
A Novel Approach to Face Pattern Analysis
by
 , , , ,
, , , ,
Shashi Bhushan
1 ,
,
Mohammed Alshehri
2,* ,
,
Neha Agarwal
3,
Ismail Keshta
4,
Jitendra Rajpurohit
1 and
Ahed Abugabah
5 1
School of Computer Science, University of Petroleum and Energy Studies, Dehradun 248001, India
2
Department of Information Technology, College of Computer and Information Sciences, Majmaah University, Majmaah 11952, Saudi Arabia
3
Department of CSE, Amity School of Engineering and Technology, Amity University Uttar Pradesh, Noida 201308, India
4
Computer Science and Information Systems Department, College of Applied Sciences, AlMaarefa University, Riyadh 12483, Saudi Arabia
5
College of Technological Innovation, Zayed University, Abu Dhabi Campus, Abu Dhabi P.O. Box 144534, United Arab Emirates
*
Author to whom correspondence should be addressed.
Electronics 2022, 11(3), 444; https://doi.org/10.3390/electronics11030444
Submission received: 12 December 2021
/
Revised: 28 January 2022
/
Accepted: 29 January 2022
/
Published: 1 February 2022
(This article belongs to the Special Issue Security and Privacy in IoT Enabled Modern Applications Using Deep/Machine Learning and Blockchain Technology)
Abstract
:Recognizing facial expressions is a major challenge and will be required in the latest fields of research such as the industrial Internet of Things. Currently, the available methods are useful for detecting singular facial images, but they are very hard to extract. The main aim of face detection is to capture an image in real-time and search for the image in the available dataset. So, by using this biometric feature, one can recognize and verify the person’s image by their facial features. Many researchers have used Principal Component Analysis (PCA), Support Vector Machine (SVM), a combination of PCA and SVM, PCA with an Artificial Neural Network, and even the traditional PCA-SVM to improve face recognition. PCA-SVM is better than PCA-ANN as PCA-ANN has the limitation of a small dataset. As far as classification and generalization are concerned, SVM requires fewer parameters and generates less generalization errors than an ANN. In this paper, we propose a new framework, called FRS-DCT-SVM, that uses GA-RBF for face detection and optimization and the discrete cosine transform (DCT) to extract features. FRS-DCT-SVM using GA-RBF gives better results in terms of clustering time. The average accuracy received by FRS-DCT-SVM using GA-RBF is 98.346, which is better than that of PCA-SVM and SVM-DCT (86.668 and 96.098, respectively). In addition, a comparison is made based on the training, testing, and classification times.
1. Introduction
A facial recognition system (FRS) is a biometric concept based on the facial features of a human being. People use a dataset of images and, based on the facial features in the images, the recognition of a person is carried out. A FRS is a type of visual recognition system. Feature extraction and classification form the basis of all facial recognition systems, where statistical and geometrical approaches are used to perform feature extraction. Various methods for facial recognition are discussed in [1,2]. Images containing faces are vital for keen vision-based human–PC communication, and exploration endeavors in face handling incorporate facial recognition, face following, present assessment, and demeanor recognition. Many detailed techniques can be used to recognize and restrict the faces in an image or an image grouping.
1.1. Facial Recognition System Principle
A FRS starts working by using an input image (captured by a camera) in a 2D or 3D way. Then, this input image is compared with the available images in the database by analyzing the input mathematically without error [3]. Facial recognition is used in some use cases, such as a second authentication factor, access to a mobile application, access to buildings, access to locked devices, and payment methods.
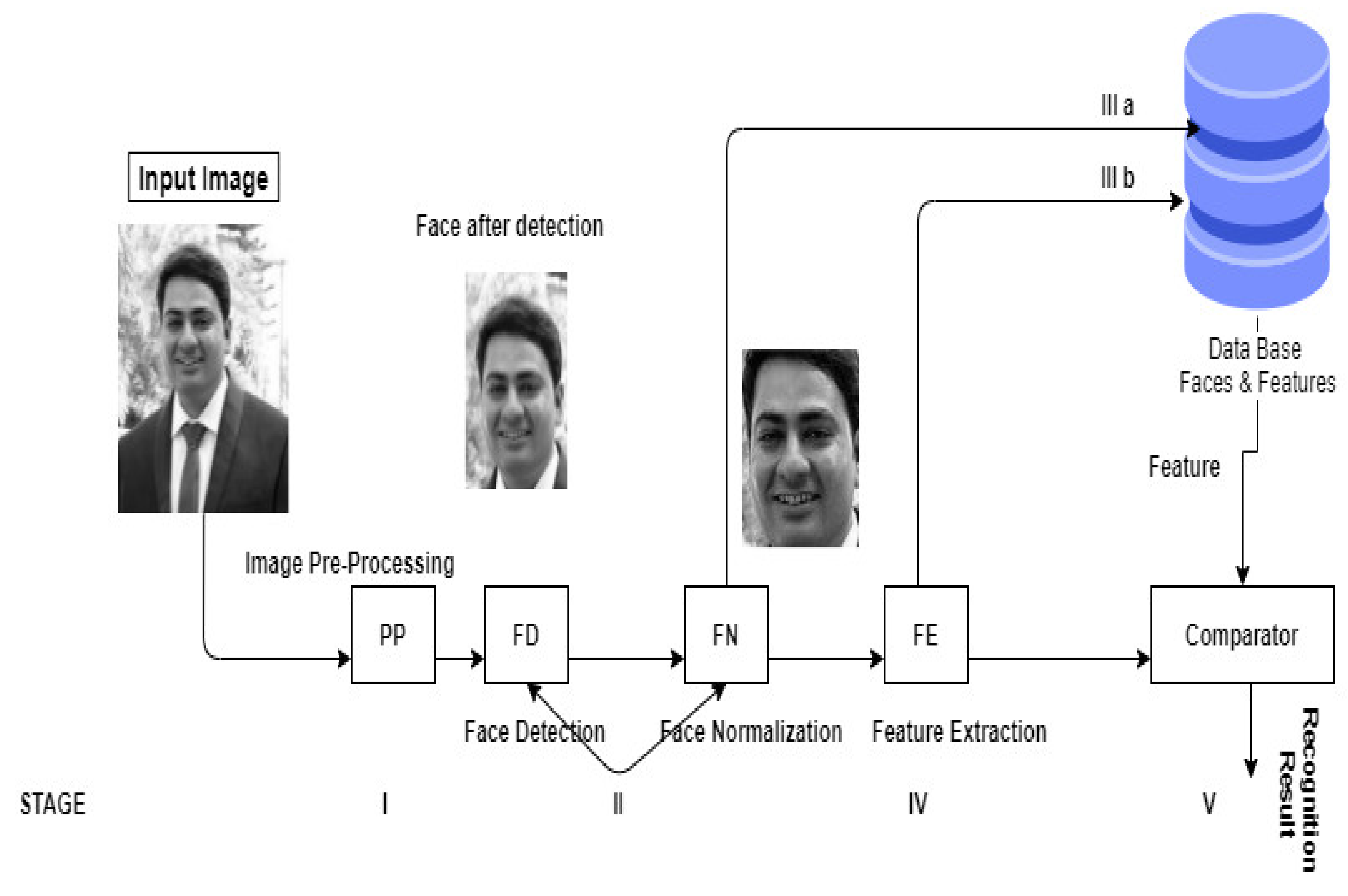
Figure 1 describes the step-by-step procedure of the facial recognition system. In stage I, the image is input, and preprocessing is done. In stage II, face detection and face normalization are done. In stage III a, images are stored in the database after normalization, and in stage III b feature extraction is performed. Then, in stage IV a comparator is used to obtain features from the database and produce results.
Image Pre-Processing
Image pre-processing is the step taken before the training of the model and is used to enhance the speed of the detection process and minimize false positives [4,5]. It reduces the noise effect, color intensity, and background and provides a difference in illumination. Some basic pre-processing procedures include face detection and cropping, image resizing, image normalization, de-noising, and filtering [6].
1.2. Face Detection
This scan identifies whether a captured/used image/video is of a human or not.
1.3. Face Normalization
Face normalization minimizes the amount of redundant information and the effect of useless things in the background, such as hair and clothes, to improve the recognition process. In [7], the authors proposed a technique for face normalization in which the normalization of geometry and the brightness of faces is done to improve the efficiency. Normalization ensures that the data distribution will be similar for all input parameters. It can be done by subtracting the mean per channel and subtracting the pixel per channel.
1.4. Feature Extraction
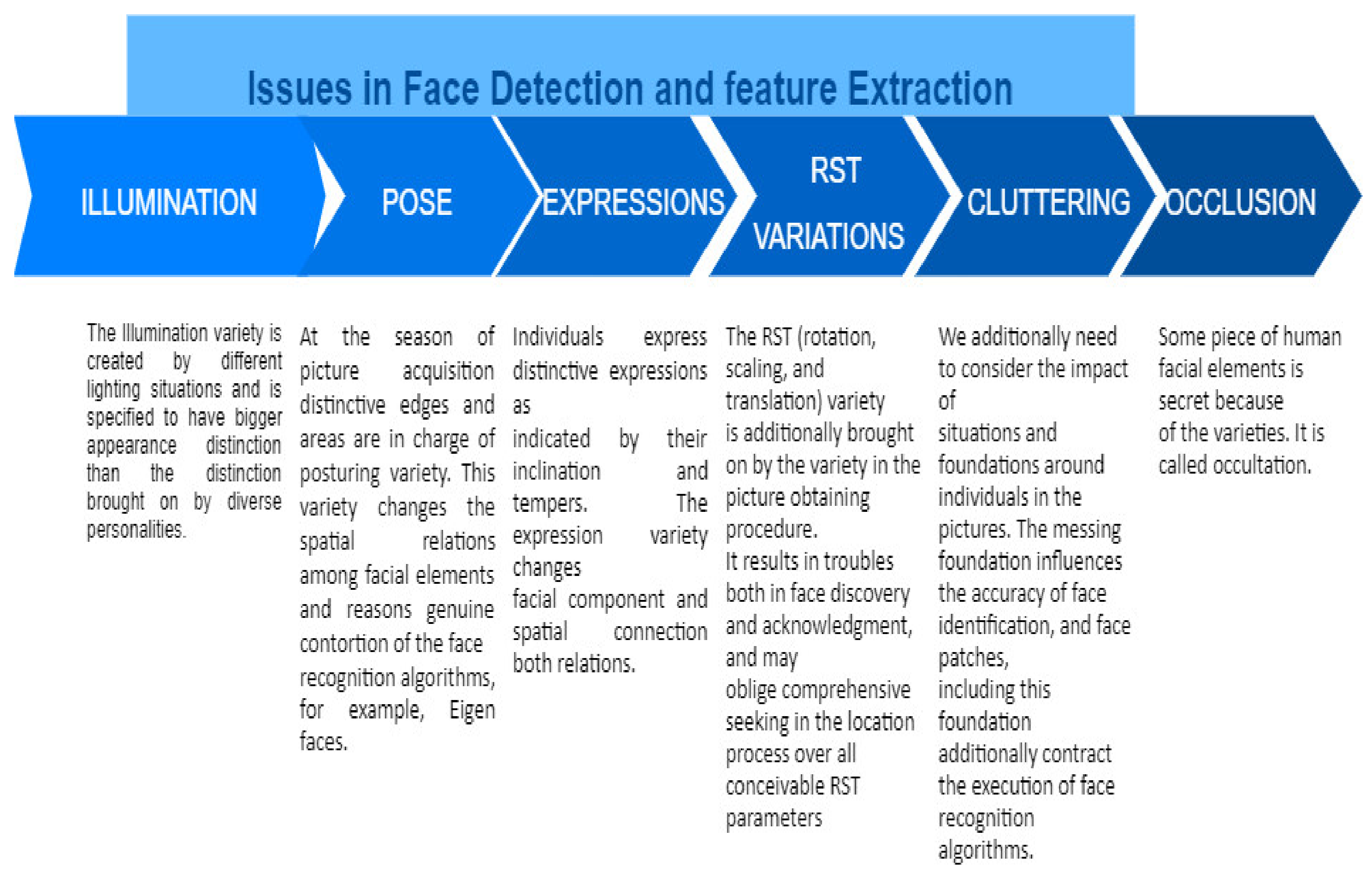
Feature extraction involves a process of reducing the dimensionality in which division and reduction of the input data are performed to make manageable groups. Some of the features of an image are edges, corners, interest points, regions, ridges, shapes, and confidence. Some of the traditional feature detection techniques are Harris corner detection [7], the Shi-Tomasi corner detector [8], Scale-Invariant Feature Transform (SIFT) [9], Speeded-Up Robust Features (SURF) [10], Features from an Accelerated Segment Test (FAST) [11], Binary Robust Independent Elementary Features (BRIEF) [12], Oriented FAST, and Rotated BRIEF (ORB) [13], and some are useful for deep learning, such as super point [14], D2-Net [15], LF-Net [16], PCA [17], and LDA [18]. Figure 2 presents a detailed description of issues in face detection and feature extraction.
1.5. Recognition Result
Image recognition is used for identity verification purposes and to identify objects, places, people, and actions in images. Trained algorithms are used for the recognition process so that some hidden representations of features can be analyzed and applied for different objectives such as classification.
The basic structure of a facial recognition system and issues related to face detection and feature extraction have been discussed. The steps of pre-processing, face detection, face normalization, feature extraction, and the use of a comparator have been explained in detail.
2. Literature Review
There is a need to develop linear feature extraction algorithms for face identification and detection under various parameters of FR to improve FR algorithms with respect to space and time complexity and performance accuracy. Additionally, features need to be extracted from the magnitude and phase components of the image in the frequency domain. The traditional and intelligent techniques for object (face and eye) detection and face identification need to be compared and a suitable classifier for the extracted features needs to be selected.
Within the classification, less variety in parameters is needed in SVM compared with an ANN. SVM minimizes the generalization error and avoids the overfitting problem. For improvement in these factors, we must propose a new algorithm.
Taleb et al. [1] discuss access control using facial detection by using PCA-LDA algorithms. In this study, an access control mechanism for vehicle parking is proposed, which works based on a camera installed in the parking area’s entryway. The camera recognizes the driver’s face, which is then matched with data images, and a decision is made as to whether this driver has authority to park the car in this parking area or not. For this, the Viola–Jones method is used for face detection and, by their proposed method, the authors detected variations in the pose, which was a severe issue at the time. In this study, the authors used PCA, which will not provide sensible results if the principal components are not linear combinations. For a facial recognition dataset with names, we can utilize a straight separate examination. It is utilized to handle arrangements. PCA requires the information fluctuation after the decrease in dimensionality to be enormous and isolated as broadly as could be expected, while LDA requires the difference inside the similar classification of information bunches after projection to be just about as small as could be expected, and the change between gatherings to be as extensive as possible. This implies that LDA regulates the decrease in dimensionality and it should utilize the mark data to isolate various classes of information as much as could reasonably be expected.
Choi et al. [2] proposed a method based on discriminant analysis that provides a composite feature vector to recognize a face. First, feature extraction from the image is performed given holistic and local features by using discriminative features. A comparison is made between the proposed composite component method and other methods such as holistic, regional, and hybrid methods. The proposed technique displayed better facial recognition compared with utilizing just the holistic or local features. Many training sets contain 2D sets in which SVM can find a set of straight lines to classify the training data correctly [2]. Because of the restriction on the quantity of information in the preparation set, the examples outside the preparation set might be nearer to the dividing line than the information in the preparation set. So, we should pick the line farthest from the closest informative element, specifically the help vector. This is the limitation of utilizing SVM.
Khan et al. [3] proposed an algorithm for face detection based on a Convolutional Neural Network (CNN). For validation purposes, the authors developed a student classroom attendance management system using face recognition. The authors used the LFW dataset for the training of the model. This system was able to detect 35 students and recognize 30 students out of 40 students in the image. An accuracy of 97.9 was obtained by using testing data. In this study, facial recognition was applied over a classroom for marking the students’ class attendance, where the features were fixed for the classroom.
Peng et al. [4] reviewed different methods and algorithms developed and used for face detection. The authors discussed the early stages of the development of the PCA and LDA algorithms. SVM, Ada Boost, small samples, and neural networks were discussed for classification. The authors focused on facial recognition based on actual conditions, for which they used deep learning.
Ganidisastra and Bandung [5] developed an online examination portal in which students give examinations in online mode using proctored mode. An online examination proctoring model is proposed that will not work if the lighting in the area is not proper or some postures cannot be identified, and the student will receive a notification informing them that they have engaged in malpractice and will be blocked.
This system was designed to monitor students during a test. The system should prevent malpractice and be able to verify that the student who is giving the examination is a verified student. For this, the authors used CNN-FR. The problem that arises during facial recognition in different postures/poses is variations in the lighting system. So, other authors have used image equalization and SURF to address this lighting issue. Here, the authors proposed an incremental training process that will reduce the computation cost and time. Yolo Face, MTCNN, LBP, and the Haar-cascade face detector were used for accuracy, and the Face Net model was tested. This deep-learning-based face detector overcomes the limitations of other available methods and achieved an accuracy of 98%. Real-time video-based facial recognition is also available [19], where the attendance of students can be managed by the recognition of faces and, by experimental analysis, researchers obtained an accuracy of 82%. When it comes to the self-learning model, a new optimized radial basis function (RBF) neural network algorithm based on the Genetic Algorithm (GA-RBF algorithm) [20] is used. The GA-RBF [21] algorithm is used to reduce the inputs over the RBF network [22], and then training and simulation of the model are conducted. Hammouch et al. [23] used four feature extraction approaches on the basis of Discrete Cosine Transform (DCT) to extract features from a digital handwritten document, and the same was used for the comparison with traditional PCA. For the COVID-19 pandemic situation, Pushpalatha et al. [24] proposed a human action recognition system to identify a person. The proposed system can be used for the surveillance of COVID-19 wards for patient identification.
PCA [25] and LDA [26] are two commonly used algorithms that are used to fuse features, human activity recognition [27,28], and feature extraction [29]. PCA extracts features based on their similarity within the class itself and the dissimilarity of a particular individual in other classes due to its covariance matrix, which is based on all images of the training set. LDA extracts features of a particular individual from within the class itself only to discriminate among the individuals. This algorithm maximizes the ratio of between-class variance to within-class variance in any particular object set to maximize the separability. A hybrid approach was also proposed in which a combination of probabilistic neural networks (PNNs) and improved kernel linear discriminant analysis (IKLDA) is used for facial recognition. The proposed hybrid approach achieved an accuracy of 97.22 over the ORL dataset.
Cook et al. [30] studied demographic factors, such as gender and age, by which support is provided to calculate performance and perform classification. They checked the performance based on 11 commercial biometric systems of the U.S. Department of Homeland Security in 2018. Out of the 11 systems, every single system had 363 subjects in a controlled environment. A commercial algorithm was used to calculate the efficiency and accuracy over the dataset. Prior work has shown that different biometric algorithms produce different results in demographic categories and found that skin phenotypes are best from this perspective. In this proposed method, all of the work was done automatically and the measurement of relative facial skin reflectance using subjects can be done easily by linear modeling. It was observed that the overall accuracy of the systems is inversely proportional to the size of the skin reflectance effect; i.e., if the accuracy is high, the size has to be at a minimum.
Yadav et al. [31] used color details of images to exploit skin, face, or eye color by applying a color convertor algorithm to remove background and other unnecessary details from images to detect/identify objects. Kalbkhani et al. [32] converted a RGB image [33,34] into YCBCR color using a nonlinear transformation and used an eye mapping algorithm based on a created face mask to detect the location of eyes on faces or the face itself in an image. The YCBCR is a color space transformation algorithm. Y is the luma component and CB and CR are the blue-difference and red-difference chroma components, respectively.
The authors of [35] located the eye coordinates by separating skin color and eye color details in the HSL color space. However, color conversion techniques are time consuming and are not suitable for real-time applications. The colored images obtain more details of faces in the color space, which affects the performance and accuracy. However, colored images require more time and memory for image analysis as compared with gray-level images. The object detection algorithms have limitations with respect to distinguishing an iris from closed eyes or eyes wearing glasses, so some researchers used these algorithms to detect the whole eye instead of the iris in order to identify and locate closed eyes. The low-pass filter of horizontal details of the Haar Discrete Wavelet Transform (DWT) is applied on sub-blocks. It provides more information about the eye as compared with high-pass filtering. Then, PCA and LDA are applied for feature extraction on the low-pass filter of horizontal details of the Wavelet transform. Testing for eye detection is performed on the ORL and Yale face databases. The authors observed that the error on translation using Wavelet Transform combined with PCA is less than that using WT without PCA. Additionally, the scaling aberration of WT + PCA is less than that of wavelet coefficients. Shape-based eye detection models provide better object detection/tracing in real-time applications. However, they are sensitive to various angle orientations, degradation, and noisy images. The PCA algorithm has been implemented on GMM data to extract significant features, which reduce the time and space dimensionality of images as well as the accuracy of eye, nose, and mouth detection.
3. Proposed Model
The decision boundary is the critical issue in SVM algorithms, where a radial basis function is the one that changes with the distance from a location. An ORL and YALE face dataset was used that contains 400 images of forty different subjects. Validation was used in this experimental work, as 80% of the dataset was used for training and the remaining 20% was used for validation.
In some of the subjects, factors such as time, lighting, and facial expressions (smile/non-smile, open eyes/closed eyes), and details of faces, such as the subject wearing glasses or not wearing glasses, will be different at different times. The issue will be in the frontal positioning in all images, and the background will be dark and homogeneous. The size of each image is 92 × 112 pixels, and each pixel has 256 grey levels. Each photo in the training and testing sets of pictures was apportioned into the equivalent size of squares. Subsequently, the DCT coefficient was determined for each square. The obtained coefficients were changed to include vectors. Then, the highlight vectors of the training set were prepared by the radial basis function-based SVM. In this, the radial basis function portion boundary of the SVM was streamlined by traditional tasks. Discrete Cosine Transform (DCT) is a strong transform used to extract features in facial recognition. After implementing DCT over all the images, feature vectors were constructed based on Zonal masking coefficients. Optimization was done through GA-RBF. When there was a requirement to compensate for illumination variations, the available low-frequency coefficients were discarded.
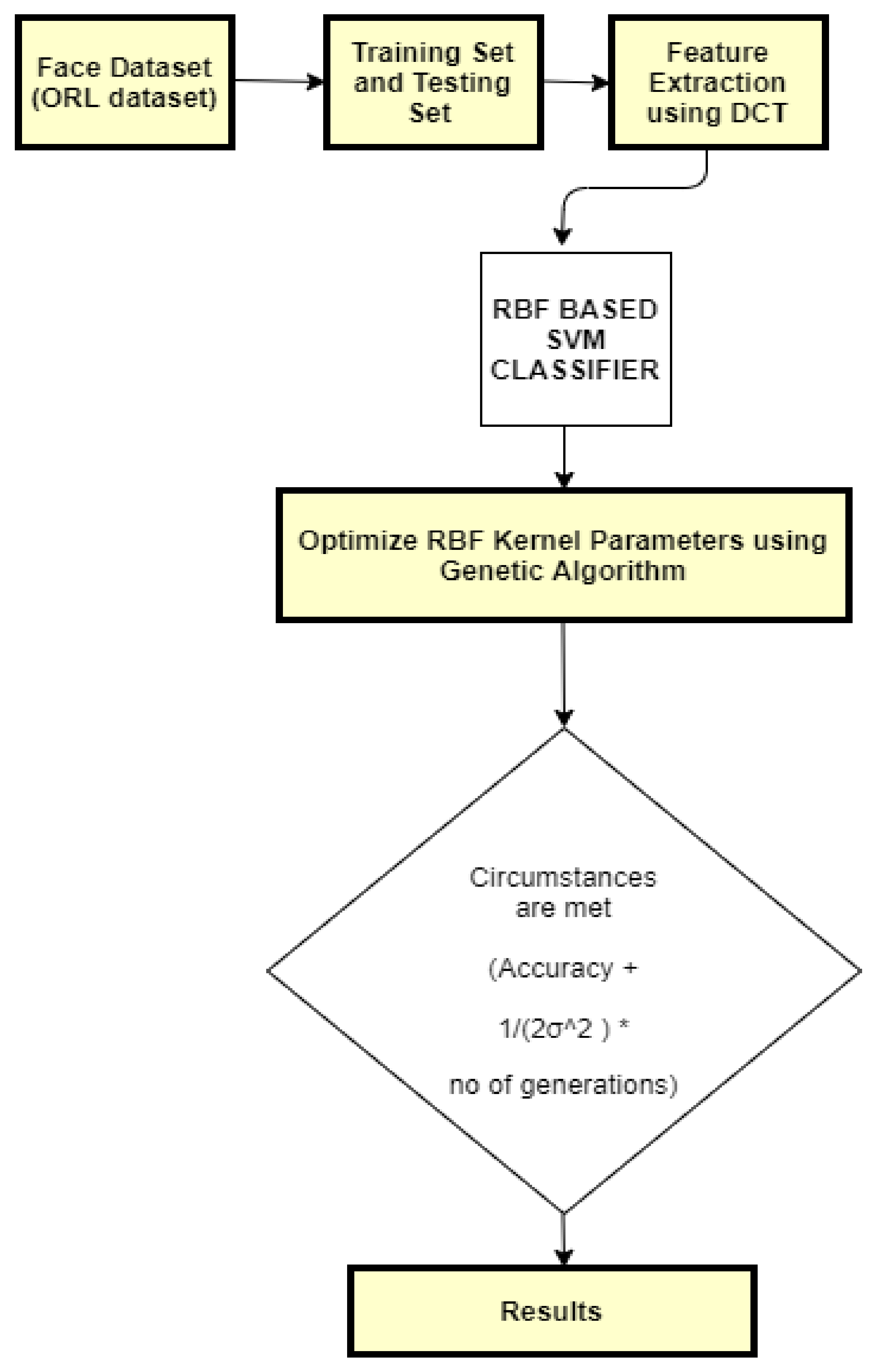
Step-by-Step Procedure of Proposed Model
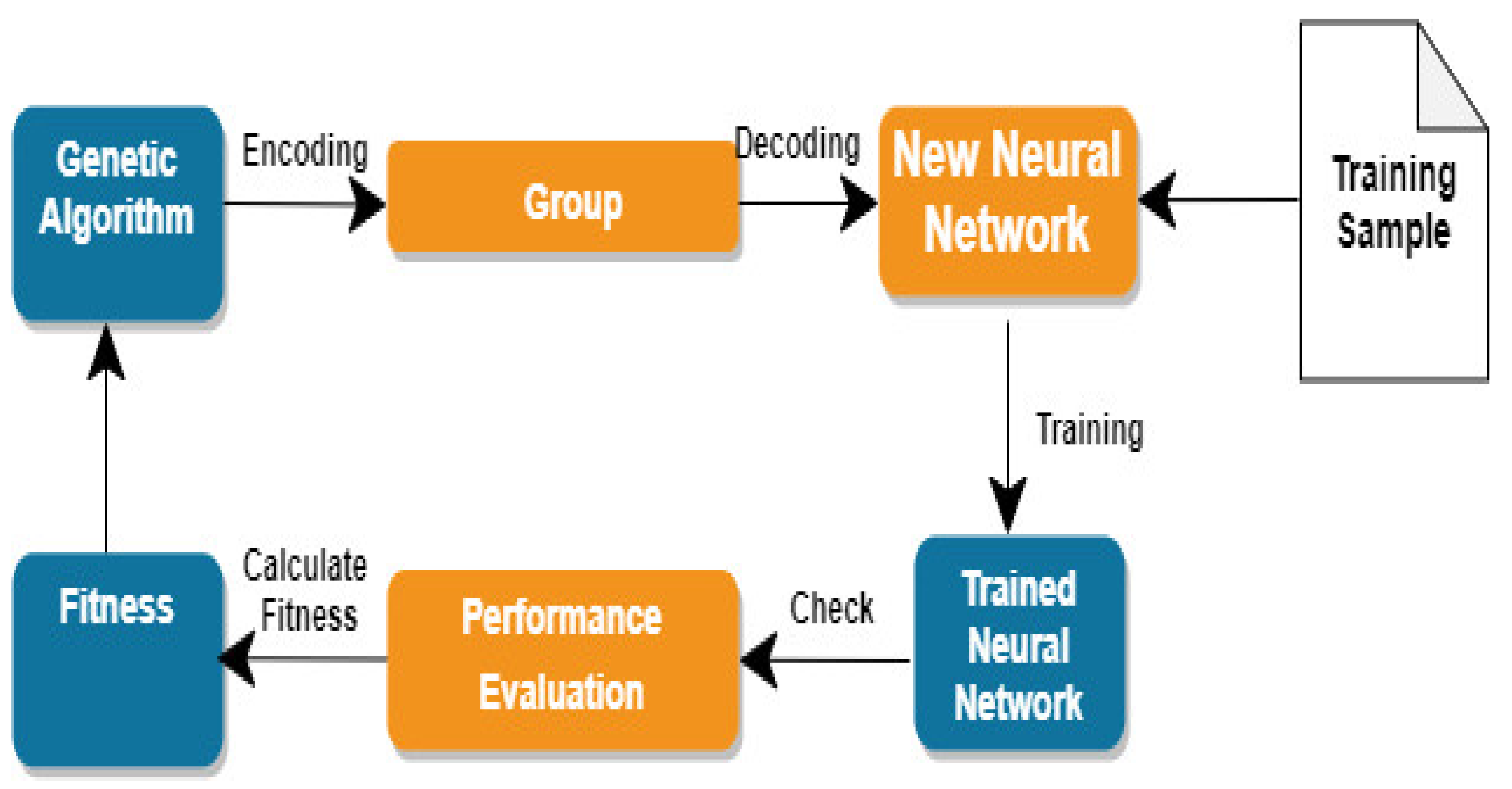
As in Figure 3 is as mentioned below:
- Divide the dataset into training and testing datasets.
- Perform feature extraction using DCT, for which DCT coefficients need to be calculated for all training set images and normalized.
- Calculate the RBF-SVM function by where the decision boundary will be decided by σ. RBF-SVM classifies benign from malignant cases.
- Define the objective function input of the RBF hyperparameters and the output of a test score. Then, use the Genetic Algorithm for optimization (GA-RBF). It is an adaptive system; it automatically changes its organization, design, and association weights without human intervention and makes it possible to join a Genetic Algorithm with the RBF Kernel parameters.
- A framework of robust capacities given as where accuracy is considered at an upgraded estimation of the optimized valueand by taking several generations to find the optimized value.
- Results.
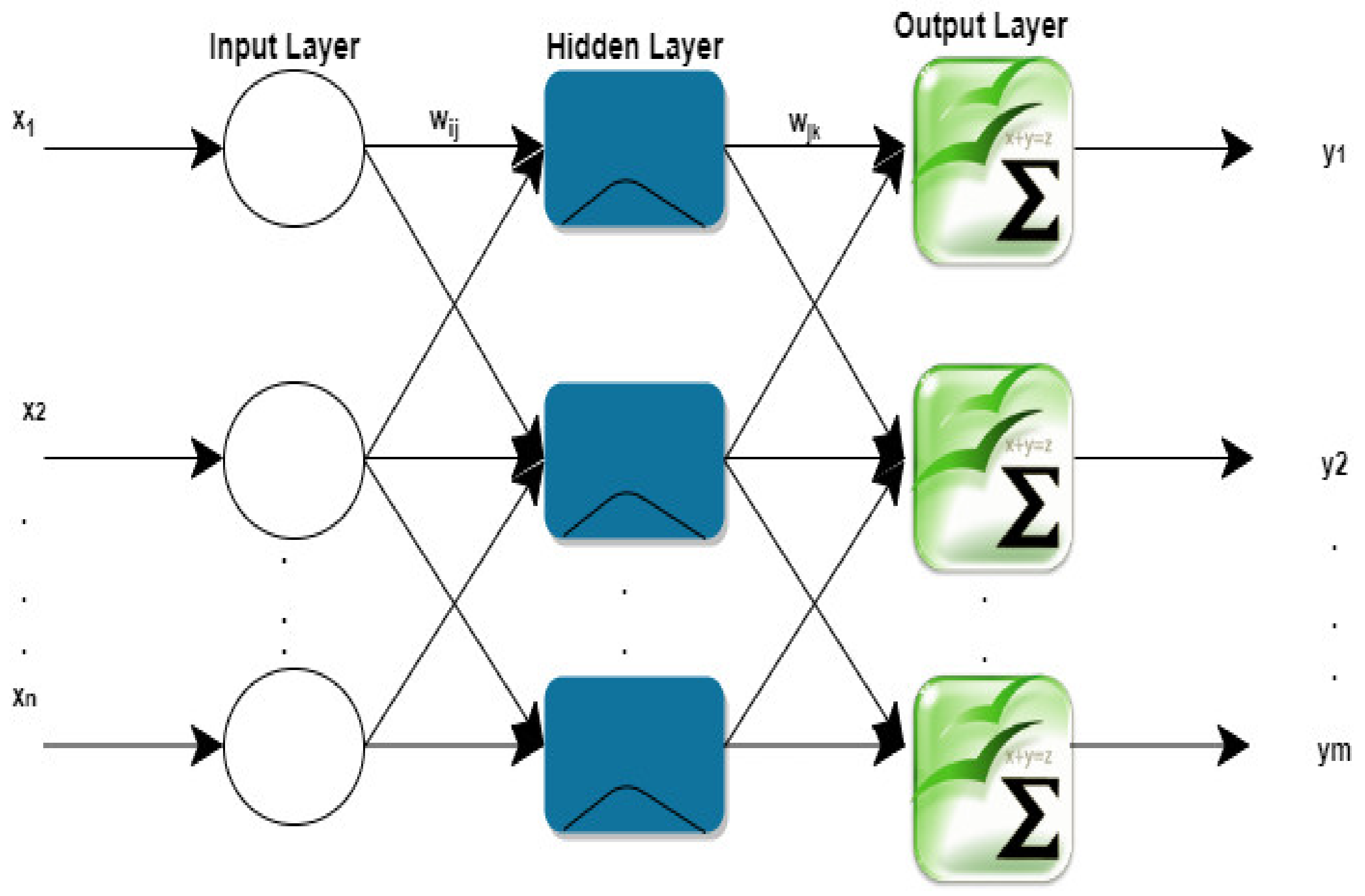
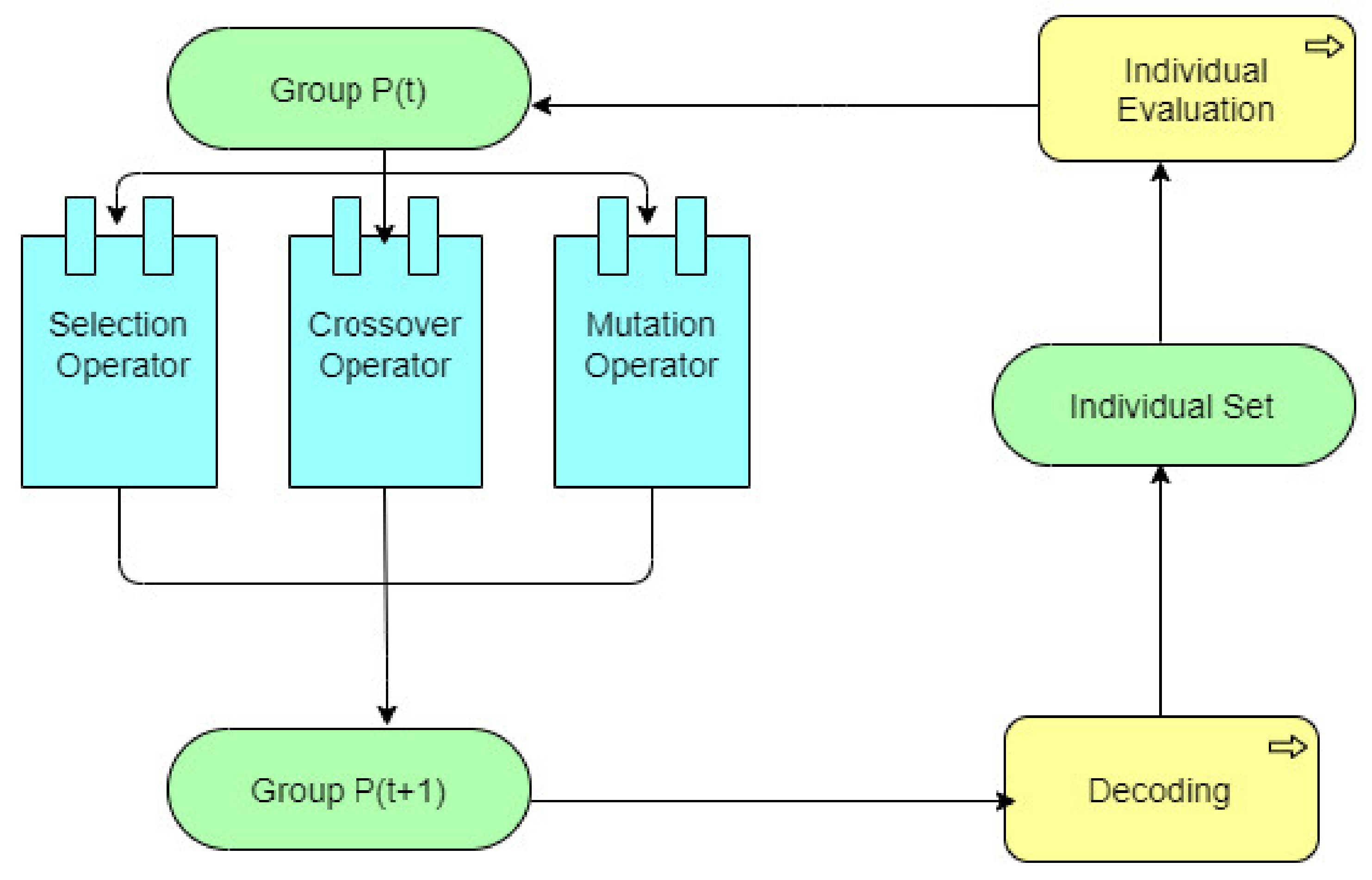
Figure 4 shows the RBF network topology, in which the activation function is taken by the hidden layer in the form of a RBF. Figure 5 shows the entire procedure of the Genetic Algorithm, and Figure 6 explains the automation in the network’s establishment/adjustment and connection weights where human intervention is not required. Accurate mapping of the Genetic Algorithm with a neural network is done.
Figure 6 explains entire structure of the mapping of the Genetic Algorithm with the neural network. In Figure 4, the network has m inputs and n outputs, the hidden layer contains s neurons, and and are the connection weights between the information layer and the hidden layer and the hidden layer and the output layer, respectively. The threshold value associated with the hidden layer is . is the input of the hidden layer and is calculated by Equation (1).
where
.
The output of the hidden layer is calculated by Equation (2).
The final output is calculated by Equation (3) as
where The error function is calculated by Equation (4) as
where is the final actual output of the network.
The input face picture is first changed from a spatial area to a recurrence area. Different fundamental transformation methods were utilized, such as Discrete Wavelet Transform (DWT) and DCT. DCT [9] is used for highlight extraction because of its information compaction property. The 2D DCT is considered a distinct administrator premise that works for pixels as in [1]. The 2D DCT is used with the assumption that the data array has a finite rectangular support on . The 2D DCT is given as [10]
where] or . Assuming
where K is the portion of the work, is the value of the preparation test, and is the boundary value of the model.
4. Result Analysis
Frontal face images were taken from the ORL and YALE face database for our experimental setup, and the number of pictures varied from 10 to 40. Ten different poses were selected from a 1:40 ratio of unique subjects. The lighting factor was fixed for all upstanding frontal images. The fixed size taken for all photos was 112 × 94 pixels. For testing, boundaries were set as square measures of 8.
Table 1 shows the experimental setup. Table 2 and Table 3 contain the practical results based on parameters such as the number of faces, accuracy, training time, testing time, and classification time for the PCA-SVM, DCT-SVM using GA-RBF, and SVM-DCT models. Table 4 contains a comparison between the proposed and other deep learning methods.
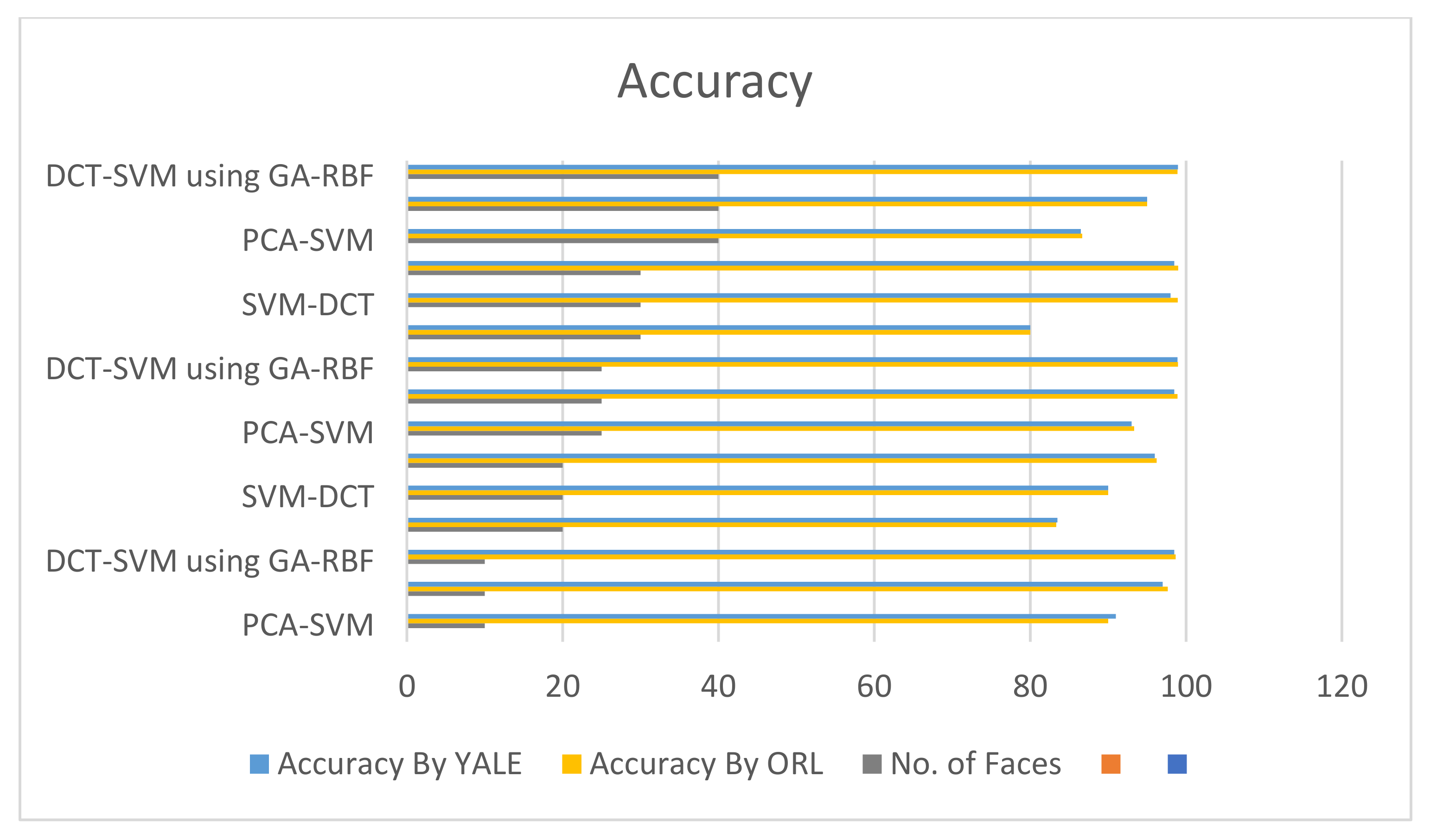
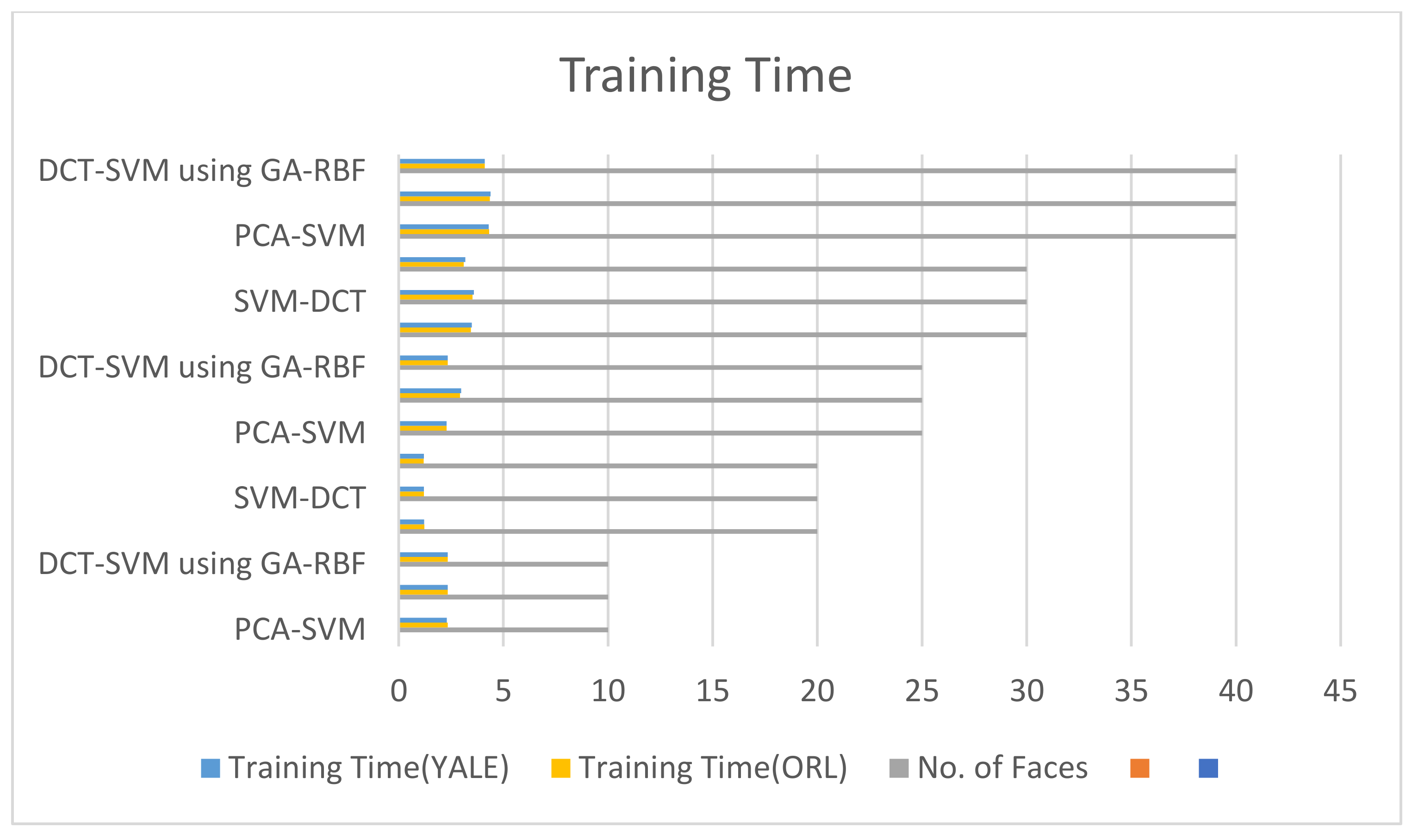
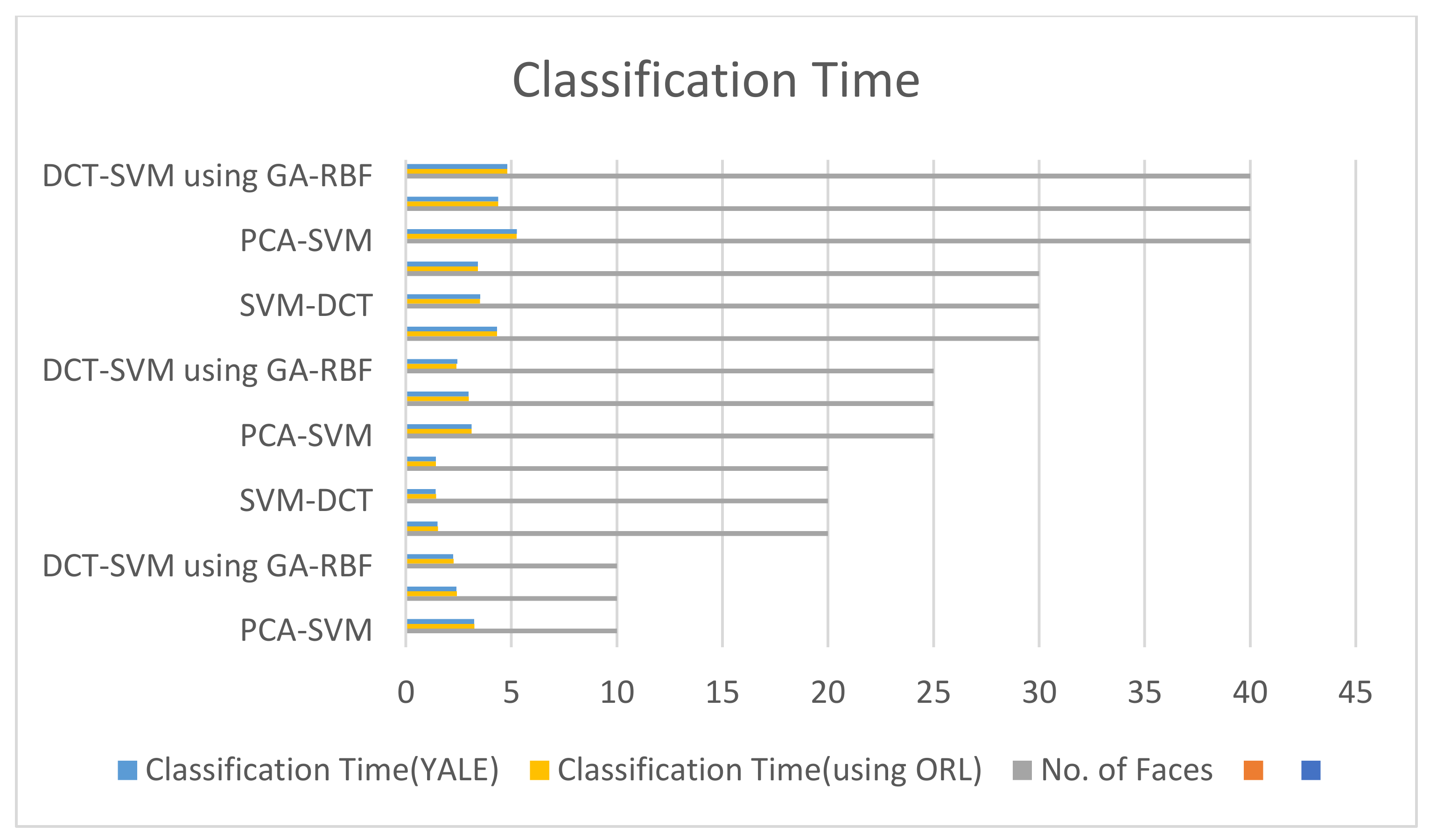
Five different experiments were conducted by varying the number of faces from 10 to 40. A comparison of the proposed model with existing models was made by using several experimental parameters, including accuracy, training time, testing time, and classification time. The accuracy of the models is presented in Figure 7. An average accuracy of 98.346 was achieved by using DCT-SVM using GA-RBF, which is better than the other two models as 86.668 was achieved by PCA-SVM and 96.098 was achieved by SVM-DCT. A comparison of training time and classification time was also made. The average training time of DCT-SVM using GA-RBF is 2.621, as presented in Figure 8, which is better than that of the DCT-SVM and PCA-SVM models. The average classification time for DCT-SVM using the GA-RBF model is 2.86, as shown in Figure 9, which is better than the 3.49 by PCA-SVM and the 2.94 by DCT-SVM. The number of samples per face was set to 6 for all five experiments.
The proposed model is better than PCA-SVM and DCT-SVM in terms of accuracy, time taken for training by the model, and time taken for classification by the model. The accuracy of the proposed model increased as the number of faces increased. The training time for the proposed model was 1.2, which was the minimum, when the number of faces was 20. The classification time for the proposed model was 1.422, which was the minimum, when the number of faces was 20. It was observed that the proposed model gave the best result when the number of faces was 30.
In [40], the authors proposed a global expansion ACNN and achieved an accuracy of 91.67% by using the ORL dataset. Chen et al. [41] used a combination of a CNN and SVM and achieved an accuracy of 97.50% by using the ORL dataset.
Our proposed model achieved an average accuracy of 98.346% by FRS-DCT-SVM using GA-RBF, which is better than the those of the ACNN and CNN+SVM.
5. Conclusions and Future Work
In this paper, we proposed a novel face detection algorithm that provides better results than the DCT-SVM and PCA-SVM models. It uses a combination of DCT and SVM and uses the Genetic Algorithm for optimization. After dividing the dataset into two pools for training and testing, DCT was used for feature extraction so that DCT coefficients could be used to train the proposed algorithm and normalize the ORL and YALE face dataset images. Furthermore, the RVM-SVM function was used to start the classification from malignant cases, and the Genetic Algorithm was used for optimization. As a result, the proposed model provides higher accuracy, takes less time for training, and requires less time for classification than the DCT-SVM and PCA-SVM models. Experimental results are presented and were compared with results from other models. An internal comparison for the proposed model was also made based on varying values of several face images for parameters such as accuracy, training time, testing time, and classification time. Future work could include some enhancement of the proposed model so that the accuracy in the case where the number of faces is 20 can also be increased as it is minimal compared with the cases where the number of faces is 10, 25, 30, and 40. The testing time for the proposed model is more than that for DCT-SVM, so we will try to minimize that and create our own dataset of facial images.
The proposed algorithm was applied to databases that are limited in terms of their size and type. In the future, it may apply to large databases and noisy pictures. In any case, we only considered the factors of lighting, presentation, illumination, and verbalization in the database. We may additionally fuse age and sex-bearing fragments. To develop a secure framework, the proposed model could be used together with other biometric structures, such as Iris Fingerprint and Retina.
Author Contributions
Conceptualization, S.B., M.A. and J.R.; methodology, I.K. and A.A.; software, A.A. and S.B.; validation, A.A., I.K. and J.R.; formal analysis, J.R.; investigation, N.A. and I.K.; resources, I.K.; data curation, S.B.; writing—original draft preparation, S.B. and J.R.; writing—review and editing, M.A. and A.A.; visualization, N.A.; supervision, M.A.; project administration, A.A.; funding acquisition, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Researchers Supporting Program (TUMA-Project-2021-14), AlMaarefa University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
Mohammed Alshehri would like to thank the Deanship of Scientific Research at Majmaah University for supporting this work under Project No. R-2022-35. The authors deeply acknowledge the Researchers Supporting Program (TUMA-Project-2021-14), AlMaarefa University, Riyadh, Saudi Arabia for supporting steps of this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Taleb, I.; Ouis, M.E.A.; Mammar, M.O. Access control using automated face recognition: Based on the PCA & LDA algorithms. In Proceedings of the 2014 4th International Symposium ISKO-Maghreb: Concepts and Tools for Knowledge Management (ISKO-Maghreb), Algiers, Algeria, 9–10 November 2014; pp. 1–5. [Google Scholar]
- Choi, S.; Lee, S.; Choi, S.T.; Shin, W. Face Recognition Using Composite Features Based on Discriminant Analysis. IEEE Access 2018, 6, 13663–13670. [Google Scholar] [CrossRef]
- Khan, M.Z.; Harous, S.; Hassan, S.U.; Khan, M.U.G.; Iqbal, R.; Mumtaz, S. Deep Unified Model For Face Recognition Based on Convolution Neural Network and Edge Computing. IEEE Access 2019, 7, 72622–72633. [Google Scholar] [CrossRef]
- Li, L.; Mu, X.; Li, S.; Peng, H. A Review of Face Recognition Technology. IEEE Access 2020, 8, 139110–139120. [Google Scholar] [CrossRef]
- Ganidisastra, A.H.S.; Bandung, Y. An Incremental Training on Deep Learning Face Recognition for M-Learning Online Exam Proctoring. In Proceedings of the 2021 IEEE Asia Pacific Conference on Wireless and Mobile (APWiMob), Bandung, Indonesia, 8–10 April 2021; pp. 213–219. [Google Scholar]
- Kamenskaya, E.; Kukharev, G. Some aspects of automated psychological characteristics recognition from the facial image. Methods Appl. Inform. Pol. Acad. Sci. 2021, 2, 29–37. [Google Scholar]
- Li, Y.; Xia, R.; Huang, Q.; Xie, W.; Li, X. Survey of Spatio—Temporal Interest Point Detection Algorithms in Video. IEEE Access 2017, 5, 10323–10331. [Google Scholar] [CrossRef]
- Nahlah, A.; Redfern, S. A Robust Tracking-by-Detection Algorithm Using Adaptive Accumulated Frame Differencing and Corner Features. J. Imaging 2020, 6, 25. [Google Scholar]
- Jalal, A.; Uddin, M.Z.; Kim, T. Depth video-based human activity recognition system using translation and scaling invariant features for life logging at smart home. IEEE Trans. Consum. Electron. 2012, 58, 863–871. [Google Scholar] [CrossRef]
- Hsieh, J.; Chen, L.; Chen, D. Symmetrical SURF and Its Applications to Vehicle Detection and Vehicle Make and Model Recognition. IEEE Trans. Intell. Transp. Syst. 2014, 15, 6–20. [Google Scholar] [CrossRef]
- Sun, R.; Qian, J.; Jose, R.H.; Gong, Z.; Miao, R.; Xue, W.; Liu, P. A Flexible and Efficient Real-Time ORB-Based Full-HD Image Feature Extraction Accelerator. IEEE Trans. Very Large Scale Integr. Syst. 2020, 28, 565–575. [Google Scholar] [CrossRef]
- Lam, S.-K.; Jiang, G.; Wu, M.; Cao, B. Area-Time Efficient Streaming Architecture for FAST and BRIEF Detector. IEEE Trans. Circuits Syst. II: Express Briefs 2019, 66, 282–286. [Google Scholar] [CrossRef]
- Ma, C.; Hu, X.; Xiao, J.; Zhang, G. Homogenized ORB Algorithm Using Dynamic Threshold and Improved Quadtree. Math. Probl. Eng. 2021, 2021, 6693627. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Seg-mentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Wang, Y.; Li, Z.; Jia, Y.; Gui, G. Deep Learning-Based Classification Methods for Remote Sensing Images in Urban Built-Up Areas. IEEE Access 2019, 7, 36274–36284. [Google Scholar] [CrossRef]
- Disabato, S.; Roveri, M.; Alippi, C. Distributed Deep Convolutional Neural Networks for the Internet-of-Things. IEEE Trans. Comput. 2021, 70, 1239–1252. [Google Scholar] [CrossRef]
- Chan, T.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Processing 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [Green Version]
- Triwiyanto, T.; Pawana, I.P.A.; Purnomo, M.H. An Improved Performance of Deep Learning Based on Convolution Neural Network to Classify the Hand Motion by Evaluating Hyper Parameter. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1678–1688. [Google Scholar] [CrossRef]
- Yang, H.; Han, X. Face Recognition Attendance System Based on Real-Time Video Processing. IEEE Access 2020, 8, 159143–159150. [Google Scholar] [CrossRef]
- Jia, W.; Zhao, D.; Shen, T.; Su, C.; Hu, C.; Zhao, Y. A New Optimized GA-RBF Neural Network Algorithm. Comput. Intell. Neurosci. 2014, 2014, 982045. [Google Scholar] [CrossRef]
- Ding, S.; Jia, W.; Su, C.; Chen, J. Research of neural network algorithm based on FA and RBF. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–18 April 2010; pp. V7-228–V7-232. [Google Scholar] [CrossRef]
- Robinson, J.; Kecman, V. Combining support vector machine learning with the discrete cosine transform in image compres-sion. IEEE Trans. Neural Netw. 2003, 14, 950–958. [Google Scholar] [CrossRef]
- El qacimy, B.; Kerroum, M.A.; Hammouch, A. Handwritten digit recognition based on DCT features and SVM classifier. In Proceedings of the 2014 Second World Conference on Complex Systems (WCCS), Agadir, Morocco, 10–12 November 2014; pp. 13–16. [Google Scholar] [CrossRef]
- Parameswari, V.; Pushpalatha, S. Human Activity Recognition using SVM and Deep Learning. Eur. J. Mol. Clin. Med. 2020, 7, 1984–1990. [Google Scholar]
- Chen, Z.; Zhu, Q.; Soh, Y.C.; Zhang, L. Robust Human Activity Recognition Using Smartphone Sensors via CT-PCA and Online SVM. IEEE Trans. Ind. Inform. 2017, 13, 3070–3080. [Google Scholar] [CrossRef]
- Yu, T.; Chen, J.; Yan, N.; Liu, X. A Multi-Layer Parallel LSTM Network for Human Activity Recognition with Smartphone Sensors. In Proceedings of the Wireless Communications and Signal Processing (WCSP) 2018 10th International Conference on, Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar]
- Hong, J.-H.; Ramos, J.; Dey, A.K. Toward personalized activity recognition systems with a semipopulation approach. IEEE Trans. Human-Mach. Syst. 2016, 46, 101–112. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.-Y. A comparative study on human activity recognition using inertial sensors in a smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Ouyang, A.; Liu, Y.; Pei, S.; Peng, X.; He, M.; Wang, Q. A hybrid improved kernel LDA and PNN algorithm for efficient face recognition. Neurocomputing 2020, 393, 214–222. [Google Scholar] [CrossRef]
- Cook, C.M.; Howard, J.J.; Sirotin, Y.B.; Tipton, J.L.; Vemury, A.R. Demographic Effects in Facial Recognition and Their De-pendence on Image Acquisition: An Evaluation of Eleven Commercial Systems. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 32–41. [Google Scholar] [CrossRef]
- Yadav, S.; Nain, N. A novel approach for face detection using hybrid skin color model. J. Reliab. Intell. Environ. 2016, 2, 145–158. [Google Scholar] [CrossRef] [Green Version]
- Kalbkhani, H.; Shayesteh, M.G.; Mohsen Mousavi, S. Efficient algorithms for detection of face, eye, and eye state. IET Comput. Vis. 2013, 7, 184–200. [Google Scholar] [CrossRef]
- Alshehri, M.; Kumar, M.; Bhardwaj, A.; Mishra, S.; Gyani, J. Deep Learning-Based Approach to Classify Saline Particles in Sea Water. Water 2021, 13, 1251. [Google Scholar] [CrossRef]
- Aggarwal, A.; Alshehri, M.; Kumar, M.; Sharma, P.; Alfarraj, O.; Deep, V. Principal component analysis, hidden Markov mod-el, and artificial neural network inspired techniques to recognize faces. Concurr. Comput. Pract. Exp. 2021, 33, e6157. [Google Scholar] [CrossRef]
- Rani, A.; Kumar, M.; Goel, P. Image Modelling: A Feature Detection Approach for Steganalysis. Int. Conf. Adv. Comput. Data Sci. 2017, 721, 140–148. [Google Scholar] [CrossRef]
- Ayyavoo, T.; Jayasudha, J.S. Face recognition using enhanced energy of discrete wavelet transform. In Proceedings of the In-ternational Conference on Control Communication and Computing (ICCC), Thiruvananthapuram, India, 13–15 December 2013; pp. 415–419. [Google Scholar]
- Abuzneid, M.A.; Mahmood, A. Enhanced Human Face Recognition Using LBPH Descriptor, Multi-KNN, and Back-Propagation Neural Network. IEEE Access 2018, 6, 20641–20651. [Google Scholar] [CrossRef]
- Arsenovic, M.; Sladojevic, S.; Anderla, A.; Stefanovic, D. FaceTime—Deep learning based face recognition attendance system. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 000053–000058. [Google Scholar] [CrossRef]
- Teoh, K.H.; Ismail, R.C.; Naziri, S.Z.M.; Hussin, R.; Isa, M.N.M.; En Basir, M. Face Recognition and Identification using Deep Learning Approach. J. Phys. Conf. Ser. 2021, 1755, 012006. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, D.; Sun, J.; Zou, G.; Li, W. Adaptive Convolutional Neural Network and Its Application in Face Recognition. Neural Processing Lett. 2016, 43, 389–399. [Google Scholar] [CrossRef]
- Guo, S.; Chen, S.; Li, Y. Face recognition based on convolutional neural network & support vector machine. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 1787–1792. [Google Scholar]
Figure 1.
Basic structure of a FRS.

Figure 2.
Issues in face detection and feature extraction.

Figure 3.
Proposed model.

Figure 4.
RBF network topology.

Figure 5.
Genetic Algorithm flowchart.

Figure 6.
Mapping of the Genetic Algorithm with the neural network.

Figure 7.
Accuracy vs. number of faces.

Figure 8.
Training time vs. number of faces.

Figure 9.
Classification time vs. number of faces.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Experimental setup.
| Mutation Rate | Population Size | Age Limit | Maximum Time | Minimum Sigma | Most Extreme Sigma |
|---|---|---|---|---|---|
| 0.1 | 30 | 40–60 | 18 s | 0.05 | 1 |
Table 2.
Results analysis using the DCT-SVM model.
| Parameters | Conduct Experiment-1 | Conduct Experiment-2 | Conduct Experiment-3 | Conduct Experiment-4 | Conduct Experiment-5 |
|---|---|---|---|---|---|
| No. of Faces | 10 | 20 | 25 | 30 | 40 |
| Samples per face | 6 | 6 | 6 | 6 | 6 |
| Accuracy | 97.67 | 90 | 98.90 | 98.92 | 95 |
| Training Time | 2.35 | 1.205 | 2.9331 | 3.5300 | 4.3600 |
| Testing Time | 0.0630 | 0.2333 | 0.0523 | 0.0013 | 0.0022 |
| Classification Time | 2.4233 | 1.4365 | 2.9844 | 3.5211 | 4.3770 |
Table 3.
Results analysis using PCA-SVM and DCT-SVM using GA-RBF.
| Parameters | Conduct Experiment-1 | Conduct Experiment-2 | Conduct Experiment-3 | Conduct Experiment-4 | Conduct Experiment-5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model Name | PCA-SVM | DCT-SVM Using GA-RBF | PCA-SVM | DCT-SVM Using GA-RBF | PCA-SVM | DCT-SVM Using GA-RBF | PCA-SVM | DCT-SVM Using GA-RBF | PCA-SVM | DCT-SVM Using GA-RBF |
| No. of Faces | 10 | 10 | 20 | 20 | 25 | 25 | 30 | 30 | 40 | 40 |
| Samples per face | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| Accuracy (ORL) | 90 | 98.66 | 83.34 | 96.23 | 93.33 | 98.95 | 80 | 98.99 | 86.67 | 98.90 |
| Accuracy (YALE) | 91 | 98.5 | 83.50 | 96.0 | 93.0 | 98.90 | 80 | 98.5 | 86.50 | 98.95 |
| Training Time (ORL) | 2.3423 | 2.341 | 1.233 | 1.200 | 2.2856 | 2.3421 | 3.4563 | 3.111 | 4.322 | 4.112 |
| Training Time (ORL) | 2.3 | 2.35 | 1.22 | 1.205 | 2.29 | 2.35 | 3.5 | 3.19 | 4.30 | 4.119 |
| Testing Time | 0.9122 | 0.0641 | 0.2933 | 0.2347 | 0.8341 | 0.0624 | 0.8653 | 0.0111 | 0.9332 | 0.0025 |
| Classification Time (ORL) | 3.2546 | 2.2670 | 1.5273 | 1.4228 | 3.1198 | 2.4044 | 4.3215 | 3.4225 | 5.2562 | 4.8144 |
| Classification Time (YALE) | 3.240 | 2.250 | 1.510 | 1.428 | 3.120 | 2.450 | 4.320 | 3.4220 | 5.2590 | 4.810 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bhushan, S.; Alshehri, M.; Agarwal, N.; Keshta, I.; Rajpurohit, J.; Abugabah, A. A Novel Approach to Face Pattern Analysis. Electronics 2022, 11, 444. https://doi.org/10.3390/electronics11030444
AMA Style
Bhushan S, Alshehri M, Agarwal N, Keshta I, Rajpurohit J, Abugabah A. A Novel Approach to Face Pattern Analysis. Electronics. 2022; 11(3):444. https://doi.org/10.3390/electronics11030444
Chicago/Turabian StyleBhushan, Shashi, Mohammed Alshehri, Neha Agarwal, Ismail Keshta, Jitendra Rajpurohit, and Ahed Abugabah. 2022. "A Novel Approach to Face Pattern Analysis" Electronics 11, no. 3: 444. https://doi.org/10.3390/electronics11030444
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.