
Convergence of a Class of Delayed Neural Networks with Real Memristor Devices
by
 , , , , and
, , , , and
Mauro Di Marco
1,* ,
,
Mauro Forti
1,
Riccardo Moretti
1,
Luca Pancioni
1,
Giacomo Innocenti
2 and
and
Alberto Tesi
2 1
Dipartimento di Ingegneria dell’Informazione e Scienze Matematiche, Università di Siena, Via Roma 56, 53100 Siena, Italy
2
Dipartimento di Ingegneria dell’Informazione, Università degli Studi di Firenze, Via S. Marta 3, 50139 Firenze, Italy
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(14), 2439; https://doi.org/10.3390/math10142439
Submission received: 31 May 2022
/
Revised: 17 June 2022
/
Accepted: 5 July 2022
/
Published: 13 July 2022
(This article belongs to the Special Issue Neural Networks and Learning Systems II)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Neural networks with memristors are promising candidates to overcome the limitations of traditional von Neumann machines via the implementation of novel analog and parallel computation schemes based on the in-memory computing principle. Of special importance are neural networks with generic or extended memristor models that are suited to accurately describe real memristor devices. The manuscript considers a general class of delayed neural networks where the memristors obey the relevant and widely used generic memristor model, the voltage threshold adaptive memristor (VTEAM) model. Due to physical limitations, the memristor state variables evolve in a closed compact subset of the space; therefore, the network can be mathematically described by a special class of differential inclusions named differential variational inequalities (DVIs). By using the theory of DVI, and the Lyapunov approach, the paper proves some fundamental results on convergence of solutions toward equilibrium points, a dynamic property that is extremely useful in neural network applications to content addressable memories and signal-processing in real time. The conditions for convergence, which hold in the general nonsymmetric case and for any constant delay, are given in the form of a linear matrix inequality (LMI) and can be readily checked numerically. To the authors knowledge, the obtained results are the only ones available in the literature on the convergence of neural networks with real generic memristors.
Keywords:
convergence; delay; differential variational inequalities (DVIs); linear matrix inequalities (LMIs); Lyapunov method; memristor; neural networksMSC:
68Q061. Introduction
Von Neumann computing machines are currently facing severe limitations in analyzing big data and handling the hard tasks which arise in the Internet of Things (IoT) or cloud computing [1,2,3]. These problems are due to the huge power needed for the continuous exchange of data between the central processing unit (CPU) and the memory (e.g., the RAM) that are placed at distinct physical locations. The use of emerging nanoscale devices, such as the memristor, is a promising way to alleviate some of the above problems via the implementation of new analog and parallel neuromorphic computing paradigms. Memristors enable implementation in memory computing systems where the same devices perform the computation and are also able to memorize the result of the computation, thus mimicking some basic principles of a biological brain [4,5,6,7,8].
One crucial aspect to account for when studying memristor neural architectures is the memristor model that is used. The ideal memristor, which was introduced in the original seminal paper by Leon Chua in 1971 [9], is the most basic and simplest model available in the literature. However, real memristor devices implemented in nanotechnology cannot be modeled in a sufficiently accurate way using ideal memristors [10,11,12,13]. Rather, more complex models, named generic or extended memristors, need to be used for real devices. The reader is referred to [14,15,16,17,18,19] for a classification and discussion of the hierarchy of memristor models and for the main models used in the literature.
One of the most fundamental dynamic properties of a neural network is the convergence of solutions toward equilibrium points. It is not possible to overemphasize the importance of convergence, since it is an essential property to implement content addressable memories and to design neural networks for solving combinatorial optimization problems and several other tasks in the field of image and signal processing [20,21,22]. There is a huge literature devoted to the convergence of traditional neural networks without memristors, see, e.g., [23,24,25,26,27,28,29] and references therein. On the other hand, the study of the convergence of memristor neural networks is only in its infancy and very few results are available in the literature. The authors of [30,31,32] addressed convergence of Hopfield-type and cellular neural networks with ideal memristors. General results on convergence have been established in the case of symmetric interconnections between neurons [30,32], and for cooperative interconnections [31], using the flux-charge analysis method developed in [15,33]. The method enables it to be shown that the state space can be decomposed in invariant manifolds for the dynamics and that, on each manifold, the dynamics is equivalent to that of a memristorless neural network, provided that flux and charge are used as variables in place of voltage and current. Other results on convergence have been established for memristors modeled as switching devices [34,35,36]. However, the usefulness and significance of such models in describing real memristor devices have not yet been clarified. As far as the authors are aware, no results on convergence are available to date for the important case of memristor neural networks with generic or extended memristors.
The goal of this manuscript is to study the convergence of a class of memristor neural networks with generic memristors obeying the voltage threshold adaptive memristor (VTEAM) model [17]. This is a relevant and highly studied model that is extremely flexible and accurately fits real memristor devices. Moreover, it is computationally efficient and appropriate for circuit simulation tools. In the neural network, we also account for the possible presence of constant delays. This feature is of importance, since, in practice, delays are unavoidable due to the interneuron distance and finite signal transmission speed. Moreover, the presence of delays enables neural networks to tackle the solution of some classes of peculiar tasks in real time, including motion detection [37] and inverse problems [38]. It is worth remarking that, due to physical limitations, the evolution of the memristor state is constrained in a closed compact interval. We therefore find it useful to model the memristor neural network via a class of delayed differential inclusions, named differential variational inequalities (DVIs) [39]. It is known that DVIs are the most adequate mathematical tool to describe systems with constraints evolving in a closed subset of the space. In the paper, we provide some easily testable sets of conditions on the interconnection and delayed interconnection matrices ensuring convergence of solutions for the memristor neural network. The conditions, which are expressed in the form of a linear matrix inequality (LMI) [40], are applicable in the general nonsymmetric case and do not require that the delay is bounded. Examples and numerical simulations are provided to illustrate the obtained dynamic results.
2. Preliminaries
In this section, we recall some basic properties of tangent and normal cones, and a class of differential inclusions named DVIs, that are used in the manuscript. The reader is referred to [39] for a more thorough treatment.
2.1. Tangent and Normal Cones
Consider a non-empty closed convex set . The tangent cone to Q at is given by [41]
where is the distance of from set Q. Furthermore, the normal cone to Q at is
If, in particular, is a hypercube, it can be verified that for any , where if , if , and if . Moreover, it can be easily checked that for any , where if , if , and if .
Property 1.
Suppose that is a non-empty closed convex set. Then:
- for any , and are non-empty closed convex cones in ;
- the normal cone to Q is a monotone operator, i.e., given any and any , , we have
- If , and , then we have for any and any , .
2.2. Differential Variational Inequalities
Let be a non-empty closed convex set and . A differential variational inequality (DVI) is a problem of the following form [39] (p. 265): find an absolutely continuous function , , such that
and
From a mathematical viewpoint, a DVI is a special class of differential inclusions whose solutions evolve in a closed convex subset of . The next property summarizes some fundamental results on DVIs in [39] (Ch. 5) that are needed in the paper.
Property 2.
3. Memristor Neural Network
3.1. VTEAM Memristor Model
The ideal memristor was introduced by Leon Chua in the seminal 1971 paper [9] as the fourth basic passive circuit element. Let (resp., ) be the voltage (resp., current) of the memristor and let (resp., ) be the flux (resp., charge) of the memristor. An ideal flux-controlled memristor is, by definition, a circuit element satisfying the constitutive relation
where , , is a given non-linear function. By differentiating in time, we obtain that an ideal memristor satisfies the quasi-static Ohm’s law
where is named memductance and the state equation is
Later on, more general classes of memristors were introduced to better model real memristor devices with respect to an ideal memristor. In the manuscript, we assume that the memristor is described by the generic memristor model [14]
where , , is the memductance and , , is a non-linear function. We stress that the state variable x of a generic memristor, in general, does not coincide with the flux .
In particular, in the paper, we focus on the VTEAM memristor model introduced in [17] for which the state evolution is ruled by the equation
where , , , , , are model parameters; the parameters are all positive, except for and , which are negative. Note that this is a model with a voltage threshold; that is, the state does not change () when the voltage belongs to the interval . Additionally, from a physical viewpoint, the state variable has to satisfy the hard constraint
where . Such a constraint is usually enforced mathematically by using some suitable window functions in (5) [17]. However, it can be more simply and effectively guaranteed by rewriting (5) as the following DVI
where is the normal cone to K at .
The memductance is not explicitly defined by the VTEAM model and can be any continuous function, such that for any , where . Indeed, the memductance can be described by linear dependence of the memristance , e.g.,
as well as an exponential dependence, e.g.,
where is a fitting parameter and .
3.2. Memristor Delayed Neural Network Model
In the following, we consider a neural network with delays whose basic cell is made by the interconnection of a capacitor C and a memristor obeying a VTEAM model. By letting, for simplicity, , the memristive neural network can be described by the following set of delayed differential inclusions for
where are the capacitor voltages and are the memristor currents (). Moreover, for , (resp., ) are the neuron interconnections (resp., delayed neuron interconnections), while the neuron activation is Lipschitz in , i.e., there exists L such that for any , it is bounded, i.e., for any , and it satisfies . Finally, is a constant delay. The neural network has an additive interconnecting structure that is typical of classic models, such as the Hopfield or cellular neural network models.
4. Existence and Uniqueness of the Solution
Let us consider the initial value problem (IVP) associated with the delayed memristor neural network (9) and (10)
with initial conditions , where and .
A solution , , of the IVP is a continuous function in such that:
We find it useful to bring back the analysis of the differential inclusion (9) and (10) to that of a DVI in a compact convex subset of , so that we can apply Property 2 to establish the existence of solutions. To this end, we prove the following.
Property 3.
Let , , be a solution of the IVP (13)–(16). Let and consider the hypercube
where
and . Then, enters in finite time and stays there thereafter.
Proof.
Consider , and let be the set of indexes such that . We note that, for any , we have
As a consequence, the set is positively invariant and globally attractive for . Additionally, since , it also holds, for any , , i.e., each component of which is outside the set approaches the same set with a speed not smaller than , thus entering the set in finite time. □
In the paper, we are interested in the asymptotic behavior as of the neural network solutions. On the basis of Property 3, it is enough to consider an IVP whose initial conditions for variables is given by . Therefore, in what follows, we consider the IVP for a DVI in the compact convex set
with initial conditions , where and .
A solution , , of the IVP (19)–(22) is defined in the same way as for the IVP (13)–(16), the only difference being that for the IVP (19)–(22), we have , .
Property 4.
Proof.
A. Existence of the solution
The proof of the existence of solutions for the system can be achieved through the method of steps.
In the first step, we show the existence of a solution in . Let us define the following IVP in for a DVI without delay:
where , and . is continuous in and . Therefore, according to Property 2, there exists at least one solution to the IVP.
Solving (23) with respect to , we obtain in . Suppose now
We have , therefore, is continuous in and belongs to . Additionally, is absolutely continuous in , and satisfies (19) and (20) for a.a. . As a consequence, is a solution in of the DVI.
As an inductive step, let us assume that is a solution in , where m is an integer value greater than 1. We define in the functions and as and , respectively. Following the procedure in the first step, and choosing as the initial condition of the IVP, we obtain a solution in .
Assuming in , we obtain that is a solution of the system in , with initial condition in . Indeed, it can be observed that:
- for the inductive step, with initial condition in is a solution in ;
- since is absolutely continuous in , we have that is absolutely continuous in ;
- is absolutely continuous in ;
- the limit of as is equal to the limit of as , i.e., we have , therefore, is continuous in ;
In conclusion, is a solution in of the system (19) and (20) with the initial condition in . By induction, this result can be extended to any .
B. Uniqueness of the solution
Suppose, for contradiction, that there exist two solutions of (19)–(22) and . The distance between the solutions is defined as:
We want to prove that the distance is 0 in any , where m is a generic integer greater than or equal to 0.
The proof is easily reached when , since . Applying again the method of steps, let us assume that is equal to 0 in . Since and are solutions of (19) and (20), when , we have that:
and
where , , e .
As a consequence
where:
According to Property 2:
Additionally, remembering that in , we observe that . As a consequence, starting from (28), we obtain:
Functions and are Lipschitz continuous, therefore, there exists such that
From the Gronwall lemma, we obtain
i.e., when .
5. Main Results on Convergence
An equilibrium point of the memristor neural network (19) and (20) is a constant solution , , of the IVP (19)–(22). Denote by the set of equilibrium points of (19) and (20). Since and , we have that
Note that there is a continuum of non-isolated equilibrium points, that is a typical feature of neural networks with non-volatile memristors [15].
Example 1.
Let us show via an example that, in the general case, the memristor neural network (19) and (20) can have equilibrium points not belonging to set π. Let , and , , as in (7) and choose
If is an equilibrium point, the following relations hold true
Since is a piecewise linear function, the equilibrium points of the network can be easily found explicitly. It can be verified that, in addition to points in π, also and are equilibrium points for the network. Note that, since , only the extremal points and can satisfy .
Definition 1.
We will address convergence under two different sets of conditions for the neuron activations and the interconnection and delay interconnection matrices A and . Firstly, we enforce the following hypotheses.
Assumption 1.
We have and for any and any .
Two interesting special cases are the sigmoidal, i.e., bounded and strictly increasing activations and used in the popular Hopfield neural network [43] and cellular neural network model [21], respectively. However, it is worth noting that neuron activation functions satisfying Assumption 1 may not be monotone-increasing.
Assumption 2.
There exist a diagonal positive definite matrix and a symmetric positive definite matrix such that the following LMI holds true
where we have let
It is worth noting that, in order to satisfy Assumption 2, it is necessary that matrix is Hurwitz, namely the real part of the eigenvalues of A is less then .
Theorem 1.
Suppose that Assumptions 1, 2 hold. Then the memristor neural network (19) and (20) is convergent. More specifically:
(1) as for any initial conditions;
(2) converges in finite time, i.e., there exists and such that , , where and depend upon the initial conditions.
Proof.
Let us consider the candidate Lyapunov function given by
Note that for any . Let
Consider now the matrix
obtained by replacing with in . Observe that and consequently implies .
The time derivative of can be written as
where , due to Assumption 2.
We have
for any , where with , we denote the minimum eigenvalue of a matrix M. Since , . By integrating the previous inequality, we obtain
Assume, for contradiction, that as . From Property 3, we know that, after a certain finite time, the dynamics of evolves in the hypercube , hence, .
Furthermore, the norm of is limited as well. In fact, from (19) in the interior of the hypercube, we have
We know that , and from Assumption 1, we can observe that . As a consequence, is limited by
where is the maximum absolute value of function f, defined in Property 3.
Hence, there exist and a sequence as such that as . Then, as . Assume without loss of generality . Since , and is bounded above, there exist and such that when we have for . Taking into account that for any t, we can write
However, this contradicts the positiveness of .
Now, consider that, since as , there exists a time instant such that for any . Taking into account (5), this implies for any , i.e., converges to in finite time . □
In Theorem 1, we have proved the convergence of and the convergence in finite time of under suitable hypotheses on the interconnection and delay interconnection matrix (cf. Assumption 2) and on the neuron activations (cf. Assumption 1). However, we have been unable to give an estimate of the convergence speed of or of the convergence time of . In what follows, we pose a different assumption on the interconnections that enables us to obtain such quantitative estimates and also permits us to weaken the restrictions in Assumption 1 for the activations.
Assumption 3.
We have for some and for any and any .
Assumption 4.
There exist three symmetric positive definite matrices , and such that the following LMI holds true
where we have let
We preliminarily recall the following two results.
Lemma 1
([44]). Given any real matrices , and a symmetric positive definite matrix of appropriate dimensions, the following inequality holds
where is a scalar.
Lemma 2
Proposition 1.
Suppose that Assumptions 3 and 4 hold. Let
where denotes the maximum eigenvalue of matrix M. Then, we have
Proof.
In order to show that , let us consider
and
Due to Assumption 4, and by applying Lemma 2 to , we have and we can rewrite as
Since and consequently , if we choose k as in (43), the following inequality holds
and hence . Taking into account the previous result, and by applying Lemma 2 to , we finally conclude that . □
Theorem 2.
Suppose that Assumptions 3 and 4 hold. Then the memristor neural network (19) and (20) is convergent. More specifically:
(1) exponentially as with convergence rate k as in (43), i.e.,
(2) converges in finite time, i.e., there exists such that , , where
and .
Proof.
Let us consider the following candidate Lyapunov function:
We have ; moreover, the time derivative of (44) can be written as
By applying Lemma 1, choosing , and , we obtain the following inequality
Similarly, letting , and , by Lemma 1, we obtain
As a consequence, we can write the following inequality involving the time derivative of (44)
Noting that , the following inequality holds
and hence
with matrix defined as
Noting that , then Proposition 1 ensures that .
Now, let us prove that exponentially as and give an estimate of the convergence rate. Since , we can assert that , . Note that
Recalling that , we finally obtain
and hence
This shows that is exponentially convergent to 0 with a convergence rate k.
Let us define . Since as , there exists a time instant such that for any . Taking into account (5), this implies for any , i.e., converges to in finite time .
The worst case estimate of is obtained by letting . From (45), we conclude that
□
The next result is an immediate consequence of the results on convergence in the two theorems.
Proposition 2.
Under the assumptions of Theorem 1, or the assumptions of Theorem 2, for the memristor neural network, we have .
6. Numerical Simulations
In this section, we report on some simulations performed using MATLAB to illustrate the dynamic behavior of the considered memristor neural network.
In the simulations, the state evolution of the VTEAM model (5) is described by the following parameters
For the memductance, we have chosen the linear dependence (7), setting its parameters as follows
We considered a two-neuron neural network with interconnection and delay interconnection matrices
The delay is set to 250 ms and the neuron activations are given by the piecewise-linear function .
According to Property 3, the hypercube in (17) is defined by V. Substituting the following matrices
in matrix defined in Assumption 4, i.e.,
and computing the eigenvalues of , i.e.,
we observe that , therefore the assumptions of Theorem 1 hold for the neural network.
6.1. Example 1
In this first example, we evaluate the neural network state evolution dynamics setting sinusoidal initial conditions for the neuron voltages
for and testing four different initial conditions for the memristor states, i.e.,
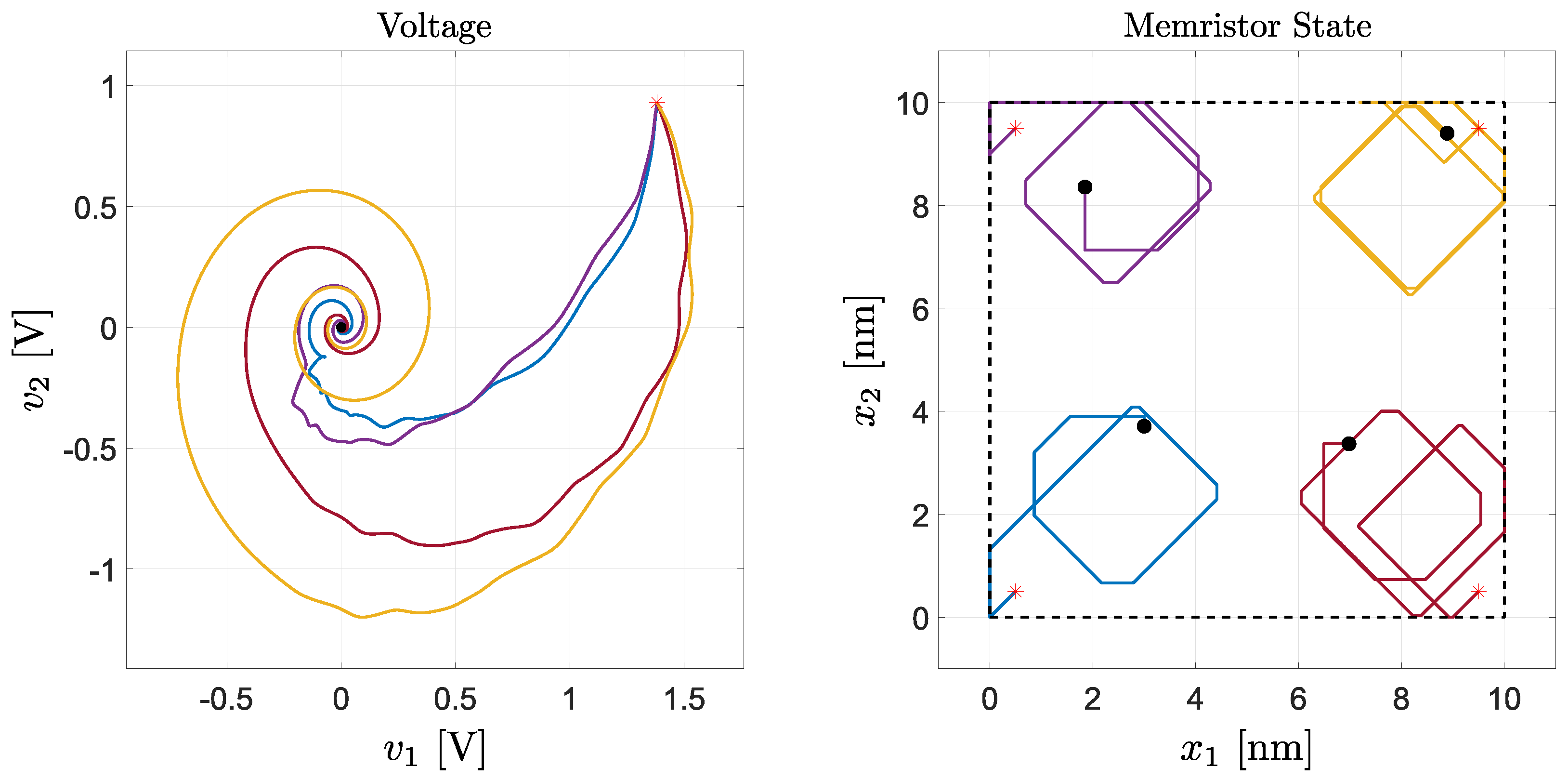
Figure 1 shows the solutions obtained starting from the initial conditions thus defined. It can be observed that, in all the simulations, the voltages converge to 0, as predicted by Theorem 1, even if the trajectories are influenced by the memristor state initial conditions and dynamics. However, note that the asymptotic values of the memristor states are different for each simulation, i.e., they depend upon the initial conditions.
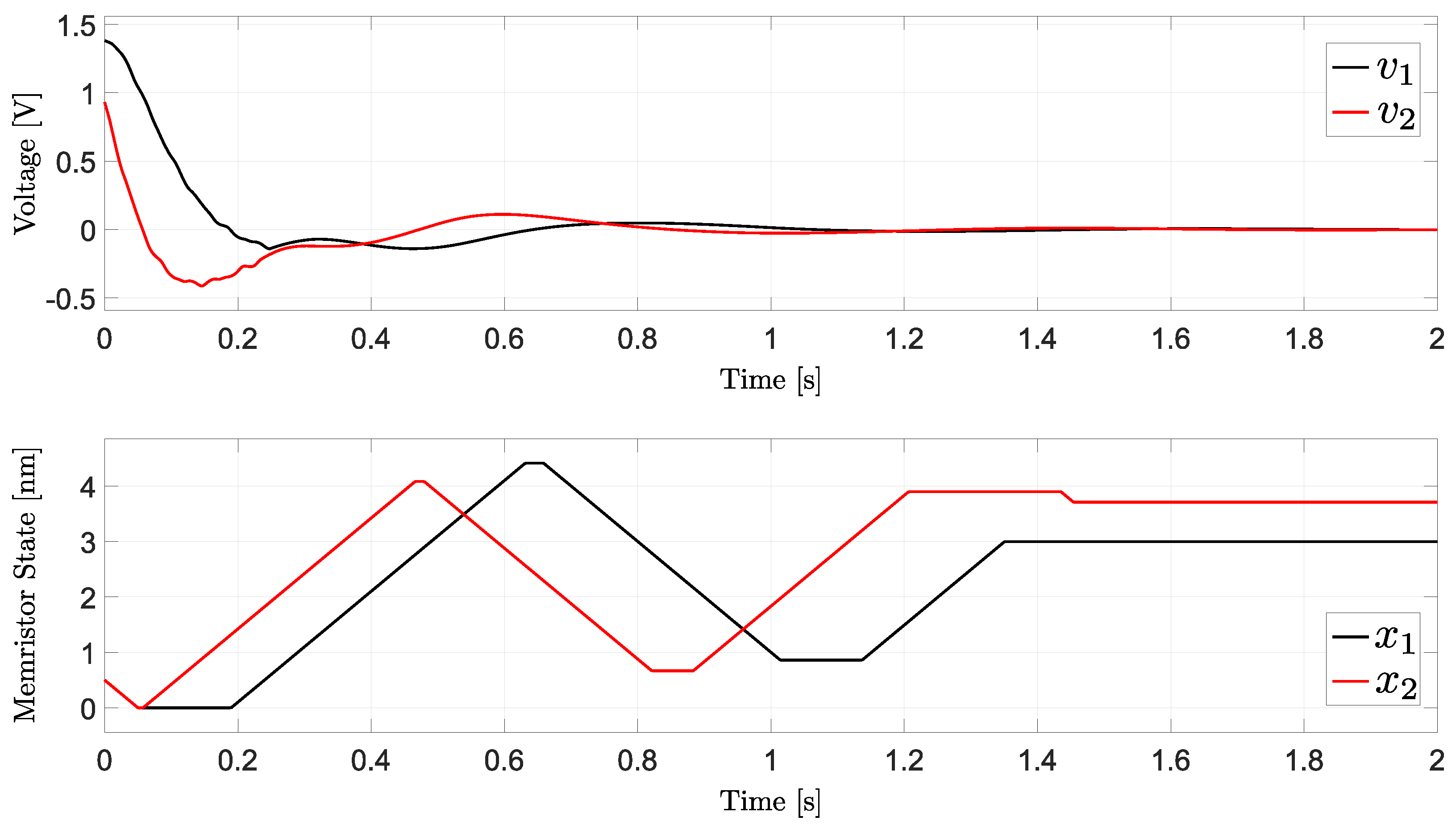
Figure 2 shows the time behavior of the specific simulation performed with initial condition nm. From the plot, we can see that when the voltages reach the threshold (), the memristor dynamics stops, i.e., the memristor states do not change anymore.
6.2. Example 2
In the second example, we set the initial conditions for the memristor states at
and we evaluated the system dynamics starting from four different sinusoidal initial conditions for the neurons voltages, i.e.,
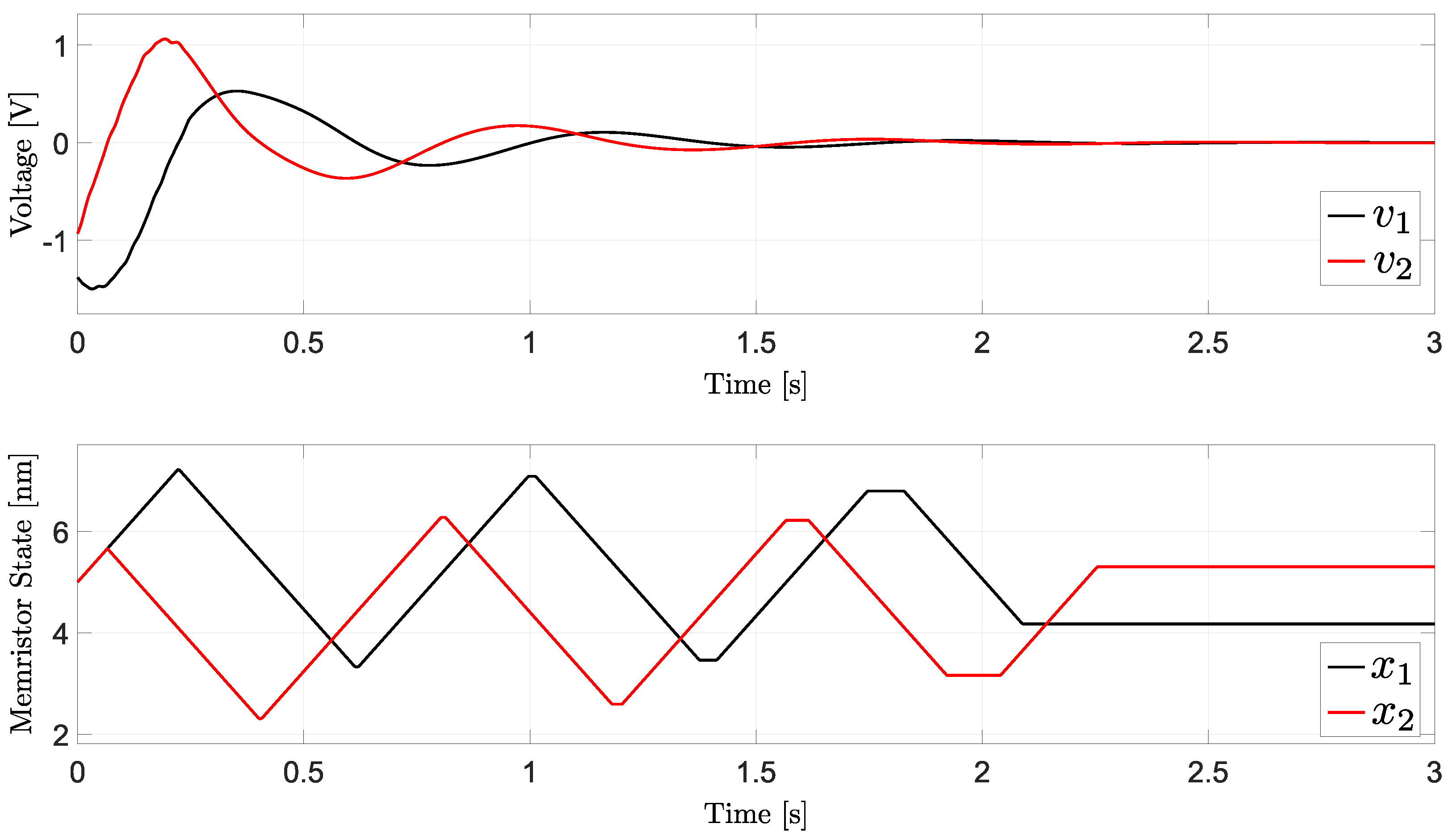
Figure 3 shows the solutions obtained starting from the initial conditions defined above. The simulations show that, regardless of the initial condition, memristor voltages always converge to 0. The different evolution in time of the neuron voltages, however, determines different dynamics of the memristor states. In fact, even if the initial memristor state is the same in each of the four analyzed cases, the subsequent dynamics are different, with the memristors that reach different asymptotic values for its states at the end of each simulation. This is better illustrated in Figure 4 for the simulation performed with initial condition V.
7. Conclusions
The paper has established some fundamental results on trajectory convergence for a class of differential inclusions, which are named DVIs, modeling delayed neural networks with real generic memristors obeying the VTEAM model. The conditions for convergence hold for any constant delay and they can be applied to nonsymmetric neuron interconnection matrices. Moreover, they can be effectively checked numerically since they are expressed in the form of LMIs. Although VTEAM can be used to fit several real memristor models, it is of interest in future work to extend the obtained results to other classes of real memristors, such as those modeled by extended memristors.
Author Contributions
Conceptualization, M.D.M., M.F., R.M., L.P., G.I. and A.T.; methodology, M.D.M., M.F., R.M., L.P., G.I. and A.T.; formal analysis, M.D.M., M.F., R.M., L.P., G.I. and A.T.; writing—original draft preparation, M.D.M., M.F., R.M., L.P., G.I. and A.T.; writing—review and editing, M.D.M., M.F., R.M., L.P., G.I. and A.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Italian Ministry of Education, University and Research (MIUR) grant PRIN 2017LSCR4K 002 (“Analogue Computing with Dynamic Switching Memristor Oscillators: Theory, Devices and Applications (COSMO)”).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Waldrop, M.M. The chips are down for Moore’s law. Nat. News 2016, 530, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, R.S. What’s Next? [The end of Moore’s law]. Comp. Sci. Eng. 2017, 19, 7–13. [Google Scholar] [CrossRef]
- Zidan, M.A.; Strachan, J.P.; Lu, W.D. The future of electronics based on memristive systems. Nat. Electron. 2018, 1, 22. [Google Scholar] [CrossRef]
- Yang, J.J.; Williams, R.S. Memristive devices in computing system: Promises and challenges. ACM J. Emerg. Technol. Comput. Syst. 2013, 9, 11. [Google Scholar] [CrossRef]
- Li, C.; Wang, Z.; Rao, M.; Belkin, D.; Song, W.; Jiang, H.; Yan, P.; Li, Y.; Lin, P.; Hu, M.; et al. Long Short-Term Memory Networks Memristor Crossbar Arrays. Nat. Mach. Intell. 2019, 1, 49. [Google Scholar] [CrossRef]
- Ielmini, D.; Pedretti, G. Device and Circuit Architectures for In-Memory Computing. Adv. Intell. Syst. 2020, 2, 2000040. [Google Scholar] [CrossRef]
- Ielmini, D.; Wong, H.S.P. In-memory computing with resistive switching devices. Nat. Electron. 2018, 1, 333–343. [Google Scholar] [CrossRef]
- Xia, Q.; Yang, J.J. Memristive crossbar arrays for brain-inspired computing. Nat. Mater. 2019, 18, 309–323. [Google Scholar] [CrossRef]
- Chua, L.O. Memristor-The missing circuit element. IEEE Trans. Circuit Theory 1971, 18, 507–519. [Google Scholar] [CrossRef]
- Chua, L.O.; Kang, S.M. Memristive devices and systems. Proc. IEEE 1976, 64, 209–223. [Google Scholar] [CrossRef]
- Hajri, B.; Aziza, H.; Mansour, M.M.; Chehab, A. RRAM device models: A comparative analysis with experimental validation. IEEE Access 2019, 7, 168963–168980. [Google Scholar] [CrossRef]
- Chen, P.Y.; Yu, S. Compact modeling of RRAM devices and its applications in 1T1R and 1S1R array design. IEEE Trans. Electron Devices 2015, 62, 4022–4028. [Google Scholar] [CrossRef]
- Mazumder, P.; Kang, S.M.; Waser, R. Special issue on memristors: Devices, models, and applications. Proc. IEEE 2012, 100, 1911–1919. [Google Scholar] [CrossRef]
- Chua, L. Everything You Wish to Know about Memristors But Are Afraid to Ask. Radioengineering 2015, 24, 319–368. [Google Scholar] [CrossRef]
- Corinto, F.; Forti, M.; Chua, L.O. Nonlinear Circuits and Systems with Memristors; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Kvatinsky, S.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. TEAM: Threshold adaptive memristor model. IEEE Trans. Circuits Syst. I Reg. Pap. 2013, 60, 211–221. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Ramadan, M.; Friedman, E.G.; Kolodny, A. VTEAM: A general model for voltage-controlled memristors. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 786–790. [Google Scholar] [CrossRef]
- Khalid, M. Review on various memristor models, characteristics, potential applications, and future works. Trans. Electr. Electron. Mater. 2019, 20, 289–298. [Google Scholar] [CrossRef]
- Ascoli, A.; Corinto, F.; Senger, V.; Tetzlaff, R. Memristor model comparison. IEEE Circuits Syst. Mag. 2013, 13, 89–105. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice-Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Chua, L.O.; Yang, L. Cellular neural networks: Theory. IEEE Trans. Circuits Syst. 1988, 35, 1257–1272. [Google Scholar] [CrossRef]
- Chua, L.O.; Yang, L. Cellular neural networks: Applications. IEEE Trans. Circuits Syst. 1988, 35, 1273–1290. [Google Scholar] [CrossRef]
- Cohen, M.A.; Grossberg, S. Absolute stability of global pattern formation and parallel memory storage by competitive neural networks. IEEE Trans. Syst. Man Cybern. 1983, 13, 815–825. [Google Scholar] [CrossRef]
- Hirsch, M. Convergent activation dynamics in continuous time networks. Neural Netw. 1989, 2, 331–349. [Google Scholar] [CrossRef] [Green Version]
- Chua, L.O. Special Issue on Nonlinear Waves, Patterns and Spatio-temporal Chaos in Dynamic Arrays. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1995, 42, 557–823. [Google Scholar]
- Michel, A.N.; Farrell, J.A.; Porod, W. Qualitative analysis of neural networks. IEEE Trans. Circuits Syst. 1989, 36, 229–243. [Google Scholar] [CrossRef]
- Di Marco, M.; Forti, M.; Grazzini, M.; Pancioni, L. Limit Set Dichotomy and Convergence of Cooperative Piecewise Linear Neural Networks. IEEE Trans. Circuits Syst. I Reg. Pap. 2011, 58, 1052–1062. [Google Scholar] [CrossRef]
- Di Marco, M.; Forti, M.; Grazzini, M.; Pancioni, L. Convergent Dynamics of Nonreciprocal Differential Variational Inequalities Modeling Neural Networks. IEEE Trans. Circuits Syst. I Reg. Pap. 2013, 60, 3227–3238. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Liu, D. A Comprehensive Review of Stability Analysis of Continuous-Time Recurrent Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1229–1262. [Google Scholar] [CrossRef]
- Di Marco, M.; Forti, M.; Pancioni, L. Complete stability of feedback CNNs with dynamic memristors and second-order cells. Int. J. Circuit Theory Appl. 2016, 44, 1959–1981. [Google Scholar] [CrossRef]
- Di Marco, M.; Forti, M.; Pancioni, L. Convergence and Multistability of Nonsymmetric Cellular Neural Networks with Memristors. IEEE Trans. Cybern. 2017, 47, 2970–2983. [Google Scholar] [CrossRef]
- Di Marco, M.; Forti, M.; Pancioni, L. Memristor standard cellular neural networks computing in the flux–charge domain. Neural Netw. 2017, 93, 152–164. [Google Scholar] [CrossRef]
- Corinto, F.; Forti, M. Memristor Circuits: Flux–Charge Analysis Method. IEEE Trans. Circuits Syst. I Reg. Pap. 2016, 63, 1997–2009. [Google Scholar] [CrossRef] [Green Version]
- Yao, W.; Wang, C.; Cao, J.; Sun, Y.; Zhou, C. Hybrid multisynchronization of coupled multistable memristive neural networks with time delays. Neurocomputing 2019, 363, 281–294. [Google Scholar] [CrossRef]
- Nie, X.; Zheng, W.X.; Cao, J. Multistability of memristive Cohen-Grossberg neural networks with non-monotonic piecewise linear activation functions and time-varying delays. Neural Netw. 2015, 71, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Pershin, Y.V.; Di Ventra, M. On the validity of memristor modeling in the neural network literature. Neural Netw. 2020, 121, 52–56. [Google Scholar] [CrossRef]
- Chua, L.O.; Roska, T. Cellular Neural Networks and Visual Computing: Foundation and Applications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Yin, W.; Yang, W.; Liu, H. A neural network scheme for recovering scattering obstacles with limited phaseless far-field data. J. Comput. Phys. 2020, 417, 109594. [Google Scholar] [CrossRef]
- Aubin, J.P.; Cellina, A. Differential Inclusions. Set-Valued Maps and Viability Theory; Springer: Berlin, Germany, 1984. [Google Scholar]
- Boyd, S.P.; El Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; SIAM: Philadelphia, PA, USA, 1994; Volume 15. [Google Scholar]
- Aubin, J.P.; Frankowska, H. Set-Valued Analysis; Birkauser: Boston, MA, USA, 1990. [Google Scholar]
- Di Marco, M.; Forti, M.; Grazzini, M.; Pancioni, L. On global exponential stability of standard and full-range CNNs. Int. J. Circuit Theory Appl. 2008, 36, 653–680. [Google Scholar] [CrossRef]
- Hopfield, J. Neural Networks and Physical Systems with Emergent Collective Computational Abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, E.N.; Perez, J.P. Input-to-state stability (ISS) analysis for dynamic neural networks. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1999, 46, 1395–1398. [Google Scholar] [CrossRef]
Figure 1.
Simulations of the memristor neural network considered in Example 1. Each color represents a different solution, obtained for a specific memristor initial condition. The initial conditions are labeled by the red markers. The final memristor states are labeled by the black dots. The black dashed box in the right plot is the hypercube bounding the memristor states.
Figure 1.
Simulations of the memristor neural network considered in Example 1. Each color represents a different solution, obtained for a specific memristor initial condition. The initial conditions are labeled by the red markers. The final memristor states are labeled by the black dots. The black dashed box in the right plot is the hypercube bounding the memristor states.

Figure 2.
Time domain behavior for the solution in Example 1 having initial condition nm.

Figure 3.
Simulations of the memristor neural network considered in Example 2. Each color represents a different solution, obtained for a specific memristor initial condition. The initial conditions are labeled by the red markers. The final memristor states are labeled by the black dots. The black dashed box in the right plot is the hypercube bounding the memristor states.
Figure 3.
Simulations of the memristor neural network considered in Example 2. Each color represents a different solution, obtained for a specific memristor initial condition. The initial conditions are labeled by the red markers. The final memristor states are labeled by the black dots. The black dashed box in the right plot is the hypercube bounding the memristor states.

Figure 4.
Time domain behavior for the state solution in Example 2 with V.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Di Marco, M.; Forti, M.; Moretti, R.; Pancioni, L.; Innocenti, G.; Tesi, A. Convergence of a Class of Delayed Neural Networks with Real Memristor Devices. Mathematics 2022, 10, 2439. https://doi.org/10.3390/math10142439
AMA Style
Di Marco M, Forti M, Moretti R, Pancioni L, Innocenti G, Tesi A. Convergence of a Class of Delayed Neural Networks with Real Memristor Devices. Mathematics. 2022; 10(14):2439. https://doi.org/10.3390/math10142439
Chicago/Turabian StyleDi Marco, Mauro, Mauro Forti, Riccardo Moretti, Luca Pancioni, Giacomo Innocenti, and Alberto Tesi. 2022. "Convergence of a Class of Delayed Neural Networks with Real Memristor Devices" Mathematics 10, no. 14: 2439. https://doi.org/10.3390/math10142439
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.