
A Multi-Feature Fusion-Based Automatic Detection Method for High-Severity Defects
by
Jie Liu
1,*,
Cangming Liang
1,
Jintao Feng
2,
Anhong Xiao
2,
Hui Zeng
2,
Qujin Wu
1 and
Tonglan Yu
1 1
Department of Computer Science, University of South China, Hengyang 421001, China
2
Nuclear Power Institute of China, Chengdu 610213, China
*
Author to whom correspondence should be addressed.
Electronics 2023, 12(14), 3075; https://doi.org/10.3390/electronics12143075
Submission received: 20 June 2023
/
Revised: 12 July 2023
/
Accepted: 12 July 2023
/
Published: 14 July 2023
(This article belongs to the Special Issue Machine Learning Methods in Software Engineering)
Abstract
:It is crucial to detect high-severity defects, such as memory leaks that can result in system crashes or severe resource depletion, in order to reduce software development costs and ensure software quality and reliability. The primary cause of high-severity defects is usually resource scheduling errors, and in the program source code, these defects have contextual features that require defect context to confirm their existence. In the context of utilizing machine learning methods for defect automatic confirmation, the single-feature label method cannot achieve high-precision defect confirmation results for high-severity defects. Therefore, a multi-feature fusion defect automatic confirmation method is proposed. The label generation method solves the dimensionality disaster problem caused by multi-feature fusion by fusing features with strong correlations, improving the classifier’s performance. This method extracts node features and basic path features from the program dependency graph and designs high-severity contextual defect confirmation labels combined with contextual features. Finally, an optimized Support Vector Machine is used to train the automatic detection model for high-severity defects. This study uses open-source programs to manually implant defects for high-severity defect confirmation verification. The experimental results show that compared with existing methods, this model significantly improves the efficiency of confirming high-severity defects.
1. Introduction
In recent years, with the development of technology and the increasing demand for software quality in the market, the complexity and scale of software have continued to grow. This has made it easier to encounter errors such as inconsistent requirements and implementations, architectural mistakes, and non-standard programming practices during the development process, resulting in a significant increase in software defects. The existence of software defects can cause accidents and economic losses. Therefore, the importance of software testing is becoming increasingly significant.
Due to the expansion of software scale, it is impossible to test hundreds of thousands of lines of code solely through manual inspection. Therefore, testers usually employ automated testing tools [1] such as Coverity, Astree, Cpplint, Findbugs, DTS, C++TEST, etc. These tools are capable of conducting static code checks based on predetermined coding rules, eliminating the need to execute the code. They offer warning data, thereby alleviating some of the manual workloads and enhancing work efficiency to a certain extent. In practical testing work, testing tools usually sacrifice accuracy for approximate calculations to reduce false negatives, resulting in false positives in the warning data submitted by the tool. Therefore, testers need to conduct a manual review of the warning data submitted by the testing tool. Nowadays, during the software testing phase, testers also use some test management platforms to manage defects, such as Bugzilla, ITracker, and JIRA [2]. Defects usually have two important attributes on these test management platforms: priority and severity [3]. Generally speaking, the severity of defects is classified into multiple levels such as Blocker, Critical, Major, Normal, Minor, Trivial, etc. Obviously, defects with higher severity levels cause greater damage to the software program. Therefore, in the testing phase, detecting high-severity defects as early as possible and prioritizing them for developers to handle can significantly reduce or even avoid possible losses in the later stages of the software production process.
High-severity defects are a type of defect with more prominent features, and their proportion in actual engineering data is relatively small. When the defect features are more prominent, machine learning methods can leverage the features more effectively for classification. Furthermore, the performance of deep learning models depends on the size of the dataset, and when the data volume is small, machine learning methods can better model and classify the data. Deep learning requires a large amount of data to train the model, and if the dataset is not large enough, the deep learning model is prone to overfitting, leading to a decrease in performance. On the other hand, machine learning methods can better handle small-scale datasets, such as decision trees, support vector machines, and other methods.
The main factor that leads to high-severity defects is resource scheduling errors, which have contextual characteristics in the source code. Using a single-feature label method cannot achieve high-precision defect confirmation for high-severity defects. Therefore, a multi-feature nested automatic confirmation method for high-severity defects is proposed. This paper mainly makes the following research contributions:
- Solving the dimensionality disaster problem caused by multi-feature fusion by using strongly correlated feature nesting. By selecting the source code of some high-severity defects and analyzing their defect patterns, the contextual features existing in the defects are extracted. Under the background of static code checking, the information of the defect context is usually ignored, leading to challenges in achieving high accuracy automatic confirmation for high-severity defects. Based on the dependency relationship, the automatic confirmation model constructed according to the contextual features strengthens the correlation between various statements in the defect code and other statements, and uses labeling principles to extract the contextual features in the defect. At the same time, by analyzing the graph path information contained in the program dependency graph transformed by the defect source code, the defect’s graph path features are extracted. Contextual feature labels replace nodes in the program dependency graph, and the two features are nested. This method avoids the low precision of the single-feature label method and reduces the risk of a dimensionality disaster caused by multi-features.
- The design of the automatic detection model for high-severity defects is completed. Based on the fusion of contextual features and graph path features, Word2vec is further used to extract features and represent the dataset as a vector in a computer-understandable data format while retaining the contextual information of the original feature nesting. After completing all data processing work, the machine learning algorithm Support Vector Machine (SVM) is used to train the classifier, and the automatic detection model for high-severity defects is finally generated.
- Application experiments are conducted on the automatic detection model for high-severity defects. The classifier is trained using the open-source dataset SARD and 1221 data constructed manually, and the accuracy of the automatic detection model for high-severity defects reaches 0.85 during the training process, and the AUC reaches 0.82. After the model training is completed, it is applied to four open-source projects to verify the model performance. The experimental results show that the accuracy of the confirmation results in the four open-source projects is above 0.76, indicating that the proposed method can effectively confirm high-severity defects and significantly improve the efficiency of software testing.
The rest of this paper is organized as follows. Section 2 reviews the related work. Section 3 describes the principles behind the methodology proposed in this paper. Section 4 presents the experimental setup and results. Section 5 interprets and discusses the findings based on the experimental results. Finally, Section 6 provides a summary of the entire paper.
2. Related Work
In recent years, machine learning and other artificial intelligence methods have become important means in the field of software testing [4,5,6,7,8], and the selection of defect features has received much attention. Chen et al. [9] proposed a multi-objective optimization method based on the file granularity feature attribute through data mining and an analysis of software libraries. Tian et al. [10] used gate recurrent units (GRU) to extract semantic features from sliced source code and trained a classifier using deep learning methods. Lin et al. [11] proposed a semantic feature learning framework based on dual sequences (SFLDS), which can capture semantic and structural information in Abstract Syntax Trees (ASTs) to generate features. Zhuang et al. [12] proposed a transferable hybrid feature learning framework for cross-project defect prediction. First, token vectors were extracted from the program’s AST, and then convolutional neural networks were used to mine the vectors to generate features. Finally, the model was trained with manually designed features to complete the cross-project defect prediction. Jia et al. [13] proposed a feature representation method for heterogeneous defect prediction based on transfer-variational autoencoder (T-VAE) technology. By combining the variational autoencoder with the maximum mean discrepancy distance, a new cross-project defect prediction model was constructed, which can effectively learn common feature representations between the target and source projects. Fan et al. [14] used a path analysis to extract path variable features to compensate for the lack of deep semantic information in traditional features. They then proposed a transfer learning method based on feature ranking matching using a two-stage approach. Zhang et al. [15] designed a set of variable-level features for building a classification model, which differs from the traditional feature representation method. Wang et al. [16] optimized the existing LASSO-SVM model to propose a software defect prediction model. They used the parameter optimization ability of the cross-validation algorithm to obtain the optimal value of the Support Vector Machine. Some of the literature also proposes a defect code semantic alarm correlation method, which establishes alarm correlation by finding real defect-related information, thereby automatically determining batches of false positives or real defects of the same type. This method effectively reduces the workload of manual inspection [17]. Similarly, there is existing literature that categorizes alarms based on reasonable dependencies, providing a systematic framework for their classification. This method assumes that if there is a real defect in a cluster of alarms, then all the alarms in the cluster are real defects. They conducted experiments on a real buffer overflow analyzer and demonstrated a 45% reduction in false positives [18]. Similarly, alarms are classified based on the dependency relationships between them, and if the center alarm in a cluster is determined to be a false positive by testers, then all other alarms in the same cluster are also false positives. However, this method has a strong bias and usually reduces the accuracy of filtering false positives in actual testing work to avoid developers missing real defects [19]. In [20], researchers leveraged tree-based ensemble models for defect prediction, where RF and ET bagging ensembles showcased a superior predictive performance among all the ensemble models employed.
In the process of software defect confirmation, the key to successfully filtering false positives using machine learning models lies in the use of classification algorithms [21], and another critical point is the selection of feature representation. Through extensive literature research, it has been discovered that current methods of automatic defect confirmation primarily rely on manual feature construction for specific types of defects. This approach is challenging to expand to include other types of defect confirmation. Another alternative is to depend on large amounts of data and computing resources for training, making it challenging to create high-performance defect confirmation models when sufficient data are lacking.
3. Methods
3.1. Software Defect Classification
Software defects are widely present in the source code of software programs, which can lead to software products not meeting user needs to some extent. They are usually caused by the inadequate coding behavior of developers due to a lack of experience or misunderstanding of requirements due to inadequate communication regarding developers and requirements. To better manage software defects in the testing process, software defects are usually classified. In the software testing process, testers assign severity attributes to software defects on the management platform [22]. Testers focus on defects with high-severity levels of a blocker and some critical defects. These defects are referred to as high-severity defects. Usually, these high-severity defects can cause software functional errors, memory leaks, user data loss or damage, modules unable to start or an abnormal exit, a system crash or freeze, and data communication errors. For example, regarding NULL Pointer Dereference, when the application dereferences a pointer that is expected to be valid but is actually NULL, a null pointer dereference occurs, which usually leads to a program crash or direct exit. This defect has a high-severity level of a blocker, and the triggering method may be a condition error or simple bad programming behavior.
As can be observed from the above example, high-severity defects arise due to errors in resource scheduling within the program. It is evident that such defects cannot be confirmed solely based on a single line of code; instead, inference through the code context is necessary. By confirming the relationship between contextual statements (such as data dependencies), the presence of the defect can be ascertained. Defects that necessitate confirmation through context statements, rather than a single line of code, are commonly referred to as contextual defects.
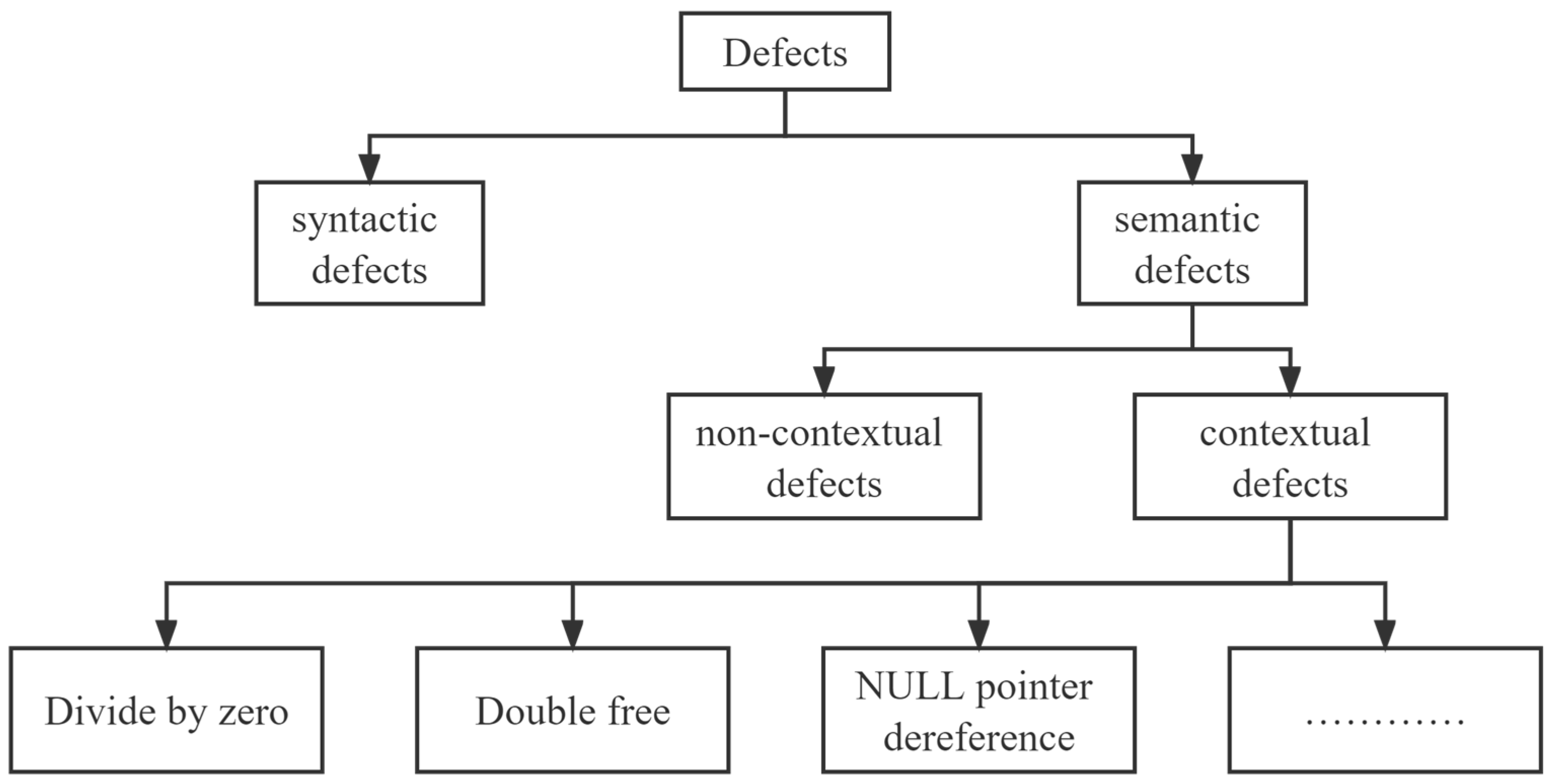
In this classification context, all defects are first divided into two categories, syntax defects and semantic defects. Syntax defects refer to errors that cannot be compiled, such as files not ending, header files not found, and a duplicate use of formal parameters in macro calls. Such defects are generally caused by poor coding habits of developers. Semantic defects refer to defects that can be compiled, but logic errors exist. Contextual defects are a type of semantic defect, and other types of defects are collectively referred to as non-contextual defects in this classification, as shown in Figure 1.
Contextual defects are defects that can only be determined by the context statements in the code. Defects such as negative number square roots, an unsafe use of boolean types, integer division, and the direct comparison of floating-point numbers are non-contextual defects, while defects such as division by zero and null pointer references cannot be confirmed by the line where the warning point is located alone, and must be confirmed by the context code of the line. These are referred to as contextual defects. In contextual defects, the statement where the warning point is located is closely related to its context statements. In the program code, the relationship between these statements is called dependency [23]. In other words, when a defect occurs in a line of code, the cause of the defect is not only caused by that line but is also closely related to the context code statements, and there are control dependencies and data dependencies between these statements. In program code, the use of a variable in one statement depends on the previous program statement that assigns the same variable, and there is a data dependence between these two program statements; if one statement determines whether another statement is executed, then there is a control dependence between these two program statements.
In summary, a brief definition of contextual defects can be given. The set of all these statements and their dependencies is the contextual defect.
Definition 1.
Contextual defect: a contextual defect can be defined as a binary tuple contextual defect = {ContextStatements, Dependencies}:
- In terms of solving ContextStatements, they are context statements that represent all the statements that cause a defect to occur.
- Dependencies are dependencies that represent the control dependencies and data dependencies between all context statements in a set.
3.2. Feature Extraction
To perform feature extraction on contextual defects, first, a dataset needs to be collected and analyzed for relevant defects. The National Institute of Standards and Technology (NIST) published a software assurance reference dataset called SARD (Software Assurance Reference Dataset) [24]. This dataset uses three attributes, Good, Bad, and Mixed, for labeling. Good represents code with fixed defects, Bad represents code with unfixed defects, and Mixed represents code with both defects and patches.
Since the initial code files are not conducive to feature extraction and it is also difficult to formalize the differences between defects and false positives, based on the relevant technologies mentioned in Section 2, the program slicing technique is used to transform the source code into a text-based and labeled directed dependency graph stored in a CSV file. The labels are designed based on the characteristics of contextual defects, and by describing the features of contextual defects, the statements of the defect’s key nodes can be abstracted as labels. For example, for defects of the memory leak type, memory allocation and release can be abstracted as labels such as malloc and free, respectively. Using this design method, Table 1 shows the design of some labels:
By utilizing a label design, this process effectively highlights the root causes of high-severity defects. To further characterize these defects, this paper extracts graph path features. The extraction of these features relies on a program dependency graph, which is first obtained from the source code of the defects using program slicing techniques. Next, graph machine learning feature extraction methods are employed to extract the path information of the program dependency graph and transform it into textual data. The graph path features are especially useful for highlighting the flow of code statements and the dependencies between statements in the defects, which in turn help explain the causes of the defects. After extracting contextual features and graph path features, the two sets of features are nested to form a mathematical expression of the program dependency graph. This expression is defined as a triple that takes into account the contextual characteristics of the defects, defined as follows: PDG = {nodeSet, connectSet, entry}.
- The nodeSet represents the set of nodes in the program dependency graph, i.e., {node1, node2, …, noden}. Each node corresponds to a program statement, and in conjunction with the extraction of contextual features, each node corresponds to a contextual feature label.
- The connectSet represents the set of connecting lines in the program dependency graph, with these lines having direction and representing the flow and dependency relationship between program statements, mainly manifested as control dependency and data dependency. If if and return are two nodes in the program dependency graph, and whether the program statement represented by the return node can be executed depends on the if node, then the return is said to have control dependency on if, denoted as return->cd.if; if def and asfunc are two nodes in the program dependency graph, and both nodes correspond to program statements involving variable v, def defines variable v, asfunc references the variable, and there exists an executable path between def and asfunc, in which there is no operation on variable v, then asfunc has a direct data dependency on def regarding variable v.
- The entry represents the entry node of the program dependency graph, and each program dependency graph has only one entry node.
After processing the data through these two types of feature extraction, the initial source code training data are transformed into text data with nested contextual features and graph path features.
3.3. Automatic Detection for High-Severity Defects
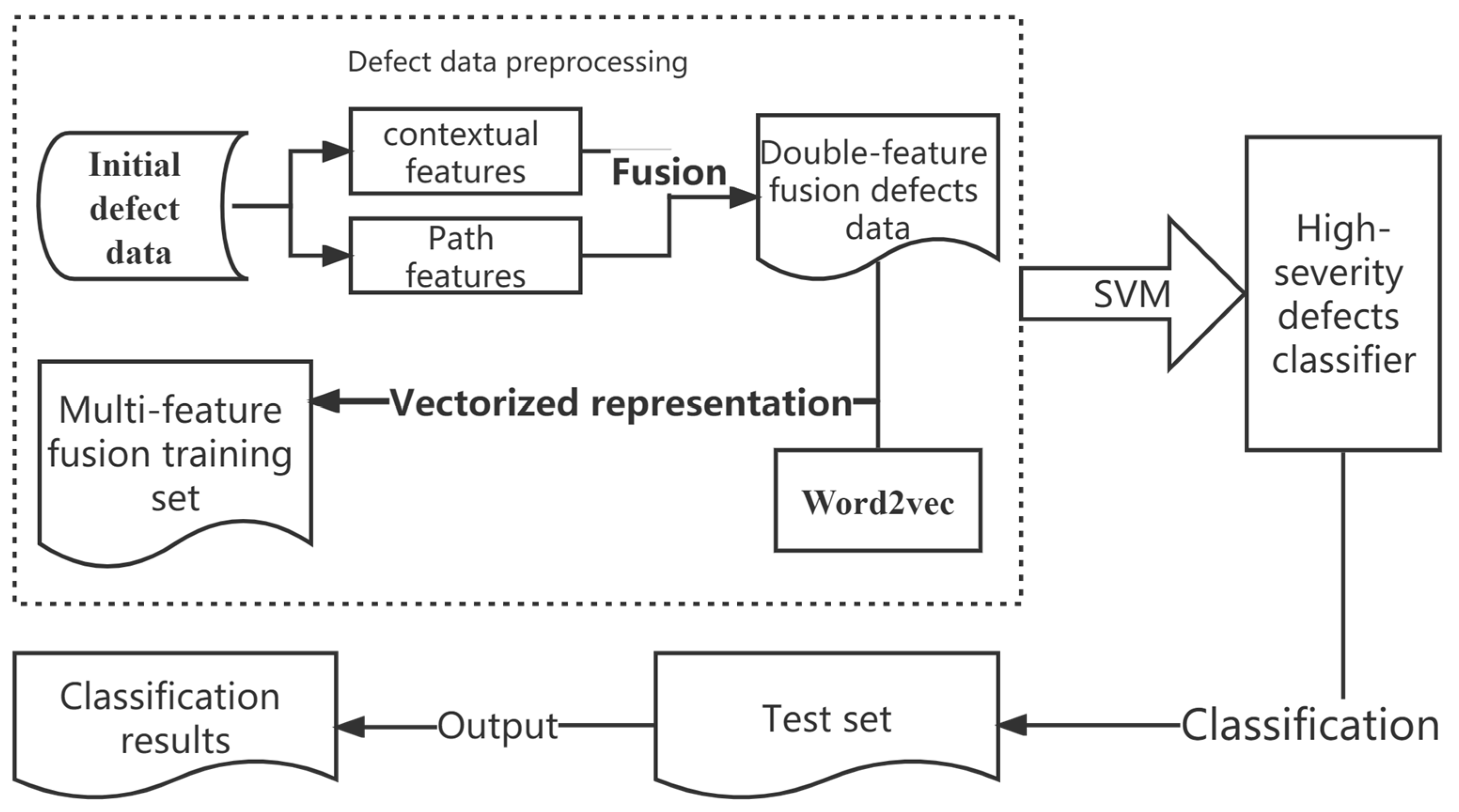
In dealing with high-severity-level defects, we characterize the dynamic process of resource scheduling with contextual information and convert the defect source code into an initial test dataset using a program dependency graph and contextual feature labels. In the machine learning-based defect automatic confirmation model, the classifier needs to learn pre-defined feature representations. In order to represent text data in a form that is easier for computers to process and reduce information loss, a new text feature extraction method is added here for fusion to achieve the best processing effect. As the text already contains two features, we opted for a simpler Word2vec method in the final feature embedding process to better address the issue of dimensionality explosion. Word2vec further extracts word vector features while preserving the original context information of the data, transforming the text data into a vector representation that is computationally tractable for computers to process and analyze [25]. After processing the double-nested feature data with Word2vec, we achieve the final multi-feature fusion of high-severity defect textual data. Based on this, combined with the SVM algorithm, an automatic detection model for high-severity defects is trained to complete automatic confirmation. The process is shown in Figure 2.
To ensure the reliability of the dataset, a large training set was obtained using SARD. After downloading the data, we performed fusion processing on the source code related to high-severity defects. Multiple features were extracted from this code and then transformed into training text for a further analysis and storage. The source code was converted into a program dependency graph, and its statements were analyzed for keywords, nodes, edges, functions, and call relationships. This information was then written into a CSV file for easy storage and retrieval. After preprocessing the defect data, Word2Vec was used to extract additional features, and the defect data were vectorized to preserve contextual information for easier processing by computers. Finally, the SVM algorithm was used to train the classifier and create the high-severity defect classification model. This model could then be used to classify the preprocessed test dataset.
4. Experiment
4.1. Data Preparation
To demonstrate the effectiveness of our proposed method, we used the Software Assurance Reference Dataset (SARD) and four open-source C projects as experimental datasets. Specifically, we downloaded the open-source projects UUCP, Httpd, Sphinxbase, and Antiword from GitHub, which comprehensively cover the 34 types of defects mentioned in this study and are suitable for validating our automated confirmation method for high-severity defects. We created the classification model for high-severity defects using the scikit-learn machine learning toolkit in Python.
The training dataset primarily consisted of SARD, while the test dataset was derived from the four open-source C projects. We performed static checks on the projects using the Parasoft component of the C++TEST tool, identified relevant defect locations through alert reports, and extracted the relevant defect context code using the program slicing methodology. After obtaining the slices of all suspected high-severity defect code, we applied the same processing operation to convert these codes into the test dataset. Since the initial data was provided by the static checking tool, the calculation of the final metrics was based on the true defects and false alarms in the alert report.
Furthermore, due to the uneven distribution of the 34 types of high-severity defects in the selected open-source programs, and the low number of data in the alert report, we manually added 137 real defects and corresponding repaired code samples as positive and negative samples into the test dataset before conducting the experiment. This ensured that the test dataset was more representative and balanced, and could better evaluate the effectiveness of our proposed method in real-world scenarios. The final alert report processed the test dataset, which consisted of 401 samples, including 187 positive samples and 214 negative samples. These samples were used to evaluate the performance of our method in accurately and efficiently confirming high-severity defects in software development.
4.2. Experimental Design
To verify the rationality of selecting Support Vector Machines (SVM) and the effectiveness of the high-severity defect classification model, we conducted experiments using the SARD dataset and open-source C project data as experimental datasets. We used five classification algorithms, including the Naive Bayes Classifier, Decision Tree Classifier, Random Forest Classifier, K-Nearest Neighbors Classifier [26], and SVM [27,28], from the scikit-learn machine learning toolkit in Python. Additionally, we used the Word2Vec model from the gensim toolkit, which was trained with multiple threads. The training process included setting the vector size for each sample unit to 30, the window size to 8, the learning rate to 0.01, the sampling frequency to 0.01, and the iteration count to 3.
- Experiment on machine learning method selection: The purpose of this experiment was to identify the most suitable machine learning algorithm for multi-feature fusion. We trained and created corresponding high-severity defect classification models using all five mentioned classification algorithms combined with Word2Vec for the fused training dataset. We then compared the various classification models using model evaluation metrics.
- Ablation experiment: The purpose of this experiment was to evaluate the impact of each feature on the classifier’s performance. We first established a baseline model and then used all features to train the classifier. We then separately established new models that extracted contextual features, graph path features, and Word2Vec features. Finally, we recorded the accuracy and other performance metrics of all classifiers. To ensure the reliability of the experiment, all classifiers used the same machine learning algorithm, training and testing dataset selections, and model parameter settings. We conducted multiple repeated experiments to achieve the best performance metrics for each classifier. We manually implanted defects into the alert report of the four open-source C projects to ensure that the data distribution of the test dataset matched that of the training dataset.
- Defect confirmation experiment: We selected the high-severity defect classification model with the highest evaluation score in the first experiment to automatically confirm defects in the original alert data of the four open-source C projects. This experiment simulated the working environment and tested the practical application ability of the multi-feature fusion high-severity defect classification model.
- Comparison experiment: We compared our proposed method with other methods in terms of the defect confirmation performance in the same project. This experiment aimed to test the advanced features of the multi-feature fusion high-severity defect classification model.
4.3. Evaluation Metrics
To demonstrate the effectiveness of a constructed model and classification results, commonly used metrics are typically used to measure them. The confusion matrix is a widely used contingency table in machine learning for summarizing the classification results of a classification model. Typically, the columns of the confusion matrix represent the predicted values, while the rows represent the actual values. Therefore, in the case of binary classification, there are four values in the confusion matrix: TP (true positive), FN (false negative), FP (false positive), and TN (true negative). In the context of defect automatic confirmation, the TP value represents the case where high-severity defects are correctly classified, the FN value represents the case where high-severity defects are classified as non-defective code, the FP value represents the case where non-defective code is classified as high-severity defects, and the TN value represents the case where non-defective code is correctly classified.
To intuitively judge the performance of the automatic detection model for high-severity defects, we selected five commonly used metrics: Accuracy, Precision, Recall, F1-score, and the Area Under the Curve (AUC) of the ROC curve (as indicators of whether the model is effective).
Accuracy represents the percentage of correct predictions made by the defect automatic confirmation model, which is the number of correctly classified samples divided by all samples.
Precision represents the percentage of correct predictions made by the defect automatic confirmation model among the predicted defects, which is the number of correctly classified defective samples divided by all samples classified as defects by the model.
Recall represents the percentage of correctly predicted defects in the actual defective samples, which is the number of correctly classified defective samples divided by all defective samples in the test dataset.
An F1-score is a balanced score that takes into account both the Precision and Recall of the defect automatic confirmation model. To more objectively evaluate a defect automatic confirmation model, this metric is usually selected to prevent the model from having significant deviations due to pursuing a high Precision or Recall. The F1-score is calculated as the product of Precision and Recall divided by the sum of Precision and Recall, and then multiplied by two.
The full name of the metric AUC is the Area Under the Receiver Operating Characteristic curve (ROC curve). This evaluation metric is more complex than the above metrics. Since there is a sample imbalance problem in the training dataset during the classification training of machine learning, evaluating the model using only the above four indicators is not objective enough. Some scholars have proposed indicators such as the True Positive Rate and False Positive Rate. However, too many indicators can affect the judgment of researchers in scientific research. Therefore, some scholars integrate these indicators into AUC. AUC simultaneously considers the classification ability of the classifier for positive and negative samples, and can still evaluate the classifier reasonably and objectively in the case of sample imbalance.
5. Results
5.1. Comparison Experiment of Machine Learning Methods
To select the most suitable machine learning method for the multi-feature nested method, we trained classifiers using five machine learning classification algorithms combined with Word2Vec. Table 2 compares the performance of each algorithm’s trained classifiers.
The comparison results of each classification algorithm lead to the conclusion that the performance of the DT, NB, and KNN models is relatively weak, possibly because these models’ assumptions about the data distribution are not reasonable enough, and the distribution of high-severity defect text data is complex. On the other hand, the SVM and RF models performed the best, which is also related to the widespread use of these two algorithms in the field of text classification. Based on the results shown in Table 2, under the task background of this article, the classification effect of the SVM algorithm is overall better than that of the RF algorithm. Overall, this experiment’s results demonstrate that the SVM model can achieve a good classification effect on this dataset and is suitable for high-severity defect classification tasks.
5.2. Ablation Experiment
Based on the results of the previous experiment, we used the SVM algorithm trained classifier model as the basis for the next experiment. We uniformly implanted artificially constructed defect data into the alarm data of four open-source C projects and mixed them with native data as the test dataset. We then used the same processing method as the training set to convert the test data into labeled data with features for experimentation. In this experiment, multiple rounds of experiments were conducted using classifiers trained by the baseline model, the context feature ablation model, the graph path feature ablation model, and the Word2Vec feature ablation model. In the Word2Vec ablation model, TF-IDF was used to model the text, with the K value set to 58. After removing the abnormal data, the classifiers trained by the four models had relatively stable indicators. Therefore, we used the best indicators of each classifier in the experiment as the evaluation criteria, and the comparison results are shown in Table 3.
From the assessment comparison of the ablation experiment, the classifier trained by the context feature ablation model had the most significant performance decline, indicating that the context feature module had the most significant impact on the model’s classification performance. This also indicates that the extraction of context feature labels can effectively improve Accuracy and Precision in the high-severity defect automatic confirmation process. The classifier trained by the graph path feature ablation model did not show a significant performance decline, but it had the longest average time consumption during the actual experiment, indicating that graph path features can effectively reduce invalid words, streamline the dataset size, and improve the efficiency of model training and subsequent classification iterations. The classifier trained by the Word2Vec feature ablation model also had a significant decline in all indicators, with an overall performance slightly higher than that of the context feature ablation model, indicating that Word2Vec is more suitable for this method and can better represent the vector of multi-feature nested defect data to improve classifier performance. The recall rate of the classifiers trained by each model remained at a high level, which may be related to the selection of the dataset and the setting of parameters, indicating that these models can better identify positive samples, reduce the missed detection rate, and minimize the adverse effects of defects on programs to the greatest extent. In summary, the multi-feature nested method has a significant contribution to improving the performance of classifiers in terms of Accuracy and Precision. The classifiers trained by the baseline model have excellent indicators, indicating that the high-severity defect automatic confirmation method based on multi-feature fusion has a significant contribution to identifying high-severity defects.
5.3. Defect Confirmation Experiment
In the ablation experiment, defect data were uniformly implanted into the alarm data of four open-source C projects, namely UUCP, Httpd, Sphinxbase, and Antiword, to further verify the effectiveness of the trained automatic detection model for high-severity defects. In the defect confirmation experiment, the model was used to classify the original alarm data of the four C projects to check the model’s performance in actual projects. The defect confirmation experiment was repeated multiple times, and the final results were calculated by taking the average of the more credible data several times and are presented in Table 4.
The confirmation results show that the automatic detection model for high-severity defects performs well in confirming high-severity defects in the Httpd project, with average values of all indicators above 0.94. This indicates that the defects in the Httpd project are closer to the defect patterns designed in this paper and are more evenly distributed among high-severity defects. The performance on the native defect data of the UUCP and Antiword projects is also good, with all indicators above 0.81, indicating that the defect patterns of the UUCP and Antiword projects are also close to the defect patterns designed in this paper but are not evenly distributed between positive and negative samples. In contrast, the performance on the native defect data of the Sphinxbase project is relatively general, but the mean values are also above 0.77. This indicates that the distribution of high-severity defects in the Sphinxbase project is more uneven compared to the other three projects. Moreover, in the native alarm data of Sphinxbase, pointer-related defect alarms account for more than 73% of the total high-severity defect data, and due to its more complex code, errors are more likely to occur when performing defect context code slicing. These reasons contribute to the lower evaluation indicators in the end.
Overall, when tested on the actual alarm data of the four projects, the highest average values of the Recall rate and Accuracy rate were observed in all indicators. This indicates that the automatic detection model for high-severity defects can effectively classify defects, reduce the missed detection rate, and significantly reduce the damage caused by defects to software in the context of software testing.
5.4. Comparison with Related Methods
Zhang et al. [15] proposed an automatic defect confirmation model based on variable-level features, which is only applicable to null pointer dereference in high-severity defects. Table 5 compares the average performance indicators of the two models in the open-source Antiword project:
As shown in Table 5, our proposed method outperforms another method in terms of the average Accuracy rate, average Precision, average Recall rate, and average F1 value on the same Antiword project, indicating that the defects in Antiword are more consistent with the defect pattern designed in our paper.
Specifically, in comparison to single-feature approaches, the multi-feature fusion technique employed in this study enables a more comprehensive analysis of defect features, thereby enhancing the performance of defect classification. Methods discussed in reference [19], for instance, focus solely on identifying NullPointer Dereference within high-severity defects. These methodologies delve deep into the exploration of specific defect features, leading to an excessive reliance on single features and a limited applicability to diverse defect types. To address this issue, this paper introduces a novel approach based on multi-feature fusion for efficient defect detection.
The experimental results strongly support the effectiveness of this approach. It facilitates the identification of a wider range of complex defect types while simultaneously reducing the dependence on individual features, thus enhancing the model’s robustness in dealing with fluctuations in data. Moreover, the evaluation metrics, namely Accuracy, Precision, Recall, and F1-score, showcase a well-balanced prediction of both positive and negative instances for high-severity defects. This illustrates the capability of the proposed model in reducing false positives and false negatives while handling a greater variety of defect types, thereby demonstrating its remarkable stability and scalability.
6. Conclusions
We conducted an in-depth study on high-severity defects and adopted a strategy that combines multi-feature fusion with machine learning methods. By fusing manually extracted features with word vector representations, we were able to more deeply represent the deep semantic information of high-severity defects. Compared to methods trained on larger and more diverse datasets, our high-severity defect automatic confirmation method is more refined and in-depth in terms of feature extraction and representation. Compared to methods that focus on a single type of defect, our method can handle a wider range of defect types while preserving the deep semantic information of the defects, demonstrating the strong scalability and applicability of the model created using this method.
In the experiments, we used the manually adjusted SARD dataset and the open-source C project alarm data as the training set and test set, respectively, to further improve the performance and robustness of the created model. Four experiments were designed to demonstrate the correctness of our proposed method and the performance of the model created based on this method. In the first experiment, we compared the results of different machine learning methods trained using the training set and found that the Support Vector Machine is the most suitable method for multi-feature fusion. In the second experiment, we used the open-source C project to construct a test set and compared the baseline model with other ablation models using various evaluation metrics, which confirmed the importance of context features and Word2Vec in constructing the model. Our automatic detection model for high-severity defects achieved high scores regarding Accuracy, the Recall rate, and the F1-score, particularly regarding the Recall rate, indicating that our method can better identify software defects and has significant potential for practical applications. In the third experiment, we applied our automatic detection model for high-severity defects to the original alarm data of four open-source C projects, and the results showed that the detection accuracy of all open-source C project alarm data exceeded 0.77, demonstrating the effectiveness of our method. In the final experiment, we compared our multi-feature fusion representation method with a variable-level feature extraction method and found that the former outperforms the latter in all performance metrics and can identify more complex types of defects.
These experimental results provide new ideas and methods for research and applications in the field of software defect detection, which can further promote the development and innovation of the field.
Author Contributions
Conceptualization, C.L. and J.L.; methodology, C.L.; software, J.F., A.X. and H.Z.; validation, C.L. and Q.W.; data curation, C.L. and T.Y.; writing—original draft preparation, C.L.; writing—review and editing, C.L., J.L. and H.Z.; funding acquisition, J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC), grant number 62003157, and the Research Foundation of Education Bureau of Hunan Province, grant number 22C0223, 21B0434.
Data Availability Statement
The data can be shared upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vassallo, C.; Panichella, S.; Palomba, F.; Proksch, S.; Harald, C.G.; Andy, Z. How developers engage with static analysis tools in different contexts. Empir. Softw. Eng. 2020, 25, 1419–1457. [Google Scholar] [CrossRef] [Green Version]
- Serrano, N.; Ciordia, I.; Bugzilla, I. Tracker, and Other Bug Trackers. IEEE Softw. 2005, 22, 11–13. [Google Scholar] [CrossRef]
- Tian, Y.; Lo, D.; Sun, C. DRONE: Predicting Priority of Reported Bugs by Multi-factor Analysis. In Proceedings of the 2013 IEEE International Conference on Software Maintenance (ICSM), Eindhoven, The Netherlands, 22–28 September 2013. [Google Scholar]
- Li, Z.L.; Chen, X.; Jiang, Z.W.; Gu, Q. Survey on information retrieval-based software bug localization methods. Ruan Jian Xue Bao/J. Softw. 2021, 32, 247–276. [Google Scholar]
- Zhou, F.S.; Wang, L.Z.; Li, X.D. Automatic defect repair and validation approach for C/C++ programs. Ruan Jian Xue Bao/J. Softw. 2019, 30, 1243–1255. [Google Scholar]
- Deng, X.; Ye, W.; Xie, R.; Zhang, S.K. Survey of Source Code Bug Detection Based on Deep Learning. Ruan Jian Xue Bao/J. Softw. 2023, 34, 625–654. [Google Scholar]
- Matloob, F.; Taher, M.g.; Taleb, N.; Aftab, S.; Ahmad, M.; Khan, M.A.; Abbas, S.; Soomro, T.R. Software Defect Prediction Using Ensemble Learning: A Systematic Literature Review. IEEE Access 2021, 9, 98754–98771. [Google Scholar] [CrossRef]
- Akimova, E.N.; Bersenev, A.Y.; Deikov, A.A.; Kobylkin, K.S.; Konygin, A.V.; Mezentsev, I.P.; Misilov, V.E. A Survey on Software Defect Prediction Using Deep Learning. Mathematics 2021, 9, 1180. [Google Scholar] [CrossRef]
- Chen, X.; Zhao, Y.Q.; Gu, Q.; Ni, C.; Wang, Z. Empirical studies on multi-objective file-level software defect prediction method. Ruan Jian Xue Bao/J. Softw. 2019, 30, 3694–3713. [Google Scholar]
- Tian, J.; Tian, Y. A Model Based on Program Slice and Deep Learning for Software Defect Prediction. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020. [Google Scholar]
- Lin, J.H.; Lu, L. Semantic Feature Learning via Dual Sequences for Defect Prediction. IEEE Access 2021, 9, 13112–13124. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Jia, X.; Zhang, W.; Li, W.; Huang, Z. Feature representation method for heterogeneous defect prediction based on variational autoencoders. Ruan Jian Xue Bao/J. Softw. 2021, 32, 2204–2218. [Google Scholar]
- Fan, G.; Wu, R.; Shi, Q.; Xiao, X.; Zhou, J.; Zhang, C. Smoke: Scalable path-sensitive memory leak detection for millions of lines of code. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019. [Google Scholar]
- Zhang, Y.; Xing, Y.; Gong, Y.; Jin, D.; Li, H.; Liu, F. A variable-level automated defect identification model based on machine learning. Soft Comput. 2020, 24, 1045–1061. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Liu, L.; Yuan, C.; Wang, Z. Software defect prediction model based on LASSO–SVM. Neural Comput. Appl. 2021, 33, 8249–8259. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Dong, Y.; Chen, H.; Zhang, L.; Yin, W. A correlation recognition method of program semantic defect warnings based on symbolic expression. Sci. Technol. Eng. 2020, 20, 3648–3655. [Google Scholar]
- Lee, S.; Hong, S.; Yi, J.; Kim, T.; Kim, C.J.; Yoo, S. Classifying False Positive Static Checker Alarms in Continuous Integration Using Convolutional Neural Networks. In Proceedings of the 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), Xi’an, China, 22–27 April 2019. [Google Scholar]
- Lee, W.; Kang, D.; Heo, K.; Oh, H.; Yi, K. Sound Non-Statistical Clustering of Static Analysis Alarms. ACM Trans. Program. Lang. Syst. 2017, 39, 1–35. [Google Scholar] [CrossRef]
- Aljamaan, H.; Alazba, A. Software defect prediction using tree-based ensembles. In Proceedings of the 16th ACM International Conference on Predictive Models and Data Analytics in Software Engineering (PROMISE), New York, NY, USA, 8–9 November 2020. [Google Scholar]
- Sarker, I.H.; Kayes, A.; Wat, T.R.P. Effectiveness analysis of machine learning classification models for predicting personalized context-aware smartphone usage. J. Big Data 2019, 6, 57. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.J.; Jiang, H. Analysis of software bug reports severity feature. Comput. Eng. Appl. 2019, 55, 48–53. [Google Scholar]
- Gu, W.; Li, Z.; Gao, C.; Wang, C.; Zhang, H.; Xu, Z.; Lyu, M.R. CRaDLe: Deep code retrieval based on semantic Dependency Learning. Neural Netw. 2021, 141, 385–394. [Google Scholar] [CrossRef]
- Liu, X.; Guo, Z.; Liu, S.; Zhang, P.; Lu, H.; Zhou, Y. Comparing Software Defect Prediction Models: Research Problem, Progress, and Challenges. Ruan Jian Xue Bao/J. Softw. 2023, 34, 582–624. [Google Scholar]
- Wang, X.; Guan, Z.; Xin, Y.; Wang, J. Source code defect detection method based on deep convolution neural network. J. Tsinghua Univ. 2021, 61, 6. [Google Scholar]
- Goyal, S. Handling Class-Imbalance with KNN (Neighbourhood) Under-Sampling for Software Defect Prediction. Artif. Intell. Rev. 2022, 55, 2023–2064. [Google Scholar] [CrossRef]
- Mohammad, A.; Yousef, E.; Ali, B.N.; Lefteris, A. Examining the performance of kernel methods for software defect prediction based on support vector machine. Sci. Comput. Program. 2023, 226, 102916. [Google Scholar]
- Shafiq, M.; Alghamedy, F.; Jamal, N.; Kamal, T.; Daradkeh, Y.I.; Shabaz, M. Scientific programming using optimized machine learning techniques for software fault prediction to improve software quality. IET Soft. 2023, 1–11. [Google Scholar] [CrossRef]
Figure 1.
Contextual defect classification.

Figure 2.
High-severity defect confirmation process based on multi-feature fusion.


{kind=link}
{kind=link}
Table 1.
Design of Some Labels.
| Label | Explanation |
|---|---|
| malloc | malloc statement for memory allocation |
| free | free statement for memory release |
| return | statement for returning a value |
| def | variable is defined |
| if | The if statement |
| while | The while statement |
| for | The for statement |
| pfunc | pointer is assigned a function’s return value |
| defpoint | pointer is defined |
| check | check macro function definition followed by usage |
| null | NULL value |
Table 2.
Comparison Results of Various Algorithms.
| NB | DT | RF | KNN | SVM | |
|---|---|---|---|---|---|
| Accuracy | 0.68 | 0.72 | 0.84 | 0.76 | 0.88 |
| AUC | 0.65 | 0.68 | 0.79 | 0.72 | 0.82 |
Table 3.
Results of Ablation Experiment.
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Baseline Model | 0.913 | 0.876 | 0.947 | 0.910 |
| Ablation Context Features | 0.840 | 0.794 | 0.888 | 0.838 |
| Ablation Graph Path Features | 0.870 | 0.832 | 0.904 | 0.867 |
| Ablation Word2Vec | 0.845 | 0.799 | 0.893 | 0.843 |
Table 4.
Defect confirmation experiment results.
| Project | Average Accuracy | Average Precision | Average Recall | Average F1-Score |
|---|---|---|---|---|
| UUCP | 0.825 | 0.814 | 0.825 | 0.819 |
| Httpd | 0.952 | 0.942 | 0.952 | 0.947 |
| Sphinxbase | 0.783 | 0.770 | 0.783 | 0.776 |
| Antiword | 0.881 | 0.872 | 0.881 | 0.876 |
Table 5.
Model Performance Comparison Results.
| Method | Average Accuracy | Average Precision | Average Recall | Average F1-Score |
|---|---|---|---|---|
| Variable-level automated defect identification model [15] | 0.861 | 0.860 | 0.861 | 0.861 |
| Our method | 0.881 | 0.872 | 0.881 | 0.876 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, J.; Liang, C.; Feng, J.; Xiao, A.; Zeng, H.; Wu, Q.; Yu, T. A Multi-Feature Fusion-Based Automatic Detection Method for High-Severity Defects. Electronics 2023, 12, 3075. https://doi.org/10.3390/electronics12143075
AMA Style
Liu J, Liang C, Feng J, Xiao A, Zeng H, Wu Q, Yu T. A Multi-Feature Fusion-Based Automatic Detection Method for High-Severity Defects. Electronics. 2023; 12(14):3075. https://doi.org/10.3390/electronics12143075
Chicago/Turabian StyleLiu, Jie, Cangming Liang, Jintao Feng, Anhong Xiao, Hui Zeng, Qujin Wu, and Tonglan Yu. 2023. "A Multi-Feature Fusion-Based Automatic Detection Method for High-Severity Defects" Electronics 12, no. 14: 3075. https://doi.org/10.3390/electronics12143075
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.