1. Introduction
Recently, video analytics has been widely deployed in various application areas including video surveillance, business intelligence, and the Internet of Things [
1,
2,
3,
4,
5,
6]. Especially in video surveillance systems, intelligent video analytics can reduce the cost of video monitoring and increase surveillance system performance by automatically analyzing video content to detect a variety of events such as intrusions, unattended objects, violence, fire, camera tamper attacks, and so on.
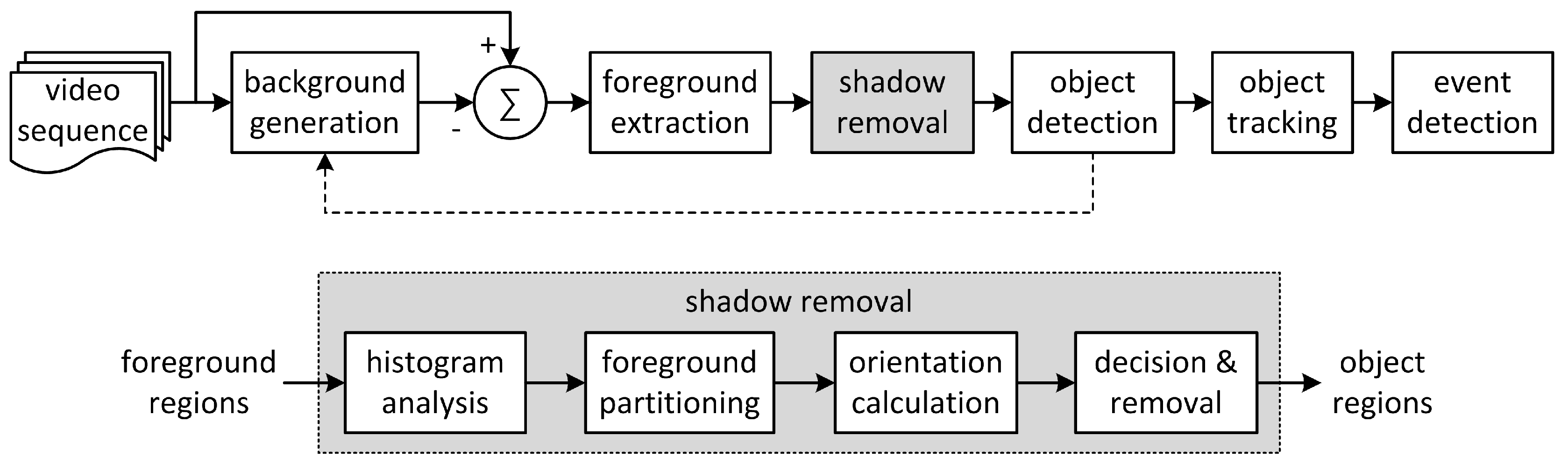
Intelligent video analytics algorithms can be deployed in IP cameras or video analytics servers located in monitoring centers or cloud networks. A conventional video analytics algorithm based on background subtraction is shown in
Figure 1 [
2,
5,
6]. To extract foreground objects, background generation, binarization, and labeling are performed on input images. Finally, object tracking and predefined event detection are performed. Most conventional video analytics algorithms have used a background frame as a reference for comparison with a current frame [
2,
5,
6]. The Gaussian mixture model (GMM) and the temporal averaging model are generally used for background generation [
6,
7]. For foreground extraction, background subtraction followed by binarization is used; this process compares the pixel difference between the background and the incoming frames with a certain threshold. Connected component labeling is used to obtain object information from the foreground pixels. Small labeled objects less than a certain threshold in size are considered to be noise blobs and are removed. Object tracking is performed on the labeled objects; this process relates the same object existing in successive frames. Event detection is the process of finding pre-configured events that have occurred in spatial and temporal directions using information such as the locations of labeled objects, the regions of interest (ROIs), the interactions among labeled objects, and the changed information of the objects.
The performance of the event detection system mostly depends on the accuracy of foreground extraction, which is degraded by either foreground pixels absorbed into the background or shadow pixels detected as foreground. If the signal characteristics of foreground pixels are similar with those of the background pixels of the same positions, these foreground pixels can be considered as background. Also, it is highly probable that each shadow region will be extracted as foreground after background subtraction because the foreground intensity may be different from that of the background for the same position depending on the intensities of the illuminating light sources.
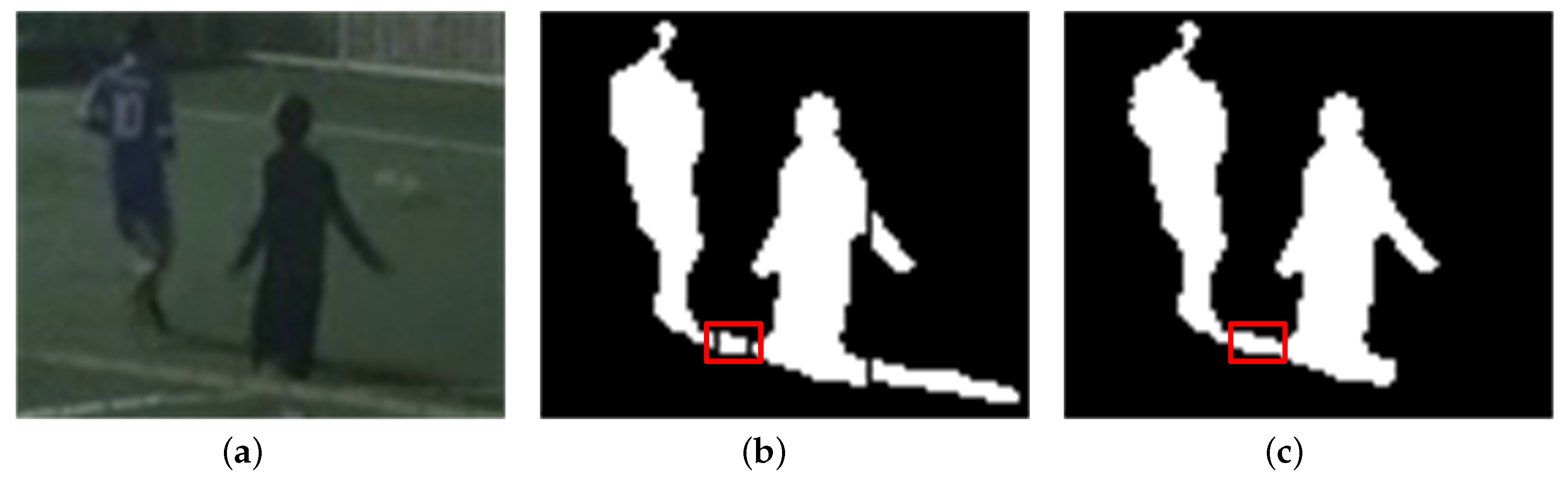
Figure 2 shows an example of foreground extraction without shadow removal for a daytime video sequence. Three foreground objects and their shadow regions are merged into one large foreground object, which results in performance degradation in the ensuing object tracking and event detection stages. Therefore, to prevent performance degradation in video analytics algorithms, it is necessary to detect and remove shadow regions from extracted foreground regions.
Shadow regions are generally assumed to become darker than background regions, but they generally have similar characteristics in terms of chromaticity and texture with the background regions of the same position. Conventional shadow detection algorithms have used the similarities in color [
8,
9,
10,
11,
12,
13,
14], geometric components [
15,
16,
17,
18], and texture [
19,
20,
21,
22,
23] of shadow regions to separate these regions from foreground regions for daytime or indoor video sequences. Most recently, shadow region learning frameworks using multiple convolutional deep neural networks have been proposed for recovering images [
24,
25] and preprocessing video for surveillance systems [
26].
Chromaticity-based shadow detection algorithms assume that background regions under shadow become darker but maintain their chromaticity; i.e., they exhibit color constancy. These algorithms choose color models of separate intensity and color components, such as normalized RGB [
8], c1c2c3 [
9], HSI [
9], YUV [
10] and HSV [
11]. Although chromaticity-based methods are computationally inexpensive, they are susceptible to noise and are less effective in low saturated scenes; they often require explicit tuning of a large set of parameters for each scene [
12,
13,
14].
Geometry-based shadow detection algorithms utilize the orientation and shape of the shadow regions, along with a knowledge of light sources, background surface condition, and object shapes such as those of vehicles [
15,
16] and pedestrians [
17,
18]. To distinguish shadow regions cast by pedestrians from foreground blobs generated by background subtraction, Hsieh [
17] and Chen [
18] assumed that human figures are posed vertically and that both human and shadow regions within a foreground blob are connected components. Hsieh [
17] separated a human figure and its shadow region on a foreground blob using a line calculated from a histogram projection and the orientation of the blob, and refined the shadow region using the Gaussian shadow model based on orientation, mean intensity, and the center position of the shadow region. Chen identified linear boundaries separating human figures and their shadow regions using a 2-stage classifier trained with a multi-cue descriptor that included aspects of color, pixel location, and edge orientation representing the spatial constraint between human figures and shadows [
18]. Although these algorithms can detect a shadow region for a single pedestrian with high accuracy under strong light sources, they cannot handle shadow regions disconnected from human figures and shadow regions of multiple pedestrians with occlusions.
Texture-based shadow detection algorithms utilize the fact that shadow regions keep most of their texture; using texture correlation, these algorithms compare the texture in the candidate shadow regions with that in the background. Various forms of texture correlation are proposed for shadow detection: gradient or edge correlation [
19,
20], orthogonal transform [
21], SIFT [
22], and Gabor filtering [
23]. Although textures are robust to illumination changes, highly distinctive, and independent of colors, analysis using textures is computationally expensive.
Physics-based shadow detection algorithms use physics-based attenuation and color features to learn local or global shadow models [
13,
27,
28,
29]. Non-linear attenuation models of light sources are used to predict the color change of shadow regions in various illumination conditions [
13,
27]. To adapt to environmental changes, statistical learning of shadow pixels has been used to model the spectral properties of shadow pixels [
13,
27,
28,
29]. However, learning of local shadow models suffers from insufficient training data [
27,
28,
29]. Also, these algorithms are still limited to handling objects with chromaticity similar to that of the background, and will require further performance improvement for practical use.
Due to the weakened signal strength of color and texture and increased noise power, these conventional algorithms have limitations in using color and texture features for shadow removal in nighttime video sequences. The conventional algorithms using the geometric characteristics of shadow [
14,
18,
22] are only targeted at removing shadow regions of single isolated objects and cannot handle the interference of shadow regions in multiple object extraction.
Machine learning based shadow detection algorithms have proposed frameworks that automatically learns the most relevant features of shadow in a supervised manner using multiple convolutional deep neural networks [
24,
25,
26]. These frameworks have strength in that there is no prior assumptions about the scene, the shadow properties, and the shape of objects. For these frameworks to be used for video pre-processing in video surveillance systems, further study is required to evaluate the cost for supervised training and the overall system complexity and to improve the shadow removal performance in various surveillance environments.
In nighttime video sequences, as in the example shown in
Figure 3, because the orientation of shadow region is determined by the displacement of an object from artificial light sources, the orientation of each object or shadow region can be used to detect shadow. In this paper, to remove shadow regions in nighttime video sequences, a novel shadow detection algorithm is proposed that partitions each foreground region into one or multiple partitioned objects based on object’s vertical histogram; the algorithm screens out shadow regions by validating the orientation of the partitioned object heading toward regions of light sources. The organization of this paper is as follows. In
Section 2, a shadow detection algorithm based on the regions of light sources and shapes and orientations of foreground objects is proposed for object extraction in nighttime video sequences. In
Section 3, experimental results for the proposed algorithm are presented and compared with results of conventional shadow detection algorithms. In
Section 4, our conclusions and suggestions for further work are presented.
2. Shadow Removal Using Regions of Light Sources in Nighttime Video
The orientations of shadow regions can be argued to be strong features for shadow removal in nighttime video sequences. In this section, a novel shadow detection algorithm is proposed for nighttime video sequences; this algorithm uses the orientations of shadow regions toward the regions of light sources (RLS).
2.1. Overview of the Proposed Shadow Detection Algorithm
For shadow removal in nighttime video sequences, four assumptions are made concerning the shapes and orientations of objects and shadow regions. First, each target object and its shadow region can be matched to ellipses with high aspect ratio. Second, the orientation of each shadow region, the direction of the major axis of the ellipse matched to the shadow region, heads toward a region of a light source existing inside or outside the video frame. Third, the horizontal axis of the video frame is parallel to the ground plane, and the orientation of each target object is perpendicular to the ground plane. Finally, the orientation of each target object is different from that of its shadow. When a target object is located between a light source and a camera, the orientations of the target object and its shadow are in similar directions. Because cameras are usually installed in locations that avoid counter-light, the case of similar orientations is excluded in this study.
Under these assumptions, each foreground object is partitioned based on its vertical histogram, and the matched ellipses of the partitioned objects are calculated. The orientation of each matched ellipse is used to validate each partitioned object as a shadow region. If the orientation heads toward the pre-configured regions of light sources, the corresponding partitioned object is classified as shadow and removed from the foreground region it belongs to. The video analytics system with the proposed shadow detection algorithm for nighttime video sequences is illustrated in
Figure 4.
After background generation from the input video frames, binary foreground regions are extracted by background subtraction followed by median filtering for noise suppression. The proposed shadow detection algorithm is applied to the labeled foreground regions to provide final labeled object regions without shadow to the ensuing processes in the video analytics system. The proposed algorithm consists of histogram analysis, foreground partitioning, orientation calculation, and shadow decision and removal. By detecting abrupt changes in the vertical histogram inside each extracted foreground region, the foreground region is partitioned into one or multiple partitioned objects. For the calculation of the orientation of each partitioned object, that object is matched to an ellipse and the direction of the major axis of the matched ellipse, i.e., its orientation, is found. For each partitioned object, if its orientation heads toward the regions of light sources, it is classified as shadow and is used to make a shadow removal mask. Final object regions are obtained by masking the partitioned objects classified as shadow from the foreground regions.
2.2. Foreground Partitioning Based on Vertical Histogram
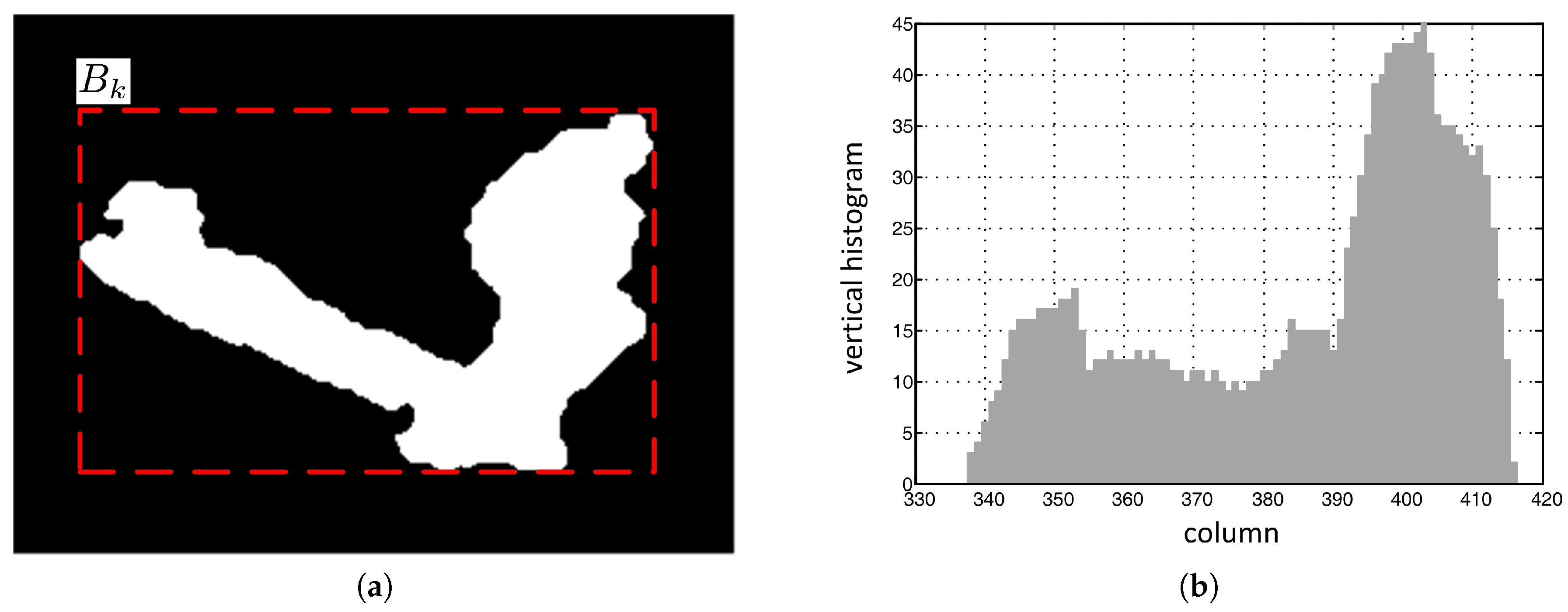
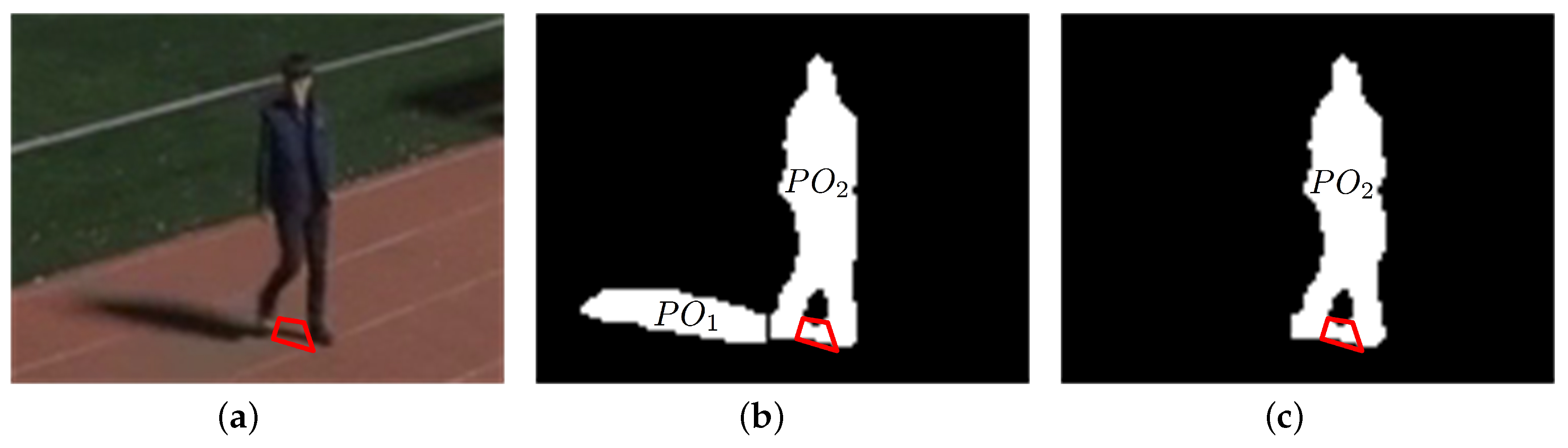
In nighttime video sequences, if the direction of a certain light is not similar to the orientation of a certain object, the object and its shadow appear as a merged foreground region that cannot be matched with a single ellipse, as shown in
Figure 5a. In the bounding box enclosing the merged foreground region in a video frame, the vertical histogram in the shadow region is smaller than that in the object region. Therefore, in this section, a vertical histogram based foreground partitioning algorithm is proposed that uses this characteristic of vertical histograms in the merged foreground region to separate the shadow from the object.
The bounding box of the kth merged foreground region is represented in matrix form by its elements , of which the values are 0 or 1 for background and foreground pixels, respectively.
The vertical histogram of the
jth column in the bounding box
is defined as the number of foreground pixels per column, and is given as follows.
where
represents the height of the bounding box
.
Figure 5b shows the vertical histogram for the foreground object in
Figure 5a.
After calculating the vertical histogram, the histogram difference between adjacent columns is compared with a given threshold to partition the foreground region . Across the boundary between a foreground object and its shadow, the histogram difference is not always large enough for partitioning due to the various shapes of non-rigid foreground objects; this histogram difference is susceptible to noise at night. Also, the boundary is hard to define explicitly. Therefore, while scanning the columns from left to right or from right to left in a bounding box, the vertical histogram of the column that is K columns away from the current column is compared with that of the current column, the reference column, to aggregate enough of a histogram difference for partitioning. For histogram comparison, the number of columns that separate these two columns, K, depends on the resolution of the video frame; this number is 5 columns for D1 resolution in this study. If there exists a column for which the vertical histogram is larger or smaller than that of the reference column by the amount of a certain threshold, the reference column is determined to be a partitioning column. A zero column vector is overwritten to the partitioning column to delineate one partitioned region from the other in the region .
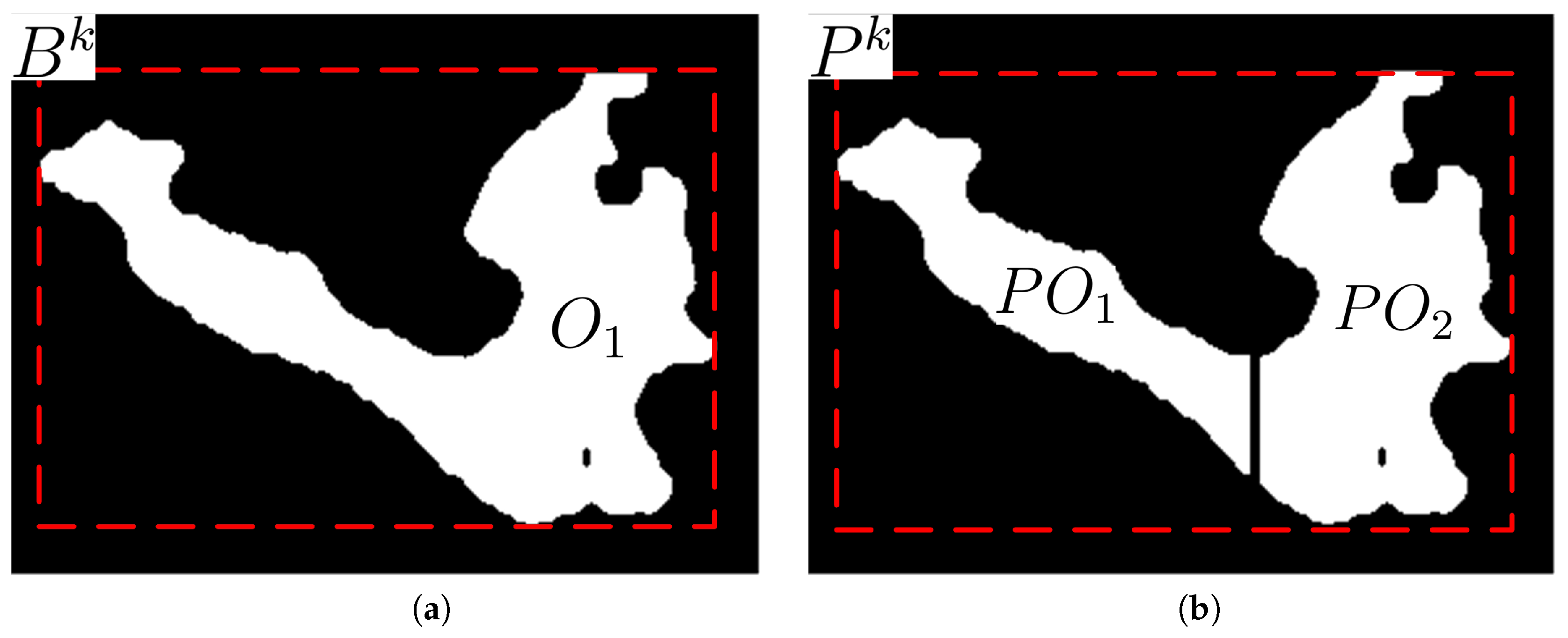
Shadow may exist either to the left or to the right of a foreground object, as shown in
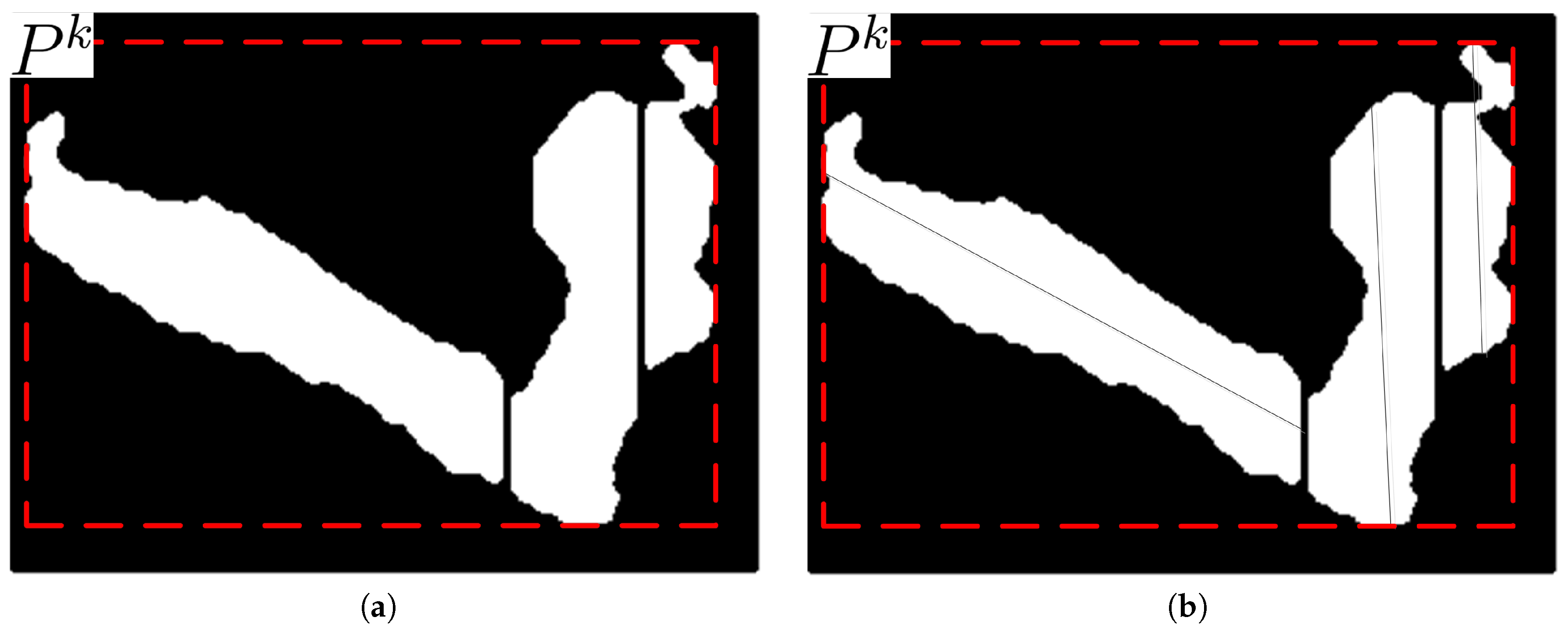
Figure 6a, depending on the location of a light source. Shadow may also exist between foreground objects. The shapes of foreground objects, mostly human bodies in this study, may vary over time while moving. For examples, due to movement of joints in arms, legs, or waists, the shape of a foreground object may be in the form of a normal cylinder, a cylinder with symmetric salience, or a cylinder with asymmetric salience. For a foreground object not in the form of a normal cylinder, thresholding the vertical histogram difference of adjacent columns may result in different partitioning results depending on the column scan directions. As shown in
Figure 6, partitioning by comparison of vertical histogram only in a certain direction during column scan may result in an erosion of the salience from the opposite direction. This erosion of the salience may cause loss in the foreground object region. Therefore, double column scans in both directions are proposed to obtain candidates for partitioning column vectors. After double column scans, the partitioning column vectors far from the center of the cylindrical body are selected as the final partitioning column vectors.
For the calculation of a partitioned bounding box from an input bounding box, a foreground partitioning algorithm in a bounding box is proposed and is described in Algorithm 1. In the algorithm description,
,
, and
represent the width, the zero column vector, and the partitioned bounding box of bounding box
, respectively. The partitioned bounding box is identical to the bounding box except for several partitioning columns overwritten by zero column vectors. The vectors
and
represent the
jth column vectors in
and
, respectively.
represents the threshold for partitioning, and is constant over all video sequences. Although the variation in this threshold may slightly change the positions of the partitioning zero column vectors in the foreground region, this cannot greatly affect the shapes and pixel areas of partitioned objects and the centers of gravity of resulting foreground objects which are related to calculate the performance measures in
Section 3.3.
Figure 7 shows the original and its partitioned regions in the bounding box and its partitioned bounding box, respectively. The partitioned regions are re-labeled as partitioned object
after the double column scan partitioning. If the number of pixels in a re-labeled object is less than
, this object is treated as noise and removed from the object list.
| Algorithm 1: PartitionBBox (.) |
![Sensors 17 00659 i001]() |
2.3. Calculation of the Direction of the Major Axis
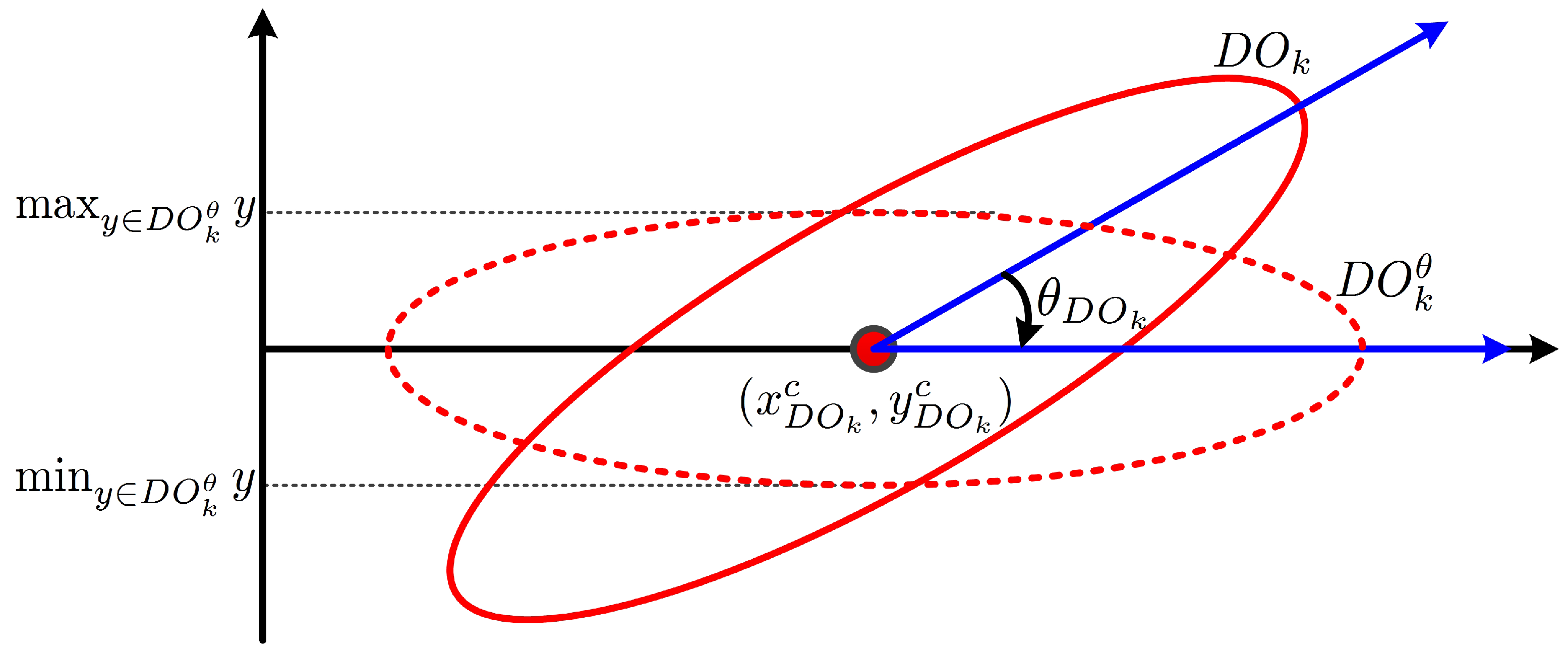
In this study, every foreground object is assumed to be in the form of an ellipse and to have a matched virtual ellipse. The orientation of a partitioned object is defined as the direction of the major axis of the matched ellipse of the partitioned object. The center of the matched ellipse is defined as the centroid of the partitioned object. The direction can be found by rotating the partitioned object clockwise with the rotation axis at the centroid until the difference between the maximum and the minimum y-coordinates of the pixels in the rotated partitioned object is minimized.
The centroid of a partitioned object can be determined as follows.
where
,
, and
represent the
x- and
y- coordinates of the
foreground pixel and the number of foreground pixels in the
kth partitioned object, respectively.
The angle between the major axis of the partitioned object and the horizontal axis, illustrated in
Figure 8, is given as follows.
where
represents the object from the partitioned object
rotated by the angle
θ in a clockwise direction.
Figure 9 shows the partitioned objects after vertical histogram analysis and after their major axes are calculated.
If the lower left corner of a video frame is set to the origin, the major axis can be represented by the following line equation.
2.4. Regions of Light Sources
Shadow regions in nighttime video sequences are formed by artificial light sources; their sizes and orientations are determined by their displacements from light sources. To estimate the orientation of each shadow, the locations of light sources should be known. Light sources in nighttime video sequences generally are not point sources, but ambient sources from buildings or explicit areas inside or outside the video frame, as shown in
Figure 10. Because it is difficult to estimate the exact locations or areas of light sources, regions of light sources are configured manually outside the video frame, as shown in
Figure 10.
Although light sources may exist inside the video frame, regions of light sources are configured on the left region or the right region outside the video frame by considering the orientations of the shadow regions formed inside the video frame. There may exist multiple RLS in or , and the overall area of RLS in or may be equal to or less than those of and .
In the proposed shadow detection algorithm, if the major axis of a partitioned object passes through the RLS, this partitioned object is considered to be a shadow. If light sources exist in the region
, the region of each foreground object overlaps with a significant portion of its shadow region. Although some saliences from a foreground object may exist due to shadow, there is little problem of a foreground region consisting of an object and its shadow being detected as a single object because the areas of the saliences are not very large. If light sources exist in the region
, it is difficult to use only the orientation of each partitioned object for shadow detection because the shadow region does not overlap the foreground object and its orientation is similar with that of the foreground object. Although this case requires other features such as color and texture as in daytime shadow removal, cameras are only rarely installed in such light source environments; rather, they are installed in environments that do not have counter-light. Therefore, in this study, as specified in
Section 2.1, light sources are assumed to exist in the regions other than the region
.
2.5. Detection and Removal of Shadow Regions
For each partitioned object, if object orientation heads toward the RLS, it is classified as shadow. The shadow indicator for each partitioned object is given as follows.
where
represents the possible
x-range of the RLS. The value of 1 represents a shadow region; 0 represents a foreground object.
The shadow indicator is used to make a shadow mask for a video frame; final foreground objects are obtained by masking the shadow regions from the input foreground regions.
4. Conclusions
In this paper, a novel shadow detection algorithm is proposed for object extraction in nighttime video sequences; this algorithm validates the possible orientations of shadow toward the region of light sources. Each extracted foreground region is partitioned by double scan based vertical histogram change detection, each partitioned object is matched to an ellipse, and the orientation of the matched ellipse is used for the validation of the partitioned object as shadow. The proposed algorithm is shown to quite accurately remove shadow in nighttime video sequences with a single object or multiple objects, with a 93.8% shadow removal rate; this algorithm improves the object extraction performance by suppressing the interference among neighboring objects caused by their shadow regions.
The proposed shadow detection algorithm, combined with a conventional daytime shadow detection algorithm, can be used around the clock in intelligent video surveillance systems to detect pre-configured surveillance events based on object extraction.
The proposed algorithm has a limitation in handling small partitioned objects, such as small shadow regions between objects and incomplete foreground regions, of which the orientations are not explicitly discernible. This limitation can be resolved by applying features used in daytime shadow removal such as color and texture or by using object tracking information. The comparative study with machine-learning approach is also required for various video surveillance environments. These topics will be left for further study.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}