
Vis-NIR Spectroscopy and Machine Learning Methods for the Discrimination of Transgenic Brassica napus L. and Their Hybrids with B. juncea

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Results and Discussion
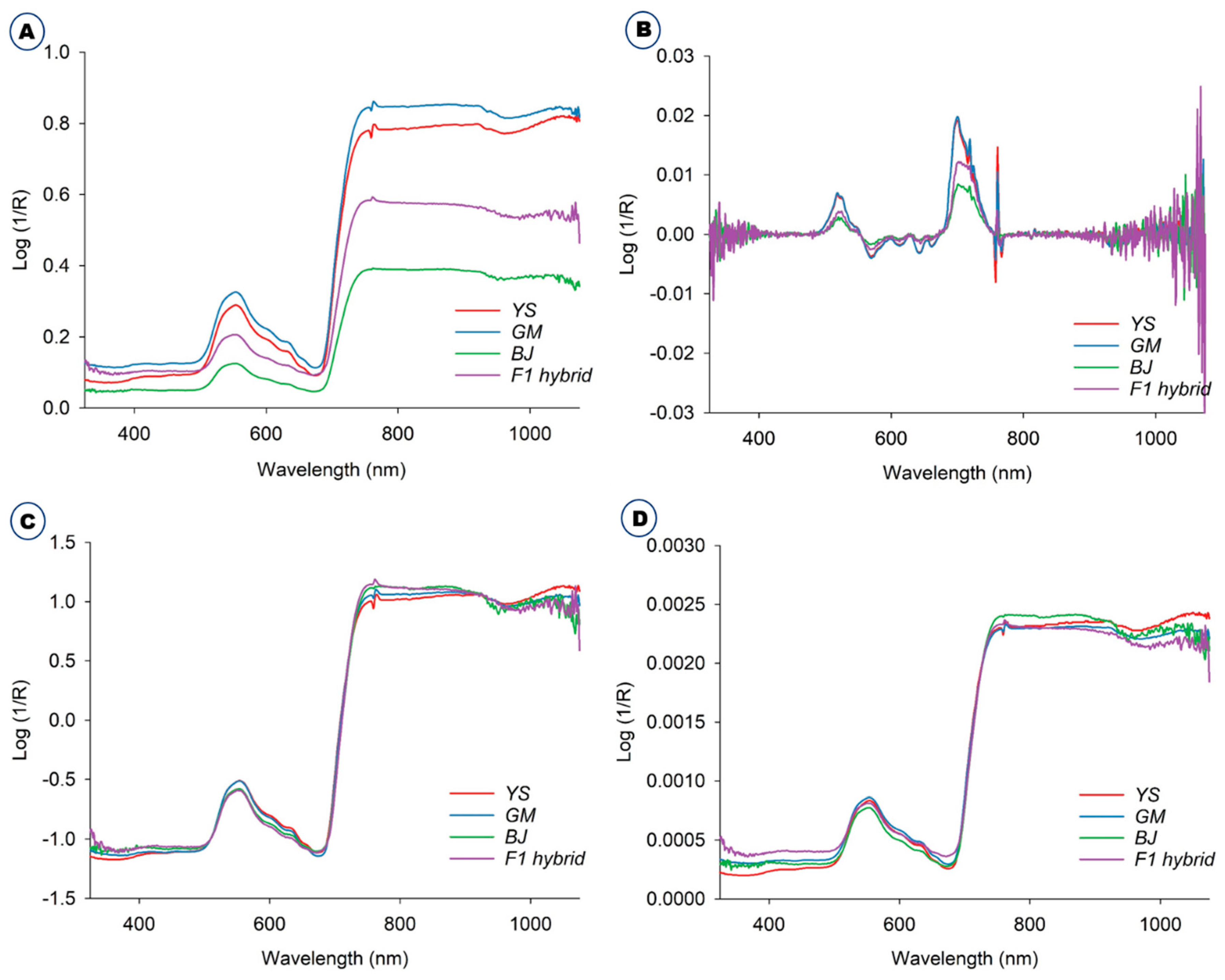
2.1. Spectral Analysis and Preprocessing
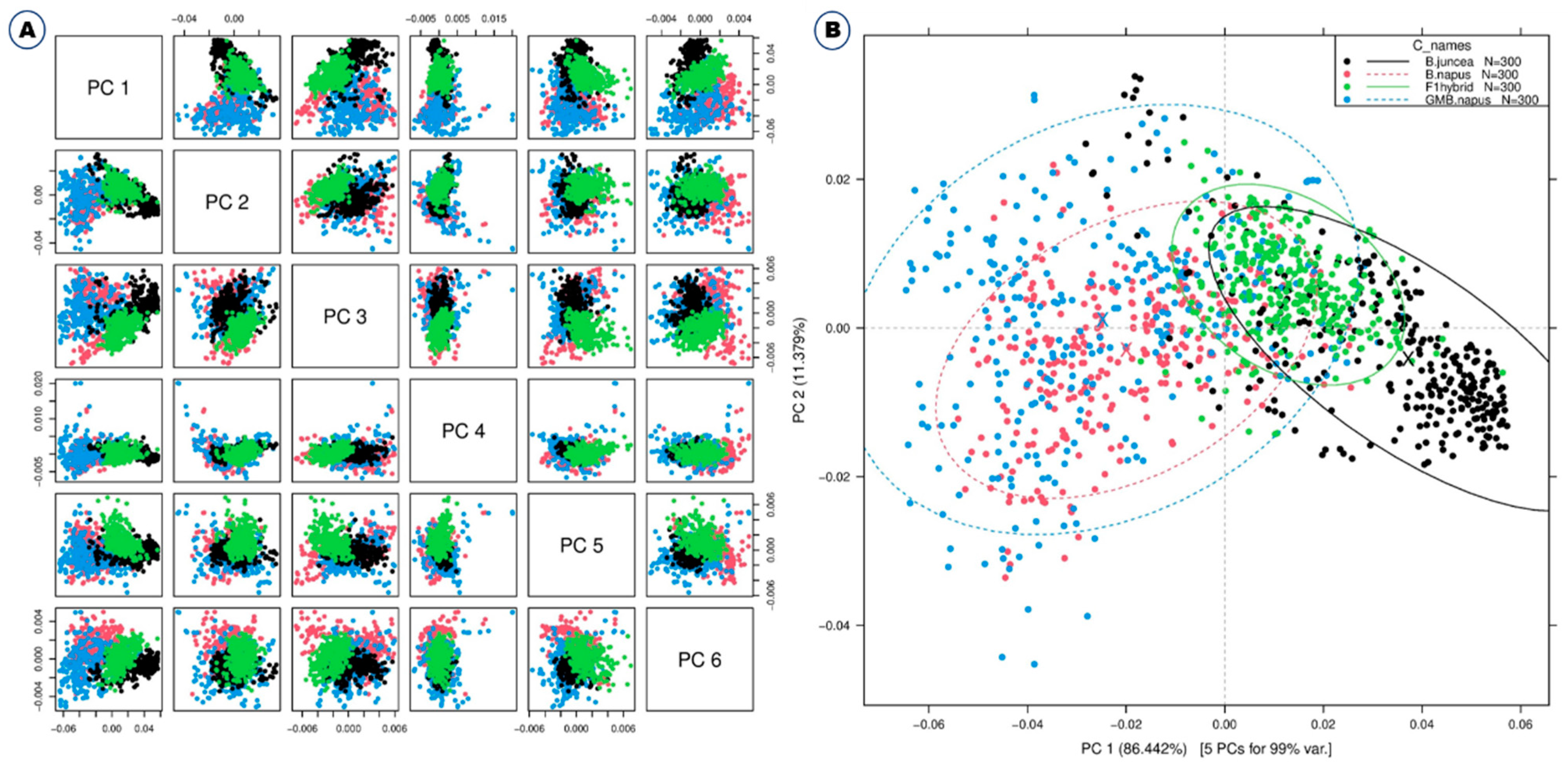
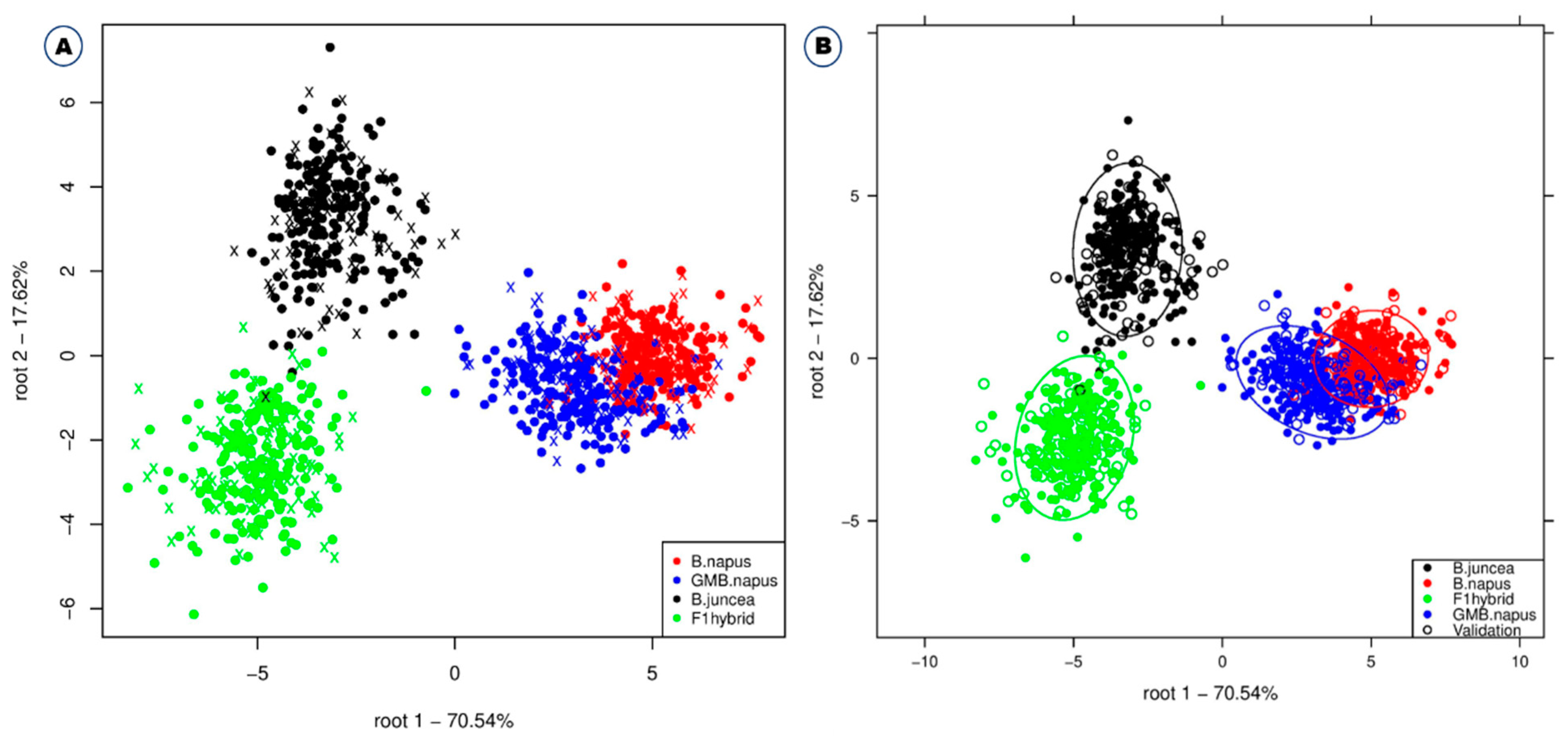
2.2. Chemometric Analysis for Discrimination of B. napus, GM B. napus, B. juncea, and F1 Hybrids
2.3. Significance of Preprocessing and Selection of Optimal Classification Model
3. Materials and Methods
3.1. Plant Materials
3.2. Spectral Data Collection
3.3. Preprocessing and Machine Learning Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, J.; Liu, D.; Wang, X.; Ji, C.; Cheng, F.; Liu, B.; Hu, Z.; Chen, S.; Pental, D.; Ju, Y.; et al. The genome sequence of allopolyploid Brassica juncea and analysis of differential homoeolog gene expression influencing selection. Nat. Genet. 2016, 48, 1225–1232. [Google Scholar] [CrossRef] [PubMed]
- Lim, Y.; Yook, M.J.; Zhang, C.J.; Nah, G.; Park, S.; Kim, D.S. Dormancy associated weedy risk of the F1 hybrid resulted from gene flow from oilseed rape to mustard. Weed Turfgrass Sci. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Zhang, C.J.; Yook, M.J.; Park, H.R.; Lim, S.H.; Kim, J.W.; Song, J.S.; Nah, G.; Song, H.R.; Jo, B.H.; Roh, K.H.; et al. Evaluation of maximum potential gene flow from herbicide resistant Brassica napus to its male sterile relatives under open and wind pollination conditions. Sci. Total Environ. 2018, 634, 821–830. [Google Scholar] [CrossRef] [PubMed]
- Devos, Y.; De Schrijver, A.; Reheul, D. Quantifying the introgressive hybridisation propensity between transgenic oilseed rape and its wild/weedy relatives. Environ. Monit. Assess. 2009, 149, 303–322. [Google Scholar] [CrossRef] [PubMed]
- Scheffler, J.A.; Dale, P.J. Opportunities for gene transfer from transgenic oilseed rape (Brassica napus) to related species. Transgenic Res. 1994, 3, 263–278. [Google Scholar] [CrossRef]
- Song, X.L.; Huangfu, C.H.; Qiang, S. Gene flow from transgenic glufosinate-or glyphosate-tolerant oilseed rape to wild rape. Chin. J. Plant Ecol. 2007, 31, 729–737. [Google Scholar]
- Cao, D.; Stewart Jr, C.N.; Zheng, M.; Guan, Z.; Tang, Z.X.; Wei, W.; Ma, K.P. Stable Bacillus thuringiensis transgene introgression from Brassica napus to wild mustard B. juncea. Plant Sci. 2014, 227, 45–50. [Google Scholar] [CrossRef]
- Liu, Y.; Neal Stewart Jr, C.; Li, J.; Wei, W. One species to another: Sympatric Bt transgene gene flow from Brassica napus alters the reproductive strategy of wild relative Brassica juncea under herbivore treatment. Ann. Bot. 2018, 122, 617–625. [Google Scholar] [CrossRef] [Green Version]
- Tang, T.; Chen, G.; Bu, C.; Liu, F.; Liu, L.; Zhao, X. Transgene introgression from Brassica napus to different varieties of Brassica juncea. Plant Breed. 2018, 137, 171–180. [Google Scholar] [CrossRef]
- Di, K.; Stewart Jr, C.N.; Wei, W.; Shen, B.C.; Tang, Z.X.; Ma, K.P. Fitness and maternal effects in hybrids formed between transgenic oilseed rape (Brassica napus L.) and wild brown mustard [B. juncea (L.) Czern et Coss.] in the field. Pest Manag. Sci. 2009, 65, 753–760. [Google Scholar] [CrossRef]
- Sohn, S.-I.; Pandian, S.; Oh, Y.-J.; Zaukuu, J.-L.Z.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S.; Cho, Y.-S.; Shin, E.-K.; Cho, B.-K. An Overview of Near Infrared Spectroscopy and Its Applications in the Detection of Genetically Modified Organisms. Int. J. Mol. Sci. 2021, 22, 9940. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, F.E. Detection of genetically modified organisms in foods. Trends Biotechnol. 2002, 20, 215–223. [Google Scholar] [CrossRef]
- Ma, Y.; Lewicki, R.; Razeghi, M.; Tittel, F.K. QEPAS based ppb-level detection of CO and N2O using a high power CW DFB-QCL. Opt. Express 2013, 21, 1008–1019. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; He, Y.; Tong, Y.; Yu, X.; Tittel, F.K. Quartz-tuning-fork enhanced photothermal spectroscopy for ultra-high sensitive trace gas detection. Opt. Express 2018, 26, 32103–32110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiao, S.; Ma, Y.; He, Y.; Patimisco, P.; Sampaolo, A.; Spagnolo, V. Ppt level carbon monoxide detection based on light-induced thermoelastic spectroscopy exploring custom quartz tuning forks and a mid-infrared QCL. Opt. Express 2021, 9, 25100–25108. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Choung, M.G. Nondestructive determination of herbicide-resistant genetically modified soybean seeds using near-infrared reflectance spectroscopy. Food Chem. 2011, 126, 368–373. [Google Scholar] [CrossRef]
- Feng, X.; Peng, C.; Chen, Y.; Liu, X.; Feng, X.; He, Y. Discrimination of CRISPR/Cas9-induced mutants of rice seeds using near-infrared hyperspectral imaging. Sci. Rep. 2017, 7, 15934. [Google Scholar] [CrossRef]
- Luna, A.S.; da Silva, A.P.; Pinho, J.S.; Ferré, J.; Boqué, R. Rapid characterization of transgenic and non-transgenic soybean oils by chemometric methods using NIR spectroscopy. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2013, 100, 115–119. [Google Scholar] [CrossRef]
- Garcia-Molina, M.D.; Garcia-Olmo, J.; Barro, F. Effective identification of low-gliadin wheat lines by near infrared spectroscopy (NIRS): Implications for the development and analysis of foodstuffs suitable for celiac patients. PLoS ONE 2016, 11, e0152292. [Google Scholar] [CrossRef]
- Li, T.; Su, C. Authenticity identification and classification of Rhodiola species in traditional Tibetan medicine based on Fourier transform near-infrared spectroscopy and chemometrics analysis. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2018, 204, 131–140. [Google Scholar] [CrossRef]
- Carvalho, L.C.; Morais, C.L.; Lima, K.M.; Leite, G.W.; Oliveira, G.S.; Casagrande, I.P.; Neto, J.P.S.; Teixeira, G.H. Using intact nuts and near infrared spectroscopy to classify Macadamia cultivars. Food Anal. Met. 2018, 11, 1857–1866. [Google Scholar] [CrossRef] [Green Version]
- Cordella, C.; Moussa, I.; Martel, A.C.; Sbirrazzuoli, N.; Lizzani-Cuvelier, L. Recent developments in food characterization and adulteration detection: Technique-oriented perspectives. J. Agric. Food Chem. 2002, 50, 1751–1764. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Ying, Y.; Ying, T.; Yu, H.; Fu, X. Discrimination of transgenic tomatoes based on visible/near-infrared spectra. Anal. Chim. Acta 2007, 584, 379–384. [Google Scholar] [CrossRef] [PubMed]
- Rinnan, Å.; Van Den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Smith, H.L.; McAusland, L.; Murchie, E.H. Don’t ignore the green light: Exploring diverse roles in plant processes. J. Exp. Bot. 2017, 68, 2099–2110. [Google Scholar] [CrossRef]
- Gaye, B.; Zhang, D.; Wulamu, A. Improvement of support vector machine algorithm in big data background. Mat. Prob. Eng. 2021, 2021, 5594899. [Google Scholar] [CrossRef]
- Liu, C.; Liu, W.; Lu, X.; Chen, W.; Yang, J.; Zheng, L. Nondestructive determination of transgenic Bacillus thuringiensis rice seeds (Oryza sativa L.) using multispectral imaging and chemometric methods. Food Chem. 2014, 153, 87–93. [Google Scholar] [CrossRef]
- Alcantara, G.B.; Barison, A.; Santos, M.D.S.; Santos, L.P.; de Toledo, J.F.; Ferreira, A.G. Assessment of genetically modified soybean crops and different cultivars by Fourier transform infrared spectroscopy and chemometric analysis. Orbital Electr. J. Chem. 2010, 2, 41–52. [Google Scholar]
- Nugraha, D.T.; Zaukuu, J.L.Z.; Bósquez, J.P.A.; Bodor, Z.; Vitalis, F.; Kovacs, Z. Near-infrared spectroscopy and aquaphotomics for monitoring mung bean (Vigna radiata) sprout growth and validation of ascorbic acid content. Sensors 2021, 21, 611. [Google Scholar] [CrossRef]
- Zaukuu, J.L.Z.; Gillay, Z.; Kovacs, Z. Standardized extraction techniques for meat analysis with the electronic tongue: A case study of poultry and red meat adulteration. Sensors 2021, 21, 481. [Google Scholar] [CrossRef]
- Zaukuu, J.L.Z.; Aouadi, B.; Lukács, M.; Bodor, Z.; Vitális, F.; Gillay, B.; Gillay, Z.; Friedrich, L.; Kovacs, Z. Detecting low concentrations of nitrogen-based adulterants in whey protein powder using benchtop and handheld NIR spectrometers and the feasibility of scanning through plastic bag. Molecules 2020, 25, 2522. [Google Scholar] [CrossRef] [PubMed]
- Sohn, S.I.; Oh, Y.J.; Pandian, S.; Lee, Y.H.; Zaukuu, J.L.Z.; Kang, H.J.; Ryu, T.H.; Cho, W.S.; Cho, Y.S.; Shin, E.K. Identification of Amaranthus Species using Visible-Near-Infrared (Vis-NIR) spectroscopy and machine learning methods. Remote Sens. 2021, 13, 4149. [Google Scholar] [CrossRef]
- Sohn, S.I.; Pandian, S.; Zaukuu, J.L.Z.; Oh, Y.J.; Park, S.-Y.; Na, C.S.; Shin, E.K.; Kang, H.J.; Ryu, T.H.; Cho, W.S.; et al. Discrimination of transgenic canola (Brassica napus L.) and their hybrids with B. rapa using Vis-NIR spectroscopy and machine learning methods. Int. J. Mol. Sci. 2022, 23, 220. [Google Scholar] [CrossRef] [PubMed]
- Pollner, B.; Kovacs, Z. Dedicated Aquaphotomics-Software R-Package „aquap2“General Introduction and Workshop. Aquaphotomics: Understanding Water in the Biological World. In Proceedings of the 5th Kobe University Brussels European Centre Symposium Innovation, Environment and Globalization—Latest EU-Japan Research Collaboration, Bruxelles, Belgium, 14 October 2014. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Model | Preprocessing | Average Accuracy (%) | Run Time (ms) |
|---|---|---|---|---|
| 1 | Linear Discriminant Analysis | Raw Spectra | 98.5 | - |
| Normalization (Area) | 96.7 | - | ||
| Standard Normal Variate | 96.5 | - | ||
| Savitzky–Golay | 98.9 | - | ||
| 2 | Deep Learning | Raw Spectra | 89.3 | 5285.4 |
| Normalization (Area) | 93.3 | 4902.0 | ||
| Standard Normal Variate | 97.2 | 3439.5 | ||
| Savitzky–Golay | 99.1 | 3287.5 | ||
| 3 | Support Vector Machine | Raw Spectra | 97.1 | 6883.3 |
| Normalization (Area) | 87.9 | 23,700.0 | ||
| Standard Normal Variate | 99.4 | 7341.6 | ||
| Savitzky–Golay | 98.8 | 7933.3 | ||
| 4 | Generalized Linear Model | Raw Spectra | 82.9 | 3691.6 |
| Normalization (Area) | 93.2 | 3364.5 | ||
| Standard Normal Variate | 93.6 | 5212.5 | ||
| Savitzky–Golay | 91.5 | 3231.2 | ||
| 5 | Decision Tree | Raw Spectra | 76.7 | 3014.5 |
| Normalization (Area) | 79.4 | 2977.0 | ||
| Standard Normal Variate | 67.1 | 2995.8 | ||
| Savitzky–Golay | 80.1 | 2785.4 | ||
| 6 | Naive Bayes | Raw Spectra | 63.5 | 7727.0 |
| Normalization (Area) | 62.6 | 3614.5 | ||
| Standard Normal Variate | 84.8 | 3691.6 | ||
| Savitzky–Golay | 92.4 | 3575.0 | ||
| 7 | Fast Large Margin | Raw Spectra | 94.6 | 9466.6 |
| Normalization (Area) | 74.8 | 10,341.6 | ||
| Standard Normal Variate | 98.8 | 9095.8 | ||
| Savitzky–Golay | 96.9 | 9552.0 | ||
| 8 | Random Forest | Raw Spectra | 79.9 | 3612.5 |
| Normalization (Area) | 85.9 | 4618.7 | ||
| Standard Normal Variate | 92.4 | 4583.3 | ||
| Savitzky–Golay | 92.6 | 4062.5 |
| Model | Species Accuracy (% ± SE) | ||||
|---|---|---|---|---|---|
| Raw Spectra | Normalization (Area) | Savitzky–Golay | SNV | Significance | |
| Naive Bayes | 63.5 ± 3.2 Cb | 62.6 ± 5.6 Cb | 92.4 ± 3.3 a | 84.8 ± 2.1 ABa | *** |
| Generalized Linear Model | 82.9 ± 3 AB | 93.2 ± 3.2 A | 91.5 ± 6 | 93.6 ± 3.5 A | ns |
| Fast Large Margin | 94.6 ± 3 ABa | 74.8 ± 2.5 BCb | 96.9 ± 3.1 a | 98.8 ± 0.8 Aa | *** |
| Deep Learning | 89.3 ± 6.1 AB | 93.3 ± 5 A | 99.1 ± 0.6 | 97.2 ± 2 A | ns |
| Decision Tree | 76.7 ± 11.7 BC | 79.4 ± 10.2 AB | 80.1 ± 15.4 | 67.1 ± 14.7 B | ns |
| Random Forest | 79.9 ± 4.4 ABC | 85.9 ± 3.7 AB | 92.4 ± 4.6 | 92.6 ± 4.6 A | ns |
| Support Vector Machine | 97.1 ± 2.9 Aa | 87.9 ± 2.5 ABb | 98.8 ± 0.8 a | 99.4 ± 0.3 Aa | ** |
| Significance | ** | ** | ns | * | |
| Source | df | SS | MS | f Value | p Value |
|---|---|---|---|---|---|
| Preprocessing (P) | 3 | 2289.98041 | 763.326803 | 5.35 | 0.002 |
| Model (M) | 7 | 6677.677368 | 1112.946228 | 7.8 | <0001 |
| P × M | 21 | 3664.723846 | 203.595769 | 1.43 | 0.0005 |
| Error | 84 | 11,992.48392 | 142.76767 | ||
| Total | 115 | 24,624.86555 |
| Classified as | |||||
|---|---|---|---|---|---|
| SNV/SVM | B. napus | GM B. napus | B. juncea | F1 Hybrid | Classification Accuracy (%) |
| B. napus | 86 | 1 | 0 | 0 | 98.85 |
| GM B. napus | 0 | 84 | 1 | 0 | 98.82 |
| B. juncea | 0 | 0 | 85 | 0 | 100 |
| F1 hybrid | 0 | 0 | 0 | 86 | 100 |
| Class recall (%) | 100 | 98.82 | 98.84 | 100 | - |
| Classified as | |||||
| Savitzky–Golay/Deep Learning | B. napus | GM B. napus | B. juncea | F1 Hybrid | Classification Accuracy (%) |
| B. napus | 84 | 1 | 0 | 0 | 98.82 |
| GM B. napus | 2 | 84 | 0 | 0 | 97.67 |
| B. juncea | 0 | 0 | 86 | 0 | 100 |
| F1 hybrid | 0 | 0 | 0 | 86 | 100 |
| Class recall (%) | 97.67 | 98.82 | 100 | 100 | - |
| Classified as | |||||
| Savitzky–Golay/SVM | B. napus | GM B. napus | B. juncea | F1 Hybrid | Classification Accuracy (%) |
| B. napus | 84 | 3 | 1 | 0 | 96.65 |
| GM B. napus | 1 | 83 | 2 | 0 | 98.81 |
| B. juncea | 0 | 0 | 85 | 0 | 100 |
| F1 hybrid | 0 | 0 | 0 | 86 | 100 |
| Class recall (%) | 98.82 | 96.51 | 100 | 100 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sohn, S.-I.; Pandian, S.; Oh, Y.-J.; Zaukuu, J.-L.Z.; Na, C.-S.; Lee, Y.-H.; Shin, E.-K.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S.; et al. Vis-NIR Spectroscopy and Machine Learning Methods for the Discrimination of Transgenic Brassica napus L. and Their Hybrids with B. juncea. Processes 2022, 10, 240. https://doi.org/10.3390/pr10020240
Sohn S-I, Pandian S, Oh Y-J, Zaukuu J-LZ, Na C-S, Lee Y-H, Shin E-K, Kang H-J, Ryu T-H, Cho W-S, et al. Vis-NIR Spectroscopy and Machine Learning Methods for the Discrimination of Transgenic Brassica napus L. and Their Hybrids with B. juncea. Processes. 2022; 10(2):240. https://doi.org/10.3390/pr10020240
Chicago/Turabian StyleSohn, Soo-In, Subramani Pandian, Young-Ju Oh, John-Lewis Zinia Zaukuu, Chae-Sun Na, Yong-Ho Lee, Eun-Kyoung Shin, Hyeon-Jung Kang, Tae-Hun Ryu, Woo-Suk Cho, and et al. 2022. "Vis-NIR Spectroscopy and Machine Learning Methods for the Discrimination of Transgenic Brassica napus L. and Their Hybrids with B. juncea" Processes 10, no. 2: 240. https://doi.org/10.3390/pr10020240