DeepBrain: Experimental Evaluation of Cloud-Based Computation Offloading and Edge Computing in the Internet-of-Drones for Deep Learning Applications



Abstract
:1. Introduction
1.1. Problem Statement
1.2. Main Contribution
- First, we propose, DeepBrain, a cloud-based Internet-of-Drones architecture that provides users with seamless access to drones over the Internet, and allows drones to offload deep learning computation to the cloud for real-time processing of the collected visual data.
- Second, we present an experimental study that demonstrates the feasibility of the proposed architecture, and we evaluate the performance of the computation offloading approach and edge computing approach in terms of energy consumption, cloud server utilization, and real-time guarantees. We also compare the computation offloading approach and the onboard computation approach. DeepBrain demos are available in [19].
2. Related Work
3. Proposed System: Deepbrain System
3.1. The Design Requirements
3.1.1. Functional Requirements
- Be able to execute a mission where it collects aerial images of points of interest using a high-resolution camera.
- Images are then transmitted to the cloud system through cellular technology (i.e., 4G/5G) for visual recognition and identification of objects and events.
- The cloud should have sufficient resources of GPU instances to run deep learning algorithms on the collected images.
- The results are shown to the end-users through a monitoring dashboard, and control commands or actions are sent back to the drone.
3.1.2. Non-Functional Requirements
- Real-time: the delay from the instant when the image is taken until the result or action is displayed to the end-user must be short and bounded. The maximum end-to-end delay shall not exceed 500 ms for the appropriate performance of the system. Such a real-time guarantee can be provided through typical 5G networks offering network bandwidth in the order of hundreds of Gigabytes and low latancies below 10 ms.
- Scalability: the DeepBrain system shall support a large number of UAVs simultaneously at the scale of a city. Several hundreds of UAVs shall have accessibility to the system for performing various missions. Distributed load balancing mechanisms should be implemented to avoid overusing particular resources.
- Energy-Efficiency: DeepBrain shall provide efficient energy management to extend the operational lifetime of the drone. Effective management between computation and communication has to be achieved. Besides, the energy consumption at the cloud side shall also be controlled for green cloud computing purposes.
- Security: DeepBrain shall provide secure access to UAVs and users and shall be able to detect and prevent malicious attacks on the system.
- Safety: The system shall ensure the safety of operations of drones and implement failsafe strategies when any hazardous event happens (e.g., communication loss with the cloud, GPS loss, occlusions)
- Reliability: The system shall perform correctly during its operation and provide a fault-tolerance mechanism to recover from any unexpected situation.
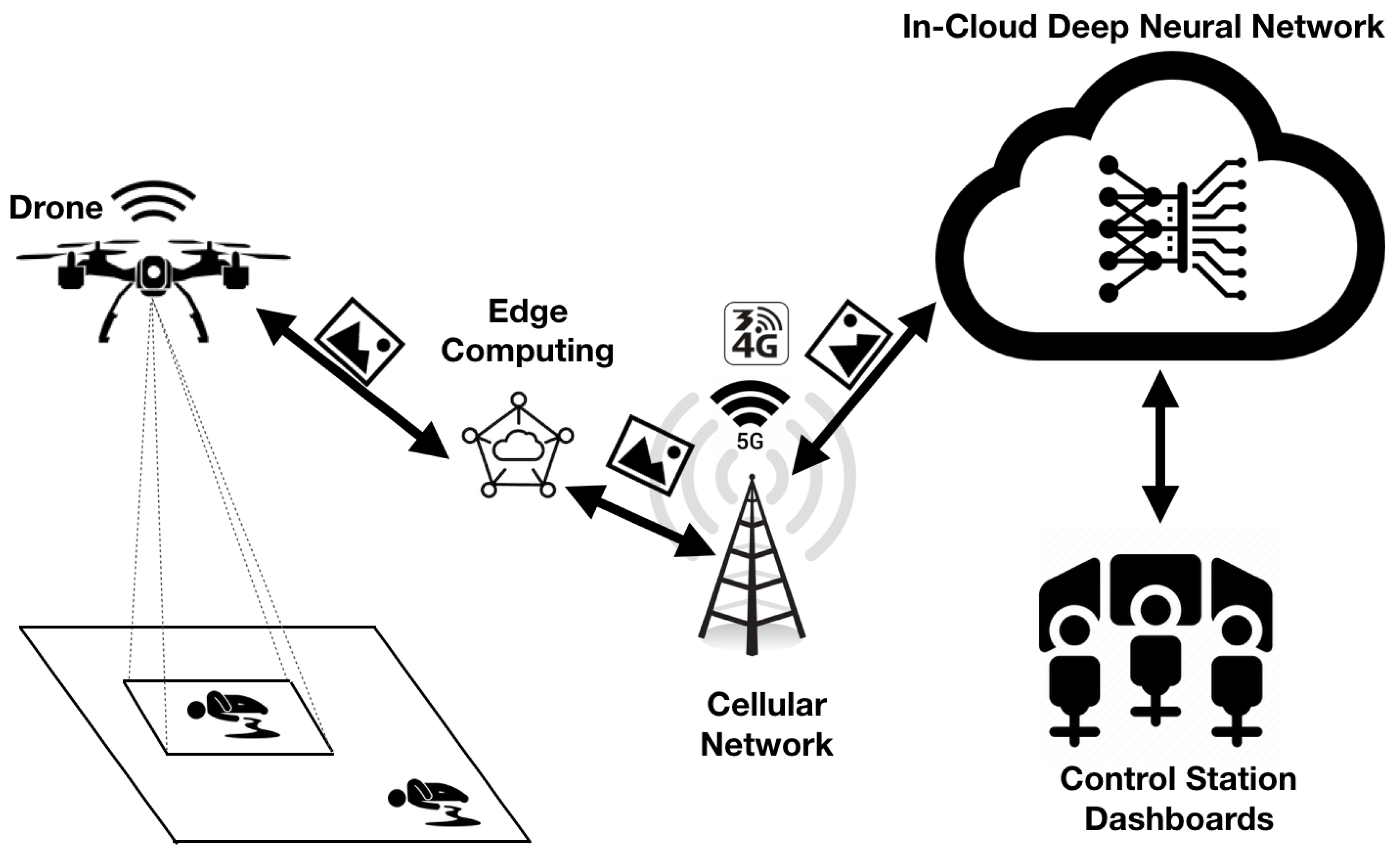
3.2. Motivating Scenario
3.3. The Deepbrain Architecture
- The Unmanned System Layer: it represents the UAV subsystem that is responsible for aerial image collection from the monitored site. It has to be noted that the unmanned system can also be a ground robot as the principle applies in the same way for any unmanned system (aerial, ground, or even submarine). Without loss of generality, in this paper, aerial systems have been considered. The UAV is equipped with sensing capabilities, namely a high-resolution camera to capture images. It also has a wireless communication interface to communicate with the edge/cloud servers. Drones connected through the cellular (4G/5G) networks have been considered. A typical setup would be to use a WiFi interface on the drone to connect to a 4G/5G portable WiFi router.
- The Edge Layer: This layer aims at increasing the scalability of the system and reducing the load of the cloud layer. Edge computing centers differ from the cloud as they are located closer to the end-devices (i.e., drones in the proposed case) and increase the decentralization of computing among multiple servers rather than on a single server. In the DeepBrain system, the Edge servers help to migrate some of the deep learning computations from the cloud to the edge. In fact, with hundreds or thousands of drones collecting images and sending them to one cloud server to process, the latter’s load might not be able to scale-up with the increasing intensive computation demands. Thus, edge computing is much more effective for real-time video stream processing and responsive feedback control of the drone.
- The Cloud Layer: The cloud subsystem deploys deep neural network algorithms that require extensive computing and storage resources that cannot be handled by edge servers. Considering the abundant resources of the cloud, it is used for processing images/videos, which requires additional resources as compared to the edge capabilities. The usage of the cloud is more suitable for less time-critical applications but has more stringent requirements in terms of computing and storage. The cloud server may also provide services not provided in the edge layer. For instance, the cloud server may deploy generative adversarial networks (GANs) and semantic segmentation algorithms [7], which are known to be more computation-intensive than standard classification and object detection deep learning applications. The cloud also offers all the drones and users management capabilities to ensure their connectivity, communication, authentication, and the availability of the services. We have already implemented this functionality in the Dronemap Planner system [37,38,41].
- The End-User Layer: This layer represents the end-users who are using the DeepBrain system through the Internet. They interact with the cloud through Web services Application Program Interfaces (APIs). They use interactive dashboards to monitor the states of their drones in real-time and to send appropriate commands when needed. They also receive the real-time video stream broadcasted from their drones after being processed by deep learning applications either located at the edge or on the cloud. The end-users may define the required business rules for their applications, such as geofencing, unmanned traffic management, path planning requirements, through their command dashboards.
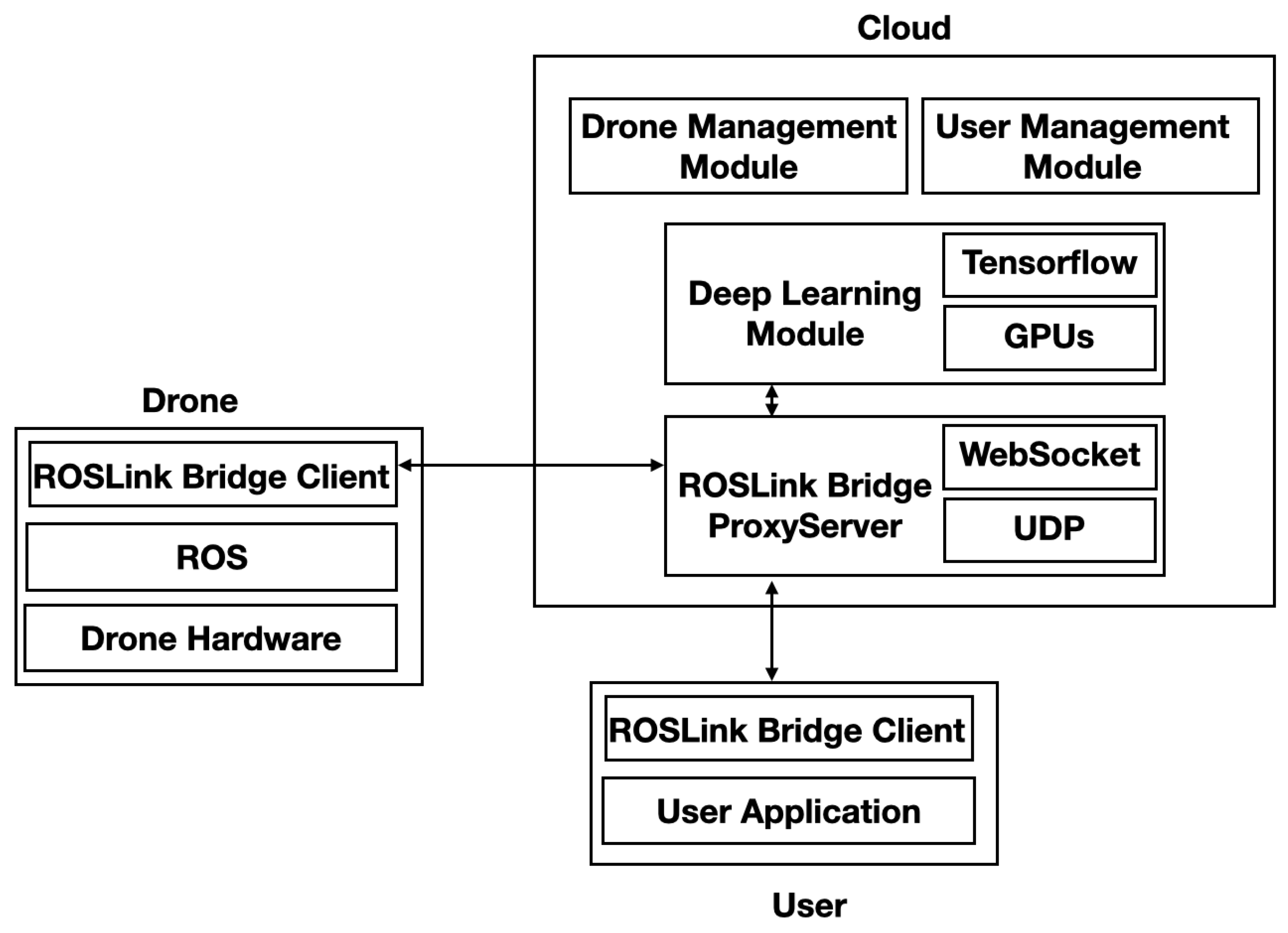
3.4. System Components
3.4.1. Drone Subsystem
3.4.2. Cloud Subsystem
3.4.3. User Subsystem
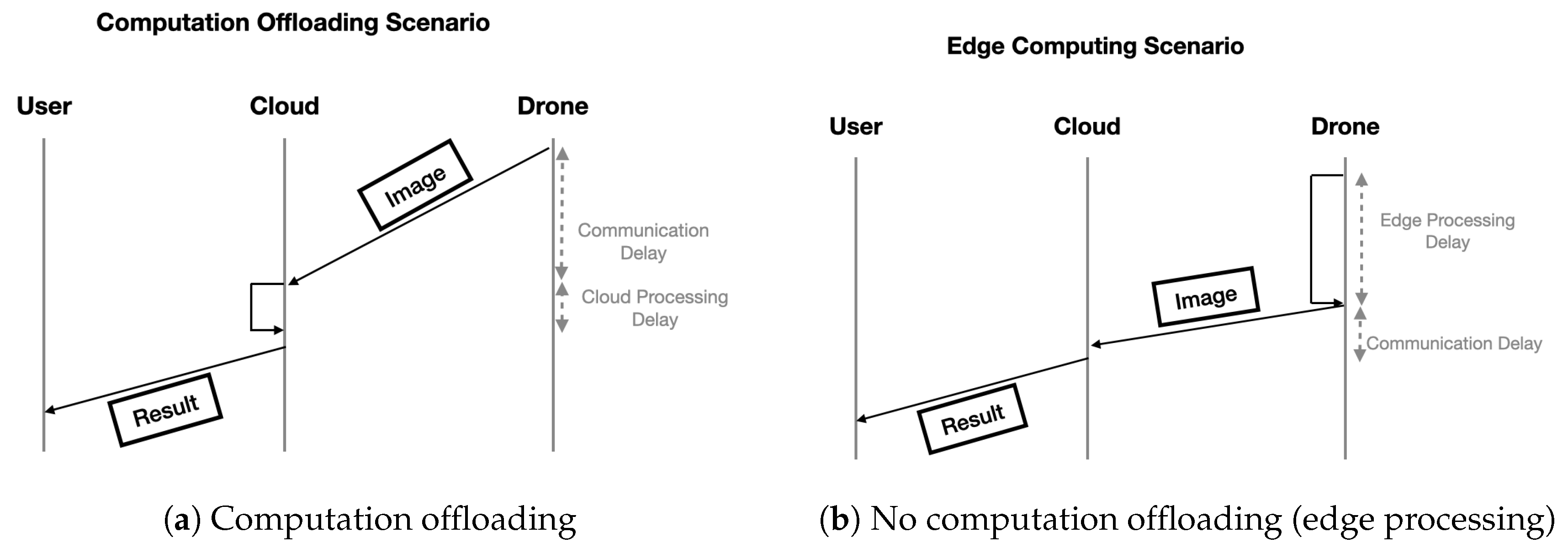
3.5. Computation Approaches
- Computation offloading (Figure 3a): it refers to the case when deep learning computation is completely offloaded to the cloud using video streaming.
- Edge computing (Figure 3b): It refers to the case when deep learning computations are performed at the edge (i.e., the drone) using devices with embedded GPUs (e.g., Jetson Nano, Raspberry Pi).
4. Results and Experimental Analysis
4.1. Experimental Setup
4.1.1. 4G Custom Drones
4.1.2. Cloud Server and GPU Server
4.1.3. Experimental Scenarios
- Scenario 1: Energy consumption (i.e., mission lifetime). In this scenario, we compare the energy consumption of the drone when running the deep learning algorithm on the drone itself against the scenario when running it on the cloud.
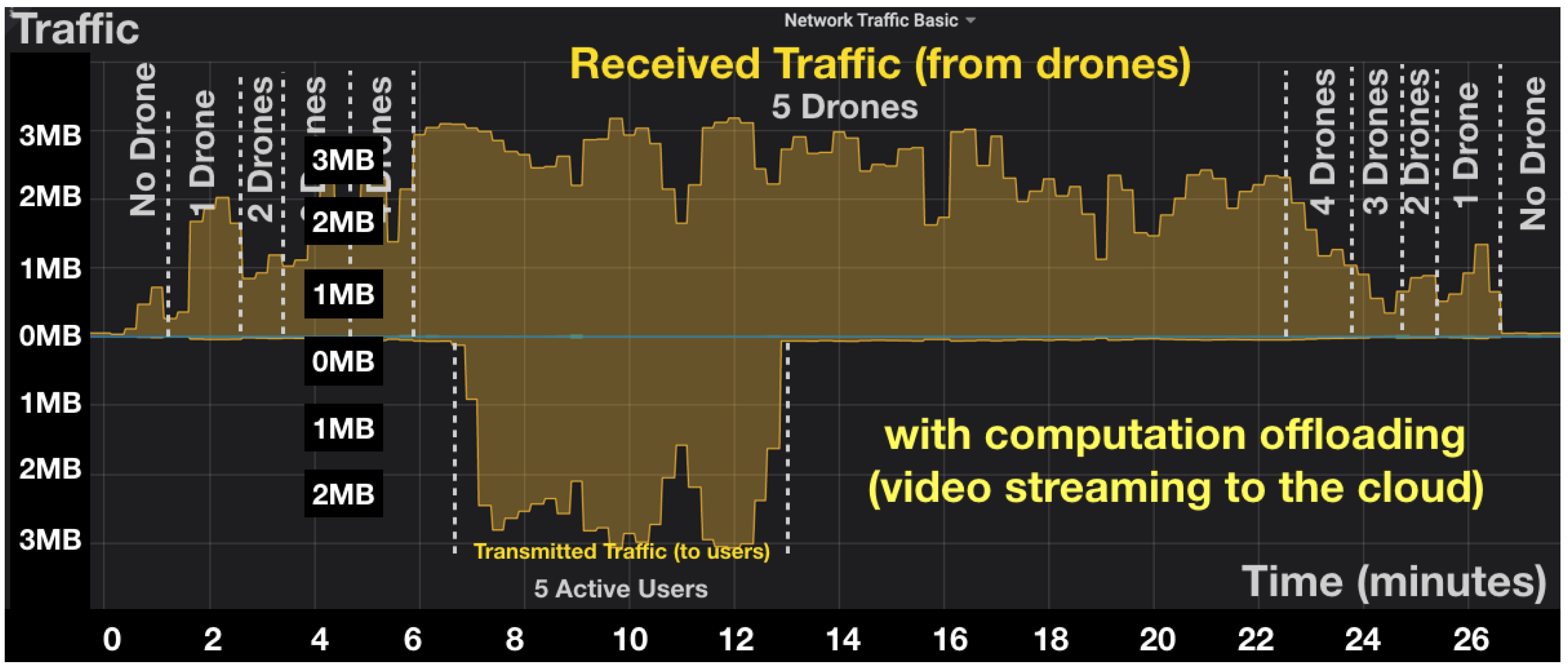
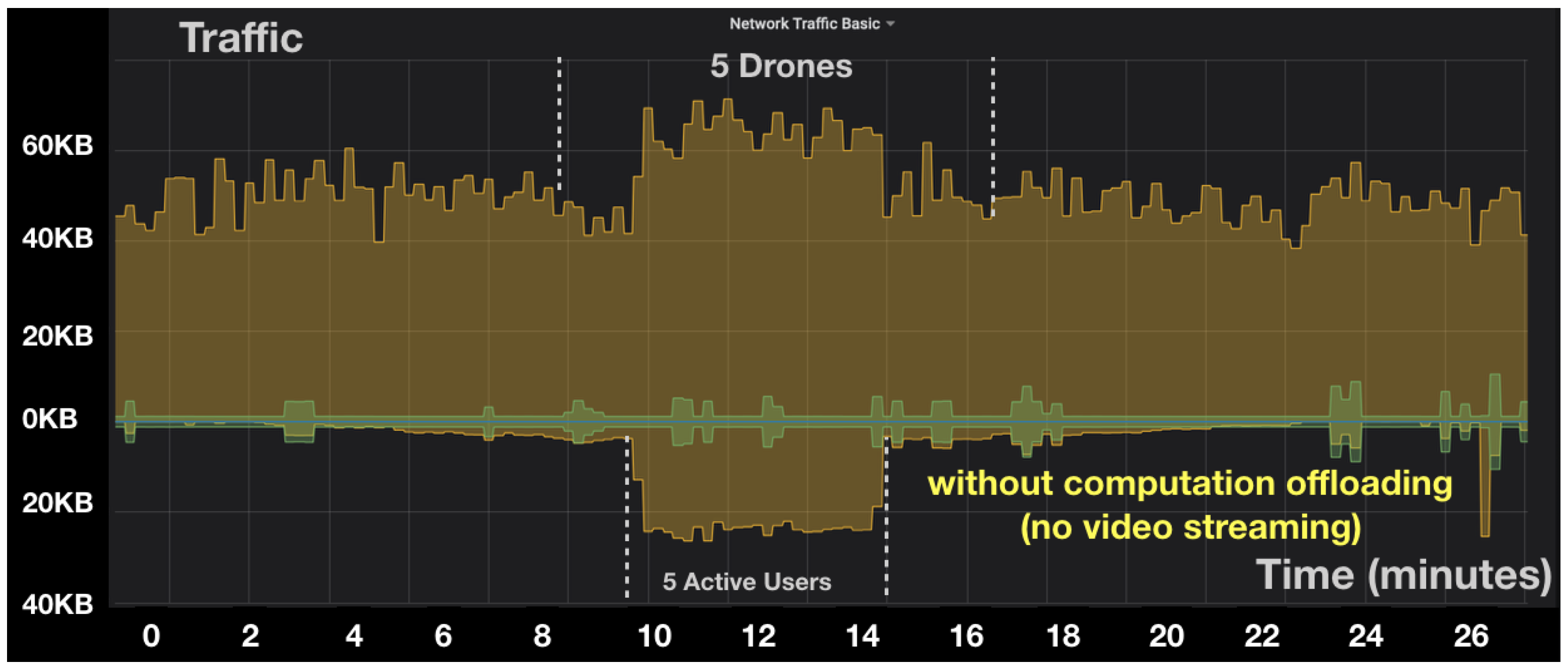
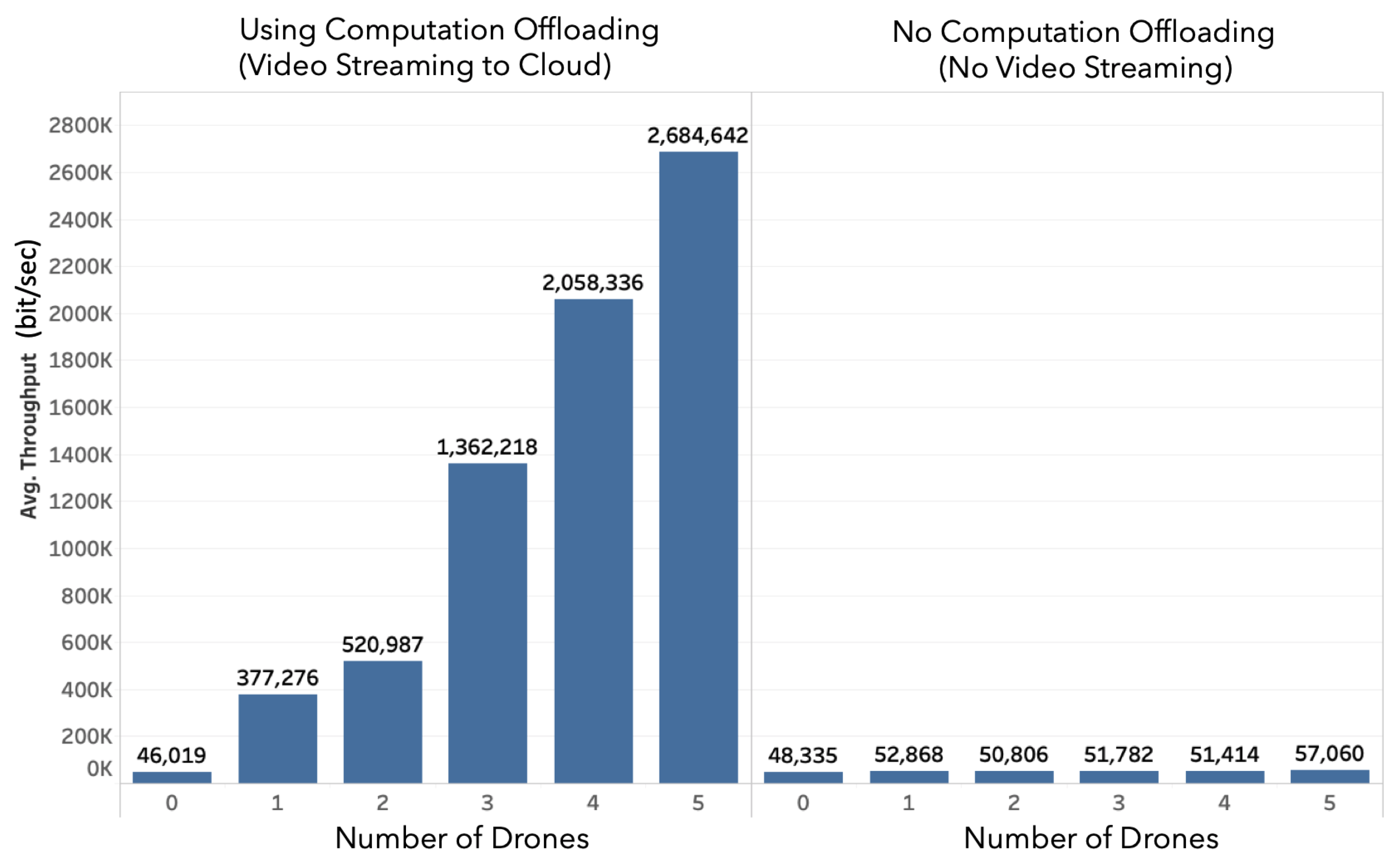
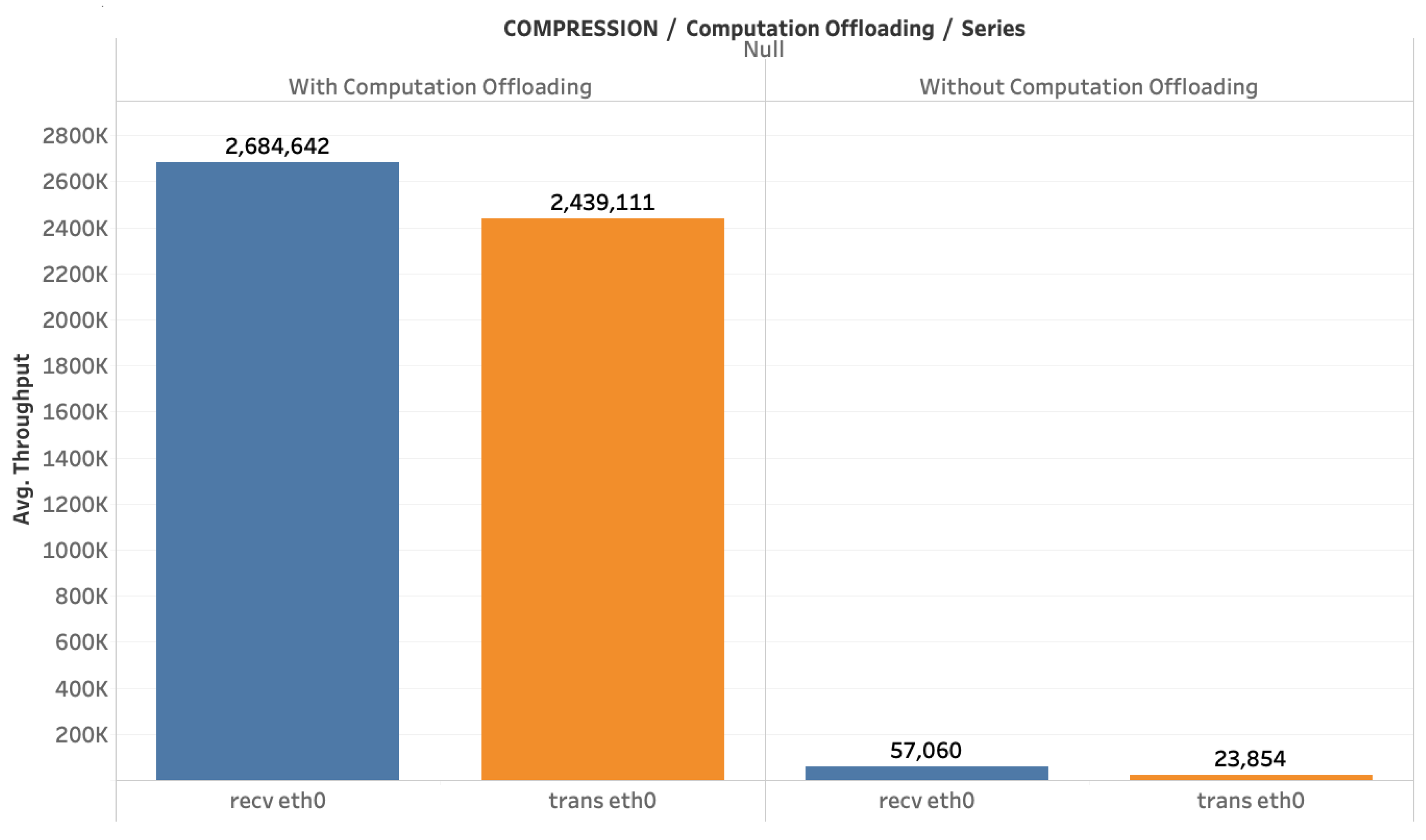
- Scenario 2: Cloud Server Utilization. In this scenario, we evaluate the utilization of the cloud server both in terms of bandwidth usage with and without computation offloading.
- Scenario 3: Real-time guarantees. We evaluate the response time of the DeepBrain architecture with and without computation offloading.
4.2. Results
4.2.1. Impact on UAV Energy
4.2.2. Impact on Bandwidth
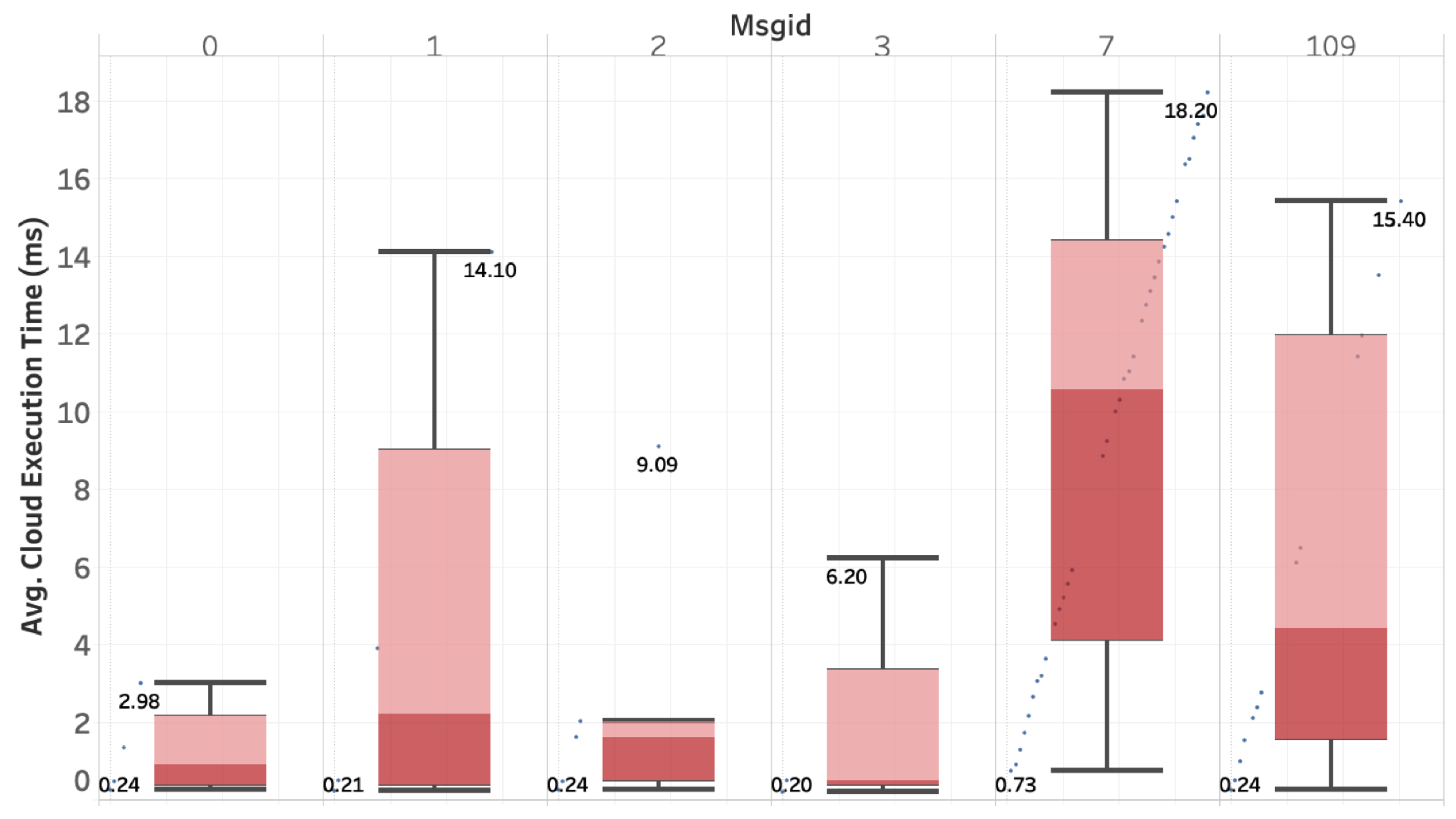
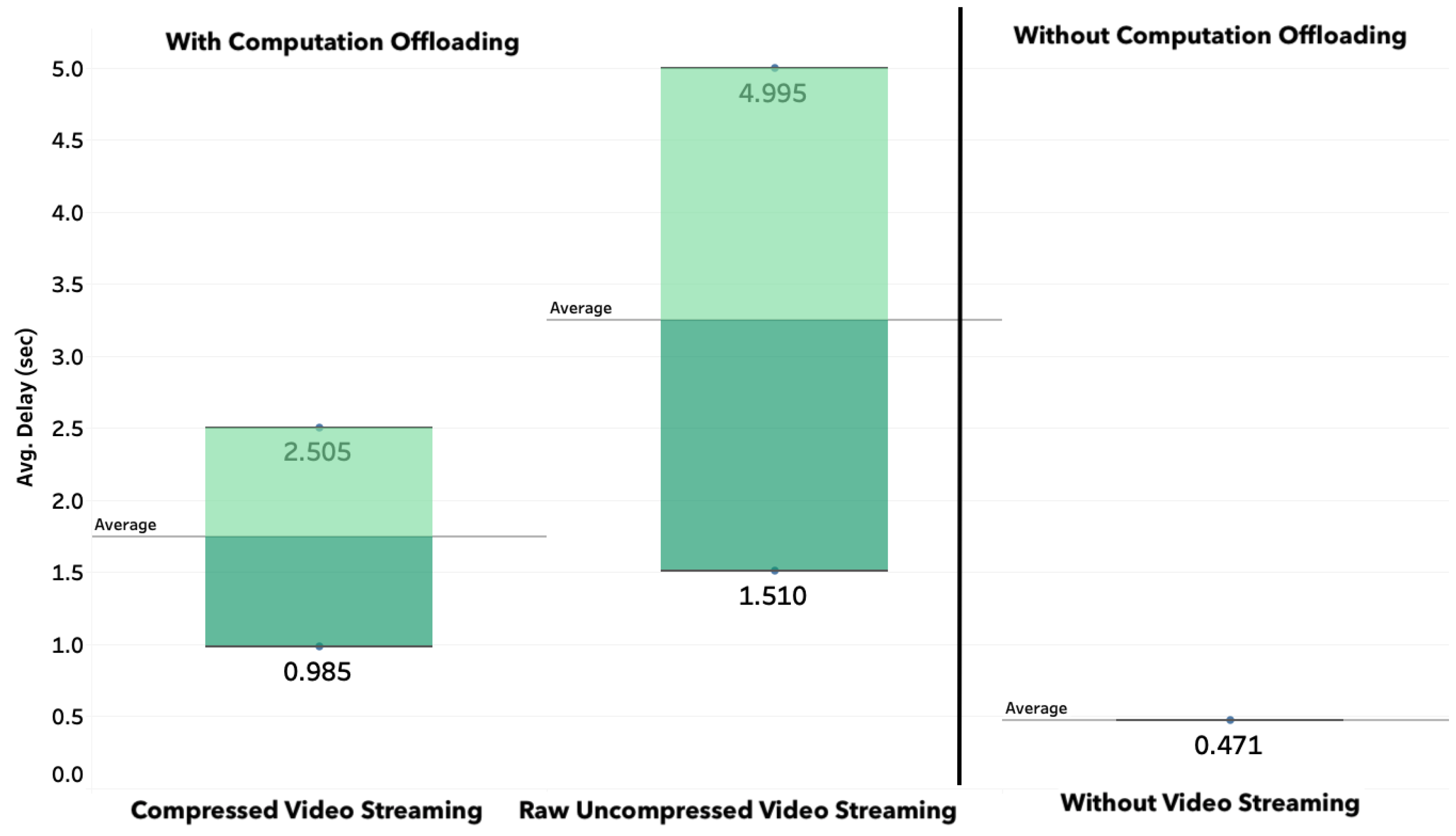
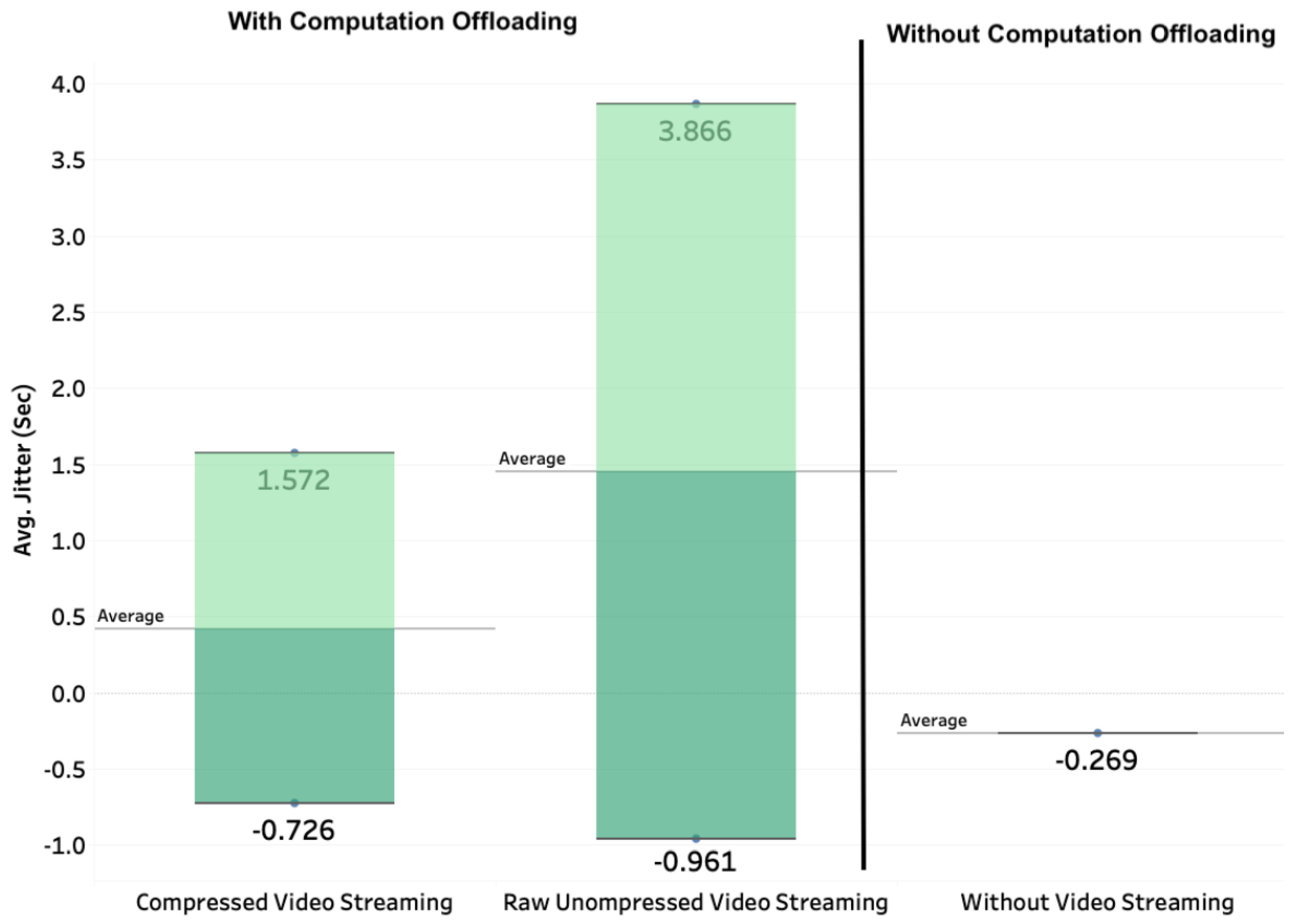
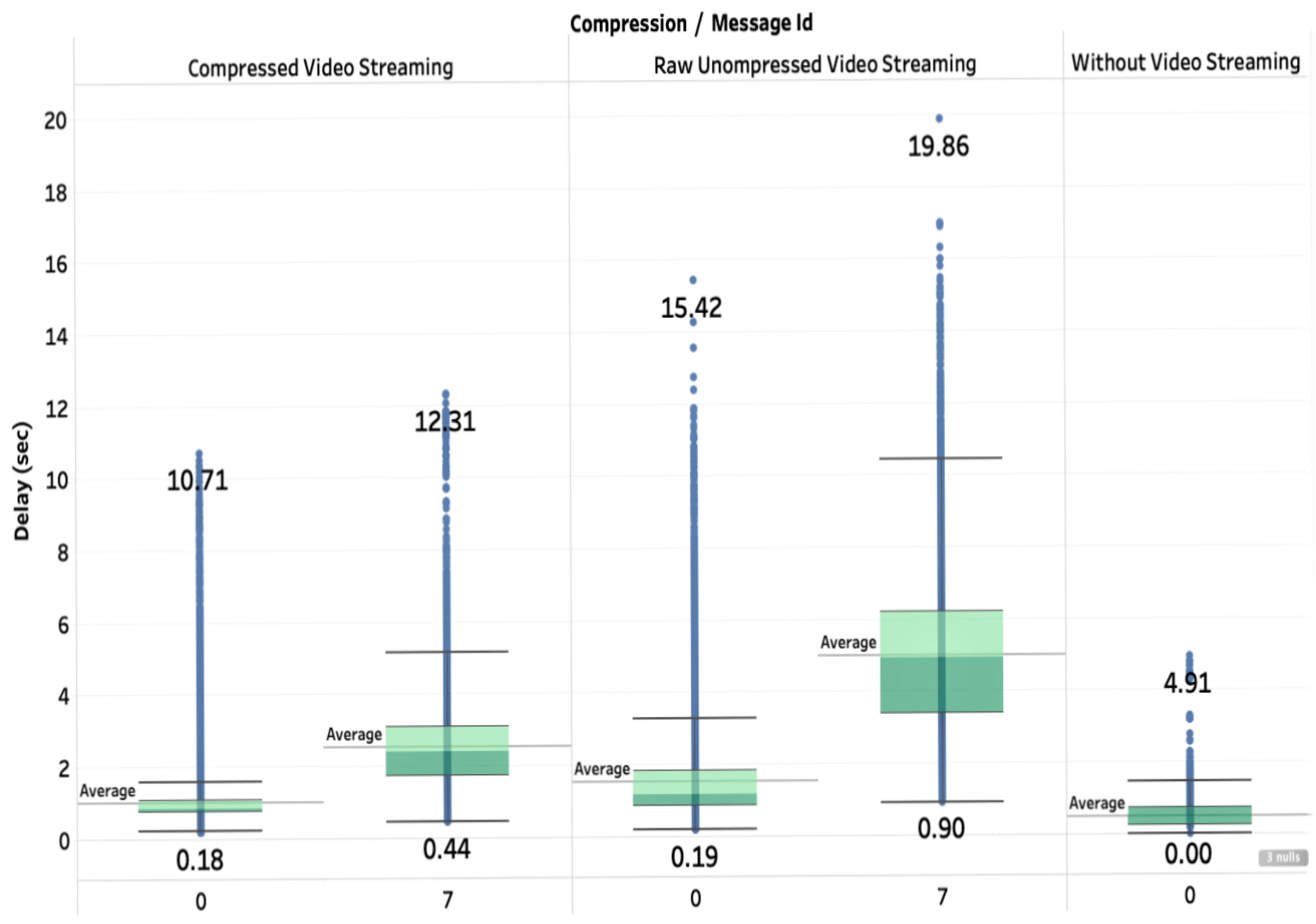
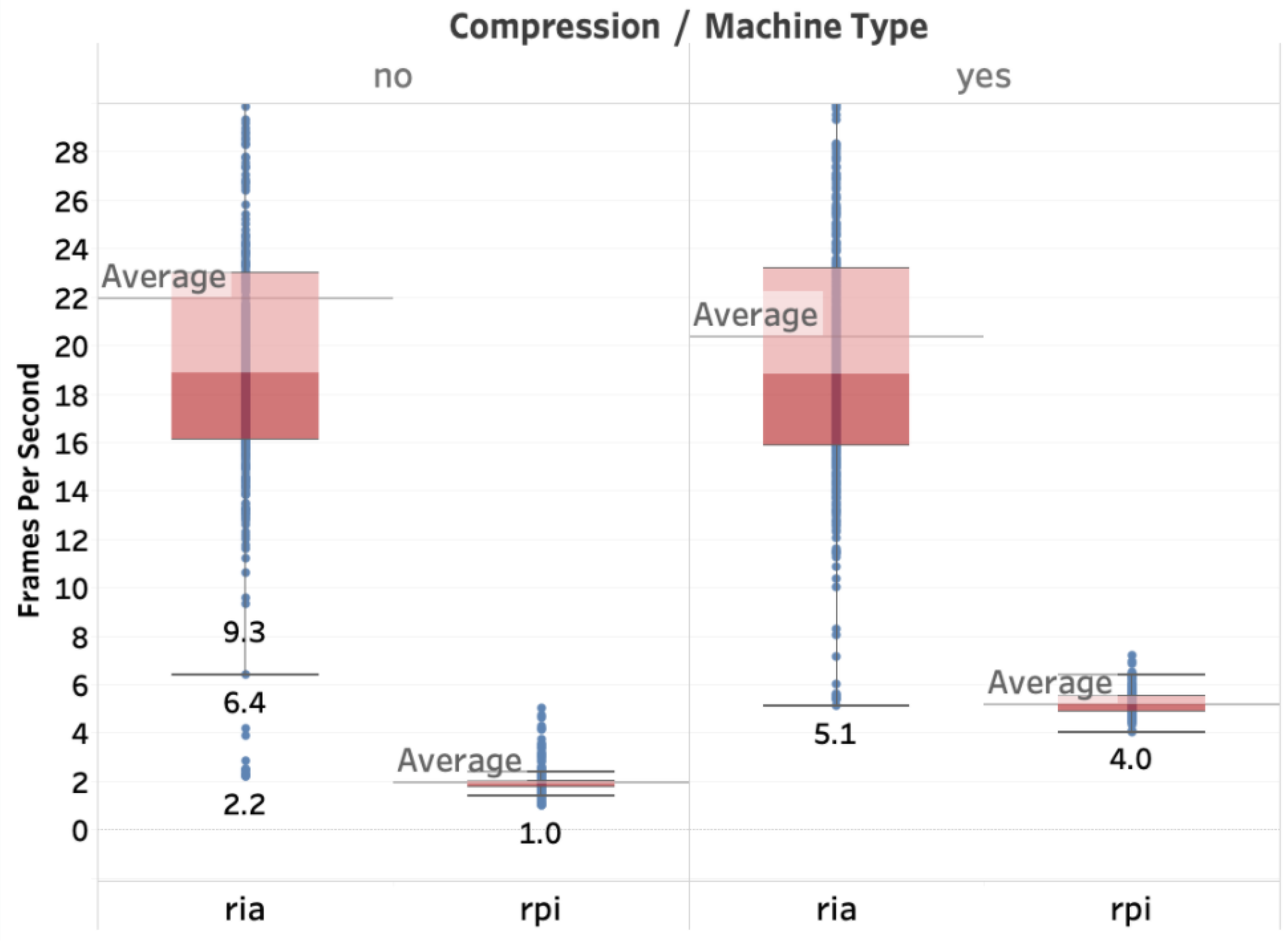
4.2.3. Real-Time Guarantee
- The Cloud Execution Times: it represents the time from the instant when a packet is received by the cloud from the drone until the instant when the packet is forwarded from the cloud to the end-user.
- End-to-End Network Delays: it represents the delay for a message to be transmitted from the drone to the end-user through the cloud. We estimate this time by computing the round-trip time for any message sent by the drone divided by two. The reason is to compute the delay using one reference clock to avoid the effect of clock skewing of two distinct machines. In fact, measuring the delay with different clocks would add much more complexity and uncertainty in the computation of delays, and would require accurate clock synchronization, which is challenging to achieve.
- Frames Per Second (FPS): it measures the number of frames per second received by the end-user. It is measured with respect to a window of 10 frames received at the destination.
Execution Time
Average Delay
Frame Rate
4.3. Execution Times of Deep Learning Computing Tasks
4.4. Lessons Learned
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Amorim, W.P.; Tetila, E.C.; Pistori, H.; Papa, J.P. Semi-supervised learning with convolutional neural networks for UAV images automatic recognition. Comput. Electron. Agric. 2019, 164, 104932. [Google Scholar] [CrossRef]
- The Global Counter-UAS Market to Reach to $1.97 Billion by 2024. Available online: shorturl.at/bkmvE (accessed on 21 December 2019).
- Deep Learning Market Global Forecast to 2023. Available online: shorturl.at/AGIXZ (accessed on 21 December 2019).
- Wani, M.A.; Bhat, F.A.; Afzal, S.; Khan, A.I. Advances in Deep Learning. In Studies in Big Data; Springer: Singapore, 2020; Volume 57. [Google Scholar]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car detection using unmanned aerial vehicles: Comparison between faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A. Aerial images processing for car detection using convolutional neural networks: Comparison between faster R-CNN and YoloV3. arXiv 2019, arXiv:1910.07234. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Xi, X.; Yu, Z.; Zhan, Z.; Tian, C.; Yin, Y. Multi-task cost-sensitive-convolutional neural network for car detection. IEEE Access 2019, 7, 98061–98068. [Google Scholar] [CrossRef]
- Kyrkou, C.; Theocharides, T. Deep-Learning-based aerial image classification for emergency response applications using Unmanned Aerial Vehicles. arXiv 2019, arXiv:1906.08716. [Google Scholar]
- KUFFNER, J. Cloud-enabled humanoid robots. In Proceedings of the 2010 10th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Nashville, TN, USA, 6–8 December 2010. [Google Scholar]
- Koubaa, A. Service-oriented software architecture for cloud robotics. arXiv 2019, arXiv:abs/1901.08173. [Google Scholar]
- Kim, B.; Min, H.; Heo, J.; Jung, J. Dynamic computation offloading scheme for drone-based surveillance systems. Sensors 2018, 18, 2982. [Google Scholar] [CrossRef] [Green Version]
- Hong, Z.; Huang, H.; Guo, S.; Chen, W.; Zheng, Z. QoS-aware cooperative computation offloading for robot swarms in cloud robotics. IEEE Trans. Veh. Technol. 2019, 68, 4027–4041. [Google Scholar] [CrossRef]
- Messous, M.; Senouci, S.; Sedjelmaci, H.; Cherkaoui, S. A game theory based efficient computation offloading in an UAV network. IEEE Trans. Veh. Technol. 2019, 68, 4964–4974. [Google Scholar] [CrossRef]
- Cheng, N.; Lyu, F.; Quan, W.; Zhou, C.; He, H.; Shi, W.; Shen, X. Space/aerial-assisted computing offloading for IoT applications: A learning-based approach. IEEE J. Sel. Areas Commun. 2019, 37, 1117–1129. [Google Scholar] [CrossRef]
- Van Le, D.; Tham, C. A deep reinforcement learning based offloading scheme in ad-hoc mobile clouds. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 760–765. [Google Scholar] [CrossRef]
- Rahman, A.; Jin, J.; Cricenti, A.; Rahman, A.; Panda, M. Motion and connectivity aware offloading in cloud robotics via genetic algorithm. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- The DeepBrain Project Demo Page. Available online: https://www.riotu-lab.org/deepbrain.php (accessed on 8 February 2020).
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. SIGARCH Comput. Archit. News 2017, 45, 615–629. [Google Scholar] [CrossRef] [Green Version]
- Wamser, F.; Loh, F.; Seufert, M.; Tran-Gia, P.; Bruschi, R.; Lago, P. Dynamic cloud service placement for live video streaming with a remote-controlled drone. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 893–894. [Google Scholar] [CrossRef]
- Tan, L.T.; Hu, R.Q. Mobility-aware edge caching and computing in vehicle networks: A deep reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 10190–10203. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, K.; Huang, H.; Miyazaki, T.; Guo, S. Traffic and computation co-offloading with reinforcement learning in fog computing for industrial applications. IEEE Trans. Ind. Inform. 2019, 15, 976–986. [Google Scholar] [CrossRef]
- Chaari, R.; Cheikhrouhou, O.; Koubaa, A.; Youssef, H.; Hmam, H. Towards a distributed computation offloading architecture for cloud robotics. In Proceedings of the 2019 15th International Wireless Communications Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 434–441. [Google Scholar] [CrossRef]
- Xu, X.; Li, D.; Dai, Z.; Li, S.; Chen, X. A heuristic offloading method for deep learning edge services in 5G networks. IEEE Access 2019, 7, 67734–67744. [Google Scholar] [CrossRef]
- Qi, Q.; Wang, J.; Ma, Z.; Sun, H.; Cao, Y.; Zhang, L.; Liao, J. Knowledge-driven service offloading decision for vehicular edge computing: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2019, 68, 4192–4203. [Google Scholar] [CrossRef]
- Alelaiwi, A. An efficient method of computation offloading in an edge cloud platform. J. Parallel Distrib. Comput. 2019, 127, 58–64. [Google Scholar] [CrossRef]
- Alam, M.G.R.; Hassan, M.M.; Uddin, M.Z.; Almogren, A.; Fortino, G. Autonomic computation offloading in mobile edge for IoT applications. Future Gener. Comput. Syst. 2019, 90, 149–157. [Google Scholar] [CrossRef]
- Ning, Z.; Wang, X.; Huang, J. Mobile edge computing-enabled 5g vehicular networks: Toward the integration of communication and computing. IEEE Veh. Technol. Mag. 2019, 14, 54–61. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Obaidat, M.S.; Hu, X.; Guo, L.; Guo, Y.; Huang, J.; Hu, B.; Li, Y. When deep reinforcement learning meets 5G-enabled vehicular networks: A distributed offloading framework for traffic big data. IEEE Trans. Ind. Inform. 2020, 16, 1352–1361. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Luo, S.; Wang, Q.; Cao, B.; Li, X. An intelligent task offloading algorithm (iTOA) for UAV edge computing network. Digit. Commun. Netw. 2020, in press. [Google Scholar] [CrossRef]
- Wu, G.; Miao, Y.; Zhang, Y.; Barnawi, A. Energy efficient for UAV-enabled mobile edge computing networks: Intelligent task prediction and offloading. Comput. Commun. 2020, 150, 556–562. [Google Scholar] [CrossRef]
- Wang, R.; Cao, Y.; Noor, A.; Alamoudi, T.A.; Nour, R. Agent-enabled task offloading in UAV-aided mobile edge computing. Comput. Commun. 2020, 149, 324–331. [Google Scholar] [CrossRef]
- Alioua, A.; Djeghri, H.E.; Cherif, M.E.T.; Senouci, S.M.; Sedjelmaci, H. UAVs for traffic monitoring: A sequential game-based computation offloading/sharing approach. Comput. Netw. 2020, 177, 107273. [Google Scholar] [CrossRef]
- Yu, S.; Langar, R. Collaborative computation offloading for multi-access edge computing. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 689–694. [Google Scholar]
- Alshareef, H.N.; Grigoras, D. Multi-service cloud of drones for multi-purpose applications. In Proceedings of the 2017 16th International Symposium on Parallel and Distributed Computing (ISPDC), Innsbruck, Austria, 3–6 July 2017; pp. 165–174. [Google Scholar] [CrossRef]
- Koubaa, A.; Qureshi, B.; Sriti, M.F.; Allouch, A.; Javed, Y.; Alajlan, M.; Cheikhrouhou, O.; Khalgui, M.; Tovar, E. Dronemap Planner: A service-oriented cloud-based management system for the Internet-of-Drones. Ad Hoc Netw. 2019, 86, 46–62. [Google Scholar] [CrossRef]
- Koubâa, A.; Qureshi, B.; Sriti, M.; Javed, Y.; Tovar, E. A service-oriented Cloud-based management system for the Internet-of-Drones. In Proceedings of the 2017 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Coimbra, Portugal, 26–28 April 2017; pp. 329–335. [Google Scholar] [CrossRef] [Green Version]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing: A machine learning-based perspective. Comput. Netw. 2020, 182, 107496. [Google Scholar] [CrossRef]
- Lin, H.; Zeadally, S.; Chen, Z.; Labiod, H.; Wang, L. A survey on computation offloading modeling for edge computing. J. Netw. Comput. Appl. 2020, 169, 102781. [Google Scholar] [CrossRef]
- Koubaa, A.; Qureshi, B. DroneTrack: Cloud-based real-time object tracking using unmanned aerial vehicles over the Internet. IEEE Access 2018, 6, 13810–13824. [Google Scholar] [CrossRef]
- Koubaa, A. Robot Operating System (ROS): The Complete Reference, 1st ed.; Springer Publishing Company, Incorporated: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- Koubaa, A.; Alajlan, M.; Qureshi, B. ROSLink: Bridging ROS with the Internet-of-Things for Cloud Robotics. In Robot Operating System (ROS): The Complete Reference; Koubaa, A., Ed.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 2, pp. 265–283. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Singgih, I.K.; Lee, J.; Kim, B. Node and edge drone surveillance problem with consideration of required observation quality and battery replacement. IEEE Access 2020, 8, 44125–44139. [Google Scholar] [CrossRef]
- Wang, J.; Feng, Z.; Chen, Z.; George, S.; Bala, M.; Pillai, P.; Yang, S.; Satyanarayanan, M. Bandwidth-efficient live video analytics for drones via edge computing. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 159–173. [Google Scholar]
- Wang, J.; Feng, Z.; Chen, Z.; George, S.A.; Bala, M.; Pillai, P.; Yang, S.; Satyanarayanan, M. Edge-based live video analytics for drones. IEEE Internet Comput. 2019, 23, 27–34. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Type | Problem/Approach | Deep Learning Applications | Validation | Main Result | |
|---|---|---|---|---|---|
| (Kang et al., 2017) [20] | mobile | Analyze the calculation and data features of 8 Deep Neural Networks (DNN) architectures, Computer vision, speech, and processing applications for natural languages and demonstrate the balance between partitioning computation at many points within the network. | Yes | Experimental | Improves end-to-end latency, reduces mobile energy consumption and improves datacenter throughput. |
| (Wamser et al., 2017) [21] | drones | Demonstrate the effect of network condition on video streaming from drones over the cloud | No | Experimental | Improve the quality-of-service of the streaming over the cloud |
| (Van Le et al., 2018) [17] | adhoc mobile | reinforcement learning for offloading of ad-hoc mobile applications to the cloud using cellular networks | No | Simulation | Obtain optimal offloading |
| (Tan et al., 2018) [22] | mobile | Joint optimal connectivity, storage and computing resource management system for vehicular network using deep reinforcement learning approach | Yes | Simulation | Significant performance by optimum selection of parameters. |
| (Wang et al., 2019) [23] | mobile | Deep Reinforcement Learning techniques and Federated Learning framework with the mobile edge system | Yes | Simulation | Achieves near-optimal performance |
| (Chaari et al., 2019) [24] | robots | Kafka broker for offloading computer vision applications from robots to cloud | No | Experimental | Communication delays may increase execution times |
| (Xu et al., 2019) [25] | Mobile | offloading deep learning mobile applications of 5G networks | Yes | Simulation | Reduces delay for deep learning tasks |
| (Qi et al., 2019) [26] | vehicles | Deep reinforcement learning to obtain optimal offloading decisions | No | Simulation | online learning of computation offloading from vehicular services |
| (Alelaiwi et al., 2019) [27] | mobile | Deep-learning-based response-time prediction computation offloading method | Yes | Simulation | Reaches a Mean Absolute Percentage Error (MAPE) below 0.1 and an R-square greater than 0.6 |
| (Alam et al., 2019) [28] | mobile | Deep Q-learning based code offloading method of computation in mobile edge/fog. | Yes | Simulation | The proposed offloading performs better for time and latency execution and energy consumption. |
| (Ning et al., 2019) [29] | mobile | Nonorthogonal Multiple Access (NOMA) system for mobile edge computing (MEC) vehicular network. | Yes | Simulation | Under the various network circumstances the scheme can increase transfer rate gain and offload efficiency. |
| (Ning et al., 2020) [30] | mobile | Deep-reinforcement-learning-based framework for 5G-enabled vehicle networks | Yes | Simulation | Achieved an overall better offloading cost. |
| (Chen et al., 2020) [31] | drones | Intelligent Task Offloading Algorithm (iTOA) for UAV edge computing network using a splitting Deep Neural Network (sDNN) | Yes | Simulation | Improves service latency performance by 33% and 60%, respectively. |
| (Wu et al., 2020) [32] | drones | Three-layer UAV-based Mobile Edge Computing (MEC) network architecture and the functions of task offloading and data communication are analyzed in IoT device layer, UAV based edge computing layer and MEC server layer | Yes | Simulation | The energy consumption of UAV is reduced, and the proposed algorithm is used to dynamically schedule the task offloading strategy. |
| (Wang et al., 2020) [33] | drones | Framework of task scheduling is presented in the unmanned aerial vehicle-aided mobile edge computing (UMEC) | Yes | Simulation | The implementation of the agent in computing tasks would reduce delays and energy consumption significantly. |
| (Alioua et al., 2020) [34] | drones | A new device architecture for offloading and exchanging computations. Then, a new device utility function is developed which combined calculation time, overhead energy, link quality, communications and computing costs | Yes | Experimental | More efficient time and energy average for data processing which ranges from 43 % to 97 % according to the calculation approach. |
| DeepBrain | drones | Design and develop a full-stack cloud-based architecture for computation offloading of deep learning applications in Internet-of-Drones | Yes | Experimental Performance Evaluation | Demonstrate the feasibility and performance of computation offloading of deep learning applications from drones connected through the Internet |
| Scenarios | Voltage Decrease Rate (Volt Per Second) | Instant Power Consumption (Watt) |
|---|---|---|
| Computation Offloading | 3.2 Watt | |
| Onboard GPU Processing | 6 Watt |
| Device | CPU | GPU | RAM | |
|---|---|---|---|---|
| Cloud-based devices | MSI Infinite workstation | Intel Core i9-9900K @ 3.7 GHz | RTX 2080 Ti (11 GB) | 64 GB |
| HP Omen workstation | Intel Core i7-8700K @ 3.7 GHz | GTX 1080 (8 GB) | 64 GB | |
| Edge-based devices for edge-computing | Jetson Nano | Quad-core ARM A57 @ 1.43 GHz | 128-core Maxwell | 4 GB |
| Raspberry Pi 4 | Quad core Cortex-A72 (ARM v8) @ 1.5GHz | Broadcom VideoCore VI | 4 GB |
| GPU Type | Average Execution Time per Frame (s) | Average FPS | Standard Deviation | |
|---|---|---|---|---|
| Cloud-based servers | RTX 2080 Ti | 0.072 | 14.3 | 1.0 |
| GTX 1080 | 0.078 | 12.9 | 1.0 | |
| Edge-based devices for edge-computing | Jetson Nano | 1.1 | 0.91 | 0.01 |
| Raspberry Pi 4 | 0.96 | 1.04 | 0.06 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koubaa, A.; Ammar, A.; Alahdab, M.; Kanhouch, A.; Azar, A.T. DeepBrain: Experimental Evaluation of Cloud-Based Computation Offloading and Edge Computing in the Internet-of-Drones for Deep Learning Applications. Sensors 2020, 20, 5240. https://doi.org/10.3390/s20185240
Koubaa A, Ammar A, Alahdab M, Kanhouch A, Azar AT. DeepBrain: Experimental Evaluation of Cloud-Based Computation Offloading and Edge Computing in the Internet-of-Drones for Deep Learning Applications. Sensors. 2020; 20(18):5240. https://doi.org/10.3390/s20185240
Chicago/Turabian StyleKoubaa, Anis, Adel Ammar, Mahmoud Alahdab, Anas Kanhouch, and Ahmad Taher Azar. 2020. "DeepBrain: Experimental Evaluation of Cloud-Based Computation Offloading and Edge Computing in the Internet-of-Drones for Deep Learning Applications" Sensors 20, no. 18: 5240. https://doi.org/10.3390/s20185240