
Beat-to-Beat Blood Pressure Estimation by Photoplethysmography and Its Interpretation

1
Faculty of Information Technology, University of Applied Sciences and Arts Dortmund, 44139 Dortmund, Germany
2
TU Dresden, Institute for Biomedical Engineering, 01069 Dresden, Germany
3
Department of Anaesthesiology, Intensive Care Medicine and Pain Therapy, Evang. Kliniken Essen-Mitte, Huyssens-Stiftung/Knappschaft, 45136 Essen, Germany
4
Department of Anaesthesiology and Operative Intensive Care Medicine (CCM, CVK), Charité—Universitätsmedizin Berlin, Corporate Member of Freie Universität Berlin, Humboldt-Universität zu Berlin, and Berlin Institute of Health, 13353 Berlin, Germany
*
Author to whom correspondence should be addressed.
Sensors 2022, 22(18), 7037; https://doi.org/10.3390/s22187037
Submission received: 23 July 2022
/
Revised: 29 August 2022
/
Accepted: 13 September 2022
/
Published: 17 September 2022
(This article belongs to the Special Issue Explainable/Interpretable Machine Learning for Biomedical Sensing, Sensor Data Fusion and Diagnostics)
Abstract
:Blood pressure (BP) is among the most important vital signals. Estimation of absolute BP solely using photoplethysmography (PPG) has gained immense attention over the last years. Available works differ in terms of used features as well as classifiers and bear large differences in their results. This work aims to provide a machine learning method for absolute BP estimation, its interpretation using computational methods and its critical appraisal in face of the current literature. We used data from three different sources including 273 subjects and 259,986 single beats. We extracted multiple features from PPG signals and its derivatives. BP was estimated by xgboost regression. For interpretation we used Shapley additive values (SHAP). Absolute systolic BP estimation using a strict separation of subjects yielded a mean absolute error of and correlation of . The results markedly improve if data separation is changed (MAE: , r: ). Interpretation by means of SHAP revealed four features from PPG, its derivation and its decomposition to be most relevant. The presented approach depicts a general way to interpret multivariate prediction algorithms and reveals certain features to be valuable for absolute BP estimation. Our work underlines the considerable impact of data selection and of training/testing separation, which must be considered in detail when algorithms are to be compared. In order to make our work traceable, we have made all methods available to the public.
1. Introduction
Blood pressure (BP) is one of the most important vital signs. It has high relevance in a variety of clinical and out-of-hospital applications. Invasive methods are the gold standard for BP measurement. Such methods are restricted to clinical environments and include discomfort as well as a risk for infections and, in case of disconnection, serious patient harm. Sphygmomanometry is the most common type of BP measurement [1]. While being non-invasive, sphygmomanometry is an intermittent measurement technique. It thus prevents beat-to-beat analyses and cannot capture the dynamic characteristics of BP [2]. Non-invasive methods such as the volume clamp method or applanation tonometry provide continuous measurements but have known limitations, e.g., regarding their robustness, carry risk for venous congestion or are sensitive to imprecise placements. Further, (commercial) measurement equipment is bulky and expensive [3,4,5,6].
Surrogate approaches provide a user-friendly alternative to assess BP, typically on a beat-to-beat basis [7]. Surrogate approaches do not measure BP but estimate BP from a single or a set of variables. The most widespread surrogate approach exploits the relationship of pulse wave velocity (PWV) (or pulse transit time (PTT) or pulse arrival time (PAT), respectively, [7,8,9,10]) and BP. PWV is estimated from time differences of proximally and distally recorded cardiovascular effects, most often from electrocardiogram (ECG) and distal photoplethysmography (PPG) [7,11]. PWV methods typically invoke initialization, i.e., a single or repeated cuff measurement to yield absolute BP. Afterwards, beat-to-beat PWV is converted into a beat-to-beat BP estimate. Most approaches make some physical assumption that can formulate the relation between PWV and BP mathematically, e.g., a linear or logarithmic dependency.
In recent years, the number of surrogate approaches that use machine learning (ML) for BP estimation increased drastically [12]. Owing to its good availability and high user comfort, the vast majority of such works use PPG. These works employ variable input information from PPG and a variety of ML techniques. Input information is represented by discrete features or complete signal excerpts (end-to-end learning), which can originate from the PPG, from its derivative(s) or from pulse wave decomposition (PWD). ML techniques range from trees and forests [13,14] over support vector machines [15,16] to (deep) neural networks [17,18,19,20,21]. Remarkably, while early surrogate approaches most often invoke initialisation and track changes in BP, an increasing number of works aim at absolute BP estimation from PPG. In fact, a reliable method for absolute BP estimation solely using PPG would have huge impact to various medical fields and is thus of immense interest.
However, the published results on absolute BP estimation vary considerably. Moreover, the function of the proposed models can hardly be explained because the input dimension typically is high and most employed models are black boxes such as CNN and LSTM [22]. In terms of medical usage and further development, explainability is considered highly important [23,24]. In different fields it has gained attention [25,26,27]; however, to the best of our knowledge, no works have investigated the explainability of ML models in the field of BP estimation.
Our work therefore aims at a PPG-based ML method for absolute BP estimation and its explanation using computational methods. Such content is accompanied by a critical appraisal of recent approaches for absolute BP estimation in face of the employed training/testing strategy. In order to be comparable to the literature, we do not propose a novel algorithm for BP estimation but adopt a feature-based method for BP estimation recently proposed by Hu et al. [13]. Hu et al.’s work uses multiple common features including PWD together with an ensemble regressor. It yields highly accurate results and it is representative of many current works in the field. We complement the proposed approach with features from second derivative and carry out an in-depth analysis of feature contribution by means of Shapley values in order to explain the model’s function. Note that the following consideration primarily focus on systolic BP as it is the most commonly estimated type of BP. However, our discussion also contains some remarks on diastolic BP.
The remainder of this work is structured as follows. Section 2 provides an overview of the feature-based methods for absolute BP estimation using PPG. Section 3 describes the used data, feature extraction and estimation models. The results from Section 4 are then discussed in Section 5. Finally, in Section 6, we provide an outlook for future work.
2. State of the Art
There are numerous works that focus on the estimation of BP with PPG [11,28,29,30,31]. In this work we concentrate on feature-based methods for absolute BP estimation using PPG. Table 1 provides on overview of such works. We included publications that do not use modalities other than a single PPG and do not use initialization (i.e., focus on absolute BP estimation). The overview only contains works that report the mean absolute error.
First, it should be noted that the comparability of the works is limited as they do not only use different approaches to BP estimation but also different datasets.
Notably, there are some works with exceptionally good prediction results (MAE ). In most cases, these results are not comparable to the rest as there is a difference in the separation of data into test and training sets. In Table 1, we highlighted such differences in the ‘Clear Separation’ column, which indicates whether subjects were exclusively assigned to test and training data (‘yes’) or not (‘no’). As ML algorithms are thus able to learn on subjects of the test set, and predictions can improve considerably. Works with an MAE of below do not use clear separation with one exception being Jain et al. [41]. Jain et al. used their own data, which consist of photoplethysmography imaging (PPGI) measurements and a single cuff measurement of BP. The dataset contains 45 normotensive subjects with ages of between 20 and 40 years. In contrast, commonly used publicly available datasets such as the MIMIC database consist of continuous BP measurements of subjects of a more diverse age and BP spectrum, thus being far more difficult to predict. Though the results of Jain et al. are remarkable (keeping in mind the non-contact approach), the data characteristic are likely to contribute to the comparatively low prediction error despite their data being clearly separated.
Otherwise, errors close to are common (which still does not fulfil the normative requirements on BP estimation). A commonality of these works is the absence of reasoning for the used features. Besides the work of Gaurav et al. [42] and Hasanzadeh et al. [34], all works either only state that they used features that are used in literature to estimate BP or do not state any reason for their feature selection. Gaurav et al. explain the physiological information contained in used feature classes. Hasanzadeh et al. state the physiological correlates for some of their features.
3. Methods And Materials
3.1. Data
For our analysis we used three datasets that contain PPG signals and blood pressure measurements. The following paragraphs provide a brief overview of the data.
3.1.1. CPT
The first dataset contains data from 22 healthy subjects (age years, 10 female) during a cold pressure test (CPT). The study was approved by the Institutional Review Board of the TU Dresden (EK119032016). All subjects provided their written informed consent. The subjects were included twice, once in a sitting position and once in a supine position. We discarded one recording due to technical problems. Thus, the dataset contains 43 usable records. After an initial resting phase of 8 , the subjects immersed their hand into cold water ( 3 ). The immersion lasted for 3 , but subjects were allowed to quit earlier. CPT, in general and within the experiment, leads to an instantaneous increase in blood pressure [46]. After the immersion, the subjects remained rested for another 21 . The data consists of non-invasive continuous BP measurements (Finometer Midi, Finapres Medical Systems) and finger PPG signals recorded from the non-immersed hand with a sampling frequency of 1000 [46].
3.1.2. PPG-BP
The publicly available PPG-BP database [47] contains records from 219 healthy and non-healthy subjects (age years, 115 female). The experiment comprised an initial resting phase of 10 and a 3 measurement phase without any applied stimuli. Each record contains one systolic and diastolic blood pressure measurement that represents the BP for the whole measurement phase as well as three PPG segments, each with a duration of . The PPG signal was measured at a sample rate of 1000 (SEP9AF-2, SMPLUS Company, Seoul, South Korea) at the fingertip of the left index finger. The BP sensor (Omron HEM-7201, Omron Company, Kyoto, Japan) was attached to the right forearm [47].
3.1.3. Queensland
As the third dataset, we included the University of Queensland Vital Signs Dataset, which consists of 32 records (gender of subjects not stated) with a duration ranging from 13 min to 5 hours (median 105 min). The data were collected from subjects under anesthesia. The data were recorded using multiple devices (Philips IntelliVue MP70 & Philips IntelliVue MP30, Philips Healthcare, Amsterdam, Netherlands; Datex- Ohmeda Aestiva/5, GE Healthcare, Chicago, IL, USA) and contain PPG waveforms at a sample rate of 100 and non-invasive BP measurements [48].
3.2. Preprocessing
We filtered the PPG signals with a bandpass filter (5th-order Butterworth filter with cut-off frequencies of and 12 ). Single beats from the PPG signals were detected with the method of Lazaro et al. [49], which considers the steepest ascent as the detection point. We then segmented each beat by detecting the minima in the segments before and after the detection point. The segmentation yielded 72,106 beats for the CPT dataset, 254,609 beats for the Queensland dataset and 1125 beats for the PPG-BP dataset.
We removed linear trends and normalized each beat to within the range of zero to one. We then applied PWD to each single beat. The aim of PWD is twofold: to yield decomposition parameters and to denoise by performing recomposition. We used the GammaGaussian2 decomposition algorithm (i.e., decomposition by a Gamma Kernel and a Gaussian Kernel, see Figure 1) that was described previously [50]. A reconstructed beat y for the Gamma–Gaussian algorithm with 2 kernels can be described as:
Each reconstructed beat is a function of time t and an optimization vector . The interior point optimization algorithm fits the kernels to the PPG beats using the following constraints:
3.3. Feature Extraction
As stated before, we adopted features used by Hu et al. [13]. Additionally, we included the feature , i.e., the relation of the b peak to the a peak of the second derivative, to assess the benefit of a second derivative analysis. Accordingly, we extracted the following four types of features from the PPG beats: PWD, second derivative, statistical, and frequency features. The used features are listed in Table 2.
PWD yields the parameters of the kernels it decomposes the beat into. Some works assess the relationships between the kernels [51,52]. We used these parameters as features without prior combination in accordance to Hu et al. [13].
The analysis of the second derivative of a PPG beat evaluates the ratios of the characteristic peaks. We included as this is the most commonly used feature of the second derivative in BP estimation [42,53,54]. The second derivative is calculated from the reconstructed beat to reduce the impact of noise.
Statistical features assess the general shape of the PPG beat. As in previous works, we included standard deviation (SD), kurtosis (kurt) and skewness (skew). All statistical features are calculated from reconstructed beats [13,42,55].
We calculated the statistical features for a PPG beat p with N samples and its mean as follows:
Like Hu et al. [13], we also included the fundamental frequency and the first to third harmonic for the BP estimation. Thereto, we extended each original beat to ten copies of itself and Fourier transformed that signal.
3.4. Estimation Models
We used the python library xgboost [56] to estimate the blood pressure as suggested in the work of Hu et al. [13]. We randomly selected 80% of the subjects of each dataset for training (231,997 samples) and used the remaining 20% for testing (27,989 samples). Both measurements of the CPT subjects were assigned to the same set (test or training). We thus implemented a strict separation of test and training data on a subject level. For the training of the model, we used all 15 features of Table 2 as inputs and SBP as the response variable. To account for the imbalanced distribution of training and test data, we applied sample weights (all samples with SBP above half the maximum BP value in the dataset were weighted with ). We used a median filter with a kernel size of 11 for the CPT and Queensland dataset on the prediction and ground truth. We did not filter the PPG-BP dataset as there were too few samples per subject. We did not attempt hyperparameter optimization as the focus of this work is the explanation of the model rather than the accuracy of the prediction.
3.5. Evaluation
The evaluation has two parts. First, we evaluate the model quality concerning absolute blood pressure estimation to show that our model performs comparably to similar ones in the literature. Secondly, we evaluate the impact of features on the prediction to interpret the model’s function.
3.5.1. BP Estimation
In order to assess our model’s quality, we used the mean absolute error (MAE), mean error (ME), standard deviation of the error (SDE) and Pearson correlation coefficient (r) from the N true BP values x and the estimated BP from the test data according to:
3.5.2. Shapley Values
The basic idea of explainable machine learning based on Shapley values is to compute the average marginal contribution of a feature value across all possible coalitions, i.e., sets of features [57]. Shapley values represent the impact of a feature on the prediction of a model for a given input. They can be computed using a weighted sum that represents the impact of each feature being added to the model averaged over all possible orders of features being introduced [58]:
In (11), represents the Shapley value for feature j of the prediction for sample x, M is the number of features and S is the subset of input features that are present in the prediction.
We used the python library SHAP (SHapley Additive exPlanations) that efficiently implements this concept from game theory for certain machine learning models by computing SHAP values [59]. In SHAP, the explanation is represented as an additive feature attribution. This means that the prediction for a sample can be represented as a linear model:
In (12), the prediction is represented as the sum of , which is the average prediction, and the sum of the SHAP values of all M features for the ith sample.
To compute a global SHAP value over all N samples, we use the mean absolute of the SHAP values of each feature, which yields the importance for the jth feature:
We also analyzed sample-wise SHAP values in relation to their feature values by creating a beeswarm plot to obtain an overview of the impact of the feature values on the prediction.
4. Results
Table 3 shows our models results for the whole dataset and for the three single datasets (CPT, Queensland and PPG-BP). Figure 2 illustrates the prediction of our model and the ground truth graphically. These results are comparable to that of other current works such as that of Zhang et al. [40] or Hasanzadeh et al. [34] (see Section 5 for a detailed analysis on the performance).
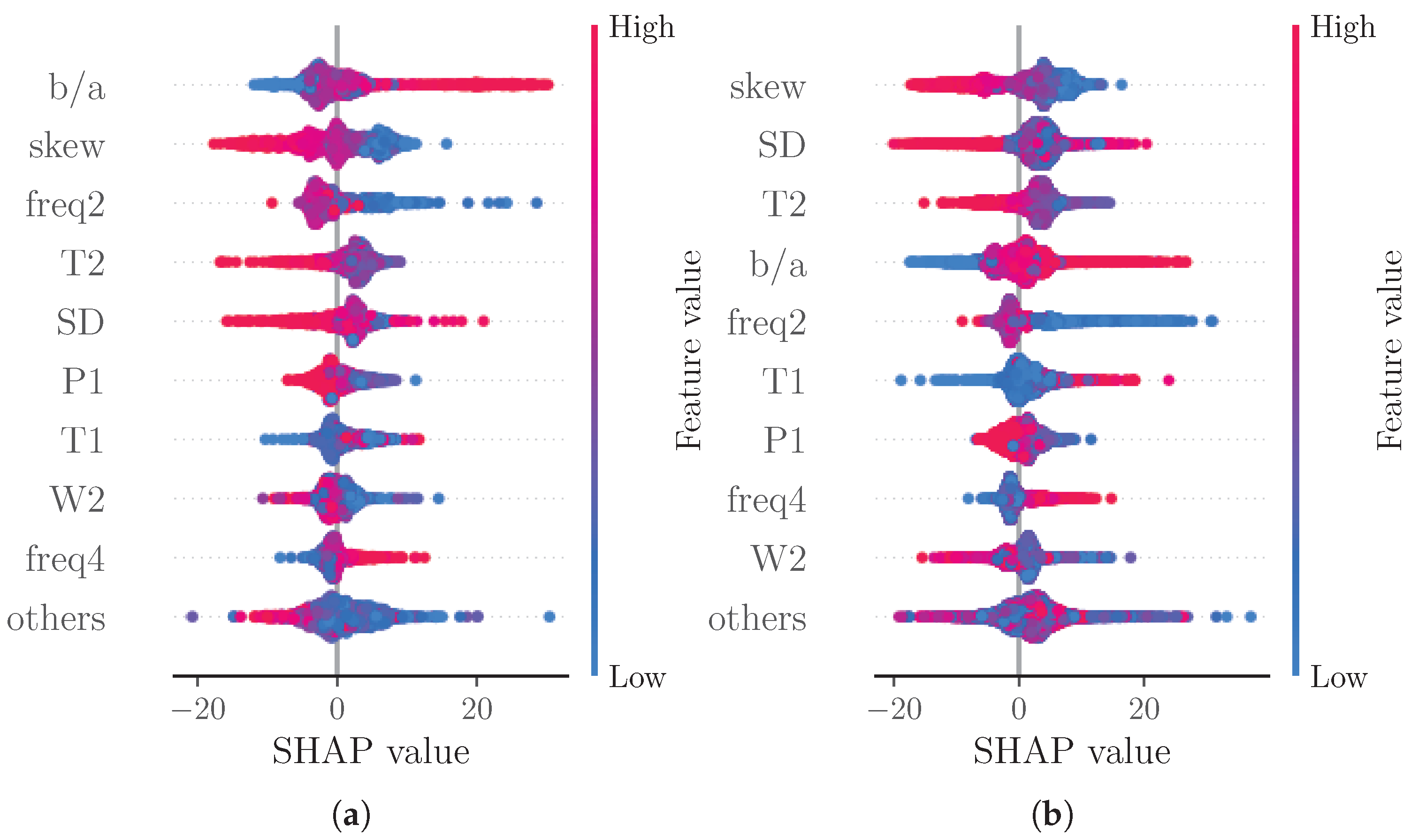
Figure 3a reports a ranking of the mean absolute SHAP values. Notably, the four most important features are: skew (), SD (), T2 () and (). The beeswarm plot in Figure 3b shows the relationship of the feature values and the SHAP values for each feature with each dot representing the SHAP value of a feature for a prediction.
5. Discussion
5.1. Quality of Absolute BP Estimation
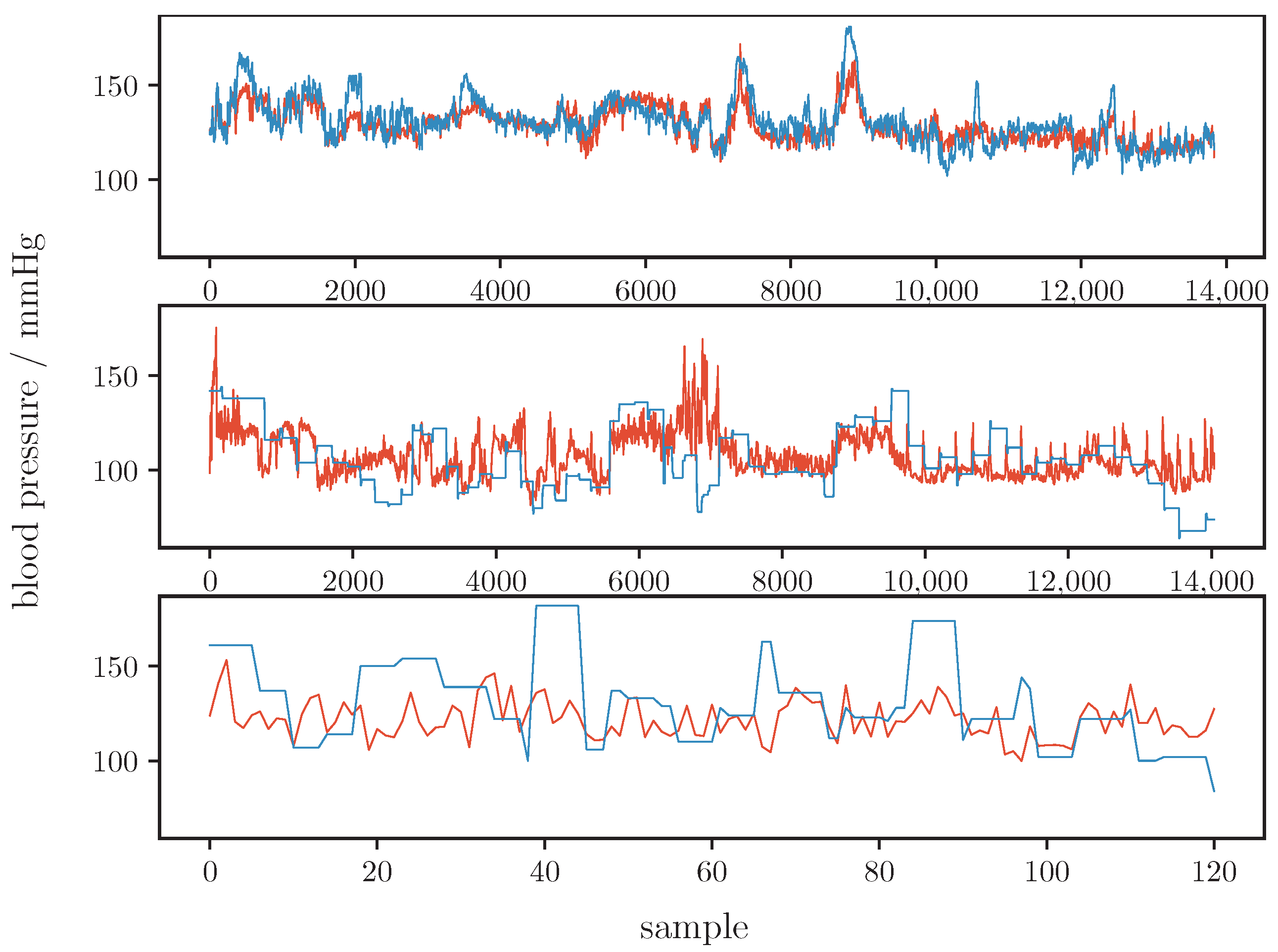
Compared to Hu et al., our results are markedly worse. At first glance, this is surprising as we reproduced Hu et al.’s work. Minor modifications relate to the integration of the second derivative and to the PWD (for PWD, we used two instead of three Kernels as we showed that algorithms with two kernels are more robust against noise but otherwise comparable [50]). Both modifications are not likely to degrade the results. However, as can be seen in Table 1, our results are comparable to those works that clearly separate between training and test subjects. Notably, if we apply the same training/testing strategy as Hu et al., i.e., if we do not strictly separate according to subjects, our results improve considerably and closely approach the results of Hu et al. (MAE: , ME: , SDE: , r: ). Such an improvement is expected, but it underlines the importance of data separation towards an objective comparison of different works. Clearly, even data selection, i.e., the characteristics of data, heavily impacts the results. With respect to our data, there are large differences in the quality of BP estimation between data from different sources. Our model achieved the best results for the CPT data, while the predictions for the Queensland and PPG-BP data are markedly worse. The most likely reasons for the difference in quality are the subjects’ states and associated BP ranges. Table 4 shows the characteristics of BP for test and training subsets of all datasets used. From Table 4 and Figure 2 it is evident that the Queensland data contain comparatively low SBP samples (below ), which is probably caused by anesthesia. Our model often overestimated BP (as indicated by a negative ME for the Queensland dataset). Further, the ground truth for the Queensland data does not seem to be recorded on a beat-to-beat basis. The authors of the study do not state a sampling rate for the non-invasive BP measurements but Figure 2 suggests intermittent BP readings. The reference BP thus neglects higher frequency variations and potentially introduces estimation inaccuracies. This problem is worse for the PPG-BP dataset. Here, BP is measured once per subject and for each subject three PPG excerpts of duration, and each from a time frame, are provide. Despite this obvious limitation, we included such data in our analysis as they are often used. However, as in the data separation process before, data selection has a critical impact on the results and must be carefully considered in comparisons of different works.
To allow meaningful comparisons and foster traceability, we included data from different origins, provided aggregated and separated results and make our sources freely available (source code available via https://github.com/vifle/ppgBP (accessed on 22 July 2022)). Overall, our results indicate the need for further improvements prior to potential clinical use. Such improvements do not only relate to data processing but should also invoke modifications to the frontend as suggested in the current work, e.g., measurement systems that are able to take the contact pressure between skin and sensor into account might add valuable information as the amplitude and morphology of the PPG vary with contact pressure [60]. Recently, Cao et al. presented a method to estimate the contact pressure by means of a single PPG sensor [61]. Another approach to enhance BP estimation in the future is to use multiple wavelengths and exploit the varying interactions of wavelengths with tissue [62]. However, notwithstanding such enhancements, taking into account the data selection and data separation, we can state that the proposed method yields state-of-the-art results on absolute BP estimation. This is a precondition for the meaningful interpretation and assessment of feature importance.
5.2. Model Interpretation
The considered features for absolute BP estimation in the literature typically originate from previous works that use these features for BP estimation. Most works included in Table 1, and on BP estimation in general, do not explain the relationship between the selected features and BP. A few of the works use large feature pools, some of which select a subset of them using varying criteria [35,39]. Hasanzadeh et al. explain some of their features’ physiological correlates [34]. Gaurav et al. state reasons for the types of features used [42].
Aside from Hu et al., other works do not use PWD features. Derivative features are used in only four of the works [35,37,39,42]. Our analysis of SHAP values shows that derivative and decomposition features are among the most important features of the model, thus indicating their importance in BP estimation. The feature importance of SD and skew is likely due to the fact that these features evaluate the shape of the PPG pulse as a whole.
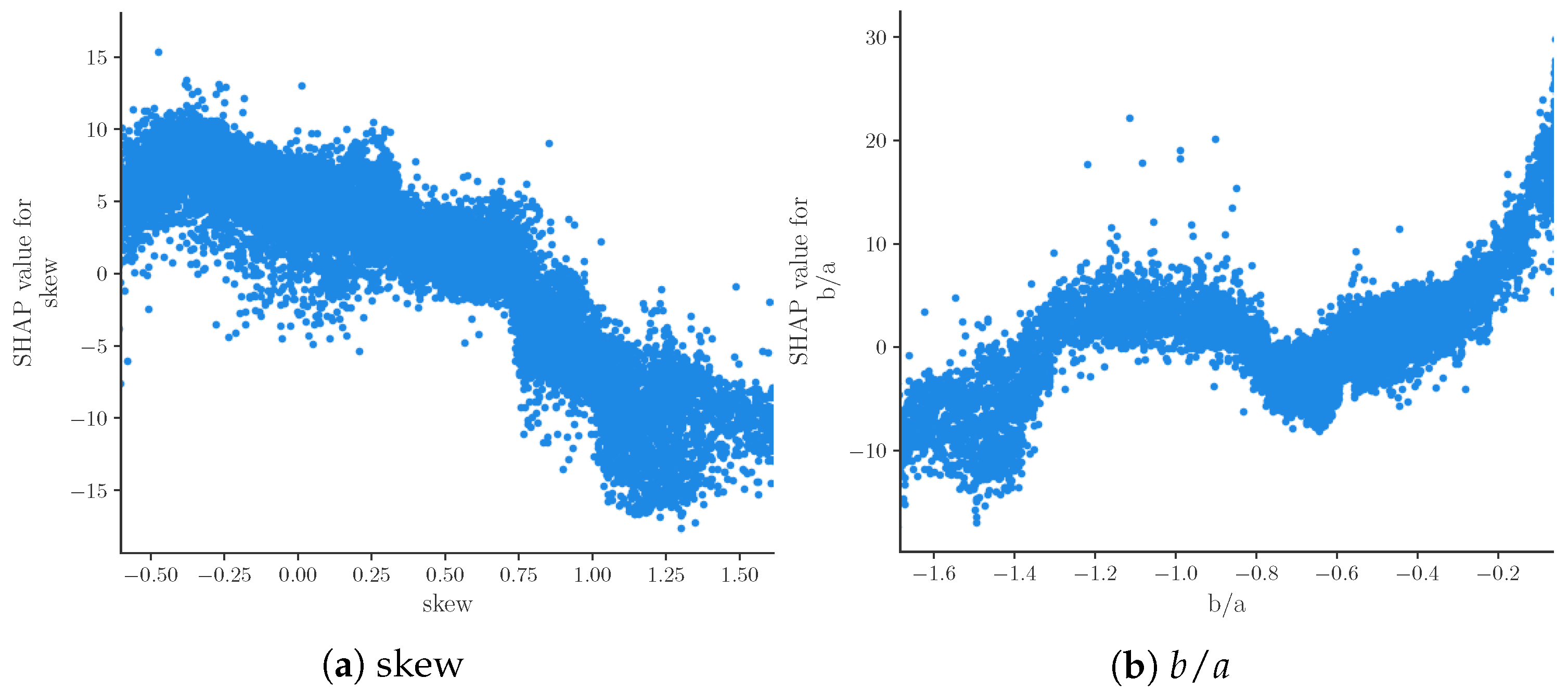
Figure 3b shows the relation of feature values and SHAP values for the nine most important features. Due to the representation of predictions as an additive model of SHAP values, positive SHAP values can be associated with high BP predictions and negative SHAP values can be associated with low BP predictions. The beeswarm plot thus provides an impression of the relationship of feature values and BP prediction. Features , T1 and freq4 seem to be positively correlated with SBP, while skew, T2 and W2 are clearly negatively correlated with SBP. The remaining features do not exhibit such clear relations. This could be caused by poor prediction or nonlinear relationships. The relationship of feature values and SHAP values can be analyzed in further depth by means of dependence plots. Figure 4 shows such a dependence plot for skew and . When outliers (the first percentile and 99th) are removed, a clearly negative correlation between feature and SHAP values can be observed for skew (see Figure 4a), while exhibits a clearly positive correlation (see Figure 4b). Nonlinear relationships could be caused by interaction effects between features. These effects are not analyzed in this work.
Note that native SHAP does not consider the quality of the prediction. We therefore also analyzed the SHAP values of subsets of the test data categorized into samples with an error greater than two times the MAE (see Figure 5a) and samples with an error lower than half the MAE (see Figure 5b). With this analysis, we assessed whether certain features significantly contribute to poor or good predictions, respectively. For the subset of good predictions, the four most important features remain unchanged. For the subset of bad predictions, however, the order of the most important features changes. The most important feature for this subset is ; additionally, freq2 supersedes T2 out of the four most important features. The increased importance of could be explained by this feature’s susceptibility to errors. As this is a feature of the second derivative, even small changes to the shape of the beats’ rising slope due to decomposition and reconstruction can cause substantial errors in the feature value.
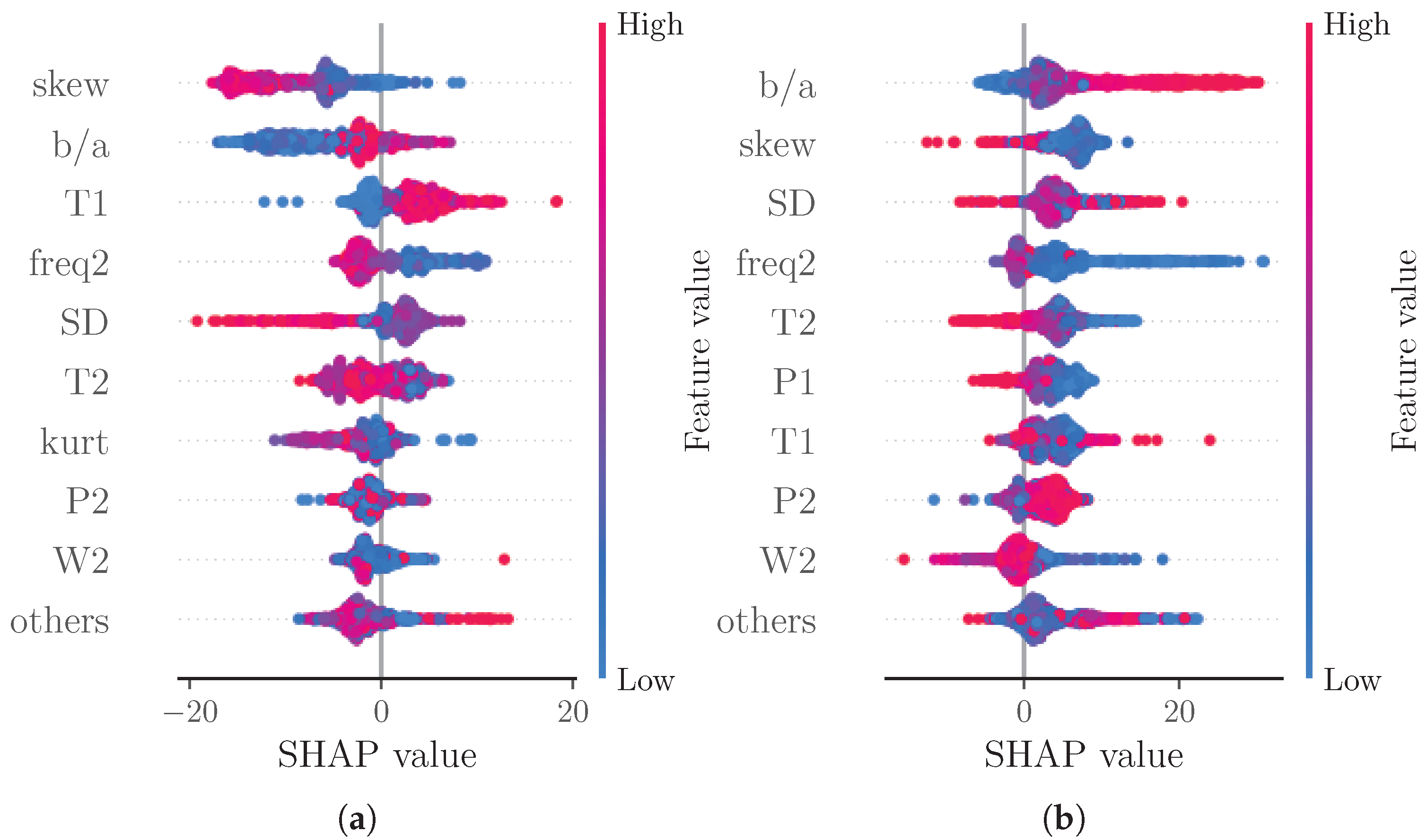
Another analysis considered SHAP values separated into subsets of low BP predictions ( times the mean prediction, see Figure 6a) and high BP predictions ( times the mean prediction, see Figure 6b). As expected due to the additive nature of SHAP values, the majority of points in the beeswarm plots shifts towards negative SHAP values for low BP predictions and towards positive SHAP values for high BP predictions. For high BP predictions, freq2 becomes more important than T2. For low BP predictions though, T1 and freq2 become more important than T2 and SD.
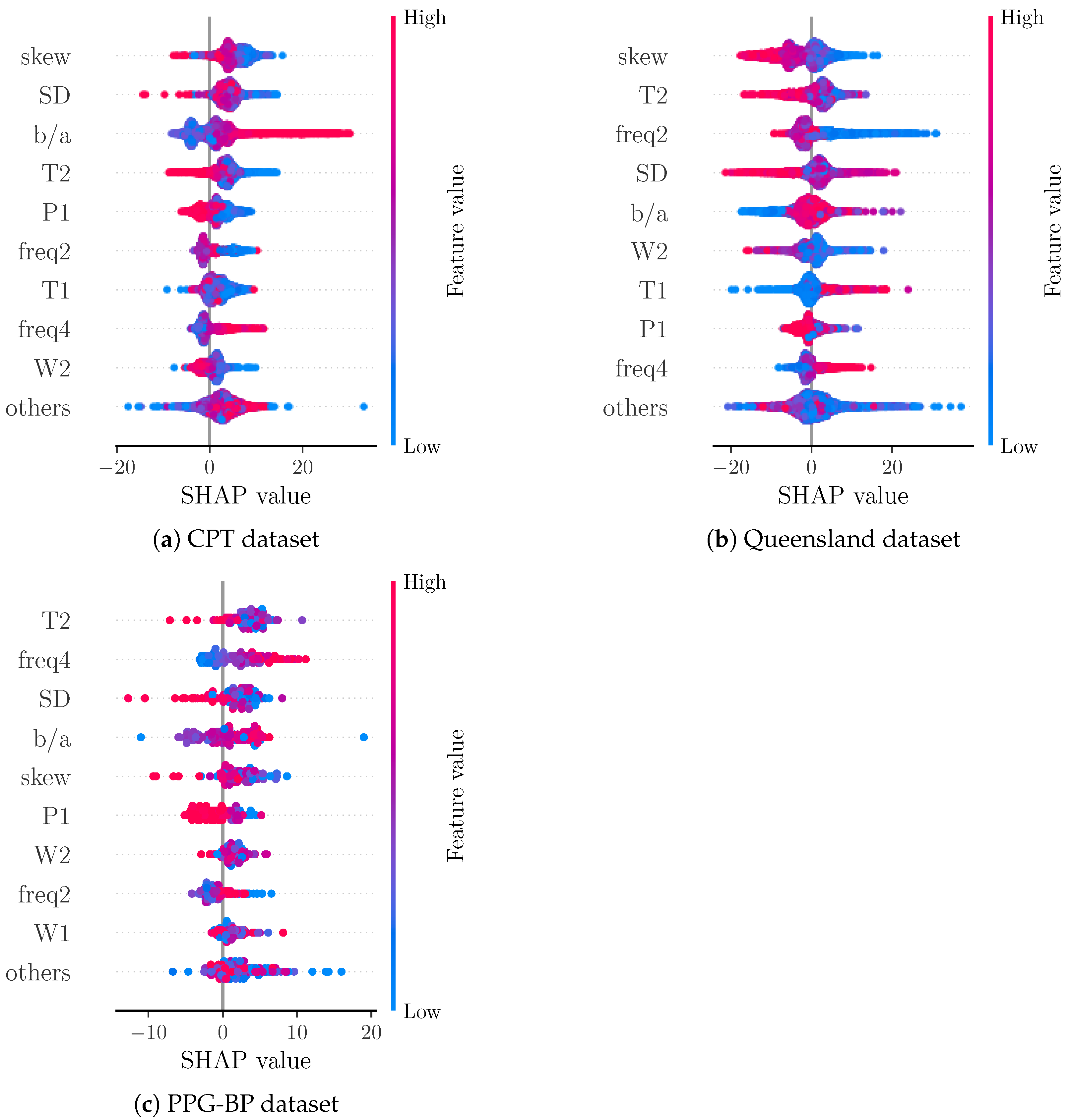
Figure 7 shows a comparison of SHAP values for the data from each included dataset separately. For CPT, the most important features remain unchanged. Interestingly, the apparently positive correlation of feature value and SHAP value for T1 from the overall analysis cannot be observed as clearly for the CPT subset. For the Queensland subset, T1 show a similar behaviour as in the overall analysis. Furthermore, the other subsets exhibit skew, T2, and SD also as the most important features. Notably, becomes the fifth most important feature for the Queensland subset, while freq2 is the third most important feature and freq4 is the second most important feature for PPG-BP with skew becoming the fifth most important feature. A difference between the datasets is the shape of the ground truth BP values (see Figure 2). The BP values of CPT fluctuate much more than those of Queensland. A possible explanation for the greater importance of in CPT could be the ability of to track small morphological changes that reflect small changes in BP. This is more important for CPT than for Queensland, as the BP for Queensland remains constant in larger segments compared to CPT. In PPG-BP, the number of samples is too low to reliably assess the relationship between feature and SHAP values.
5.3. Feature Importance in an Alternative Model
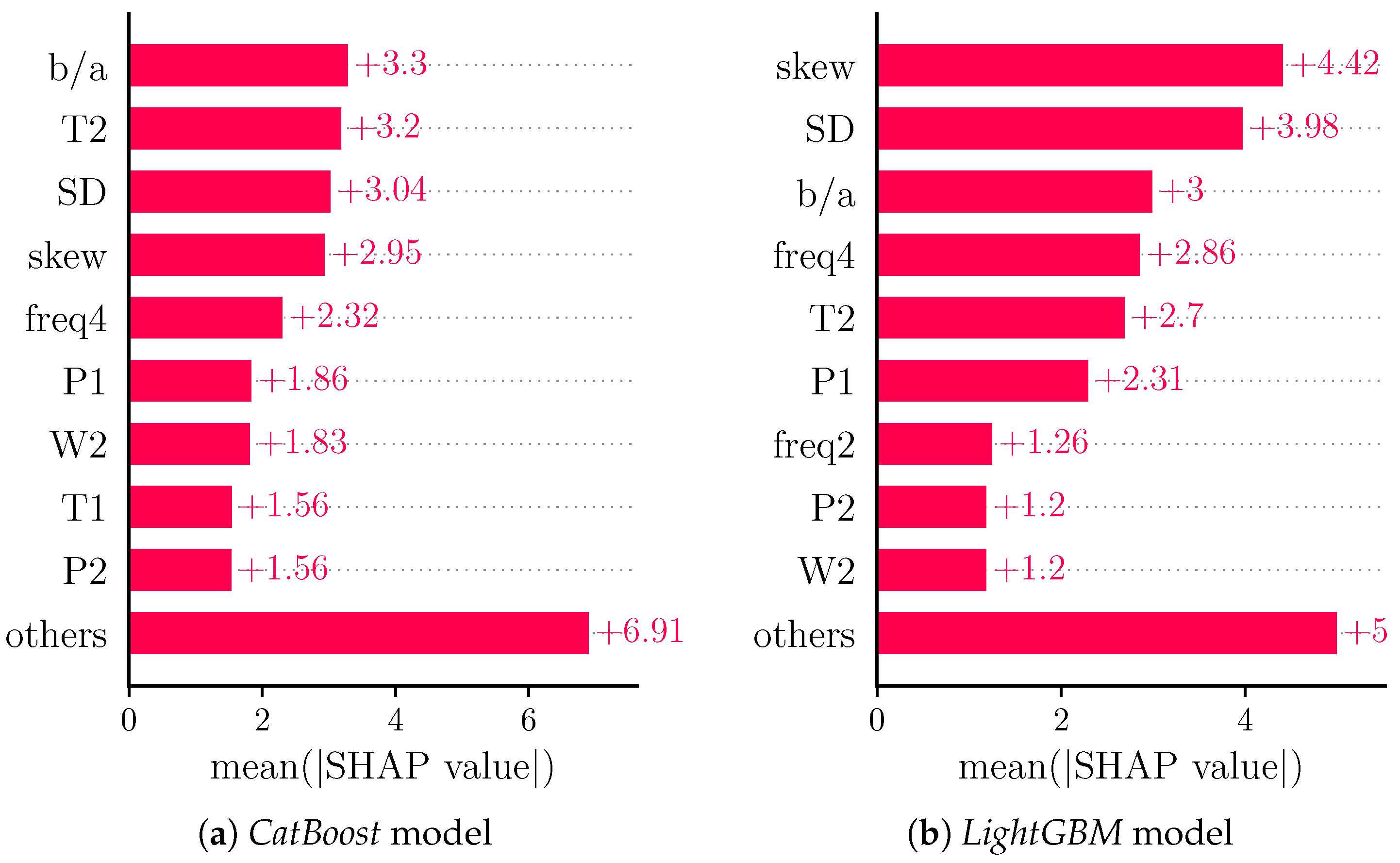
In order to provide a more general view on feature importance than is achieved with a single model, we analyzed the feature importances for regression models generated by CatBoost [63] (Figure 8a) and LightGBM (Figure 8b) [64].
Both models exhibit different orders of features in terms of feature importance. Notably, the four most important features remain , T2, SD and skew for the CatBoost model, whereas freq4 supersedes T2 in the LightGBM model, underlying the general relevance of such features.
5.4. Analysis with Respect to DBP
Our analysis primarily focused on SBP. It can, however, be readily applied to DBP. For illustration, we conducted some analyses on DBP. DBP yields an MAE of and ME of .
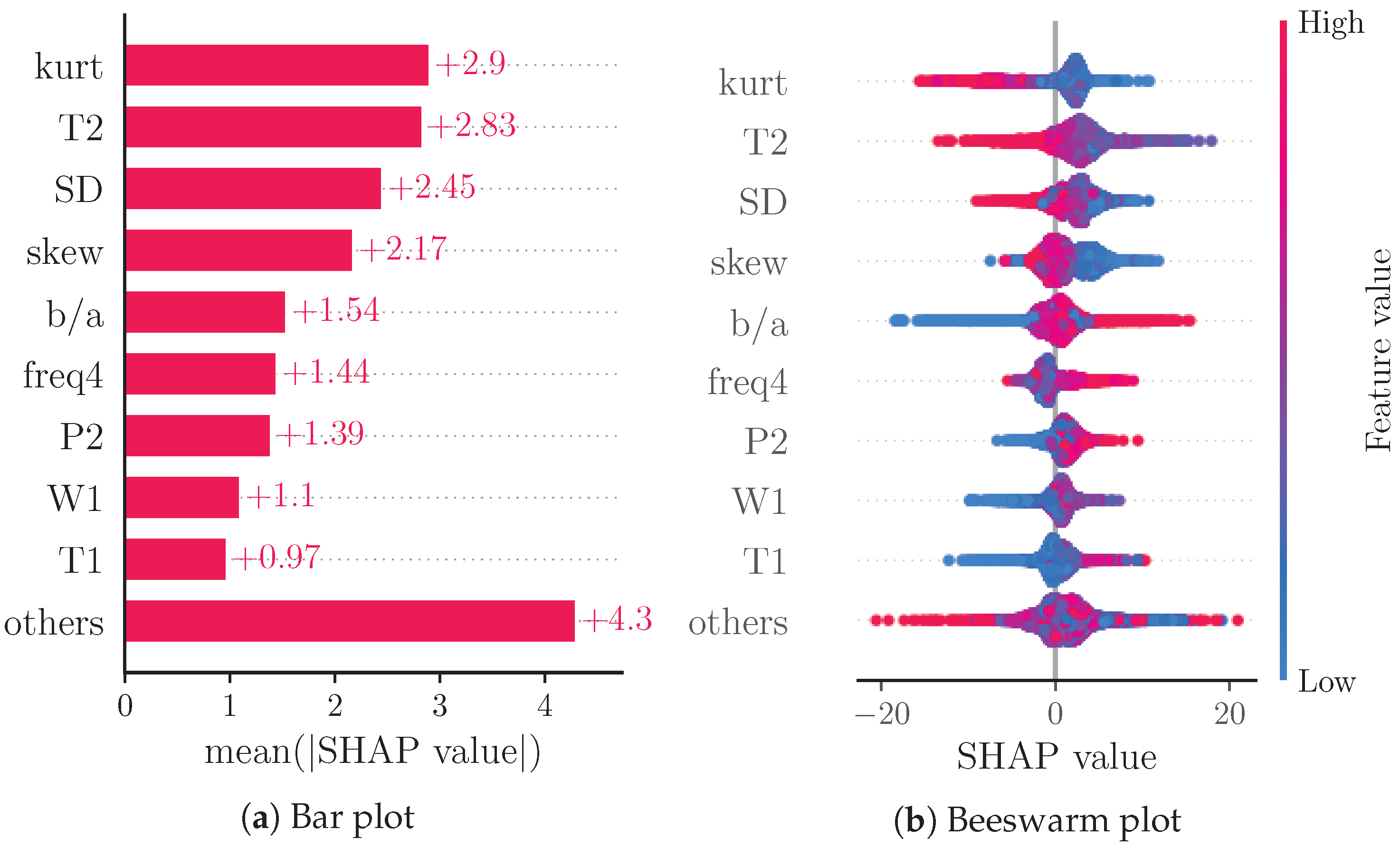
Figure 9 shows the SHAP values for a DBP prediction model based on the same features as our SBP prediction model. The four most important features of the SBP model are ranked two to five for the DBP model. This shows the importance of general BP estimation of these four features. For this model, kurt becomes the most important feature. For the SBP overall model, this feature was not one of the nine most important features, but was relevant for SBP predictions of lower than times the mean prediction (see Figure 6a). Notably, the SHAP values for the DBP model seem to be lower than those for the SBP model on average. This can be explained by the additive nature of SHAP values as DBP values are generally lower than SBP values.
6. Conclusions & Outlook
The presented work demonstrates one approach to interpreting the function of multivariate ML methods. Our results provide strong evidence of using features from PPG and its derivatives. Such finding should affect future methods on BP estimation using the PPG, which usually do not account for the selected features. Our considerations further highlight the immense impact of data selection and separation. In future works, further in-depth analyses should consider the interaction effects between features to develop a better understanding of the relationship between feature values and predictions.
Author Contributions
Conceptualization, V.F. and S.Z.; methodology, V.F. and S.Z.; software, V.F.; validation, V.F. and S.Z.; formal analysis, V.F.; investigation, V.F.; resources, V.F. and S.Z.; data curation, S.Z.; writing—original draft preparation, V.F. and S.Z.; writing—review and editing, V.F., A.F. and S.Z.; visualization, V.F.; supervision, S.Z.; project administration, S.Z.; funding acquisition, S.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) grant number 401786308.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board of the TU Dresden (EK119032016).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Publicly available datasets were analyzed in this study. The PPG-BP data can be found here: https://figshare.com/articles/dataset/PPG-BP_Database_zip/5459299 (accessed on 22 July 2022). The Queensland data can be found here: https://outbox.eait.uq.edu.au/uqdliu3/uqvitalsignsdataset/index.html (accessed on 22 July 2022).
Acknowledgments
The authors want to thank the graduate center of the University of Applied Sciences Dortmund for funding this work. The authors also want to thank Lundberg and all the other contributors to the SHAP toolbox for sharing it with the scientific community.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Saugel, B.; Dueck, R.; Wagner, J.Y. Measurement of blood pressure. Best Pract. Res. Clin. Anaesthesiol. 2014, 28, 309–322. [Google Scholar] [CrossRef] [PubMed]
- Wagner, J.Y.; Prantner, J.S.; Meidert, A.S.; Hapfelmeier, A.; Schmid, R.M.; Saugel, B. Noninvasive continuous versus intermittent arterial pressure monitoring: Evaluation of the vascular unloading technique (CNAP device) in the emergency department. Scand. J. Trauma Resusc. Emerg. Med. 2014, 22, 8. [Google Scholar] [CrossRef] [PubMed]
- Carós, J.M.S.I. Continuous Non—Invasive Blood Pressure Estimation. Doctoral Thesis, ETH Zürich, Zürich, Germany, 2011. [Google Scholar] [CrossRef]
- Rastegar, S.; GholamHosseini, H.; Lowe, A. Non-invasive continuous blood pressure monitoring systems: Current and proposed technology issues and challenges. Phys. Eng. Sci. Med. 2020, 43, 11–28. [Google Scholar] [CrossRef]
- Pandit, J.A.; Lores, E.; Batlle, D. Cuffless Blood Pressure Monitoring. Clin. J. Am. Soc. Nephrol. 2020, 15, 1531–1538. [Google Scholar] [CrossRef]
- Quan, X.; Liu, J.; Roxlo, T.; Siddharth, S.; Leong, W.; Muir, A.; Cheong, S.M.; Rao, A. Advances in Non-Invasive Blood Pressure Monitoring. Sensors 2021, 21, 4273. [Google Scholar] [CrossRef]
- Pielmus, A.G.; Mühlstef, J.; Bresch, E.; Glos, M.; Jungen, C.; Mieke, S.; Orglmeister, R.; Schulze, A.; Stender, B.; Voigt, V. Surrogate based continuous noninvasive blood pressure measurement. Biomed. Eng./Biomed. Tech. 2021, 66, 231–245. [Google Scholar] [CrossRef] [PubMed]
- Esmaili, A.; Kachuee, M.; Shabany, M. Nonlinear Cuffless Blood Pressure Estimation of Healthy Subjects Using Pulse Transit Time and Arrival Time. IEEE Trans. Instrum. Meas. 2017, 66, 3299–3308. [Google Scholar] [CrossRef]
- Shao, J.; Shi, P.; Hu, S.; Liu, Y.; Yu, H. An Optimization Study of Estimating Blood Pressure Models Based on Pulse Arrival Time for Continuous Monitoring. J. Healthc. Eng. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Yousefian, P.; Shin, S.; Mousavi, A.S.; Tivay, A.; Kim, C.S.; Mukkamala, R.; Jang, D.G.; Ko, B.H.; Lee, J.; Kwon, U.K.; et al. Pulse Transit Time-Pulse Wave Analysis Fusion Based on Wearable Wrist Ballistocardiogram for Cuff-Less Blood Pressure Trend Tracking. IEEE Access 2020, 8, 138077–138087. [Google Scholar] [CrossRef]
- Le, T.; Ellington, F.; Lee, T.Y.; Vo, K.; Khine, M.; Krishnan, S.K.; Dutt, N.; Cao, H. Continuous Non-Invasive Blood Pressure Monitoring: A Methodological Review on Measurement Techniques. IEEE Access 2020, 8, 212478–212498. [Google Scholar] [CrossRef]
- El-Hajj, C.; Kyriacou, P. A review of machine learning techniques in photoplethysmography for the non-invasive cuff-less measurement of blood pressure. Biomed. Signal Process. Control 2020, 58, 101870. [Google Scholar] [CrossRef]
- Hu, Q.; Deng, X.; Wang, A.; Yang, C. A novel method for continuous blood pressure estimation based on a single-channel photoplethysmogram signal. Physiol. Meas. 2020, 41, 125009. [Google Scholar] [CrossRef] [PubMed]
- Goudarzi, R.H.; Somayyeh Mousavi, S.; Charmi, M. Using imaging Photoplethysmography (iPPG) Signal for Blood Pressure Estimation. In Proceedings of the Iranian Conference on Machine Vision and Image Processing, MVIP, Tehran, Iran, 18–20 February 2020. [Google Scholar] [CrossRef]
- Kei Fong, M.W.; Ng, E.; Er Zi Jian, K.; Hong, T.J. SVR ensemble-based continuous blood pressure prediction using multi-channel photoplethysmogram. Comput. Biol. Med. 2019, 113, 103392. [Google Scholar] [CrossRef] [PubMed]
- Hassani, A.; Foruzan, A.H. Improved PPG-based estimation of the blood pressure using latent space features. Signal Image Video Process. 2019, 13, 1141–1147. [Google Scholar] [CrossRef]
- Liu, Z.; Miao, F.; Wang, R.; Liu, J.; Wen, B.; Li, Y. Cuff-less Blood Pressure Measurement Based on Deep Convolutional Neural Network. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 3775–3778. [Google Scholar] [CrossRef]
- Lee, D.; Kwon, H.; Son, D.; Eom, H.; Park, C.; Lim, Y.; Seo, C.; Park, K. Beat-to-Beat Continuous Blood Pressure Estimation Using Bidirectional Long Short-Term Memory Network. Sensors 2020, 21, 96. [Google Scholar] [CrossRef] [PubMed]
- Jeong, D.U.; Lim, K.M. Combined deep CNN–LSTM network-based multitasking learning architecture for noninvasive continuous blood pressure estimation using difference in ECG-PPG features. Sci. Rep. 2021, 11, 13539. [Google Scholar] [CrossRef]
- Schrumpf, F.; Frenzel, P.; Aust, C.; Osterhoff, G.; Fuchs, M. Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning. Sensors 2021, 21, 6022. [Google Scholar] [CrossRef]
- Tang, Q.; Chen, Z.; Ward, R.; Menon, C.; Elgendi, M. Subject-Based Model for Reconstructing Arterial Blood Pressure from Photoplethysmogram. Bioengineering 2022, 9, 402. [Google Scholar] [CrossRef]
- Panwar, M.; Gautam, A.; Biswas, D.; Acharyya, A. PP-Net: A Deep Learning Framework for PPG-Based Blood Pressure and Heart Rate Estimation. IEEE Sens. J. 2020, 20, 10000–10011. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Teredesai, A.; Eckert, C. Interpretable Machine Learning in Healthcare. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 February 2018; p. 447. [Google Scholar] [CrossRef]
- Yoon, C.H.; Torrance, R.; Scheinerman, N. Machine learning in medicine: Should the pursuit of enhanced interpretability be abandoned? J. Med. Ethics 2021, 48, 581–585. [Google Scholar] [CrossRef]
- Bloch, L.; Friedrich, C.M. Data analysis with Shapley values for automatic subject selection in Alzheimer’s disease data sets using interpretable machine learning. Alzheimer’s Res. Ther. 2021, 13, 155. [Google Scholar] [CrossRef] [PubMed]
- Bloch, L.; Friedrich, C. Developing a Machine Learning Workflow to Explain Black-box Models for Alzheimer’s Disease Classification. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies, SCITEPRESS—Science and Technology Publications, Vienna, Austria, 11–13 February 2021; pp. 87–99. [Google Scholar] [CrossRef]
- Ibrahim, L.; Mesinovic, M.; Yang, K.W.; Eid, M.A. Explainable Prediction of Acute Myocardial Infarction using Machine Learning and Shapley Values. IEEE Access 2020, 8, 210410–210417. [Google Scholar] [CrossRef]
- Elgendi, M.; Fletcher, R.; Liang, Y.; Howard, N.; Lovell, N.H.; Abbott, D.; Lim, K.; Ward, R. The use of photoplethysmography for assessing hypertension. Npj Digit. Med. 2019, 2, 60. [Google Scholar] [CrossRef] [PubMed]
- Welykholowa, K.; Hosanee, M.; Chan, G.; Cooper, R.; Kyriacou, P.A.; Zheng, D.; Allen, J.; Abbott, D.; Menon, C.; Lovell, N.H.; et al. Multimodal Photoplethysmography-Based Approaches for Improved Detection of Hypertension. J. Clin. Med. 2020, 9, 1203. [Google Scholar] [CrossRef]
- Chao, P.C.; Wu, C.C.; Nguyen, D.H.; Nguyen, B.S.; Huang, P.C.; Le, V.H. The Machine Learnings Leading the Cuffless PPG Blood Pressure Sensors Into the Next Stage. IEEE Sens. J. 2021, 21, 12498–12510. [Google Scholar] [CrossRef]
- Bassiouni, M.M.; Hegazy, I.; Rizk, N.; El-Dahshan, E.S.A.; Salem, A.M. Combination of ECG And PPG Signals For Smart HealthCare Systems: Techniques, Applications, and Challenges. In Proceedings of the 2021 Tenth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2021; pp. 448–455. [Google Scholar] [CrossRef]
- El-Hajj, C.; Kyriacou, P.A. Deep learning models for cuffless blood pressure monitoring from PPG signals using attention mechanism. Biomed. Signal Process. Control 2021, 65, 102301. [Google Scholar] [CrossRef]
- Morassi Sasso, A.; Datta, S.; Jeitler, M.; Steckhan, N.; Kessler, C.S.; Michalsen, A.; Arnrich, B.; Böttinger, E. HYPE: Predicting Blood Pressure from Photoplethysmograms in a Hypertensive Population. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12299, pp. 325–335. [Google Scholar] [CrossRef]
- Hasanzadeh, N.; Ahmadi, M.M.; Mohammadzade, H. Blood Pressure Estimation Using Photoplethysmogram Signal and Its Morphological Features. IEEE Sens. J. 2020, 20, 4300–4310. [Google Scholar] [CrossRef]
- Hsu, Y.C.; Li, Y.H.; Chang, C.C.; Harfiya, L.N. Generalized Deep Neural Network Model for Cuffless Blood Pressure Estimation with Photoplethysmogram Signal Only. Sensors 2020, 20, 5668. [Google Scholar] [CrossRef]
- El Hajj, C.; Kyriacou, P.A. Cuffless and Continuous Blood Pressure Estimation From PPG Signals Using Recurrent Neural Networks. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 4269–4272. [Google Scholar] [CrossRef]
- Slapničar, G.; Mlakar, N.; Luštrek, M. Blood Pressure Estimation from Photoplethysmogram Using a Spectro-Temporal Deep Neural Network. Sensors 2019, 19, 3420. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, W.; Xing, Y.; Zhou, X. A Novel Neural Network Model for Blood Pressure Estimation Using Photoplethesmography without Electrocardiogram. J. Healthc. Eng. 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Dey, J.; Gaurav, A.; Tiwari, V.N. InstaBP: Cuff-less Blood Pressure Monitoring on Smartphone using Single PPG Sensor. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; Volume 2018, pp. 5002–5005. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, Z. A SVM method for continuous blood pressure estimation from a PPG signal. Acm Int. Conf. Proc. Ser. 2017, Part F1283, 128–132. [Google Scholar] [CrossRef]
- Jain, M.; Deb, S.; Subramanyam, A.V. Face video based touchless blood pressure and heart rate estimation. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing, MMSP 2016, Montreal, QC, Canada, 21–23 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Gaurav, A.; Maheedhar, M.; Tiwari, V.N.; Narayanan, R. Cuff-less PPG based continuous blood pressure monitoring—A smartphone based approach. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 607–610. [Google Scholar] [CrossRef]
- Gao, S.C.; Wittek, P.; Zhao, L.; Jiang, W.J. Data-driven estimation of blood pressure using photoplethysmographic signals. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; Volume 2016, pp. 766–769. [Google Scholar] [CrossRef]
- Duan, K.; Qian, Z.; Atef, M.; Wang, G. A feature exploration methodology for learning based cuffless blood pressure measurement using photoplethysmography. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; Volume 2016, pp. 6385–6388. [Google Scholar] [CrossRef]
- Suzuki, A. Inverse-model-based cuffless blood pressure estimation using a single photoplethysmography sensor. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2015, 229, 499–505. [Google Scholar] [CrossRef] [PubMed]
- Zaunseder, S.; Trumpp, A.; Ernst, H.; Förster, M.; Malberg, H. Spatio-temporal analysis of blood perfusion by imaging photoplethysmography. Opt. Diagn. Sens. XVIII Toward Point- Diagn. 2018, 10501, 15. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, Z.; Liu, G.; Elgendi, M. A new, short-recorded photoplethysmogram dataset for blood pressure monitoring in China. Sci. Data 2018, 5, 180020. [Google Scholar] [CrossRef]
- Liu, D.; Görges, M.; Jenkins, S.A. University of Queensland Vital Signs Dataset. Anesth. Analg. 2012, 114, 584–589. [Google Scholar] [CrossRef] [PubMed]
- Lazaro, J.; Gil, E.; Vergara, J.M.; Laguna, P. Pulse Rate Variability Analysis for Discrimination of Sleep-Apnea-Related Decreases in the Amplitude Fluctuations of Pulse Photoplethysmographic Signal in Children. IEEE J. Biomed. Health Inf. 2014, 18, 240–246. [Google Scholar] [CrossRef]
- Fleischhauer, V.; Ruprecht, N.; Sorelli, M.; Bocchi, L.; Zaunseder, S. Pulse decomposition analysis in photoplethysmography imaging. Physiol. Meas. 2020, 41, 095009. [Google Scholar] [CrossRef] [PubMed]
- Goswami, D.; Chaudhuri, K.; Mukherjee, J. A new two-pulse synthesis model for digital volume pulse signal analysis. Cardiovasc. Eng. 2010, 10, 109–117. [Google Scholar] [CrossRef] [PubMed]
- Couceiro, R.; Carvalho, P.; Paiva, R.P.; Henriques, J.; Quintal, I.; Antunes, M.; Muehlsteff, J.; Eickholt, C.; Brinkmeyer, C.; Kelm, M.; et al. Assessment of cardiovascular function from multi-Gaussian fitting of a finger photoplethysmogram. Physiol. Meas. 2015, 36, 1801–1825. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, Y.; Cho, S.Y.; Correia, R.; Morgan, S.P. Non-invasive cuff-less blood pressure estimation using a hybrid deep learning model. Opt. Quantum Electron. 2021, 53, 1–20. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, Z.; Ward, R.; Elgendi, M. Hypertension Assessment via ECG and PPG Signals: An Evaluation Using MIMIC Database. Diagnostics 2018, 8, 65. [Google Scholar] [CrossRef]
- Chowdhury, M.H.; Shuzan, M.N.I.; Chowdhury, M.E.; Mahbub, Z.B.; Uddin, M.M.; Khandakar, A.; Reaz, M.B.I. Estimating Blood Pressure from the Photoplethysmogram Signal and Demographic Features Using Machine Learning Techniques. Sensors 2020, 20, 3127. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’16), San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning, 2nd ed.; Lulu. com: Morrisville, NC, USA, 2022. [Google Scholar]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Chandrasekhar, A.; Yavarimanesh, M.; Natarajan, K.; Hahn, J.O.; Mukkamala, R. PPG Sensor Contact Pressure Should Be Taken Into Account for Cuff-Less Blood Pressure Measurement. IEEE Trans. Biomed. Eng. 2020, 67, 3134–3140. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, H.; Li, F.; Wang, Y. Crisp-BP: Continuous Wrist PPG-based Blood Pressure Measurement. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2021; ACM: New York, NY, USA, 2021; pp. 378–391. [Google Scholar] [CrossRef]
- Ray, D.; Collins, T.; Woolley, S.; Ponnapalli, P. A Review of Wearable Multi-wavelength Photoplethysmography. IEEE Rev. Biomed. Eng. 2021, 15, 1. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 1–11. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 1–9. [Google Scholar]
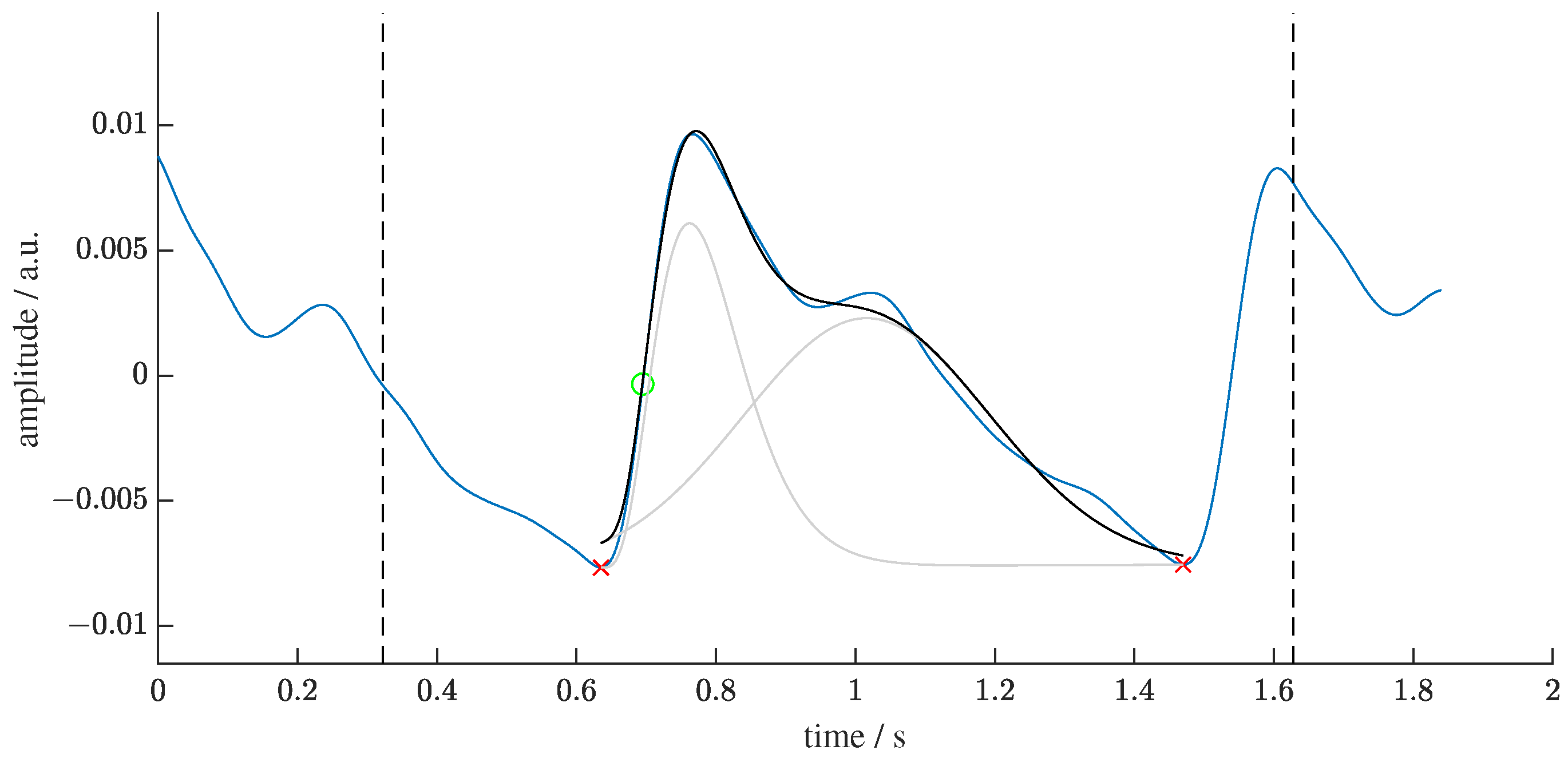
Figure 1.
Visualization of the segmentation and decomposition of a PPG beat. The green circle marks the detection point from the algorithm of Lazaro et al. [49]. The black dashed lines display the interval around the detection point in which the minima (red crosses) are searched. The beat between these minima is then decomposed into two kernels (light grey). The sum of the kernels is the recomposed beat (black line).
Figure 1.
Visualization of the segmentation and decomposition of a PPG beat. The green circle marks the detection point from the algorithm of Lazaro et al. [49]. The black dashed lines display the interval around the detection point in which the minima (red crosses) are searched. The beat between these minima is then decomposed into two kernels (light grey). The sum of the kernels is the recomposed beat (black line).

Figure 2.
Comparison of estimated blood pressure (orange line) and ground truth (blue line) for all samples of the test set. The top plot shows the CPT data, the middle plot shows the Queensland data, the bottom plot shows the PPG-BP data.
Figure 2.
Comparison of estimated blood pressure (orange line) and ground truth (blue line) for all samples of the test set. The top plot shows the CPT data, the middle plot shows the Queensland data, the bottom plot shows the PPG-BP data.

Figure 3.
(a) shows a bar plot of mean absolute SHAP values that indicates global feature importance (mean absolute for each feature over all given samples). (b) depicts a beeswarm plot of SHAP values. For each sample, this plot shows a dot on each feature row. The features are ordered according to the mean absolute SHAP values for each feature. Depicted are the nine features with the highest mean absolute SHAP value and the sum of the remaining features.
Figure 3.
(a) shows a bar plot of mean absolute SHAP values that indicates global feature importance (mean absolute for each feature over all given samples). (b) depicts a beeswarm plot of SHAP values. For each sample, this plot shows a dot on each feature row. The features are ordered according to the mean absolute SHAP values for each feature. Depicted are the nine features with the highest mean absolute SHAP value and the sum of the remaining features.

Figure 4.
Dependence plot for features skew and showing the relationship of the value of the feature and its SHAP value for all samples. All samples with feature values in the first and 99th percentile are removed.
Figure 4.
Dependence plot for features skew and showing the relationship of the value of the feature and its SHAP value for all samples. All samples with feature values in the first and 99th percentile are removed.

Figure 5.
Beeswarm plot of SHAP values for subsets of samples of test set according to the MAE values of the prediction models. (a) error greater than two times the MAE, (b) error lower than half the MAE.
Figure 5.
Beeswarm plot of SHAP values for subsets of samples of test set according to the MAE values of the prediction models. (a) error greater than two times the MAE, (b) error lower than half the MAE.

Figure 6.
Beeswarm plot of SHAP values for subsets of samples of test set according to the predicted SBP. (a) prediction lower than 0.8 times the mean prediction, (b) prediction greater than 1.2 times the mean prediction.
Figure 6.
Beeswarm plot of SHAP values for subsets of samples of test set according to the predicted SBP. (a) prediction lower than 0.8 times the mean prediction, (b) prediction greater than 1.2 times the mean prediction.

Figure 7.
Beeswarm plot of SHAP values for subsets of samples of test set according to the database.
Figure 7.
Beeswarm plot of SHAP values for subsets of samples of test set according to the database.

Figure 8.
Bar plot of mean absolute SHAP values for comparison models. Shows global feature importance (mean absolute for each feature over all given samples).
Figure 8.
Bar plot of mean absolute SHAP values for comparison models. Shows global feature importance (mean absolute for each feature over all given samples).

Figure 9.
SHAP values for DBP prediction model on the whole dataset. (a) shows a bar plot of mean absolute SHAP values that indicates global feature importance (mean absolute for each feature over all given samples). (b) depicts a beeswarm plot of SHAP values. For each sample this plot shows a dot on each feature row. The features are ordered according to the mean absolute SHAP values for each feature. Depicted are the nine features with the highest mean absolute SHAP value and the sum of the remaining features.
Figure 9.
SHAP values for DBP prediction model on the whole dataset. (a) shows a bar plot of mean absolute SHAP values that indicates global feature importance (mean absolute for each feature over all given samples). (b) depicts a beeswarm plot of SHAP values. For each sample this plot shows a dot on each feature row. The features are ordered according to the mean absolute SHAP values for each feature. Depicted are the nine features with the highest mean absolute SHAP value and the sum of the remaining features.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Works regarding feature-based absolute BP estimation from PPG. Each entry reports the machine learning model, datasets, number of features and feature types used. The ‘Clear Separation’ column indicates whether the subjects are clearly separated into test and training data (‘yes’) or not (‘no’). Publications that do not declare their method of separation are labelled ‘unknown’. We show the best results achieved for each publication.
Table 1.
Works regarding feature-based absolute BP estimation from PPG. Each entry reports the machine learning model, datasets, number of features and feature types used. The ‘Clear Separation’ column indicates whether the subjects are clearly separated into test and training data (‘yes’) or not (‘no’). Publications that do not declare their method of separation are labelled ‘unknown’. We show the best results achieved for each publication.
| Author | Method | Datasets | Number of Features | Feature Types | Clear Separation | MAESBP ± SDSBP in mmHg |
|---|---|---|---|---|---|---|
| [32] | Bi-GRU + GRU + attention | MIMIC II | 22 | original | unknown | |
| [13] | XgBoost | MIMIC, Queensland, PPG BP | 16 | PWD, original, frequency | no | |
| [33] | gradient boosting machine | HYPE, EVAL | 21 | original | yes | |
| [34] | AdaBoost | UCI (MIMIC II) | 19 | original | yes | |
| [35] | fully connected neural network | MIMIC II | 32 | original, first derivative, second derivative | no | |
| [36] | LSTM | MIMIC II | 7 | original | unknown | |
| [37] | random forest | MIMIC III | 16 | original, first derivative, frequency | yes | |
| [16] | ANN, SVR | MIMIC II | 21 | original | unknown | |
| [38] | multilayer perceptron (ANN) | MIMIC | 22 | original, frequency | no | |
| [39] | Lasso Regression | own data | >233 | demographic, frequency, original, derivatives (1–4) | unknown | |
| Lasso Regression | >233 | frequency, original, derivatives (1–4) | unknown | |||
| [40] | SVR | Queensland | 9 | original | yes | |
| [41] | linear regression | own data | 21 | original, frequency | yes | |
| [42] | combinatorial ANN | UCI (MIMIC II), own data | 46 | original, second derivative | no | |
| [43] | SVR | own data | 12 | demographic, original | no | |
| [44] | SVR | Queensland | 18 | original | no | |
| [45] | linear regression | own data | unknown | unknown | yes |
Table 2.
Description of used features. The ‘Beat’ column indicates whether the original beat (‘original’) or the sum of the kernels (‘reconstructed’) was used to extract the feature. All features but are from the work of Hu et al. [13].
Table 2.
Description of used features. The ‘Beat’ column indicates whether the original beat (‘original’) or the sum of the kernels (‘reconstructed’) was used to extract the feature. All features but are from the work of Hu et al. [13].
| Category | Feature | Description | Beat |
|---|---|---|---|
| PWD | P1 | amplitude of first kernel | reconstructed |
| P2 | amplitude of second kernel | reconstructed | |
| T1 | mode of first kernel | reconstructed | |
| T2 | mode of second kernel | reconstructed | |
| W1 | width of first kernel | reconstructed | |
| W2 | width of second kernel | reconstructed | |
| Second Derivative | quotient of amplitudes of b and a wave of second derivative | reconstructed | |
| Statistical Features | SD | standard deviation of pulse wave | reconstructed |
| kurt | kurtosis of pulse wave | reconstructed | |
| skew | skewness of pulse wave | reconstructed | |
| PW | width of pulse wave | reconstructed | |
| Frequency Features | Freq0 | fundamental frequency | original |
| Freq1 | frequency of first harmonic | original | |
| Freq2 | frequency of second harmonic | original | |
| Freq3 | frequency of third harmonic | original |
Table 3.
Results of the prediction of our model for the all datasets combined and the single datasets separately.
Table 3.
Results of the prediction of our model for the all datasets combined and the single datasets separately.
| Metric | Whole Dataset | CPT | Queensland | PPG-BP |
|---|---|---|---|---|
| MAE | ||||
| ME | ||||
| SDE | ||||
| r |
Table 4.
BP characteristics for the test and training set of the single datasets separately.
| Metric | Split | CPT | Queensland | PPG-BP |
|---|---|---|---|---|
| maximum | training | |||
| test | ||||
| minimum | training | |||
| test | ||||
| mean | training | |||
| test | ||||
| standard deviation | training | |||
| test |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fleischhauer, V.; Feldheiser, A.; Zaunseder, S. Beat-to-Beat Blood Pressure Estimation by Photoplethysmography and Its Interpretation. Sensors 2022, 22, 7037. https://doi.org/10.3390/s22187037
AMA Style
Fleischhauer V, Feldheiser A, Zaunseder S. Beat-to-Beat Blood Pressure Estimation by Photoplethysmography and Its Interpretation. Sensors. 2022; 22(18):7037. https://doi.org/10.3390/s22187037
Chicago/Turabian StyleFleischhauer, Vincent, Aarne Feldheiser, and Sebastian Zaunseder. 2022. "Beat-to-Beat Blood Pressure Estimation by Photoplethysmography and Its Interpretation" Sensors 22, no. 18: 7037. https://doi.org/10.3390/s22187037
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.