Probabilistic Updating of Structural Models for Damage Assessment Using Approximate Bayesian Computation


1
Key Laboratory of Wind and Bridge Engineering of Hunan Province, College of Civil Engineering, Hunan University, Changsha 410082, China
2
State Key Laboratory of Advanced Design and Manufacturing for Vehicle Body, Hunan University, Changsha 410082, China
*
Author to whom correspondence should be addressed.
Sensors 2020, 20(11), 3197; https://doi.org/10.3390/s20113197
Submission received: 11 April 2020
/
Revised: 1 June 2020
/
Accepted: 3 June 2020
/
Published: 4 June 2020
(This article belongs to the Special Issue Innovative Sensors for Civil Infrastructure Condition Assessment)
Abstract
:A novel probabilistic approach for model updating based on approximate Bayesian computation with subset simulation (ABC-SubSim) is proposed for damage assessment of structures using modal data. The ABC-SubSim is a likelihood-free Bayesian approach in which the explicit expression of likelihood function is avoided and the posterior samples of model parameters are obtained using the technique of subset simulation. The novel contributions of this paper are on three fronts: one is the introduction of some new stopping criteria to find an appropriate tolerance level for the metric used in the ABC-SubSim; the second one is the employment of a hybrid optimization scheme to find finer optimal values for the model parameters; and the last one is the adoption of an iterative approach to determine the optimal weighting factors related to the residuals of modal frequency and mode shape in the metric. The effectiveness of this approach is demonstrated using three illustrative examples.
1. Introduction
Structural health monitoring (SHM) refers to the damage detection and characterization of engineering structures, which is very important for guaranteeing the safety and serviceability of structures. In recent years, this research field has gained much attention and has made many ground-breaking improvements. The SHM approaches can be roughly divided into two sorts: local approaches and global approaches. The former ones refer to the methods of assessing the highly localized behavior of structures (such as strain at a single location), which includes many local forms of non-destructive evaluation (NDE) [1,2,3]. The latter ones refer to the methods of assessing the global behavior of structures (such as modal parameters), which includes many vibration-based damage assessment methods [4]. A large portion of these damage assessment methods are built using model updating: based on the experimental (modal) data, structural damages are detected, located, and quantified by calibrating the stiffness parameters of structural model [5].
Structural model updating based on modal data is a process of correcting the initial model to a better model that reflects the dynamic behavior of the structure. Besides damage assessment, structural model updating has also been widely used in model validation, response prediction, structural control, etc. [6]. Due to a variety of uncertainties such as modeling error and measurement noise, the discrepancy between the theoretical finite element (FE) model and the actual structure is inevitable, so it is often necessary to update the initial/prior FE model. This topic has become a research hotspot in recent years [7,8,9,10,11,12,13,14,15]. The methods of model updating can be broadly divided into two types: deterministic methods and probabilistic methods. In deterministic methods, one’s objective is to find a single set of optimal model parameters by using an optimization technique to minimize a single-objective function [9,16] or multiple objective functions [17,18] that measure the goodness of fit between the quantities of model prediction and measurement, while the probabilistic approaches estimate the statistical distributions of the model parameters (not only the optimal parameters but also their uncertainties) given a family of possible models [19,20]. By providing well-defined formulations, the deterministic methods can effectively obtain a set of optimal values of model parameters for a well-posed identification or updating problem; nevertheless, they usually fail to deliver satisfactory results when many uncertainties are present. In contrast, probabilistic methods have more advantages in dealing with uncertainty because they can provide the probability distribution of model parameters, as well as the plausibility of the model itself based on measured data.
In recent years, probabilistic methods have been more and more popular in model updating, among which the Bayesian method is one of them. In this method, the available information involved in the measured data is utilized for statistical inference by constructing a suitable likelihood function [7,19]. In the updating framework of the Bayesian approach, the posterior distribution of model parameters is expressed as a product of the prior distribution and the likelihood function. The likelihood function represents the probability of obtaining measured data based on a given stochastic prediction model. Due to a lack of prior information, the prior distribution is often a non-informative distribution, so the likelihood function is crucial to the posterior distribution. If different probability models are assumed in the likelihood function, the subsequent posterior distribution will be different. Usually, the likelihood function is formulated as normal distribution based on the maximum entropy principle [19]. However, challenges still exist in construction of the likelihood function. For some complex models, the explicit expression of the likelihood function may be difficult or even impossible. Another difficulty is the correlation formula of the model parameters, i.e., it is difficult to explicitly express these correlations in the joint probability density function (PDF) of the likelihood function [21]. For finite-element model updating, the likelihood is a probabilistic model for the error between predictions and observations. Most often, a zero-mean uncorrelated Gaussian prediction error is assumed, but this assumption may be questionable in some cases. For model updating in the time domain, the prediction errors of time histories may be non-Gaussian, and they may also show temporal correlation in adjacent time instants; on the other hand, the prediction errors corresponding to different measurements may be correlated as well. For model updating in the frequency domain, the components of a mode shape may show spatial correlation when densely populated sensor grids are used. The assumption of prediction error correlation highly influences the results of Bayesian model updating, and it is a challenging task for us to choose a suitable correlation structure of prediction errors in the likelihood function.
In order to solve above problems, approximate Bayesian computation (ABC) was well-conceived to steer clear of the explicit expression of likelihood function, using a simulation-based approach instead [22]. Thus, it is a likelihood-free Bayesian method. ABC does not directly use the observed data to make statistical inference according to Bayes’ theorem, but it obtains the model prediction output through sampling and simulation, and the discrepancy between the predicted output and the observed data is acceptable under certain metric. Therefore, an approximate likelihood function is defined as the probability that the simulated predicted output falls into the neighboring region of the observed data vector. Obviously, the accuracy of this approximation depends on the selected tolerance level . In theory, when → 0, the algorithm gives the exact posterior distribution, but this cannot be done in practice. To get a good approximation of the posterior distribution in the ABC method, the tolerance parameter ϵ has to be small enough so that only the predicted output very close to the observed data vector is accepted. As a result, this becomes a simulation problem for rare events. If a Monte Carlo simulation is used, a large number of model prediction outputs must be calculated as candidate samples in order to obtain an acceptable sample size in the given approximate region of observed data. Jin and Jung presented a feasibility study on structural model calibration by using a Markov chain Monte Carlo (MCMC)-based ABC [23]. Fang et al. adopted ABC incorporated with the Metropolis–Hastings sampling (MHS) algorithm and stochastic response surface (SRS) for probabilistic damage identification [24]. Abdessalem et al. presented ABC sequential Monte Carlo (SMC) [25] and ABC ellipsoidal nested sampling (NS) [26] as efficient tools for model selection and parameter estimation in structural dynamics. Though MCMC can reduce computation cost, its efficiency is still not very high due to its slow chain initialization and convergence speed. In order to improve the efficiency of the ABC, Chiachio et al. [27] recently put forward the efficient subset simulation technique [28] into the ABC framework, naming it as ABC-SubSim. The basic idea is to take the nested descending sequence in the subset simulation as the approximate region that is increasing close to the observed data vector [29,30].
This paper proposes a new probabilistic structural model updating approach based on the ABC-SubSim for structural model updating using modal data. Obviously, the accuracy of the method depends on the selection of the tolerance level on the chosen metric. First, an appropriate metric should be chosen to measure the closeness of the predicted modal data vector and the observed modal data vector. The tolerance parameter should be sufficiently small to make a good approximation of the posterior distribution. However, the question of how small is sufficient enough is also questionable. To this end, we propose some new stopping criteria to cease the subset simulation, where the tolerance parameter for the metric is not predetermined. On the other hand, by using subset simulation, although the approximation region of the observed data vector for a given tolerance level can be easily reached, a refined optimal value may not be easily obtained due to the stochastic exploration nature of the subset simulation. To this end, we propose a hybrid optimization scheme that combines the subset simulation with a faster local optimization technique to obtain a more refined optimal value of the model parameter vector. The last contribution of this paper is that we adopt an iterative approach to determine the optimal weighting factors relating to the residuals of modal frequencies and mode shapes in the metric.
The remainder of the paper is organized as follows. The ABC-SubSim is reviewed in Section 2, where the choice of some important parameters such as intermediate tolerances, conditional probability and variance of proposal distribution is discussed. The procedures of model updating with ABC-SubSim is presented in Section 3. Section 4 presents a damage assessment approach using model updating. Three illustrative examples are presented in Section 5, and conclusions are drawn in Section 6.
2. Recap of ABC-SubSim
2.1. Approximate Bayesian Computation
Based on a set of measured data , the parameter of interest in a parameterized model class M can be updated from prior distribution to posterior distribution by Bayesian inference. On the basis of Bayes’ theorem, the posterior PDF of the parameters θ in model M is written as follows [19]:
where is a posterior distribution of after taking measured data into account, c is a normalizing constant to make the integral of posterior PDF to be one, is the likelihood function which represents the distribution of the observed data conditional on its parameters θ, and is a prior distribution of the parameters θ before any data are observed. For a given model, we only care about the parameters in the model, not the selection of the model, so the conditioning on model class M can be removed in the notation. Although this Bayesian framework is powerful for uncertainties treatment, construction of the likelihood function is still a challenge in some cases. Approximate Bayesian computation methods circumvent the explicit expression of the likelihood function by using simulation-based methods. Let denote a dataset sampled from , the ABC algorithms take the approximate likelihood function , where is an approximate neighborhood of observed data for a chosen tolerance level on the given metric ρ and . η(·) is a low-dimensional vector of summary statistics that provides a comparison of the closeness of x and y. From the Bayes’ theorem, the approximate posterior is given by
where is an indicator function that assigns a value of one when and zero otherwise. The marginal approximate posterior:
It should be noted that the quality of the approximated posterior in Equations (2) and (3) depends on an appropriate choice of the metric , the tolerance level and the summary statistic η [31,32].
In order to obtain a good approximate posterior distribution, the tolerance need to be small enough, which leads to the simulation of rare events. Direct Monte Carlo simulation is inefficient, and although MCMC sampling can improve the efficiency, it is still not very efficient.
2.2. The ABC-SubSim Algorithm
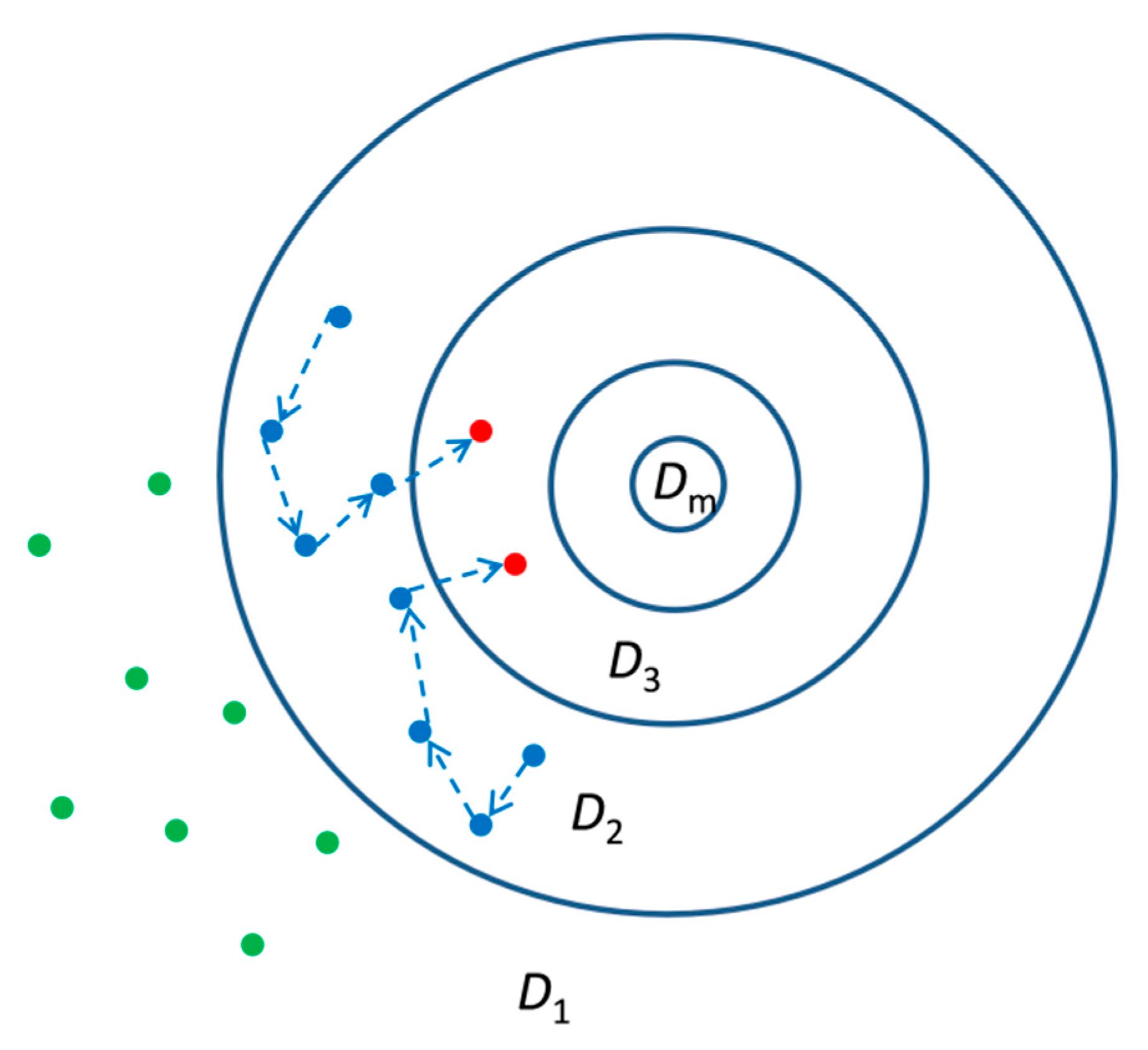
To enhance the efficiency of ABC, a new algorithm called ABC-SubSim was conceived by Chiachio et al. [27]. In this algorithm, the subset simulation technique [28] is incorporated into the ABC framework, and the idea is to select the nested descending sequence in the subset simulation as the approximate region where the simulated dataset gets closer and closer to the observed data (Figure 1).
Let’s define z as , so that . A sequence of nested decreasing regions Dj, j = 1…, m, are defined as
where is intermediate tolerance. The sequence of intermediate tolerances , with , are chosen adaptively which will be described later. The number of levels m is chosen so that , a specified tolerance. Thus, it follows that
The samples of the first level are drawn using a direct Monte Carlo simulation from the prior distribution, while the samples of higher levels are drawn using a modified Metropolis algorithm (MMA) [28]. Instead of drawing a complete parameter vector candidate from a multidimensional proposal PDF as the original algorithm would do, MMA chooses a univariate proposal PDF for each component of the parameter vector, and the generated component candidate is accepted or rejected separately. It should be noted that although ABC-SubSim and ABC-SMC do have some similarities—they both have a series of intermediate tolerances; they differ in the way of generation of new samples from the samples in the previous level. In the ABC-SMC [25,33], samples are drawn from the previous population with some weights at first, and then they perturb the sample to obtain a new sample according to a perturbation kernel; while in the ABC-SubSim, the new samples are generated using the modified Metropolis algorithm from the seeds provided by the previous level.
2.2.1. Intermediate Tolerances
In the actual implementation of subset simulation, the intermediate tolerances are adaptively chosen so that and , j = 1, …, m are equal to a fixed value P0. In this way, the value of intermediate tolerance is determined as the average of the (NP0)th and (NP0 + 1)th values of the set of distances , n = 1, …, N, arranged in increasing order, where N is the number of samples in each level. In this algorithm, the number of samples generated in Dj−1 falling in Dj is equal to NP0, and these NP0 samples are utilized as seeds to generate NP0 Markov chains with a length of 1/P0 samples, in which the new (1/P0 − 1) samples of each chain are produced by MMA [28]. For the sake of implementation, the numbers NP0 and 1/P0 are both integers. Thus, the total number of samples in Dj is also N, of which NP0 samples are produced in the (j−1)th level.
2.2.2. Conditional Probability
The parameter P0 determines the number of intermediate domains Dj required to reach the target region D, which thereby influences the simulation efficiency. A smaller value of P0 connotes that fewer intermediate levels are required to reach D, but it makes for larger number of samples N required at each level to accurately estimate small conditional probabilities. On the other hand, a larger value of P0, although decreasing the number of samples required for each level, will increase the number of intermediate levels m. Therefore, we need to take a compromise value, and a theoretical study shows that the optimal choice is [34].
2.2.3. Variance of Proposal Distribution
It was observed in [28] that the type of proposal PDFs (Gaussian, uniform, etc.) has no significant impact the efficiency of MMA, while their spread (variance) has a greater impact. In case of Gaussian proposal PDFs, too large or too small variances tend to increase the correlation between successive samples. Larger variances may reduce the acceptance rate and increase the number of duplicate MCMC samples. Conversely, smaller variances may result in higher acceptance rates, but because they are closely related, the chain moves too slowly and produces many correlated samples. A theoretical study on the optimal variances for the proposal PDF has shown that the nearly optimal variances can be selected to make the acceptance rate between 30% and 50% at each conditional level [34]. Unfortunately, achieving this target acceptance rate usually requires the user’s prior experience or through inefficient brute force searches. Recently, Vakilzadeh et al. [29] proposed a self-regulating algorithm in which the proposal variance is adjusted adaptively in ABC-SubSim to realize effective sampling in the posterior PDF. By using this algorithm, the proposal variance can be dynamically adjusted to force the average acceptance rate to an ideal target value.
3. Model Updating Using ABC-SubSim
3.1. Choice of Metric Function
The quality of the posterior approximation depends on a suitable choice of the metric and the tolerance parameter . In this subsection, the choice of the metric is presented. In the following subsection, the tolerance parameter will be discussed. We choose the metric for measuring the closeness of the model predicted modal data vector and the observed modal data vector as follows
where and are the weighting factors for the residues of the rth modal frequency and the rth mode shape, respectively; is the rth model predicted modal frequency, is the rth observed modal frequency in the ith data set; is the rth model predicted partial mode shape confined on the observed degrees of freedom (DOFs), is the rth observed mode shape in the ith data set, is a scaling factor that guaranties that the predicted model mode shape is closest to the measured mode shape at the measured DOFs, and Nm and Ns is the number of modes and number of observed data sets. The determination of the weighting factors and is discussed in details in Section 3.4. It should be noted that besides the metric presented above, one can also choose another function as the metric to measure the closeness of the mode prediction and the observations [9,35,36,37].
3.2. Stopping Criteria
The tolerance parameter is another important factor that controls the quality of the posterior approximation. In theory, when → 0, the algorithm can get an accurate posterior distribution, but this could not be achieved in practice. If one wants to get a good approximate posterior distribution in the ABC approach, has to be small enough so that the predicted outputs are accepted only if they fall into the nearest neighboring domain centered on the observation data vector. However, how small is sufficient is unknown in advance. By using a different metric, the tolerance level may be quite different to get a satisfactory accuracy. For example, if we use another set of weighting factors for the metric presented in Equation (6), for the same tolerance level , the accuracy of the posterior approximation may be quite different. In contrast, we set the stopping criteria by justifying the convergence of the model parameters through looking at two relative indexes. The new stopping criteria to cease the subset simulation are as follows:
where and are the maximum and minimum values of the metric in the jth conditional level, respectively; is the tolerance of R, which can be chosen as a very small value (e.g., 10−3); and are the optimal model parameter vector in the jth and (j − 1)th conditional levels, respectively; and is the tolerance of S, which can be chosen as a relatively larger value (e.g., 10−2). If both the stopping criteria in Equations (7) and (8) are satisfied, the subset simulation is stopped. Rj is defined to measure the diversity of the jth conditional level, and Sj is defined as the improvement of the jth conditional level. In such a way, although we have to specify two tolerance values, the meanings behind these two values are more clear and straightforward, and this approach is more operable in practice. It should be noted that this is only an expedient. To completely solve this problem, we still need to deeply study the relationship between likelihood-informed Bayesian inference and likelihood-free approximate Bayesian computation so as to provide a theoretical basis for selecting the appropriate tolerance [38].
3.3. Hybrid Optimization Scheme
Stochastic sampling techniques such as subset simulation have the advantage of efficient posterior sampling capacity, but their ability of finding an optimum or “maximum a-posteriori” is relatively low. The stochastic sampling techniques can reach the region near an optimum point relatively quickly, but it can take many levels (generations) to achieve the convergence to the exact optimum. Therefore, in order to improve the overall search ability, it is necessary to combine a powerful global search sampler with an efficient local search operator to develop a hybrid scheme. For example, Jung and Kim proposed a hybrid genetic algorithm to update their structural model by combining the genetic algorithm and the improved Nelder–Mead’s simplex method [39]. Sun and Betti proposed a hybrid optimization algorithm that combines a modified artificial bee colony (MABC) algorithm and the Broyden-Fletcher-Goldfarb-Shanno (BFGS) method for Bayesian model updating [40]. As a global stochastic sampler, the subset simulation is able to quickly reach the approximation region of the posterior for a given tolerance level, and this region stands for the approximate posterior distribution of the model parameter vector θ. However, the optimal value given by the subset simulation may not be the “exact” optimum, and this “exact” optimum can be rapidly refined by a local optimization search operator.
In this study, the BFGS method was used to fine-tune the optimal solution given by the subset simulation to obtain a better solution. Herein, in order to make sure that the hybrid scheme did not disturb the stochastic process of the subset simulation, the BFGS method was just introduced at the final level of the subset simulation. The optimal value at the final level of the subset simulation was taken as the initial guess in the BFGS method. The BFGS method is a gradient-based quasi-Newton method that uses the BFGS approximation of the hessian matrix. The details of the BFGS method can be found in the literature [41,42,43,44]
3.4. Weighting Factors Determination
In the metric function as presented in Equation (6), weight factors are imposed a relative difference between the modal frequency and the mode shape, as well as between different modes, because the measurement precision of these quantities may be different. The identification accuracy of experimental modal frequencies is usually higher than that of modal shapes, so appropriate weights are necessary. In the literature, most of them chose these weighting factors by engineering experience [9,45]. A rigorous theoretical study on the optimal weighting factors in the weighted modal residuals metric for structural model updating was conducted by Christodoulou and Papadimitriou [46]. The results showed that the optimal weight of the modal residual is asymptotically inversely proportional to the value of the modal residual at the optimal model parameters when there is a large amount of measured data. The weighted modal residuals metric in Equation (6) can be rewritten as:
where is the residual of a specific modal group and is its weighting factor. The optimal weights in Equation (6) are given by
where is a scale reflecting the proportion of the data volume contained in each modal group to the total data volume in a modal data set. Nm denotes the number of modes, and No denotes the number of observed degree of freedom; as such, the total number and for modal frequency, while for mode shape, satisfying . However, the optimal weighting factors given in Equation (10) is dependent on the optimal model parameter vector , which is unknown in advance. Therefore, one should solve it in an iterative approach. The initial value for the weighting factors can be calculated using Equation (10) when taking the nominal value of the model parameter vector as its optimal value . By using ABC-SubSim and the BFGS method, a new optimal value for is obtained, and then the new weighting factors can be calculated using Equation (10) again. These procedures are repeated several times until the convergence satisfied.
3.5. Summary of the Procedures
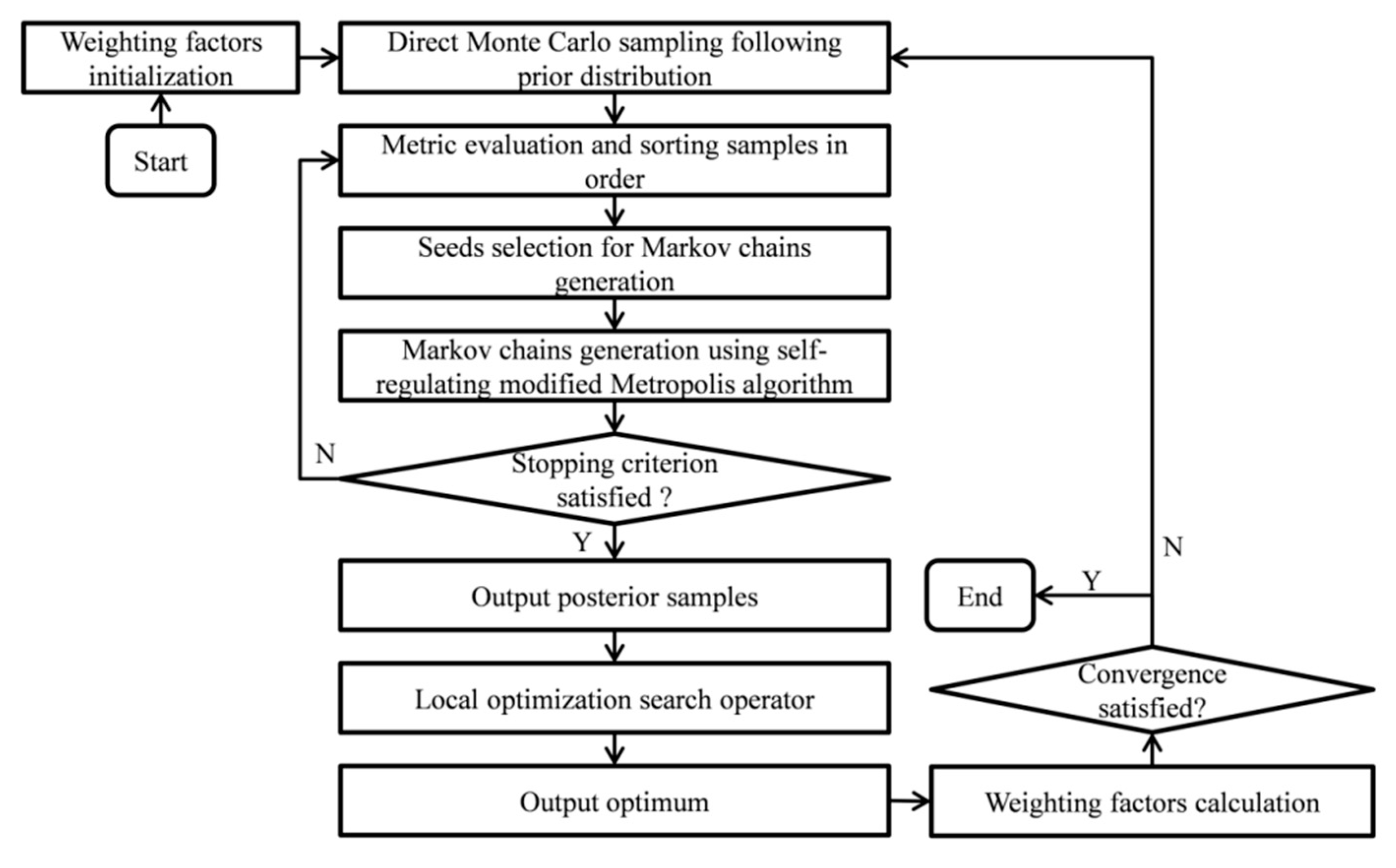
The proposed algorithm for probabilistic model updating can be schematically described below:
- Calculate the initial values for the weighting factors used in the metric as presented in Equation (6) using Equation (10) when taking the nominal value of the model parameter vector as its optimal value.
- Using direct Monte Carlo simulation to get N samples following the prior distribution of the model parameter vector.
- Evaluate the metric and sort the samples in order according to their metric values.
- Select NP0 samples which corresponding to the first NP0 smallest metric values. These samples will be taken as the seeds for Markov chains generation.
- Generating NP0 Markov chains with length of 1/P0 for each chain using a self-regulating modified Metropolis algorithm [29].
- Check whether the stopping criteria proposed in Equations (7) and (8) is satisfied. If it is not satisfied then repeat the steps iii–vi. If it is satisfied then output the posterior samples.
- Take the optimal value in the posterior samples as the initial guess for a local optimization search operator, and conduct the local optimization search to obtain a fine optimum.
- Using the fine optimum to calculate the weighting factors using Equation (10).
- Check the convergence of the weighting factors. If the convergence satisfied, then the algorithm ends. If not, take the newly calculated weighting factors for the metric and repeat the steps i–ix.
A flowchart of the proposed algorithm is given in Figure 2, and a pseudocode is provided in Appendix A.
4. Damage Assessment Based on Model Updating
4.1. Structural Model Parameterization
For model updating and damage assessment of linear structures, the structure is usually partitioned into substructures, and a substructure can be a group of elements or just one single element. The global stiffness matrix is parameterized as follows:
where K0 is the global stiffness matrix before updating, Kn is the nominal stiffness matrix of the nth substructure, and θn is a perturbation scaling factor used to change the nominal substructure stiffness Kn so that the updated model is more in line with the actual behavior of structure. When a substructure is damaged, the optimal value of the parameter θn decreases. The mass matrix can be parameterized in a similar substructural manner, but mass updates were not considered here, because the main interest of this paper was damage assessment, and the mass was assumed to be known accurately enough and to not change with the occurrence of damage.
4.2. Probabilistic Damage Assessment
According to a two-stage procedure for structural damage assessment using Bayesian model updating proposed by Ching and Beck [47], experimental modal parameters are identified from measured data at intact and damaged state in the first stage; in the second stage, the PDFs of structural stiffness parameters are updated using the Bayesian approach before and after damage, and the updated PDFs are used to evaluate the probability of damage of each substructure. Assuming that the stiffness parameters in the intact state and the possible damaged state are conditionally independent (and by using Gaussian asymptotic approximation), the probability of stiffness reduction of parameter θn which has been reduced by certain fraction d compared with the undamaged state can be obtained:
where Φ( ) is the cumulative distribution function of the standard normal distribution; and stand for the a maximum a posterior probability (MAP) estimate of the stiffness parameters at the undamaged state and possibly damaged state, respectively; and and denote the corresponding standard deviations of the stiffness parameters.
5. Application Examples
5.1. Model Updating of a Shear Building
An eight-story shear building was considered in this example. The mass per floor was assumed to be 2 × 104 kg, while the nominal inter-story stiffness for all floors was assumed to be 15 × 106 N/m. The actual value of the inter-story stiffness for the first four stories had a 20% reduction of the nominal ones, while that for the remaining four stories had a 20% increase of the nominal ones. We denoted the model parameters vector θ as the increment ratio of the inter-story stiffness, compared to their nominal ones, so their true values were θ = {−0.2, −0.2, −0.2, −0.2, 0.2, 0.2, 0.2, 0.2}. Twenty sets of modal data were assumed to be available for the structural model updating, where the incomplete measurements were considered; that is, only five floors (1, 3, 5, 7, and 8) were measured, and only the first four modes were identified. For the simulated modal data, zero-mean Gaussian noise with a diagonal covariance matrix was added to the exact calculated modal frequencies and mode shapes. Two cases of noise level were considered in this study. In noise level 1, a 1% coefficient of variation (CV) noise was added to the modal frequencies, while a 5% of CV noise was added to the mode shapes for all modes, a reasonable value for typical modal tests. Noise level 2 was a more severe noise level situation, where 2% of CV noise was added to the modal frequencies, while 10% of CV noise was added to the mode shapes for all modes. In order to study the effect of the BFGS method on the accuracy of the results in the fine-tuning stage, the results before and after the fine-tuning were compared. Moreover, two sets of different values for the stopping criteria parameters were used to study their impact on the final results. In tolerance level 1, we set the stopping criteria parameters Rtol = 10−3 and Stol = 10−2, while in tolerance level 2, stricter stopping criteria parameters were used: Rtol = 10−4 and Stol = 10−3. Totally, there were four cases in the simulations: case 1 with noise level 1, fine-tuning, and tolerance level 1; case 2 with noise level 2, fine-tuning, and tolerance level 1; case 3 with noise level 1, without fine-tuning, and tolerance level 1; and case 4 with noise level 1, fine-tuning, and tolerance level 2.
We used the method proposed in Section 3 to update the stiffness parameters vector θ. In the subset simulation, we chose the number of samples in each level N = 2000 and the level conditional probability P0 = 0.2. The variance in Gaussian proposal distribution was regulated using a self-regulating algorithm proposed by Vakilzadeh et al. [29].
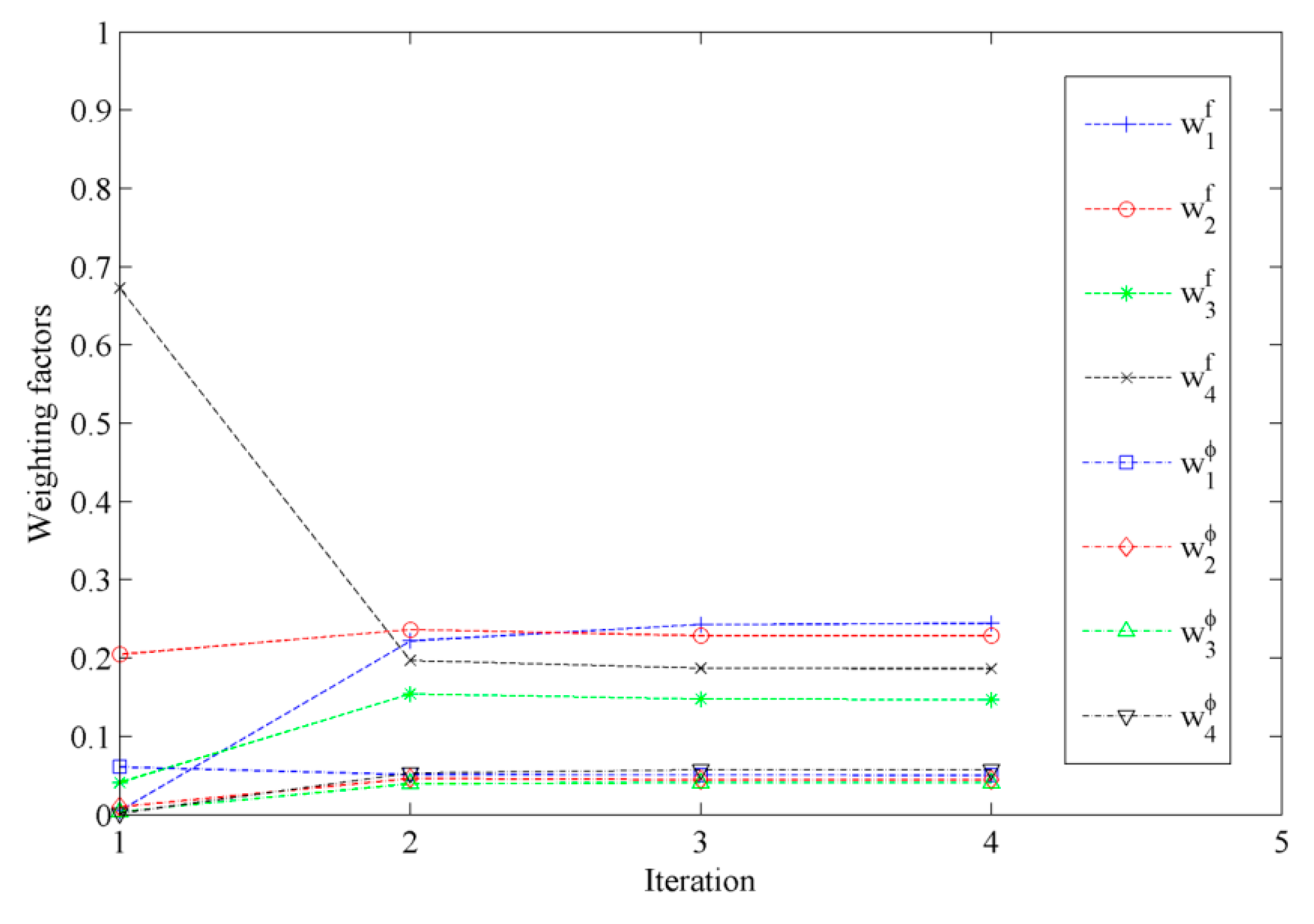
The optimal weighting factors in the metric are obtained using an iterative approach. The evolution of the optimal weighting factors with the iteration steps is shown in Figure 3. It can be seen that the weighting factors converge very fast. It also can be seen that the weighting factors for the modal frequency are larger than those for the mode shape, which means that more uncertainness are contained in the mode shape. It agrees with our preset simulated modal data, in which we added lager noise to the mode shapes than the modal frequencies.
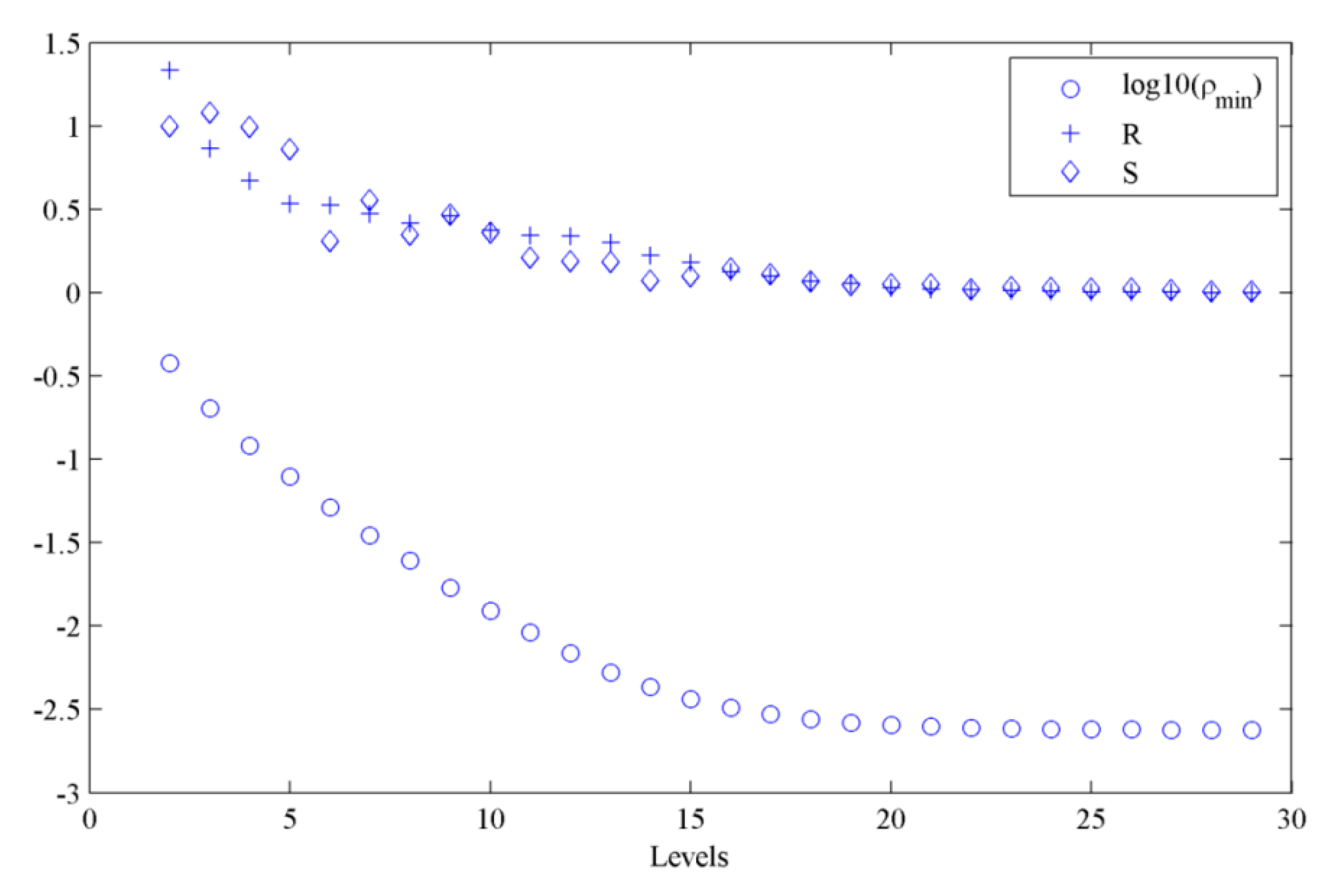
The convergence of the metric and the model parameters vector with the subset levels when using the optimal weighting factors in the metric for case 1 is shown in Figure 4, where R and S are the quantities defined in Equations (7) and (8) to measure the convergence of the metric and the model parameters vector, respectively, and log10 (ρmin) is the logarithm of the minimum value of the metric in each level. It can be seen that the convergence parameters (R, S) nearly became flat from the 20th level, and the subset simulation stopped at the 29th level based on our preset tolerances of Rtol and Stol.
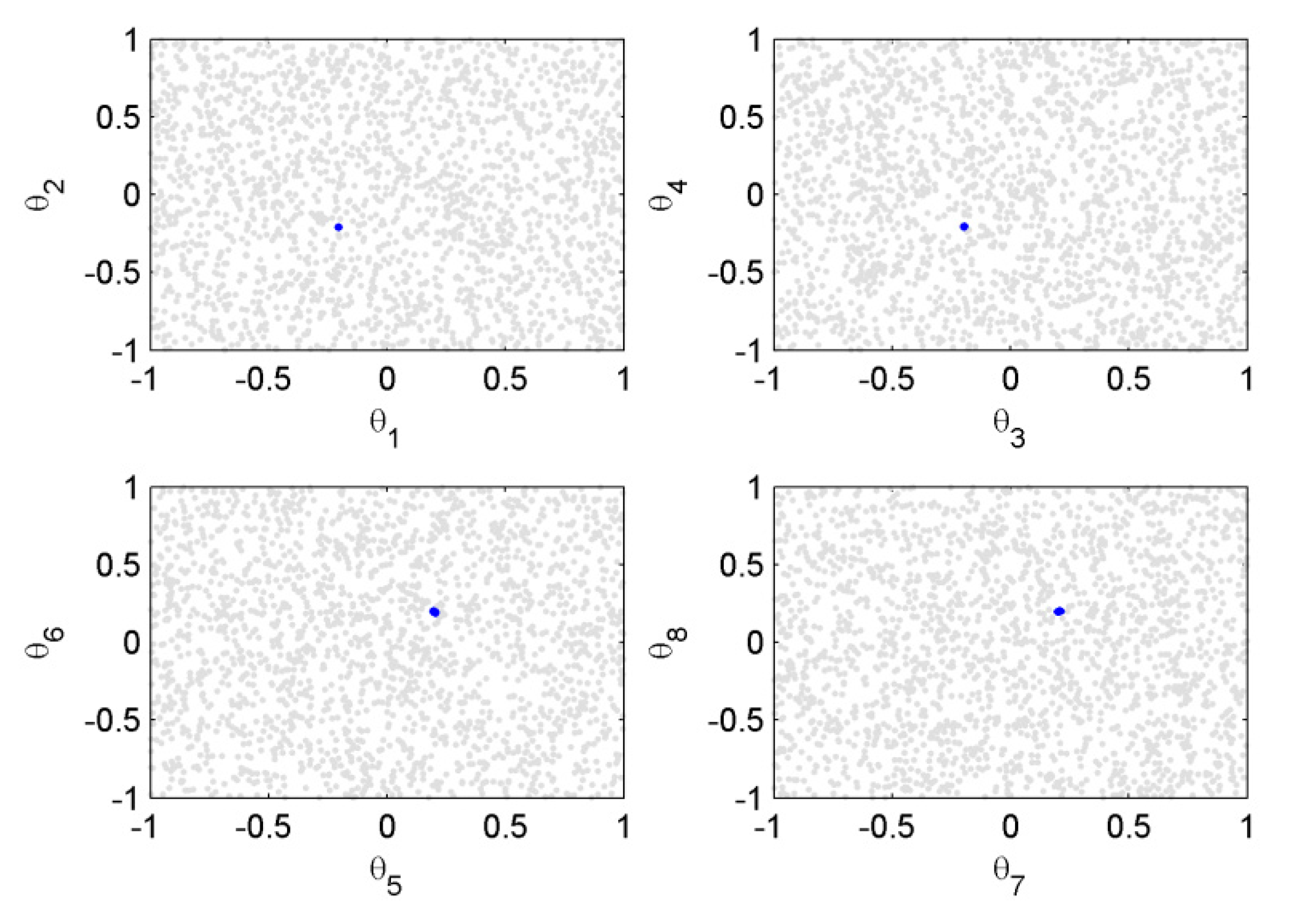
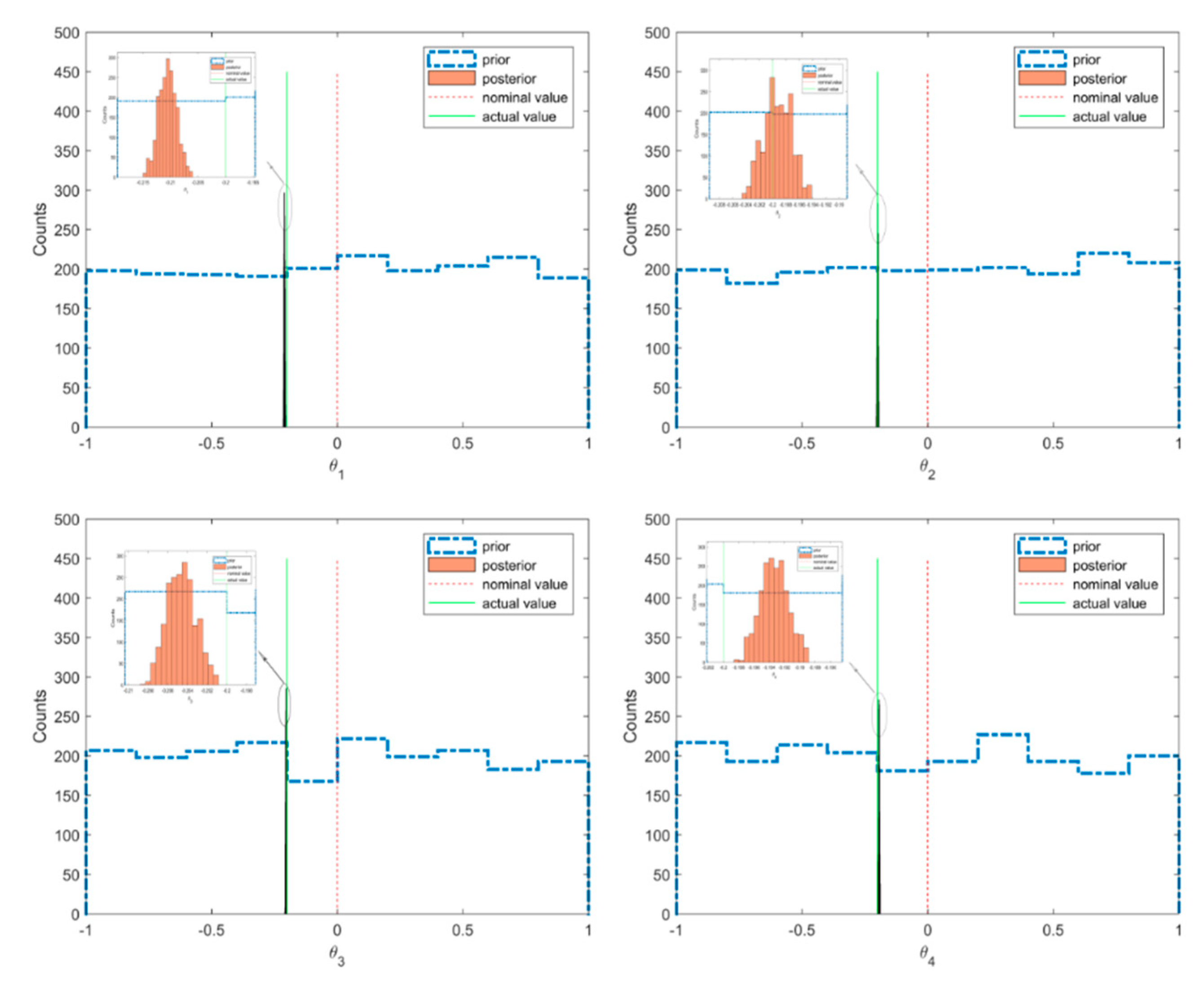
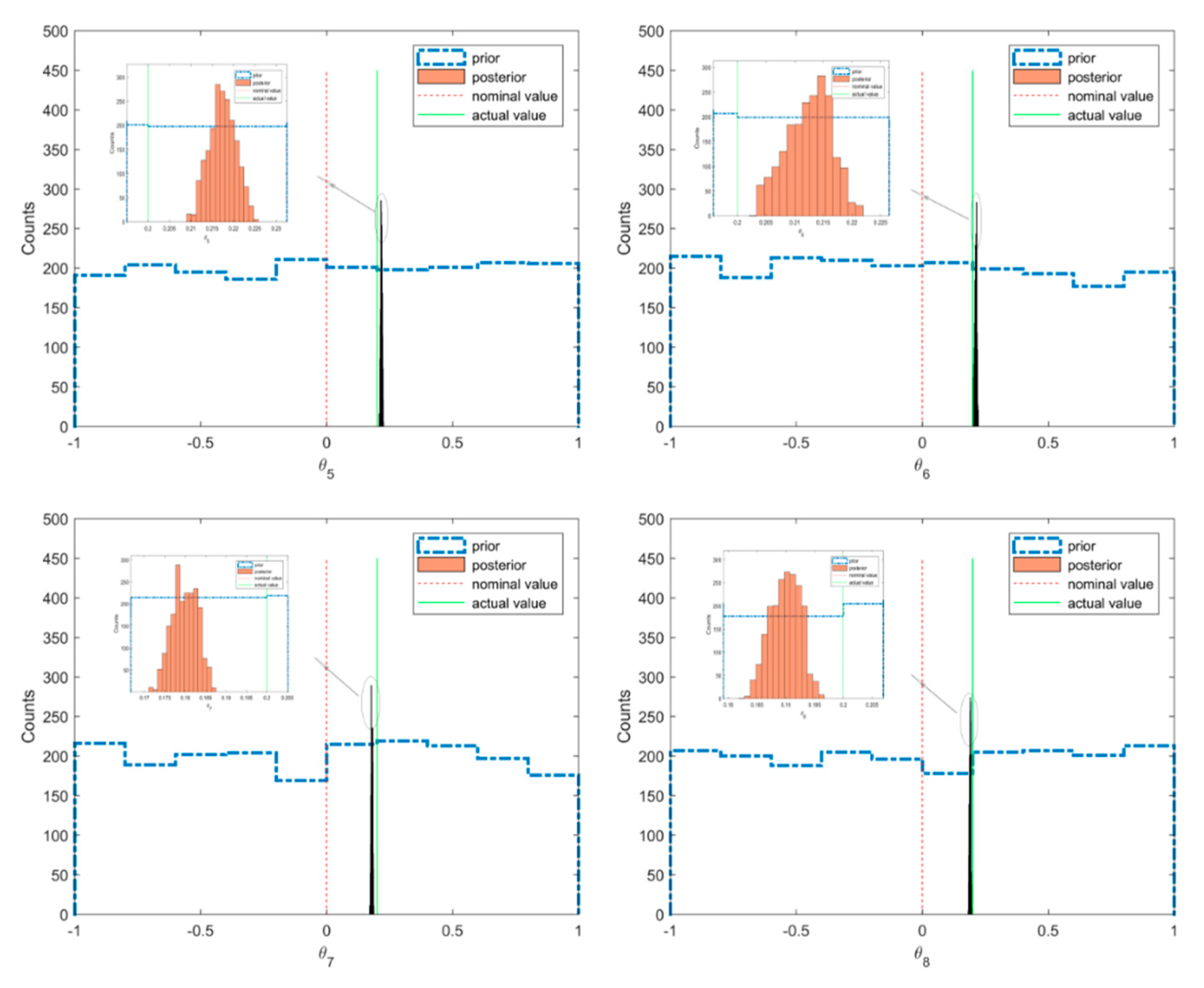
The scatter plot of the posterior and prior samples for case 1 are shown in Figure 5, where the prior distributions of the model parameters were taken as uniform distribution within the interval [−1,1]. It can be seen that the posterior samples were confined in very small regions compared with the prior samples. This means that when using Bayesian inference from the informative measured modal data, the uncertainties of the model parameters contained in the posterior distribution were reduced much more compared to the prior distribution. The histograms of the prior and posterior samples of the model parameters are provided in Figure 6. It can be seen that the posterior samples were concentrated in a smaller range compared to the prior samples, leading to a peaked posterior PDF around the actual values of −0.2 or 0.2.
The updated results of the model parameters are tabulated in Table 1. It can be seen that the optimal values identified in case 1 were very close to their true values. Though the accuracy of the results in case 2 was not as good as that in case 1, it was also acceptable. On the other hand, it can be seen that the coefficients of variation (CV) of the model parameters identified in case 2 were larger than those in case 1, which means that more uncertainties were involved in the identified model parameters based on the modal data in case 2. Comparing case 3 and case 1, it could be seen that the accuracy of the optimal values was improved through fine-tuning with the BFGS method. The coefficients of variation were reduced in case 4, which means that the uncertainty could be reduced by setting a stricter tolerance level for the stopping criteria.
5.2. Damage Assessment of a Truss Structure
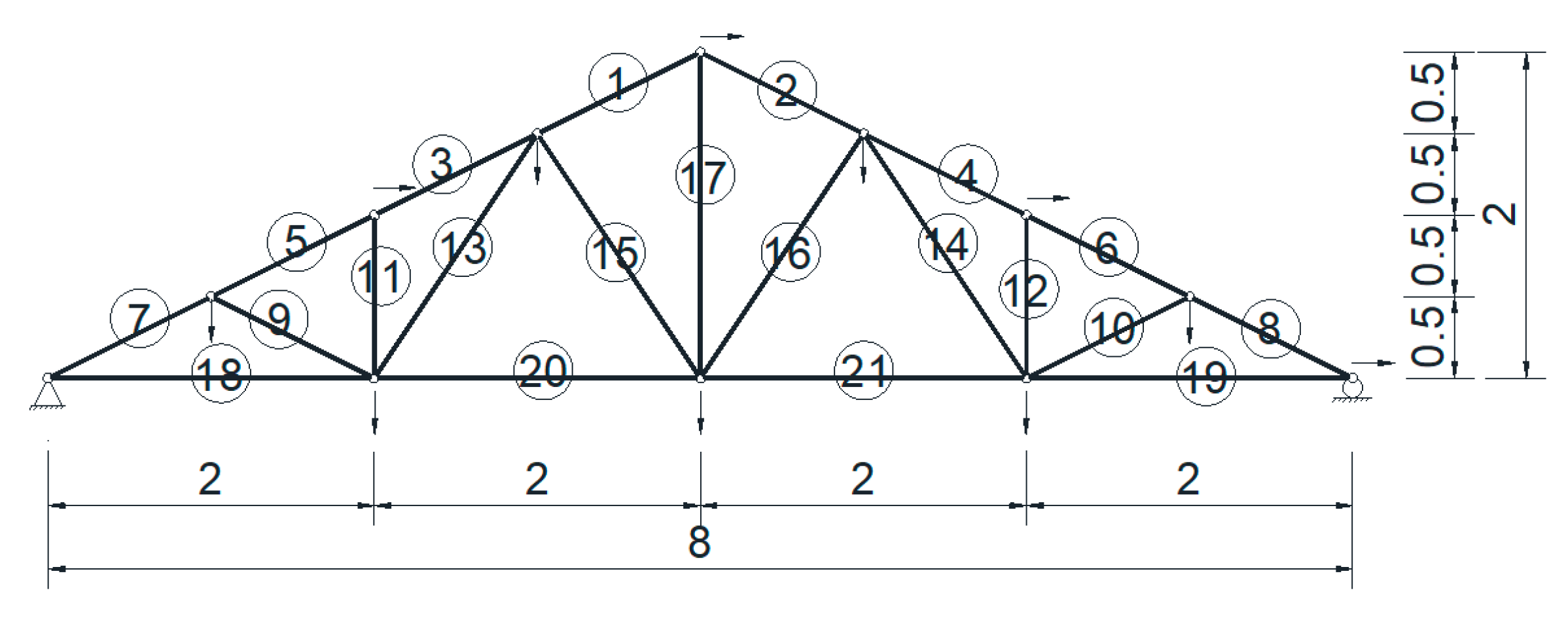
A 21-bar planar truss model is shown in Figure 7, and the structure was simply supported with a span of 8 m. The cross sectional area of each bar was 100 mm2. The mass density was 7850 kg/m3. The actual value of the elastic modulus was 190 GPa, and the nominal value was set to be 200 GPa. This means that a stiffness reduction factor of 5% was assumed for each bar element in the undamaged state, while additional stiffness reductions of 20% and 40% were assumed for bar 20 and 21, respectively. This means that the damage extents of bar #20 and #21 at the damage state were 21% (0.2/0.95) and 42% (0.4/0.95), respectively. The structure had 12 nodes, 21 elements, and 21 DOFs. It was assumed that only the first eight modes were available, and only 11 DOFs were measured (marked with arrows in Figure 7). Some nodes were only measured in the vertical direction, and some nodes were only measured in the horizontal direction. This means that the measurements were incomplete, both in modes and DOFs, which was also the case in real situation. It was also assumed that there were 20 data sets of modal frequencies and mode shapes contaminated with white noise of 1% and 5%, respectively.
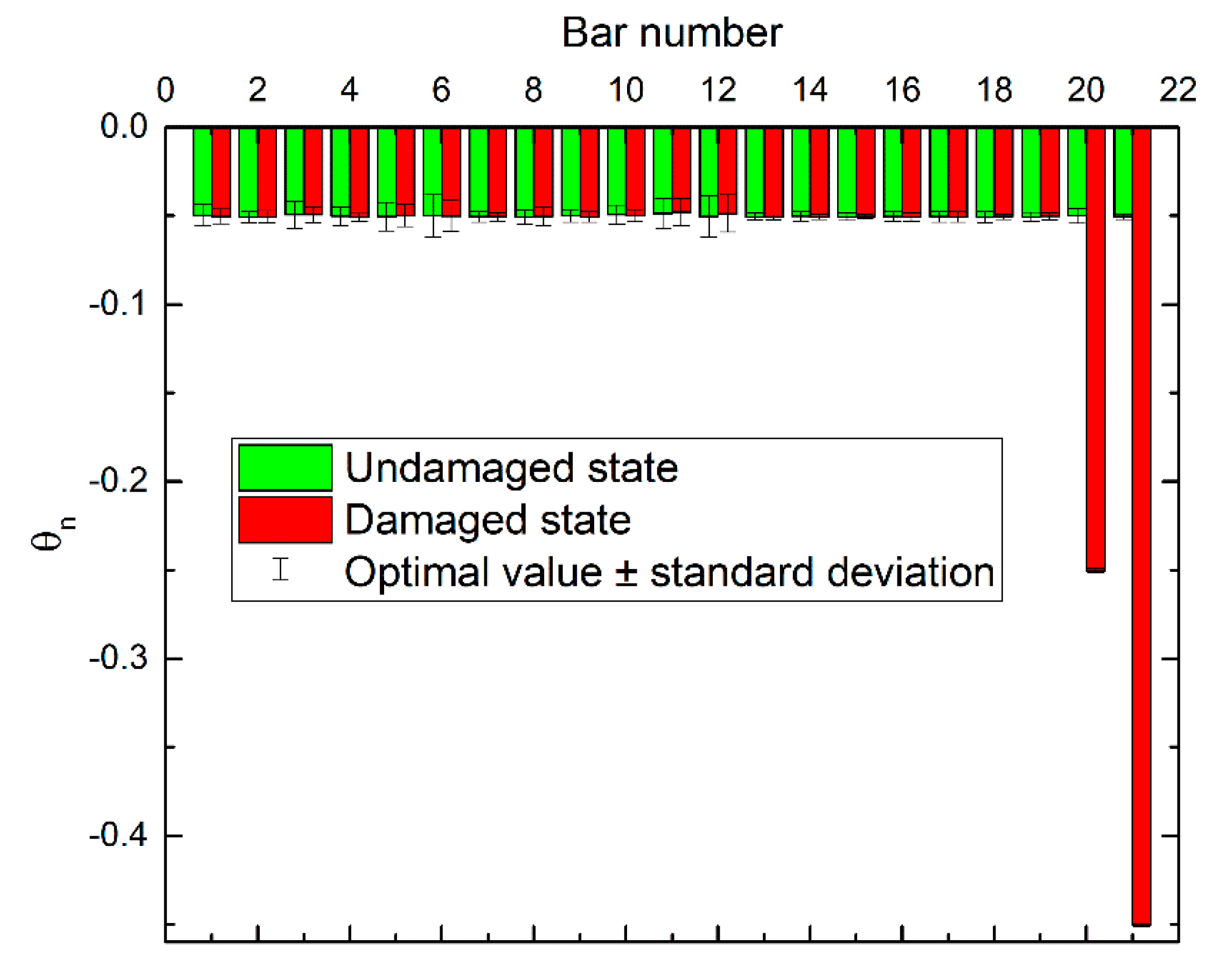
Using the model updating method proposed in Section 3, the updated results of the perturbation scaling factors of stiffness θ are shown in Figure 8, both in the undamaged and damaged states. It can be seen that the optimal values of the updated parameters were very close to their true values. Their standard deviations were also obtained by the posterior samples that corresponded to the samples in the last level of subset simulation. From the figure, it can be seen that bars #6 and #12 had relatively larger standard deviations than the others, which means that more uncertainties were involved in these two bars based on the current sensor configuration. This reflects the fact that the information contained in the monitoring data, which was critical for damage detection, was dependent on the sensor layout. This was a sensor placement optimization issue, which is not the subject of this article, so readers can refer to some literature on this subject [48,49].
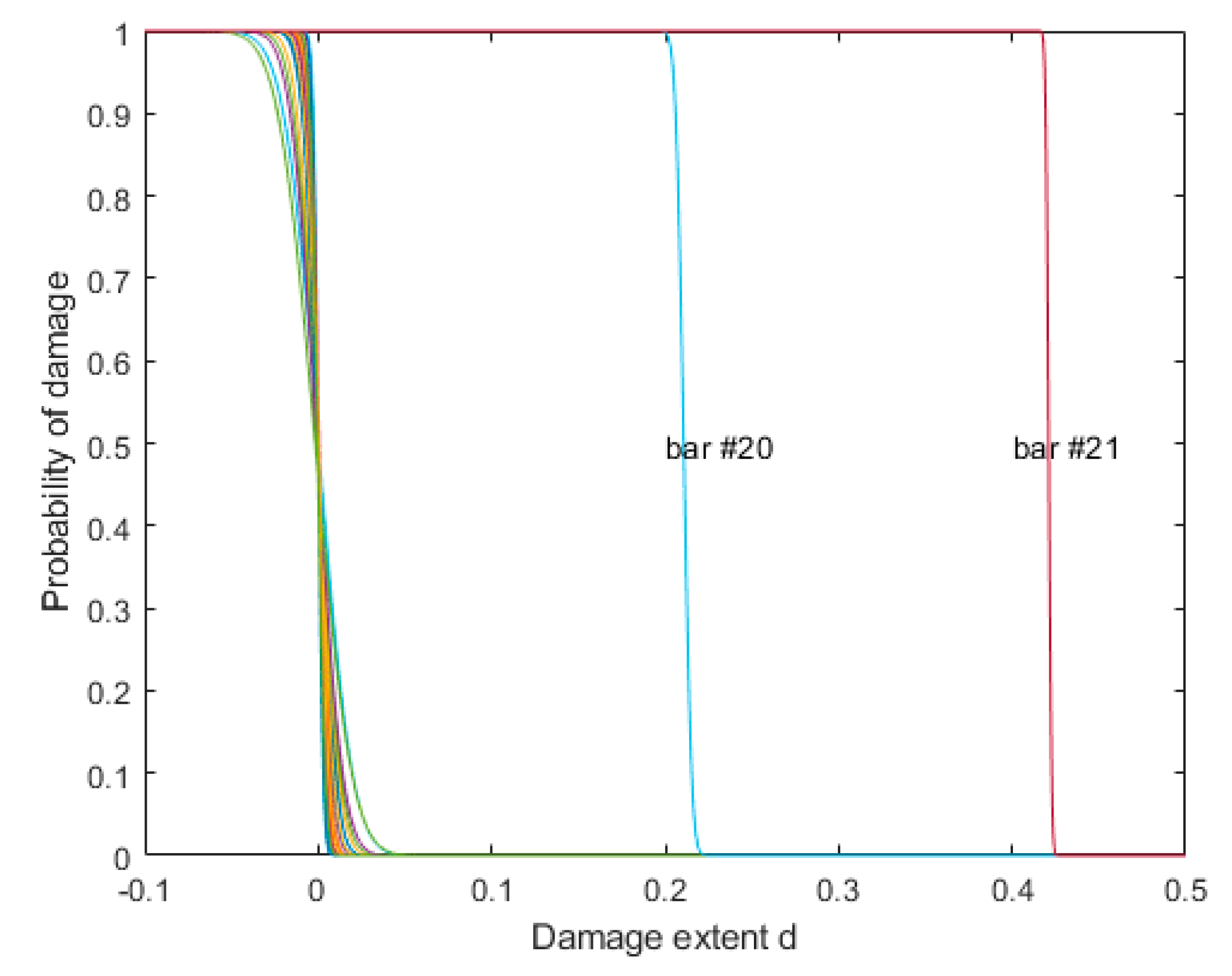
Using the damage assessment method proposed in Section 4, the probability curve of damage extent for each bar is shown in Figure 9. This figure clearly shows the probability of damage extent defined in Equation (12). It can be seen that there were damages with extents of 21% and 42% in bar #20 and #21, respectively, which agreed well with our preset values.
5.3. Damage Assessment of a Simply Supported Beam
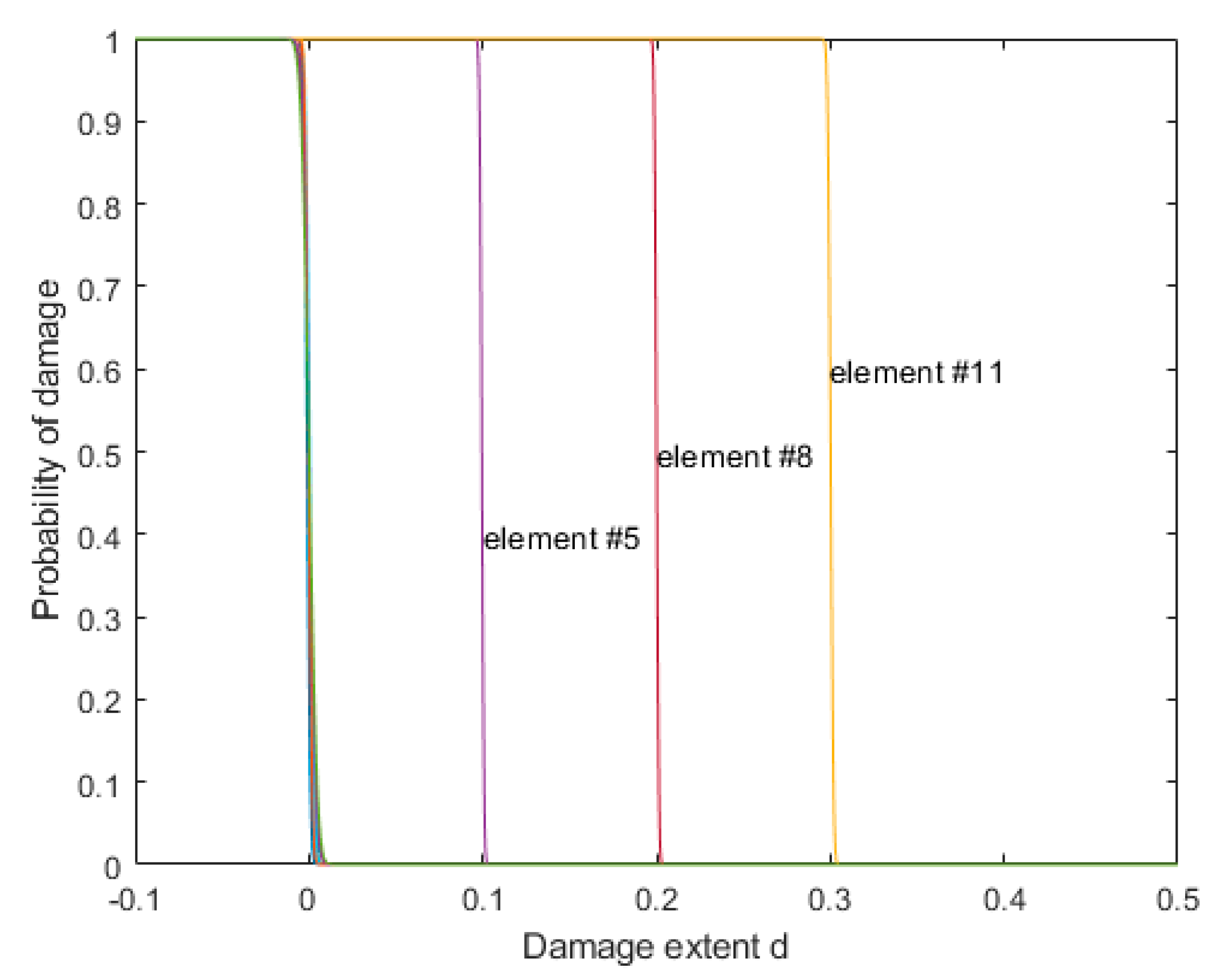
A simply supported steel beam before and after damages at different locations was used for further verification. The beam and the sensor layout (marked with S1~S11) are shown in Figure 10. The total length of the beam was 200 cm, and the span length was 180 cm. The width and the thickness of the beam were 7 and 0.5 cm, respectively. For the finite element modeling of the beam, 15 nodes and 14 elements were used, where two ends, two supports, and eleven sensor locations were set as nodes. Only vertical displacements at the sensor locations were measured, while the rotations were difficult to be measured in the real case. The mass per unit volume was 7850 kg/m3. The true value of the modulus of elasticity was 190 GPa, while the nominal value was set to be 200 GPa, which means a stiffness reduction factor of 5% was assumed for each element in the undamaged state. It was also assumed that 20 data sets of modal frequencies and mode shapes of the first five modes contaminated with white noise of 1% and 5%, respectively, were available. The damages were introduced in elements 5, 8, and 11, where the extents were 10%, 20%, and 30% (compared with undamaged state not nominal model), respectively.
By using the proposed model updating algorithm in Section 3 and the damage assessment method proposed in Section 4, the probability curve of damage extent for each element is shown in Figure 11. It can be seen that there were damages with extents of 10%, 20%, and 30% in elements 5, 8, and 11, respectively, which agreed well with the predefined damaged model.
6. Conclusions
A structural model updating and damage assessment method using the ABC-SubSim algorithm was presented. An iterative procedure to find the optimal weighting factors related to different modal residuals and a new stopping criterion to find a proper tolerance level were proposed for the metric used in the ABC-SubSim. A hybrid optimization scheme was proposed to identify the structural parameters based on incomplete modal data with uncertainty. A high accuracy of the structural model updating is guaranteed by the proposed ABC-SubSim algorithm, even though the noise level of modal data was up to 10%. Three illustrative examples well-demonstrated the effectiveness and reliability of the proposed algorithm. Possible directions of future research related to the ABC method may be a relation study between likelihood-informed Bayesian inference and likelihood-free approximate Bayesian computation, thus leading to a more reasonable selection of key parameters in the ABC method.
Author Contributions
All authors made scientific contributions: Z.F. conceived the idea of this research, derived the formulas, made the calculations of the first example and wrote the manuscript; Y.L. and W.W. made the calculations of the second and third examples; X.H. and Z.C. revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under grant No. 51708203, the Fundamental Research Funds for the Central Universities under grant No. 531118010047, the Open Research Fund Program for innovation platforms of universities in the Hunan province from the Education Department of Hunan Province under grant No. 17K022, and the independent research project funds from the State Key Laboratory of Advanced Design and Manufacturing for Vehicle Body in Hunan University under grant No. 71860006.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
A pseudocode for the proposed algorithm as described in Section 3.5 is provided below.
| The proposed ABC-SubSim algorithm for structural model updating using modal data |
| Input |
| M, K0: the mass and nominal stiffness matrix |
| y = {, }: the measured frequencies and mode shapes, i = 1:Ns, r = 1:Nm |
| θ0, p(θ): the nominal value and prior PDF of model parameters |
| Output |
| θopt, Θpost: the optimal value and posterior samples of model parameters |
| /*Initialization*/ |
| , : tolerances for stopping criterion of subset simulation |
| P0, N: the conditional probability and the number of samples in each level of subset simulation |
| w0: calculate the initial values for the weighting factors based on nominal value θ0 |
| εw: tolerances for stopping criterion of weighting factors iteration |
| k = 1 |
| while (k==1 or ) do /*External loop for weighting factors iteration*/ |
| Sample , where |
| j = 1 |
| while (j==1 or Rj > and Sj > ) do /*Internal loop for subset simulation*/ |
| for n: 1, …, N do |
| Evaluate |
| end for |
| Sort and renumber the samples so that |
| for l = 1, …, do |
| Select as a seed |
|
| end for |
| Renumber as |
| j = j + 1 |
| Update Rj and Sj |
| end while |
| k = k + 1 |
|
| Update the weighting factors based on the newly obtained optimal model parameters |
| end while |
References
- Chen, G.; Mu, H.; Pommerenke, D.; Drewniak, J.L. Damage detection of reinforced concrete beams with novel distributed crack/strain sensors. Struct. Heal. Monit. An. Int. J. 2004, 3, 225–243. [Google Scholar] [CrossRef]
- Xu, B.; Chen, G.; Wu, Z.S. Parametric identification for a truss structure using axial strain. Comput. Civ. Infrastruct. Eng. 2007, 22, 210–222. [Google Scholar] [CrossRef]
- Fan, L.; Bao, Y.; Chen, G. Feasibility of distributed fiber optic sensor for corrosion monitoring of steel bars in reinforced concrete. Sensors 2018, 18, 3722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farrar, C.R.; Doebling, S.W.; Nix, D.A. Vibration-based structural damage identification. Philos. Trans. R. Soc. A Lond. Ser. Math. Phys. Eng. Sci. 2001, 359, 131–149. [Google Scholar] [CrossRef]
- Simoen, E.; De Roeck, G.; Lombaert, G. Dealing with uncertainty in model updating for damage assessment: A review. Mech. Syst. Signal Process. 2015, 56–57, 123–149. [Google Scholar] [CrossRef] [Green Version]
- Mao, J.-X.; Wang, H.; Feng, D.-M.; Tao, T.-Y.; Zheng, W.-Z. Investigation of dynamic properties of long-span cable-stayed bridges based on one-year monitoring data under normal operating condition. Struct. Control Health Monit. 2018, 25, e2146. [Google Scholar] [CrossRef]
- Beck, J.L.; Katafygiotis, L.S. Updating models and their uncertainties. I: Bayesian statistical framework. J. Eng. Mech. 1998, 124, 455–461. [Google Scholar] [CrossRef]
- Brownjohn, J.M.W.; Xia, P.-Q.; Hao, H.; Xia, Y. Civil structure condition assessment by FE model updating: Methodology and case studies. Finite Elem. Anal. Des. 2001, 37, 761–775. [Google Scholar] [CrossRef]
- Jaishi, B.; Ren, W.-X. Structural finite element model updating using ambient vibration test results. J. Struct. Eng. 2005, 131, 617–628. [Google Scholar] [CrossRef]
- Hua, X.G.; Ni, Y.Q.; Chen, Z.Q.; Ko, J.M. An improved perturbation method for stochastic finite element model updating. Int. J. Numer. Methods Eng. 2008, 73, 1845–1864. [Google Scholar] [CrossRef]
- Yan, W.-J.; Katafygiotis, L.S. A novel Bayesian approach for structural model updating utilizing statistical modal information from multiple setups. Struct. Saf. 2015, 52, 260–271. [Google Scholar] [CrossRef]
- Lee, Y.-J.; Cho, S. SHM-based probabilistic fatigue life prediction for bridges based on FE model updating. Sensors 2016, 16, 317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Y.; Beck, J.L.; Li, H. Bayesian system identification based on hierarchical sparse Bayesian learning and Gibbs sampling with application to structural damage assessment. Comput. Methods Appl. Mech. Eng. 2017, 318, 382–411. [Google Scholar] [CrossRef]
- Asadollahi, P.; Huang, Y.; Li, J. Bayesian finite element model updating and assessment of Cable-stayed bridges using wireless sensor data. Sensors 2018, 18, 3057. [Google Scholar] [CrossRef] [Green Version]
- Qin, S.; Zhang, Y.; Zhou, Y.-L.; Kang, J. Dynamic model updating for bridge structures using the Kriging model and PSO algorithm ensemble with higher vibration modes. Sensors 2018, 18, 1879. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Luş, H.; Betti, R. Identification of structural models using a modified Artificial Bee Colony algorithm. Comput. Struct. 2013, 116, 59–74. [Google Scholar] [CrossRef]
- Perera, R.; Ruiz, A. A multistage FE updating procedure for damage identification in large-scale structures based on multiobjective evolutionary optimization. Mech. Syst. Signal Process. 2008, 22, 970–991. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.-S.; Cho, S.; Jung, H.-J.; Lee, J.-J.; Yun, C.-B. A new multi-objective approach to finite element model updating. J. Sound Vib. 2014, 333, 2323–2338. [Google Scholar] [CrossRef]
- Beck, J.L. Bayesian system identification based on probability logic. Struct. Control Health Monit. 2010, 17, 825–847. [Google Scholar] [CrossRef]
- Sun, H.; Büyüköztürk, O. Probabilistic updating of building models using incomplete modal data. Mech. Syst. Signal Process. 2016, 75, 27–40. [Google Scholar] [CrossRef]
- Simoen, E.; Papadimitriou, C.; Lombaert, G. On prediction error correlation in Bayesian model updating. J. Sound Vib. 2013, 332, 4136–4152. [Google Scholar] [CrossRef]
- Marin, J.-M.; Pudlo, P.; Robert, C.P.; Ryder, R.J. Approximate Bayesian computational methods. Stat. Comput. 2012, 22, 1167–1180. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.-S.; Jung, H.-J. Likelihood-free Bayesian computation for structural model calibration: A feasibility study. In Proceedings of the SPIE 9803, Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2016, Las Vegas, NV, USA, 21–24 March 2016; p. 980323. [Google Scholar]
- Fang, S.-E.; Chen, S.; Lin, Y.-Q.; Dong, Z.-L. Probabilistic damage identification incorporating approximate Bayesian computation with stochastic response surface. Mech. Syst. Signal Process. 2019, 128, 229–243. [Google Scholar] [CrossRef]
- Abdessalem, A.B.; Dervilis, N.; Wagg, D.; Worden, K. Model selection and parameter estimation in structural dynamics using approximate Bayesian computation. Mech. Syst. Signal Process. 2018, 99, 306–325. [Google Scholar] [CrossRef]
- Abdessalem, A.B.; Dervilis, N.; Wagg, D.; Worden, K. Model selection and parameter estimation of dynamical systems using a novel variant of approximate Bayesian computation. Mech. Syst. Signal Process. 2019, 122, 364–386. [Google Scholar] [CrossRef]
- Chiachio, M.; Beck, J.L.; Chiachio, J.; Rus, G. Approximate Bayesian computation by Subset Simulation. SIAM J. Sci. Comput. 2014, 36, A1339–A1358. [Google Scholar] [CrossRef] [Green Version]
- Au, S.-K.; Beck, J.L. Estimation of small failure probabilities in high dimensions by Subset Simulation. Probabilistic Eng. Mech. 2001, 16, 263–277. [Google Scholar] [CrossRef] [Green Version]
- Vakilzadeh, M.K.; Huang, Y.; Beck, J.L.; Abrahamsson, T. Approximate Bayesian computation by Subset Simulation using hierarchical state-space models. Mech. Syst. Signal Process. 2017, 84, 2–20. [Google Scholar] [CrossRef]
- Vakilzadeh, M.K.; Beck, J.L.; Abrahamsson, T. Using approximate Bayesian computation by Subset Simulation for efficient posterior assessment of dynamic state-space model classes. SIAM J. Sci. Comput. 2018, 40, B168–B195. [Google Scholar] [CrossRef] [Green Version]
- Sunnåker, M.; Busetto, A.G.; Numminen, E.; Corander, J.; Foll, M.; Dessimoz, C. Approximate Bayesian computation. PLoS Comput. Biol. 2013, 9, e1002803. [Google Scholar] [CrossRef] [Green Version]
- Sisson, S.A.; Fan, Y.; Beaumont, M. Handbook of Approximate Bayesian Computation, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Toni, T.; Welch, D.; Strelkowa, N.; Ipsen, A.; Stumpf, M.P. Approximate Bayesian computation scheme for parameter inference and model selection in dynamical systems. J. R. Soc. Interface 2009, 6, 187–202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zuev, K.M.; Beck, J.L.; Au, S.-K.; Katafygiotis, L.S. Bayesian post-processor and other enhancements of Subset Simulation for estimating failure probabilities in high dimensions. Comput. Struct. 2012, 92, 283–296. [Google Scholar] [CrossRef] [Green Version]
- Moaveni, B.; Conte, J.P.; Hemez, F.M. Uncertainty and sensitivity analysis of damage identification results obtained using finite element model updating. Comput. Civ. Infrastruct. Eng. 2009, 24, 320–334. [Google Scholar] [CrossRef] [Green Version]
- Moaveni, B.; He, X.; Conte, J.P.; Restrepo, J.I. Damage identification study of a seven-story full-scale building slice tested on the UCSD-NEES shake table. Struct. Saf. 2010, 32, 347–356. [Google Scholar] [CrossRef] [Green Version]
- Moller, P.W.; Friberg, O. Updating large finite element models in structural dynamics. AIAA J. 1998, 36, 1861–1868. [Google Scholar] [CrossRef]
- Jia, X.; Papadimitriou, C. Data features-based likelihood-informed bayesian finite element model updating. In Proceedings of the 3rd International Conference on Uncertainty Quantification in Computational Sciences and Engineering (UNCECOMP 2019), Athens, Greece, 24–26 June 2019; pp. 103–113. [Google Scholar]
- Jung, D.-S.; Kim, C.-Y. FE model updating based on hybrid genetic algorithm and its verification on numerical bridge model. Struct. Eng. Mech. 2009, 32, 667–683. [Google Scholar] [CrossRef]
- Sun, H.; Betti, R. A hybrid optimization algorithm with Bayesian inference for probabilistic model updating. Comput. Civ. Infrastruct. Eng. 2015, 30, 602–619. [Google Scholar] [CrossRef]
- Broyden, C.G. The convergence of a class of double-rank minimization algorithms 1. General considerations. IMA J. Appl. Math. 1970, 6, 76–90. [Google Scholar] [CrossRef]
- Fletcher, R. A new approach to variable metric algorithms. Comput. J. 1970, 13, 317–322. [Google Scholar] [CrossRef] [Green Version]
- Goldfarb, D. A family of variable-metric methods derived by variational means. Math. Comput. 1970, 24, 23–26. [Google Scholar] [CrossRef]
- Shanno, D.F. Conditioning of quasi-Newton methods for function minimization. Math. Comput. 1970, 24, 647–656. [Google Scholar] [CrossRef]
- Truong, T.C.; Cho, S.; Yun, C.B.; Sohn, H. Finite element model updating of Canton Tower using regularization technique. Smart Struct. Syst. 2012, 10, 459–470. [Google Scholar] [CrossRef]
- Christodoulou, K.; Papadimitriou, C. Structural identification based on optimally weighted modal residuals. Mech. Syst. Signal Process. 2007, 21, 4–23. [Google Scholar] [CrossRef]
- Ching, J.; Beck, J.L. New Bayesian model updating algorithm applied to a structural health monitoring benchmark. Struct. Health Monit. 2004, 3, 313–332. [Google Scholar] [CrossRef]
- Yi, T.-H.; Li, H.-N.; Gu, M. Optimal sensor placement for health monitoring of high-rise structure based on genetic algorithm. Math. Probl. Eng. 2011, 2011. [Google Scholar] [CrossRef]
- Yi, T.-H.; Li, H.-N. Methodology developments in sensor placement for health monitoring of civil infrastructures. Int. J. Distrib. Sens. Netw. 2012, 8, 612726. [Google Scholar] [CrossRef]
Figure 1.
Schematic diagram of approximate Bayesian computation with subset simulation (ABC-SubSim).
Figure 1.
Schematic diagram of approximate Bayesian computation with subset simulation (ABC-SubSim).

Figure 2.
The flowchart of the proposed algorithm.

Figure 3.
The evolution of the optimal weighting factors with iteration steps (case 1).

Figure 4.
The convergence of the metric and the model parameters vector with the subset levels (case 1).
Figure 4.
The convergence of the metric and the model parameters vector with the subset levels (case 1).

Figure 5.
Scatter plot graph of posterior (in blue) and prior (in gray) samples of the model parameters (case 1).
Figure 5.
Scatter plot graph of posterior (in blue) and prior (in gray) samples of the model parameters (case 1).

Figure 6.
Prior and posterior samples of the model parameters with actual and nominal values (case 1).
Figure 6.
Prior and posterior samples of the model parameters with actual and nominal values (case 1).


Figure 7.
Schematic of a 21-bar planar truss (unit: m).

Figure 8.
Updated perturbation scaling factors of stiffness for truss model.

Figure 9.
Probability curve of damage extent for truss model.

Figure 10.
Simply supported beam model.

Figure 11.
Probability curve of damage extent for beam model.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The identified results of the model parameters.
| θ1 | θ2 | θ3 | θ4 | θ5 | θ6 | θ7 | θ8 | |
|---|---|---|---|---|---|---|---|---|
| True | −0.2000 | −0.2000 | −0.2000 | −0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2000 |
| Optimal 1 | −0.2052 | −0.2085 | −0.1968 | −0.2050 | 0.2002 | 0.1968 | 0.2052 | 0.2000 |
| CV 1 | 0.0059 | 0.0072 | 0.0063 | 0.0084 | 0.0126 | 0.0165 | 0.0173 | 0.0063 |
| Optimal 2 | −0.1930 | −0.2058 | −0.2067 | −0.2044 | 0.2184 | 0.2144 | 0.2104 | 0.2011 |
| CV 2 | 0.0135 | 0.0157 | 0.0120 | 0.0165 | 0.0240 | 0.0336 | 0.0361 | 0.0120 |
| Optimal 3 | −0.2121 | −0.2007 | −0.2050 | −0.1920 | 0.2167 | 0.2159 | 0.1799 | 0.1848 |
| CV 3 | 0.0059 | 0.0072 | 0.0063 | 0.0084 | 0.0126 | 0.0165 | 0.0173 | 0.0063 |
| Optimal 4 | −0.1992 | −0.1969 | −0.2005 | −0.2102 | 0.1941 | 0.1863 | 0.2043 | 0.2029 |
| CV 4 | 0.0005 | 0.0008 | 0.0004 | 0.0005 | 0.0005 | 0.0015 | 0.0011 | 0.0010 |
Note: Optimal i and CV i denote the optimal values and the coefficients of variation of the model parameters identified in case i (i = 1,2,3,4).
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Feng, Z.; Lin, Y.; Wang, W.; Hua, X.; Chen, Z. Probabilistic Updating of Structural Models for Damage Assessment Using Approximate Bayesian Computation. Sensors 2020, 20, 3197. https://doi.org/10.3390/s20113197
AMA Style
Feng Z, Lin Y, Wang W, Hua X, Chen Z. Probabilistic Updating of Structural Models for Damage Assessment Using Approximate Bayesian Computation. Sensors. 2020; 20(11):3197. https://doi.org/10.3390/s20113197
Chicago/Turabian StyleFeng, Zhouquan, Yang Lin, Wenzan Wang, Xugang Hua, and Zhengqing Chen. 2020. "Probabilistic Updating of Structural Models for Damage Assessment Using Approximate Bayesian Computation" Sensors 20, no. 11: 3197. https://doi.org/10.3390/s20113197
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.