
A New Similarity Measure of Fuzzy Signatures with a Case Study Based on the Statistical Evaluation of Questionnaires Comparing the Influential Factors of Hungarian and Lithuanian Employee Engagement



Abstract
:1. Introduction
2. Fuzzy Signatures and Similarity
2.1. Fuzzy Signatures and Their Role in Modelling Employee Attitudes
2.2. A New Similarity Measure of Two Fuzzy Memberships and of Two Fuzzy Signatures
3. Employee Engagement: Introduction to the Application Study
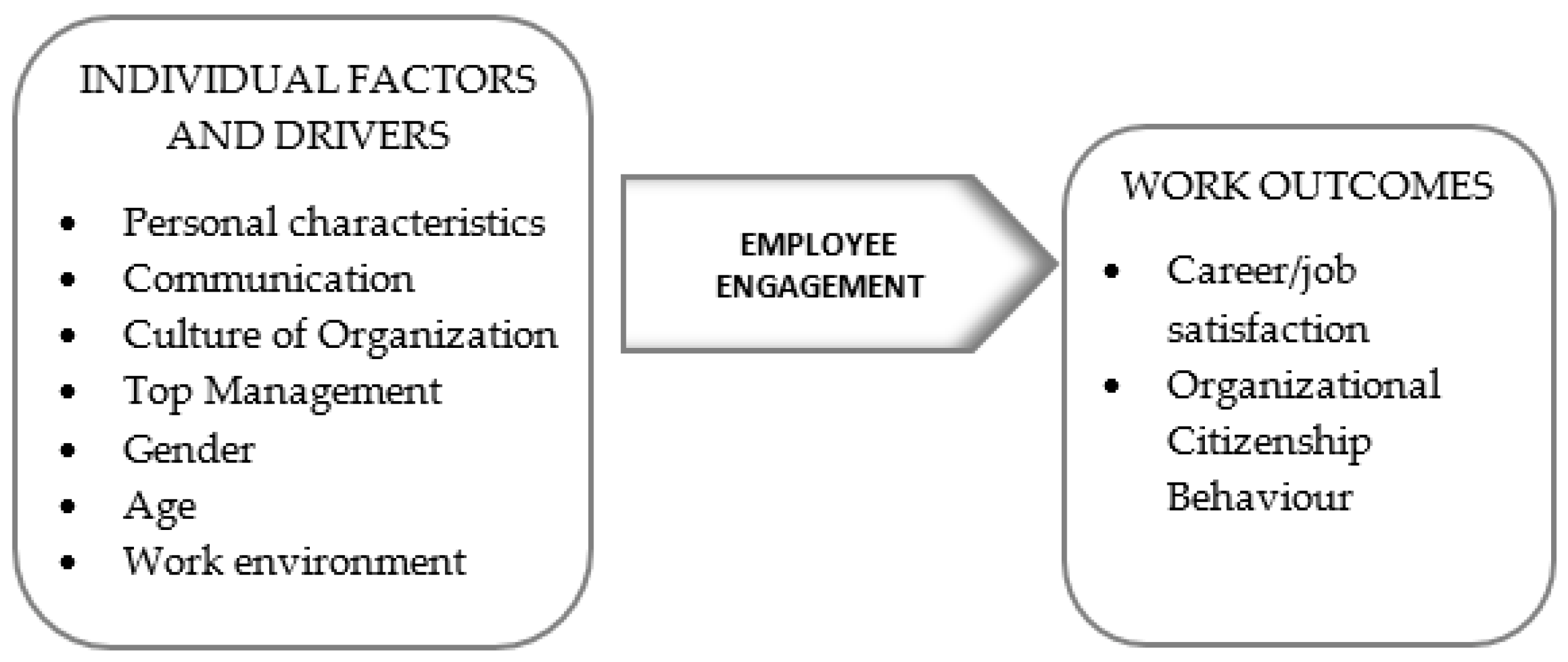
3.1. The Concept of Employee Engagement
3.2. The Methodology of Collecting Data
- Communication style;
- Work experience, type, and size of a company and gender composition;
- Personal characteristics;
- Work environment and top management team;
- Culture of organization;
- OCB and CWB;
- Career satisfaction;
- Demographic data.
4. Modelling Employee Engagement by Fuzzy Signatures
4.1. Transforming the Responses into Fuzzy Degrees
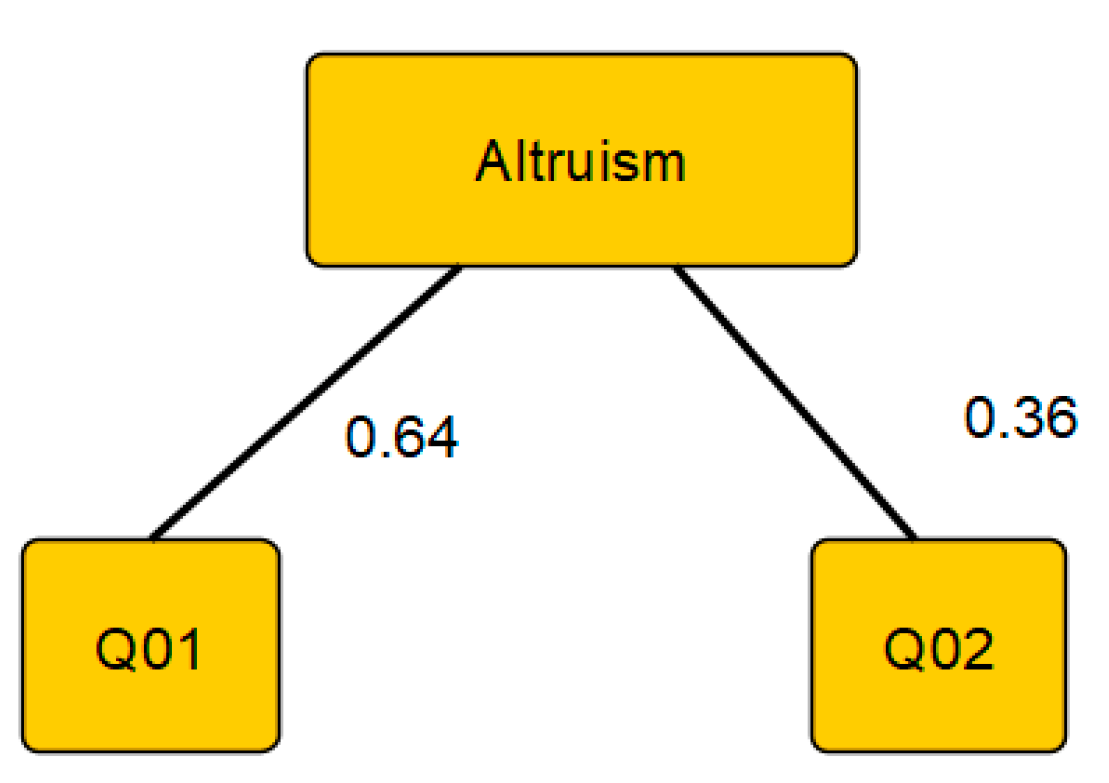
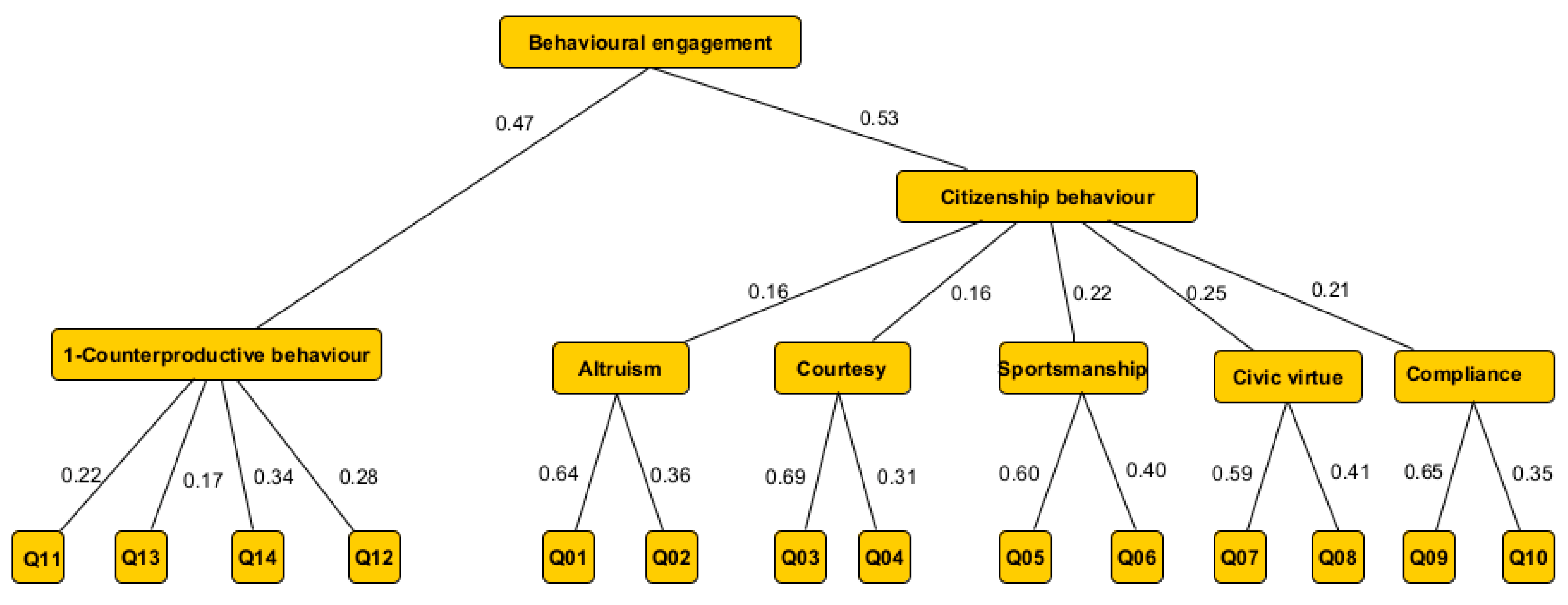
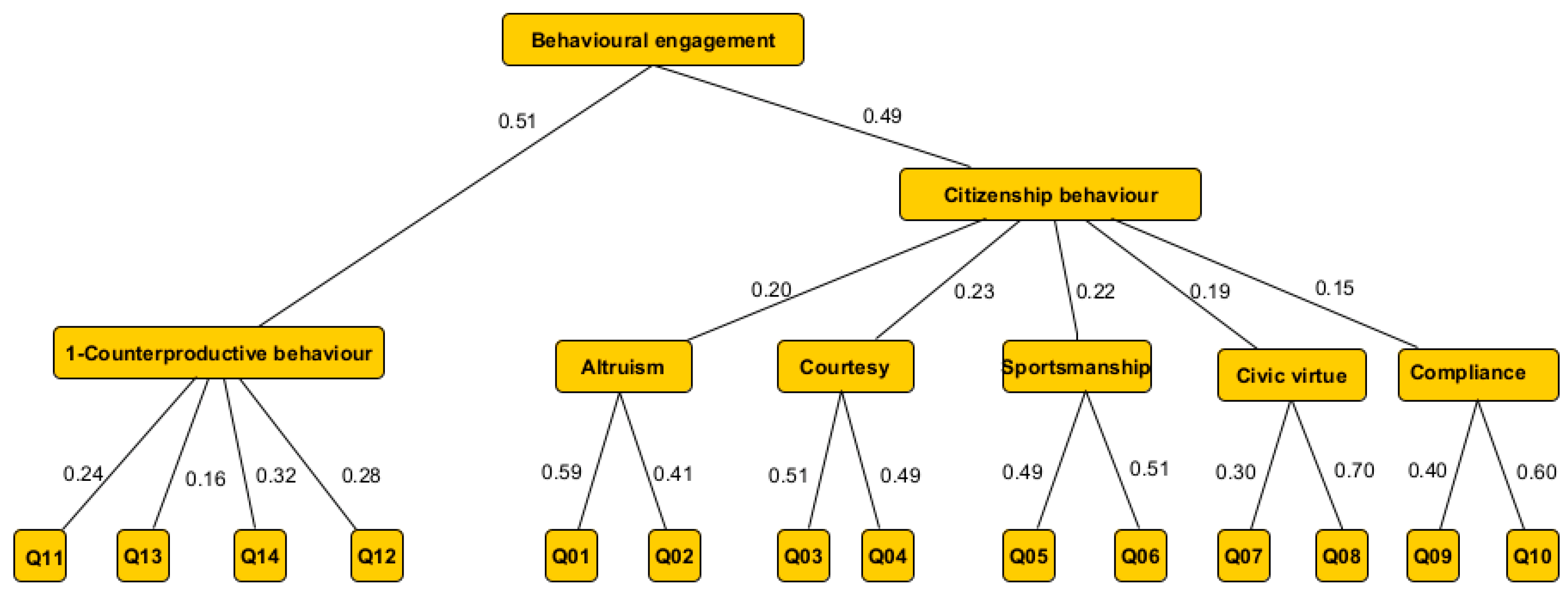
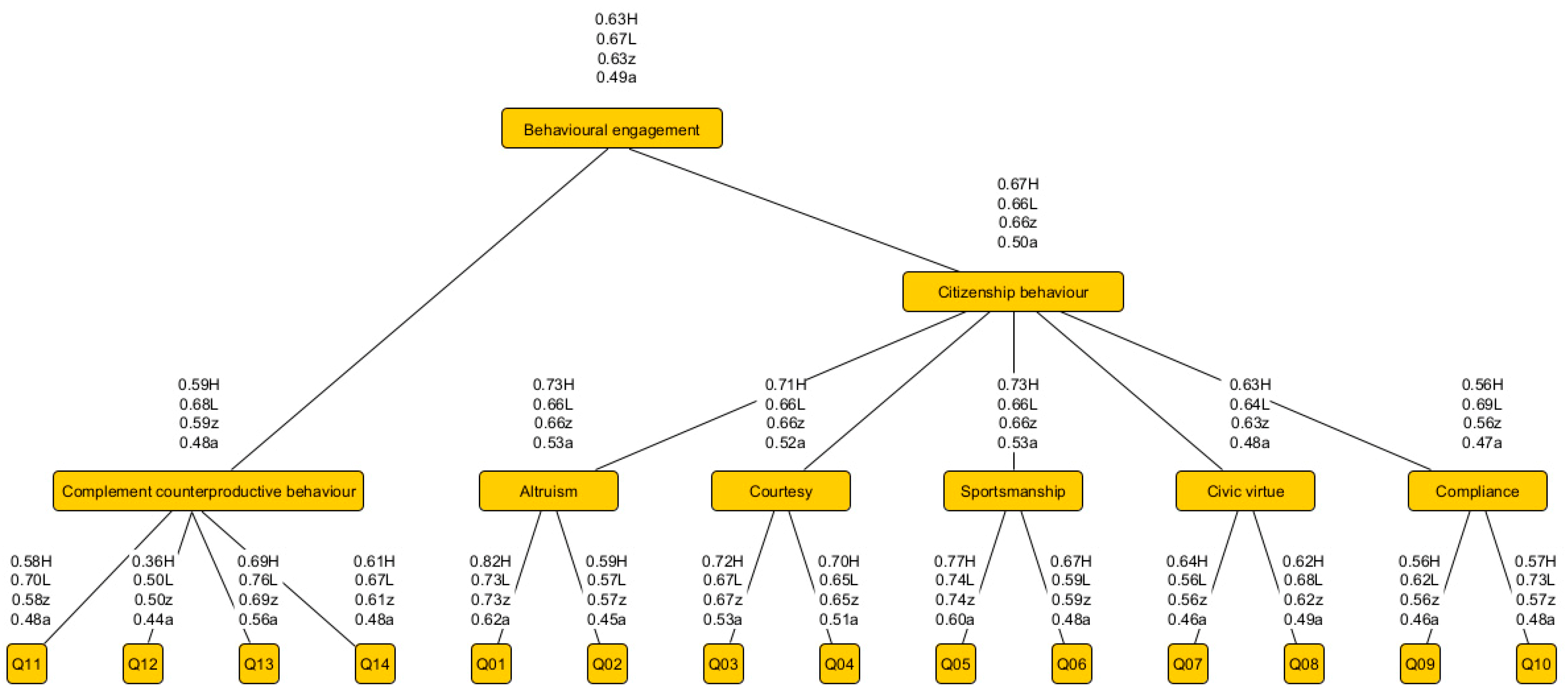
4.2. The Structure of the Proposed Fuzzy Model
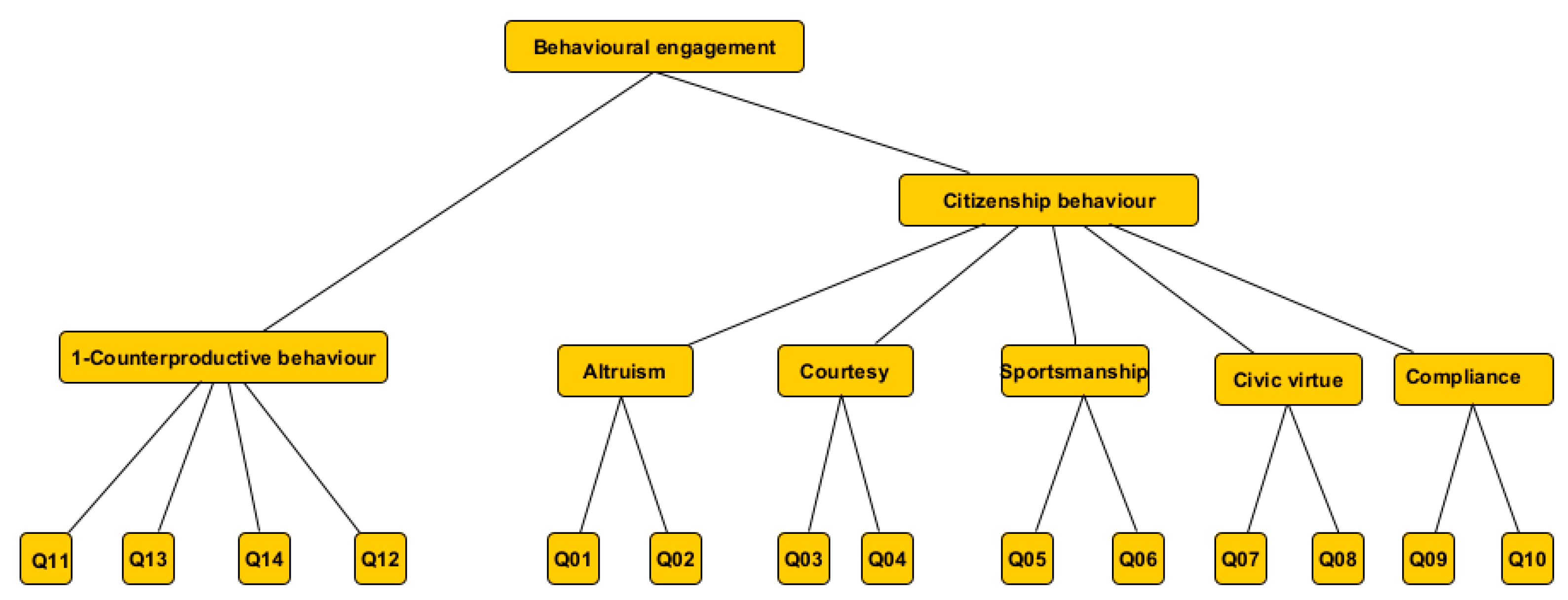
4.3. The Collected OCB vs. CWB Replies and Influential Factors
4.4. Clusters in the Responses
4.4.1. Cluster 1
4.4.2. Cluster 2
4.4.3. Cluster 3
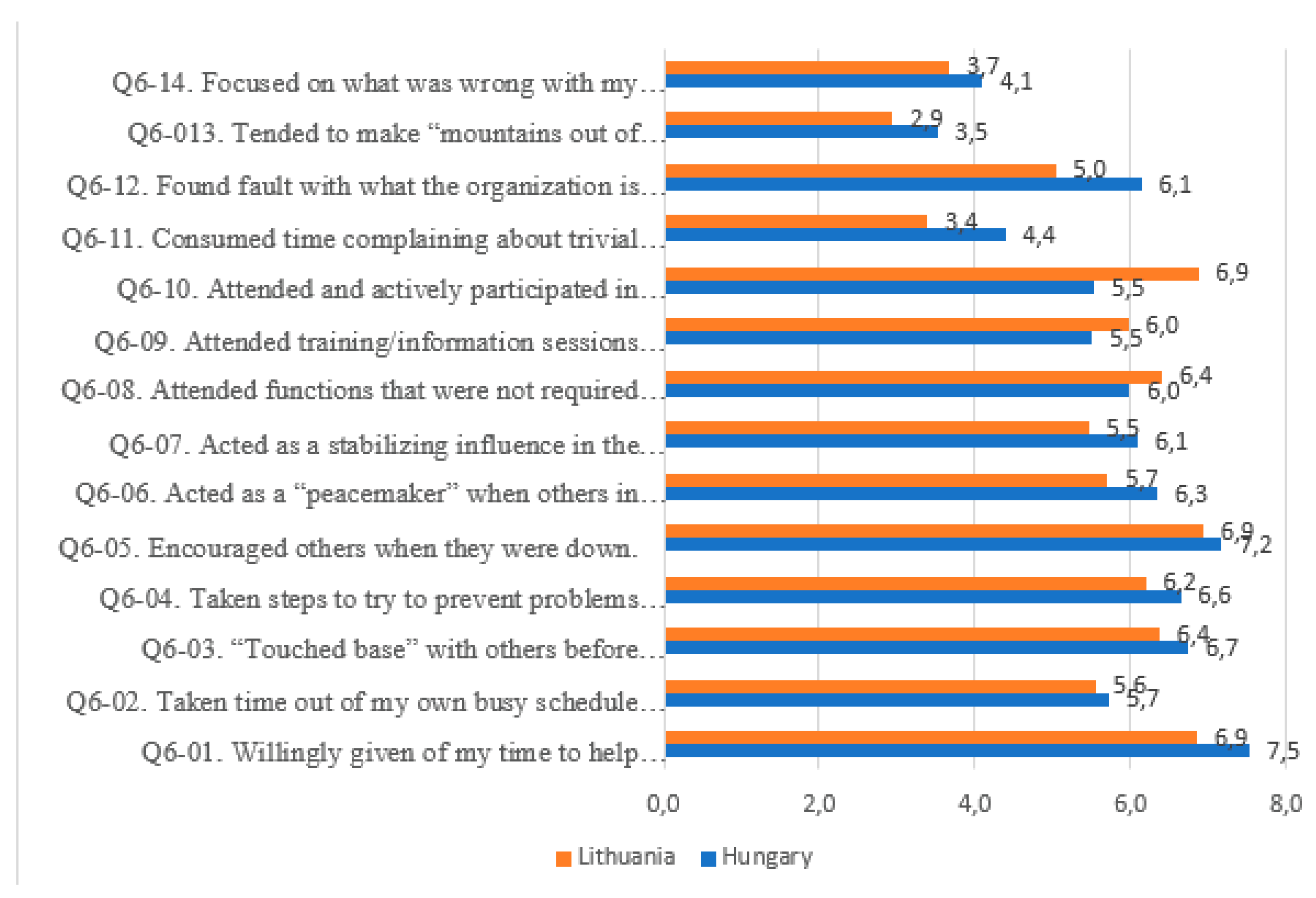
- Q6-01 (Willingly given of my time to help co-workers who have work-related problems);
- Q6-05 (Encouraged others when they were down).
4.5. Correlation Analysis of the Responses
4.6. ANOVA Analysis of the Data
5. Comparison of the Fuzzy Signatures
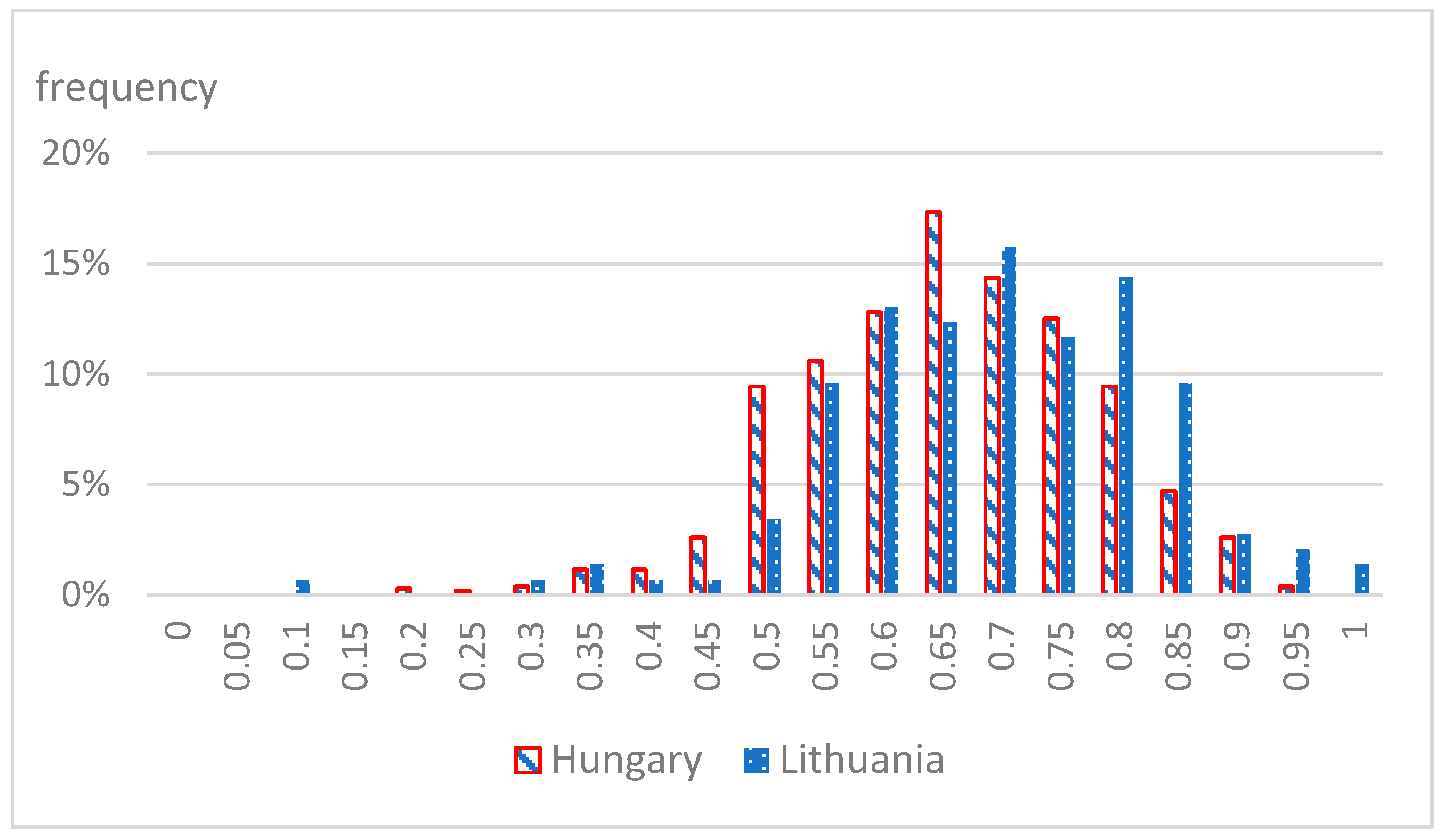
5.1. Calcuations on the Data
5.2. Some Evaluation Remarks
6. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- Willingly given of my time to help co-workers who have work-related problems.
- Taken time out of my own busy schedule to help with recruiting or training new employees.
- “Touched base” with others before initiating actions that might affect them.
- Taken steps to try to prevent problems with co-workers and any other personnel in the organization.
- Encouraged others when they were down.
- Acted as a “peacemaker” when others in the organization have disagreements.
- Acted as a stabilizing influence in the organization when dissention occurs.
- Attended functions that were not required but which helped the organization’s image.
- Attended training/information sessions that employees were encouraged but not required to attend.
- Attended and actively participated in organizational meetings.
- Consumed time complaining about trivial matters.
- Found fault with what the organization is doing.
- Tended to make “mountains out of molehills” (make problems bigger than they are).
- Focused on what was wrong with my situation rather than the positive side of it.
References
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Kóczy, L.T.; Hajnal, M. Texture analysis by vector valued fuzzy sets. In BUSEFAL—Bulletin for Studies and Exchanges on Fuzziness and Its Applications; BUSEFAL: Toulouse, France, 1980; pp. 79–94. [Google Scholar]
- Vámos, T.; Bíró, G.; Kóczy, L.T. Fuzzy signatures. SIC-Eurofuse 1999, 99, 210–217. [Google Scholar]
- Wong, K.W.; Chong, A.; Gedeon, T.D.; Koczy, L.T.; Vamos, T. Hierarchical Fuzzy Signature Structure for Complex Structured Data. In Proceedings of the ISCIII 2003 International Symposium on Computational Intelligence and Intelligent Informatics; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2003; pp. 105–109. [Google Scholar]
- Pozna, C.; Minculete, N.; Precup, R.E.; Kóczy, L.T.; Ballagi, Á. Signatures: Definitions, operators and applications to fuzzy modelling. Fuzzy Sets Syst. 2012, 201, 86–104. [Google Scholar] [CrossRef]
- Mendis, B.S.U.; Gedeon, T.D.; Koczy, L.T. Flexibility and Robustness of Hierarchical Fuzzy Signature Structures with Perturbed Input Data. In Proceedings of the International Conference of Information Processing and Management of Uncertainty in Knowledge Based Systems (IPMU), Paris, France, 2–7 July 2006; pp. 2552–2559. [Google Scholar]
- Kóczy, L.T.; Cornejo, M.E.; Medina, J. Algebraic structure of fuzzy signatures. Fuzzy Sets Syst. 2021, 418, 25–50. [Google Scholar] [CrossRef]
- University Fellows International Research Consortium. Available online: https://www.fea.usp.br/en/ufirc-university-fellows-international-research-consortium (accessed on 4 July 2022).
- Kóczy, L.T.; Susniene, D.; Purvinis, O.; Zostautiene, D. Analyzing employee behavior related questionnaires by combined fuzzy signature model. Fuzzy Sets Syst. 2020, 395, 254–272. [Google Scholar] [CrossRef]
- Ali, M.I.; Feng, F.; Shabir, M. A note on (Î, Î Ú q)-fuzzy equivalence relations and indistinguishability operators. Hacet. J. Math. Stat. 2011, 40, 383–400. [Google Scholar]
- Peng, X. New similarity measure and distance measure for Pythagorean fuzzy set. Complex Intell. Syst. 2019, 5, 101–111. [Google Scholar] [CrossRef]
- Rödder, W. On “and” and “or” Connectives in Fuzzy Set Theory; Arbeitsbericht 75/07; Institut für Wirtschaftswissenschaften, RWTH Aachen: Aachen, Germany, 1975. [Google Scholar]
- Hamacher, H. Uber logische Verknunpfungenn unscharfer Aussagen und deren Zugenhorige Bewertungsfunktione. In Progress in Cybernatics and Sytems Research; Trappl, R., Klir, G.J., Riccardi, L., Eds.; Hemisphere: Washington, DC, USA, 1978; Volume 3, pp. 276–288. [Google Scholar]
- Donia, M.B.L.; Tetrault-Sirsly, C.A. Determinants and consequences of employee attributions of corporate social responsibility as substantive or symbolic. Eur. Manag. J. 2016, 34, 232–242. [Google Scholar] [CrossRef]
- Ariani, D.W. The Relationship between Employee Engagement, Organizational Citizenship Behavior, and Counterproductive Work Behavior. Int. J. Bus. Adm. 2013, 4, 46–56. [Google Scholar] [CrossRef]
- Podsakoff, N.P.; Blume, B.D.; Whiting, S.W.; Podsakoff, P.M. Individual- and organizational-level consequences of organizational citizenship behaviors: A meta-analysis. J. Appl. Psychol. 2009, 94, 22–141. [Google Scholar] [CrossRef]
- Podsakoff, N.P.; Whiting, S.; Podsakoff, P.M.; Mishra, P. Effects of organizational citizenship behaviors on selection decisions in employment interviews. J. Appl. Psychol. 2011, 96, 310–326. [Google Scholar] [CrossRef]
- Organ, D.W.; Podsakoff, P.M.; MacKenzie, S.P. Organizational Citizenship Behavior: Its Nature, Antecedents, and Consequences; Sage Publications: London, UK, 2006. [Google Scholar]
- Nielsen, T.M.; Hrivnak, G.A.; Shaw, M. Organizational citizenship behavior and performance: A meta-analysis of group-level research. Small Group Res. 2009, 40, 555–577. [Google Scholar] [CrossRef]
- Kahn, W.A. Psychological Conditions of Personal Engagement and Disengagement at Work. Acad. Manag. J. 1990, 33, 692–724. [Google Scholar]
- Konovsky, M.A.; Organ, D.W. Dispositional and contextual determinants of organizational citizenship behaviour. J. Organ. Behav. 1996, 17, 253–266. [Google Scholar] [CrossRef]
- Ellis, C.M.; Sorensen, A. Assessing Employee Engagement: The Key to Improving Productivity. Perspectives 2007, 15, 1–9. [Google Scholar]
- Bakker, A.B.; Demerouti, E. The Job Demands-Resources model: State of the art. J. Manag. Psychol. 2007, 22, 309–328. [Google Scholar] [CrossRef]
- Markos, S.; Sridevi, M.S. Employee engagement: The key to improving performance. Int. J. Bus. Manag. 2010, 5, 89–95. [Google Scholar] [CrossRef]
- Purvanova, R.K.; Bono, J.E.; Dzieweczynski, J. Transformational Leadership, Job Characteristics, and Organizational Citizenship Performance. Hum. Perform. 2006, 19, 1–22. [Google Scholar] [CrossRef]
- Piccolo, R.F.; Colquitt, J.A. Transformational Leadership and Job Behaviors: The Mediating Role of Core Job Characteristics. Acad. Manag. J. 2006, 49, 327–340. [Google Scholar] [CrossRef]
- Rich, B.L.; Lepine, J.A.; Crawford, E. Job Engagement: Antecedents and Effects on Job Performance. Acad. Manag. J. 2010, 53, 617–635. [Google Scholar] [CrossRef]
- Sackett, P.R.; Berry, C.M.; Wiemann, S.A.; Laczo, R.M. Citizenship and Counterproductive Behaviour: Clarifying Relations between the Two Domains. Hum. Perform. 2006, 19, 441–464. [Google Scholar] [CrossRef]
- Goguen, J.A. L-Fuzzy Sets. J. Math. Anal. Appl. 1967, 18, 145–174. [Google Scholar] [CrossRef]
- Birkhoff, G.D.; Bartee, T.C. Modern Applied Algebra. In Applied Multivariate Statistical Analysis, 5th ed.; Härdle, W.K., Simar, L., Eds.; McGraw-Hill: New York, NY, USA, 1970; Volume 431, p. 32. [Google Scholar]
- Chander, B. Clustering and Bayesian Networks. In Handbook on Research on Big Data Clustering and Machine Learning; IGI Global: Hershey, PA, USA, 2020; pp. 50–73. [Google Scholar]
- Härdle, W.K.; Simar, L. Applied Multivariate Statistical Analysis, 5th ed.; Springer: Upper Saddle River, NJ, USA, 2019. [Google Scholar]
- Paolella, M.S. Linear Models and Time-Series Analysis: Regression, ANOVA, ARMA and GARCH; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Loehlin, J.C.; Beaujean, A.A. Latent Variable Models. An Introduction to Factor, Path, and Structural Equation Analysis, 5th ed.; Routledge: London, UK, 2017. [Google Scholar]
- Brown, T.A. Confirmatory Factor Analysis for Applied Research, 2nd ed.; Guilford Press: New York, NY, USA, 2015. [Google Scholar]
- Aksyonov, K.; Bykov, E.; Dorosinskiy, L.; Smoliy, E.; Aksyonova, O.; Antonova, A.; Spitsina, I. Decision Support Systems Application to Business Pro cesses at Enterprises in Russia, Multidisciplinary Domains. In Efficient Decision Support Systems-Practice and Challenges in Multidisciplinary Domains; Jao, C., Ed.; IntechOpen: London, UK, 2011; pp. 83–108. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Questions | Hungary | Lithuania | ||||
|---|---|---|---|---|---|---|
| Cluster-1 380-Records | Cluster 2 329-Records: | Cluster 3 329-Records: | Cluster 1 60-Records | Cluster 2 57-Records- | Cluster 3 30-Records | |
| Q6-01 | 7.9 | 7.8 | 6.8 | 7.8 | 6.9 | 5.0 |
| Q6-02 | 6.5 | 6.4 | 4.2 | 6.4 | 6.2 | 2.7 |
| Q6-03 | 7.2 | 7.1 | 5.8 | 7.2 | 6.7 | 4.0 |
| Q6-04 | 7.2 | 7.0 | 5.6 | 7.0 | 6.6 | 3.8 |
| Q6-05 | 7.9 | 7.6 | 6.0 | 7.6 | 7.1 | 5.2 |
| Q6-06: | 7.3 | 6.7 | 5.0 | 6.6 | 6.1 | 3.1 |
| Q6-07 | 6.9 | 6.5 | 4.7 | 6.2 | 6.1 | 2.9 |
| Q6-08 | 6.9 | 7.1 | 4.0 | 7.3 | 6.3 | 4.8 |
| Q6-09 | 6.5 | 6.3 | 3.6 | 7.0 | 6.1 | 3.8 |
| Q6-10 | 6.3 | 6.6 | 3.5 | 7.7 | 6.9 | 5.0 |
| Q6-11 | 4.0 | 6.0 | 3.2 | 2.1 | 5.6 | 1.8 |
| Q6-12 | 5.3 | 7.1 | 6.1 | 5.0 | 6.4 | 2.6 |
| Q6-13 | 2.2 | 5.3 | 3.2 | 1.8 | 4.7 | 1.9 |
| Q6-14 | 2.4 | 5.9 | 4.2 | 2.6 | 5.3 | 2.8 |
| Groups of Factors | Hungary | Lithuania | ||
|---|---|---|---|---|
| OCB (Q6-01 through Q6-10) | CWB (Q6-11 through Q6-14) | OCB (Q6-01 through Q6-10) | CWB (Q6-11 through Q6-14) | |
| Communication styles (Q1-01 through Q1-23) | 0.64 | 0.40 | 0.69 | 0.59 |
| Work experience (Q2-01, Q2-02) | 0.18 | 0.22 | 0.39 | 0.30 |
| Personal characteristics (Q3-01 through Q3-20) | 0.64 | 0.34 | 0.67 | 0.59 |
| Perception of the organization (Q4a-01 through Q4a-7) | 0.38 | 0.20 | 0.49 | 0.33 |
| Perception of top management (Q4b-01 through Q4b-23) | 0.46 | 0.43 | 0.67 | 0.52 |
| Culture of the organization (Q5-01 through Q5-06) | 0.36 | 0.35 | 0.69 | 0.50 |
| Perception of career satisfaction (Q7-01 through Q7-05) | 0.35 | 0.19 | 0.59 | 0.32 |
| Age (Q8-01) | 0.17 | 0.20 | 0.37 | 0.28 |
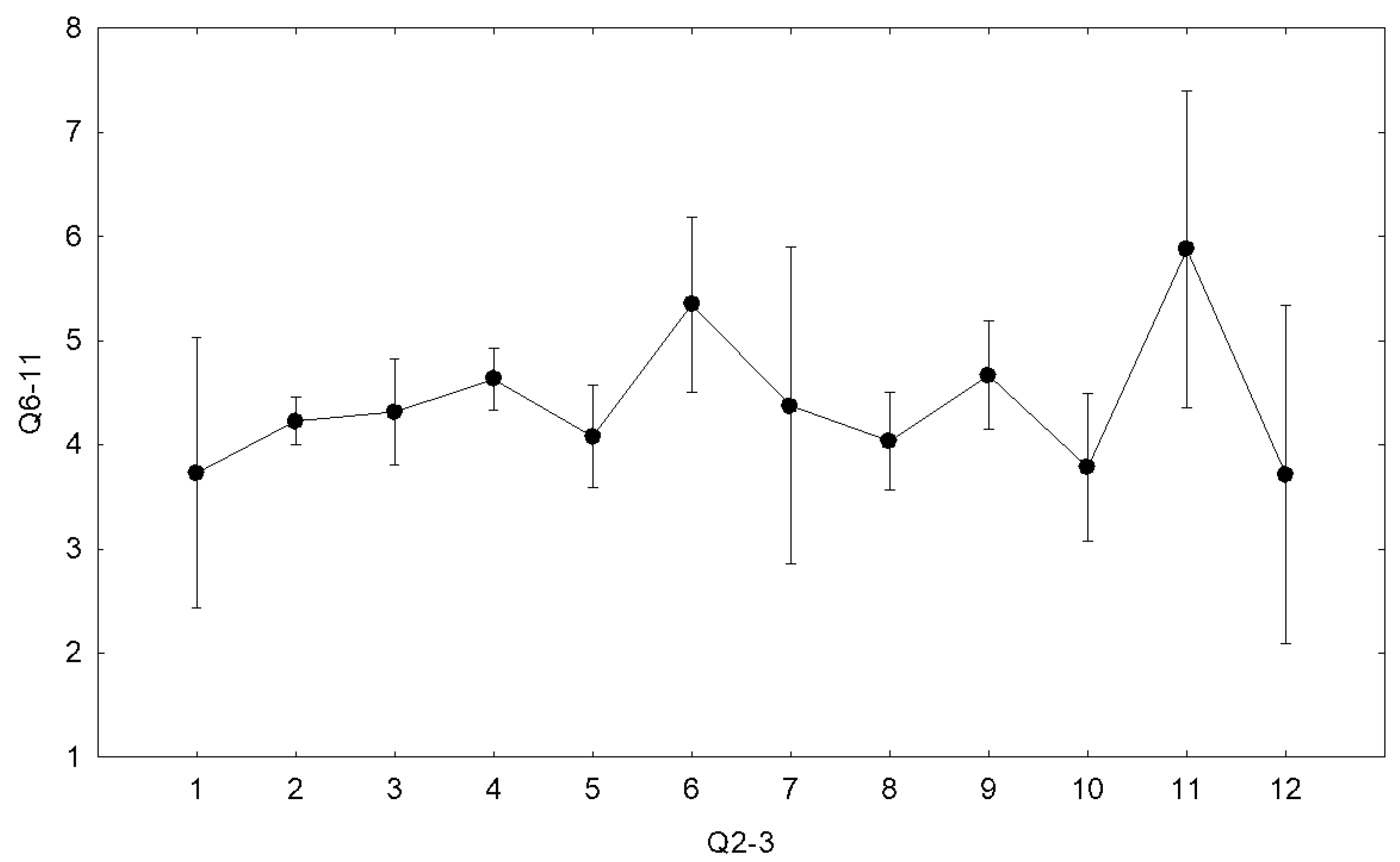
| Q2-03 | Q2-04 | Q2-05 | Q2-06 | Q2-07 | Q2-08 | Q2-09 | Q2-10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HU | LT | HU | LT | HU | LT | HU | LT | HU | LT | HU | LT | HU | LT | HU | LT | |
| Q6-01 | 0.01 | 0.73 | 0.34 | 0.58 | 0.23 | 0.75 | 0.08 | 0.05 | 0.08 | 0.67 | 0.58 | 0.24 | 0.01 | 0.75 | 0.01 | 0.65 |
| Q6-02 | 0.01 | 0.47 | 0.06 | 0.77 | 0.04 | 0.01 | 0.28 | 0.05 | 0.28 | 0.12 | 0.27 | 0.26 | 0.01 | 0.04 | 0.01 | 0.71 |
| Q6-03 | 0.33 | 0.47 | 0.18 | 0.12 | 0.19 | 0.11 | 0.38 | 0.16 | 0.38 | 0.91 | 1.00 | 0.39 | 0.00 | 0.02 | 0.00 | 0.50 |
| Q6-04 | 0.75 | 0.86 | 0.22 | 0.92 | 0.02 | 0.01 | 0.06 | 0.01 | 0.06 | 0.35 | 0.04 | 0.84 | 0.43 | 0.31 | 0.43 | 0.33 |
| Q6-05 | 0.00 | 0.70 | 0.27 | 0.64 | 0.00 | 0.71 | 0.00 | 0.47 | 0.00 | 0.01 | 0.01 | 0.11 | 0.17 | 0.30 | 0.17 | 0.59 |
| Q6-06 | 0.22 | 0.9 | 0.31 | 0.86 | 0 | 0.71 | 0.01 | 0.17 | 0.01 | 0.79 | 0.38 | 0.38 | 0.45 | 0.68 | 0.45 | 0.37 |
| Q6-07 | 0.28 | 0.85 | 0.19 | 0.91 | 0.14 | 0.83 | 0.13 | 0.16 | 0.13 | 0.52 | 0.63 | 0.16 | 0.24 | 0.71 | 0.24 | 0.27 |
| Q6-08 | 0.36 | 0.96 | 0.21 | 0.12 | 0.87 | 0.43 | 0.74 | 0.15 | 0.74 | 0.54 | 0.6 | 0.79 | 0.02 | 0.16 | 0.02 | 0.21 |
| Q6-09 | 0.77 | 0.97 | 0.10 | 0.60 | 0.00 | 0.78 | 0.03 | 0.39 | 0.03 | 0..89 | 0.70 | 0.07 | 0.00 | 0.05 | 0.00 | 0.86 |
| Q6-10 | 0.29 | 0.66 | 0.00 | 0.40 | 0.06 | 0.13 | 0.06 | 0.50 | 0.06 | 0.86 | 0.87 | 0.10 | 0.00 | 0.25 | 0.00 | 0.40 |
| Q6-11 | 0.04 | 0.61 | 0.06 | 0.32 | 0.14 | 0.15 | 0.52 | 0.93 | 0.52 | 0.61 | 0.63 | 0.42 | 0.74 | 0.03 | 0.74 | 0.28 |
| Q6-12 | 0.02 | 0.71 | 0.01 | 0.32 | 0.4 | 0.14 | 0.01 | 0.05 | 0.01 | 0.85 | 0.04 | 0.9 | 0.01 | 0.34 | 0.01 | 0.44 |
| Q6-13 | 0.00 | 0.01 | 0.02 | 0.36 | 0.65 | 0.15 | 0.71 | 0.37 | 0.71 | 0.84 | 0.86 | 0.45 | 0.93 | 0.19 | 0.93 | 0.85 |
| Q6-14 | 0.03 | 0.67 | 0.65 | 0.57 | 0.46 | 0.27 | 0.19 | 0.27 | 0.19 | 0.85 | 0.14 | 0.43 | 0.46 | 0.36 | 0.46 | 0.71 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q6-01 | 1.0 | 0.4 | 0.4 | 0.3 | 0.4 | 0.3 | 0.3 | 0.2 | 0.2 | 0.2 | −0.1 | −0.1 | 0.1 | 0.1 |
| Q6-02 | 0.4 | 1.0 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.4 | 0.3 | −0.2 | 0.0 | 0.0 | 0.1 |
| Q6-03 | 0.4 | 0.3 | 1.0 | 0.4 | 0.4 | 0.4 | 0.3 | 0.2 | 0.2 | 0.2 | −0.2 | −0.1 | 0.0 | 0.0 |
| Q6-04 | 0.3 | 0.3 | 0.4 | 1.0 | 0.5 | 0.4 | 0.3 | 0.3 | 0.2 | 0.2 | −0.1 | 0.0 | 0.0 | 0.0 |
| Q6-05 | 0.4 | 0.3 | 0.4 | 0.5 | 1.0 | 0.6 | 0.5 | 0.3 | 0.3 | 0.3 | −0.2 | 0.0 | 0.0 | 0.1 |
| Q6-06 | 0.3 | 0.3 | 0.4 | 0.4 | 0.6 | 1.0 | 0.7 | 0.3 | 0.3 | 0.2 | −0.2 | 0.1 | 0.0 | 0.1 |
| Q6-07 | 0.3 | 0.3 | 0.3 | 0.3 | 0.5 | 0.7 | 1.0 | 0.4 | 0.4 | 0.3 | −0.2 | 0.0 | 0.0 | 0.1 |
| Q6-08 | 0.2 | 0.3 | 0.2 | 0.3 | 0.3 | 0.3 | 0.4 | 1.0 | 0.4 | 0.4 | −0.2 | −0.1 | −0.1 | 0.0 |
| Q6-09 | 0.2 | 0.4 | 0.2 | 0.2 | 0.3 | 0.3 | 0.4 | 0.4 | 1.0 | 0.5 | −0.3 | 0.0 | 0.0 | 0.1 |
| Q6-10 | 0.2 | 0.3 | 0.2 | 0.2 | 0.3 | 0.2 | 0.3 | 0.4 | 0.5 | 1.0 | −0.3 | −0.1 | 0.0 | 0.0 |
| Q6-11 | −0.1 | −0.2 | −0.2 | −0.1 | −0.2 | −0.2 | −0.2 | −0.2 | −0.3 | −0.3 | 1.0 | 0.2 | 0.4 | 0.2 |
| Q6-12 | −0.1 | 0.0 | −0.1 | 0.0 | 0.0 | 0.1 | 0.0 | −0.1 | 0.0 | −0.1 | 0.2 | 1.0 | 0.3 | 0.3 |
| Q6-13 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | −0.1 | 0.0 | 0.0 | 0.4 | 0.3 | 1.0 | 0.5 |
| Q6-14 | 0.1 | 0.1 | 0.0 | 0.0 | 0.1 | 0.1 | 0.1 | 0.0 | 0.1 | 0.0 | 0.2 | 0.3 | 0.5 | 1.0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q6-01 | 1.0 | 0.5 | 0.5 | 0.5 | 0.5 | 0.4 | 0.4 | 0.4 | 0.2 | 0.3 | 0.0 | −0.2 | 0.0 | 0.0 |
| Q6-02 | 0.5 | 1.0 | 0.5 | 0.5 | 0.3 | 0.4 | 0.3 | 0.2 | 0.2 | 0.2 | −0.2 | −0.3 | −0.2 | −0.2 |
| Q6-03 | 0.5 | 0.5 | 1.0 | 0.6 | 0.5 | 0.4 | 0.3 | 0.3 | 0.3 | 0.2 | −0.1 | −0.2 | −0.1 | 0.0 |
| Q6-04 | 0.5 | 0.5 | 0.6 | 1.0 | 0.6 | 0.7 | 0.4 | 0.4 | 0.3 | 0.2 | −0.1 | −0.2 | −0.1 | −0.1 |
| Q6-05 | 0.5 | 0.3 | 0.5 | 0.6 | 1.0 | 0.6 | 0.4 | 0.4 | 0.4 | 0.3 | −0.1 | −0.2 | −0.1 | 0.0 |
| Q6-06 | 0.4 | 0.4 | 0.4 | 0.7 | 0.6 | 1.0 | 0.7 | 0.3 | 0.3 | 0.2 | −0.1 | −0.3 | −0.2 | −0.1 |
| Q6-07 | 0.4 | 0.3 | 0.3 | 0.4 | 0.4 | 0.7 | 1.0 | 0.4 | 0.4 | 0.3 | −0.2 | −0.4 | −0.2 | −0.2 |
| Q6-08 | 0.4 | 0.2 | 0.3 | 0.4 | 0.4 | 0.3 | 0.4 | 1.0 | 0.3 | 0.4 | 0.0 | −0.2 | 0.0 | 0.1 |
| Q6-09 | 0.2 | 0.2 | 0.3 | 0.3 | 0.4 | 0.3 | 0.4 | 0.3 | 1.0 | 0.6 | −0.1 | −0.1 | −0.1 | 0.1 |
| Q6-10 | 0.3 | 0.2 | 0.2 | 0.2 | 0.3 | 0.2 | 0.3 | 0.4 | 0.6 | 1.0 | −0.1 | −0.3 | 0.0 | 0.1 |
| Q6-11 | 0.0 | −0.2 | −0.1 | −0.1 | −0.1 | −0.1 | −0.2 | 0.0 | −0.1 | −0.1 | 1.0 | 0.3 | 0.6 | 0.5 |
| Q6-12 | −0.2 | −0.3 | −0.2 | −0.2 | −0.2 | −0.3 | −0.4 | −0.2 | −0.1 | −0.3 | 0.3 | 1.0 | 0.3 | 0.3 |
| Q6-13 | 0.0 | −0.2 | −0.1 | −0.1 | −0.1 | −0.2 | −0.2 | 0.0 | −0.1 | 0.0 | 0.6 | 0.3 | 1.0 | 0.7 |
| Q6-14 | −0.0 | −0.2 | −0.0 | −0.1 | −0.0 | −0.1 | −0.2 | 0.1 | 0.1 | 0.1 | 0.5 | 0.3 | 0.7 | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kóczy, L.T.; Susniene, D.; Purvinis, O.; Konczosné Szombathelyi, M. A New Similarity Measure of Fuzzy Signatures with a Case Study Based on the Statistical Evaluation of Questionnaires Comparing the Influential Factors of Hungarian and Lithuanian Employee Engagement. Mathematics 2022, 10, 2923. https://doi.org/10.3390/math10162923
Kóczy LT, Susniene D, Purvinis O, Konczosné Szombathelyi M. A New Similarity Measure of Fuzzy Signatures with a Case Study Based on the Statistical Evaluation of Questionnaires Comparing the Influential Factors of Hungarian and Lithuanian Employee Engagement. Mathematics. 2022; 10(16):2923. https://doi.org/10.3390/math10162923
Chicago/Turabian StyleKóczy, László T., Dalia Susniene, Ojaras Purvinis, and Márta Konczosné Szombathelyi. 2022. "A New Similarity Measure of Fuzzy Signatures with a Case Study Based on the Statistical Evaluation of Questionnaires Comparing the Influential Factors of Hungarian and Lithuanian Employee Engagement" Mathematics 10, no. 16: 2923. https://doi.org/10.3390/math10162923