
Complex Dynamics of a Cournot Quantum Duopoly Game with Memory and Heterogeneous Players

Complex Systems Group, Universidad Politécnica de Madrid, Ciudad Universitaria, 28040 Madrid, Spain
*
Author to whom correspondence should be addressed.
Entropy 2022, 24(10), 1333; https://doi.org/10.3390/e24101333
Submission received: 15 June 2022
/
Revised: 23 August 2022
/
Accepted: 2 September 2022
/
Published: 22 September 2022
(This article belongs to the Special Issue Quantum Computing for Complex Dynamics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Previous authors tend to consider a certain range of values of the parameters involved in a game, not taking into account other possible values. In this article, a quantum dynamical Cournot duopoly game with memory and heterogeneous players (one of them is boundedly rational and the other one, a naive player) is studied, where the quantum entanglement can be greater than one and the speed of adjustment can be negative. In this context, we analyzed the behavior of the local stability and the profit in those values. Considering the local stability, it is observed that the stability region increases in the model with memory regardless of whether the quantum entanglement is greater than one or whether the speed of adjustment is negative. However, it is also shown that the stability is greater in the negative than in the positive zone of the speed of adjustment and, therefore, it improves the results obtained in previous experiments. This increase of stability enables higher values of speed of adjustment and, as a result of that, the system reaches the stability faster, resulting in a remarkable economic advantage. Regarding the behavior of the profit with these parameters, the principal effect shown is that the application of memory causes a certain delay in the dynamics. Through this article, all these statements are analytically proved and widely supported with several numerical simulations, using different values of the memory factor, the quantum entanglement, and the speed of adjustment of the boundedly rational player.
1. Introduction
In the context of game theory, there is a common tendency to study a certain range of values of the parameters in the analysis of the models, without considering other possible ones. This paper intends to take into account some different values of the parameters involved in a game to find new scenarios which can lead to interesting results. This point of view can be relevant if we consider the variety of applications of game theory in fields such as economics, psychology, biology, etc. It may occur that a special value of a parameter in a game only has a sense in a specific science or subject of study, so that we would analyze the model partially if we did not take it into account. Taking this view as a starting point, we considered a wider range of values of some parameters involved in the Cournot duopoly game to find new cases which have not been studied before. As this analysis is focused on the economics, values with no economic meaning are excluded from the study. This paper can be seen as a next step in the researched previously started in [1]. Below, we briefly describe some common premises for both works, outlining the variations considered in this study. In economics, one of the typical market structures is the oligopoly, in which a few firms produce similar products. Cournot, in [2], presented a theoretical model of olygopoly, where the firms involved attempted to maximize profits by simultaneously choosing the amount of output to produce. Other models were proposed by authors such as Bertrand in [3], who proposed a duopoly model based on setting the prices of the players, or Stackelberg in [4] with a sequential model of the Cournot duopoly model. Another condition applicable to the game is the election of the player expectations, which defines the production of each firm in future periods. Each type of player adjusts the production for future periods to maximize the profit by using a different strategy. This article considers two players, one is a boundedly rational player and the other one with naive expectations in a similar way to [5,6], in the study of a nonlinear discrete-time Cournot duopoly game. The model of a boundedly rational player depends on a parameter, called speed of adjustment, which is usually positive; however, negative values of this parameter are also considered in this article.
Since the application of quantum game theory usually improves the results comparing to the classical games, it is also included in the game modelization. This technique was used for the first time in [7] and, through the years, many authors have carried on with this issue, highlighting the contribution of [8] where the two players of the Cournot duopoly virtually cooperate due to the quantum entanglement between them, since the quantity produced by each firm depends not only on the strategy of that player, but also on the strategy of the other one. In this context, it is shown that when the entanglement increases, the profits increase. As a consequence of that, a lot of articles related to the quantization of games have appeared, applying entanglement to different duopoly games such as the Cournot model in [9], the Bertrand model in [10], or the Stackelberg model in [11]. Other authors have analyzed this subject from a different point of view. In, e.g., [12], economic activity is described from a viewpoint of quantum games. The authors define a quantum commodity as a good which can be interchangeable between players to trade and it is studied how some of these goods, called quantum commodity money, can emerge as a media of exchange not to be consumed or used in production, under certain conditions. In order to compare the results with those described in [1,13], the model proposed in this paper follows the Li–Du–Massar scheme proposed in [8]. The difference is that not only values between zero and one of the quantum entanglement are considered, but also values greater than one of this parameter are analyzed. The maximum quantum entanglement is limited by the conditions required to verify the economic meaning of the game, as is explained in the following sections.
Our model implements a model of memory based on an average of all the past states with geometric decay, since the results obtained previously are better compared to the system in absence of memory. Most of the works with memory are related with the popular logistic map [14]. The pioneers in these studies with the logistic map were [15,16]. Before this paper, we investigated the effect of memory in systems that are discrete in all their components (space, time, and state variable), i.e., cellular automata, in [17], as well as in the logistic map in [18,19].
Finally, at the end of the paper, there is a study of the behavior of the profit for the two players with and without memory and applying different values of the quantum entanglement and the speed of adjustment of the boundedly rational player. This analysis is focused on searching an economic sense to the model under different conditions to understand the variations observed as a result of that.
This paper is organized as follows. In Section 2, a dynamical quantum Cournot duopoly game model with heterogeneous players is briefly described. The equilibrium points, as well as their local stability conditions, and the relationship between quantum entanglement and stability region are also studied in this section, with special emphasis on the new conditions, i.e., speed of adjustment less than zero and degree of entanglement greater than one. In Section 3, numerical simulation is used to show the dynamics of the system and to support the results obtained in the previous section. Section 4 analyzes the behavior of the profit with and without memory with different values of the quantum entanglement and the speed of adjustment of the boundedly rational player. Finally, Section 5 presents the conclusions and meaning of this paper.
2. The Model
Based on the article [13], we consider the classical Cournot’s duopoly in which two firms are producing perfect substitute goods in a duopolistic market. The cost function is the same for both firms and is taken in linear form: . This classical Cournot’s duopoly competition is taken in the quantum domain with the use of the Li–Du–Massar entanglement structure based on quantum methods for continuous-variable quantum games. We apply this model of quantization but there are other examples of similar models, such as EWL or MW schemes [20]. Specifically, Eisert et al. described the EWL model in [21] and applied it to the prisoners’ dilemma, showing that this game ceases to pose a dilemma if quantum strategies are allowed for. We used the LDM model of quantization to compare the results with those described in [1,13], since it has been applied successfully by other authors. This entangled model has several steps. First, the game starts from initial state. This state undergoes a unitary entanglement operation , where represents the creation (annihilation) operator of the firm’s i electromagnetic field and is known as the squeezing parameter and can be reasonably regarded as a measure of entanglement. Next, the two firms execute their strategic moves via unitary operation . Finally, these two firms’ states are measured after a disentanglement operation . Thus, the final state is carried out by . The final measurement gives the respective quantum quantities of the two firms:
where and represent the independent quantities and and are the entangled quantities used by the two firms in the quantum game. When the degree of entanglement is zero, i.e., , then the quantum game turns into the original classic form and . Therefore, the market quantum price, based on the linear inverse demand function, is
being and and and . Then, we can find that the dynamical quantum profits of the two firms are
We also consider this study with different expectations (heterogeneous expectations), the first player being a boundedly rational player, and the other one a naive player. Since the knowledge of the market is usually incomplete, the first firm with boundedly rational expectations builds his output decision on the basis of the estimation of the marginal profit . This player decides to increase or decrease the production if the marginal profit is positive or negative, respectively. Then, this boundedly rational player can be modeled as
where is a parameter which represents the speed of adjustment.
The independent quantity of the naive player maximizes the expected profit. To obtain the maximum benefit we have to derive with respect to and equalize to 0 to resolve ; then, the naive player can be modeled as follows:
It is shown that it is really a maximum because it verifies the second-order condition, i.e.,
recalling that b is a positive constant.
Based on the article [13], we also add the memory effect studied earlier in these articles [17,18,19]. We consider a weighted average memory with geometric decay , which is defined in the article [19] as
being,
and,
where represents the memory factor and and . The limit case corresponds to a memory with equally weighted records (full memory), whereas intensifies the contribution of the most recent states (short-term working memory). The choice leads to the memoryless model. Therefore, the dynamical quantum Cournot duopoly game with heterogeneous players with memory can be described using the following two-dimensional discrete-time dynamical system:
where is a parameter which represents the speed of adjustment in the game with memory for the first player.
As are the independent quantities, they must have a positive value and, if at any step, the result of the equation is negative, we consider that this quantity is zero.
2.1. Equilibrium Points
Considering, for long times and , , the two-dimensional discrete-time dynamical system of Equation (10) can be written as
To find the equilibrium points of Equation (11), we can replace all and for into Equation (11), obtaining the following nonlinear algebraic system:
In Equation (12) there are two fixed points. As can be seen in the first equation, one solution for player 1 is given by (where, for a long time, ), and then substituting into the second equation, we have for player 2
due to and based on the article [1], where for long times
it is obtained:
Then, the first fixed point of the system is .
The other fixed point is determined by these equations:
Thus, the second fixed point of the system is , where
and so , then:
Since the quantum Nash equilibrium has economic meaning and the fixed point is stable when , as is shown in [1], then it must verify that
If we set these values
then Equation (19) can be expressed as
where m represents the relative marginal cost difference.
2.2. Local Stability
In this section, we analyze the local stability of the equilibrium points for all the values of , positive and negative, taking into account the new conditions, and , and considering two different zones in this study: and . When , as is shown in [1], the fixed point is stable and gives the stability condition of the system:
with the equivalences mentioned in Equation (20), we can simplify as follows:
To study the stability when , it is necessary to usethe Jacobian matrix J of Equation (11), which can be expressed as
We start with the analysis of the stability of the second equilibrium point . The Jacobian matrix Equation (24) at this point can be written as
The characteristic polynomial can be expressed as
where and represent the trace and the determinant of the Jacobian matrix and are given by
At this point, the Jury criterion can be applied to analyze the local stability of the second equilibrium point , checking these three conditions:
The first condition can be written as follows, taking into account Equation (27)
which is never satisfied when . Then, it is not necessary to verify the other conditions to prove that the fixed point is unstable for . Now, considering the first equilibrium point , the Jacobian matrix Equation (24) in this point can be calculated as
There are two eigenvalues of the Jacobian matrix :
The equilibrium point will be stable if the modulus of both eigenvalues are less than 1. Since is one of the assumptions mentioned previously in the model, it is clear that . Considering the eigenvalue , the condition is satisfied for when it verifies
This compound inequality can be divided into two parts and it results in
When , according to the condition , Equation (35) is always verified if
or for the same, . Additionally, if we isolate in Equation (36), then we have
Therefore, the first equilibrium point is stable when Equation (38) is verified, in contrast to the case , described previously in [1], where this fixed point is unstable. It is also proved that, having , the stability region is bigger when increases.
Since in the non-memory model with the stability condition is , we can express as a function of , as follows:
Thus, having and , it is proved that the stability region in the game with memory is bigger than in the non-memory game in every value of the quantum entanglement , assuming the same conditions. As a conclusion, it can be stated that the system is stable for the values of which verify the following expression:
This expression can be simplified as follows:
where and can be expressed as
It is shown that the stability is greater in the negative than in the positive zone because it always verifies that , independently of the value of and considered.
It is important to obtain the values of m and where this study is valid (economic meaning). In , as we mentioned in Equation (21), due to the economic meaning of the Nash equilibrium, the expressions and must be positive. On one side, is always verified when and but, in contrast, when , this expression can be positive, negative, or zero depending on the value of . At this point, we calculate the value of where to establish the limit between the negative and positive values of this parameter. This particular value of , called , can be expressed as follows:
From , we can deduce the positive and negative region of when :
On the other side, is always verified when , but, on the contrary, it does not happen when . Then, we obtain the value of , called , where , as we obtain in the previous case:
From , we can deduce the positive and negative region of when :
Therefore, in , the study of the stability of this section is only valid for these values:
In , to ensure that the Nash equilibrium point has economic meaning, the value of Equation (15) must be positive. As and , it verifies that the denominator is always positive. Considering the numerator of the equation, since when , then it must be or forthe same , which is always true. As is shown in Equation (37), the condition is necessary for the stability of . This condition is always verified when and , but, in contrast, when this expression can be positive, negative, or zero depending on the value of . At this point, as we calculated previously, the value of where establishes the limit between the negative and positive values of this expression. This particular value of , called , is expressed in Equation (45). Therefore, in , the study of the stability of this section is only valid for these values:
3. Numerical Simulation
On this basis, we use numerical simulation to study the effect of memory in the system and graphically support the results analytically obtained throughout this paper. We consider the previous simulations carried out in [1] as a starting point and, as is described within, two different zones are included in this study: and . Under these premises, memory is applied to the quantum game to observe the variation of the stability and dynamical behavior of the system, with special attention given to the values and .
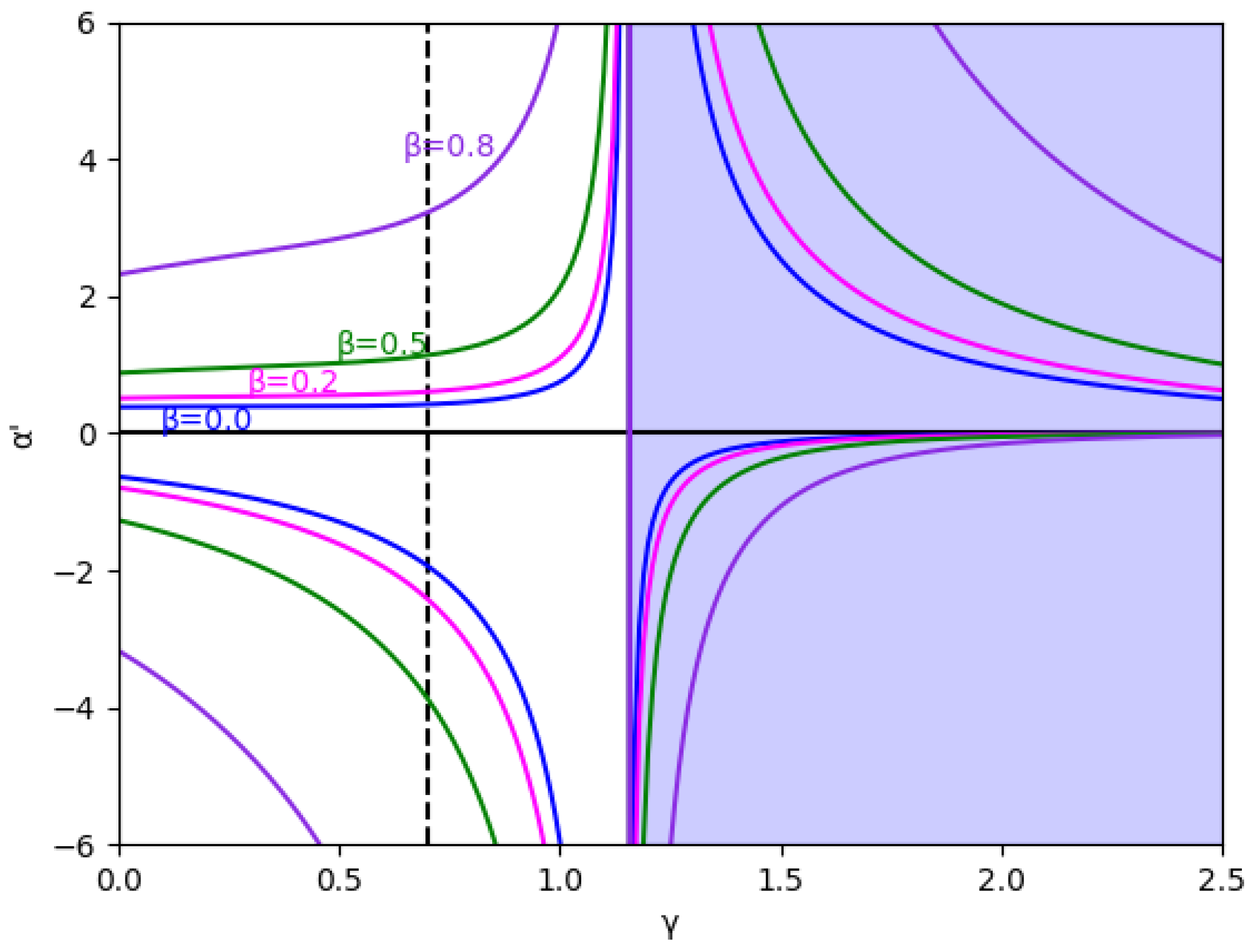
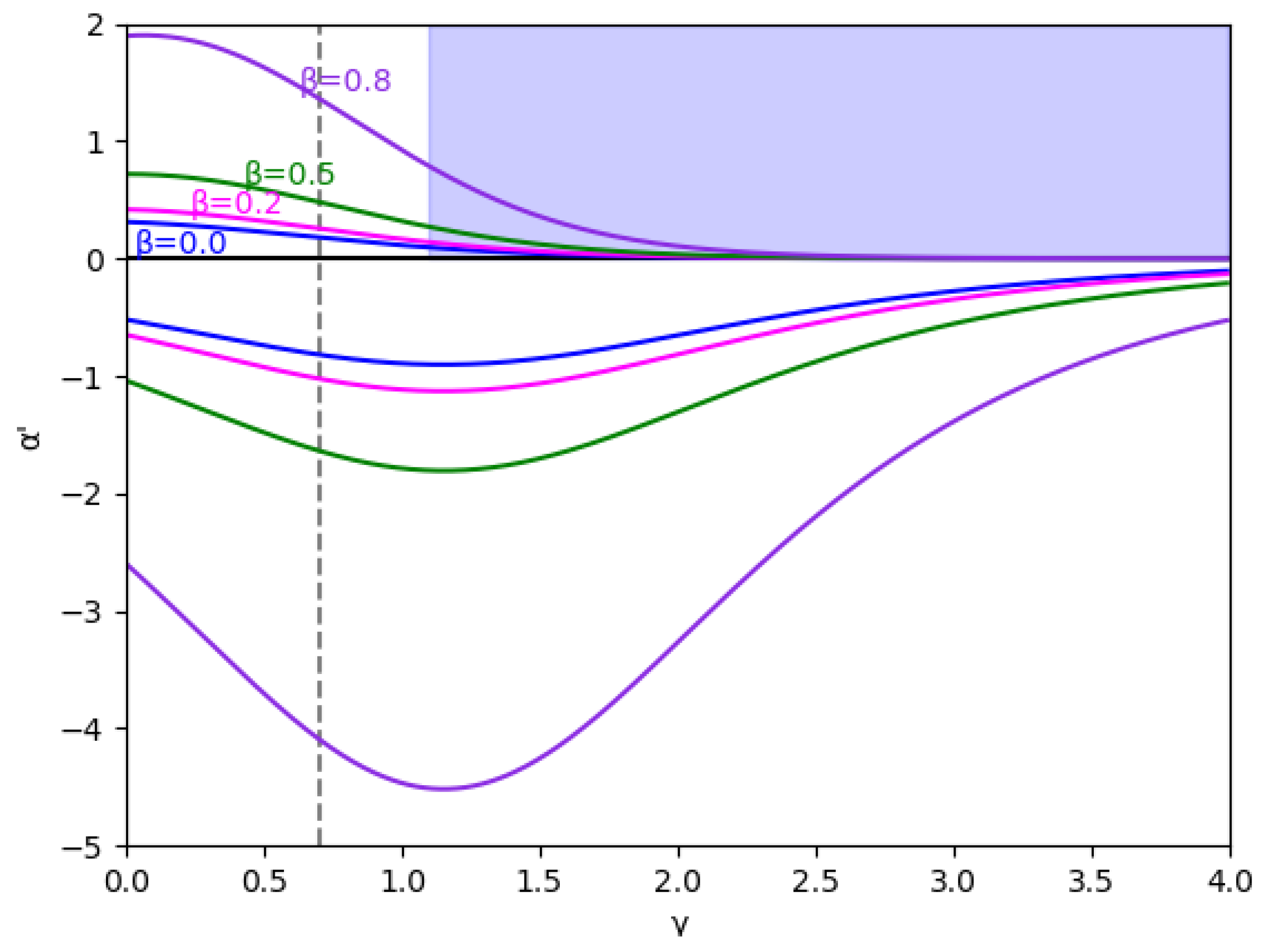
At first, the region is analyzed, considering the value (we set ) without memory in Figure 1 and with several values of the memory factor, (0, 0.2, 0.5, and 0.8) in Figure 2. These figures show that the stability is greater in negative values of than in positive ones for every specific value of and , and the stability region increases with , both in negative and positive values of .
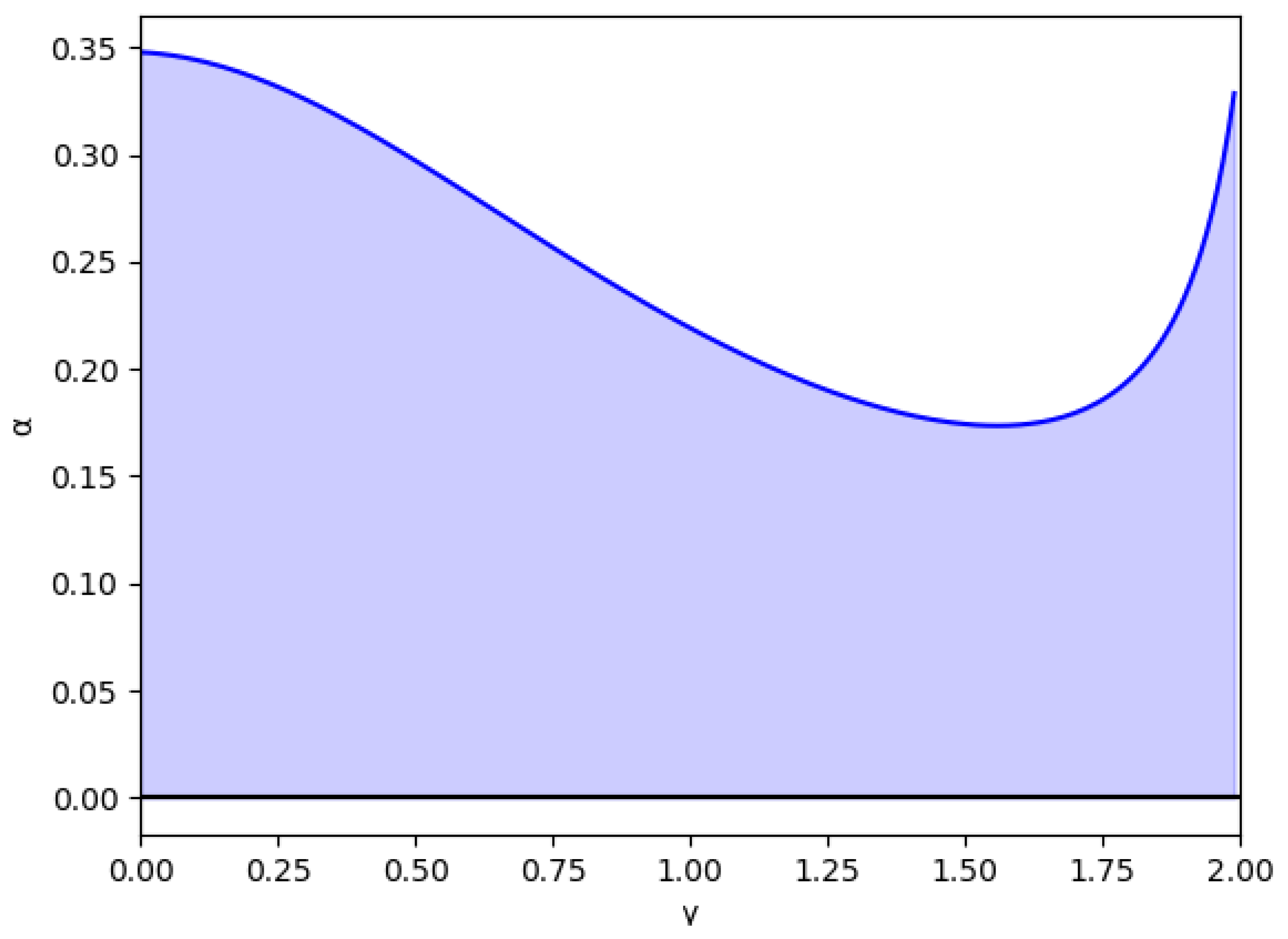
Due to its mathematical importance, the region without economic meaning is also represented by a blue shaded area, i.e., , where in this example, according to Equation (45). Apart from being the edge between both regions, there is an asymptote in , which can be deduced from the inequality Equation (41) because the denominators cancel out since it verifies in this point. It is relevant that the equilibrium of the fixed points is inverted when due to the sign change of the expression , as is shown in Equation (46).
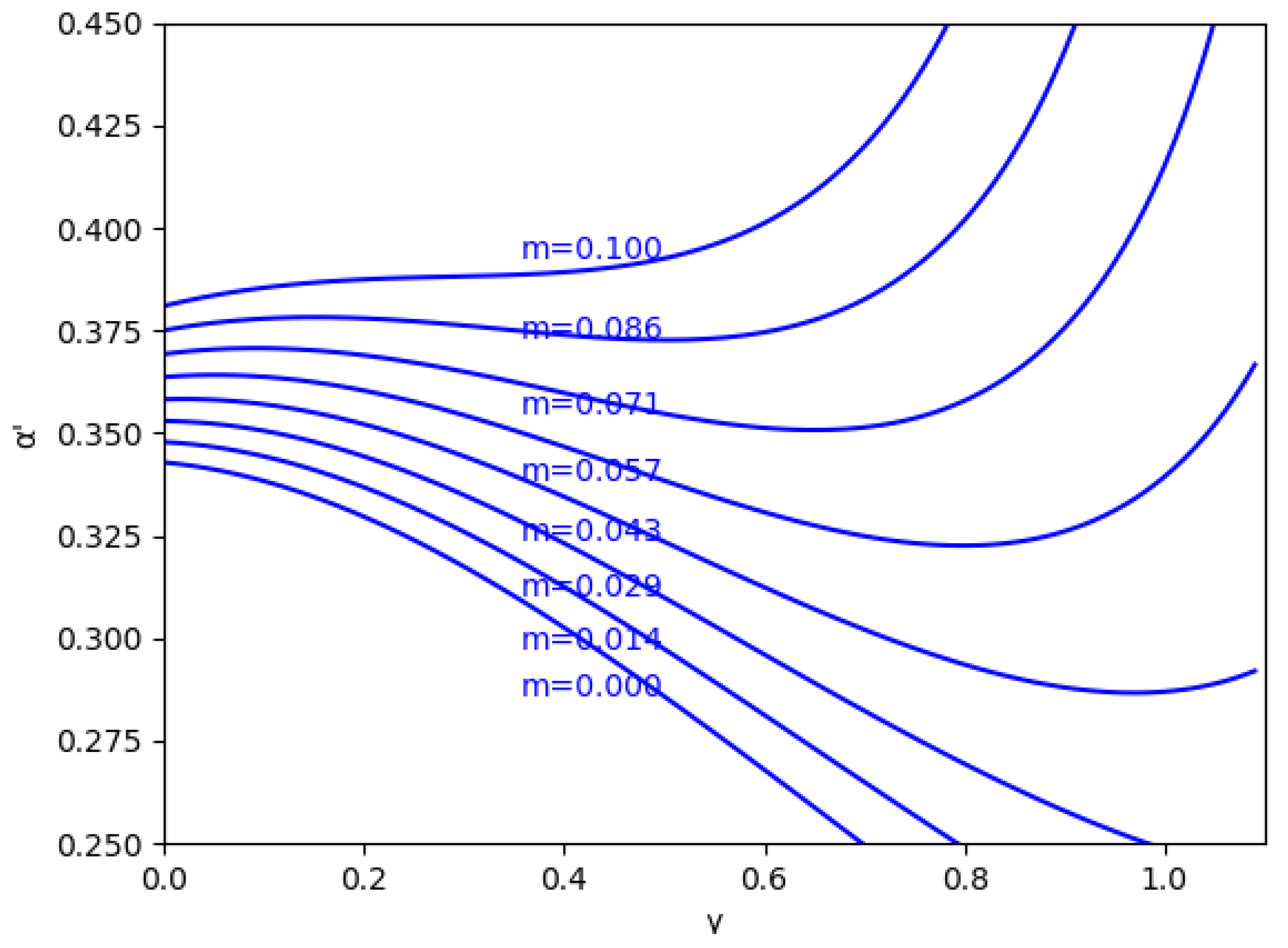
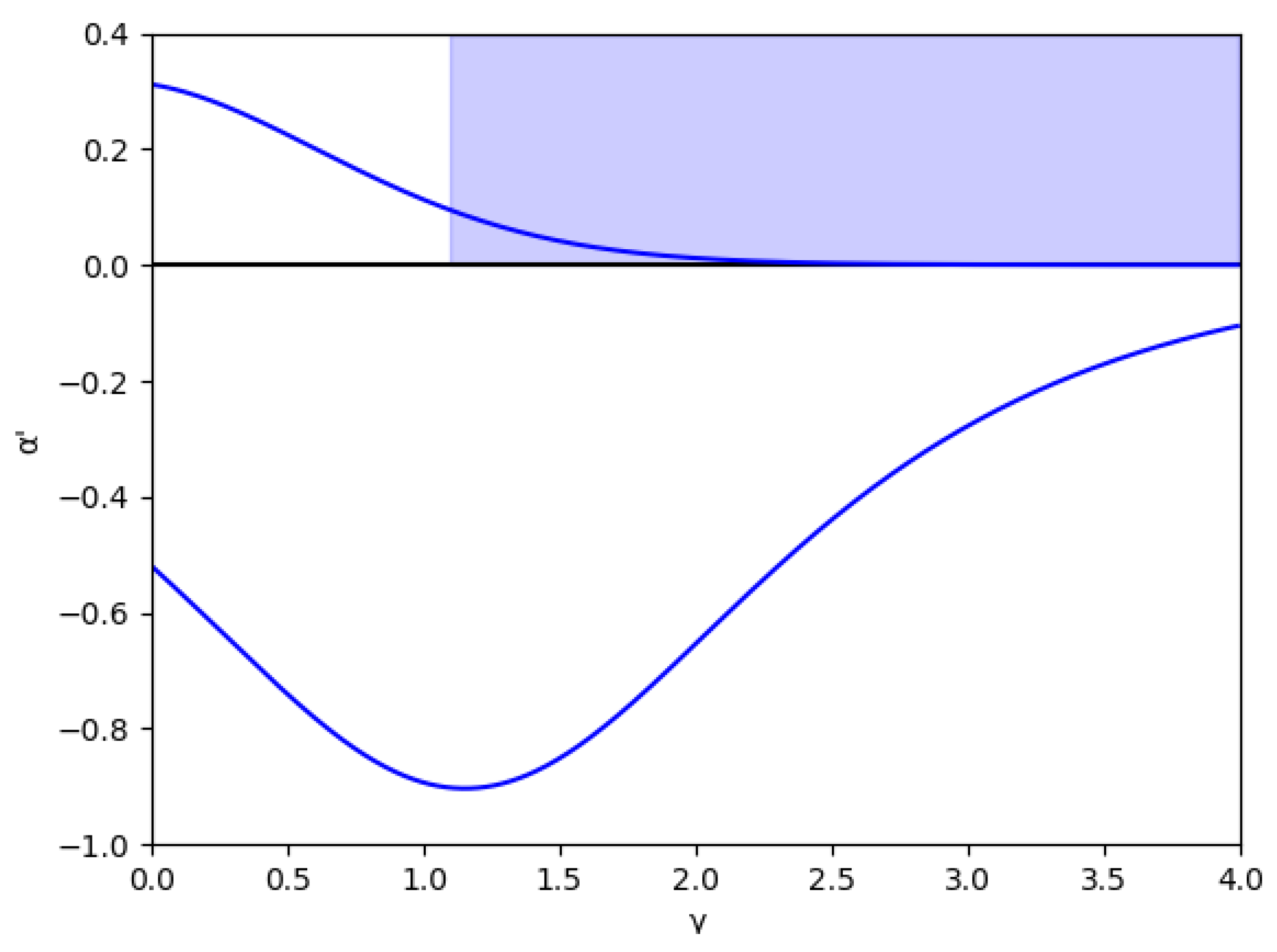
In these figures, it is also shown that for negative values of , if increases, the stability zone is greater because the modulus of increases up to this asymptote in , and it has the same behavior than the case of positive values of . This verifies up to a point because there is an exception when the value of the relative marginal cost difference m is between 0 and 0.1. As can be seen in Figure 3 with the example , there is a range of values of where decreases when increases, which means that the stability zone is smaller in these values. Likewise, Figure 4 shows that from to there is a range of values of where decreases when increases.
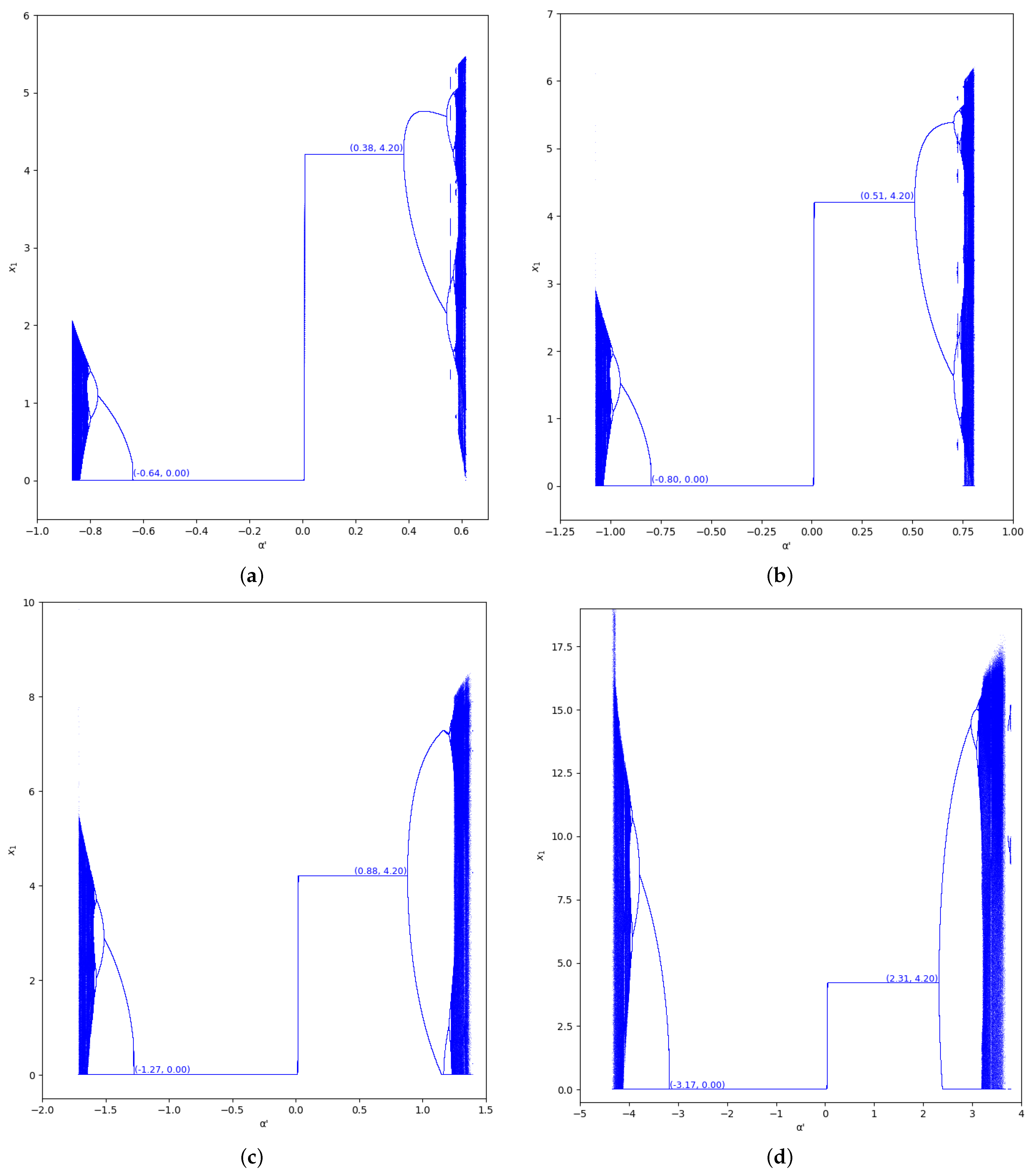
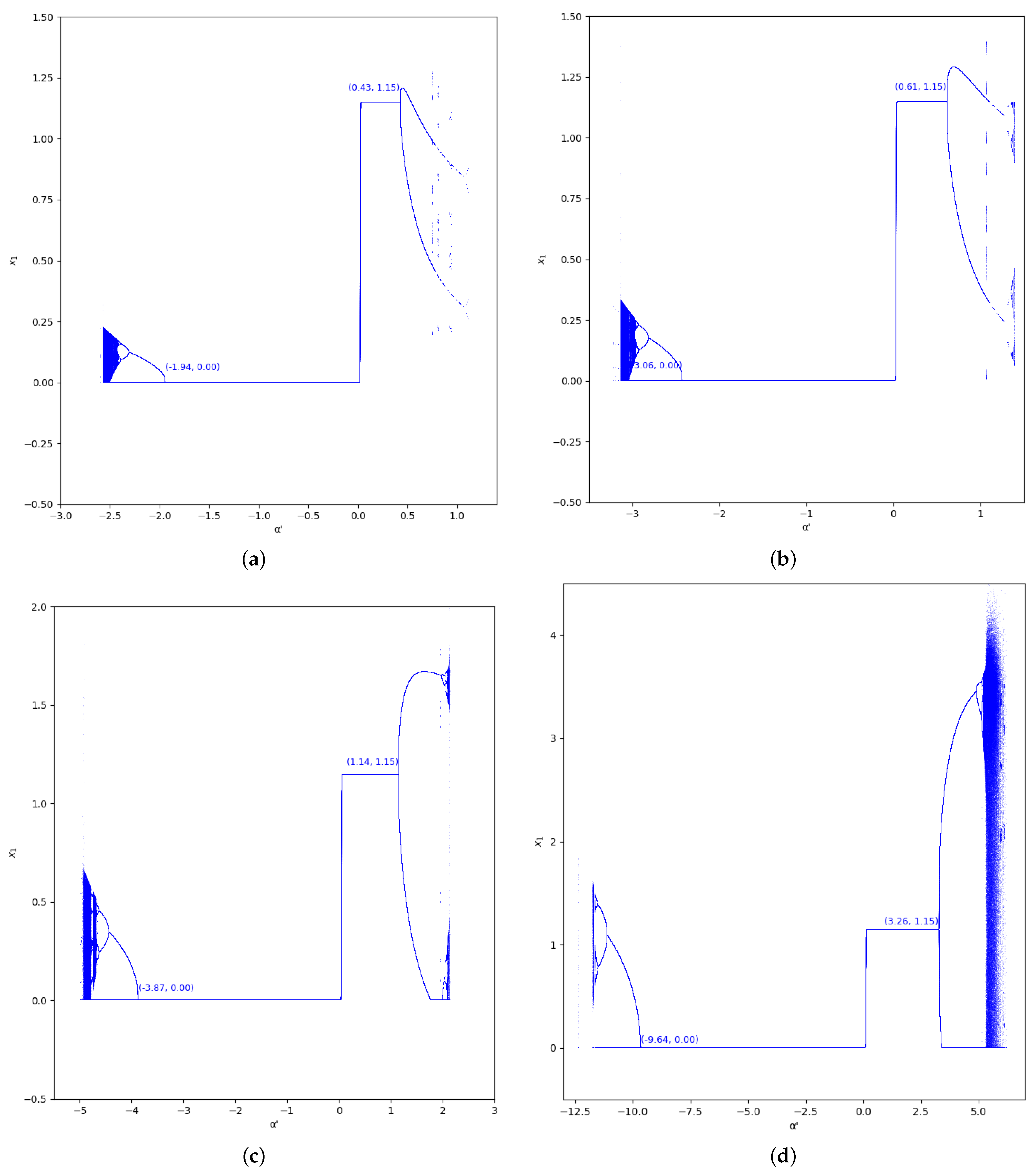
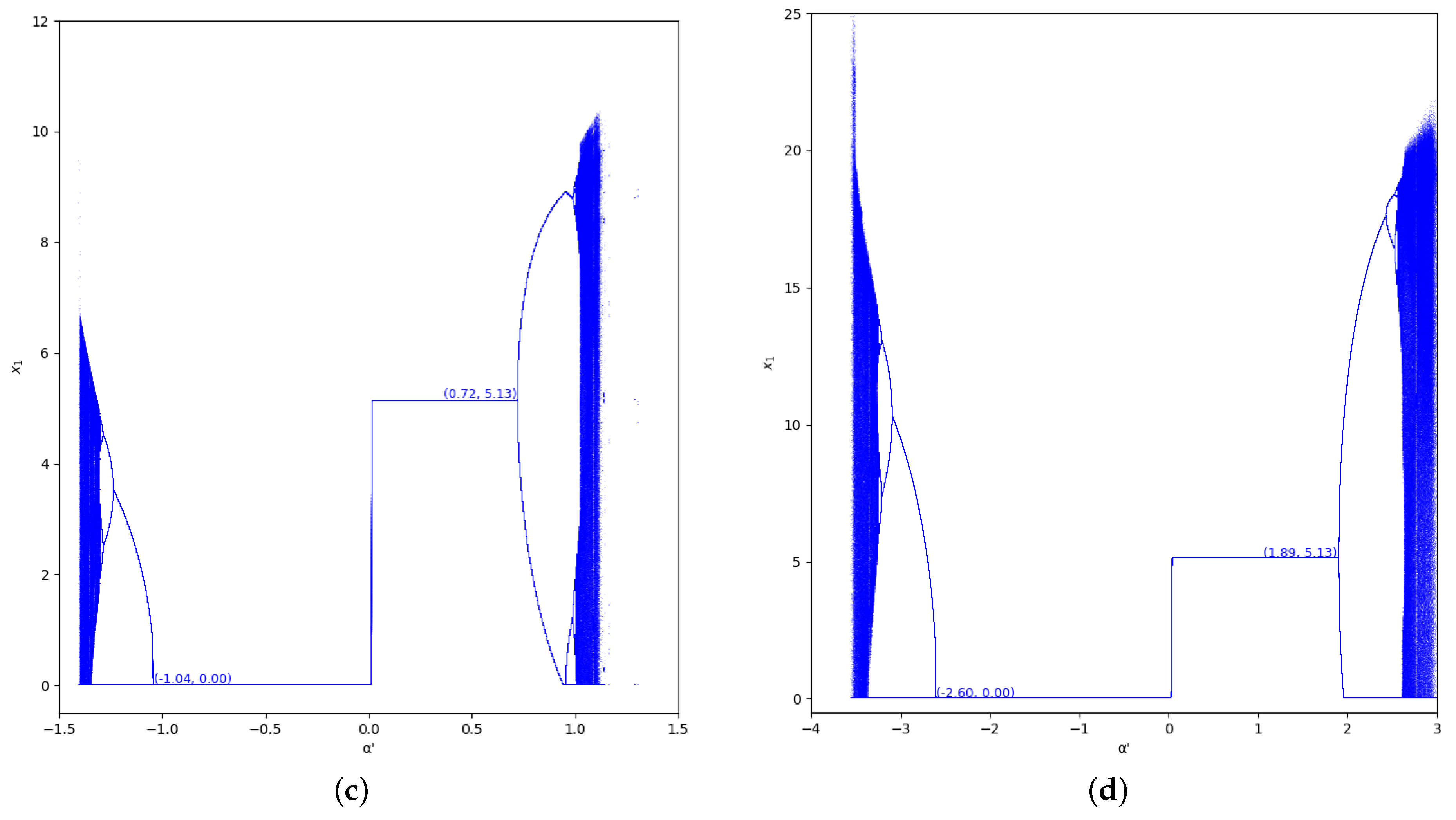
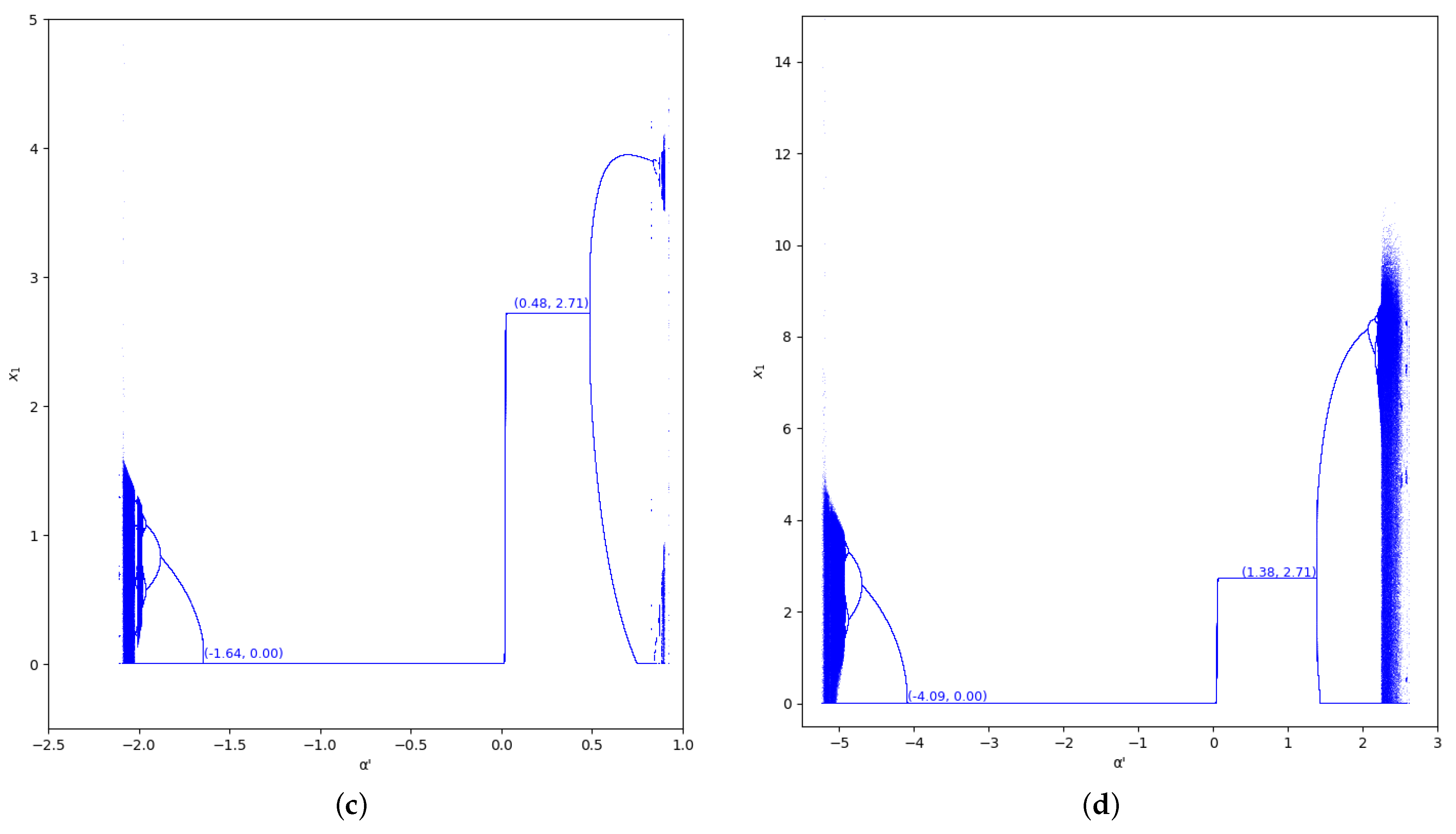
The bifurcation diagrams of output of the first player are also represented for the values and in the region , considering (we set , ) in Figure 5 and Figure 6. In these figures we show the increase of stability for when the value of is greater, as well as for .
Secondly, the local stability in the region for (we set ) without memory is represented in Figure 7 and with several values of the memory factor, (0, 0.2, 0.5, and 0.8) in Figure 8. As we previously mentioned, it can be seen that the stability is always greater in the negative zone for every and considered, and the stability region increases with , both in negative and positive values of .
Similarly to the previous region of study, the zone without economic meaning, where considering Equation (47), is also represented in the figures because it is interesting from a mathematical point of view. In fact, a minimum in the negative zone of can be observed, which corresponds to a stability maximum in this zone. To calculate the value of for this maximum, we can substitute the expression into Equation (39), and simplifying, we obtain
Then, the stability maximum is given by the derivative of the right term of the inequality equals zero:
Since the term is always positive, the value of the maximum, , can be obtained from the expression , which results in
It is shown that it is really a minimum because it verifies the second-order condition, i.e.,
replacing for this of Equation (53), and , it can be verified that the result is positive:
We can observe the coincidence of the expressions of where and where , given by Equations (45) and (53), respectively. Therefore, we can write the following equation:
Regarding the variation of the stability with , the behavior is different when is negative and , the stability zone is greater as increases in contrast to the case of positive, where the stability zone decreases as increases. In this sense, considering the stability zone, the results obtained for when is negative are better than in the same case when is positive.
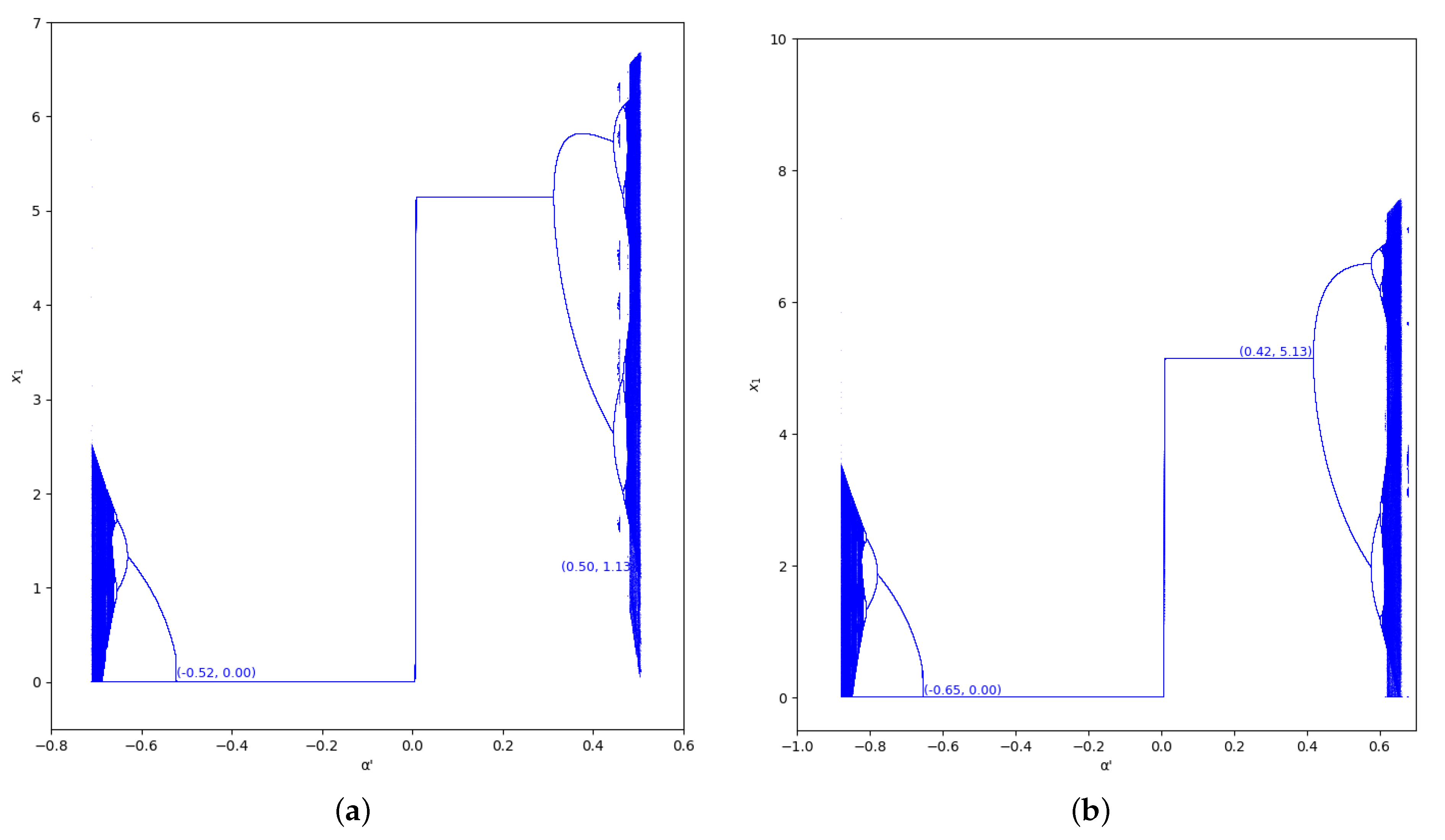
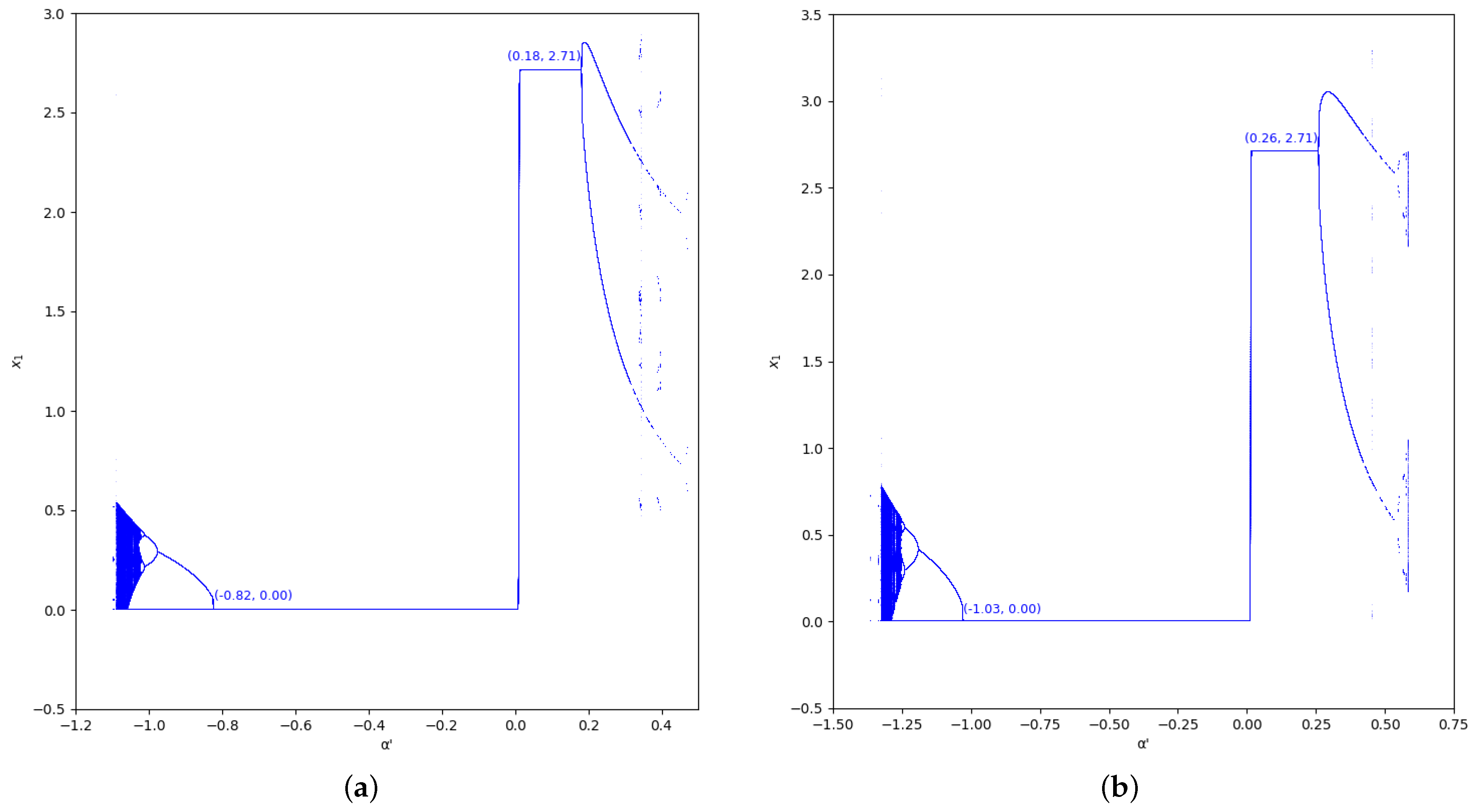
As happens in the previous region considered, the bifurcation diagrams of output of the first player for the values and in the region , with (we set ), are also represented in Figure 9 and Figure 10. In these figures, the increase of stability is shown for when the value of is greater, as well as for .
4. Profit
From the point of view of the quantum profit, we study the behavior of the benefit with and without memory with different values of the quantum entanglement . We start from the quantum profit Equation (3), considering that there is not memory in , then the quantum profit of the two firms can be obtained, replacing the initial value of both firms in Equation (3). After that, in is found from Equation (10), with being the initial value of the i-firm. With these values of , we can resolve the quantum profit of both firms in , again with Equation (3). Repeating the process, we can find of both firms in with Equation (10), being . With these values of , we can resolve the quantum profit in with Equation (3). For , we can resolve the values with Equation (10), calculating from Equations (7)–(9). With these values, , the value of in can be resolved and so on to the next interaction of time.
4.1. Without Speed of Adjustment of the Boundedly Rational Player ()
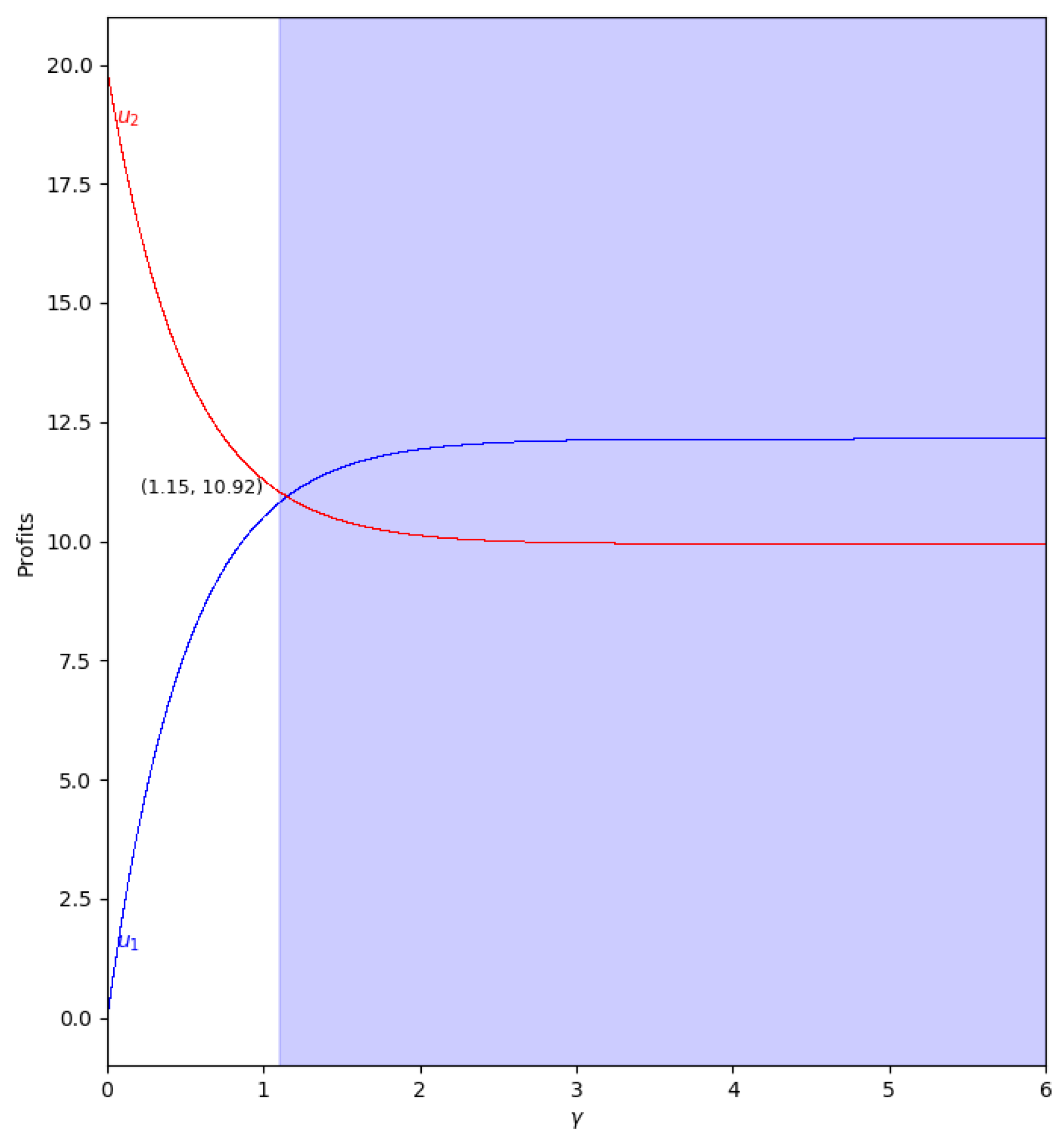
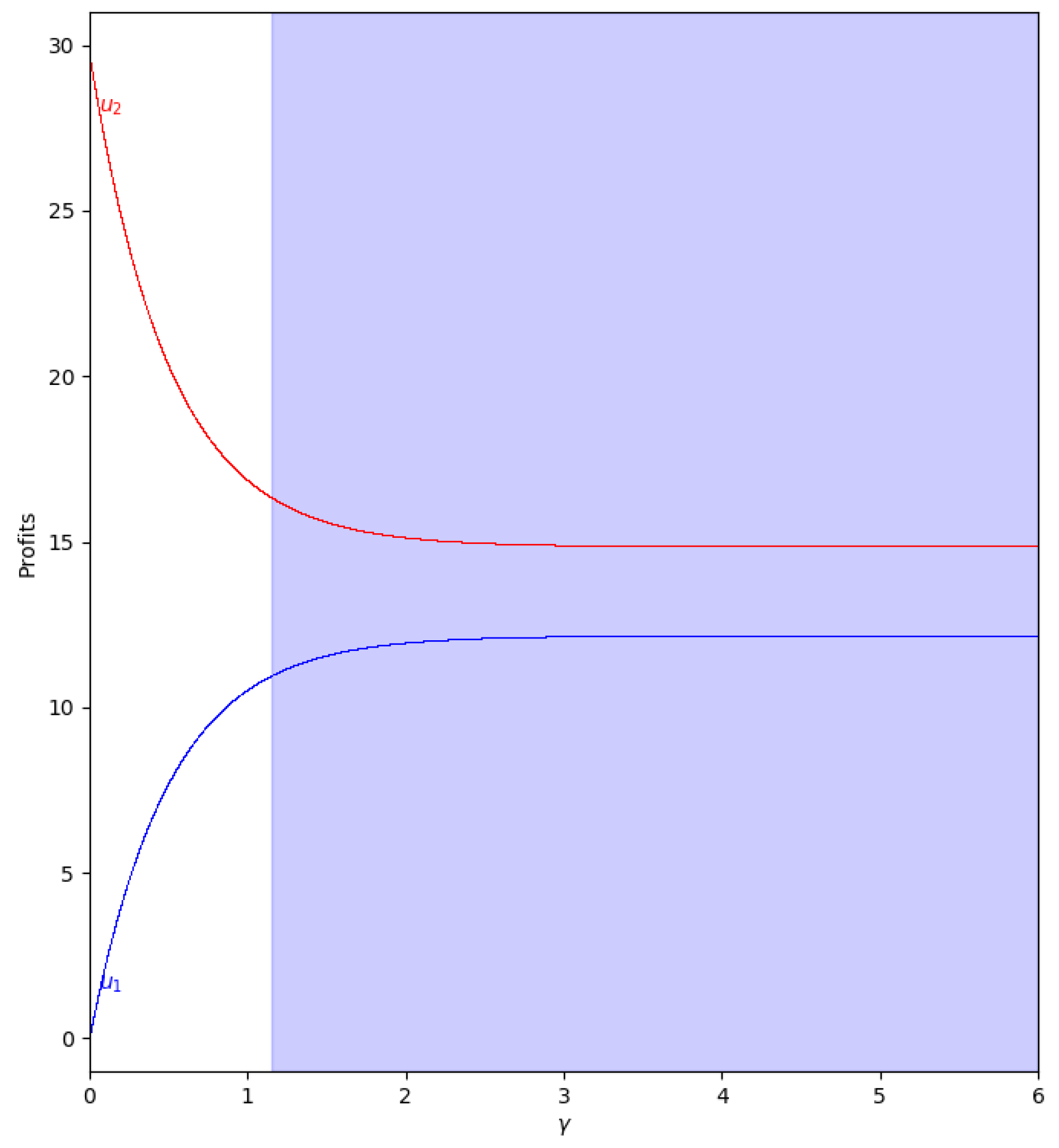
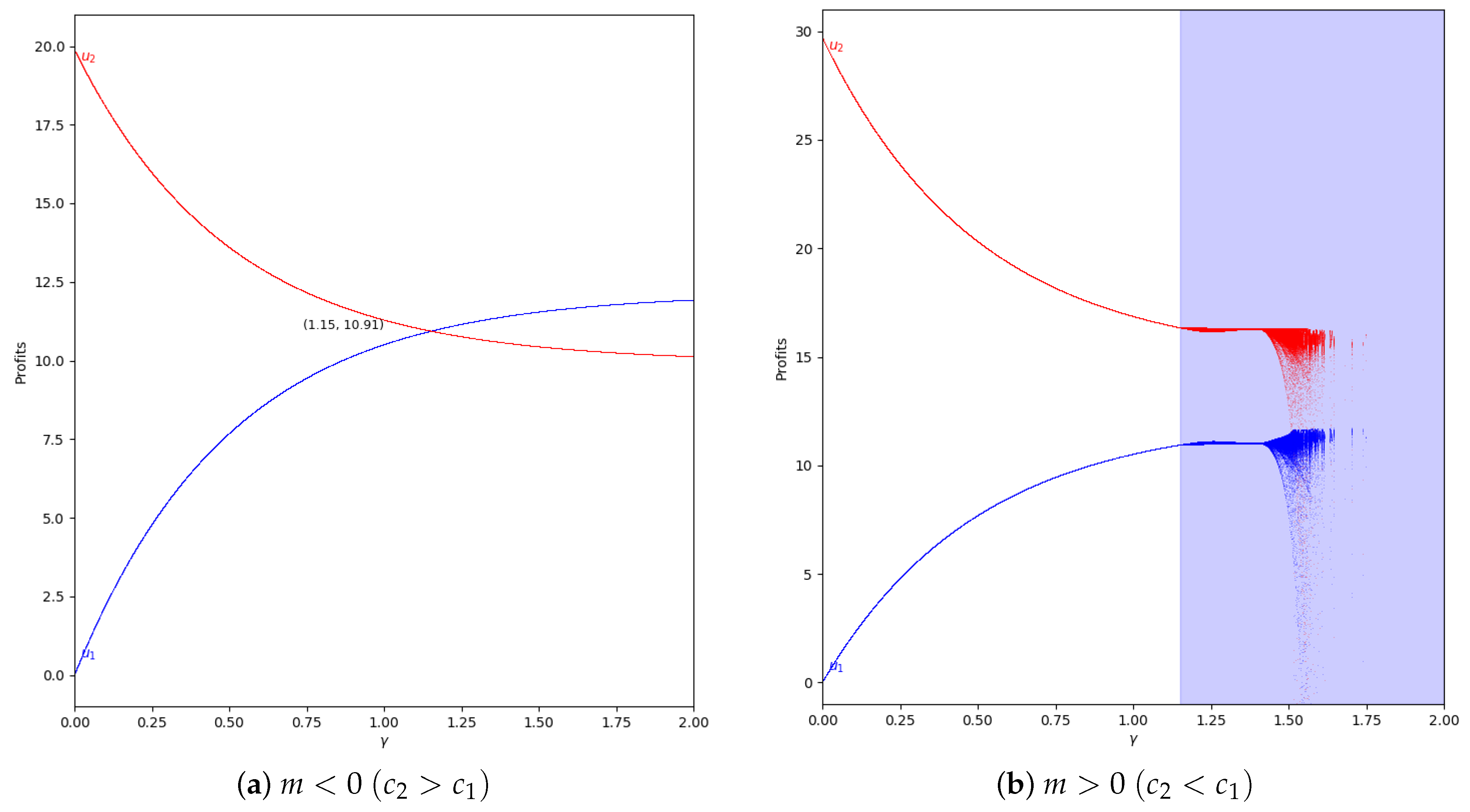
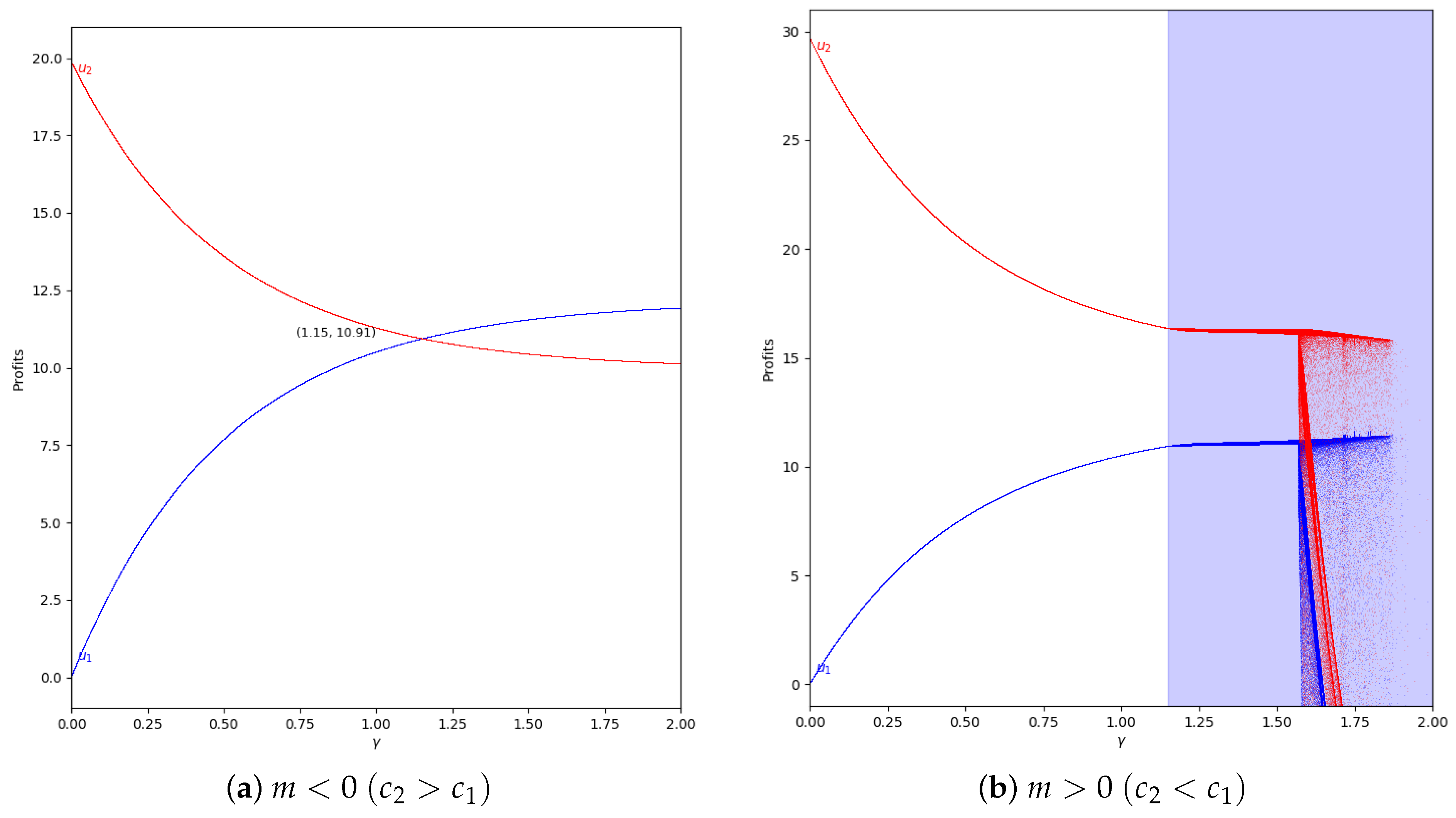
When there is not speed of adjustment of the boundedly rational player (), the values of the quantum profits of both players are the same with or without memory. First of all, we represent the behavior of the quantum profit without memory of the two firms as a function of the quantum entanglement in the two cases, with and . With (, the cost of player 2 is greater than the cost of player 1), the quantum profit of the two firms with different can be seen in Figure 11, where the quantum profit in player 1 is lower than in player 2 when (classic game). As the value of the degree of quantum entanglement increases, the quantum profits of both players move closer to the value of equal to 1.15, where both quantum profits are equal to 10.92. Due to the economic meaning of the game, this point is never reached because the value of has to be less than 1.09 according to Equation (47).
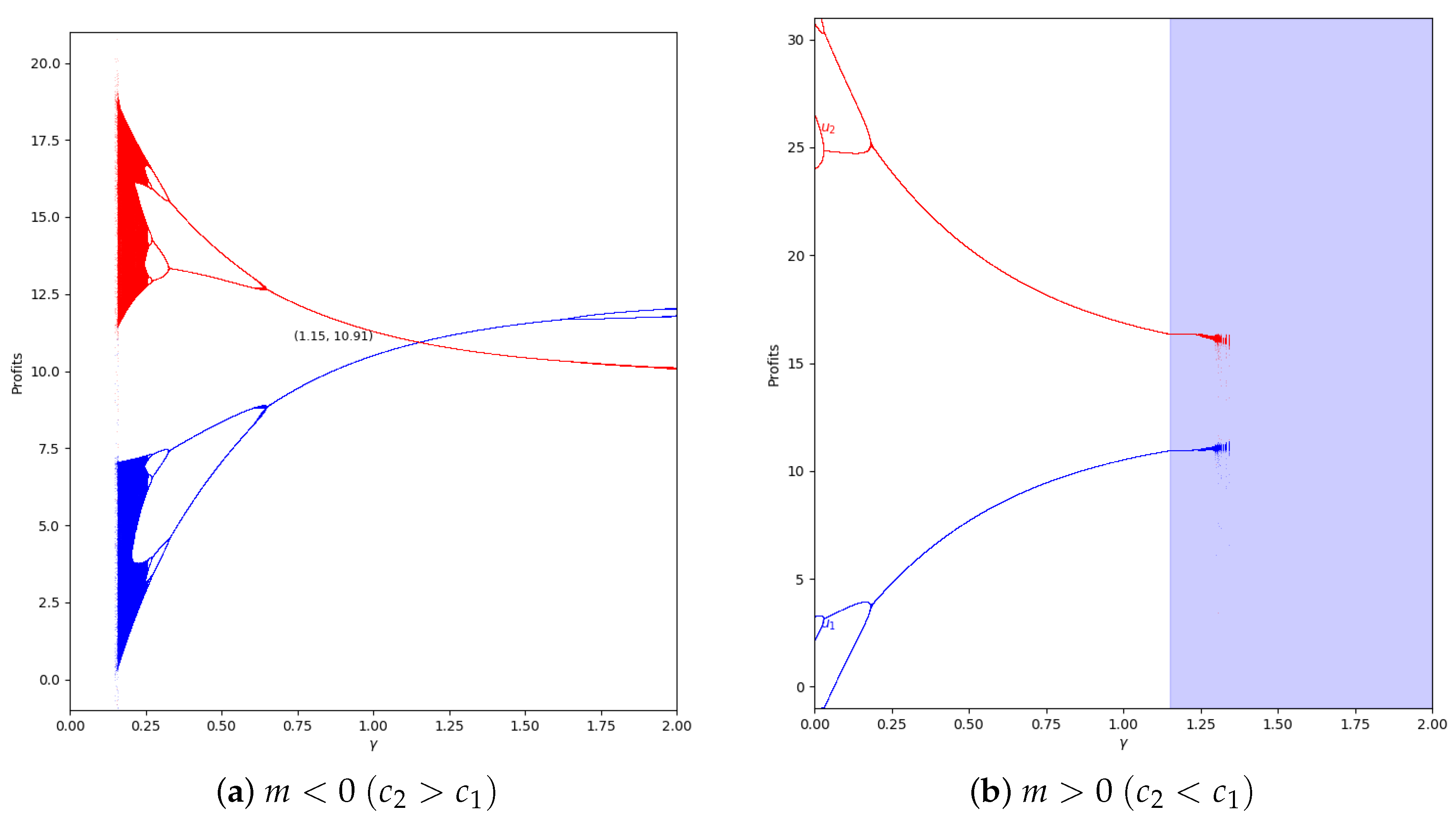
With (, the cost of player 1 is greater than the cost of player 2), the quantum profit of the two firms with different is shown in Figure 12, where the quantum profit in player 1 is lower than in player 2 when (classic game). If the value of the degree of quantum entanglement increases, the quantum profits of both players move closer but the profit of player 2 is always greater than the quantum profit of player 1. As in the previous case, when , the values have no economic meaning according to Equation (45).
4.2. With Positive Values of Speed of Adjustment of the Boundedly Rational Player ()
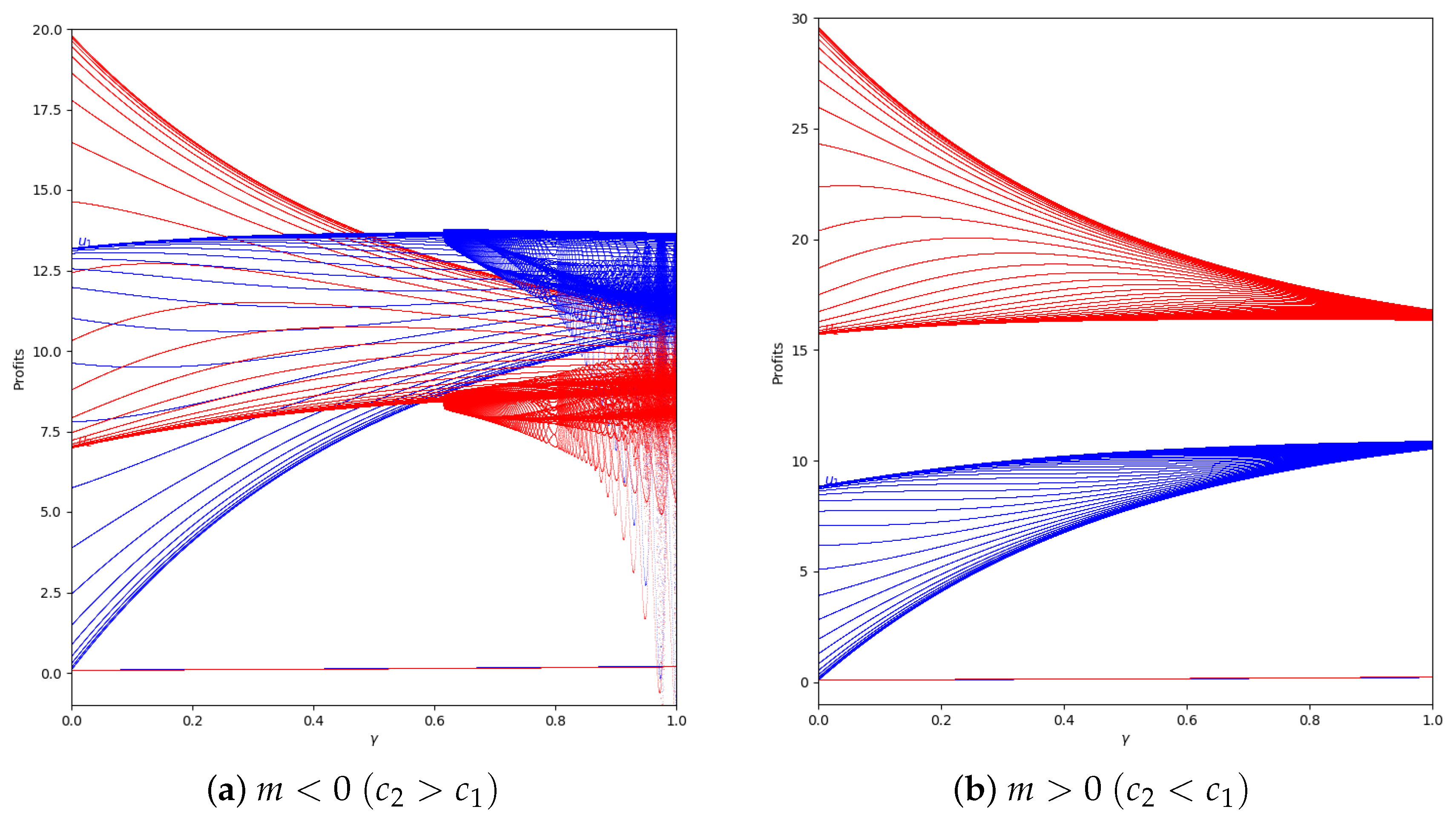
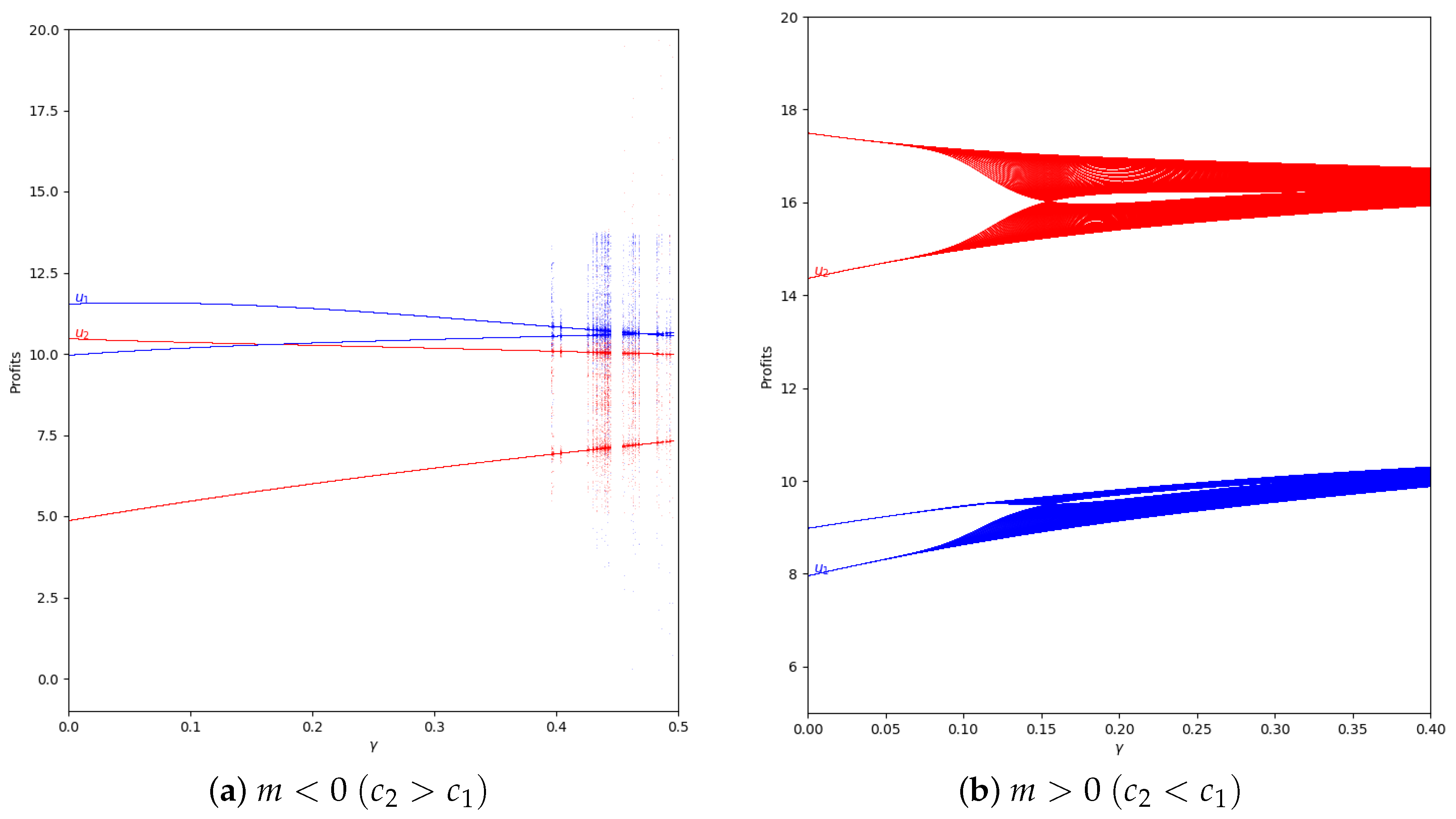
We study the behavior of the quantum profit with positive values of the speed of adjustment of the boundedly rational player (). We start with and without memory in two cases, with and with , representing them in Figure 13.
As is shown, if we remove the first 50 iterations, the quantum profit tends to be stable except when the value of is high, as can be seen in Figure 14.
In the system with memory (), the chaotic effect observed in high values of is delayed, as can be seen in Figure 15.
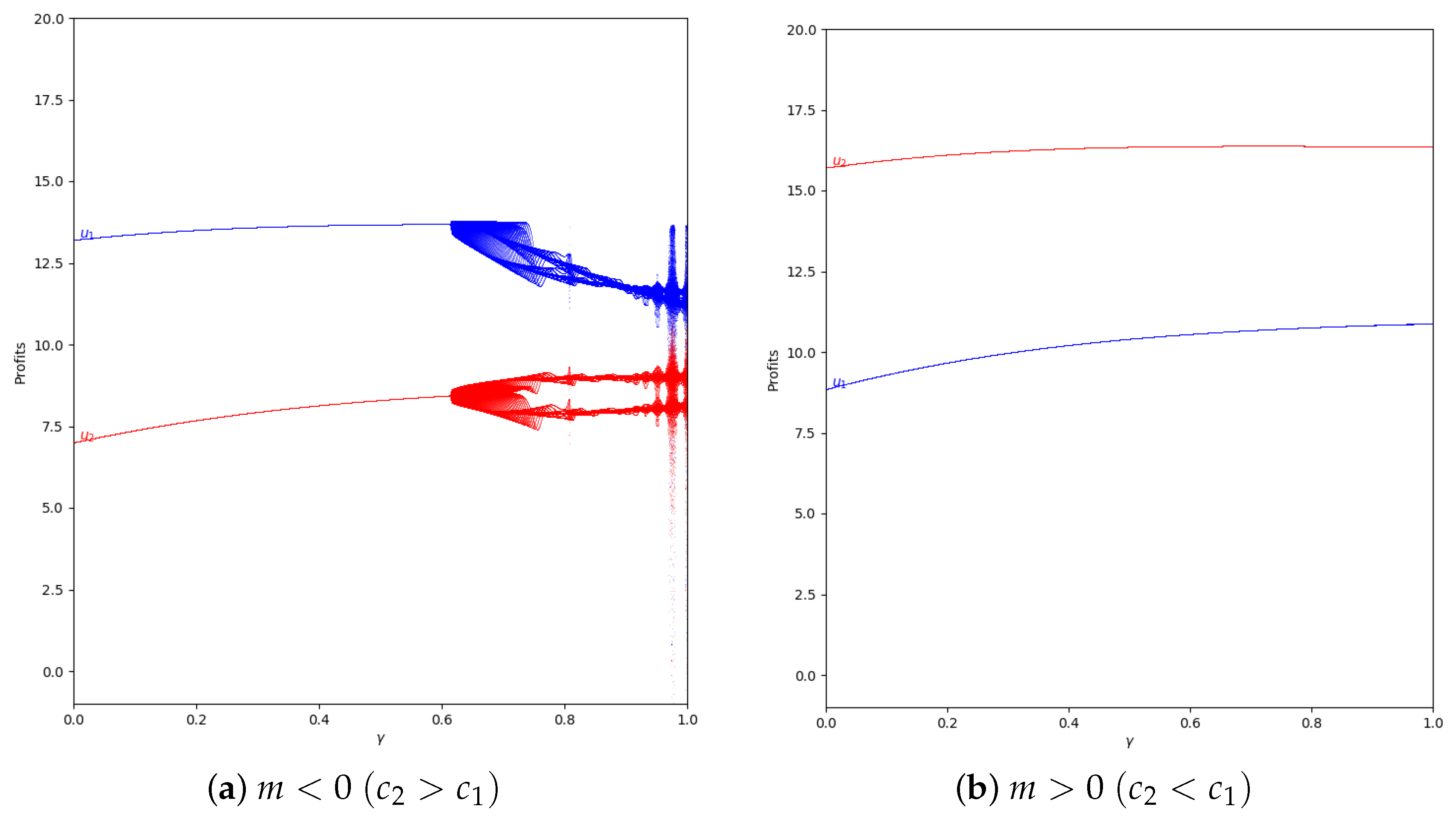
When increases, and, therefore, the quantum profit are outside the stability zone. Then, the profits can have different values in t and in . The profits can vary between two or more values if the system is in the chaotic zone, as can be seen in Figure 16.
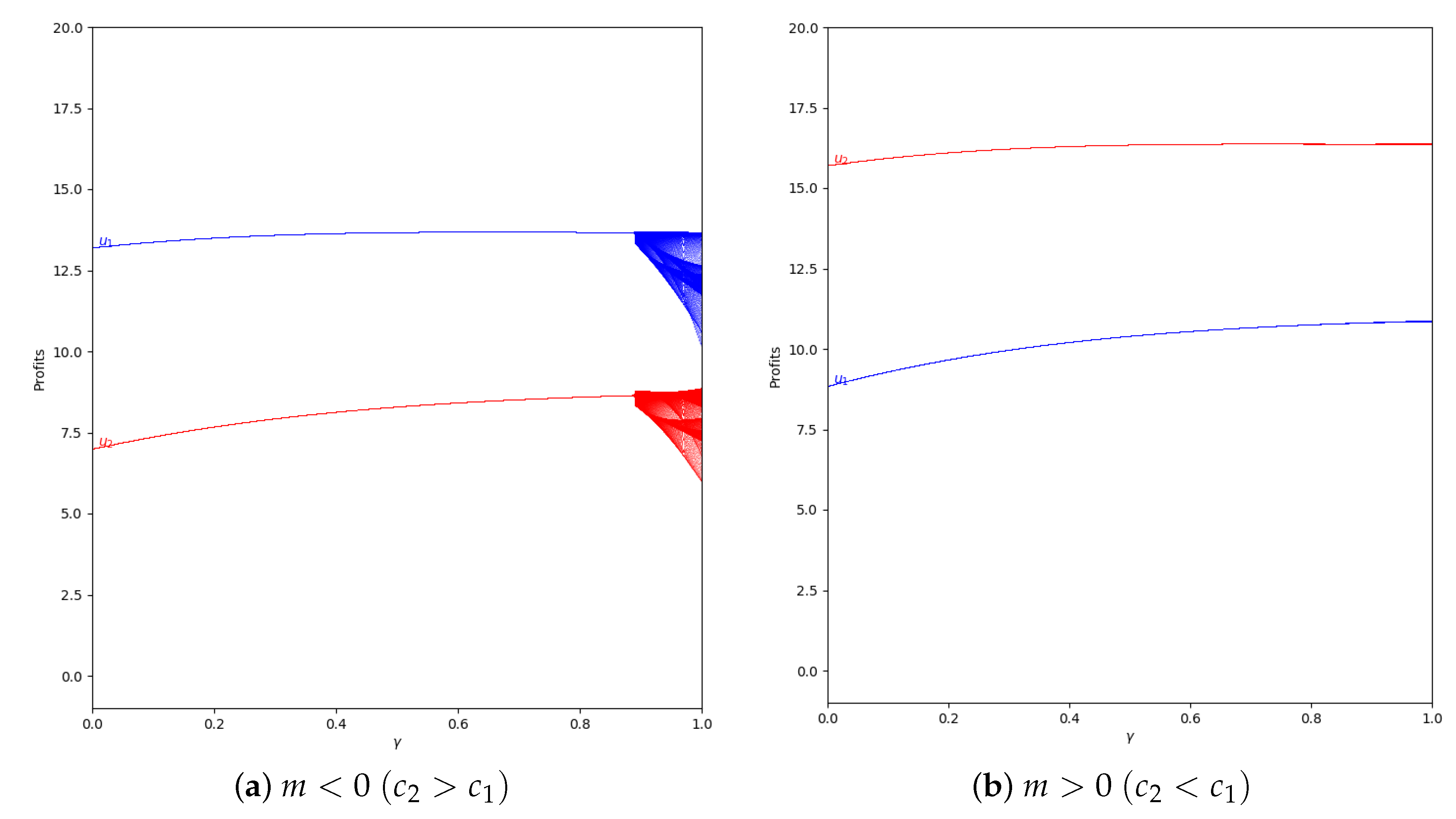
Considering the same value of and applying a greater value of memory (), we can see that the quantum profits do not vary between two or more values because the system is in the stability zone, as is represented in Figure 17.
4.3. With Negative Values of Speed of Adjustment of the Boundedly Rational Player ()
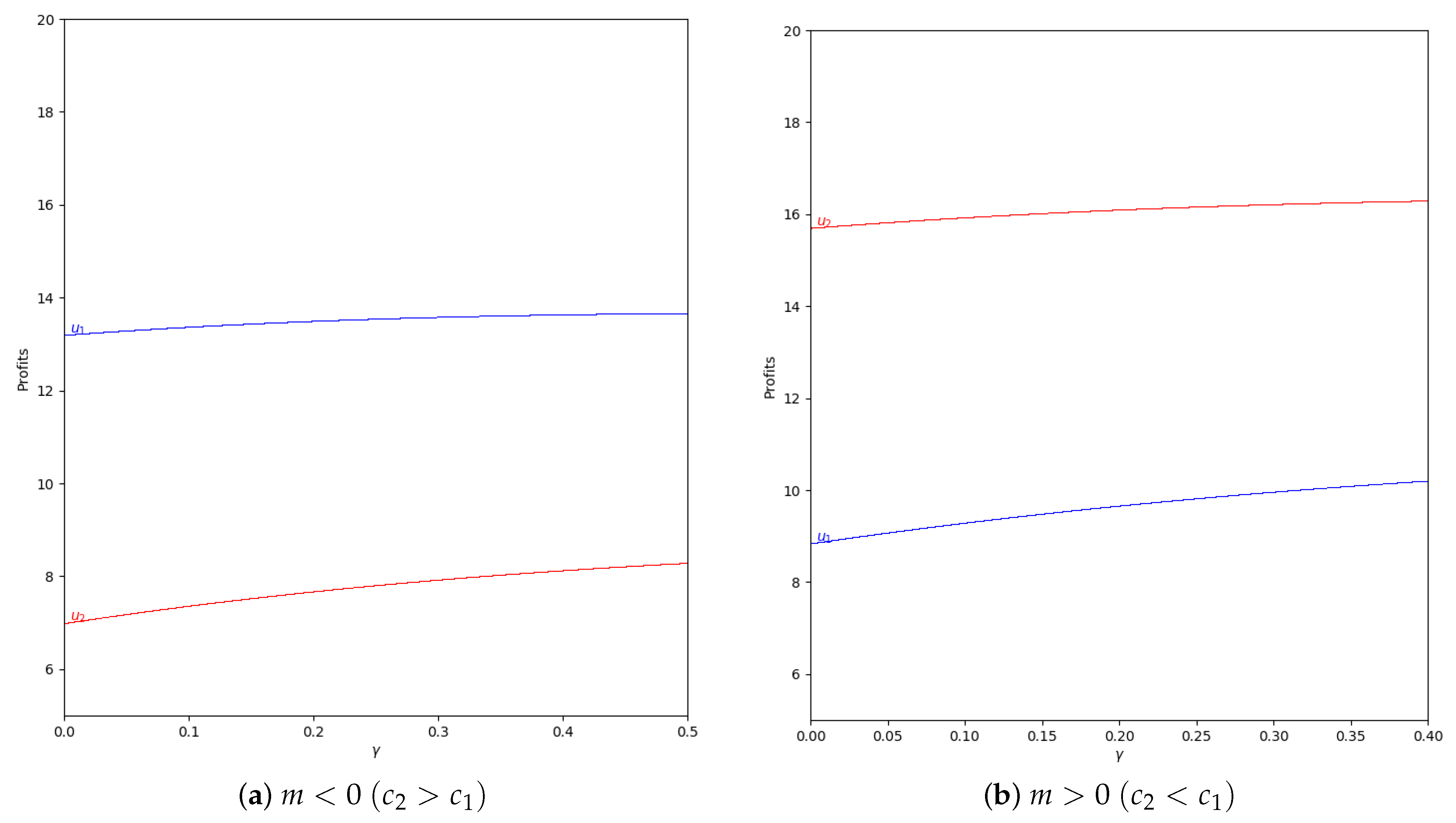
The next step is analyzing the behavior of the quantum profit with negative values of the speed of adjustment of the boundedly rational player (). Initially it is considered that and there is absence of memory in both cases, with and with , as is shown in Figure 18.
As can be seen, the behavior is the same as if there is not speed of adjustment of the boundedly rational player, as in Figure 11 and Figure 12. That means that the effect of memory is the increase of the stability zone, delaying the presence of chaos.
Taking into account the Equation (50), in , when all values of are valid and therefore, there is a point in where the quantum profits of both players have the same value and are equal to 10.91. However, when you increase , player 2 has more profit than the player 1. In only the values of are valid regarding to the Equation (45).
At this point, we increase the value of the speed of adjustment of the boundedly rational player to without applying memory. Then, the behavior is similar to the case with except in values of near 0, because the system is in the chaotic zone as can be seen in Figure 19. This is because it is outside of the stability zone, as is shown in Figure 2 and Figure 8.
If we add memory to the system, the stability zone increases and the profits do not vary chaotically, as happens in the example with and , which can be seen in Figure 20.
5. Conclusions
In this paper, we analyzed the effect of memory in a dynamical Cournot duopoly game with heterogeneous players (one of them is boundedly rational and the other one, a naive player), applying a quantum scheme when the quantum entanglement () has values greater than one and the speed of adjustment () is negative. We consider these special and unusual values of the parameters to study the behavior of local stability and profit in this case, in contrast to the conventional values. In all this analysis, we only took into consideration the cases with economic meaning, obtaining the values of the parameters where the study is valid. Additionally, to analytically verify the statements, we represented them graphically and we performed some numerical simulations to visualizethe results obtained.
Considering a negative speed of adjustment, it is proved that the stability zone in the game with memory is greater than in the classic game and it also increases when the memory factor is greater, as happens with a positive speed of adjustment. It verifies that the stability is greater in the negative than in the positive zone of the speed of adjustment, improving, in this sense, the results previously obtained.
Regarding the variation of the stability with , when the relative marginal cost m is positive and is negative, the stability zone increases if increases. This is the same behavior previously observed when is positive, except in the interval of m between 0 and 0.1, where the stability decreases as increases. Considering the case where and is negative, the stability zone is greater as increases. This is the opposite behavior to the case of positive values of , where the stability decreases as increases. This increase of stability when enables the model to reach Nash equilibrium faster as the speed of adjustment increases, reaching the equilibrium payoff in fewer steps, compared to the case of .
In the analysis of the profit, when , it is shown that the memory has no influence on the results and it is observed that the profit of both players tends to move closer, but there is not a point of coincidence of both profits in the zone of economic meaning. In the cases with and , the memory influences the results in the sense of causing a delay in the dynamics.
In summary, it can be considered that the results obtained with speed of adjustment less than zero and degree of entanglement greater than one in some of the analyzed cases improved the previous ones, which shows progress in this area. As we mentioned, we focused on the economic field, but we hope this study can also be useful in other fields.
Author Contributions
Conceptualization, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Formal analysis, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Methodology, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Project administration, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Software, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Supervision, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Validation, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Writing—original draft, L.G.-P., J.G.-C., R.A.-S. and J.C.L.; Writing—review & editing, L.G.-P., J.G.-C., R.A.-S. and J.C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Spanish Grant PID2021-122711NB-C21. The computations of this work were performed in FISWULF, an HPC machine of the International Campus of Excellence of Moncloa, funded by the UCM and Feder Funds.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Grau-Climent, J.; Garcia-Perez, L.; Alonso-Sanz, R.; Losada, J.C. Effect of memory in a nonlinear dynamical of a quantum Cournot duopoly game with heterogeneous players. J. Phys. A. 2022; submitted. [Google Scholar]
- Cournot, A. Récherches sur les Principes Mathématiques de la Théorie des Richesses; Hachette: Paris, France, 1938. [Google Scholar]
- Bertrand, J. Book review of theorie mathematique de la richesse sociale and of recherches sur les principles mathematiques de la theorie des richesses. J. Savants 1983, 67, 499–508. [Google Scholar]
- Von Stackelberg, H.F. Marktform und Gleichgewicht; Springer: Viena, Austria, 1934. [Google Scholar]
- Agiza, H.N.; Elsadany, A.A. Nonlinear dynamics in the Cournot duopoly game with heterogeneous players. Physica A 2003, 20, 512–524. [Google Scholar] [CrossRef]
- Zhang, J.; Da, Q.; Wang, Y. Analysis of nonlinear duopoly game with heterogeneous players. Econ. Model. 2007, 24, 138–148. [Google Scholar] [CrossRef]
- Meyer, D.A. Quantum games and quantum strategies. Phys. Rev. Lett. 1999, 82, 1052–1055. [Google Scholar] [CrossRef]
- Li, H.; Du, J.; Massar, S. Continuos-Varianle Quantum Games. Phys. Lett. A 2002, 306, 73–78. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, D.; Jiang, W. Dynamics of a heterogeneous quantum Cournot duopoly with adjusting players and quadratic costs. Quantum Inf. Process. 2020, 19, 403. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, D.; Ma, S.; Zhang, S. The dynamics of a quantum Bertrand duopoly with differentiated products and heterogeneous expectations. Physica A 2020, 557, 124878. [Google Scholar] [CrossRef]
- Frackiewicz, P. On subgame perfect equilibria in quantum Stackelberg duopoly with incomplete information. Physica A 2018, 382, 3463–3469. [Google Scholar] [CrossRef]
- Ikeda, K.; Aoki, S. Theory of quantum games and quantum economic behavior. Quantum Inf. Process. 2022, 21, 27. [Google Scholar] [CrossRef]
- Shi, L.; Xu, F. Nonlinear Dynamics of a Quantum Cournot Duopoly Game with Heterogeneous Players. Quantum Inf. Process. 2019, 18, 227. [Google Scholar] [CrossRef]
- May, R. Simple mathematical models with very complicated dynamics. Nature 1976, 261, 459–467. [Google Scholar] [CrossRef] [PubMed]
- Giona, M. Dynamics and relaxation properties of complex systems with memory. Nonlinearity 1991, 4, 911–925. [Google Scholar] [CrossRef]
- Aicardi, F.; Invernizzi, S. Memory effects in discrete dynamical systems. Int. J. Bifurc. Chaos 1992, 2, 815–830. [Google Scholar] [CrossRef]
- Alonso-Sanz, R. Discrete Systems with Memory; Word Scientific: Singapore, 2011. [Google Scholar]
- Alonso-Sanz, R. Extending the paramater interval in the logistic map with memory. Int. J. Bifurc. Chaos 2011, 21, 101–111. [Google Scholar] [CrossRef]
- Alonso-Sanz, R.; Losada, J.C.; Porras, M.A. Bifurcation and Chaos in the Logistic Map with Memory. Int. J. Bifurc. Chaos 2017, 27, 1750190. [Google Scholar] [CrossRef]
- Khan, F.S.; Solmeyer, N.; Balu, R.; Humble, T.S. Quantum games: A review of the history, current state, and interpretation. Quantum Inf. Process. 2018, 17, 309. [Google Scholar] [CrossRef]
- Eisert, J.; Wilkens, M.; Lewenstein, M. Quantum Games and Quantum Strategies. Phys. Rev. Lett. 1988, 83, 3077–3080. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Stability region for () in the absence of memory. The area with no economic sense is shaded in blue, that is, when .
Figure 1.
Stability region for () in the absence of memory. The area with no economic sense is shaded in blue, that is, when .

Figure 2.
Stability region for () and different values of (0, 0.2, 0.5, and 0.8). The vertical line is represented because this value and are the values used in the bifurcation diagrams. The area with no economic sense is shaded in blue, that is, when .
Figure 2.
Stability region for () and different values of (0, 0.2, 0.5, and 0.8). The vertical line is represented because this value and are the values used in the bifurcation diagrams. The area with no economic sense is shaded in blue, that is, when .

Figure 3.
Stability region as a function of for () and without memory, .

Figure 4.
Stability region as a function of for m between and without memory, .

Figure 5.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .
Figure 5.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .

Figure 6.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .
Figure 6.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .

Figure 7.
Stability region for () in the absence of memory. The area with no economic sense is shaded in blue, that is, when and .
Figure 7.
Stability region for () in the absence of memory. The area with no economic sense is shaded in blue, that is, when and .

Figure 8.
Stability region for () and different values of (0, 0.2, 0.5, and 0.8). The vertical line is represented because this value and are the values used in the bifurcation diagrams. The area with no economic sense is shaded in blue, that is, when and .
Figure 8.
Stability region for () and different values of (0, 0.2, 0.5, and 0.8). The vertical line is represented because this value and are the values used in the bifurcation diagrams. The area with no economic sense is shaded in blue, that is, when and .

Figure 9.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .
Figure 9.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .


Figure 10.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .
Figure 10.
Bifurcation diagrams of output of the first player as a function of with and in the zone (). (a) ; (b) ; (c) ; (d) .


Figure 11.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and =0 (speed of adjustment is zero, therefore ) in the zone () with initial value of . The point where is when , but according to Equation (47), to have economic meaning.
Figure 11.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and =0 (speed of adjustment is zero, therefore ) in the zone () with initial value of . The point where is when , but according to Equation (47), to have economic meaning.

Figure 12.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and =0 (speed of adjustment is zero, therefore ) in the zone () with initial value of . When the game has economic meaning according to Equation (45).
Figure 12.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and =0 (speed of adjustment is zero, therefore ) in the zone () with initial value of . When the game has economic meaning according to Equation (45).

Figure 13.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = 0.2 (speed of adjustment): (a) in the zone (, ) and (b) in the zone (, ), with initial value of .
Figure 13.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = 0.2 (speed of adjustment): (a) in the zone (, ) and (b) in the zone (, ), with initial value of .

Figure 14.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory), = 0.2 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) in the zone (), with initial value of .
Figure 14.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory), = 0.2 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) in the zone (), with initial value of .

Figure 15.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (with memory), = 0.2 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) (), with initial value of .
Figure 15.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (with memory), = 0.2 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) (), with initial value of .

Figure 16.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory), = 0.4 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) (), with initial value of .
Figure 16.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory), = 0.4 (speed of adjustment), and without the first 50 iterations: (a) in the zone () and (b) (), with initial value of .

Figure 17.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (with memory), = 0.4 (speed of adjustment), and without the first 100 iterations: (a) in the zone () and (b) (), with initial value of .
Figure 17.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (with memory), = 0.4 (speed of adjustment), and without the first 100 iterations: (a) in the zone () and (b) (), with initial value of .

Figure 18.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = −0.2 (speed of adjustment): (a) in the zone () and (b) in the zone (, ), with initial value of . Regarding Equation (50), in , when all values of are valid, but when , only the values of are valid according to Equation (45).
Figure 18.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = −0.2 (speed of adjustment): (a) in the zone () and (b) in the zone (, ), with initial value of . Regarding Equation (50), in , when all values of are valid, but when , only the values of are valid according to Equation (45).

Figure 19.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = −0.8 (speed of adjustment): (a) in the zone () and (b) in the zone (, ), with initial value of . Regarding Equation (50), in , when all values of are valid, but when , only the values of are valid according to Equation (45).
Figure 19.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with (without memory) and = −0.8 (speed of adjustment): (a) in the zone () and (b) in the zone (, ), with initial value of . Regarding Equation (50), in , when all values of are valid, but when , only the values of are valid according to Equation (45).

Figure 20.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with and (speed of adjustment): (a) in the zone () and (b) in the zone (), with initial value of . Regarding Equation (50), in , when , all values of are valid, but when , only the values of are valid according to Equation (45).
Figure 20.
Quantum profits of the two firms ( in blue and in red) as a function of (degree of quantum entanglement) with and (speed of adjustment): (a) in the zone () and (b) in the zone (), with initial value of . Regarding Equation (50), in , when , all values of are valid, but when , only the values of are valid according to Equation (45).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Garcia-Perez, L.; Grau-Climent, J.; Alonso-Sanz, R.; Losada, J.C. Complex Dynamics of a Cournot Quantum Duopoly Game with Memory and Heterogeneous Players. Entropy 2022, 24, 1333. https://doi.org/10.3390/e24101333
AMA Style
Garcia-Perez L, Grau-Climent J, Alonso-Sanz R, Losada JC. Complex Dynamics of a Cournot Quantum Duopoly Game with Memory and Heterogeneous Players. Entropy. 2022; 24(10):1333. https://doi.org/10.3390/e24101333
Chicago/Turabian StyleGarcia-Perez, Luis, Juan Grau-Climent, Ramon Alonso-Sanz, and Juan C. Losada. 2022. "Complex Dynamics of a Cournot Quantum Duopoly Game with Memory and Heterogeneous Players" Entropy 24, no. 10: 1333. https://doi.org/10.3390/e24101333
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.