A Bayesian Approach to Real-Time Monitoring and Forecasting of Chinese Foodborne Diseases

Abstract
:1. Introduction
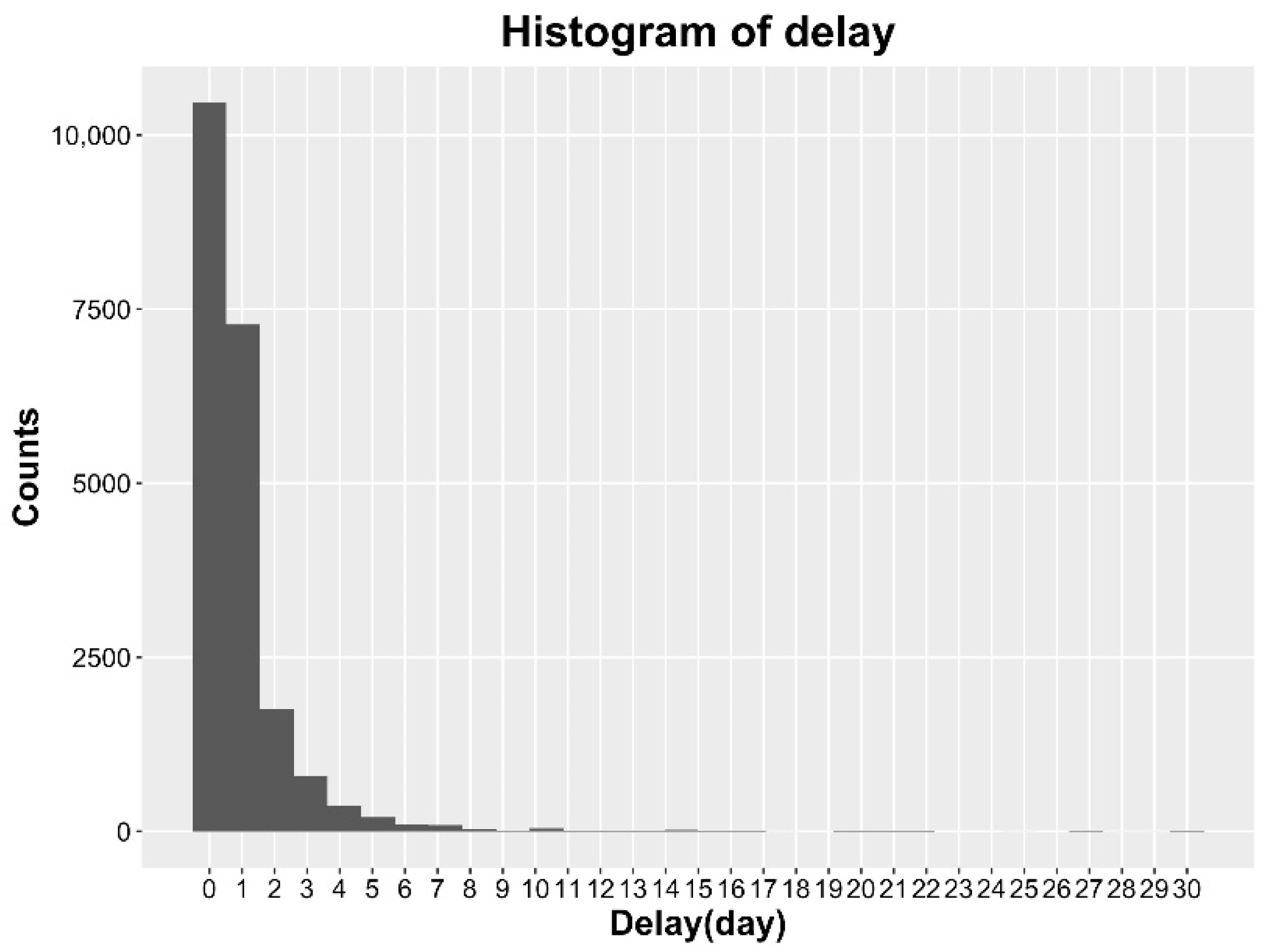
2. Data Material for Foodborne Diseases
3. Bayesian Nowcasting
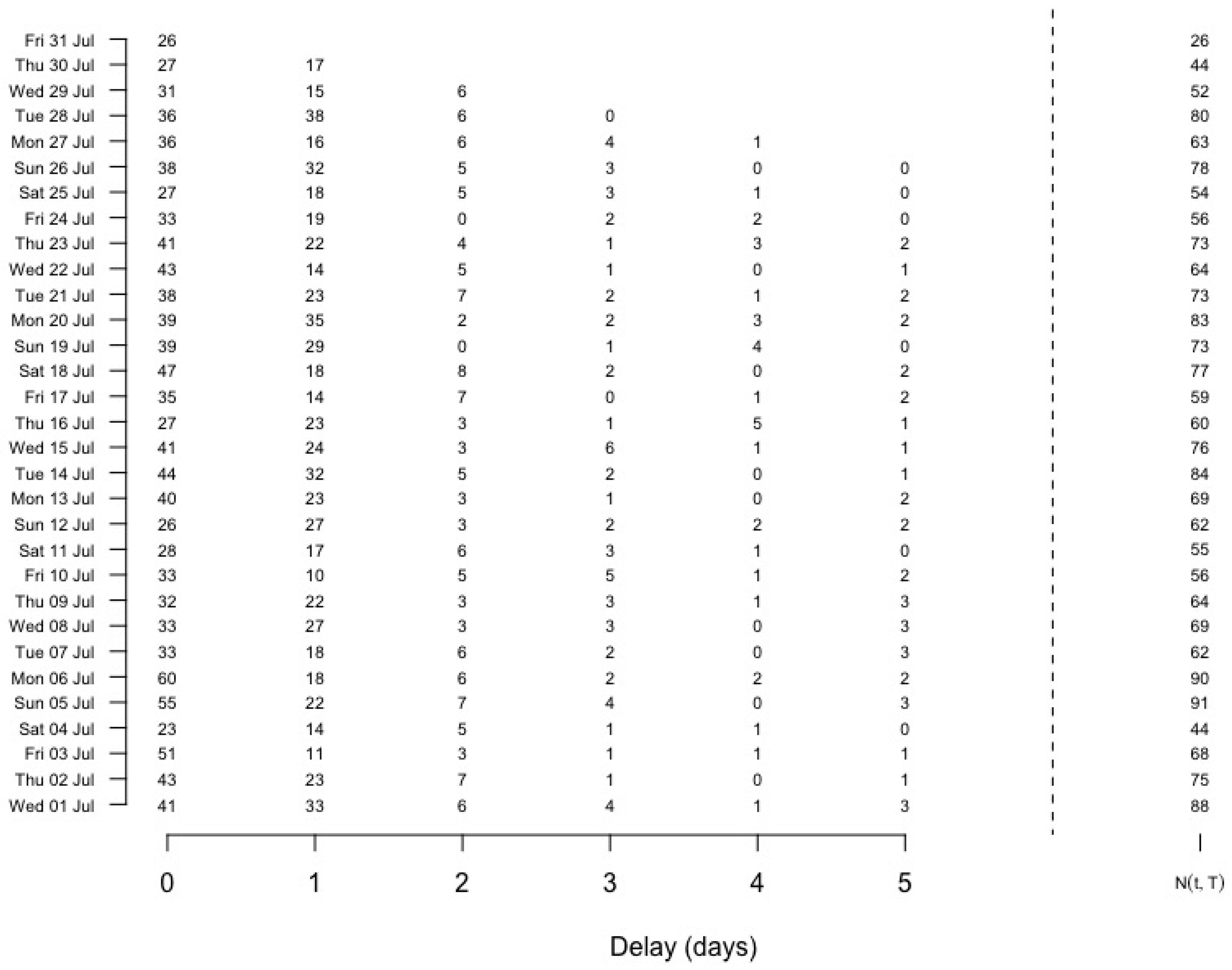
3.1. Notation and Assumptions
3.2. Predict the Distribution for
- For the given T we compute as stated above. We then We draw for random vectors by the algorithm of Wong (1998) and calculate
- Given the updated delay distribution and the observed counts , we can now update the prediction of .
4. Main Results
4.1. Setup for Hyper-Parameters
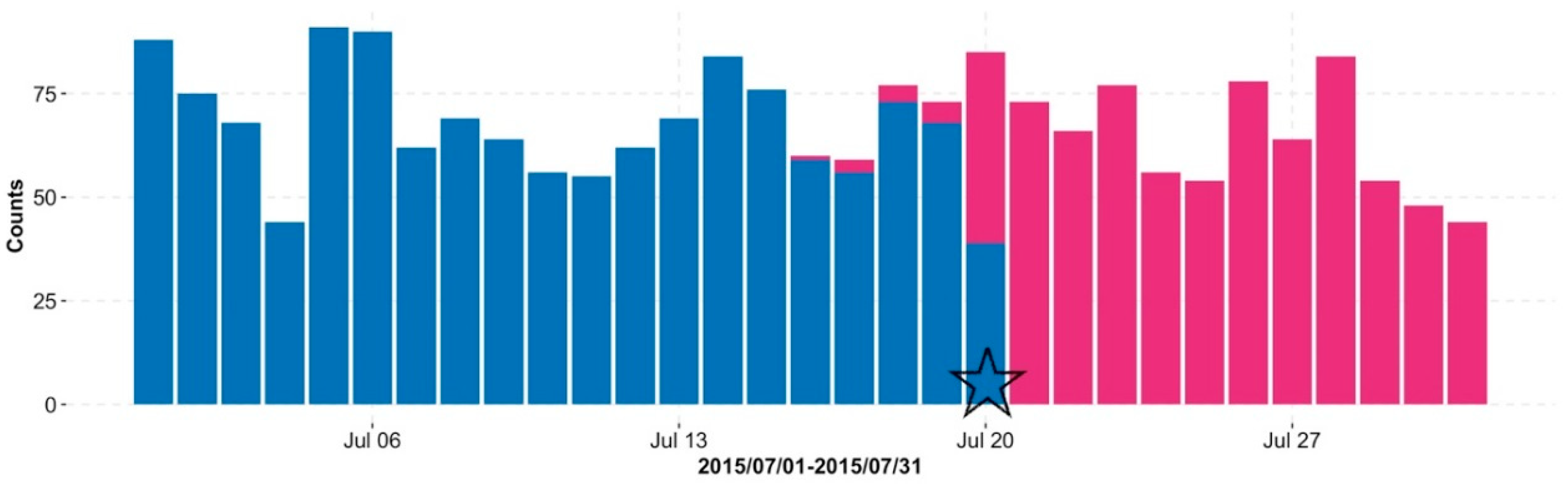
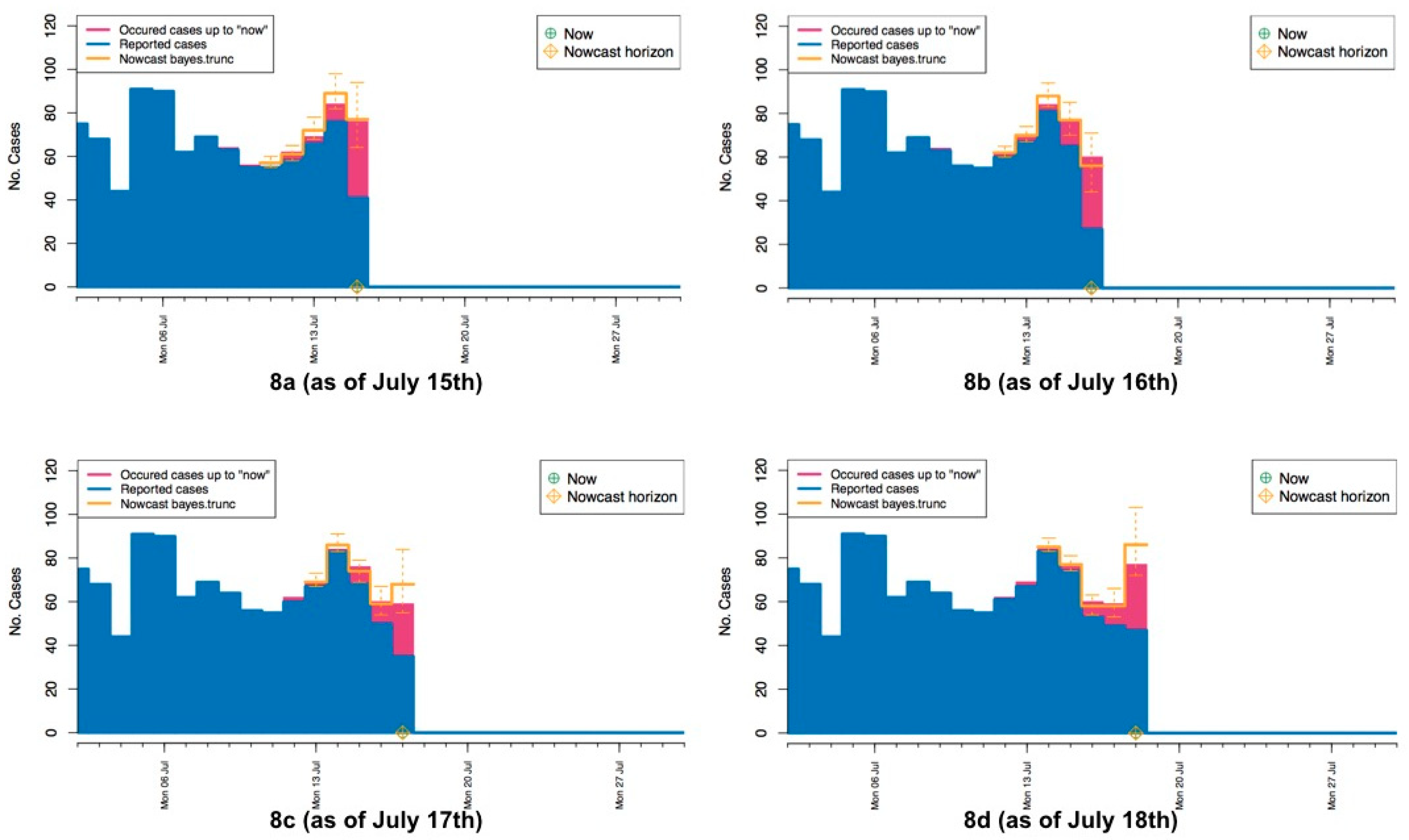
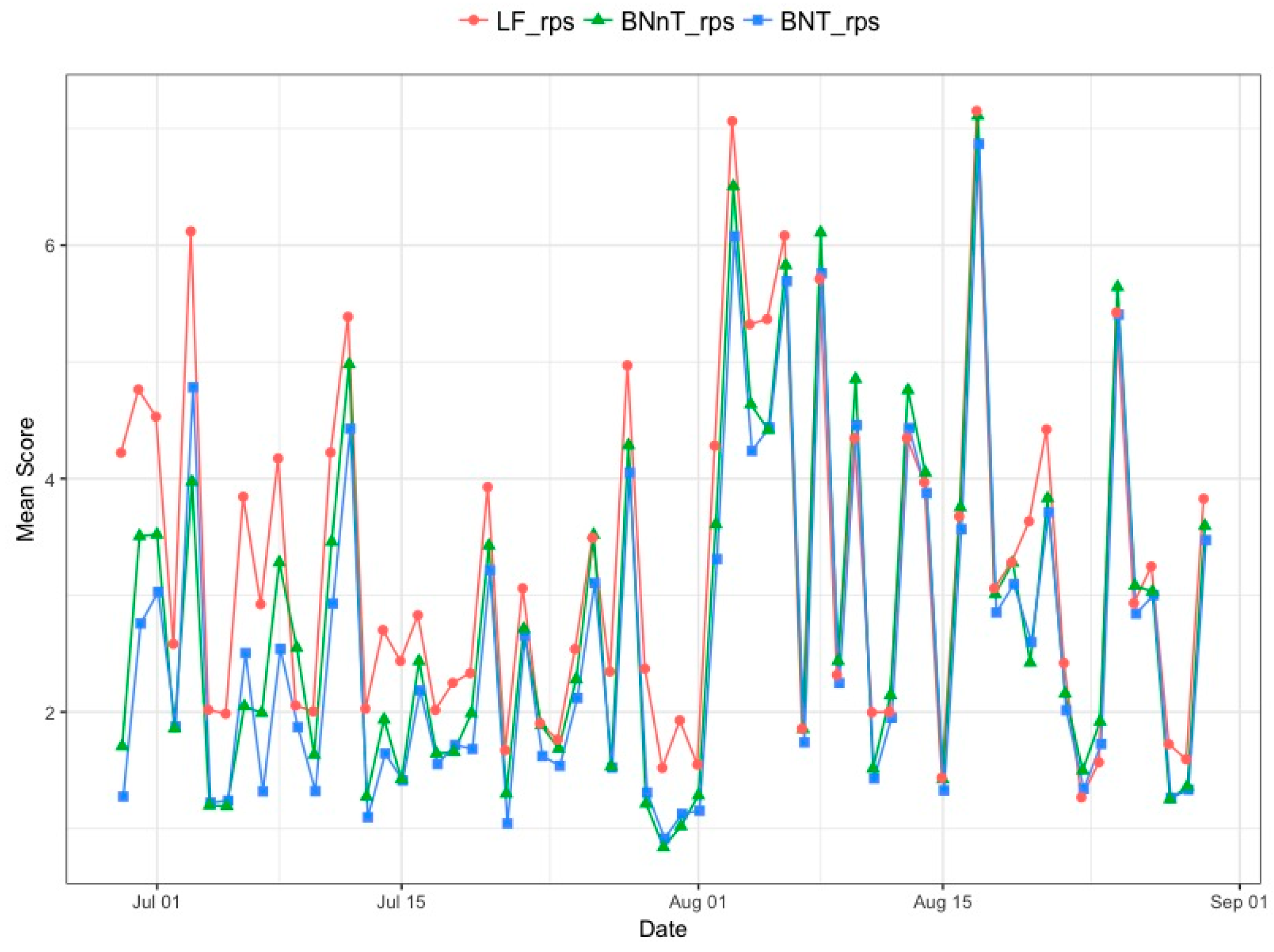
4.2. Daily Surveillance
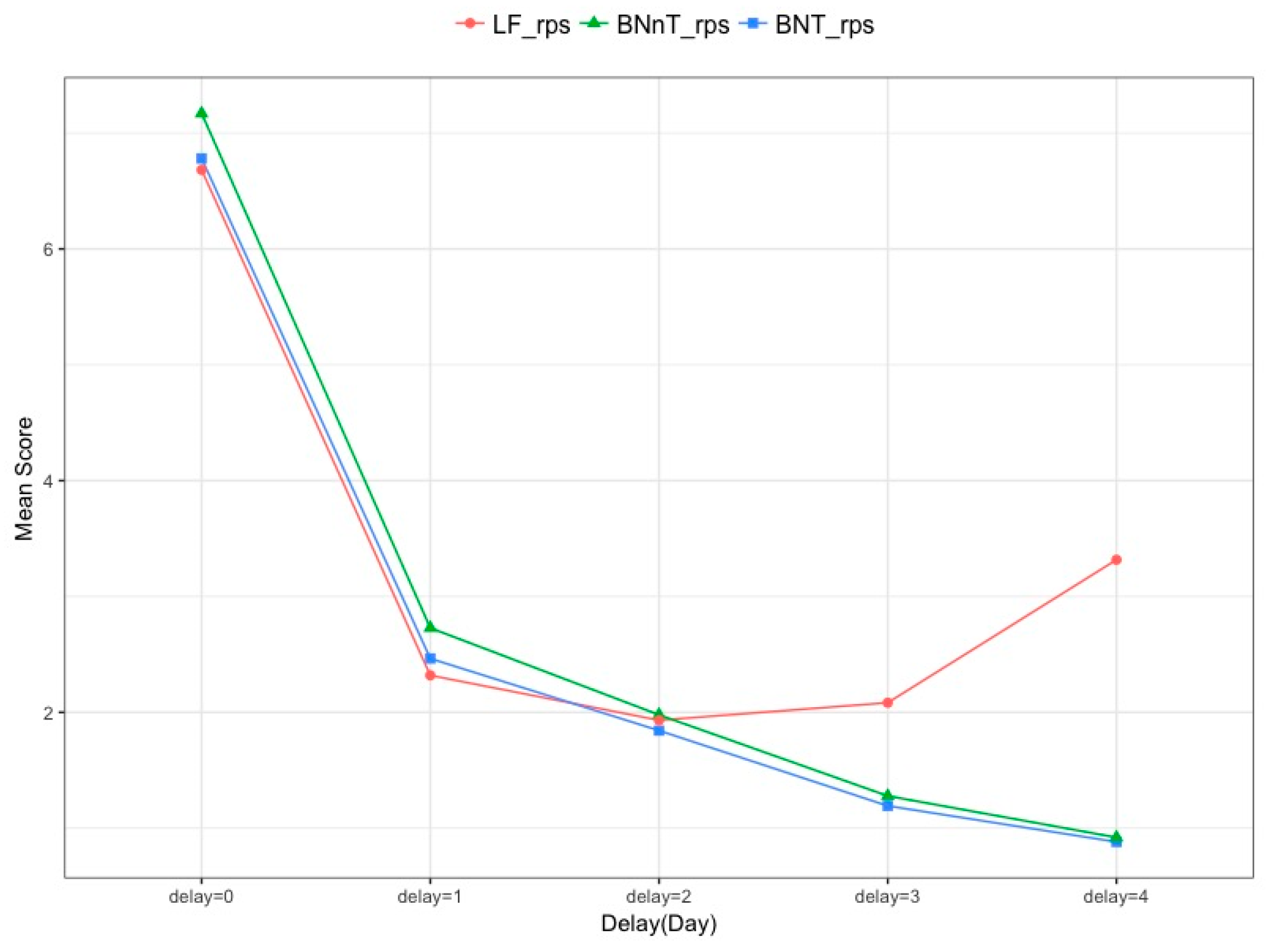
4.3. Evaluating the Nowcasting
- (i)
- Logarithmic score (logS) [27]:
- (ii)
- Ranking probability score (RPS) [28,29]:where is the predictive distribution for time t based on the information available at T and with being the number of occurred cases. is the probability mass function (PMF) of the predictive distribution , and where denotes the cumulative distribution function (CDF) of the predictive distribution . And from the data prior information, here we choose 300.
- (iii)
- The proportion of times that the observed value lay outside the equal-tailed 95% predicted interval (OutCI).
5. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mead, P.S.; Slutsker, L.; Dietz, V.; Mccaig, L.F.; Bresee, J.S.; Shapiro, C.; Griffin, P.M.; Tauxe, R.V. Food-related illness and death in the United States. Emerg. Infect. Dis. 1999, 5, 607–625. [Google Scholar] [CrossRef]
- Astride, K.H.; McPherson, M.; Kirk, M.D.; Knope, K.; Gregory, J.; Kardamanidis, K.; Bell, R. Foodborne disease outbreaks in Australia 2001–2009. Food Aust. 2011, 63, 44–50. [Google Scholar]
- Gould, L.H.; Mungai, E.A.; Johnson, S.D.; Richardson, L.T.C.; Williams, I.T.; Griffin, P.M. Surveillance for foodborne disease outbreaks—United States, 2009–2010. Morb. Mortal. Wkly. Rep. 2013, 60, 1197–1202. [Google Scholar]
- Masoumi, A.H.; Gouya, M.M.; Soltandallal, M.M.; Aghili, N. Surveillance for foodborne disease outbreak in Iran, 2006–2011. Med. J. Islam. Repub. Iran 2015, 29, 285. [Google Scholar]
- Yong, S.K.; Lee, S.H.; Joo, Y.; Bahk, G.J. Inverstigation of the experience of foodborne illness and estimation of the incidence of foodborne disease in south Korea. Food Control 2015, 47, 226–230. [Google Scholar]
- World Health Organization. WHO Estimates of the Global Burden of Foodborne: Foodborne Diseases Burden Epidemiology Reference Group 2007–2015; WHO Press: Geneva, Switzerland, 2015; ISBN 978-9-24-156516-5. [Google Scholar]
- Voetsch, A.C.; Van Gilder, T.J.; Angulo, F.J.; Farley, M.M.; Shallow, S.; Marcus, R.; Cieslak, P.R.; Deneen, V.C.; Tauxe, R.V. Emerging Infections Program FoodNet Working Group. FoodNet estimate of the burden of illness caused by nontyphoidal Salmonella infections in the United States. Clin. Infect. Dis. 2004, 38, S127–S134. [Google Scholar] [CrossRef] [PubMed]
- Flint, J.A.; Van Duynhoven, Y.T.; Angulo, F.J.; Delong, S.M.; Braun, P.; Kirk, M.; Scallan, E.; Fitzgerald, M.; Adak, G.K.; Sockett, P. Estimating the Burden of Acute Gastroenteritis, Foodborne Disease, and Pathogens Commonly Transmitted by Food: An International Review. Clin. Infect. Dis. 2005, 41, 698–704. [Google Scholar] [CrossRef] [Green Version]
- Scallan, E.; Hoekstra, R.M.; Widdowson, M.; Hall, A.; Griffin, P. Foodborne illness acquired in the United States. Emerg. Infect. Dis. 2011, 17, 1339–1340. [Google Scholar] [CrossRef]
- Bouwknegt, M.; Pelt, W.V.; Havelaar, A.H. Scoping the Impact of Changes in Population Age-Structure on the Future Burden of Foodborne Disease in The Netherlands, 2020–2060. Int. J. Environ. Res. Public Health 2013, 10, 2888–2896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heino, J.; Toivonen, H. Automated Detection of Epidemics from the Usage Logs of a Physicians Reference Database. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Volume 2838, pp. 180–191. [Google Scholar]
- Neill, D.B.; Moore, A.W. A Fast Multi-Resolution Method for Detection of Significant Spatial Disease Clusters. Adv. Neural Inf. Process. Syst. 2004, 13, 651–658. [Google Scholar]
- Xiao, H.; Xiao, G.X. Application of space-time permutation scan statistics inbacillary dysentery surveillance. Chin. J. Food Hyg. 2014, 26, 83–87. [Google Scholar]
- Xiao, G.X.; Xiao, H. Current status and prospect of spatial statistics in food safety. Chin. J. Food Hyg. 2016, 28, 409–414. [Google Scholar]
- Wong, W.K.; Moore, A.W.; Cooper, G.F.; Wagner, M.M. Bayesian network anomaly pattern detection for disease outbreaks. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 808–815. [Google Scholar]
- Yang, E.; Park, H.W.; Choi, Y.H.; Kim, J.; Munkhdalai, L.; Musa, I.; Ryu, K.H. A Simulation-Based Study on the Comparison of Statistical and Time Series Forecasting Methods for Early Detection of Infectious Disease Outbreaks. Int. J. Environ. Res. Public Health 2018, 15, 966. [Google Scholar] [CrossRef] [PubMed]
- Guo, D.H.; Cui, W.J.; Guo, Y.C.; Li, J.H.; Center, S.D. Foodborne disease event detection and risk assessment based on big-data. Syst. Eng. Theory Pract. 2015, 35, 2523–2530. [Google Scholar]
- Lawless, J.F. Adjustments for reporting delays and the prediction of occurred but not reported events. Can. J. Stat. 1994, 22, 15–31. [Google Scholar] [CrossRef]
- Donker, T.; Boven, M.V.; Ballegooijen, W.M.V.; Klooster, T.M.V.; Wielders, C.C.; Wallinga, J. Nowcasting pandemic influenza A/H1N1 2009 hospitalizations in the Netherlands. Eur. J. Epidemiol. 2011, 26, 195–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Höhle, M.; an der Heiden, M. Bayesian nowcasting during the STEC O104:H4 outbreak in Germany, 2011. Biometrics 2014, 70, 993–1002. [Google Scholar] [CrossRef] [Green Version]
- Salmon, M.; Schumacher, D.; Stark, K.; Hohle, M. Bayesian outbreak detection in the presence of reporting delays. Biom. J. 2015, 57, 1051–1067. [Google Scholar] [CrossRef]
- Krzyścin, J.W.; Lesiak, A.; Narbutt, J.; Sobolewski, P.; Guzikowski, J. Perspectives of UV nowcasting to monitor personal pro-health outdoor activities. J. Photochem. Photobiol. B 2018, 184, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wu, J.T. Characterizing the dynamics underlying global spread of epidemics. Nat. Commun. 2018, 9, 218. [Google Scholar] [CrossRef]
- Salmon, M.; Schumacher, D.; Höhle, M. Monitoring count time series in R: Aberration detection in public health surveillance. J. Stat. Softw. 2016, 70, 1–35. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Lawless, J.F. Inference Based on Retrospective Ascertainment: An Analysis of the Data on Transfusion-Related AIDS. J. Am. Stat. Assoc. 1989, 84, 360–372. [Google Scholar] [CrossRef]
- Zeger, S.L.; See, L.C.; Diggle, P.J. Statistical methods for monitoring the AIDS epidemic. Stat. Med. 1989, 8, 3–21. [Google Scholar] [CrossRef] [PubMed]
- Murphy, A.H. A Note on the Ranked Probability Score. J. Appl. Meteorol. 1971, 10, 155. [Google Scholar] [CrossRef]
- Czado, C.; Gneiting, T.; Held, L. Predictive Model Assessment for Count Data. Biometrics 2009, 65, 1254. [Google Scholar] [CrossRef]
- Kaufman, J.; Lessler, J.; Edlund, S.; Hu, K.; Douglas, J.; Thoens, C.; Kasbohrer, A.; Filter, M.; Harry, A.; Appel, B. Correction: A likelihood-based approach to identifying contaminated food products using sales data: Performance and challenges. PLoS Comput. Biol. 2014, 10, e1003692. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patient ID | Hospital Information | Onset Date | Visit Date | Confirmed | ||
|---|---|---|---|---|---|---|
| Province | City | Sentinel Hospital | ||||
| HN073408-2015-00040 | Hunan | Changsha | The Fourth Hospital of Changsha | 10 September 2015 | 11 September 2015 | Yes |
| HN073402-2015-00086 | Hunan | Hengyang | Hengyang Centre Hospital of Hunan | 7 June 2015 | 10 June 2015 | Yes |
| HN073002-2015-00128 | Hunan | Yueyang | Yueyang Second People’s Hospital | 30 September 2015 | 30 September 2015 | Yes |
| Method | RPS | logS | OutCI |
|---|---|---|---|
| BNT | 2.63 | 2.52 | 0.07 |
| BNnT | 2.81 | 2.80 | 0.12 |
| LF | 3.27 | 2.58 | 0.07 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhou, M.; Jia, J.; Geng, Z.; Xiao, G. A Bayesian Approach to Real-Time Monitoring and Forecasting of Chinese Foodborne Diseases. Int. J. Environ. Res. Public Health 2018, 15, 1740. https://doi.org/10.3390/ijerph15081740
Wang X, Zhou M, Jia J, Geng Z, Xiao G. A Bayesian Approach to Real-Time Monitoring and Forecasting of Chinese Foodborne Diseases. International Journal of Environmental Research and Public Health. 2018; 15(8):1740. https://doi.org/10.3390/ijerph15081740
Chicago/Turabian StyleWang, Xueli, Moqin Zhou, Jinzhu Jia, Zhi Geng, and Gexin Xiao. 2018. "A Bayesian Approach to Real-Time Monitoring and Forecasting of Chinese Foodborne Diseases" International Journal of Environmental Research and Public Health 15, no. 8: 1740. https://doi.org/10.3390/ijerph15081740