Review of Anaerobic Digestion Modeling and Optimization Using Nature-Inspired Techniques



1
Heriot Watt University, Dubai Campus, Dubai International Academic City, Dubai 294345, UAE
2
School of Energy, Geoscience, Infrastructure and Society (EGIS), Heriot-Watt University, Edinburgh EH14 4AS, UK
*
Author to whom correspondence should be addressed.
Processes 2019, 7(12), 953; https://doi.org/10.3390/pr7120953
Submission received: 23 October 2019
/
Revised: 24 November 2019
/
Accepted: 10 December 2019
/
Published: 13 December 2019
(This article belongs to the Special Issue Current Trends in Anaerobic Digestion Processes)
{kind=link}
Abstract
:Although it is a well-researched topic, the complexity, time for process stabilization, and economic factors related to anaerobic digestion call for simulation of the process offline with the help of computer models. Nature-inspired techniques are a recently developed branch of artificial intelligence wherein knowledge is transferred from natural systems to engineered systems. For soft computing applications, nature-inspired techniques have several advantages, including scope for parallel computing, dynamic behavior, and self-organization. This paper presents a comprehensive review of such techniques and their application in anaerobic digestion modeling. We compiled and synthetized the literature on the applications of nature-inspired techniques applied to anaerobic digestion. These techniques provide a balance between diversity and speed of arrival at the optimal solution, which has stimulated their use in anaerobic digestion modeling.
1. Introduction
With the onset of urbanization, waste management has become a global crisis. Keeping in mind the growing energy requirement, the need of the hour is to concentrate on low-carbon technologies that do not exacerbate the global warming problem. Anaerobic digestion (AD) is one such process, which not only reduces waste but also produces energy in the form of biogas. Biogas is a mixture of methane, carbon dioxide, hydrogen sulfide, hydrogen, ammonia, and some trace elements. The presence of greenhouse gases in the mixture makes it a dangerous air pollutant if left untapped [1]. However, the aim of using this technology for waste treatment is to put the energy content of biogas, methane, into uses such as combined heat and power (CHP), vehicle fuel, boilers, kitchen stoves, or injection into the natural gas grid. The various applications of biogas require different quality specifications. For use in CHP and boilers, very little purification of biogas is necessary, as these uses can accept hydrogen sulfide. In Europe—Germany for example—hydrogen sulfide is normally removed from biogas because of its corrosive properties, in most cases by adsorption on activated carbon. However, for use as natural gas and vehicle fuel, the methane content needs to be highly enriched, even to as high as 90% [2]. Water vapor (humidity) and carbon dioxide also need to be removed for such applications.
There are several sources of feedstock for such processes, such as sludge from municipal and industrial wastewater treatment, agricultural, solid wastes, fruit and vegetable wastes, etc. Choosing the right substrate is an important aspect of the process. Extensive research is available in the literature correlating the substrate to amount of biogas produced, and also investigating co-digestion of various substrates to enhance biogas production [3,4,5,6,7]. Carbon to nitrogen (C/N) ratio of the feedstock is an indicator of methane content. Experiments conducted by Gómez et al. [8] proved that a C/N ratio of 20–30 is ideal for anaerobic digestion. Municipal sewage sludge has a low nitrogen content, and thus has a higher C/N ratio of 40–70 [9], which makes it a good source for biogas generation.
Sludge disposal accounts for 50% of the operating cost of municipal wastewater treatment plants [10]. Thus, anaerobic digestion is a means to optimize the economic and environment footprint of such treatment plants. However, the high moisture content in the sludge leads to lower methane yield [11], which calls for co-digestion with organic wastes with highly degradable carbon content. Anaerobic digestion being a very sensitive process, long-term use of a single substrate can also lead to nutrient deficiency. Hence, for better efficiency of the AD process, single-substrate simulation models should include various substrates as feedstocks to analyze the biomethane potential and optimize the process.
Anaerobic reactors are designed with reference to stable operating conditions, which are seldom met. In fact, the process is subject to wide fluctuations in both flow and load, leading to performance drop and lessening of biogas quality. Thus, it is economically very difficult to optimize the biomethane yield under fluctuating load in the field. Modeling of the process is an advisable solution as it allows monitoring, control, and prediction of the system behavior even in transient conditions. The objective of this paper was to evaluate various modeling techniques for anaerobic digestion.
2. Anaerobic Digestion Modeling
There are several mechanistic mathematical models for modeling anaerobic digestion [12,13,14,15]. The main advantage of using these models is that they help to gain and explicit understanding of the process dynamics. Anaerobic digestion Model 1 (ADM1), developed by Batstone et al. [16], is one of the most widely used mathematical models for anaerobic digestion. The ADM1 includes a disintegration of the substrate, the four main stages of anaerobic degradation—hydrolysis, acidogenesis, acetogenesis, and methanogenesis—as well as growth and decay of different biomass fractions. Moreover, physicochemical reactions like acid–base equilibria and gas–liquid transfers are included. In total, there are 29 processes, 37 fractions, and more than 100 parameters. For this reason, the calibration of the model (parameters) constitutes a major difficulty, but there is already a wide range of publications describing the successful application of ADM1 for the simulation of biogas plants with a large number of different substrates and operating modes. Additionally, the ADM1 has been used for forecasting and for optimization and flexible operation of biogas plants. A calibrated ADM1 model can also be used to identify problems caused, for example, by inhibition effects or accumulation of organic acids. Multiple steps involving biochemical and physicochemical processes in a completely stirred tank reactor are involved in the model. However, a large amount of prior information is required for modeling, which requires an extensive database. Due to the complexity of the anaerobic digestion process and the involvement of biomass kinetics, it is not possible to always define a mathematical equation driving a specific reaction. This calls for the use of artificial intelligence techniques. Black box models/systems like neural networks are pure mathematical models without any information about the underlying biological system and processes. The quality of the model depends on the quality and accuracy of the underlying datasets that were used for the calibration/fitting “training” of the model. There has to be a correlation between the input values and the corresponding output values. It must be ensured that each input value that enters the biogas reactor at a time t is correlated with the resulting output value that leaves the reactor at a time t + Δt. This time shift Δt (retention time) is not easy to determine because it is affected by several factors (e.g., flows and mixing inside the reactor). Additionally, the datasets and also the resulting model are based on the current conditions (like composition of the used substrates, mixing and dosage of different substrates). Therefore, it is problematic to use this model(s) for forecasting if the conditions are changing (e.g., new/other substrates or different dosage of substrates). These techniques perform complex learning and cognition that equal or exceed human expertise. There are several types of artificial intelligence techniques, such as artificial neural networks, fuzzy logic, expert systems, etc., which show great advantages in simulation, control, and prediction of the anaerobic process.
The other “nature-inspired techniques” were originally developed for very specific biological systems/communities (such as natural selection/mutation, animal behavior in groups, behavior of fireflies, ant colonies) which have barely any connection with biogas production and the underlying biological processes. Therefore, from a scientific point of view, the question arises as to whether it is appropriate to use these models for the simulation of biogas plants.
This paper focused on a recently developed branch of artificial intelligence known as nature-inspired computing, and gives an insight into its applications and future prospects in the field of anaerobic digestion.
3. Nature-Inspired Computing
Process modeling can be broadly divided into deterministic and stochastic models. Under each umbrella, the models can be further divided into steady-state and dynamic modeling [17]. Most conventional algorithms based on mathematical modeling are deterministic in nature and follow set procedures which are less flexible. Some of the examples are hill climbing algorithms, gradient based algorithms, linear programming, and dynamic programming, for which detailed descriptions are available in Siddique and Adeli [18]. However, these algorithms are based on functions and derivatives and work properly only when the problems are uniform or steady; they cannot handle discontinuity. Stochastic or non-deterministic models have built-in randomness factors and do not require differentiable objective functions, which allows the discovery of numerous solutions. Several domains of the problem can be searched in parallel and these models are suitable for solving real-world problems.
Nature-inspired computing (NIC) is a recently developed branch of artificial intelligence techniques. Natural systems (living and non-living) have an innate ability to evolve, often in parallel and against each other, in a dialectic way. The harmony, beauty, and vigor of life underlie this complexity of evolution. Even without a central control, the processing of information happens in a distributed, self-organized, and optimal way. Equilibrium is maintained in nature through optimal searching, and this forms the basis of algorithm development for optimization problems in process engineering. Algorithms are iterative procedures for providing calculations or guidelines in a step-wise manner tailored for specific goals. Computational optimization aims to create algorithms to design, implement, and test for solving optimization problems [19]. Optimization works on various levels, including maximization of performance, efficiency, and profit, or minimization of energy and economics. If infinite time were available, any problem could be solved, but that is not the case with real situations. When time and resources are constrained, intelligent techniques are required. To address non-linear systems like anaerobic digestion, computer simulation becomes an indispensable tool.
Stochastic optimization techniques, which form a groups of modern search algorithms wherein the solution is searched for in an entire domain with little knowledge on the same, can be divided into heuristic and metaheuristic techniques [20]. Heuristic methods find solution by trial and error. Due to the complexity of real-world problems, it is very difficult to search for each and every possible solution. Nevertheless, feasible, good quality solutions for problems need to be found. Heuristic methods have the advantage of finding optimal solutions in a limited amount of time, but the main disadvantage is that there is no assurance that the identified solution is the optimal one. Artificial neural networks and support vector machines, detailed in the next section, can be classified as heuristic methods as they are based on trial and error to minimize learning and prediction errors.
Metaheuristics is a second-generation optimization method and can be used for more complex problems. Random and specific rules, mainly inspired by natural phenomena, help the search agents in metaheuristics to explore the search domain. Metaheuristic algorithms are based on principles of diversification and intensification or exploration and exploitation [21]. Diversification aims at exploring the entire search space so as to create diverse solutions. Each of these solutions is defined by its respective local regions. Intensification focuses on local region search by exploiting information that the region contains a good solution. The combination of the two principles maintains a good balance between random and local searching, thus preventing the problems of premature convergence of local minima and infinite time required to arrive at global optima.
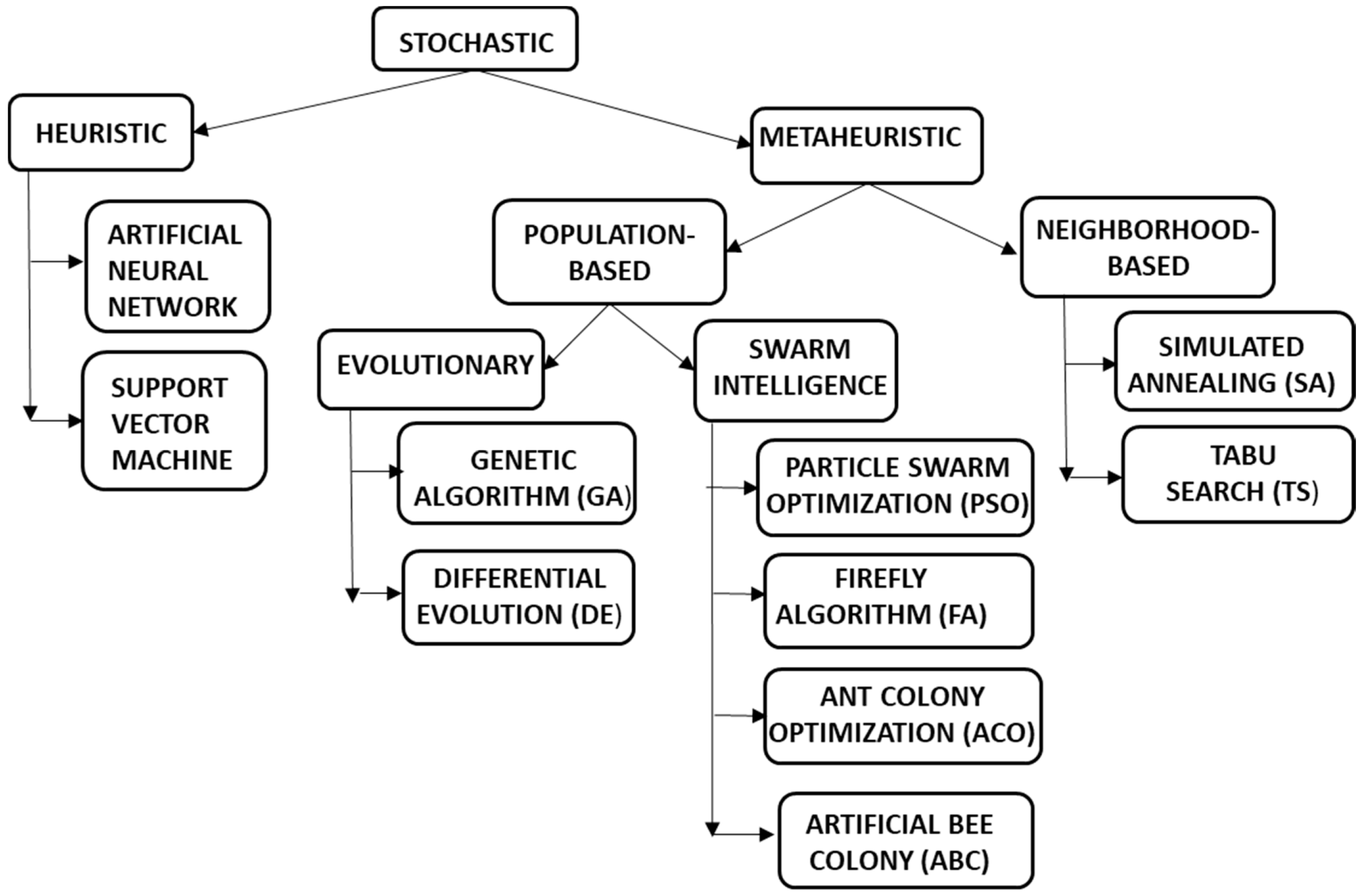
Figure 1 shows the general classification of the main algorithms.
Neighborhood-based algorithms are based on a random starting point and then move on to the next plausible space and so on, thus forming a path towards the solution. Population-based algorithms encompass a group of search agents which are designated to a search domain and information is shared to find the optimal solution. Further population-based algorithms can be subdivided into evolutionary and swarm-intelligence-based. Evolutionary algorithms are fundamentally based on Darwin’s theory of evolution and survival of the fittest. Adaptation of this technique ensures the preservation of functional advantage of the superior species (or solutions in terms of algorithms) over inferior ones. Swarm intelligence utilizes the collective behavior of animal species such as birds, ants, and bees, which is a result of indirect communication among the individuals of the species and also self-organization [22]. The following sections detail some nature-inspired algorithms and their importance in anaerobic digestion modeling.
3.1. Artificial Neural Network (ANN)
Artificial neural networks imitate the way the human brain processes information. By making their own rules by learning from examples, these networks automatically search for the best relationships, both linear and non-linear, between input and output [23]. ANN generally has three layers, namely input, hidden, and output. Weights are assigned to input neurons and the weighted sums of these inputs are transmitted to the hidden neurons. The weights are then transformed using an activation function, such that the output of the hidden neurons becomes the input of the output neurons. The algorithm proceeds by iterative steps of training, validation, and testing or prediction. During training, inputs are applied to the networks, and output is calculated and compared to the required results with mean square error through a number of epochs. For validation, a part of the input/output datasets not used for training is used. Once this learning is complete, ANN can be used for prediction. There are several variations of ANN, such as feed-forward, backpropagation, recurrent, counter-propagation, radial basis function, pulsed, and fuzzy-based [24,25,26,27] and, as it is a well-researched field, ANN has applications in almost all engineering fields.
Data-mining algorithms, namely adaptive neuro-fuzzy inference system (ANFIS), support vector machine (SVM), neural network (NN), and k-nearest neighbor were compared by Kusiak and Wei [28], showing that ANFIS outperformed the rest for prediction of methane with least percentage error and zero fractional bias, indicating high prediction accuracy and agreement between predicted and observed values. Up-flow anaerobic sludge blanket process, which is very susceptible to load fluctuations, was simulated using ANN to predict the organic content of the effluent, giving good relationships between dominant system dynamics and output [29]. Feed-forward backpropagation ANN was used by Nair et al. [30] to investigate the effects of varying organic loading rate and substrates such as vegetable waste, food waste, and yard trimmings on methane generation, and achieved a target of 60–70% methane from municipal solid waste. The study helped to find out the optimum parameters for efficient methane production; correlation coefficients greater than 0.88 for training and validation gave a good learning and generalization capacity of the model. The anaerobic fermentation process of slurry from agricultural and animal waste was simulated using ANN for prediction of methane by Dach et al. [31], wherein multilayer, radial basis, and regression network techniques were employed. ANN was found to be appropriate for quantitative and qualitative prediction of methane, and several structures were tried with varying input/hidden/output layers. Several other studies using ANN and its variants for anaerobic digestion modeling can be found in the literature [32,33,34,35,36,37,38,39]. All of these studies have shown that ANN is very suitable for non-linear multivariable systems. It is highly suitable for black-box processes where it is very difficult to assess the impact of input parameters on the outputs. Very large amounts of data are also required to calibrate ANN, and the technique does not handle missing data well. Once the model is created, it works only on input data similar to the data used for training, showing its lack of capacity for extrapolation. For problems requiring process explanation, ANN is not suitable to explain the reasons for failure of algorithm convergence.
3.2. Simulated Annealing (SA)
Simulated annealing (SA) can be treated as a probabilistic algorithm that uses the idea of annealing in metallurgical process, which is a method to increase the size of crystals and diminish flaws by cycles of heating and controlled cooling with a minimum energy requirement. The internal energy of the system corresponds to the objective function to be minimized [40]. As it is a trajectory- or neighborhood-based technique, new solutions are based on random walks. At every step, the algorithm studies some neighboring regions of the current search and probabilistically choose whether to move to the new region or stay put. As optimization progresses, this step is repeated and the search radius is reduced, resulting in solutions with more probability of being global optima.
Implementation of SA in Matlab toolbox was described by Gaida et al. [41], using the parameters of ADM1. SA provides a good graphical user interface and can be used to optimize agricultural and industrial biogas plants. Furthermore, SA has been used for some domains of anaerobic digestion modeling, such as
- -
- estimation of parameters for non-linear systems using SA and random search with comparison to real world bioprocesses [42];
- -
- upgrading of ADM1 to include phosphorous (P), sulfur (S), and iron (Fe) interactions, using a hybrid between SA and the gradient method [43];
- -
- simulation of anaerobic co-digestion with optimization of model parameters with SA [44].
From these studies, the simulated annealing technique has demonstrated good exploration ability in the search domains but, as the search domain is scanned extensively, taking into account large number of problem parameters, the convergence of local optima is time consuming.
3.3. Genetic Algorithm (GA)
Genetic algorithm, an evolutionary algorithm, simulates the biological process of natural selection and evolution. The major components that make up the algorithm are fitness function, chromosome population, chromosome selection, crossover, and mutation [45]. The primary population is generally randomly selected. The term chromosome is used to depict each solution, which is a string of parameters. Each such parameter or bit of chromosome is called a gene, which represents an element of the solution. The fitness function or objective function defines the goodness of the chromosome [46]. Selection is the choice of a chromosome with a higher fitness value than the others. There are several ways to do the selection process, such as roulette wheel, wherein divisions of the wheel are assigned to chromosomes proportional to the fitness values, tournament selection, wherein set chromosomes are compared with each other to find the best-performing individual, or ranking selection [47].
GA has been applied to various diverse fields of engineering, as it was introduced in the 1960–70s. Due to extensive research in the field, hybrid GA involving other artificial intelligence techniques has been found to be more effective. GA and particle swarm analysis (PSO) has been used by Wolf et al. [48] to optimize substrate feed for agricultural and industrial biogas plants with ADM1.
Methane production has been optimized with GA [49], in a study which also defined the optimal operational conditions for best results. The biogas was used for an internal combustion engine where the model was used to optimize the use of biogas for such applications. To enhance biogas quality and fertilizer value of slurry, an ANN–GA model was developed by Barik and Murugan [50], which found the optimal combination of cattle dung and Karanja seeds, giving a biogas yield of 89.8% with 73% methane content.
Chemical oxygen demand (COD) effluent prediction for anaerobic treatment of cheese dairy wastewater was done by model development by backpropagation neural network (BPNN) and feature selection by GA, which proved the use of GA in reducing the computation time for BPNN by reducing the influential parameters [51].
Tackling multi-objective optimization problems is a major advantage of GA. A model for optimization of biomethane was developed [52], considering three conflicting objectives such as biomethane production, green energy maximization, and energy minimization. Non-dominated sorting genetic algorithm (NSGA II) produced a pareto-optimal surface, revealing a good trade-off between the objectives.
GA has good exploration, can work in parallel due to the presence of multiple chromosomes, and can handle discontinuous data, as the function is not derivative or gradient-free. However, while using GA, the choice of parameters such as population size, rate of mutation, and crossover is crucial to preventing problems of convergence and unproductive results. Mutation, even though it helps in finding the global optima, can increase the time taken for convergence. As GA keeps a population of solutions rather than one, the computational time taken for each iteration is long compared to the more advanced NIC techniques.
3.4. Particle Swarm Optimization (PSO)
PSO is basically a search algorithm which simulates animal group behavior such as bird flocking and fish schooling. The individuals in these swarms cooperate and exchange data about the regions they have searched. Similarly to GA, a population of random solutions is initialized and optima are searched by updating generations [53]. These potential solutions are called particles. All these particles have neighborhood and fitness valves weighed by fitness functions which have to be optimized. The particles fly through the search domain with a certain velocity, searching for the optimum. The velocity is proportional to the distance of the particle from the target. Each particle also remembers two best values. The first is the best solution achieved by the particle so far, which is the local best (lbest), and the second is the best value attained by any particle in the population, which is the global best (gbest) [54]. PSO algorithm iteration consists of three steps, which are fitness function evaluation of each particle, update local and global best fitness and position, and update velocity.
Unlike GA, PSO maintains the same population from generation to generation, but through updating of the positions of the particles. The “mutation” operator is not present in PSO but, like GA, the particles or individuals of the population interact with and influence each other. PSO has been applied to several areas in engineering both as standard PSO and as variant and hybrid PSOs by combination with other artificial intelligence techniques like ANN, fuzzy, GA, and ACO. In the field of anaerobic digestion, optimization of substrate feed for agricultural biogas plants using PSO was found to give best results compared to other evolutionary methods. The method was stable during changes in number of parameters [55]. Offline estimation of yield and kinetic coefficients in anaerobic wastewater treatment by reducing the error between actual measured response and simulated response has been done using PSO [56], and PSO has been used for parameter estimation in a modified ADM1 model for modeling volatile fatty acids (VFA), showing its advantage in directly seeking the optima in a multidimensional space without crossover and mutation [57]. Multilayer perceptron neural network (MLPNN) and PSO were combined [58] to obtain maximum methane percentage in biogas, biogas quantity, and biogas quality. MLPNN was used for model prediction, giving a regression coefficient as high as 0.91, providing good prediction of modeled outputs, and PSO used for model optimization helped in utilization of biogas production at maximum output levels. Assessment of kinetic parameters under steady and transient states with limited parameters in continuous and batch anaerobic reactors was done using PSO by Yang et al. [59], which proved the successful application of the algorithm in non-linear systems.
PSO outperforms conventional algorithms and genetic algorithms for optimization problems; it requires only simple mathematical operators and thus is less expensive computationally with respect to memory and speed. However, these algorithms have the disadvantage of premature convergence [47]. Global best or gbest drives the algorithm and, if it is far from the optimum, then the particles may get trapped in the local optima, leading to premature convergence. At times, the gbest may not even be the local minima, leading to a problem called stagnation. Partial restart of the process by introducing new particles in the search space could help solve this problem.
3.5. Firefly Algorithm (FA)
Firefly algorithm was developed in 2008, inspired by the flashing patterns of fireflies in order to attract other fireflies [60]. The developed algorithm is based mainly on three rules: as all fireflies are unisex, they are attracted to one another irrespective of their sex; attractiveness is proportional to the brightness of the fireflies, which decreases with increase in distance between them; the landscape of the objective function affects the brightness of the firefly. If the brightness is same for all fireflies, they move randomly.
The main two parameters that define the algorithm are attractiveness and randomization, which determine the convergence speed [61]. During the first iterations, the firefly locations are distributed evenly throughout the search domain. As FA proceeds, the local optima are found. The global optima are obtained by evaluating the best among all the optima. This is an important feature of FA, wherein both the local and global optima can be found simultaneously.
A study was conducted by Reference [62] to find the most suitable algorithm for clustering, in which firefly algorithm outweighed other population-based algorithms like particle swarm analysis (PSO) and artificial bee colony algorithm (ABC). To make the comparison, a classification error percentage (CEP) was used, which is the percentage of incorrect patterns in the total data set. FA showed the least error with 11.36%, compared to ABC (13.13%) and PSO (15.99%). However, a literature survey showed no research on FA applied anaerobic digestion modeling and optimization.
Like PSO, firefly algorithm can also get trapped in local minima, which causes problems with global search; however, it is powerful for local search. Unlike PSO, firefly algorithm’s local optima are not influenced by global optima, which limits its exploration ability [47].
3.6. Ant Colony Optimization (ACO)
Ant colony algorithm uses the principles of the foraging behavior of ant colonies. Ants have an ability to find the shortest path between food and their colony. This is done through indirect communication between ants using chemical pheromone trails, which is utilized by the algorithm to solve optimization problems [63]. Simple ant colony optimization (S-ACO) was developed by Dorigo and Stutzle [64], in which artificial ants move towards the destination or solution from a source node by probabilistically choosing the succeeding nodes. Artificial ants do not deposit pheromone while moving forward towards the destination. During their deterministic backward movement from the food source to the nest, they memorize the path using explicit memory, retrace it, and deposit pheromones. The pheromone density is defined by probability distribution, which is subjective to stronger pheromones deposited by ants in the earlier searches. Two important terms influence the efficiency of the algorithm, which are pheromone update and pheromone evaporation [65]. Pheromone update is the increase of pheromone value of a node on the route due to deposition, which increases the chances of the next ant visiting the node. Pheromone evaporation is a parameter included to increase the quality of solution by helping the ants forget poor results.
S-ACO was developed for discrete optimization problems. For complex problems like anaerobic digestion modeling, algorithms capable of handling continuous non-linear variables are required. A new ACO called continuous ant colony optimization (ACOR) was developed by Reference [66]. The main difference of S-ACO is that instead of probability distribution, a continuous probability density function (PDF), which can be defined by Gaussian function or any gradient function, is used so that the algorithm can handle non-linearity. ACOR proceeds by constructing candidate solutions through PDF over the search space. These candidate solutions are then used to update the PDF in such a way as to direct the future search towards high quality solutions. ACOR defines pheromone distribution using a solution archive. Unlike S-ACO, there is an unlimited number of possible solutions for ACOR [67]. At initialization, the archive is given a “k” set of random solutions. After each iteration, “m” number of solutions are generated, which are added to the initial archive. From the total “k + m” solutions, “m” worst solutions are eliminated, and the rest of the “k” solutions are ranked according to their quality, with the best solution on top.
The non-linear application of ACO was utilized in the research conducted by Satya and Venkateswarlu [25] to estimate the kinetic and film thickness model parameters that give the best performance of an anaerobic biofilm reactor. An optimal substrate composition was achieved by Verdaguer et al. [68] for co-digestion of sewage sludge and agrifood wastes by ACO for combinatorial or continuous optimization, and the simulation resulted in maximized volume of waste and biogas. Biogas production was analyzed with regard to biogas flow rate, in which the ADM1 model was used to produce data [69], ANN was used for process modeling and prediction of flow rate, and ACO was used for parameter selection for co-digestion of cow manure and grass silage. Parameter selection was based on pheromone concentration values greater than 0.8, which gave R2 valves close to 0.9 for ANN model, thus proving the ability of ACO in systematic variable reduction and reducing the computation time.
The main advantage of ACOR is that it can handle a mix of discrete–continuous optimization problems, and it is an area with very little research. ACO has good global search ability, but as it lacks a crossover feature, exploitation is limited. Moreover, to suit the problem, the PDF function needs to be defined by the right gradient function and not always a Gaussian, as a single Gaussian function will have only one maximum and would be limited if more promising search spaces were present.
4. Conclusions
There are two main points to consider when choosing an algorithm for model development and optimization. First: Which is the best algorithm for the given problem? Second: Which problems can be solved with the chosen algorithm? This paper analyzed the existing recent artificial intelligence techniques, keeping in mind their computational ability, shortcomings, adaptability to work in parallel with other algorithms, and processing time. Advantages and disadvantages of the discussed techniques, as well as their application in the field of anaerobic digestion allowed comparison between them and assessment of their flexibility in handling complex processes. Nature-inspired algorithms are a preferred area of computing, as anaerobic digestion deals with large number of variables and has non-linearity, and traditional modeling techniques cannot handle such diversity. Optimizing anaerobic digestion processes is a non-linear problem which is not based on a single guaranteed optimum. A set of solutions is desired rather than a single output, as we deal with multiple objectives such as high-quality biogas, good digestate properties, good effluent quality, and low energy. There are several nature-inspired techniques available in the literature; however, this paper focused on selected techniques relevant for anaerobic digestion modeling. Modeling of anaerobic digestion of sewage sludge using the above techniques to produce bio-resource energy is the ultimate goal of our future research.
Author Contributions
A.R. wrote the manuscript with input from all authors, R.R. conceived of the presented idea and supervised the findings of this work, A.J.A. discussed the results and contributed to the final manuscript and also helped supervise the project.
Funding
This work did not receive any specific grant from funding agencies in the public, commercial or not-for-profit sectors.
Acknowledgments
The authors are thankful to Heriot-Watt University enabling the research project.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Breach, P.A. Wastewater Treatment Energy Recovery Potential For Adaptation To Global Change: An Integrated Assessment. Environ. Manag. 2018, 61, 624–636. [Google Scholar] [CrossRef] [PubMed]
- Harasimowicz, M.; Orluk, P.; Zakrzewska-Trznadel, G.; Chmielewski, A.G. Application of polyimide membranes for biogas purification and enrichment. J. Hazard. Mater 2007, 144, 698–702. [Google Scholar] [CrossRef] [PubMed]
- Nelson, R. Methane Generation from Anaerobic Digesters: Considering Different Substrates. Environ. Biotechnol. 2010, 1–11. [Google Scholar]
- Wang, X.; Yang, G.; Feng, Y.; Ren, G.; Han, X. Optimizing feeding composition and carbon-nitrogen ratios for improved methane yield during anaerobic co-digestion of dairy, chicken manure and wheat straw. Bioresour. Technol. 2012, 120, 78–83. [Google Scholar] [CrossRef] [PubMed]
- Maile, I.I.; Muzenda, E. Production of Biogas from Various Sustrates under Anaerobic Conditions. Int. Conf. Innov. Eng. Technol. 2014, 78–80. [Google Scholar]
- Shah, F.A.; Mahmood, Q.; Rashid, N.; Pervez, A.; Raja, I.A.; Shah, M.M. Co-digestion, pretreatment and digester design for enhanced methanogenesis. Renew. Sustain. Energy Rev. 2015, 42, 627–642. [Google Scholar] [CrossRef]
- Hagos, K.; Zong, J.; Li, D.; Liu, C.; Lu, X. Anaerobic co-digestion process for biogas production: Progress, challenges and perspectives. Renew. Sustain. Energy Rev. 2017, 76, 1485–1496. [Google Scholar] [CrossRef]
- Gómez, X.; Cuetos, M.J.; Cara, J.; Morán, A.; García, A.I. Anaerobic co-digestion of primary sludge and the fruit and vegetable fraction of the municipal solid wastes. Conditions for mixing and evaluation of the organic loading rate. Renew. Energy 2006, 31, 2017–2024. [Google Scholar] [CrossRef]
- Demirbas, A.; Taylan, O.; Kaya, D. Biogas production from municipal sewage sludge. Energy Sources Part A Recovery Util. Environ. Eff. 2016, 38, 3027–3033. [Google Scholar] [CrossRef]
- Dewil, R.; Appels, L.; Baeyens, J.; Degre, J. Principles and potential of the anaerobic digestion of waste-activated sludge. Prog. Energy Combust. Sci. 2008, 34, 755–781. [Google Scholar]
- Dai, X.; Duan, N.; Dong, B.; Dai, L. High-solids anaerobic co-digestion of sewage sludge and food waste in comparison with mono digestions: Stability and performance. Waste Manag. 2013, 33, 308–316. [Google Scholar] [CrossRef] [PubMed]
- Lardon, L.; Steyer, J.P. Advances in Diagnosis of Biological Anaerobic Wastewater Treatment Plants. In Selected Topics in Dynamics and Control of Chemical and Biological Processes; Lecture Notes in Control and Information Sciences; Oscar Méndez-Acosta, H., Femat, R., González-Álvarez, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 361. [Google Scholar]
- Dewil, R.; Lauwers, J.; Appels, L.; Gins, G.; Degrève, J.; Van Impe, J.F. Anaerobic digestion of biomass and waste: Current trends in mathematical modeling. IFAC 2011, 44, 5024–5033. [Google Scholar] [CrossRef] [Green Version]
- Lauwers, J.; Appels, L.; Thompson, I.P.; Degrève, J.; van Impe, J.F.; Dewil, R. Mathematical modelling of anaerobic digestion of biomass and waste: Power and limitations. Prog. Energy Combust. Sci. 2013, 39, 383–402. [Google Scholar] [CrossRef] [Green Version]
- Batstone, D.J.; Puyol, D.; Flores-Alsina, X.; Rodríguez, J. Mathematical modelling of anaerobic digestion processes: Applications and future needs. Rev. Environ. Sci. Biotechnol. 2015, 14, 595–613. [Google Scholar] [CrossRef]
- Batstone, D.J.; Keller, J.; Angelidaki, I.; Kalyuzhnyi, S.V.; Pavlostathis, S.G.; Rozzi, A.; Sanders, W.T.M.; Siegrist, H.; Vavilin, V.A. The IWA anaerobic digestion model no 1 (ADM1). Water Sci. Technol. 2002, 45, 65–73. [Google Scholar] [CrossRef]
- Srikanta, P.; Xin-She, Y. Nature-Inspired Computing and Optimization; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Siddique, N.; Adeli, H. Nature Inspired Computing: An Overview and Some Future Directions. Cognit. Comput. 2015, 7, 706–714. [Google Scholar] [CrossRef] [Green Version]
- Manzano-agugliaro, F.; Montoya, F.G.; Gil, C.; Alcayde, A.; Gómez, J.; Banose, R. Optimization methods applied to renewable and sustainable energy: A review. Renew. Sustain. Energy Rev. 2011, 15, 1753–1766. [Google Scholar]
- Nikolic, K.P. Stochastic search algorithms for identification, optimization, and training of artificial neural networks. Adv. Artif. Neural Syst. 2015, 2015, 2. [Google Scholar] [CrossRef] [Green Version]
- Yang, X. Nature-Inspired Metaheuristic Algorithms: Success and New Challenges. J Comput. Eng. Inf. Technol. 2012, 1, 1–3. [Google Scholar] [CrossRef]
- Gupta, S.; Bhardwaj, S.; Bhatia, P.K. A reminiscent study of nature inspired computation. Int. J. Adv. Eng. Technol. 2011, 1, 117. [Google Scholar]
- Dias, A.M.A.; Ferreira, E.C. Computational Intelligence Techniques for Supervision and Diagnosis of Biological Wastewater Treatment Systems. In Computational Intelligence Techniques for Bioprocess Modelling, Supervision and Control; Studies in Computational Intelligence; do Carmo Nicoletti, M., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 218. [Google Scholar]
- Yetilmezsoy, K.; Ozkaya, B.; Cakmakci, M. Artificial Intelligence-Based Prediction Models for Environmental Engineering. Neural Netw. World 2011, 21, 193–218. [Google Scholar] [CrossRef]
- Satya, E.J.; Venkateswarlu, C. Evaluation of Anaerobic Biofilm Reactor Kinetic Parameters Using Ant Colony Optimization. Environ. Eng. Sci. 2013, 30, 527–535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levstek, T.; Lakota, M. The use of artificial neural networks for compounds prediction in biogas from anaerobic digestion—A review. Agricultura 2010, 7, 15–22. [Google Scholar]
- Manu, D.S.; Thalla, A.K. Artificial intelligence models for predicting the performance of biological wastewater treatment plant in the removal of Kjeldahl Nitrogen from wastewater. Appl. Water Sci. 2017, 7, 3783–3791. [Google Scholar] [CrossRef] [Green Version]
- Kusiak, A.; Wei, X. Prediction of methane production in wastewater treatment facility: A data-mining approach. Ann. Oper. Res. 2014, 216, 71–81. [Google Scholar] [CrossRef]
- Mendes, C.; Magalhes, R.d.; Esquerre, K.; Queiroz, L.M. Artificial Neural Network Modeling for Predicting Organic Matter in a Full-Scale Up-Flow Anaerobic Sludge Blanket (UASB) Reactor. Environ. Model. Assess. 2015, 20, 625–635. [Google Scholar] [CrossRef]
- Nair, V.V.; Dhar, H.; Kumar, S.; Thalla, A.K.; Mukherjee, S.; Wong, J.W.C. Artificial neural network based modeling to evaluate methane yield from biogas in a laboratory-scale anaerobic bioreactor. Bioresour. Technol. 2016, 217, 90–99. [Google Scholar] [CrossRef]
- Dach, J.; Koszela, K.; Boniecki, P.; Zaborowicz, M.; Lewicki, A.; Czekała, W.; Skwarcz, J.; Qiao, W.; Piekarska-Boniecka, H.; Białobrzewskid, I. The use of neural modelling to estimate the methane production from slurry fermentation processes. Renew. Sustain. Energy Rev. 2016, 56, 603–610. [Google Scholar] [CrossRef]
- Tay, J.H.; Zhang, X. A fast predicting neural fuzzy model for high-rate anaerobic wastewater treatment systems. Water Res. 2000, 34, 2849–2860. [Google Scholar] [CrossRef]
- Holubar, P.; Zani, L.; Hager, M.; Fröschl, W.; Radak, Z.; Braun, R. Advanced controlling of anaerobic digestion by means of hierarchical neural networks. Water Res. 2002, 36, 2582–2588. [Google Scholar] [CrossRef]
- Strik, D.P.B.T.B.; Domnanovich, A.M.; Zani, L.; Braun, R.; Holubar, P. Prediction of trace compounds in biogas from anaerobic digestion using the MATLAB Neural Network Toolbox. Environ. Model. Softw. 2005, 20, 803–810. [Google Scholar] [CrossRef]
- Özkaya, B.; Visa, A.; Lin, C.; Puhakka, J.A.; Yli-Harja, O. An Artificial Neural Network Based Model for Predicting H 2 Production Rates in a Sucrose- Based Bioreactor System. Int. J. Chem. Mol. Eng. 2008, 2, 20–25. [Google Scholar]
- Perendeci, A.; Arslan, S.; Serdar, S.C. Prediction of effluent quality of an anaerobic treatment plant under unsteady state through ANFIS modeling with on-line input variables. Chem. Eng. J. 2008, 145, 78–85. [Google Scholar] [CrossRef]
- Yetilmezsoy, K.; Turkdogan, F.I.; Temizel, I.; Gunay, A. Development of Ann-Based Models to Predict Biogas and Methane Productions in Anaerobic Treatment of Molasses Wastewater. Int. J. Green Energy 2013, 10, 885–907. [Google Scholar] [CrossRef]
- Yetilmezsoy, K.; Sapci-Zengin, Z. Stochastic modeling applications for the prediction of COD removal efficiency of UASB reactors treating diluted real cotton textile wastewater. Stoch. Environ. Res. Risk Assess. 2009, 23, 13–26. [Google Scholar] [CrossRef]
- Sathish, S.; Vivekanandan, S. Parametric optimization for floating drum anaerobic bio-digester using Response Surface Methodology and Artificial Neural Network. Alex. Eng. J. 2016, 55, 3297–3307. [Google Scholar] [CrossRef] [Green Version]
- Donoso-Bravo, A.; Mailier, J.; Martin, C.; Rodríguez, J.; Aceves-Lara, C.A.; Wouwer, A.V. Model selection, identification and validation in anaerobic digestion: A review. Water Res. 2011, 45, 5347–5364. [Google Scholar] [CrossRef]
- Gaida, D.; Wolf, C.; Bongards, M.; Back, T. MATLAB Toolbox for Biogas Plant Modelling and Optimization. Prog. Biogas II-Biogas Prod. Agric. Biomass Org. Residues 2011, 67–70. [Google Scholar]
- Saoud, L.S.; Rahmoune, F.; Tourtchine, V.; Baddari, K. Identification of bioprocesses using random search and Simulated Annealing algorithms. In Proceedings of the 2012 6th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT), Sousse, Tunisia, 21–24 March 2012; pp. 65–68. [Google Scholar]
- Flores-Alsina, X.; Solon, K.; Kazadi, M.C.; Tait, S.; Gernaey, K.V.; Jeppsson, U.; Batstone, D.J. Modelling phosphorus (P), sulfur (S) and iron (Fe) interactions for dynamic simulations of anaerobic digestion processes. Water Res. 2016, 95, 370–382. [Google Scholar] [CrossRef] [Green Version]
- Kovalovszki, A.; Alvarado-Morales, M.; Fotidis, I.A.; Angelidaki, I. A systematic methodology to extend the applicability of a bioconversion model for the simulation of various co-digestion scenarios. Bioresour. Technol. 2017, 235, 157–166. [Google Scholar] [CrossRef] [Green Version]
- Carr, J. An introduction to genetic algorithms. Sr. Proj. 2014, 1–40. [Google Scholar]
- Garzia, F.; Fiamingo, F.; Veca, G.M. Energy Management Using Genetic Algorithms—Transactions on Ecology and the Environment; WIT Press: Southampton, UK, 2003; Volume 62, Available online: https://www.witpress.com/Secure/elibrary/papers/EENV03/EENV03009FU.pdf (accessed on 13 Demcember 2019).
- Du, K.-L.; Swamy, M.N.S. Search and Optimization by Metaheuristics; Springer: New York, NY, USA, 2016. [Google Scholar]
- Wolf, C.; McLoone, S.; Bongards, M. Biogas Plant Control and Optimization Using Computational Intelligence Methods—Biogasanlagenregelung und -optimierung mit Computational Intelligence Methoden. Autom. Methoden Anwend. Steuer. Regel. Inf. 2009, 57, 638–649. [Google Scholar]
- Kamalinasab, M.; Vakili, A. Utilization of Genetic Algorithm to Optimize Biogas Production from Livestock Waste to Use in a CHP Plant in Agricultural Farms. Br. Biotechnol. J. 2014, 4, 1149–1164. [Google Scholar] [CrossRef]
- Barik, D.; Murugan, S. An Artificial Neural Network and Genetic Algorithm Optimized Model for Biogas Production from Co-digestion of Seed Cake of Karanja and Cattle Dung. Waste Biomass Valorization 2015, 6, 1015–1027. [Google Scholar] [CrossRef]
- Rajagopal, V.; Rajagopal, R. Improving the efficiency of the prediction system for anaerobic wastewater treatment process using Genetic Algorithm. Aust. J. Basic Appl. Sci. 2013, 7, 119–126. [Google Scholar]
- Yan, N.; Ren, B.; Wu, B.; Bao, D.; Zhang, X.; Wang, J. Multi-objective optimization of biomass to biomethane system. Green Energy Environ. 2016, 1, 156–165. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R.C.; Shi, Y. Swarm Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001. [Google Scholar]
- Blondin, J. Particle Swarm Optimization: A Tutorial. Available online: http//cs.armstrong.edu/saad/csci8100/psotutorial.pdf (accessed on 12 December 2019).
- Gaida, D.; Brito, A.L.S.; Wolf, C.; Baeck, T.; Bongards, M.; McLoone, S. Optimal Control of Biogas Plants using Nonlinear Model Predictive Control. In Proceedings of the ISSC 2011, Dublin, Ireland, 23–24 June 2011. [Google Scholar]
- Sendrescu, D.; Roman, M. Parameter identification of bacterial growth bioprocesses using particle swarm optimization. In Proceedings of the 2013 9th Asian Control Conference (ASCC), Istanbul, Turkey, 23–26 June 2013; pp. 1–6. [Google Scholar]
- Bai, J.; Liu, H.; Yin, B.; Ma, H. Modeling of enhanced VFAs production from waste activated sludge by modified ADM1 with improved particle swarm optimization for parameters estimation. Biochem. Eng. J. 2015, 103, 22–31. [Google Scholar] [CrossRef]
- Akbas, H.; Bilgen, B.; Turhan, A.M. An integrated prediction and optimization model of biogas production system at a wastewater treatment facility. Bioresour. Technol. 2015, 196, 566–576. [Google Scholar] [CrossRef]
- Yang, J.; Lu, L.; Ouyang, W.; Gou, Y.; Chen, Y.; Ma, H.; Guo, J.; Fang, F. Estimation of kinetic parameters of an anaerobic digestion model using particle swarm optimization. Biochem. Eng. J. 2017, 120, 25–32. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly algorithms for multimodal optimization. In International Symposium on Stochastic Algorithms; Springer: New York, NY, USA, 2009; pp. 169–178. [Google Scholar]
- Farahani, S.M.; Abshouri, A.A.; Nasiri, B.; Meybodi, M.R. Some hybrid models to improve firefly algorithm performance. Int. J. Artif. Intell. 2012, 8, 97–117. [Google Scholar]
- Senthilnath, J.; Omkar, S.N.; Mani, V. Clustering using firefly algorithm: Performance study. Swarm EComput. 2011, 1, 164–171. [Google Scholar] [CrossRef]
- Blum, C. Ant colony optimization: Introduction and recent trends. Phys. Life Rev. 2005, 2, 353–373. [Google Scholar] [CrossRef] [Green Version]
- Dorigo, M.; Stutzle, T. Ant Colony Optimization; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Hajizadeh, Y. Population-Based Algorithms for Improved History Matching and Uncertainty Quantification of Petroleum Reservoirs. Ph.D Thesis, Heriot Watt University, Edinburgh, Scotland, 2011; p. 331. [Google Scholar]
- Socha, K.; Dorigo, M. Ant colony optimization for continuous domains. Eur. J. Oper. Res. 2008, 185, 1155–1173. [Google Scholar] [CrossRef] [Green Version]
- Socha, K. Ant Colony Optimization for Continuous and Mixed-Variable Domains; Université Libre de Bruxelles: Bruxelles, Belgium, 2008. [Google Scholar]
- Verdaguer, M.; Molinos-Senante, M.; Poch, M. Optimal management of substrates in anaerobic co-digestion: An ant colony algorithm approach. Waste Manag. 2016, 50, 49–54. [Google Scholar] [CrossRef]
- Beltramo, T.; Ranzan, C.; Hinrichs, J.; Hitzmann, B. Artificial neural network prediction of the biogas flow rate optimised with an ant colony algorithm. Biosyst. Eng. 2016, 143, 68–78. [Google Scholar] [CrossRef]
Figure 1.
Hierarchy of algorithms.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ramachandran, A.; Rustum, R.; Adeloye, A.J. Review of Anaerobic Digestion Modeling and Optimization Using Nature-Inspired Techniques. Processes 2019, 7, 953. https://doi.org/10.3390/pr7120953
AMA Style
Ramachandran A, Rustum R, Adeloye AJ. Review of Anaerobic Digestion Modeling and Optimization Using Nature-Inspired Techniques. Processes. 2019; 7(12):953. https://doi.org/10.3390/pr7120953
Chicago/Turabian StyleRamachandran, Anjali, Rabee Rustum, and Adebayo J. Adeloye. 2019. "Review of Anaerobic Digestion Modeling and Optimization Using Nature-Inspired Techniques" Processes 7, no. 12: 953. https://doi.org/10.3390/pr7120953
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.