
TADA: A Transferable Domain-Adversarial Training for Smart Grid Intrusion Detection Based on Ensemble Divergence Metrics and Spatiotemporal Features


Abstract
:1. Introduction
- 1.
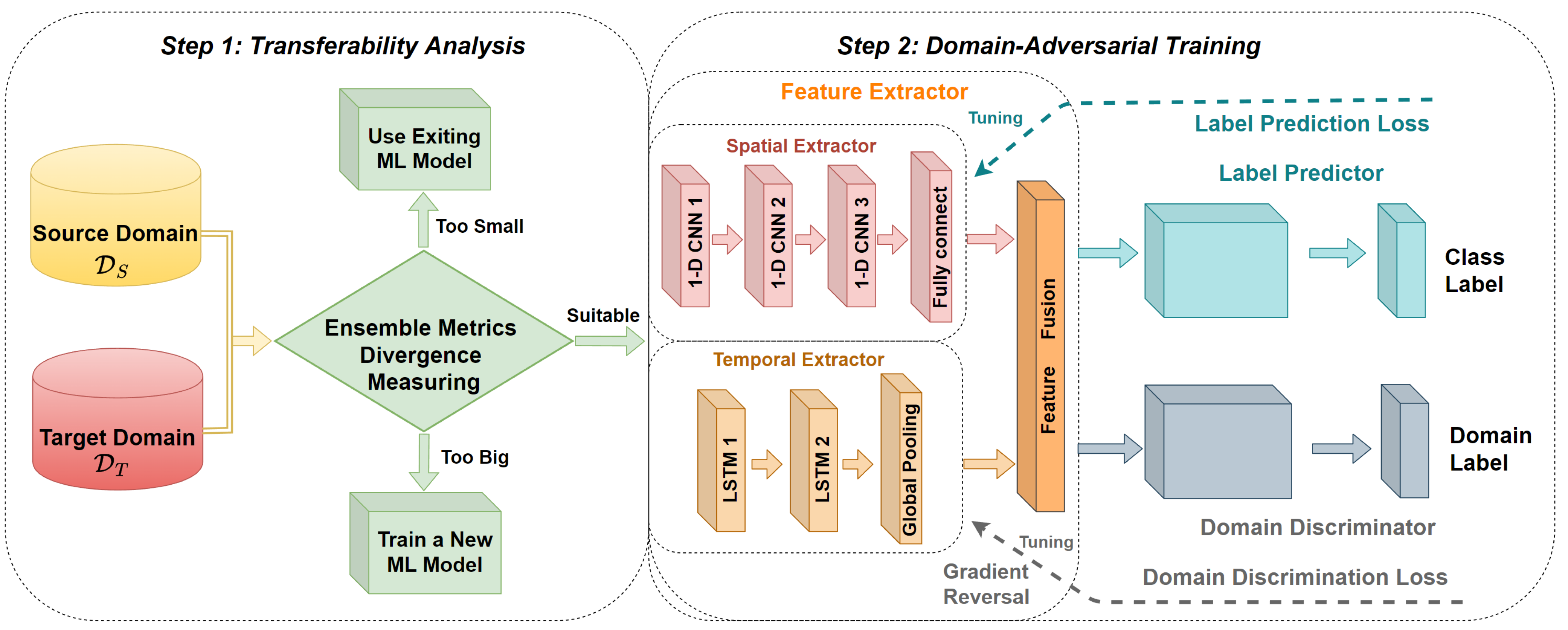
- This work proposes a two-stage transfer learning framework, including a transferability analysis and spatiotemporal domain-adversarial training, which leverages a CNN and LSTM along with domain-adversarial training to extract spatiotemporal domain-invariant features and enhance attack detection performance.
- 2.
- This work proposes an ensemble method that combines different types of metrics to capture multiple data distribution information, predict accuracy drop, and justify the need for TL in cybersecurity situation awareness.
2. Related Work
2.1. Transferability Analysis
2.2. Spatiotemporal Domain-Adversarial Training for IDS
3. Transferability Analysis and Domain-Adversarial Training
3.1. Problem Formulation
3.2. Ensemble Metrics Transferability Analysis
3.2.1. Distribution Divergence Metrics
3.2.2. Regression Models
3.3. Spatiotemporal Domain-Adversarial Training
4. Experiments Setup
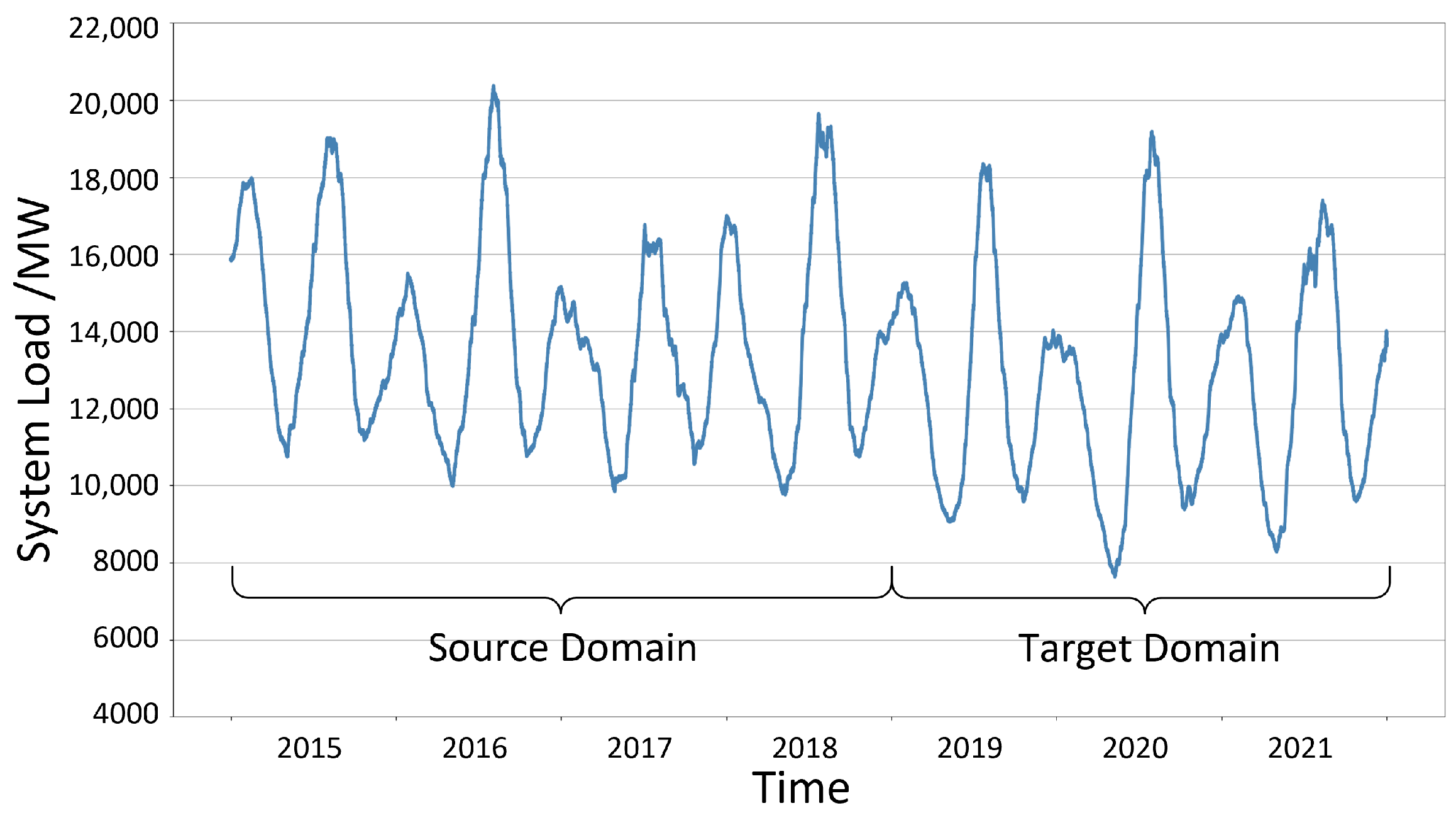
4.1. Data Generation
4.2. Spatiotemporal TL Setup
4.3. Comparison Models
4.4. Model Implementation
5. Results and Discussion
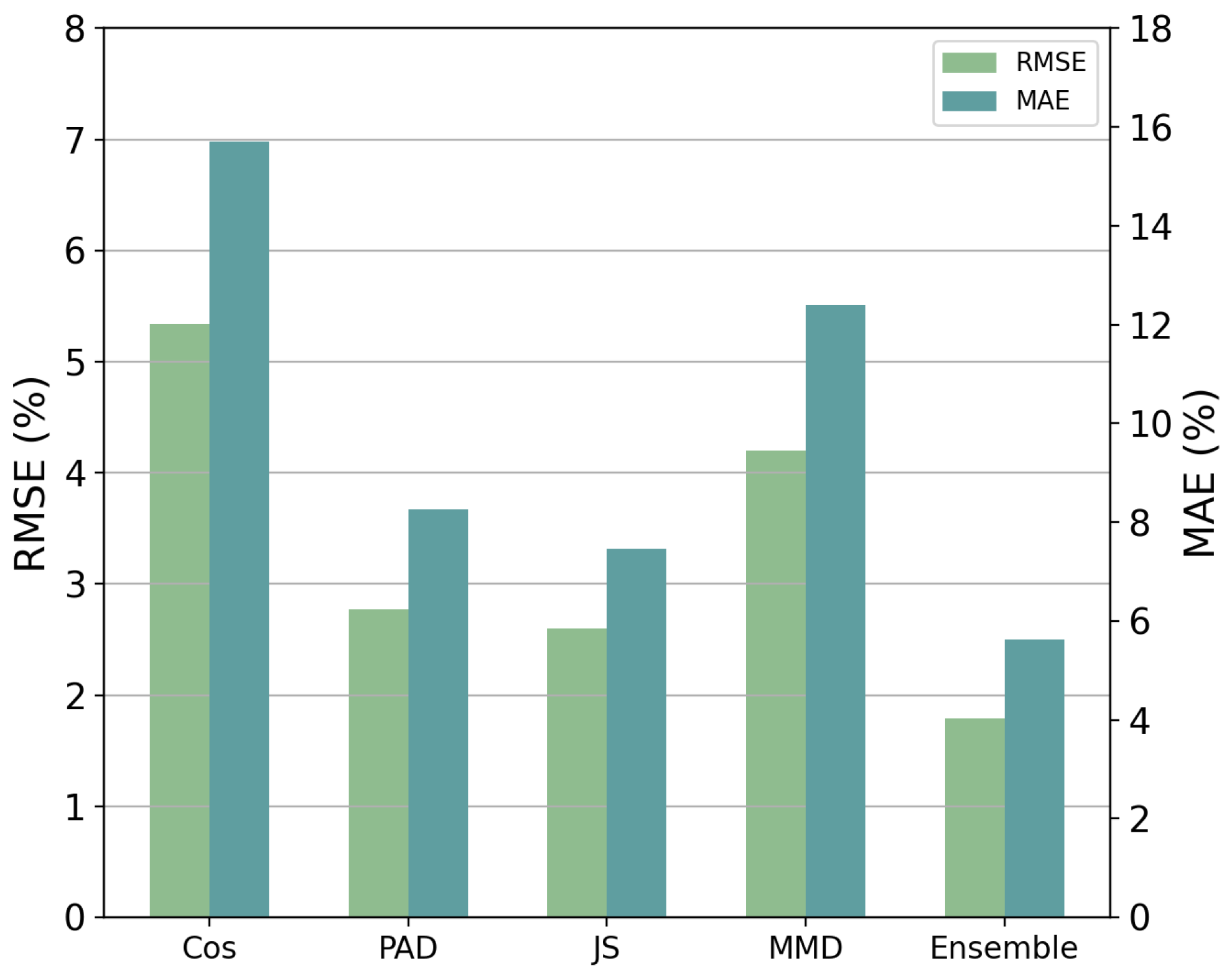
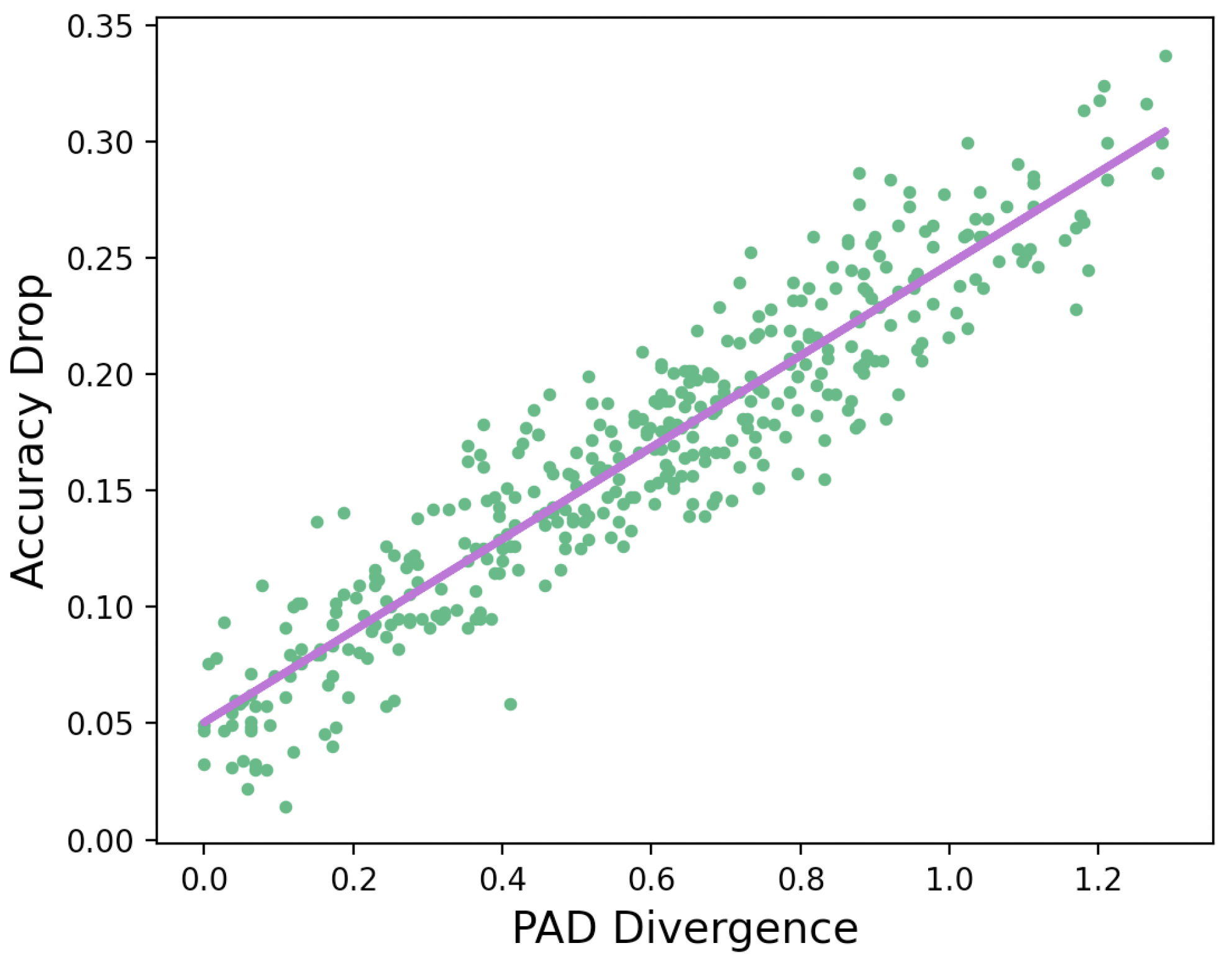
5.1. Evaluation of Transferability Analysis
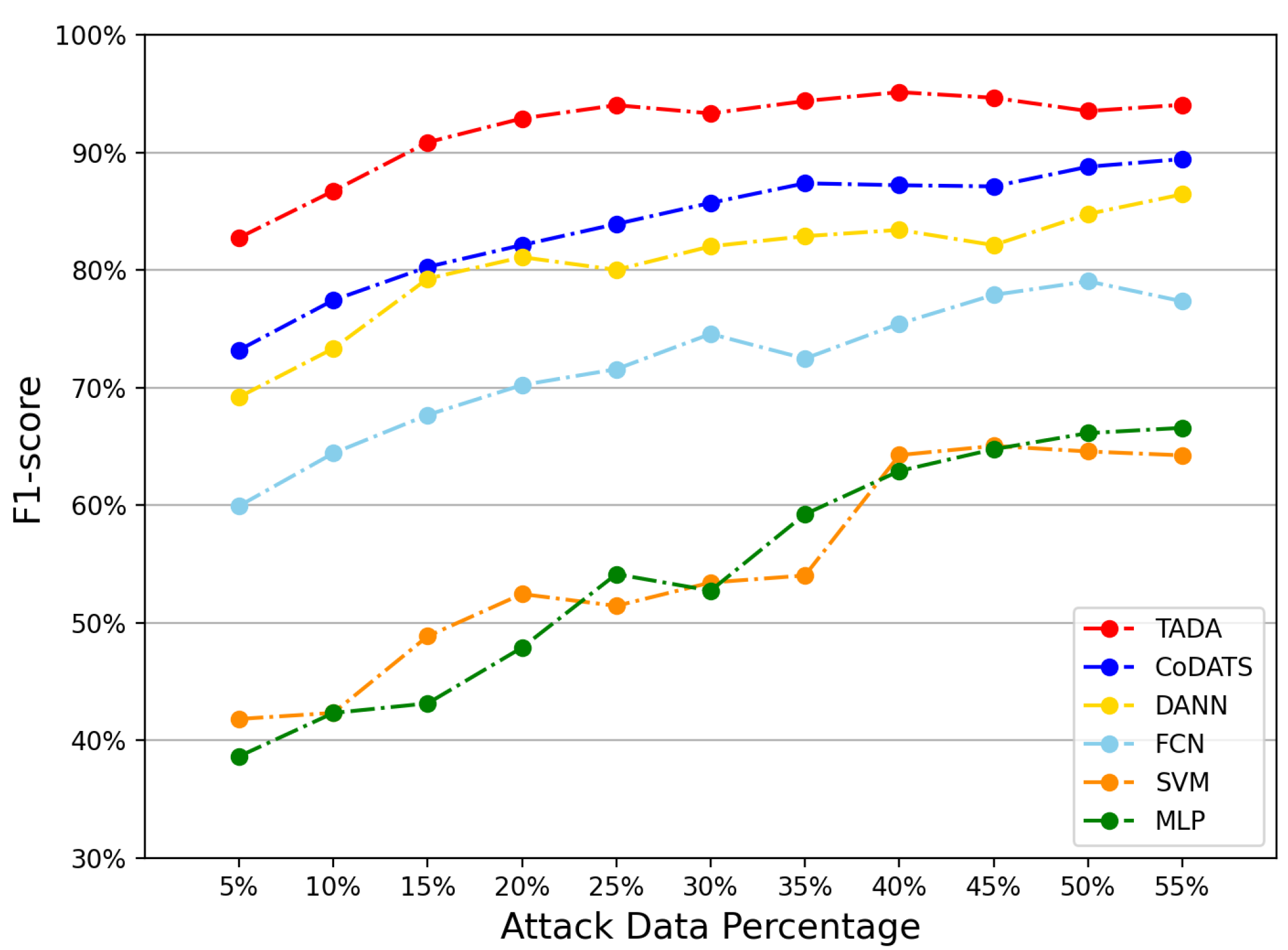
5.2. FDI Detection Performance
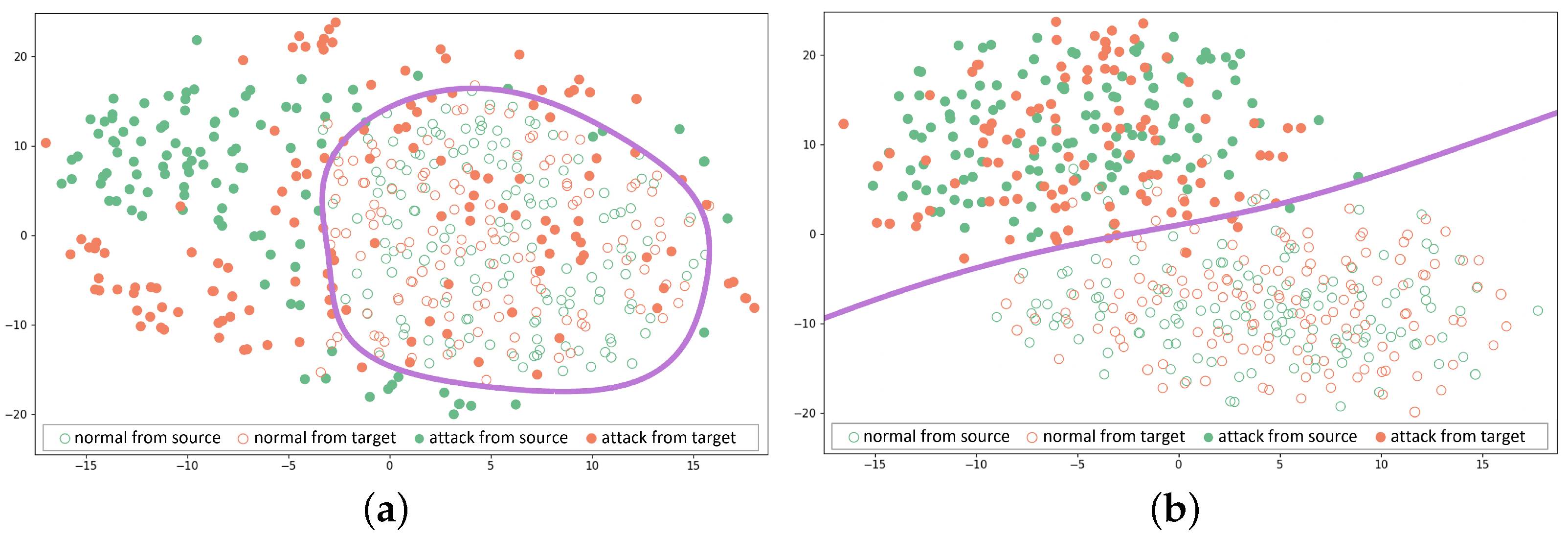
5.3. Visualization of Data Distribution
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TADA | Transferability analysis and domain-adversarial training |
| CPS | Cyberphysical systems |
| IDS | Intrusion detection system |
| FDI | False data injection |
| BDD | Bad data detection |
| ML | Machine learning |
| TL | Transfer learning |
| DANN | Domain-adversarial neural network |
| GRL | Gradient reversal layer |
| DAN | Deep adaptation network |
| DNN | Deep neural network |
| CDBN | Conditional deep belief network |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| GAP | Global average pooling |
| NLP | Natural language processing |
| CV | Computer vision |
| FCN | Fully convolutional network |
| CoDATS | Convolutional deep domain adaptation model for time series data |
| MLP | Multilayer perceptron |
| kNN | k-nearest neighbors |
| SVM | Support vector machine |
| PAD | Proxy -distance |
| KL | Kullback–Leibler |
| JS | Jensen–Shannon |
| CMD | Central moment discrepancy |
| CORAL | Correlation alignment |
| MMD | Maximum mean discrepancy |
| RKHS | Reproducing kernel Hilbert space |
| DC-OPF | DC optimal power flow |
References
- Ge, L.; Li, Y.; Li, Y.; Yan, J.; Sun, Y. Smart Distribution Network Situation Awareness for High-Quality Operation and Maintenance: A Brief Review. Energies 2022, 15, 828. [Google Scholar] [CrossRef]
- Li, Y.; Yan, J. Cybersecurity of Smart Inverters in the Smart Grid: A Survey. IEEE Trans. Power Electron. 2022, 38, 2364–2383. [Google Scholar] [CrossRef]
- Rahman, M.; Li, Y.; Yan, J. Multi-Objective Evolutionary Optimization for Worst-Case Analysis of False Data Injection Attacks in the Smart Grid. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Cheng, G.; Lin, Y.; Zhao, J.; Yan, J. A Highly Discriminative Detector Against False Data Injection Attacks in AC State Estimation. IEEE Trans. Smart Grid 2022, 13, 2318–2330. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Kumar, A.; Saxena, N.; Jung, S.; Choi, B.J. Improving Detection of False Data Injection Attacks Using Machine Learning with Feature Selection and Oversampling. Energies 2022, 15, 212. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, J. Domain-Adversarial Transfer Learning for Robust Intrusion Detection in the Smart Grid. In Proceedings of the 2019 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Beijing, China, 21–23 October 2019; pp. 1–6. [Google Scholar]
- Zhang, Y.; Yan, J. Semi-Supervised Domain-Adversarial Training for Intrusion Detection against False Data Injection in the Smart Grid. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Houidi, S.; Fourer, D.; Auger, F.; Sethom, H.B.A.; Miègeville, L. Comparative Evaluation of Non-Intrusive Load Monitoring Methods Using Relevant Features and Transfer Learning. Energies 2021, 14, 2726. [Google Scholar] [CrossRef]
- Zhang, Y. Domain Adversarial Transfer Learning for Robust Cyber-Physical Attack Detection in the Smart Grid. Ph.D. Thesis, Concordia University, Montréal, QC, Canada, 2020. [Google Scholar]
- Cui, M.; Wang, J.; Chen, B. Flexible Machine Learning-Based Cyberattack Detection Using Spatiotemporal Patterns for Distribution Systems. IEEE Trans. Smart Grid 2020, 11, 1805–1808. [Google Scholar] [CrossRef]
- Liu, Y.; Ning, P.; Reiter, M.K. False Data Injection Attacks Against State Estimation in Electric Power Grids. ACM Trans. Inf. Syst. Secur. 2011, 14, 1–33. [Google Scholar] [CrossRef]
- Deng, Q.; Sun, J. False Data Injection Attack Detection in a Power Grid Using RNN. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 5983–5988. [Google Scholar] [CrossRef]
- England, I.N. ISO New England—Energy, Load, and Demand Reports. [EB/OL]. Available online: https://www.iso-ne.com/isoexpress/web/reports/load-and-demand/-/tree/dmnd-five-minute-sys (accessed on 1 January 2022).
- Miller, J.P.; Taori, R.; Raghunathan, A.; Sagawa, S.; Koh, P.W.; Shankar, V.; Liang, P.; Carmon, Y.; Schmidt, L. Accuracy on the Line: On the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 7721–7735. [Google Scholar]
- Fort, S.; Ren, J.; Lakshminarayanan, B. Exploring the Limits of Out-of-Distribution Detection. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 7068–7081. [Google Scholar]
- Elsahar, H.; Gallé, M. To annotate or not? predicting performance drop under domain shift. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2163–2173. [Google Scholar]
- Deng, W.; Zheng, L. Are labels always necessary for classifier accuracy evaluation? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15069–15078. [Google Scholar]
- Liao, P.; Yan, J.; Sellier, J.M.; Zhang, Y. Divergence-Based Transferability Analysis for Self-Adaptive Smart Grid Intrusion Detection With Transfer Learning. IEEE Access 2022, 10, 68807–68818. [Google Scholar] [CrossRef]
- Ramesh Kashyap, A.; Hazarika, D.; Kan, M.Y.; Zimmermann, R. Domain Divergences: A Survey and Empirical Analysis. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1830–1849. [Google Scholar] [CrossRef]
- Ruder, S.; Plank, B. Learning to select data for transfer learning with Bayesian Optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–8 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 372–382. [Google Scholar] [CrossRef] [Green Version]
- Durairaj, D.; Venkatasamy, T.K.; Mehbodniya, A.; Umar, S.; Alam, T. Intrusion detection and mitigation of attacks in microgrid using enhanced deep belief network. In Energy Sources, Part A: Recovery, Utilization, and Environmental Effects; Taylor & Francis: Abingdon, UK, 2022; pp. 1–23. [Google Scholar]
- Nakagawa, F.H.Y.; Barbon Junior, S.; Zarpelão, B.B. Attack Detection in Smart Home IoT Networks using CluStream and Page-Hinkley Test. In Proceedings of the 2021 IEEE Latin-American Conference on Communications (LATINCOM), Santo Domingo, Dominican Republic, 17–19 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Liang, J.; Ma, M. Co-maintained database based on blockchain for idss: A lifetime learning framework. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1629–1645. [Google Scholar] [CrossRef]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Wei, J.; Chen, Y.; Lai, Y.; Wang, Y.; Zhang, Z. Domain adversarial neural network-based intrusion detection system for in-vehicle network variant attacks. IEEE Commun. Lett. 2022, 26, 2547–2551. [Google Scholar] [CrossRef]
- Hong, W.C.; Huang, D.R.; Chen, C.L.; Lee, J.S. Towards accurate and efficient classification of power system contingencies and cyber-attacks using recurrent neural networks. IEEE Access 2020, 8, 123297–123309. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International joint conference on neural networks (IJCNN), Anchorage, AL, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- He, Y.; Mendis, G.J.; Wei, J. Real-Time Detection of False Data Injection Attacks in Smart Grid: A Deep Learning-Based Intelligent Mechanism. IEEE Trans. Smart Grid 2017, 8, 2505–2516. [Google Scholar] [CrossRef]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning Hierarchical Spatial-Temporal Features Using Deep Neural Networks to Improve Intrusion Detection. IEEE Access 2018, 6, 1792–1806. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. Classification score approach for detecting adversarial example in deep neural network. Multimed. Tools Appl. 2021, 80, 10339–10360. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, J. AdvGuard: Fortifying Deep Neural Networks against Optimized Adversarial Example Attack. IEEE Access 2020, 1. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, J. Diversity Adversarial Training against Adversarial Attack on Deep Neural Networks. Symmetry 2021, 13, 428. [Google Scholar] [CrossRef]
- Plank, B.; van Noord, G. Effective Measures of Domain Similarity for Parsing. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 1566–1576. [Google Scholar]
- Remus, R. Domain Adaptation Using Domain Similarity- and Domain Complexity-Based Instance Selection for Cross-Domain Sentiment Analysis. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012; pp. 717–723. [Google Scholar] [CrossRef]
- Zellinger, W.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Zhang, D.; Yao, L.; Zhang, X.; Wang, S.; Chen, W.; Boots, R. EEG-based intention recognition from spatio-temporal representations via cascade and parallel convolutional recurrent neural networks. arXiv 2017, arXiv:1708.06578. [Google Scholar]
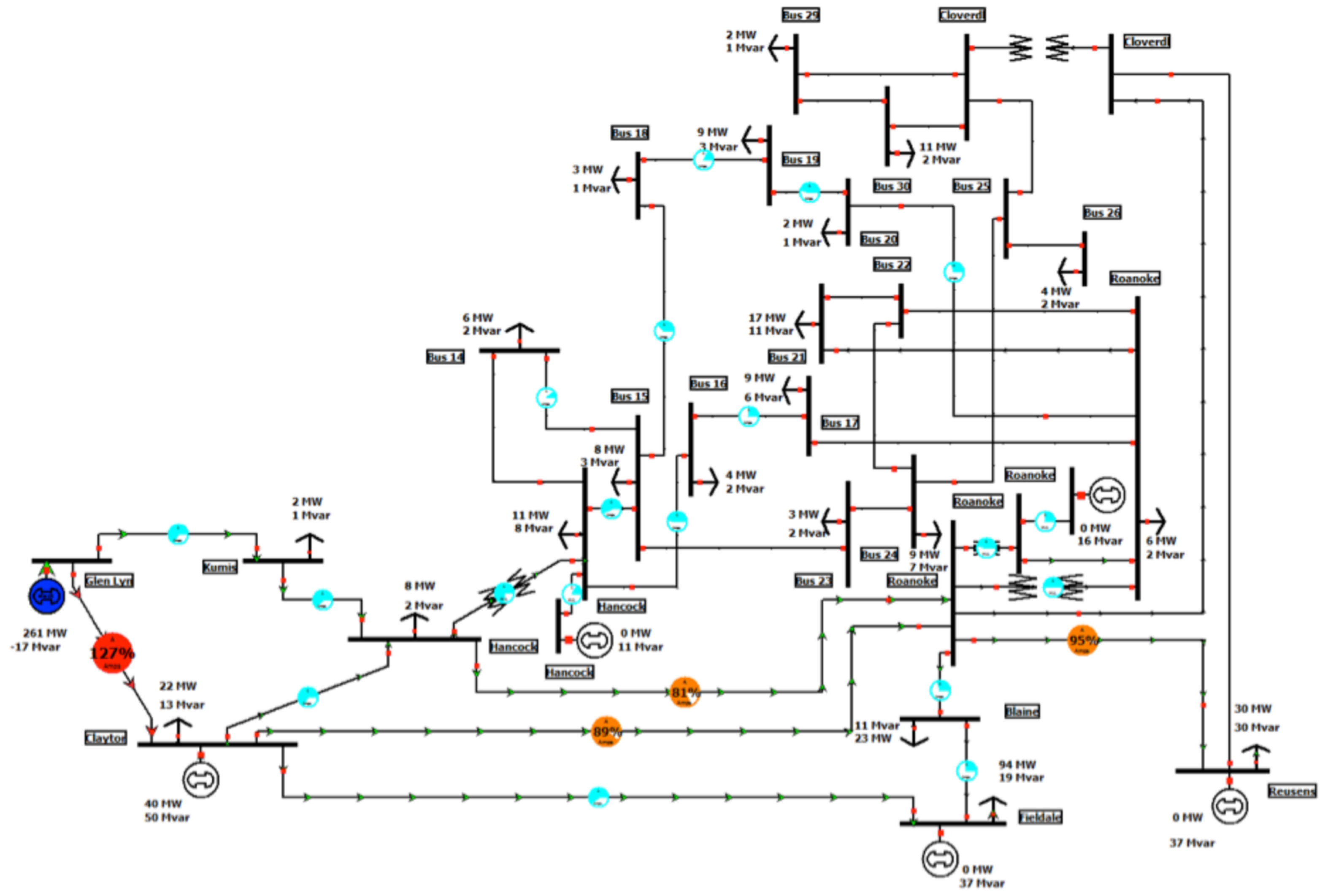
- Illinois Center for a Smarter Electric Grid (ICSEG). IEEE 30-Bus System. [EB/OL]. Available online: https://icseg.iti.illinois.edu/ieee-30-bus-system/ (accessed on 2 October 2013).
- Wei, L.; Gao, D.; Luo, C. False data injection attacks detection with deep belief networks in smart grid. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 2621–2625. [Google Scholar]
- Wilson, G.; Doppa, J.R.; Cook, D.J. Multi-source deep domain adaptation with weak supervision for time-series sensor data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1768–1778. [Google Scholar]
- Akoglu, H. User’s guide to correlation coefficients. Turk. J. Emerg. Med. 2018, 18, 91–93. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Seasons | Months | Source Domain from Year 2015 to 2018 | Target Domain from Year 2019 to 2021 | ||
|---|---|---|---|---|---|---|
| Mean of Load (MW) | Standard Deviation of Load (MW) | Mean of Load (MW) | Standard Deviation of Load (MW) | |||
| 1 | Winter | Mid-December to mid-March | 14,482.95 | 750.09 | 13,851.43 | 500.32 |
| 2 | Spring | Mid-March to mid-June | 12,744.30 | 560.54 | 11,838.29 | 627.72 |
| 3 | Summer | Mid-June to mid-September | 15,390.25 | 953.51 | 14,890.62 | 961.39 |
| 4 | Fall | Mid-September to mid-December | 13,107.20 | 533.23 | 12,501.28 | 613.43 |
| Cases | Source Seasons | Target Seasons | Predicted Drop | Actual Drop | TADA | CoDATS | DANN | FCN | SVM | MLP | Best-Case Margin | Worst-Case Margin |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Winter | Winter | 8.97 | 8.89 | 97.31 | 93.86 | 91.17 | 86.68 | 79.56 | 81.03 | +17.74 | +3.44 |
| Spring | 26.01 | 25.20 | 94.87 | 87.69 | 85.69 | 72.44 | 67.65 | 66.93 | +27.94 | +7.18 | ||
| Summer | 11.47 | 11.23 | 95.74 | 93.31 | 89.13 | 79.82 | 74.13 | 75.57 | +21.61 | +2.43 | ||
| Fall | 20.97 | 20.65 | 94.84 | 90.93 | 85.51 | 71.41 | 66.02 | 69.27 | +28.82 | +3.91 | ||
| 2 | Spring | Winter | 18.55 | 18.74 | 96.68 | 89.14 | 88.16 | 77.30 | 71.74 | 70.42 | +26.25 | +7.54 |
| Spring | 12.81 | 13.02 | 96.05 | 93.00 | 89.74 | 81.50 | 75.66 | 78.91 | +20.39 | +3.04 | ||
| Summer | 19.62 | 19.14 | 95.42 | 90.49 | 88.03 | 70.23 | 67.72 | 71.04 | +27.70 | +4.93 | ||
| Fall | 6.26 | 6.36 | 97.89 | 93.21 | 90.23 | 86.22 | 78.85 | 82.69 | +19.04 | +4.68 | ||
| 3 | Summer | Winter | 17.28 | 17.62 | 95.08 | 90.55 | 86.03 | 78.55 | 72.15 | 73.56 | +22.93 | +4.53 |
| Spring | 28.21 | 27.19 | 92.90 | 89.47 | 84.39 | 70.83 | 64.86 | 66.98 | +28.04 | +3.43 | ||
| Summer | 7.19 | 7.29 | 96.87 | 89.79 | 90.12 | 85.07 | 79.25 | 81.89 | +17.61 | +6.75 | ||
| Fall | 23.17 | 23.80 | 94.99 | 86.57 | 82.80 | 71.50 | 68.19 | 64.67 | +30.32 | +8.42 | ||
| 4 | Fall | Winter | 11.76 | 11.49 | 96.52 | 90.78 | 91.06 | 84.12 | 78.53 | 78.10 | +18.42 | +5.46 |
| Spring | 14.48 | 14.75 | 94.98 | 93.30 | 90.04 | 78.42 | 74.35 | 76.44 | +20.63 | +1.68 | ||
| Summer | 24.77 | 23.92 | 93.08 | 89.68 | 81.19 | 72.99 | 67.32 | 67.40 | +25.75 | +3.39 | ||
| Fall | 9.20 | 9.09 | 96.08 | 94.51 | 92.56 | 81.91 | 74.76 | 80.70 | +21.32 | +1.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, P.; Yan, J.; Sellier, J.M.; Zhang, Y. TADA: A Transferable Domain-Adversarial Training for Smart Grid Intrusion Detection Based on Ensemble Divergence Metrics and Spatiotemporal Features. Energies 2022, 15, 8778. https://doi.org/10.3390/en15238778
Liao P, Yan J, Sellier JM, Zhang Y. TADA: A Transferable Domain-Adversarial Training for Smart Grid Intrusion Detection Based on Ensemble Divergence Metrics and Spatiotemporal Features. Energies. 2022; 15(23):8778. https://doi.org/10.3390/en15238778
Chicago/Turabian StyleLiao, Pengyi, Jun Yan, Jean Michel Sellier, and Yongxuan Zhang. 2022. "TADA: A Transferable Domain-Adversarial Training for Smart Grid Intrusion Detection Based on Ensemble Divergence Metrics and Spatiotemporal Features" Energies 15, no. 23: 8778. https://doi.org/10.3390/en15238778