An Adaptive Feature Learning Model for Sequential Radar High Resolution Range Profile Recognition


College of Electronic Science and Engineering, National University of Defense Technology, Changsha 410073, China
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(7), 1675; https://doi.org/10.3390/s17071675
Submission received: 12 June 2017
/
Revised: 17 July 2017
/
Accepted: 19 July 2017
/
Published: 20 July 2017
(This article belongs to the Section Remote Sensors)
Abstract
:This paper proposes a new feature learning method for the recognition of radar high resolution range profile (HRRP) sequences. HRRPs from a period of continuous changing aspect angles are jointly modeled and discriminated by a single model named the discriminative infinite restricted Boltzmann machine (Dis-iRBM). Compared with the commonly used hidden Markov model (HMM)-based recognition method for HRRP sequences, which requires efficient preprocessing of the HRRP signal, the proposed method is an end-to-end method of which the input is the raw HRRP sequence, and the output is the label of the target. The proposed model can efficiently capture the global pattern in a sequence, while the HMM can only model local dynamics, which suffers from information loss. Last but not least, the proposed model learns the features of HRRP sequences adaptively according to the complexity of a single HRRP and the length of a HRRP sequence. Experimental results on the Moving and Stationary Target Acquisition and Recognition (MSTAR) database indicate that the proposed method is efficient and robust under various conditions.
1. Introduction
In the radar automatic target recognition (RATR) community, recognition techniques based on radar high-resolution range profile (HRRP) have been widely studied [1,2,3,4,5]. An HRRP can be understood as a result of “scanning” the target from the direction of the radar line-of-sight, it contains discriminative features of the target such as the size and the distribution of scattering centers, etc. The common scheme for HRRP recognition is firstly to divide the full target-radar aspect angles into several stationary areas (also named “frames”) [2,5,6,7,8]. After that, target detection [9,10,11,12] is performed to select the region of interest in an HRRP. Finally, the HRRPs of each frame are further processed for recognition, which is also called feature extraction. Common feature extraction techniques include HRRP templates [13], HRRP stochastic modeling [2,3,5], time-frequency transform features [14,15], transform invariant features [16,17]. All these feature extraction techniques have their own advantages and disadvantages, none of them is optimal for target recognition.
Since the information of the target provided by a single HRRP is limited, utilizing sequential HRRP from multiple target-radar aspect angles can be a better choice for recognition. To make use of the spatial or temporal dependence in a sequence, HMM is often utilized for several sequential problems, such as sequential event detection in wireless sensor networks [18,19] and radar HRRP sequence recognition [20,21,22], where each HMM “state” consists of a set of generally contiguous target-sensor orientations over which the HRRP statistics are relatively stationary, and the statistical relationships in the HRRP sequence are described via the transition probabilities from one state to the next under HMM formulation. There are two paradigms of forming an HRRP sequence. One is done by continuously receiving HRRPs in a short period of time or aspect angles [21]. The angular sampling rate is dense, and the interval between adjacent HRRPs is often less than 0.1°. In this case, the HMM tries to model HRRP sequences in a single frame. Another way of forming an HRRP sequence is done by receiving HRRPs from different aspect-frames [20,22]. The sampling interval is often larger than 3° in this case, and the HMM tries to model the transitions between frames. The problem for the HMM is that it can only represent local dependencies between states, and it is not efficient to deal with high dimensional data, preprocessing of HRRP using the feature extraction techniques mentioned above is still required beforehand.
Modeling high dimensional sequential data has also been studied for decades in the machine learning community. Recently, the restricted Boltzmann machines (RBMs) have achieved great success in capturing spatial or temporal patterns in different types of data [23,24,25]. More specifically, an RBM is a bipartite graphical model that uses a layer of “hidden” binary variables or units to model the probability distribution of a layer of “visible” variables [26,27].The RBM and its various extensions have enjoyed much popularity for pattern analysis and generating due to the generality and flexibility of its graphical structure. However, for all types of RBMs, choosing a proper number of hidden units is essential but difficult. In order to deal with this issue, Côté [28] proposed a non-parametric model called the Infinite Restricted Boltzmann Machine (iRBM). The iRBM can automatically adjust the effective number of hidden units according to the training data, which is especially beneficial when the data size is changeable.
In this paper, we propose a new approach to sequential radar HRRPs recognition based on the iRBM. In order to make the iRBM to be capable of learning discriminative features, we modified the model to make it learning the joint probability distribution of sequential HRRPs and the corresponding target label. The HRRP data is converted from the SAR data of MSTAR [29]. HRRP sequences with different lengths are directly used to train the model. The maximal length covers about 1/3 of the full aspect. We didn’t train a full-aspect model for the reason that in real recognition scenarios, it is difficult to acquire HRRPs from all aspect angles, but it is much easier to acquire HRRPs from a fragment of aspect angles. The influence of HRRP sequences with different angular sampling rates at test phase has also been studied to investigate the robustness of our method. The features of the proposed method can be summarized as follows:
- (a)
- It is an end-to-end model of which the input is the raw HRRP sequence and the output is the target class. Feature extraction and target classification are done in a single model.
- (b)
- The model can efficiently capture the global pattern in a HRRP sequence, which is more powerful than other dynamic models such as the HMM.
- (c)
- It is an adaptive model which can automatically decide the model complexity according to the complexity of HRRPs and the length of HRRP sequence.
The rest of the paper is summarized as follows: in Section 2, the RBM and iRBM are briefly introduced as a preparation for the proposal of the method. In Section 3, the proposed model for sequential HRRP recognition is presented in detail, followed by the training method for the model in Section 4. After that, several experiments on the MSTAR dataset have been performed to evaluate our model under various recognition scenarios in Section 5. Finally, we conclude our work in Section 6.
For convenience of reading, some notations for variables and equations in the paper are listed as follows:
- (1)
- All one-dimensional variables are formatted in italic;
- (2)
- All vectors and matrices are formatted in boldface;
- (3)
- represents the probability distribution of .
2. Preliminaries
2.1. Restricted Boltzmann Machines
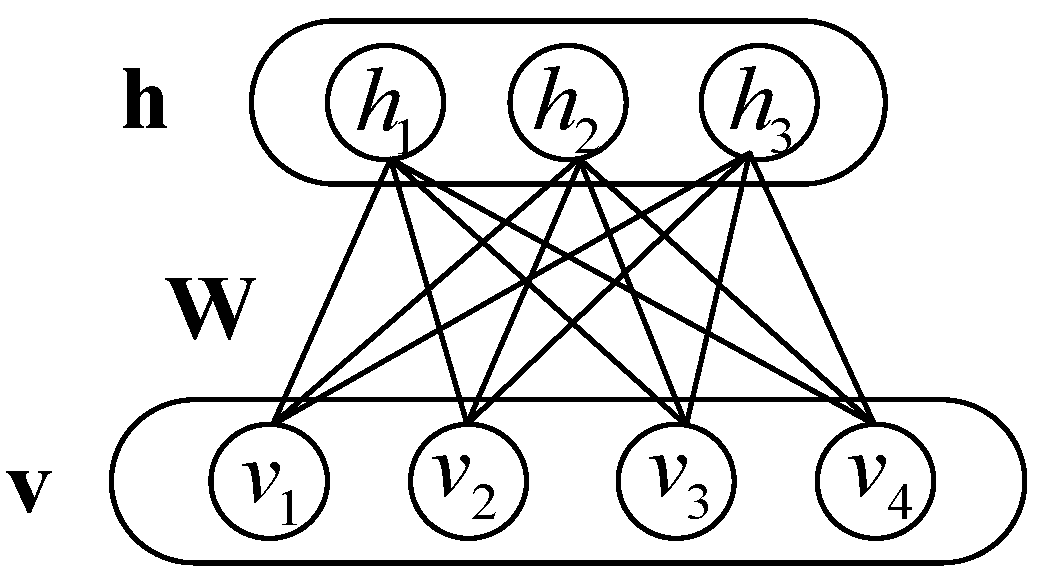
The RBM is a bipartite graphic model, which means that it contains two layers, the visible layer and the hidden layer. The visible layer consists of the visible vector representing the observable data, the hidden layer consists of the hidden vector . And each unit of the hidden layer is connected with all the units of visible layer and vice versa, while there is no connection within each layer. Both and are binary vectors. The corresponding graphical model for the RBM is illustrated in Figure 1.
The RBM represents a joint probability distribution with the so-called energy function defined below [26]:
where is the set of parameters. And is given as follows:
where is the partition function which ensures that Equation (2) is a valid probability distribution.
An RBM can be used to model the distribution of the observed data by learning from the training data . The training is done in an unsupervised manner. After the model is trained, we can sample new data from the model. The hidden layer can be also treated as a representation of the data using . In this case, an RBM is treated as a feature extractor which preprocesses the data for other purposes such as classification [30].
2.2. Infinite Restricted Boltzmann Machines
The iRBM [28] is proposed to settle the difficulty of choosing proper number of hidden units for the RBMs, it can effectively adapt its capacity as training progresses. The iRBM is an extension of the ordinary RBM, which mixes infinite number of RBMs with different number of hidden units from 1 to ∞, and all the RBMs choose the hidden units in sequence from the same set. The energy function of the iRBM is defined as follows:
where, is the dimensional visible vector representing the observable data. is the element of the infinite-dimensional hidden vector . is the penalty for each selected hidden unit . is the row of weight matrix connecting the visible units and the hidden units. is the visible units biases. is the hidden unit bias. The random variable can be understood as the total number of hidden units being selected to participate in the energy function.
It should be noticed that for a given , the value of the energy function is irrelevant for the dimensions of from to ∞, which means that where will never be activated. Thus, (3) has the same form with the energy function of ordinary RBM with hidden units except the penalty which the latter does not have.
The joint probability over , and is:
where:
and , where is the set of all possible values takes. Thus defines the legal values of given .
The hidden units are selected in sequence as takes the value from 1 to ∞, and if the penalty is chosen properly, an infinite pool of hidden units can be achieved. A way to parameterize is suggested in [28], which is . This will ensure the partition function is convergent as long as and the number of hidden units having non-zero weights and biases is always finite. In this paper, we just used the same value in all the experiments, as we found that the performance of the model is robust to the choices of . The major effect of is on learning speed rather than the final performance.
It needs to be pointed out here that, for both RBMs and iRBMs, exactly computing is intractable as computing the partition function Z involves summing all possible states of hidden units. However, inferring from or conversely is easy. Thus, the model can be used to draw new samples , , , efficiently by conducting Gibbs sampling ().
3. The Proposed Model
The iRBM has a nice property of adaptively learning the numbers of hidden units, which is especially beneficial when the dataset size is changeable. However, it can only perform unsupervised learning, there is no guarantee that the learnt features are helpful for discrimination. In this section, a modified version of iRBM is proposed which can jointly learn the distribution of the HRRP sequence with sequence length L, and its corresponding label .
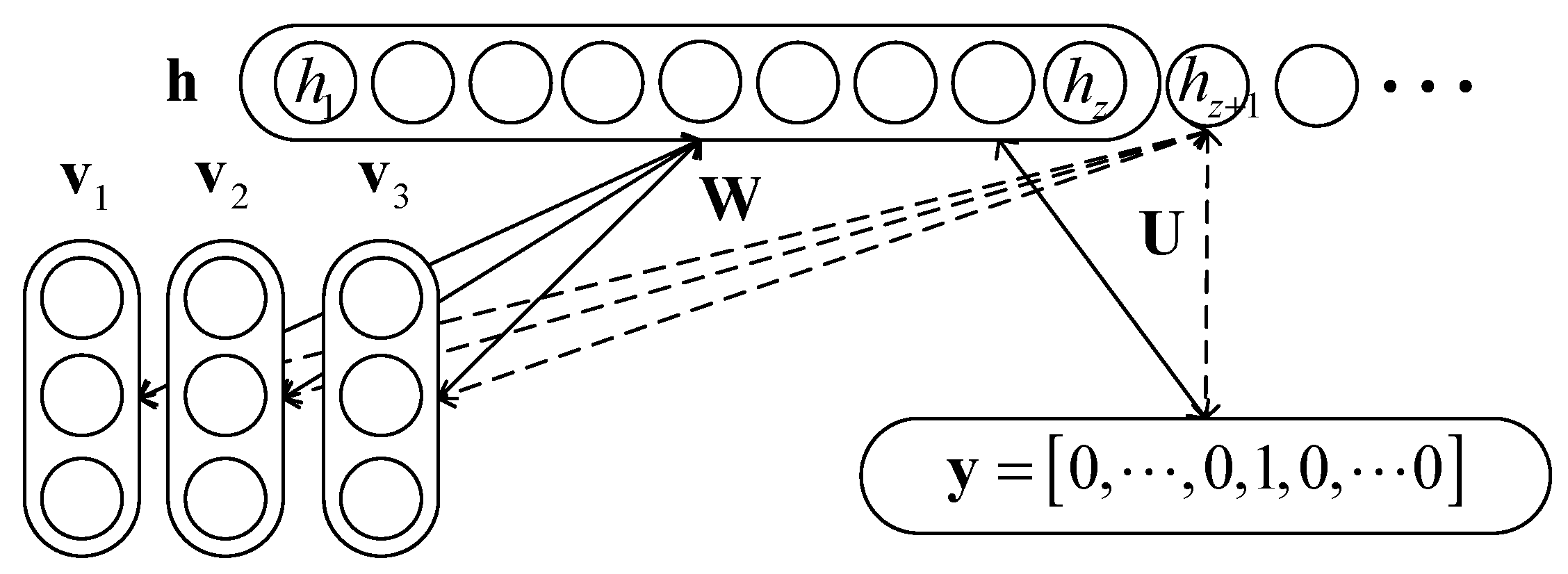
By introducing the label of data into the energy function (3), a new model representing the joint probability of , , and is achieved, which is:
where the modified energy function is:
where, is the HRRP vector of the sequence. is the “one hot” representation of the label , and is the total number of classes. is the label bias vector with the same dimension to . is the row of weight matrix connecting the HRRP vector and the hidden units . is the row of the weight matrix which connects and .
By marginalizing out and , we get the marginal distribution as follows:
where:
We name this model the discriminative infinite restricted Boltzmann machine (Dis-iRBM). The graphical structure of the proposed model is demonstrated in Figure 2.
The Dis-iRBM has a self-contained structure for supervised learning just as the ClassRBM [31] does. Furthermore, it learns features more flexibly. It can be trained discriminatively or generatively [31]. In the following section, a hybrid training objective combining discriminative and generative training objective together is proposed to learn the parameters of the model.
4. Learning the Parameters of the Model
The training objective to learn the parameters is a hybrid training objective combining the generative and the discriminative training objective similar to [31], and is given below:
where, is the set of training examples, and . The way to construct training examples of HRRP sequences will be explicitly introduced in Section 5. corresponds to the discriminative part modeling , and corresponds to the generative part modeling the inputs only. controls the proportion of each part. The second part can be thought of as a model regularization term.
The learning of the generative part is identical with the learning of the iRBM introduced in Section 2. The Contrastive Divergence (CD) and the Persistent Contrastive Divergence (PCD) [32,33] can be directly used to compute the gradients. The approximated gradient for the generative part is given below:
where, is sampled from , and are sampled from by K-step Gibbs sampling, the detail of learning a iRBM is provided in [24].
In order to calculate the gradient of the discriminative part , the conditional probability is derived as follows:
where:
By taking Equations (12) and (13) into the discriminative part of (11), the gradient of is derived as follows:
where:
and
The gradients can be exactly computed, as shown in the Appendix. However, this involves computing gradients for infinite many parameters. To avoid this issue, we only compute the gradients for parameters of first hidden units whose parameters are non-zero at gradient descent step , and leave all the remaining parameters to be 0. The complexity of computing (16) is .
The maximum number of activated hidden units changes gradually during training. Practically, if the Gibbs sampling chain ever samples a value of larger than , we clamp it to . This avoids filling large memory for a large (but rare) value of . The training procedure for the proposed recognition model is summarized as follows:
- Step 1:
- Divide the training dataset of HRRPs into several aspect frames;
- Step 2:
- Construct the sequential HRRP training data with length L by L HRRPs from L adjacent aspect frames, and each frame provides one HRRP. See the details in Section 5.
- Step 3:
- Train several different models on the data with different lengths L using the training method described above.
After the model is trained, a new sample of the sequential HRRP data is obtained using the same aspect frame detecting technique in the training phase. And the likelihood of each label conditioned on the new data is computed using the trained model with the same sequence length L. Finally, it is assigned to the class according to the following decision rule:
As mentioned above, the complexity of computing (16) or (17) is . , and is the number of dimensions of a single HRRP, of which the order of magnitude is 100. The sequence length L is usually less than 50. And the class numbers C has a magnitude order of about 10. Thus the approximate computational complexity for a typical recognition problem is , which is a quadratic function of the model size . The computation can be performed in real-time as long as is not extremely large.
5. Experimental Results
In this section, several experiments on the MSTAR dataset have been performed to evaluate the proposed recognition model. Firstly, the way of arranging the training and testing HRRP sequences have been introduced. Then, two kinds of experiments have been done on this dataset. The first experiment investigated the influence of HRRP sequence length on recognition performance. The second experiment investigated the robustness of the proposed model when the angular sampling rates at test phase were different from that at training phase. To accelerate the learning of Dis-iRBMs, we used a new training strategy referred as “RP” training [34] to train the Dis-iRBMs in all experiments.
5.1. The Dataset
SAR images of three types of targets (the T-72 main battle tank, the BMP-2 armored personnel carrier, and the BTR-70 armored personnel carrier) in MSTAR were used to construct the sequential HRRP dataset. The SAR images of the training set were taken at a depression angle of 17°, while the testing set depression angle is 15°. SAR images of all targets covered the full aspect angles, and the training and the testing images of the same vehicle at the same aspect angle are different. Variants (different serial number) of the three targets were also used in the testing set to evaluate the generalization ability of the recognition method. The dataset of three-target problem is briefly illustrated in Table 1. The size of the training and testing sets of SAR images is 698 and 1365, respectively.
We converted each SAR image into 10 mean HRRPs, thus the training set and testing set contain 6980 HRRPs and 13,650 HRRPs respectively. In many literatures, the clutter is removed to get “clean” HRRPs, while we directly used the raw HRRPs, the only preprocessing were normalizing the magnitude of each HRRP to its total energy. This setting could make the experiments more closed to real recognition scenarios. We divided the 360° of aspect angles into 50 aspect frames uniformly, each frame covers 7.2°, this division of aspect frames may not be optimized, but is similar to that described in [20], which allow us to conveniently compare between these two methods. Suppose the total number of HRRPs for a target is N, then each aspect frame contains about N/50 HRRPs. The following steps were taken to construct the sequential HRRP data:
- Step 1:
- The first HRRPs from aspect frame 1 to aspect frame are chosen to form an HRRP sequence with length . Slide one unit to the right to choose the second HRRPs from the same frames to form another HRRP sequence. Repeat this procedure until the end of each frame;
- Step 2:
- Slide one frame to the right and repeat step 1;
- Step 3:
- Repeat step 2 until the end of all aspect frames. If the sequence starts after () th frame, then the first frames are cyclically used one by one to form complete sequences.
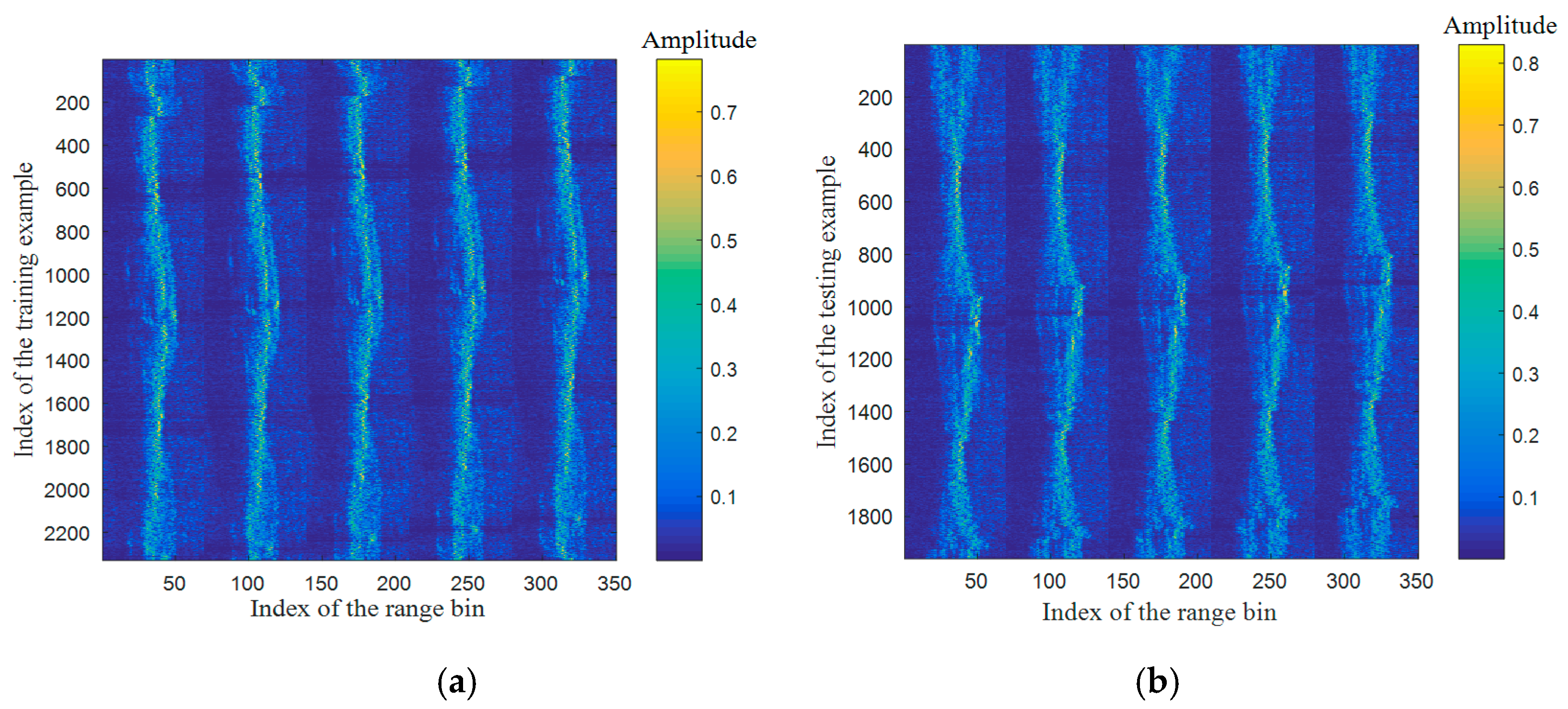
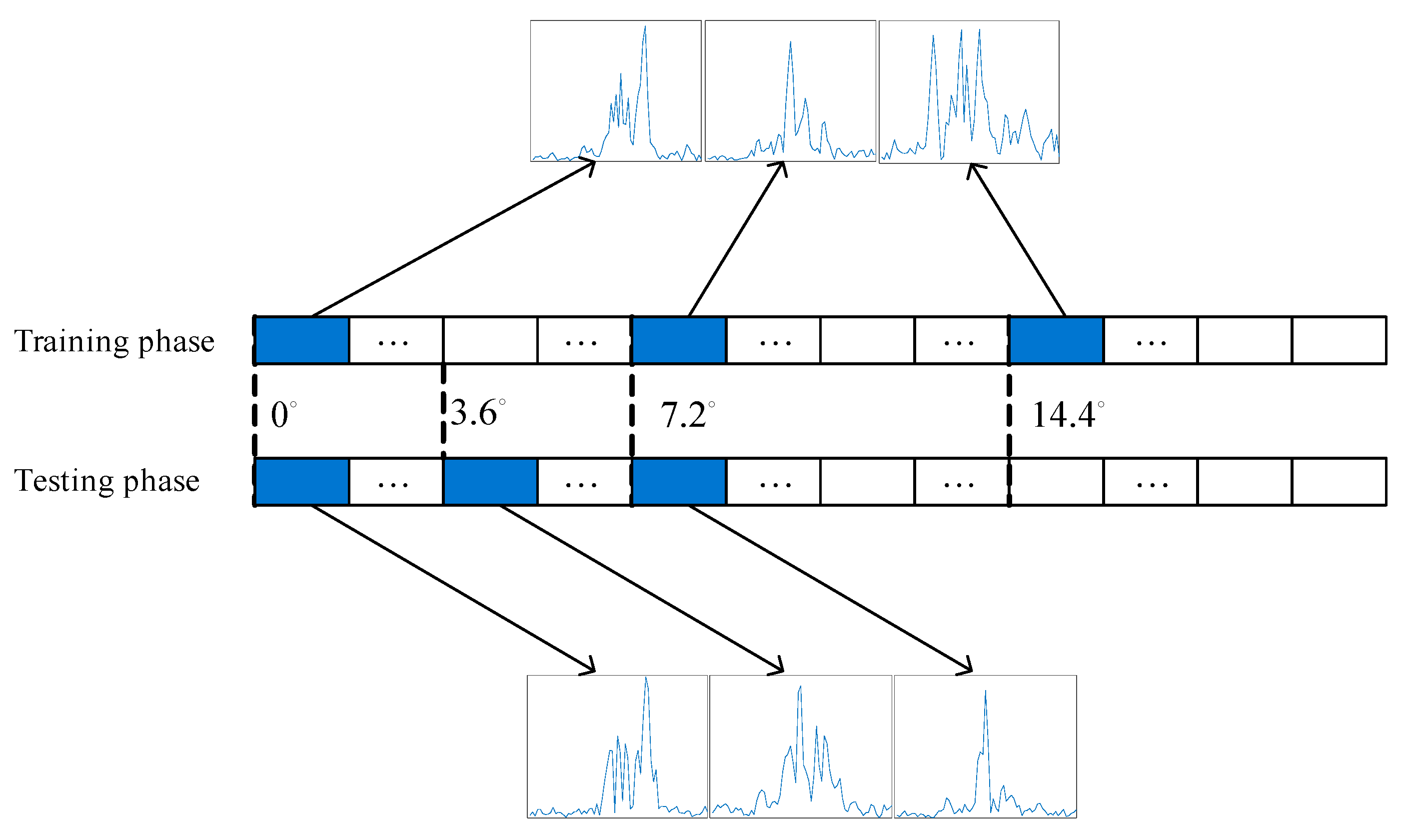
The total number of HRRP sequences is exactly N by constructing the data in this way, and each HRRP sample can appear at anywhere of the sequence. Part of training set and testing set are illustrated in Figure 3, where the sequence length .
5.2. Experiment 1: Investigating the Influence of HRRP Sequence Length on Recognition Performance
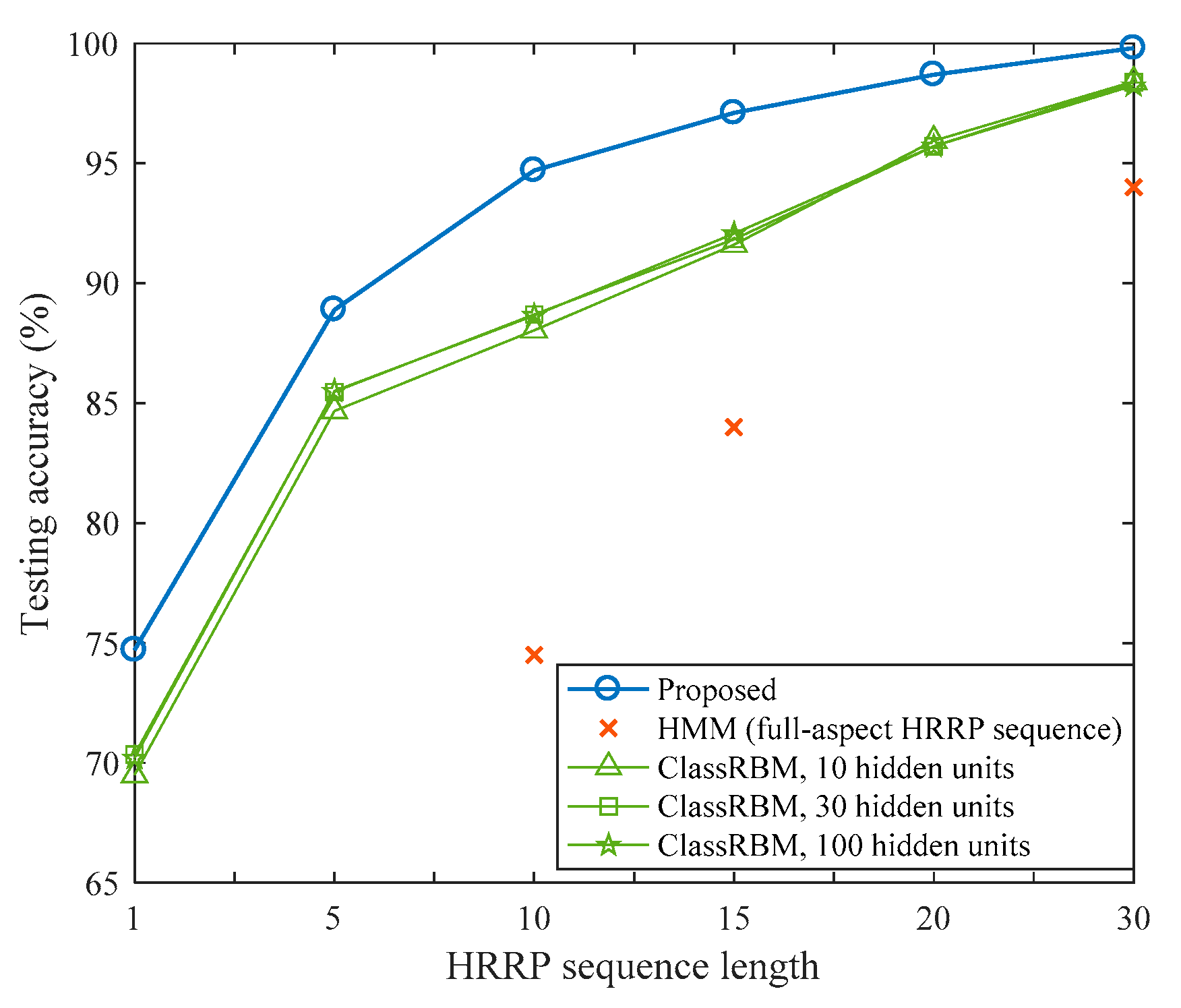
In this sub-section, five individual models were trained by the data with different sequence lengths (L = 1, 5, 10, 15, 20, 30). We also trained ClassRBMs with different hidden layer sizes as comparisons to the proposed method. At the testing phase, the data has the same angular sampling rate and sequence length with the training data. In this case, each model is supposed to have the best performance, thus comparison between different models is fair. The recognition performance of each model is shown in Figure 4.
As shown in Figure 4, the longer the sequence is, the higher the test accuracy can achieve. This is not surprising as multiple HRRP contains more information about the target than a single HRRP. The proposed model can efficiently utilize more complicated information owing to the strong representation power and adaptive feature learning property. Reference [20] used a similar way of constructing the sequence data which resulted in 55 aspect frames. They trained HMMs on the full-aspect HRRP sequences (L = 55), and the maximal sequence length for test was 30 with the same angular sampling rate in the test phase. By this setting, they reached a result of 94%. But the sequence length is too long (covering more than half of the aspect angles), which often cannot be fulfilled in real recognition scenarios. Our model outperforms [20] when the length is longer than 10. The best performance in this experiment is 99.8% when the sequence length L = 30. This result is ideal as the test and training angular sampling rates are identical and the sequence length is long enough. As for ClassRBM, the number of hidden units cannot be learnt, it has to be specified before training. We tried three different hidden layer sizes ( = 10, 30, 100). The performances of ClassRBMs indicate that increasing the model complexity would not necessarily result in increasing the recognition performance. And a too large model is also more likely to over fit the data. Thus it is essential to decide a proper size of the model for better generalization. The confusion matrix achieved by the model train on HRRP sequence with L = 15 is illustrated in Table 2.
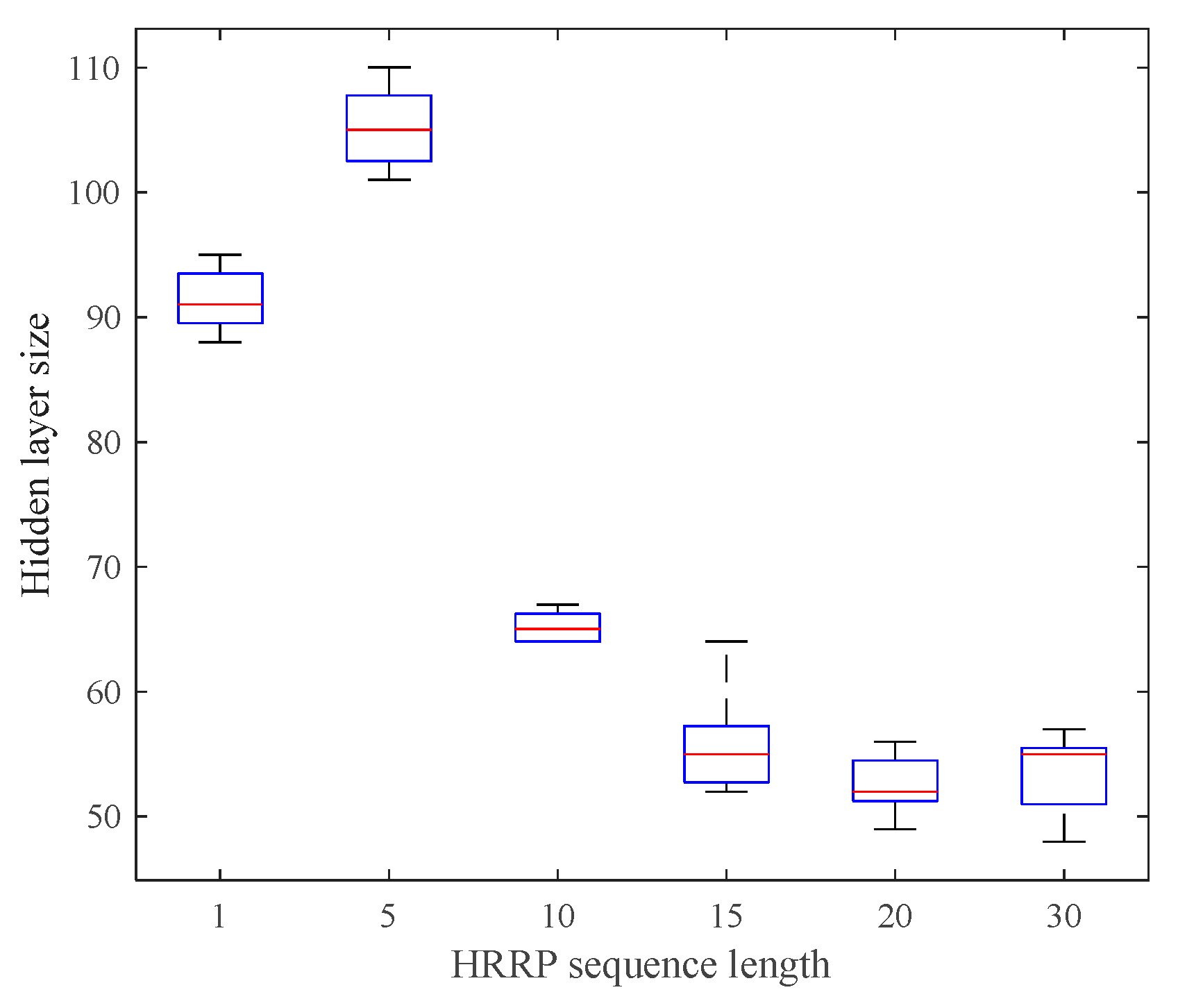
To validate the adaptive property of the proposed model, we repeated the training procedure on each sequence length five times. The average model size over five trials on each sequence length is illustrated in Figure 5. We can see from the figure that the number of hidden units went down and became stable at 50~60 when the sequence length was larger than 15. This is not surprising. As the sequence becomes longer, the visible data become more structured and regular. The hidden units can discover global patterns more efficiently and share it with each other, which results in the need of less number of hidden units.
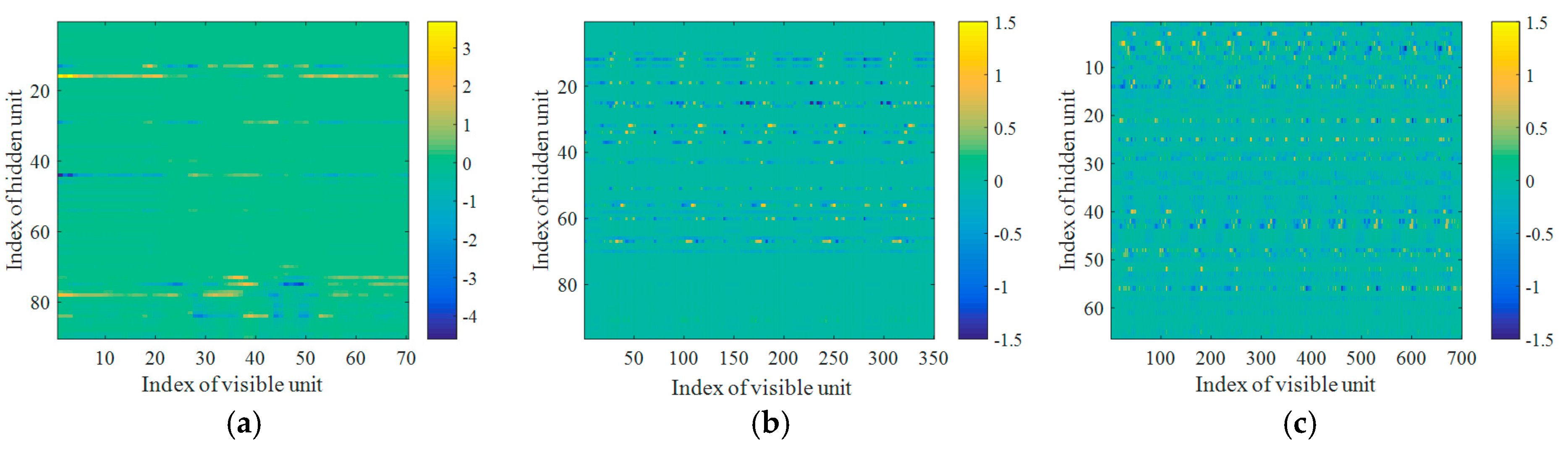
Figure 6 illustrates weight matrices or filters learnt by Dis-iRBMs, where each row in the weight matrix represents a filter learnt by the corresponding hidden unit.
5.3. Experiment 2: Investigating Robustness of the Proposed Model on Alternative Angular Sampling Rates in Test Phase
In real recognition scenarios, it is difficult to ensure that the angular sampling rate in the test phase is identical to that in the training phase, especially when the relative pose of the target is unavailable. Thus it is essential for the recognition method to have some robustness to the change of the sampling rate. The difference in training and test angular sampling intervals is illustrated in Figure 7.
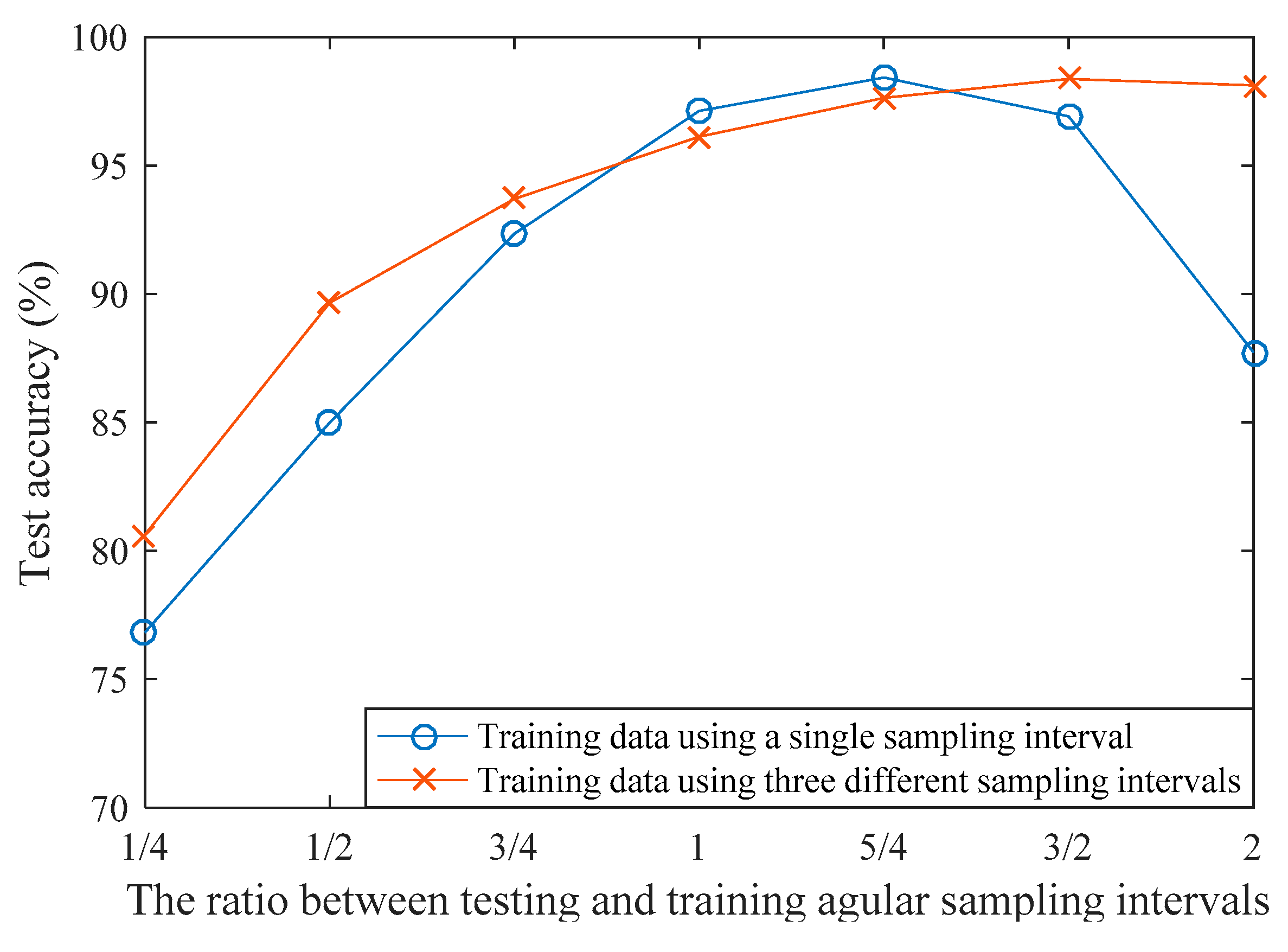
Here, we used the best model trained on the data with L = 15 and sampling interval T0 = 7.2° to evaluate this property. Several different testing datasets were constructed using different ratios between testing and training sampling intervals (1/4, 1/2, 3/4, 1, 5/4, 3/2, 2). The results are shown in Figure 8. The test accuracy ranges from 76.8% to 98.4%. In overall, the recognition performance is improved when the testing and training angular sampling intervals get closer to each other. Intuitively, the model will perform the best when sampling ratio is 1. However this is not the case in this experiment, the model performs the best when the ratio is 5/4. The reason of this unexpected result may come from the fact that, the whole aspect angles was uniformly divided into 50 frames. This division of frames may not be optimized, e.g., the evolution of statistic property of HRRP with respect to the aspect angle is often not uniform. Better performance will be achieved if more elaborate way of frame division is utilized. We also used an expanded training set containing three different angular sampling intervals (T0 = 7.2°, T1 = 3.6°, T2 = 14.4°) to train the model, and T0 = 7.2° was used as benchmark for comparing to the testing sampling intervals. Its test performance ranges from 80.6% to 98.4%. An interesting fact from this experiment is that, higher sampling interval is preferred for better recognition. For a single radar, it is not easy to sampling the HRRPs with large angular intervals. However, this condition can be fulfilled more easily if there exist multiple radars observing the target from different aspect angles.
6. Conclusions
This paper provides an approach for efficiently recognizing radar HRRP sequences. The proposed model has appealing properties of adaptive feature learning and capturing global features in a HRRP sequence. It is an end-to-end method which directly processes the raw HRRP sequence data and outputs the target label. It achieves high recognition accuracy when the sequence length covers more than 1/5 of the aspect angles, which outperforms the HMM using the HRRP sequences covering the whole aspect angles. It is more flexible and generalizes better than the ClassRBM. The model also shows some robustness to the change of angular sampling rate, the results with respect to angular sampling intervals also indicates that higher sampling interval might be preferred for better recognition. In the future, the proposed model can be improved in three directions. The first is trying to import area knowledge of the HRRP signal into the model to make it representing the HRRP more accurately. The second is studying the effects of angular sampling interval or frame division on model’s performance. The third is developing a model which can efficiently take different scales of relative angular speeds into account thus may enhance its robustness to the change of angular sampling rates in real recognition scenarios.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 6157450).
Author Contributions
Xuan Peng provided the idea of this work. Xunzhang Gao and Xuan Peng designed the experiments. Yifan Zhang performed the experiments. Xuan Peng and Yifan Zhang wrote the paper. Xiang Li supervised this work.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Derivation of gradients (14) w.r.t. is presented as follows. Recall the Equation (14):
where:
In order to compute (A1), we need to compute first, which are shown as follows:
Similarly:
where:
substituting (A2)–(A5) into (A1), we get:
where, .
References
- Jacobs, S.P.; O’Sullivan, J.A. Automatic target recognition using sequences of high resolution radar range profiles. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 364–382. [Google Scholar] [CrossRef]
- Du, L.; Liu, H.; Bao, Z. Radar HRRP statistical recognition: Parametric model and model selection. IEEE Trans. Signal Proc. 2008, 56, 1931–1944. [Google Scholar] [CrossRef]
- Webb, A.R. Gamma mixture models for target recognition. Pattern Recognit. 2000, 33, 2045–2054. [Google Scholar] [CrossRef]
- Du, L.; Wang, P.; Zhang, L.; He, H.; Liu, H. Robust statistical recognition and reconstruction scheme based on hierarchical Bayesian learning of HRR radar target signal. Expert Syst. Appl. 2015, 42, 5860–5873. [Google Scholar] [CrossRef]
- Copsey, K.; Webb, A. Bayesian gamma mixture model approach to radar target recognition. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1201–1217. [Google Scholar] [CrossRef]
- Cohen, M.N. Variability of ultrahigh-range-resolution radar profiles and some implications for target recognition. Aerosp. Sens. Int. Soc. Opt. Photonics 1992, 1699. [Google Scholar] [CrossRef]
- Zywechm, A.; Bogner, R.E. Coherent averaging of range profiles. IEEE Int. Radar Conf. 1995, 456–461. [Google Scholar] [CrossRef]
- Liu, H.; Du, L.; Wang, P. Radar HRRP automatic target recognition: Algorithms and applications. In Proceedings of the 2011 IEEE CIE International Conference on Radar (Radar), Chengdu, China, 24–27 October 2011. [Google Scholar]
- Conte, E.; Lops, M. Clutter-map CFAR detection for range-spread targets in non-Gaussian clutter. I. System design. IEEE Trans. Aerosp. Electron. Syst. 1997, 32, 432–443. [Google Scholar] [CrossRef]
- Meng, X.W.; Dong-Cai, Q.U.; You, H.E. CFAR detection for range-extended target in Gaussian background. Syst. Eng. Electron. 2005, 27, 1012–1015. [Google Scholar]
- Ciuonzo, D.; De Maio, A.; Orlando, D. A unifying framework for adaptive radar detection in homogeneous plus structured interference—Part I: On the maximal invariant statistic. IEEE Trans. Signal Proc. 2016, 64, 2894–2906. [Google Scholar] [CrossRef]
- Ciuonzo, D.; De Maio, A.; Orlando, D. A unifying framework for adaptive radar detection in homogeneous plus structured interference—Part II: Detectors design. IEEE Trans. Signal Proc. 2016, 64, 2907–2919. [Google Scholar] [CrossRef]
- Shaw, A.K. Automatic target recognition using Eigen templates. Proc. SPIE Int. Soc. Opt. Eng. 1998, 3370, 448–459. [Google Scholar]
- Huether, B.M.; Gustafson, S.C.; Broussard, R.P. Wavelet preprocessing for high range resolution radar classification. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 1321–1332. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, X.D.; Hu, Y.F. Gabor Filter Approach to Joint Feature Extraction and Target Recognition. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 17–30. [Google Scholar]
- Du, L.; Liu, H.; Bao, Z.; Xing, M. Radar HRRP target recognition based on higher order spectra. IEEE Trans. Signal Proc. 2005, 53, 2359–2368. [Google Scholar]
- Li, J.; Stoica, P. Efficient mixed-spectrum estimation with applications to target feature extraction. IEEE Trans. Signal Proc. 2008, 44, 281–295. [Google Scholar]
- Hu, P.; Zhou, Z.; Liu, Q.; Li, F. The HMM-based modeling for the energy level prediction in wireless sensor networks. In Proceedings of the 2nd IEEE Conference on Industrial Electronics and Applications (ICIEA 2007), Harbin, China, 23–25 May 2007. [Google Scholar]
- Rossi, S.P.; Ciuonzo, D.; Ekman, T. HMM-based decision fusion in wireless sensor networks with noncoherent multiple access. IEEE Commun. Lett. 2015, 19, 871–874. [Google Scholar] [CrossRef]
- Albrecht, T.W.; Gustafson, S.C. Hidden Markov models for classifying SAR target images. Def. Secur. Int. Soc. Opt. Photonics 2004, 5427, 302–308. [Google Scholar]
- Liao, X.; Runkle, P.; Carin, L. Identification of ground targets from sequential high-range-resolution radar signatures. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 1230–1242. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, X.D.; Hu, Y.F.; Xie, D. Nonstationary hidden Markov models for multiaspect discriminative feature extraction from radar targets. IEEE Trans. Signal Proc. 2007, 55, 2203–2214. [Google Scholar] [CrossRef]
- Sutskever, I.; Hinton, G.E. Learning multilevel distributed representations for high-dimensional sequences. J. Mach. Learn. Res. 2007, 2, 548–555. [Google Scholar]
- Eslami, S.M.A.; Heess, N.; Williams, C.K.I. The shape Boltzmann machine: A strong model of object shape. Int. J. Comput. Vis. 2014, 107, 155–176. [Google Scholar] [CrossRef]
- Mittelman, R.; Kuipers, B.; Savarese, S.; Lee, H. Structured recurrent temporal restricted Boltzmann machines. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Smolensky, P. Information processing in dynamical systems: Foundations of harmony theory. Parallel Distrib. Proc. Exp. Microstruct. Cogn. Found. 1986, 1, 194–281. [Google Scholar]
- Fischer, A.; Igel, C. Training restricted Boltzmann machines: An introduction. Pattern Recognit. 2014, 47, 25–39. [Google Scholar] [CrossRef]
- Côté, M.A.; Larochelle, H. An infinite restricted Boltzmann machine. Neural Comput. 2016, 18, 1265–1288. [Google Scholar] [CrossRef] [PubMed]
- MSTAR (Public) Targets: T-72, BMP-2, BTR-70, SLICY. Available online: http://www.mbvlab.wpafb.af.mil/public/MBVDATA (accessed on 14 May 2017).
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Heidelberg, Germany; Dordrecht, The Netherlands; London, UK; New York, NY, USA, 2012; pp. 599–619. [Google Scholar]
- Larochelle, H.; Mandel, M.; Pascanu, R.; Bengio, Y. Learning algorithms for the classification restricted Boltzmann machine. J. Mach. Learn. Res. 2012, 13, 643–669. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Tieleman, T. Training restricted Boltzmann machines using approximations to the likelihood gradient. Int. Conf. Mach. Learn. ACM 2008, 1064–1071. [Google Scholar] [CrossRef]
- Peng, X.; Gao, X.; Li, X. On better training the infinite restricted Boltzmann machines. Mach. Learn. 2017. submitted. [Google Scholar]
Figure 1.
Graphical structure of the RBM.

Figure 2.
Graphical structure of the Dis-iRBM for sequential HRRP.

Figure 3.
Some examples of training and testing HRRP sequences, (a) training; (b) testing.

Figure 4.
Recognition performance on models trained with different sequence length data. The result of HMM is provided by [20] in which a full-aspect HMM containing 55 states (aspect frames) was trained.
Figure 4.
Recognition performance on models trained with different sequence length data. The result of HMM is provided by [20] in which a full-aspect HMM containing 55 states (aspect frames) was trained.

Figure 5.
Effective hidden layer sizes of Dis-iRBMs trained on the data with different sequence lengths.
Figure 5.
Effective hidden layer sizes of Dis-iRBMs trained on the data with different sequence lengths.

Figure 6.
Weight matrices or filters learnt by Dis-iRBMs, (a) L = 1; (b) L = 5; (c) L = 10.

Figure 7.
A illustration of the difference of angular sampling intervals between training and testing phase. Where the ratio between testing and training sampling intervals is 1/2.
Figure 7.
A illustration of the difference of angular sampling intervals between training and testing phase. Where the ratio between testing and training sampling intervals is 1/2.

Figure 8.
Recognition performance on different ratios between testing and training angular sampling intervals.
Figure 8.
Recognition performance on different ratios between testing and training angular sampling intervals.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Training and testing set of SAR images for the three-target problem.
| Training Set | Size | Testing Set | Size |
|---|---|---|---|
| T72 (Sn_132) | 232 | T72 (Sn_132) | 196 |
| T72 (Sn_812) | 195 | ||
| T72 (Sn_S7) | 191 | ||
| BTR70 (Sn_C71) | 233 | BTR70 (Sn_C71) | 196 |
| BMP2 (Sn_C9563) | 233 | BMP2 (Sn_C9563) | 195 |
| BMP2 (Sn_C9566) | 196 | ||
| BMP2 (Sn_C21) | 196 |
Table 2.
Confusion matrix of the best model (L = 15) for three targets problem.
| True Inferred | BMP2 | BTR70 | T72 | Accuracy (%) |
|---|---|---|---|---|
| BMP2 | 5613 | 45 | 212 | 95.62 |
| BTR70 | 54 | 1906 | 0 | 97.24 |
| T72 | 81 | 0 | 5731 | 98.61 |
| Total accuracy(%) | 97.13 | |||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Peng, X.; Gao, X.; Zhang, Y.; Li, X. An Adaptive Feature Learning Model for Sequential Radar High Resolution Range Profile Recognition. Sensors 2017, 17, 1675. https://doi.org/10.3390/s17071675
AMA Style
Peng X, Gao X, Zhang Y, Li X. An Adaptive Feature Learning Model for Sequential Radar High Resolution Range Profile Recognition. Sensors. 2017; 17(7):1675. https://doi.org/10.3390/s17071675
Chicago/Turabian StylePeng, Xuan, Xunzhang Gao, Yifan Zhang, and Xiang Li. 2017. "An Adaptive Feature Learning Model for Sequential Radar High Resolution Range Profile Recognition" Sensors 17, no. 7: 1675. https://doi.org/10.3390/s17071675
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.