
Particle Swarm Optimization and Multiple Stacked Generalizations to Detect Nitrogen and Organic-Matter in Organic-Fertilizer Using Vis-NIR


Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
2.2. Visible Near-Infrared Spectroscopy (Vis-NIR) Measurements and Preprocessing
2.3. Construction of the Multiple Stacked Generalizations
- Support vector machine (SVM): this selects important instances to create a separating surface between data instances [20]. After performing a grid search, the obtained optimized learning parameters for SVM were C = 1, gamma = 0.01, kernel = rbf.
- Logistic regression (L.R.): this is used to define variables and illustrate a relationship between one dependent variable and one or more independent variables [21]. After examining a wide collection of options using a grid search, the best parameter settings were C = 100, penalty = l2, solver = newton-cg.
- K-nearest neighbor (KNN): this model is among the simplest of all ML methods, and it is used to define and for prediction. The best hyperparameters for this model were metric = Euclidean, n neighbors = 1, weights = uniform [22].
- Random forest (RF): this approach is better than a single decision tree since it eliminates over-fitting by averaging the answer. The optimized learning parameters of SVM were max_depth = 80, max_features = 2, min_samples_leaf = 3, min_samples_split = 10, n_estimators = 200 [23].
- Multilayer perceptron (MLP): this is made of three layers of nodes that use a nonlinear activation function [24]. The best parameters for this model after running 5 folds were activation = tanh, alpha = 0.0001, hidden_layer_sizes = 103,010, learning_rate = constant and solver = adam.
- Gaussian naïve Bayes (N.B.): this algorithm focuses on the Bayes theorem, and it is used for classification, but it has a high versatility when the dimensions of the inputs are large. Complex classification issues can also be tackled using the Naive Bayes Classifier [25].
- Ridge: this is a straightforward linear regression that applies a slight degree of bias to obtain a significant decrease in volatility. Using grid search cross-validation, it has been found that the best bias value is 0.1.
2.4. Feature Selection
- Step 1: Create the multiple-stacked generalization classifier.
- Step 2: Evaluate each particle in the swarm.
- Step 3: Verification of the best values of swarm and particle.
- Step 4: Update velocities of the movement in the search space.
- Step 5: Update the position of the particle by using the logistic function of the velocity.
- Step 6: Continue the iterative process.
2.5. Model Evaluation and Software
3. Results
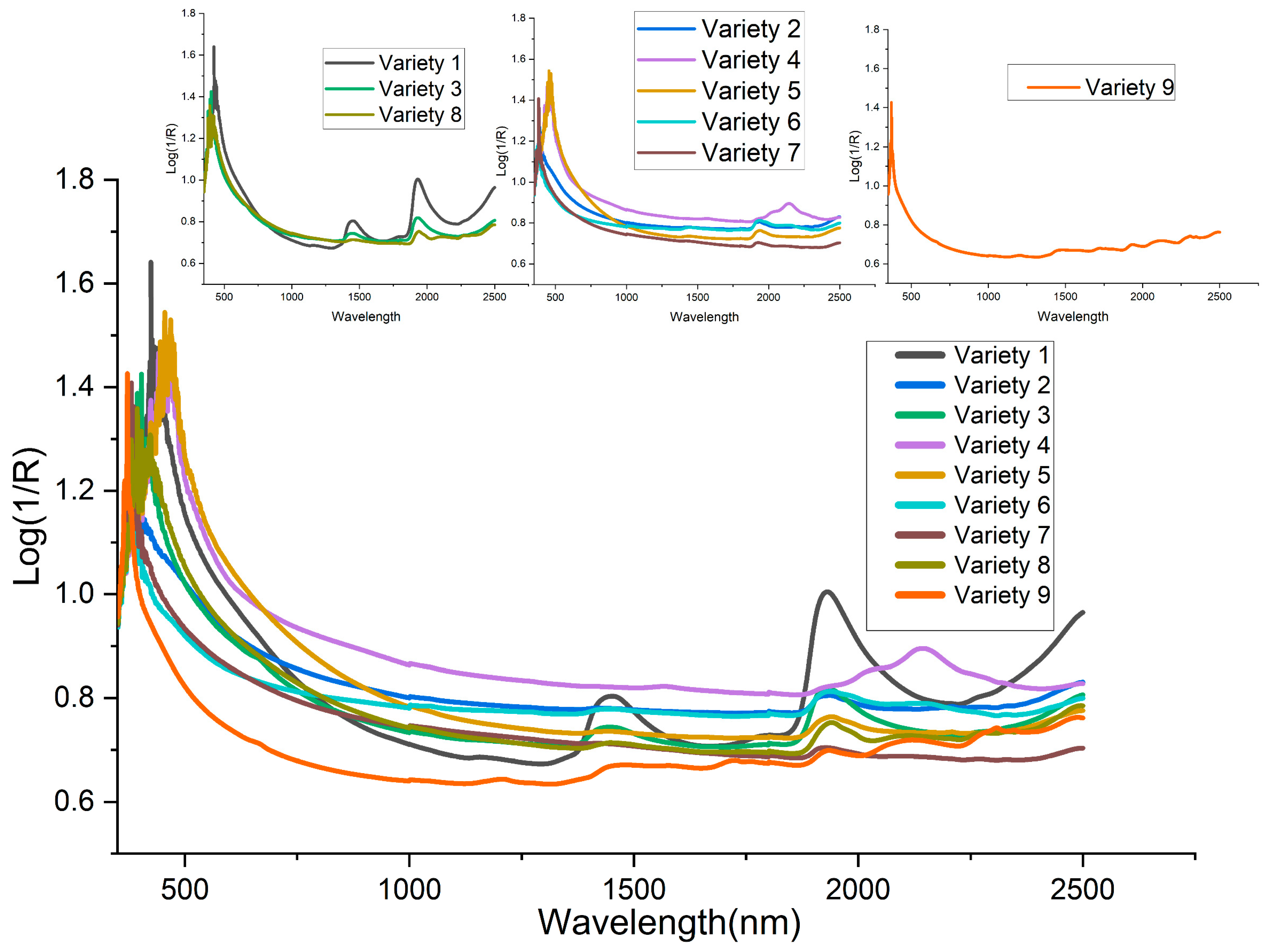
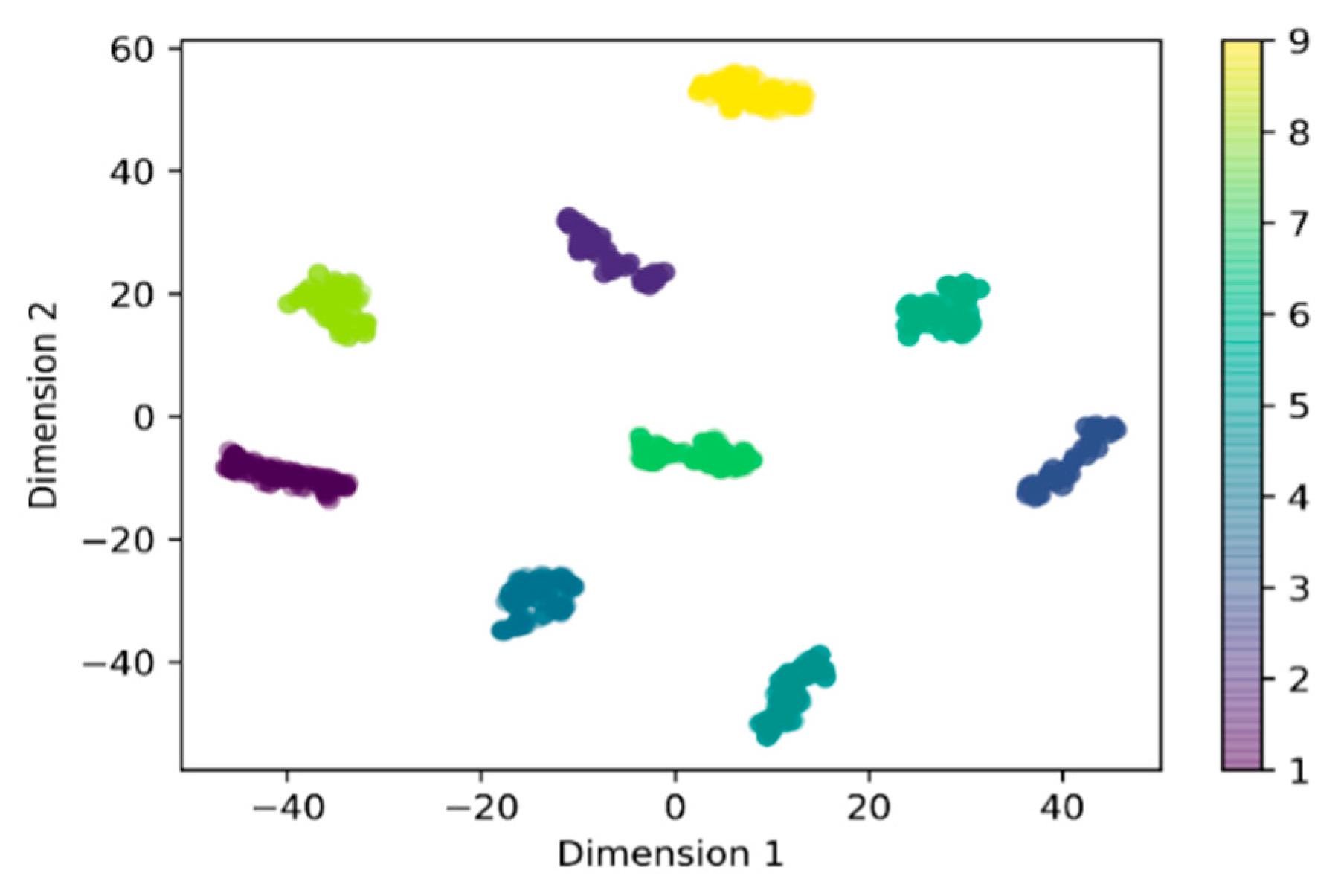
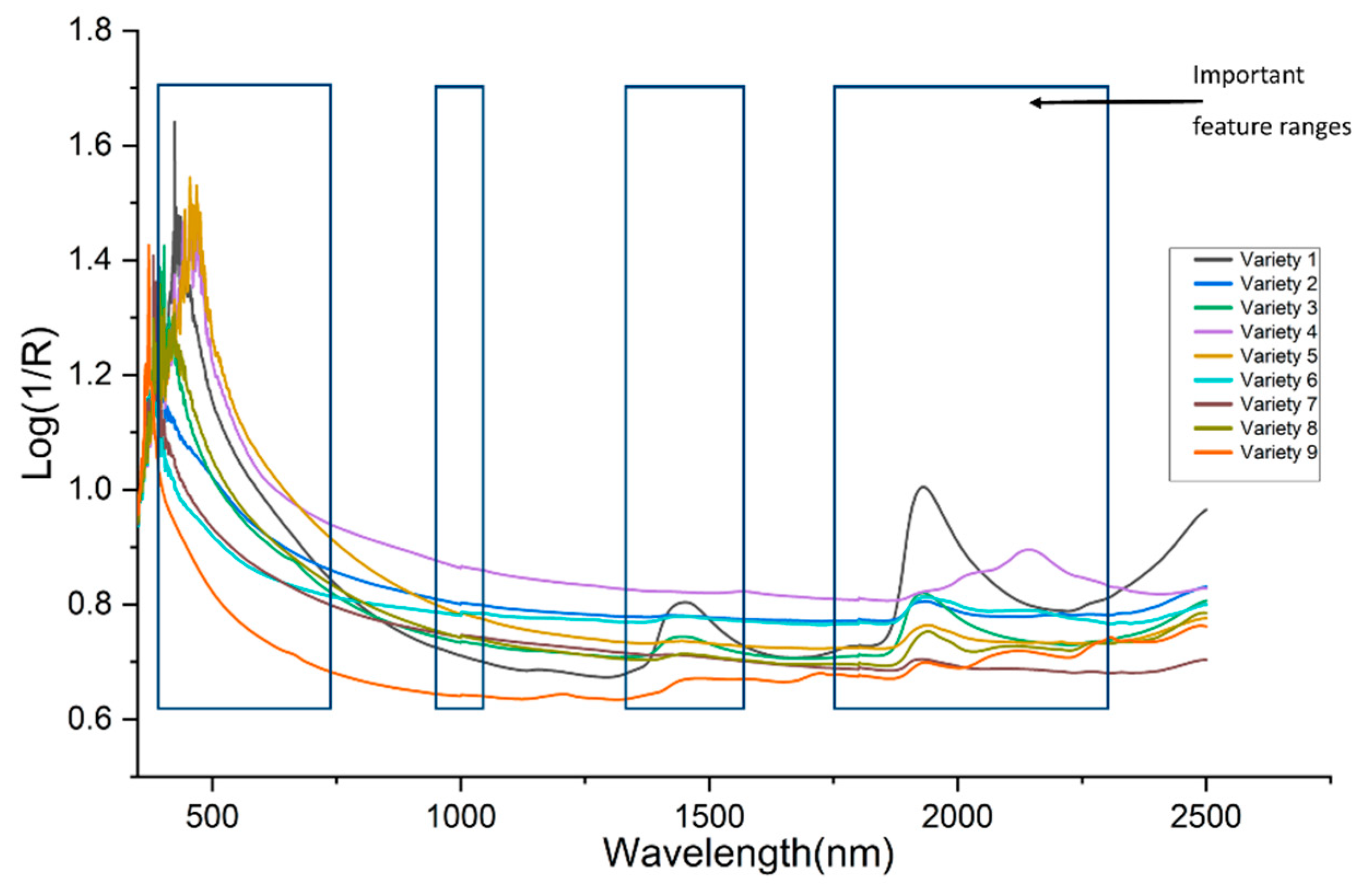
3.1. Spectra Analysis and Visualization
3.2. Models for the Stacked Generalization
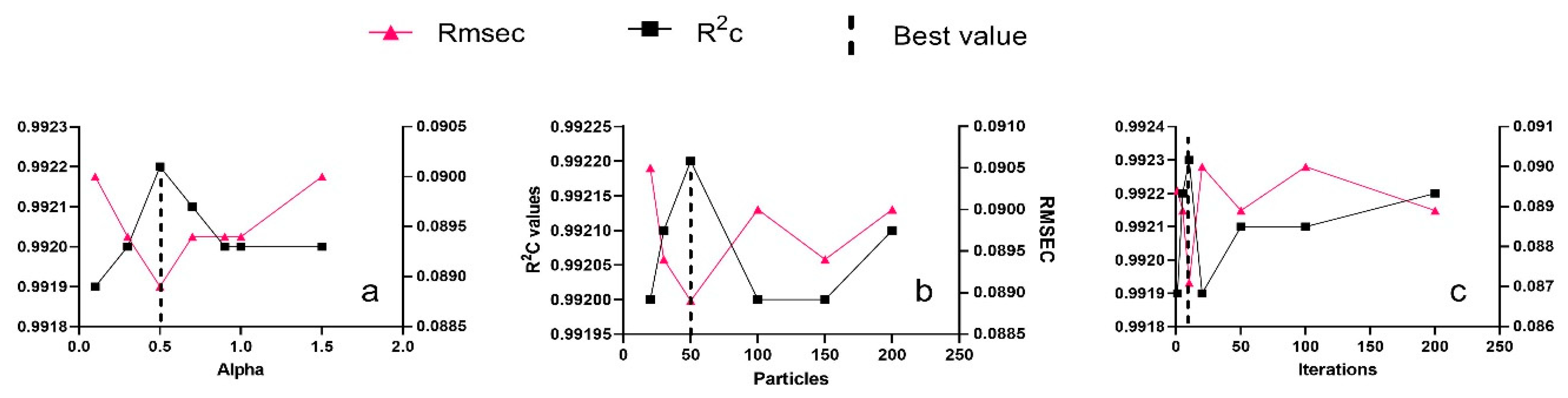
3.3. Particle Swarm Optimization (PSO) Parameters Optimization
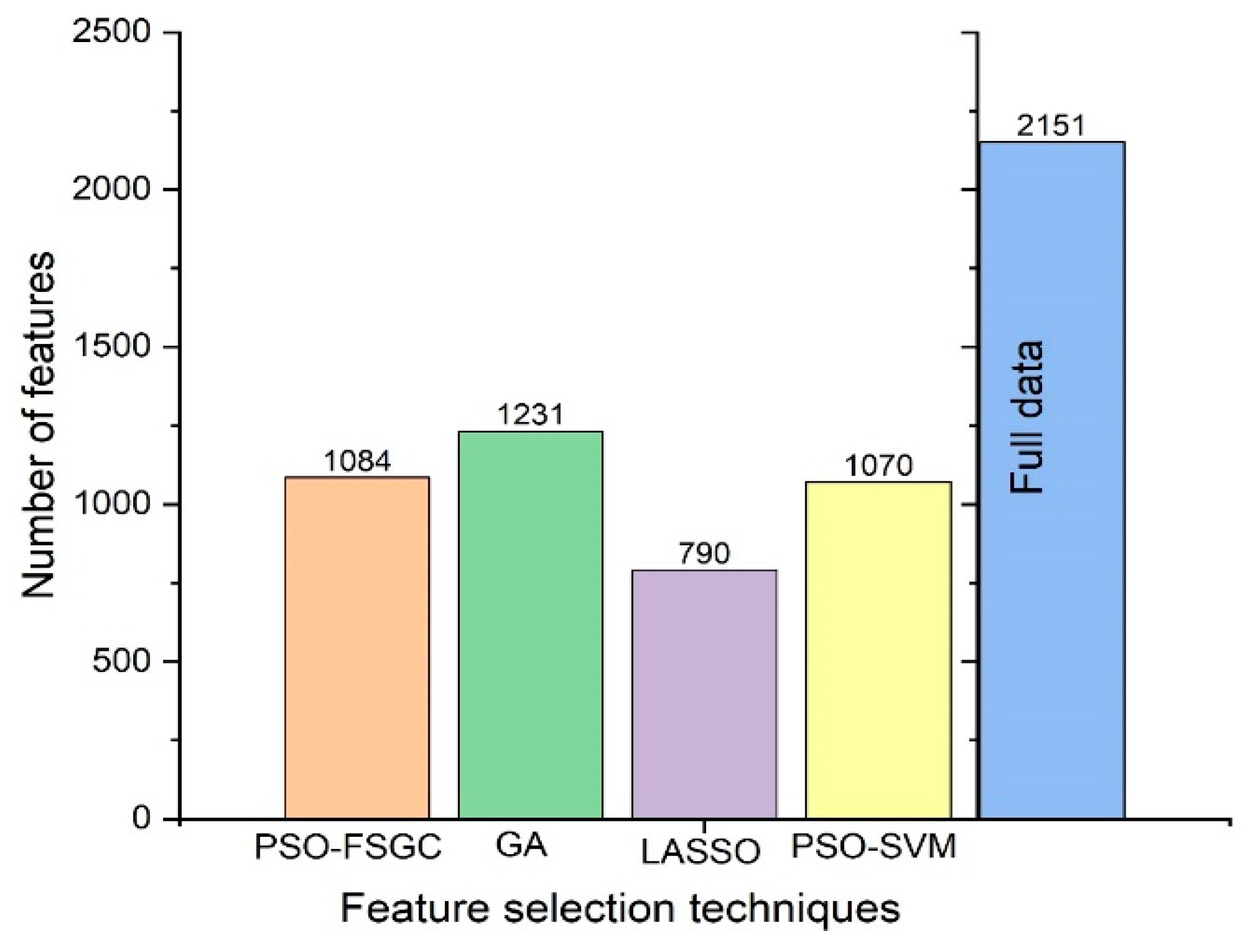
3.4. Comparison between the Proposed Method with Lasso, Genetic Algorithm (GA), PSO-Support Vector Machine (SVM)
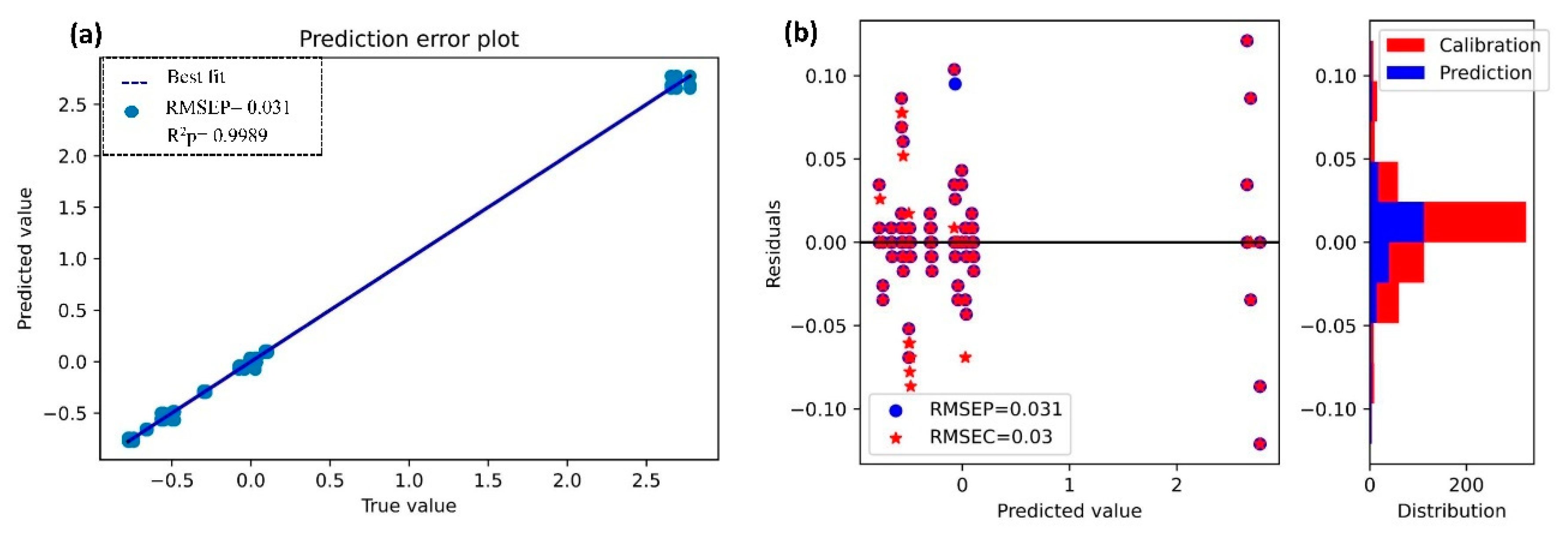
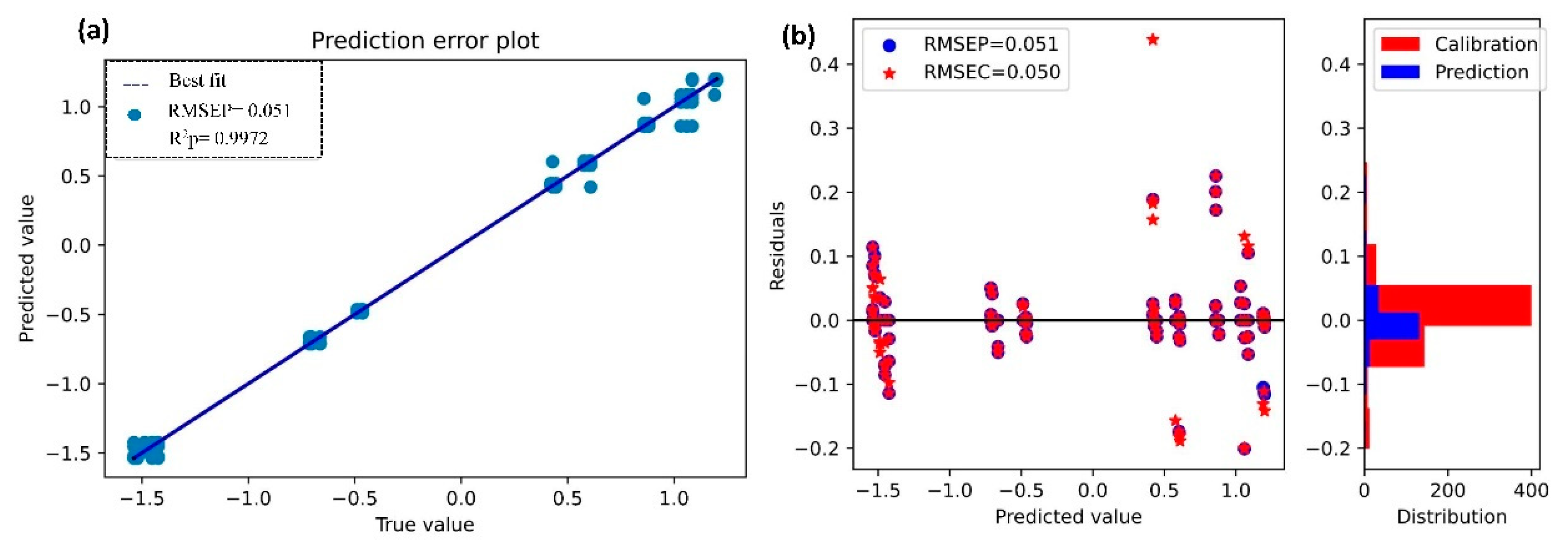
3.5. Prediction of Nitrogen (N) and Organic Matter (OM) Using Second Stacked Generalizations for Regression (SSGR)
3.5.1. Prediction of Nitrogen (N)
3.5.2. Prediction of Organic Matter (OM)
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Xu, J. Restoration of surface soil fertility of an eroded red soil in southern China. Soil Tillage Res. 2005, 80, 13–21. [Google Scholar] [CrossRef]
- Vincent, B.; Dardenne, P. Application of NIR in Agriculture. In Near-Infrared Spectroscopy: Theory, Spectral Analysis, Instrumentation, and Applications; Ozaki, Y., Huck, C., Tsuchikawa, S., Engelsen, S.B., Eds.; Springer: Singapore, 2021; pp. 331–345. [Google Scholar]
- Currà, A.; Gasbarrone, R.; Cardillo, A.; Trompetto, C.; Fattapposta, F.; Pierelli, F.; Missori, P.; Bonifazi, G.; Serranti, S. Near-infrared spectroscopy as a tool for in vivo analysis of human muscles. Sci. Rep. 2019, 9, 8623. [Google Scholar] [CrossRef]
- Ullah, S.; Ferreira-Neto, E.; Hazra, C.; Parveen, R.; Rojas-Mantilla, H.; Calegaro, M.; Serge-Correales, Y.; Rodrigues-Filho, U.; Ribeiro, S. Broad spectrum photocatalytic system based on BiVO4 and NaYbF4: Tm3+ upconversion particles for environmental remediation under UV-vis-NIR illumination. Appl. Catal. B Environ. 2019, 243, 121–135. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Huck, C.W. Near-Infrared Spectroscopy in Bio-Applications. Molecules 2020, 25, 2948. [Google Scholar] [CrossRef] [PubMed]
- Gholizadeh, A.; Saberioon, M.; Ben-Dor, E.; Rossel, R.A.V.; Borůvka, L. Modelling potentially toxic elements in forest soils with vis–NIR spectra and learning algorithms. Environ. Pollut. 2020, 267, 115574. [Google Scholar] [CrossRef] [PubMed]
- Stenberg, B.; Viscarra Rossel, R.A.; Mouazen, A.M.; Wetterlind, J. Chapter Five-Visible and Near Infrared Spectroscopy in Soil Science. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2010; Volume 107, pp. 163–215. [Google Scholar]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Yan, C.; Liang, J.; Zhao, M.; Zhang, X.; Zhang, T.; Li, H. A novel hybrid feature selection strategy in quantitative analysis of laser-induced breakdown spectroscopy. Anal. Chim. Acta 2019, 1080, 35–42. [Google Scholar] [CrossRef]
- Dong, H.; Li, T.; Ding, R.; Sun, J. A novel hybrid genetic algorithm with granular information for feature selection and optimization. Appl. Soft Comput. J. 2018, 65, 33–46. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, W.; Kang, J.; Zhang, X.; Wang, X. A problem-specific non-dominated sorting genetic algorithm for supervised feature selection. Inf. Sci. 2021, 547, 841–859. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.W.; Cheng, J. Multi-objective particle swarm optimization approach for cost-based feature selection in classification. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 14, 64–75. [Google Scholar] [CrossRef]
- Shang, J.; Wang, X.; Wu, X.; Sun, Y.; Ding, Q.; Liu, J.-X.; Zhang, H. A review of ant colony optimization based methods for detecting epistatic interactions. IEEE Access 2019, 7, 13497–13509. [Google Scholar] [CrossRef]
- Rostami, M.; Forouzandeh, S.; Berahmand, K.; Soltani, M. Integration of multi-objective PSO based feature selection and node centrality for medical datasets. Genomics 2020, 112, 4370–4384. [Google Scholar] [CrossRef]
- Almomani, O. A feature selection model for network intrusion detection system based on PSO, GWO, FFA and GA algorithms. Symmetry 2020, 12, 1046. [Google Scholar] [CrossRef]
- Ben Dor, E.; Ong, C.; Lau, I.C. Reflectance measurements of soils in the laboratory: Standards and protocols. Geoderma 2015, 245–246, 112–124. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Breiman, L. Heuristics of instability and stabilization in model selection. Ann. Stat. 1996, 24, 2350–2383. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Support Vector Machines and Flexible Discriminants. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Hastie, T., Tibshirani, R., Friedman, J., Eds.; Springer: New York, NY, USA, 2009; pp. 417–458. [Google Scholar]
- Pampel, F.C. Logistic Regression: A Primer; SAGE Publications: Thousand Oaks, CA, USA, 2020. [Google Scholar]
- Kramer, O. K-Nearest Neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Kramer, O., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Neural Networks. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Hastie, T., Tibshirani, R., Friedman, J., Eds.; Springer: New York, NY, USA, 2009; pp. 389–416. [Google Scholar]
- Amor, N.B.; Benferhat, S.; Elouedi, Z. Naive Bayes vs decision trees in intrusion detection systems. In Proceedings of the 2004 ACM Symposium on Applied Computing; Association for Computing Machinery: Nicosia, Cyprus, 2004; pp. 420–424. [Google Scholar]
- Vieira, S.M.; Mendonça, L.F.; Farinha, G.J.; Sousa, J.M.C. Modified binary PSO for feature selection using SVM applied to mortality prediction of septic patients. Appl. Soft Comput. 2013, 13, 3494–3504. [Google Scholar] [CrossRef]
- Chuang, L.-Y.; Chang, H.-W.; Tu, C.-J.; Yang, C.-H. Improved binary PSO for feature selection using gene expression data. Comput. Biol. Chem. 2008, 32, 29–38. [Google Scholar] [CrossRef]
- Hu, L.; Yin, C.; Ma, S.; Liu, Z. Vis-NIR spectroscopy combined with wavelengths selection by PSO optimization algorithm for simultaneous determination of four quality parameters and classification of soy sauce. Food Anal. Methods 2019, 12, 633–643. [Google Scholar] [CrossRef]
- Shi, T.; Chen, Y.; Liu, H.; Wang, J.; Wu, G. Soil organic carbon content estimation with laboratory-based visible–near-infrared reflectance spectroscopy: Feature selection. Appl. Spectrosc. 2014, 68, 831–837. [Google Scholar] [CrossRef]
- Yang, M.; Xu, D.; Chen, S.; Li, H.; Shi, Z. Evaluation of machine learning approaches to predict soil organic matter and pH using vis-NIR spectra. Sensors 2019, 19, 263. [Google Scholar] [CrossRef] [Green Version]
- Reda, R.; Saffaj, T.; Ilham, B.; Saidi, O.; Issam, K.; Brahim, L.; El Hadrami, E.M. A comparative study between a new method and other machine learning algorithms for soil organic carbon and total nitrogen prediction using near infrared spectroscopy. Chemom. Intell. Lab. Syst. 2019, 195, 103873. [Google Scholar] [CrossRef]
- Leme, L.M.; Rocha Montenegro, H.; da Rocha dos Santos, L.; Sereia, M.J.; Valderrama, P.; Março, P.H. Relation between near-infrared spectroscopy and physicochemical parameters for discrimination of honey samples from Jatai weyrauchi and Jatai angustula Bees. Food Anal. Methods 2018, 11, 1944–1950. [Google Scholar] [CrossRef]
- Vohland, M.; Ludwig, M.; Thiele-Bruhn, S.; Ludwig, B. Determination of soil properties with visible to near- and mid-infrared spectroscopy: Effects of spectral variable selection. Geoderma 2014, 223–225, 88–96. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Lark, R.M. Improved analysis and modelling of soil diffuse reflectance spectra using wavelets. Eur. J. Soil Sci. 2009, 60, 453–464. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Propriety | Variety | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| N | Min. | 1.460 | 2.030 | 1.540 | 1.220 | 2.110 | 1.350 | 2.220 | 1.220 | 5.190 |
| Max. | 1.480 | 2.070 | 1.560 | 1.260 | 2.160 | 1.360 | 2.240 | 5.330 | 5.330 | |
| Mean | 1.470 | 2.047 | 1.550 | 1.237 | 2.140 | 1.353 | 2.230 | 2.107 | 5.250 | |
| SD | 0.010 | 0.020 | 0.010 | 0.020 | 0.026 | 0.005 | 0.010 | 1.117 | 0.072 | |
| OM | Min. | 55.97 | 40.23 | 40.56 | 58.15 | 57.11 | 47.12 | 54.12 | 40.23 | 45.65 |
| Max. | 56.12 | 40.34 | 40.98 | 58.22 | 57.46 | 47.29 | 54.33 | 58.22 | 45.98 | |
| Mean | 56.02 | 40.30 | 40.78 | 58.19 | 57.29 | 47.22 | 54.25 | 50.21 | 45.78 | |
| SD | 0.083 | 0.058 | 0.210 | 0.035 | 0.175 | 0.090 | 0.111 | 6.348 | 0.175 |
| Proprieties Methods | Calibration | Prediction | ||||
|---|---|---|---|---|---|---|
| R2c | RMSEC | R2p | RMSEP | LOD | ||
| N | SSGR | 0.9990 | 0.030 | 0.9989 | 0.031 | 2.97 |
| Ridge | 0.9987 | 0.036 | 0.9987 | 0.036 | 2.77 | |
| SVR | 0.9954 | 0.066 | 0.9951 | 0.068 | 2.81 | |
| PLS (Lv = 3) | 0.9790 | 0.143 | 0.9782 | 0.150 | 3.04 | |
| PLS (Lv = 6) | 0.9939 | 0.076 | 0.9934 | 0.082 | 2.99 | |
| PLS (Lv = 9) | 0.9985 | 0.038 | 0.9984 | 0.038 | 2.98 | |
| OM | SSGR | 0.9973 | 0.050 | 0.9972 | 0.051 | 2.97 |
| Ridge | 0.9858 | 0.011 | 0.9796 | 0.137 | 3.03 | |
| SVR | 0.9955 | 0.067 | 0.9945 | 0.071 | 3.00 | |
| PLS (Lv = 3) | 0.4953 | 0.708 | 0.4683 | 0.716 | 6.01 | |
| PLS (Lv = 6) | 0.9641 | 0.190 | 0.9516 | 0.213 | 3.09 | |
| PLS (Lv = 9) | 0.9829 | 0.131 | 0.9755 | 0.151 | 3.03 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guindo, M.L.; Kabir, M.H.; Chen, R.; Liu, F. Particle Swarm Optimization and Multiple Stacked Generalizations to Detect Nitrogen and Organic-Matter in Organic-Fertilizer Using Vis-NIR. Sensors 2021, 21, 4882. https://doi.org/10.3390/s21144882
Guindo ML, Kabir MH, Chen R, Liu F. Particle Swarm Optimization and Multiple Stacked Generalizations to Detect Nitrogen and Organic-Matter in Organic-Fertilizer Using Vis-NIR. Sensors. 2021; 21(14):4882. https://doi.org/10.3390/s21144882
Chicago/Turabian StyleGuindo, Mahamed Lamine, Muhammad Hilal Kabir, Rongqin Chen, and Fei Liu. 2021. "Particle Swarm Optimization and Multiple Stacked Generalizations to Detect Nitrogen and Organic-Matter in Organic-Fertilizer Using Vis-NIR" Sensors 21, no. 14: 4882. https://doi.org/10.3390/s21144882