Multiple-Antenna Emitters Identification Based on a Memoryless Power Amplifier Model


Department of Electrical Engineering and Information Science, University of Science and Technology of China, Hefei 230026, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(23), 5233; https://doi.org/10.3390/s19235233
Submission received: 22 October 2019
/
Revised: 21 November 2019
/
Accepted: 25 November 2019
/
Published: 28 November 2019
(This article belongs to the Section Electronic Sensors)
Abstract
:Power amplifier (PA) nonlinearity is typically unique at the radio frequency (RF) front-end for particular emitters. It can play a crucial role in the application of specific emitter identification (SEI). In this paper, under the Multi-Input Multi-Output (MIMO) multipath communication scenario, two data-aided approaches are proposed to identify multi-antenna emitters using PA nonlinearity. Built upon a memoryless polynomial model, the first approach formulates a linear least square (LLS) problem and presents the closed-form solution of nonlinear coefficients in a MIMO system by means of singular value decomposition (SVD) operation. Another alternative approach estimates nonlinear coefficients of each individual PA through nonlinear least square (NLS) solved by the regularized Gauss–Newton iterative scheme. Moreover, there are some practical discussions of our proposed approaches about the mismatch of the order of PA model and the rank-deficient condition. Finally, the average misclassification rate is derived based on the minimum error probability (MEP) criterion, and the proposed approaches are validated to be effective through extensively numerical simulations.
1. Introduction
Specific emitter identification (SEI) is committed to distinguish individual radiation sources by using essential radio frequency fingerprint (RFF) features extracted from different emitters. It can be applied to military communication [1], physical layer authentication [2], and enhancement of the security in wireless network, such as very high frequency (VHF) radio networks, Wi-Fi networks, cognitive radios, cellular networks [3], and so on.
In general, based on different states of signals, the identifiable RFF features for SEI are usually extracted from the transient signal or the steady-state signal. The transient signal, actually the turn-on signal, carries unique and unintentional information that is advantageous to emitter identification, and the features underlying are mainly extracted from the instantaneous amplitude, phase, frequency, and energy envelope [4,5,6]. Nevertheless, it is difficult to capture the transient signal since the duration time is often too short to use. As for the steady-state signal, many researchers focus on extracting the distinguishable features that are generated by hardware imperfection of the components inside the radiation source through advanced signal processing techniques. On one hand, the statistical characteristics of the original RF signal, such as the high order spectrum, have been used as the features to identify different emitters [7,8]. On the other hand, the Time-Frequency Analysis (TFA) methods [9,10], Wavelet Transform (WT) [11,12], and Hilbert–Huang Transform (HHT) [13,14] are successively applied to extract the transform domain characteristics from the received RF signals. However, these methods have little knowledge of impairments inside the individual emitter, and the performance can be easily affected by the wireless channels. Hence, there are many additional works in literature to model the characteristic of hardware imperfection of the internal component such as digital to analog converter (DAC) [15], modulator [16,17], and power amplifier (PA) [18,19,20,21], etc., and to extract the unique RF front-end feature for a particular emitter. This paper concentrates on the extraction of PA nonlinear features to identify communication emitters with multiple antennas under Multiple-Input Multiple-Output (MIMO) multipath channels.
It is well known that the MIMO transmission scheme can improve the spectral efficiency by introducing additional spatial diversity. In practice, transceivers with multiple transmit and receive antennas have shown their powerful merits and served as the major mechanism for current and future wireless communication systems. Meanwhile, due to the increasing number of antennas for MIMO emitters, there will be more diverse PA nonlinearities available at the RF front end for SEI. A lot of research efforts have been afforded to analyze the nonlinearity incurred by PAs with the Saleh model [22], polynomial model [23], and Volterra model [24], etc. in MIMO systems, whereas they are mainly devoted to implementing predistortion or PA linearization. However, to the authors’ best knowledge, there are few open results of SEI in MIMO communication systems. In [21], Li uses a modified artificial bee colony (ABC) algorithm to estimate the coefficients of the Hammerstein model, a simplified version of the Volterra model, in a MIMO system. However, the impact of wireless propagation channels is not considered, and the ABC algorithm also appears complicated to obtain the optimal solution in the context of SEI. Recently, in [25,26], an estimation of signal parameters via rotational invariance technique (ESPRIT)-based approach, which takes advantage of the multiple antennas at the receiver to separate the RFF from wireless channel, is proposed for RFF estimation in orthogonal frequency division multiplexing (OFDM) systems, whereas it is only suitable for a Single-Input Multiple-Output (SIMO) system rather than the MIMO one. In [19,20], a memoryless polynomial model is used to characterize the nonlinearity of PA, and a data-aided iterative algorithm is proposed to estimate nonlinear coefficients of the PA model for SEI from the observations in both MIMO and single-input single-output (SISO) scenarios.
Treating the fact that all PAs of a multiple-antenna emitter are independent from each other and following a memoryless polynomial model, in this paper, we propose two data-aided solutions that are different from the idea of [19,20] in the MIMO multipath scenario. Given received signals, we extend the method in [27] to the MIMO multipath scenario; a closed-form solution of the nonlinear coefficients is thus obtained by combining the linear least square (LLS) and singular value decomposition (SVD) methods. An alternative but more effective approach is also presented through solving a nonlinear least square (NLS) problem with independent variables consisting of both channel coefficients and nonlinear coefficients of the PA model. Furthermore, we explicitly provide deep discussion on the parameter estimate bias for the general case of unknown order of the PA model. In particular, it is proved in this paper that the rank-deficient property of both the NLS and LLS problems are in association with the amplitude level of the training sequence. The average misclassification rate based on the minimum error probability (MEP) criterion is theoretically derived, and we finally verify the proposed approaches via extensive numerical simulations.
The rest of the paper is organized as follows. In Section 2, we introduce the memoryless nonlinear model of PA in the MIMO multipath system. In Section 3, we present the linear and nonlinear frameworks for SEI, respectively. Then, the practical discussions for the proposed approaches and the misclassification rate are separately given in Section 4 and Section 5. In Section 6, numerical results are presented to demonstrate the effectiveness. Section 7 summarizes the paper.
2. Preliminaries and Problem Formulation
This paper mainly considers the scenario that K communication emitters equipped with multiple antennas are identified through a multiple-antenna receiver in the MIMO multipath environment. Since constant modulus modulation schemes such as phase-shift keying (PSK) may generally introduce less nonlinear distortion, we thus consider how to extract the underlying PA nonlinearity of each emitter from the received signal, with the help of a quadrature amplitude modulation (QAM) training sequence. In other words, PA nonlinearity is treated as a unique RFF of the emitter to fulfill the identification task, and we assume QAM is used by emitters when communicating with the receiver.
2.1. Memoryless Nonlinear PA Modeling
Generally, the memoryless polynomial model is simple in expression and can describe the intermodulation distortion of an RF PA well, such as PA9440 amplifier [28], in the narrowband communication system. More specifically, the polynomial coefficients are corresponding to the intermodulation coefficient such as third-order interception point () and fifth-order interception point (). In this work, we choose the memoryless polynomial model to characterize the nonlinear behavior of all PA units in a multi-antenna emitter; then, the relationship between baseband equivalent input and output of the PA [20] at jth antenna branch can be written as
where P denotes the max order of the PA model and can be configured as . At the RF front-end of emitters, the frequency components that resulted from the even terms in the model can be removed by the bandpass filter, thus the even terms are ignored in Equation (1). is the baseband equivalent input of the nonlinear system, denoting the nth QAM symbol transmitted over the jth antenna. The superscript “*” is the conjugate operator. denotes the normalized th order PA coefficient of the jth antenna and without loss of generality, we set hereafter. stands for the response of the nonlinear system.
In this paper, we suppose that each emitter is equipped with J antennas. Therefore, the normalized discrete-time baseband equivalent form of the nonlinear distortion model for the multi-antenna system can be expressed as
where is the normalized version of .
2.2. MIMO Multipath Channel
The propagation channel considered in this paper is a linear discrete MIMO system with J transmit antennas and R receive antennas. Given the length of the training sequence N, the signal received at the antenna r can be represented by
where ⊗ denotes the convolution operation. is the nonlinear distortion signal transmitted over the jth antenna, represents the channel impulse response between the jth transmit antenna to the rth receive antenna and remains time-invariant during the data receiving process, and is the zero-mean additive white Gaussian noise received at the antenna r. Thus, we can unfold Equation (3) naturally in the form of
where the order of the channel is L, is a Toeplitz matrix populated by in Equation (3). Note that the nonlinear coefficients are cross-coupled with channel coefficients in Equation (4); therefore, the major target arising in this paper is to get the accurate estimations of the separate nonlinear coefficient via the received signal with the aid of training sequences in MIMO multipath scenarios, before we can identify a specific emitter.
3. The Proposed Estimation Approaches
As mentioned above, it has been reported in [19,20] that the nonlinear coefficients of PAs can be estimated with two stages. The first stage establishes the initial estimation of channel coefficients and nonlinear coefficients through some well-designed training sequences sorted by amplitude. Then, an iterative method is applied at the second stage to eliminate the estimate bias. In [27], a PA parameter estimator combined the best linear unbiased estimation (BLUE) and singular value decomposition (SVD) is proposed for the SISO system. Since the method in [27] can get a closed-form solution of the PA nonlinear coefficients and has no constraint on the ordering of the amplitude of training symbols, which is more practical compared to the one in [19], we extend it to the MIMO multi-path scenarios and mark it as linear method in MIMO (LMM). Furthermore, we propose an alternative method to extract PA parameters in a nonlinear least square (NLS) manner. It should be noted that both LMM and NLS approaches can be degraded into SISO systems.
3.1. The LMM Approach
Note that, in [27], if the product terms of the channel coefficients and the nonlinear coefficients are substituted by some new integrated variables, we can obtain a set of linear equations with regard to the new variables, thus the product terms can be readily solved by LLS. Then, the only thing left to us is to extract from the solution.
According to Equation (4), we first vectorize signals received by all R antennas into vector , i.e., , where the superscript “T” is the transpose operator. In addition, the signal at the receiver side now is
where is the corresponding reshaped noise vector. is the integrated vector composed of all independent variables and can be represented as:
with
in which , is a unit matrix and is the block diagonalization function. In addition, is defined by
with being constructed by the known training sequence. To elaborate the process, we provide a numerical example in Appendix A.
Consequently, the least square (LS) estimation of in Equation (5) is
where the superscript “†” denotes the pseudo-inverse operation. It is worth noting that, compared to the BLUE method in [27], the least square solution of Equation (12) has no requirement on the estimation of noise power. Obviously, the condition of a unique solution to Equation (12) is natural that is full column rank and is satisfied.
Afterwards, we define
and further perform SVD on the matrix to get a closed-form estimation of the PA parameters in the MIMO system. Since the normalized first-order nonlinear coefficients are assumed equal to 1, the execution steps of PA nonlinear coefficients estimator can be summarized as:
- (1)
- (2)
- Reshape the into the matrix , then perform SVD on , where is a submatrix consisting of the th to th rows of the matrix .
- (3)
- Estimate the nonlinear coefficients of jth transmitting antenna as follows:where and are the first column and first element of , respectively.
3.2. The NLS Approach
Bearing in mind the received signal in Equation (4) for MIMO multipath transmission system, we can now further expand the expression with a series of nonlinear equations due to the existence of product term of the nonlinear coefficient and the channel coefficient . As a consequence, the problem of nonlinear coefficients estimation can thus be alternatively transformed into a NLS optimization one when introducing a training sequence with length N.
In order to get a more robust solution, we choose to solve a constrained NLS optimization problem with independent variables, and the cost function can be given by:
where denotes 2-norm. is the vector consisting of the independent variables and can be described as , in which and are respectively as
with
is the regularization. denotes the residual function: with , that is,
with
According to [29], the regularized Gauss–Newton iterative method is introduced here to figure out , i.e.,
with
The superscript “H” denotes conjugate transposition, and is a unit matrix. is the Jacobian matrix of , that is, the first-order derivative of with respect to .
In general, given the Jacobian matrix with full column rank, one can apply the regularized Gauss–Newton method in Equation (21) to optimize problem Equation (15) and can eventually obtain the optimal solution . In addition, the appropriate regularization factor can improve the condition number of the inverse matrix in Equation (22), which guarantees the robustness of the NLS optimization.
4. Practical Discussions on the Proposed Approaches
As mentioned in Section 3, we can get a closed-form solution for the problem of nonlinear coefficient estimation through the LMM approach. Alternatively, an iterative NLS approach can also be applicable to extract PA parameters from observations. However, in practice, there are two main factors that affect the accuracy of our proposed algorithms. The first factor is the case where the order of PA model is mismatched between the transmitting and receiving ends. The second one is the case where the matrix and the Jacobian matrix are rank-deficient. In the next Section 4.1 and Section 4.2, we first theoretically analyze the impact of the mismatched model. After that, we present the rank-deficient condition of the and matrix in Section 4.3.
4.1. Overdetermined Order of the PA Model
In this subsection, we consider the impact of the overdetermined order of the PA model on the estimation accuracy of the nonlinear coefficients. Assume that all the PAs of an emitter actually have the same model order as P. If we obtain an overdetermined order of the PA model beforehand, e.g., with , the expected observation of may be formulated as instead. Since equals , the estimation of can thus be expressed as follows:
where denotes a matrix that is populated by the ath to the bth order versions of training sequence, and denotes a vector that is populated by the corresponding ath to the bth order nonlinear coefficients. Some numerical examples for the construction process are also provided in Appendix A.
Note that the th to the th order the nonlinear coefficients and should be all zeros in this case, then, we have , which is equivalent to the unbiased estimation of the , and the additive white noise has no effect on the unbiasedness of the estimation results. Therefore, we can conclude that, if the order of the PA model is overdetermined, the estimation of the nonlinear coefficients obtained by the LMM approach is still unbiased.
4.2. Underdetermined Order of the PA Model
In the sequel, we attempt to analyze the case that the order of the PA model is underdetermined, i.e., is lower than the actual P. It is easy to understand that now equals , so that the estimation of can be written as:
Attention must be paid to non-zero in Equation (24) due to the non-zero nonlinear PA coefficients through the th to the Pth order. The resulting is a biased estimation w.r.t. and the estimate bias equals .
Furthermore, if we define a guess as:
Guess 1.
If the training squences are discrete amplitude communication symbols such as PSK and QAM, then
whereis a constant matrix withand.
Then, the estimate bias of the nonlinear PA coefficients can be given as the following Proposition 1.
Proposition 1.
If Guess 1 holds true, the estimate bias of the nonlinear PA coefficients obtained by SVD according to Equation (14) is shown as
Proof of Proposition 1.
See Appendix B. □
Therefore, we can conclude that, when the order of the PA model is underdetermined, the bias term of each nonlinear coefficient is related to training sequence and the higher-order nonlinear coefficients. In addition, the high-order nonlinear coefficients (i.e., to ) are still unknown.
4.3. Rank Deficiency Condition of the Proposed Approaches
As mentioned earlier, it is impossible to determine a unique solution for the LLS problem in Equation (12) when the matrix is rank-deficient. In addition, for the NLS problem in Equation (15), it is also hard for the regularized Gauss–Newton method in Equation (21) to find the global optimal solution when the Jacobian matrix is rank-deficient at every . However, since QAM is employed by all emitters, the training sequence has only a limited level of amplitude. We find that the rank attributes of and are both associated with the maximum order of the PA model. The specific relationship can be revealed by Proposition 2 as follows.
Proposition 2.
Given QAM symbols with M modulus values as the training sequence and the maximum P order of the PA model, the matrix is rank-deficient and the Jacobian matrix is also rank-deficient at every , if .
Proof of Proposition 2.
See Appendix C. □
According to the Proposition 2, the and are full rank as long as the amplitude type of signal is sufficient. Therefore, our proposed approach can be applied in some single-carrier communication systems with higher order QAM modulation such as 16-QAM, 64-QAM and 256-QAM, which have 3, 9, and 32 different modulus values, respectively. Actually, it appears that our proposed approaches are readily suitable for other popular wireless communication systems, such as MIMO-OFDM systems, where there will be no rank-deficient problem of and in nature since the amplitude of the transmitted signal is generally continuous. Moreover, it is not necessary to estimate the channel order in a MIMO-OFDM system due to its ability to resist multipath effects, which will make the proposed approach more practical.
5. Error Rate Analysis For Classification
In this paper, we apply a minimum error probability (MEP) criterion [30] based on Bayesian theory to classify different emitters, and the RFF feature of each emitter is composed of the estimated nonlinear coefficients and can be expressed as follows:
with
where .
Here, we take the case where there are two emitters as an example to give the derivation of the decision criteria, and the binary hypothesis test model can be considered as
where denotes the category i, ; is composed of the residual additive Gaussian noise in the estimations of the nonlinear coefficients and we assume that each element of obeys a Gaussian distribution with a zero mean and a variance of ; and are respectively the mean vectors of the estimated feature vector for the two emitters, which can be obtained from the samples collected offline. Thus, the decision rule can be derived based on MEP criterion as follows:
where the test statistic is and the decision threshold is .
For simplicity, if we assume that the variables in are independent of each other, then the test statistic , for the i-th emitter, the mean is as , and the variance is as with being the k-th element of . As a result, with the assumption of equally probable hypotheses, the average misclassification rate based on MEP criterion can be derived as
where and . When x increases, decreases.
As for the case where the estimations of the nonlinear coefficients are unbiased, the mean values of the RFF feature for the two emitters are readily as
with
where is the nonlinear coefficient of the i-th emitter. However, for the case of biased estimations, , where
with
being the mean of the biases with in the estimation of RF fingerprint features. Therefore, according to Equation (31), the average misclassification rate for this case can be obtained by:
where is the k-th element of and
Therefore, we can conclude as follows:
- (1)
- The decreases as the variance of the additive noise decrease.
- (2)
- The decreases as the difference between the mean values of the RF fingerprint feature for the two emitters increases, which indicates that the PA parameters of each emitter should be designed to be as different as possible in a bid to achieve better performance.
- (3)
- According to Equation (31), as for a fixed P, more nonlinear coefficients are used as features will make the larger, which obviously leads to better classification performance.
- (4)
- According to Equation (36), when there are biases in the estimations, the additional terms and may cause to decrease compared to the case where there is no bias.
More generally, as for K () emitters, with the assumption of equally probable hypotheses, the average misclassification rate based on MEP criterion can be represented as
where is the average correct classification rate; indicates the discriminant domain of the kth class and it shows as Equation (39)
Therefore, the can be obtained by solving the multiple integrals in Equation (40)
where with ( and ), and is a standard deviation similar to the in Equation (31).
6. Numerical Results
6.1. Simulation Setting
In the following simulations, if not specified, we use a MIMO channel with Rayleigh multipath fading model, and the number of paths L is set to 2. The training sequences are QAM symbols with for proper complexity and performance trade-off. The regularization factor is set to 0.05 for the trade-off between the variance and bias in the estimation of NLS approach. The complex nonlinear coefficients lead to AM–AM and AM–PM distortion, where the AM–AM distortion is mainly caused by the and , and higher order intermodulation distortion is usually ignored [28,31]. Generally, the actual communication system has specific requirements for the out-of-band spectral emission level of RF signals. Therefore, for the rationality of PA parameters in reality, we select the PA parameters that AM–AM characteristic obeys the method in [28,31] and the AM–PM is obtained by slightly adjusting the phase of the parameter in [20]. The nonlinear PA coefficients are displayed in Table 1, and it has been verified that the out-of-band emission level of the amplified signals is about 40 dBr, which meets the requirement of general agreement.
In all experiments, we use the Normalized Mean Squared Error (NMSE) to evaluate the estimation accuracy of the nonlinear coefficients, i.e.,
where , is the estimation of the , and denotes the Mathematical Expectation.
6.2. Simulation Results
6.2.1. The Impact of SNR
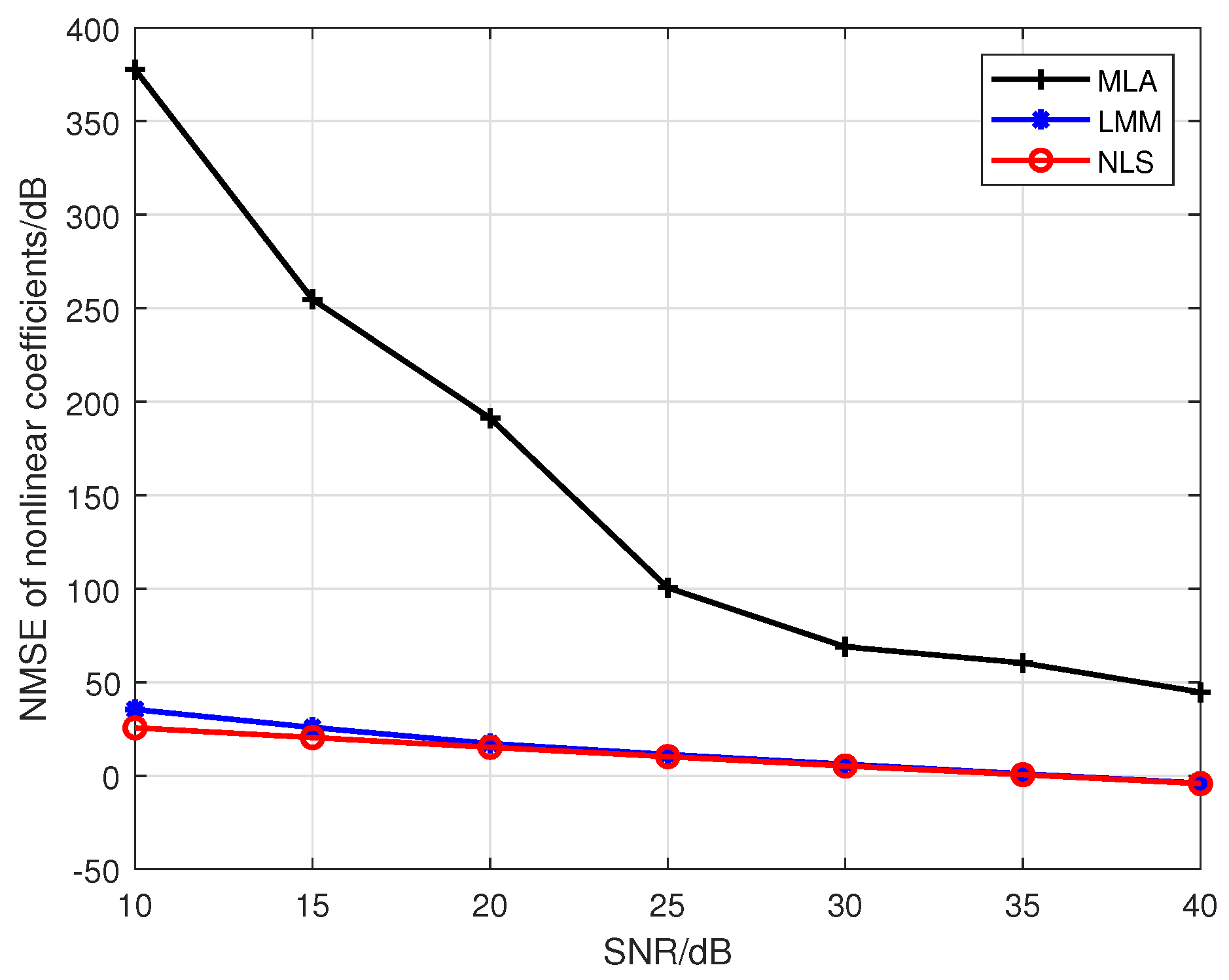
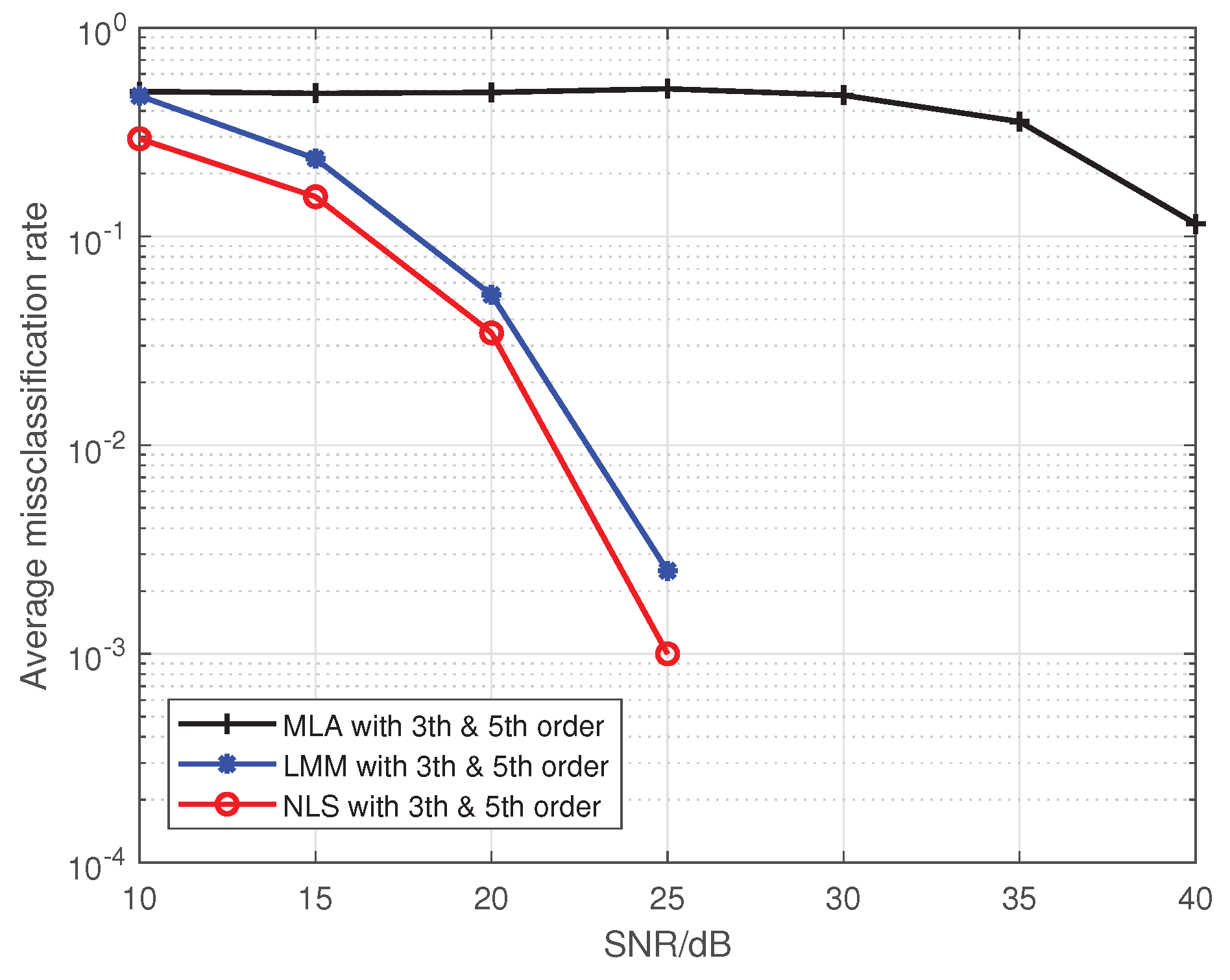
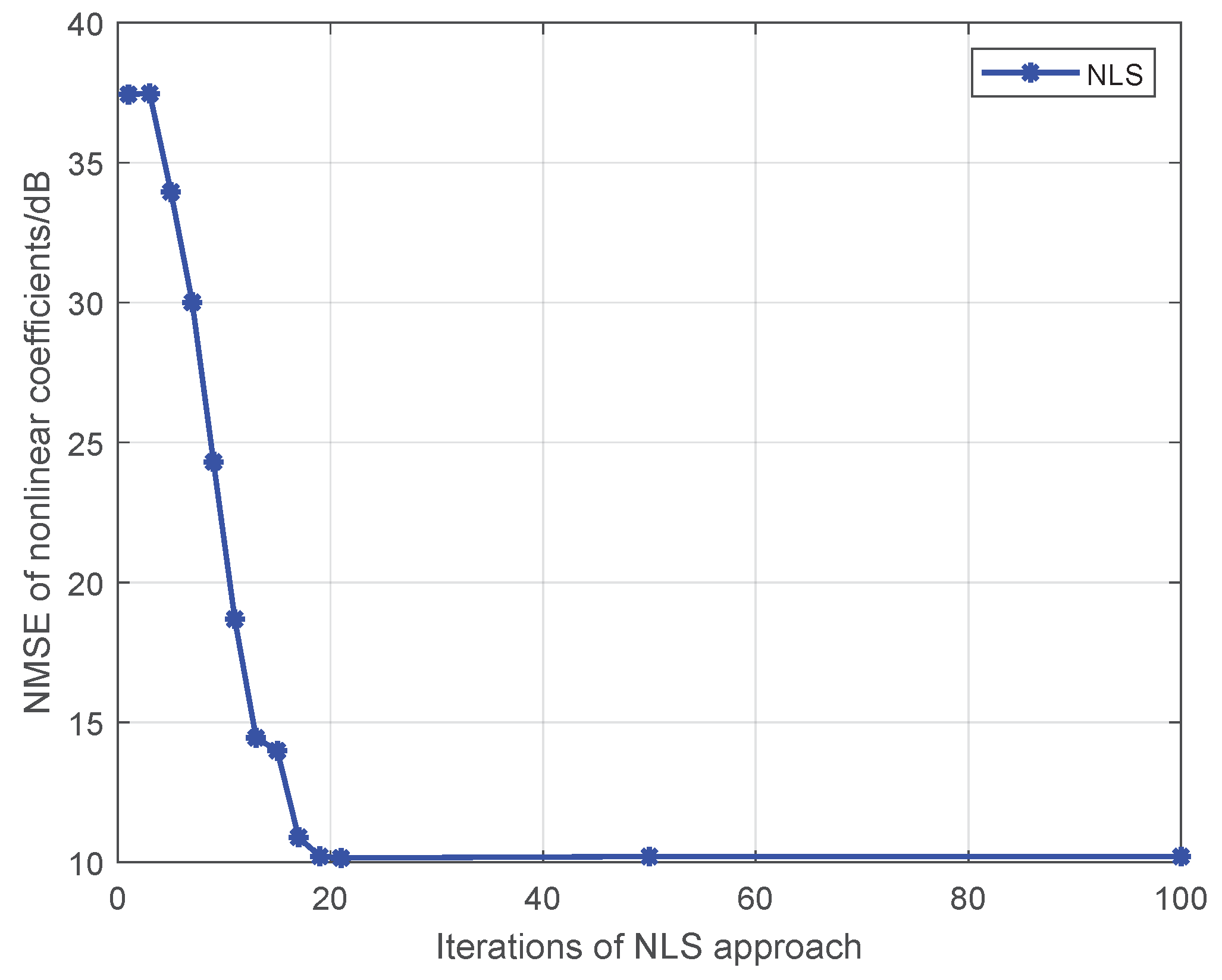
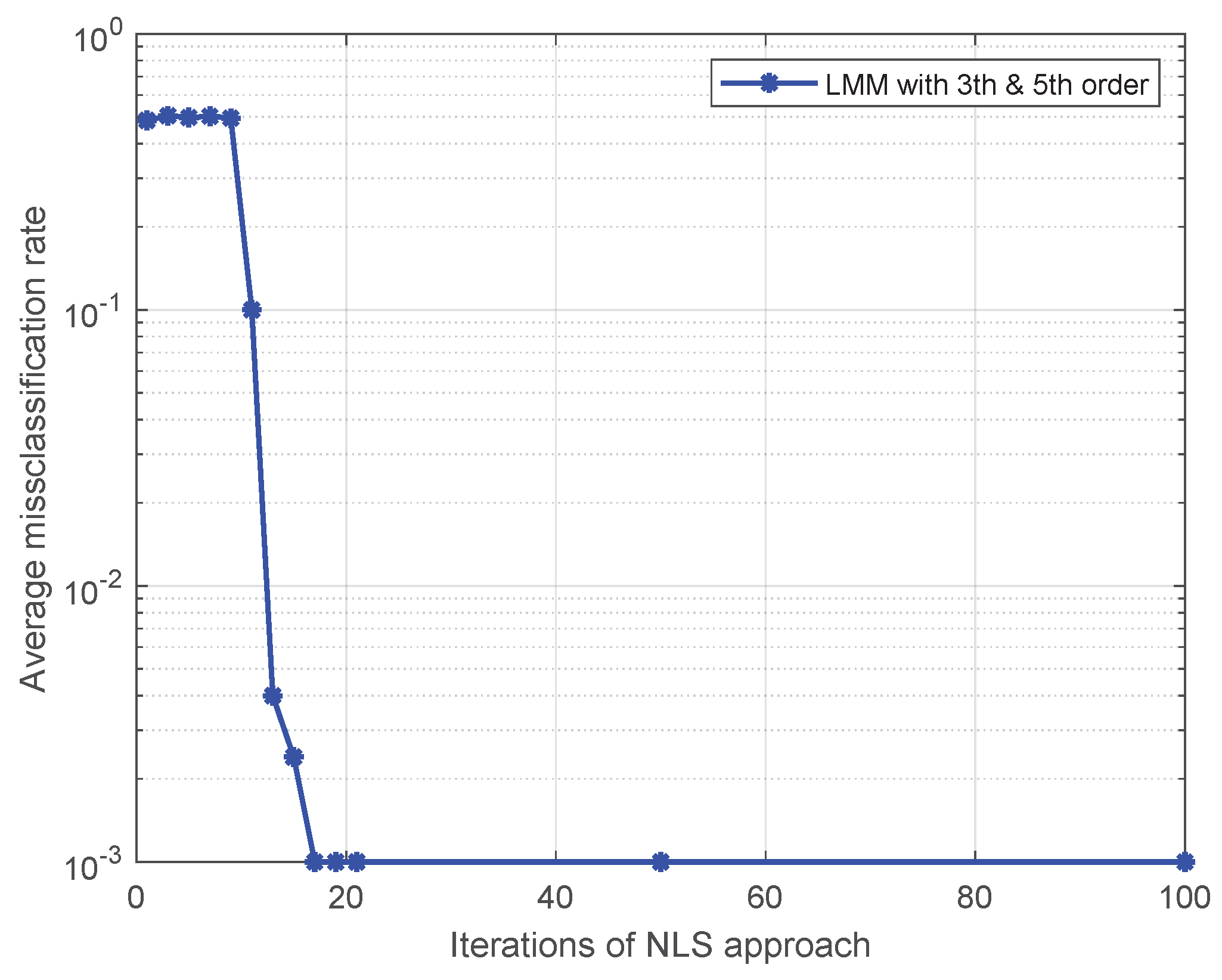
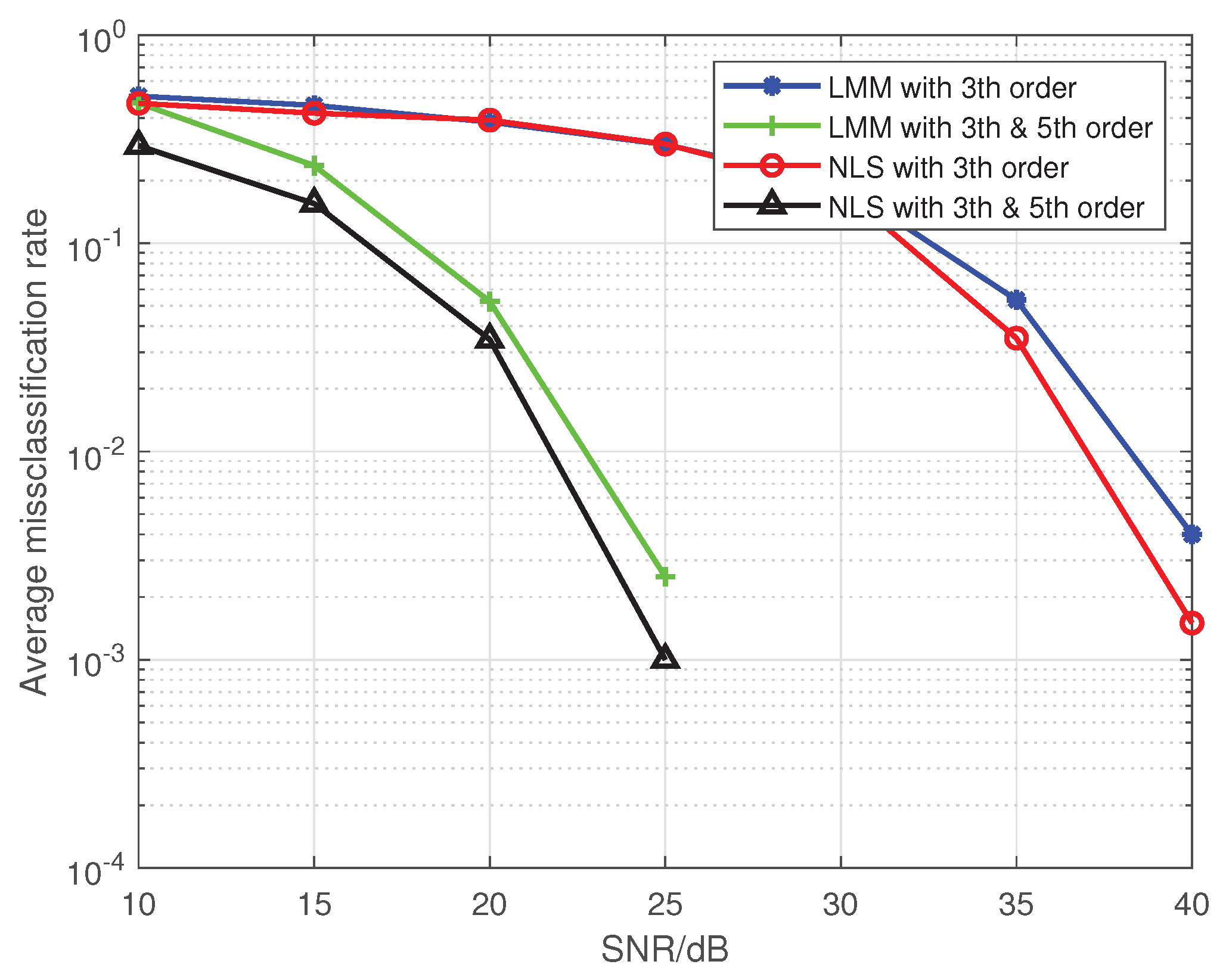
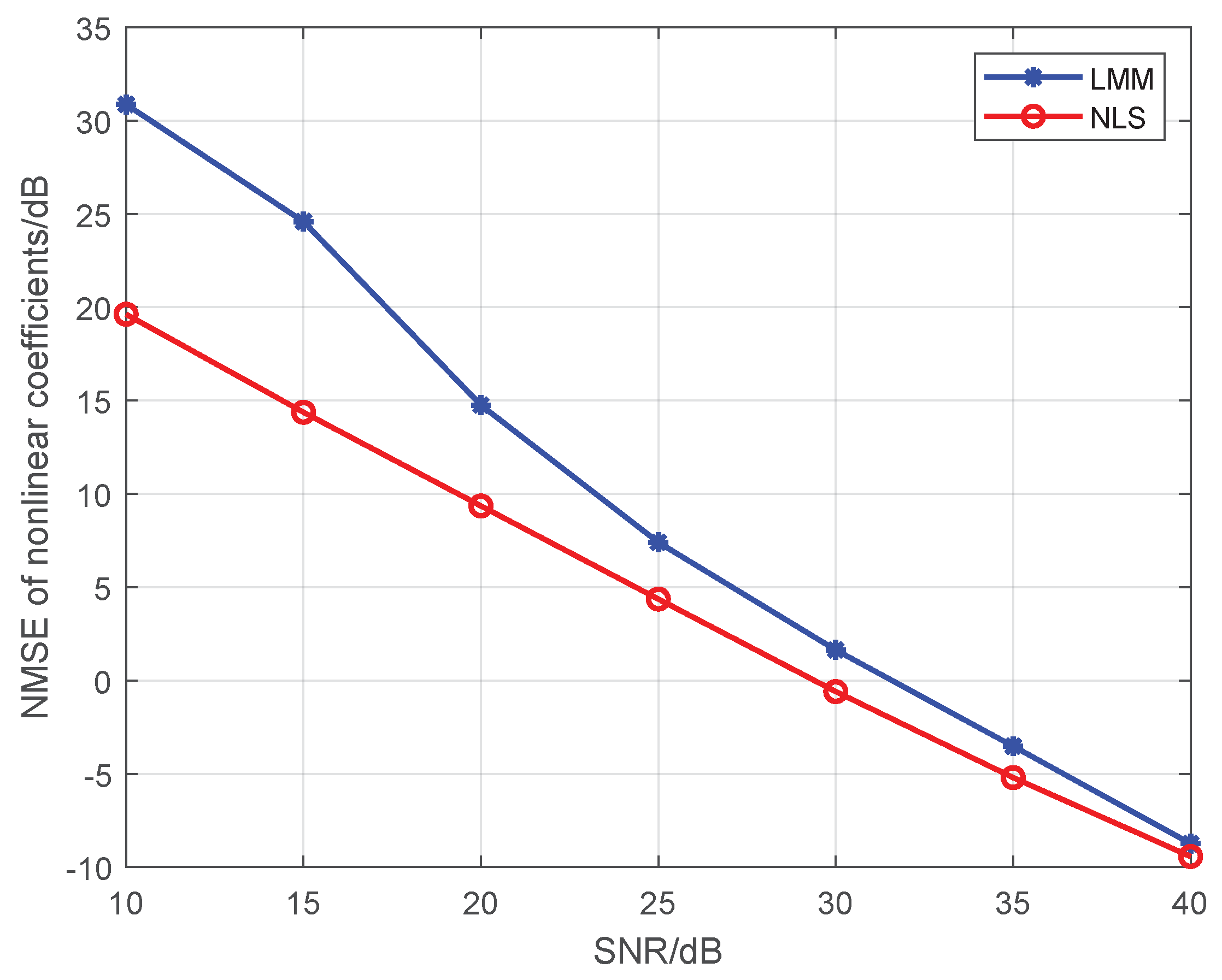
Note that Liu’s algorithm in [19] assumes all PAs in one emitter are the same. To facilitate the comparison of the proposed approaches with Liu’s algorithm, we extend Liu’s algorithm to be suitable for our MIMO scenario. For brevity, we use the name Modified Liu Algorithm (MLA) to represent the modified version in the following. Here, we set P to 5, and the training sequence is 16-QAM symbols. At first, we give comparisons among the MLA, LMM, and NLS in Figure 1 and Figure 2, where the third-order and fifth-order coefficients are combined as a classification feature, from which one can see that the performance of the LMM and NLS are apparently better than that of MLA, especially at low signal to noise ratio (SNR) regime. One possible reason lies in that when P equals 5 and the training sequence is composed of 16-QAM symbols, the and are both full column rank, whereas the matrix populated by the training sequence for the initial estimation of MLA method is rank-deficient regardless of how long the training sequence is. In addition, we notice that the NLS approach also performs better than the LMM one, which is because the introduction of regularization during the process of optimization. Furthermore, in order to explore the impact of iterations on performance of NLS approach, when SNR is 25 dB, we give some results in Figure 3 and Figure 4 to demonstrate the convergence speed of NLS approach, where 19 iterations are needed to obtain the optimal solution.
In Figure 5, we fit a PA with , when third-order and fifth-order coefficients are combined as a classification feature, the classification performance is better than when only the third-order coefficient is used. This confirms the analysis that, for a fixed P, features with more nonlinear coefficients can effectively improve classification performance in Section 5. In the next simulations, if not specified, we use the estimated third-order and fifth-order coefficients together as classification features.
Moreover, in Figure 6 and Figure 7, we present results of the proposed approaches under a MIMO scenario; as you can see, more RF channels bring more nonlinear coefficients, which is beneficial to improve classification performance. Here, for convenience, we take the nonlinear coefficients of Emitter2 and Emitter4 in Table 1 as those of the first 4-antenna emitter, and take the nonlinear coefficients of Emitter3 and Emitter6 in Table 1 as those of the second 4-antenna emitter.
6.2.2. Identification for Multiple Emitters
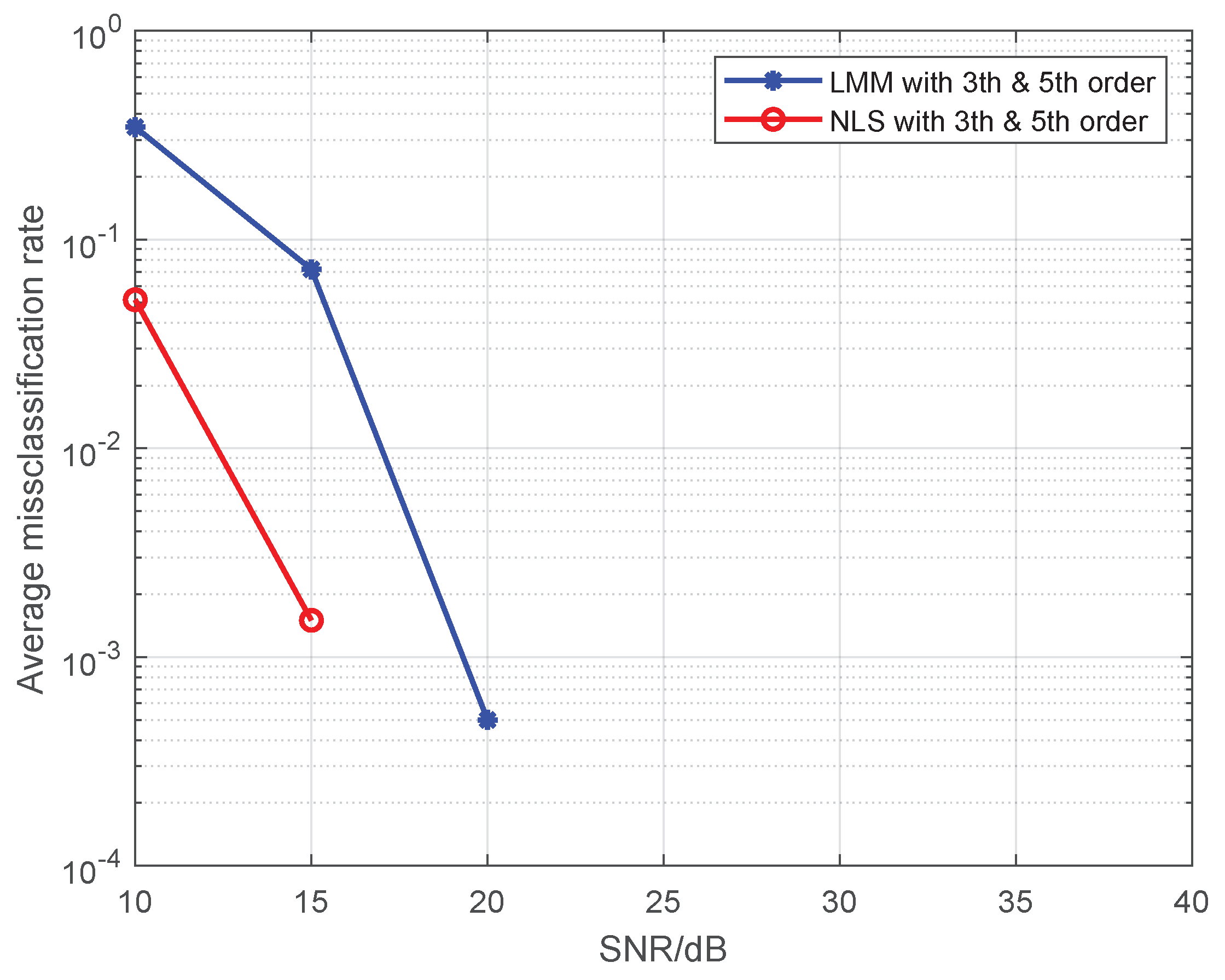
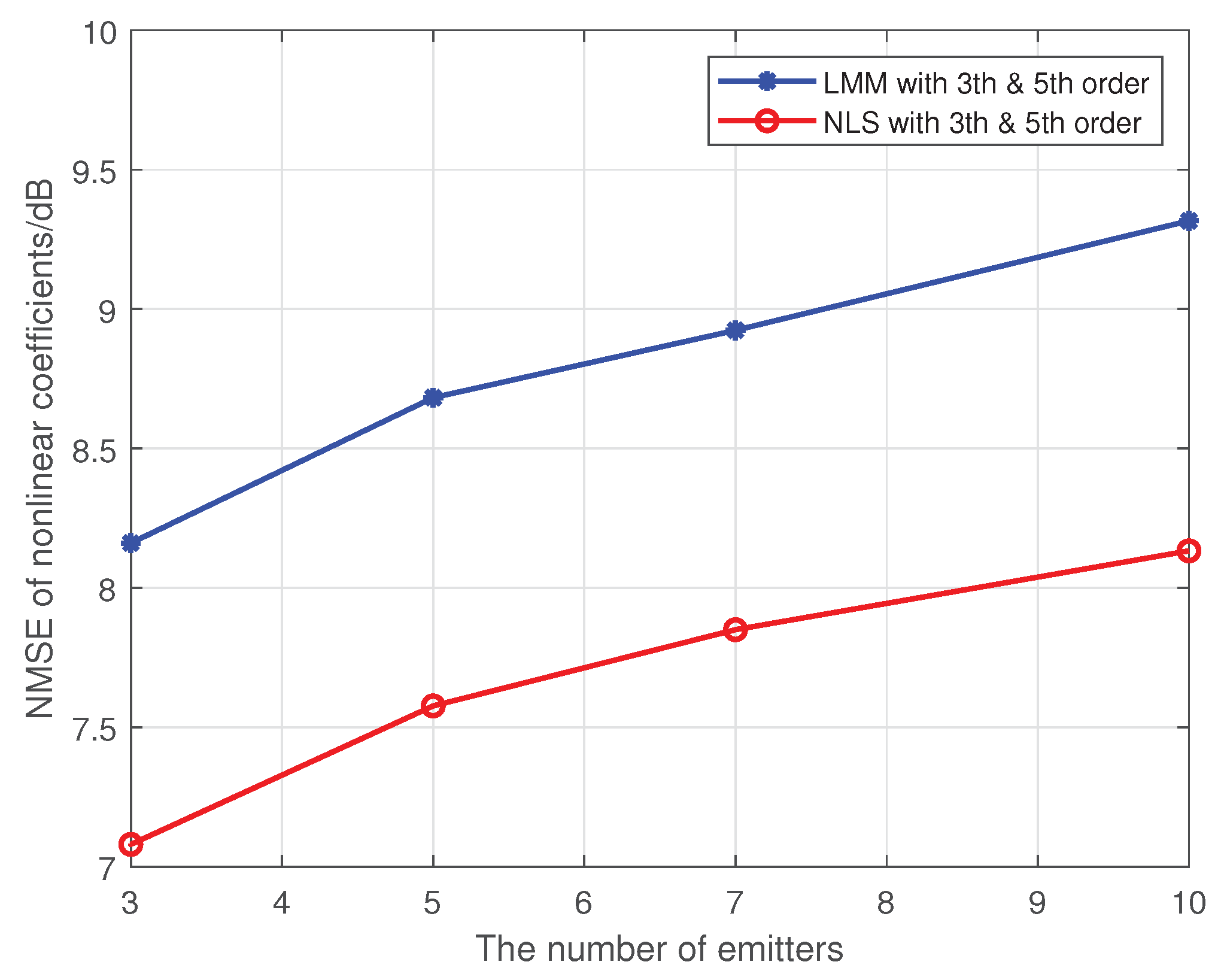
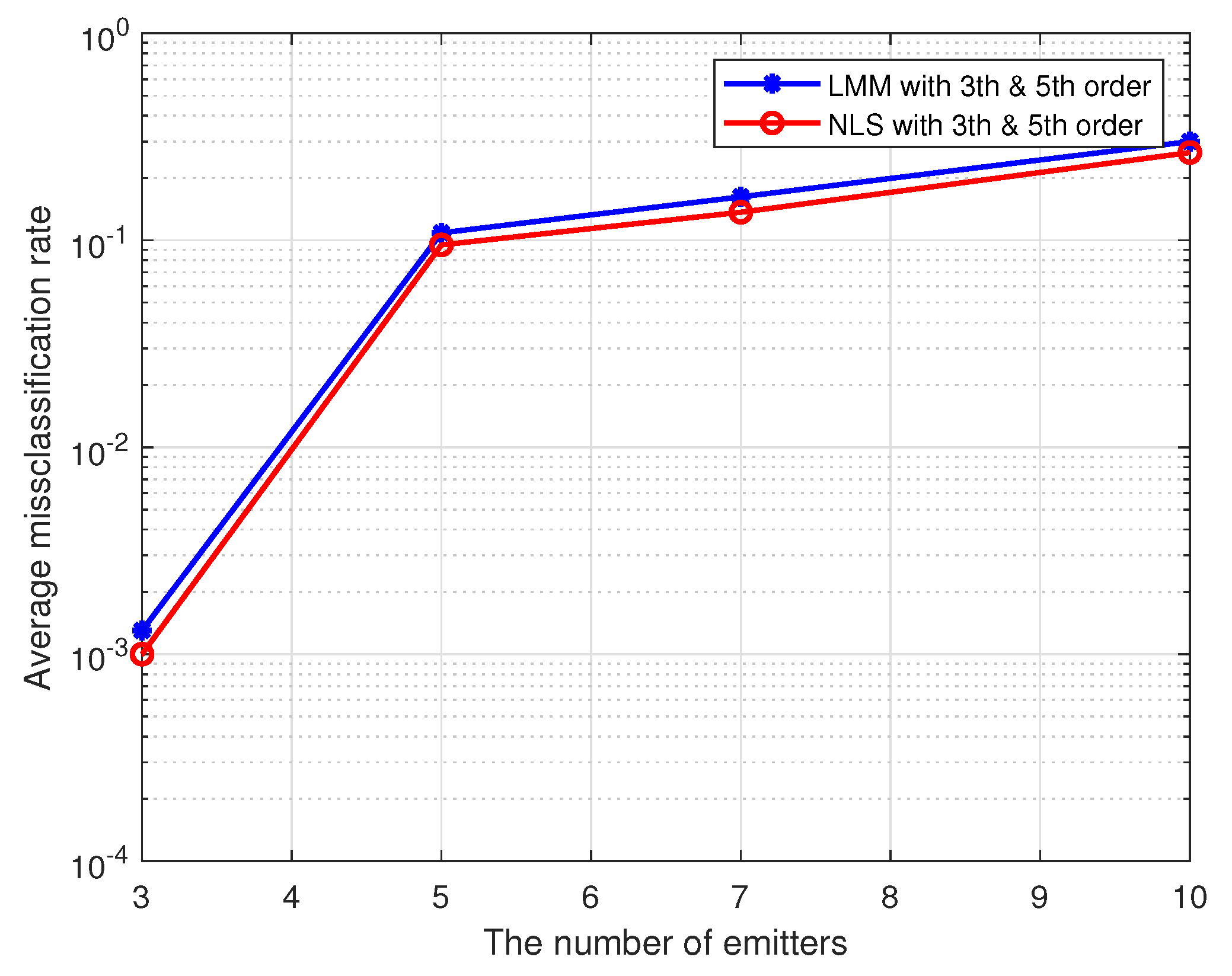
In this simulation, we test the performance of proposed methods under the multi-user case. Here, we set the maximum order of PAs in individual emitters to 5, and 16-QAM symbols are used as the training sequence. The detailed nonlinear coefficients of each emitter are displayed in Table 1. The results are shown in Figure 8 and Figure 9, where the SNR is set to 25 dB, and each method is performed by 1000 Monte Carlo simulations.
As we can see from the Figure 8 and Figure 9, our proposed approaches are also robust and applicable to the multi-user case, and average misclassification rates of them are both increased as the number of emitters increased. Obviously, the greater the difference in nonlinear characteristics between emitters, the higher the resolution of the proposed approaches. In this simulation, as far as the nonlinear coefficients in Table 1 are concerned, the proposed approaches can resolve up to seven emitters at most.
6.2.3. The Confirmation of Practical Discussions
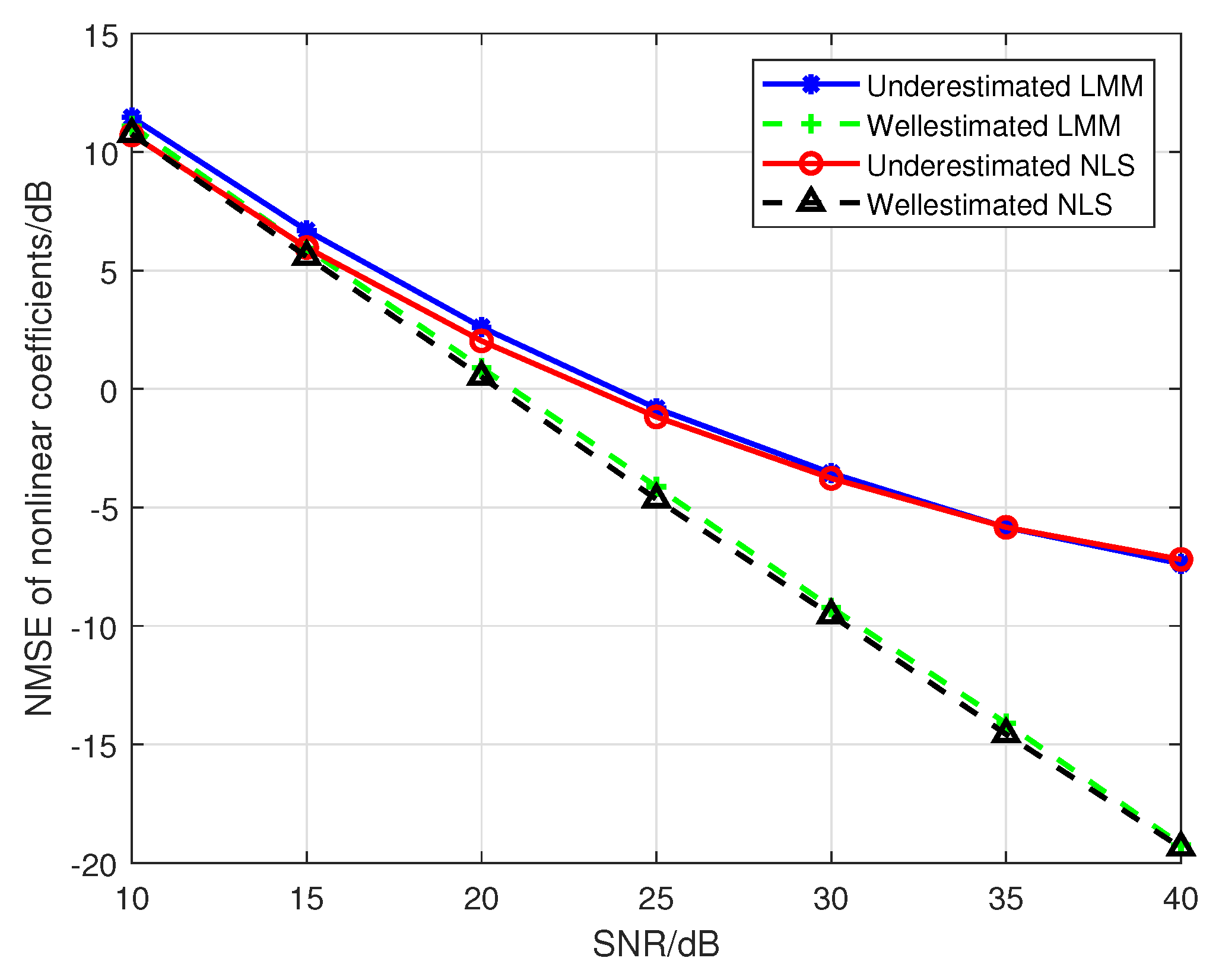
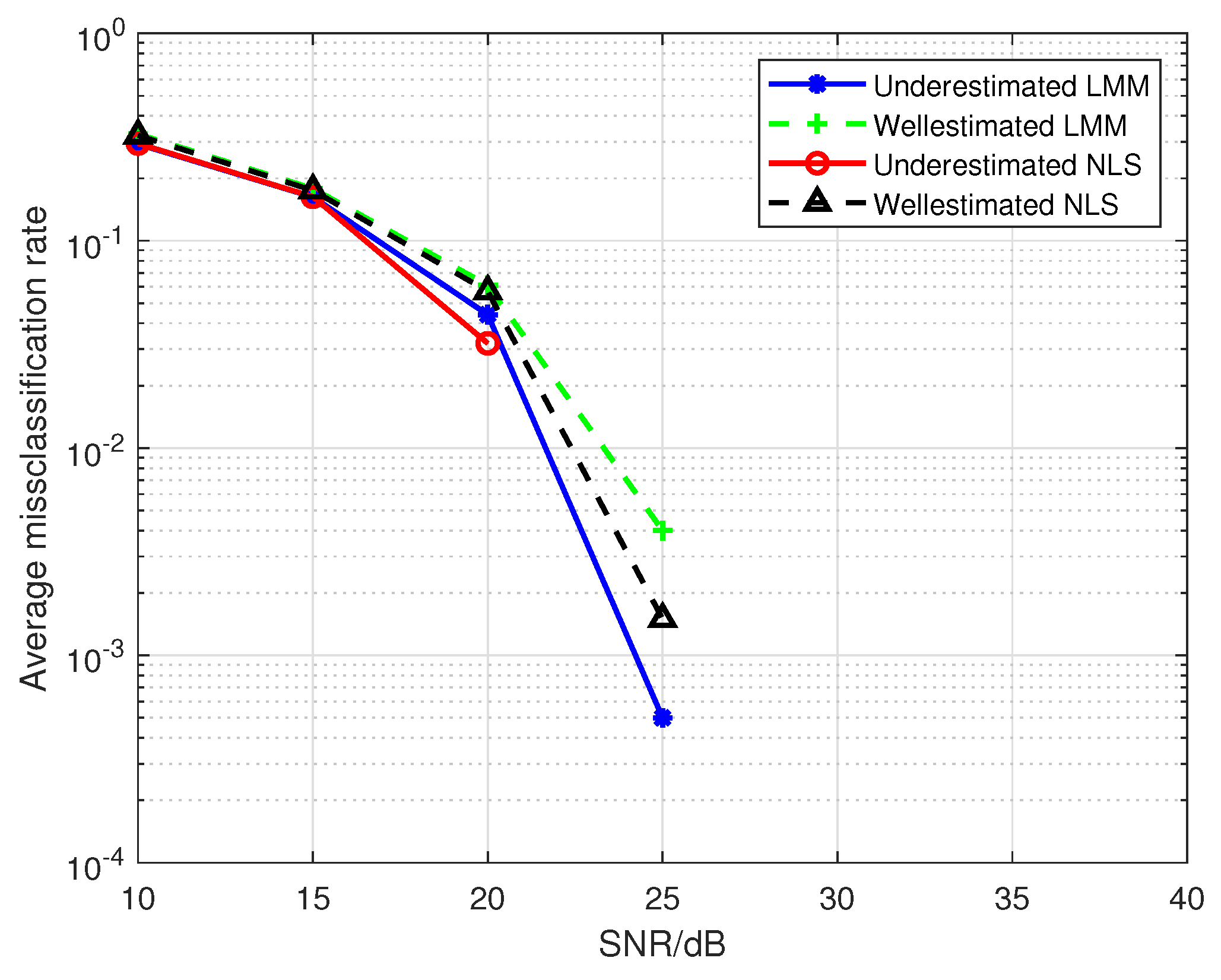
Hereafter, we set the number of emitters to 2 (i.e., emitter1 and emitter2), the maximum order of the PA model P to 5. The first to fifth order parameters are selected from Table 1. When we use a PA model with to fit the nonlinearity of the emitters, the results of Figure 10 confirm the conclusion in the Section 4.2 that the underdetermined order of the PA model indeed leads to the biases in the estimations of PA parameters. However, the results in Figure 11 show that the classification performance can be improved by using the biased estimations as features, which reveals that the biases in Equation (36) can make the difference between the classification features of emitters larger. Where the training sequence is 16-QAM symbols, the estimated third-order are used as classification features, and the legends “Well-estimated LMM(NLS)” in Figure 10 and Figure 11 denote that results obtained from a well-determined order of PA model with .
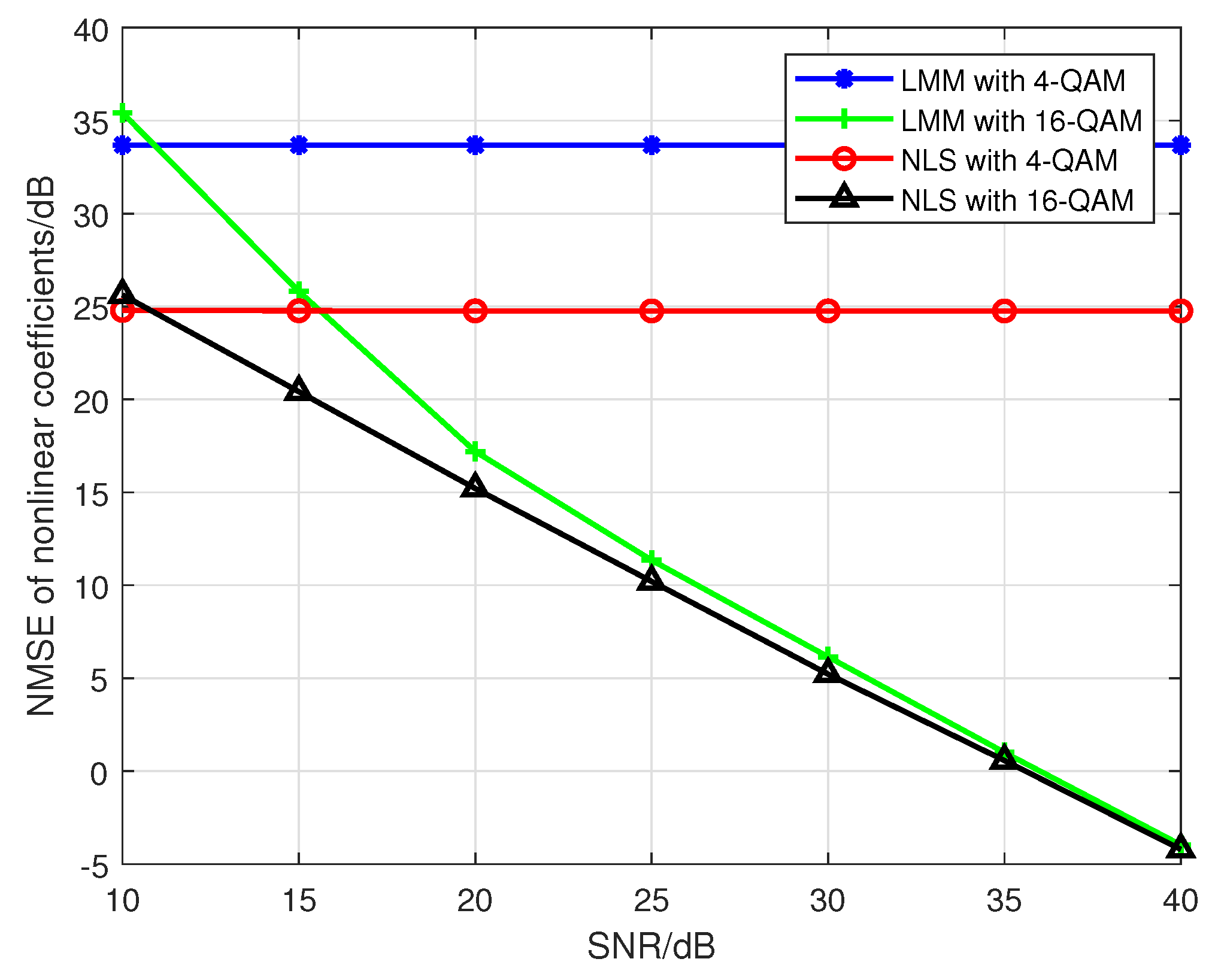
Then, according to the Proposition 2, when we use a PA model with to fit the nonlinearity of emitters, if 4-QAM, which is a constant modulus modulation, is adopted by each emitter, then it is clear that the and are both rank-deficient, and there is no unique solution in this case. Here, we compare the estimation accuracy of when taking 4-QAM and 16-QAM symbols as training sequence; the results are shown in Figure 12, which obviously corroborates the correctness of Proposition 2.
6.3. Experimental Results
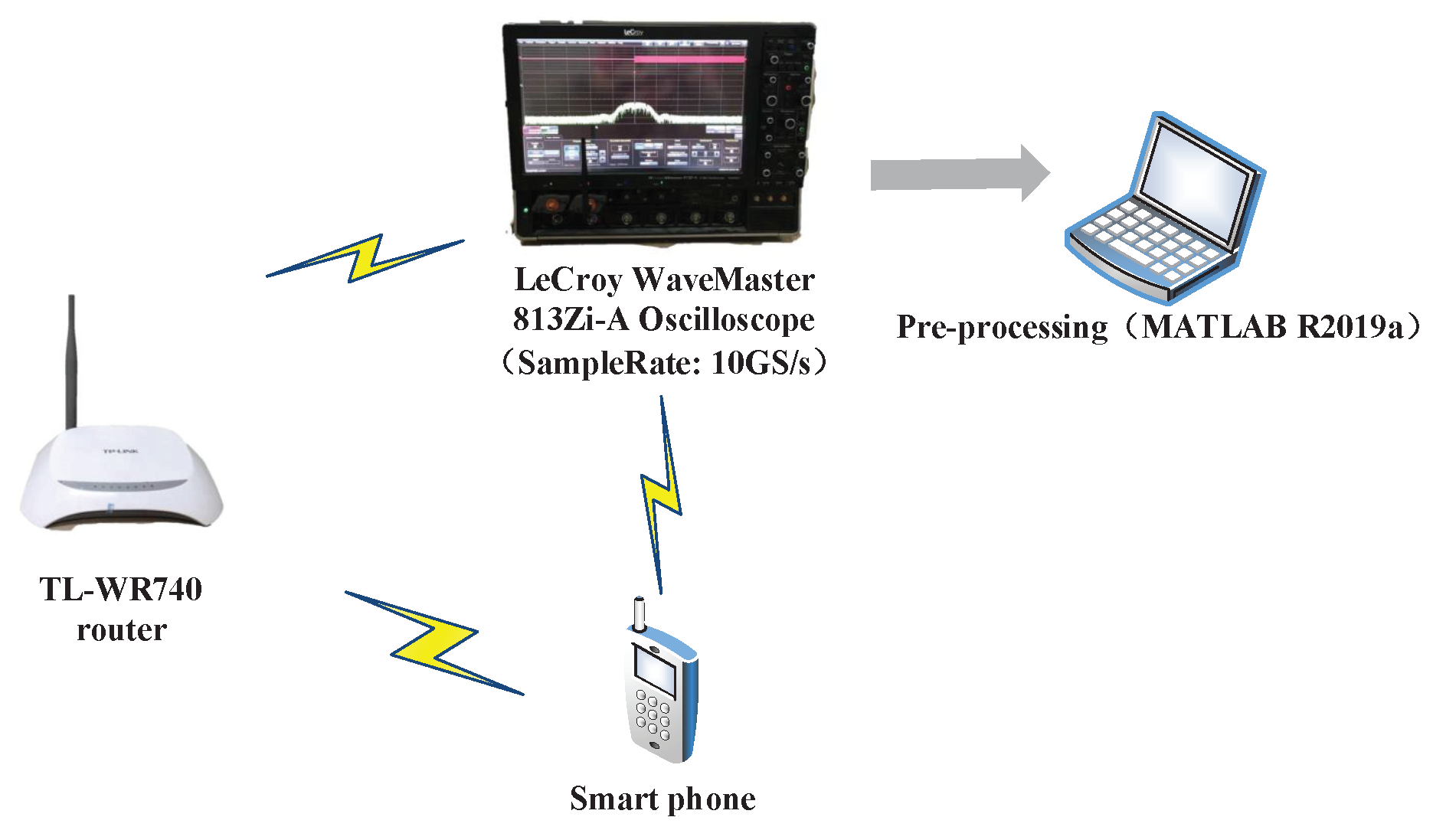
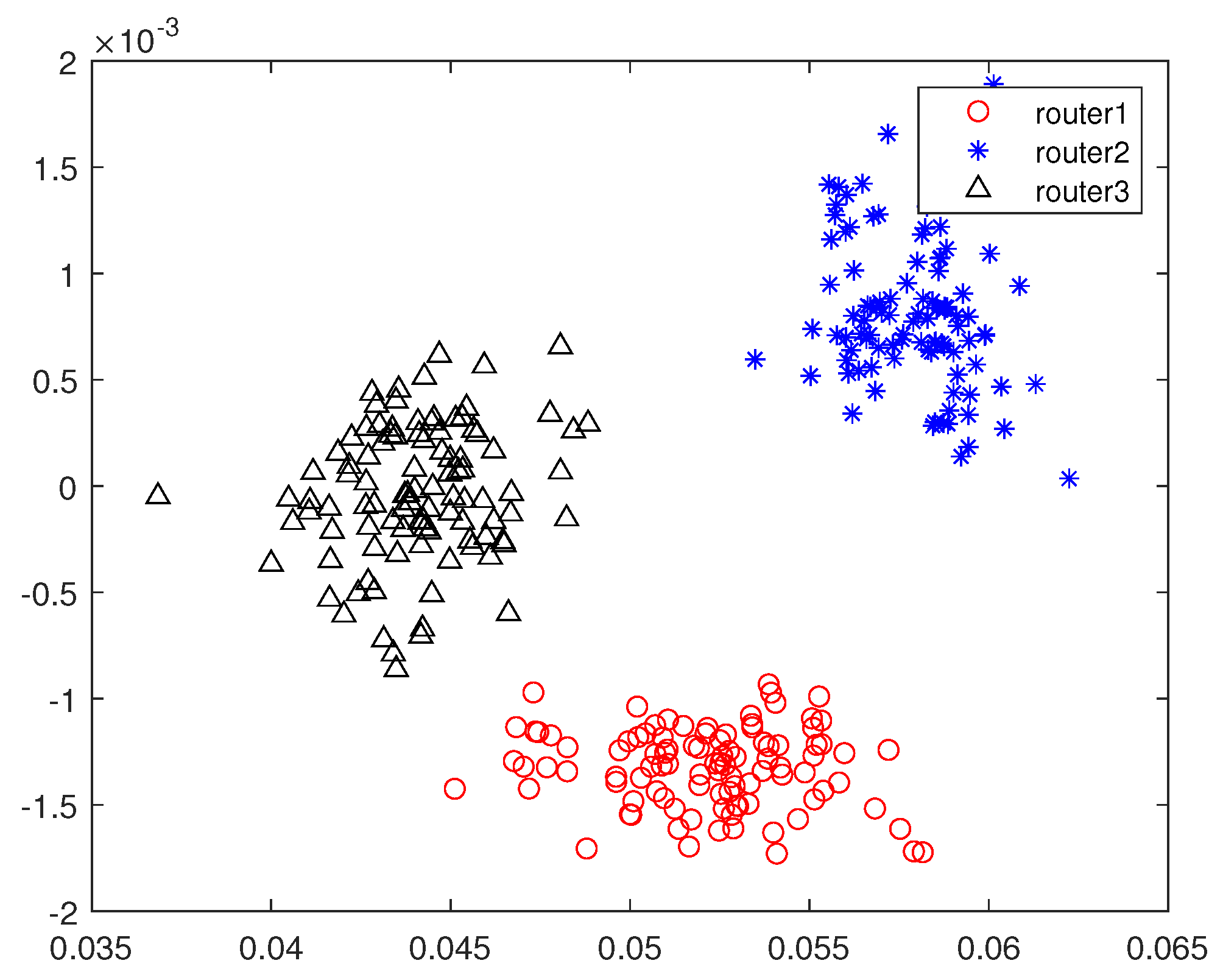
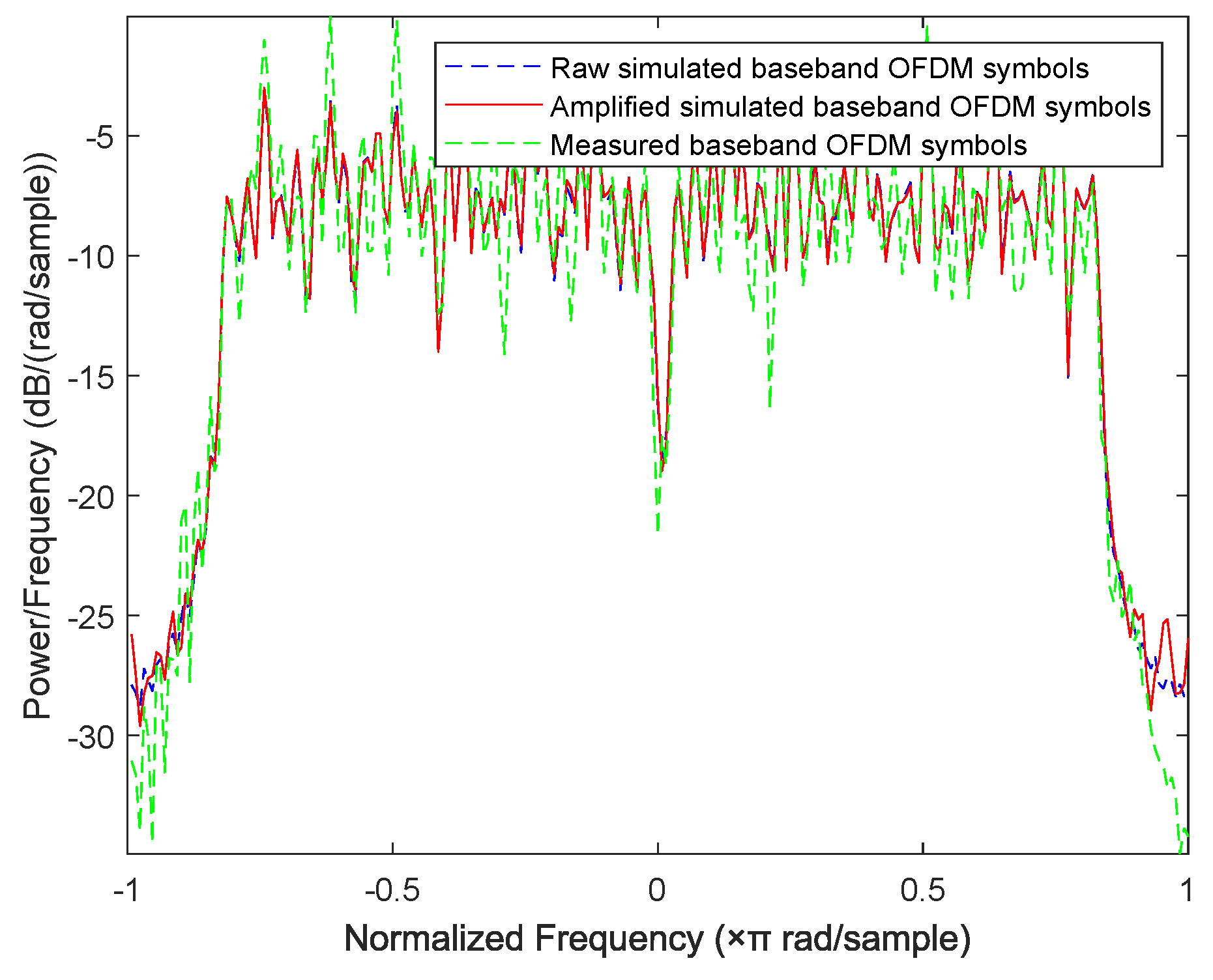
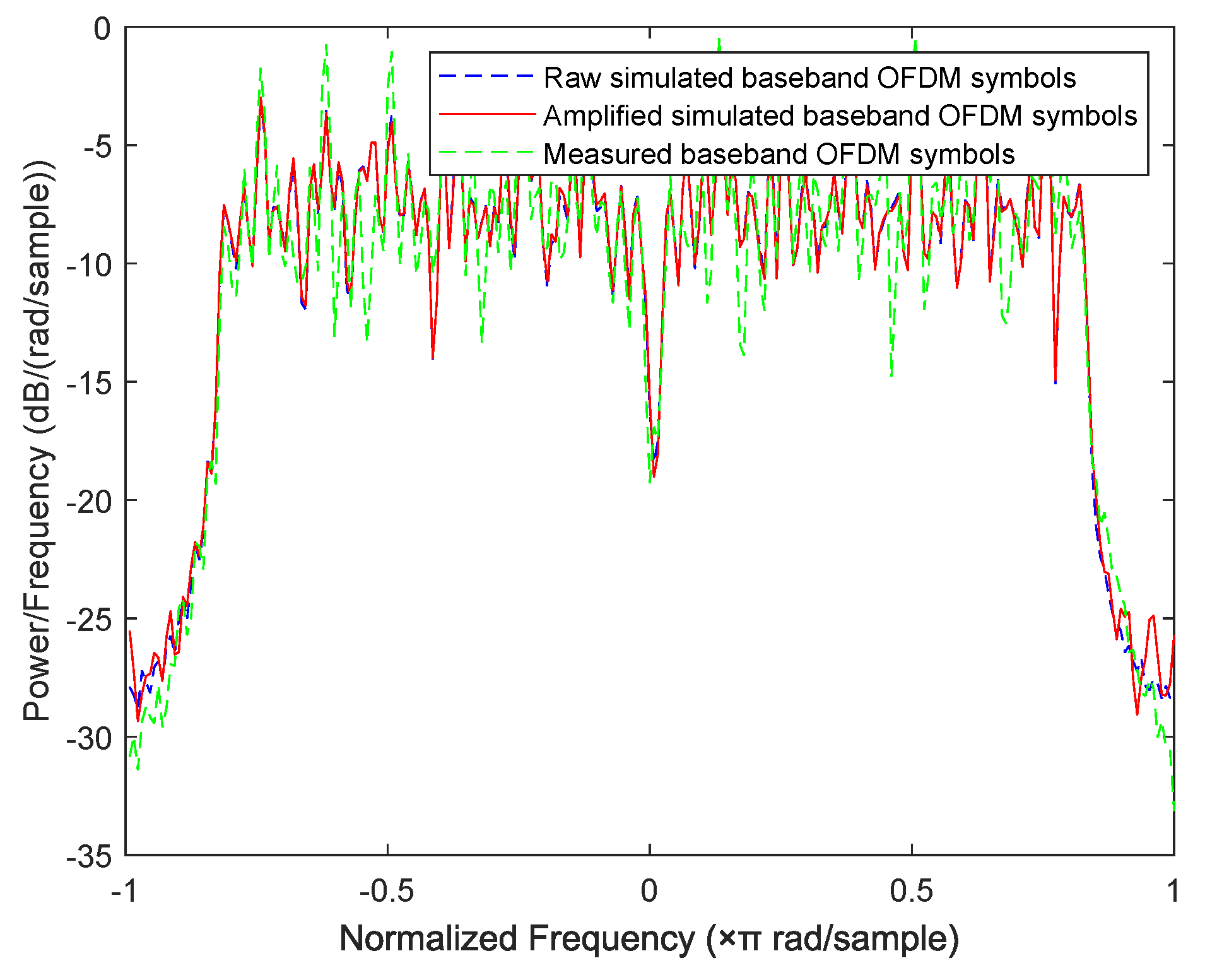
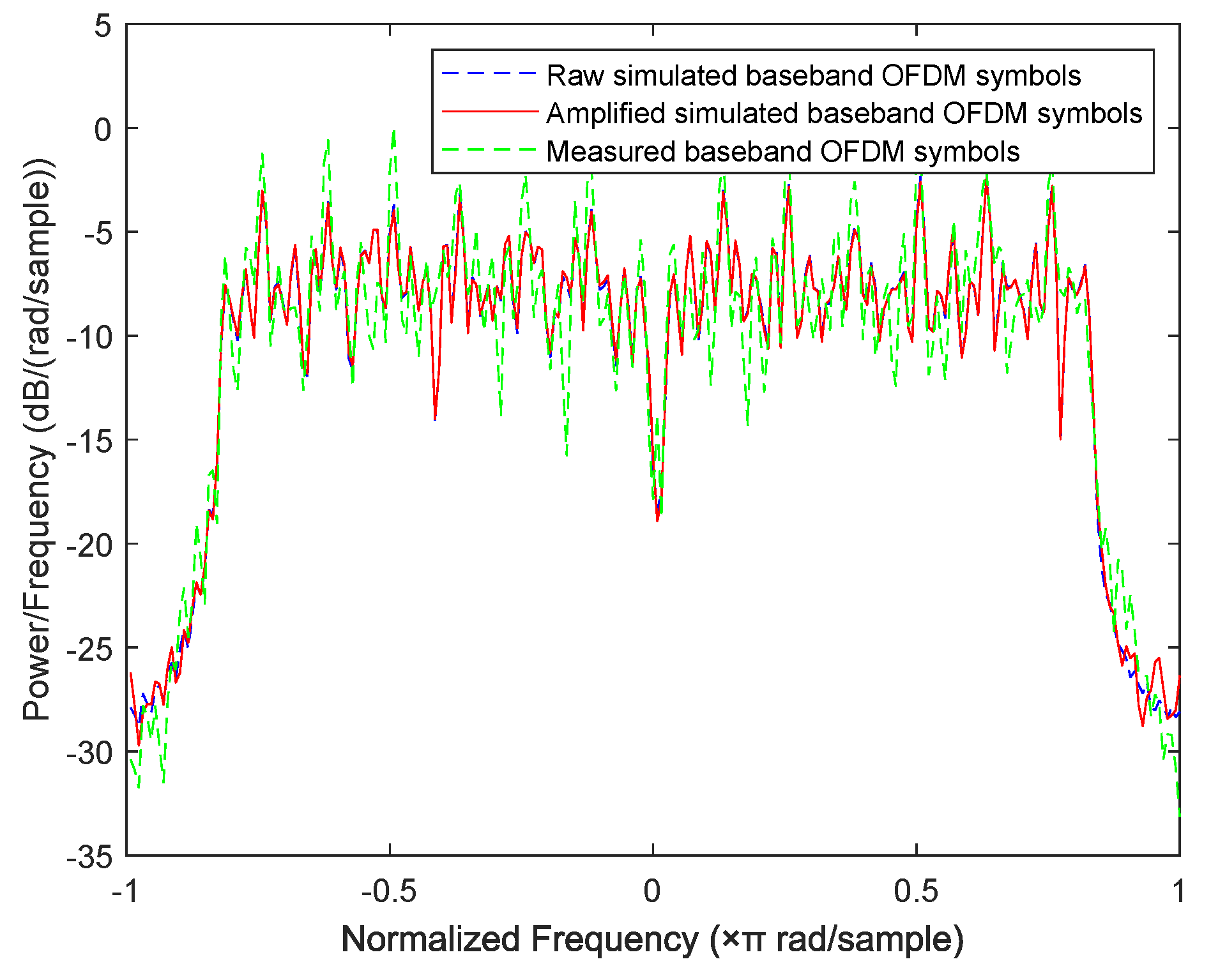
In this subsection, we design a preliminary verification experiment to explore the effectiveness of our proposed approaches in reality. Due to the limitation of single-channel acquisition, we limit the proposed approaches in the SISO-OFDM system and validate them in a 802.11.g-based wireless local area network (WLAN) that is very common in real life. Therefore, we build an experiment platform, which is shown in Figure 13, to collect the measured router data. In this platform, we first use a LeCroy WaveMaster 813Zi-A Oscilloscope (Chestnut Ridge, NY, USA) equipped with a single antenna to acquire the RF signals from three TL-WR740 routers communicating with a smart phone on the 2.412 GHz channel, respectively. In this experiment, we use the extended NLS approach as an example to estimate nonlinear coefficients of each router, here we use the “wlan toolbox” in MATLAB R2019a (MathWorks, Natick, Massachusetts, USA) to perform pre-processing such as timing, synchronization, and de-frequency offset on the acquired RF signals. Since the nonlinearity of PA mainly caused by , we set . Finally, a MEP-based classifier is used to identify the individual router. Note that the memoryless polynomial model may not be able to describe the nonlinearity of the PA in a broadband WLAN system, whereas Table 2 indicates that, according to the estimated PA coefficients in Figure 14, the mean is far greater than the variance for each router, thus the three routers are identifiable based on the extended NLS approach. Moreover, the average misclassification rates of the three routers are all 0. Therefore, we can conclude that the mismath of PA model does not affect classification performance. In addition, we also compare the power spectral density among measured data and simulated data for three routers in Figure 15, Figure 16 and Figure 17, respectively, where the legend “Measured baseband OFDM symbols” denotes downconverted acquired RF signals, the legend “Amplified simulated baseband OFDM symbols” denotes simulated baseband OFDM signals amplified by the PA with measured nonlinear coefficients, and the legend “Raw simulated baseband OFDM symbols” denotes raw simulated baseband OFDM signals, all of their power being normalized. In order to explain the results in Figure 15, Figure 16 and Figure 17, we calculate the NMSE between the PSDs of “Amplified simulated baseband OFDM symbols” and that of “Measured baseband OFDM symbols” for each router, and the NMSEs of three routers are, respectively, , and dB, which reveal that the PSD of the signal reconstructed by using the estimated PA coefficient can well fit that of the measured signal.
7. Conclusions
This paper investigates the SEI scheme for multiple-antenna communication emitters, using PA nonlinearity as RFF features with the assumption that all PAs of a multiple-antenna emitter are independent from each other. Both the LMM and the NLS approaches are proposed to estimate the nonlinear coefficients in association with the memoryless polynomial PA model, where a closed-form solution can be obtained by the LMM approach, and the alternative NLS approach achieves better performance by adopting a regularized Newton–Gauss scheme. Practical discussion on the PA model mismatch is presented, and some theoretical results about the estimate bias and rank-deficient condition are provided to guide the design and implementation of the SEI over MIMO channels. In addition, an error rate analysis is also introduced for the MEP classifier. Simulation results demonstrate that the proposed approaches outperform the other existing schemes, especially in the rank-deficient case, and are effective to deal with SEI in MIMO communication systems. Moreover, the proposed approaches are verified to be effective on a 802.11.g-based experiment platform.
Author Contributions
Conceptualization, X.X.; methodology, J.L.; software, J.L.; validation, J.L., X.X.; formal analysis, J.L.; resources, X.X.; data curation, J.L.; writing—original draft preparation, J.L.; writing—review and editing, X.X.; supervision, X.X.; project administration, X.X.; funding acquisition, X.X.
Funding
This research was funded in part by ZTE Corporation (Shenzhen, China) (WiFi Interference Source Recognition) and the National Natural Science Foundation of China (No. 61271272).
Acknowledgments
The authors would like to thank Yingke Lei from the National University of Defense Technology for his valuable discussion on PA modeling introduced in this paper. The authors also appreciate anonymous reviewers for their helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this appendix, we give a simplified example for the composition of the matrix in the proposed LMM approach. Here, the parameters are assigned as and . Therefore, the matrix should be as
where is a zero vector, , and , , is as follows:
Then, is
which is actually the same as .
As for the case where the order of the PA order is overdetermined, note that the parameters are assigned as and , whereas equals 7, then is equivalent to the matrix in Equation (A3). and are respectively written as
where
and , , , and are respectively expressed by:
Similarly, as for the case that the order of the PA model is underdetermined, be aware that the parameters are assigned as and , whereas equals 5, then is equivalent to the matrix in Equation (A3). and are equivalent to the matrix and in Equation (A4a) and Equation (A4b), respectively.
The examples for and are shown as
and
where denotes a diagonal function, is a unit matrix, and .
Appendix B
In this appendix, we first give the basis of Guess 1.
Proof.
At first, we discuss the case where the parameters are set to be and , respectively. As mentioned in Appendix A, and can be expressed as block matrices as follows:
We thus have
where
with being the inverse of a matrix. Then, according to the mathematic formula for the inverse of the block matrix, we get
with
Therefore, if we guess that
which is actually valid for 16-QAM symbols in practice, then the matrix is a block diagonal matrix. As a result, for arbitrary J and L, we can guess that
□
Next, we give the proof of Proposition 1.
Proof.
When the order of the PA model is underdetermined (i.e., ), according to Equation (24), ignoring the white noise term, if the Guess 1 holds true, then the jth submatrix of in Equation (13) can be expanded into
where and denote the and that are populated by the ath to the bth order PA parameters, respectively. is populated by the th to the Pth order PA parameters and the matrix in Equation (A19), whose ith element is as .
Since the is a matrix with rank 1, the first left singular vector of obtained by SVD is equivalent to the eigenvector corresponding to the non-zero eigenvalue of the matrix . Thus, the of Equation (A20) can be computed by the eigenvalue decomposition (EVD) of , which is as
then, according to Equation (14), we have biased as
Eventually, we can obtain the biases as shown in Equations (26a)–(26c). □
Appendix C
In this appendix, we give the proof for Proposition 2.
At first, we prove that, when the training sequence, consisting of QAM symbols, has M different modulus values and the maximum order of the PA model is P, if , then the matrix is rank deficient.
Proof.
At first, we consider a matrix , which is
when , is actually a Vandermonde matrix and its determinant can be expressed as
Therefore, if the level of the amplitude of is less than , then equals 0 and is definitely singular.
When , if the level of the amplitude of is less than , then any sub-matrix of is a singular Vandermonde matrix, that is, any sub-matrix of is column linear correlation, then is also column linear correlation, which means is a column rank-deficient matrix.
Now, we consider the matrix in Equation (A2), here , and it can be rewritten by
where is a reversible diagonal matrix. In addition, is equivalent to the matrix when we set , . Since the training sequence is composed of QAM symbols that have only M different moduli values, then any sub-matrix of is a singular Vandermonde matrix when . Thus, is column rank-deficient, and, according to Appendix A, is also column rank-deficient. Eventually, and are both column rank-deficient due to the linear correlation among their column vectors. However, when , as long as N is large enough, then at least one of sub-matrix of the is a non-singular Vandermonde matrix. Thus, the is a column full-rank matrix, and is also a column full-rank matrix. □
Next, we prove that when the training sequence, QAM symbols, has M different modulus values and the maximum order of the PA model is P, if , then the matrix is rank-deficient at every .
Proof.
When the number of transmit antennas is J, then the Jacobian matrix can be computed from in Equation (15) as
with
where and are respectively shown as
Note that and are
respectively, and
If we define a matrix as
then, as for , a sub-matrix of , composed of the elements corresponding to the jth transmit antenna, which is
Similar to the discussion of the matrix in Equation (A23), as for the matrix ,
when the training sequence is composed of QAM symbols that have only M different moduli values and , if , then there are at least identical row vectors in any sub-matrix of , which means that any sub-matrix of is a singular matrix, and the column vectors of it are also considered to be linear correlation. As a result, is also column linear correlation, that is, the is a column rank-deficient matrix.
Since the matrix has been proved to be a column rank-deficient matrix, the matrix is obviously column rank-deficient, and there must be a set of coefficients that are not all equal to 0. Consequently, the following formula holds
where denotes the -th column of the matrix .
Therefore, for the matrix , there are also a set of coefficients that are not all equal to 0 to make the following expression valid, i.e.,
with
Then, we can conclude that the matrix is rank-deficient and the matrix is also rank-deficient. Thus, the Jacobian matrix is also rank-deficient because is the elementary column transformation of the matrix and the elementary column transformation does not change the rank of the matrix. Eventually, the the Jacobian matrix in Equation (A26) is rank-deficient. □
References
- Rehman, S.U.; Sowerby, K.W.; Coghill, C. Radio-frequency fingerprinting for mitigating primary user emulation attack in low-end cognitive radios. IET Commun. 2014, 8, 1274–1284. [Google Scholar] [CrossRef]
- Suski, W.C., II; Temple, M.A.; Mendenhall, M.J. Radio frequency fingerprinting commercial communication devices to enhance electronic security. Int. J. Electron. Secur. Digit. Forensics 2008, 1, 301–322. [Google Scholar]
- Ureten, O.; Serinken, N. Wireless security through RF fingerprinting. Can. J. Electr. Comput. Eng. 2007, 32, 27–33. [Google Scholar]
- Ureten, O.; Serinken, N. Bayesian detection of Wi-Fi transmitter RF fingerprints. Electron. Lett. 2005, 41, 373–374. [Google Scholar] [CrossRef]
- Choe, H.C.; Poole, C.E.; Andrea, M.Y. Novel identification of intercepted signals from unknown radio transmitters. In Proceedings of the Wavelet Applications II, Orlando, FL, USA, 6 April 1995; Volume 2491, pp. 504–518. [Google Scholar]
- Hawkes, K.D. Transient Analysis System for Characterizing RF Transmitters by Analyzing Transmitted RF Signals. U.S. Patent 5,758,277, 26 May 1998. [Google Scholar]
- Du, L.; Liu, H.; Bao, Z. Radar HRRP target recognition based on higher order spectra. IEEE Trans. Signal Process. 2005, 53, 2359–2368. [Google Scholar]
- Zhang, X.D.; Shi, Y.; Bao, Z. A new feature vector using selected bispectra for signal classification with application in radar target recognition. IEEE Trans. Signal Process. 2001, 49, 1875–1885. [Google Scholar] [CrossRef]
- Reising, D.R.; Temple, M.A. WiMAX mobile subscriber verification using Gabor-based RF-DNA fingerprints. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 1005–1010. [Google Scholar]
- Reising, D.R.; Temple, M.A.; Oxley, M.E. Gabor-based RF-DNA fingerprinting for classifying 802.16 e WiMAX mobile subscribers. In Proceedings of the 2012 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 7–13. [Google Scholar]
- Klein, R.W.; Temple, M.A.; Mendenhall, M.J. Application of wavelet-based RF fingerprinting to enhance wireless network security. J. Commun. Netw. 2009, 11, 544–555. [Google Scholar] [CrossRef]
- Klein, R.W.; Temple, M.A.; Mendenhall, M.J. Application of wavelet denoising to improve OFDM-based signal detection and classification. Secur. Commun. Netw. 2010, 3, 71–82. [Google Scholar] [CrossRef]
- Yuan, Y.; Huang, Z.; Wu, H. Specific emitter identification based on Hilbert-Huang transform-based time-frequency-energy distribution features. IET Commun. 2014, 8, 2404–2412. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, S.; Zhang, E. Specific Emitter Identification based on nonlinear complexity of signal. In Proceedings of the 2016 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Hong Kong, China, 5–8 August 2016; pp. 1–6. [Google Scholar]
- Polak, A.C.; Dolatshahi, S.; Goeckel, D.L. Identifying wireless users via transmitter imperfections. IEEE J. Sel. Areas Commun. 2011, 28, 1469–1479. [Google Scholar] [CrossRef]
- Brik, V.; Banerjee, S.; Gruteser, M. Wireless device identification with radiometric signatures. In Proceedings of the 14th ACM International Conference on Mobile Computing and Networking, San Francisco, CA, USA, 14–19 September 2008; pp. 116–127. [Google Scholar]
- Huang, Y.; Zheng, H. Radio frequency fingerprinting based on the constellation errors. In Proceedings of the 2012 18th Asia-Pacific Conference on Communications (APCC), Jeju Island, Korea, 15–17 October 2012; pp. 900–905. [Google Scholar]
- Schubert, B.; Liszewski, J.; Keusgen, W. Identification of the volterra kernels of nonlinear power amplifiers. In Proceedings of the 2009 International Conference on Communications, Circuits and Systems, Milpitas, CA, USA, 23–25 July 2009; pp. 767–771. [Google Scholar]
- Liu, M.W.; Doherty, J.F.; Keusgen, W. Wireless device identification in MIMO channels. In Proceedings of the 2009 43rd Annual Conference on Information Sciences and Systems, Baltimore, MD, USA, 18–20 March 2009; pp. 563–567. [Google Scholar]
- Liu, M.W.; Doherty, J.F. Nonlinearity estimation for specific emitter identification in multipath channels. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1076–1085. [Google Scholar]
- Li, D.; Jia, Y.; Li, Q. Identification and nonlinear model predictive control of MIMO Hammerstein system with constraints. J. Cent. South Univ. 2017, 24, 448–458. [Google Scholar] [CrossRef]
- Belkacem, O.B.H.; Ammari, M.L.; Bouallegue, R. Effect of Power Amplifier Nonlinearity on the Physical Layer Security of MIMO Systems. Wirel. Pers. Commun. 2017, 96, 5587–5601. [Google Scholar] [CrossRef]
- Zou, Y.; Raeesi, O.; Antilla, L. Impact of power amplifier nonlinearities in multi-user massive MIMO downlink. In Proceedings of the 2015 IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015; pp. 1–7. [Google Scholar]
- Fernandes, C.A.R. Nonlinear MIMO Communication Systems: Channel Estimation and Information Recovery Using Volterra Models. Ph.D. Thesis, Universit de Nice Sophia Antipolis, Nice, France, 2010. [Google Scholar]
- Wang, D.; Hu, A.; Chen, Y. An esprit-based approach for rf fingerprint estimation in multi-antenna ofdm systems. IEEE Wirel. Commun. Lett. 2017, 6, 702–705. [Google Scholar] [CrossRef]
- Wang, D.; Hu, A.; Peng, L. Energy Selected Transmitter RF Fingerprint Estimation in Multi-Antenna OFDM Systems. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar]
- Cai, K.; Li, H.; Mitola, J. Channel Identification of communication system with nonlinear power amplifier. In Proceedings of the 2013 47th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 20–22 March 2013; pp. 1–5. [Google Scholar]
- Wu, Q.; Testa, M.; Larkin, R. On design of linear RF power amplifier for CDMA signals. Int. J. RF Microw. Comput.-Aided Eng. 2015, 8, 283–292. [Google Scholar] [CrossRef]
- Eriksson, J.; Wedin, P.A.; Gulliksson, M.E. Regularization methods for uniformly rank-deficient nonlinear least-squares problems. J. Optim. Theory Appl. 2005, 127, 1–26. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley-Interscience: Hoboken, NJ, USA, 2000. [Google Scholar]
- Liu, C.; Xiao, H.; Wu, Q. Spectrum Design of RF Power Amplifier for Wireless Communication Systems. IEEE Trans. Consum. Electron. 2002, 48, 72–80. [Google Scholar]
Figure 1.
The comparison of the estimation accuracy among the MLA, LMM, and NLS.

Figure 2.
The comparison of the average misclassification rate among the MLA, LMM, and NLS.

Figure 3.
The impact of iterations on the estimation accuracy for the NLS approach.

Figure 4.
The impact of iterations on the average misclassification rate for the NLS approach.

Figure 5.
The impact of SNR on the average misclassification rate for two emitters.

Figure 6.
The impact of SNR on the estimation accuracy under a MIMO scenario.

Figure 7.
The impact of SNR on the average misclassification rate under a MIMO scenario.

Figure 8.
The impact of the number of emitters on the estimation accuracy for multiple transmitters.
Figure 8.
The impact of the number of emitters on the estimation accuracy for multiple transmitters.

Figure 9.
The impact of the number of emitters on the average misclassification rate for multiple transmitters.
Figure 9.
The impact of the number of emitters on the average misclassification rate for multiple transmitters.

Figure 10.
The impact of SNR on the estimation accuracy for a mismatched PA model.

Figure 11.
The impact of SNR on the average misclassification rate for a mismatched PA model.

Figure 12.
The impact of SNR on the estimation accuracy for rank-deficient approaches.

Figure 13.
The 802.11.g-based experiment platform.

Figure 14.
The scatter plot of the estimated 3rd order coefficients for three routers.

Figure 15.
Comparison of power spectral density between measured data and simulated data for router 1.
Figure 15.
Comparison of power spectral density between measured data and simulated data for router 1.

Figure 16.
Comparison of power spectral density between measured data and simulated data for router 2.
Figure 16.
Comparison of power spectral density between measured data and simulated data for router 2.

Figure 17.
Comparison of power spectral density between measured data and simulated data for router 3.
Figure 17.
Comparison of power spectral density between measured data and simulated data for router 3.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Nonlinear coefficients of the separate PA for each RF chain.
| Emitter1 | ||||
| Emitter2 | ||||
| Emitter3 | ||||
| Emitter4 | ||||
| Emitter5 | ||||
| Emitter6 | ||||
| Emitter7 | ||||
| Emitter8 | ||||
| Emitter9 | ||||
| Emitter10 |
Table 2.
The mean and variance of the estimated nonlinear coefficients in Figure 14 for the three routers.
Table 2.
The mean and variance of the estimated nonlinear coefficients in Figure 14 for the three routers.
| Router1 | Router2 | Router3 | |
|---|---|---|---|
| Mean | |||
| Variance |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lu, J.; Xu, X. Multiple-Antenna Emitters Identification Based on a Memoryless Power Amplifier Model. Sensors 2019, 19, 5233. https://doi.org/10.3390/s19235233
AMA Style
Lu J, Xu X. Multiple-Antenna Emitters Identification Based on a Memoryless Power Amplifier Model. Sensors. 2019; 19(23):5233. https://doi.org/10.3390/s19235233
Chicago/Turabian StyleLu, Jun, and Xiaodong Xu. 2019. "Multiple-Antenna Emitters Identification Based on a Memoryless Power Amplifier Model" Sensors 19, no. 23: 5233. https://doi.org/10.3390/s19235233
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.