Prediction of Mental Illness in Heart Disease Patients: Association of Comorbidities, Dietary Supplements, and Antibiotics as Risk Factors



Abstract
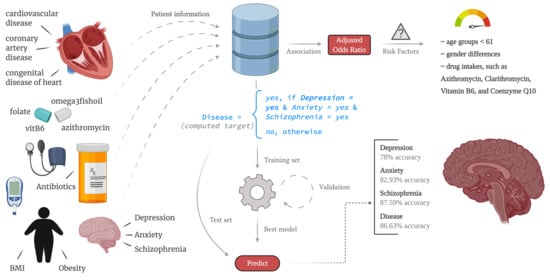
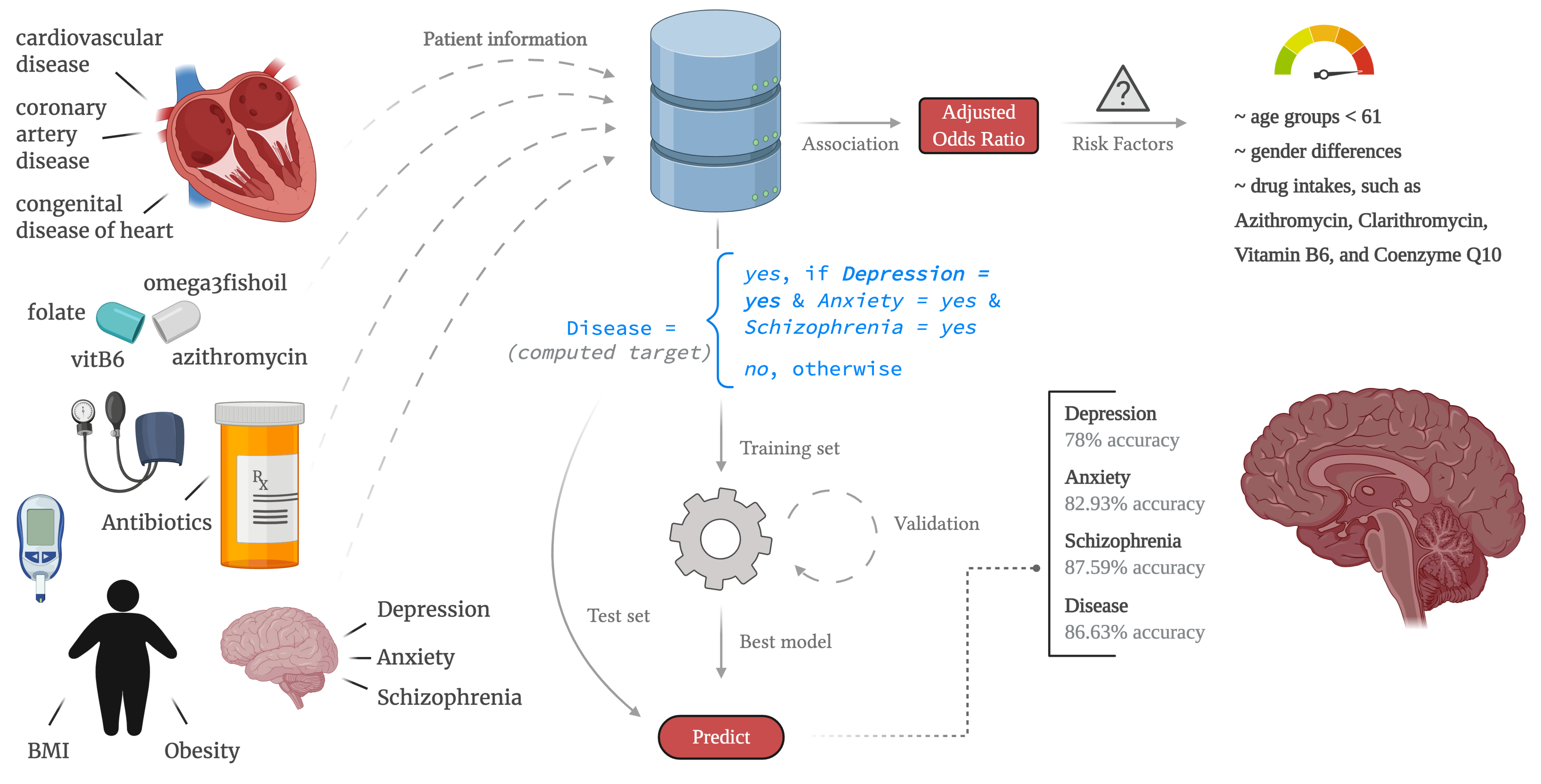
:
1. Introduction
2. Materials and Methods
2.1. Variable Selection
2.2. Prediction
2.3. Performance Measure
3. Results
3.1. Dataset
3.2. Association of Dietary Supplements, Comorbidities and Drug Usage in Mental Illness Patients
3.3. Modeling the Mental Illness Prediction Framework
4. Discussion
4.1. Risk Factors of Mental Illness
4.2. Depression
4.3. Anxiety
4.4. Schizophrenia
4.5. Disease
4.6. Strengths and Limitations of the Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Heron, M. Deaths: Leading Causes for 2017. Natl. Vital Stat. Rep. 2019, 68, 1–77. [Google Scholar] [PubMed]
- Benjamin, E.J.; Muntner, P.; Alonso, A.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Das, S.R.; et al. Heart Disease and Stroke Statistics-2019 Update: A Report From the American Heart Association. Circulation 2019, 139, e56–e528. [Google Scholar] [CrossRef]
- Fryar, C.D.; Chen, T.C.; Li, X. Prevalence of Uncontrolled Risk Factors for Cardiovascular Disease: United States, 1999–2010; US Department of Health and Human Services, Centers for Disease Control and Prevention, National Center for Health Statistics: Hyattsville, MD, USA, 2012.
- Chaddha, A.; Robinson, E.A.; Kline-Rogers, E.; Alexandris-Souphis, T.; Rubenfire, M. Mental Health and Cardiovascular Disease. Am. J. Med. 2016, 129, 1145–1148. [Google Scholar] [CrossRef] [Green Version]
- Hare, D.L.; Toukhsati, S.R.; Johansson, P.; Jaarsma, T. Depression and Cardiovascular Disease: A Clinical Review. Eur. Heart J. 2014, 35, 1365–1372. [Google Scholar] [CrossRef] [Green Version]
- Thomas, A.J.; Kalaria, R.N.; O’Brien, J.T. Depression and Vascular Disease: What Is the Relationship? J. Affect. Disord. 2004, 79, 81–95. [Google Scholar] [CrossRef]
- Riba, M.; Wulsin, L.; Rubenfire, M. Psychiatry and Heart Disease: The Mind, Brain, and Heart; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Ormel, J.; Von Korff, M.; Burger, H.; Scott, K.; Demyttenaere, K.; Huang, Y.; Posada-Villa, J.; Pierre Lepine, J.; Angermeyer, M.C.; Levinson, D.; et al. Mental Disorders among Persons with Heart Disease—Results from World Mental Health Surveys. Gen. Hosp. Psychiatry 2007, 29, 325–334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cunningham, R.; Poppe, K.; Peterson, D.; Every-Palmer, S.; Soosay, I.; Jackson, R. Prediction of Cardiovascular Disease Risk among People with Severe Mental Illness: A Cohort Study. PLoS ONE 2019, 14, e0221521. [Google Scholar] [CrossRef] [PubMed]
- Vance, M.C.; Wiitala, W.L.; Sussman, J.B.; Pfeiffer, P.; Hayward, R.A. Increased Cardiovascular Disease Risk in Veterans with Mental Illness. Circ. Cardiovasc. Qual. Outcomes 2019, 12, e005563. [Google Scholar] [CrossRef] [PubMed]
- De Hert, M.; Detraux, J.; Vancampfort, D. The Intriguing Relationship between Coronary Heart Disease and Mental Disorders. Dialogues Clin. Neurosci. 2018, 20, 31–40. [Google Scholar] [PubMed]
- Sesso, H.D.; Kawachi, I.; Vokonas, P.S.; Sparrow, D. Depression and the Risk of Coronary Heart Disease in the Normative Aging Study. Am. J. Cardiol. 1998, 82, 851–856. [Google Scholar] [CrossRef]
- Correll, C.U.; Solmi, M.; Veronese, N.; Bortolato, B.; Rosson, S.; Santonastaso, P.; Thapa-Chhetri, N.; Fornaro, M.; Gallicchio, D.; Collantoni, E.; et al. Prevalence, Incidence and Mortality from Cardiovascular Disease in Patients with Pooled and Specific Severe Mental Illness: A Large-Scale Meta-Analysis of 3,211,768 Patients and 113,383,368 Controls. World Psychiatry 2017, 16, 163–180. [Google Scholar] [CrossRef] [Green Version]
- Simon, G.E.; Ludman, E.J.; Linde, J.A.; Operskalski, B.H.; Ichikawa, L.; Rohde, P.; Finch, E.A.; Jeffery, R.W. Association between Obesity and Depression in Middle-Aged Women. Gen. Hosp. Psychiatry 2008, 30, 32–39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luppino, F.S.; De Wit, L.M.; Bouvy, P.F.; Stijnen, T.; Cuijpers, P.; Penninx, B.W.J.H.; Zitman, F.G. Overweight, Obesity, and Depression: A Systematic Review and Meta-Analysis of Longitudinal Studies. Arch. Gen. Psychiatry 2010, 67, 220–229. [Google Scholar] [CrossRef]
- Pan, Y.; Cai, W.; Cheng, Q.; Dong, W.; An, T.; Yan, J. Association between Anxiety and Hypertension: A Systematic Review and Meta-Analysis of Epidemiological Studies. Neuropsychiatr. Dis. Treat. 2015, 11, 1121–1130. [Google Scholar] [CrossRef] [Green Version]
- Licht, C.M.M.; Geus, E.J.C.D.; Seldenrijk, A.; Hout, H.P.J.V.; Zitman, F.G.; Van Dyck, R.; Penninx, B.W.J.H. Depression Is Associated with Decreased Blood Pressure, but Antidepressant Use Increases the Risk for Hypertension. Hypertension 2009, 53, 631–638. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lurie, I.; Yang, Y.X.; Haynes, K.; Mamtani, R.; Boursi, B. Antibiotic Exposure and the Risk for Depression, Anxiety, or Psychosis: A Nested Case-Control Study. J. Clin. Psychiatry 2015, 76, 1522–1528. [Google Scholar] [CrossRef]
- Nightingale, S.D.; Koster, F.T.; Mertz, G.J.; Loss, S.D. Clarithromycin-Induced Mania in Two Patients with AIDS. Clin. Infect. Dis. 1995, 20, 1563–1564. [Google Scholar] [CrossRef]
- Elahi, F.; Bhamjee, M. A Case of Clarithromycin Psychosis. Ir. J. Psychol. Med. 2005, 22, 73–74. [Google Scholar] [CrossRef]
- Negrín-González, J.; Peralta Filpo, G.; Carrasco, J.L.; Robledo Echarren, T.; Fernández-Rivas, M. Psychiatric Adverse Reaction Induced by Clarithromycin. Eur. Ann. Allergy Clin. Immunol. 2014, 46, 114–115. [Google Scholar]
- Voelker, R. Another Caution for Clarithromycin. Jama 2018, 319, 1314. [Google Scholar] [CrossRef]
- Šakić, B.O.; Babović, S.S.; Gajić, Z.M. Erythromycin-Induced Psychotic Decompensation in a Patient Affected by Paranoid Schizophrenic Psychosis. Klin. Psikofarmakol. Bul. 2014, 24, 368–370. [Google Scholar] [CrossRef]
- Sachdeva, A.; Rathee, R. Akathisia with Erythromycin: Induced or Precipitated? Saudi Pharm. J. 2015, 23, 541–543. [Google Scholar] [CrossRef] [Green Version]
- Gao, K.; Khoshgoftaar, T.M.; Napolitano, A. Combining Feature Subset Selection and Data Sampling for Coping with Highly Imbalanced Software Data. In Proceedings of the International Conference on Software Engineering and Knowledge Engineering, SEKE, Pittsburgh, PA, USA, July 2015; pp. 439–444. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; IOP Publishing: Burr Ridge, IL, USA, 1997. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 3147–3155. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Osborn, D.P.J.; Hardoon, S.; Omar, R.Z.; Holt, R.I.G.; King, M.; Larsen, J.; Marston, L.; Morris, R.W.; Nazareth, I.; Walters, K.; et al. Cardiovascular Risk Prediction Models for People With Severe Mental Illness. JAMA Psychiatry 2015, 72, 143. [Google Scholar] [CrossRef]
- D’Agostino, R.B.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General Cardiovascular Risk Profile for Use in Primary Care: The Framingham Heart Study. Circulation 2008, 117, 743–753. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Wu, H.; Jin, X.; Zheng, P.; Hu, S.; Xu, X.; Yu, W.; Yan, J. Study of Cardiovascular Disease Prediction Model Based on Random Forest in Eastern China. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ghiasi, M.M.; Zendehboudi, S.; Mohsenipour, A.A. Decision Tree-Based Diagnosis of Coronary Artery Disease: CART Model. Comput. Methods Programs Biomed. 2020, 192, 105400. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Kumar, L.; Jain, R.; Nagrath, P. Heart Disease Prediction Using Classification (Naive Bayes). In Lecture Notes in Networks and Systems; Springer: Singapore, 2020; Volume 121, pp. 561–573. [Google Scholar] [CrossRef]
- Rajliwall, N.S.; Davey, R.; Chetty, G. Cardiovascular Risk Prediction Based on XGBoost. In Proceedings—5th Asia-Pacific World Congress on Computer Science and Engineering, APWC on CSE; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 246–252. [Google Scholar] [CrossRef]
- Altan, G.; Allahverdi, N.; Kutlu, Y. Diagnosis of Coronary Artery Disease Using Deep Belief Networks. Eur. J. Eng. Nat. Sci. 2017, 2, 29–36. [Google Scholar]
- Greenfield, B.; Henry, M.; Weiss, M.; Tse, S.M.; Guile, J.M.; Dougherty, G.; Zhang, X.; Fombonne, E.; Lis, E.; Lapalme-Remis, S.; et al. Previously Suicidal Adolescents: Predictors of Six-Month Outcome. J. Can. Acad. Child Adolesc. Psychiatry 2008, 17, 197–201. [Google Scholar]

{kind=link}
| Total | Non-Disease | Disease (=Yes) | Depression (=Yes) | Anxiety (=Yes) | Schizophrenia (=Yes) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variables | ||||||||||||
| Total | 68,209 | 100.0 | 45,968 | 67.39 | 22,241 | 32.61 | 10,080 | 14.72 | 15,229 | 22.24 | 258 | 0.38 |
| Gender b | ||||||||||||
| Male | 37,959 | 44.35 | 23,552 | 51.26 | 6698 | 30.12 | 2912 | 28.89 | 4445 | 29.19 | 150 | 58.14 |
| Female | 30,250 | 55.65 | 22,416 | 48.76 | 15,543 | 69.88 | 7168 | 71.11 | 10,784 | 70.81 | 108 | 41.86 |
| Age (Years) | ||||||||||||
| 0–10 | 487 | 0.71 | 237 | 0.52 | 250 | 1.12 | 25 | 0.25 | 229 | 1.50 | 0 | 0.0 |
| 11–20 | 2637 | 3.87 | 634 | 1.38 | 2003 | 9.01 | 858 | 8.51 | 1455 | 9.55 | 5 | 1.94 |
| 21–30 | 4641 | 6.80 | 1264 | 2.75 | 3377 | 15.18 | 1312 | 13.02 | 2571 | 16.88 | 19 | 7.36 |
| 31–40 | 5647 | 8.28 | 2235 | 4.86 | 3412 | 15.34 | 1402 | 13.91 | 2517 | 16.53 | 46 | 17.83 |
| 41–50 | 7727 | 11.33 | 4368 | 9.50 | 3359 | 15.10 | 1521 | 15.09 | 2356 | 15.47 | 34 | 13.18 |
| 51–60 | 13,491 | 19.78 | 9480 | 20.62 | 4011 | 18.03 | 1944 | 19.29 | 2632 | 17.28 | 72 | 27.91 |
| 61–70 | 14,811 | 21.71 | 11,789 | 25.65 | 3022 | 13.59 | 1556 | 15.44 | 1787 | 11.73 | 61 | 23.64 |
| >70 | 18,768 | 27.51 | 15,961 | 34.72 | 2807 | 12.62 | 1462 | 14.50 | 1682 | 11.04 | 21 | 8.14 |
| IDD | ||||||||||||
| No | 67,481 | 98.93 | 45,365 | 98.69 | 22,115 | 99.43 | 10,013 | 99.34 | 15,157 | 99.53 | 253 | 98.06 |
| Yes | 729 | 1.07 | 603 | 1.31 | 126 | 0.57 | 67 | 0.66 | 72 | 0.47 | 5 | 1.94 |
| HT | ||||||||||||
| No | 48,777 | 28.49 | 5718 | 12.44 | 13,714 | 61.66 | 5847 | 58.01 | 9739 | 63.95 | 152 | 58.91 |
| Yes | 19,433 | 71.51 | 40,250 | 87.56 | 8527 | 38.34 | 4233 | 41.99 | 5490 | 36.05 | 106 | 41.09 |
| OA | ||||||||||||
| No | 65,501 | 96.02 | 43,933 | 95.57 | 21,567 | 96.97 | 9714 | 96.37 | 14,785 | 97.08 | 248 | 96.12 |
| Yes | 2709 | 3.97 | 2035 | 4.43 | 674 | 3.03 | 366 | 3.63 | 444 | 2.92 | 10 | 3.88 |
| CM | ||||||||||||
| No | 68,016 | 99.72 | 45,808 | 99.65 | 22,207 | 99.85 | 10,063 | 99.83 | 15,209 | 99.87 | 258 | 100.0 |
| Yes | 194 | 0.28 | 160 | 0.35 | 34 | 0.15 | 17 | 0.17 | 20 | 0.13 | 0 | 0.0 |
| Obesity | ||||||||||||
| No | 59,601 | 87.38 | 39,346 | 85.59 | 20,255 | 91.07 | 9019 | 89.47 | 13,974 | 91.76 | 226 | 87.60 |
| Yes | 8609 | 12.62 | 6622 | 14.41 | 1986 | 8.93 | 1061 | 10.53 | 1255 | 8.24 | 32 | 12.40 |
| CDH | ||||||||||||
| No | 68,153 | 99.92 | 45,918 | 99.89 | 22,234 | 99.97 | 10,076 | 99.96 | 15,225 | 99.97 | 258 | 100.0 |
| Yes | 57 | 0.08 | 50 | 0.11 | 7 | 0.03 | 4 | 0.04 | 4 | 0.03 | 0 | 0.0 |
| HF | ||||||||||||
| No | 66,069 | 96.86 | 44,189 | 96.13 | 21,879 | 98.37 | 9876 | 97.98 | 15,005 | 98.53 | 256 | 99.22 |
| Yes | 2141 | 3.14 | 1779 | 3.87 | 362 | 1.63 | 204 | 2.02 | 224 | 1.47 | 2 | 0.78 |
| CVD | ||||||||||||
| No | 68,115 | 99.86 | 45,899 | 99.85 | 22,215 | 99.88 | 10,063 | 99.83 | 15,216 | 99.91 | 257 | 99.61 |
| Yes | 95 | 0.14 | 69 | 0.15 | 26 | 0.12 | 17 | 0.17 | 13 | 0.09 | 1 | 0.39 |
| AS | ||||||||||||
| No | 68,145 | 99.90 | 45,915 | 99.88 | 22,229 | 99.95 | 10,071 | 99.91 | 15,222 | 99.95 | 258 | 100.0 |
| Yes | 65 | 0.10 | 53 | 0.12 | 12 | 0.05 | 9 | 0.09 | 7 | 0.05 | 0 | 0.0 |
| CAD | ||||||||||||
| No | 59,504 | 87.24 | 38,433 | 83.61 | 21,070 | 94.73 | 9455 | 93.80 | 14,523 | 95.36 | 245 | 94.96 |
| Yes | 8706 | 12.76 | 7535 | 16.39 | 1171 | 5.27 | 625 | 6.20 | 706 | 4.64 | 13 | 5.04 |
| ND | ||||||||||||
| No | 68,121 | 99.87 | 45,901 | 99.85 | 22,219 | 99.90 | 10,075 | 99.95 | 15,213 | 99.989 | 256 | 99.22 |
| Yes | 89 | 0.13 | 67 | 0.15 | 22 | 0.10 | 5 | 0.05 | 16 | 0.10 | 2 | 0.78 |
| E-CRP | ||||||||||||
| No | 67,969 | 99.65 | 45,800 | 99.63 | 22,168 | 99.67 | 10,059 | 99.79 | 15,167 | 99.59 | 256 | 99.22 |
| Yes | 241 | 0.35 | 168 | 0.37 | 73 | 0.33 | 21 | 0.21 | 62 | 0.41 | 2 | 0.78 |
| E-ESR | ||||||||||||
| No | 67,900 | 99.55 | 45,757 | 99.54 | 22,142 | 99.55 | 10,039 | 99.59 | 15,154 | 99.51 | 258 | 100.0 |
| Yes | 310 | 0.45 | 211 | 0.46 | 99 | 0.45 | 41 | 0.41 | 75 | 0.49 | 0 | 0.0 |
| LTUA | ||||||||||||
| No | 67,911 | 99.56 | 45,715 | 99.45 | 22,195 | 99.79 | 10,058 | 99.78 | 15,195 | 99.78 | 258 | 100.0 |
| Yes | 299 | 0.44 | 253 | 0.55 | 46 | 0.21 | 22 | 0.22 | 34 | 0.22 | 0 | 0.0 |
| BMIc (mean ± std) | (50.25 ± 1108.60) | |||||||||||
| Underweight (<18.5) | 1323 | 1.93 | 616 | 1.34 | 707 | 3.18 | 225 | 2.23 | 563 | 3.70 | 3 | 1.16 |
| Normal (18.5–24.99) | 12,535 | 18.38 | 7062 | 15.36 | 5473 | 24.61 | 2142 | 21.25 | 4008 | 26.32 | 59 | 22.87 |
| Overweight (25–29.99) | 18,757 | 27.50 | 12,939 | 28.14 | 5817 | 26.15 | 2532 | 25.12 | 4052 | 26.61 | 84 | 32.56 |
| Obese (30–39.99) | 26,075 | 38.23 | 18,720 | 40.72 | 7532 | 33.06 | 3571 | 35.43 | 4803 | 31.54 | 88 | 34.11 |
| Severe Obese (40) | 9523 | 13.96 | 6631 | 14.43 | 2892 | 13.00 | 1610 | 15.97 | 1803 | 11.84 | 24 | 9.30 |
| LAB d | ||||||||||||
| CRP | 595 | 41.01 | 382 | 42.97 | 213 | 37.90 | 87 | 38.16 | 170 | 38.81 | 0 | 0.00 |
| ESR | 856 | 58.99 | 507 | 57.03 | 349 | 62.10 | 141 | 61.84 | 268 | 61.19 | 1 | 100.0 |
| LabValue e (mean ± std) | (17.79 ± 28.97) | |||||||||||
| E_Mycin | ||||||||||||
| No | 68,192 | 99.97 | 45,958 | 99.98 | 22,233 | 99.96 | 10,076 | 99.96 | 15,223 | 99.96 | 258 | 100.0 |
| Yes | 18 | 0.03 | 10 | 0.02 | 8 | 0.04 | 4 | 0.04 | 6 | 0.04 | 0 | 0.00 |
| C_Mycin | ||||||||||||
| No | 67,636 | 99.16 | 45,619 | 99.24 | 22,016 | 98.99 | 9988 | 99.09 | 15,066 | 98.93 | 257 | 99.61 |
| Yes | 574 | 0.84 | 349 | 0.78 | 225 | 1.01 | 92 | 0.91 | 163 | 1.07 | 1 | 0.39 |
| Z_pak | ||||||||||||
| No | 48,024 | 70.41 | 33,374 | 72.60 | 14,649 | 65.86 | 6437 | 63.86 | 9969 | 65.46 | 201 | 77.91 |
| Yes | 20,186 | 29.59 | 12,594 | 27.40 | 7592 | 34.14 | 3643 | 36.14 | 5260 | 34.54 | 57 | 22.09 |
| Folate | ||||||||||||
| No | 68,131 | 99.88 | 45,921 | 99.90 | 22,209 | 99.86 | 10,062 | 99.82 | 15,209 | 99.87 | 257 | 99.61 |
| Yes | 79 | 0.12 | 47 | 0.10 | 32 | 0.14 | 18 | 0.18 | 20 | 0.13 | 1 | 0.39 |
| VitB6 | ||||||||||||
| No | 68,050 | 99.77 | 45,862 | 99.77 | 22,187 | 99.76 | 10,054 | 99.74 | 15,194 | 99.77 | 258 | 100.0 |
| Yes | 160 | 0.23 | 106 | 0.23 | 54 | 0.24 | 26 | 0.26 | 35 | 0.23 | 0 | 0.00 |
| CoQ | ||||||||||||
| No | 67,589 | 99.09 | 45,490 | 98.96 | 22,098 | 99.36 | 10,017 | 99.37 | 15,137 | 99.40 | 258 | 100.0 |
| Yes | 621 | 0.91 | 478 | 1.04 | 143 | 0.64 | 63 | 0.63 | 92 | 0.60 | 0 | 0.0 |
| O3FO | ||||||||||||
| No | 68,026 | 99.73 | 45,823 | 99.68 | 22,202 | 99.82 | 10,058 | 99.78 | 15,202 | 99.82 | 257 | 99.61 |
| Yes | 184 | 0.27 | 145 | 0.32 | 39 | 0.18 | 22 | 0.22 | 27 | 0.18 | 1 | 0.39 |
| Disease | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22,241 | 32.61 | ||||||||||||||
| Non-Disease | Depression | Anxiety | Schizophrenia | (D, A) a | (D, S) b | (A, S) c | (A, D, S) d | ||||||||
| 45,968 | 67.39 | 10,080 | 14.78 | 15,229 | 22.33 | 258 | 0.38 | 3261 | 32.35 | 36 | 0.36 | 39 | 0.26 | 10 | 0.31 |
| a | LCL b | UCL c | aOR d | p-Value | |
|---|---|---|---|---|---|
| age | |||||
| 0–10 | Ref e | ||||
| 11–20 | 858 | 4.4327 | 10.2297 | 6.7335 | 0.0000 |
| 21–30 | 1312 | 3.8046 | 8.7597 | 5.7730 | 0.0000 |
| 31–40 | 1402 | 4.0315 | 9.2835 | 6.1178 | 0.0000 |
| 41–50 | 1521 | 4.1224 | 9.4920 | 6.2551 | 0.0000 |
| 51–60 | 1944 | 3.6822 | 8.4682 | 5.5840 | 0.0000 |
| 61–70 | 1556 | 2.9935 | 6.8981 | 4.5440 | 0.0000 |
| Over–70 | 1462 | 2.3545 | 5.4319 | 3.5762 | 0.0000 |
| Gender | |||||
| Male | Ref | ||||
| Female | 7168 | 1.6113 | 1.7788 | 1.6930 | 0.0000 |
| Z_pak | 3643 | 1.3227 | 1.4563 | 1.3879 | 0.0000 |
| BMI | |||||
| <18.5 | Ref | ||||
| >=40 | 1610 | 1.0832 | 1.5228 | 1.2843 | 0.0040 |
| Osteoarthritis | 366 | 0.6892 | 0.8760 | 0.7770 | 0.0000 |
| CoronaryArteryDisease | 625 | 0.6284 | 0.7547 | 0.6887 | 0.0000 |
| Obesity | 1061 | 0.4774 | 0.5561 | 0.5153 | 0.0000 |
| Hypertension | 4233 | 0.2373 | 0.2653 | 0.2509 | 0.0000 |
| a | LCL b | UCL c | aOR d | p-Value | |
|---|---|---|---|---|---|
| Gender | |||||
| Male | Ref e | ||||
| Female | 10,784 | 1.7604 | 1.9275 | 1.8421 | 0.0000 |
| Clarithromycin | 163 | 1.4329 | 2.1862 | 1.7699 | 0.0000 |
| Intercept | 1.4021 | 2.1573 | 1.7392 | 0.0000 | |
| Z_pak | 5260 | 1.4481 | 1.5880 | 1.5163 | 0.0000 |
| CoQ | 92 | 1.1736 | 1.8996 | 1.4932 | 0.0011 |
| age | |||||
| 0–10 | Ref | ||||
| 21–30 | 2571 | 1.1618 | 1.7834 | 1.4394 | 0.0009 |
| 31–40 | 2517 | 1.0576 | 1.6216 | 1.3096 | 0.0134 |
| 51–60 | 2632 | 0.5436 | 0.8317 | 0.6724 | 0.0003 |
| 61–70 | 1787 | 0.3454 | 0.5304 | 0.4280 | 0.0000 |
| >70 | 1682 | 0.2489 | 0.3827 | 0.3086 | 0.0000 |
| HeartFailure | 224 | 0.6440 | 0.8746 | 0.7505 | 0.0002 |
| BMI | |||||
| <18.5 | Ref | ||||
| 18.5–24.99 | 4,008 | 0.5725 | 0.7615 | 0.6603 | 0.0000 |
| 25–29.99 | 4,052 | 0.4727 | 0.6286 | 0.5451 | 0.0000 |
| 30–39.99 | 4,803 | 0.3818 | 0.5078 | 0.4403 | 0.0000 |
| >=40 | 1,803 | 0.3542 | 0.4796 | 0.4121 | 0.0000 |
| Osteoarthritis | 444 | 0.5357 | 0.6772 | 0.6023 | 0.0000 |
| CoronaryArteryDisease | 706 | 0.5396 | 0.6439 | 0.5894 | 0.0000 |
| ElevatedCRP | 62 | 0.3983 | 0.7934 | 0.5621 | 0.0011 |
| Obesity | 1,255 | 0.3027 | 0.3519 | 0.3264 | 0.0000 |
| Hypertension | 5,490 | 0.1857 | 0.2055 | 0.1954 | 0.0000 |
| a | LCL b | UCL c | aOR d | p-Value | |
|---|---|---|---|---|---|
| Z_pak | 57 | 0.5168 | 0.9400 | 0.6970 | 0.018 |
| Gender | |||||
| Male | Ref e | ||||
| Female | 108 | 0.3436 | 0.5766 | 0.4451 | 0.0000 |
| Hypertension | 106 | 0.1567 | 0.2823 | 0.2103 | 0.0000 |
| a | LCL b | UCL c | aOR d | p-Value | |
|---|---|---|---|---|---|
| age | |||||
| 0–10 | Ref e | ||||
| 11–20 | 2003 | 2.0997 | 3.3290 | 2.6438 | 0.0000 |
| 21–30 | 3377 | 2.4145 | 3.7744 | 3.0189 | 0.0000 |
| 31–40 | 3412 | 2.1247 | 3.3040 | 2.6496 | 0.0000 |
| 41–50 | 3359 | 1.5622 | 2.4222 | 1.9453 | 0.0000 |
| 51–60 | 4011 | 1.0804 | 1.6695 | 1.3430 | 0.0079 |
| >70 | 2807 | 0.5097 | 0.7887 | 0.6341 | 0.0000 |
| Intercept | 1.8792 | 2.9404 | 2.3507 | 0.0000 | |
| Gender | |||||
| Male | Ref | ||||
| Female | 15,543 | 2.0153 | 2.1931 | 2.1024 | 0.0000 |
| Clarithromycin | 225 | 1.4559 | 2.1904 | 1.7857 | 0.0000 |
| Z_pak | 7592 | 1.5693 | 1.7137 | 1.6398 | 0.0000 |
| VitB6 | 54 | 1.0515 | 2.4383 | 1.6011 | 0.0283 |
| CoQ | 143 | 1.2244 | 1.8736 | 1.5145 | 0.0001 |
| BMI | |||||
| <18.5 | Ref | ||||
| 18.5–24.99 | 5473 | 0.5887 | 0.7924 | 0.6830 | 0.0000 |
| 25–29.99 | 5817 | 0.4823 | 0.6479 | 0.5590 | 0.0000 |
| 30–39.99 | 7352 | 0.4246 | 0.5702 | 0.4921 | 0.0000 |
| >=40 | 2892 | 0.4342 | 0.5913 | 0.5067 | 0.0000 |
| ElevatedESR | 99 | 0.4614 | 0.8791 | 0.6369 | 0.0061 |
| HeartFailure | 362 | 0.5487 | 0.7188 | 0.6280 | 0.0000 |
| CoronaryArteryDisease | 1171 | 0.4861 | 0.5663 | 0.5247 | 0.0000 |
| Osteoarthritis | 674 | 0.4119 | 0.5139 | 0.4601 | 0.0000 |
| ElevatedCRP | 73 | 0.1946 | 0.3936 | 0.2768 | 0.0000 |
| Obesity | 1986 | 0.2164 | 0.2501 | 0.2327 | 0.0000 |
| Hypertension | 8527 | 0.0987 | 0.1094 | 0.1039 | 0.0000 |
| InsulinDependentDiabetes | 126 | 0.0778 | 0.1216 | 0.0973 | 0.0000 |
| Illness | Variable Selection | Under Sampling | Model | Accuracy | F1-Score | Sensitivity | Specificity | AUC |
|---|---|---|---|---|---|---|---|---|
| Depression | A- | Yes | LGBM | 0.7801 | 0.7913 | 0.8338 | 0.7265 | 0.8626 |
| No | Yes | LGBM | 0.7648 | 0.7745 | 0.8083 | 0.7214 | 0.8518 | |
| No | No | LGBM | 0.8530 | 0.9199 | 0.9903 | 0.0615 | 0.7648 | |
| LR | No | LGBM | 0.8524 | 0.9201 | 0.9974 | 0.0160 | 0.7567 | |
| Anxiety | A- | Yes | LGBM | 0.8293 | 0.8286 | 0.8251 | 0.8335 | 0.8845 |
| No | Yes | LGBM | 0.8242 | 0.8231 | 0.8178 | 0.8306 | 0.8775 | |
| No | No | LGBM | 0.8558 | 0.9100 | 0.9380 | 0.5701 | 0.8318 | |
| LR | No | LGBM | 0.8550 | 0.9091 | 0.9331 | 0.5833 | 0.8289 | |
| Schizophrenia | LR | Yes | RF | 0.8759 | 0.8770 | 0.8976 | 0.8514 | 0.9292 |
| No | Yes | RF | 0.8779 | 0.8799 | 0.8983 | 0.8544 | 0.9268 | |
| No | No | XGB | 0.9962 | 0.9981 | 1.0000 | 0.0000 | 0.7423 | |
| LR | No | XGB | 0.9962 | 0.9981 | 1.0000 | 0.0000 | 0.7361 | |
| Disease | No | Yes | LGBM | 0.8663 | 0.8772 | 0.9550 | 0.7776 | 0.9159 |
| A- | Yes | XGB | 0.8670 | 0.8788 | 0.9646 | 0.7695 | 0.9130 | |
| No | No | LGBM | 0.8565 | 0.9035 | 0.9971 | 0.5659 | 0.8522 | |
| LR | No | LGBM | 0.8555 | 0.9028 | 0.9957 | 0.5656 | 0.8515 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sivakumar, J.; Ahmed, S.; Begdache, L.; Jain, S.; Won, D. Prediction of Mental Illness in Heart Disease Patients: Association of Comorbidities, Dietary Supplements, and Antibiotics as Risk Factors. J. Pers. Med. 2020, 10, 214. https://doi.org/10.3390/jpm10040214
Sivakumar J, Ahmed S, Begdache L, Jain S, Won D. Prediction of Mental Illness in Heart Disease Patients: Association of Comorbidities, Dietary Supplements, and Antibiotics as Risk Factors. Journal of Personalized Medicine. 2020; 10(4):214. https://doi.org/10.3390/jpm10040214
Chicago/Turabian StyleSivakumar, Jayanth, Saba Ahmed, Lina Begdache, Swati Jain, and Daehan Won. 2020. "Prediction of Mental Illness in Heart Disease Patients: Association of Comorbidities, Dietary Supplements, and Antibiotics as Risk Factors" Journal of Personalized Medicine 10, no. 4: 214. https://doi.org/10.3390/jpm10040214