
Human-Mimetic Estimation of Food Volume from a Single-View RGB Image Using an AI System

 , ,
, ,
Abstract
:1. Introduction
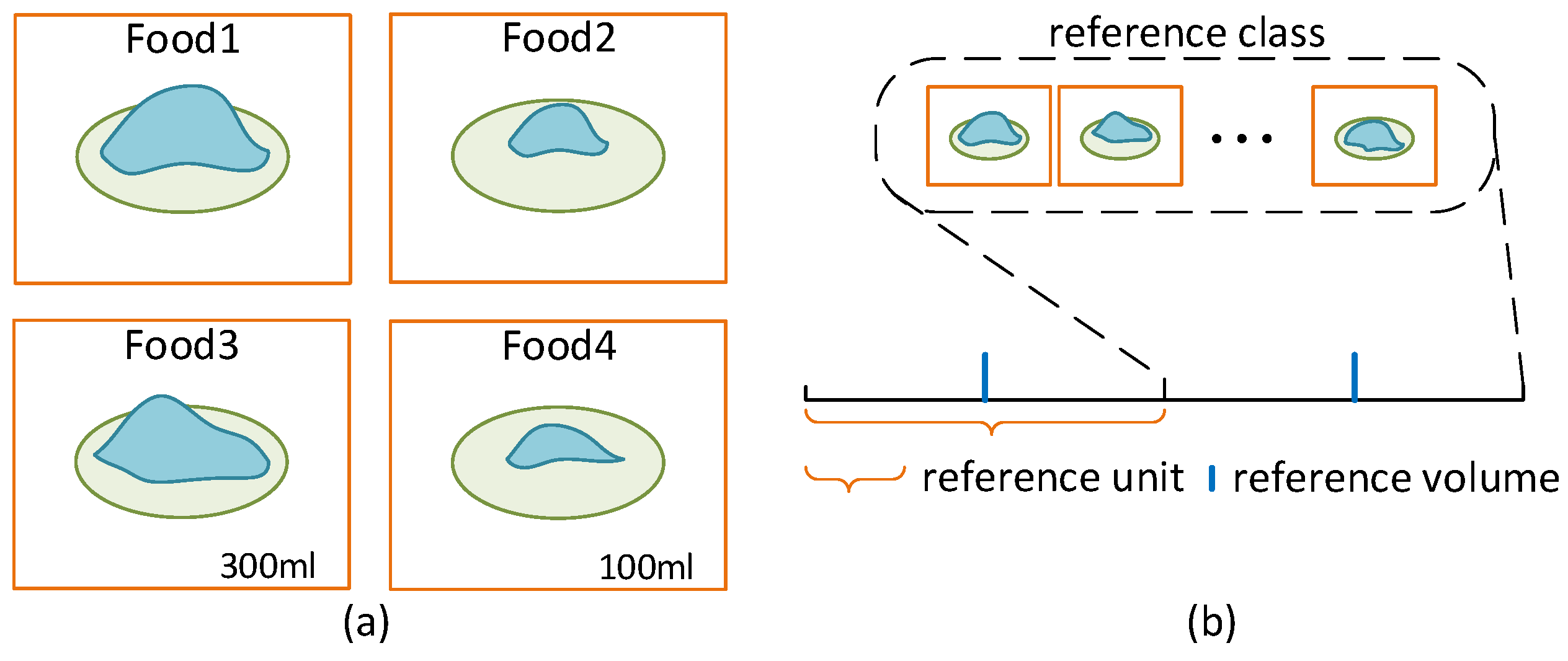
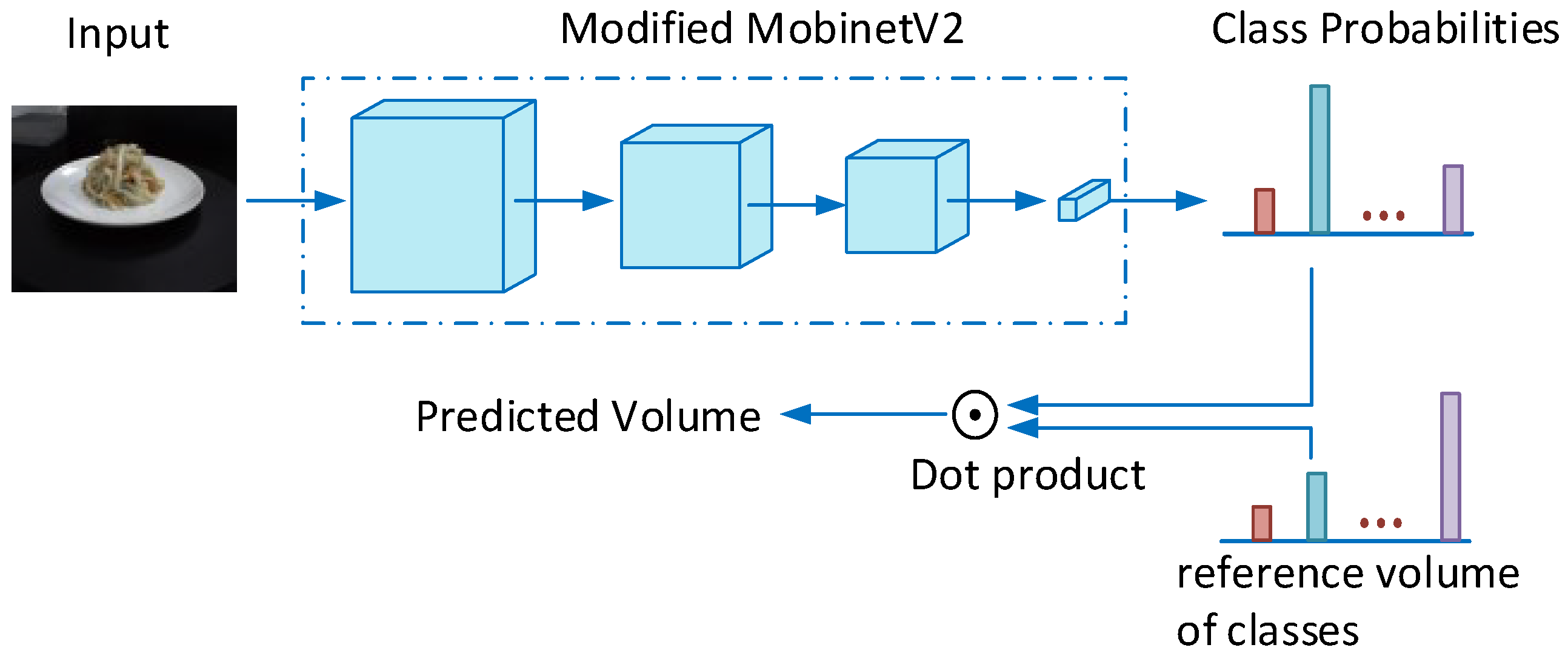
- Over the years, dietitians have used a popular portion size estimation method by comparing the observed food with a set of common objects of known volumes. We propose to use the AI technology to mimic this mental process. In the human case, the food size is first matched with the most similar size of a known object. In an AI system, we use a similar strategy formulated as an image classification step. In the second step, while the human mentally fine-tunes the estimation by portioning with respect to the known object sizes, we mimic this process using an inner product between a probability vector and a reference volume vector.
- To validate the effectiveness of our method quickly, we used two large-scale Virtual Food Datasets (VFD), constructed by computer simulation, of different volume ranges. Our method achieves a high accuracy with an average volumetric error less than 9% on both datasets.
- To evaluate the real-world performance of our method, two Real Food Datasets (RFD) are collected with different degrees of difficulties in estimation tasks. Our method achieves 11.6% and 20.1% mean relative volumetric errors on the easy and hard food datasets, respectively.
2. Related Work
3. Methodology
3.1. Motivation
3.2. Neural Network for Food Classification
3.2.1. Inverted Residual Block
3.2.2. Food Volume Classification Network
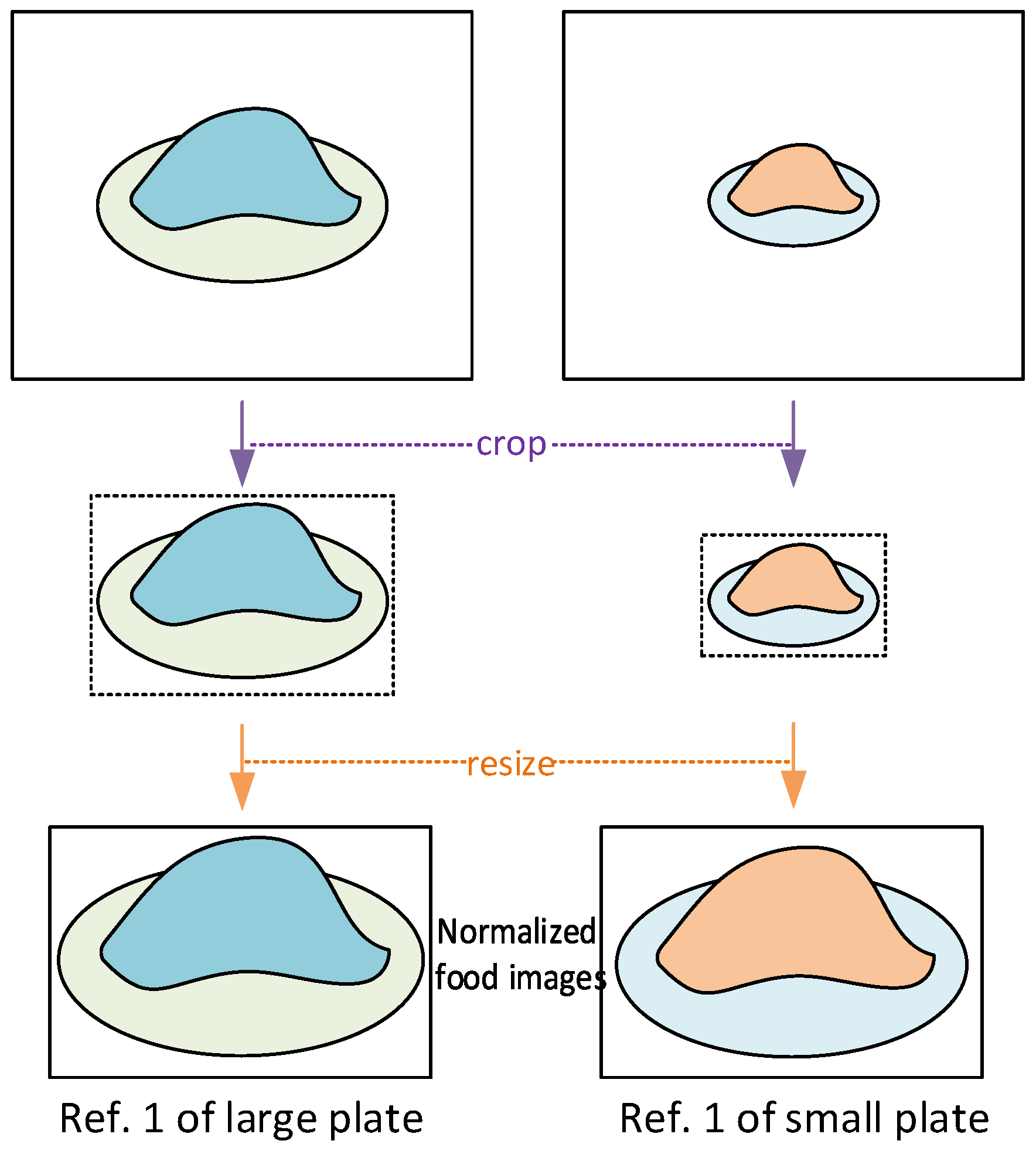
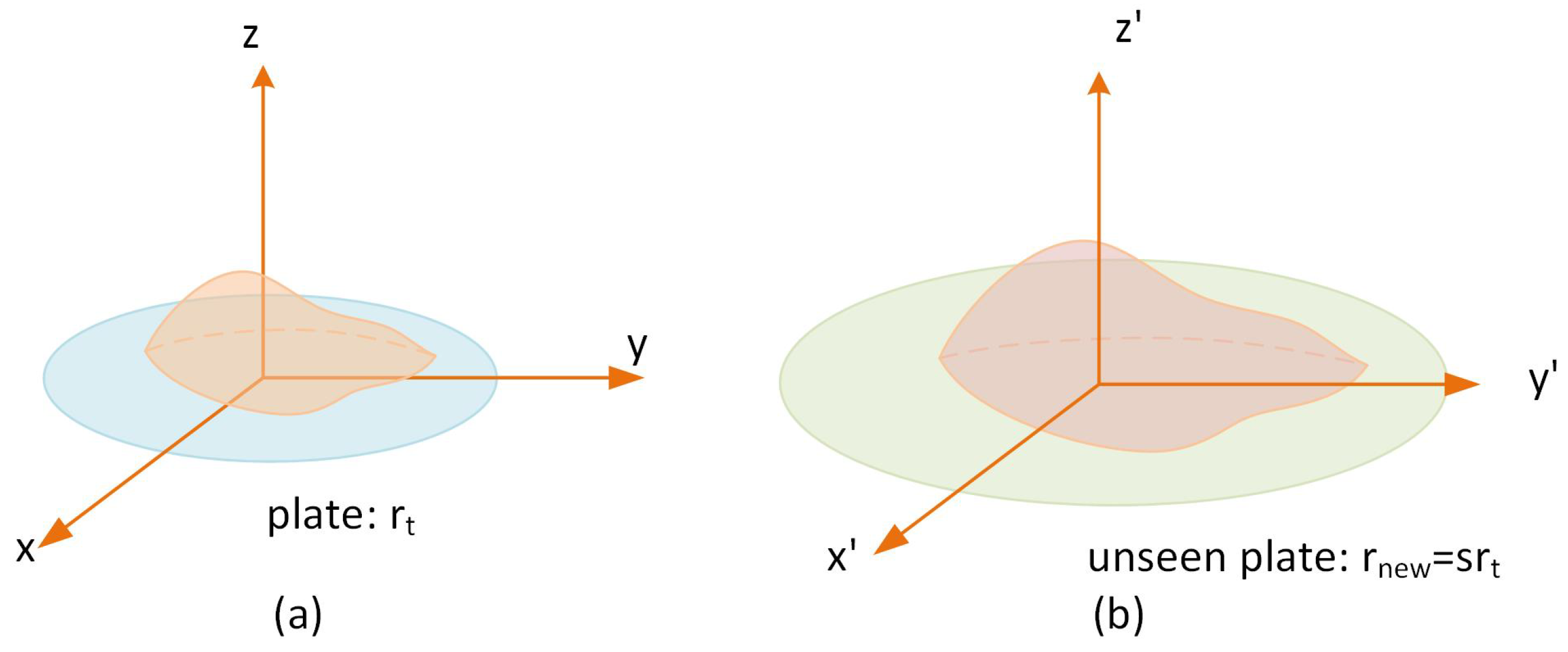
3.3. References Volume Normalization
4. Datasets
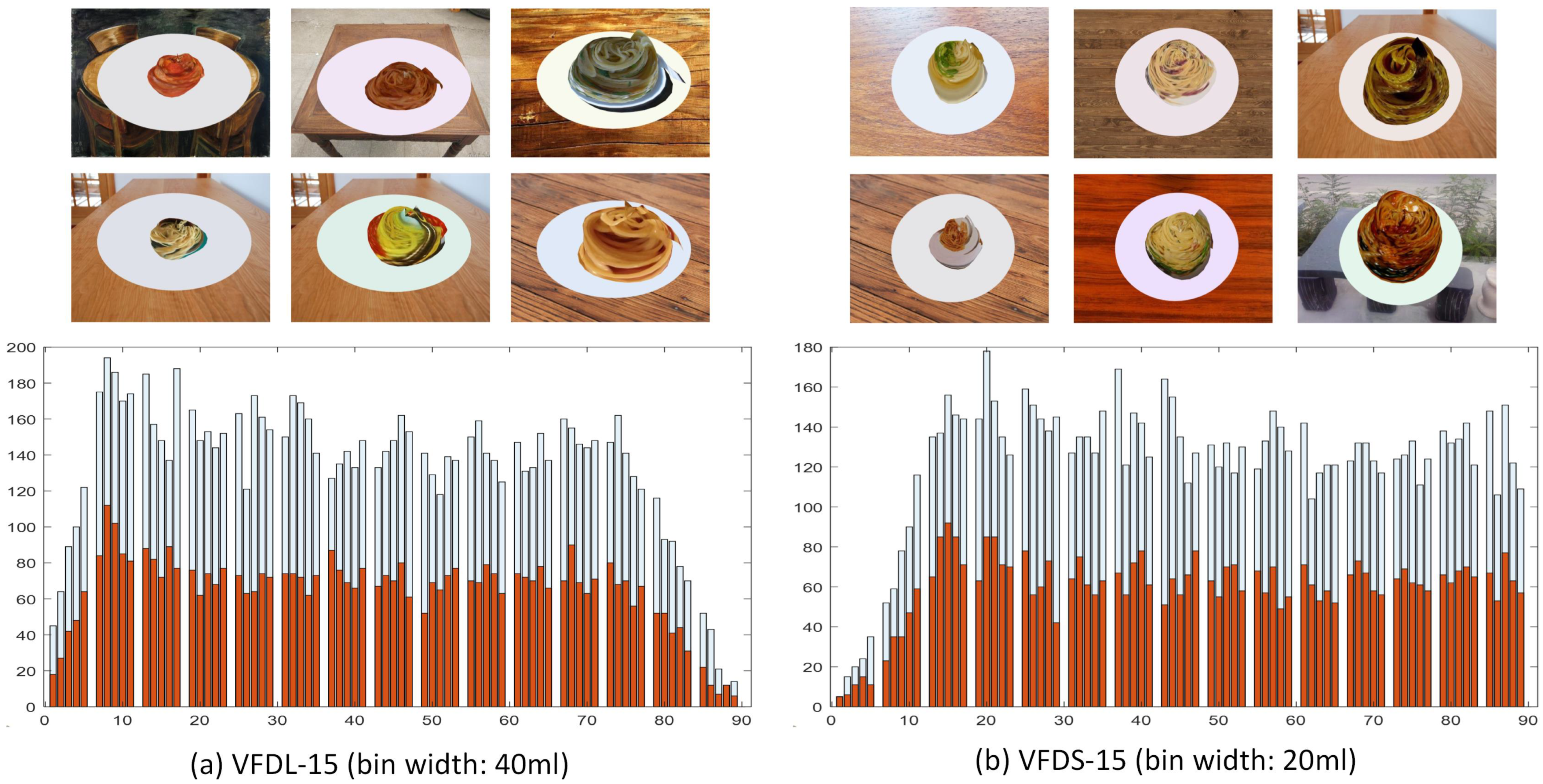
4.1. Virtual Food Dataset
4.2. Real Food Dataset
5. Experiments
5.1. Experimental Setups
5.1.1. Training Policy
5.1.2. Data Augmentation
5.1.3. Evaluation Protocol
5.1.4. Computing Systems
5.2. Experiments on VFD
5.2.1. 15 Reference Classes
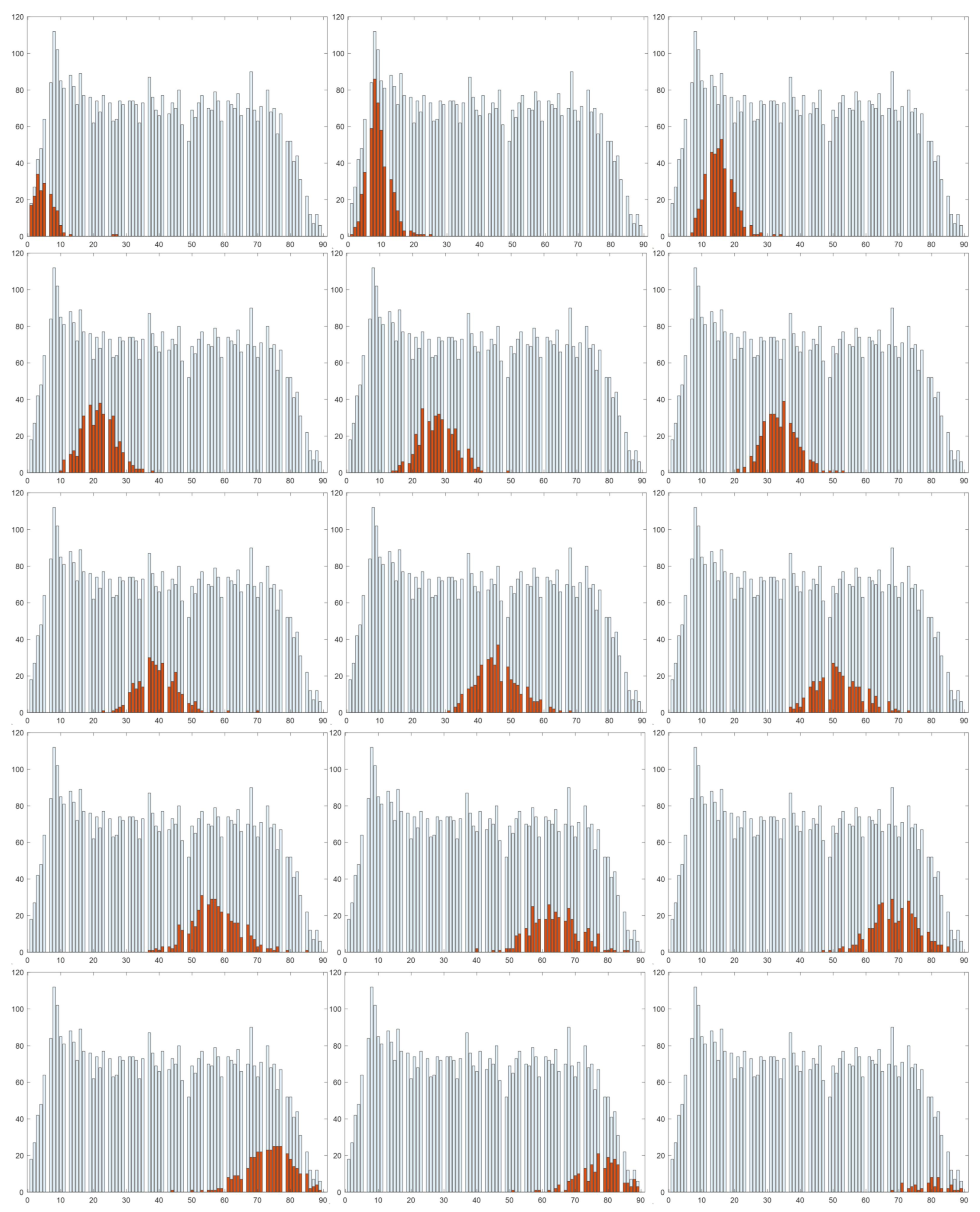
- Our human-mimetic AI system achieved a 86.7% and 83.7% top3 accuracy on VFDL-15 and VFDS-15, respectively, which demonstrated that this system is able to find the three closest volume reference classes of the input, in a similar way that a human uses to compare a food size with the sizes of a set of reference objects. In addition, according to the histograms shown in Figure 8, it is unlikely for our method to classify the input images to the reference classes far away from their true reference class. Thus, although the top1 accuracy was relatively low, our method still achieved 8.7% and 8.7% mRVE on VFDL-15 and VFDS-15, respectively.
- Most top1 classification accuracies achieved on large volume classes were fewer than 40%, suggesting that the food volume classification model cannot distinguish large volume classes very well. This was mainly because the relative volumetric changes between large volume classes were much smaller than the changes across small classes, which made large volume classes less differentiable. Nevertheless, the volume estimation errors in large volume classes were typically smaller than the ones of small volume classes. This is reasonable since the RVE is more sensitive to the absolute error at small classes according to (10). For example, given an absolute error equal to 100, for the VFDL-15 dataset, the mRVE of class 1 (400–600 mL) is in the range of 16.7% to 25%, while the mRVE of class 15 (3200–3400 mL) lies between 2.9% to 3.1%.
- Using soft predictions for volume estimation achieved lower mRVE than using hard predictions on both VFDL-15 and VFDS-15, proving the effectiveness of our soft predictions-based volume estimation mentioned in Section 3.2.2.
- Not surprisingly, our method achieved a better performance on a VFDL-15 dataset for the reference classification task according to the top1 and top3 accuracy measures. However, for the volume estimation task, our method showed a similar mRVE on the VFDS-15 and VFDL-15. Together with observation 2, it can be concluded that a better reference classes classification accuracy, which usually requires a larger interval between neighbor classes, does not imply a better volume estimation result.
- We achieved 8.7% mRVE on the VFDS-15 dataset that has a similar volume range to that in the real world, which demonstrated strongly the effectiveness of our human-mimetic approach.
5.2.2. Increased 30 References Classes
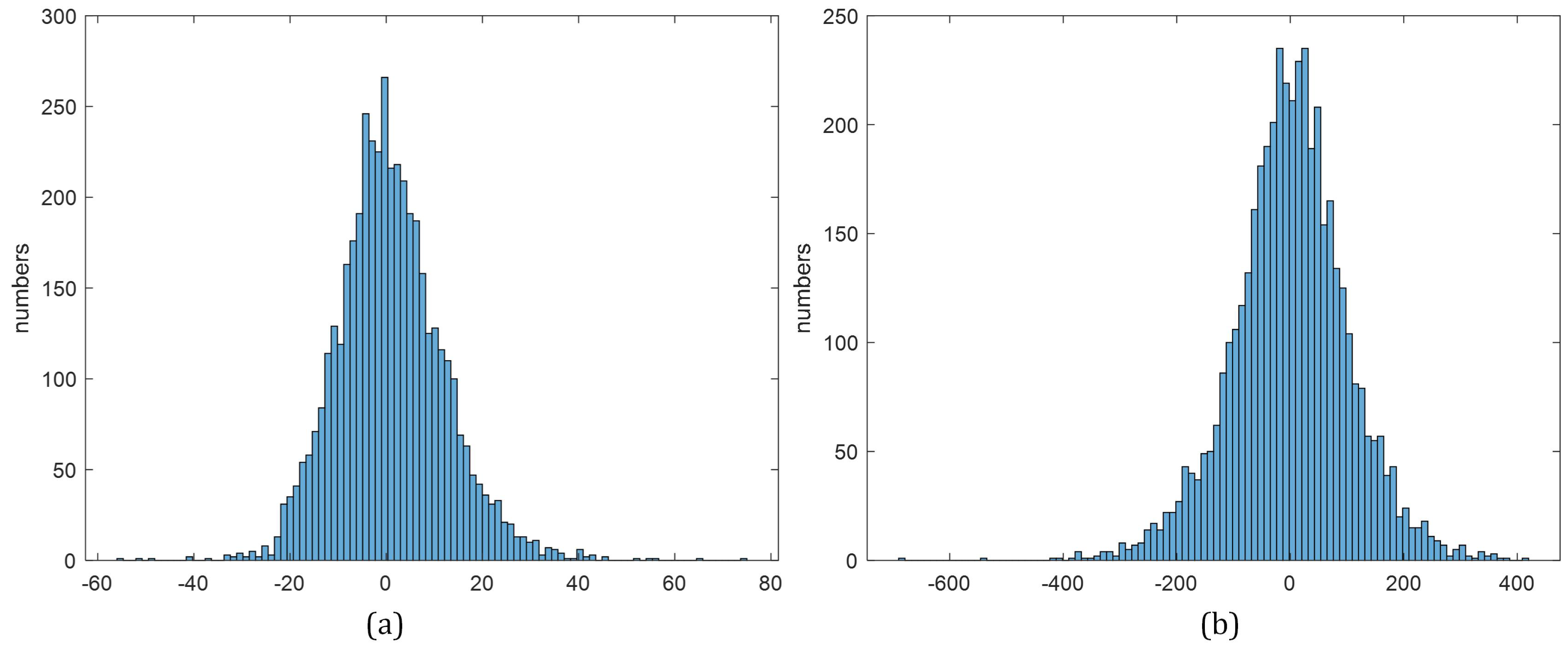
5.2.3. Bias Analysis
5.2.4. Training with Normalized Reference Class
5.3. Experiments on RFD
5.4. Comparison with Other Methods
6. Discussion
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hales, C.M.; Carroll, M.D.; Fryar, C.D.; Ogden, C.L. Prevalence of obesity among adults and youth: United States, 2015–2016. NCHS Data Brief 2017, 288, 1–8. [Google Scholar]
- Chen, H.C.; Jia, W.; Yue, Y.; Li, Z.; Sun, Y.N.; Fernstrom, J.D.; Sun, M. Model-based measurement of food portion size for image-based dietary assessment using 3D/2D registration. Meas. Sci. Technol. 2013, 24, 105701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dehais, J.; Anthimopoulos, M.; Shevchik, S.; Mougiakakou, S. Two-view 3D reconstruction for food volume estimation. IEEE Trans. Multimed. 2016, 19, 1090–1099. [Google Scholar] [CrossRef] [Green Version]
- Livingstone, M.B.E.; Robson, P.; Wallace, J. Issues in dietary intake assessment of children and adolescents. Br. J. Nutr. 2004, 92, S213–S222. [Google Scholar] [CrossRef] [PubMed]
- Arab, L.; Estrin, D.; Kim, D.H.; Burke, J.; Goldman, J. Feasibility testing of an automated image-capture method to aid dietary recall. Eur. J. Clin. Nutr. 2011, 65, 1156. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Burke, L.E.; Baranowski, T.; Fernstrom, J.D.; Zhang, H.; Chen, H.C.; Bai, Y.; Li, Y.; Li, C.; Yue, Y.; et al. An exploratory study on a chest-worn computer for evaluation of diet, physical activity and lifestyle. J. Healthc. Eng. 2015, 6, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Jobarteh, M.L.; McCrory, M.A.; Lo, B.; Sun, M.; Sazonov, E.; Anderson, A.K.; Jia, W.; Maitland, K.; Qiu, J.; Steiner-Asiedu, M.; et al. Development and validation of an objective, passive dietary assessment method for estimating food and nutrient intake in households in low- and middle-income countries: A study protocol. Curr. Developments Nutr. 2020, 4, nzaa020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Johns, E.; Atallah, L.; Pettitt, C.; Lo, B.; Frost, G.; Yang, G.Z. An intelligent food-intake monitoring system using wearable sensors. In Proceedings of the 2012 Ninth International Conference on Wearable and Implantable Body Sensor Networks, London, UK, 9–12 May 2012; pp. 154–160. [Google Scholar]
- Kagaya, H.; Aizawa, K.; Ogawa, M. Food detection and recognition using convolutional neural network. In Proceedings of the 22nd ACM international conference on Multimedia, New York, NY, USA, 3–7 November 2014; pp. 1085–1088. [Google Scholar]
- Mezgec, S.; Koroušić Seljak, B. NutriNet: A deep learning food and drink image recognition system for dietary assessment. Nutrients 2017, 9, 657. [Google Scholar] [CrossRef] [PubMed]
- Aguilar, E.; Remeseiro, B.; Bolaños, M.; Radeva, P. Grab, Pay, and Eat: Semantic Food Detection for Smart Restaurants. IEEE Trans. Multimed. 2018, 20, 3266–3275. [Google Scholar] [CrossRef] [Green Version]
- U.S. Department of Agriculture, Agricultural Research Service. FoodData Central. 2019. Available online: https://fdc.nal.usda.gov/ (accessed on 25 June 2021).
- Hassannejad, H.; Matrella, G.; Ciampolini, P.; Munari, I.; Mordonini, M.; Cagnoni, S. A new approach to image-based estimation of food volume. Algorithms 2017, 10, 66. [Google Scholar] [CrossRef] [Green Version]
- Puri, M.; Zhu, Z.; Yu, Q.; Divakaran, A.; Sawhney, H. Recognition and volume estimation of food intake using a mobile device. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar]
- Rahman, M.H.; Li, Q.; Pickering, M.; Frater, M.; Kerr, D.; Bouchey, C.; Delp, E. Food volume estimation in a mobile phone based dietary assessment system. In Proceedings of the 2012 Eighth International Conference on Signal Image Technology and Internet Based Systems, Sorrento, Italy, 25–29 November 2012; pp. 988–995. [Google Scholar]
- Woo, I.; Otsmo, K.; Kim, S.; Ebert, D.S.; Delp, E.J.; Boushey, C.J. Automatic portion estimation and visual refinement in mobile dietary assessment. Comput. Imaging VIII. Int. Soc. Opt. Photonics 2010, 7533, 75330O. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Lo, F.; Sun, Y.; Qiu, J.; Lo, B. Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map. Nutrients 2018, 10, 2005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar]
- Chen, W.; Fu, Z.; Yang, D.; Deng, J. Single-image depth perception in the wild. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 730–738. [Google Scholar]
- Meyers, A.; Johnston, N.; Rathod, V.; Korattikara, A.; Gorban, A.; Silberman, N.; Guadarrama, S.; Papandreou, G.; Huang, J.; Murphy, K.P. Im2Calories: Towards an automated mobile vision food diary. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1233–1241. [Google Scholar]
- Li, H.; Han, T. DeepVol: Deep Fruit Volume Estimation. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2018; pp. 331–341. [Google Scholar]
- Xu, C.; He, Y.; Khanna, N.; Boushey, C.J.; Delp, E.J. Model-based food volume estimation using 3D pose. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 2534–2538. [Google Scholar]
- Gao, A.; Lo, F.P.W.; Lo, B. Food volume estimation for quantifying dietary intake with a wearable camera. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Las Vegas, NV, USA, 4–7 March 2018; pp. 110–113. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers, Inc.: San Francisco, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ferdinand Christ, P.; Schlecht, S.; Ettlinger, F.; Grun, F.; Heinle, C.; Tatavatry, S.; Ahmadi, S.A.; Diepold, K.; Menze, B.H. Diabetes60-Inferring Bread Units From Food Images Using Fully Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1526–1535. [Google Scholar]
- Lu, Y.; Allegra, D.; Anthimopoulos, M.; Stanco, F.; Farinella, G.M.; Mougiakakou, S. A multi-task learning approach for meal assessment. In Proceedings of the Joint Workshop on Multimedia for Cooking and Eating Activities and Multimedia Assisted Dietary Management, Stockholm, Sweden, 15 July 2018; pp. 46–52. [Google Scholar]
- Konkle, T.; Oliva, A. A familiar-size Stroop effect: Real-world size is an automatic property of object representation. J. Exp. Psychol. Hum. Percept. Perform. 2012, 38, 561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Chen, M.; Dhingra, K.; Wu, W.; Yang, L.; Sukthankar, R.; Yang, J. PFID: Pittsburgh fast-food image dataset. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 289–292. [Google Scholar]
- Matsuda, Y.; Hoashi, H.; Yanai, K. Recognition of multiple-food images by detecting candidate regions. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 25–30. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 446–461. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Lo, F.P.W.; Sun, Y.; Qiu, J.; Lo, B. Image-Based Food Classification and Volume Estimation for Dietary Assessment: A Review. IEEE J. Biomed. Health Inform. 2020, 24, 1926–1939. [Google Scholar] [CrossRef]
- Gao, J.; Tan, W.; Ma, L.; Wang, Y.; Tang, W. MUSEFood: Multi-Sensor-based food volume estimation on smartphones. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Leicester, UK, 19–23 August 2019; pp. 899–906. [Google Scholar]
- Fang, S.; Zhu, F.; Jiang, C.; Zhang, S.; Boushey, C.J.; Delp, E.J. A comparison of food portion size estimation using geometric models and depth images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 26–30. [Google Scholar]
- Lo, F.P.W.; Sun, Y.; Qiu, J.; Lo, B.P. Point2volume: A vision-based dietary assessment approach using view synthesis. IEEE Trans. Ind. Inform. 2019, 16, 577–586. [Google Scholar] [CrossRef]
- Yuan, D.; Hu, X.; Zhang, H.; Jia, W.; Mao, Z.H.; Sun, M. An automatic electronic instrument for accurate measurements of food volume and density. Public Health Nutr. 2021, 24, 1248–1255. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Yang, Z.; Tan, L.; Wang, Y.; Sun, W.; Sun, M.; Tang, Y. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, H.; Sun, W.; Mao, Z.; Sun, M. Locally shared features: An efficient alternative to conditional random field for semantic segmentation. IEEE Access 2018, 7, 2263–2272. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, H.; Feng, M.; Sun, W.; Lin, X.; Sun, M.; Mao, Z.; Mian, A. Small Object Augmentation of Urban Scenes for Real-Time Semantic Segmentation. IEEE Trans. Image Process. 2020, 29, 5175–5190. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Burke, L.E.; Mao, Z.H.; Chen, Y.; Chen, H.C.; Bai, Y.; Li, Y.; Li, C.; Jia, W. eButton: A wearable computer for health monitoring and personal assistance. In Proceedings of the 51st Annual Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
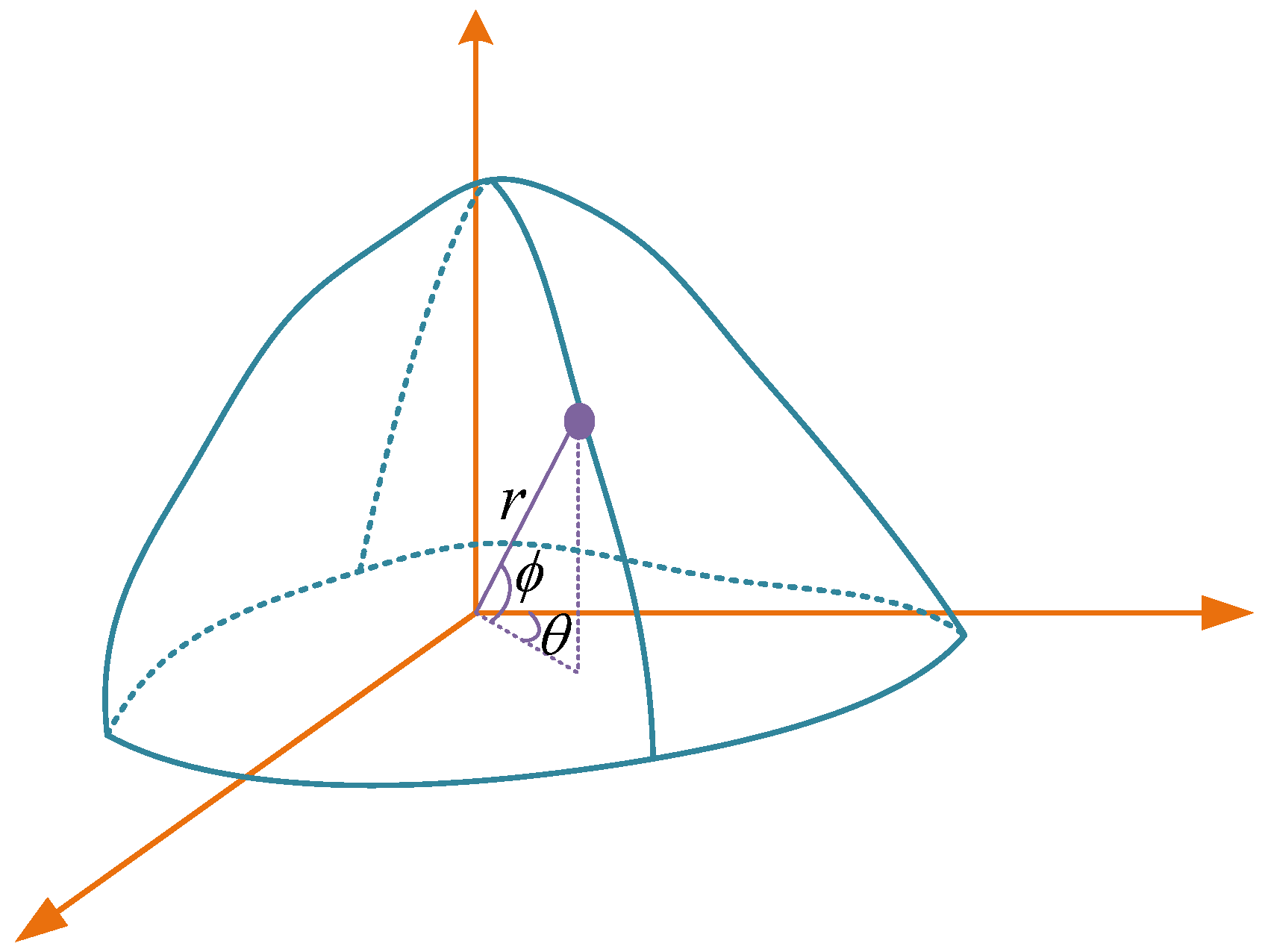{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Stride | Components |
|---|---|---|
| block1 | 2 | |
| block2 | 4 | |
| block3 | 8 | |
| block4 | 16 | |
| block5 | 32 | |
| Classes | Overall | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |||
| VFDL-15 | top1 | 63.8 | 67.6 | 56.1 | 46.7 | 41.3 | 44.5 | 35.7 | 39.6 | 30.1 | 36.9 | 28.6 | 28.7 | 35.4 | 36.8 | 16.9 | 42.1 |
| top3 | 100 | 98.3 | 96.8 | 96.1 | 93.4 | 89.6 | 84.3 | 83.2 | 83.3 | 78.0 | 76.7 | 75.5 | 81.2 | 83.2 | 55.9 | 86.7 | |
| mRVE | 15.1 | 11.1 | 10.6 | 9.9 | 9.7 | 9.1 | 9.3 | 8.0 | 7.6 | 7.3 | 7.3 | 6.8 | 5.9 | 5.0 | 8.2 | 8.7 | |
| 15.9 | 12.3 | 11.9 | 11.1 | 10.7 | 9.8 | 10.2 | 8.9 | 8.6 | 8.0 | 9.0 | 7.6 | 6.2 | 5.7 | 8.4 | 9.6 | ||
| VFDS-15 | top1 | 54.2 | 60.3 | 58.8 | 50.3 | 43.7 | 37.0 | 40.4 | 40.0 | 34.7 | 32.4 | 25.4 | 25.9 | 19.7 | 31.4 | 50.8 | 39.5 |
| top3 | 95.8 | 96.9 | 96.7 | 95.4 | 92.2 | 85.5 | 82.0 | 85.0 | 79.8 | 75.9 | 74.2 | 69.3 | 69.1 | 85.4 | 80.1 | 83.7 | |
| mRVE | 19.6 | 12.8 | 10.7 | 10.1 | 9.4 | 10.2 | 9.2 | 8.4 | 8.1 | 8.2 | 8.4 | 7.8 | 7.2 | 5.4 | 5.3 | 8.7 | |
| 19.8 | 13.7 | 11.4 | 11.1 | 10.7 | 10.8 | 10.3 | 8.7 | 8.6 | 9.0 | 9.2 | 8.7 | 8.0 | 6.2 | 5.1 | 9.4 | ||
| Top1 | Top3 | mRVE | |
|---|---|---|---|
| VFDL-30 | 22.2 | 58.7 | 8.7 |
| VFDS-30 | 21.2 | 55.1 | 8.6 |
| Top1 | Top3 | mRVE | |
|---|---|---|---|
| VFDL-15 | 43.8 | 88.1 | 8.5 |
| VFDS-15 | 40.1 | 84.6 | 8.5 |
| Classes | Overall | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| 100 mL | top1 | 89.0 | 82.4 | 60.7 | - | - | 79.6 |
| mRVE | 13.0 | 10.8 | 11.8 | - | - | 11.7 | |
| 50 mL | top1 | 78.4 | 27.5 | 79.4 | 35.0 | 75.4 | 67.4 |
| top3 | 97.3 | 100 | 87.6 | 100 | 88.4 | 93.5 | |
| mRVE | 13.2 | 17.7 | 8.9 | 11.6 | 8.9 | 11.6 | |
| Classes | Overall | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| 100 mL | top1 | 100.0 | 35.0 | 40.0 | 0.0 | 59.6 | 42.5 |
| top3 | 100 | 100 | 85.0 | 97.6 | 100 | 96.0 | |
| mRVE | 25.8 | 27.3 | 20.9 | 19.1 | 15.3 | 20.1 | |
| Classes | Overall | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | |||
| 100 mL | training samples | 350 | 400 | 210 | 960 |
| test samples | 210 | 200 | 130 | 540 | |
| top1 | 88.1 | 76.0 | 78.5 | - | |
| mRVE | 13.6 | 14.0 | 8.3 | 12.5 | |
| Method | Scale Reference | Input | Core Idea | Error |
|---|---|---|---|---|
| MuseFood [39] | Depth | RGB Image (Top + Side View) | Differential Modeling | −0.27~12.37% Test dataset: 3 food items |
| Eye-Measurement [39] | n/a | RGB Image | Visually Gauged by Human | −13.84~22.87% Test dataset: 3 food items |
| Hassannejad et al. [13] | Checkerboard | Multi-View (6) RGB Images | 3D Modeling with Structure from Motion | 1.70~19.10% Test dataset: 10 food items |
| im2calories [21] | Depth | RGB + Depth Image | 3D Reconstruction with Deep Learning | - Test dataset NFood-3D dataset |
| Fang et al. [40] | Depth | Gray + Depth Image | 3D Voxel Representation from depth | 11.00~33.90% [38] Test dataset: 10 food objects |
| Lo et al. [18] | Depth | Depth Image (Front + Back View) | 3D Reconstruction with Iterative Closest Point | 3.30~9.40% Test dataset: 8 synthetic food objects |
| Point2Volume. [41] | Depth | RGB + Depth Image | 3D Point Cloud Completion | 15.32% Test dataset: 11 food items |
| VD Meter [42] | - | Multi-View (192) RGB Images | 3D Reconstruction | 0.83~5.23% Test dataset: 6 food items |
| Ours | Learned | Single RGB Image | Reference Volume Classification | 11.60~20.10% Test dataset: 174~540 food images |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Yu, H.; Cao, S.; Xu, Q.; Yuan, D.; Zhang, H.; Jia, W.; Mao, Z.-H.; Sun, M. Human-Mimetic Estimation of Food Volume from a Single-View RGB Image Using an AI System. Electronics 2021, 10, 1556. https://doi.org/10.3390/electronics10131556
Yang Z, Yu H, Cao S, Xu Q, Yuan D, Zhang H, Jia W, Mao Z-H, Sun M. Human-Mimetic Estimation of Food Volume from a Single-View RGB Image Using an AI System. Electronics. 2021; 10(13):1556. https://doi.org/10.3390/electronics10131556
Chicago/Turabian StyleYang, Zhengeng, Hongshan Yu, Shunxin Cao, Qi Xu, Ding Yuan, Hong Zhang, Wenyan Jia, Zhi-Hong Mao, and Mingui Sun. 2021. "Human-Mimetic Estimation of Food Volume from a Single-View RGB Image Using an AI System" Electronics 10, no. 13: 1556. https://doi.org/10.3390/electronics10131556