Using Artificial Neural Networks and Remotely Sensed Data to Evaluate the Relative Importance of Variables for Prediction of Within-Field Corn and Soybean Yields


Abstract
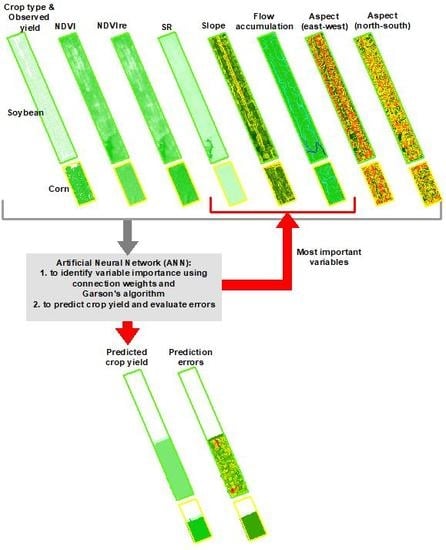
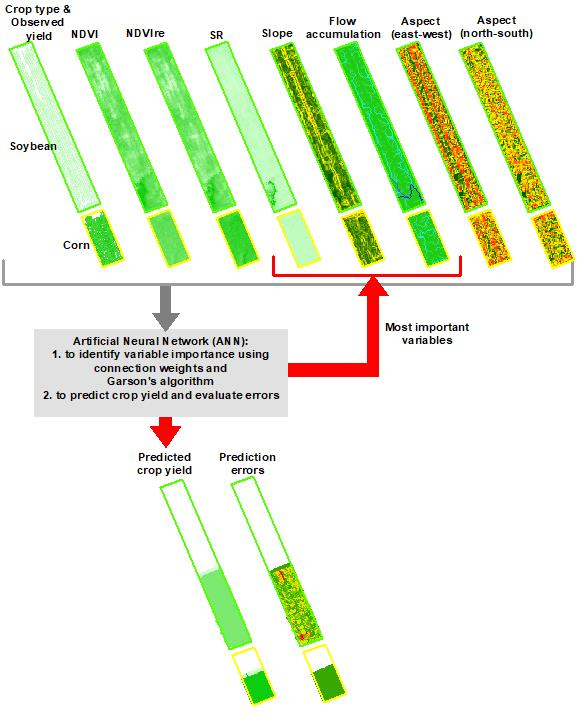
:
1. Introduction
2. Materials and Methods
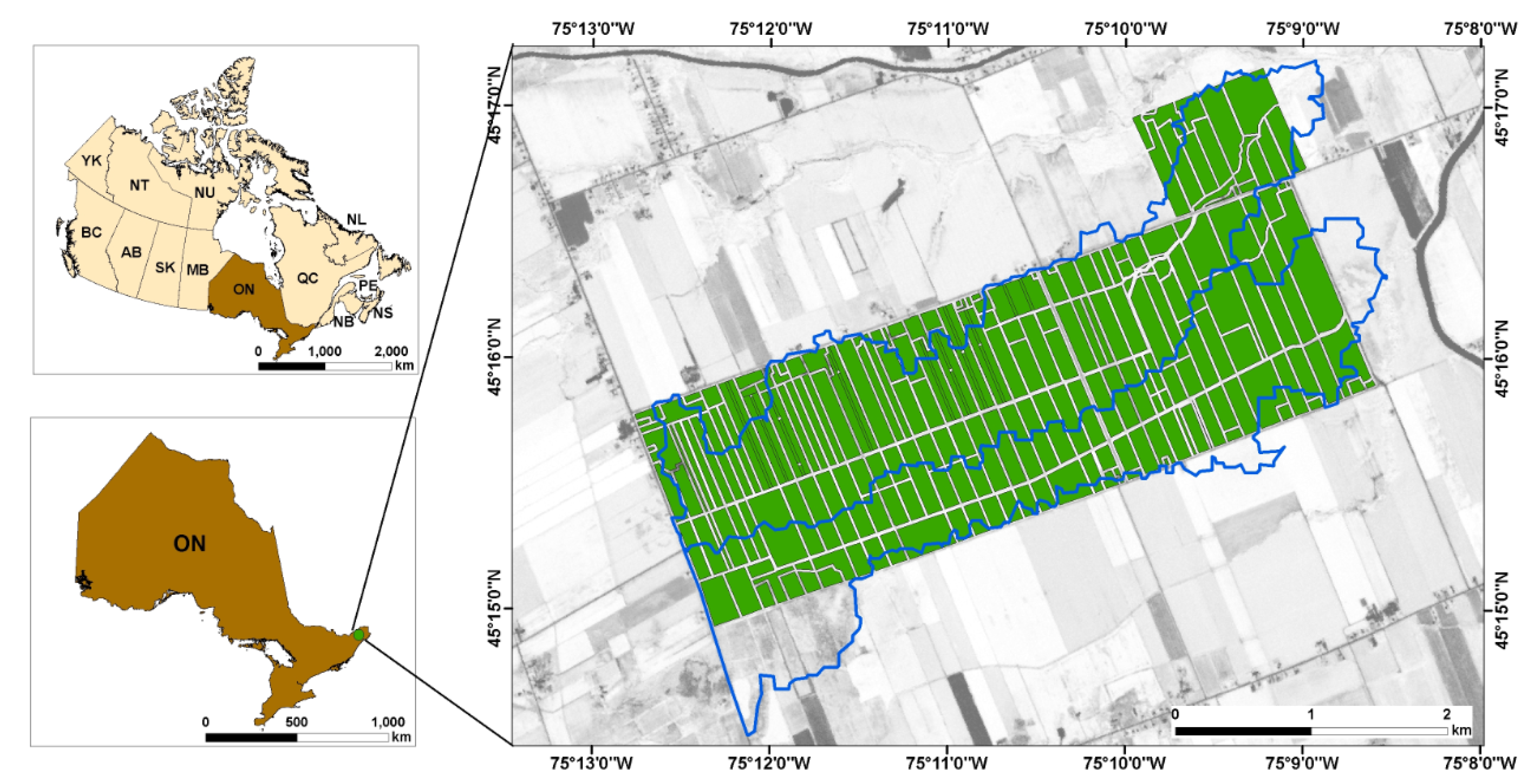
2.1. Study Area
2.2. Data
2.2.1. Field Data
2.2.2. LIDAR and Topographic Derivatives
2.2.3. Optical Remote Sensing Derived Data
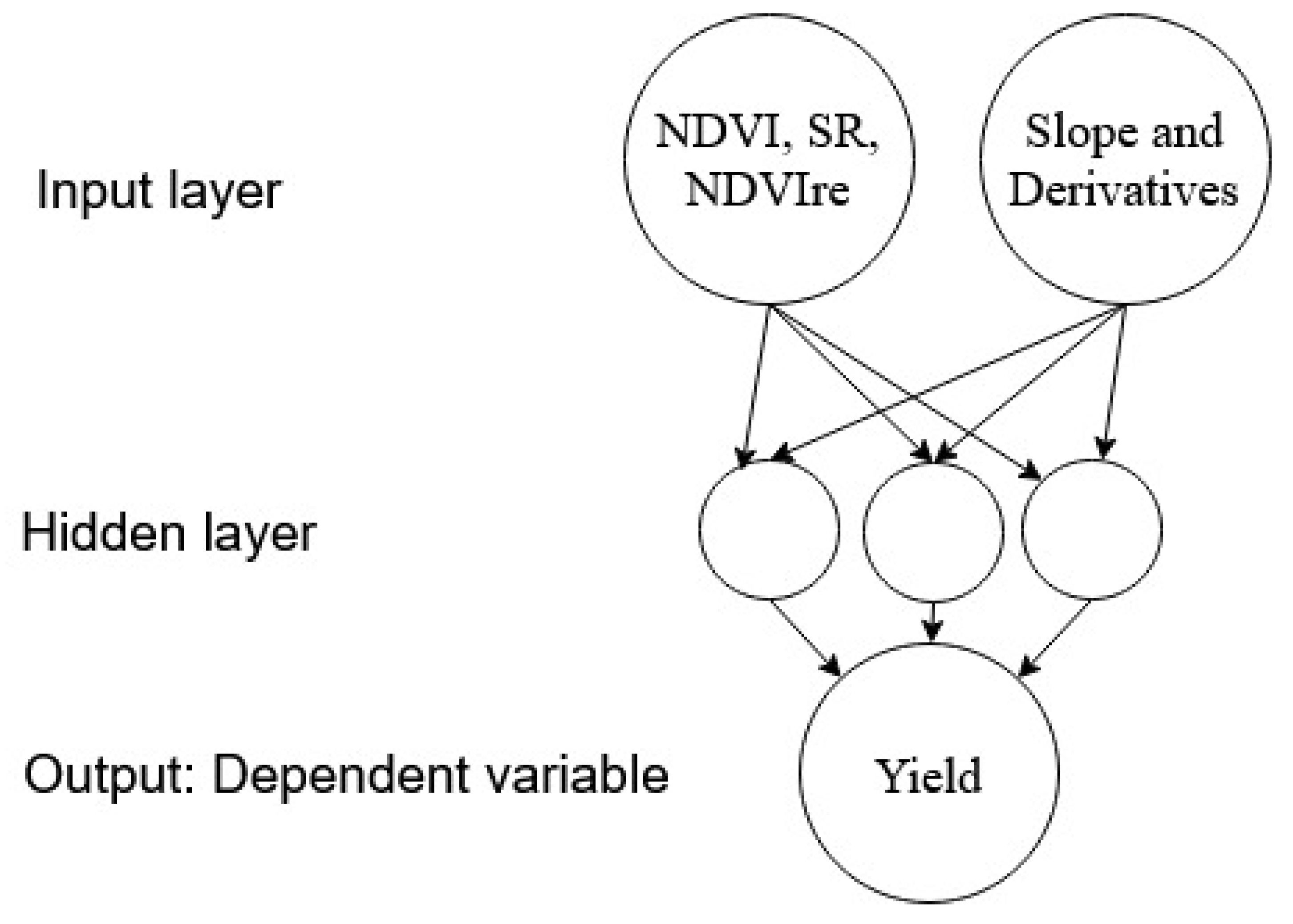
2.3. ANN Model
2.4. Analysis
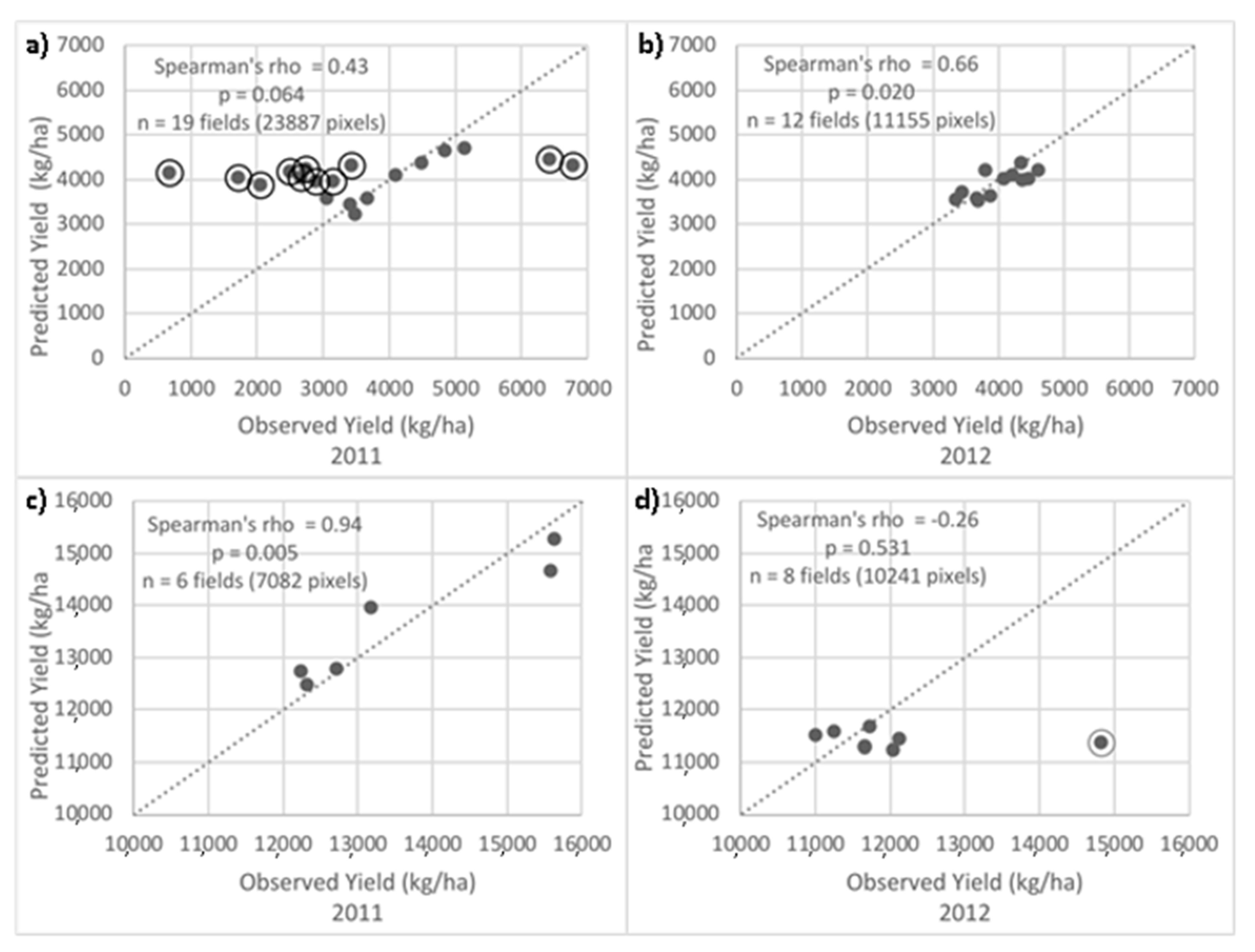
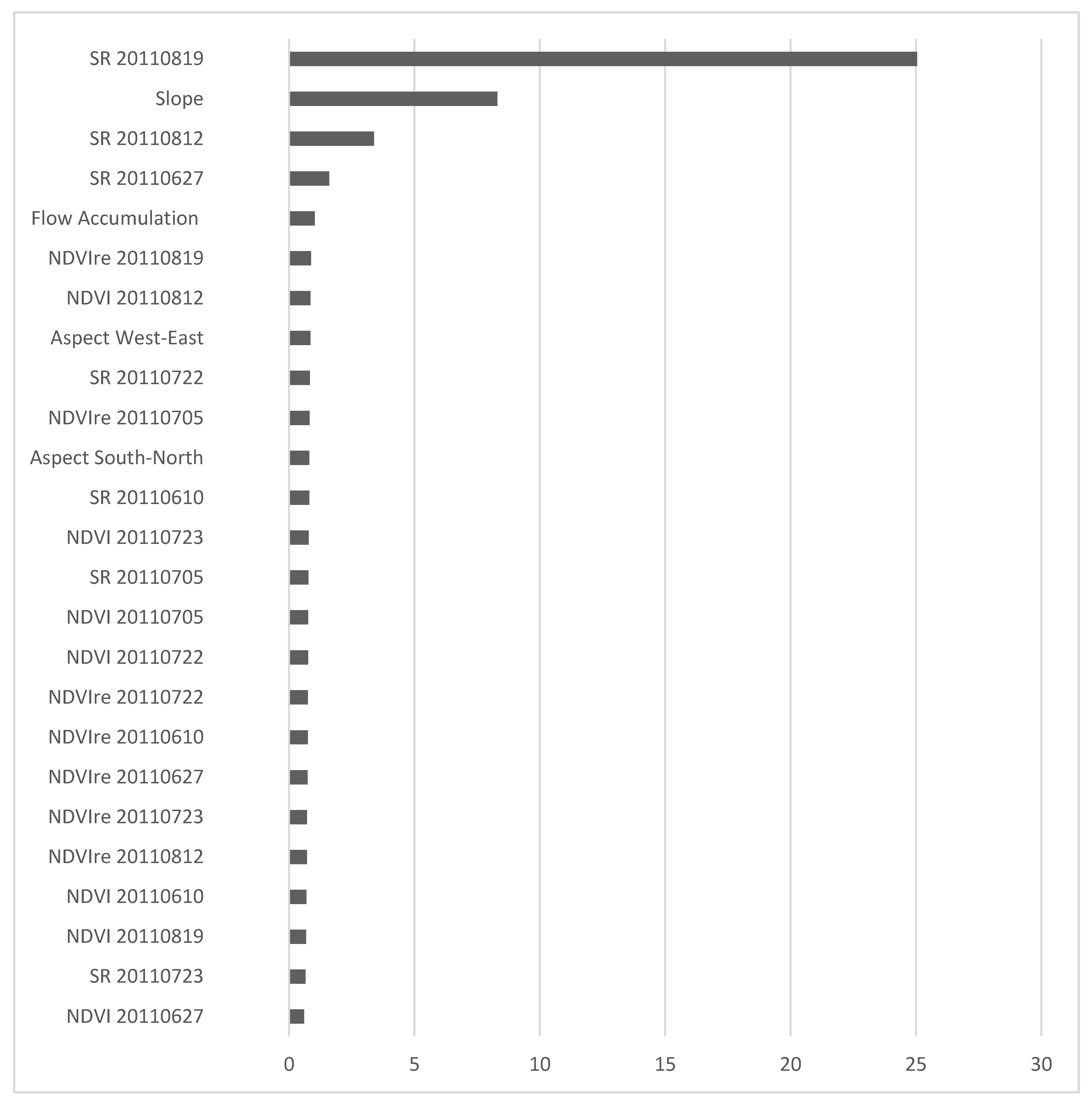
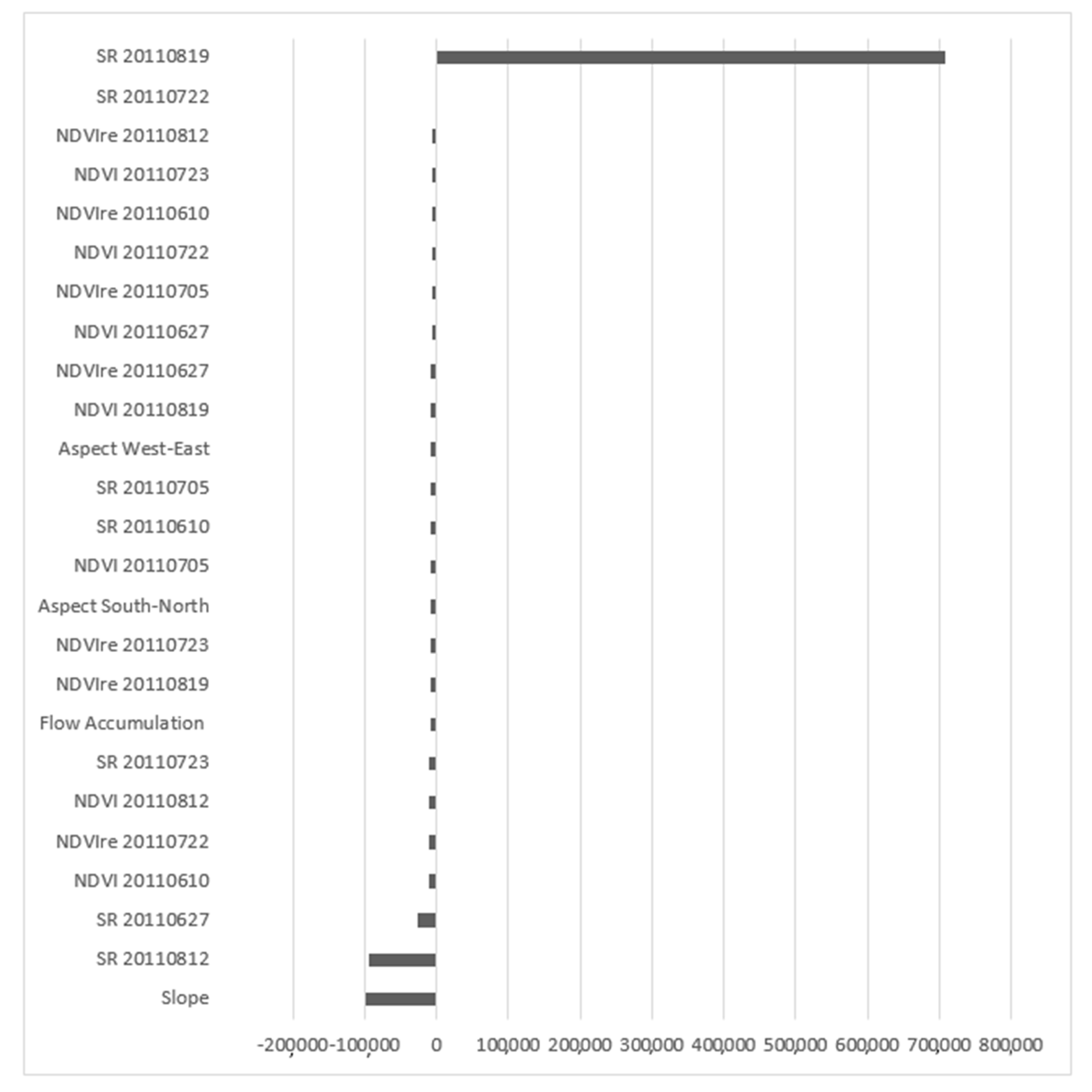
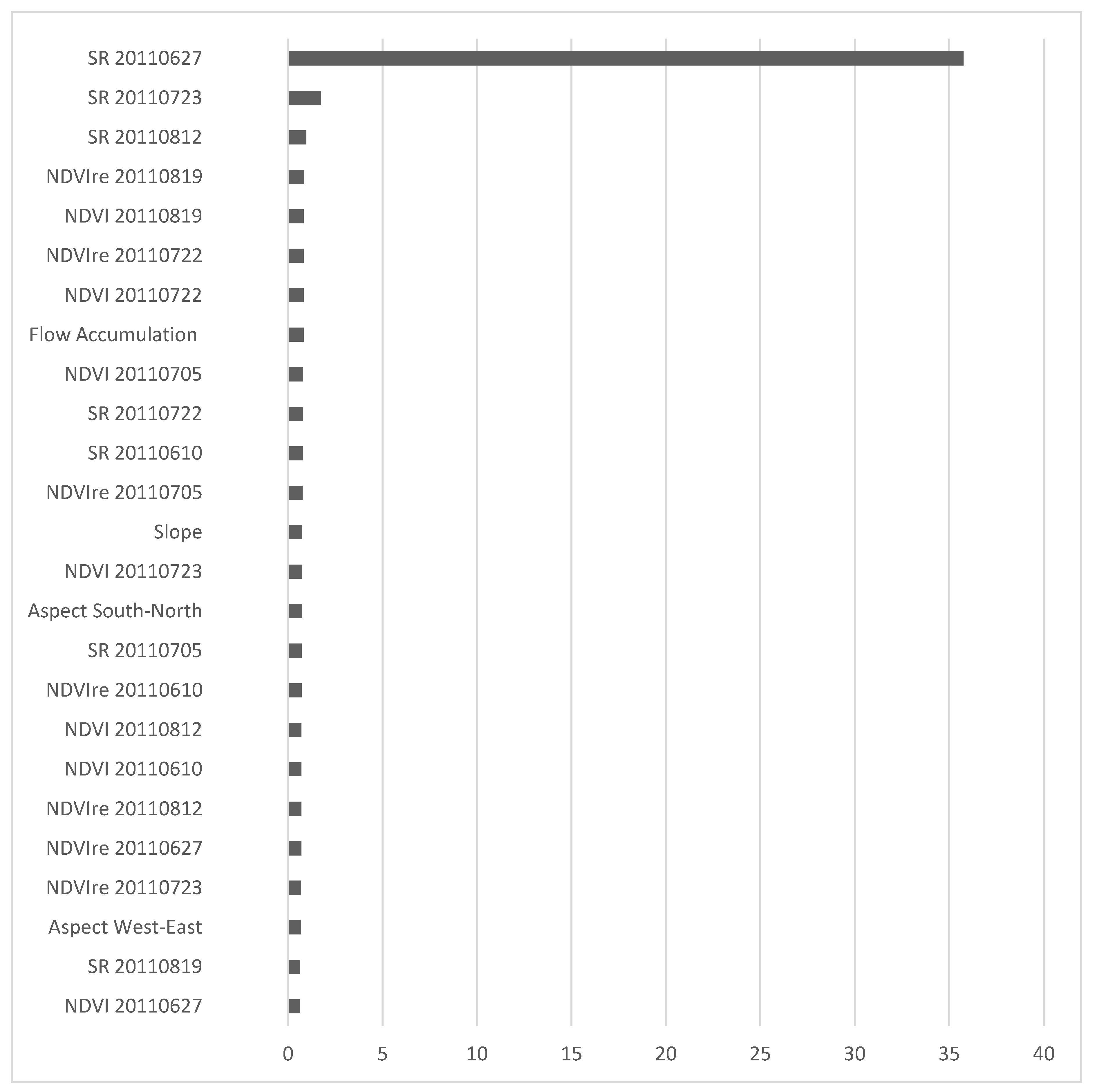
3. Results and Discussion
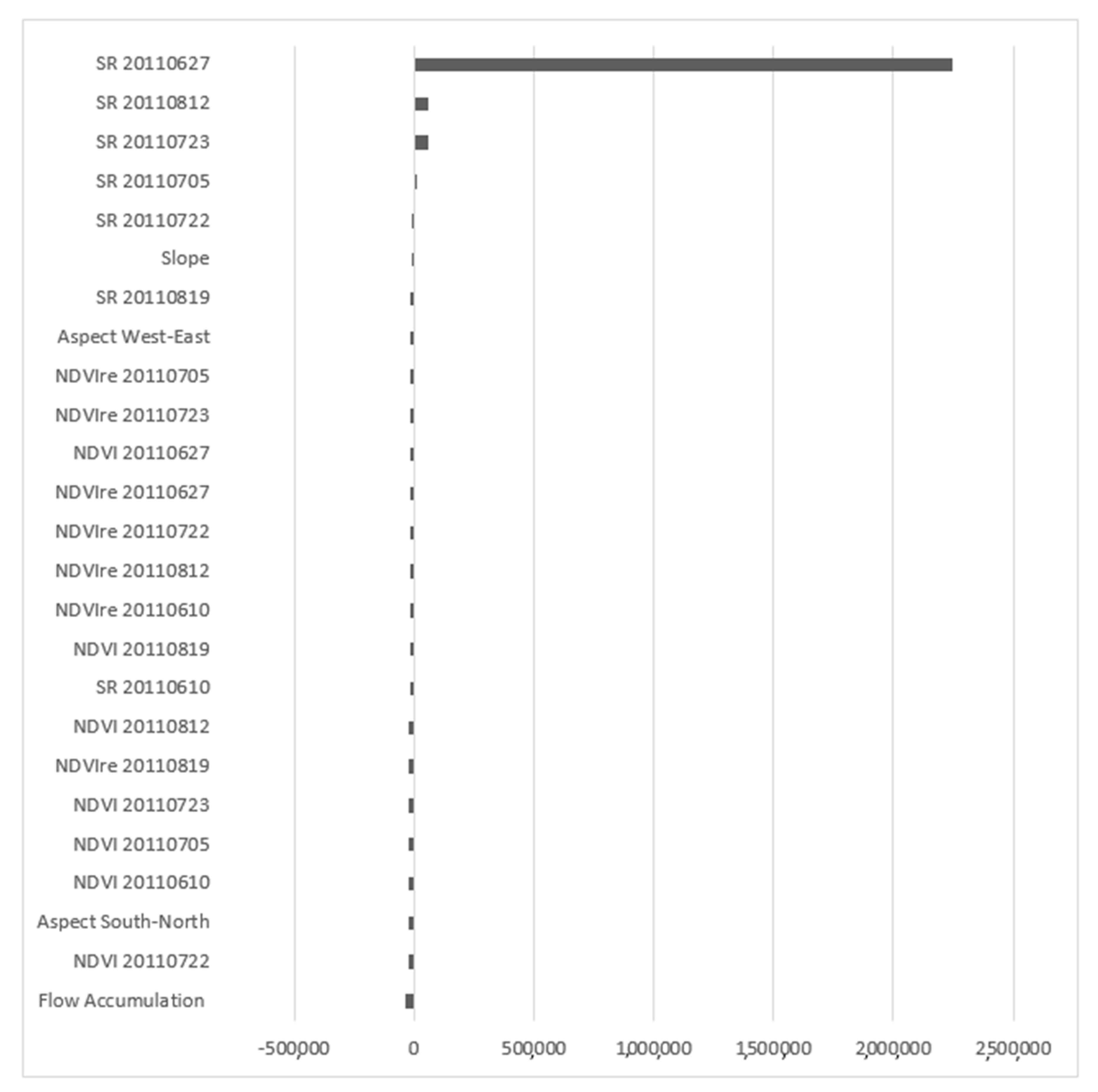
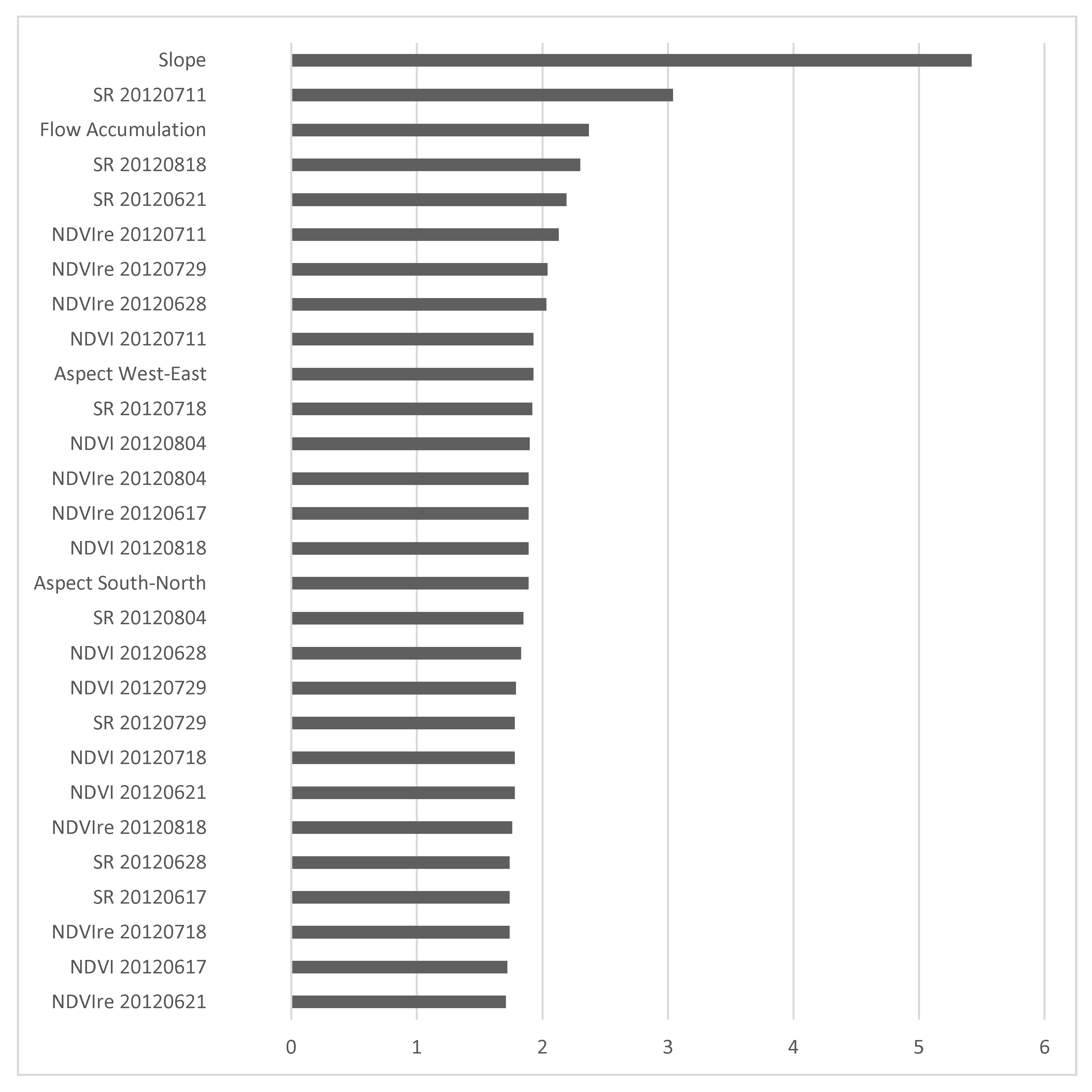
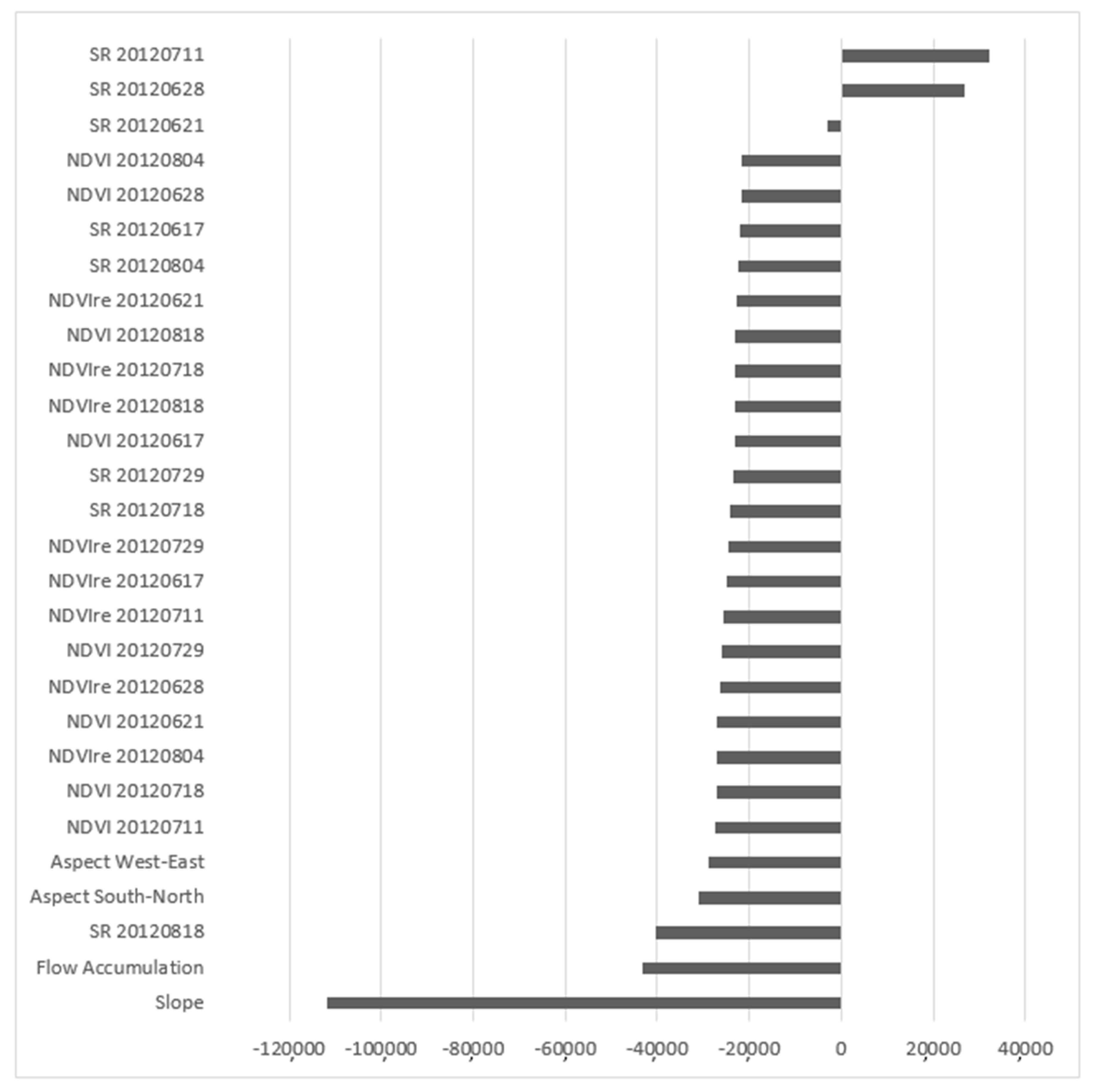
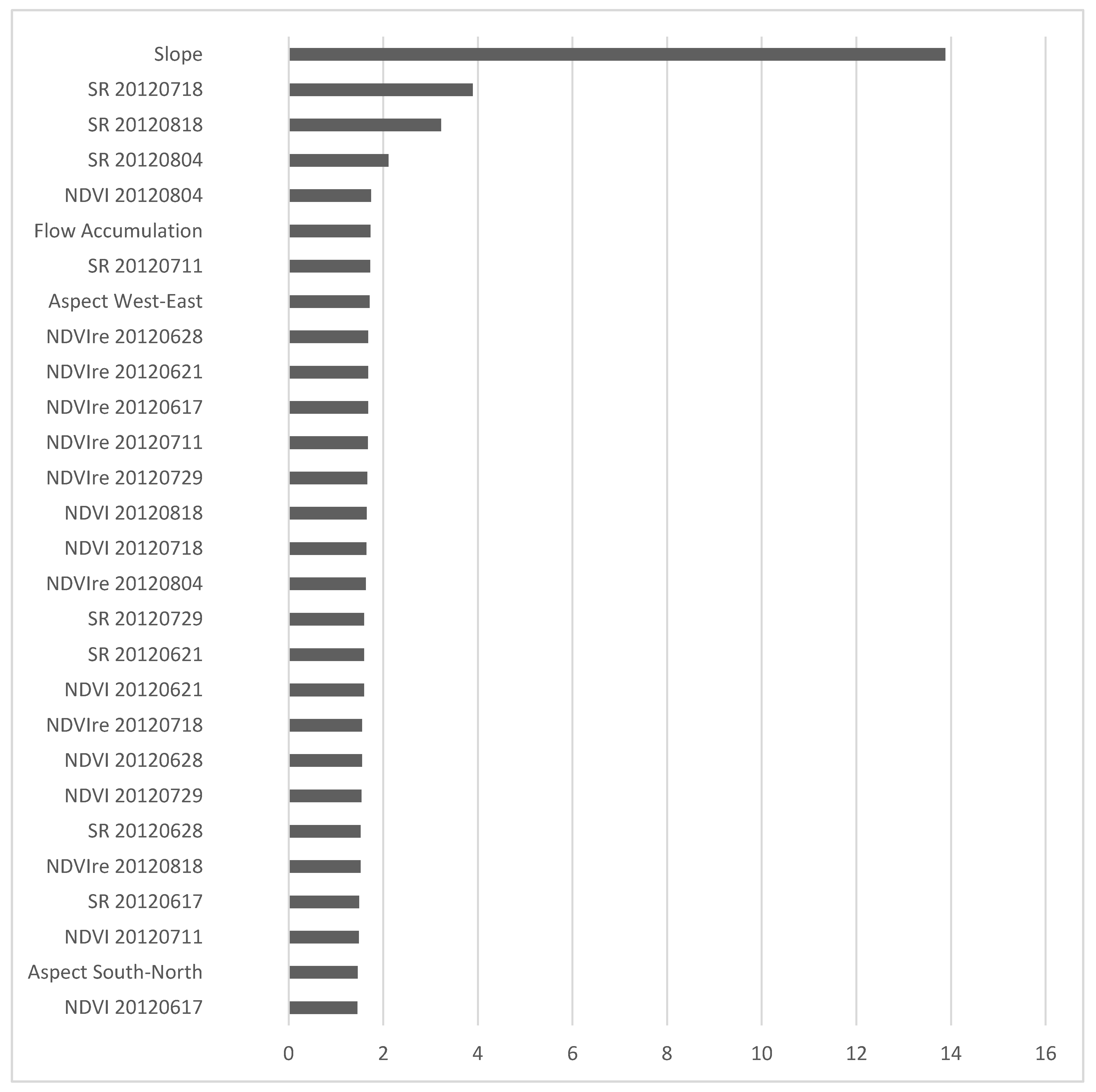
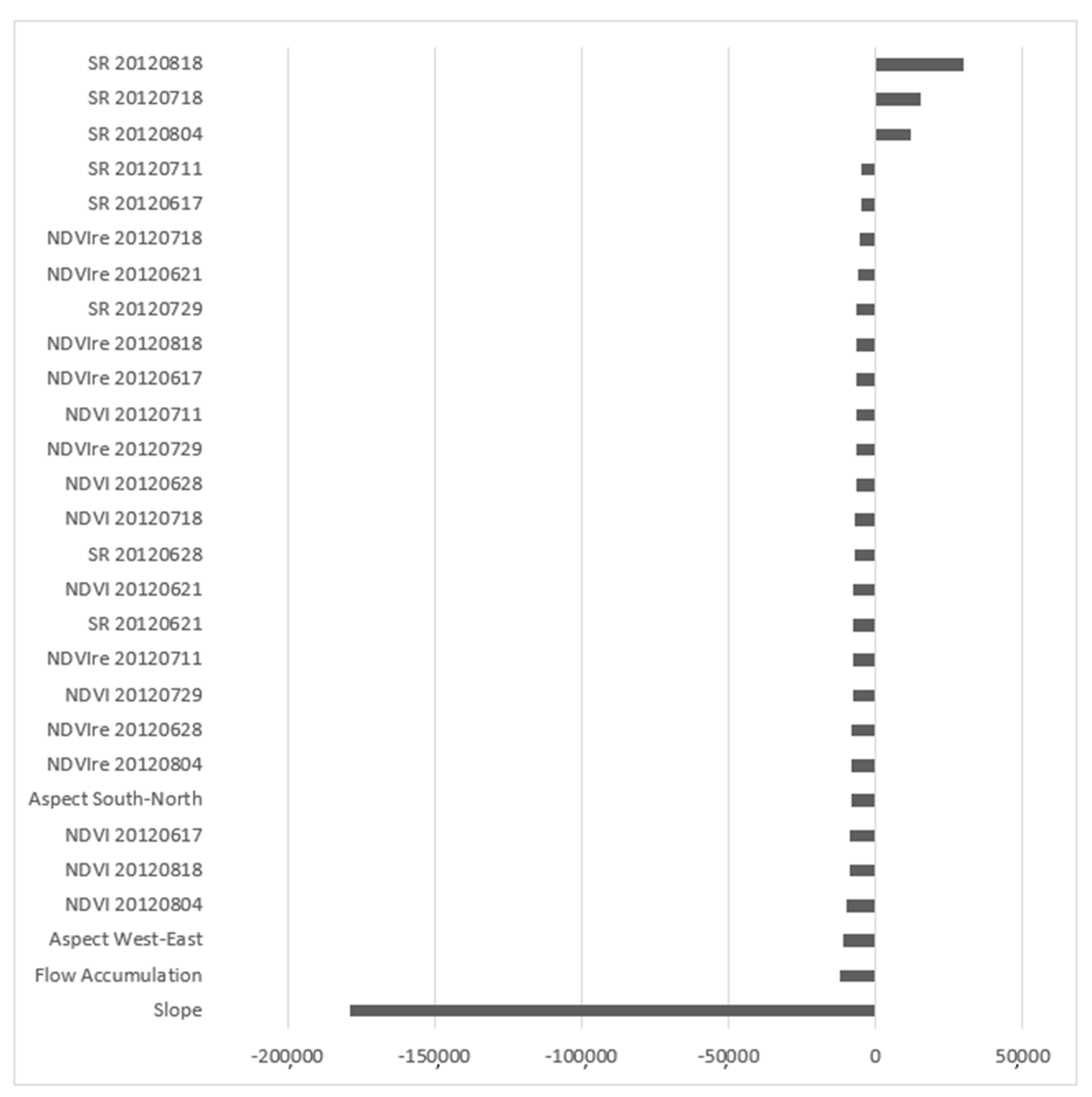
3.1. Relative Importance of Predictor Variables
3.2. Predicted within-Field Corn and Soybean Yields
- (i)
- differences in phenological development stages: the final models were developed based on images of specific dates. Even though the images of the application years mostly matched the model dates closely, actual crop development stages may not necessarily match.
- (ii)
- differences in image dates: 2016 image dates, for example, differed by up to 24 days from the image dates from the trained models, the largest errors were also observed in this year.
- (iii)
- differences in environmental and weather conditions: 2012, for example, was much drier than 2011.
- the crop type: future studies should explore potential variables for the development of crop-independent models or create crop-specific models.
- the canopy and surface wetness: information about water availability should be included (weekly data if possible).
- critical crop development stages: satellite images that match the critical crop stages should be included, which means that the phenological stages should be measured or estimated.
- field micro-topography: slope was an important indicator overall; future research should explore the inclusion of micro-topography metrics derived from slope data.
- differences in planting, spacing and management practices: the transferability of the models will depend on the homogeneity of crop management factors.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Application Years and Crops | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2011 | 2012 | 2016 | |||||||
| Training Year | Training Crop Yield | Models | Optimized Models 2011 | Soybean | Corn | Soybean | Corn | Soybean | Corn |
| 2011 | Combined | PM001 | Slope (−) SR June 27 (+) SR August 12 (−) SR August 19 (−) | Slope SR June 27 SR August 12 SR August 19 | Slope SR June 28 SR August 04 SR August 18 | Slope SR June 25 SR July 20 SR August 26 | |||
| Soybean | PM004 | Slope (−) SR June 27 (−) SR August 12 (−) SR August 19 (+) | Slope SR June 27 SR August 12 SR August 19 | Slope SR June 28 SR August 04 SR August 18 | Slope SR June 25 SR July 20 SR August 26 | ||||
| Corn | PM006 | SR June 27 (+) SR July 23 (+) | SR June 27 SR July 23 | SR June 28 SR July 18 | SR June 25 SR July 20 | ||||
| Optimized models 2012 | Soybean | Corn | Soybean | Corn | Soybean | Corn | |||
| 2012 | Combined | PM015 | Slope (−) SR June 28 (+) SR July 29 (−) SR August 18 (−) | Slope SR June 27 SR July 23 SR August 19 | Slope SR June 28 SR July 29 SR August 18 | Slope SR June 25 SR July 20 SR August 26 | |||
| Soybean | PM019 | Slope (−) Flow acc (−) SR July 11 (+) SR August 18 (−) | Slope Flow acc SR July 05 SR August 19 | Slope Flow acc SR July 11 SR August 18 | Slope Flow acc SR July 20 SR August 26 | ||||
| Corn | PM021 | Slope (−) SR July 18 (+) SR August 04 (−) SR August 18 (−) | Slope SR July 22 SR August 12 SR August 19 | Slope SR July 18 SR August 04 SR August 18 | |||||








References
- Basso, B.; Liu, L. Seasonal crop yield forecast: Methods, applications, and accuracies. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2019; Volume 154, pp. 201–255. [Google Scholar]
- Noack, S.; Knobloch, A.; Etzold, S.H. Spatial predictive mapping using artificial neural networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, XL-2, 79–86. [Google Scholar] [CrossRef] [Green Version]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Verrelst, J.; Camps-Valls, G.; Muñoz-Marí, J. Optical remote sensing and the retrieval of terrestrial vegetation bio-geophysical properties—A review. ISPRS J. Photogramm. Remote Sens. 2015, 108, 273–290. [Google Scholar] [CrossRef]
- Sun, C.; Bian, Y.; Zhou, T. Using of Multi-Source and Multi-Temporal Remote Sensing Data Improves Crop-Type Mapping in the Subtropical Agriculture Region. Sensors 2019, 19, 2401. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Magagi, R.; Goïta, K. Crop phenology retrieval via polarimetric SAR decomposition and Random Forest algorithm. Remote Sens. Environ. 2019, 231, 111234. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218–219, 74–84. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crops Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Gandhi, N.; Petkar, O.; Armstrong, L.J. Rice crop yield prediction using artificial neural networks. In Proceedings of the 2016 IEEE Technological Innovations in ICT for Agriculture and Rural Development (TIAR), Chennai, India, 15–16 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 105–110. [Google Scholar]
- Kuwata, K.; Shibasaki, R. Eestimating corn yield in the United States with MODIS EVI and machine learning methods. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-8, 131–136. [Google Scholar] [CrossRef]
- Fieuzal, R.; Marais Sicre, C.; Baup, F. Estimation of corn yield using multi-temporal optical and radar satellite data and artificial neural networks. Int. J. Appl. Earth Obs. Geoinf. 2017, 57, 14–23. [Google Scholar] [CrossRef]
- Li, A.; Liang, S.; Wang, A. Estimating Crop Yield from Multi-temporal Satellite Data Using Multivariate Regression and Neural Network Techniques. Photogramm. Eng. Remote Sens. 2007, 73, 1149–1157. [Google Scholar] [CrossRef] [Green Version]
- Kaul, M.; Hill, R.L.; Walthall, C. Artificial neural networks for corn and soybean yield prediction. Agric. Syst. 2005, 85, 1–18. [Google Scholar] [CrossRef]
- Fortin, J.G.; Anctil, F.; Parent, L.-É. Site-specific early season potato yield forecast by neural network in Eastern Canada. Precis. Agric. 2011, 12, 905–923. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating wheat yields in Australia using climate records, satellite image time series and machine learning methods. ISPRS J. Photogramm. Remote Sens. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Jiang, D.; Yang, X.; Clinton, N. An artificial neural network model for estimating crop yields using remotely sensed information. Int. J. Remote Sens. 2004, 25, 1723–1732. [Google Scholar] [CrossRef]
- Green, T.R.; Salas, J.D.; Martinez, A. Relating crop yield to topographic attributes using Spatial Analysis Neural Networks and regression. Geoderma 2007, 139, 23–37. [Google Scholar] [CrossRef]
- Miao, Y.; Mulla, D.J.; Robert, P.C. Identifying important factors influencing corn yield and grain quality variability using artificial neural networks. Precis. Agric. 2006, 7, 117–135. [Google Scholar] [CrossRef]
- Statistics Canada. Table 2.4 Principal Field Crop Production, by Province; Statistics Canada: Ottawa, ON, Canada, 2011.
- Statistics Canada. Cropland in Ontario Grows Despite Fewer Farms; Statistics Canada: Ottawa, ON, Canada, 2017.
- Sunohara, M.D.; Gottschall, N.; Wilkes, G. Long-term observations of nitrogen and phosphorus export in paired-agricultural watersheds under controlled and conventional tile drainage. J. Environ. Qual. 2015, 44, 1589–1604. [Google Scholar] [CrossRef]
- Turpin, K.M.; Lapen, D.R.; Gregorich, E.G. Using multivariate adaptive regression splines (MARS) to identify relationships between soil and corn (Zea mays L.) production properties. Can. J. Soil Sci. 2005, 85, 625–636. [Google Scholar] [CrossRef] [Green Version]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Barth, A.; Knobloch, A.; Noack, S. Neural network—Based spatial modeling of natural phenomena and events. In Systems and Software Development, Modeling, and Analysis: New Perspectives and Methodologies; IGI Global: Hershey, PA, USA, 2014; pp. 186–211. [Google Scholar]
- Garson, G. Interpreting neural-network connection weights. AI Expert 1991, 6, 46–51. [Google Scholar]
- Bagg, J.; Banks, S.; Baute, H. Agronomy Guide for Field Crops: Publication 811; Ontario Ministry of Agriculture, Food and Rural Affairs (OMAFRA): Toronto, ON, Canada, 2009.
- Kross, A.; Lapen, D.R.; McNairn, H. Satellite and in situ derived corn and soybean biomass and leaf area index: Response to controlled tile drainage under varying weather conditions. Agric. Water Manag. 2015, 160, 118–131. [Google Scholar] [CrossRef]











| Year | Crop | Average (kg/ha) | Standard Deviation (kg/ha) | Coefficient of Variation (%) 1 | Total Precipitation May–August (mm) (360 mm) 2 |
|---|---|---|---|---|---|
| 2011 | Corn | 13619 | 1013 | 8 | 319.80 |
| Soybean | 4200 | 1191 | 29 | ||
| 2012 | Corn | 11819 | 1245 | 11 | 205.40 |
| Soybean | 3996 | 497 | 12 | ||
| 2016 | Corn | 12547 | 1380 | 11 | 284.80 |
| Soybean | 3890 | 364 | 10 |
| Satellite Sensors | Dates | Bands (nm) |
|---|---|---|
| RapidEye | 2011: June 10, June 27, July 05, July 22, July 23, August 12, August 19 2012: June 17, June 21, June 28, July 11, July 18, July 29, August 04, August 18 2016: June 25, July 20, August 26 | Blue (440–510), Green (520–590), Red (630–685), Red Edge (690–730), NIR (760–850) |
| Spectral Indices | Equation | Reference |
|---|---|---|
| Normalized difference vegetation index (NDVI) | (RNIR − RRED)/(RNIR + RRED) | Rouse et al. (1974) 1 |
| Simple ratio (SR) | RNIR/RRED | Jordan (1969) 2 |
| Red edge normalized difference vegetation index (NDVIre) | (RNIR − RREDedge)/(RNIR + RREDedge) | Gitelson and Merzlyak (1994) 3 |
| Predictor Variables | 2011 | 2012 |
|---|---|---|
| Topographic attributes | Aspect south–north (degrees) Aspect west–east (degrees) Flow accumulation (number of pixels) Slope (%) | Aspect south–north (degrees) Aspect west–east (degrees) Flow accumulation (number of pixels) Slope (%) |
| Crop/canopy health | NDVI, NDVIre (June 10, June 27, July 05, July 22, July 23, August 12, August 19) (dimensionless) | NDVI, NDVIre (June 17, June 21, June 28, July 11, July 18, July 29, August 04, August 18) (dimensionless) |
| Crop/canopy structure | SR (June 10, June 27, July 05, July 22, July 23, August 12, August 19) (dimensionless) | SR (June 17, June 21, June 28, July 11, July 18, July 29, August 04, August 18) (dimensionless) |
| Landuse | Corn and soybean classes (categories) | Corn and soybean classes (categories) |
| Prediction Application Years and Crops | ||||||||
|---|---|---|---|---|---|---|---|---|
| Training Year | Training Crop Yield | Model Names | Soybean 2011 | Corn 2011 | Soybean 2012 | Corn 2012 | Soybean 2016 | Corn 2016 |
| 2011 | Combined | PM001 | 19/23887 2 | 6/7082 | 22/23308 | 10/19109 | 9/12996 | 6/9960 |
| Soybean | PM004 | 19/23887 | 22/23308 | 9/12996 | ||||
| Corn | PM006 | 6/7082 | 7/11894 | 6/9960 | ||||
| 2012 | Combined | PM015 | 19/23887 | 6/7082 | 12/11155 | 9/11296 | 9/12996 | 6/9960 |
| Soybean | PM019 | 19/23887 | 12/11155 | 9/12996 | ||||
| Corn | PM021 | 6/7082 | 8/10241 | |||||
| Yield Training Data | Input Predictor Variables | Most Important Predictor Variables Used in Final Optimized Models |
|---|---|---|
| Corn and Soybean (2011) | Slope, aspect, flow accumulation (2011), NDVIre, SR and NDVI (June 10, 27; July 05, 22, 23; Aug 12, 19) | SR August 19 (−), SR August 12 (−), Slope (−), SR June 27 (+) |
| Soybean (2011) | SR August 19 (+), Slope (−), SR August 12 (−), SR June 27 (−) | |
| Corn (2011) | SR June 27 (+), SR July 23 (+) | |
| Corn and Soybean (2012) | Slope, aspect, flow accumulation (2011), NDVIre, SR and NDVI (June 17, 21, 28; July 11, 18, 29; August 04, 18) | SR 29 July (−), SR 18 August (−), Slope (−), SR 28 June (+) |
| Soybean (2012) | Slope (−), SR 11 July (+), Flow accumulation (−), SR 18 August (−) | |
| Corn (2012) | Slope (−), SR 18 July (+), SR 18 August (+), SR 04 August (−) |
| Corn | Description |
| V12 | Vegetative development stage: plant has 12 leaf collars |
| VT | Vegetative development stage: tassel emergence |
| R1 | First reproductive development stage: silking |
| Soybean | |
| R1 | First reproductive development stage: beginning bloom |
| R4-R6 | Reproductive stages R4 to R6, ranging from full pod (R4) to full seed (R6) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kross, A.; Znoj, E.; Callegari, D.; Kaur, G.; Sunohara, M.; Lapen, D.R.; McNairn, H. Using Artificial Neural Networks and Remotely Sensed Data to Evaluate the Relative Importance of Variables for Prediction of Within-Field Corn and Soybean Yields. Remote Sens. 2020, 12, 2230. https://doi.org/10.3390/rs12142230
Kross A, Znoj E, Callegari D, Kaur G, Sunohara M, Lapen DR, McNairn H. Using Artificial Neural Networks and Remotely Sensed Data to Evaluate the Relative Importance of Variables for Prediction of Within-Field Corn and Soybean Yields. Remote Sensing. 2020; 12(14):2230. https://doi.org/10.3390/rs12142230
Chicago/Turabian StyleKross, Angela, Evelyn Znoj, Daihany Callegari, Gurpreet Kaur, Mark Sunohara, David R. Lapen, and Heather McNairn. 2020. "Using Artificial Neural Networks and Remotely Sensed Data to Evaluate the Relative Importance of Variables for Prediction of Within-Field Corn and Soybean Yields" Remote Sensing 12, no. 14: 2230. https://doi.org/10.3390/rs12142230