A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages





Abstract
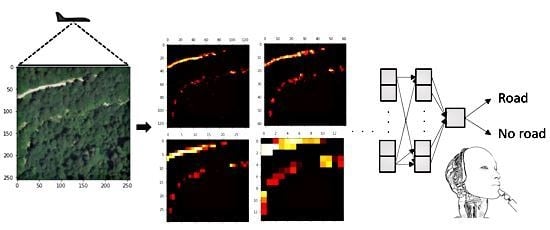
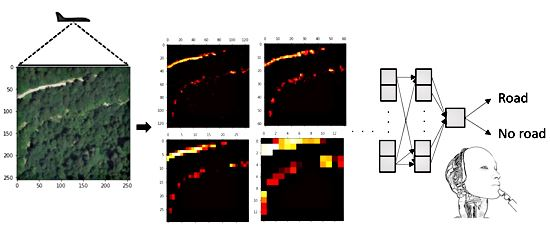
:
1. Introduction
- We design a novel framework based on deep convolutional neural networks to classify secondary roads in high resolution aerial orthoimagery. The solution integrates modified configurations (focusing on improving the computational efficiency) of three of the most popular CNN architectures for computer vision problems, together with a network especially built for this task;
- We contrast the performance of state-of-the-art CNN architectures and deep learning techniques in recognizing secondary roads in high resolution aerial imagery under various scenarios;
- We study how different architectural tweaks and changes in default hyperparameters affect a base model’s performance in the road classification task;
- Different from the previous works, we focus on challenging situations, where the borders of the roads are easily confused with the surroundings (secondary transport routes). In addition, the remotely sensed imagery often includes shadows and occlusions, further complicating the classification operation;
- We carry our experiments on a new dataset composed of sampled locations with ground truth labels obtained by dividing high resolution aerial imagery in tiles of 256 × 256 pixels and manually annotating them.
2. Related Work
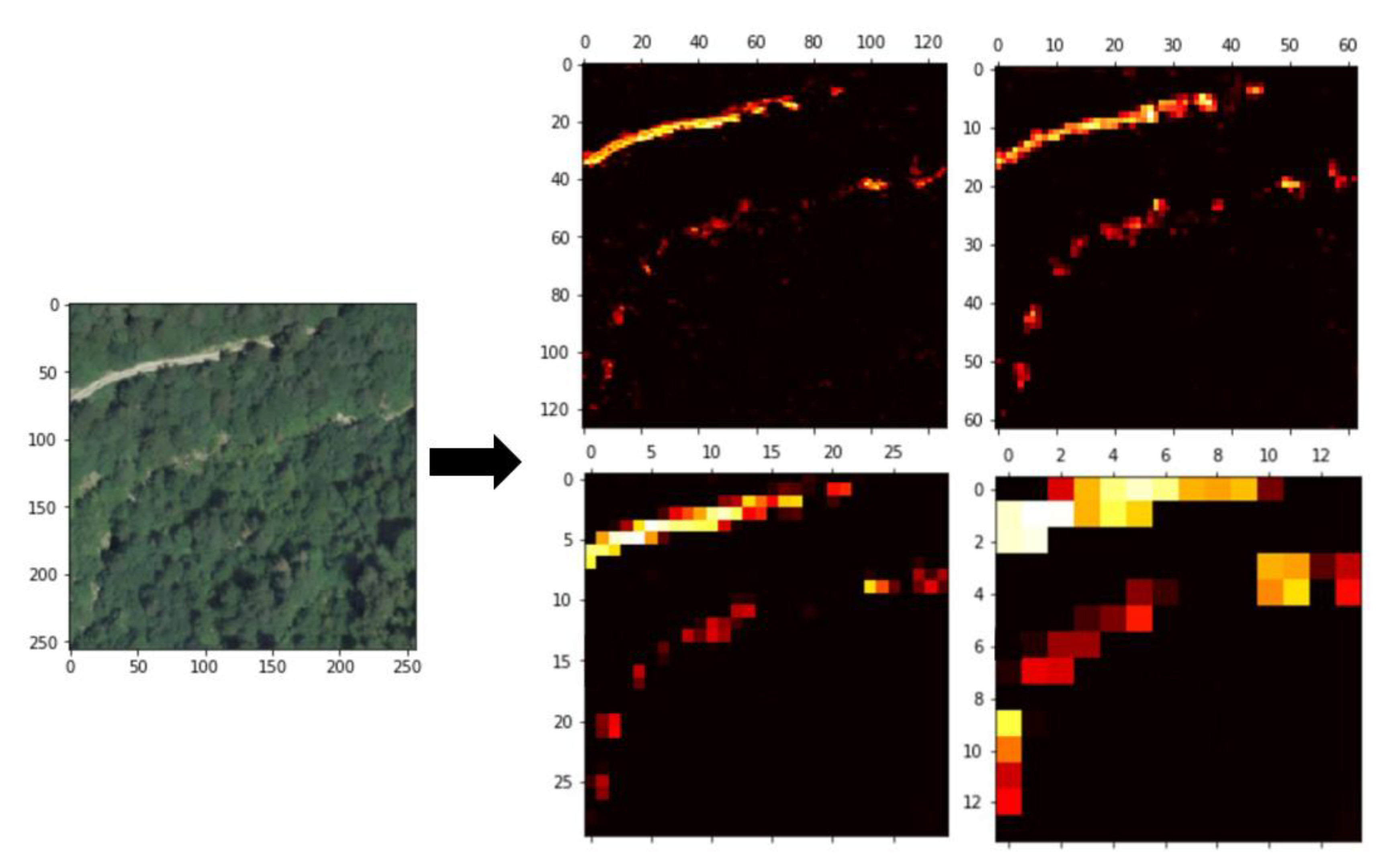
3. Dataset
4. Framework
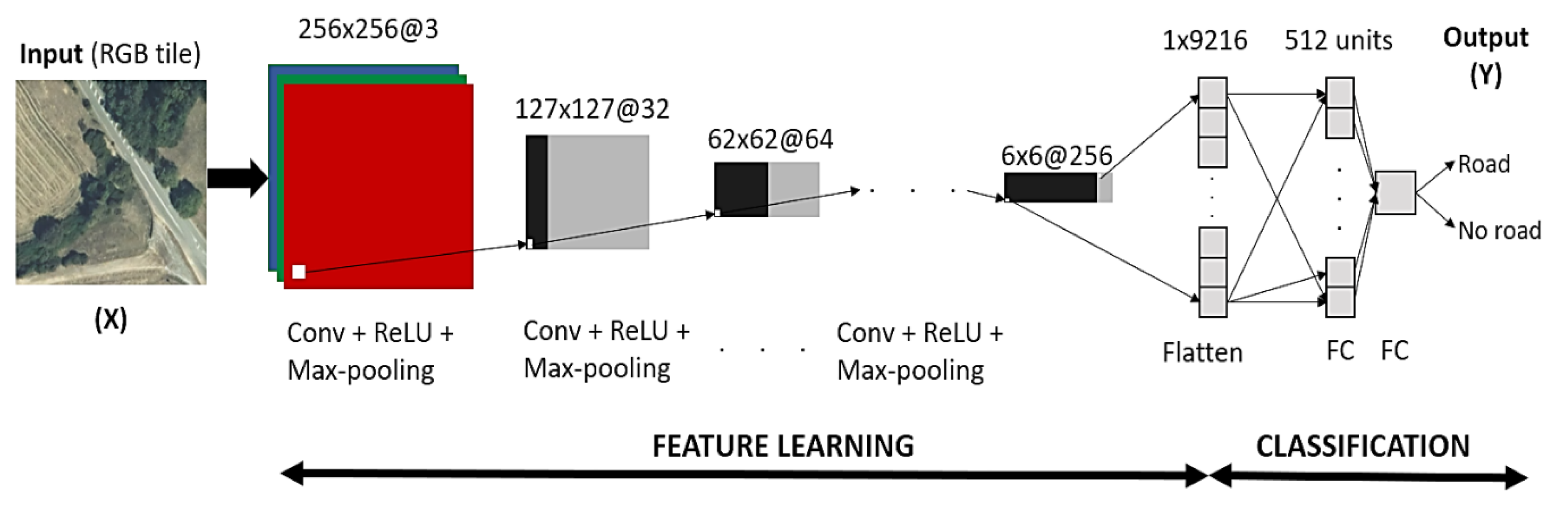
4.1. CNN Built from Scratch
4.2. VGGNet-Like Network
4.3. Modified ResNet
4.4. Inception-ResNet
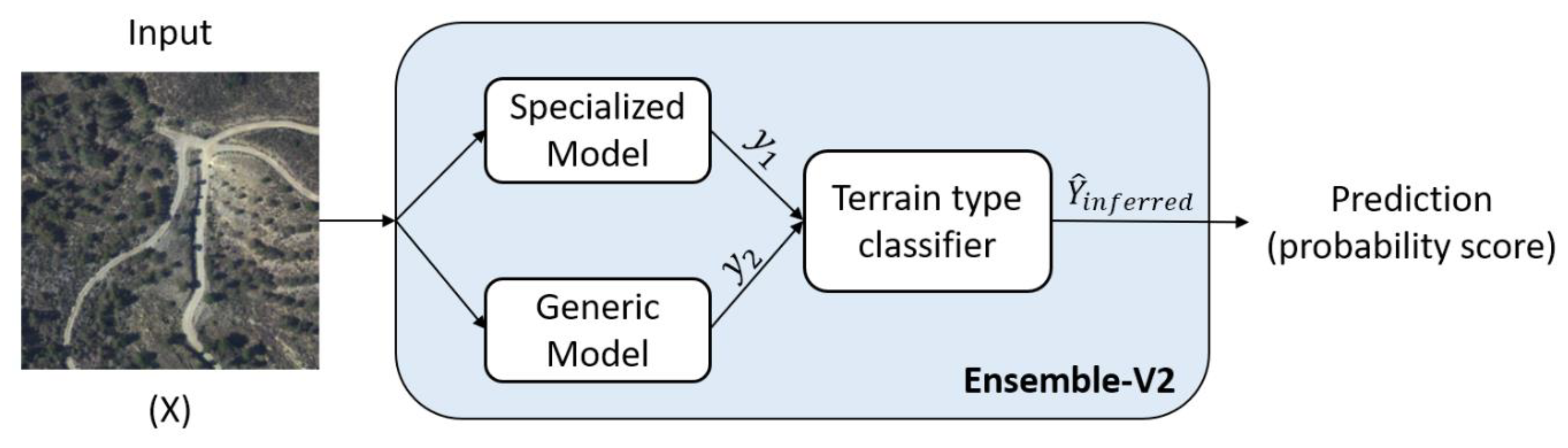
4.5. Ensemble-V2
5. Experiments
- A full training set of 14,400 tiles (80% of the data) and five training subsets containing 90% of the full training set (12,960 tiles) with their corresponding labels were used to perform the weights initialization. The five subsets represent variations of the training population and were used to repeat the experiments and to conduct a statistical analysis of the performance metrics;
- A validation set (10% of the data) was formed by 1800 tiles and used for tuning the model’s hyperparameters and comparing how changing them would affect the model’s predictive performance;
- A test set (10% of the data) containing 1800 tiles to evaluate the performance of the models on unseen data.
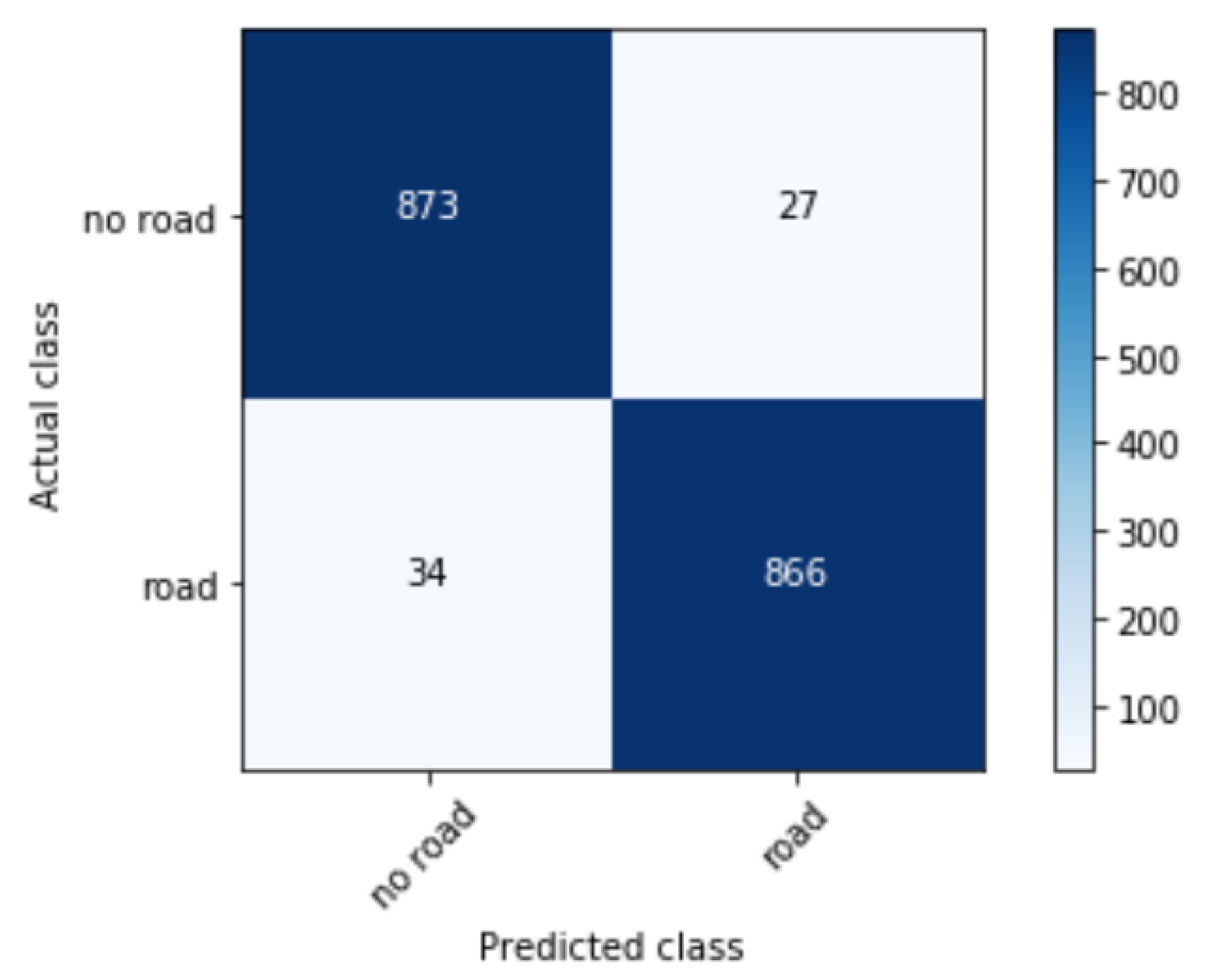
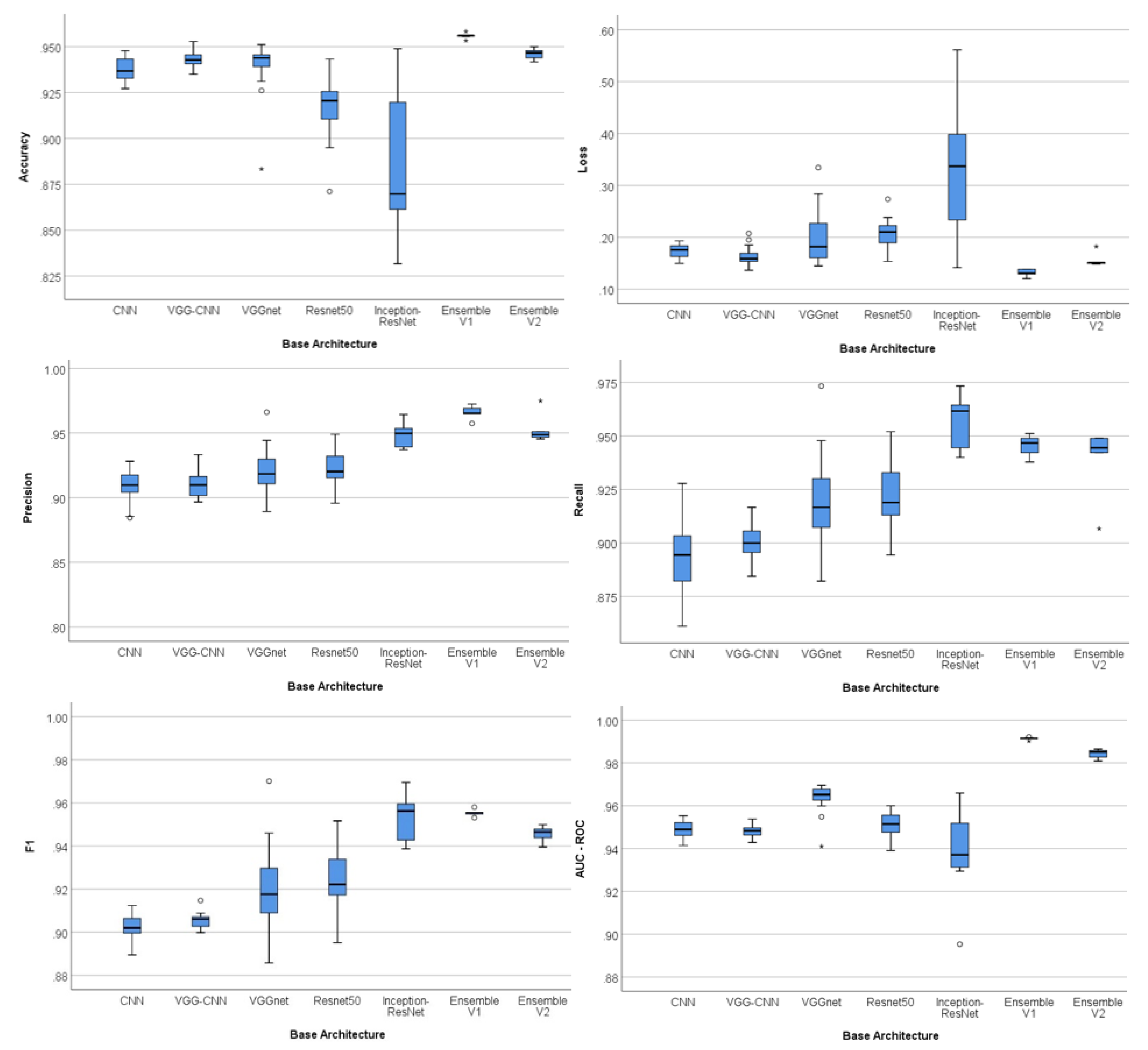
6. Results and Discussion
7. Conclusions and Future Lines of Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Sirotkovic, J.; Dujmic, H.; Papic, V. Image segmentation based on complexity mining and mean-shift algorithm. In Proceedings of the 2014 IEEE Symposium on Computers and Communications (ISCC), Funchal, Portugal, 23–26 June 2014; pp. 1–6. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the Contribution to International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference of Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Cira, C.-I.; Alcarria, R.; Manso-Callejo, M.-Á.; Serradilla, F. A Deep Convolutional Neural Network to Detect the Existence of Geospatial Elements in High-Resolution Aerial Imagery. Proceedings 2019, 19, 17. [Google Scholar] [CrossRef] [Green Version]
- Cira, C.-I.; Alcarria, R.; Manso-Callejo, M.-Á.; Serradilla, F. Evaluation of Transfer Learning Techniques with Convolutional Neural Networks (CNNs) to Detect the Existence of Roads in High-Resolution Aerial Imagery. In Applied Informatics; Florez, H., Leon, M., Diaz-Nafria, J.M., Belli, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 1051, pp. 185–198. ISBN 978-3-030-32474-2. [Google Scholar]
- Chollet, F. Deep Learning with Python; Manning Publications Co.: Shelter Island, NY, USA, 2018; ISBN 978-1-61729-443-3. [Google Scholar]
- Cai, B.; Jiang, Z.; Zhang, H.; Zhao, D.; Yao, Y. Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sens. 2017, 9, 1198. [Google Scholar] [CrossRef] [Green Version]
- Zuo, J.; Xu, G.; Fu, K.; Sun, X.; Sun, H. Aircraft Type Recognition Based on Segmentation with Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 282–286. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, Y.; Deng, W.-J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Alidoost, F.; Arefi, H. A CNN-Based Approach for Automatic Building Detection and Recognition of Roof Types Using a Single Aerial Image. PFG J. Photogramm. Remote Sens. Geoinf. Sci. 2018, 86, 235–248. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S.L. Aerial Imagery for Roof Segmentation: A Large-Scale Dataset towards Automatic Mapping of Buildings. ISPRS J. Photogramm. Remote. Sens. 2019, 147, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building Extraction at Scale Using Convolutional Neural Network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Sheppard, C.; Rahnemoonfar, M. Real-time scene understanding for UAV imagery based on deep convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2243–2246. [Google Scholar]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using Convolutional Networks and Satellite Imagery to Identify Patterns in Urban Environments at a Large Scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’17, Halifax, NS, Canada, 13 September 2017; pp. 1357–1366. [Google Scholar]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; Nierstrasz, O.; Pandu Rangan, C.; Steffen, B.; et al. Learning to Detect Roads in High-Resolution Aerial Images. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6316, pp. 210–223. ISBN 978-3-642-15566-6. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images with Deep Fully-Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. RoadNet: Learning to Comprehensively Analyze Road Networks in Complex Urban Scenes from High-Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2043–2056. [Google Scholar] [CrossRef]
- Luque, B.; Morros, J.R.; Ruiz-Hidalgo, J. Spatio-temporal Road Detection from Aerial Imagery using CNNs. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Porto, Portugal, 27 February–1 March 2017; pp. 493–500. [Google Scholar]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding Structured Contour and Location Prior in Siamesed Fully Convolutional Networks for Road Detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef] [Green Version]
- Instituto Geográfico Nacional Plan Nacional de Ortofotografía Aérea. Available online: https://pnoa.ign.es/caracteristicas-tecnicas (accessed on 25 November 2019).
- Gómez-Barrón, J.P.; Alcarria, R.; Manso-Callejo, M.-Á. Designing a Volunteered Geographic Information System for Road Data Validation. Proceedings 2019, 19, 7. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1857, pp. 1–15. ISBN 978-3-540-67704-8. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. Available online: https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf (accessed on 31 January 2020).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Goodfellow, I.; Yoshua, B.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- May, R.J.; Maier, H.R.; Dandy, G.C. Data splitting for artificial neural networks using SOM-based stratified sampling. Neural Netw. 2010, 23, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Others Keras. 2015. Available online: https://keras.io (accessed on 15 November 2019).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Greg, S.C.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the Contribution to International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, X.; Liu, S.; Sun, R.; Hong, M. On the Convergence of a Class of Adam-Type Algorithms for Non-Convex Optimization. In Proceedings of the Contribution to International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G. On the Importance of Initialization and Momentum in Deep Learning. 9. Available online: https://www.cs.toronto.edu/~fritz/absps/momentum.pdf (accessed on 17 January 2020).
- Hinton, G.E.; Srivastava, N.; Swersky, K. Lecture 6d—A separate, adaptive learning rate for each connection. In Slides of Lecture Neural Networks for Machine Learning; 2012; Available online: https://www.cs.toronto.edu/~hinton/coursera/lecture6/lec6.pdf (accessed on 15 November 2019).
- Hijazi, S.; Kumar, R.; Rowen, C. Using Convolutional Neural Networks for Image Recognition. 2015, 12. Available online: https://ip.cadence.com/uploads/901/cnn_wp-pdf (accessed on 17 January 2020).
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2656–2666. [Google Scholar]
- Ferris, M.H.; McLaughlin, M.; Grieggs, S.; Ezekiel, S.; Blasch, E.; Alford, M.; Cornacchia, M.; Bubalo, A. Using ROC curves and AUC to evaluate performance of no-reference image fusion metrics. In Proceedings of the 2015 National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 June 2015; pp. 27–34. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. In Proceedings of the International Conference on Machine Learning (ICML) Workshop, Lille, France, 6–11 July 2015. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Category 0 “No Road” | Category 1 “Road Exists” | ||||
|---|---|---|---|---|---|---|
| Areas with Dense Vegetation | Drier (Mediterranean) Areas | Total | Areas with Dense Vegetation | Drier (Mediterranean) Areas | Total | |
| Total | 4500 | 4500 | 9000 | 4500 | 4500 | 9000 |
| Percentages | 25.00% | 25.00% | 50.00% | 25.00% | 25.00% | 50.00% |
| Block1 | Block2 | Block3 | Block4 | Block5 | Output Block |
|---|---|---|---|---|---|
| Conv (3 × 3, 32) | Conv (3 × 3, 64) | Conv (3 × 3, 64) | Conv (3 × 3, 64) | Conv (3 × 3, 128) | Flatten |
| Conv (3 × 3, 32) | Conv (3 × 3, 64) | Conv (3 × 3, 64) | Conv (3 × 3, 64) | Conv (3 × 3, 128) | FC (512) |
| Maxpool (2 × 2) | Maxpool (2 × 2) | Maxpool (2 × 2) | Maxpool (2 × 2) | Maxpool (2 × 2) | Dropout (0.5) |
| Dropout (0.25) | Dropout (0.25) | Dropout (0.25) | Dropout (0.25) | Dropout (0.25) | FC (1, sigmoid) |
| Stage | Structure | Output Size (Volume) |
|---|---|---|
| 1 | Conv (7 × 7, 32, stride = 1) + BN + Activation Maxpool (3 × 3) | Input = 256 × 256 × 3 Output= 85 × 85 × 32 |
| 2 | ConvBlock (3 × 3, [32,32,64], stride = 1) 2 × (ID_block (3 × 3, [32,32,64]) | 85 × 85 × 128 |
| 3 | ConvBlock (3 × 3, [64,64,256], stride = 2) 3 × (ID_block (3 × 3, [64,64,256]) | 43 × 43 × 256 |
| 4 | ConvBlock (3 × 3, [128, 128, 256], stride = 2) 4 × (ID_block (3 × 3, [128, 128, 256]) | 22 × 22 × 512 |
| 5 | ConvBlock (3 × 3, [256, 256, 1024], stride = 2) 2 × (ID_block (3 × 3, [256, 256, 1024]) | 11 × 11 × 1024 |
| Output | Global Average Pooling (2 × 2) FlattenFC ( classes, softmax) | 5 × 5 × 1024 15,600 2 |
| ConvBlock: Conv (1 × 1, [Filter], stride = 1) + BN + Activation BN = Batch Normalization Conv (KernelSize, [Filter], stride = 1) + BN + Activation Conv (1 × 1, [Filter]) + BN Shortcut = Conv (1 × 1, [Filter], stride = s) + BN Add (Shortcut + ID_block) + Activation | ||
| ID_block: Conv (1 × 1, [Filter], stride = 1) + BN + Act, stride = s Conv (KernelSize, [Filter], stride = 1) + BN + Act Conv (1 × 1, [Filter], stride = 1) + BN Add (ID_block + Shortcut) + Act | ||
| Data Split | Metric | Initial Results (Each Column Represents a Trained Configuration) | |||||
|---|---|---|---|---|---|---|---|
| 50%-25%-25% | Loss | 0.2219 | 0.2411 | 0.2123 | 0.2233 | 0.1601 | 0.1816 |
| Accuracy | 0.9262 | 0.9271 | 0.9264 | 0.9331 | 0.9409 | 0.9391 | |
| Precision | 0.8829 | 0.9158 | 0.8693 | 0.8379 | 0.8554 | 0.8686 | |
| Recall | 0.8916 | 0.8604 | 0.9107 | 0.8613 | 0.8569 | 0.8431 | |
| F1 score | 0.8800 | 0.8873 | 0.8895 | 0.8494 | 0.8561 | 0.8557 | |
| 60%-20%-20% | Loss | 0.2139 | 0.2087 | 0.1729 | 0.1901 | 0.1696 | 0.1678 |
| Accuracy | 0.9372 | 0.9355 | 0.9433 | 0.9361 | 0.9406 | 0.9394 | |
| Precision | 0.9028 | 0.8978 | 0.9137 | 0.9099 | 0.9137 | 0.9096 | |
| Recall | 0.8978 | 0.9078 | 0.9056 | 0.8867 | 0.8944 | 0.8944 | |
| F1 score | 0.9003 | 0.9028 | 0.9096 | 0.8981 | 0.9040 | 0.902 | |
| 80%-10%-10% | Loss | 0.1560 | 0.1811 | 0.1624 | 0.1468 | 0.1733 | 0.1551 |
| Accuracy | 0.9511 | 0.9461 | 0.9483 | 0.9533 | 0.9367 | 0.9472 | |
| Precision | 0.9133 | 0.9068 | 0.9198 | 0.9216 | 0.8938 | 0.9244 | |
| Recall | 0.9133 | 0.9078 | 0.9044 | 0.9011 | 0.8978 | 0.8967 | |
| F1 score | 0.9133 | 0.9073 | 0.912 | 0.9112 | 0.8958 | 0.9103 | |
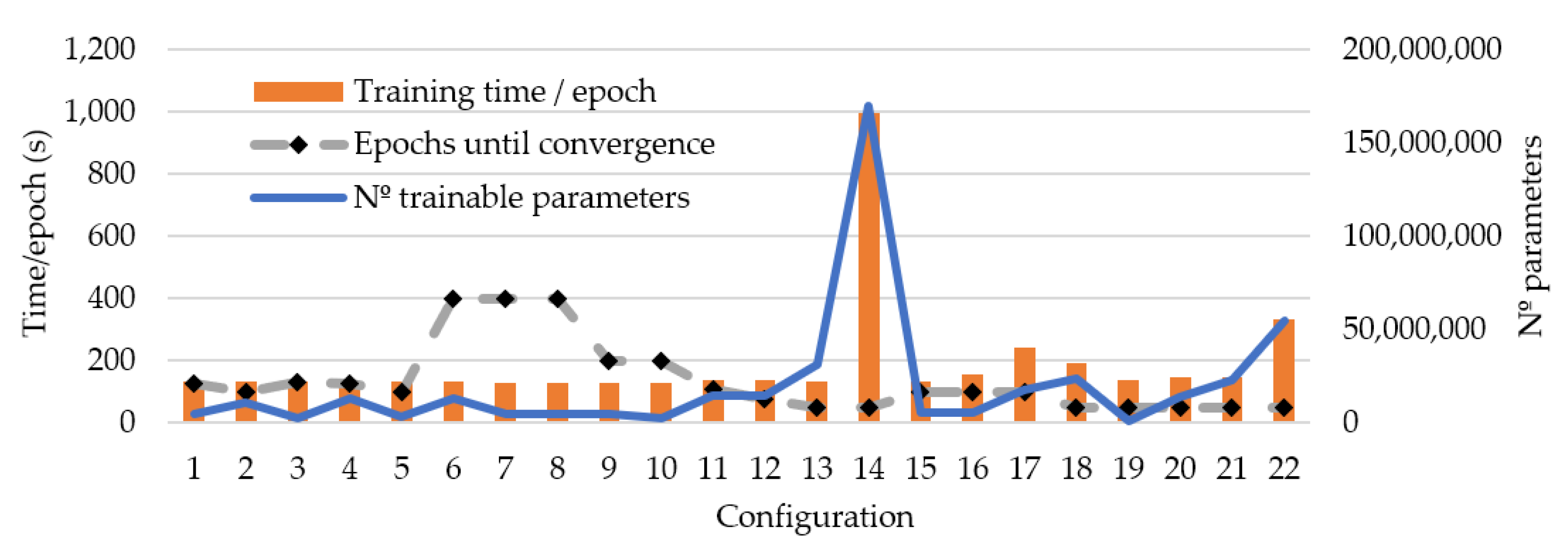
| Nº | Base Architecture | Configuration | Filters/Conv (Block) | Size of the Last Feature Map | FC Units (Classifier) | Optimizer and Learning Rate | Other Aspects | |
|---|---|---|---|---|---|---|---|---|
| 1 | Built CNN (Figure 1) | 4 × convolutional blocks | [32, 64, 128, 128] | 14 × 14 × 128 | 512, 1 | Adam (lr = ) | - | |
| 2 | 5 × convolutional blocks | [32, 64, 128, 128, 128] | 6 × 6 × 128 | |||||
| 3 | 5 × convolutional blocks | [32, 64, 128, 128, 256] | 6 × 6 × 256 | |||||
| 4 | 5 × convolutional blocks | [32, 64, 128, 256, 512] | 6 × 6 × 512 | |||||
| 5 | 5 × convolutional blocks | [32, 64, 128, 128, 256] | 4 × 4 × 256 | Filter size = 5 × 5 | ||||
| 6 | VGGNet | VGG–like CNN (Table 2) | 3 × convolutional blocks | [32, 64, 64] | 28 × 28 × 64 | 256, 1 | SDG (lr = , decay = , Nesterov momentum = ) | - |
| 7 | 4 × convolutional blocks | [32, 64, 64, 64] | 12 × 12 × 64 | 512, 1 | ||||
| 8 | 5 × convolutional blocks | [32, 64, 64, 64, 128] | 8 × 8 × 128 | 512, 1 | ||||
| 9 | 5 × convolutional blocks | [32, 64, 64, 64, 128] | 8 × 8 × 128 | 512, 1 | Adam (lr = ) | |||
| 10 | 5 × convolutional blocks | [32, 64, 64, 64, 128] | 8 × 8 × 128 | 256, 1 | ||||
| 11 | Standard [3] | Fine-tuning the last convolutional block (ImageNet weights) | Default configuration [3] | 8 × 8 × 512 | 512, 1 | Adam (lr = ) | Global Average Pooling instead of Flatten | |
| 12 | Adam (lr = ) | |||||||
| 13 | RMSprop (lr = ) | |||||||
| 14 | No weights (from scratch) | [3] | Adam (lr = ) | MSRA [30] initialization | ||||
| 15 | Resnet50 | Modified ResNet | Described in Table 3 | Adam (lr = ) | Activation = ReLU | |||
| 16 | Activation = Leaky ReLU | |||||||
| 17 | Activation = PReLU | |||||||
| 18 | No weights (from scratch) | Default configuration [4] | 8 × 8 × 2048 | [4] | Adam (lr = ) | - | ||
| 19 | Inception-ResNet | Feature Extraction | Default configuration [5] | 6 × 6 × 1536 | 512, 1 | Adam (lr = ) | Global Average Pooling instead of Flatten | |
| 20 | Fine-tuning the last module | Adam (lr = ) | ||||||
| 21 | Fine-tuning the last 2 modules | Adam (lr = ) | ||||||
| 22 | No weights (from scratch) | [5] | Adam (lr =) | - | ||||
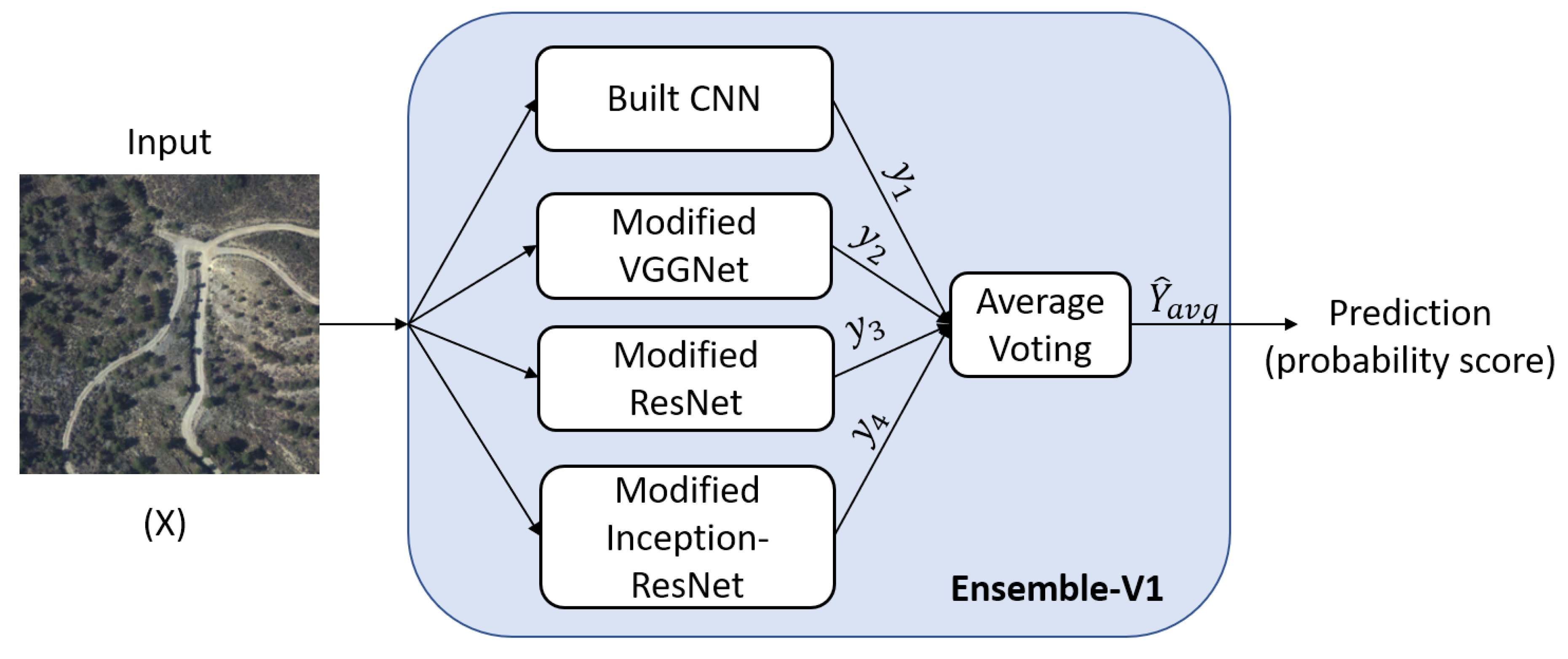
| 23 | Ensemble | Variant I: Average Voting | Described in Figure 3 | - | ||||
| 24 | Variant II: Specialized model | Described in Figure 5 | ||||||
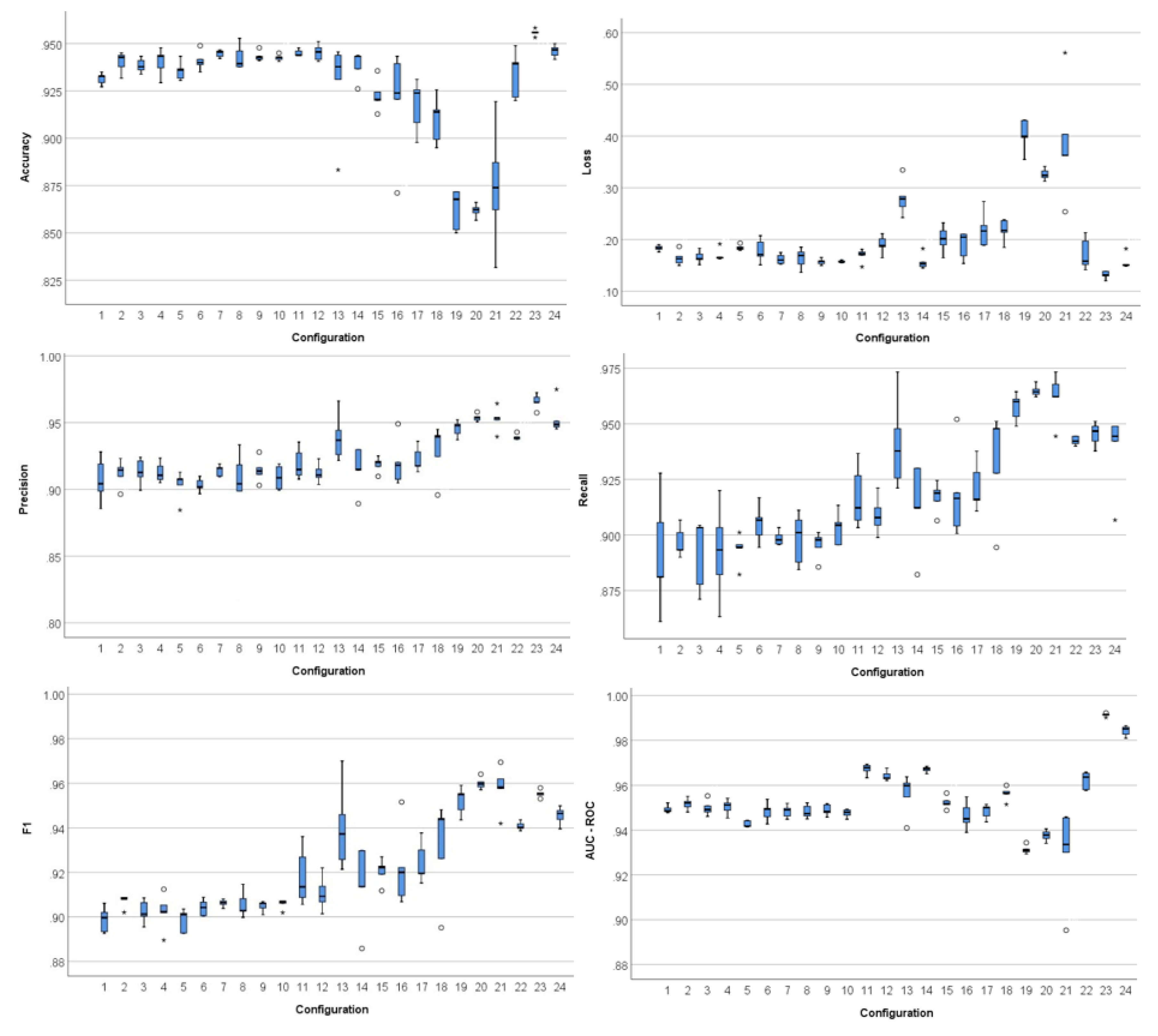
| Config. Nº | Accuracy | Loss | Precision | Recall | F1 | AUC–ROC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | |
| 1 | 0.931 | 0.003 | 0.183 | 0.005 | 0.907 | 0.017 | 0.891 | 0.026 | 0.899 | 0.006 | 0.949 | 0.002 |
| 2 | 0.940 | 0.006 | 0.164 | 0.014 | 0.912 | 0.010 | 0.897 | 0.007 | 0.922 | 0.035 | 0.952 | 0.003 |
| 3 | 0.938 | 0.004 | 0.166 | 0.012 | 0.913 | 0.010 | 0.892 | 0.016 | 0.902 | 0.005 | 0.950 | 0.003 |
| 4 | 0.940 | 0.007 | 0.170 | 0.012 | 0.913 | 0.008 | 0.892 | 0.021 | 0.902 | 0.008 | 0.950 | 0.003 |
| 5 | 0.936 | 0.005 | 0.184 | 0.005 | 0.903 | 0.011 | 0.894 | 0.007 | 0.898 | 0.005 | 0.943 | 0.001 |
| 6 | 0.941 | 0.005 | 0.178 | 0.022 | 0.903 | 0.005 | 0.905 | 0.008 | 0.904 | 0.004 | 0.948 | 0.004 |
| 7 | 0.945 | 0.002 | 0.162 | 0.010 | 0.914 | 0.004 | 0.899 | 0.003 | 0.906 | 0.002 | 0.948 | 0.003 |
| 8 | 0.943 | 0.007 | 0.164 | 0.019 | 0.893 | 0.047 | 0.898 | 0.012 | 0.906 | 0.006 | 0.948 | 0.003 |
| 9 | 0.943 | 0.003 | 0.157 | 0.006 | 0.914 | 0.009 | 0.896 | 0.006 | 0.905 | 0.002 | 0.949 | 0.003 |
| 10 | 0.943 | 0.002 | 0.157 | 0.002 | 0.909 | 0.009 | 0.903 | 0.007 | 0.906 | 0.002 | 0.948 | 0.002 |
| 11 | 0.945 | 0.002 | 0.169 | 0.013 | 0.919 | 0.012 | 0.917 | 0.014 | 0.918 | 0.013 | 0.967 | 0.002 |
| 12 | 0.945 | 0.004 | 0.190 | 0.017 | 0.912 | 0.007 | 0.909 | 0.008 | 0.911 | 0.008 | 0.964 | 0.002 |
| 13 | 0.928 | 0.026 | 0.281 | 0.034 | 0.939 | 0.018 | 0.941 | 0.021 | 0.940 | 0.019 | 0.956 | 0.009 |
| 14 | 0.939 | 0.008 | 0.157 | 0.015 | 0.916 | 0.017 | 0.913 | 0.020 | 0.914 | 0.018 | 0.967 | 0.001 |
| 15 | 0.923 | 0.008 | 0.201 | 0.026 | 0.919 | 0.006 | 0.917 | 0.007 | 0.921 | 0.006 | 0.952 | 0.003 |
| 16 | 0.920 | 0.029 | 0.189 | 0.027 | 0.920 | 0.018 | 0.918 | 0.020 | 0.922 | 0.018 | 0.946 | 0.006 |
| 17 | 0.917 | 0.014 | 0.219 | 0.035 | 0.922 | 0.009 | 0.922 | 0.011 | 0.924 | 0.009 | 0.948 | 0.003 |
| 18 | 0.910 | 0.012 | 0.218 | 0.022 | 0.929 | 0.020 | 0.934 | 0.024 | 0.932 | 0.022 | 0.956 | 0.003 |
| 19 | 0.863 | 0.011 | 0.403 | 0.031 | 0.946 | 0.006 | 0.958 | 0.006 | 0.952 | 0.006 | 0.931 | 0.002 |
| 20 | 0.862 | 0.003 | 0.326 | 0.011 | 0.954 | 0.003 | 0.965 | 0.003 | 0.960 | 0.003 | 0.938 | 0.003 |
| 21 | 0.875 | 0.032 | 0.389 | 0.111 | 0.953 | 0.009 | 0.962 | 0.011 | 0.958 | 0.010 | 0.930 | 0.021 |
| 22 | 0.934 | 0.013 | 0.172 | 0.031 | 0.939 | 0.002 | 0.942 | 0.002 | 0.941 | 0.002 | 0.962 | 0.004 |
| 23 | 0.956 | 0.002 | 0.132 | 0.008 | 0.966 | 0.006 | 0.945 | 0.005 | 0.955 | 0.002 | 0.991 | 0.001 |
| 24 | 0.946 | 0.003 | 0.156 | 0.014 | 0.953 | 0.012 | 0.938 | 0.018 | 0.946 | 0.004 | 0.984 | 0.002 |
| Total | 0.928 | 0.028 | 0.204 | 0.076 | 0.924 | 0.023 | 0.919 | 0.027 | 0.923 | 0.023 | 0.953 | 0.015 |
| F-statistic | 22.738 | 29.680 | 8.768 | 15.042 | 14.423 | 34.520 | ||||||
| p-value 1 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ||||||
| Config. Nº | Homogeneous Subsets | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 21 | 0.930 | |||||||
| 19 | 0.931 | |||||||
| 20 | 0.938 | 0.938 | ||||||
| 5 | 0.943 | 0.943 | 0.943 | |||||
| 16 | 0.946 | 0.946 | 0.946 | |||||
| 10 | 0.948 | 0.948 | 0.948 | |||||
| 8 | 0.948 | 0.948 | 0.948 | |||||
| 6 | 0.948 | 0.948 | 0.948 | |||||
| 7 | 0.948 | 0.948 | 0.948 | |||||
| 17 | 0.948 | 0.948 | 0.948 | |||||
| 9 | 0.949 | 0.949 | 0.949 | |||||
| 1 | 0.949 | 0.949 | 0.949 | |||||
| 3 | 0.950 | 0.950 | 0.950 | 0.950 | ||||
| 4 | 0.950 | 0.950 | 0.950 | 0.950 | ||||
| 2 | 0.952 | 0.952 | 0.952 | 0.952 | ||||
| 15 | 0.952 | 0.952 | 0.952 | 0.952 | ||||
| 13 | 0.956 | 0.956 | 0.956 | 0.956 | ||||
| 18 | 0.956 | 0.956 | 0.956 | 0.956 | ||||
| 22 | 0.962 | 0.962 | 0.962 | |||||
| 12 | 0.964 | 0.964 | ||||||
| 14 | 0.967 | |||||||
| 11 | 0.967 | |||||||
| 24 | 0.984 | |||||||
| 23 | 0.991 | |||||||
| Sig. | 0.057 | 0.051 | 0.436 | 0.395 | 0.077 | 0.061 | 0.179 | 0.907 |
| Base Architecture | Accuracy | Loss | Precision | Recall | F1 | AUC–ROC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | |
| Built CNN | 0.937 | 0.006 | 0.174 | 0.013 | 0.910 | 0.011 | 0.893 | 0.016 | 0.905 | 0.018 | 0.949 | 0.004 |
| VGG-like CNN | 0.943 | 0.004 | 0.164 | 0.015 | 0.907 | 0.022 | 0.900 | 0.008 | 0.905 | 0.003 | 0.948 | 0.003 |
| VGGNet | 0.939 | 0.014 | 0.199 | 0.054 | 0.921 | 0.017 | 0.920 | 0.020 | 0.921 | 0.018 | 0.964 | 0.006 |
| Resnet50 | 0.917 | 0.017 | 0.207 | 0.028 | 0.923 | 0.014 | 0.923 | 0.017 | 0.925 | 0.015 | 0.951 | 0.005 |
| Inception-ResNet | 0.883 | 0.035 | 0.322 | 0.109 | 0.948 | 0.008 | 0.957 | 0.011 | 0.953 | 0.010 | 0.940 | 0.016 |
| Ensemble-V1 | 0.956 | 0.002 | 0.132 | 0.008 | 0.966 | 0.006 | 0.945 | 0.005 | 0.955 | 0.002 | 0.991 | 0.001 |
| Ensemble-V2 | 0.946 | 0.003 | 0.156 | 0.014 | 0.953 | 0.012 | 0.938 | 0.018 | 0.946 | 0.004 | 0.984 | 0.002 |
| Total | 0.928 | 0.028 | 0.204 | 0.076 | 0.924 | 0.023 | 0.919 | 0.027 | 0.923 | 0.023 | 0.953 | 0.015 |
| F-statistic | 32.480 | 23.600 | 27.736 | 46.689 | 39.445 | 49.889 | ||||||
| p-value 1 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ||||||
| Base Architecture | Homogenous Subset | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Inception-ResNet | 0.940 | |||
| VGG-like CNN | 0.948 | 0.948 | ||
| Built CNN | 0.949 | 0.949 | ||
| Resnet50 | 0.951 | |||
| VGGNet | 0.964 | |||
| Ensemble-V2 | 0.984 | |||
| Ensemble-V1 | 0.991 | |||
| Sig. | 0.158 | 0.988 | 1.000 | 0.346 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cira, C.-I.; Alcarria, R.; Manso-Callejo, M.-Á.; Serradilla, F. A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages. Remote Sens. 2020, 12, 765. https://doi.org/10.3390/rs12050765
Cira C-I, Alcarria R, Manso-Callejo M-Á, Serradilla F. A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages. Remote Sensing. 2020; 12(5):765. https://doi.org/10.3390/rs12050765
Chicago/Turabian StyleCira, Calimanut-Ionut, Ramon Alcarria, Miguel-Ángel Manso-Callejo, and Francisco Serradilla. 2020. "A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages" Remote Sensing 12, no. 5: 765. https://doi.org/10.3390/rs12050765