1. Introduction
As the world population is expected to continue to grow in the next decades, food security will become a crucial problem requiring political decisions and strategic solutions [
1]. Optical remote sensing technologies have been employed to monitor the terrestrial Earth surface routinely and thus provide a viable tool to measure fundamental crop traits in the context of sustainable agriculture [
2]. Among a diversity of platforms, satellite sensors can acquire data over vast cultivated regions, which allows the generation of efficient and useful products for managing agricultural systems. In the next coming years, an increasing number of spaceborne imaging spectroscopy missions will complement current multispectral Earth observation (EO) systems, such as the Copernicus Sentinel-2 from the European Space Agency (ESA), leading to an unprecedented flow of data in high spectral dimensionality [
3]. These hyperspectral missions include, among others, the PRecursore IperSpettrale della Missione Applicativa (PRISMA) [
4], launched on 22 March 2019, and the Environmental Mapping and Analysis Program (EnMAP) [
5], launched on 1 April 2022. Following the two precursor missions, forthcoming operational missions are planned, such as the FLuorescence EXplorer (FLEX) [
6], the NASA Surface Biology and Geology observing system (SBG) [
7], and the Copernicus Hyperspectral Imaging Mission for the Environment (CHIME) [
8].
CHIME will be designed to provide routine hyperspectral observations through the Copernicus Programme starting between 2025 and 2030 [
3], thus complementing the Sentinel-2 multispectral mission [
9]. The CHIME sensor is built upon a pushbroom concept providing contiguous spectra assembled by more than 200 narrow bands in the 400–2500 nm spectral range. The spectral sampling interval will be <10 nm and each sensor will record at a spatial sampling distance of 30 m. The mission will provide data in a repeat cycle of 20 to 25 days for a single satellite and 10–12.5 days for two satellites using a sun-synchronous orbit [
10].
CHIME’s main objective will be to improve and develop new services focusing on the precise management of natural resources to support a range of related policies and decisions. Within the natural resources management, a primary pillar will be ‘sustainable agriculture and food security,’ including, among others, food nutrition and quality [
11]. To support this, CHIME shall deliver required quantitative measures of essential crop traits in space and time and high accuracy meeting user requirements within the agricultural services [
11]. In this way, the mission will support European Union (EU)-related policies, such as the green and performance-based EU Common Agricultural Policy (see:
https://ec.europa.eu/info/food-farming-fisheries/key-policies/common-agricultural-policy, accessed on 15 March 2022), aiming for sustainable agricultural management. With the background of these green EU goals, dedicated retrieval algorithms that can be easily implemented into operational schemes to obtain prioritized variables need to be identified. To support the preparatory activities of CHIME, an end-to-end (E2E) instrument simulator was established, which can approximate the complete chain starting from data recording, sensor calibration, and data pre-processing to sensor products up to final surface properties mapping [
12]. Following the atmospheric and geometric correction processes providing Level-2A (L2A) products, multiple vegetation traits models will be implemented in the Level-2B (L2B) module of the E2E simulator [
13]. These traits encompass biochemical and biophysical vegetation properties, such as leaf and canopy chlorophyll content (
, CCC), specific leaf area (SLA), leaf area index (LAI), leaf and canopy water content (LWC, CWC), the fraction of absorbed photosynthetic active radiation (FAPAR), and fractional vegetation cover (FVC). Retrieval of these traits is relevant for diverse agricultural applications to support sustainable management and thus food production [
14,
15]. While the majority of these traits have been derived numerous times experimentally or in operational missions (see reviews Verrelst et al. [
16,
17]), currently no mission in space routinely provides a catalog of these vegetation products.
When it comes to the routine production of biochemical and biophysical traits from EO data, efficient retrieval methods need to be implemented. The key challenge lies in finding the trade-off between site-specific accuracy and operational continuity. An overview and elaborated taxonomy of variable retrieval methods from Earth observation data is provided by Verrelst et al. [
16,
17]. From the main families of retrieval methods, i.e., (1) parametric regressions, (2) nonparametric regressions, (3) physically-based methods, and (4) hybrid approaches, the last method evolved as the most appealing in operational contexts [
18,
19,
20,
21,
22,
23,
24,
25,
26]. Hybrid strategies blend the physics described by radiative transfer models (RTM) and use the efficiency of machine learning regression algorithms (MLRAs) in a synergistic way to infer the traits of interest. Within such workflows, synthetic training data sets are firstly generated from RTM simulations describing multiple states of vegetation characteristics. Subsequently, a selected machine learning algorithm learns the nonlinear relationships between the pairs of simulated reflectance and vegetation traits to build a predictive model [
16,
27]. However, when hybrid methods are applied to hyperspectral data, some challenges must be overcome. Imaging spectrometers, such as CHIME, are characterized by numerous contiguous spectral bands providing a vast amount of detailed information but also contain spectral redundancy and noise [
28]. Consequently, ingesting all these bands directly into an MLRA would lead to long training times and suboptimal mapping performances [
27,
29].
To circumvent this redundant information and improve model efficiency, dimensionality reduction (DR) in both the sampling (i) and spectral (ii) domains need to be accomplished [
27]. With respect to (i), active learning (AL) methods were proposed to reduce training sample sizes and thus also final models effectively [
30,
31,
32]. Traditionally used for classification [
33], recently, AL techniques have been pursued to solve numerous regression problems in the context of EO data analysis targeting vegetation properties retrieval [
34]. When applying AL, a machine learning algorithm can reach superior accuracies as it learns from an optimized and representative training data set [
35]. In addition, computational runtime is reduced, allowing the implementation of MLRAs that require a relatively small number of training points, such as Gaussian process regression (GPR) algorithms [
36,
37]. GPRs are outstanding in delivering competitive performances [
38] and can provide associated uncertainty looking at predictive variance estimates [
39]. Consequently, they may be the preferred methods in the framework of hybrid retrieval strategies [
17].
Regarding spectral dimensionality reduction (ii), we can broadly distinguish between (1) feature extraction or band selection [
20,
31] and (2) feature transformation, also known as feature engineering [
40]. Both reduction techniques convert the spectral data into a lower-dimensional feature space, assuring that the majority of the spectral information is kept. In the case of feature extraction, a subset of the most relevant bands is selected to construct a model. Hereby we differentiate between three different methods: filter, wrapper, and embedded modeling [
41,
42]. In view of filter methods, traditionally, vegetation indices have been employed, extracting two or three bands and building linear relationships with the variables of interest [
43,
44,
45,
46,
47]. However, despite straightforward implementation and successful usage in multiple studies, these methods may fail to find the correct subset of bands (or features). In addition, available (hyperspectral) information is underexploited and noise sensitivity can be enhanced if narrow bands with relatively low signal-to-noise ratios were combined [
48]. For these reasons, embedded or wrapper methods should be preferred, as demonstrated by a few variable retrieval studies [
2,
31,
49]. Feature engineering is usually based on mathematical projections, which attempt to transform the original features into an appropriate feature space. After transformation, the original meaning of the features is usually lost [
40]. The most prominent method is principal component analysis (PCA) [
50]. For further explanation and discussion about these methods, we refer to Berger et al. [
20]. In prior studies, spectral dimensionality reduction was incorporated in hybrid strategies, either using band selection [
20], but mainly using feature engineering in the form of PCA [
12,
13,
22,
23,
32,
51,
52]. However, a direct comparison is lacking and the most efficient strategy for retrieving multiple vegetation traits from hyperspectral data sets remains to be investigated.
Altogether, with the ambition to support the upcoming CHIME with efficient retrieval methods, the overarching objective of this study was to identify the optimal hybrid strategy for deriving essential crop traits, such as SLA, LAI, CCC, CWC, FAPAR, and FVC from imaging spectroscopy data. To achieve this objective, we applied AL in the sampling domain to obtain representative training samples and compared two different spectral feature reduction strategies. Direct and indirect evaluation of the retrieval models is provided by exploring a field data set. As CHIME is yet to be launched, in anticipation of the upcoming hyperspectral data stream, the developed models will be applied and tested on a hyperspectral PRISMA image covering large cultivated areas.
2. Material & Methods
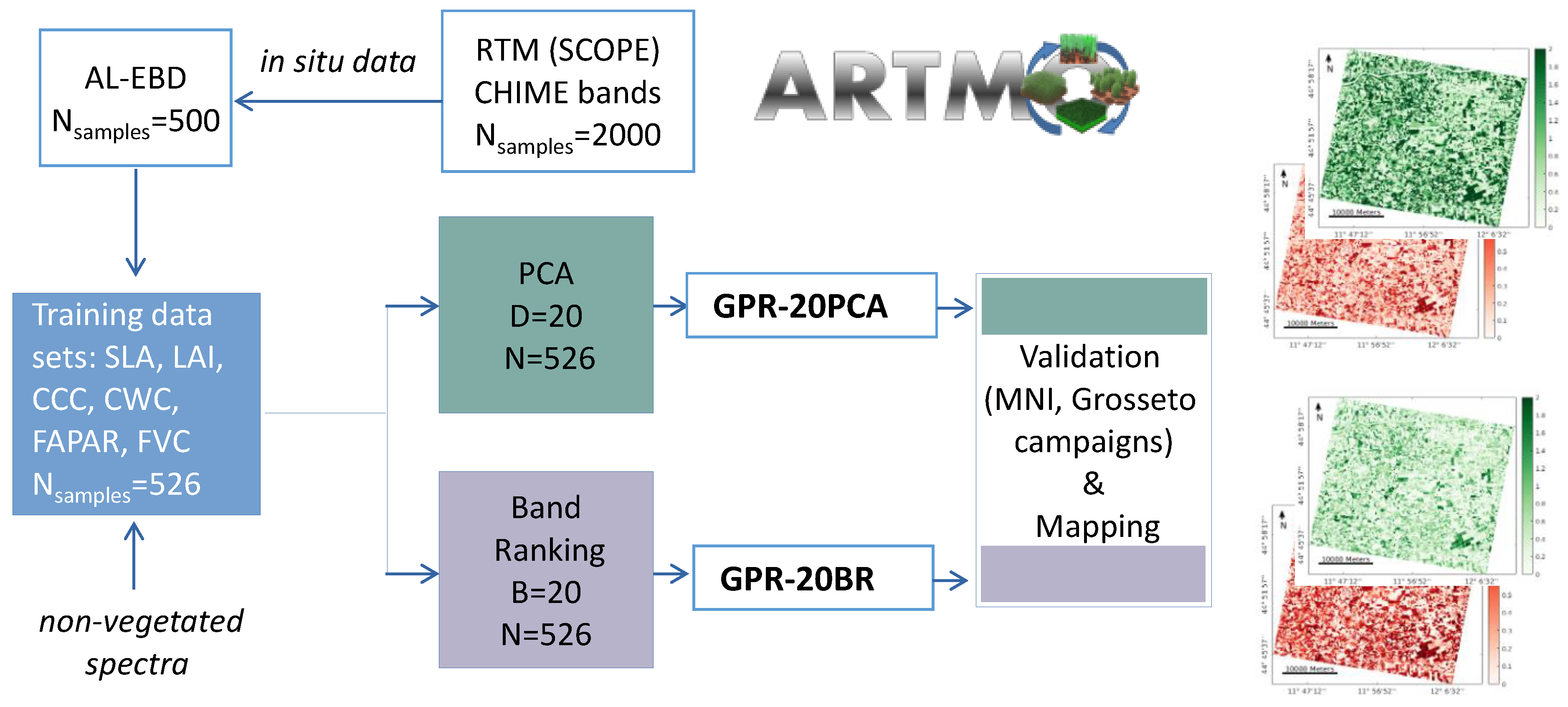
2.1. Study Design & Workflow
The foundations of this study are based on a hybrid method, combining RTMs with machine learning algorithms, and applying dimensionality reduction in the sampling and in the spectral domains.
Figure 1 delineates the workflow with the two pursued retrieval strategies consisting of six main steps, which will be detailed in the following subsections.
Generating a training database with an RTM (see
Section 2.2);
Applying AL methods to reduce and optimize the training data sets for each variable (see
Section 2.3);
Reducing dimensionality of simulated and measured spectra with: (i) PCA and (ii) an iterative band ranking (BR) procedure (see
Section 2.5);
Mapping using PRISMA scenes, resampled to CHIME, over cultivated areas of the agricultural site close to Jolanda di Savoia, Italy (data set description see
Section 2.6).
For all analyses performed in our study, the scientific Automated Radiative Transfer Models Operator (ARTMO,
https://artmotoolbox.com/, accessed on 2 January 2022 [
53]) software framework was employed. ARTMO includes the machine learning regression algorithm (MLRA) toolbox with an integrated active learning module [
32] for retrieval applications. Different kinds of MLRAs, AL methods, and spectral dimensionality reduction (PCA, GPR-BAT tool) as well as sampling strategies using RTMs can be tested and applied.
2.2. Training Database Establishment
Ideally, a training data set for an ML algorithm should mimic the spectra encountered in real scenes as realistically as possible. This can be achieved by generating multiple combinations of vegetation variables with the RTM and applying wide statistical distributions.
We selected the Soil Canopy Observation, Photochemistry and Energy fluxes (SCOPE) model (version 1.7) [
54] for our purpose. SCOPE is based on a modular architecture, encoding knowledge of radiative transfer, micrometeorology, and plant physiology. The different modules can be used separately or integrated into a cascade, exchanging inputs and outputs. Within SCOPE, optical properties of the leaves are modeled by PROSPECT-5 [
55] and Fluspect [
56], whereas the canopy structural properties are described by SAIL. We also chose SCOPE due to the energy balance module, which iteratively calculates heat and radiation fluxes. Therefore, it allowed for the indirect definition of FAPAR and FVC.
For the establishment of the training database, we set the ranges of the target variables (see
Table 1) according to OPTICLEAF database (OPTICLEAF;
http://opticleaf.ipgp.fr/, accessed on 23 December 2021), as well as similar studies using PROSPECT-4SAIL or SCOPE [
16,
23,
27,
57,
58,
59,
60]. Leaf optical properties such as leaf chlorophyll content (
), leaf water content (
), and leaf dry matter content (
) were generated with truncated Gaussian distributions as this corresponds to their natural distributions. With respect to total leaf carotenoid content (
), the variable was distributed in its habitual range of variation to render spectra more realistic for the photosynthetically active radiation (PAR) region. However, the chosen distribution was uniform since this is not a target variable. Lastly, anthocyanin content (
) and senescent material (
) have been set to 0 as this retrieval scheme is aimed at modeling green canopies. For the retrieval of brown (or senescent) canopies, specific retrieval strategies relying on the modeling of senescent leaf compounds [
61] need to be developed. Soil reflectance was described by the Brightness-Shape-Moisture (BSM) soil reflectance model [
62,
63]. For all input parameters of BSM, i.e., soil moisture content (SMC), soil brightness, longitude, and latitude, the distributions were set to Gaussian. Although these variables are not of interest for the retrieval scheme, it is necessary to account for their variability in the training data to make the spectra as realistic as possible. Illumination and viewing variables, i.e., sun zenith angle (SZA), observer zenith angle (OZA), and relative azimuth between sun and observer (RAA), were varied to cover the range of possible sun-sensor-target configurations for the imagery. These have uniform distributions since there is no preferred observation direction. Lastly, regarding canopy structure variables, LAI and LIDFa/b are input from the SAIL model. Though LAI is not a priority variable, it is required for the upscaling of leaf variables to canopy level (see
Table 2). In this case, uniform distributions within the usual range of variation have been specified.
Given the provided ranges in
Table 1, the number of randomly selected simulations resulting from the combination of the parameters was set to 2000. In other studies, [
59,
60] the number of performed simulations was substantially higher (e.g., order of 100,000). However, previous studies have also proven that for hybrid retrieval strategies, competitive results can be achieved with fewer but intelligently selected samples [
32,
34,
64]. Thus, the 2000 samples generated in this training data set were subsequently used as input to a specific active learning method for selecting the most relevant samples (see
Section 2.3).
Lastly, the generation of the training database required an additional step to obtain the variables selected for retrieval (see
Table 2). This included upscaling of the leaf variables to the canopy level, i.e., CCC and CWC, by multiplying the corresponding leaf variables with LAI (all in g/m
).
was converted into SLA by calculating its inverse. Note that the use of SCOPE allowed us to indirectly define FVC and FAPAR, which rely on the primary variables LAI and
.
FAPAR was calculated as the ratio between the downward direct and diffuse photosynthetically active radiation (PAR, 400–700 nm) and upward fluxes of PAR, as calculated in SCOPE [
54]. FVC is obtained empirically from the gap fraction (
P) at nadir, by the expression defined in De Grave et al. [
23] as follows in Equation (
1):
where
k is the extinction coefficient. Given this relation, we can obtain FVC in Equation (
2) as:
Though these variables were not defined as a priority for CHIME, they are essential to disentangle structural and biochemical influences on the reflected spectral signals.
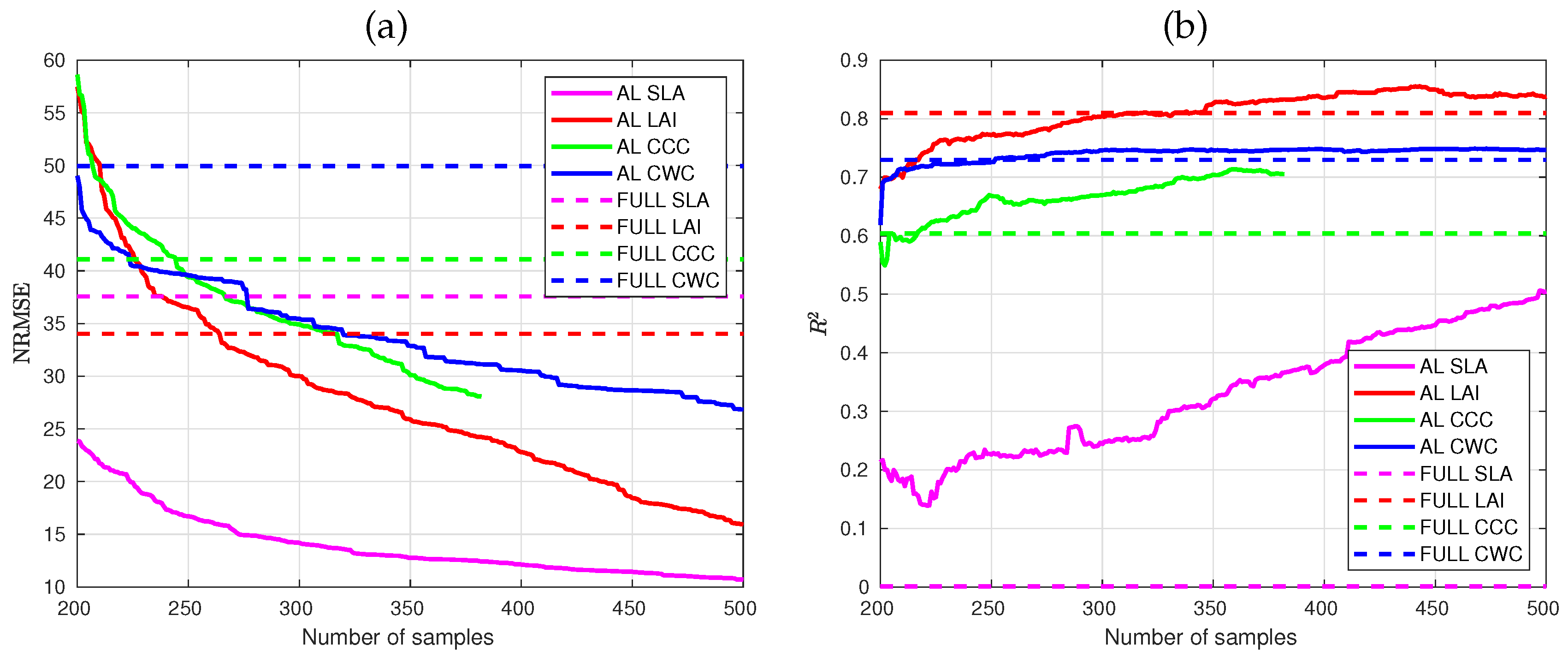
2.3. Sample Reduction: Active Learning
AL aims to optimize training datasets through intelligent sampling using an iterative procedure. In the context of regression for terrestrial EO data analysis, AL techniques are typically categorized into two groups:
uncertainty and
diversity [
64]. In a recent survey [
34] it was observed that choosing samples according to their diversity often led to optimal results. Particularly, the Euclidean distance-based diversity (EBD) method was the best performing in most reviewed studies, and, therefore, we chose to adapt this method for our study. The EBD method [
65] selects those samples out of the pool that are distant from the already included ones in the training set, using squared Euclidean distance (Equation (
3)):
where
is a sample from the candidate set, and
is a sample from the training set. All distances between samples are computed and then the most remote are selected. An additional optimization option was introduced by Verrelst et al. [
32]. Thereby, the AL algorithm is run against in situ data. In this way, the training database becomes optimized against real data. It must be remarked that the spectral data were compressed into principal components for running the AL procedure as GPR models require exhaustive processing times with hundreds of spectral bands. Yet, that step is only for efficient GPR running; the AL-reduced database preserves all bands. The stopping criterion was set to 500 samples to provide the optimal compromise between final model sizes and accuracy. The selection was performed using the root mean squared error (RMSE), but results will also be demonstrated with the coefficient of determination (
) and normalized RMSE (NRMSE) in %, being RMSE divided by the range of observations.
Subsequently to the AL optimization, we added 26 non-vegetated spectra to each variable-specific training database defining respective variable values to zero. These spectra were selected from the PRISMA scene (see
Section 2.7) and included bare soils, water bodies, and man-made surfaces. This step allowed one to reduce the mapping errors by augmenting the model’s ability to recognize multiple non-vegetated spectral surfaces in the scene.
2.4. Gaussian Process Regression
Gaussian process regression [
36] algorithms have been chosen as core algorithms in the hybrid retrieval scheme as they have proven good performance in variable retrieval studies [
38,
66,
67]. In particular, GPR models address the key question of providing uncertainties for the estimates in remote sensing products. See [
16,
17,
37] for a rationale for using GPR as opposed to alternative statistical methods.
Notationally, the GPR model establishes a relation between the input (
B-bands spectra)
and the output variable (canopy parameter to be retrieved)
of the form (Equation (
4)):
where
are the spectra used in the training phase,
is the weight assigned to each one of them, and
K is a function evaluating the similarity between the test spectrum
x and all
N training spectra,
,
. We used ARD Rational Quadratric Kernel:
This kernel can be interpreted as a combination of exponential quadratic kernels with the mixture parameter determining the weighting between them. is the scaling factor derived from the total variance. These two are the habitual parameters of the Rational Quadratic Kernel, but in our case, we also allowed feature-dependent lengthscales, i.e., .
For training purposes, we assume that the observed variable is formed by noisy observations of the true underlying function
. Moreover, we assume the noise to be additive independently identically Gaussian distributed with zero mean and variance
. Let us define the stacked output values
, the covariance terms of the test point
, and
represents the self-similarity of
. From the previous model assumption, the output values are distributed according to Equation (
6):
For prediction purposes, the GPR is obtained by computing the posterior distribution over the unknown output
,
, where
is the training dataset. Interestingly, this posterior can be shown to be a Gaussian distribution,
=
, for which one can estimate the
predictive mean (point-wise predictions), see Equation (
7):
and the
predictive variance (confidence intervals) as in Equation (
8):
The corresponding hyperparameters
are typically selected by Type-II Maximum Likelihood, using the marginal likelihood (also called
evidence) of the observations, which is also analytical. When the derivatives of the log evidence are also analytical, which is often the case, conjugated gradient ascent is typically used for optimization (see [
36] for further details).
In summary, despite being trained with often rather small data sets, GPR models proved to perform well in EO data analysis. GPR even outperformed other non-parametric regression methods, such as random forests (RF) or artificial neural networks (ANN), in remote sensing applications, which may be among others due to the ARD kernel function rendering the model quite flexible. Besides the information about uncertainty, GPR models deliver information about the relevance of bands, which can be used for identifying the sensitive spectral regions [
31,
37,
68].
Note that in our study, we implemented the MATLAB version of GPR models according to Verrelst et al. [
12]. In contrast to other programming versions, the MATLAB GPR provides a higher efficiency in the training phase, which leads to lower processing times. A small gain in runtime is essential when using AL methods or processing large scenes within operational setups.
2.5. Retrieval with Dimensionality Reduction Strategies
In this section, the two proposed dimensionality reduction approaches are detailed. Specifically, we compared a PCA retrieval strategy (i) against a band ranking procedure (ii). When using PCA (i), spectral data is mapped into a lower-dimensional feature space, which captures most of the variance of the original data. In this way, PCA identifies dominant spectral features but also detects signals in some other bands, depending on the number of considered principal components [
21,
69]. To obtain the dominant spectral features, PCA solves an optimization problem that seeks to maximize the variance in the transformed space, this is posed under the Rayleigh quotient as:
where
is the covariance matrix. The above unconstrained optimization problem (Equation (
9)) is equivalent to the following constrained optimization problem:
The solution of the above optimization problem (Equation (
10)) can be achieved through the Lagrange multipliers methods, in particular the derived cost function is
. By computing the partial derivatives, we end up with the equation
, which requires the computation of the eigenvalues and eigenvectors of the covariance matrix
.
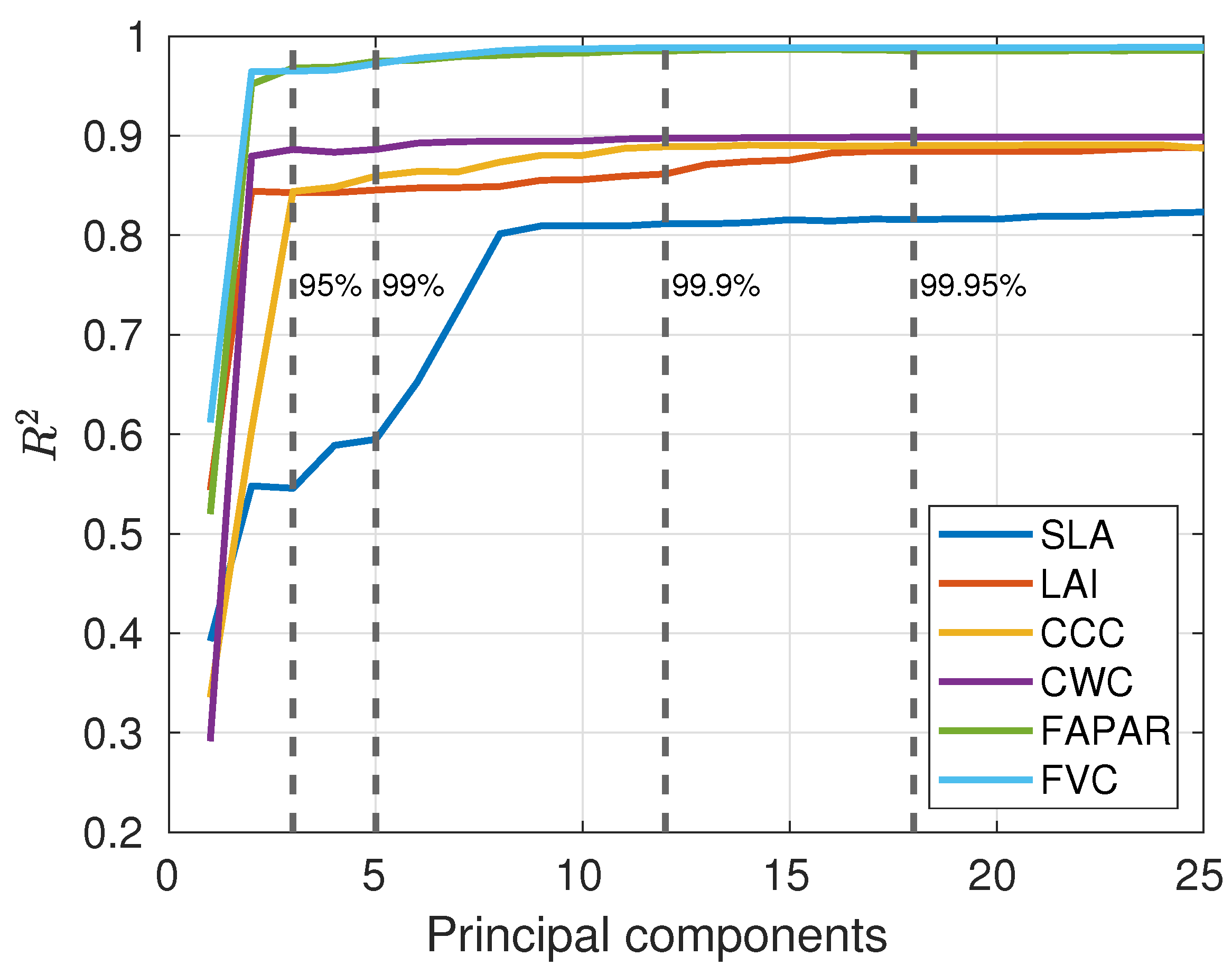
is a Positive Semi Definite matrix formed by non-negative eigenvalues; these eigenvalues summarize the contribution to the total amount of retained variance by each corresponding eigenvector which are the called principal components of the PCA method. In particular, we follow the criterion based on normalizing the eigenvalues by their total sum. Then, each normalized eigenvalue represents a fraction of the total variance (by summing to one). Our selection rule for the number of principal components is to ensure more than 99.95% of the original variance. To optimally explore the spectral information, at first, we tested the variable estimation accuracy as a function of the total number of PCs. For this purpose, 1 to 25 components were applied to the spectral training data set, GPR algorithms trained, and models run against the in situ data set.
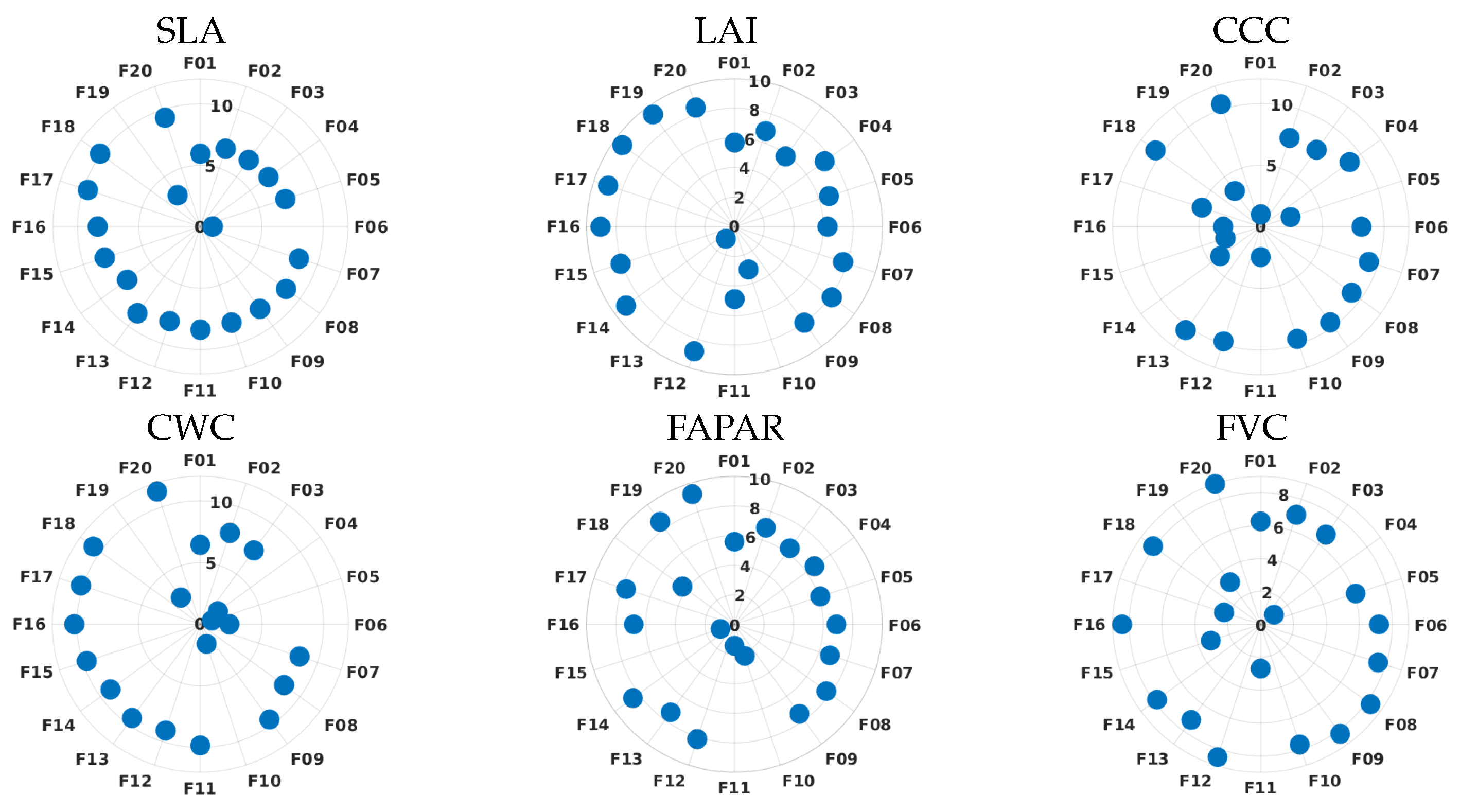
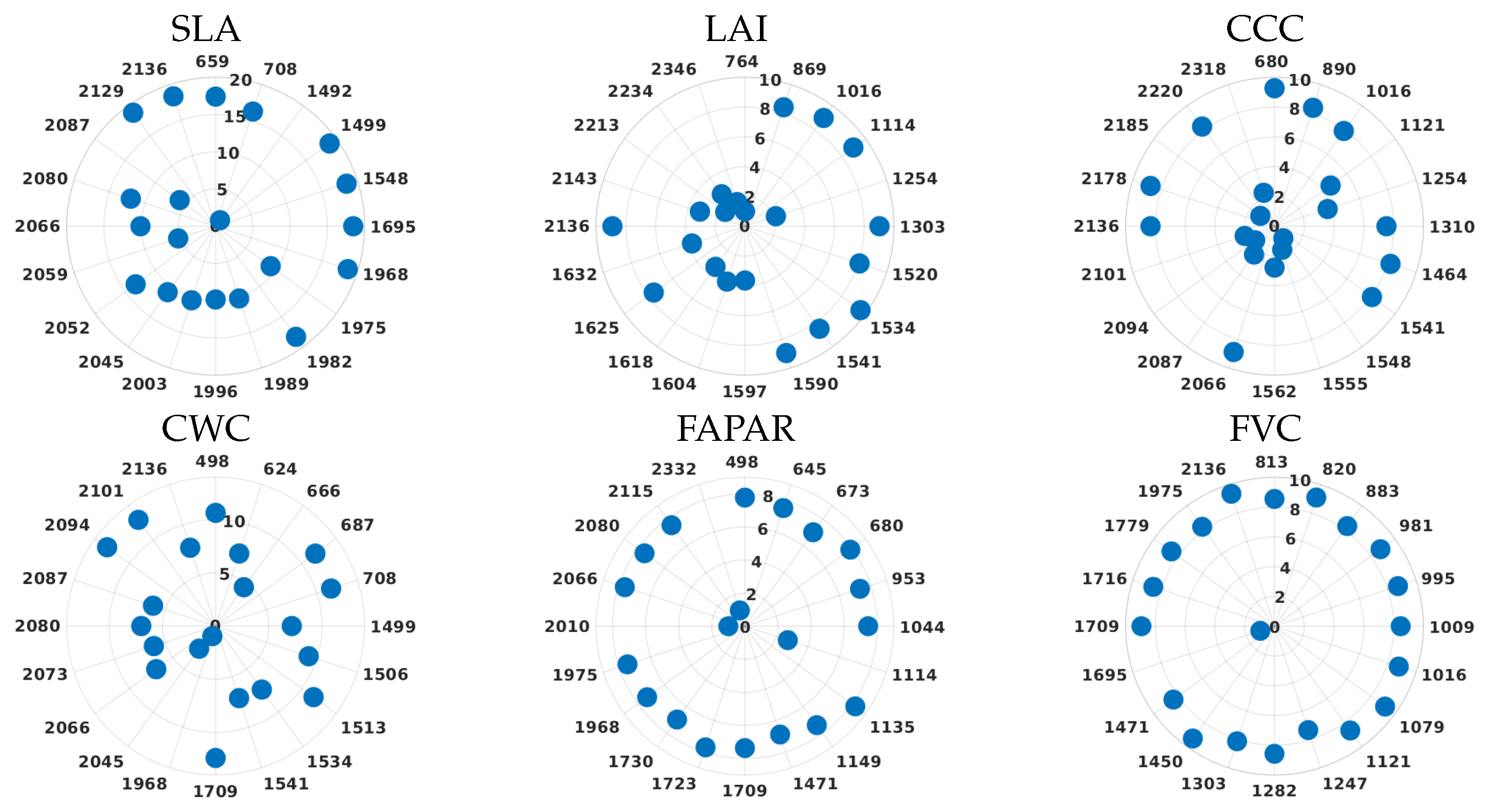
Second (ii), we explored the band ranking procedure. To create the models, we also selected the optimized variable-specific training data sets provided by the AL methodology with the complete CHIME-like spectral setting. We explored a wrapper technique, i.e., feature selection using GPR for automatic band selection, embedded in ARTMO’s GPR-BAT tool. It explores the capability of GPR algorithms to evaluate the predictive power of each available spectral band during the development of a retrieval model. A sequential backward band removal (SBBR) algorithm reveals the bands that contribute most to the development of the model by exploring the automatic relevance determination (ARD) covariance. By eliminating the least contributing band (highest ) and then retraining and validating a new GPR model, the procedure is repeated until, finally only one band remains, indicated by the overall lowest . Consequently, this routine eventually leads to the identification of the optimal band setting for the variable under consideration.
Therefore, information about the spectral relevance of each band was obtained through the parameter
of the ARD kernel (see Equation (
5)), which is the kernel width assigned to the
m-th band. The
parameter is inversely proportional to the relevance of the band, as it measures the uncertainty of the model with that particular band (highest value means higher uncertainty). To provide a direct relation between
and its relevance, we converted as proposed by [
70], and we refer to the value of relevance for each band as
, as follows:
In addition, to ensure a robust identification of the most sensitive bands and to ensure the inclusion of all simulated samples for validation, the method was combined with k-fold cross-validation (CV) sub-sampling scheme. Specifically, a 3-k sub-group sampling strategy was pursued. Goodness-of-fit validation statistics were averaged for the k validation subsets, i.e.,
,
,
, as well as associated SD and min–max rankings. Based on k repetitions, the generated
were k times ranked. A detailed description of the GPR-BAT procedure can be found in Verrelst et al. [
31].
2.6. Experimental Sites
The dataset explored in our study was collected during two different campaigns (see
Figure 2). The first campaign took place in an agricultural site in the North of Grosseto, located in central Italy (N 42°49.78
, E 11°4.21
) during the summer season of 2018. Sampling was performed within two corn (
Zea mays L.) fields of varying phenological cycles due to different sowing dates (i.e., early May and mid of June, respectively). The data were collected from 2–7 July and 31 July–1 August 2018 at homogeneous elementary sampling units (ESUs) of 10 × 10 m
2. LAI was measured at 87 ESUs using either an LAI-2200 plant analyser (LI-COR Biosciences, Lincoln, NE, USA) or a digital hemispherical camera (Nikon CoolPix 990, Tokyo, Japan) equipped with a fish-eye lens (Nikon FC-E8 8 mm, Tokyo, Japan). The LAI-2200 measurements were carried out at the ESUs, repeating one above and four below canopy readings. The hemispherical photographs were processed using the CAN-EYE software (
https://www6.paca.inrae.fr/can-eye/, accessed on 24 September 2021), providing an average estimate of LAI for each ESU. To obtain CCC, measurements of
were performed within 87 ESUs using a SPAD device (Konica Minolta, Tokyo, Japan), taking the last fully expanded leaf (with five readings at each sampled leaf). In addition, we sampled the last fully developed leaf from three plants within 31 of the 87 ESUs. A few samples under chlorosis conditions, not corresponding to any ESU, were as well collected to enlarge variability.
laboratory extractions were performed on a set of three disks with a 2.2 cm diameter sampled at each leaf. The laboratory analysis included homogenization with methanol (Ultra-Turrax, IKA-Werk, Staufen, Germany), followed by repeated centrifugation and cooling at −20°. After merging of supernates and filtering (0.45 μm PTFE syringe filter)
could be measured. Lab-extracted
values and corresponding SPAD measurements were used to build the SPAD-
relationship obtaining
= 0.93. The study of Candiani et al. [
52] provides in detail the entire laboratory procedure, including resulting equations. This high agreement between SPAD and destructive measurements confirms our choice of the measurement device. However, it must be remarked that SPAD shows some sensitivity towards leaf thickness, which differs between cultivars, developmental stages, and environmental conditions. Nonetheless, several comparative studies found similarly high correlations encouraging the usage of SPAD for in-field sampling [
71,
72]. Calculation of final
measurements was based on the empirical relationship between the destructive
measurements and the SPAD readings (see also [
52]). Finally, LAI was used to upscale the leaf trait to the canopy-level (i.e., CCC in [g/m
] = LAI ×
×
). Measured canopy water content was calculated using LAI and
(i.e., CWC in [g/m
] = LAI ×
×
), which was destructively measured along with
within 31 ESUs. Hereby, leaf disks with a 2.2 cm diameter were collected from three corn plants at each ESU and weighted before and after oven-drying (80 °C for 48 h) using an analytical balance (0.0001 g sensitivity). The two leaf traits were then calculated according to:
= (
)/Area;
=
/Area, where
and
are fresh and dry weights, respectively.
Simultaneously to the variable sampling, two airborne hyperspectral acquisitions were performed on 7 July and 30 July 2018 in clear sky conditions using the HyPlant DUAL sensor. The sensor covers a spectral range from 380 to 2530 nm (629 bands) with FWHM of 3–10 nm; and provides a ground sampling distance (GSD) from 1 m (7 July 2018) to 4.5 m (30 July 2018). HyPlant raw images were geometrically and atmospherically corrected to top-of-canopy reflectance through a dedicated processing chain described in Siegmann et al. [
73].
Data from a second campaign were explored, where measurements were performed at an agricultural test site located in the North of Munich, Southern Germany (N 48°16
, E 11°42
). The long-term consolidated Munich-North-Isar (MNI) site is surrounded by communal farmlands owned by the city of Munich. In the last years, the agricultural test site has been established as a validation site for preparing agricultural algorithms in the context of the German hyperspectral EnMAP mission. The dataset was collected in the growing seasons of 2017 and 2018 of winter wheat (
Triticum aestivum L.) and corn (
Zea mays L.). Biophysical and biochemical crop variables were sampled simultaneously with field spectroscopic measurements. Detailed descriptions of the MNI site along with visual documentation can be found in the studies by Berger et al. [
20], Danner et al. [
74], Wocher et al. [
75].
At two fields, a 30 × 30 m
2 area (according to EnMAP GSD) was defined containing nine ESUs of 10 × 10 m
2. LAI measurements, in [m
/m
], were performed with the LI-COR Biosciences LAI-2200 device. Hereby we collected seven below and one above canopy readings and then repeated them twice at each ESU. Finally, the average of all measurements over the nine ESUs was calculated. Measurements of
, in [μg/cm
], were collected with a Konica-Minolta SPAD-502 handheld instrument (5 leaves per ESU) at different heights of the crops. To obtain
from SPAD values, a calibration formula was applied obtained from destructive measurements performed at prior campaigns at the MNI site. To achieve this, coefficients of Lichtenthaler [
76] were used to estimate
from the SPAD samples [
77].
In addition, destructive sampling was performed at each date to determine and . For this, several leaves were cut at each ESU, then weighed, closed in bags, and transported to the laboratory. An LI-COR Biosciences LI-3000C scanner attached to the LI-3050C conveyor belt accessory was employed to measure the leaf area of all samples. , in [cm] equivalent water thickness, and , in [g/cm], were calculated from the mass difference (per unit leaf size) of sample leaves before and after oven-drying at 105 °C (minimum of 24 h) to constant weight.
As for the Grosseto measurements, leaf traits were upscaled to the canopy level by multiplication with LAI. SLA in cm
/g was finally obtained by calculating 1/
for both campaigns.
Table 2 provides an overview of the measured (and calculated) variables from Grosseto and MNI site, with mean values, standard deviations, range, and number of samples. From Grosseto, we have a total of 31 measurements from SLA and CWC and 87 from LAI and CCC. From the MNI site, 28 samples were available for all four variables.
Note that in both campaigns, the optical LAI-2200 instrument was used, which provides an indirect estimate of LAI based on canopy gap fraction following the Beer-Lambert law [
78]. Hence, the resulting measurements rather refer to the effective LAI [
79,
80]. Moreover, the contribution of stalks and fruits or non-photosynthetic biomass may be seen by the instrument. Thus, the obtained values correspond to the effective plant area index [
81]. To keep consistency with other studies, we will use the term “LAI” throughout the manuscript.
2.7. PRISMA Imagery Acquisition and Pre-Processing
In this study, we explored the data provided by scientific precursor PRISMA of the Italian Space Agency (ASI). PRISMA is a push-broom imaging spectrometer with 240 wavebands providing contiguous spectral information from 400 to 2500 nm, with a nominal spectral sampling interval < 11 nm and an FWHM < 15 nm. The 240 bands are resolved on 1000 across-track pixels with a 12-bit radiometric resolution. PRISMA has a ground spatial resolution of 30 and a swath width of 30 . The spacecraft has a body pointing capability, which allows off-nadir observations up to ±14.7.
For the current study, one PRISMA image was selected, acquired on 26 June 2020 over the agricultural area of Jolanda di Savoia, Italy. The L2D PRISMA reflectance cube was downloaded from the ASI PRISMA mission portal in HDF5 format and read using the
prismaread tool [
82]. The at-surface reflectance cube was pre-processed to remove artifacts and obtain smooth reflectance spectra. Pre-processing was performed pixel-wise with the R software [
83]. In a first step, spikes occurring along track were filtered using the
findpeaks function of the
pracma package using a threshold of 0.018. In a second step, the spectral regions located within atmospheric gaseous absorption were excluded, as anomalous spikes and dips occurred. These corrections were performed comparing to in situ canopy reflectance spectra collected simultaneously to the PRISMA acquisitions, with wavelengths located at 535–550 nm, 755–780 nm, 755–775 nm, 810–855 nm, 885–970 nm, 1015–1050 nm, 1080–1165 nm, 1225–1285 nm, 1330–1490 nm, 1685–1700 nm, 1725–1750 nm, 1780–1960 nm, and 1990–2030 nm. In a third step, all remaining spectral bands were interpolated using the
SplineSmoothGapfilling function included in the
FieldSpectroscopyCC package [
84]. Finally, we removed atmospheric water absorption domains, i.e., around 1350–1510 nm and 1795–2000 nm, and also the rather noisy bands from 2320 nm onwards. The final PRISMA cube contained 170 spectral bands ranging from 400 to 2320 nm. Correction of PRISMA spectra was also illustrated by Verrelst et al. [
12] (see
Figure 2), along with the corresponding in situ spectral measurements. For details of the spectral corrections, please refer to Tagliabue et al. [
51].
Both the simulated (training) and measured (validation) data sets as well the PRISMA image were spectrally resampled to CHIME-like bands, according to theoretical Gaussian spectral response functions with 10 nm bandwidth. Depending on the quality of the spectral ground measurements and the PRISMA scene, several bands were removed due to noise, as described above. Finally, the spectral datasets contained 198 (for SLA and CWC) or 235 (LAI, CCC, FVC, FAPAR) spectral bands, respectively.
5. Conclusions
Recent advances in hyperspectral instrument designs potentially allow accurate quantification of the status and dynamics of crucial crop traits, like SLA, LAI, or CWC, over vast agricultural areas. These unprecedented data streams, as delivered by new-generation and upcoming operational spaceborne imaging spectroscopy missions, such as CHIME, can improve our understanding of physiological processes related to photosynthesis, transpiration and respiration, being the main drivers of crop growth and development.
A workflow was developed to optimize hybrid hyperspectral retrieval models where we first applied reduction in the sampling domain through active learning and then compared two spectral dimensionality reduction strategies, i.e., GPR-20PCA and GPR-20BR. We found that retrieval results of the PCA strategy slightly outperformed those of the band ranking procedure for all considered variables, which may indicate a higher fidelity of the GPR-20PCA models. Besides physical validation using in situ data, demonstrating accurate spatial application is crucial for indirectly evaluating the models’ capabilities. In this respect, both modeling approaches achieved meaningful mapping results over a heterogeneous landscape, including multiple cover types.
Overall, based on these findings, we recommend using GPR-20PCA models as the most efficient strategy for estimating multiple traits from hyperspectral data streams. However, if inconsistent retrieval performances occur, GPR-20BR models are recommended as a backup. With the ambition to pave the way for operational usage within CHIME, we suggest further evaluating the generality of the proposed models in their capability of global coverage processing.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








