there was a significant interaction between task-type and condition, F(1, 56) = 3.99, p = .051, η p 2 = .068. This suggested that the speeded condition compromised performance in the II task to a greater degree. II participants were .88 and .78 correct in the unspeeded and deadline conditions, respectively. The cost to the response deadline on trained II categorization was 10 %, a serious decline in performance even excluding the trials responded too late. RB participants were .92 and .86 correct in these conditions. The cost to the deadline on trained RB categorization was only 6 %, about half as much. There was no significant main effect or interaction with condition order (speeded-unspeeded, unspeeded, speeded). However, see the supplementary materials for figures of task and condition performance during testing by condition order. Post hoc comparisons explored whether in each task (RB, II) the deadline trials were performed less accurately. Tukey’s HSD test showed that the deadline condition was significantly less accurate in both cases. The interaction already described confirms in addition that the II task suffered the larger impairment.Footnote 1
Model-based analyses
We modeled the performance of all participants using the procedures already specified. This let us evaluate how deadline conditions affect participants’ already learned decision strategies in RB and II tasks.
Figure 7 shows the decision bounds for 30 RB and II participants during their last 60 trials of the training phase, so that we could model their most mature category performance in training. The decision bounds for the RB participants were organized appropriately along the midline of the Y dimension. They chose collectively an appropriate strategy toward completing the RBh task by applying a one-dimensional rule involving density. The decision bounds for the II participants were organized appropriately along the minor diagonal of the stimulus space. These participants chose collectively a decision strategy for the II task by which they learned to integrate the informational signals provided by the two stimulus dimensions. Thus, both RB and II category learners carried forward appropriate categorization algorithms into their speeded and unspeeded testing phases.

(A, B) The decision bounds that provided the best fits for the last 60 trials of training for RB and II tasks in Experiment 2
Figure 8 shows the decision bounds for RB participants during their unspeeded and speeded testing phases. The decision bounds for these phases were remarkably similar, confirming from the perspective of formal modeling that the response deadline had little effect on RB categorization. Both participant groups maintained well the horizontal decision bounds that they had developed during the training phase. In fact, the number of participants with strictly one-dimensional decision bounds on the Y-axis actually increased from the unspeeded to the speeded condition, from 16 to 22. If anything, participants became more analytic under deadline. Thus, the modeling results converged with the accuracy results to suggest that deadline conditions did not impair the application of category learning and decision strategies by RB participants.

The decision bounds that fit best categorization responses in the testing trials of the RB-unspeeded, RB-deadline, II-unspeeded, and II-deadline conditions in Experiment 2
Figure 8 also shows the decision bounds for II participants during their unspeeded and speeded testing phases. In sharp contrast to RB performance, modeling strongly confirmed that the deadline condition had a seriously negative impact on the application of II category knowledge and decision strategies. In the II-unspeeded case, the decision bounds were organized appropriately along the minor diagonal of the stimulus space. But this was not true in the II-speeded case. The deadline requirement decreased the number of appropriate diagonal boundaries from 27 to 16. It increased from two to five the number of participants who showed a vertical (X dimension) decision bound that was not appropriately applicable to the task. It increased from one to eight the number of participants who showed a horizontal (Y dimension) decision bound that also was not appropriately applicable to the task. Thus, remarkably, the deadline condition increased dramatically the number of participants who had one-dimensional decision bounds from three to 13. This finding converges with several other results in this article to suggest that speed actually pushes participants toward more analytic and dimensional decisional strategies. Indeed, Experiments 1 and 2 both showed that this can be true even in an II task in which the one-dimensional strategies are not adaptive. We pursue this suggestion in the discussion.
We conducted an additional modeling analysis of the participants in the II task during the speeded condition by including a conjunctive decision model. This decision bound is defined by vertical and horizontal rules used simultaneously. For example, a conjunctive-rule user might call all stimuli with a size below 40 and a density above 70 “A” and everything else “B.” We found six out of 30 II participants in the speeded condition whose performance was best fit by a conjunctive decision boundary. We looked at mean reaction time on trials completed before the 600-ms deadline during the speeded condition. Those with the appropriate diagonal bound (12 participants) were still slower on average than the six conjunctive rule users, t(16) = 2.24, p < .05 (0.46 s for participants with diagonal boundaries and 0.43 s for participants with conjunctive boundaries). Performance accuracy was slightly better (68 % correct) for conjunctive than for diagonal (64 % correct) during the speeded condition but this difference was not significant, t < 1. Nevertheless, the reaction time differences suggest that even when participants use rules that require the processing of both dimensions, they can respond faster than participants using a dimensionally integrated decision boundary (see the supplementary materials for a table of mean reaction times). Only one II participant out of 30 used conjunctive rules in the unspeeded condition, suggesting that time pressure may push II participants toward the use of both unidimensional and conjunctive rules. These conjunctive-model results suggest that the II performance vulnerability to the deadline condition cannot simply be explained by use of two dimensional criteria instead of one as in the RB case, since the conjunctive rules also used two dimensional criteria but they are still faster.
General discussion
Summary
We explored the time course of explicit and implicit category learning, using new stimuli to broaden the literature. Participants learned categories, or applied their trained category knowledge, under unspeeded or speeded conditions. Matched category tasks fostered explicit (ruled-based) or implicit (information-integration) categorization. Figure 3’s backward learning curves confirmed that there were different learning processes at work in the RB and II tasks, a confirmation that is also provided by the many RB–II dissociative phenomena in the literature (Maddox & Ashby, 2004; Smith et al., 2011, 2010, 2014; Waldron & Ashby, 2001). In particular, the RB task showed a qualitatively sudden arrival at a task solution that is only consistent with the realization of a category rule by an explicit category-learning system (also, Smith et al., 2014, Fig. 3).
Explicit RB category learning and trained RB categorization were less impaired by the imposed deadline than were implicit, II category learning and mature categorization. Speeded conditions even appeared to push II participants toward maladaptive, RB strategies that were poorly suited to the II task.
Addressing a theoretical mystery
The present results help resolve a lasting issue. Kemler Nelson (1984) joined Brooks (1978) to make the general theoretical statement that intentional learners, adult learners, and reflective learners adopt analytic cognition that comprises stimulus analysis, deliberate hypothesis testing, and rule formation. The implication was that a variety of “primitivizing” conditions that interfered with explicit cognition would throw participants off their analytic stride and produce II category learning instead. Thus, II learning was viewed as a fallback mode of cognition: developmentally early, perhaps phylogenetically prior, and available when explicit cognition is absent.
It is a tribute to this framework that it substantially held up. There is sometimes a shift toward II category learning when a concurrent cognitive load saps explicit attentional resources (Kemler Nelson, 1984; Smith & Shapiro, 1989; Waldron & Ashby, 2001). There is a shift toward II category learning seen in cognitive depression that in a sense also saps explicit attentional resources (Smith et al., 1993). There are supportive developmental findings. Supportive cross-species research has emerged as well (Smith et al., 2011, 2012).
But this framework has not accommodated well the effect of response deadlines. Smith and Shapiro (1989) tried to broaden the fallback-mode hypothesis to include the primitivizing condition of speeded classification. But categorization was not pushed by deadlines toward II responding as occurs under concurrent loads or depression.
Why? The present results suggest several possible answers. One possibility is that participants might be able to prepare better before stimulus presentation in RB tasks than in II tasks. In RB tasks, participants can rehearse their categorization rule and response criterion before the stimulus appears, whereas no analogous preparation seems possible in II tasks. Another possibility is that II categorization may have properties of timing, staging, and reinforcement delivery that limit the speed with which category responses can be recruited and category knowledge updated. In current descriptions, II learning is deemed to be dependent on a dopamine reinforcement signal that must occur in the time window following a correct category response. By this signal, the neural connections that produced the response, and that may have brought the reward, are strengthened. These timing and staging properties could explain why II category learning and II categorization cannot be rushed (Ashby & Ennis, 2006; Maddox & Ashby, 2004). Then II categorization would not be the default mode under speeded conditions. To the contrary, it would be more affected by speed than RB categorization.
Then, too, response deadlines and dispositional impulsiveness might tilt processing toward RB categorization by compromising II categorization. Though speeded conditions demand that attentional resources be recruited and applied quickly, our RB results suggest that these resources are agile and quick in recruitment and application.
However, we note that our study used RB tasks with only a one-dimensional decision criterion. Rule-based performance under speeded deadlines could be different if the task involves more than two categories. An important question for future research is whether RB category learning can survive speeded response deadlines in more complex tasks, such as the four-category tasks used by Ell et al. (2009). These researchers found that delaying the feedback signal on categorization trials does impair RB learning in a complex four-category task, but was not the case with a simple, one-dimensional rule (Maddox et al., 2003). The same patterning might hold for response deadlines, too.
We also point out that different results might obtain at the point at which highly trained performers had achieved essential automaticity with RB and II category tasks. Models in Hélie and Ashby (2009), Hélie, Waldschmidt, and Ashby (2010), and Ashby, Ennis, and Spiering (2007) developed the idea that both RB and II performance—in the end—come to be controlled by stimulus–response linkages or associatively triggered responding (also Logan, 1988, 1992). At that point of categorization automaticity, response latencies between RB and II category responses could converge, though they were different during earlier stages of category learning.
Dissociative frameworks in human categorization
Our results add a new empirical distinction between explicit and implicit categorization. They show that response deadlines selectively impair II category learning and trained II categorization. Others have shown that II category learning is selectively impaired if feedback on categorization trials is delayed for a few seconds (Maddox et al., 2003; Maddox & Ing, 2005), if category learning is unsupervised (Ashby, Queller, & Berretty, 1999; Ell, Ashby, & Hutchinson, 2012), or if category knowledge is imparted observationally and not through trial-based reinforcement (Ashby, Maddox, & Bohil, 2002). These results support the idea described above that II category learning is served by a cascade of temporally organized (and temporally inflexible) events that surround the reinforcement-mediated strengthening of dopamine-related synapses (Ashby et al., 2007). They help explain why II category learning cannot be rushed.
Likewise, our results show that RB category learning—especially the application of a single-dimensional rule—is agile facing response deadlines. Others have shown that RB category learning survives feedback delays of many seconds, observationally delivered category knowledge, unsupervised learning conditions, and so forth. These results support the general idea that RB categorization relies on rules and hypotheses actively held in working memory. This also helps explain why RB categorization is robust to speeded conditions in our two-category task. It does not depend on a time-locked cascade of events. RB categorization may be timeless in a sense, because it is constantly available to consciousness, and it can be applied or adjusted before, during, or after the trial.
Adaptive complementarity in categorization
The temporal dimension explored here points to an elegant division of labor in categorization that is insufficiently appreciated. Humans’ II category-learning system solves in one basic way the problem of using consequences to associate adaptive behaviors to stimuli. It creates stimulus–response bonds in a sense and it may be allied to the processes of conditioning. It is crucial to humans’ procedural learning. It may have underlain vertebrates’ learning capacity for 100 million years or more.
This system has notable strengths. It reliably produces the behavior with the highest probability of reinforcement. It provides powerful statistical-averaging and contingency-prediction algorithms (Ashby & Alfonso-Reese, 1995). It is slow and cautious to commit to behavioral solutions, as documented here by the absence of any sudden arrival at criterial learning (also Smith et al., 2014). It is conservative and slow to let successful behavioral solutions go (Crossley, Ashby, & Maddox, 2013). It can operate out of consciousness and awareness (e.g., Casale et al., 2012; Smith et al., 2014), granting it the potential to have great phylogenetic depth.
But this system has constraints. It depends on particular forms of information and reinforcement, on persistent event repetition, and on a temporally bound cascade of perception–behavior–feedback as already discussed that cannot be disrupted, re-sequenced, or stretched or compressed in time. The empirical dissociations discussed in the last section show that II learning cannot occur with displacement, that is, at a separate time or spatial location. New behavioral approaches cannot be evaluated off-line. They cannot be chosen instantly at need. The organism may not be able to learn anew before unlearning the old (the class of extinction phenomena and these are often threatened by recovery, reminder, and recidivism effects---Crossley et al., 2013). This learning system turns slowly with a wide radius.
The explicit system of category learning is a perfect complement to this procedural system. Its role in cognition is intriguingly different. The present results show that it is not necessarily rigidly time-locked. The empirical dissociations discussed in the last section show that it does not need a fixed sequence of stimulus, behavior, and feedback. It does not need immediate feedback or even any feedback. The organism can consider learning episodes off-line, with displacement. Learning can occur suddenly at need (see Fig. 3A). Extended processes of unlearning now no longer apply—a new hypothesis can be tried out on the very next trial if warranted. This learning system turns on a dime. It is an intriguing aspect of contemporary cognitive and neuroscience research in categorization that humans seem to have, among multiple categorization utilities and processes, a “fast-twitch” categorization utility that complements the “slow-twitch” categorization utility within the procedural-learning system.
One sees from this discussion that the dissociative framework describing explicit and implicit systems of categorization continues to illuminate and enrich the cognitive literature on categorization. It guides productive empirical research, generates testable predictions, and expresses important adaptive complementarities among humans’ multiple categorization utilities.
Notes
We also analyzed participants using the appropriate decision strategy at the end of training. The same performance pattern was found but with less power. See the supplementary materials for analyses and descriptive statistics.
References
Ahn, W. K., & Medin, D. L. (1992). A two-stage model of category construction. Cognitive Science, 16, 81–121. doi:10.1207/s15516709cog1601_3
Aschkenasy, J. R., & Odom, R. D. (1982). Classification and perceptual development: Exploring issues about integrality and differential sensitivity. Journal of Experimental Child Psychology, 34, 435–448.
Ashby, F. G. (2014). Is state-trace analysis an appropriate tool for assessing the number of cognitive systems? Psychonomic Bulletin & Review, 21, 935–946. doi:10.3758/s13423-013-0578-x
Ashby, F. G., & Alfonso-Reese, L. A. (1995). Categorization as probability density estimation. Journal of Mathematical Psychology, 39, 216–233.
Ashby, F. G., Alfonso-Reese, L. A., Turken, A. U., & Waldron, E. M. (1998). A neuropsychological theory of multiple systems in category learning. Psychological Review, 105, 442–481. doi:10.1037/0033-295X.105.3.442
Ashby, F. G., & Crossley, M. J. (2010). Interactions between declarative and procedural-learning categorization systems. Neurobiology of Learning and Memory, 94, 1–12.
Ashby, F. G., & Ell, S. W. (2001). The neurobiology of human category learning. Trends in Cognitive Sciences, 5, 204–210. doi:10.1016/S1364-6613(00)01624-7
Ashby, F. G., & Ennis, J. M. (2006). The role of the basal ganglia in category learning. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 46, pp. 1–36). San Diego, CA: Academic Press.
Ashby, F. G., Ennis, J. M., & Spiering, B. J. (2007). A neurobiological theory of automaticity in perceptual categorization. Psychological Review, 114, 632–656.
Ashby, F. G., & Gott, R. E. (1988). Decision rules in the perception and categorization of multidimensional stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14, 33–53. doi:10.1037/0278-7393.14.1.33
Ashby, F. G., & Maddox, W. T. (2011). Human category learning 2.0. Annals of the New York Academy of Sciences, 1224, 147–161.
Ashby, F. G., Maddox, W. T., & Bohil, C. J. (2002). Observational versus feedback training in rule-based and information-integration category learning. Memory & Cognition, 30, 666–677. doi:10.3758/BF03196423
Ashby, F. G., Queller, S., & Berretty, P. M. (1999). On the dominance of unidimensional rules in unsupervised categorization. Perception & Psychophysics, 61, 1178–1199. doi:10.3758/BF03207622
Ashby, F. G., & Valentin, V. V. (2005). Multiple systems of perceptual category learning: Theory and cognitive tests. In H. Cohen & C. Lefebvre (Eds.), Categorization in cognitive science (pp. 547–572). New York, NY: Elsevier.
Bamber, D. (1969). Reaction times and error rates for “same”–“different” judgments of multidimensional stimuli. Perception & Psychophysics, 6, 169–174. doi:10.3758/BF03210087
Broadbent, D. E. (1977). Levels, hierarchies, and the locus of control. Quarterly Journal of Experimental Psychology, 29, 181–201.
Brooks, L. R. (1978). Nonanalytic concept formation and memory for instances. In E. Rosch & B. B. Lloyd (Eds.), Cognition and categorization (pp. 169–211). Hillside, NJ: Erlbaum.
Casale, M. B., & Ashby, F. G. (2008). A role for the perceptual representation memory system in category learning. Perception & Psychophysics, 70, 983–999. doi:10.3758/PP.70.6.983
Casale, M. B., Roeder, J. L., & Ashby, F. G. (2012). Analogical transfer in perceptual categorization. Memory & Cognition, 40, 434–449. doi:10.3758/s13421-011-0154-4
Cook, R. G., & Smith, J. D. (2006). Stages of abstraction and exemplar memorization in pigeon category learning. Psychological Science, 17, 1059–1067. doi:10.1111/j.1467-9280.2006.01833.x
Crossley, M. J., Ashby, F. G., & Maddox, W. T. (2013). Erasing the engram: The unlearning of procedural skills. Journal of Experimental Psychology: General, 142, 710–741.
Ell, S. W., Ashby, F. G., & Hutchinson, S. (2012). Unsupervised category learning with integral-dimension stimuli. Quarterly Journal of Experimental Psychology, 65, 1537–1562. doi:10.1080/17470218.2012.658821
Ell, S. W., Ing, A. D., & Maddox, W. T. (2009). Criterial noise effects on rule-based category learning: The impact of delayed feedback. Attention, Perception, & Psychophysics, 71, 1263–1275. doi:10.3758/APP.71.6.1263
Erickson, M. A., & Kruschke, J. K. (1998). Rules and exemplars in category learning. Journal of Experimental Psychology: General, 127, 107–140. doi:10.1037/0096-3445.127.2.107
Feldman, J. (2000). Minimization of Boolean complexity in human concept learning. Nature, 407, 630–633.
Fukunaga, K. (1972). Introduction to statistical pattern recognition. New York, NY: Academic Press.
Garner, W. R. (1974). The processing of information and structure. Potomac, MD: Erlbaum.
Hélie, S., & Ashby, F. G. (2009). A neurocomputational model of automaticity and maintenance of abstract rules. In Proceedings of the International Joint Conference on Neural Networks (pp. 1192–1198). Piscataway, NJ: IEEE Press.
Hélie, S., Waldschmidt, J. G., & Ashby, F. G. (2010). Automaticity in rule-based and information-integration categorization. Attention, Perception, & Psychophysics, 72, 1013–1031. doi:10.3758/APP.72.4.1013
Homa, D., Sterling, S., & Trepel, L. (1981). Limitations of exemplar-based generalization and the abstraction of categorical information. Journal of Experimental Psychology: Human Learning and Memory, 7, 418–439. doi:10.1037/0278-7393.7.6.418
Huang-Pollock, C. L., Maddox, W. T., & Karalunas, S. L. (2011). Development of implicit and explicit category learning. Journal of Experimental Child Psychology, 109, 321–335.
Kemler, D. G. (1978). Patterns of hypothesis testing in children’s discriminative learning: A study of the development of problem-solving strategies. Developmental Psychology, 14, 653–673.
Kemler, D. G. (1982a). The ability for dimensional analysis in preschool and retarded children: Evidence from comparison, conservation, and prediction tasks. Journal of Experimental Child Psychology, 34, 469–489. doi:10.1016/0022-0965(82)90072-8
Kemler, D. G. (1982b). Classification in young and retarded children: The primacy of overall similarity relations. Child Development, 53, 768–779.
Kemler Nelson, D. G. (1984). The effect of intention on what concepts are acquired. Journal of Verbal Learning and Verbal Behavior, 23, 734–759. doi:10.1016/S0022-5371(84)90442-0
Knowlton, B. J., & Squire, L. R. (1993). The learning of categories: Parallel brain systems for item memory and category knowledge. Science, 262, 1747–1749. doi:10.1126/science.8259522
Krueger, L. E. (1973). Effect of irrelevant surrounding material on speed of same–different judgment of two adjacent letters. Journal of Experimental Psychology, 98, 252–259.
Lamberts, K. (1998). The time course of categorization. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 695–711. doi:10.1037/0278-7393.24.3.695
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95, 492–527. doi:10.1037/0033-295X.95.4.492
Logan, G. D. (1992). Shapes of reaction-time distributions and shapes of learning curves: A test of the instance theory of automaticity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 883–914. doi:10.1037/0278-7393.18.5.883
Maddox, W. T., & Ashby, F. G. (1993). Comparing decision bound and exemplar models of categorization. Perception & Psychophysics, 53, 49–70. doi:10.3758/BF03211715
Maddox, W. T., & Ashby, F. G. (2004). Dissociating explicit and procedural-learning based systems of perceptual category learning. Behavioural Processes, 66, 309–332. doi:10.1016/j.beproc.2004.03.011
Maddox, W. T., Ashby, F. G., & Bohil, C. J. (2003). Delayed feedback effects on rule-based and information-integration category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 650–662. doi:10.1037/0278-7393.29.4.650
Maddox, W. T., Bohil, C. J., & Ing, A. D. (2004). Evidence for a procedural-learning-based system in perceptual category learning. Psychonomic Bulletin & Review, 11, 945–952. doi:10.3758/BF03196726
Maddox, W. T., & Ing, A. D. (2005). Delayed feedback disrupts the procedural-learning system but not the hypothesis-testing system in perceptual category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 100–107. doi:10.1037/0278-7393.31.1.100
Medin, D. L., & Schaffer, M. M. (1978). Context theory of classification learning. Psychological Review, 85, 207–238. doi:10.1037/0033-295X.85.3.207
Medin, D. L., Wattenmaker, W. D., & Hampson, S. E. (1987). Family resemblance, conceptual cohesiveness, and category construction. Cognitive Psychology, 19, 242–279.
Murphy, G. L. (2003). Ecological validity and the study of concepts. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 43, pp. 1–41). San Diego, CA: Academic Press.
Newell, B. R., Dunn, J. C., & Kalish, M. (2010). The dimensionality of perceptual category learning: A state-trace analysis. Memory & Cognition, 38, 563–581. doi:10.3758/MC.38.5.563
Nomura, E. M., Maddox, W. T., Filoteo, J. V., Ing, A. D., Gitelman, D. R., Parrish, T. B., … Reber, P. J. (2007). Neural correlates of rule-based and information-integration visual category learning. Cerebral Cortex, 17, 37–43. doi:10.1093/cercor/bhj122
Nosofsky, R. M. (1987). Attention and learning processes in the identification and categorization of integral stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13, 87–108. doi:10.1037/0278-7393.13.1.87
Nosofsky, R. M., Palmeri, T. J., & McKinley, S. C. (1994). Rule-plus-exception model of classification learning. Psychological Review, 101, 53–79. doi:10.1037/0033-295X.101.1.53
Regehr, G., & Brooks, L. R. (1995). Category organization in free classification: The organizing effect of an array of stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 347–363. doi:10.1037/0278-7393.21.2.347
Rosseel, Y. (2002). Mixture models of categorization. Journal of Mathematical Psychology, 46, 178–210.
Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics, 6, 461–464. doi:10.1214/aos/1176344136
Shepard, R. N., Hovland, C. I., & Jenkins, H. M. (1961). Learning and memorization of classifications. Psychological Monographs: General and Applied, 75, 1–42.
Shepp, B. E., Burns, B., & McDonough, D. (1980). The relation of stimulus structure to perceptual and cognitive development: Further tests of a separability hypothesis. In J. Becker & F. Wilkening (Eds.), The integration of information by children (pp. 113–145). Hillsdale, NJ: Erlbaum.
Smith, J. D., Ashby, F. G., Berg, M. E., Murphy, M. S., Spiering, B. J., Cook, R. G., & Grace, R. C. (2011). Pigeons’ categorization may be exclusively nonanalytic. Psychonomic Bulletin & Review, 18, 414–421. doi:10.3758/s13423-010-0047-8
Smith, J. D., Beran, M. J., Crossley, M. J., Boomer, J., & Ashby, F. G. (2010). Implicit and explicit category learning by macaques (Macaca mulatta) and humans (Homo sapiens). Journal of Experimental Psychology: Animal Behavior Processes, 36, 54–65.
Smith, J. D., Berg, M. E., Cook, R. G., Murphy, M. S., Crossley, M. J., Boomer, J., … Grace. R. C. (2012). Implicit and explicit categorization: A tale of four species. Neuroscience and Biobehavioral Reviews, 36, 2355–2369. doi:10.1016/j.neubiorev.2012.09.003
Smith, J. D., Boomer, J., Zakrzewski, A. C., Roeder, J. L., Church, B. A., & Ashby, F. G. (2014). Deferred feedback sharply dissociates implicit and explicit category learning. Psychological Science, 25, 447–457. doi:10.1177/0956797613509112
Smith, J. D., & Kemler Nelson, D. G. (1984). Overall similarity in adults’ classification: The child in all of us. Journal of Experimental Psychology: General, 113, 137–159. doi:10.1037/0096-3445.113.1.137
Smith, J. D., & Kemler Nelson, D. G. (1988). Is the more impulsive child a more holistic processor? A reconsideration. Child Development, 59, 719–727.
Smith, J. D., & Minda, J. P. (1998). Prototypes in the mist: The early epochs of category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 1411–1436. doi:10.1037/0278-7393.24.6.1411
Smith, J. D., & Shapiro, J. H. (1989). The occurrence of holistic categorization. Journal of Memory and Language, 28, 386–399.
Smith, J. D., Tracy, J. I., & Murray, M. J. (1993). Depression and category learning. Journal of Experimental Psychology: General, 122, 331–346. doi:10.1037/0096-3445.122.3.331
Waldron, E. M., & Ashby, F. G. (2001). The effects of concurrent task interference on category learning: Evidence for multiple category learning systems. Psychonomic Bulletin & Review, 8, 168–176. doi:10.3758/BF03196154
Ward, L. M. (1983). On processing dominance: Comment on Pomerantz. Journal of Experimental Psychology: General, 112, 541–546. doi:10.1037/0096-3445.112.4.541
Ward, T. B. (1988). When is category learning holistic? A reply to Kemler Nelson. Memory & Cognition, 16, 85–89. doi:10.3758/BF03197749
Ward, T. B., & Scott, J. (1987). Analytic and holistic modes of learning family-resemblance concepts. Memory & Cognition, 15, 42–54. doi:10.3758/BF03197711
Ward, T. B., Vela, E., & Hass, S. D. (1990). Children and adults learn family-resemblance categories analytically. Child Development, 61, 593–605.
Author note
The preparation of this article was supported by Grant No. HD-060563 from NICHD, Grant No. P01 NS044393 from NINDS, and by support from the US Army Research Office through the Institute for Collaborative Biotechnologies under Grant No. W911NF-07-1-0072. We thank our undergraduate research assistants in the UB lab for help with data analyses and data collection.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOC 466 kb)
Rights and permissions
About this article

Cite this article
Smith, J.D., Zakrzewski, A.C., Herberger, E.R. et al. The time course of explicit and implicit categorization. Atten Percept Psychophys 77, 2476–2490 (2015). https://doi.org/10.3758/s13414-015-0933-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-015-0933-2