Fast and Robust Monocular Visua-Inertial Odometry Using Points and Lines

State Key Laboratory of Virtual Reality Technology and Systems, School of Automation Science and Eletrical Engineering, Beihang University, Beijing 100191, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(20), 4545; https://doi.org/10.3390/s19204545
Submission received: 7 September 2019
/
Revised: 15 October 2019
/
Accepted: 17 October 2019
/
Published: 19 October 2019
(This article belongs to the Section Physical Sensors)
Abstract
:When the camera moves quickly and the image is blurred or the texture in the scene is missing, the Simultaneous Localization and Mapping (SLAM) algorithm based on point feature experiences difficulty tracking enough effective feature points, and the positioning accuracy and robustness are poor, and even may not work properly. For this problem, we propose a monocular visual odometry algorithm based on the point and line features and combining IMU measurement data. Based on this, an environmental-feature map with geometric information is constructed, and the IMU measurement data is incorporated to provide prior and scale information for the visual localization algorithm. Then, the initial pose estimation is obtained based on the motion estimation of the sparse image alignment, and the feature alignment is further performed to obtain the sub-pixel level feature correlation. Finally, more accurate poses and 3D landmarks are obtained by minimizing the re-projection errors of local map points and lines. The experimental results on EuRoC public datasets show that the proposed algorithm outperforms the Open Keyframe-based Visual-Inertial SLAM (OKVIS-mono) algorithm and Oriented FAST and Rotated BRIEF-SLAM (ORB-SLAM) algorithm, which demonstrates the accuracy and speed of the algorithm.
1. Introduction
Simultaneous Localization and Mapping (SLAM) [1,2,3] is used to incrementally estimate the pose of the mobile platform and simultaneously construct a map of the surrounding environment. Due to its ability to locate in an unknown environment, it is widely used in applications such as robot navigation [4,5,6] and Augmented Reality [7]. With the increasing demand for artificial intelligence and human-computer interaction, SLAM will play an increasingly important role in the future of science and technology. Robustness and real-time performance in challenging environments are two key factors in the application of this technology to engineering practice.
At present, the mainstream visual SLAM (vSLAM) scheme is divided into feature-based method [8,9,10], direct method [11,12,13], and semi-direct method [14] according to the way of using image information. Regarding the way of establishing the map, it is divided into sparse method [13], dense method [15], and semi-dense method [12]. The feature-based approach estimates the camera pose and constructs an environmental map by minimizing the reprojection errors observed and corresponding reprojection features. The most representative algorithms include Parallel Tracking And Mapping (PTAM) [9] and Oriented FAST and Rotated BRIEF-SLAM (ORB-SLAM) [10], which have achieved good performance in large scenes. The direct method does not need to extract salient features that can be repeatedly identified. Instead, it uses all the pixels with strong gradients in the image to optimize the pose by minimizing the photometric error to establish a dense or semi-dense environment map. Newcombe et al. proposed a completely straightforward method called Dense Tracking And Mapping (DTAM) [11]. DTAM tracks all the pixels of the entire image and builds a dense map of the environment that must be real-time on the GPU. Large-Scale Direct Monocular SLAM (LSD-SLAM) [12] is another dominant method in the direct approach. The core idea of LSD-SLAM follows the idea of semi-dense visual odometry. The semi-direct method only extracts features, does not calculate descriptors, does not perform feature matching, uses photometric error to establish data association between corresponding pixels, performs pose optimization, and uses the significant information in the image to establish sparse maps. Forster et al. proposed a more sparse semi-direct VO (SVO) [14]. It uses direct methods to track and triangulate pixels with high image gradients, but relies on a proven feature-based approach for joint optimization of structure and motion.
With the development of technology, more and more open-source systems have emerged, and visual SLAM technology has gradually matured. However, there are still many practical problems to be solved. Point features are widely used features in visual SLAM and are mature in feature extraction, matching, and representation. Common feature point description algorithms include Scale Invariant Feature Transform (SIFT) [16], Speeded Up Robust Features (SURF) [17], and Oriented FAST and Rotated BRIEF (ORB) [18]. However, point features are more dependent on the environment, and are not effective when the motion is too fast, resulting in blurred images and in weak textures scenes. In addition, the map constructed based on the point feature is a 3D point cloud map, and the point cloud map is sparse, but the map for robot navigation needs to reflect the structural information of the object in the scene, so as to study the path planning of the robot. Compared with point features, line features [19] are also widely present in various environmental scenarios, and line features are not susceptible to changes in viewpoints and illumination. Since the spatial dimension of a line is one-dimensional higher than a point, for some structured scenes, the line feature has an advantage and more accurately expresses the structural information of the environment [20,21]. The point feature [22,23] and the line feature [24,25,26] are complementary to each other. In weakly textured areas such as the ground and walls, almost no point features are extracted, but at the junction of the ground and the wall, there are abundant line segments. The environment map constructed by the combination of point and line features has more intuitive geometric information, and can also improve the accuracy and robustness of the SLAM system.
In addition, robot applications often require robots to be positioned in real-time [27]. When the robot moves quickly, the line feature extraction and tracking algorithm are relatively slow, which causes the movement and location to be out of synchronization. The longer the single location process, the less overlap between the two frames before and after, which will undoubtedly reduce the accuracy of the robot location. Compared with the feature-based method, the direct method does not need to detect and match features in each frame, and directly estimates the camera pose based on the photometric error of the corresponding points of adjacent frames, which greatly improves the running speed of the SLAM algorithm. Extending the line segment feature to the direct method can reduce the computational resource consumption and improve the robustness of the SLAM algorithm without significantly increasing the system computation time.
Although the indoor environment texture information is rich, it is inevitable that there will be no texture or weak texture. The existing solution is to combine visual and inertial [28] information for positioning, and according to the degree of fusion, it is loosely coupled [29,30] or tightly coupled [31,32,33]. The camera captures the rich information in the scene, and the IMU is able to obtain accurate estimates in a short time at high frequencies, mitigating the effects of dynamic objects on the camera [34]. In the absence of features, during fast motion, or in the case of dynamic obstacles, it is very helpful to use a priori from the IMU. A motion prior is an additional item attached to a cost function that penalizes motion that is inconsistent with a priori estimates. By using the complementarity of the inertial sensor and the image sensor, the pose estimation result with higher precision and better robustness can be obtained. In the literature [35], a novel tightly coupled monocular visual-inertial odometry algorithm PL-VIO is introduced, which optimizes the state of the system in a sliding window with point and line features. But this algorithm is a feature-based method, and has weak real-time performance.
In this paper, we present a visual-inertial odometry that combines point and line features. This algorithm is based on an extension of the semi-direct method SVO. First, line features provide more geometric information about the environment than point features. Line features help improve system robustness in challenging scenarios, such as low-texture environments or lighting variations, when point features cannot be reliably detected or tracked. Based on the extension of the direct method, the extraction and matching of the line segment features are reduced, and a faster speed can be achieved. The second extension, combined with motion prior information, allows the system to be robust in environments with the lack of features or fast motion, while at the same time restoring the precise scale of the camera pose.
2. Methodology
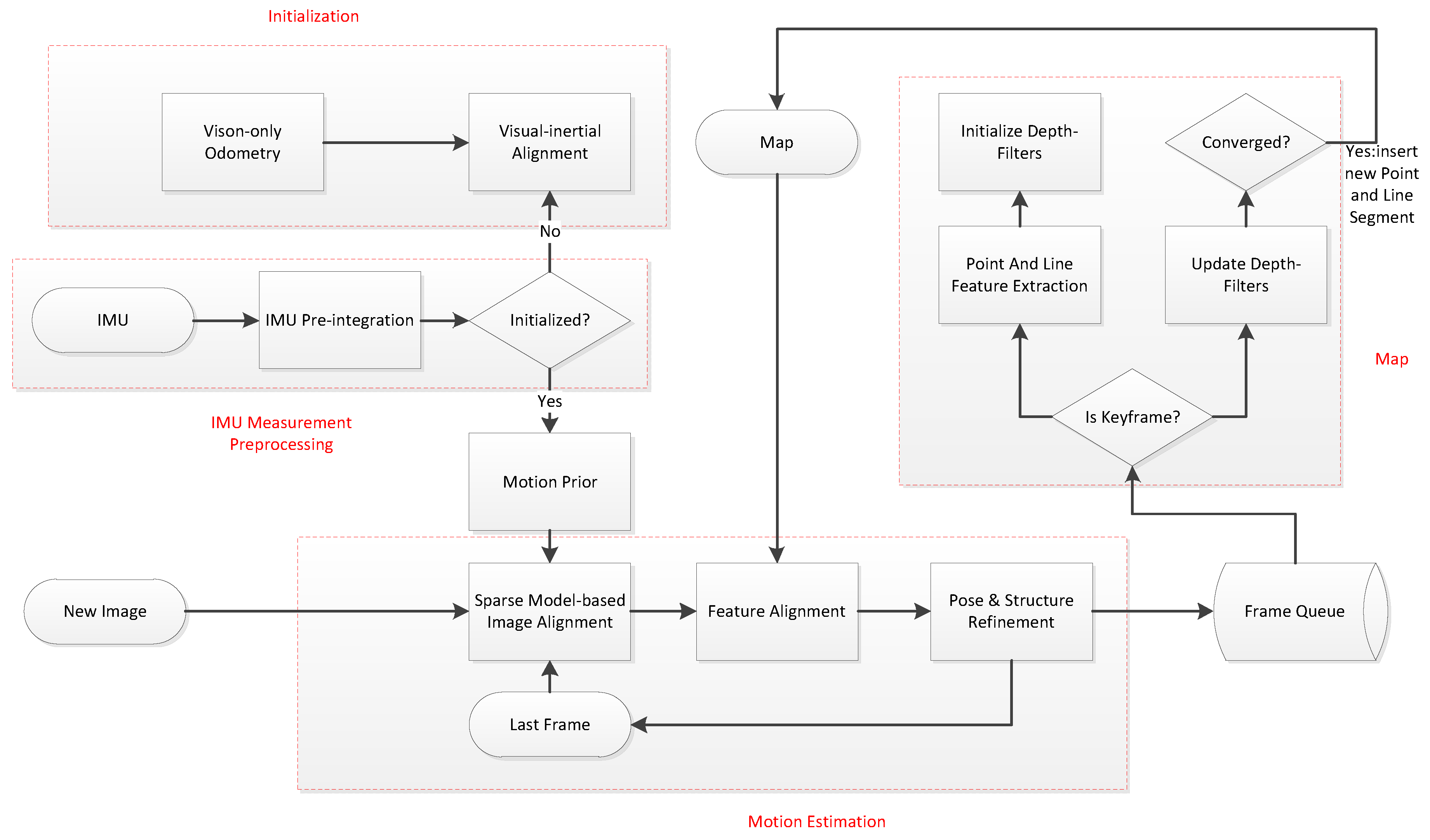
Figure 1 shows the overall framework of our approach, adding line segment features and motion prior extensions to SVO. The whole algorithm includes four modules: IMU measurement preprocessing, visual-inertial initialization, motion estimation, and mapping.
The measurement pre-processing module pre-integrates the IMU measurement data between consecutive frames. In the visual inertia alignment module, the SFM is first used to estimate the pose and 3D point inverse depth of all frames in the sliding window, and then the IMU pre-integration is used to solve the initialization parameters. The motion estimation module performs point and line segment feature tracking based on the direct method, and combines the motion prior information to estimate the camera pose. Finally, the mapping thread recursively estimates the 3D position of the image features with an unknown depth.
2.1. Notations
We define some of the notations and coordinate system definitions needed in this paper. represents the world coordinate system. represents the IMU and body coordinate system. represents the camera coordinate system. We use rotation matrices and quaternions to represent rotation, and represents translation. and are rotation and translation from the body frame to the world frame. is the body frame while taking the kth image. is the camera frame while taking the kth image. ⊗ represents the multiplication operation.
The image acquired from one camera C at time k is denoted as , where is the image field. Any 3D point projection to image coordinates through the camera projection model: . Given the inverse scene depth at pixel , the position of the 3D point is obtained using the inverse projection model . Among them, we use to represent the pixel point whose depth is known in camera C at time k.
In the case of a line segment, we use the two endpoints of the line segment to represent a line segment feature with and , respectively. In order to introduce a motion prior constraint, we define a body coordinate system b that is rigidly connected to the camera frame c, and this external calibration parameters are known in the provided datasets or calibrated with the Kalibr calibration toolbox [36]. The line segment feature whose endpoint depth is known in camera C at time K is represented by , and the endpoints of the line segment feature are denoted by and . The projection model is obtained by pre-calibrating the camera.
The position and rotation of the world frame W relative to the kth camera frame can be described by the rigid body transformation . A 3D point expressed in the world coordinate system can be transformed to the kth camera: .
2.2. Visual-Inertial Initialization
The main purpose of the visual-inertial odometry system initialization [37,38] is to obtain the parameters necessary for the system to optimize and the initial value of the state variables. Since the monocular inertial odometry system is a system with a high degree of nonlinearity, the quality of the initialization directly affects the robustness of the entire tightly coupled system and the location accuracy. Therefore, it is necessary to initialize the system in a specific way to provide accurate parameters and initial values.
In the process of initialization, the information that needs to be initialized or estimated can be divided into two categories: (1) Parameters that are almost constant or have little change during system operation, such as absolute scale and gravitational acceleration; (2) The initial value of the system starting state quantity, including the pose and velocity information of the first few keyframes and the position of the 3D landmark points, and the bias of the IMU accelerometer and the gyroscope.
We use the initialization method proposed in [38]. The initialization method of the algorithm in this paper is divided into two processes. First, the initial visual keyframes are tracked using the semi-direct method of pure vision. The semi-direct method monocular visual odometry can initialize the initial keyframes pose information and the 3D landmark point position information changed with scale. The second process is visual-inertial alignment, which can initialize precise scales, gravitational acceleration, speed information of the camera state, and zero offsets of the accelerometer and gyroscope. The processing of the IMU data is to calculate the pre-integration result between adjacent keyframes, input to the visual-inertial alignment module for an initial solution, solve an accurate scale, and convert the results of the pose estimation into the IMU coordinate system. The initialization flow chart is shown in Figure 2.
As shown in Figure 2, a keyframe with a large number of matching feature points of the current frame is searched in the sliding window as a reference frame, and the relative pose of the current frame to the reference frame is calculated by solving the fundamental matrix. Next, SFM is performed on these two keyframes to obtain the camera pose and feature position of any scale. For each frame of the image in the sliding window, the solvePnP [39] is performed to get pose with all the 3D landmark points obtained by the SFM.
At this point, the pose information of all keyframes and the 3D information of the points and line segments can be obtained. Since the external parameters between the camera and the IMU are known, all variables can be transformed into the IMU coordinate system to represent:
where s is an unknown scale factor. According to the method in [38], the vision-only pose estimation result and the IMU measurement pre-integration are visual-inertial aligned, and the absolute scale, the gravity acceleration, the speed information of the camera state, and the zero offsets of the IMU can be estimated.
Since the IMU pose estimation data is of absolute scale, the camera pose estimation is not drifting. After the two are aligned, the absolute scale of the camera pose can be well estimated. At this point, the initialization process is complete.
2.3. IMU Measurement Pre-Integration
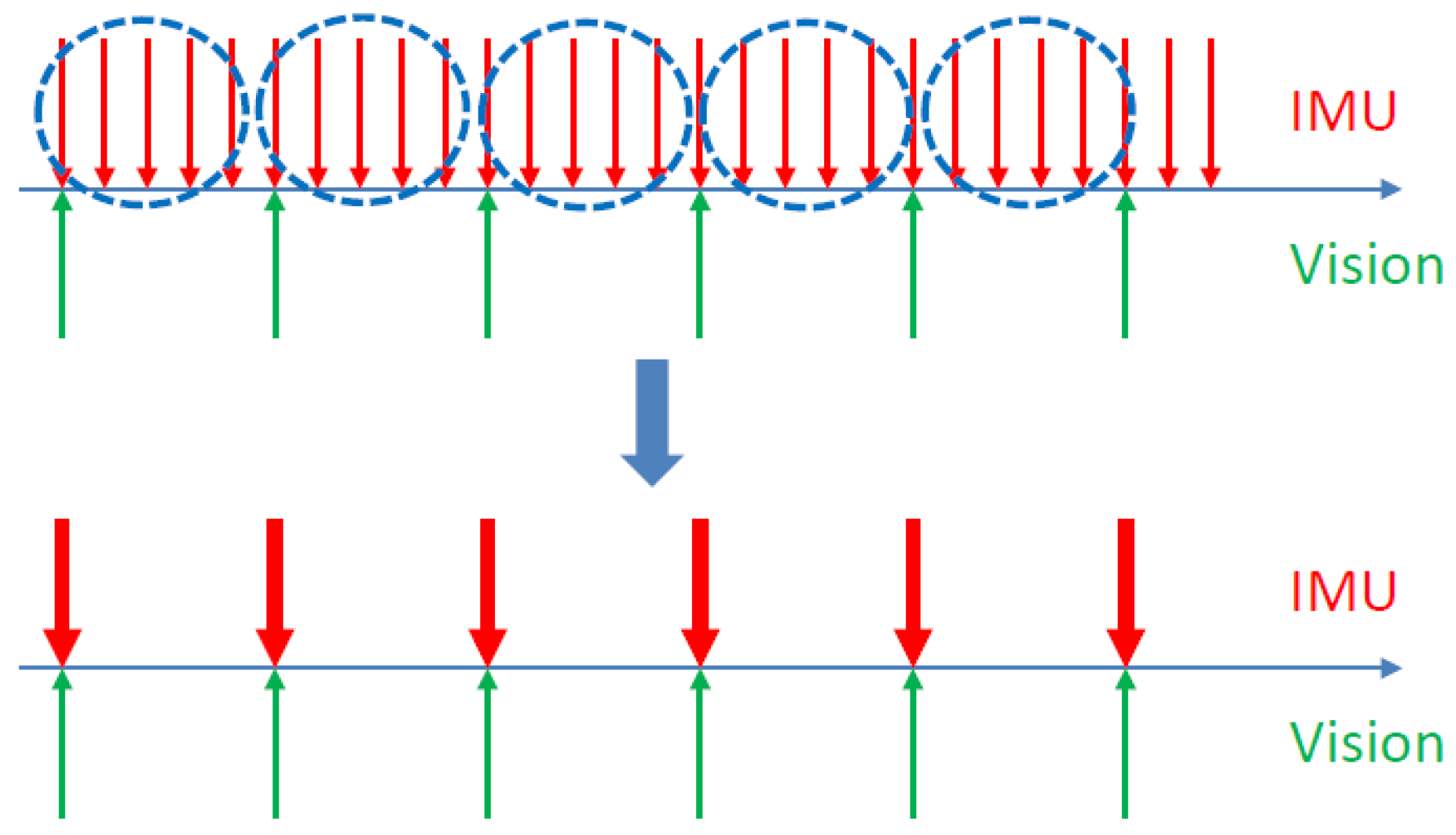
The IMU consists of a three-axis accelerometer and a three-axis gyroscope that measure angular velocity and acceleration relative to the inertial coordinate system. Since the measurement frequency of the IMU is much faster than that of the vision camera, as shown in Figure 3, it is desirable to incorporate constraints from inertial measurements into the motion estimation, which requires integrating the measurements of the numerous IMU data of two adjacent visual keyframes into one constraint. The manifold-based pre-integration theory adopted in this paper was proposed by Forster et al. in 2016 [40], which uses the IMU pre-integration method to transform IMU measurement data into visual keyframe constraints.
The state variables at time k of the IMU coordinate system B are defined as the position , velocity , and rotation . All accelerometer and gyroscope measurement data between time k and time are given. At the time , the position , velocity and rotation are calculated by integrating all the IMU data between time k and time , and are defined as the initial values of the visual estimation.
where and are the acceleration and angular velocity measured by the IMU. is the gravity vector in the world frame. is the acceleration bias and is the gyroscope bias. In practical use, the IMU data is discrete, and the discrete formula based on the median integration method is given below. That is the integration process from the time i to the time .
where:
By observing the Formula (2), the pre-integration of the IMU needs to depend on the and of the kth frame. When we perform nonlinear optimization on the backend, we need to iteratively update the and of the kth frame. We need to re-integrate based on the value after each iteration, which is very time-consuming. Therefore, we consider separating the optimization variable from the IMU pre-integration term from the k frame to the frame. By multiplying the left and right sides of the Formula (2) by , it can be reduced to:
where:
In this way, we obtain the IMU pre-integration formula for continuous-time. It can be found that the value of the IMU pre-integration obtained by the above formula is only related to and at different times.
Similarly, we give the IMU pre-integration formula for discrete moments based on the median integration method. The IMU increment information from time i to time is:
where:
3. Visual Odometry Combined with Point and Line Features
The main purpose of this study is to develop a more robust semi-direct method SLAM algorithm combining point and line features. The algorithm achieves the same accuracy as the most advanced feature-based methods and maximizes the speed of the algorithm so that it can be used for a variety of lightweight platform tasks such as cell phones and micro drones.
3.1. Monocular Initialization
We use a feature-based approach to obtain the pose and initial map of the initial two keyframes. First, the Fast corner feature and the LSD segment feature are extracted on the first keyframe, and then the features on the first keyframe are tracked using the klt optical flow algorithm [41]. The disparity between the two frames is calculated until the image that reaches the set disparity threshold is selected as the second keyframe. We calculate the homography matrix by the local plane hypothesis to obtain the pose transformation of the second keyframe relative to the first keyframe, and obtain reliable inlier matching. An initial map of random scales is obtained by triangulation between the initial two keyframes. With the pose and map of the initial two keyframes, the direct method can be used to estimate the pose of the new frame.
3.2. Sparse Model-Based Image Alignment with Motion Prior
The motion between two consecutive camera frames can be estimated by direct tracking of sparse features. By minimizing the photometric error of the corresponding pixels between two consecutive camera frames, we can get an initial estimate of the pose between two adjacent frames. We need to define the photometric cost function of the point and line segment features separately. Model-based image alignment estimates the pose increment between adjacent frames by minimizing the intensity difference (photometric error) of pixels viewing the same 3D point and line segment.
Our goal is to estimate the incremental motion of the body coordinate system . Next, we define the residual functions corresponding to points, line segments, and motion priors. Define the intensity residuals of the point features as:
where the photometric residual is defined by the intensity difference of the pixels of the same 3D point observed in subsequent images and .
The 3D point (represented in the reference frame ) can be calculated by back-projection pixels with a known depth :
But the optimization in Equation (9) only includes a subset of these pixels , indicating that these back-projection points are also visible in the image :
Unlike the point-based approach, we cannot directly align the entire area occupied by a line segment between two frames because it is computationally expensive. To this end, we only minimize the image residuals between patches that are evenly distributed along the line segment, as shown in Figure 4. We define as the image region where the endpoint depth is known at the previous time , and at the current time k, the endpoints and are visible in the image domain .
where refers to the intermediate point defined evenly along the line segment.
The intensity residual of line segment is then defined as the photometric difference between the pixels of the same 3D line segment point, i.e.,:
In the case of and , the point refers to the endpoints p and q respectively.
We further assume that the a prior of the body coordinate system motion increment is given. In this case, we define the residuals corresponding to the rotation prior and the translation prior:
In order to jointly calculate the optimal pose increment, we unify the point features, line segment features, and motion prior residuals into a least-squares optimization cost function. The goal is to solve for incremental camera rotation and translation by minimizing the sum of the squared errors below:
where:
where the covariance , is set according to the uncertainty of the motion prior, and the variable is the current estimate of the relative position and rotation (represented in the B frame). A logarithmic map transforms a rotation matrix to its rotation vector.
To facilitate the solution, we write the cost function in matrix form.
where is a block diagonal matrix consisting of measurement covariances. The solution to the optimization variable is non-linear, equivalent to solving a least-squares problem. We use the iterative method Gauss-Newton to solve this problem, adding the following perturbations to the optimization variable rotation and translation :
The operator turns a three-dimensional vector into an orthogonal matrix of 3 × 3, where is a Lie algebra. The perturbation form is used to define the residual function in the vecto space. This allows us to linearize the current estimated quadratic costs, form normal equations, and solve them for the best perturbations:
We introduce the matrix , which superimposes all Jacobian matrices from linearization. The solution result is then used to update the estimate of according to Equation (19). This process is repeated until the norm of the update vector is small enough, which indicates convergence.
In the following, we give the Jacobian matrix obtained by linearizing the residual:
where is the inverse of the SO(3) right Jacobian matrix, is the image derivative at pixel u, and is the derivative of the camera projection model. For the standard pinhole camera projection model focal length and camera center , we define:
In this case, we look for the linear Jacobian determinant of the line segment residual, which can be expressed as the sum of the Jacobian determinants for each intermediate point of the sample:
Then, we can estimate the optimal pose by the robust Gaussian Newton minimization of the above cost function in Equation (18). Note that this formula allows for fast-tracking of line segments without the need to extract and match LSD segment features, and the traditional feature-based approach introduces high computational load.
3.3. Feature Alignment
In the previous step, we estimated the incremental motion between successive frames by sparse image alignment. With the known pose , we can reproject all visible 3D features into the new image to get an initial estimate of the position. Because of the inaccuracy of the 3D feature position, the feature position in the new image can be improved. In order to reduce the drift of the pose, the camera pose should be further aligned with the map, not just the previous frame. The feature alignment method selects the older keyframes as a reference for feature alignment, ignoring the geometric constraints given by the re-projection of the 3D points and performing a separate 2D alignment of the corresponding feature blocks.
All 3D points in the map visible in the new image are projected onto the image plane, resulting in a corresponding 2D feature position estimate (as shown in Figure 5). For each re-projection feature, the visual keyframe closest to the new image is determined to be the reference frame. Next, all 2D feature positions are respectively optimized by establishing photometric errors of the feature blocks in the new image and the feature blocks in the corresponding keyframe r. The 2D feature alignment minimizes the intensity difference of the small image block P centered on the feature projection position . The size of the P of the image block is a larger 8 pixels × 8 pixels because the closest keyframe we project the feature is usually farther away. In order to improve the accuracy of the alignment, we apply the affine warping to the reference block, which is calculated from the relative estimated pose between the reference frame and the current frame. For the corner feature, the optimization calculates the correction of the predicted feature position , minimizing the photometric cost function:
where is an iterator variable that is used to calculate the sum of patch P. This alignment is solved using the inverse component Lucas-Kanade algorithm.
In the case of a line segment, we only need to refine the position of the 2D endpoint, which defines the line equation used for projection error estimation:
where is the two-dimensional estimated position of the feature in the current frame ( representing the two endpoints of the line segment, respectively), and is the position of the feature in the reference frame r. For line segments, this is a bold assumption because their endpoints are much less than the description of the key points.
In comparison with the feature-based approach, in this step we skip the limits of the polar constraint, but achieve the feature correlation of subpixel precision.
3.4. Pose and Structure Refinement
After feature alignment, we established feature correlations related to subpixel precision. However, feature alignment violates the epipolar line constraint and introduces a reprojection error . After separately optimizing the position of each feature in the image by skipping the epipolar line constraint, the camera pose obtained in Formula (16) must be further refined by minimizing the reprojection error between the 3D feature and the corresponding 2D feature position in the image (see Figure 6). If the new image frame is a keyframe, the next step is to perform a bundle adjustment of the local map. We define the vector as the variable to be optimized, including the pose of the new keyframe, the position of each 3D point, and the 3D position of each end of the line segment. Therefore, in the final step of motion estimation, we refine the camera pose and landmark position by minimizing the sum of the squares of the reprojection errors:
where K is the set of all keyframes in the map, is the set of landmarks associated with all the corner features, and is the set of line features observed in the keyframe.
In the above formula, the projection error represents the distance error between the feature position of the image plane optimized in the previous step and the corresponding map projection point, which can be expressed as:
The processing of line segments is slightly different because we cannot simply compare the position of the endpoint because it may be shifted along the line or occluded from one frame to the next. To this end, we consider the distance between the projected endpoint of the 3D line segment and the corresponding infinite line in the image plane as an error function. In this case, the projection error of the line segment can be expressed as:
where and refer to the 3D endpoint of the line segment in the world coordinate system, and is the infinite line equation corresponding to the 3D line segment in the image plane, which can be obtained by the cross product between the 2D endpoints of the line segment in the image plane, i.e.,: . The reprojection error of a line segment is defined as the vector product of the projection of the two endpoints , of the 3D line segment and at the image plane.
3.5. Map
The task of the mapping thread is to estimate the depth information of the key frame image feature points and line segments whose depth is unknown. The depth error model of the pixel is regarded as a probability distribution, and the inverse depth of the Gauss-uniform mixture distribution (the depth value obeys the Gaussian distribution, and the probability of the outlier point obeys the Beta distribution) is called a depth filter. Each feature point serves as a seed (a pixel whose depth is not converged) and has a separate depth filter. The depth filter mainly performs the following two steps.
Initialize the seed: If a keyframe is entered, the new feature points on the keyframe are extracted, and the depth filter is initialized and placed as a seed point in a seed queue.
Update seed: If a normal frame is entered, the probability distribution of all seed points is updated with the information of the normal frame; if the depth distribution of a seed point has converged, it is placed in the map for use by the tracking thread.
For line segment features, we need to estimate the three-dimensional coordinates of the two endpoints. The LSD line segment feature is extracted in the key frame, and the endpoint is used as an initialization seed to update the seed in the non-key frame. This also incorporates line segment features into the unified framework of the depth filter.
4. Experimental
To evaluate the performance of the proposed algorithm, we tested our algorithm on the public visual inertial dataset EuRoC [42] and compared it with other open-source SLAM algorithms. EuRoC is stereo IMU datasets collected in the room by Swiss Federal Institute of Technology Zurich using drones. The datasets consist of two scenes, a mechanical room and a man-made common room. The hardware device includes a global shutter stereo camera with a frequency of 20 Hz and an IMU sensor with a frequency of 200 Hz. The datasets contain a total of 11 sequences, each of which provides ground-truth. In addition, the calibrated camera internal parameters and IMU-camera joint external parameters are also provided in the datasets.
The experiment was performed on a personal computer configured with an Intel Core i5-7500 CPU, 3.4 GHz × 4, 8 GB RAM. Section 4.1 compares our method with the state of art methods and gives detailed evaluation results.
4.1. Experimental Results
Before conducting the accuracy analysis of the experimental results, we first introduce the indicators for measuring accuracy. When evaluating the accuracy of the SLAM algorithm, there are two main indicators: Relative Pose Error (RPE) and Absolute Pose Error (APE). The relative pose error is calculated over a fixed time interval, which measures the local correctness of the estimated trajectory. Let the estimated pose be , the true value of the pose is , and the relative pose error of the time i is defined as:
Absolute pose error: The global error of the trajectory is measured by comparing the estimated distance between the pose and the ground-truth, which can reflect the degree of deviation of the global path. Let the estimated pose be , the true value of the pose is , and the absolute pose error of the time i is defined as:
The root mean square error can be calculated using the absolute pose error at all times:
We will compare the proposed method with the current state-of-the-art open-source algorithms ORB-SLAM [10] and OKVIS-mono [31]. As an extension of SVO, we also compare our algorithm with the original SVO. The experiment is unified on the data on the left image, and the estimated trajectory is saved and compared with the ground-truth. Using the open-source evaluation tool Evo [43] (github.com/MichaelGrupp/evo) to evaluate, the RPE and APE between the estimated trajectory and the ground-truth can be directly obtained, and each algorithm is evaluated 5 times on average.
Next, we evaluate the tracking results of the proposed algorithm for point and line features between consecutive frames. As shown in Figure 7, the figure shows the tracking results of point and line segment features between consecutive frames on the sequence. Point features are shown in green and line segments are shown in red. As can be seen from Figure 7, a large number of line features are successfully tracked between consecutive frames, which is advantageous for improving the accuracy of the pose estimation.
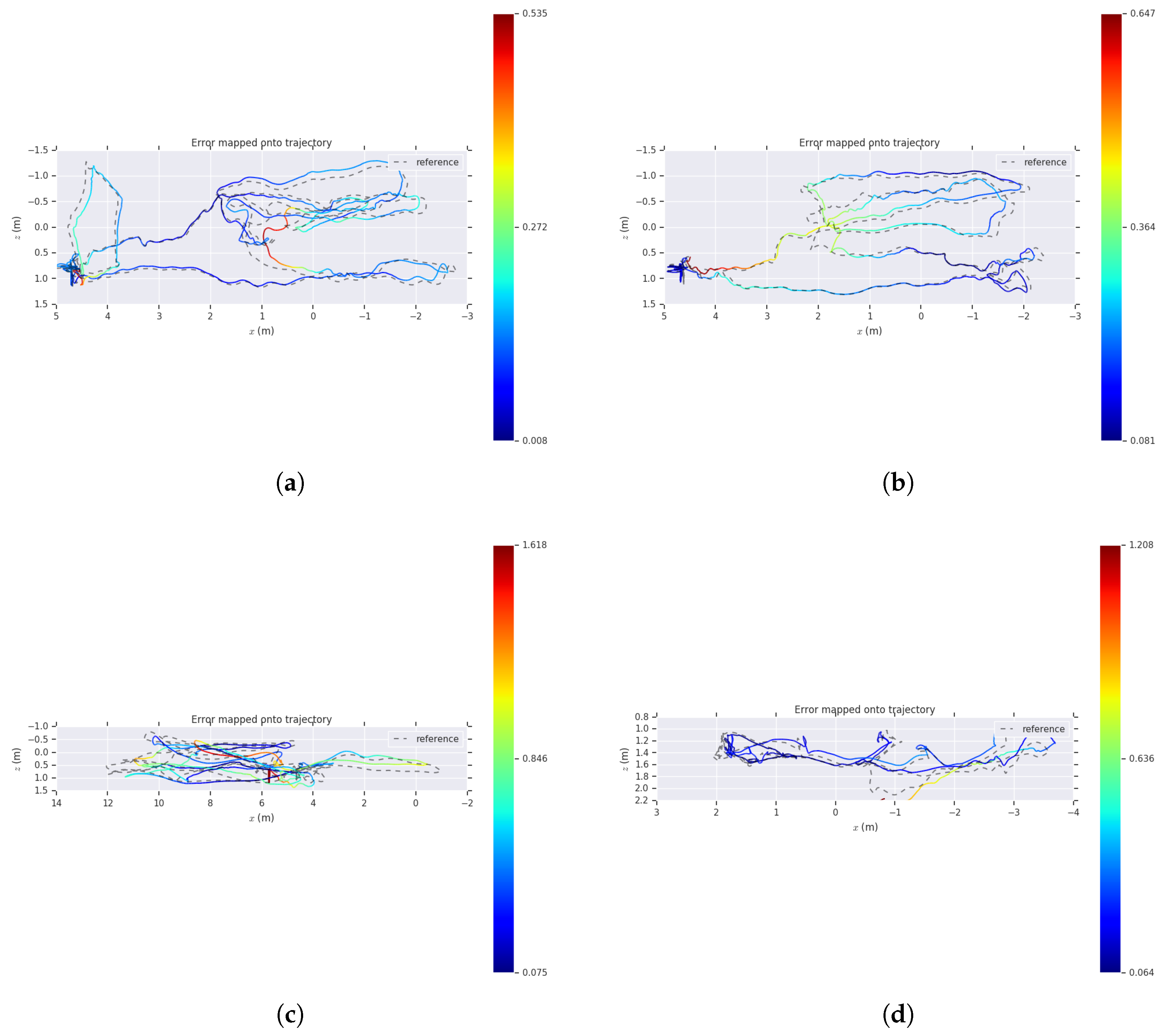
Figure 8 shows a comparison of the estimated trajectory and the reference trajectory of our algorithm on several sequences. The dashed line indicates the ground-truth of the sequence, and the solid line is the trajectory estimated by our algorithm, and the color indicates the APE error from the true value. As we can see, our algorithm shows good performances on different sequences.
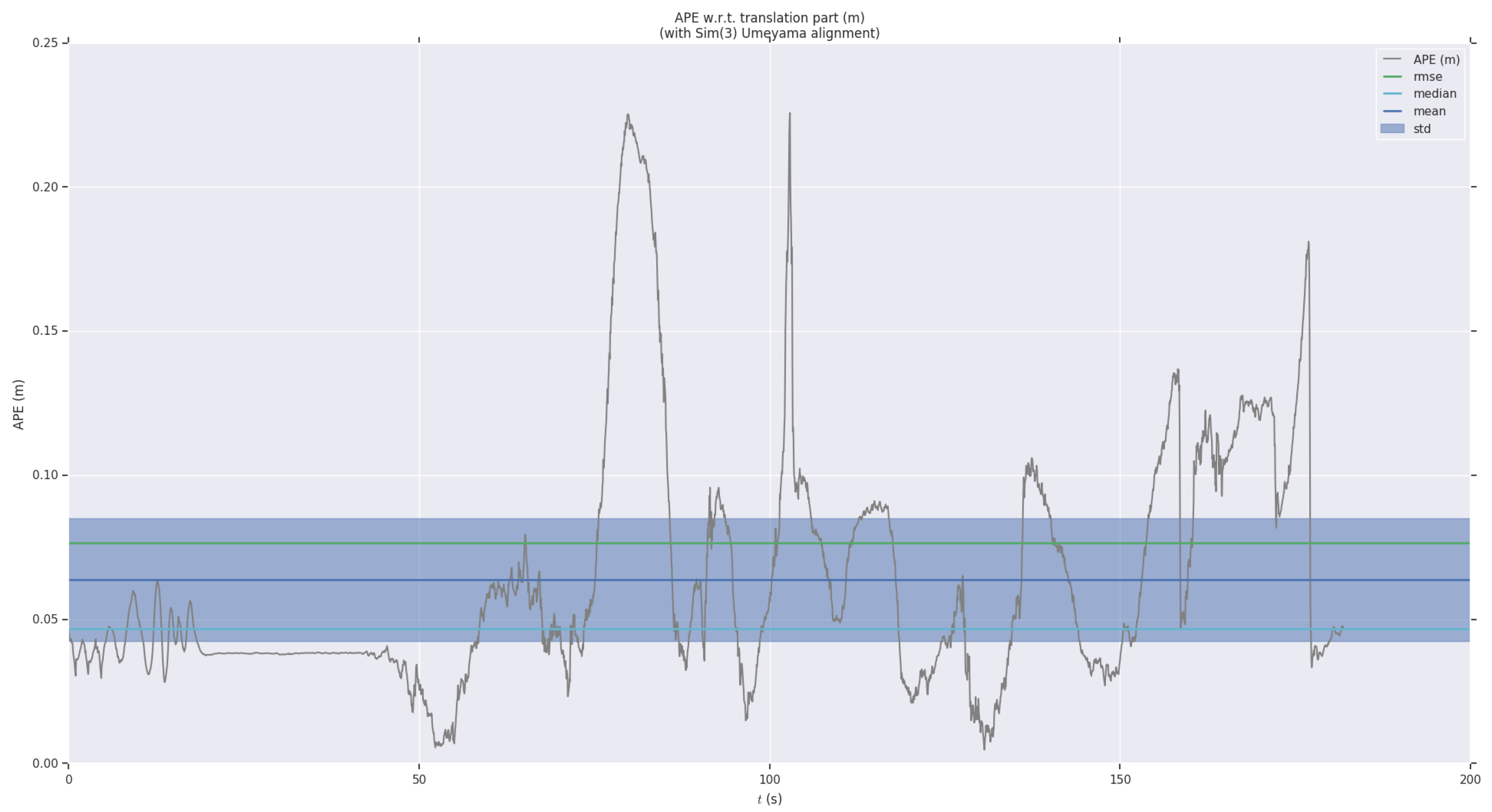
For detailed analysis, we have visualized the APE and RPE in a sequence. As shown in Figure 9 and Figure 10, we paint the APE and RPE error on over time. We can analyze from this that the RPE and APE are relatively large when camera moves faster.
For quantitative evaluation, our algorithm is compared to OKVIS-mono, ORB-SLAM, and SVO. The algorithm in this paper has no loop-closure detection and global bundle adjustment optimization. For a fair comparison, compare our algorithm to ORB-SLAM and OKVIS-mono without loop-closure. As shown in Table 1, in a total of 8 sequences, our method achieved the smallest APE error in the three sequences , , , and OKVIS-mono achieved the smallest APE error in the remaining five sequences. From the above analysis, we can achieve an absolute attitude evaluation result with OKVIS-mono, which is better than the ORB-SLAM algorithm without loop-closure. Compared to SVO, we achieved better performance in the four sequences , , , . However, SVO tracks failures in most sequences, and our algorithm can successfully track the entire trajectory, showing superior robustness.
We further estimate the results of the algorithm on the RPE and evaluate the local trajectory accuracy of the algorithm. Figure 9 shows the RPE over time in the sequence. Table 2 shows the root mean error (RMSE) of the translation part of the RPE of our algorithm on 8 different sequences and compared with ORB-SLAM and OKVIS-mono. Our proposed algorithm achieves the smallest RPE error in seven sequences. It shows that the local location accuracy of the algorithm is very high.
In order to analyze the impact of loop closure on APE, we compared the ORB-SLAM algorithm with and without loop closure on APE. The results show in Table 3. It can be seen from the comparison of the presence or absence of loop-closure of the same sequence that the global error APE is reduced by adding loop-closure detection. The reason for the analysis shows that the purpose of loop-closure detection and global optimization is to reduce the cumulative error and make the system output trajectory have global consistency, which is consistent with the experimental results obtained in this paper to reduce the APE error.
4.2. Processing Time
Finally, we analyze the processing time comparison between the direct method of combining point and line features and the feature-based method. Table 4 shows the comparison of the mean consumption time of tracking one frame using our algorithm with other algorithms. We also recorded the runtime of each module of the algorithm in this paper. The time of each module of the algorithm in this paper is shown in Table 5.
By analyzing Table 4 and Table 5, it can be concluded that on the same hardware platform, the average time of our algorithm to process one camera frame is 16.34 ms less than the ORB-SLAM without loop-closure, which indicates that the real-time performance of the algorithm is good. This is also the advantage of the direct method compared to the feature-based method. The reason for the analysis shows that our algorithm does not need to detect and match features in every frame. Especially for line segment features, LSD line segment feature detection and LBD [44] line segment feature matching scheme is a feature time-consuming method. Our method only performs feature extraction of points and line segments on key frames in the map thread. The feature-based method ORB-SLAM requires feature matching between successive frames and between the latest frames and maps, which takes a lot of time.
4.3. Discussion
The algorithm in this paper can be seen as an extension of SVO, adding line segment features and motion priors. In challenging environments such as lighting changes, motion blur, and fast motion, camera tracking robustness can be improved. Compared with the feature-based method, this algorithm is based on the direct method to construct the photometric error of adjacent frames, which is free of feature extraction and matching of image frames, and can achieve fast tracking with competitive accuracy. Compared with SVO, the line segment feature can increase the number of feature tracking. When the point feature tracking is insufficient, the line segment feature can increase the number of feature tracking, increase the probability of successful consecutive frame tracking, and improve the robustness of the algorithm. Combined with the motion prior information of IMU, the accurate scale is successfully restored.
Compared with the ORB-SLAM and OKVIS-mono algorithms, the algorithm does not have loop-closure detection and global bundle adjustment module to reduce the long-term accumulated trajectory drift. Therefore, the absolute pose error (APE) of the estimated trajectory is slightly weaker, but better than the ORB-SLAM algorithm without the loop-closure detection module. However, the relative pose error (RPE) is kept at a good level, and most of the EuRoC datasets sequences are superior to ORB-SLAM and OKVIS-mono. The algorithm of this paper is accurate enough to estimate the pose change of adjacent frames, and the short-term pose estimation can achieve better accuracy. For applications that require short-term fast motion estimation, our algorithm is more suitable for such scenarios, and for map reconstruction, the ORB-SLAM algorithm is more suitable for reconstructing accurate scene maps. The algorithm in this paper is significantly faster than the other two methods under similar accuracy, so it is more suitable for lightweight applications, such as AR applications on the mobile terminal, to achieve fast tracking with a small computational load.
5. Conclusions
In this paper, we propose a novel visual odometry algorithm, which can be seen as an extension of SVO, combining line segment features and motion prior information. Line features help to improve system robustness in the lack of point features, such as weak textures and illumination change, so we have a more robust system. When a new camera frame is introduced, there is no need to detect and match features, achieving faster speed and less resource consumption than a feature-based approach with similar accuracy.
The direct method can quickly track line segment features and combine motion prior to obtaining accurate scales. We also provide a comparison of the proposed algorithm with the most advanced SLAM method on the EuRoC datasets, including OKVIS-mono, ORB-SLAM. The experimental results show that the proposed algorithm has a smaller RPE error, better than ORB-SLAM and OKVIS-mono, indicating better local accuracy. For the absolute pose error, the algorithm can achieve the accuracy equivalent to OKVIS-mono, which is better than the loop-closure ORB-SLAM algorithm. Compared with semi-direct method SVO, our method shows better results in half of the total sequences and has better robustness. In addition, we also evaluate the mean time that the algorithm takes to process one image frame. The results show that the algorithm has a great speed advantage and better real-time performance than ORB-SLAM and OKVIS-mono.
Author Contributions
Conceptualization, N.Z.; Funding acquisition, Y.Z.; Methodology, N.Z.; Writing—original draft, N.Z.; Writing—review & editing, Y.Z.
Funding
This work was supported by the National Key Research and Development Plan of China (No. 2018AAA0102902).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Manuel Rendon-Mancha, J. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2012, 43, 55–81. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef]
- Choi, J.; Kong, K. Optimal sensor fusion and position control of a low-price self-driving vehicle in short-term operation conditions. Int. J. Control Autom. Syst. 2017, 15, 2859–2870. [Google Scholar] [CrossRef]
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W. Autonomous aerial navigation using monocular visual-inertial fusion. J. Field Robot. 2018, 35, 23–51. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Mei, Y.; Yang, K.; Cai, B. IMU-Assisted 2D SLAM Method for Low-Texture and Dynamic Environments. Appl. Sci. 2018, 8, 2534. [Google Scholar] [CrossRef]
- Polvi, J.; Taketomi, T.; Yamamoto, G.; Dey, A.; Sandor, C.; Kato, H. Slidar: A 3d positioning method for slam-based handheld augmented reality. Comput. Graph. 2016, 55, 33–43. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces (PTAM). In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Washington, DC, USA, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Mur-Artal, R.; Montiel, J.; Manuel Rendon-Mancha, J. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 IEEE International Conference on Computer Vision Systems, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the European Conference on Computer and Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Lindeberg, T. Scale invariant feature transform. Scholarpedia 2012, 7, 2012–2021. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Grompone, V.G.R.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar]
- Zhang, G.; Lee, J.H.; Lim, J.; Suh, I.H. Building a 3-D Line-Based Map Using Stereo SLAM. IEEE Trans. Robot. 2015, 31, 1364–1377. [Google Scholar] [CrossRef]
- Bartoli, A.; Sturm, P. The 3D line motion matrix and alignment of line reconstructions. Int. J. Comput. Vis. 2004, 57, 159–178. [Google Scholar] [CrossRef]
- Basam, M.; David, M.; Arturo de la, E. Visual ego motion estimation in urban environments based on U-V disparity. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Alcala de Henares, Spain, 3–7 June 2012; pp. 444–449. [Google Scholar]
- Musleh, B.; Martín, D.; Armingol, J.M.; de la Escalera, A. Continuous pose estimation for stereo vision based on UV disparity applied to visual odometry in urban environments. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3983–3988. [Google Scholar]
- Gomez-Ojeda, R.; Gonzalez-Jimenez, J. Robust stereo visual odometry through a probabilistic combination of points and line segments. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2521–2526. [Google Scholar]
- Gomez-Ojeda, R.; Moreno, F.A.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A Stereo SLAM System through the Combination of Points and Line Segments. arXiv 2017, arXiv:1705.09479. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Shen, S.; Mulgaonkar, Y.; Michael, N.; Kumar, V. Vision-based state estimation for autonomous rotorcraft MAVs in complex environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1758–1764. [Google Scholar]
- Zhang, Z.; Liu, S.; Tsai, G. PIRVS: An Advanced Visual–Inertial SLAM System with Flexible Sensor Fusion andHardwareCo-Design. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3826–3832. [Google Scholar]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A robust and modular multi-sensor fusion approach applied to mav navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3923–3929. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Leutenegger, S.; Lynen, S.; Bosse, M. Keyframe-Based Visual–Inertial Odometry Using Nonlinear Optimization. Int. J. Robot. Res. 2014, 34, 314–334. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Visual–inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Qiu, X.; Zhang, H.; Fu, W.; Zhao, C.; Jin, Y. Monocular Visual–Inertial Odometry with an Unbiased Linear System Model and Robust Feature Tracking Front-End. Sensors 2019, 19, 1941. [Google Scholar] [CrossRef]
- Gui, J.; Gu, D.; Wang, S.; Hu, H. A review of visual inertial odometry from filtering and optimisation perspectives. Adv. Robot. 2015, 29, 1289–1301. [Google Scholar] [CrossRef]
- He, Y.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. PL-VIO: Tightly-Coupled Monocular Visual–Inertial Odometry Using Point and Line Features. Sensors 2018, 18, 1159. [Google Scholar] [CrossRef] [PubMed]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Yang, Z.; Shen, S. Monocular visual–inertial state estimation with online initialization and camera–IMU extrinsic calibration. IEEE Trans. Autom. 2017, 14, 39–51. [Google Scholar] [CrossRef]
- Vincent, L.; Francesc, M.; Pascal, F. Epnp: An accurate o(n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-manifold preintegration for real-time visual-inertial odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef]
- Baker, S.; Matthews, I. Lucas–Kanade 20 years on: A unifying framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Michael Grupp. EVO. Available online: https://github.com/MichaelGrupp/evo (accessed on 8 August 2019).
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
Figure 1.
Flow chart of the proposed algorithm.

Figure 2.
Initialization flow chart.

Figure 3.
IMU Pre-integration diagram.

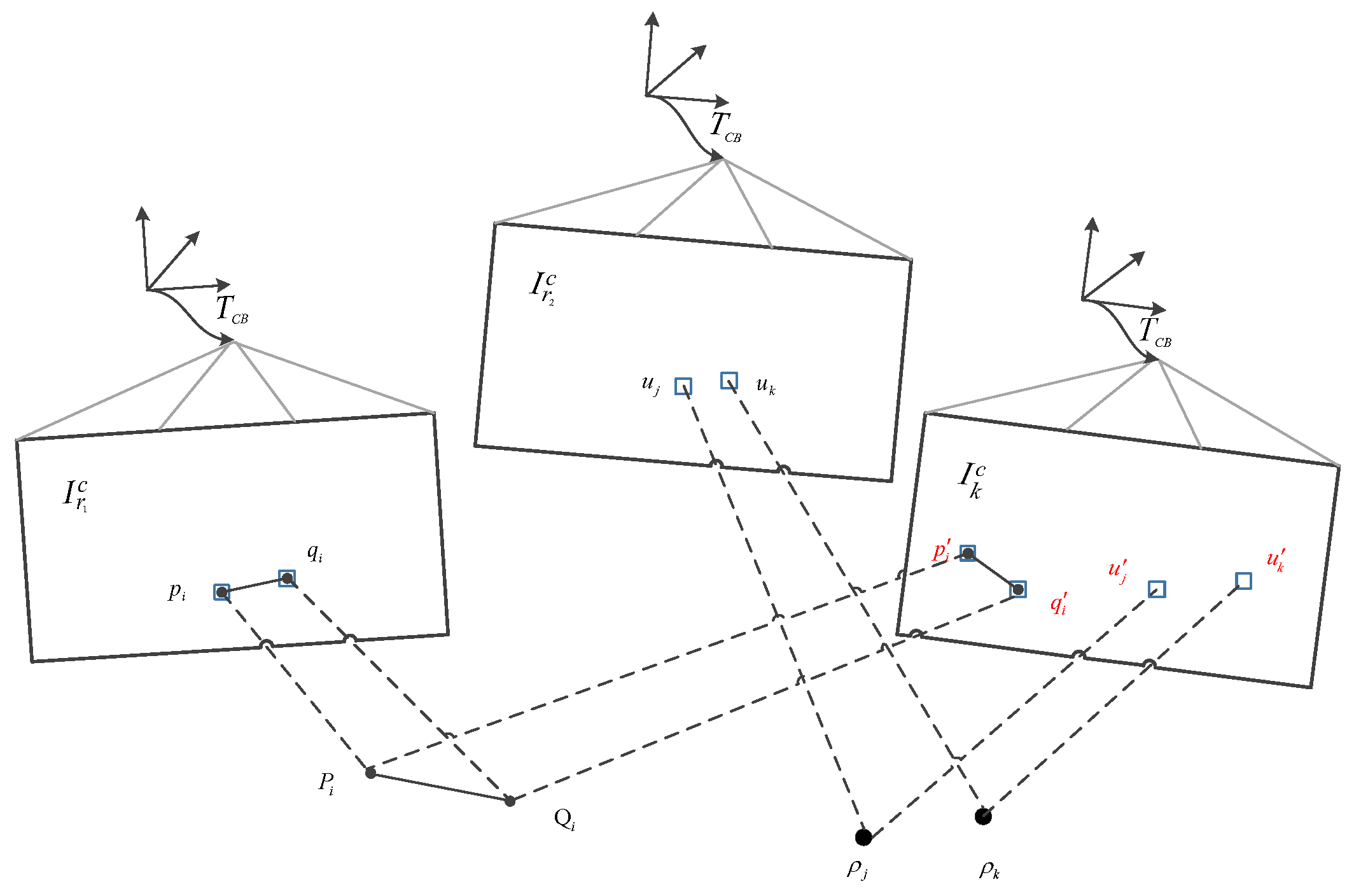
Figure 4.
Relative pose between the current frame and the previous frame parameterizes the position of the reprojection point in the new image. Perform sparse image alignment to minimize luminosity error between image blocks corresponding to the same 3D point (blue block) to solve pose increment .
Figure 4.
Relative pose between the current frame and the previous frame parameterizes the position of the reprojection point in the new image. Perform sparse image alignment to minimize luminosity error between image blocks corresponding to the same 3D point (blue block) to solve pose increment .

Figure 5.
The 2D position of each point is individually optimized to minimize photometric errors in its image block. For line segments, the endpoints are similarly optimized.
Figure 5.
The 2D position of each point is individually optimized to minimize photometric errors in its image block. For line segments, the endpoints are similarly optimized.

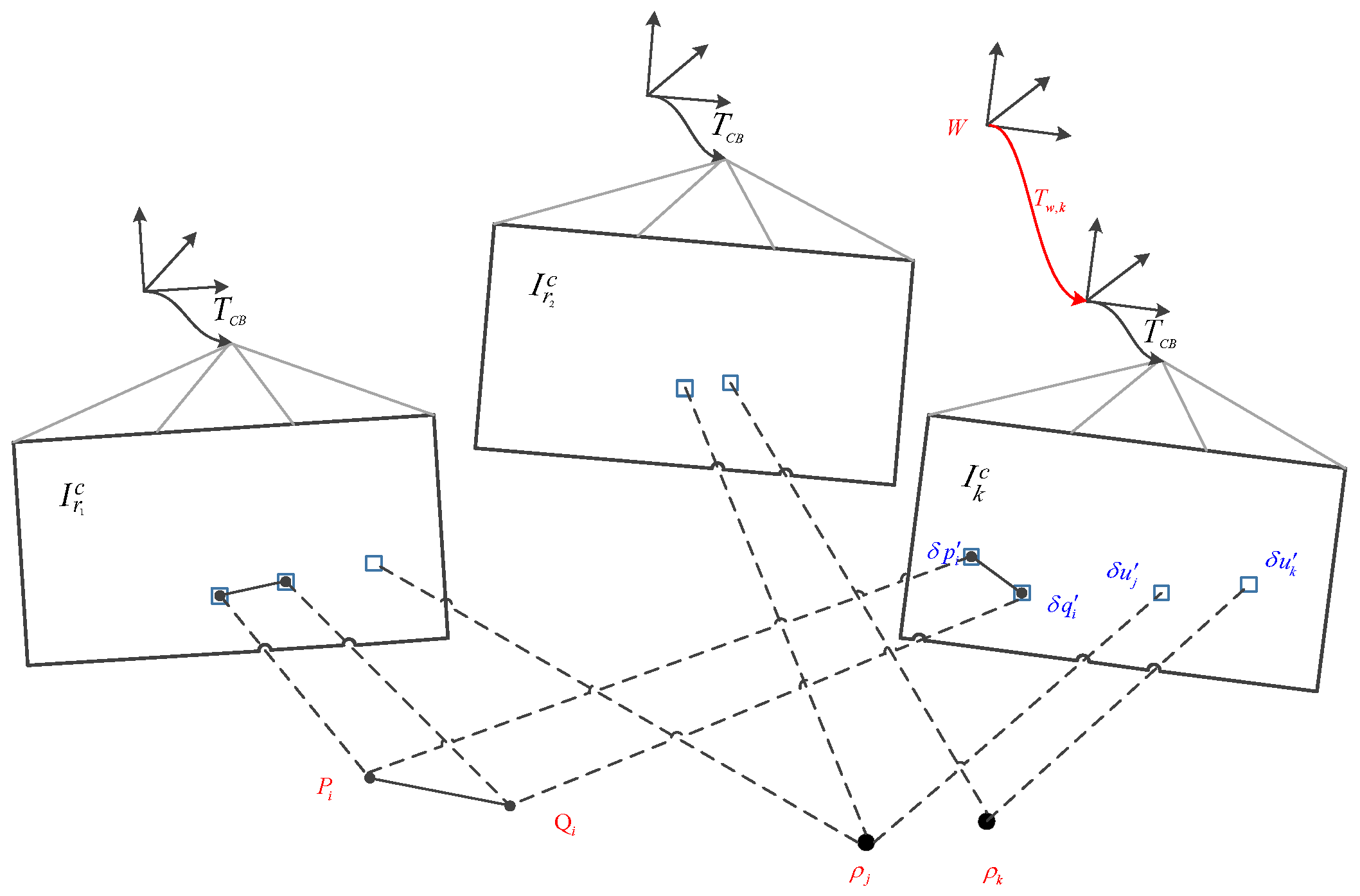
Figure 6.
In the final step of motion estimation, the camera pose and structure (3D points and line segments) are optimized to minimize the reprojection errors established in the previous feature alignment steps.
Figure 6.
In the final step of motion estimation, the camera pose and structure (3D points and line segments) are optimized to minimize the reprojection errors established in the previous feature alignment steps.

Figure 7.
The sequence tracks the point and line features of successive frames. The points are indicated in green and the segments are indicated in red. Figure (a–d) are consecutive images on the sequence, drawed with point and line features which can be successfully tracked.
Figure 7.
The sequence tracks the point and line features of successive frames. The points are indicated in green and the segments are indicated in red. Figure (a–d) are consecutive images on the sequence, drawed with point and line features which can be successfully tracked.

Figure 8.
The comparison of the estimated pose trajectory and the ground-truth on several EuRoC sequences. (a) ; (b) ; (c) ; (d) . The dashed line indicates the reference trajectory, the solid line is the trajectory estimated by our algorithm, and the color indicates the absolute pose error (APE) error from the true value.
Figure 8.
The comparison of the estimated pose trajectory and the ground-truth on several EuRoC sequences. (a) ; (b) ; (c) ; (d) . The dashed line indicates the reference trajectory, the solid line is the trajectory estimated by our algorithm, and the color indicates the absolute pose error (APE) error from the true value.

Figure 9.
Absolute pose error of sequence as a function of time.

Figure 10.
Relative pose error of sequence as a function of time.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Evaluation results of the evo tools on different algorithms. The table shows the error in the translation part of the APE in meter. Bold numbers indicate that the estimated trajectory is closer to the true value. The results of ORB-SLAM are for reference only and do not participate in comparison. Compare our algorithm to Oriented FAST and Rotated BRIEF-Simultaneous Localization and Mapping (ORB-SLAM) (no loop closure), Open Keyframe-based Visual–Inertial SLAM (OKVIS-mono), and semi-direct VO (SVO).
Table 1.
Evaluation results of the evo tools on different algorithms. The table shows the error in the translation part of the APE in meter. Bold numbers indicate that the estimated trajectory is closer to the true value. The results of ORB-SLAM are for reference only and do not participate in comparison. Compare our algorithm to Oriented FAST and Rotated BRIEF-Simultaneous Localization and Mapping (ORB-SLAM) (no loop closure), Open Keyframe-based Visual–Inertial SLAM (OKVIS-mono), and semi-direct VO (SVO).
| Ours | ORB-SLAM (No Loop Closure) | OKVIS-Mono | SVO | |
|---|---|---|---|---|
| Sequences | APE (Translation) | APE (Translation) | APE (Translatin) | APE (Translation) |
| 0.076546 | 0.61 | 0.394244 | 0.17 | |
| 0.227209 | 0.72 | 0.309899 | 0.27 | |
| 0.927710 | 1.70 | 0.316398 | 0.43 | |
| 1.852429 | 6.32 | 0.432456 | 1.36 | |
| 2.574021 | 5.66 | 0.496211 | 0.51 | |
| 1.089041 | 1.35 | 0.073794 | 0.20 | |
| 0.203892 | 0.53 | 0.150363 | 0.30 | |
| 0.192047 | 0.68 | 0.207845 | 0.47 |
Table 2.
Evo tool evaluation results on different algorithms. The table shows the error in the translation of the relative pose error (RPE) in meter. Bold numbers indicate that the estimated trajectory is closer to the true value.
Table 2.
Evo tool evaluation results on different algorithms. The table shows the error in the translation of the relative pose error (RPE) in meter. Bold numbers indicate that the estimated trajectory is closer to the true value.
| Ours | ORB-SLAM | OKVIS-Mono | |
|---|---|---|---|
| Sequences | RPE (Translation) | RPE (Translation) | RPE (Translation) |
| 0.027975 | 0.574031 | 0.068366 | |
| 0.028485 | 0.467114 | 0.064683 | |
| 0.070834 | 1.333867 | 0.172124 | |
| 0.173901 | 0.728156 | 0.094539 | |
| 0.065546 | 0.637773 | 0.139324 | |
| 0.027194 | 0.585675 | 0.049214 | |
| 0.019217 | 0.230216 | 0.044451 | |
| 0.043202 | 0.625564 | 0.094399 |
Table 3.
Evaluation results of the evo tools on ORB-SALM algorithms. The table shows the error in the translation part of the APE in meter. Bold numbers indicate that the estimated trajectory is closer to the true value.
Table 3.
Evaluation results of the evo tools on ORB-SALM algorithms. The table shows the error in the translation part of the APE in meter. Bold numbers indicate that the estimated trajectory is closer to the true value.
| ORB-SLAM | ORB-SLAM (No Loop Closure) | |
|---|---|---|
| Sequences | APE (Translation) | APE (Translation) |
| 0.043234 | 0.61 | |
| 0.037499 | 0.72 | |
| 0.036133 | 1.70 | |
| 0.062301 | 6.32 | |
| 0.065937 | 5.66 | |
| 0.094841 | 1.35 | |
| 0.056340 | 0.53 | |
| 0.056987 | 0.68 |
Table 4.
The mean time to process a camera frame on a hardware platform using the Intel Core i5-7500 CPU (3.4 GHz × 4).
Table 4.
The mean time to process a camera frame on a hardware platform using the Intel Core i5-7500 CPU (3.4 GHz × 4).
| Meantime (ms) | |
|---|---|
| This Work | 11.91 |
| ORB-SLAM (No loop closure) | 28.25 |
| OKVIS-mono | 25.16 |
Table 5.
The algorithm in this pap5.
| Meantime (ms) | |
|---|---|
| Pyamid Creation | 0.23 |
| Sparse Image Alignment | 4.37 |
| Feature Alignment | 6.58 |
| Pose and Structure Refinement | 0.73 |
| Total Motion Estimation | 11.91 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, N.; Zhao, Y. Fast and Robust Monocular Visua-Inertial Odometry Using Points and Lines. Sensors 2019, 19, 4545. https://doi.org/10.3390/s19204545
AMA Style
Zhang N, Zhao Y. Fast and Robust Monocular Visua-Inertial Odometry Using Points and Lines. Sensors. 2019; 19(20):4545. https://doi.org/10.3390/s19204545
Chicago/Turabian StyleZhang, Ning, and Yongjia Zhao. 2019. "Fast and Robust Monocular Visua-Inertial Odometry Using Points and Lines" Sensors 19, no. 20: 4545. https://doi.org/10.3390/s19204545
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.