
Reinforcement Procedure for Randomized Machine Learning


1
Federal Research Center “Computer Science and Control” of Russian Academy of Sciences, 44/2 Vavilova, 119333 Moscow, Russia
2
Trapeznikov Institute of Control Sciences of Russian Academy of Sciences, 65 Profsoyuznaya, 117997 Moscow, Russia
3
Faculty of Computer Science, National Research University “Higher Schools of Economics”, 20 Myasnitskaya, 109028 Moscow, Russia
*
Author to whom correspondence should be addressed.
Mathematics 2023, 11(17), 3651; https://doi.org/10.3390/math11173651
Submission received: 24 July 2023
/
Revised: 17 August 2023
/
Accepted: 22 August 2023
/
Published: 23 August 2023
(This article belongs to the Section Mathematics and Computer Science)
{kind=link}
Abstract
:This paper is devoted to problem-oriented reinforcement methods for the numerical implementation of Randomized Machine Learning. We have developed a scheme of the reinforcement procedure based on the agent approach and Bellman’s optimality principle. This procedure ensures strictly monotonic properties of a sequence of local records in the iterative computational procedure of the learning process. The dependences of the dimensions of the neighborhood of the global minimum and the probability of its achievement on the parameters of the algorithm are determined. The convergence of the algorithm with the indicated probability to the neighborhood of the global minimum is proved.
Keywords:
randomized machine learning; reinforcement learning; utility function; payoff function; Bellman’s optimality principleMSC:
68Q87; 68T051. Introduction
The beginning of this century has been marked by an increased interest in the problems of reinforcement learning. The essence of this branch of machine learning is to train an object (model, algorithm, etc.) by interacting not with a teacher but with an environment, using the trial-and-error method with reward or penalty depending on the results.
Let us look at this idea, abstracting from the specifics of the experiment, exclusively from the methodological point of view. Clearly, it represents a virtual game procedure where the game is simulated by two player-agents, their strategies, and quantitative assessments of their payoffs and losses. Reflecting on the peculiarities of learning processes, F. Rosenblatt, the author of the perceptron, introduced the concept of learning without a teacher and classified the types of structural tuning for playing automata [1].
The same concept can be traced in the paper [2] by I.M. Gelfand, I.I. Pyatetskij-Shapiro, and M.L. Tsetlin. The authors proposed a mathematical model of a game between two automata with a variable structure changing in the course of interaction with the environment. The interaction results were characterized by quantitative assessments.
Later, the response to the action of “environment” was given a particular term, the so-called “reinforcement.” It became a whole branch in the theory and applications of machine learning. Admittedly, both focused on two problems, clustering (visualization) and pattern recognition. Such problems involve objects with their quantitative characteristics (feature), and, most importantly, the “distances” between them can be calculated. Some kinds of rewards or penalties in the algorithm parameters were arranged based on the distance matrix. Neural networks were used as algorithms [3]. In particular, the so-called “Kohonen maps” were one of the first research works in this area; for details, see [4]. In such maps, the weights of a neural network are adjusted using a game-theoretic model that implements the principle of competition between its nodes: an advantage is gained for the nodes with the minimum distance between the objects at each step of the algorithm.
Subsequently, reinforcement learning was actively developed based on the automata models of an object (agent) interacting with the environment in game-theoretic terms (strategies, utility functions, and payoffs). It was presented to the scientific community as a certain model of human management [5].
Numerous algorithms appeared with different models and volumes of a priori information about the environment, different methods for choosing strategies, and different procedures for forming utility functions. For example, we refer to [6,7,8]. A fairly comprehensive survey of reinforcement learning methods was prepared at the Department of Mathematical Methods of Forecasting (Faculty of Computational Mathematics and Cybernetics, Moscow State University) [9].
The general structure of reinforcement learning procedures is interpreted in terms of a Markov decision process, an extremely general construction of one-step iterations in continuous time t with feedback, accompanied by a specific terminology [10]. Its main components are an agent model with output (agent’s action) and inputs in the form of environment states and rewards, current or averaged over a certain number of iterations, and an environment model with input (agent’s action) and outputs in the form of specified rewards and responses (environment states). The fundamental feature of this procedure is the empirical estimation of the conditional probabilities of rewards for the agent’s actions based on adjustable random Monte Carlo simulations. Such simulations (also called iterations or trials) are used to average a fixed number of current rewards or discount them. The resulting function depends on the environment state and the agent’s strategy and is being taken as a utility function (an analog of the objective function in teacher-assisted learning procedures). During learning, this function is sequentially maximized [11,12] using Bellman’s optimality principle [13] in its stochastic setting [14] (Many researchers of reinforcement learning interpret it as learning without a teacher. Indeed, this approach involves no goal-setting in the form of a teacher’s error-and-response function to be minimized. However, the corresponding role is played by experimentally generated utility and reward functions, which represent a virtual “teacher.” The structures of these functions and methods for calculating their mathematical expectations are based on experimental statistical material and expert opinions. Therefore, the results of using reinforcement learning often provoke discussions.).
Reinforcement learning is actively applied in its traditional field—robotics [15,16,17]—as well as in self-tuning procedures for trade forecasting [18], adaptive programming technologies [19,20], and dynamic decision support [21].
In the papers [22,23], and the book [24], a new machine learning procedure (Randomized Machine Learning, RML) was developed. The basic concept of RML is based on the use of a parameterized model with random parameters, its optimization using the conditional information entropy maximization method, and the subsequent generation of random parameters with optimized probability density functions. According to this concept, it consists of three stages: analytical (determining the entropy-optimal probability density function of randomized model parameters and measurement noises consistent with empirical balances with the data), computational (solving the empirical balance equations numerically), and experimental (performing Monte Carlo simulations to reproduce random sequences with the entropy-optimal probabilistic characteristics).
Because all machine learning problems incorporate intrinsic uncertainty in models and data, it was proposed to maximize the informational entropy of probability density functions (PDFs) of the model parameters and measurement noises as a measure of uncertainty subject to empirical balances with real data. This is a functional entropy-linear programming problem of the Lyapunov type [24]. It has an analytical solution, i.e., the optimal PDFs parameterized by Lagrange multipliers, which are determined from the empirical balance equations.
They are specific nonlinear equations containing the so-called integral components (multidimensional parametrized definite integrals). Therefore, it is impossible to establish any fruitful properties of the equations that would ensure the convergence of iterative procedures for their solution.
In this paper, we employ the GFS method based on Monte Carlo batch iterations [25,26]. The basic method GFS (Generation, Filtration, Selection) is an improved method for finding an approximate value of the global minimum on a unit cube, with an estimate of the size of the neighborhood and the probability of reaching it.
A problem-oriented version of the reinforcement concept is being developed to fundamentally improve the computational properties of the GFS method and the RML procedure as a whole. We prove the theorem on the strict monotonic decrease of the residual function for a system of nonlinear equations of empirical balances in which only measurements of the values of the functions are available. The latter is used to study the convergence with probability 1 of an iterative procedure with reinforcement and to estimate the size of the neighborhood of the global minimum and the probability of reaching it with a finite number of iterations.
Therefore, our contribution to the theory and practice of RMS is to develop a reinforcement scheme that allows us to increase the computational efficiency of the procedure and prove its convergence to the neighborhood of the global minimum with a certain probability.
2. The Mathematical Model of the RML Procedure
We study the problem of learning the model of dependence between one-dimensional input and output data. Consider a set of measurements of input data and output data The latter are measured with random and independent noises of the interval type:
where are left and right boundaries of the interval. The probabilistic properties of the measurement noises are characterized by PDFs , . Suppose that they are continuously differentiable.
The mathematical model of the general dynamic dependence with finite memory is described by a functional [24]:
where parameters .
If the functional is linear and continuous, it can be represented by a segment of the Volterra functional power series [24].
In the equality above, the parameters are random and interval-type:
The probabilistic properties of the parameters are characterized by a PDF which is supposed to be continuously differentiable as well.
The output of the model is observed with additive noises:
Because the model parameters are random and measurements of the output are distorted by random noises, according to (1) and (4) it is generated ensembles of random trajectories and , where .
To form the morphological properties of the PDFs, we adopt the numerical characteristics of ensembles based on moments and called normalized total moments:
where s is a degree of the moment, and S is a number of moments.
The numerical characteristics (5) are the values of the normalized total moments along the trajectories of the observed model output. Output data , , are assumed to be similar indicators of some real process:
In this case, the basic RML algorithm [24] has the following form:
subject to
—the normalization conditions
and
—the empirical balance conditions
Problem (8)–(10) has an analytical solution parameterized by Lagrange multipliers :
where
The Lagrange multipliers figuring in these equations satisfy the empirical balance equations
It can be seen from these equations that they contain the so-called integral components, namely, definite parametrized multidimensional integrals on m-dimensional parallelepipeds (3). In general, it is possible to determine numerically only the values of the functions in which they are included. The latter excludes the possibility of a reasonable declaration of the properties of functions in the left parts of these equations.
3. The Adaptive Method of Monte Carlo Packet Iterations with Reinforcement (the GFS-RF Algorithm)
To solve these equations, in [26], the GFS algorithm was proposed, which is a modification of the random search method, in which the generation (G) of the number of random and independent points specified at each iteration step i on the unit cube in , filtering (F) “good” points, i.e., that fall into the admissible region, their selection (S) according to the values of the residual functional adopted for these equations. The convergence properties of GFS were based on the existence of certain functional properties of the functions involved in these equations. It is proposed to fundamentally modify this algorithm using the ideas of reinforcement.
The Canonical Form of the Problem
The system of formula (13) can be represented in the following form:
where —Lagrange multipliers matrix, and functions
In the vectorization procedure [29], Equations (14) and (15) can be written as
where the vector function , the variable and the 0-vector on the right-hand side have the dimension . The vector , i.e., its components take values .
We reduce problem (16) to the canonical form using the following change of variables:
where is a parameter. This mapping changes the infinity interval to the interval .
As a result, Equation (16) takes the form
We introduce the residual function (the Euclidean norm)
Solving Equation (18) is equivalent to finding points , in which the global minimal of the residual function is reached. Such an interpretation turns out to be fruitful since the global minimum is known:
Thus, solving Equation (18) is reduced to finding the global minimum of a continuous function that is bounded below and algorithmically computable function values on the unit cube:
Because the function is continuous and , there exist its modulus of continuity and positive constants :
where the constants are unknown. In order to use these constants to study the properties of the iterative process, we have to estimate them using only the values of the residual function.
4. Structure of Reinforcement Procedure
Let us introduce a useful terminological framework. The function is treated as an environment and its values on iteration k are responses to the agent’s strategy (action) The quality of the environment response is assessed by a utility function , whose values on iteration k are . The quality of the agent’s actions (strategies) is characterized by a payoff function .
The self-learning algorithm minimizing the residual function (21) based on Monte Carlo packet iterations has the following reinforcement scheme. Note that this algorithm enumerates in a controlled way the values of the residual function on the unit cube. Therefore, the reinforcement scheme is focused on learning rational controllability to accelerate the iterative process.
Agent. The agent’s strategy on iteration k is to generate a packet of uniformly distributed random vectors on the unit cube. The strategy is characterized by the grid step and the number of random values for each component of the vector from the interval . They have the relation
where q is a fixed parameter.
Due to this relation, let the agent’s strategy be the value .
On a given grid step, it is possible to generate a different number of independent random vectors (agent’s strategies) with the uniform distribution on the cube
Assume that in this packet (As has been emphasized, we employ simple Monte Carlo simulations: the same number of independent random numbers with the uniform distribution on is generated for each coordinate of the original space),
For each pair of the th and kth packets, the corresponding -records, and the decrements are calculated by the formulas
and
respectively.
Utility function. The performance of the iterative process is characterized by the values of the decrements. Because the iterative process involves Monte Carlo simulations, the values appear to be random. To operate more reliable trend indicators of the iterative process, we organize m simple Monte Carlo simulations with (23) trials on each iteration k and compute the mean values :
To describe the state of the iterative process, we adopt the concept of exponential comparative utility [30,31]. In this context, the utility function is assumed continuously differentiable, positive, and monotonically decreasing in the variable :
Following [30,31], we choose the exponential comparative utility function
where and are some parameters.
Payoff function. In the concept of reinforcement, the payoff function reflects the dependence of the payoff on the utility . By assumption, the payoff grows with increasing the exponential comparative utility. Therefore, the payoff function satisfies the condition and is monotonically increasing in the variable i.e.,
The reinforcement decision is taken after accumulating a given number L of the payoffs by iteration i.e., the mean payoff over L iterations:
The value is an important characteristic of the reinforcement procedure and is used to optimize the main parameter of MC trials—the number of required random points at the -th iteration step.
Formation of the Monotonic Sequences of Records
Following the concept of reinforcement, we use a Markov iterative process for RML; the state of this process on iteration depends only on the state of the previous iteration (k.)
To search for the agent’s optimal strategy (the value ), let us use Bellman’s optimality principle [13]. In its extended interpretation, the agent’s optimal strategy on iteration depends on the weighted optimal strategy on iteration This principle can be implemented within the additive
or multiplicative
form of the algorithm. Here, and are some parameters.
Remark 1.
where are some parameters.
Generally speaking, Bellman’s optimality principle is only a declaration here, which sometimes may fail. In particular, learning processes and their internal mechanisms are underinvestigated, and they do not necessarily satisfy the Markov property. As a result, the agent’s strategy on iteration can be formed from the weighted optimal strategies on iterations
- For example,
The reinforcement procedure generates an optimal number of random values for each iteration. The local record and the decrement are then determined for the resulting value . They are compared to their counterparts obtained on the previous iteration k. If the first record is smaller than the previous one, it becomes a member of the strictly monotonically decreasing sequence of local records. In this case, the sequence of decrements has strictly negative elements:
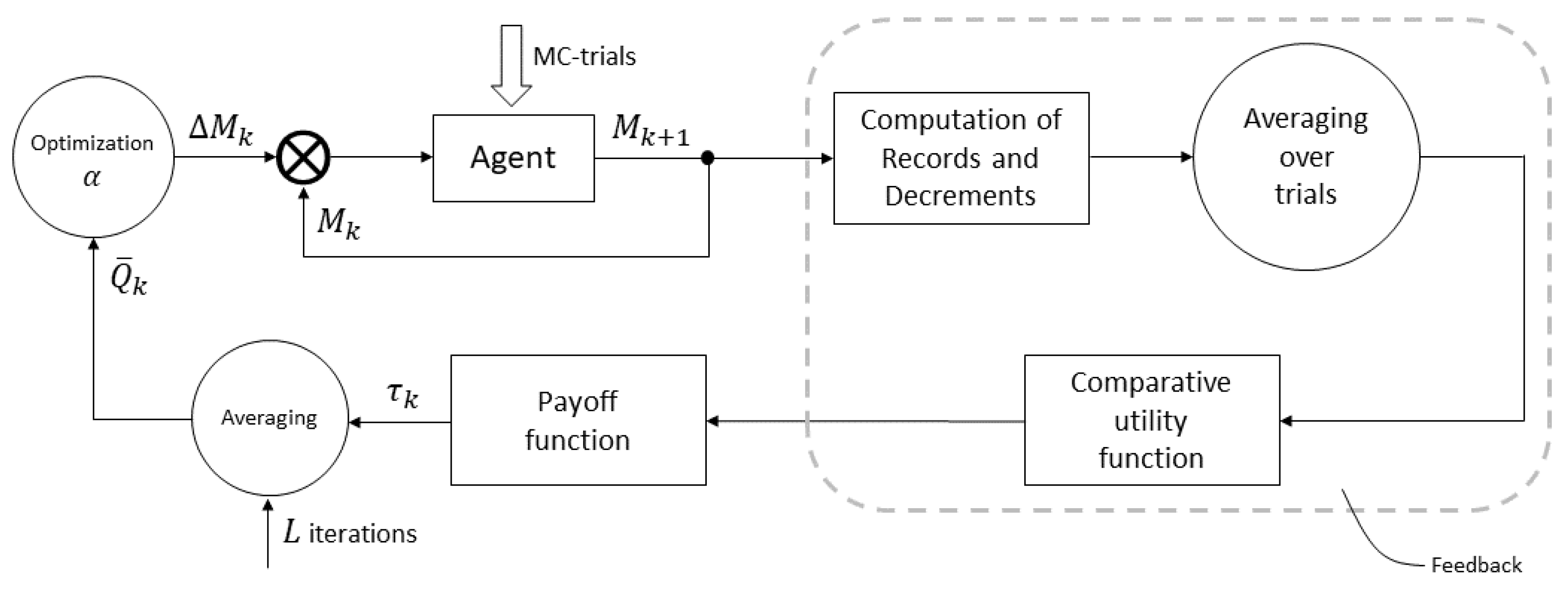
Thus, the Reinforcement module has the logical diagram shown in Figure 1. Agent is the central block of this diagram. It generates the number of random values on iteration as the sum of the number of random values on the previous iteration k and the optimized component with the parameter . At each iterative step, the Optimization block outputs the maximum of the payoffs accumulated over L iterations (a fixed number), which are calculated in the Payoff function block. The necessary values of the comparative utility function , records and and their decrements and are calculated in the Feedback block.
Thus, the described reinforcement procedure proves the following assertion:
Let at each step of the iterative process of finding a solution to the Equations (14) and (16) a reinforcement procedure (30)–(32) is carried out, which implements the Belman optimality principle in the form (33) or (34).
Then, a strictly monotonically decreasing sequence of local records is generated:
Note that the sequence of local records consists of random elements but satisfies the chain of inequalities (36).
5. The Probabilistic Properties of Random Sequences Generated by the GFS-RF Algorithm
5.1. The Probabilistic Characteristics of the Packet
The iterative procedure is based on generating the packet of random and independent vectors with a uniform distribution on the unit d-dimensional cube. The source of this packet is a random generator that produces on each iteration k a -dimensional array of independent random variables with a uniform distribution on the interval .
Consider the d-dimensional unit cube and the grid with step (23). The cube is the union of the elementary cubes with side . We estimate the probability that each elementary cube will contain at least one of the random vectors from the packet generated on iteration
Lemma 1.
The probability satisfies the upper bound
where
as
Proof.
Consider the partition of the interval by a grid with step (23). At least one random value from will fall into the elementary interval with the probability . Let this grid be applied to all sides of the unit cube. Then the event A that at least one random vector from will fall into the elementary cube and has the probability . Hence, the complementary event (not getting into the elementary cube) has the probability .
The upper bounds on the number of elementary intervals and the number of elementary cubes are and respectively. Therefore, the upper bound on the probability of the event A is given by
For large values
which yields (39). □
5.2. The Probabilistic Properties of the Local Record Sequence (36)
The reinforcement procedure forms the strictly monotonically decreasing sequence of local records and the sequence of their arguments . Because of their strict monotonic decrease, it is more convenient to renumber the elements by integers :
Let denote the set of points corresponding to the zero value of the residual function: (20). Due to the continuity of the function , this set is compact.
We introduce the distance between an arbitrary point in the cube and the set :
The elements of the local record sequence are ordered but random values. Therefore, the deviation from the global record (the global minimum) takes a random value on each iteration. Using the assumption that the residual function (19) has a modulus of continuity (22), we can formulate the following Lemma 2.
Lemma 2.
Proof.
Consider the random points generated on iteration i among them, let be the closest one to the set in terms of the distance (42).
At least one of these points will fall with a probability not smaller than into each elementary cube with side see Lemma 1. Hence,
This happens if the point corresponding to the zero value of the residual function is in the center of the elementary cube with side and its nearest random points are in the cube vertices so that each cube contains at least one random point.
By the Hölder condition (22), we have
On the other hand,
This chain of inequalities implies
Inequality (48) provides an upper bound on the deviation from the zero value of the residual function on each iteration obtained after the reinforcement procedure and a lower bound on the probability (38) of its realization. The upper bound is the value of the modulus of continuity of the function J on these iterations. In other words, according to (22),
It gives a lower bound on the probability that the current record will fall into the neighborhood of the global minimum as well as determines its size.
5.3. The Size of the Neighborhood of the Global Minimum
Consider a sequence of decrements on a finite number of iterations k:
We represent the decrements as
The boundary value of the modulus of continuity of the decrement for k iterations is
or, in the logarithmic scale,
Thus, we have a linear dependence with unknown parameters and p, which are related to the parameters of the modulus of continuity (22). Their values can be estimated using the available data on and by the least squares method. The parameters D and p determine the size of the neighborhood of the global minimum and the probability of reaching it (50) and (51).
Remark 2.
The upper bound (54) is very conservative: it focuses on estimating the elements of the local record sequence and neglects an essential feature of the decrement sequence. In the latter, the number of random values on iteration changes compared to iteration k due to the reinforcement procedure (33) and (34).
This feature is reflected in the expression for the decrement boundary value:
where the reinforcement procedure (34) generates the values
By analogy with (57), we obtain
This dependence still has two parameters, D and p, but the data include and additionally generated by the reinforcement procedure. The dependence (60) is nonlinear. Its parameters can be restored using the least squares method as well. As in the previous case, however, there is no guarantee of obtaining the optimal result.
6. The Convergence of the GFS-RF Algorithm to the Global Minimum
The reinforcement procedure (30)–(33), combined with the selection of local records, makes their sequence the property of a strictly monotonic decrease (37), accompanied by a sequence of decrements with negative elements (36). Based on them, we can formulate the following Theorem 1.
Theorem 1.
Let the following conditions be satisfied for a finite number of iterations equal to k:
(б). function is of Hoelder type with parameters of mudulus of continuity which are estimated by (57);
(b). area of the existence of global extrema is as follows:
where
Then the sequence of local records at k iterations achieve the area with probability not less than
and at high values of
Proof.
The proof follows from Lemmas 1 and 2 and the estimate (51). □
7. Discussion and Conclusions
The concept and computational procedure of Randomized Machine Learning proposed in [22] turned out to be very useful in terms of inaccurate data estimation probability distributions, and also an effective computer technique for solving many applied problems [24]. The modules of this procedure have been applied to practical problems of the randomized forecasting of World population [32], electrical load in the power systems [33], the evolution of the thermokarst lakes in the Arctic zone [34], randomized classification of the objects [35,36]. In these works, we used public datasets of the UN [37], and [38]. However, its practical application is associated with solving a very difficult problem of finding solutions to a specific system of nonlinear equations in which only the values of the functions included in it are available.
In this paper, we propose to use the idea of reinforcement to give adaptive properties to computational algorithms. A problem-oriented reinforcement procedure based on the agent-based approach is proposed, in which the agent generates a strategy in terms of the optimal number of random numbers generated at each step of the iterative process. As a utility function, the exponential comparative utility function is used, which depends on the average decrements of local records achieved at each main iteration. An important role in the reinforcement procedure is played by the payoff function, which generates “penalties” on the values of the utility function. Optimization of the agent’s strategy is carried out using R. Belman’s principle of optimality. As a result of applying the reinforcement procedure, the dimensions of the neighborhood of the global minimum of the quadratic residual function and the probability of its achievement with a finite number of iterations are determined.
Author Contributions
Conceptualization, Y.S.P.; Data curation, A.Y.P.; Methodology, Y.S.P., A.Y.P. and Y.A.D.; Software, A.Y.P. and Y.A.D.; Supervision, Y.S.P.; Writing–original draft, Y.S.P., A.Y.P. and Y.A.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Higher Education of the Russian Federation, project no. 075-15-2020-799.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rosenblatt, F. Principles of Neirodynamic: Perceptrons and the Theory of Brain Mechanisms; Spartan Books: Washington, DC, USA, 1962. [Google Scholar]
- Gelfand, I.M.; Pyatetskij-Shapiro, I.I.; Tsetlin, M.L. Certain Classes of Games and Automata Games. Sov. Phys. Dokl. 1964, 8, 964–966. [Google Scholar]
- Wasserman, P.D. Neural Computing: Theory and Practice; Van Nostrand Reinhold Co.: New York, NY, USA, 1992. [Google Scholar]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A. Human-level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Russel, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- van Hasselt, H. Reinforcement Learning in Continuous State and Action Spaces. In Reinforcement Learning: State-of-the-Art; Wiering, M., van Otterio, M., Eds.; Springer Sciences & Business Media: Berlin/Heidelberg, Germany, 2012; pp. 207–257. [Google Scholar]
- Kropotov, D.; Bobrov, E.; Ivanov, S.; Temirchev, P. Reinforcement Learning Textbook. arXiv 2022, arXiv:2201.09746v1. (In Russian) [Google Scholar]
- Bozinovski, S. Crossbar Adaptive Array: The First Connectionist Network That Solved the Delayed Reinforcement Learning Problem. In Artificial Neural Nets and Genetic Algorithms; Dobnikar, A., Steele, N.C., Pearson, D.W., Albrecht, R.F., Eds.; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999; pp. 320–325. [Google Scholar]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the 13th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Spong, M.W.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Koshmanova, N.P.; Pavlovsky, V.E.; Trifonov, D.S. Reinforcement Learning for Manipulator Control. Rus. J. Nonlin. Dyn. 2012, 8, 689–704. (In Russian) [Google Scholar] [CrossRef]
- Fu, Y.; Jha, D.K.; Zhang, Z.; Yuan, Z.; Ray, A. Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot. Machines 2019, 7, 24. [Google Scholar] [CrossRef]
- Nikitin, P.V.; Gorokhova, R.I.; Korchagin, S.A.; Krasnikov, V.S. Applying Deep Reinforcement Learning to Algorithmic Trading. Mod. Inf. Technol. IT-Educ. 2020, 16, 510–517. (In Russian) [Google Scholar]
- Esfahani, N.; Malek, S. Uncertainty in Self-Adaptive Software Systems. In Software Engineering for Self-Adaptive Systems II; de Lemos, R., Giese, H., Müller, H.A., Shaw, M., Eds.; Lecture Notes in Computer Science Book Series; Springer: Berlin/Heidelberg, Germany, 2013; pp. 214–238. [Google Scholar] [CrossRef]
- Ghezzi, C.; Salvaneschi, G.; Pradella, M. ContextErlang. Sci. Comput. Program. 2015, 102, 20–43. [Google Scholar] [CrossRef]
- Bencvoma, N.; Belaggoun, A. Supporting Decision-Making for Soft-Adaptive Systems: From Goal Models to Dynamic Decision Network. In Requirements Engineering: Foundation for Software Quality, proceedings of the 19th International Working Conference, REFSQ 2013, Essen, Germany, 8–11 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 221–236. [Google Scholar]
- Popkov, Y.S.; Popkov, A.Y. New Nethod of Entropy-Robust Estimation for Randomized Models under Limited Data. Entropy 2014, 16, 675–698. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Randomized Machine Learning: Statement, Solution, Applications. In Proceedings of the IEEE 8th International Conference on Intelligent Systems, Sofia, Bulgaria, 4–6 September 2016; pp. 27–39. [Google Scholar]
- Popkov, Y.S.; Popkov, A.Y.; Dubnov, Y.A. Entropy Randomization in Machine Learning; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Darkhovskii, B.S.; Popkov, A.Y.; Popkov, Y.S. Monte Carlo Method of Batch Iterations: Probabilistic Characteristics. Autom. Remote Control 2015, 76, 775–784. [Google Scholar] [CrossRef]
- Popkov, A.Y.; Darkhovskii, B.S.; Popkov, Y.S. Iterative MC-Algorithm to Solve the Global Optimization Problems. Autom. Remote Control 2017, 78, 261–275. [Google Scholar] [CrossRef]
- Avellaneda, M. Minimum-Relative-Entropy Calibration of Asset-Pricing Models. Int. J. Theor. Appl. Financ. 1998, 1, 447–472. [Google Scholar] [CrossRef]
- Vine, S. Options: Trading Strategy and Risk Management, 1st ed.; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Magnus, J.R.; Neudecker, H. Matrix Differential Calculus (with Applications in Statistics and Econometrics); John Wiley and Sons: New York, NY, USA, 1999. [Google Scholar]
- von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton Univiversity Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Fishburn, P.C. Utility Theory for Decision Making; Wiley: New York, NY, USA, 1970. [Google Scholar]
- Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. New Method of Randomized Forecasting Using Entropy-Robust Estimation: Application to the World Population Prediction. Mathematics 2016, 4, 16. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Popkov, A.Y.; Dubnov, Y.A.; Solomatine, D. Entropy-Randomized Forecasting of Stochastic Dynamic Regression Models. Mathematics 2020, 8, 1119. [Google Scholar] [CrossRef]
- Dubnov, Y.A.; Popkov, A.Y.; Polyschuk, V.Y.; Sokol, E.A.; Melnikov, A.V.; Polyschuk, Y.M.; Popkov, Y.S. Randomized Machine Learning to Forecast the Evolution of Thermokarst Lakes in Permafrost Zones. Autom. Remote Control 2023, 84, 56–70. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Volkovich, Z.; Dubnov, Y.A. Entropy “2”-Soft Classification of Objects. Entropy 2017, 19, 178. [Google Scholar] [CrossRef]
- Dubnov, Y.A. Entropy-Based Estimation in Classification Problems. Autom. Remote Control 2019, 80, 502–512. [Google Scholar] [CrossRef]
- UNdata—A World of Information. Available online: https://data.un.org (accessed on 17 August 2023).
- Hong, T.; Prinson, P.; Fan, S.; Zareipour, H.; Triccoli, A.; Hyndman, R.J. Probabilistic Energy Forecasting: Global Energy Forecasting Competition 2014 and Beyond. Int. J. Forecast. 2016, 32, 896–913. [Google Scholar] [CrossRef]
Figure 1.
Logical diagram of the Reinforcement module.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Reinforcement Procedure for Randomized Machine Learning. Mathematics 2023, 11, 3651. https://doi.org/10.3390/math11173651
AMA Style
Popkov YS, Dubnov YA, Popkov AY. Reinforcement Procedure for Randomized Machine Learning. Mathematics. 2023; 11(17):3651. https://doi.org/10.3390/math11173651
Chicago/Turabian StylePopkov, Yuri S., Yuri A. Dubnov, and Alexey Yu. Popkov. 2023. "Reinforcement Procedure for Randomized Machine Learning" Mathematics 11, no. 17: 3651. https://doi.org/10.3390/math11173651
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.