Exact Recovery of Stochastic Block Model by Ising Model


1
Department of Electronics, Tsinghua University, Beijing 100084, China
2
Tsinghua Berkeley Shenzhen Institute, Berkeley, CA 94704, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2021, 23(1), 65; https://doi.org/10.3390/e23010065
Submission received: 29 November 2020
/
Revised: 20 December 2020
/
Accepted: 30 December 2020
/
Published: 2 January 2021
(This article belongs to the Special Issue Phase Transitions and Emergent Phenomena: How Change Emerges through Basic Probability Models)
{kind=link}
{kind=link}
Abstract
:In this paper, we study the phase transition property of an Ising model defined on a special random graph—the stochastic block model (SBM). Based on the Ising model, we propose a stochastic estimator to achieve the exact recovery for the SBM. The stochastic algorithm can be transformed into an optimization problem, which includes the special case of maximum likelihood and maximum modularity. Additionally, we give an unbiased convergent estimator for the model parameters of the SBM, which can be computed in constant time. Finally, we use metropolis sampling to realize the stochastic estimator and verify the phase transition phenomenon thfough experiments.
1. Introduction
In network analysis, community detection consists in inferring the group of vertices that are more densely connected in a graph [1]. It has been used in many domains, such as recommendation systems [2], task allocation in distributed computing [3], gene expressions [4], and so on. The stochastic block model (SBM) is one of the most commonly used statistical models for community detection problems [5,6]. It provides a benchmark artificial dataset to evaluate different community detection algorithms and inspires the design of many algorithms for community detection tasks. These algorithms, such as semi-definite relaxation, spectral clustering, and label propagation, not only have theoretical guarantees when applied to the SBM, but also perform well on datasets without the SBM assumption. The study of the theoretical guarantee of the SBM model can be divided between the problem of exact recovery and that of partial recovery. Exact recovery requires that the estimated community should be exactly the same as the underlining community structure of the SBM whereas partial recovery expects the ratio of misclassified nodes to be as small as possible. For both cases, the asymptotic behavior of the detection error is analyzed when the scale of the graph tends to infinity. There are already some well-known results for the exact recovery problem on the SBM. To name but a few, Abbe and Mossel established the exact recovery region for a special sparse SBM with two communities [7,8]. Later on, the result was extended to a general SBM with multiple communities [9].
Parameter inference in the SBM is often considered alongside the exact recovery problem. Previous inference methods require the joint estimation of node labels and model parameters [10], which have high complexity since the recovery and inference tasks are done simultaneously. In this article, we will decouple the inference and recovery problems, and propose an unbiased convergent estimator for SBM parameters when the number of communities is known. Once the estimator is obtained, the recovery condition can be checked to determine whether it is possible to recover the labels exactly. Additionally, the estimated parameter will guide the choice of parameters for our proposed stochastic algorithm.
In this article, the exact recovery of the SBM is analyzed by considering the Ising model, which is a probability distribution of node states [11]. We use the terms node states and node labels interchangeably throughout this paper, both of which refer to the membership of the underlining community. The Ising model was originally proposed in statistical mechanics to model the ferromagnetism phenomenon but has wide applications in neuroscience, information theory, and social networks. Among different variants of Ising models, the phase transition property is shared. Phase transition can be generally formulated when some information quantity changes sharply in a small neighborhood of parameters. Based on the random graph generated by an SBM with two underlining communities, the connection of the SBM and the Ising model was first studied by [12]. Our work will extend the existing result to the multiple community case, establish the phase transition property, and give the recovery error an upper bound. The error bounds decay in a polynomially fast rate in different phases. Then we will propose an alternative approach to estimate the labels by finding the Ising state with maximal probability. Compared with sampling from the Ising model directly, we will show that the optimization approach has a sharper error upper bound. Solving the optimization problem is a generalization of maximum likelihood and also has a connection with maximum modularity. Additionally, searching the state with maximal probability could also be done within all balanced partitions. We will show that this constrained search is equivalent to the graph minimum cut problem, and the detection error upper bound for the constrained maximization will also be given.
The exact solution to maximize the probability function or exact sampling from the Ising model is NP-hard. Many polynomial time algorithms have been proposed for approximation purposes. Among these algorithms, simulated annealing performs well and produces a solution that is very close to the true maximal value [13]. On the other hand, in the original Ising model, metropolis sequential sampling is used to generate samples for the Ising model [14]. Simulated annealing can be regarded as metropolis sampling with decreasing temperature. In this article, we will use the metropolis sampling technique to sample from the Ising model defined on the SBM. This approximation enables us to verify the phase transition property of our Ising model numerically.
This paper is organized as follows. Firstly, in Section 3 we introduce the SBM and give an estimator for the parameters of the SBM. Then, in Section 4, our specific Ising model is given and its phase transition property is obtained. Derived from the Ising model, in Section 5, the energy minimization method is introduced, and we establish its connection with maximum likelihood and modularity maximization algorithm. Furthermore, in Section 6, we realize the Ising model using the metropolis algorithm to generate samples. Numerical experiments and conclusion are given lastly to finish this paper.
Throughout this paper, the community number is denoted by k; the random undirected graph G is written as with vertex set V and edge set E; ; the label of each node is , which is chosen from , and we further require W to be a cyclic group with order k; is the n-ary Cartesian power of W; f is a permutation function on W and is extended to in an element-wise manner; is the complement set of U and is the cardinality of U; the set is used to represent all permutation functions on W and for ; the indicator function is defined as when , and when ; if there exists a constant such that for large n; holds if ; we define the distance of two vectors as: and the distance of a vector to a space as . For example, when and , ; ; ; let f be a mapping such that and , then and ; ; ; and .
2. Related Works
The classical Ising model is defined on a lattice and confined to two states . This definition can be extended to a general graph and multiple-state case [15]. In [16], Liu considered the Ising model as defined on a graph generated by sparse SBM and his focus was to compute the log partition function, which was averaged over all random graphs. In [17], an Ising model with a repelling interaction was considered on a fixed graph structure, and the phase transition condition was established, which involves both the attracting and repelling parameters. Our Ising model derives from the work of [12], but we extend their results by considering the error upper bound and multiple-community case.
The exact recovery condition for the SBM can be derived as a special case of many generalized models, such as pairwise measurements [18], minimax rates [19], and side information [20]. The Ising model in this paper provides another way to extend the SBM model and derives the recovery condition. Additionally, the error upper bound for exact recovery of the two-community SBM by constrained maximum likelihood has been obtained in [7]. Compared with previous results, we establish a sharper upper bound for the multiple-community case in this paper.
The connection between maximum modularity and maximal likelihood was investigated in [21]. To get an optimal value of maximum modularity approximately, simulated annealing was exploited [22], which proceeds by using the partition approach, while the Metropolis sampling used in this paper is applied to estimate the node membership directly.
3. Stochastic Block Model and Parameter Estimation
In this paper, we consider a special symmetric stochastic block model (SSBM), which is defined as follows:
Definition 1 (SSBM with k communities).
Let , and . X satisfies the constraint that for . The random graph G is generated under if the following two conditions are satisfied.
- There is an edge of G between the vertices i and j with probability p if and with probability q if .
- The existences of each edge are mutually independent.
To explain SSBM in more detail, we define the random variable , which is the indicator function of the existence of an edge between nodes i and j. Given the node labels X, follows Bernoulli distribution, whose expectation is given by:
Then the random graph G with n nodes is completely specified by in which all are jointly independent. The probability distribution for SSBM can be written as:
We will use the notation to represent the set containing all graphs with n nodes. By the normalization property, .
In Definition 1, we have supposed that the node label X is fixed instead of a uniformly distributed random variable. Since the maximum posterior estimator is equivalent to the maximum likelihood when the prior is uniform, these two definitions are equivalent. Although the random variable definition is more commonly used in previous literature [6], fixing X makes our formal analysis more concise.
Given the SBM, the exact recovery problem can be formally defined as follows:
Definition 2 (Exact recovery in SBM).
Given X, the random graph G is drawn under . We say that the exact recovery is solvable for if there exists an algorithm that takes G as input and outputs such that:
In the above definition, the notation is called the probability of accuracy for estimator . Let represent the probability of error. Definition 2 can also be formulated as as . The notation means that we can only expect a recovery up to a global permutation of the ground truth label vector X. This is common in unsupervised learning as no anchor exists to assign labels to different communities. Additionally, given a graph G, the algorithm can be either deterministic or stochastic. Generally speaking, the probability of should be understood as , which reduced to for the deterministic algorithm.
For constants , which are irrelevant with the graph size n, we can always find algorithms to recover X such that the detection error decreases exponentially fast as n increases; that is to say, the task with a dense graph is relatively easy to handle. Within this paper, we consider a sparse case when . This case corresponds to the sparsest graph when exact recovery of the SBM is possible. And under this condition, a well known result [9] states that exact recovery is possible if and only if:
Before diving into the exact recovery problem, we first consider the inference problem for SBM. Suppose k is known, and we want to estimate from the graph G. We offer a simple method by counting the number of edges and the number of triangles of G, and the estimators are obtained by solving the following equation systems:
The theoretical guarantee for the solution is given by the following theorem:
Theorem 1.
When n is large enough, the equation system of Equations (4) and (5) has the unique solution , which are unbiased consistent estimators of . That is, , and and converge to in probability, respectively.
Given a graph generated by the SBM, we can use Theorem 1 to obtain the estimated and determine whether exact recovery of label X is possible by Equation (3). Additionally, Theorem 1 provides good estimation of to initialize their parameters of some recovery algorithm like maximum likelihood or our proposed Metropolis sampling in Section 6.
4. Ising Model for Community Detection
In the previous section, we have defined SBM and its exact recovery problem. While SBM is regarded as obtaining the graph observation G from node label X, the Ising model provides a way to generate estimators of X from G by a stochastic procedure. The definition of such an Ising model is given as follows:
Definition 3 (Ising model with k states).
Given a graph G sampled from , the Ising model with parameters is a probability distribution of the state vector whose probability mass function is
where
The subscript in indicates that the distribution depends on G, and is the normalizing constant for this distribution.
In physics, refers to the inverse temperature and is called the partition function. The Hamiltonian energy consists of two terms: the repelling interaction between nodes without edge connection and the attracting interaction between nodes with edge connection. The parameter indicates the ratio of the strength of these two interactions. The term is added to balance the two interactions because there are only connecting edges for each node. The probability of each state is proportional to , and the state with the largest probability corresponds to that with the lowest energy.
The classical definition of the Ising model is specified by for . There are two main differences between Definition 3 and the classical one. Firstly, we add a repelling term between nodes without an edge connection. This makes these nodes have a larger probability to take different labels. Secondly, we allow the state at each node to take k values from W instead of the two values . When and , Definition 3 is reduced to the classical definition of the Ising model up to a scaling factor.
Definition 3 gives a stochastic estimator for X: is one sample generated from the Ising model, which is denoted as . The exact recovery error probability for can be written as . From this expression we can see that the error probability is determined by two parameters . When these parameters take proper values, , and the exact recovery of the SBM is achievable. On the contrary, if takes other values. These two cases are summarized in the following theorem:
Theorem 2.
Define the function as follows:
and:
where . Let be defined as:
which is the solution to the equation and . Then depending on how take values, for any given and , when n is sufficiently large, we have:
- If and , ;
- If and , ;
- If , for any .
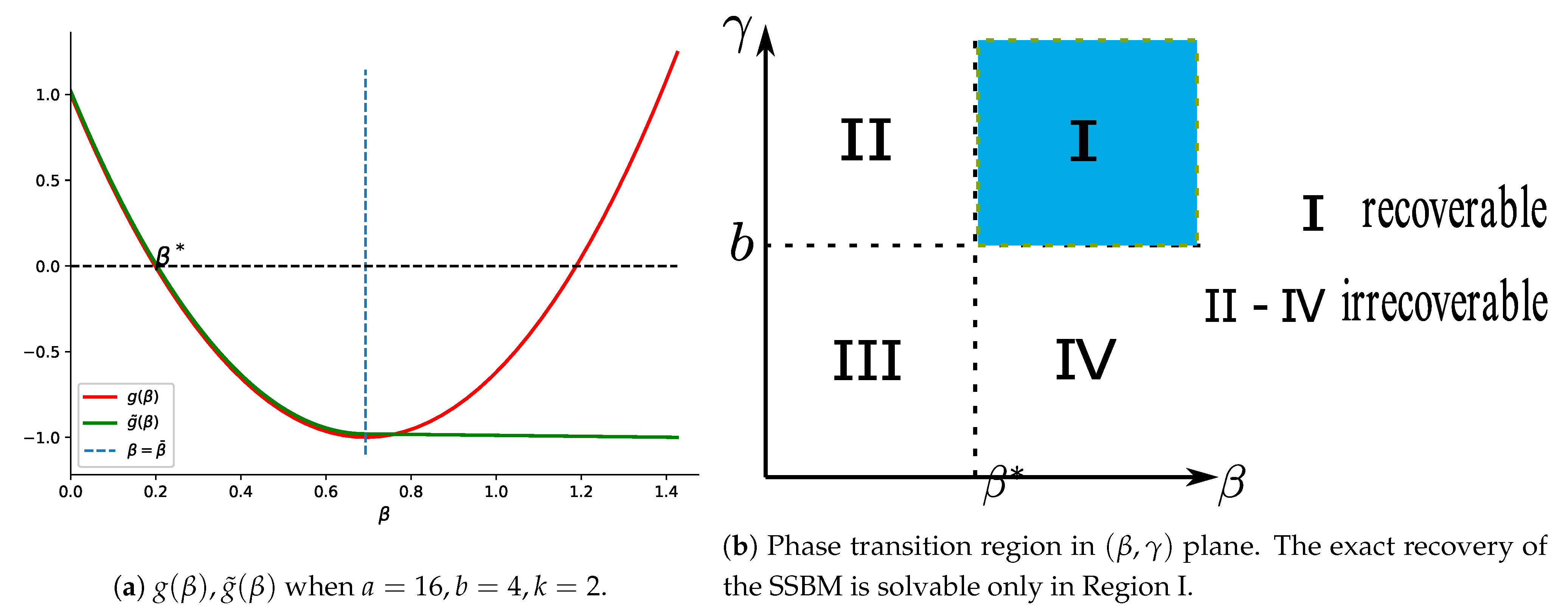
By simple calculus, for and for . follows from Equation (3). The illustration of is shown in Figure 1a. Therefore, for sufficiently small and as , the upper bounds in Theorem 2 all converge to 0 at least in polynomial speed. Therefore, Theorem 2 establishes the sharp phase transition property of the Ising model, which is illustrated in Figure 1b.
Theorem 2 can also be understood from the marginal distribution for . Let be the event when is closest to among all its permutations. That is,
Then Theorem 2 can be stated with respect to the marginal distribution :
Corollary 1.
Suppose , depending on how β takes values:
- When , ;
- When , .
Below we outline the proof ideas of Theorem 2. The insight is obtained from the analysis of the one-flip energy difference. This useful result is summarized in the following lemma:
Lemma 1.
Suppose differs from only at position r by . Then the change of energy is:
where , and .
Lemma 1 gives an explicit way to compare the probability of two neighboring states by the following equality:
Additionally, since the graph is sparse and every node has neighbors, from Equation (12) the computational cost (time complexity) for the energy difference is also .
When , we can expect is far less than . Roughly speaking, if converges to zero, we can expect the probability of all other states differing from converges to zero. On the contrary, if tends to infinity, then converges to zero. This illustrates the idea behind the proof of Theorem 2. The rigorous proof can be found in Section 8.
5. Community Detection via Energy Minimization
Since is irrelevant with n, when , we can choose a sufficiently large such that , then by Theorem 2, almost surely, which implies that has the largest probability for almost all graphs G sampled from the SBM. Therefore, instead of sampling from the Ising model, we can directly maximize the conditional probability to find the state with the largest probability. Equivalently, we can proceed by minimizing the energy term in Equation (7):
In (14), we allow to take values from . Since we know X has equal size for each label u, another formulation is to restrict the search space to . When , minimizing is equivalent to:
where the minimal value is the minimum cut between different detected communities.
When , we must have to satisfy the constraint . Additionally, the estimator of is parameter-free whereas depends on . The extra parameter in the expression of can be regarded as a kind of Lagrange multiplier for this integer programming problem. Thus, the optimization problem for is the relaxation of that for by introducing a penalized term and enlarging the searched space from to .
When , becomes a constant value. Therefore, we can get as the tightest error upper bound for the Ising estimator from Theorem 2. For the estimator and , we can obtain a sharper error upper bound, which is summarized in the following theorem:
Theorem 3.
When , for sufficiently large n,
- If , ;
- .
As , , Theorem 3 implies that has the sharpest upper bound among the three estimators. This can be intuitively understood as the result of smaller search space. The proof technique of Theorem 3 is to consider the probability of events for . Then by union bound, these error probabilities can be summed up. We note that a loose bound was obtained in [7] for the estimator when . For a general case, since , Theorem 3 implies that exact recovery is possible using as long as is satisfied.
Estimator has one parameter, . When takes different values, is equivalent with maximum likelihood or maximum modularity in the asymptotic case. The following analysis shows their relationship intuitively.
The maximum likelihood estimator is obtained by maximizing the log-likelihood function. From (2), this function can be written as:
where the parameter in satisfies and C is a constant irrelevant with . When n is sufficiently large, we have . That is, the maximum likelihood estimator is equivalent to when asymptotically.
The maximum modularity estimator is obtained by maximizing the modularity of a graph [23], which is defined by:
For the i-th node, is its degree and is its community belonging. A is the adjacency matrix. Up to a scaling factor, the modularity Q can be re-written using the label vector as:
From (17), we can see that with as . Indeed, we have . Therefore, we have . That is, the maximum modularity estimator is equivalent with when asymptotically.
Using and the inequality for we can verify that . That is, both the maximum likelihood and the maximum modularity estimator satisfy the exact recovery conditions in Theorem 3.
6. Community Detection Based on Metropolis Sampling
From Theorem 2, if we could sample from the Ising model, then with large probability, the sample is aligned with X. However, exact sampling is difficult when n is very large since the cardinality of the state space increases in the rate of . Therefore, some approximation is necessary, and the most common way to generate an Ising sample is using Metropolis sampling [14]. Empirically speaking, starting from a random state, the Metropolis algorithm updates the state by randomly selecting one position to flip its state at each iteration step. Then after some initial burning time, the generated samples can be regarded as sampling from the Ising model.
The theoretical guarantee of Metropolis sampling is based on the Markov chain. Under some general conditions, Metropolis samples converge to the steady state of the Markov chain, and the steady state follows the probability distribution to be approximated. For the Ising model, there are many previous works which have shown the convergence of Metropolis sampling [24].
For our specific Ising model and energy term in Equation (7), the pseudo code of our algorithm is summarized in Algorithm 1. This algorithm requires that the number of the communities k is known and the strength ratio parameter is given. We should choose where b is estimated by in Theorem 1. The iteration time N should also be specified in advance.
| Algorithm 1 Metropolis sampling algorithm for SBM. |
Inputs: the graph G, inverse temperature , the strength ratio parameter Output:
|
The computation of needs time from Lemma 1. For some special Ising model, it needs to take to generate the sample for good approximation [25]. For our model, it is unknown whether is sufficient, and we empirically chose in numerical experiments. Then the time complexity of Algorithm 1 is .
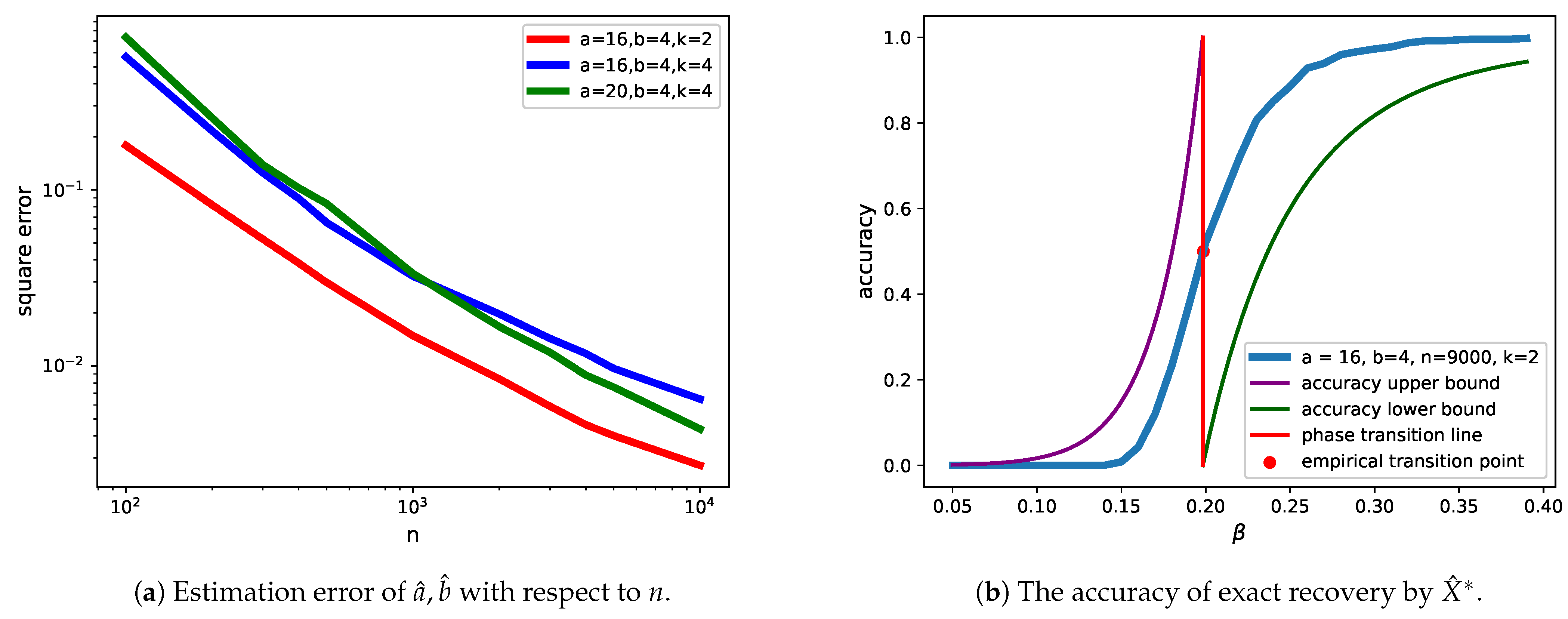
In the remaining part of this section, we present experiments conducted to verify our theoretical results. Firstly, we considered several combinations of and obtained the estimator by Theorem 1. Using the empirical mean squared error (MSE) as the criterion and choosing , the result is shown in Figure 2a. As we can see, as n increases, the MSE decreases polynomially fast. Therefore, the convergence of and was verified.
Secondly, using Metropolis sampling, we conducted a moderate simulation to verify Theorem 2 for the case . We chose , and the empirical accuracy was computed by . In this formula, is the number of times the random graph was generated by the SBM, whereas is the number of times consecutive samples were generated by Algorithm 1 for a given graph. We chose , which is fairly large and can achieve a good approximation of by the law of large numbers. The result is shown in Figure 2b.
The vertical red line (), computed from (10), represents the phase transition threshold. The point in the figure can be regarded as the empirical phase transition threshold, whose first coordinate is close to . The green line is the theoretical lower bound of accuracy for , and the purple line is the theoretical upper bound of accuracy for . It can be expected that as n becomes larger, the empirical accuracy curve (blue line in the figure) will approach the step function, which jumps from 0 to 1 at .
7. Conclusions
In this paper, we presented one convergent estimator (in Theorem 1) to infer the parameters of the SBM and analyzed three label estimators to detect communities of the SBM. We gave the exact recovery error upper bound for all label estimators (in Theorems 2 and 3) and studied their relationships. By introducing the Ising model, our work makes a new path to study the exact recovery problem for the SBM. More theoretical and empirical work will be done in the future, such as convergence analyses on modularity (in Equation (17)), the necessary iteration time (in Algorithm 1) for Metropolis sampling, and so on.
8. Proof of Main Theorems
8.1. Proof of Theorem 1
Lemma 2.
Consider an Erdős–Rényi random graph G with n nodes, in which edges are placed independently with probability p [26]. Suppose , the number of edges is denoted by while the number of triangles is T. Then and in probability.
Proof.
Let represent a Bernoulli random variable with parameter p. Then , are i.i.d. and . Then by Chebyshev’s inequality,
For a given , when n is sufficiently large,
Therefore, by the definition of convergence in probability, we have as .
Let represents a Bernoulli random variable with parameter . Then . It is easy to compute that . Since are not independent, the variance of T needs careful calculation. From [27] we know that:
Therefore by Chebyshev’s inequality,
Hence, . □
The convergence of in the Erdős–Rényi graph can be extended directly to the SBM since the existence of each edge is independent. However, for T, it is a little tricky since the existences of each triangle are mutually dependent. The following two lemmas give the formula for the variance of inter-community triangles in the SBM.
Lemma 3.
Consider a two-community SBM and count the number of triangles T, which has a node in and an edge in . Then the variance of T is:
Lemma 4.
Consider a three-community SBM and count the number of triangles T, which has a node in , one node in , and one node in . Then the variance of T is:
The proof of the above two lemmas uses some counting techniques and is similar to that in [27], and we omit it here.
Lemma 5.
For a SBM where . The number of triangles is T. Then converges to in probability as .
Proof.
We split T into three parts: the first is the number of triangles within community i, . There are k terms of . The second is the number of triangles that have one node in community i and one edge in community j, . There are terms of . The third is the number of triangles that have one node in community i, one node in community j and one node in community k.
We only need to show that:
The convergence of comes from Lemma 2. For we use the conclusion from Lemma 3. We replace n with , , and in Equation (18). . Since the expectation of is , by Chebyshev’s inequality we can show that:
Therefore, converges to .
To prove , from Lemma 4 we can get :
□
Proof of Theorem 1.
Let , and . From Lemma 2, . From Lemma 5, as . Using , we can get:
This equation has a unique real root since is increasing on : . Next we show that the root lies within .
Therefore, we can get a unique solution y within . Since is a solution for the equation array, the conclusion follows.
By taking expectation on both sizes of Equations (4) and (5) we can show . By the continuous property of , and follows similarly. □
8.2. Proof of Theorem 2
Proof of Lemma 1.
First we rewrite the energy term in (7) as:
Then calculating the energy difference term by:
□
Before diving into the technical proof of Theorem 2, we need to introduce some extra notations. When differs from X only at position r, taking in Lemma 1, we have:
where is defined as . Since the existence of each edge in G is independent, for and .
For the general case, we can write:
in which we use or to represent the binomial random variable with parameter or , respectively, and is a deterministic positive number depending on but irrelevant with the graph structure. The following lemma gives the expression of and :
Lemma 6.
For SSBM , we assume differs from the ground truth label vector X in the coordinate. Let for and . We further denote the row sum as and the column sum as . Then:
The proof of Lemma 6 is mainly composed of careful counting techniques, and we omit it here. When is small compared to n, we have the following Lemma, which is an extension of Proposition 6 in [12].
Lemma 7.
For and
where .
Corresponding to the three cases of Theorem 2, we use three non-trivial lemmas to establish the properties of the Ising model.
Lemma 8.
Let . When and , the event happens with a probability (with respect to SSBM) less than , where C is an arbitrary constant and is a positive number.
Proof.
We denote the event as . By Equation (24), is equivalent to:
We claim that must satisfy at least one of the following two conditions:
- s.t.
- s.t. and
If neither of the above two condition holds, then from condition 1 we have or for any . Since , there exists such that . Under such conditions, we also assume . Let be the vector that exchanges the value of with in X. We consider:
which contracts with the fact that is nearest to X. Therefore, we should have . Now the pair satisfies condition 2, which contracts with the fact that satisfies neither of the two conditions.
Under condition 1, we can get a lower bound on from Equation (27). Let for and . Then we can simplify as:
We further have where satisfies condition 1. Therefore, . As a result,
Under condition 2, we can get a lower bound on . Since , from (30) we have . Since , we have . Now consider . From (25): .
Now we use the Chernoff inequality to bound Equation (29); we can omit on the left-hand side since it is far smaller than 1. Let , then:
Using we can further simplify the exponential term as:
Now we investigate the function and . Both functions take zero values at and . Therefore, and we can choose such that . To compensate the influence of the term we only need to make sure that the order of is larger than n. This requirement is satisfied since either or . □
Lemma 9.
If , , For and , there is a set such that:
and for every ,
For , there is a set such that:
and for every ,
Proof.
We distinguish the discussion between two cases: and .
When , we can show that implies by using the triangle inequality of dist. For , where is the identity mapping, we have:
Therefore, and Equation (33) is equivalent with:
The left-hand side can be written as:
where .
Define and we only need to show that:
Define the event , and we proceed as follows:
For the first term, since , by Lemma 7, . For the second term, we use Markov inequality:
The conditional expectation can be estimated as follows:
, therefore, . Using Lemma 7, we have:
Since , , when n is sufficiently large we have . Therefore,
Combining the above equations, we have:
When , using Lemma 8, we can choose a sufficiently large constant such that :
happens with probability less than . Therefore, Equation (35) holds.□
If and , we have the following lemma:
Lemma 10.
If and , there is a set such that and:
Lemma 10 is an extension of Proposition 10 in [12] and can be proved using almost the same analysis. Thus we omit the proof of Lemma 10 here.
Lemma 11.
If and , there is a set such that:
and for every ,
Proof.
The left-hand side of Equation (41) can be rewritten as:
Let be defined in Lemma 10 and .
Using Chebyshev’s inequality, we have:
Let :
and for every ,
Therefore, from Equation (42) we have:
□
Let where is the all-ones vector with dimension n, and we have the following lemma:
Lemma 12.
Suppose and satisfies and . Then the event happens with a probability (with respect to SSBM) less than where C is an arbitrary constant, is a positive number.
Proof.
Let . Then for since . Without loss of generality, we suppose . Define . Denote the event as , which can be transformed as:
Firstly we estimate the order of , and obviously . Using the conclusion in Appendix A of [18], we have:
By assumption of , we have and follows from . When , we have . The second inequality is achieved if . When , and the second inequality is achieved when . Thus generally we have .
Since we can rewrite Equation (43) as:
Let and .
Using the Chernoff inequality we have:
Since and , we further have:
Let , which satisfies for , and take , using we have:
□
Proof of Theorem 2.
(1) Since , we only need to establish . From Lemma 9, we can find for . Let and choose ; from Equations (32) and (34), we have:
where the last equality follows from the estimation of sum of geometric series. On the other hand, for every , from Equations (33) and (35), we have:
from which we can get the estimation . Finally,
(2) When , using Lemma 11, for every we can obtain:
We then have:
Then:
(3) When , for any , we have . Therefore, using Lemma 12, we can find a graph such that and for any , . Therefore,
The conclusion of follows since C can take any positive value. □
8.3. Proof of Theorem 3
Lemma 13
(Lemma 8 of [7]). Let m be a positive number larger than n. When are i.i.d. Bernoulli() and are i.i.d Bernoulli(), independent of , then:
Proof of Theorem 3.
Let denote the probability when there is satisfying and .
From Equation (23), when differs from X only by one coordinate, from Lemma 13 the probability for is bounded by . Therefore, . Using Lemma 7, we can get for . For , choosing in Lemma 8 we can get . That is, the dominant term is since the other part decreases exponentially fast. Therefore, the upper bound for error rate of is:
When , since , we have . From Lemma 6, we can see and . Then from Equation (24), is equivalent with .
Therefore, when and , from Equation (31), we have . We use Lemma 13 by letting when ; the error term is bounded by , which decreases exponentially fast. For , we can use Lemma 7 directly by considering . The summation starts from since . Therefore,
□
Author Contributions
The work of this paper was conceptualized by M.Y., who also developed the mathematical analysis methodology for the proof of the main theorem of this paper. All simulation code was written by F.Z., who also extended the idea of M.Y., concreted the proof and wrote this paper. The work is supervised and funded by S.-L.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Natural Science Foundation of China under Grant 61807021, in part by the Shenzhen Science and Technology Program under Grant KQTD20170810150821146, and in part by the Innovation and Entrepreneurship Project for Overseas High-Level Talents of Shenzhen under Grant KQJSCX20180327144037831.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SBM | Stochastic Block Model |
| SSBM | Symmetric Stochastic Block Model |
| MSE | Mean Squared Error |
| ML | maximum likelihood |
| MQ | maximum modularity |
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Feng, H.; Tian, J.; Wang, H.J.; Li, M. Personalized recommendations based on time-weighted overlapping community detection. Inf. Manag. 2015, 52, 789–800. [Google Scholar] [CrossRef]
- Hendrickson, B.; Kolda, T.G. Graph partitioning models for parallel computing. Parallel Comput. 2000, 26, 1519–1534. [Google Scholar] [CrossRef] [Green Version]
- Cline, M.S.; Smoot, M.; Cerami, E.; Kuchinsky, A.; Landys, N.; Workman, C.; Christmas, R.; Avila-Campilo, I.; Creech, M.; Gross, B.; et al. Integration of biological networks and gene expression data using Cytoscape. Nat. Protoc. 2007, 2, 2366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Abbe, E. Community detection and stochastic block models: Recent developments. J. Mach. Learn. Res. 2017, 18, 6446–6531. [Google Scholar]
- Abbe, E.; Bandeira, A.S.; Hall, G. Exact recovery in the stochastic block model. IEEE Trans. Inf. Theory 2015, 62, 471–487. [Google Scholar] [CrossRef] [Green Version]
- Mossel, E.; Neeman, J.; Sly, A. Consistency thresholds for the planted bisection model. Electron. J. Probab. 2016, 21, 24. [Google Scholar] [CrossRef] [Green Version]
- Abbe, E.; Sandon, C. Community detection in general stochastic block models: Fundamental limits and efficient algorithms for recovery. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 17–20 October 2015; pp. 670–688. [Google Scholar]
- Nowicki, K.; Snijders, T.A.B. Estimation and prediction for stochastic blockstructures. J. Am. Stat. Assoc. 2001, 96, 1077–1087. [Google Scholar] [CrossRef]
- Ising, E. Beitrag zur theorie des ferromagnetismus. Z. Für Phys. 1925, 31, 253–258. [Google Scholar] [CrossRef]
- Ye, M. Exact recovery and sharp thresholds of Stochastic Ising Block Model. arXiv 2020, arXiv:2004.05944. [Google Scholar]
- Liu, J.; Liu, T. Detecting community structure in complex networks using simulated annealing with k-means algorithms. Phys. A Stat. Mech. Appl. 2010, 389, 2300–2309. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef] [Green Version]
- Potts, R.B. Some generalized order-disorder transformations. In Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1952; Volume 48, pp. 106–109. [Google Scholar]
- Liu, L. On the Log Partition Function of Ising Model on Stochastic Block Model. arXiv 2017, arXiv:1710.05287. [Google Scholar]
- Berthet, Q.; Rigollet, P.; Srivastava, P. Exact recovery in the Ising blockmodel. Ann. Stat. 2019, 47, 1805–1834. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Suh, C.; Goldsmith, A.J. Information recovery from pairwise measurements. IEEE Trans. Inf. Theory 2016, 62, 5881–5905. [Google Scholar] [CrossRef] [Green Version]
- Hajek, B.; Wu, Y.; Xu, J. Achieving exact cluster recovery threshold via semidefinite programming. IEEE Trans. Inf. Theory 2016, 62, 2788–2797. [Google Scholar] [CrossRef] [Green Version]
- Saad, H.; Nosratinia, A. Community detection with side information: Exact recovery under the stochastic block model. IEEE J. Sel. Top. Signal Process. 2018, 12, 944–958. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. Equivalence between modularity optimization and maximum likelihood methods for community detection. Phys. Rev. E 2016, 94, 052315. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Chen, D.; Sun, C. A fast simulated annealing strategy for community detection in complex networks. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; pp. 2380–2384. [Google Scholar]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [Green Version]
- Diaconis, P.; Saloff-Coste, L. What do we know about the Metropolis algorithm? J. Comput. Syst. Sci. 1998, 57, 20–36. [Google Scholar] [CrossRef] [Green Version]
- Frigessi, A.; Martinelli, F.; Stander, J. Computational Complexity of Markov Chain Monte Carlo Methods for Finite Markov Random Fields. Biometrika 1997, 84, 1–18. [Google Scholar] [CrossRef]
- Erdős, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 1960, 5, 17–60. [Google Scholar]
- Holland, P.W.; Leinhardt, S. A Method for Detecting Structure in Sociometric Data. Am. J. Sociol. 1970, 76, 492–513. [Google Scholar] [CrossRef]
Figure 1.
Illustration of Theorem 2.

Figure 2.
Experimental results.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhao, F.; Ye, M.; Huang, S.-L. Exact Recovery of Stochastic Block Model by Ising Model. Entropy 2021, 23, 65. https://doi.org/10.3390/e23010065
AMA Style
Zhao F, Ye M, Huang S-L. Exact Recovery of Stochastic Block Model by Ising Model. Entropy. 2021; 23(1):65. https://doi.org/10.3390/e23010065
Chicago/Turabian StyleZhao, Feng, Min Ye, and Shao-Lun Huang. 2021. "Exact Recovery of Stochastic Block Model by Ising Model" Entropy 23, no. 1: 65. https://doi.org/10.3390/e23010065
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.