
Deep-Learning-Based Hepatic Ploidy Quantification Using H&E Histopathology Images
 , , , , , , ,
, , , , , , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
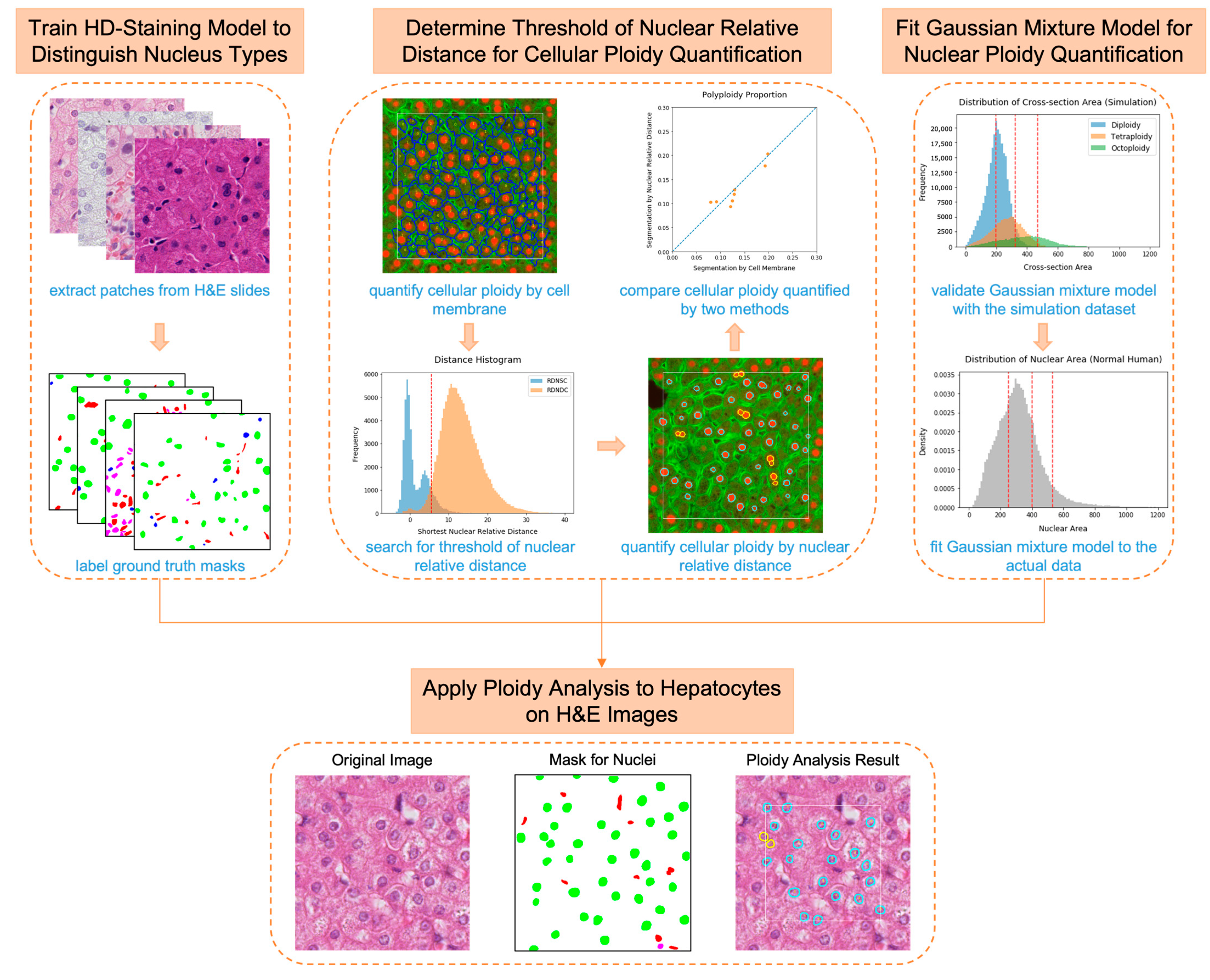
- We developed the first automated algorithm to quantify hepatic ploidy based on H&E histopathology images;
- We trained a deep learning model to segment and classify cell nuclei in liver tissue;
- We overcame the difficulty of quantifying cellular ploidy in the absence of cell membrane information on H&E images. We proved the validity of using nuclear relative distance as a new standard to determine the relationship between neighboring hepatic nuclei;
- We built a Gaussian mixture model to quantify nuclear ploidy on H&E images and validated its reliability with a simulation dataset;
- We created a user-friendly website to facilitate the widespread use of this algorithm.
2. Materials and Methods
2.1. Data Collection
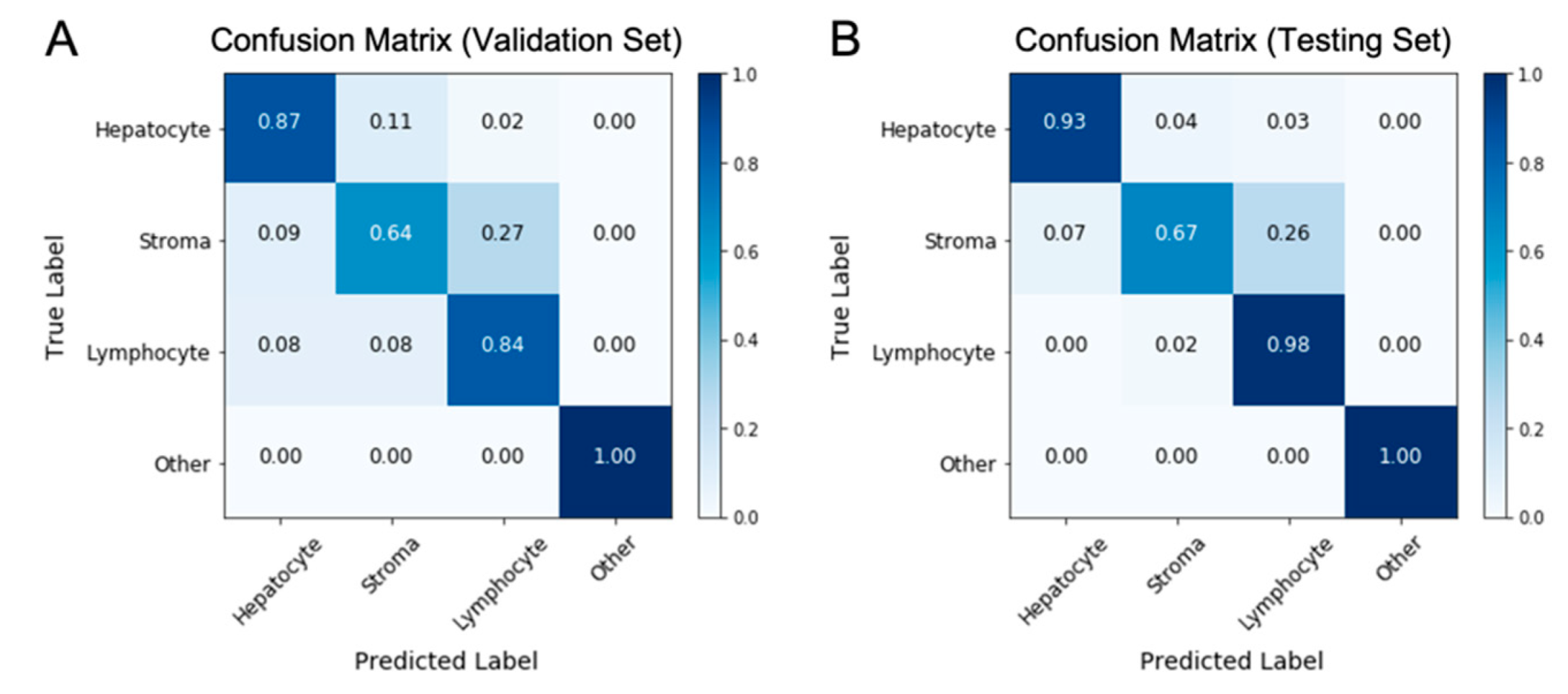
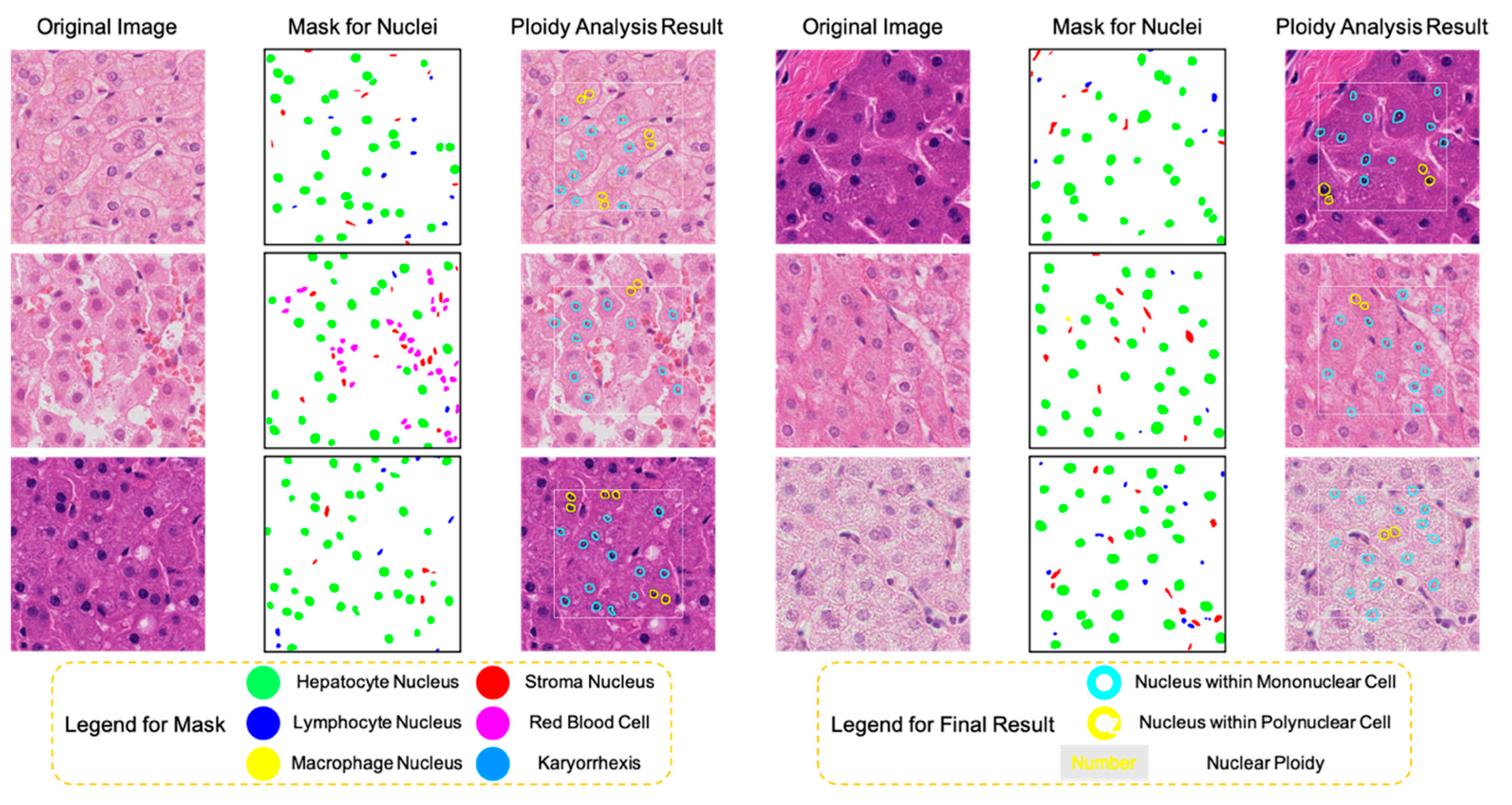
2.2. Nuclei Segmentation and Classification on H&E Images Using the HD-Staining Model
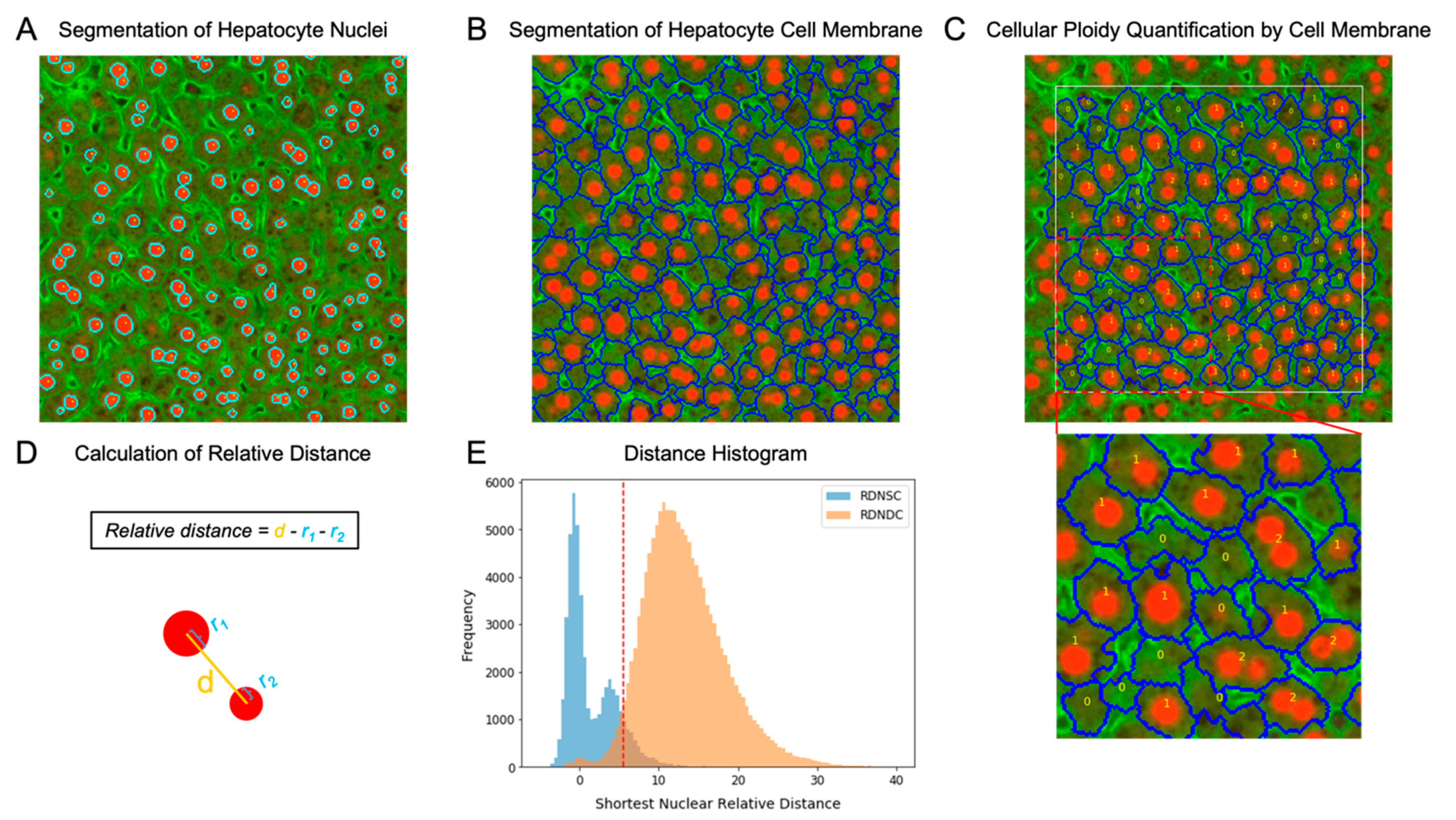
2.3. Thresholding for Nuclear Relative Distance
2.4. Hepatocyte Cellular Ploidy Determination by Nuclear Relative Distance
2.5. Hepatocyte Nuclear Ploidy Quantification by Nuclear Area
2.5.1. Establishment of the Simulation Dataset
2.5.2. Gaussian Mixture Model Fitting and Predicting Process
3. Results
3.1. The HD-Staining Model Recognized Hepatocyte Nuclei on H&E Images
3.2. Nuclear Relative Distance Determined Hepatic Cellular Ploidy
3.3. Nuclear Area Determined Hepatic Nuclear Ploidy
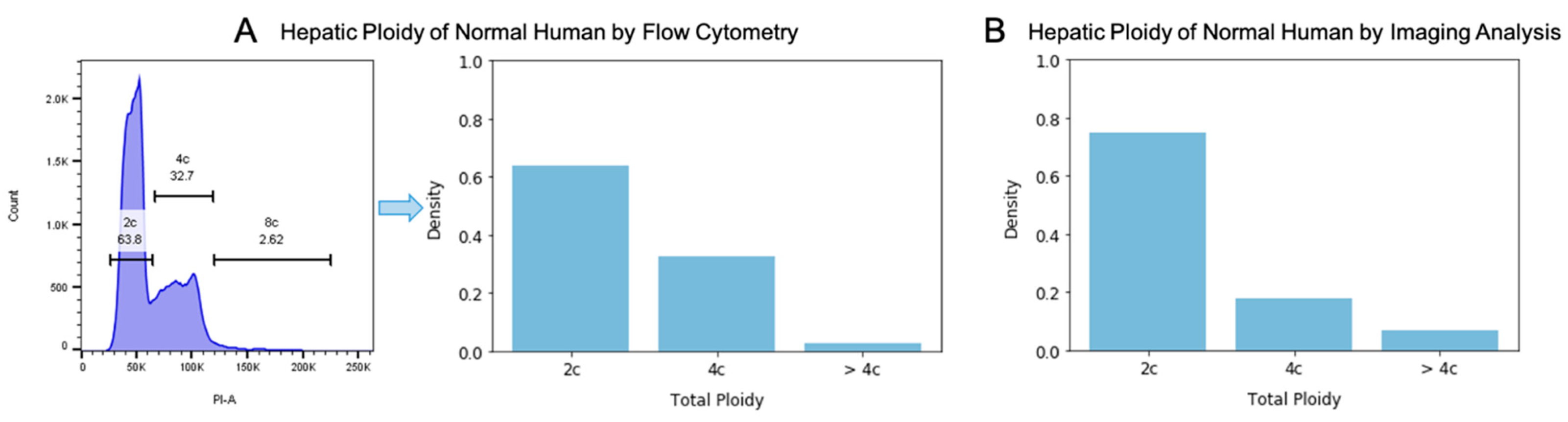
3.4. Total Ploidy Analysis of Hepatocytes on Human H&E Images
3.5. Online Implementation of Hepatic Ploidy Quantification on Human H&E Images
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Unhavaithaya, Y.; Orr-Weaver, T.L. Polyploidization of glia in neural development links tissue growth to blood–brain barrier integrity. Genes Dev. 2012, 26, 31–36. [Google Scholar] [CrossRef] [PubMed]
- Anatskaia, O.; Vinogradov, A. Polyploidy: Significance for cardiomyocyte function and heart aerobic capacity. Tsitologiia 2004, 46, 105–113. [Google Scholar] [PubMed]
- González-Tizón, A.; Martínez-Lage, A.; Ausio, J.; Méndez, J. Polyploidy in a natural population of mussel, Mytilus trossulus. Genome 2000, 43, 409–411. [Google Scholar] [CrossRef] [PubMed]
- Borgström, G.H.; Vuopio, P.; de la Chapelle, A. Polyploidy of the bone marrow. Scand. J. Haematol. 1976, 17, 123–131. [Google Scholar] [CrossRef] [PubMed]
- Knuutila, S.; Simell, O.; Lipponen, P.; Saarinen, I. Bone-marrow chromosomes in healthy subjects. Hereditas 1976, 82, 29–35. [Google Scholar] [CrossRef]
- Gupta, S. Hepatic polyploidy and liver growth control. Semin. Cancer Biol. 2000, 10, 161–171. [Google Scholar] [CrossRef]
- Gentric, G.; Desdouets, C. Polyploidization in liver tissue. Am. J. Pathol. 2014, 184, 322–331. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, Y.-H.; Tarlow, B.; Zhu, H. The origins and functions of hepatic polyploidy. Cell Cycle 2019, 18, 1302–1315. [Google Scholar] [CrossRef]
- Kudryavtsev, B.; Kudryavtseva, M.; Sakuta, G.; Stein, G. Human hepatocyte polyploidization kinetics in the course of life cycle. Virchows Arch. B 1993, 64, 387–393. [Google Scholar] [CrossRef]
- Donne, R.; Saroul-Aïnama, M.; Cordier, P.; Celton-Morizur, S.; Desdouets, C. Polyploidy in liver development, homeostasis and disease. Nat. Rev. Gastroenterol. Hepatol. 2020, 17, 391–405. [Google Scholar] [CrossRef]
- Toyoda, H.; Bregerie, O.; Vallet, A.; Nalpas, B.; Pivert, G.; Brechot, C.; Desdouets, C. Changes to hepatocyte ploidy and binuclearity profiles during human chronic viral hepatitis. Gut 2005, 54, 297–302. [Google Scholar] [CrossRef]
- Gentric, G.; Maillet, V.; Paradis, V.; Couton, D.; L’hermitte, A.; Panasyuk, G.; Fromenty, B.; Celton-Morizur, S.; Desdouets, C. Oxidative stress promotes pathologic polyploidization in nonalcoholic fatty liver disease. J. Clin. Investig. 2015, 125, 981–992. [Google Scholar] [CrossRef]
- Hsu, S.-h.; Duncan, A.W. Pathological polyploidy in liver disease. Hepatol. Baltim. Md. 2015, 62, 968. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, F.; Yang, T.; Su, J.; Song, S.; Fu, Z.-R.; Li, Y.; Hu, Y.-P.; Wang, M.-J. Aged-related function disorder of liver is reversed after exposing to young milieu via conversion of hepatocyte ploidy. Aging Dis. 2021, 12, 1238. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, K.; Luo, X.; Li, L.; Tu, H.C.; Sehgal, A.; Nguyen, L.H.; Zhang, Y.; Gopal, P.; Tarlow, B.D.; et al. The Polyploid State Plays a Tumor-Suppressive Role in the Liver. Dev. Cell 2018, 44, 447–459.e445. [Google Scholar] [CrossRef]
- Wilkinson, P.D.; Alencastro, F.; Delgado, E.R.; Leek, M.P.; Weirich, M.P.; Otero, P.A.; Roy, N.; Brown, W.K.; Oertel, M.; Duncan, A.W. Polyploid hepatocytes facilitate adaptation and regeneration to chronic liver injury. Am. J. Pathol. 2019, 189, 1241–1255. [Google Scholar] [CrossRef]
- Wilkinson, P.D.; Delgado, E.R.; Alencastro, F.; Leek, M.P.; Roy, N.; Weirich, M.P.; Stahl, E.C.; Otero, P.A.; Chen, M.I.; Brown, W.K.; et al. The Polyploid State Restricts Hepatocyte Proliferation and Liver Regeneration in Mice. Hepatology 2019, 69, 1242–1258. [Google Scholar] [CrossRef]
- Lin, Y.H.; Zhang, S.; Zhu, M.; Lu, T.; Chen, K.; Wen, Z.; Wang, S.; Xiao, G.; Luo, D.; Jia, Y.; et al. Mice With Increased Numbers of Polyploid Hepatocytes Maintain Regenerative Capacity But Develop Fewer Hepatocellular Carcinomas Following Chronic Liver Injury. Gastroenterology 2020, 158, 1698–1712.e1614. [Google Scholar] [CrossRef]
- Lin, H.; Huang, Y.-S.; Fustin, J.-M.; Doi, M.; Chen, H.; Lai, H.-H.; Lin, S.-H.; Lee, Y.-L.; King, P.-C.; Hou, H.-S. Hyperpolyploidization of hepatocyte initiates preneoplastic lesion formation in the liver. Nat. Commun. 2021, 12, 645. [Google Scholar] [CrossRef]
- Müller, M.; May, S.; Bird, T.G. Ploidy dynamics increase the risk of liver cancer initiation. Nat. Commun. 2021, 12, 1896. [Google Scholar] [CrossRef]
- Matsumoto, T.; Wakefield, L.; Peters, A.; Peto, M.; Spellman, P.; Grompe, M. Proliferative polyploid cells give rise to tumors via ploidy reduction. Nat. Commun. 2021, 12, 646. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.-J.; Chen, F.; Lau, J.T.; Hu, Y.-P. Hepatocyte polyploidization and its association with pathophysiological processes. Cell Death Dis. 2017, 8, e2805. [Google Scholar] [CrossRef] [PubMed]
- Donne, R.; Sangouard, F.; Celton-Morizur, S.; Desdouets, C. Hepatocyte polyploidy: Driver or gatekeeper of chronic liver diseases. Cancers 2021, 13, 5151. [Google Scholar] [CrossRef] [PubMed]
- Matsumoto, T. Implications of Polyploidy and Ploidy Alterations in Hepatocytes in Liver Injuries and Cancers. Int. J. Mol. Sci. 2022, 23, 9409. [Google Scholar] [CrossRef]
- Sladky, V.C.; Knapp, K.; Soratroi, C.; Heppke, J.; Eichin, F.; Rocamora-Reverte, L.; Szabo, T.G.; Bongiovanni, L.; Westendorp, B.; Moreno, E. E2F-family members engage the PIDDosome to limit hepatocyte ploidy in liver development and regeneration. Dev. Cell 2020, 52, 335–349.e337. [Google Scholar] [CrossRef]
- Barajas, J.M.; Lin, C.-H.; Sun, H.-L.; Alencastro, F.; Zhu, A.C.; Aljuhani, M.; Navari, L.; Yilmaz, S.A.; Yu, L.; Corps, K. METTL3 regulates liver homeostasis, hepatocyte ploidy, and circadian rhythm–controlled gene expression in mice. Am. J. Pathol. 2022, 192, 56–71. [Google Scholar] [CrossRef]
- Jin, Y.; Anbarchian, T.; Nusse, R. Assessment of Hepatocyte Ploidy by Flow Cytometry, Hepatocytes: Methods and Protocols; Springer: Cham, Switzerland, 2022; pp. 171–181. [Google Scholar]
- Liang, C.-Q.; Zhou, D.-C.; Peng, W.-T.; Chen, W.-Y.; Wu, H.-Y.; Zhou, Y.-M.; Gu, W.-L.; Park, K.-S.; Zhao, H.; Pi, L.-Q. FoxO3 restricts liver regeneration by suppressing the proliferation of hepatocytes. NPJ Regen. Med. 2022, 7, 33. [Google Scholar] [CrossRef]
- Metcalfe, C.J.; Li, J.; Giorgi, D.; Doležel, J.; Piperidis, N.; Aitken, K.S. Flow cytometric characterisation of the complex polyploid genome of Saccharum officinarum and modern sugarcane cultivars. Sci. Rep. 2019, 9, 19362. [Google Scholar] [CrossRef]
- Bou-Nader, M.; Caruso, S.; Donne, R.; Celton-Morizur, S.; Calderaro, J.; Gentric, G.; Cadoux, M.; L’hermitte, A.; Klein, C.; Guilbert, T. Polyploidy spectrum: A new marker in HCC classification. Gut 2020, 69, 355–364. [Google Scholar] [CrossRef]
- Jain, D.; Torres, R.; Celli, R.; Koelmel, J.; Charkoftaki, G.; Vasiliou, V. Evolution of the liver biopsy and its future. Transl. Gastroenterol. Hepatol. 2021, 6, 20. [Google Scholar] [CrossRef]
- Chan, J.K. The wonderful colors of the hematoxylin–eosin stain in diagnostic surgical pathology. Int. J. Surg. Pathol. 2014, 22, 12–32. [Google Scholar] [CrossRef]
- Wang, S.; Rong, R.; Yang, D.M.; Fujimoto, J.; Yan, S.; Cai, L.; Yang, L.; Luo, D.; Behrens, C.; Parra, E.R.; et al. Computational Staining of Pathology Images to Study the Tumor Microenvironment in Lung Cancer. Cancer Res. 2020, 80, 2056–2066. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, Y.; Dai, X.; Tian, Z.; Lei, Y.; Wynne, J.F.; Patel, P.; Chen, Y.; Liu, T.; Yang, X. Landmark tracking in liver US images using cascade convolutional neural networks with long short-term memory. Meas. Sci. Technol. 2023, 34, 054002. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Wang, S.; Yang, D.M.; Rong, R.; Zhan, X.; Xiao, G. Pathology image analysis using segmentation deep learning algorithms. Am. J. Pathol. 2019, 189, 1686–1698. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, L. Selecting and Composing Learning Rate Policies for Deep Neural Networks. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–25. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Jaccard, P. The distribution of the flora in the alpine zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Kornilov, A.S.; Safonov, I.V. An overview of watershed algorithm implementations in open source libraries. J. Imaging 2018, 4, 123. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, M.; Abeler, V.; Danielsen, H.; Sandstad, B.; Tropé, C.; Kristensen, G.; Risberg, B. Prognostic importance of DNA ploidy and DNA index in stage I and II endometrioid adenocarcinoma of the endometrium. Ann. Oncol. 2012, 23, 1178–1184. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Chen, P.; Zhang, L.; Wang, L.; Sun, T.; Zhou, L.; Li, Z.; Wu, A. Prognostic value of nucleotyping, DNA ploidy and stroma in high-risk stage II colon cancer. Br. J. Cancer 2020, 123, 973–981. [Google Scholar] [CrossRef]
- Peng, J.; Li, W.; Fan, W.; Zhang, R.; Li, X.; Xiao, B.; Dong, Y.; Wan, D.; Pan, Z.; Lin, J. Prognostic value of a novel biomarker combining DNA ploidy and tumor burden score for initially resectable liver metastases from patients with colorectal cancer. Cancer Cell Int. 2021, 21, 554. [Google Scholar] [CrossRef]
- Saini, G.; Joshi, S.; Garlapati, C.; Li, H.; Kong, J.; Krishnamurthy, J.; Reid, M.D.; Aneja, R. Polyploid giant cancer cell characterization: New frontiers in predicting response to chemotherapy in breast cancer. Semin. Cancer Biol. 2022, 81, 220–231. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Z.; Lin, Y.-H.; Wang, S.; Fujiwara, N.; Rong, R.; Jin, K.W.; Yang, D.M.; Yao, B.; Yang, S.; Wang, T.; et al. Deep-Learning-Based Hepatic Ploidy Quantification Using H&E Histopathology Images. Genes 2023, 14, 921. https://doi.org/10.3390/genes14040921
Wen Z, Lin Y-H, Wang S, Fujiwara N, Rong R, Jin KW, Yang DM, Yao B, Yang S, Wang T, et al. Deep-Learning-Based Hepatic Ploidy Quantification Using H&E Histopathology Images. Genes. 2023; 14(4):921. https://doi.org/10.3390/genes14040921
Chicago/Turabian StyleWen, Zhuoyu, Yu-Hsuan Lin, Shidan Wang, Naoto Fujiwara, Ruichen Rong, Kevin W. Jin, Donghan M. Yang, Bo Yao, Shengjie Yang, Tao Wang, and et al. 2023. "Deep-Learning-Based Hepatic Ploidy Quantification Using H&E Histopathology Images" Genes 14, no. 4: 921. https://doi.org/10.3390/genes14040921