
Multi-Camera and Structured-Light Vision System (MSVS) for Dynamic High-Accuracy 3D Measurements of Railway Tunnels

Abstract
:1. Introduction
2. Measurement Principle and Calibration Parameters
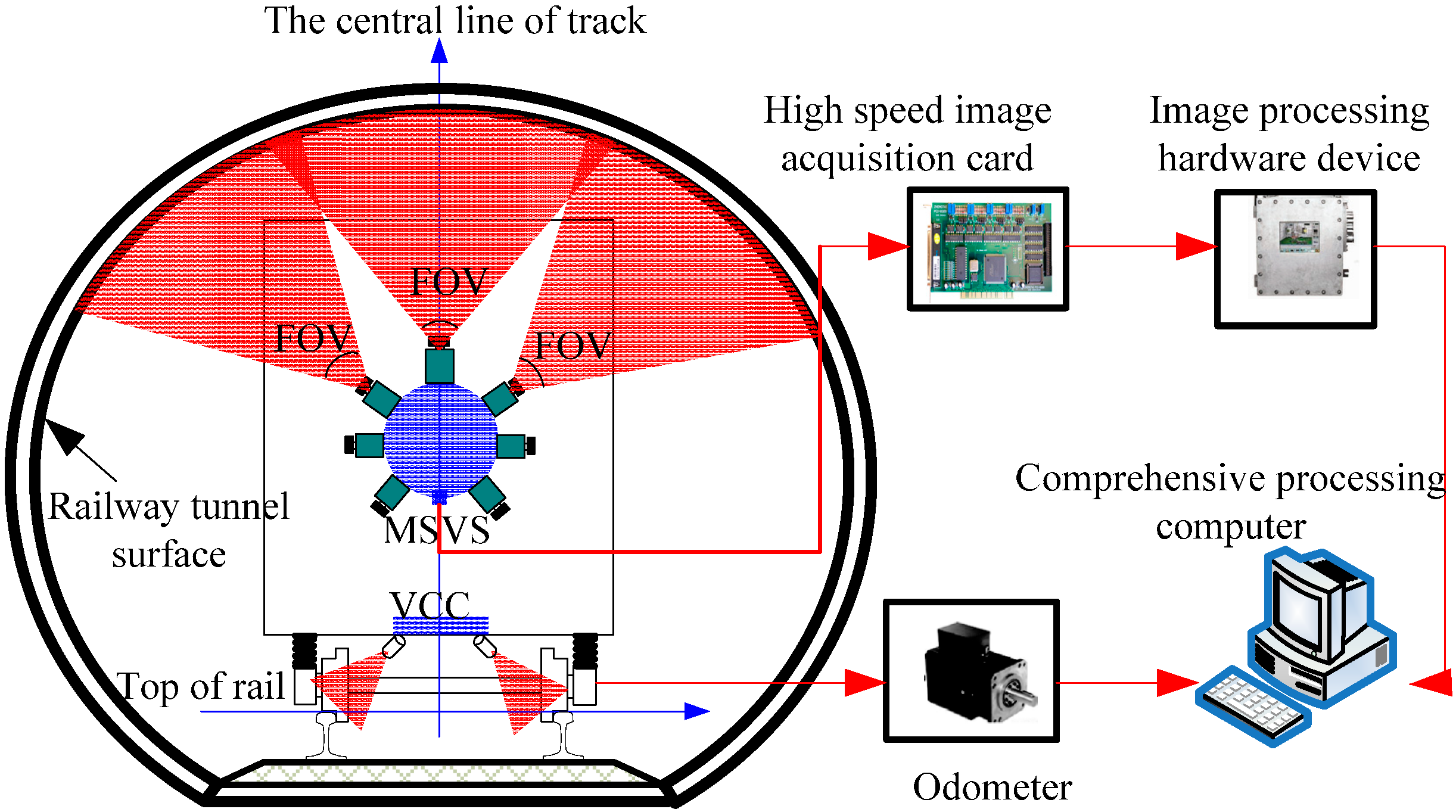
2.1. Measurement Principle
- (1)
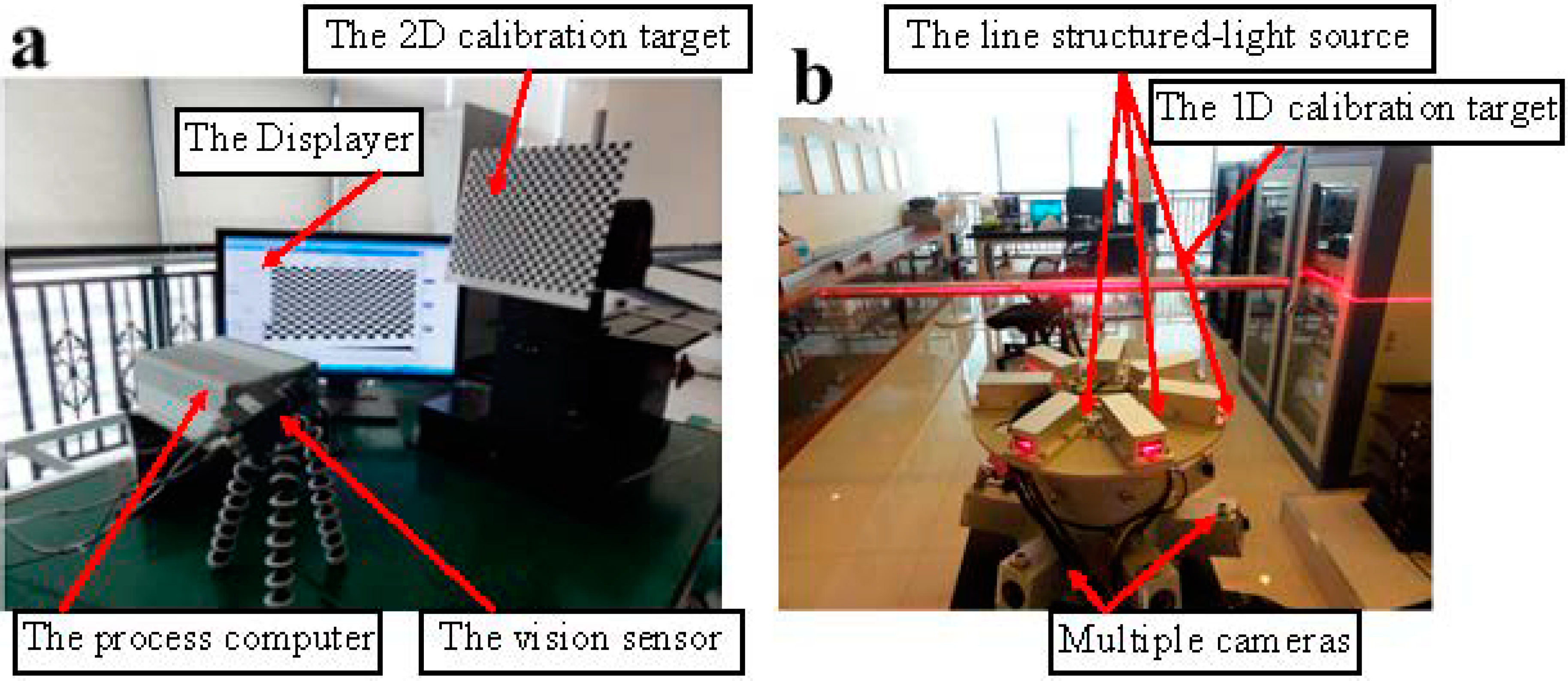
- MSVS: including multiple cameras and structured-light projectors. The FOV of the cameras and projectors are overlapping in the measurement range.
- (2)
- High-speed image acquisition block: used to collect images and send them to the computer.
- (3)
- Odometer: including an optical-electrical encoder on the train axle transforming the turning angle of the axle to pulse signals and a signal controller calculating mileage from the number of pulses.
- (4)
- VCC: including two line structured-light vision sensors installed at the bottom of the vehicle body to monitor the feature point of the railhead.

2.2. Calibration Approach
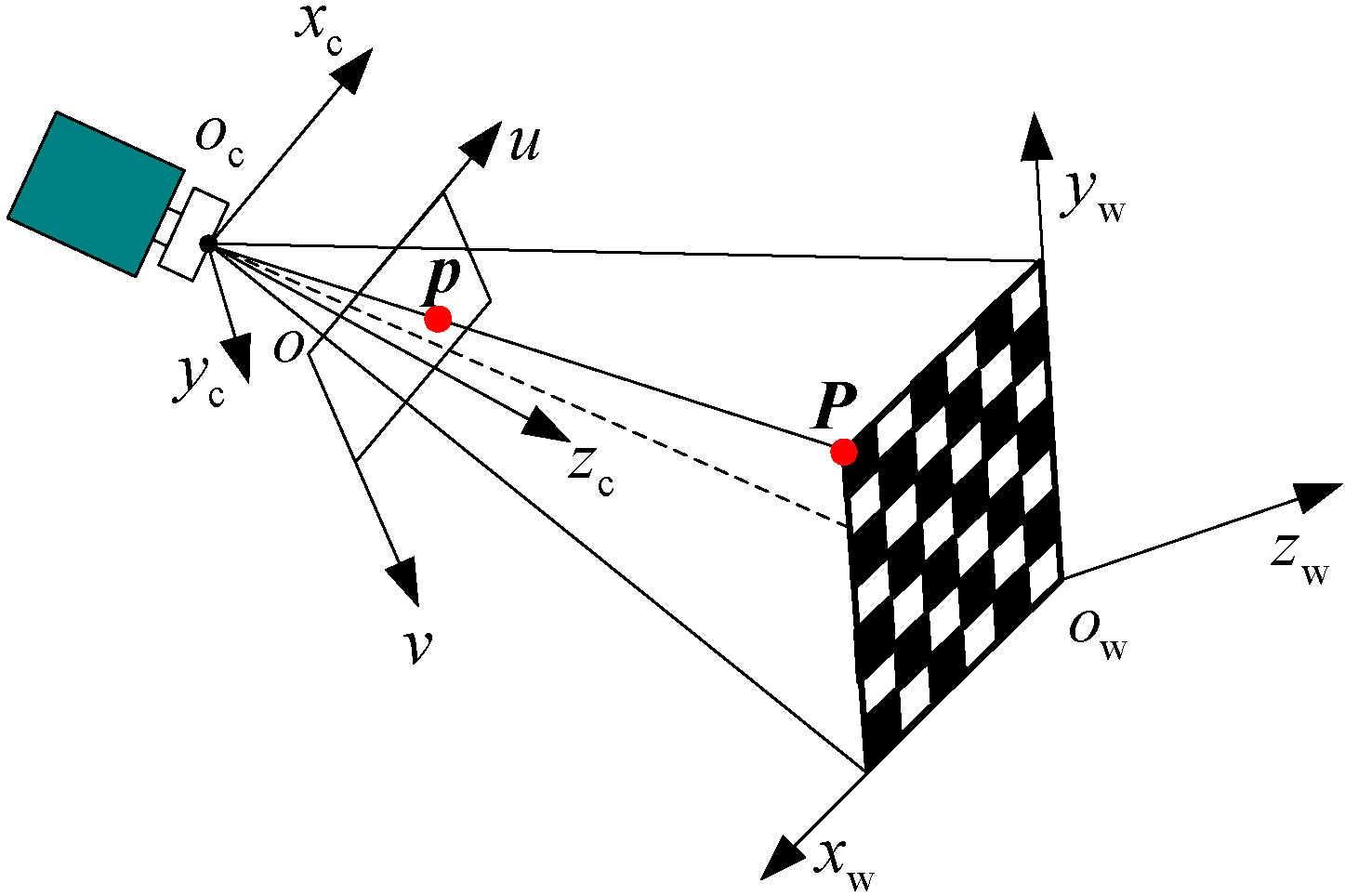
- (1)
- For each camera, the perspective projective matrix and lens distortion coefficients are calibrated off-line by the 2D planar target.
- (2)
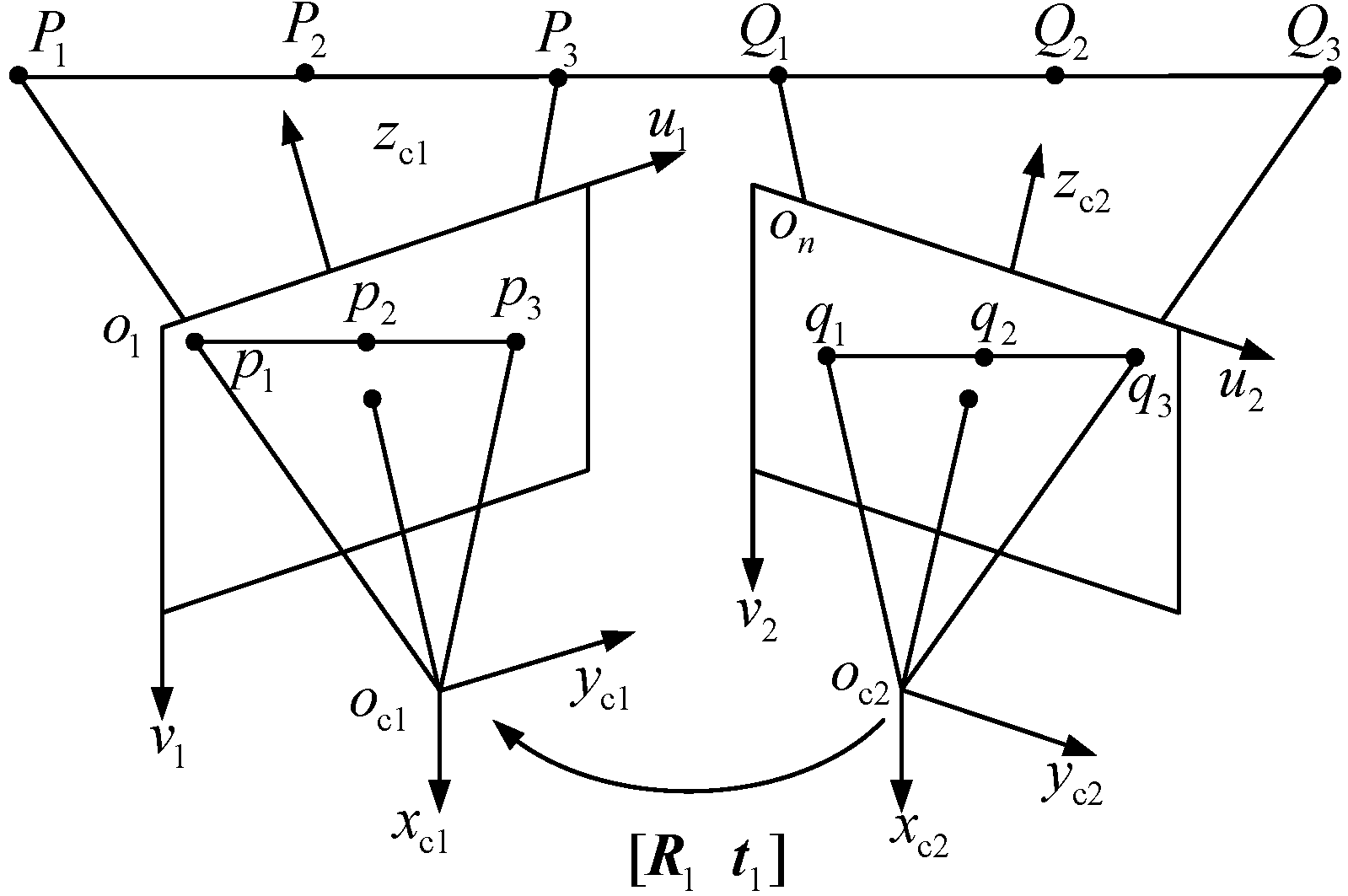
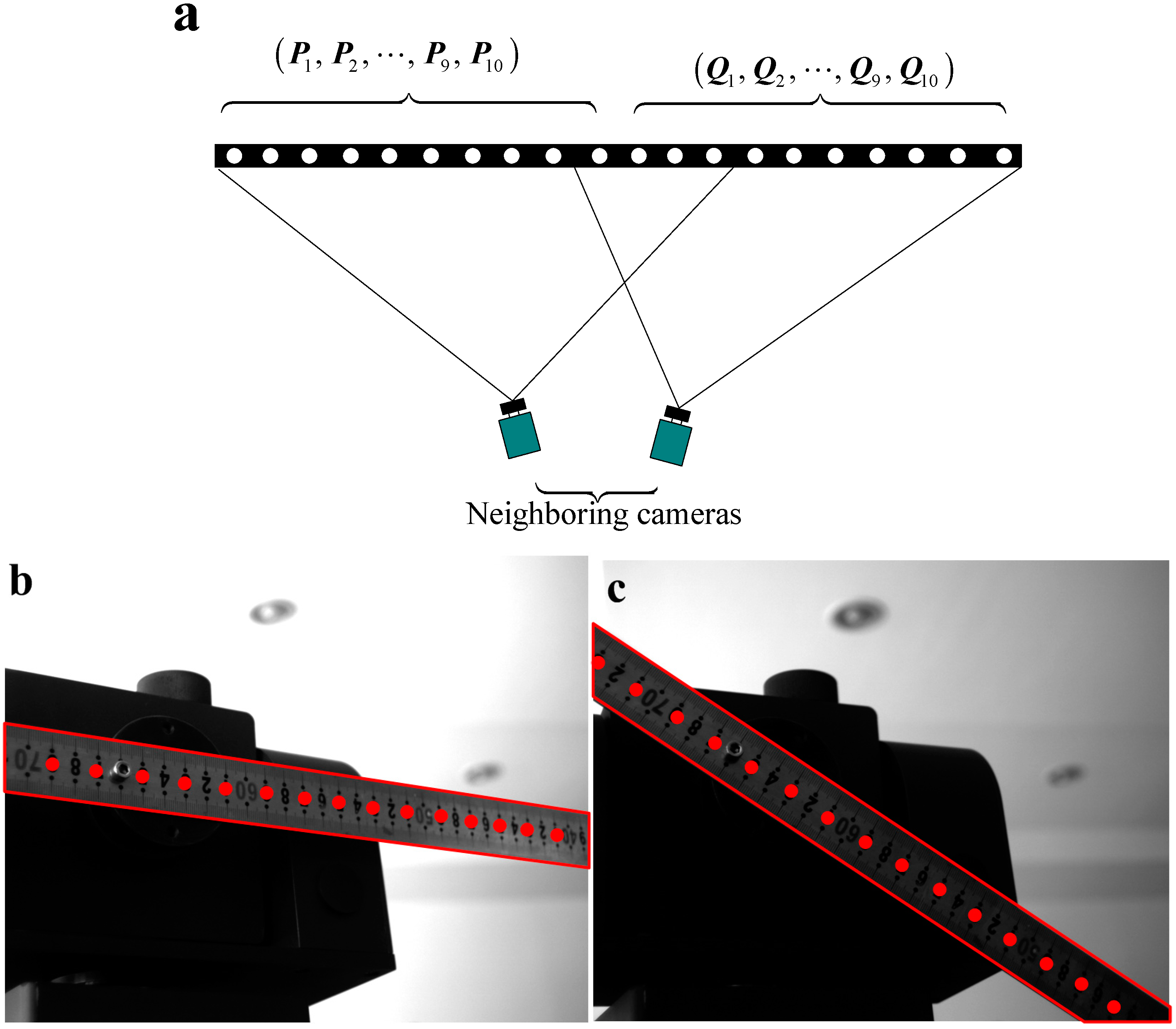
- After, the MSVS is assembled, placing the 1D target to cover the FOV of two neighboring cameras and then computing the extrinsic parameters of each neighboring cameras on-line, including the rotation matrix and translation vector, according to the collinear property and known distances of feature points on the 1D target [24,25,26,27]. Then, an arbitrary camera coordinate frame is selected as the global coordinate frame. By utilizing the extrinsic parameters of each neighboring camera, we can transform the measurement results of the other cameras from their local coordinate frame to the global coordinate frame.
- (3)
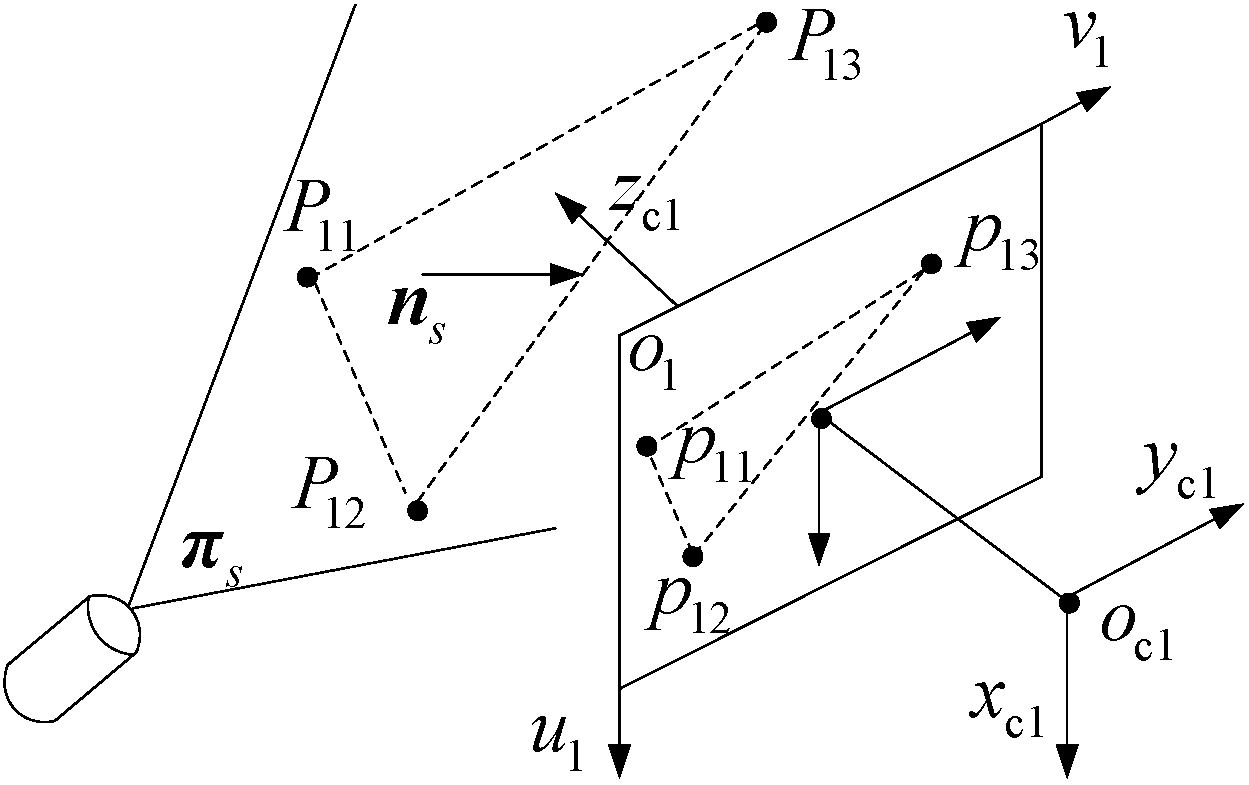
- Using the same computation method in Step 2 and through at least three non-collinear feature points on the structured-light plane, the equation of the structured-light plane can also be determined.
- (4)
- With the help of the intrinsic parameters of each camera, the extrinsic parameters of the neighboring cameras and the structured-light plane equation, the global measurement model of the MSVS can ultimately be obtained.
3. The Global Calibration of the Vision System
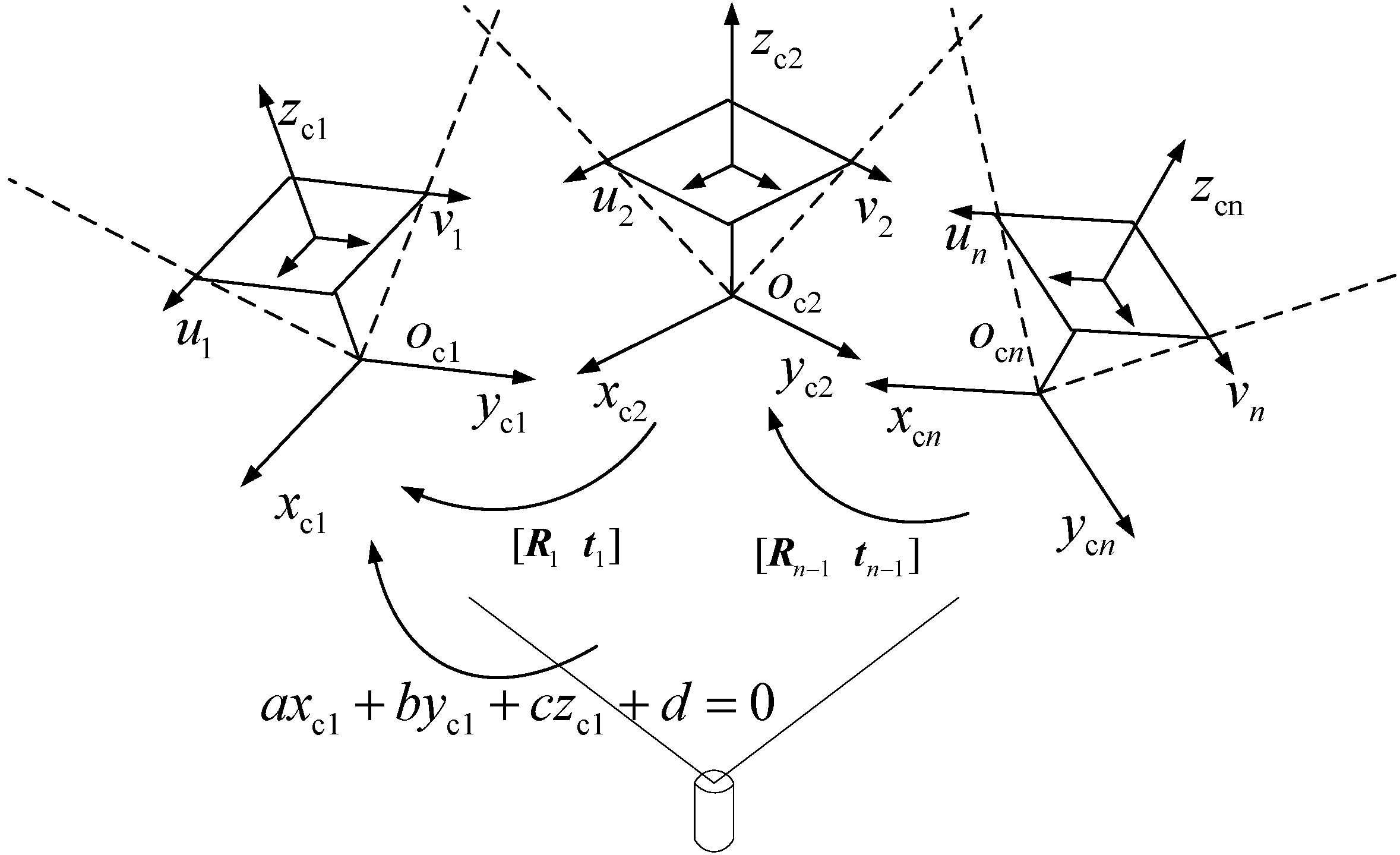
3.1. Basic Notations

3.2. Extrinsic Parameters Calibration of Neighboring Cameras

3.3. Structured-Light Plane Equation Calibration

3.4. Global Optimization

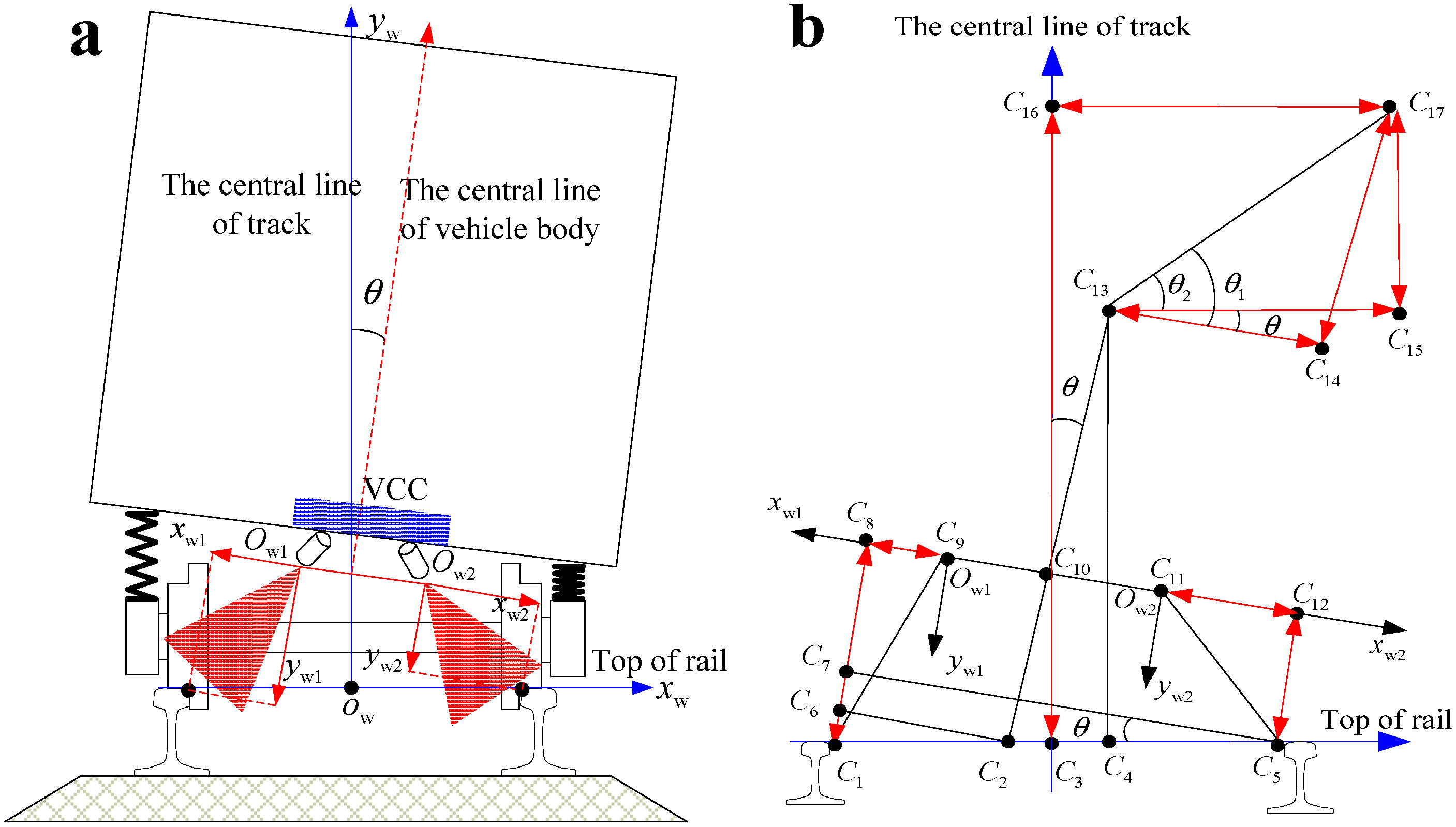
4. Vehicle Vibration Compensation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Parameters |
|---|---|
| The feature point of the left rail | |
| The intersection point of the vehicle central line and the rail top surface | |
| The middle point of | |
| The vertical intersection point of and the line through | |
| The feature point of the right rail | |
| The vertical intersection point of and the line through | |
| The vertical intersection point of and the line through | |
| The vertical intersection point of and the line through | |
| The left calibration center of the VCC | |
| The middle point of | |
| The right calibration center of the VCC | |
| The vertical intersection point of and the line through | |
| The calibration center of the MSVS | |
| An arbitrary feature point on the surface of the railway tunnel | |
| The central line of the track | |
| The central line of the vehicle body | |
| The vertical ranging result of VCC for the left rail | |
| The horizontal ranging result of VCC for the left rail | |
| The vertical ranging result of VCC for the right rail | |
| The horizontal ranging result of VCC for the right rail | |
| The vertical ranging result of the MSVS for the railway tunnel | |
| The horizontal ranging result of the MSVS for the railway tunnel | |
| The vehicle rolling vibration angle |
- (1)
- Computing the rolling vibration angle and the auxiliary angles:
- (2)
- Decomposing orthogonally in the track central coordinate frame:
- (3)
- Computing the ranging variables and :
- (4)
- Computing the coordinates of an arbitrary feature point on the surface of the railway tunnel reference to the track central coordinate frame:
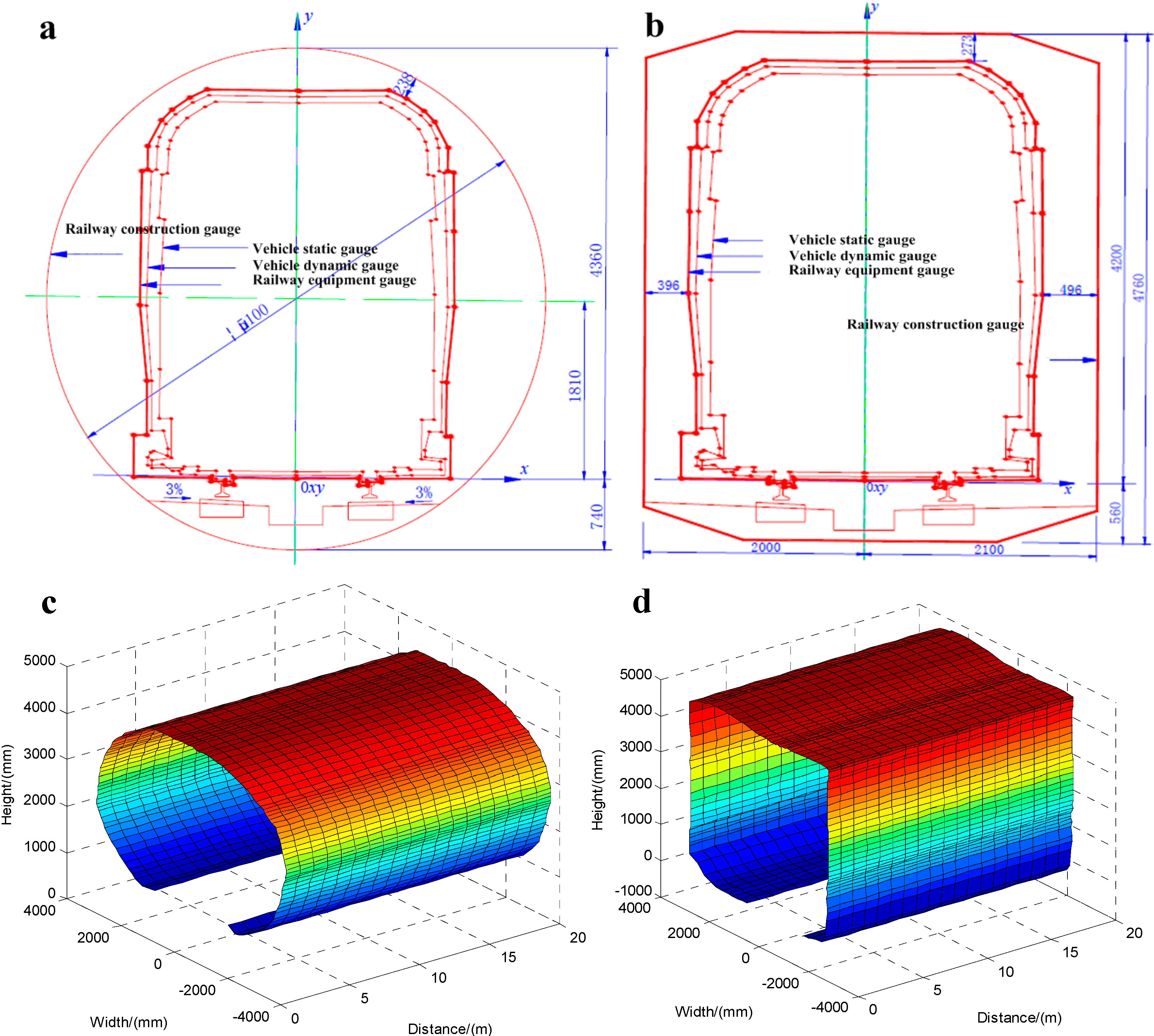
5. Experimental Section
5.1. Calibration Experiments

| Parameters | Camera 1 | Camera 2 | Camera 3 | Camera 4 | Camera 5 | Camera 6 | Camera 7 |
|---|---|---|---|---|---|---|---|
| 2265.17 | 2268.45 | 2262.75 | 2267.32 | 2268.89 | 2260.77 | 2269.53 | |
| 2268.23 | 2269.23 | 2266.91 | 2265.41 | 2265.42 | 2265.92 | 2267.48 | |
| −0.81 | 1.08 | −1.34 | −0.88 | 1.07 | −1.14 | −0.56 | |
| 639.24 | 645.32 | 640.25 | 639.45 | 637.46 | 637.55 | 643.55 | |
| 518.05 | 516.41 | 513.25 | 511.90 | 514.12 | 513.51 | 516.02 |

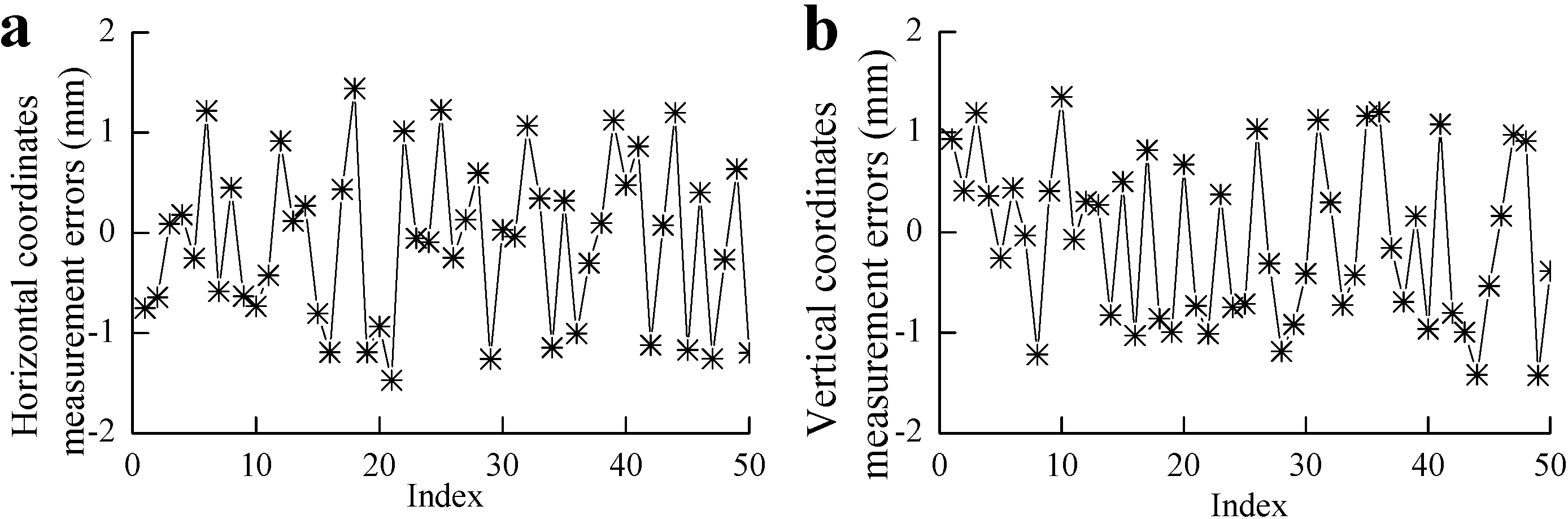
5.2. Dynamic Inspection Experiments



| Notation | (mm) | (mm) | (mm) |
|---|---|---|---|
| Horizontal measurement errors | 0.12 | −1.47 | 0.81 |
| Vertical measurement errors | −0.10 | 1.43 | 0.82 |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ministry of Construction of the People’s Republic of China. Stand of Metro Gauge, CJJ96–2003; Ministry of Construction of the People’s Republic of China Press: Beijing, China, 2003.
- Höfler, H.; Baulig, C.; Blug, A. Optical high-speed 3D metrology in harsh environments recording structural data of railway lines. Proc. SPIE 2005, 5856, 296–306. [Google Scholar]
- John Laurent, M.S.; Richard, F.I. Use of 3D Scanning Technology for Automated Inspection of Tunnels. In Proceedings of the World Tunnel Congress, Foz do Iguaçu, Brazil, 9–15 May 2014; pp. 1–10.
- Hu, Q.W.; Chen, Z.Y.; Wu, S. Fast and automatic railway building structure clearance detection technique based on mobile binocular stereo vision. J. China Railw. Soc. 2012, 34, 65–71. [Google Scholar]
- Mark, E. Television measurement for railway structure gauging. Proc. SPIE 1986, 654, 35–42. [Google Scholar]
- Markus, A.; Thierry, B.; Marc, L. Laser ranging: A critical review of usual techniques for distance measurement. Opt. Eng. 2001, 40, 10–19. [Google Scholar] [CrossRef]
- Richard, S.; Peter, T.; Michael, S. Distance measurement of moving objects by frequency modulated laser radar. Opt. Eng. 2001, 40, 33–37. [Google Scholar] [CrossRef]
- Dar, I.M.; Newman, K.E.; Vachtsevanos, G. On-line inspection of surface mount devices using vision and infrared sensors. In Proceedings of the AUTOTESTCON ’95. Systems Readiness: Test Technology for the 21st Century. Conference Record, Atlanta, GA, USA, 8–10 August 1995; pp. 376–384.
- Alippi, C.; Casagrande, E.; Scotti, F. Composite real-time processing for railways track profile measurement. IEEE Trans. Instrum. Meas. 2000, 49, 559–564. [Google Scholar] [CrossRef]
- Lu, R.S.; Li, Y.F.; Yu, Q. On-line measurement of straightness of seamless steel pipe using machine vision technique. Sens. Actuators A: Phys. 2001, 74, 95–101. [Google Scholar] [CrossRef]
- Lu, R.S.; Li, Y.F. A global calibration technique for high-accuracy 3D measurement systems. Sens. Actuators A: Phys. 2004, 116, 384–393. [Google Scholar] [CrossRef]
- Guo, Y.S.; Shi, H.M.; Yu, Z.J. Research on tunnel complete profile measurement based on digital photogrammetric technology. Proc. SPIE 2011, 521–526. [Google Scholar]
- Wang, J.H.; Shi, F.H.; Zhang, J. A new calibration model of camera lens distortion. Pattern Recognit. 2008, 41, 607–615. [Google Scholar] [CrossRef]
- Xu, K.; Yang, C.L.; Zhou, P. 3D detection technique of surface defects for steel rails based on linear lasers. J. Mech. Eng. 2010, 46, 1–5. [Google Scholar]
- Xu, G.Y.; Liu, L.F.; Zeng, J.C. A new method of calibration in 3D vision system based on structured-light. Chin. J. Comput. 1995, 18, 450–456. [Google Scholar]
- Duan, F.J.; Liu, F.M.; Ye, S.H. A new accurate method for the calibration of line structured light sensor. Chin. J. Sci. Instrum. 2002, 21, 108–110. [Google Scholar]
- Liu, Z.; Zhang, G.J.; Wei, Z.Z. Global calibration of multi-sensor vision system based on two planar targets. J. Mech. Eng. 2009, 45, 228–232. [Google Scholar] [CrossRef]
- Zhang, Z.Y. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Zhang, Z.Y. Camera calibration with one-dimensional objects. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 892–899. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.Q.; Cai, F.H. Calibrating structured-light vision sensor with one-dimensional target. J. Mech. Eng. 2010, 46, 7–11. [Google Scholar] [CrossRef]
- Wang, L.; Wu, F.C. Multi-camera calibration based on 1D calibration object. Acta Autom. Sin. 2007, 33, 225–231. [Google Scholar] [CrossRef]
- Zhou, F.Q.; Zhang, G.J.; Wei, Z.Z. Calibrating binocular vision sensor with one- dimensional target of unknown motion. J. Mech. Eng. 2006, 42, 92–96. [Google Scholar] [CrossRef]
- Maybank, S.J.; Faugeras, O.D. A theory of self-calibration of a moving camera. Int. J. Comput. Vis. 1992, 8, 123–151. [Google Scholar] [CrossRef]
- Liu, Z.; Wei, X.G.; Zhang, G.J. External parameter calibration of widely distributed vision sensors with non-overlapping fields of view. Opt. Lasers Eng. 2013, 51, 643–650. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, G.J.; Wei, Z.Z. Novel calibration method for non-overlapping multiple vision sensors based on 1D target. Opt. Lasers Eng. 2011, 49, 570–577. [Google Scholar] [CrossRef]
- Weng, J.Y.; Paul, C.; Marc, H. Camera calibration with distortion models and accuracy evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 965–980. [Google Scholar] [CrossRef]
- Zhan, D.; Yu, L.; Xiao, J. Calibration approach study for the laser camera transducer of track inspection. J. Mech. Eng. 2013, 49, 39–47. [Google Scholar] [CrossRef]
- Zhang, G.J.; He, J.J.; Yang, X.M. Calibrating camera radial distortion with cross-ratio invariability. Opt. Laser Technol. 2003, 35, 457–461. [Google Scholar] [CrossRef]
- Huynh, D.Q. Calibration a structured light stripe system: A novel approach. Int. J. Comput. Vis. 1999, 33, 73–86. [Google Scholar] [CrossRef]
- Hu, K.; Zhou, F.Q.; Zhang, G.J. Fast extrication method for subpixel of structured-light stripe. Chin. J. Sci. Instrum. 2006, 27, 1326–1329. [Google Scholar]
- Edward, P.L.; Owen, R.M.; Mark, L.A. Subpixel Measurement Using a Moment-Based Edge Operator. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 1293–1309. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometric in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Caprile, B.; Torre, V. Using vanishing points for camera calibration. Int. J. Comput. Vis. 1990, 4, 127–140. [Google Scholar] [CrossRef]
- He, B.W.; Li, Y.F. Camera calibration from vanishing points in a vision system. Opt. Laser Technol. 2008, 40, 555–561. [Google Scholar] [CrossRef]
- Zhou, F.Q.; Zhang, G.J.; Jiang, J. Field calibration method for line structured light vision sensor. J. Mech. Eng. 2004, 40, 169–173. [Google Scholar] [CrossRef]
- Zhou, F.Q.; Zhang, G.J. Complete calibration of a structured light stripe vision sensor through planar target of unknown orientations. Image Vis. Comput. 2005, 23, 59–67. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–152.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, D.; Yu, L.; Xiao, J.; Chen, T. Multi-Camera and Structured-Light Vision System (MSVS) for Dynamic High-Accuracy 3D Measurements of Railway Tunnels. Sensors 2015, 15, 8664-8684. https://doi.org/10.3390/s150408664
Zhan D, Yu L, Xiao J, Chen T. Multi-Camera and Structured-Light Vision System (MSVS) for Dynamic High-Accuracy 3D Measurements of Railway Tunnels. Sensors. 2015; 15(4):8664-8684. https://doi.org/10.3390/s150408664
Chicago/Turabian StyleZhan, Dong, Long Yu, Jian Xiao, and Tanglong Chen. 2015. "Multi-Camera and Structured-Light Vision System (MSVS) for Dynamic High-Accuracy 3D Measurements of Railway Tunnels" Sensors 15, no. 4: 8664-8684. https://doi.org/10.3390/s150408664