
Atomistic Descriptors for Machine Learning Models of Solubility Parameters for Small Molecules and Polymers
by
 , , and
, , and
Mingzhe Chi
1 ,
,
Rihab Gargouri
2,
Tim Schrader
1,
Kamel Damak
2,
Ramzi Maâlej
2 and
and
Marek Sierka
1,* 1
Otto Schott Institute of Materials Research, Friedrich Schiller University Jena, 07743 Jena, Germany
2
Georesources Materials Environment and Global Changes Laboratory (GEOGLOB), Faculty of Sciences of Sfax, Sfax University, Sfax 3018, Tunisia
*
Author to whom correspondence should be addressed.
Polymers 2022, 14(1), 26; https://doi.org/10.3390/polym14010026
Submission received: 29 October 2021
/
Revised: 8 December 2021
/
Accepted: 15 December 2021
/
Published: 22 December 2021
(This article belongs to the Special Issue Polymers and Digitalization)
Abstract
:Descriptors derived from atomic structure and quantum chemical calculations for small molecules representing polymer repeat elements were evaluated for machine learning models to predict the Hildebrand solubility parameters of the corresponding polymers. Since reliable cohesive energy density data and solubility parameters for polymers are difficult to obtain, the experimental heat of vaporization of a set of small molecules was used as a proxy property to evaluate the descriptors. Using the atomistic descriptors, the multilinear regression model showed good accuracy in predicting of the small-molecule set, with a mean absolute error of 2.63 kJ/mol for training and 3.61 kJ/mol for cross-validation. Kernel ridge regression showed similar performance for the small-molecule training set but slightly worse accuracy for the prediction of of molecules representing repeating polymer elements. The Hildebrand solubility parameters of the polymers derived from the atomistic descriptors of the repeating polymer elements showed good correlation with values from the CROW polymer database.
1. Introduction
Computer-aided predictions of polymer solubility and miscibility with small molecules and drugs are of fundamental importance in a number of industrial applications, including the use of polymers as drug carriers in the growing field of nanomedicine [1]. Among various approaches, solubility and miscibility predictions based on Hildebrand solubility parameters are often used for polymer blends, polymer solutions and polymer–drug mixtures [2]. The Hildebrand model uses a solubility parameter (SP), , defined as the square root of the cohesive energy density:
where is the cohesive energy, and is the molar volume. The miscibility of two substances can be estimated by comparing the absolute value of the difference in their SPs. If it is more than 2 MPa1/2, the two substances are deemed immiscible, and with a difference of less than 2 MPa1/2, they are considered miscible [3]. The factor 2 MPa1/2 was determined on the basis of empirical considerations [3]. The Hildebrand SP can also be used to roughly estimate the Flory–Huggins interaction parameter [4], which is another useful tool for predicting the miscibility of polymer blends [5].
For low-molecular-weight compounds, and can be estimated from the heat of vaporization:
where is the heat of vaporization [2]. However, for polymers, SP is difficult to obtain from experiments [6]. Various experimental methods can be used to indirectly derive SP, such as hot-stage microscopy, differential scanning calorimetry (DSC) and ultraviolet spectroscopy [7,8], but these methods provide limited accuracy and can only be used for a small range of polymer species.
In addition to experimental methods, SP can also be calculated by empirical approaches and computer simulations. A group-contribution method (GC) is an empirical approach, which uses the sum of the contributions of structural and functional groups to estimate polymer properties [9]. GC is easy to apply but has limited accuracy due to the use of empirical assumptions. Although new GC approaches are being developed, a general model that can cover a wide range of polymer species and polymer properties is not available [10]. Atomistic simulations employing force fields and interatomic potential functions are another tool for predicting polymer properties [5,11]. However, accurate SP predictions using atomistic simulations are computationally demanding, especially for polymers and compounds with complex structures [12].
In this regard, data-driven approaches based on machine learning (ML) models have become an appealing alternative to simple empirical approaches and atomistic simulations. ML models have been developed to predict the physical or chemical properties of materials with good accuracy, including solubility parameters [11]. However, the predictive power of ML models depends heavily on the availability of accurate and consistent target data covering a wide structural and compositional range, as well as unbiased descriptors, i.e., readily available observables that can be linked to the target property [13]. Such observables can be derived, e.g., from experimental data or from quantum chemical or atomistic calculations [13,14]. It is difficult to obtain relevant experimental data on target properties and descriptors for predicting the SP of polymers. In the case of descriptors, one approach is to use the features derived for monomer molecules [13]. However, polymer properties may be fundamentally different from those of the monomer. Therefore, small organic molecules that are structurally similar to the repeating element (RE) of the polymer may be a better choice. For a given polymer, different molecules can be identified that represent REs, as shown in Figure 1 for polyethylene glycol (PEG). Both ethylene glycol and ethanol, as polar molecules forming strong hydrogen bonds, are poor choices for deriving molecular descriptors for ML models for PEG.
In this work, descriptors derived from the atomic structure and quantum chemical calculations of small molecules as potential polymer REs are evaluated for ML models of the polymer SP. Since reliable cohesive energy density and SP data for polymers are difficult to obtain in experiments and simulations, a surrogate target property is used to evaluate the descriptors, namely, the experimental heat of vaporization of the small molecules. For low-molecular-weight compounds, can usually be determined with good accuracy [15]. Subsequently, the relationship between of the polymer RE and the available SP of the polymers is investigated.
2. Method
2.1. Molecular Datasets
ML models for predicting were trained and tested on a dataset of small organic molecules including hydrocarbons, alcohols, acids, amines, ketones, aldehydes, nitriles, organic chlorides and benzene derivatives. A summary of the dataset is shown in Table 1. Figure 2 shows examples of the largest molecules used. The ML models were then applied to another dataset of organic molecules with structural similarity to REs of popular polymers to predict and correlate it with the polymer SP. This dataset is summarized in Table 2.
The organic molecules in both datasets cover a wide range of values, from 8.19 kJ/mol (methane) to 69.00 kJ/mol (heptanoic acid), and represent different chemical structures. The experimental values of for all molecules, measured around a normal boiling point, were collected from the literature (see Supplementary Materials).
2.2. Computational Details
All density functional theory calculations were performed as a gas phase using the Turbomole program package [16]. The Becke 3-parameter Lee–Yang–Parr (B3-LYP) [17] exchange–correlation functional was employed, along with triple zeta valence plus polarization (def2-TZVP) [18] basis sets and Grimme dispersion correction (DFT-D3) [19]. The geometry convergence criteria for DFT calculations were hartree for the energy change and hartree/bohr for the gradient norm. Count descriptors and topological descriptors were calculated with the PaDEL-Descriptor program [20]. Python 3 with the Scikit-learn package was used for building all machine learning models [21].
2.3. Molecular Descriptors
In the current work, four quantum chemical descriptors were obtained using DFT calculations: atomization energy (AE), quadrupole moment (QM), chemical hardness and electronegativity . There are different definitions for the quadrupole moment [22,23]. In the present work, the quadrupole moment was defined as the second moment of charge [23], and QM was taken as
where , and are diagonal elements of the second moment of the charge tensor.
Chemical hardness and electronegativity are chemical reactivity descriptors that were applied in an artificial neural network for predicting solvation energies [24]. They are defined as
and
where and denote the energies of the highest occupied (HOMO) and lowest unoccupied molecular orbitals (LUMO), respectively.
The remaining descriptors, such as number of aromatic bonds (nAromBond) and number of heavy atoms (nHeavyAtom), were generated using the PaDEL-Descriptor [20] program based on the atomic structures of molecules. The descriptors were obtained using exactly the same method for both datasets (Table 1 and Table 2). The full specification of the descriptors is given in the Supplementary Materials.
2.4. Machine Learning Models
Two supervised machine learning models were used: multilinear regression (MLR) and kernel ridge regression (KRR) [25]. MLR is the simplest ML model using the least square method and has been widely applied in data analysis. The MLR model can be represented as a linear combination of all descriptors
where is the coefficient of each descriptor , and is the intercept. The training of the MLR model involves the determination of the best and . All hyperparameters used for MLR training used the default values implemented in the Scikit-learn package.
KRR is a combination of the kernel function and ridge regression, which is an improvement on the ordinary linear regression method [26,27]. There are several kernel functions available for different tasks, and in the present work, the polynomial kernel function was applied
where and are descriptors, and hyperparameters c and d are the soft margin constant and degree of the polynomial kernel, respectively. The accuracy and performance of the model usually depend on the choice of hyperparameters. Since the dataset was relatively small, changes in parameters other than c and d had little effect on the model accuracy and were therefore set to constant values (alpha (regularization strength) = 0.001 and gamma = none). In the current work, c and d in Equation (7) were determined using the grid search function of Scikit-learn. Based on the grid search results, the value of c had little effect on the model and was finally set to 1. The models with d = 1 and d = 2 showed similar performance, and both models were retained for further study. Changes in parameters other than c and d had little effect on the model accuracy and were therefore left at the default values implemented in the Scikit-learn package.
Due to the limited size of the dataset (61 molecules in total), the leave-one-out cross-validation (LOOCV) method was used in the current work, aiming to make optimal use of each sample and to obtain a more justified model. LOOCV is an extreme case of cross-validation, in which only one sample is selected for testing in each cycle, and the other samples are used to train the model until all samples have been selected once. The final model is optimized by averaging the LOOCV results. MLR and KRR models were trained with the same dataset, and LOOCV was applied for all models. After training and LOOCV, all models were used to predict of polymer REs (16 molecules in Table 2), and the performance of all models was analyzed [28] using root-mean-square error (RMSE)
mean absolute error (MAE)
and the average of relative error (ARE)
where and are the reference and predicted values, respectively. In addition, the coefficient of determination (R2) was used to describe the proportion of variability in a dataset that can be explained by the model [29].
3. Discussion
3.1. Selection of Molecular Descriptors
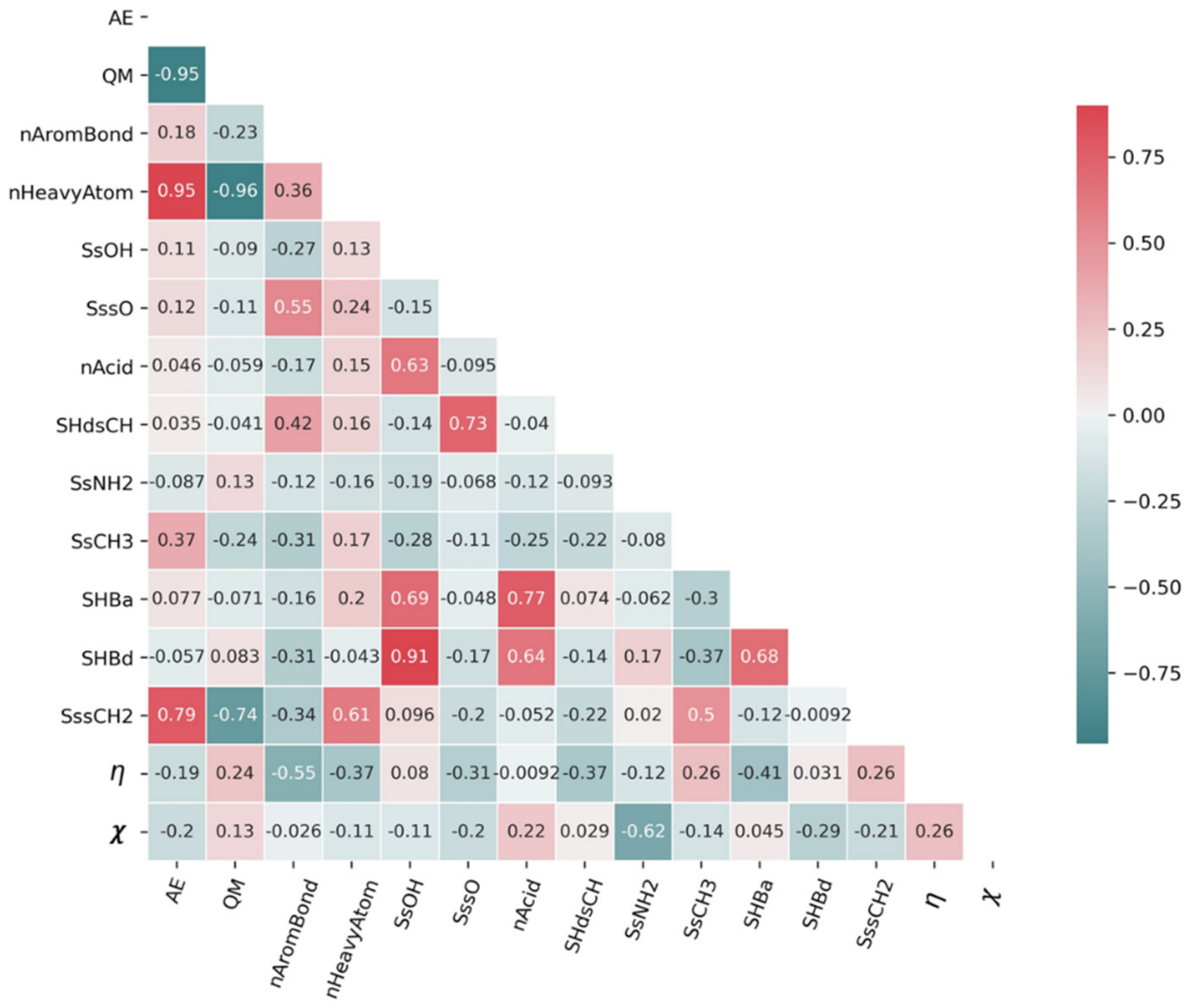
Molecular descriptors were manually selected and filtered by analyzing multicollinearity based on correlation coefficients. For this, descriptors were selected in addition to the quantum chemical descriptors that showed low multicollinearity (correlation coefficient within ±0.75) and a high degree of correlation with . The 15 descriptors finally selected are shown in Figure 3.
3.2. Predictions of for Small Organic Molecules
The final MLR model for predicting (in kJ/mol) is given as
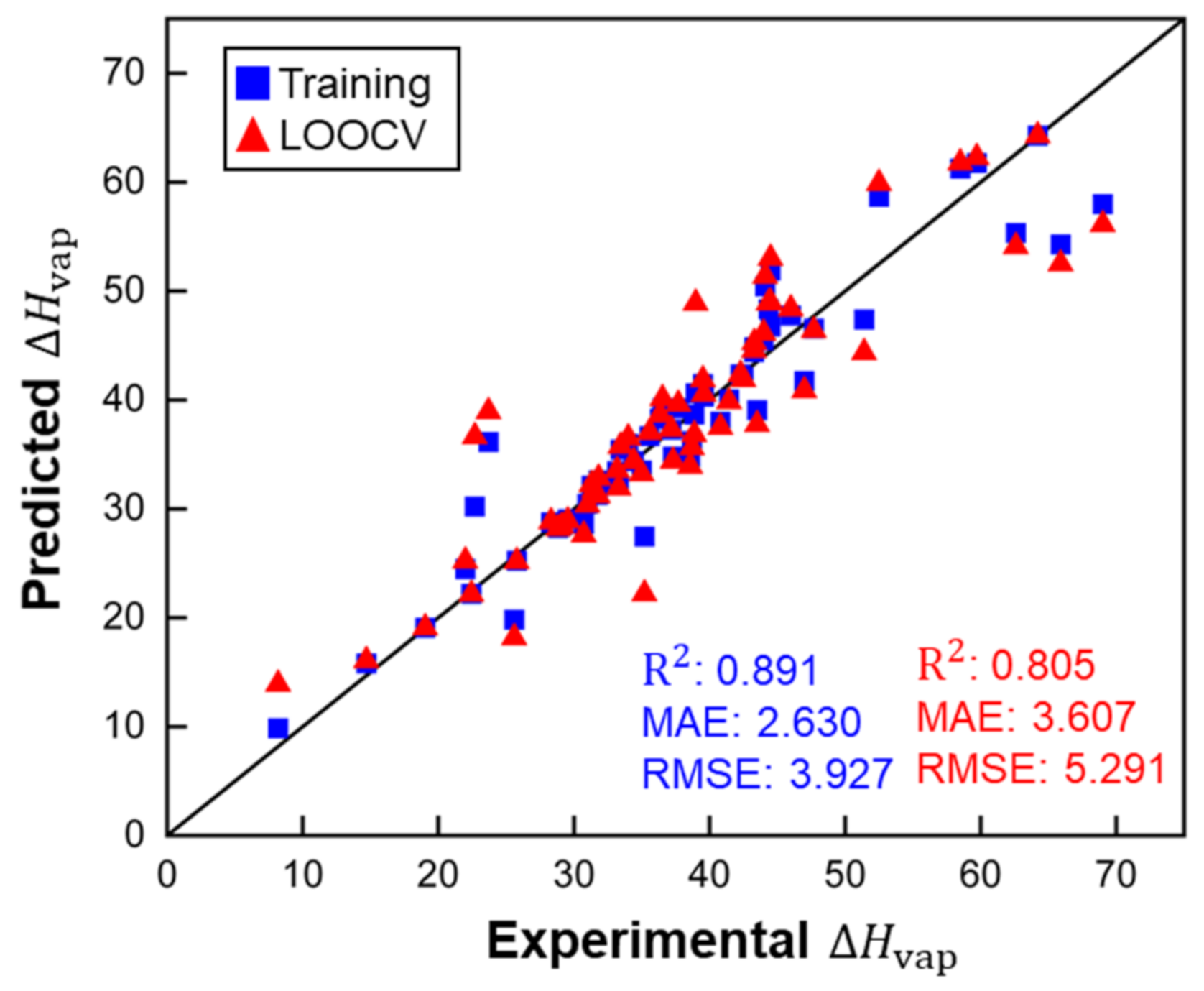
This model does not contain any unreasonably small or large factors for descriptors, which indicates that there are no irrelevant or redundant descriptors. Figure 4 shows that MLR performed well for the training set of small molecules and the LOOCV, according to the R2 score and other metrics. ARE for training (0.071) and LOOCV (0.105) showed the same trend as the other metrics. The MLR model showed good accuracy for predicting of molecules, with a maximum deviation of 12.43 kJ/mol for ethanoic acid. However, there are large disparities in the values of for ethanoic acid across the literature (from 23.7 (at 391.1 K) to 42 (at 305 K) kJ/mol) [32,33]. The overall deviation is within experimental accuracy. For the LOOCV, both the RMSE of 5.291 kJ/mol and MAE of 3.607 kJ/mol are within ranges indicative of good accuracy.
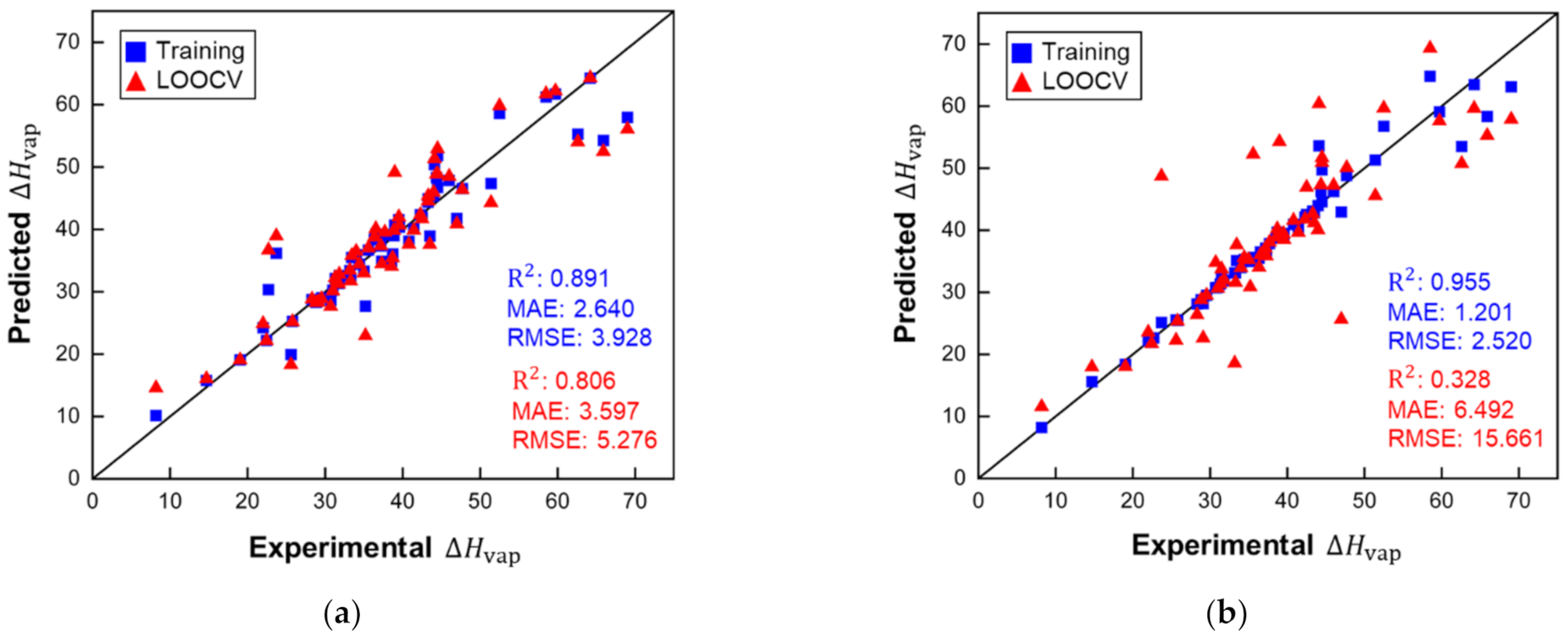
Compared to the MLR model, the KRR model (d = 1) did not perform better in training, but all metrics had a small lead in cross-validation, which showed slightly better stability. KRR (d = 2) performed best during training but was the worst in LOOCV, and this case was most likely due to the overfitting. Considering the size of the datasets used in the current work, high-scoring ML models trained with small datasets can often suffer from overfitting.
3.3. Predictions of for Polymer Repeating Elements
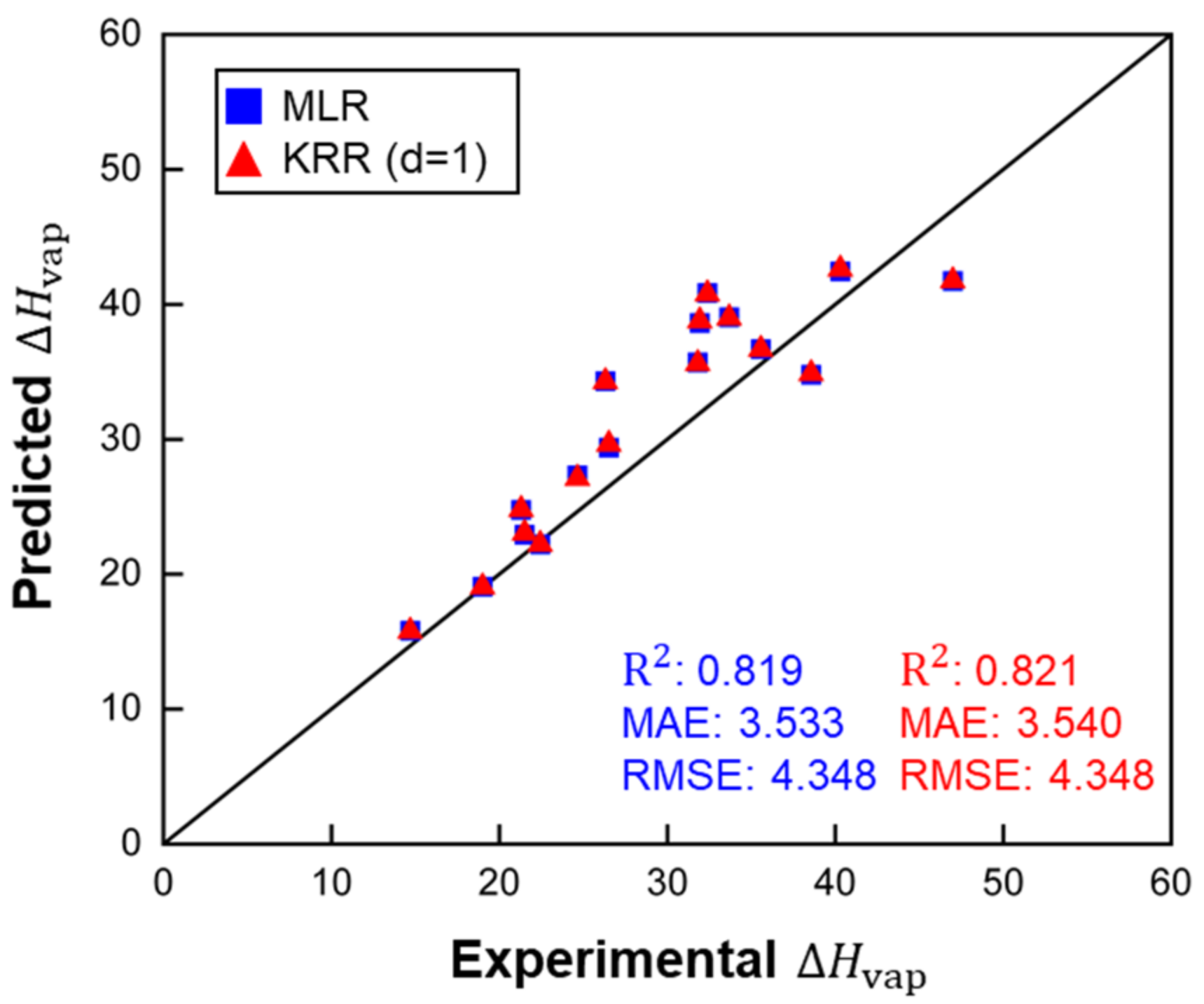
All three models were applied to predict of molecules representing polymer REs. Table 3 and Figure 6 show that the MLR and KRR (d = 1) models provided the best accuracy. The KRR (d = 2) model failed to predict of polymer RE, and the much larger error of the KRR (d = 2) suggests that the model was overfitted. As mentioned, KRR algorithms do not offer advantages on small datasets.
Figure 4, Figure 5 and Figure 6 demonstrate that the MLR model showed slightly worse performance than the two KRR models during training and cross-validation, but the MAE of MLR for polymer RE was better than that of KRR (d = 1). Therefore, the MLR model and the KRR model (d = 1) in the current work have better extrapolation ability than the KRR (d = 2) models. However, the KRR algorithm with higher d could still yield better results for a larger dataset with more complex structures and chemical compositions.
3.4. Hildebrand Solubility Parameter of Polymers
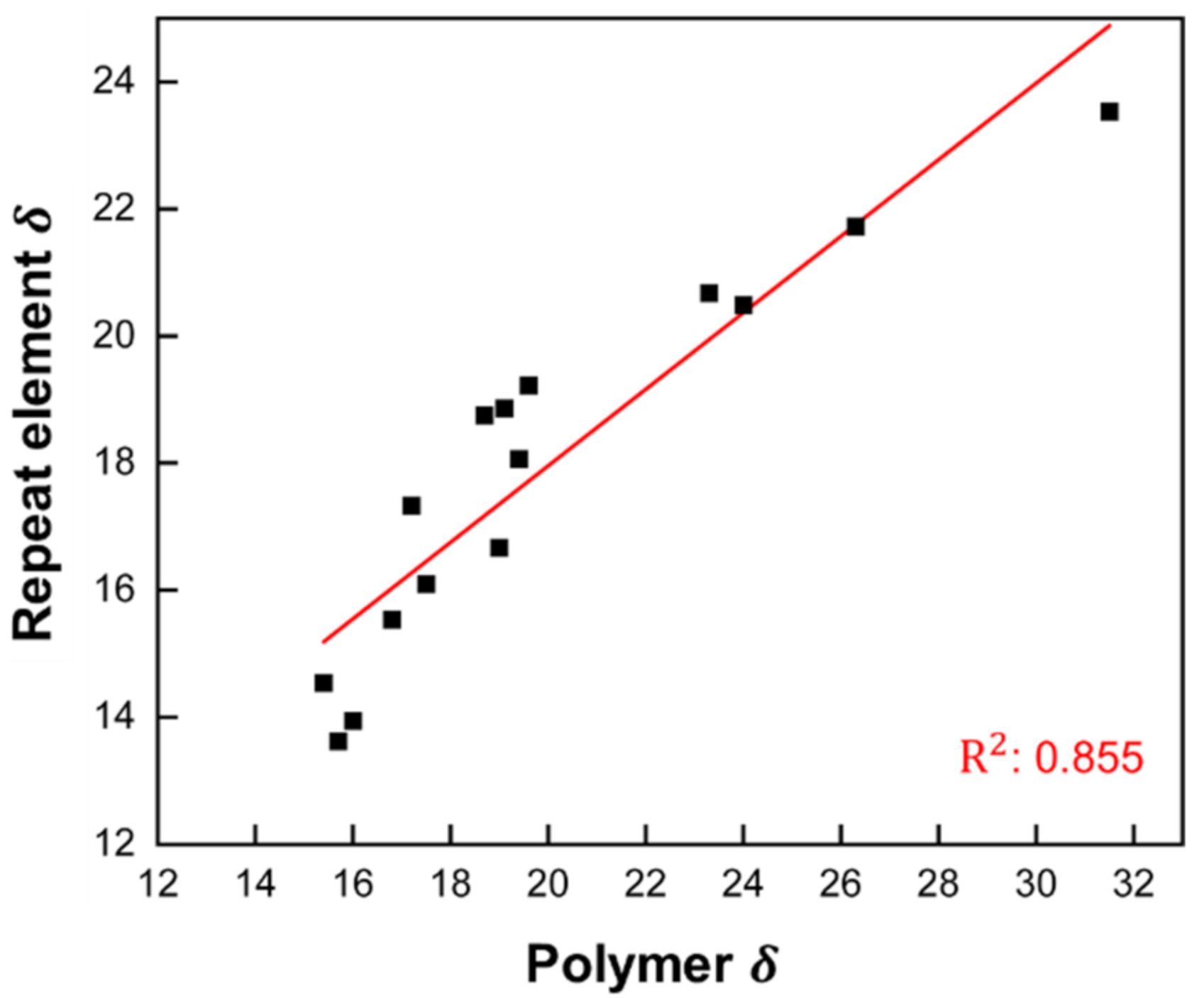
Our results show that the heat of vaporization of small molecules and polymeric REs, and thus their SPs, can be predicted with good accuracy using the MLR and KRR (d = 1) models. The question now is how well the Hildebrand SP of RE correlates with the SP of the corresponding polymers. For this, Hildebrand SPs of polymers were collected from the CROW polymer database [34] with recommended values, and SPs of REs were calculated from MLR-predicted (see Supplementary Materials). Figure 7 shows the correlation of Hildebrand SPs between polymers and REs. The linear model yields an R2 value of 0.855.
There are several factors that can affect the accuracy of Hildebrand SP predictions for polymers. First, the experimental values of SPs for polymers can only be determined indirectly, and the accuracy of such values is essentially indeterminate. Second, the SPs are determined not only by the internal structure of the polymer chains, reflected here in the descriptors derived from the polymer RE, but also by factors such as the degree of polymerization, polydispersity, and the nature of the end groups. Such factors cannot be determined from the properties of REs alone and must be derived from experimental data. How well the two descriptors, chemical hardness and electronegativity, actually help in the prediction of solubility parameters needs to be further investigated, as intuitively, the association between the two and polymer solubility is not strong. In addition, larger chemical structures, such as oligomers with several repeating units, may provide more information about inter- and intramolecular interactions and can improve the accuracy of machine learning models. Simulations of such structures are obviously less computationally expensive than simulations of polymers, but finding suitable descriptors may still be a challenge. This is also one of the pathways for future research studies.
4. Conclusions
In this work, descriptors derived from atomic structure and quantum chemical calculations for small molecules as potential polymer repeating elements were evaluated for machine learning models to predict the Hildebrand solubility parameters of the corresponding polymers. Since reliable cohesive energy density data and solubility parameters for polymers are difficult to obtain, the experimental heat of vaporization of small molecules was used as a proxy property to evaluate the descriptors. The multilinear and kernel ridge regression model (with polynomial kernel degree = 1) showed good and very similar performance in training, cross-validation and the prediction of molecules representing polymer repeating elements. The kernel ridge regression model (degree = 2) was strongly overfitted, which was revealed by its poor performance in cross-validation and prediction. The Hildebrand solubility parameters derived from the multilinear regression model for the of polymer repeating elements showed good correlation with the solubility parameters of the corresponding polymers collected from the CROW polymer database. However, atomistic descriptors derived from polymer repeating elements only reflect the internal structure of the polymer chains. More accurate models for predicting the Hildebrand solubility parameters of polymers must take into account additional relevant factors, such as the degree of polymerization, polydispersity and the nature of the polymer end groups. Such factors cannot be determined from the properties of the repeating elements of the polymer alone and must be derived from experimental data.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/polym14010026/s1, Table S1: Heat of vaporization of small molecules; Table S2: Heat of vaporization of polymer REs; Table S3: MLR predictions on polymer RE dataset; Table S4: KRR predictions on polymer RE dataset; Table S5: Hildebrand solubility parameter of polymers and calculated of REs; Table S6: Complete dataset of small organic molecules; Table S7: Complete dataset of polymer REs.
Author Contributions
Conceptualization, M.S.; methodology, M.S.; investigation, M.C., R.G. and T.S.; writing—original draft preparation, M.C., R.G., M.S., K.D. and R.M.; writing—review and editing, M.C., R.G., M.S., K.D. and R.M.; supervision, M.S. and R.M.; project administration, M.S.; funding acquisition, M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) within the Collaborative Research Center PolyTarget (SFB 1278, project number 316213987, project A01).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All related data and results can be found in Supplementary Materials.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qiu, L.Y.; Bae, Y.H. Polymer architecture and drug delivery. Pharm. Res. 2006, 23, 1–30. [Google Scholar] [CrossRef]
- Hansen, C.M. 50 Years with solubility parameters—Past and future. Prog. Org. Coat. 2004, 51, 77–84. [Google Scholar] [CrossRef]
- Venkatram, S.; Kim, C.; Chandrasekaran, A.; Ramprasad, R. Critical Assessment of the Hildebrand and Hansen Solubility Parameters for Polymers. J. Chem. Inf. Model. 2019, 59, 4188–4194. [Google Scholar] [CrossRef]
- Erlebach, A.; Ott, T.; Otzen, C.; Schubert, S.; Czaplewska, J.; Schubert, U.S.; Sierka, M. Thermodynamic compatibility of actives encapsulated into PEG-PLA nanoparticles: In Silico predictions and experimental verification. J. Comput. Chem. 2016, 37, 2220–2227. [Google Scholar] [CrossRef]
- Erlebach, A.; Muljajew, I.; Chi, M.Z.; Buckmann, C.; Weber, C.; Schubert, U.S.; Sierka, M. Predicting Solubility of Small Molecules in Macromolecular Compounds for Nanomedicine Application from Atomistic Simulations. Adv. Theor. Simul. 2020, 3, 2000001. [Google Scholar] [CrossRef] [Green Version]
- Belmares, M.; Blanco, M.; Goddard, W.A.; Ross, R.B.; Caldwell, G.; Chou, S.H.; Pham, J.; Olofson, P.M.; Thomas, C. Hildebrand and Hansen solubility parameters from molecular dynamics with applications to electronic nose polymer sensors. J. Comput. Chem. 2004, 25, 1814–1826. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, S.P.; Lucas, E.F.; Gonzalez, G.; Spinelli, L.S. Determining Hildebrand Solubility Parameter by Ultraviolet Spectroscopy and Microcalorimetry. J. Brazil. Chem. Soc. 2013, 24, 1998–2007. [Google Scholar] [CrossRef]
- Forster, A.; Hempenstall, J.; Tucker, I.; Rades, T. Selection of excipients for melt extrusion with two poorly water-soluble drugs by solubility parameter calculation and thermal analysis. Int. J. Pharm. 2001, 226, 147–161. [Google Scholar] [CrossRef]
- Constantinou, L.; Gani, R. New Group-Contribution Method for Estimating Properties of Pure Compounds. AIChE J. 1994, 40, 1697–1710. [Google Scholar] [CrossRef]
- Stefanis, E.; Constantinou, L.; Panayiotou, C. A group-contribution method for predicting pure component properties of biochemical and safety interest. Ind. Eng. Chem. Res. 2004, 43, 6253–6261. [Google Scholar] [CrossRef]
- Walden, D.M.; Bundey, Y.; Jagarapu, A.; Antontsev, V.; Chakravarty, K.; Varshney, J. Molecular Simulation and Statistical Learning Methods toward Predicting Drug-Polymer Amorphous Solid Dispersion Miscibility, Stability, and Formulation Design. Molecules 2021, 26, 182. [Google Scholar] [CrossRef]
- Cailliez, F.; Bourasseau, A.; Pernot, P. Calibration of Forcefields for Molecular Simulation: Sequential Design of Computer Experiments for Building Cost-Efficient Kriging Metamodels. J. Comput. Chem. 2014, 35, 130–149. [Google Scholar] [CrossRef]
- Karelson, M.; Lobanov, V.S.; Katritzky, A.R. Quantum-chemical descriptors in QSAR/QSPR studies. Chem. Rev. 1996, 96, 1027–1043. [Google Scholar] [CrossRef]
- Cano, G.; Garcia-Rodriguez, J.; Garcia-Garcia, A.; Perez-Sanchez, H.; Benediktsson, J.A.; Thapa, A.; Barr, A. Automatic selection of molecular descriptors using random forest: Application to drug discovery. Expert. Syst. Appl. 2017, 72, 151–159. [Google Scholar] [CrossRef]
- Gopinathan, N.; Saraf, D.N. Predict heat of vaporization of crudes and pure components—Revised II. Fluid Phase Equilibr. 2001, 179, 277–284. [Google Scholar] [CrossRef]
- Perdew, J.P.; Burke, K.; Ernzerhof, M. Generalized gradient approximation made simple. Phys. Rev. Lett. 1996, 77, 3865–3868, Erratum: Phys. Rev. Lett. 1997, 78, 1396. [Google Scholar] [CrossRef] [Green Version]
- Van Nhu, N.; Singh, M.; Leonhard, K. Quantum mechanically based estimation of perturbed-chain polar statistical associating fluid theory parameters for analyzing their physical significance and predicting properties. J. Phys. Chem. B 2008, 112, 5693–5701. [Google Scholar] [CrossRef]
- Zheng, J.J.; Xu, X.F.; Truhlar, D.G. Minimally augmented Karlsruhe basis sets. Theor. Chem. Acc. 2011, 128, 295–305. [Google Scholar] [CrossRef]
- Grimme, S.; Ehrlich, S.; Goerigk, L. Effect of the Damping Function in Dispersion Corrected Density Functional Theory. J. Comput. Chem. 2011, 32, 1456–1465. [Google Scholar] [CrossRef]
- Yap, C.W. PaDEL-Descriptor: An Open Source Software to Calculate Molecular Descriptors and Fingerprints. J. Comput. Chem. 2011, 32, 1466–1474. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Applequist, J. Traceless Cartesian Tensor Forms for Spherical Harmonic-Functions—New Theorems and Applications to Electrostatics of Dielectric Media. J. Phys. A-Math. Gen. 1989, 22, 4303–4330. [Google Scholar] [CrossRef]
- Buckingham, A.D.; Disch, R.L.; Dunmur, D.A. Quadrupole Moments of Some Simple Molecules. J. Am. Chem. Soc. 1968, 90, 3104–3107. [Google Scholar] [CrossRef]
- Yang, J.; Knape, M.J.; Burkert, O.; Mazzini, V.; Jung, A.; Craig, V.S.J.; Miranda-Quintana, R.A.; Bluhmki, E.; Smiatek, J. Artificial neural networks for the prediction of solvation energies based on experimental and computational data. Phys. Chem. Chem. Phys. 2020, 22, 24359–24364. [Google Scholar] [CrossRef]
- Butler, K.T.; Davies, D.W.; Cartwright, H.; Isayev, O.; Walsh, A. Machine learning for molecular and materials science. Nature 2018, 559, 547–555. [Google Scholar] [CrossRef]
- Douak, F.; Melgani, F.; Benoudjit, N. Kernel ridge regression with active learning for wind speed prediction. Appl. Energ. 2013, 103, 328–340. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Duchi, J.; Wainwright, M. Divide and Conquer Kernel Ridge Regression: A Distributed Algorithm with Minimax Optimal Rates. J. Mach. Learn. Res. 2015, 16, 3299–3340. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model. Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Szlek, J.; Paclawski, A.; Lau, R.; Jachowicz, R.; Kazemi, P.; Mendyk, A. Empirical search for factors affecting mean particle size of PLGA microspheres containing macromolecular drugs. Comput. Meth. Prog. Bio. 2016, 134, 137–147. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carre, G.; Marquez, J.R.G.; Gruber, B.; Lafourcade, B.; Leitao, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Dietterich, T. Overfitting and undercomputing in machine learning. ACM Comput. Surv. 1995, 27, 326–327. [Google Scholar] [CrossRef]
- Stephenson, R.M.; Malanowski, S. Handbook of the Thermodynamics of Organic Compounds, 1st ed.; Stephenson, R.M., Ed.; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1987; p. 552. [Google Scholar]
- Majer, V.; Svoboda, V. Enthalpies of Vaporization of Organic Compounds: A Critical Review and Data Compilation; Blackwell Scientific Publications: Oxford, UK, 1986. [Google Scholar]
- Chemical Retrieval on the Web (CROW). Available online: http://www.polymerdatabase.com/ (accessed on 24 October 2021).
Figure 1.
Polyethylene glycol (PEG) and different choices of small molecules with a structural motif of the repeating element of PEG.
Figure 1.
Polyethylene glycol (PEG) and different choices of small molecules with a structural motif of the repeating element of PEG.

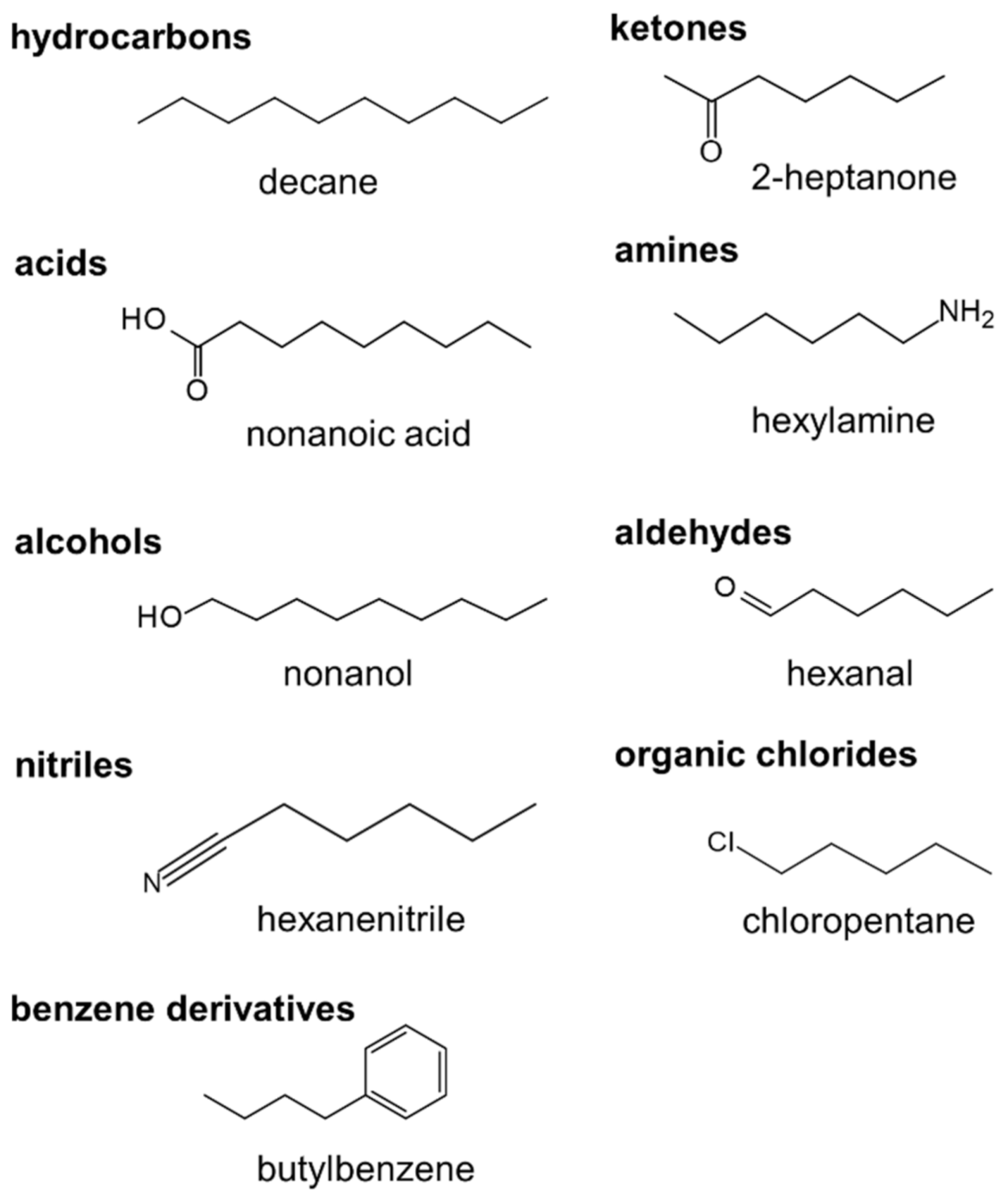
Figure 2.
The largest molecule of each type used in the training dataset: decane (C10H22), nonanoic acid (C8H17COOH), nonanol (C9H19OH), 2-heptanone (C7H14O), hexylamine (C6H13NH2), hexanal (C5H11CHO), hexanenitrile (C5H11CN), chloropentane (C5H11Cl) and butylbenzene (C6H5C4H9).
Figure 2.
The largest molecule of each type used in the training dataset: decane (C10H22), nonanoic acid (C8H17COOH), nonanol (C9H19OH), 2-heptanone (C7H14O), hexylamine (C6H13NH2), hexanal (C5H11CHO), hexanenitrile (C5H11CN), chloropentane (C5H11Cl) and butylbenzene (C6H5C4H9).

Figure 3.
Correlation coefficients among 15 descriptors. AE: atomization energy, QM: quadrupole moment, nAromBond: number of aromatic bonds; nHeavyAtom: number of heavy atoms (all but hydrogen); SsOH: sum of (-OH) E-States; SssO: sum of (-O-) E-States; nAcid: number of acidic groups; SHdsCH: sum of (=CH-) E-States; SsNH2: sum of (-NH2) E-States; SsCH3: sum of (-CH3) E-States; SHBa: sum of E-States for hydrogen bond acceptors; SHBd: sum of E-States for hydrogen bond donors; SssCH2: sum of (-CH2) E-States (see Supplementary Materials); : chemical hardness; : electronegativity.
Figure 3.
Correlation coefficients among 15 descriptors. AE: atomization energy, QM: quadrupole moment, nAromBond: number of aromatic bonds; nHeavyAtom: number of heavy atoms (all but hydrogen); SsOH: sum of (-OH) E-States; SssO: sum of (-O-) E-States; nAcid: number of acidic groups; SHdsCH: sum of (=CH-) E-States; SsNH2: sum of (-NH2) E-States; SsCH3: sum of (-CH3) E-States; SHBa: sum of E-States for hydrogen bond acceptors; SHBd: sum of E-States for hydrogen bond donors; SssCH2: sum of (-CH2) E-States (see Supplementary Materials); : chemical hardness; : electronegativity.

Figure 4.
Performance of the MLR model for predictions of small molecules (ARE for the training set: 0.072 and for LOOCV: 0.105). , MAE and RMSE in kJ/mol.
Figure 4.
Performance of the MLR model for predictions of small molecules (ARE for the training set: 0.072 and for LOOCV: 0.105). , MAE and RMSE in kJ/mol.

Figure 5.
Performance of the KRR models for predictions of small molecules: (a) d = 1 (ARE for the training set: 0.072 and for LOOCV: 0.106), (b) d = 2 (ARE for the training set: 0.026 and for LOOCV: 0.184). , MAE and RMSE in kJ/mol.
Figure 5.
Performance of the KRR models for predictions of small molecules: (a) d = 1 (ARE for the training set: 0.072 and for LOOCV: 0.106), (b) d = 2 (ARE for the training set: 0.026 and for LOOCV: 0.184). , MAE and RMSE in kJ/mol.

Figure 6.
predictions of polymer RE by MLR and KRR (d = 1), ARE for MLR: 0.118 and for KRR (d = 1): 0.118. , MAE and RMSE in kJ/mol.
Figure 6.
predictions of polymer RE by MLR and KRR (d = 1), ARE for MLR: 0.118 and for KRR (d = 1): 0.118. , MAE and RMSE in kJ/mol.

Figure 7.
Correlation of Hildebrandt SP between polymers and REs. All values in MPa1/2. Linear fit model: .
Figure 7.
Correlation of Hildebrandt SP between polymers and REs. All values in MPa1/2. Linear fit model: .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of the molecules included in the training dataset with experimental (see Supplementary Materials, Tables S1 and S6).
Table 1.
Summary of the molecules included in the training dataset with experimental (see Supplementary Materials, Tables S1 and S6).
| Type | Formula | Size n | Number of Molecules |
|---|---|---|---|
| hydrocarbons | CnH2n+2 | 1–10 | 10 |
| acids | CnH2n+1COOH | 0–8 | 9 |
| alcohols | CnH2n+1OH | 1–9 | 9 |
| ketones | CnH2nO/C6H5COCH3 | 3–7 | 6 |
| amines | CnH2n+1NH2 | 1–6 | 5 |
| aldehydes | Cn−1H2n−1CHO/C6H5CHO | 3–6 | 5 |
| nitriles | CnH2n+1CN | 1, 3–6 | 5 |
| organic chlorides | CnH2n+1Cl | 1, 3–6 | 5 |
| benzene derivatives | C6H6/C6H5OCH3/C6H5OCH2CH3/C6H5CH2OCH3 /C6H5CnH2n+1 | 1, 2, 4 | 7 |
Table 2.
Summary of polymer repeating elements (REs) included in the validation set with experimental (see Supplementary Materials, Tables S2 and S7).
Table 2.
Summary of polymer repeating elements (REs) included in the validation set with experimental (see Supplementary Materials, Tables S2 and S7).
| Polymer | Formula | RE | Formula of RE |
|---|---|---|---|
| poly(acrylic acid) | (C3H4O2)n | propanoic acid | CH3CH2COOH |
| poly(allyl cyanide) | (C4H5N)n | butanenitrile | CH3CH2CH2CN |
| polyacrylonitrile | (C3H3N)n | propanenitrile | CH3CH2CN |
| polybutylene | (C4H8)n | butane | CH3CH2CH2CH3 |
| polyethylene (HDPE) | (C2H4)n | ethane | CH3CH3 |
| poly(ethylene glycol) | (C2H4O)n | dimethyl ether | CH3OCH3 |
| cis-1,4-polyisoprene | (C5H8)n | 2-methyl-2-butene | CH3CHC(CH3)2 |
| polyisobutene | (C4H8)n | isobutane | (CH3)2CHCH3 |
| polymethacrylonitrile | (C4H5N)n | isobutyronitrile | (CH3)2CHCN |
| poly(methyl methacrylate) | (C5H8O2)n | methyl butyrate | CH3CH2CH2COOCH3 |
| polypropylene | (C3H6)n | propane | CH3CH2CH3 |
| polystyrene | (C8H8)n | ethylbenzene | C6H5C2H5 |
| poly(vinyl alcohol) | (C2H4O)n | ethanol | CH3CH2OH |
| poly(vinyl acetate) | (C4H6O2)n | ethyl acetate | CH3COOCH2CH3 |
| poly(vinyl chloride) | (C2H3Cl)n | chloroethane | CH3CH2Cl |
| poly(vinyl ethyl ether) | (C4H6O)n | diethyl ether | CH3CH2OCH2CH3 |
Table 3.
Performance comparison of MLR and KRR models (MAE and RMSE in kJ/mol).
| Training Set (LOOCV) | Polymer REs | |||||||
|---|---|---|---|---|---|---|---|---|
| R2 | MAE | RMSE | ARE | R2 | MAE | RMSE | ARE | |
| MLR | 0.805 | 3.607 | 5.291 | 0.105 | 0.819 | 3.533 | 4.348 | 0.118 |
| ) | 0.806 | 3.597 | 5.276 | 0.106 | 0.821 | 3.540 | 4.348 | 0.118 |
| ) | 0.328 | 2.520 | 15.661 | 0.184 | 0.311 | 23.472 | 36.536 | 0.820 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chi, M.; Gargouri, R.; Schrader, T.; Damak, K.; Maâlej, R.; Sierka, M. Atomistic Descriptors for Machine Learning Models of Solubility Parameters for Small Molecules and Polymers. Polymers 2022, 14, 26. https://doi.org/10.3390/polym14010026
AMA Style
Chi M, Gargouri R, Schrader T, Damak K, Maâlej R, Sierka M. Atomistic Descriptors for Machine Learning Models of Solubility Parameters for Small Molecules and Polymers. Polymers. 2022; 14(1):26. https://doi.org/10.3390/polym14010026
Chicago/Turabian StyleChi, Mingzhe, Rihab Gargouri, Tim Schrader, Kamel Damak, Ramzi Maâlej, and Marek Sierka. 2022. "Atomistic Descriptors for Machine Learning Models of Solubility Parameters for Small Molecules and Polymers" Polymers 14, no. 1: 26. https://doi.org/10.3390/polym14010026
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.