4.2.2. Experimental Results and Analysis
To further thoroughly evaluate the benefits of global optimization model, the accuracy of the camera poses is determined by computing the discrepancies in the contiguous frames. Instead of placing targets on the ground, the exact truth poses are obtained through frame alignment manually. To reduce the time complexity, only the truth rotation and translation between the adjacent key frames are obtained as referenced, the translational error and the angular error of the sequential alignment can be obtained by comparing with the ground-truth poses. As can be seen in
Table 3, by combining ICP and global optimization, it achieves accuracy which is superior to using the ICP algorithm only. In the ICP algorithm, the alignment accuracy highly depended on the geometric information in the adjacent frames. However, in the corridor experiment, it provides little geometric information, and the frames mainly contain several single flat walls. It is reasonable that global optimization model can improve the alignment accuracy due to involving additional RGB information.
In addition, the corridor model generated from the structure sensor is compared with a laser scan point cloud. As shown in
Figure 6a (right), these two models can match well in both horizontal and vertical direction. To evaluate the absolute accuracy of the coordinator model, some key point pairs are selected from the sensor model and the laser scanner and the distance between two point pairs selected at random is calculated. The average distance errors are shown in
Table 3. Similar with two others, ICP + Global Optimization can achieve the absolute accuracy to centimeter level, which is higher than that of the ICP algorithm.
After applying global optimization for the pose of depth camera, we implement the robust geometric registration m to register the 3D model based on image-based modeling method to the model generated from depth images, and then the results is compared with the model totally generated from depth images. Check points are selected from the results of feature matching. For each check point, two sets of object coordinates can be obtained from the image-based model and the model from depth respectively. Then, we achieved a relative accuracy assessment of the obtained result through the root mean square error (RMSE) of the discrepancies of each check points in the object space. It should be noted that only the depth within 3 m of the depth frame is used for accuracy assessment.
In the corridor experiment, 172 frames are selected as key frames and then are used for 3D modeling. The feature matches in the key frames are first checked with the false matches rejection method, the corresponding
and
are set at 10 pixels and 0.2 m, respectively, according to the initial accuracy of the camera pose.
Figure 8 shows the comparison of feature matches in the corridor images. The original 3980 feature matches are obtained after using a traditional RANSAC false matches rejection method. In RANSAC, the threshold for estimating
F matrix is 2, and the threshold for estimating
H matrix is 4. The maximum iterations in RANSAC is 1000. In this experiment, 42 more false matches can be rejected by using the refined false matches rejection method in this paper. Then, 432 feature matches identified from the first frame are used for geometric registration. Due to the measurement distance limitation of depth sensor, 1302 feature points with depth value within 3 m are used to check the performance of geometric registration.
The performance of geometric registration approach is evaluated in object space. The 1302 check points are compared based on the object coordinates from depth information and the transformed coordinates from RGB sequences.
Table 4 lists registration results including the recovered scale, rigid transformation and the statistics of discrepancies between two models after geometric integration. As
Table 4 shows, the discrepancies between the scene from depth images and the scene from RGB images can accurate to centimeter-level (within 3 cm) in all the three directions. This indicates that the geometric inconsistencies between the geometry of RGB images and depth images are nearly eliminated.
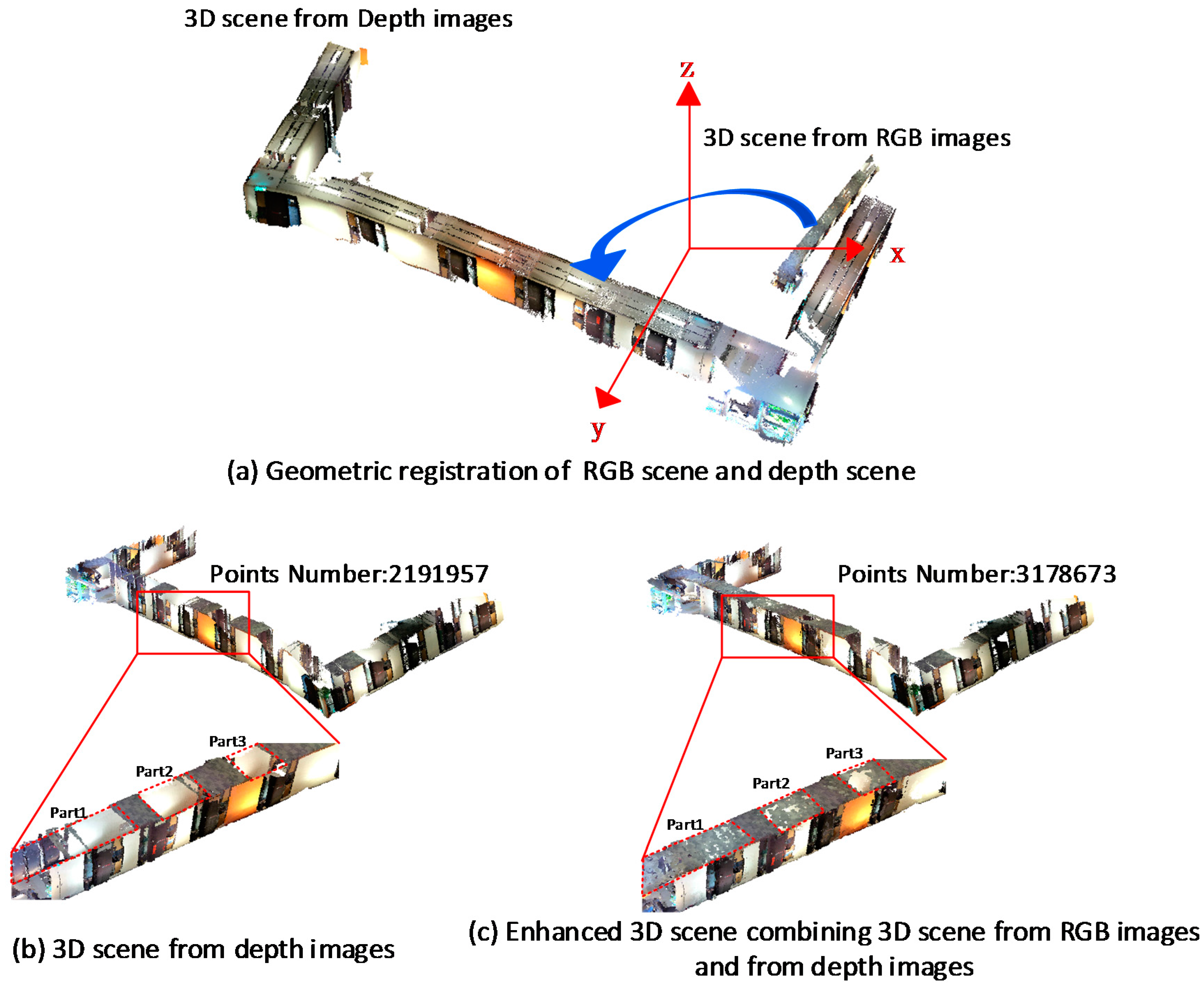
In
Figure 9a, the 3D scene from RGB images is first transformed to the coordinate system of depth scene based on the recovered scale and rigid transformation parameters.
Figure 9b shows the original 3D scene totally generated from depth image. Although all of the depth frames were used for scene modeling, significant details are lost, especially on the ceiling and the floor.
Figure 9c shows the enhanced 3D scene combining 3D scene from RGB images and from depth images after geometric registration. The vertices have significantly increased from about two million to three million. In
Figure 9b, the broken regions are marked with red dotted borders. As expected, the scene detail in the corresponding regions is enriched significantly after geometric registration shown in
Figure 9c. It means that the model generated from the corresponding RGB images can be a good supplement to the model from depth images.
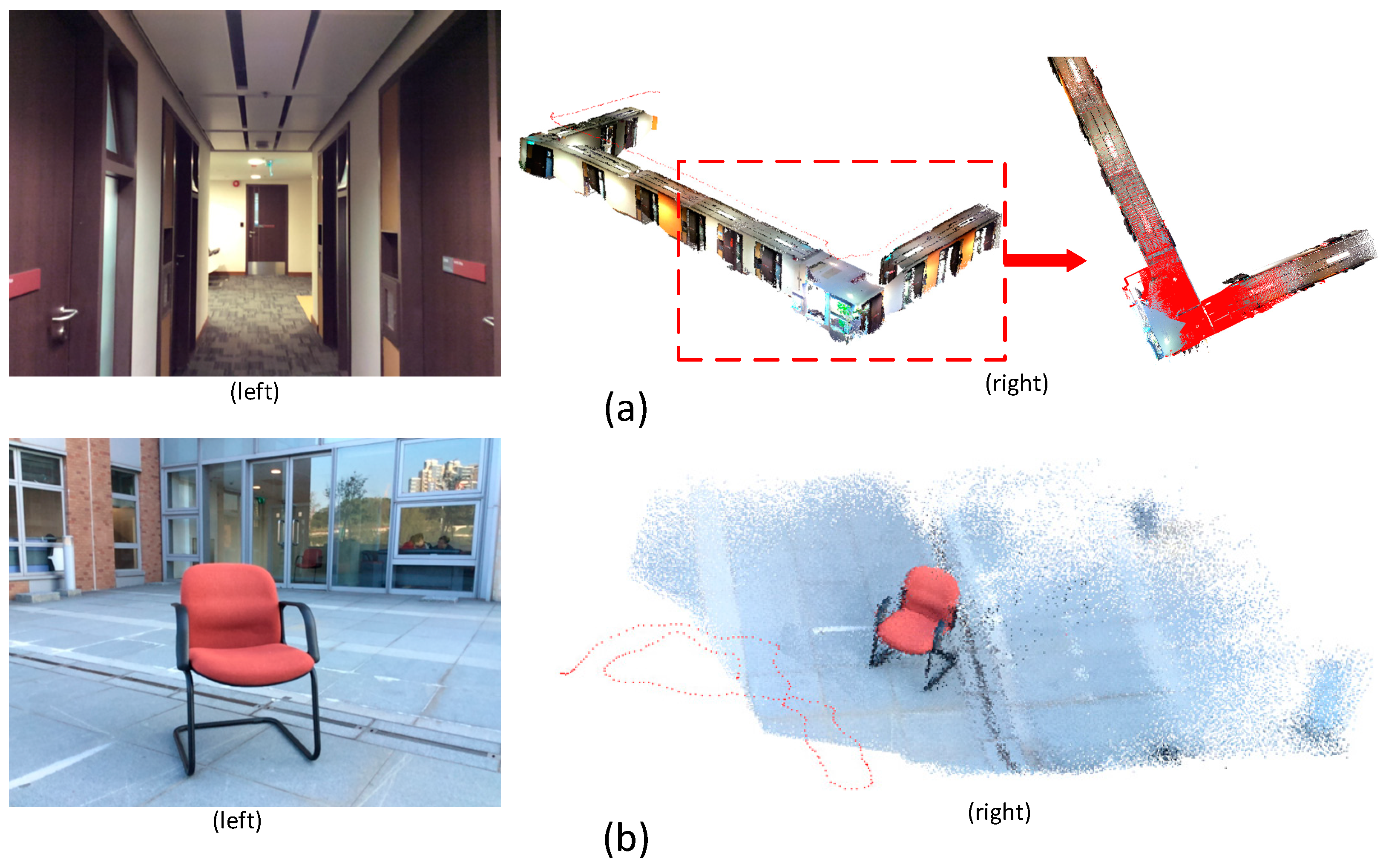
For the chair model collected outside, 86 frames are selected as key frames. The corresponding and parameters for false matches rejection are set at 3 pixels and 0.05 m, respectively, due to high accuracy of the camera pose. The 6293 feature matches were obtained and 38 more false matches are rejected. The 246 feature points are used for geometric registration. The performance of the geometric registration is examined with 1278 check points.
The performance of geometric registration approach was evaluated in object space. The 1278 check points were compared based on the object coordinates from depth information and the transformed coordinates from RGB images.
Table 4 lists registration results including the recovered scale, rigid transformation and the statistics of discrepancies between two models after geometric integration. As
Table 4 shows, the geometric registration accuracy can obtain an accuracy of less than 2 cm in all three directions. Since the model from depth images is used as reference for geometric registration accuracy evaluation and the check points are selected from different frame, the consistency between depth frames can directly influence the performance of the registration method. The inconsistency between frames grows with the distance of the trajectory due to error propagation during frames alignment. In the corridor experiment, the length of the camera trajectory is much higher than that of the outdoor experiment, the global consistency of the scene is worse than that of the scene of the outdoor. The better consistency results in higher accuracy of the initial pose parameters. Therefore, the geometric registration accuracy should be higher in the chair scene than that in the corridor scene.
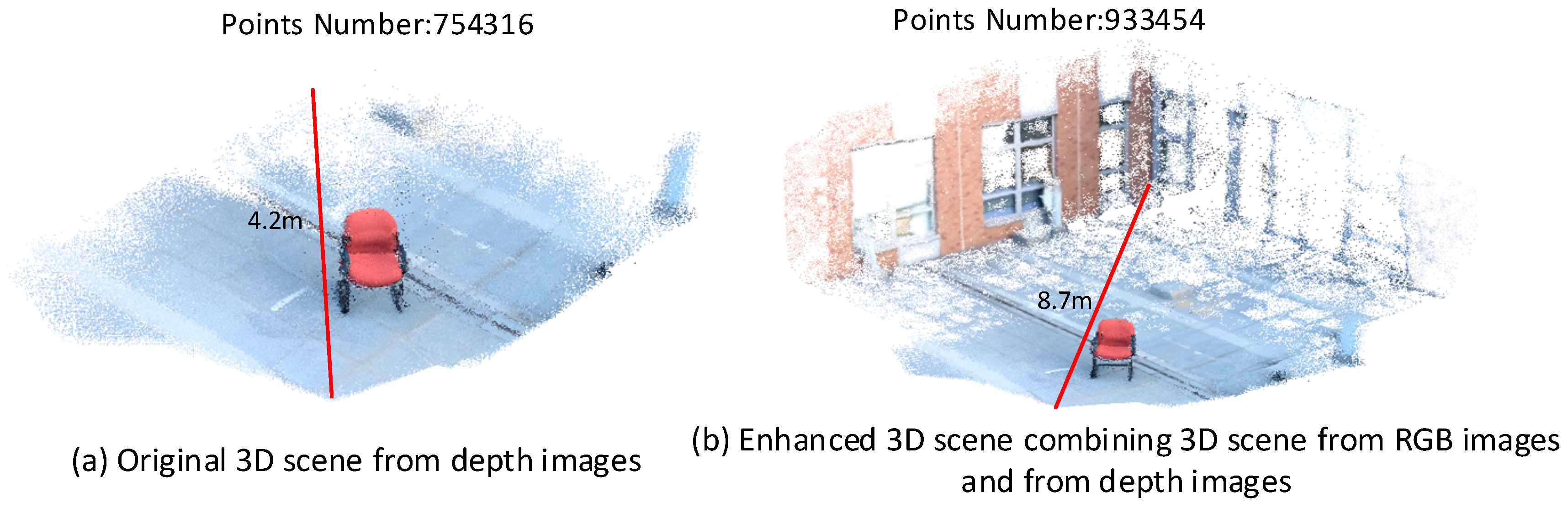
Figure 10a,b shows the original 3D scene generated from depth image and the enhanced 3D scene combining 3D information from RGB images and from depth images after geometric registration, respectively. Only a close-range scene with about 4.2 m maximum length can be obtained from the depth images. As the far-range model generated from the RGB images is added to the original 3D scene from depth image, the vertices number have a significant increase from 754,316 to 933,454 and the measurement distance can be extended to about 9 m. In this case, the information from the RGB image sequences both enriched the details for the close-range model from the depth images and greatly broadened the modeling range of the RGB-D camera.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}