Predicting Image Aesthetics for Intelligent Tourism Information Systems

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
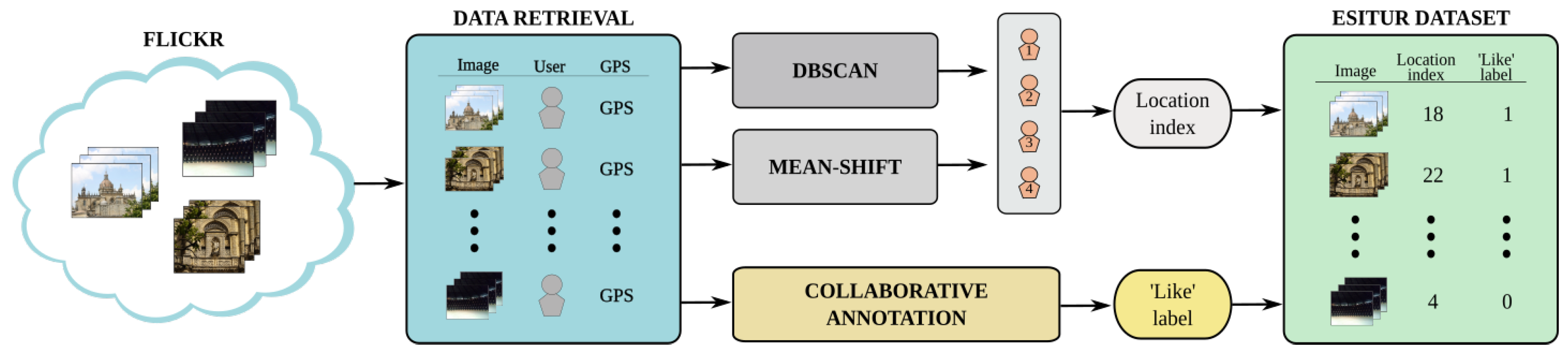
3. ESITUR Data Collection
3.1. Pictures Retrieval
3.2. Labeling Procedure
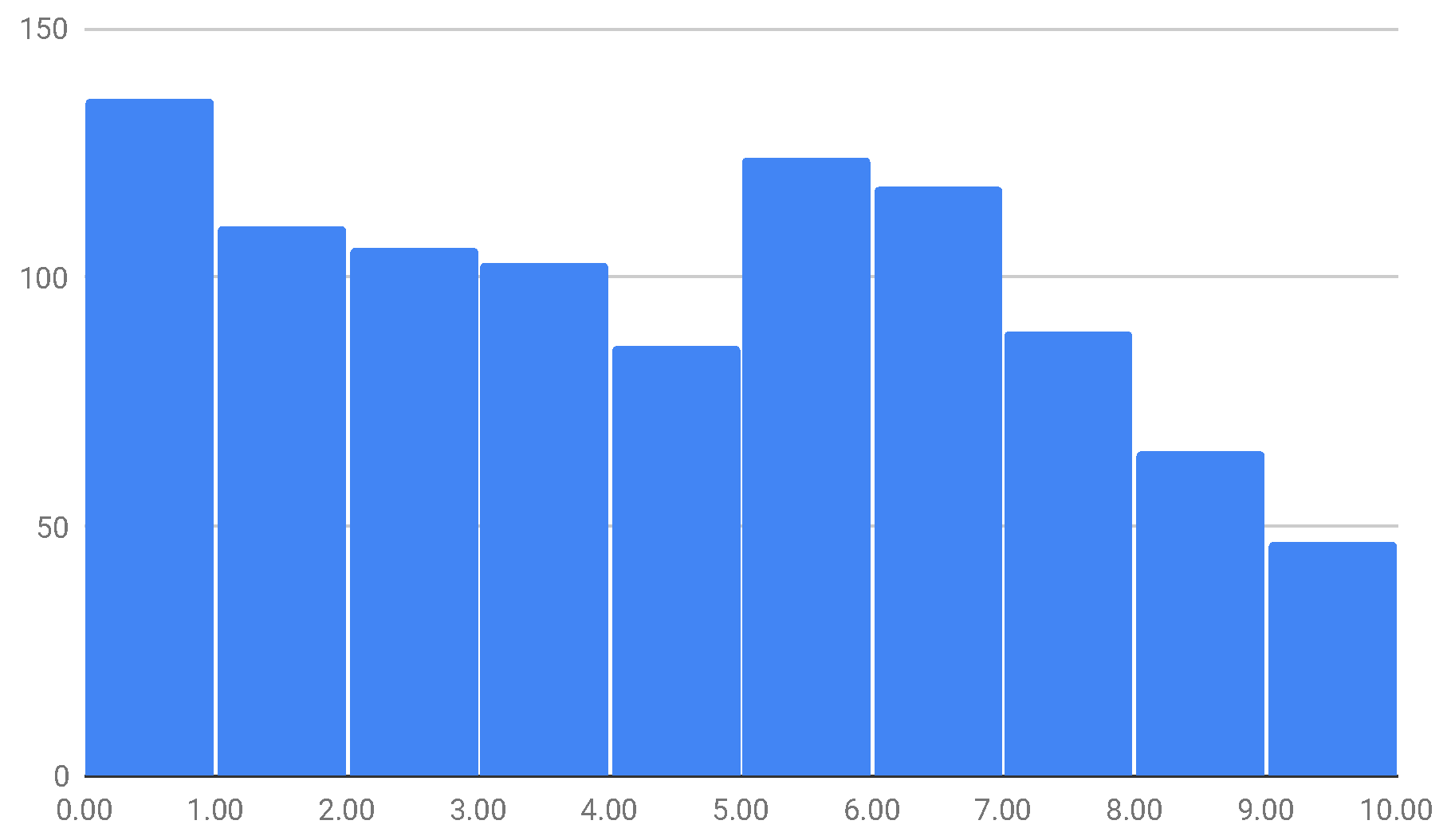
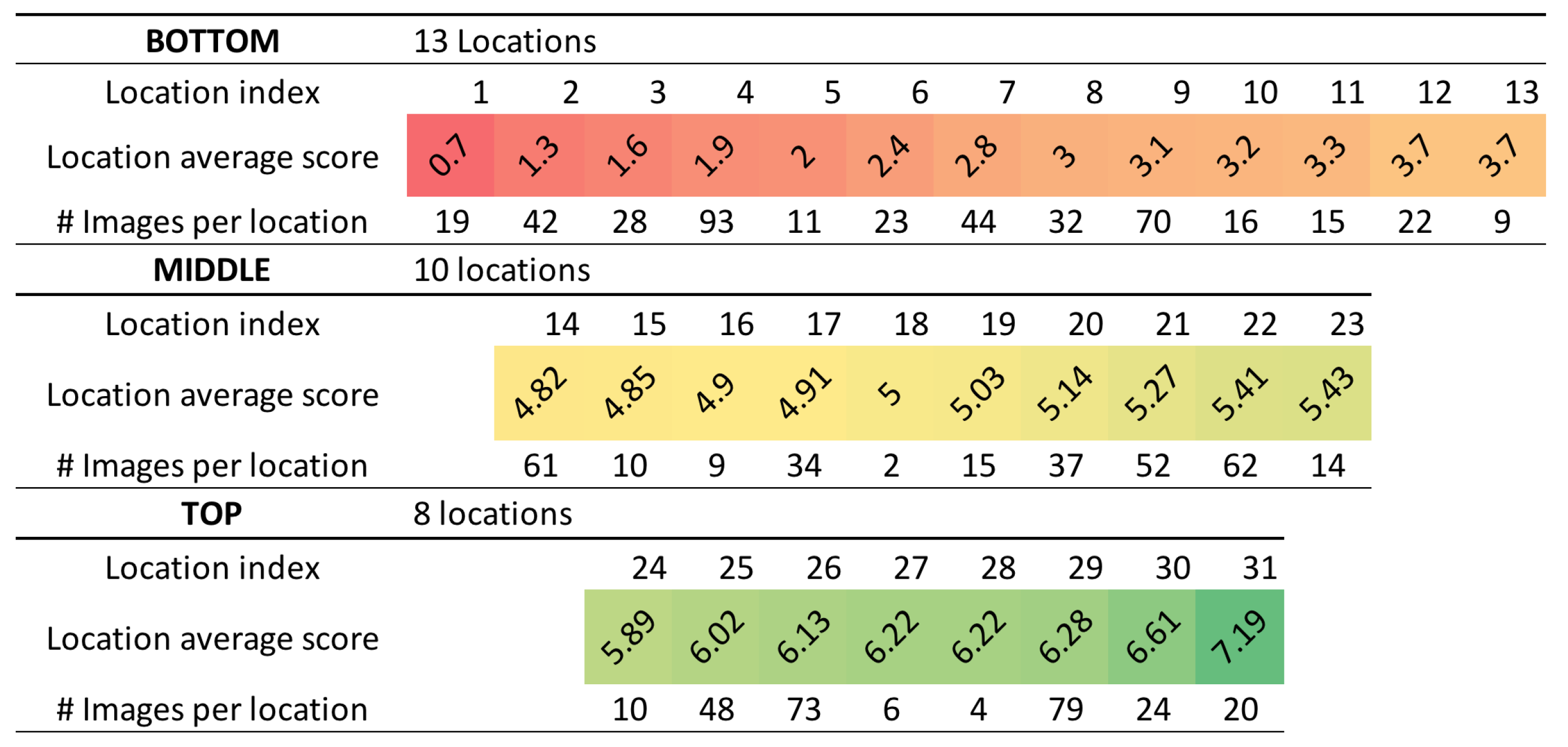
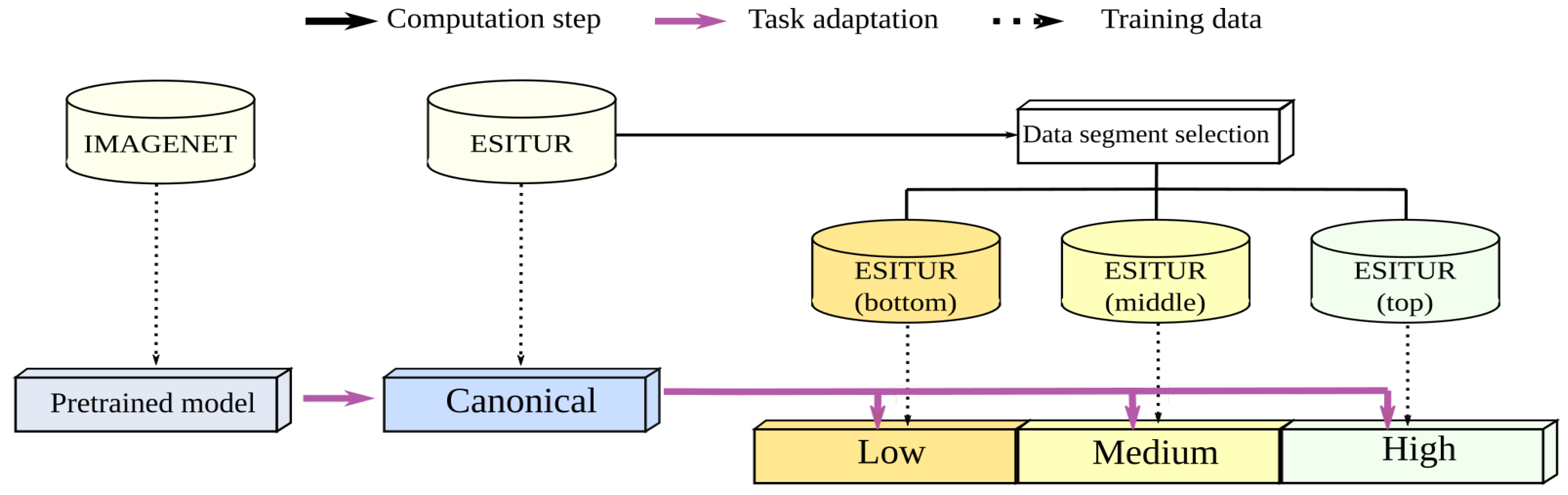
3.3. Segmentation of the Corpus
4. Aesthetics Label Prediction Models and Experimental Setup
4.1. Feature-Based Model
4.1.1. Visual Descriptors
4.1.2. Feature Selection and Classification Model
4.2. Deep Learning Approach
4.2.1. Canonical Model
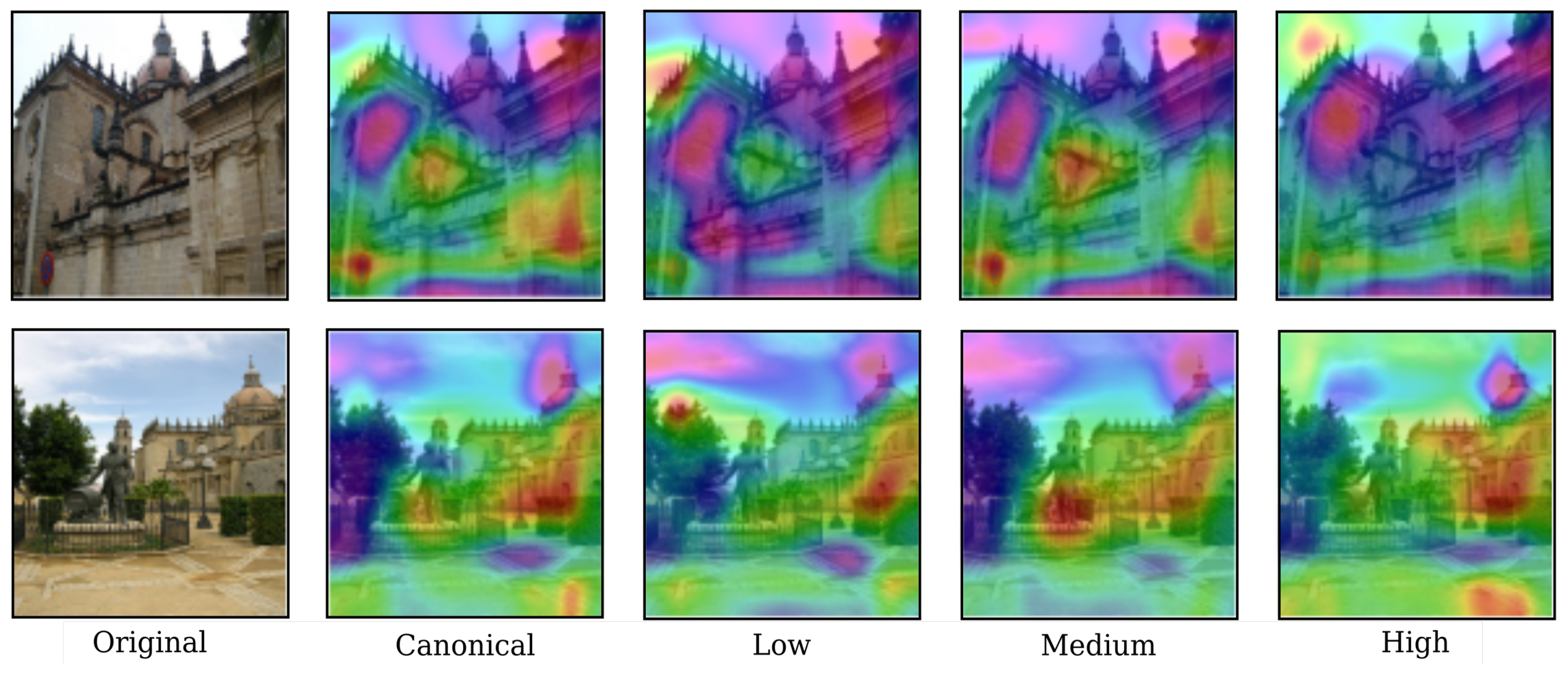
4.2.2. Model-Wise Mixture of Experts
5. Results
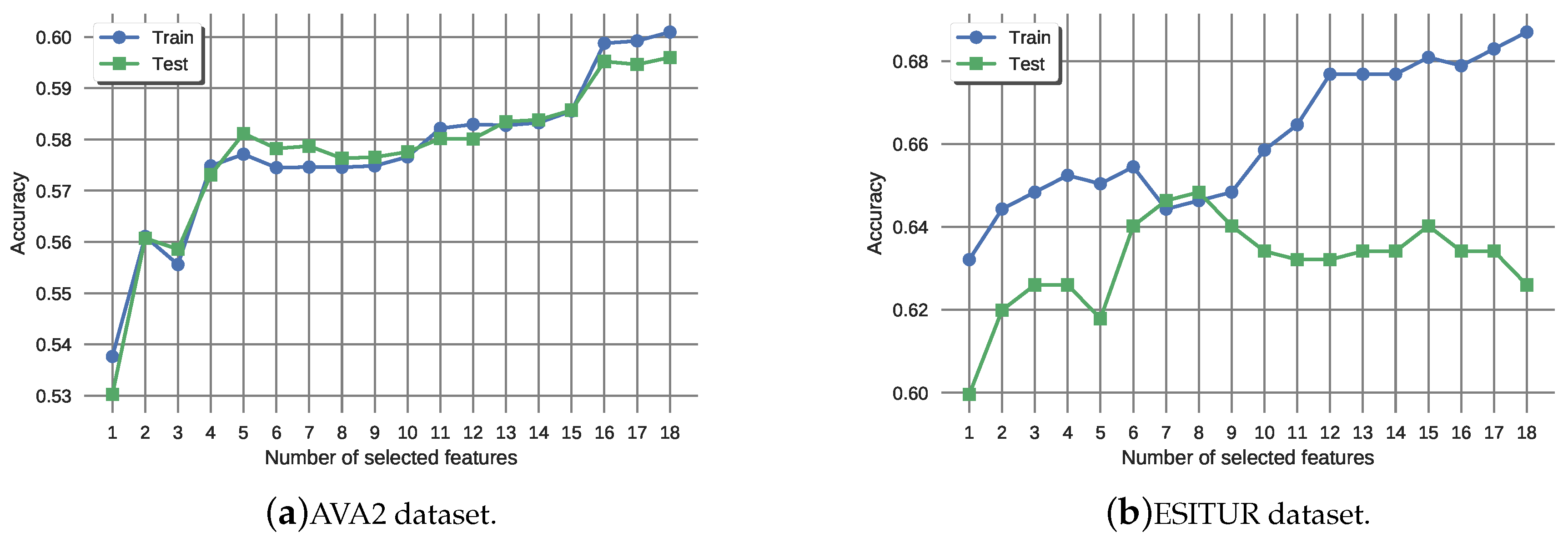
5.1. Hand-Crafted Features
5.2. Deep Convolutional Models
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chatterjee, A.; Vartanian, O. Neuroscience of aesthetics. Ann. N. Y. Acad. Sci. 2016, 1369, 172–194. [Google Scholar] [CrossRef] [PubMed]
- Östen Axelsson. Towards a Psychology of Photography: Dimensions Underlying Aesthetic Appeal of Photographs. Percept. Mot. Skills 2007, 105, 411–434. [Google Scholar] [CrossRef]
- Liu, J.; Lughofer, E.; Zeng, X. Toward Model Building for Visual Aesthetic Perception. Comput. Int. Neurosci. 2017, 2, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Brattico, E.; Pearce, M. The Neuroaesthetics of Music. Psychol. Aesthet. Creat. Arts 2013, 7. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Wang, Z.; Cormack, L.; Bovik, A.C. Blind quality assessment for JPEG2000 compressed images. In Proceedings of the Conference Record of the Thirty-Sixth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 3–6 November 2002; pp. 1735–1739. [Google Scholar] [CrossRef]
- Tong, H.; Li, M.; Zhang, H.J.; Zhang, C. No-reference quality assessment for JPEG2000 compressed images. In Proceedings of the International Conference on Image Processing (ICIP ’04), Singapore, 24–27 October 2004; Volume 5, pp. 3539–3542. [Google Scholar] [CrossRef]
- Winkler, S. Issues in Vision Modeling for Perceptual Video Quality Assessment. Signal Process. 1999, 78, 231–252. [Google Scholar] [CrossRef]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Studying Aesthetics in Photographic Images Using a Computational Approach. In Proceedings of the 9th European Conference on Computer Vision—Volume Part III, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; ECCV’06; pp. 288–301. [Google Scholar] [CrossRef]
- Datta, R.; Li, J.; Wang, J.Z. Algorithmic inferencing of aesthetics and emotion in natural images: An exposition. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 105–108. [Google Scholar] [CrossRef]
- Ke, Y.; Tang, X.; Jing, F. The Design of High-Level Features for Photo Quality Assessment. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 419–426. [Google Scholar] [CrossRef]
- Luo, Y.; Tang, X. Photo and Video Quality Evaluation: Focusing on the Subject. In Computer Vision—ECCV 2008, Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 386–399. [Google Scholar]
- Dhar, S.; Ordonez, V.; Berg, T.L. High level describable attributes for predicting aesthetics and interestingness. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–15 June 2011; pp. 1657–1664. [Google Scholar] [CrossRef]
- Temel, D.; AlRegib, G. A comparative study of computational aesthetics. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 590–594. [Google Scholar] [CrossRef]
- Khan, S.S.; Vogel, D. Evaluating Visual Aesthetics in Photographic Portraiture. In Proceedings of the Eighth Annual Symposium on Computational Aesthetics in Graphics, Visualization, and Imaging, Annecy (CAe ’12), France, 4–6 June 2012; Eurographics Association: Goslar, Germany, 2012; pp. 55–62. [Google Scholar]
- Mai, L.; Jin, H.; Liu, F. Composition-Preserving Deep Photo Aesthetics Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 497–506. [Google Scholar] [CrossRef]
- Ma, S.; Liu, J.; Chen, C.W. A-Lamp: Adaptive Layout-Aware Multi-Patch Deep Convolutional Neural Network for Photo Aesthetic Assessment. arXiv 2017, arXiv:1704.00248. [Google Scholar]
- Kao, Y.; Huang, K.; Maybank, S. Hierarchical aesthetic quality assessment using deep convolutional neural networks. Signal Process. Image Commun. 2016, 47, 500–510. [Google Scholar] [CrossRef] [Green Version]
- Kao, Y.; He, R.; Huang, K. Deep Aesthetic Quality Assessment With Semantic Information. Trans. Img. Proc. 2017, 26, 1482–1495. [Google Scholar] [CrossRef] [PubMed]
- Talebi, H.; Milanfar, P. NIMA: Neural Image Assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef] [Green Version]
- Xue, W.; Zhang, L.; Mou, X. Learning without Human Scores for Blind Image Quality Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 995–1002. [Google Scholar] [CrossRef]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional Neural Networks for No-Reference Image Quality Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1733–1740. [Google Scholar] [CrossRef]
- Bosse, S.; Maniry, D.; Wiegand, T.; Samek, W. A deep neural network for image quality assessment. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3773–3777. [Google Scholar] [CrossRef]
- Lu, X.; Lin, Z.; Shen, X.; Mech, R.; Wang, J.Z. Deep Multi-patch Aggregation Network for Image Style, Aesthetics, and Quality Estimation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 990–998. [Google Scholar] [CrossRef]
- Kao, Y.; Wang, C.; Huang, K. Visual aesthetic quality assessment with a regression model. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1583–1587. [Google Scholar] [CrossRef]
- Lu, X.; Lin, Z.; Jin, H.; Yang, J.; Wang, J.Z. Rating Image Aesthetics Using Deep Learning. IEEE Trans. Multimedia 2015, 17, 2021–2034. [Google Scholar] [CrossRef]
- Kim, J.; Zeng, H.; Ghadiyaram, D.; Lee, S.; Zhang, L.; Bovik, A.C. Deep Convolutional Neural Models for Picture-Quality Prediction: Challenges and Solutions to Data-Driven Image Quality Assessment. IEEE Signal Process. Mag. 2017, 34, 130–141. [Google Scholar] [CrossRef]
- Kong, S.; Shen, X.; Lin, Z.; Mech, R.; Fowlkes, C.C. Photo Aesthetics Ranking Network with Attributes and Content Adaptation. arXiv 2016, arXiv:1606.01621. [Google Scholar]
- Tong, H.; Li, M.; Zhang, H.J.; He, J.; Zhang, C. Classification of Digital Photos Taken by Photographers or Home Users. In Advances in Multimedia Information Processing—PCM, Proceedings of the 5th Pacific Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004; Springer: Berlin/Heidelberg, Germany, 2005; pp. 198–205. [Google Scholar]
- Isola, P.; Xiao, J.; Torralba, A.; Oliva, A. What makes an image memorable? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 145–152. [Google Scholar]
- Isola, P.; Parikh, D.; Torralba, A.; Oliva, A. Understanding the Intrinsic Memorability of Images. In Advances in Neural Information Processing Systems 24; Curran Associates, Inc.: Red Hook, NY, USA, 2011; pp. 2429–2437. [Google Scholar]
- Marchesotti, L.; Perronnin, F.; Larlus, D.; Csurka, G. Assessing the Aesthetic Quality of Photographs Using Generic Image Descriptors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE Computer Society: Washington, DC, USA, 2011; ICCV ’11; pp. 1784–1791. [Google Scholar] [CrossRef]
- Jacobs, R.A.; Jordan, M.I.; Nowlan, S.J.; Hinton, G.E. Adaptive Mixtures of Local Experts. Neural Comput. 1991, 3, 79–87. [Google Scholar] [CrossRef]
- Ferrari, D.B.; Milioni, A.Z. Choices and pitfalls concerning mixture-of-experts modeling. Pesquisa Operacional 2011, 31, 95–111. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Ranzato, M.; Sutskever, I. Learning Factored Representations in a Deep Mixture of Experts. arXiv 2013, arXiv:1312.4314. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.V.; Hinton, G.E.; Dean, J. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Flickr. Available online: https://www.flickr.com/ (accessed on 12 June 2019).
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters a Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Menlo Park, CA, USA, 1996. KDD’96. pp. 226–231. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intel. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Pla-Sacristán, E.; González-Díaz, I.; Martínez-Cortés, T.; de María, F.D. Finding landmarks within settled areas using hierarchical density-based clustering and meta-data from publicly available images. Expert Syst. Appl. 2019, 123, 315–327. [Google Scholar] [CrossRef]
- Murray, N.; Marchesotti, L.; Perronnin, F. AVA: A Large-scale Database for Aesthetic Visual Analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’12), Washington, DC, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 2408–2415. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; SAGE Publications: Thousand Oaks, CA, USA, 2013. [Google Scholar]
- Jin, X.; Chi, J.; Peng, S.; Tian, Y.; Ye, C.; Li, X. Deep Image Aesthetics Classification using Inception Modules and Fine-tuning Connected Layer. In Proceedings of the 2016 8th International Conference on Wireless Communications & Signal Processing (WCSP), Yangzhou, China, 13–15 October 2016. [Google Scholar]
- Moorthy, A.K.; Obrador, P.; Oliver, N. Towards Computational Models of the Visual Aesthetic Appeal of Consumer Videos. In Proceedings of the 11th European Conference on Computer Vision: Part V (ECCV’10), Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Statist. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar] [Green Version]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms, 1st ed.; Chapman & Hall/CRCL: Boca Raton, FL, USA, 2012. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intel. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Mosteller, F.; Tukey, J.W. Data analysis, including statistics. Handbook of Social Psychology; Lindzey, G., Aronson, E., Eds.; Addison-Wesley: Boston, MA, USA, 1968; Volume 2. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | Data Segment | # Locations | # Pics. | Mean Score | Mean Diff (Low, High) | % High Aesthetics Pics. |
|---|---|---|---|---|---|---|
| Train | All | 31 | 492 | 4.22 | 4.74 | 38.41 |
| Bottom | 13 | 203 | 2.21 | 5.02 | 9.36 | |
| Middle | 10 | 147 | 4.96 | 3.82 | 46.26 | |
| Top | 8 | 142 | 6.33 | 3.44 | 71.83 | |
| Test | All | 31 | 492 | 4.23 | 4.75 | 38.62 |
| Bottom | 13 | 221 | 2.61 | 5.11 | 16.29 | |
| Middle | 10 | 149 | 5.17 | 3.94 | 48.99 | |
| Top | 8 | 122 | 6.02 | 3.59 | 66.39 |
| Feature | Description |
|---|---|
| Intensity | Mean brightness |
| Hue | Mean value of hue channel after transforming to HSV color space |
| Saturation | Mean value of saturation channel after transforming to HSV color space |
| Entropy | Entropy of image’s pixels |
| Colorfulness | Difference between image’s color histogram and an uniform color histogram |
| Color profiles | Difference between image’s color histogram and a reference histogram for 8 colors |
| Rule of thirds | Measure of how consistent the horizontal lines in the image are with this composition technique |
| Horizon line | Presence and properties of an horizon line in the image, estimated using the vanishing point position. |
| Strategy | Model | Accuracy on AVA(%) ± 95% Conf. |
|---|---|---|
| Low-Level Features | Murray et al. [40] | 66.70 ± 0.18 |
| Marchesotti et al. [31] | 68.55 ± 0.18 | |
| Datta et al. [8] | 68.67 ± 0.18 | |
| Ke et al. [10] | 71.06 ± 0.18 | |
| Convolutional Networks | Alexnet (pretrained) | 74.04 ± 0.17 |
| VGG-19 (pretrained) | 77.59 ± 0.16 | |
| Talebi, H. & Milanfar, P. [19] | 80.60 ± 0.15 | |
| Ma et al. [16] | 82.5 ± 0.15 |
| Model Type | Model | Model | Model Adaptation | Accuracy ± 95% Interval (%) | |
|---|---|---|---|---|---|
| Number | Training Data | (Starting Model) | AlexNet | VGG-19 | |
| Regular pre-trained models | 1 | AVA | - | 45.7 ± 3.11 | 46.29 ± 3.11 |
| (no ESITUR adaptation) | 2 | AVA | - | 45.7 ± 3.11 | 50.39 ± 3.12 |
| Canonical | 3 | ESITUR | Model 1 | 77.64 ± 2.6 | 76.51 ± 2.65 |
| (adapted to ESITUR from | 4 | ESITUR | Model 2 | 77.76 ± 2.6 | 76.92 ± 2.63 |
| pre-trained models) | 5 | ESITUR | Imagenet pre-trained | 82.02 ± 2.4 | 81.46 ± 2.43 |
| MEX | 6 | ESITUR | Model 3 | 80.72 ± 2.46 | 80.37 ± 2.48 |
| (adapted from | 7 | ESITUR | Model 4 | 83.53 ± 2.32 | 79.5 ± 2.52 |
| canonical models) | 8 | ESITUR | Model 5 | 84.27 ± 2.27 | 85.08 ± 2.23 |
| Initialization | Data Segment | Model | ||||
|---|---|---|---|---|---|---|
| Low | Medium | High | Canonical | zeroR | ||
| AVA | All | 76.52 | 75.29 | 77.32 | 76.51 | 61.38 |
| Bottom | 91.52 | 84.91 | 88.46 | 88.7 | 83.71 | |
| Middle | 70.03 | 74.93 | 69.23 | 71.51 | 51.01 | |
| Top | 60.81 | 61.84 | 68.58 | 63.5 | 66.39 | |
| AVA | All | 76.72 | 76.51 | 76.4 | 76.92 | 61.38 |
| Bottom | 90.84 | 87.07 | 86.81 | 88.96 | 83.71 | |
| Middle | 69.62 | 74.53 | 70.36 | 73.03 | 51.01 | |
| Top | 62.78 | 63.1 | 66.85 | 63.1 | 66.39 | |
| Imagenet | All | 77.71 | 76.53 | 78.91 | 81.46 | 61.38 |
| Bottom | 92.95 | 79.85 | 84.45 | 90.11 | 83.71 | |
| Middle | 64.54 | 81.8 | 73.13 | 77.71 | 51.01 | |
| Top | 67.67 | 67.06 | 76.12 | 72.43 | 66.39 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kleinlein, R.; García-Faura, Á.; Luna Jiménez, C.; Montero, J.M.; Díaz-de-María, F.; Fernández-Martínez, F. Predicting Image Aesthetics for Intelligent Tourism Information Systems. Electronics 2019, 8, 671. https://doi.org/10.3390/electronics8060671
Kleinlein R, García-Faura Á, Luna Jiménez C, Montero JM, Díaz-de-María F, Fernández-Martínez F. Predicting Image Aesthetics for Intelligent Tourism Information Systems. Electronics. 2019; 8(6):671. https://doi.org/10.3390/electronics8060671
Chicago/Turabian StyleKleinlein, Ricardo, Álvaro García-Faura, Cristina Luna Jiménez, Juan Manuel Montero, Fernando Díaz-de-María, and Fernando Fernández-Martínez. 2019. "Predicting Image Aesthetics for Intelligent Tourism Information Systems" Electronics 8, no. 6: 671. https://doi.org/10.3390/electronics8060671