TSARM-UDP: An Efficient Time Series Association Rules Mining Algorithm Based on Up-to-Date Patterns


1
School of Control Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
2
College of Computer and Communication Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(3), 365; https://doi.org/10.3390/e23030365
Submission received: 4 February 2021
/
Revised: 9 March 2021
/
Accepted: 15 March 2021
/
Published: 19 March 2021
(This article belongs to the Section Signal and Data Analysis)
Abstract
:In many industrial domains, there is a significant interest in obtaining temporal relationships among multiple variables in time-series data, given that such relationships play an auxiliary role in decision making. However, when transactions occur frequently only for a period of time, it is difficult for a traditional time-series association rules mining algorithm (TSARM) to identify this kind of relationship. In this paper, we propose a new TSARM framework and a novel algorithm named TSARM-UDP. A TSARM mining framework is used to mine time-series association rules (TSARs) and an up-to-date pattern (UDP) is applied to discover rare patterns that only appear in a period of time. Based on the up-to-date pattern mining, the proposed TSAR-UDP method could extract temporal relationship rules with better generality. The rules can be widely used in the process industry, the stock market, etc. Experiments are then performed on the public stock data and real blast furnace data to verify the effectiveness of the proposed algorithm. We compare our algorithm with three state-of-the-art algorithms, and the experimental results show that our algorithm can provide greater efficiency and interpretability in TSARs and that it has good prospects.
1. Introduction
Data mining is a recently emerging technology that can mine the information behind the massive data in many domains. Through years of research in data mining, many mining methods were proposed, such as techniques for association rules, classification rules, clusters, sequential patterns, and so on. Among the numerous algorithms in data mining, association rules mining (ARM) can effectively handle quantitative data. Due to the ARM results being linguistic and easily understood and explained [1,2], it has been used in many fields, such as bio-informatics [3,4], recommender systems [5], medicine sciences [6], process industry manufacturing [7], and the economic sphere [8], to discover knowledge and play an auxiliary role in decision making [9,10].
However, in the real world, most data are always generated in a data stream form like industrial data, network data, and business data. These data often have time labels. Usually, the correlation of multiple time-series represents the nature of the data. Thus, excavating TSARs is a meaningful job. Haupt et al. [11] extracted frequent patterns from calendar schemes; then, Lucia Sacchi et al. proposed a kind of temporal association rule and the related extraction algorithm for complex patterns defined over clinical time-series. The proposed approach was based on a qualitative representation of increase, decrease, and stationery trends, which relied on the formalism of knowledge-based temporal abstractions [12]. Chen et al. [13] applied the membership function in fuzzy theory to association rules mining, and the method reflected the lifespan of an item by redefining Support and Confidence. The algorithm obtained the effective time of rules through the lifespan of each item. Furthermore, Chen et al. proposed a fuzzy time-series mining algorithm. The algorithm can effectively mine TSARs with a sliding window, but it was problematic in that the mining results related to the window size and the types of membership function were difficult to assert [14]. Two tree-based algorithms were presented in [15] to mine the frequent temporal patterns that considered not only the Support of patterns, but also their weights. Yu et al. used the information-filtering algorithm to filter the interference information and redundant information in the social network and applied fuzzy data clustering to the mining and clustering of relational data in hierarchical networks in [16]. In [17], Park et al. proposed a method for discovering the rules to describe deviant event patterns from multivariate time-series, called SAX-ARM. The algorithm first uses inverse normal transformation to convert the distribution of time-series to the normal distribution and then applies symbolic aggregate approximation to symbolize time-series for discovering frequent rules. However, most such algorithms are based on the traditional a priori algorithm [18], which discovers the frequent pattern is greater than or equal to a user-specified minimum support in a top-down level-wise process. The frequent patterns represent the expected patterns in the whole database, but may ignore some information that is usually hidden behind temporal relationship patterns.
To extract the temporal relationships in TSARs, in [19,20], the concept of a time cube and the a priori algorithm were presented to mine the temporal association rules. However, these methods do not consider multiple items between transactions, and inherent information is difficult to mine, which causes the rules to be less interpretable. A new visualization solution explicitly dealing with temporal association rules was presented in [21]. In [22], a compact FP-tree-based and divide-and-conquer algorithm was presented to mine inter-transactional association rules. Rules generated from this algorithm are interpretable, but the algorithm is susceptible to the size of the sliding window. Ruan et al. presented a framework that allowed parallel and quantitative mining of sequential patterns [23]. Kaustubh Beedkar et al. proposed a scalable, distributed sequence mining algorithm dealing with large amounts of data. The authors built a distributed framework for frequent sequence mining [24]. The description of temporal trends for the clinical domain of hemodialysis was proposed in [25], which considered specific temporal features with respect to the chosen time granularity. In [26], Hong et al. firstly proposed the concept of up-to-date patterns, which can mine rare patterns effectively. Wang et al. proposed the frequent itemset tree, and the algorithm can discover temporal association rules among multiple variables [27,28]. Lin and Hong proposed the tree structure temporal mining algorithm based on their previous up-to-date studies, and the mining result of their algorithms can discover implicit knowledge and obtain satisfactory results [29,30,31]. Recent work about graph association rule mining [32] has the potential to take temporal information into account. In [33], to resolve the issue of incremental rare association rule mining, Borah et al. presented a single-pass tree-based approach for extracting rare association rules when new data were inserted into the original database. The approach is capable of generating the complete set of frequent and rare patterns without rescanning the updated database and reconstructing the entire tree structure when new transactions are added to the existent database. However, rules mined by the above works are TSARs with a time interval, but not the whole time. Such rules are effective in a period, but not for the entire time. In some fields, such as the process industry and medical treatment, TSARs with a lifespan would be no longer effective, and TSARs with generality are more useful.
In this paper, to solve the problems mentioned above, a new TSAR mining framework is proposed to mine TSARs with generality. Since multiple variables need to be considered, they are divided into one-dimensional TSARM and multi-dimensional TSARM to elaborate. Furthermore, to discover implicit knowledge, we propose TSARM with up-to-date patterns (TSARM-UDP). TSARM-UDP integrates the a priori mining algorithm with the new TSAR mining framework proposed in this paper to identify TSAR from the given multivariate time-series data. Then, the UDP method is used as a reference to discover the rare frequent temporal patterns and express the mined implicit knowledge in the form of TSARs. The algorithm first scans the database to record the Count and Timelist of each item. Then, it identifies the frequent temporal patterns by the predefined min_sup threshold and the rare frequent temporal patterns by the UDP method. After the frequent temporal patterns have been found, TSARs can be discovered from the given time-series data. The general framework of the algorithm is shown in Figure 1.
Briefly, the novelty of this work can be highlighted as follows:
- A new TSAR mining framework is proposed in this paper to mine more rules for time-series data with higher accuracy.
- Aiming at the rare patterns that occur only for a period, the proposed algorithm can find more effective association rules.
- The proposed TSAR-UDP method can extract temporal relationships without experienced knowledge and extend the rules’ applicability to the whole dataset.
The remainder of this paper is organized as follows. The preliminaries of the proposed algorithm are given in Section 2. In Section 3, we discuss the one-dimensional TSARs and multidimensional TSARs in detail and introduce the UDP method briefly. Experimental results are given in Section 4. Conclusions and future research are given in Section 5.
2. Preliminaries of Our Proposed Algorithm
2.1. Time Series
Definition 1.
Time-series X consists of the value of X in different time stamps: = (x, x, x, …, x), where X is a variable and x is the value of X in the time stamp.
Definition 2.
A temporal transaction consists of the values of multiple variables in the time stamp, which can be described as:
= (V, V, V, …, V), whereis the variable.
2.2. Association Rules Mining
ARM was initially used to discover the customers’ purchasing behavior patterns through the relationships among goods in supermarkets. Today, it has become one of the most popular methods in data mining. ARM can be described briefly as follows: D = Database{Trans, Trans, …, Trans} with m temporal transactions, and I = {i, i, …, i} is an itemset that contains k variables. An association rule is an implication in the form of X⊂Y, and the general form of the rule is Rule: X → Y, in which X and Y are disjoint itemsets in D. Here, X is called the antecedent of the rule, and Y is called the consequent. There are two very important concepts in ARM called: Support and Confidence. We show the definitions of these two concepts below.
Definition 3.
Support(X) describes the probability that transaction X appears in D:
Definition 4.
Support(X → Y) describes the probability that transactions X and Y appear simultaneously in D:
Definition 5.
Confidence(X → Y) describes the probability that transaction Y appears in D under the condition that X appears in D:
In the process of mining association rules, is usually used to test the validity of rules. The rule is effective only when the value of the rule is greater than one, and that rule is called a strong association rule. The formula of is given below:
In this paper, we consider a rule to be strong when its Confidence and are greater than and one, respectively.
The a priori algorithm is one of the most classic ARM algorithms; it was first proposed by Agrawal in 1993. The process of mining rules can be summarized in two parts as follows:
- (1)
- Find all frequent items in the original log database by the predefined min_sup.
- (2)
- Generate association rules in frequent items by the predefined min_conf.
3. The Proposed TSARM-UDP
In this section, a new TSARM framework is proposed to discover TSARs with generality. We divided it into one-dimensional TSARs and multidimensional TSARs to clarify the proposed framework. In the last section, a novel algorithm named TSARM-UDP is proposed to discover implicit knowledge in the form of TSARs.
3.1. Time Series Association Rules Mining
Understanding temporal relationships among multiple variables can help decision making, and the discovered knowledge can be inherited and learned later. However, traditional ARM mining frameworks cannot discover the temporal relationships from time-series data. To mine TSARs in time-series from a temporal database, several issues need to be solved: (1) a strict time order relationship should be considered; (2) candidate itemsets generated by the a priori method may not satisfy the downward property; (3) a new mining framework should be proposed to discover the rules with generality.
3.1.1. One-Dimensional TSARs
The definition of one-dimensional TSARs proposed in this paper is given below:
Definition 6.
If X occurs at time t, then Y will appear at time t + T, and the TSARs’ form can be expressed as , where T is a time constant.
Definition 7.
describe the probability that variable X occurs at time t and variable Y occurs at time ,
where is the total number of transactions in the log database.
Definition 8.
is the total number of transaction that satisfy the following: if X appears at time t, then Y appears at time t + T.
The differences in the Support calculation between TSARs and traditional association rules mainly lie in the calculation methods of the numerator and the denominator in Formula (5). The TSAR takes the relationship among multiple variables on a time scale into account. To further clarify the improvement, the process of calculating in TSAR is shown in Figure 2. We assume that there are n temporal transactions in the log database, and each transaction can be expressed as . Each temporal transaction has an equal time interval.
Assuming that we are trying to determine whether the itemset (a, c) is frequent, we have to calculate the value of this itemset. The red solid line represents the way that the numerator in the formula is calculated in the traditional method, which considers that only when the item a and c occurred at the same time can be counted. The green dotted line represents the method of calculating the numerator in Formula (5), which considers the lagged time T (T is considered as two here) of item a and c for time series data in an actual industry production situation. Similarly, the total valid transactions are changed due to considering T, because the transactions in the blue dotted circle cannot be counted in the process of calculating . Thus, the denominator in Formula (5) is .
Definition 9.
in one-dimensional TSARs is defined as follows:
As mentioned above, to maintain the downward property in the process of mining TSARs, the candidate items’ generation method must be modified. Thus, an algorithm is presented to generate a candidate itemset in one-dimensional TSARs, which is shown in Algorithm 1. A simple example is given to illustrate the algorithm. Assuming that we have a time-series X, we apply the TSARM to X and obtain the frequent L. We assume that . Traditional association rules are used to generate candidate , for which and are regarded as the same situation. However, a clear time relationship should be noted between items when generating candidate itemsets in TSARs. Thus, the meanings of and are different. The candidate in TSARs should be . Note that this method is only applicable to generate candidate , and the method of generating will be presented in multi-dimensional TSARs.
| Algorithm 1 Generating candidate itemsets |
|
3.1.2. Multi-Dimensional TSARs
The multidimensional TSARs can generally be expressed as follows:
Thus, if occur at time t, then will occur simultaneously at time .
In terms of calculating Support and Confidence, there are some differences between multidimensional TSARs and one-dimensional TSARs. The related definitions are given below:
Definition 10.
Briefly, describes the probability of variables occurring at time t simultaneously and variable occurring at time :
Definition 11.
Here, is the total number of transactions that satisfy the following: if appear at time t, then appear at time t + T.
Definition 12.
in multidimensional TSARs is defined as follows:
In many domains, the order of items is strict, especially in the process industry. We need to consider the order of items when generating candidate . To avoid being confused by the order of items with the increase of itemsets, we rewrite the frequent itemsets and candidate itemsets in a more specific manner. For example, if we have a frequent two-itemsets , as mentioned earlier, there is a clear order in the itemsets: item a is the antecedent, and item c is the consequent. Thus, we rewrite the frequent two-itemsets as . The order of items can be clearly seen from this form, and this form also plays an important role in generating temporal association rules. In the remainder of the article, we use this form to represent and .
Next, we explain the process of generating . According to the representation of frequent items , we classify the itemsets in as two parts. The part on the left side of the arrow is recorded as , and the part on the right side of the arrow is recorded as . If we have the frequent itemsets , it has to be ensured that equals . Here, is the number of items in of , and is the number of items in of . When the antecedents (or consequents) of two itemsets are equal and satisfy the requirement that the first (or ) items of the consequents (or antecedents) are equal, but the (or ) item is different, any subset of candidate itemsets can be obtained by combining the two itemsets as frequent. However, if the antecedents and consequents of two itemsets are not equal, there is no guarantee that all subsets of the candidate sets are frequent. Then, we consider four situations: (1) if =1 and ; (2) if =1 and ; (3) ; and (4) .
In the first case, the number of items in the antecedents of and is one, and the consequents of and are the same. Therefore, if and are different, the candidate itemsets can be obtained by combining two frequent itemsets and . The second case is similar to the first case, and we will not go into detail.
In the third case, the antecedents of and are the same. Then, we have to identify whether the items in of and satisfy the requirement that the first items are equal, but the item is different. If and satisfy the requirement, then combine and to obtain . The fourth case is similar to the third case, and we will not go into detail. For example, if we have the frequent one-itemset and frequent two-itemsets , we would like to obtain candidate itemsets . Where and satisfy the first case, the two itemsets are combined, and we can get . Similarly, and satisfy the second case, so we can get . The antecedents and consequents of and are not equal. The subset of combining these two itemsets cannot be guaranteed to be frequent, so this case is pruned. Finally, the candidate three-itemsets are and .
We give the pseudo code of generating candidate in Algorithm 2. The rules generated in TSARs are also different from the traditional association rules. Taking the a priori algorithm as an example, unordered items are dealt with by it, which need not consider the order of items when generating rules. However, the order of items must be considered in TSARs for the reason of time-series applications. Therefore, we need to consider it when generating rules. In the step of generating rules, the order of the antecedent and consequent in frequent itemsets cannot be changed, which means the form of the rule is , and i means the frequent itemsets in .
| Algorithm 2 Generating candidate itemsets |
|
3.2. Up-To-Date Patterns
Mining frequent itemsets in traditional ARM exclusively relies on the Support threshold to determine whether an item or an itemset is frequent. However, some transactions do not occur for the whole time period. In other words, some itemsets may be frequent in a period of time, but not for the entire database. In the real world, some cases only exist in a certain period other than the whole time. For example, the abnormal conditions in the process industry only occur in a period of time. The Support calculation can only be used to mine frequent itemsets in the whole database, exhibiting a very small probability to mine implicit rules about abnormal conditions. Actually, we should pay more attention to TSAR with abnormal conditions, and such rules facilitate better decision-making.
In the past, Hong et al. [26] proposed the concept of up-to-date patterns (UDPs), which were frequent patterns within their up-to-date lifetime. Lin et al. also proposed an algorithm to derive up-to-date patterns from transactions [29,30,31]. One of the advantages of the UDP method is that it can mine the implicit association rules that satisfy the current Support threshold.
We combine Formula (10) for reference from the UDP with the a priori algorithm. The proposed mining framework is used to mine rare patterns in the form of TSARs.
Here, n is the total number of transactions in the log database, is the first transaction ID in , is the number of occurrences of item i in the log database, and is the minimum Support, which is set in advance. If item i satisfies (10), then put the pattern in the set of one-items from D; otherwise, decrease by one, and repeat (10) until is equal to zero or (10) is satisfied.
3.3. The Proposed TSARM-UDP
3.3.1. Description
The purpose of the proposed TSARM-UDP algorithm is to mine the TSARs from time-series. The specific steps of the proposed algorithm are elaborated in the next section. The flowchart of TSARM-UDP is shown in Figure 3. Note that all data in this paper are time-series data with equal intervals.
3.3.2. The Construction of the Algorithm
Time series association rules mining with up-to-date patterns:
Input: A log database D with n transactions stored in the order of transaction time with equal time intervals; each of them includes the transaction ID, transaction time, and items. The time T, the minimum support threshold , the minimum UDP threshold min_UDP, and the minimum confidence threshold are also included.
Output: Rules mined from the time-series.
Step 1: Scan the database D to generate the candidate , and record the count value and the of item i in the log database.
Step 2: Complete the following substeps for the items in :
Substep 2.1: Calculate the Support of the item in .
Substep 2.2: If the Support of the item is more than , then put the item in . Otherwise, put the item in .
Step 3: For the items i in , complete the following substeps.
Substep 3.1: Set the as the first transaction ID in the of the item i, and verify if the item i satisfies Formula (10). If the item i satisfies Formula (10), then it will be retained in and then will be put in .
Substep 3.2: Set the as the next transaction ID in the of the item i; decrease the count of item i by one; and repeat this substep until is equal to zero. If is equal to zero and the item or itemset still cannot satisfy Formula (10), then it will be deleted from .
Step 4: Calculate the item or itemset as greater than or equal to or not. If so, save the item or itemset; else, delete it.
Step 5: Combine the set and the set to form . Set r = 1, where r is used to keep the current number of items in the itemset to be processed.
Step 6: Generate the candidate set from in a similar manner to the a priori algorithm; moreover, the order of items should be considered as we mentioned above.
Step 7: Generate the frequent -patterns from in a similar manner to STEPS 2 and 3.
Step 8: If the is null, proceed to the next step. Otherwise, jump to STEPS 5 and 6.
Step 9: Calculate the Confidence and Lift of the itemsets in the with Formulas (9) and (4). If the Confidence of the itemsets is greater than , then generate the rules in a manner similar to the a priori algorithm. Otherwise, delete the itemsets that cannot meet the requirement in .
Step 10: Output the association rules mined from the log database.
Note that in the above algorithm, transactions in the log database must be the time-series with equal intervals.
3.3.3. Set the Algorithm Parameters
Aiming at the characteristics of an actual industrial production database, we propose the TSARM-UDP algorithm. The parameters in our algorithm that need to be predefined are TSupport, TConfidence, the time T, the minimum TSupport threshold , the minimum UDP threshold min_UDP, and the minimum TConfidence threshold . Considering the differences of different datasets, these parameters should be set up according to the different situations.
3.3.4. An Example
In this section, an example is given to illustrate the proposed TSARM-UDP algorithm. Table 1 shows the log database used in the example. The database contains 10 transactions and six items, denoted from a to f.
Input: T = 3, = 0.5, = 0.1, = 0.4, log database D.
Output: Rules mined from D.
Step 1: Scan the database, and find the and the of item i in D. Take item a as an example. It appears in Transactions 4, 5, and 8. Thus, is three, and is {4, 5, 8}. The result of STEP 1 is shown in Table 2.
Step 2: Calculate the TSupport in Table 2 using Formula (8). Using item b as an example, the count of b is five. Thus, according to Formula (8), the TSupport of b is 0.5. The given above is 0.5, so b will be placed in . The TSupport of item c is 0.3. This value is less than , so it will be placed in . The TSupport calculation results are shown in Table 3, namely and .
Step 3: For the items in , the following steps are performed. Items a and c are used as examples. For item a, , so . In addition, , , and . Substitute the above parameters into Formula (10). On the left side of the inequation is . On the right side of the inequation is . The results do not satisfy the inequation, so the algorithm jumps to Substep3.2. , and . Thus, the updated parameters are substituted for the inequation, and recalculate. The result still cannot satisfy the inequation. Repeat SUBSTEP 3.2. , and . Then, substitute the updated parameters into the inequation, and recalculate. The result still cannot satisfy the inequation. Repeat SUBSTEP 3.2. . Thus, delete item a from .
For item c, , so , , , and . The method of calculating item a above is used to calculate item c. The left side of the inequation is six, and the right side of the inequation is also six. Thus, the result satisfies the inequation, and c will remain in .
After calculating each item in , then delete the items that do not satisfy the inequation. The items that remain in are .
Step 4: Calculate the count of each item in , and delete the items that do not satisfy being equal to or greater than . Update .
Step 5: Combine set and set to form . Set .
Step 6: Generate the candidate set from through the method mentioned above, and the order of items should be considered. is shown in Table 4.
Step 7: Generate the frequent two-patterns in a way similar to STEPS 2 and 3. are null, and . Thus, .
Step 8: We can generate from , according to the method we mentioned in the previous article. We can get = , but each itemset in cannot satisfy the threshold and Formula (9). Thus, are null. The algorithm runs to STEP 8.
Step 9: In this step, we calculate the TConfidence of itemsets in by Formula (9). Taking itemsets as an example: , and . According to Formula (9), the TConfidence of itemsets is equal to . Then, we calculate the Lift of itemsets, , which is greater than one. Thus, is valid. The TConfidence and Lift of each itemset are given in Table 5.
As shown in Table 5, two itemsets satisfy the and Lift requirement. The rule generation method is similar to the a priori algorithm, but needs to consider the order of items and the other steps. The generated rules are given below:
, with TConfidence = 3/7, Lift = 10/7
, with TConfidence = 4/7, Lift = 10/7
Step 9: Output the rules.
4. Simulation Experiments
To better illustrate the effectiveness of the proposed TSARM-UDP algorithm, we performed several experiments on the public stock dataset [34] and real historical data of a blast furnace (BF) collected from a steel plant in China. All experiments were performed in MATLAB 2017a on a PC with a 2.5 GHz Intel Core CPU.
4.1. Experiment Results on the Stock Dataset
In stock market analysis, ARM is one of the widely used data mining tools to mine the underlying regularities behind the phenomenon. ARM aims to dig out the association rules (ARs) and frequent itemsets from the database. ARs reveal the relationship among different stocks, and frequent itemsets mean multiple stocks portfolio patterns in the stock dataset.
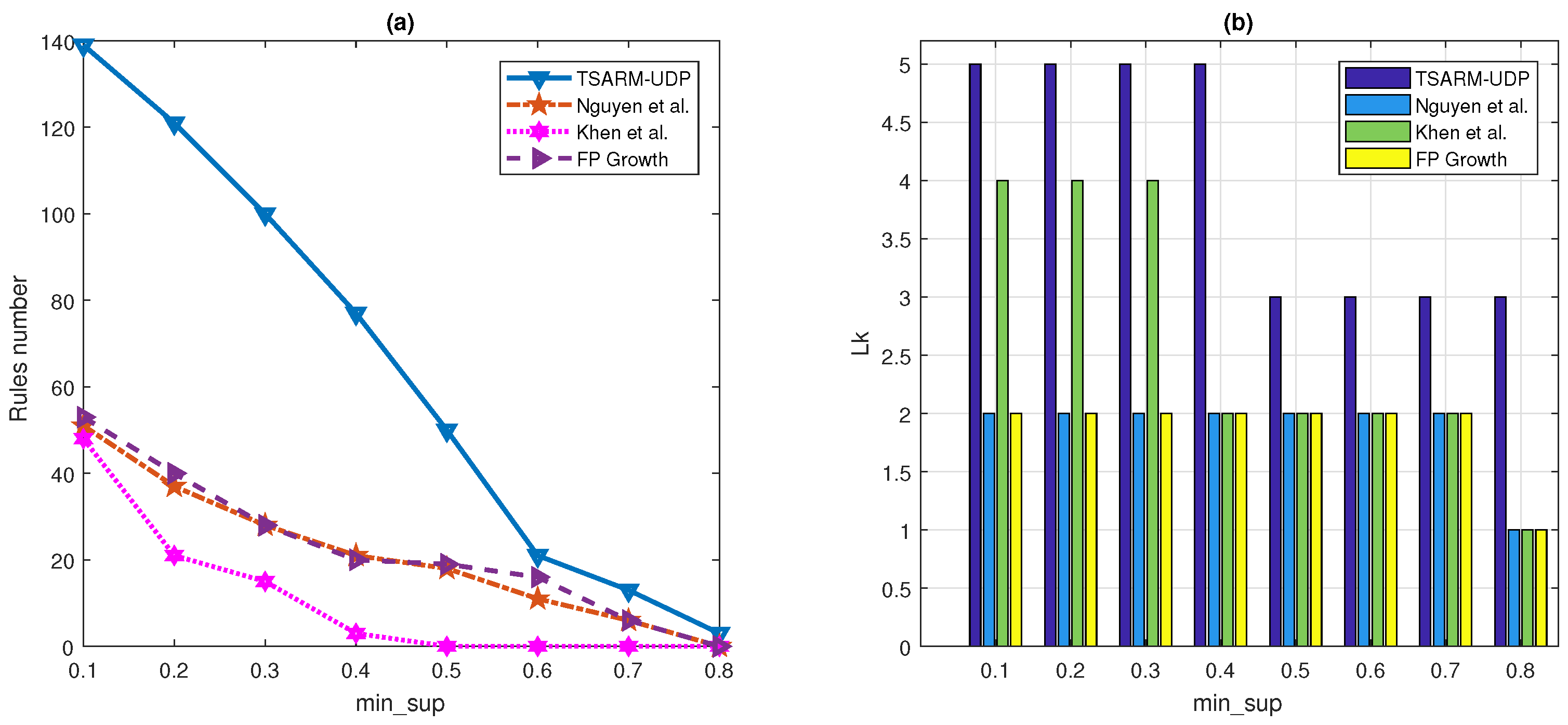
In this section, we apply the TSARM-UDP algorithm to the public stock dataset to mine time-series association rules. Furthermore, a performance comparison is done of the TSARM-UDP algorithm with other temporal algorithms presented in [35,36] and FPgrowth [22]. The mining results are shown in Figure 4 and Figure 5.
In Figure 4, we compare the mining results of the proposed algorithm and the other three algorithms on the stock dataset. is 0.7, and . As shown in Figure 4, , , , and the number of rules mined from the stock dataset by the proposed method are larger than the other state-of-the-art methods. The larger number of rules and frequent itemset means we mine more abundant information in the finite database.
In Figure 5, we give the comparison of the number of rules and produced by the four methods at different . is 0.8, and . Although is improved, the algorithm proposed in this paper remains superior to other recent methods in the number of and rules.
In order to verify the accuracy rate of the rules, we divided the public stock dataset into two parts: one part was used to generate ARs, and the other one, which included the last three months of data, was used to test the forecast accuracy rate of some extra rules not obtained by traditional algorithms. The experiment was also implemented under the condition of the min conf being 0.8, min sup = 0.7, and T = 7. The test results are shown in Table 6. It can be observed that the accuracy rate of the extra rules is at a high level. The rules are as follows:
={(USD BASEDISE, down)∧(TLBASED ISE, flat)∧(DAX, flat)(EM, flat)}
={(USD BASED ISE, down)∧(SP, down)∧(DAX, flat)(EM, flat)}
={(TL BASED ISE, flat)∧(USD BASED ISE, down)∧(DAX, flat)∧(BOVESPA, down) (EM, flat)}
={(USD BASED ISE, down)∧(SP, down)∧(DAX, flat)∧(NIKKEI, down)(EM, flat)}
In Table 7, the running time of the above four methods is presented. The proposed TSARM-UDP algorithm needs a longer running time because of it mining more implicit rules. In addition, for practical application, the above running time is still within an acceptable range.
4.2. Experiment Results on the BF Dataset
The blast furnace (BF) plays an important role in national iron making, and the stability of the BF directly determines the quality of molten iron. The characteristics of the BF data are the time sequence, strong correlation, and rich information. Therefore, we are encouraged to use data mining methods to discover the potential relationships among multiple variables and mine implicit knowledge to assist decision-making. Moreover, since the BF is a time sensitive system, mining implicit knowledge can provide more useful information to workers for the stabilization of the furnace condition.
We applied the proposed algorithm to mine TSARs from the authentic smelting data of a BF in a steel plant in China. The data were discrete time-series with a 30-min sampling time. Based on previous research on BFs, eleven variables were chosen as the input of the algorithm. Noise was present in the BF data, so it was necessary to deal with abnormal values first. In this paper, the box diagram method was applied to remove the abnormal values in the BF data. Then, the data needed to be symbolized, and an intuitive method was used to divide the range of quantitative attributes into finite intervals of assigned symbols to form <attributes, interval>pairs. According to expert knowledge, each variable was divided into three states: descent, normal fluctuation, and ascent. The input variables and corresponding discretization intervals are shown in Table 8.
The interval division and codes are shown in Table 9, and the variable codes are shown in Table 10. To illustrate further, a simple example is presented. Assume that the blast wind volume is 3450. According to Table 8 and Table 9, three-thousand four-hundred fifty is in the range of normal fluctuation and should be encoded as 2. For the attribute of blast wind volume, the encoding number is 1 in Table 10. Therefore, the final discrete pair for this instance is . The former number represents blast wind volume, and the latter one represents normal fluctuation. According to the above method, all blast furnace data can be symbolized and used as the input for the proposed algorithm. In total, one-thousand four-hundred thirty-eight data of the authentic blast furnace were selected as the sample for time-series association rules mining. To verify the validity of this method, we compared the proposed method with that proposed in [35,36] and FP growth [22].
In the first experiment, the relationships between the numbers of the frequent one-itemset for different thresholds are shown in Figure 6a. It is clear that the number of frequent itemsets discovered by TSARM-UDP is larger than the other methods.
The relationships between the numbers of the frequent two-itemsets for different thresholds are shown in Figure 6b. As shown in Figure 6b, the frequent two-itemsets without using the up-to-date method are close to zero when is 0.8, but the proposed TSARM-UDP can still mine frequent two-itemsets. The main reason is that some items may appear in some time period, but not in the whole time, and it is difficult for other methods in [35,36] and FP growth [22] to mine frequent itemsets like that. Besides, the rules with high are important because these situations occur frequently.
In Figure 6c, we give the maximal frequent k-itemsets that can be mined by the four methods. For example, when is 0.1, TSARM-UDP can mine frequent five-itemsets, but the method proposed by [35,36] and FP growth [22] can only mine two-itemsets. The method proposed by [35] can mine more itemsets than the other two methods when is less than 0.5. However, when is greater than 0.5, the maximal itemsets that can be mined by these three methods are the same. The proposed TSARM-UDP method in this paper can mine more maximal itemsets than the other three methods when takes different values. In ARM, the more frequent itemsets are mined, the more relationships between variables can be found. Therefore, the method proposed in this paper outperforms other methods in finding the relationship between multiple variables.
In Figure 6d, the number of rules produced by the four methods at different is presented, and is 0.6, . As shown in this figure, compared with the other three methods, more rules were mined by the TSARM-UDP method.
It is essential to compare the maximal itemsets and rule numbers for different values. Therefore, we compared the rule numbers and maximal itemsets that can be mined by the four methods when the values are 0.7 and 0.8, respectively. As shown in Figure 7a, more rules were mined by the proposed TSARM-UDP compared with the other methods. These rules can play a better role in decision-making. In Figure 7b, it can be clearly seen that the maximal itemsets mined by the TSARM-UDP are larger than other methods. In Figure 8, we set the and . Furthermore, the numbers of rules and that can be mined with different are compared. The experiment results shown in this figure can also draw the same conclusions as discussed in Figure 6.
Given that T is an artificially determined parameter, it is a novel parameter for the proposed TSARM-UDP algorithm. In the experiments we discussed above, T was set to six. Now, we explore the effect of different T values on the number of rules mined by the proposed method. The experimental results are shown in Table 11. When we chose different values for T, the number and content of rules were generally different. Thus, the value of T depends on the temporal information that users want to mine.
In Table 12, we give a comparison of the running time of each algorithm. is 0.6, and . Comprehensive analyses of Figure 7 and Table 12 show that although TSARM-UDP has the longest operation time among the four methods, it can mine more effective rules. Although other method had a faster operation time than TSARM-UDP, it ignored the implicit knowledge. Moreover, in practical applications, the algorithm is generally used for offline mining, which means the requirement of operation time is not very high.
Setting , and , we used the proposed TSARM-UDP method and LTARMalgorithm [33,35] to discover knowledge from the BF data. Finally, twenty-five rules and 11 rules were obtained, respectively. The rules mined by LTARM can also be mined by TSARM-UDP. Given space constraints, we do not list all the rules mined by the TSARM-UDP method. Only a few rules that cannot be mined by LTARM are listed in Table 13, and all rules mined by the LTARM method are provided in Table 14.
4.3. Rules’ Evaluation
In this subsection, we compare the rules mined by the above two methods and explain some rules listed in Table 13. The analyses and explanations of the mined rules revealed that the proposed algorithm can effectively mine TSARs from BF data. Furthermore, these rules provide an effective theoretical basis for decision-making. The interval of time-series was equal to 30 min, and T = 6. Thus, if X happens, Y will occur after 3 h.
As shown in Table 14, the rules mined by LTARM can only assess two items, which means the method can only obtain temporal relationships between two variables in most cases. By comparing Table 13 and Table 14, the proposed TSARM-UDP method can efficiently mine the rules among multiple variables and discover the implicit rules. Moreover, more rules were mined by TSARM-UDP compared with LTARM. Lift shows that the implicit rules mined by TSARM-UDP are not redundant, but effective, which further proves the effectiveness of our algorithm. Next, we illustrate the meaning of some rules in Table 13.
Take as an example. The antecedent of this rule indicates that if blast wind volume exhibits normal fluctuation, but blast wind temperature and normal blast velocity are increased, then the blast furnace bosh gas volume will fluctuate normally after 3 h.
serves as another example. If blast wind temperature, oxygen enrichment, and normal blast velocity are increased and the top temperature exhibits normal fluctuation, then the blast furnace bosh gas volume and theoretical combustion temperature will fluctuate normally after 3 h.
The temporal relationships among variables in the BF data are very complicated. Changing one variable may cause variations of other variables, so it is hard to predict how the impact on the furnace condition would happen because of the early operations. However, TSARs mined by the proposed TSARM-UDP algorithm can reveal temporal relationships among multiple items, which can provide effective evidence to help people make decisions. The rules obtained were confirmed to be valid by operators on site.
5. Conclusions and Further Research
In this paper, to discover the temporal relationships among multiple variables in time-series data, a new TSARM framework and a novel algorithm named TSARM-UDP are proposed. The TSARM mining framework is applied to mine TSARs and the up-to-date pattern to discover rare patterns that only appear in a period. Compared with other methods, the proposed algorithm can mine TSARs with more efficiency and better generality. Experiments on stock and BF datasets are conducted to evaluate the effectiveness and the generality of the proposed algorithms. From the results, it can be found that the proposed algorithm significantly outperforms other methods in terms of the number of frequent itemsets and the rules without depending on certain parameters. Furthermore, the mined rules have great applicability to predict stock movements with high forecast accuracy. In general, the results also show that this method could be applied in other industrial areas to make decision management more objective, reliable, and powerful.
For future work, we will consider working on future advanced versions of TSARM-UDP; e.g., updating temporal association rules according to the characteristics of a dynamic database or improving its time efficiency. We plan to work with different real-world applications and other industrial production problems.
Author Contributions
Conceptualization, methodology, software, resources, and data curation, Q.Z. and D.Y.; validation, formal analysis, and investigation, Q.L.; writing–original draft preparation, D.Y.; writing–review and editing, Q.L.; visualization, supervision, project administration, and funding acquisition, Q.Z. and Y.H. All authors read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China, Grant Number 2017YFB0304100; the National Natural Science Foundation of China, Grant Number U1908213; the Colleges and Universities in Hebei Province Science Research Program, Grant Number QN2020504; the Fundamental Research Funds for the Central Universities, Grant Number N182303037; the Foundation of Northeastern University at Qinhuangdao, Grant Number XNB201803.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| List of abbreviations | |
| ARs | association rules |
| ARM | association rules mining |
| BF | blast furnace |
| TSARM | time-series association rules mining algorithm |
| TSARs | time-series association rules |
| UDP | up-to-date pattern |
| Notation | |
| D | the log database |
| the number of transactions in the log database | |
| i | an item or an itemset |
| count(i) | the number of an item’s occurrence in the database |
| the minimum Support threshold | |
| the minimum Confidence threshold | |
| the temporal Support | |
| the temporal Confidence | |
| the set used to keep the item or itemsets that cannot meet the | |
| requirement in the step of generating frequent itemsets | |
| the set of frequent i-itemsets in the log database | |
| the set of candidate i-itemsets in the log database | |
| the set used to save the item or itemsets satisfying | |
| Transaction_ID | the ordinal number of the transaction in which the item is located. |
| Timelist | the set of the item’s Transaction_ID |
| the first Transaction_ID in the Timelist | |
| T | the length of time, which is predefined |
| a frequent itemset in | |
| of in | |
| of in | |
| the number of items in of | |
| the number of items in of |
References
- Jerry, C.W.L.; Wensheng, G.; Philippe, F.V.; Tzung, P.H.; Vincent, S.T. Fast algorithms for mining high-utility itemsets with various discount strategies. Adv. Eng. Inf. 2016, 30, 109–126. [Google Scholar]
- Galit, S.; Bruce, P.C.; Yahav, I.; Patel, N.R.; Lichtendahl, K.C. Data Mining for Business Analytics: Concepts, Techniques, and Applications in R; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- John, A.; Church, G.M. Aligning gene expression time-series with time warping algorithms. Bioinformatics 2001, 17, 495–508. [Google Scholar]
- Mridu, S.; Nagwani, N.K. Optimal channel selection on Electroencephalography (EEG) device data using feature re-ranking and rough set theory on eye state classification problem. J. Med. Imaging Health Inform. 2018, 8, 214–222. [Google Scholar]
- Zhiang, W.; Li, C.; Cao, J.; Ge, Y. On Scalability of Association-rule-based recommendation: A unified distributed-computing framework. ACM Trans. Web. 2020, 14, 1–21. [Google Scholar]
- Chih-Wen, C.; Tsai, C.F.; Tsai, Y.H.; Wu, Y.C.; Chang, F.R. Association rule mining for the ordered placement of traditional Chinese medicine containers: An experimental study. Medicine 2020, 99, 102–126. [Google Scholar]
- Alam, S.; Ila, M.; Sickles, R.C. Time series analysis of deregulatory dynamics and technical efficiency: The case of the US airline industry. Int. Econ. Rev. 2000, 41, 203–218. [Google Scholar] [CrossRef]
- Fu-lai, C.; Fu, T.C.; Luk, R.; Ng, V. Evolutionary time-series segmentation for stock data mining. In Proceedings of the IEEE Congress on Evolutionary Computation, ICDM 2002, Maebashi City, Japan, 9–12 December 2002; IEEE Computer Society: Washington, DC, USA, 2002; pp. 83–90. [Google Scholar]
- Matthews, S.G.; Gongora, M.A.; Hopgood, A.A.; Ahmadi, S. Web usage mining with evolutionary extraction of temporal fuzzy association rules. Knowl.-Based Syst. 2013, 54, 66–72. [Google Scholar] [CrossRef] [Green Version]
- Okolica, J.S.; Peterson, G.L.; Mills, R.F.; Grimaila, M.R. Sequence pattern mining with variables. IEEE Trans. Knowl. Data Eng. 2018, 32, 177–187. [Google Scholar] [CrossRef]
- Haupt, R.L.; Haupt, S.E. Practical Genetic Algorithms; Khosravy, M., Gupta, N., Eds.; Wiley-IEEE Publication: New York, NY, USA, 2004; pp. 154–196. [Google Scholar]
- Sacchi, L.; Larizza, C.; Combi, C.; Bellazzi, R. Data mining with temporal abstractions: Learning rules from time-series. Data Min. Knowl. Discov. 2007, 15, 217–247. [Google Scholar] [CrossRef]
- Chen, C.-H.; Lan, G.C.; Hong, T.P.; Lin, S.B. Mining fuzzy temporal association rules by item lifespans. Appl. Soft. Comput. 2016, 41, 265–274. [Google Scholar] [CrossRef]
- Chen, C.-H.; Hong, T.-P.; Tseng, V.S. Fuzzy data mining for time-series data. Appl. Soft. Comput. 2012, 12, 536–542. [Google Scholar] [CrossRef]
- Shirsath, P.A.; Verma, V.K. A recent survey on incremental temporal association rule mining. IJITEE 2013, 13, 2278–3075. [Google Scholar]
- Yang, Y.; Tang, Y. The construction of hierarchical network model and wireless activation diffusion optimization model in English teaching. EURASIP J. Wirel. Commun. Netw. 2020, 20, 1–14. [Google Scholar]
- Park, H.; Jung, J.-Y. SAX-ARM: Deviant event pattern discovery from multivariate time-series using symbolic aggregate approximation and association rule mining. Expert Syst. Appl. 2020, 141, 112950–112961. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 712–720. [Google Scholar]
- Ghorbani, M.; Abessi, M. A new methodology for mining frequent itemsets on temporal data. IEEE Trans. Eng. Manag. 2017, 64, 566–573. [Google Scholar] [CrossRef]
- Mantovani, M.; Combi, C.; Zeggiotti, M. Discovering and analyzing trend-event patterns on clinical data. In Proceedings of the 2019 IEEE International Conference on Healthcare Informatics, Beijing, China, 10–13 June 2019; pp. 212–226. [Google Scholar]
- Combi, C.; Sabaini, A. Extraction, analysis, and visualization of temporal association rules from interval-based clinical data. In Proceedings of the 2013 Conference on Artificial Intelligence in Medicine in Europe, Murcia, Spain, 7–9 June 2013; pp. 238–247. [Google Scholar]
- Qin, L.X.; Shi, Z.Z. Research on multiple time-series inter-transaction association analysi. Comput. Eng. Appl. 2005, 41, 10–12. [Google Scholar]
- Ruan, G.; Zhang, H.; Plale, B. Parallel and quantitative sequential pattern mining for large-scale interval-based temporal data. In Proceedings of the 2014 IEEE International Conference on Big Data, Sydney, Australia, 27–30 October 2014; pp. 703–710. [Google Scholar]
- Beedkar, K.; Gemulla, R.; Martens, W. A unified framework for frequent sequence mining with subsequence constraints. ACM Trans. Database Syst. 2019, 44, 1–42. [Google Scholar] [CrossRef]
- Combi, C.; Pozzi, G.; Rossato, R. Querying temporal clinical databases on granular trends. J. Biomed. Inform. 2012, 45, 273–291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, T.-P.; Wu, Y.-Y.; Wang, S.-L. An effective mining approach for up-to-date patterns. Expert Syst. Appl. 2009, 36, 9747–9752. [Google Scholar] [CrossRef]
- Wang, L.; Meng, J.; Xu, P.; Peng, K. Mining temporal association rules with frequent itemsets tree. Appl. Soft. Comput. 2018, 62, 817–829. [Google Scholar] [CrossRef]
- Wang, L.; Li, L.L.; Meng, J.Y. Temporal association rules mining algorithm based on frequent item sets tree. Control Decis. 2018, 33, 591–599. [Google Scholar]
- Lin, J.C.-W.; Gan, W.; Hong, T.P.; Tseng, V.S. Efficient algorithms for mining up-to-date high-utility patterns. Adv. Eng. Inform. 2015, 29, 648–661. [Google Scholar] [CrossRef]
- Lin, C.-W.; Hong, T.-P.; Lu, W.-H. Mining up-to-date knowledge based on tree structures. In Proceedings of the 2009 International Conference of Soft Computing and Pattern Recognition, Dalian, China, 14–16 October 2009; pp. 123–127. [Google Scholar]
- Lin, C.-W.; Hong, T.-P. Temporal data mining with up-to-date pattern trees. Expert Syst. Appl. 2011, 38, 15143–15150. [Google Scholar] [CrossRef]
- Namaki, M.H.; Wu, Y.; Song, Q.; Lin, P.; Ge, T. Discovering graph temporal association rules. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 3–7 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1697–1706. [Google Scholar]
- Borah, A.; Nath, B. Rare association rule mining from incremental databases. Pattern Anal. Appl. 2020, 23, 113–134. [Google Scholar] [CrossRef]
- ISTANBUL STOCK EXCHANGE Data Set. Available online: https://archive.ics.uci.edu/ml/d (accessed on 22 July 2020).
- Nguyen, D.; Luo, W.; Phung, D.; Venkatesh, S. LTARM: A novel temporal association rule mining method to understand toxicities in a routine cancer treatment. Knowl.-Based Syst. 2018, 161, 313–328. [Google Scholar] [CrossRef]
- Khan, S.; Parkinson, S. Eliciting and utilising knowledge for security event log analysis: An association rule mining and automated planning approach. Expert Syst. Appl. 2018, 113, 116–127. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The framework of TSARM-UDP.

Figure 2.
The difference of calculating Support between Formula (2) and Formula (5).

Figure 3.
The flowchart of the proposed TSARM-UDP.

Figure 4.
Comparisons of mining results on the stock dataset (, ).

Figure 5.
Comparisons of the rule numbers and on the stock dataset ( and ).

Figure 6.
, , and rule numbers comparison on the BF dataset ( and ).

Figure 7.
Rule numbers and comparison on the BF dataset (, ).

Figure 8.
Rule numbers and comparison on the BF dataset (, ).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The log database in this example.
| Transaction ID | Transaction Time | Items |
| 1 | 2018/9/1 10:00 | b, d, f |
| 2 | 2018/9/1 10:05 | b, d, f |
| 3 | 2018/9/1 10:10 | d, f |
| 4 | 2018/9/1 10:15 | a, d |
| 5 | 2018/9/1 10:20 | a, b, d |
| 6 | 2018/9/1 10:25 | d |
| 7 | 2018/9/1 10:30 | c |
| 8 | 2018/9/1 10:35 | a, b, c |
| 9 | 2018/9/1 10:40 | c, f, e |
| 10 | 2018/9/1 10:45 | b, d |
Table 2.
The results of and of each item in D.
| Item | Timelist | Count |
| a | 4, 5, 8 | 3 |
| b | 1, 2, 5, 8, 10 | 5 |
| c | 7, 8, 9 | 3 |
| d | 1, 2, 3, 4, 5, 6, 10 | 7 |
| e | 9 | 1 |
| f | 1, 2, 3, 9 | 4 |
Table 3.
The results of Timelist(i) and TSupport of each item in D.
| Item | Timelist | TSupport |
| a | 4, 5, 8 | 0.3 |
| b | 1, 2, 5, 8, 10 | 0.5 |
| c | 7, 8, 9 | 0.3 |
| d | 1, 2, 3, 4, 5, 6, 10 | 0.7 |
| e | 9 | 0.1 |
| f | 1, 2, 3, 9 | 0.4 |
Table 4.
The results of Timelist(i) and Count(i) of candidate T.
| Itemsets | Count | Timelist | Itemsets | Count | Timelist |
| () | 1 | {5} | () | 1 | {6} |
| () | 2 | {1, 2} | () | 1 | {6} |
| () | 0 | Null | () | 0 | Null |
| () | 0 | Null | () | 0 | Null |
| () | 0 | Null | () | 0 | Null |
| () | 0 | Null | () | 0 | Null |
| () | 0 | Null | () | 1 | {2} |
| () | 0 | Null | () | 0 | Null |
| () | 2 | {2, 5} | () | 3 | {1, 2, 3} |
| () | 3 | {4, 5, 6} | () | 0 | Null |
Table 5.
The results of TConfidence and Lift in .
| Itemsets | Confidence | Lift |
Table 6.
The accuracy rate of the rules.
| Rules | Accuracy Rate (%) |
| Rule 1 | 75 |
| Rule 2 | 100 |
| Rule 3 | 100 |
| Rule 4 | 100 |
Table 7.
Comparisons of the running time of the four algorithms on the stock dataset.
| min_sup | TSARM-UDP | Nguyen et al. [35] | Khen et al. [36] | FP Tree [22] |
| 0.3 | 146.6700 s | 4.1460 s | 3.7000 s | 2.9920 s |
| 0.4 | 58.5040 s | 3.4150 s | 3.4640 s | 2.8190 s |
| 0.5 | 41.7840 s | 3.2090 s | 3.2700 s | 2.7840 s |
| 0.6 | 27.6320 s | 3.1430 s | 3.1900 s | 2.7400 s |
| 0.7 | 11.3200 s | 2.8100 s | 2.9940 s | 2.6320 s |
Table 8.
Input variables and their corresponding discretization intervals.
| Input | Descent | Normal Fluctuation | Ascent |
| Blast wind volume | <3400 | 3400∼3500 | ≥3500 |
| Blast wind temperature | <1170 | 1170∼1190 | ≥1190 |
| Blast wind pressure | <335 | 335∼350 | ≥350 |
| Oxygen enrichment | <4400 | 4400∼5000 | ≥5000 |
| Top temperature | <100 | 100∼140 | ≥140 |
| Normal blast velocity | <190 | 190∼200 | ≥200 |
| Actual blast velocity | <220 | 220∼230 | ≥230 |
| Permeability index (PI) | <23 | 23∼26 | ≥26 |
| Blast furnace bosh gas volume | <4400 | 4400∼4500 | ≥4500 |
| Theoretical combustion temperature | <2200 | 2200∼2300 | ≥2300 |
| Permeability coefficient | <6 | 6∼7 | ≥7 |
Table 9.
Interval division and coding.
| Interval Division | Descent | B | Ascent |
| Coding | 1 | 2 | 3 |
Table 10.
Variable coding.
| Input | Encoding Number |
| Blast wind volume | 1 |
| Blast wind temperature | 2 |
| Blast wind pressure | 3 |
| Oxygen enrichment | 4 |
| Top temperature | 5 |
| Normal blast velocity | 6 |
| Actual blast velocity | 7 |
| Permeability index (PI) | 8 |
| Blast furnace bosh gas volume | 9 |
| Theoretical combustion temperature | 10 |
| Permeability coefficient | 11 |
Table 11.
Rule numbers mined by the proposed algorithm with different T.
| T | Rule Numbers | T | Rule Numbers |
| () | 25 | () | 25 |
| () | 27 | () | 29 |
| () | 31 | () | 28 |
| () | 29 | () | 27 |
| () | 27 | () | 25 |
Table 12.
Comparisons of the running time of the four algorithms on the BF dataset.
| min_sup | TSARM-UDP | Nguyen et al. [35] | Khen et al. [36] | FP Tree [22] |
| 1.1809 × s | 7.0400 s | 6.8650 s | 5.7770 s | |
| 438.1290 s | 5.6700 s | 5.8360 s | 4.5320 s | |
| 162.0220 s | 4.9260 s | 5.1850 s | 4.0640 s | |
| 45.2970 s | 4.1600 s | 4.6900 s | 3.7080 s | |
| 29.0880 s | 3.4410 s | 3.4440 s | 3.6820 s |
Table 13.
Example rules mined from the blast furnace data with TSARM-UDP.
| Rules | Confidence | Lift | T |
| 0.97952 | 1.1013 | ||
| 1 | 1.1395 | ||
| 0.98868 | 1.1266 | ||
| 0.90352 | 1.0766 | ||
| 0.98305 | 1.1053 | ||
| 1 | 1.1395 | ||
| 0.97952 | 1.1612 | ||
| 1 | 1.1395 | ||
| 0.95819 | 1.1359 | ||
| 0.98675 | 1.1094 | ||
| 0.98817 | 1.1715 | ||
| 0.97895 | 1.1605 |
Table 14.
Rules mined from the blast furnace data with LTARM.
| Rules | TConfidence | Lift | T |
| 0.95491 | 1.0881 | ||
| 0.95049 | 1.0686 | ||
| 0.98489 | 1.0599 | ||
| 0.93668 | 1.0673 | ||
| 0.94573 | 1.0633 | ||
| 0.91852 | 1.0466 | ||
| 0.93654 | 1.053 | ||
| 0.78473 | 1.0429 | ||
| 0.95038 | 1.0829 | ||
| 0.91674 | 1.0307 | ||
| 0.80067 | 1.0641 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhao, Q.; Li, Q.; Yu, D.; Han, Y. TSARM-UDP: An Efficient Time Series Association Rules Mining Algorithm Based on Up-to-Date Patterns. Entropy 2021, 23, 365. https://doi.org/10.3390/e23030365
AMA Style
Zhao Q, Li Q, Yu D, Han Y. TSARM-UDP: An Efficient Time Series Association Rules Mining Algorithm Based on Up-to-Date Patterns. Entropy. 2021; 23(3):365. https://doi.org/10.3390/e23030365
Chicago/Turabian StyleZhao, Qiang, Qing Li, Deshui Yu, and Yinghua Han. 2021. "TSARM-UDP: An Efficient Time Series Association Rules Mining Algorithm Based on Up-to-Date Patterns" Entropy 23, no. 3: 365. https://doi.org/10.3390/e23030365
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.